
Surface Classification from Robot Internal Measurement Unit Time-Series Data Using Cascaded and Parallel Deep Learning Fusion Models






Abstract
1. Introduction
2. Related Work
3. Proposed Deep Learning Model Architecture
3.1. Model Building Blocks
3.1.1. 1-D CNN
3.1.2. LSTM
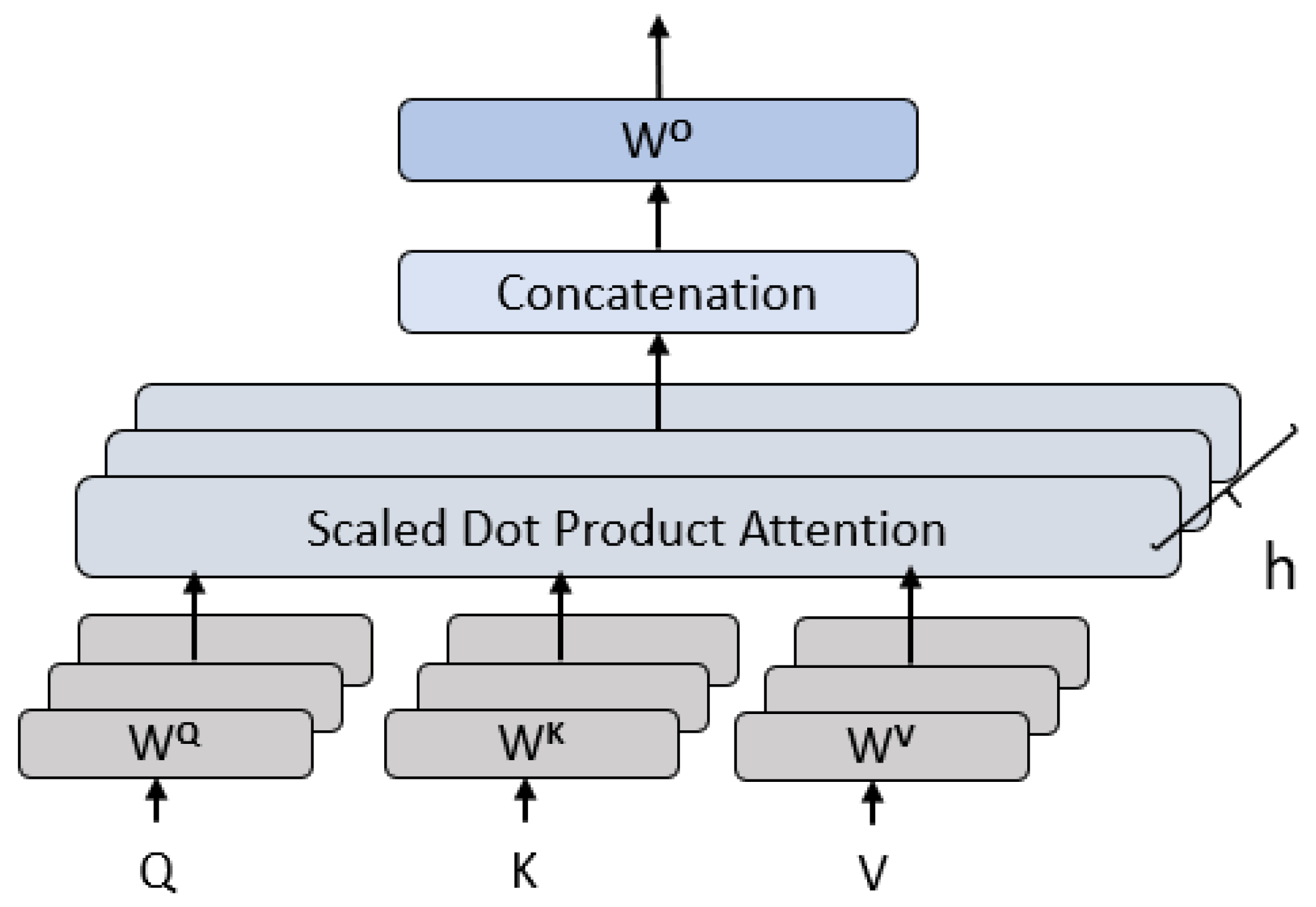
3.1.3. Multi-Head Attention Mechanism
- Q = Query matrix;
- K = Key matrix;
- V = Value matrix;
- dk = Dimensionality of the key vectors (for scaling).
- headi = Attention();
- = learned projection matrices for the i-th head;
- = Learned weight matrix for the output transformation.
3.2. Feature Fusion Models
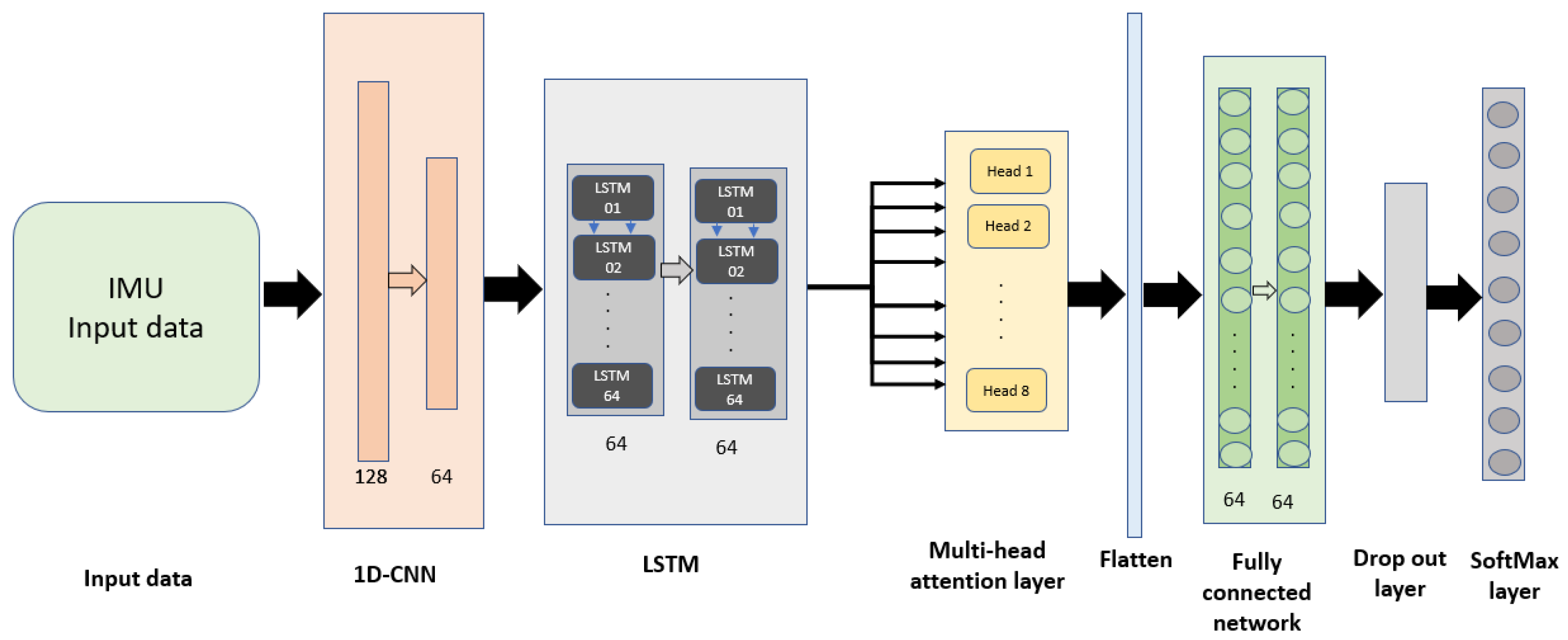
3.2.1. Cascaded Feature Fusion Model
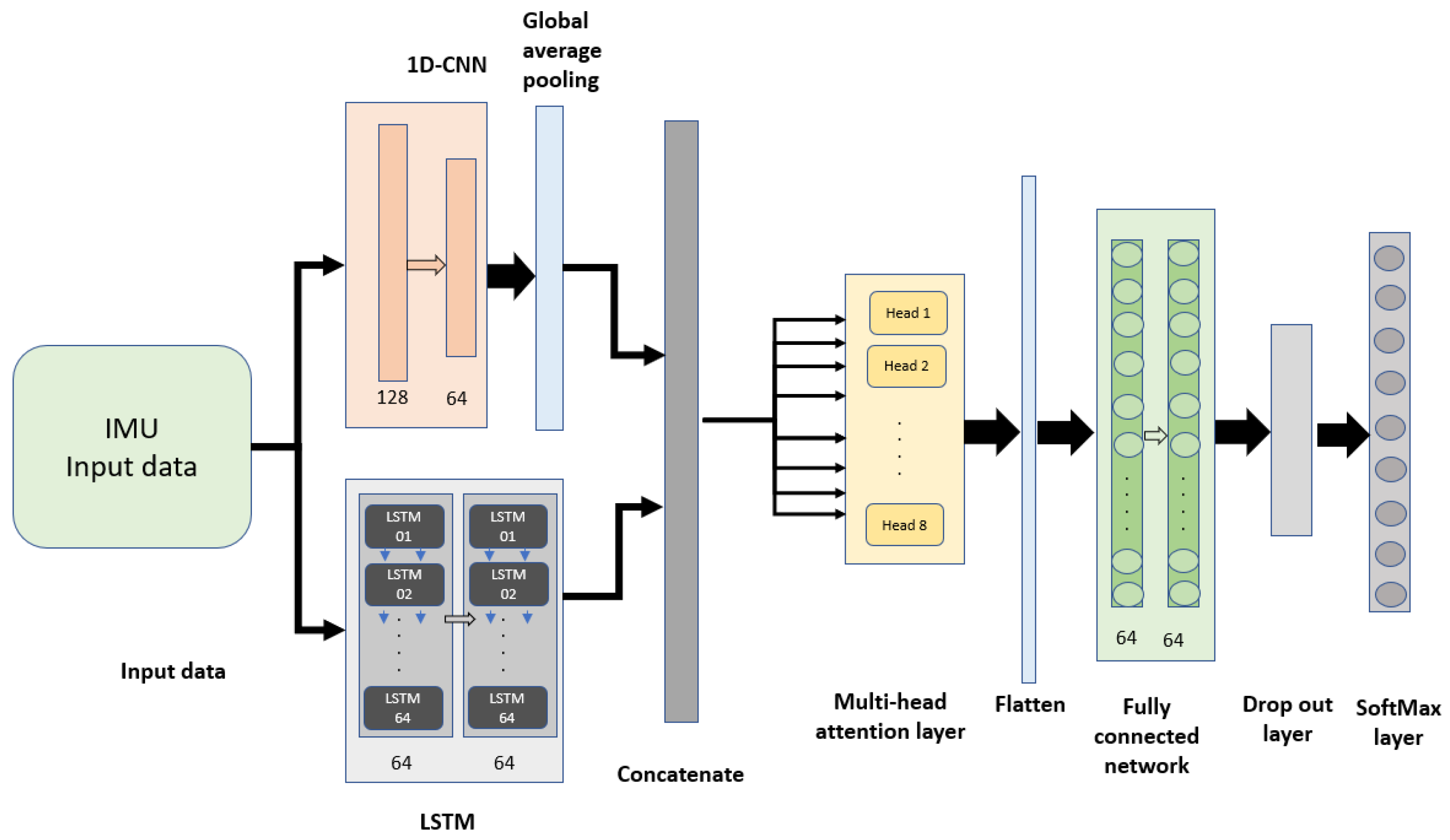
3.2.2. Parallel Feature Fusion Model
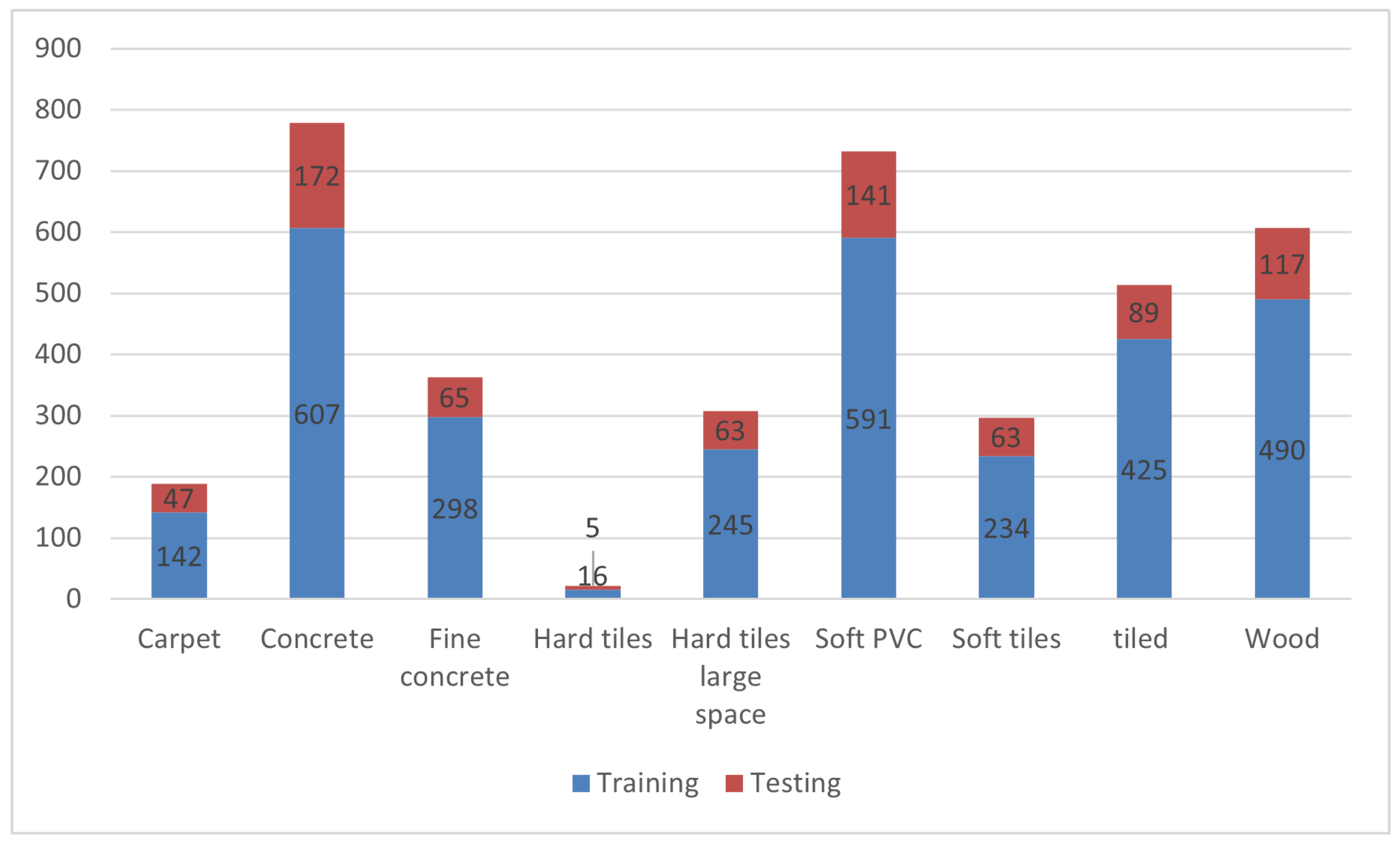
4. Dataset and Training Process
5. Evaluation Metrics
6. Results
6.1. Baseline vs. Cascaded Fusion Model
6.2. Baseline vs. Parallel Fusion Model
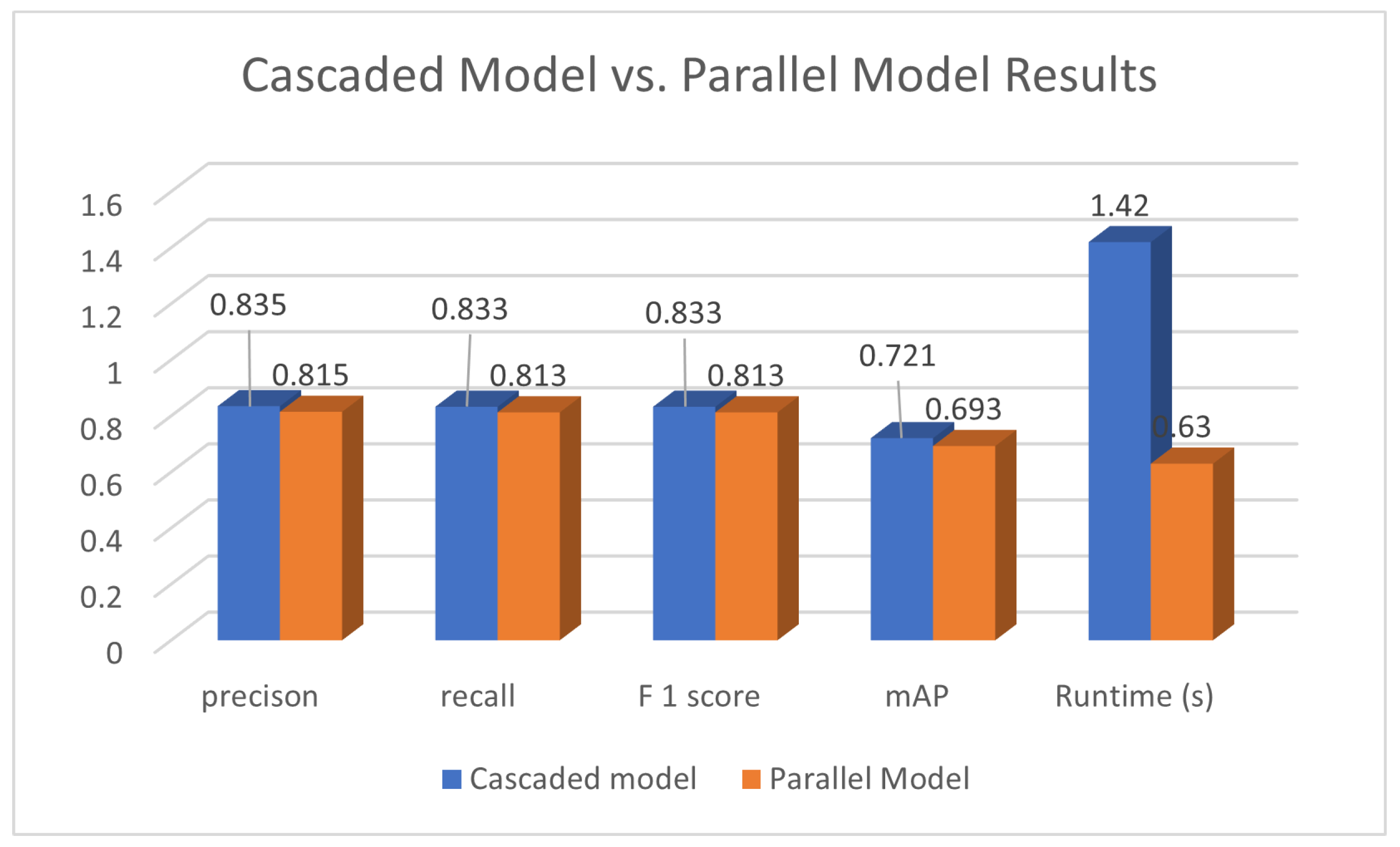
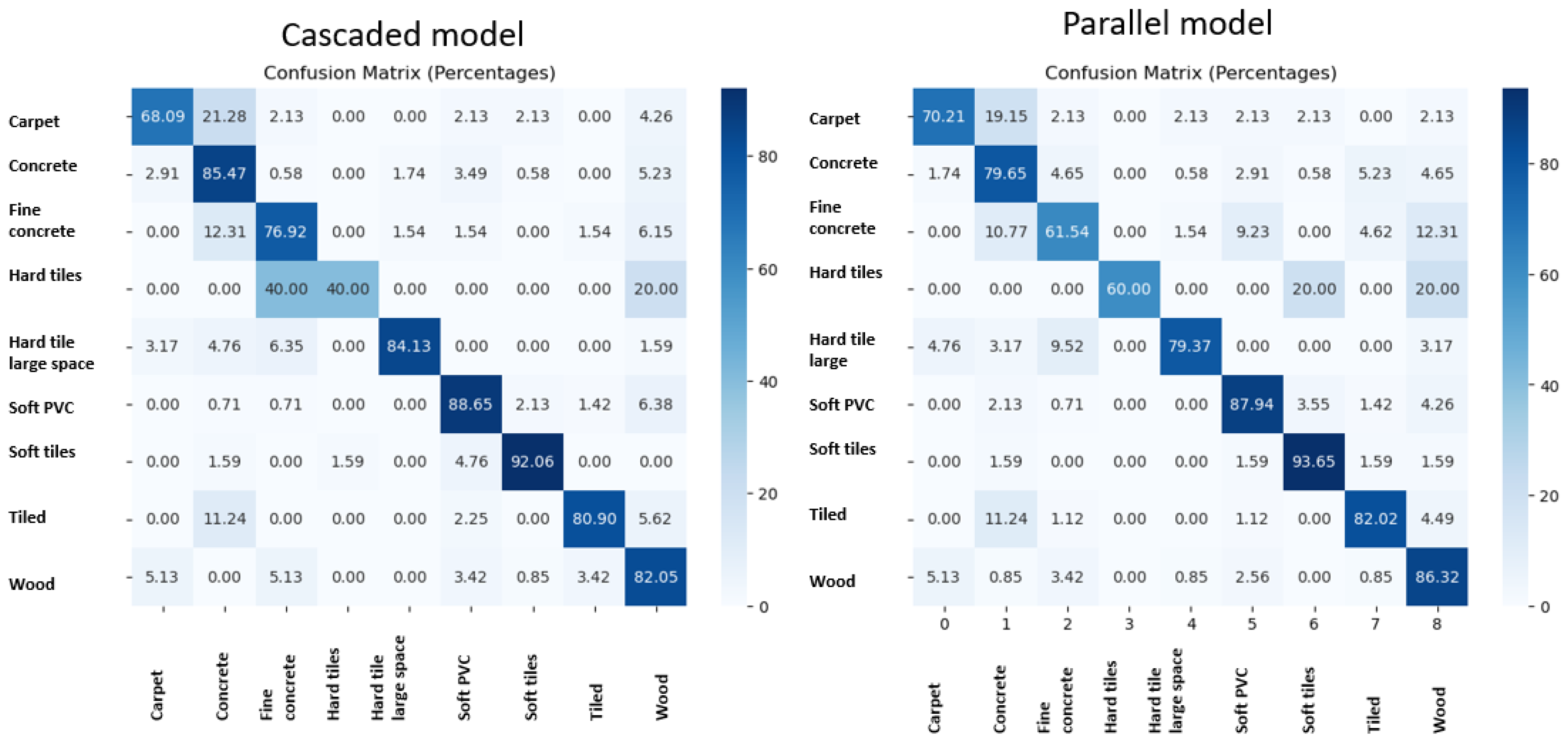
6.3. Cascaded Fusion Model vs. Parallel Fusion Model
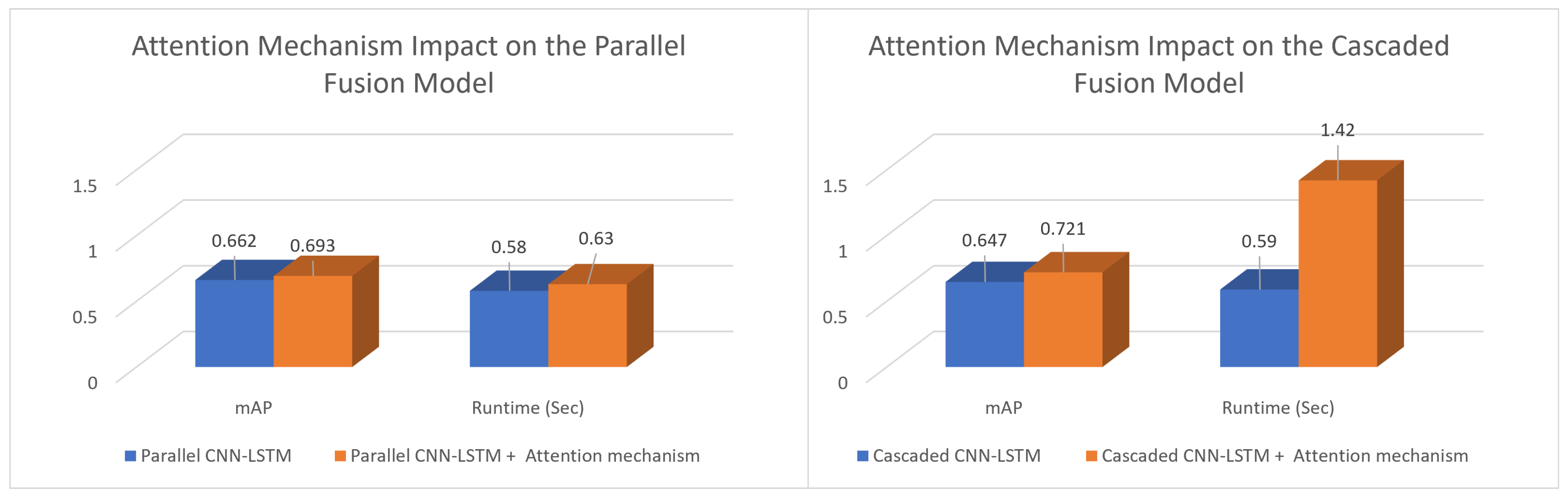
6.4. The Multi-Head Attention Mechanism Impact
7. Discussion
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LSTM | Long Short-Term Memory |
| RNN | Recurrent Neural Network |
| 1-D CNN | One dimensional Convolutional Neural Network |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
| FCN | Fully Connected Network |
| XGBOOST | Extreme Gradient Boosting |
| mAP | Mean Average Precision |
| IMU | Internal Measurement Unit |
| HAR | Human Activities Recognition |
References
- Wang, H.; Luo, N.; Zhou, T.; Yang, S. Physical Robots in Education: A Systematic Review Based on the Technological Pedagogical Content Knowledge Framework. Sustainability 2024, 16, 4987. [Google Scholar] [CrossRef]
- Obrenovic, B.; Gu, X.; Wang, G.; Godinic, D.; Jakhongirov, I. Generative AI and human–robot interaction: Implications and future agenda for business, society and ethics. AI Soc. 2024, 1–14. [Google Scholar] [CrossRef]
- Silvera-Tawil, D. Robotics in Healthcare: A Survey. SN Comput. Sci. 2024, 5, 189. [Google Scholar]
- Walas, K. Terrain classification and negotiation with a walking robot. J. Intell. Robot. Syst. 2015, 78, 401–423. [Google Scholar]
- Khaleghian, S.; Taheri, S. Terrain classification using intelligent tire. J. Terramech. 2017, 71, 15–24. [Google Scholar]
- Oliveira, F.G.; Santos, E.R.; Neto, A.A.; Campos, M.F.; Macharet, D.G. Speed-invariant terrain roughness classification and control based on inertial sensors. In Proceedings of the 2017 Latin American Robotics Symposium (LARS) and 2017 Brazilian Symposium on Robotics (SBR), São Paulo, Brazil, 19–21 October 2017; pp. 1–6. [Google Scholar]
- Hoepflinger, M.A.; Remy, C.D.; Hutter, M.; Spinello, L.; Siegwart, R. Haptic terrain classification for legged robots. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 2828–2833. [Google Scholar]
- Zenker, S.; Aksoy, E.E.; Goldschmidt, D.; Wörgötter, F.; Manoonpong, P. Visual terrain classification for selecting energy efficient gaits of a hexapod robot. In Proceedings of the 2013 IEEE/ASME International Conference on Advanced Intelligent Mechatronics, Wollongong, NSW, Australia, 9–12 July 2013; pp. 577–584. [Google Scholar]
- Zhao, T.; Guo, P.; Wei, Y. Road friction estimation based on vision for safe autonomous driving. Mech. Syst. Signal Process. 2024, 208, 111019. [Google Scholar]
- Iglesias, F.; Aguilera, A.; Padilla, A.; Vizán, A.; Diez, E. Application of computer vision techniques to estimate surface roughness on wood-based sanded workpieces. Measurement 2024, 224, 113917. [Google Scholar]
- Laible, S.; Khan, Y.N.; Zell, A. Terrain classification with conditional random fields on fused 3D LIDAR and camera data. In Proceedings of the 2013 European Conference on Mobile Robots, Warsaw, Poland, 2–4 September 2013; pp. 172–177. [Google Scholar]
- Walas, K.; Nowicki, M. Terrain classification using laser range finder. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 5003–5009. [Google Scholar]
- Borrmann, D.; Nüchter, A.; Ðakulović, M.; Maurović, I.; Petrović, I.; Osmanković, D.; Velagić, J. A mobile robot based system for fully automated thermal 3D mapping. Adv. Eng. Inform. 2014, 28, 425–440. [Google Scholar] [CrossRef]
- Hu, K.; Chen, Z.; Kang, H.; Tang, Y. 3D vision technologies for a self-developed structural external crack damage recognition robot. Autom. Constr. 2024, 159, 105262. [Google Scholar]
- Tang, Y.; Huang, Z.; Chen, Z.; Chen, M.; Zhou, H.; Zhang, H.; Sun, J. Novel visual crack width measurement based on backbone double-scale features for improved detection automation. Eng. Struct. 2023, 274, 115158. [Google Scholar]
- Yi, J.; Zhang, J.; Song, D.; Jayasuriya, S. IMU-based localization and slip estimation for skid-steered mobile robots. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 2845–2850. [Google Scholar]
- Botero Valencia, J.S.; Rico Garcia, M.; Villegas Ceballos, J.P. A simple method to estimate the trajectory of a low cost mobile robotic platform using an IMU. Int. J. Interact. Des. Manuf. (IJIDeM) 2017, 11, 823–828. [Google Scholar]
- Apaydın, N.N.; Kılıç, İ.; Apaydın, M.; Yaman, O. Decision Tree-Based Direction Detection Using IMU Data in Autonomous Robots. Batman Üniv. Yaşam Bilim. Derg. 2024, 14, 57–68. [Google Scholar]
- Zevering, J.; Bredenbeck, A.; Arzberger, F.; Borrmann, D.; Nüchter, A. IMU-based pose-estimation for spherical robots with limited resources. In Proceedings of the 2021 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Seoul, Republic of Korea, 25–27 August 2021; pp. 1–8. [Google Scholar]
- Barnea, A.; Berrabah, S.A.; Oprisan, C.; Doroftei, I. IMU (Inertial Measurement Unit) Integration for the Navigation and Positioning of Autonomous Robot Systems. J. Control. Eng. Appl. Inform. 2011, 13, 38–43. [Google Scholar]
- Wang, L.; Jiang, Z.; Hu, Y.; Yang, S. Research on the Self-Stability Control and Gait Planning of Quadruped Robot Based on IMU. In Proceedings of the 2021 IEEE 21st International Conference on Communication Technology (ICCT), Xi’an, China, 19–21 October 2021; pp. 1078–1081. [Google Scholar]
- Hammoudeh, M.A.A.; Alsaykhan, M.; Alsalameh, R.; Althwaibi, N. Computer Vision: A Review of Detecting Objects in Videos–Challenges and Techniques. Int. J. Online Biomed. Eng. 2022, 18, 15. [Google Scholar]
- Mariniello, G.; Pastore, T.; Menna, C.; Festa, P.; Asprone, D. Structural damage detection and localization using decision tree ensemble and vibration data. Comput. Aided Civ. Infrastruct. Eng. 2021, 36, 1129–1149. [Google Scholar]
- Kumar, P.; Pandi, S.S.; Kumaragurubaran, T.; Chiranjeevi, V.R. Human Activity Recognitions in Handheld Devices Using Random Forest Algorithm. In Proceedings of the 2024 International Conference on Automation and Computation (AUTOCOM), Dehradun, India, 14–16 March 2024; pp. 159–163. [Google Scholar]
- Al-refai, G.; Elmoaqet, H.; Ryalat, M. In-vehicle data for predicting road conditions and driving style using machine learning. Appl. Sci. 2022, 12, 8928. [Google Scholar] [CrossRef]
- Barman, U.; Choudhury, R.D. Soil texture classification using multi class support vector machine. Inf. Process. Agric. 2020, 7, 318–332. [Google Scholar]
- Kim, D.; Kim, S.H.; Kim, T.; Kang, B.B.; Lee, M.; Park, W.; Ku, S.; Kim, D.; Kwon, J.; Lee, H.; et al. Review of machine learning methods in soft robotics. PLoS ONE 2021, 16, e0246102. [Google Scholar]
- Shirmard, H.; Farahbakhsh, E.; Müller, R.D.; Chandra, R. A review of machine learning in processing remote sensing data for mineral exploration. Remote Sens. Environ. 2022, 268, 112750. [Google Scholar]
- Gupta, S. Deep learning based human activity recognition (HAR) using wearable sensor data. Int. J. Inf. Manag. Data Insights 2021, 1, 100046. [Google Scholar]
- Qi, W.; Ovur, S.E.; Li, Z.; Marzullo, A.; Song, R. Multi-sensor guided hand gesture recognition for a teleoperated robot using a recurrent neural network. IEEE Robot. Autom. Lett. 2021, 6, 6039–6045. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, H.; Ye, W. Classification of human activities based on radar signals using 1D-CNN and LSTM. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seoul, Republic of Korea, 18–22 October 2020; pp. 1–5. [Google Scholar]
- Al-refai, G.; Al-refai, M.; Alzu’bi, A. Driving Style and Traffic Prediction with Artificial Neural Networks Using On-Board Diagnostics and Smartphone Sensors. Appl. Sci. 2024, 14, 5008. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. Lstm networks using smartphone data for sensor-based human activity recognition in smart homes. Sensors 2021, 21, 1636. [Google Scholar] [CrossRef] [PubMed]
- Pham, T.D. Time–frequency time–space LSTM for robust classification of physiological signals. Sci. Rep. 2021, 11, 6936. [Google Scholar]
- Matar, M.; Xia, T.; Huguenard, K.; Huston, D.; Wshah, S. Multi-head attention based bi-lstm for anomaly detection in multivariate time-series of wsn. In Proceedings of the 2023 IEEE 5th International Conference on Artificial Intelligence Circuits and Systems (AICAS), Bangalore, India, 9–11 March 2023; pp. 1–5. [Google Scholar]
- Junior, R.F.R.; dos Santos Areias, I.A.; Campos, M.M.; Teixeira, C.E.; da Silva, L.E.B.; Gomes, G.F. Fault detection and diagnosis in electric motors using 1d convolutional neural networks with multi-channel vibration signals. Measurement 2022, 190, 110759. [Google Scholar]
- Cui, W.; Deng, X.; Zhang, Z. Improved convolutional neural network based on multi-head attention mechanism for industrial process fault classification. In Proceedings of the 2020 IEEE 9th Data Driven Control and Learning Systems Conference (DDCLS), Hangzhou, China, 23–25 October 2020; pp. 918–922. [Google Scholar]
- Li, X.; Wu, J.; Li, Z.; Zuo, J.; Wang, P. Robot ground classification and recognition based on CNN-LSTM model. In Proceedings of the 2021 IEEE 2nd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Beijing, China, 16–18 December 2021; pp. 1110–1113. [Google Scholar]
- AlRadaideh, S.; Aljoan, I.; Al-refai, G.; Elmoaqet, H. Ground Classification for Robots Navigation Using Time Series Dataset with LSTM and CNN. In Proceedings of the 2024 22nd International Conference on Research and Education in Mechatronics (REM), Dead Sea, Jordan, 24–26 September 2024; pp. 375–380. [Google Scholar]
- Feng, C.; Dong, K.; Ou, X. A Robot Ground Medium Classification Algorithm Based on Feature Fusion and Adaptive Spatio-Temporal Cascade Networks. Neural Process. Lett. 2024, 56, 235. [Google Scholar]
- Jiang, Y.; Zhou, W.; Zhang, S.; Gao, S. Floor Surface Classification with Robot IMU Sensors Data. Available online: https://noiselab.ucsd.edu/ECE228_2019/Reports/Report14.pdf (accessed on 17 March 2025).
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Van Houdt, G.; Mosquera, C.; Nápoles, G. A review on the long short-term memory model. Artif. Intell. Rev. 2020, 53, 5929–5955. [Google Scholar]
- Hanin, B. Which neural net architectures give rise to exploding and vanishing gradients? Adv. Neural Inf. Process. Syst. 2018, 31, 580–589. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar]
- Lomio, F.; Skenderi, E.; Mohamadi, D.; Collin, J.; Ghabcheloo, R.; Huttunen, H. Surface type classification for autonomous robot indoor navigation. arXiv 2019, arXiv:1905.00252. [Google Scholar]
- Movella. Datasheet for XSENS MTi-300 IMU. Available online: https://www.xsens.com/hubfs/Downloads/Leaflets/MTi-300.pdf (accessed on 17 March 2025).
- Maggie; Dane, S. CareerCon 2019—Help Navigate Robots. Available online: https://kaggle.com/competitions/career-con-2019 (accessed on 19 October 2024).
- Erickson, B.J.; Kitamura, F. Magician’s Corner: 9. Performance Metrics for Machine Learning Models. Radiol. Artif. Intell. 2021, 3, e200126. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Batch size | 32 |
| Epoch size | 60 |
| Optimization function | Adam |
| dropout rate | 0.2 |
| Attention mechanism number of heads | 8 |
| Attention mechanism key vector dimension | 64 |
| Number of LSTM units | 64 |
| Metric | Baseline (LSTM) | Cascaded (CNN-LSTM) | Cascaded (CNN-LSTM + Attention) | % Improvement (Cascaded Model to LSTM) |
|---|---|---|---|---|
| Precision | 0.764 | 0.787 | 0.835 | +9.3% |
| Recall | 0.752 | 0.777 | 0.833 | +10.8% |
| F1 Score | 0.751 | 0.779 | 0.833 | +10.9% |
| mAP | 0.608 | 0.647 | 0.721 | +18.6% |
| Runtime (ms) | 580 | 590 | 1420 | −144.8% |
| Metric | Baseline (LSTM) | Parallel (CNN-LSTM) | Parallel (CNN-LSTM + Attention) | % Improvement (Parallel Model to LSTM) |
|---|---|---|---|---|
| Precision | 0.764 | 0.794 | 0.815 | +6.7% |
| Recall | 0.752 | 0.793 | 0.813 | +8.1% |
| F1 Score | 0.751 | 0.791 | 0.813 | +8.3% |
| mAP | 0.608 | 0.662 | 0.693 | +14.0% |
| Runtime (ms) | 580 | 580 | 630 | −8.6% |
| Metric | Cascaded (CNN-LSTM + Attention) | Parallel (CNN-LSTM + Attention) | % Improvement (Cascaded to Parallel Fusion Model) |
|---|---|---|---|
| Precision | 0.835 | 0.815 | +2.4% |
| Recall | 0.833 | 0.813 | +2.4% |
| F1 Score | 0.833 | 0.813 | +2.4% |
| mAP | 0.721 | 0.693 | +3.9% |
| Runtime (ms) | 1420 | 630 | −55.6% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-refai, G.; Karasneh, D.; Elmoaqet, H.; Ryalat, M.; Almtireen, N. Surface Classification from Robot Internal Measurement Unit Time-Series Data Using Cascaded and Parallel Deep Learning Fusion Models. Machines 2025, 13, 251. https://doi.org/10.3390/machines13030251
Al-refai G, Karasneh D, Elmoaqet H, Ryalat M, Almtireen N. Surface Classification from Robot Internal Measurement Unit Time-Series Data Using Cascaded and Parallel Deep Learning Fusion Models. Machines. 2025; 13(3):251. https://doi.org/10.3390/machines13030251
Chicago/Turabian StyleAl-refai, Ghaith, Dina Karasneh, Hisham Elmoaqet, Mutaz Ryalat, and Natheer Almtireen. 2025. "Surface Classification from Robot Internal Measurement Unit Time-Series Data Using Cascaded and Parallel Deep Learning Fusion Models" Machines 13, no. 3: 251. https://doi.org/10.3390/machines13030251
APA StyleAl-refai, G., Karasneh, D., Elmoaqet, H., Ryalat, M., & Almtireen, N. (2025). Surface Classification from Robot Internal Measurement Unit Time-Series Data Using Cascaded and Parallel Deep Learning Fusion Models. Machines, 13(3), 251. https://doi.org/10.3390/machines13030251