

An Internet of Things-Based Production Scheduling for Distributed Two-Stage Assembly Manufacturing with Mold Sharing



Abstract
1. Introduction
2. Literature Review
2.1. Distributed Two-Stage Assembly Scheduling
2.2. Mold Sharing
2.3. CPS in Distributed Scheduling
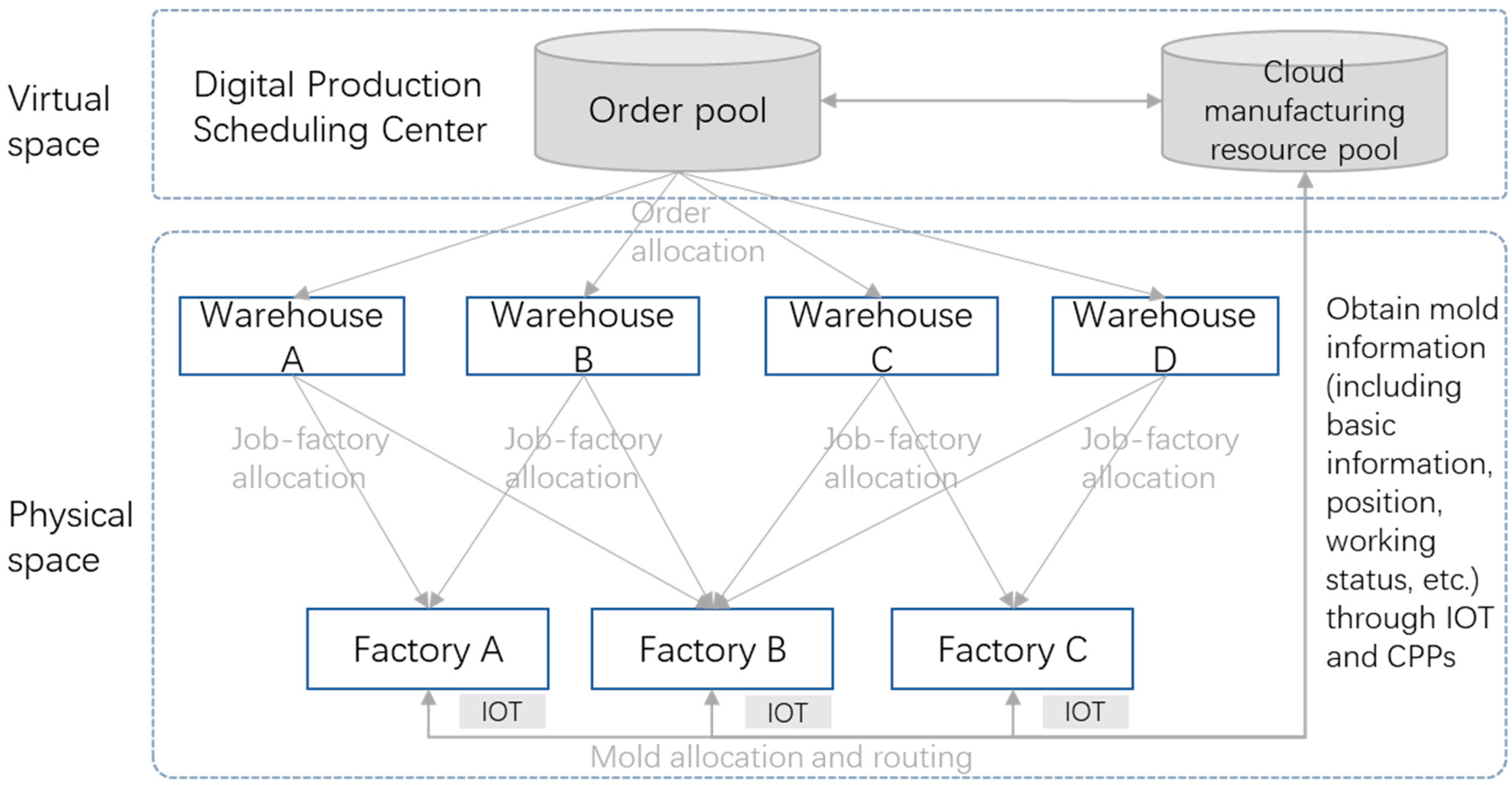
3. DTAFSP Model Design with Mold Sharing
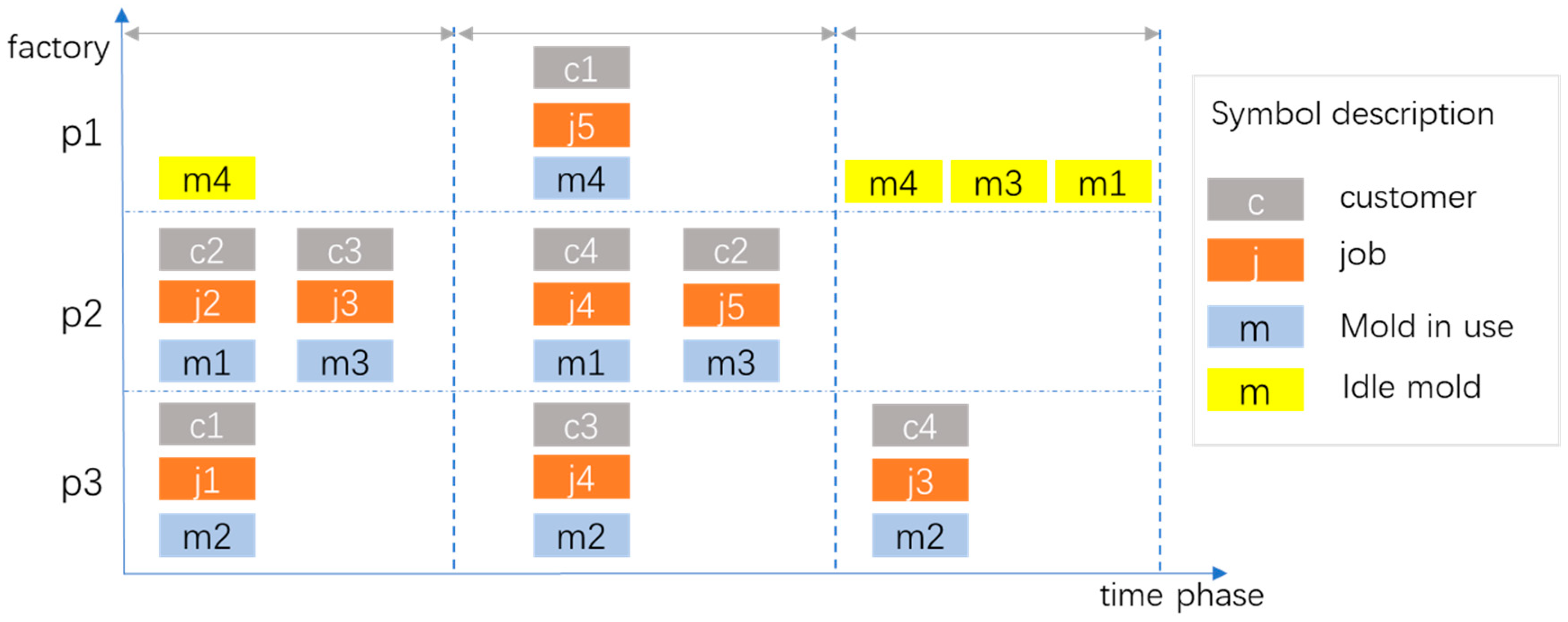
3.1. Problem Description
- (1)
- All factories and distribution warehouses have a common “order pool” and orders are homogeneous. Considering the delivery time and allocation cost of orders, different orders should be allocated to candidate distribution warehouses and factories.
- (2)
- All factories are homogeneous and can produce any order in the order pool.
- (3)
- The capacity of the same mold is the same and fixed. Each mold can only process one job at a time.
- (4)
- The household appliance production line mainly includes two stages, namely injection molding and final assembly. Mold injection molding is in the first stage of the production line.
- (5)
- When each factory starts, all molds are scheduled from the “cloud manufacturing resource pool”, and all molds are scheduled from the beginning of job allocation. If there is no job assigned to factory p in the next stage, the molds in this factory p are returned to the mold warehouse or transferred to other factories which are assigned new jobs. The mold resource information in the “cloud manufacturing resource pool” is updated synchronously.
- (6)
- In the process of order execution in each factory, except for sharing some molds, it is completely produced independently, and there is no timing constraint between orders in different factories.
- (7)
- Different mold transfer strategies only affect the mold transfer cost and do not consider the possible impact on other costs of the production plant.
- (8)
- Each factory has its own raw material procurement and sufficient inventory reserves Therefore, the transfer cost and time of raw materials and other materials are not considered.
- (9)
- The transfer time of the mold from to is the same as that transferred from to .
- (10)
- The setting time is negligible, the transportation time in factories is zero, the buffer size between the two stages is unlimited, and the mold and machine are continuously available.
3.2. Symbol Definition
3.3. Mathematical Model
4. Solution Algorithm
4.1. Solution Parsing Heuristics
4.2. Algorithm Design
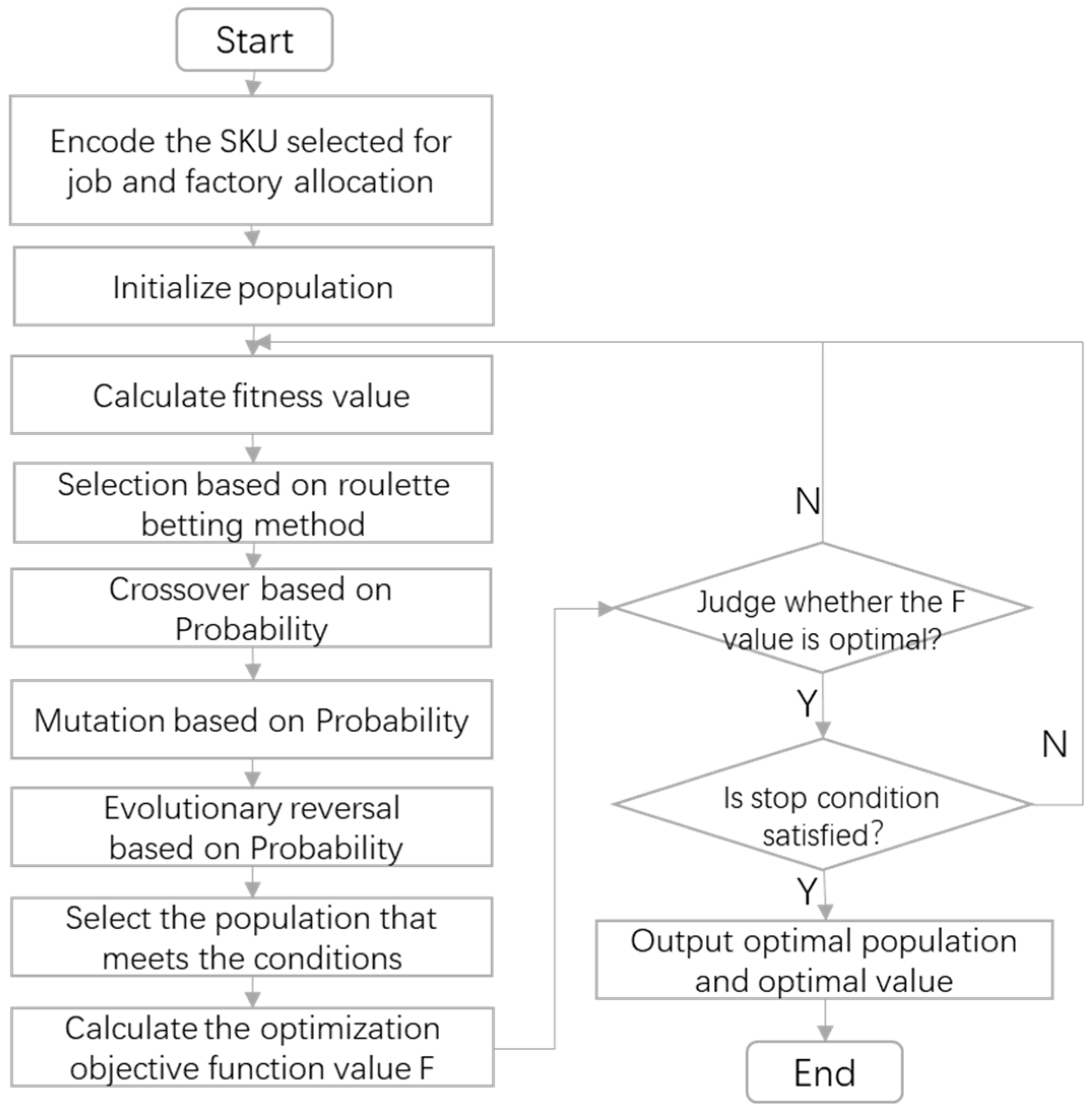
4.2.1. Genetic Algorithm
- Encoding and decoding schemes
- 2.
- Fitness function
- 3.
- Select operator
- 4.
- Cross-operation
- 5.
- Mutation operation
- 6.
- Evolutionary reversal
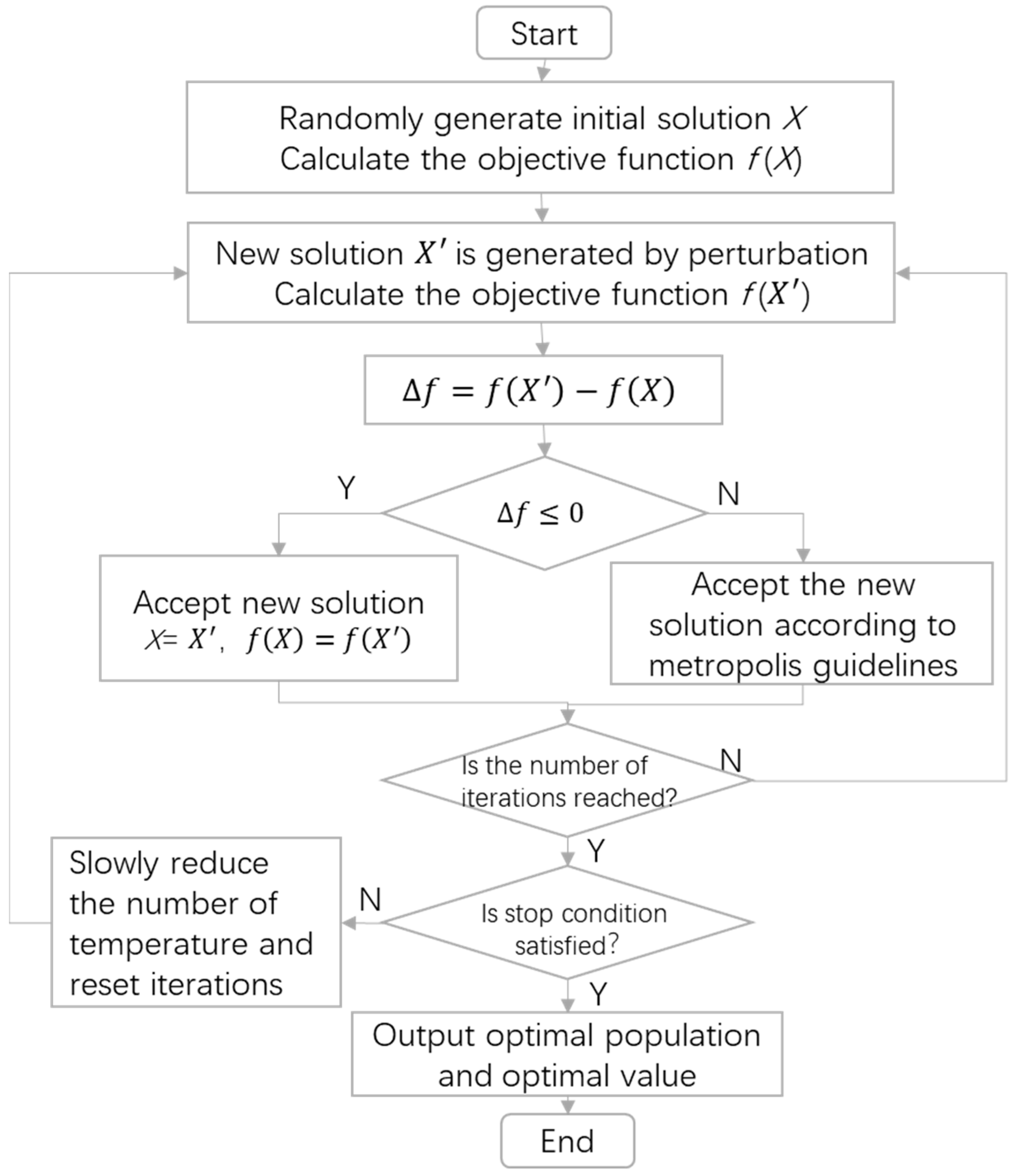
4.2.2. Simulated Annealing Algorithm
- Initialization: initial temperature T0, final temperature , the state of the initial solution (the starting point of the algorithm iteration), and the number of iterations of each t value
- For , perform steps 3 to 6.
- Generate new solutions : .
- Calculate increment , where is the optimization objective.
- If (if looking for the minimum value, then ), then accept as the current solution; otherwise, accept as the current solution with probability , where k is the Boltzmann constant and is usually set as k = 1 in practical problems.
- If the stop conditions are met, then the current solution is output as the optimal solution, the current population is taken as the optimal population, and the program ends.
- If T0 decreases gradually, and , then go to step 2.
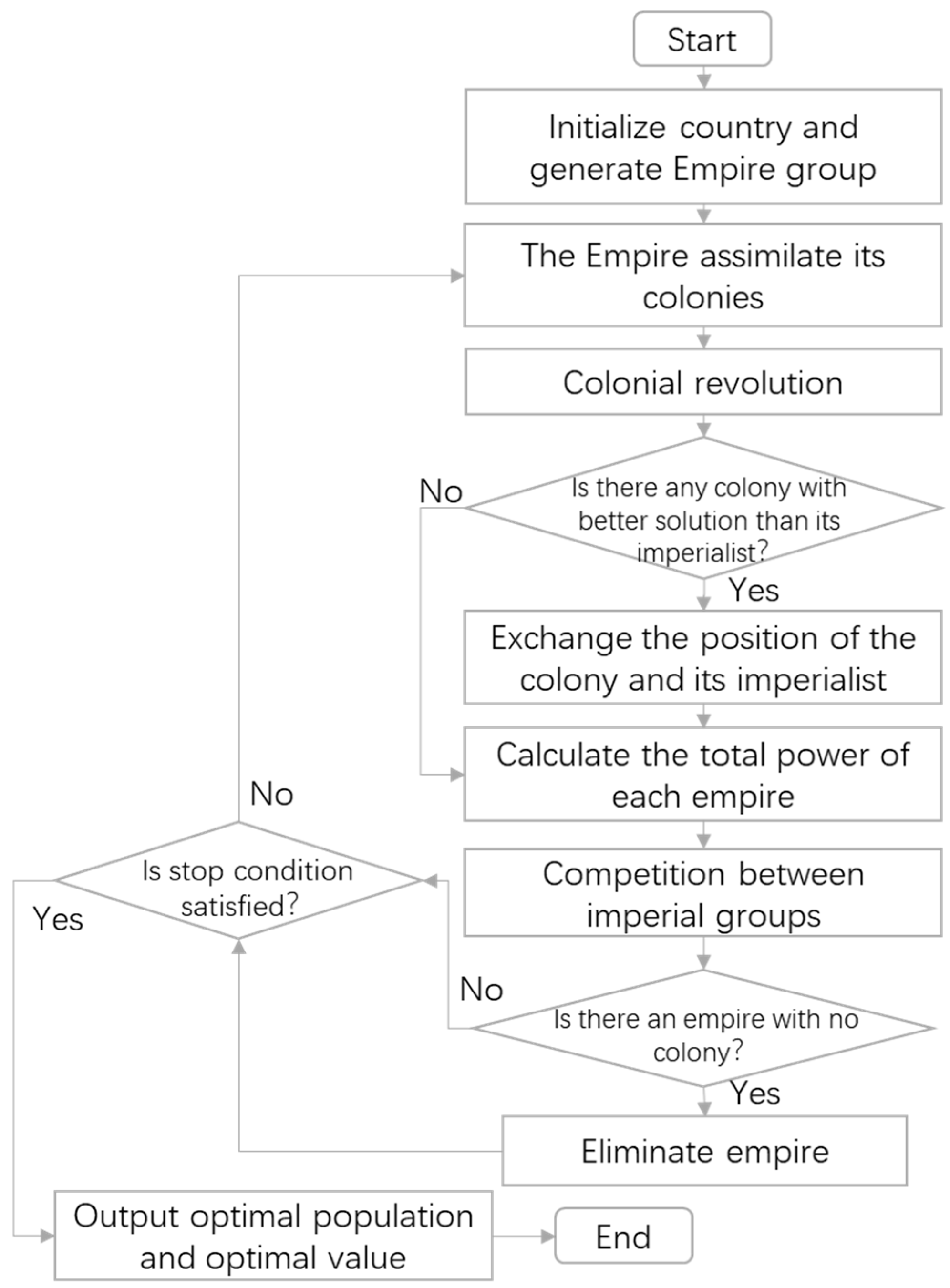
4.2.3. Imperial Competition Algorithm
- Initialize country and generate Empire
- 2.
- The empire assimilates its colonies
- 3.
- Colonial revolution
- 4.
- Exchange the positions of colonies and empires
- 5.
- Competition between imperial groups
- 6.
- Eliminate empire
5. Numerical Simulation and Result Analysis
5.1. Parameters Setting
5.2. Algorithms Comparison
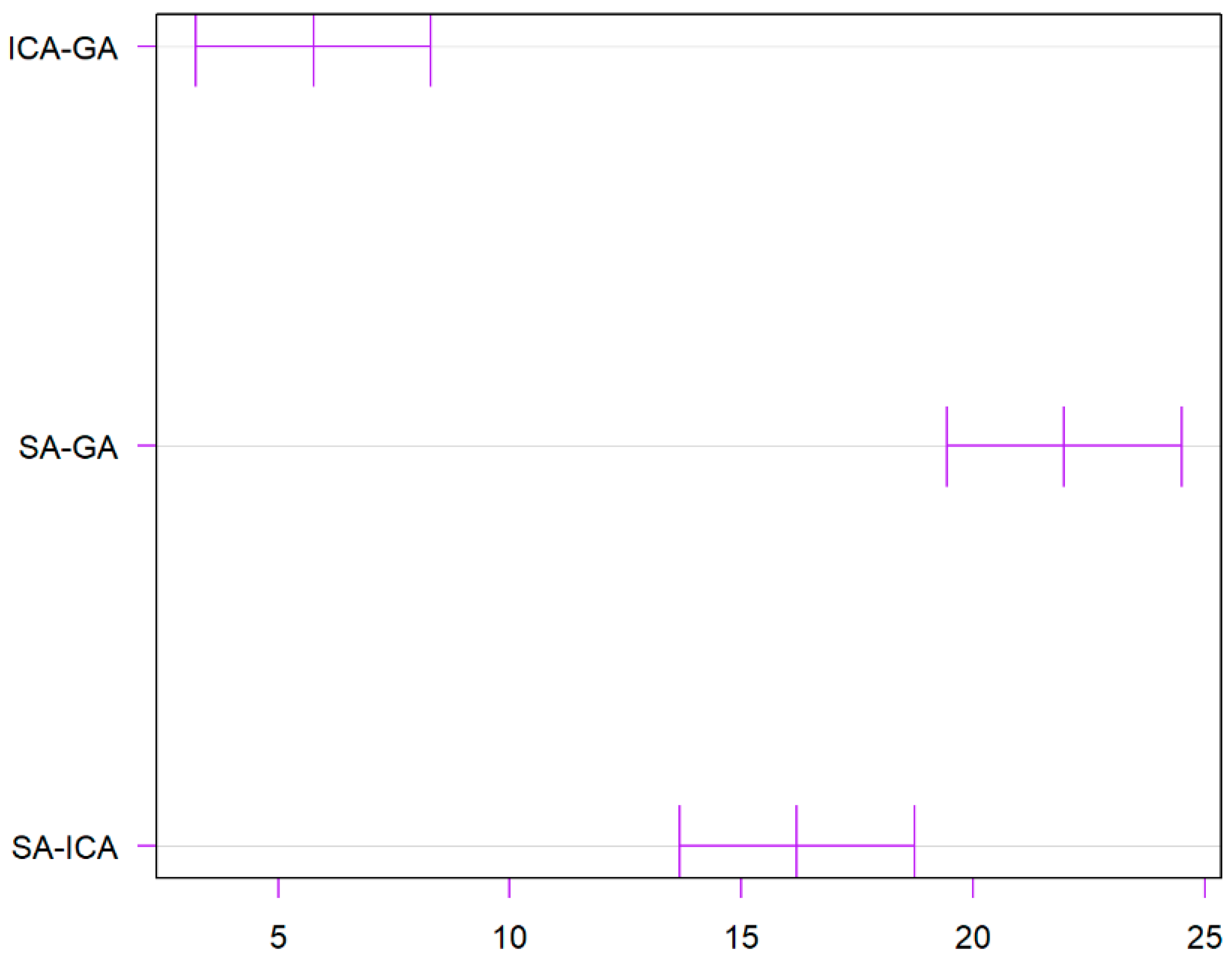
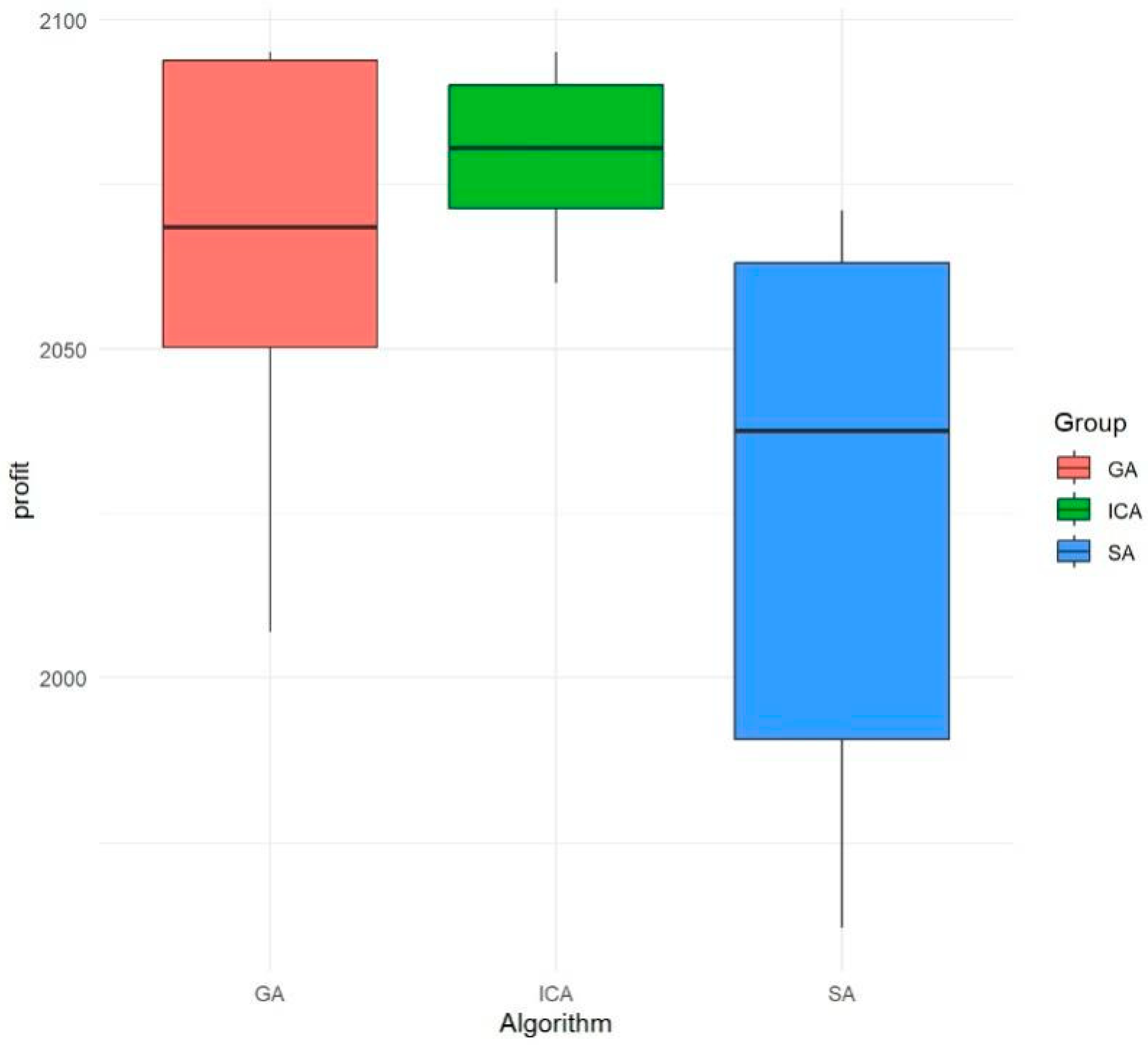
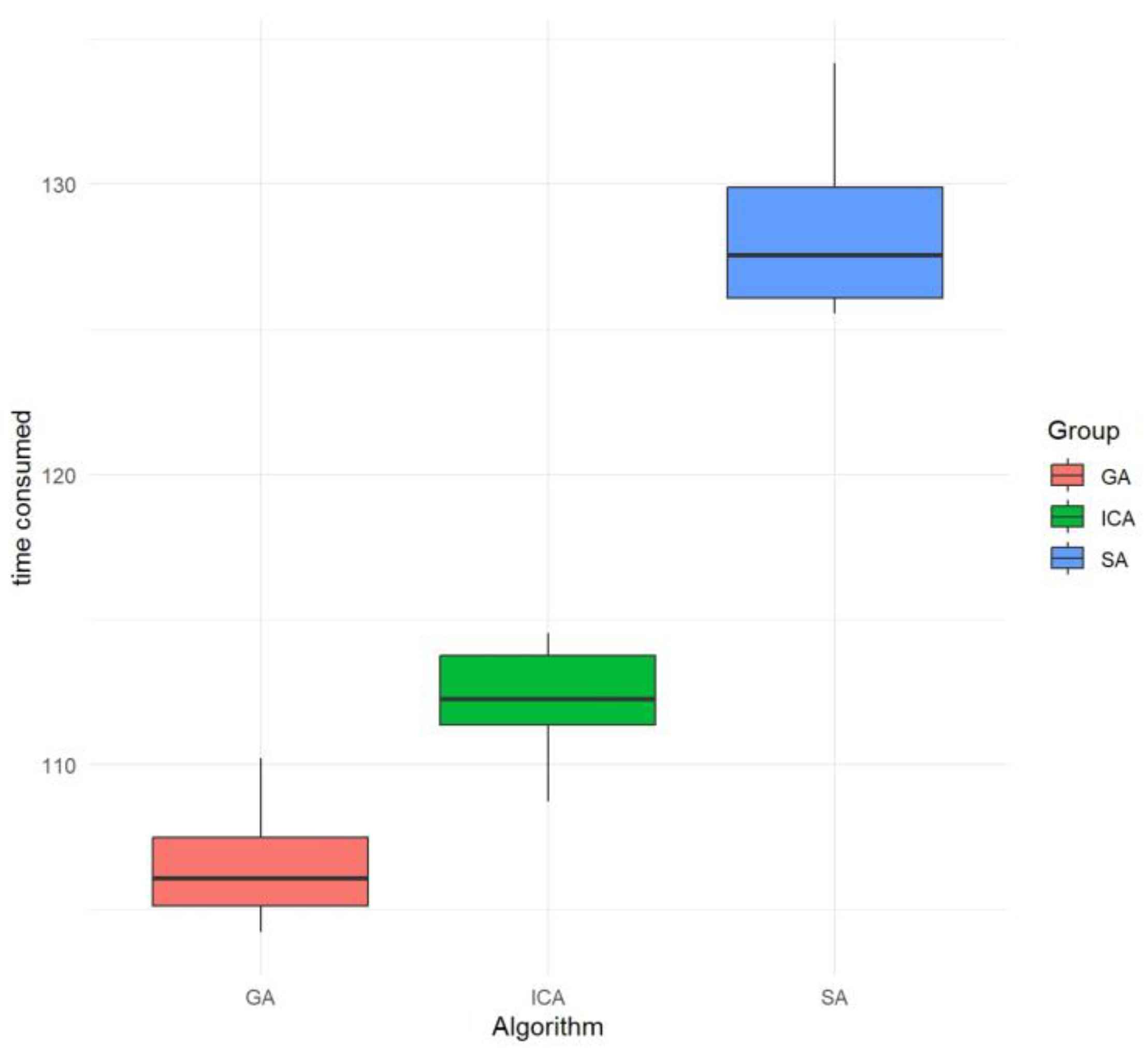
5.3. Results Analysis
6. Conclusions and Future Recommendation
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ling, W.; Jin, D.; Sheng-yao, W. Survey on optimization algorithms for distributed shop scheduling. J. Control Decis. Mak. 2016, 31, 1–11. [Google Scholar] [CrossRef]
- Raa, B.; Dullaert, W.; Aghezzaf, E.H. A matheuristic for aggregate production-distribution planning with mould sharing. Int. J. Prod. Econ. 2013, 145, 29–37. [Google Scholar] [CrossRef]
- Yavari, M.; Marvi, M.; Akbari, A.H. Semi-permutation-based genetic algorithm for order acceptance and scheduling in two-stage assembly problem. Neural Comput. Appl. 2020, 32, 2989–3003. [Google Scholar] [CrossRef]
- Xiong, F.L.; Xing, K.Y. Meta-heuristics for the distributed two-stage assembly scheduling problem with bi-criteria of makespan and mean completion time. Int. J. Prod. Res. 2014, 52, 2743–2766. [Google Scholar] [CrossRef]
- Deng, J.; Wang, L.; Wang, S.Y.; Zheng, X.L. A competitive memetic algorithm for the distributed two-stage assembly flow-shop scheduling problem. Int. J. Prod. Res. 2016, 54, 3561–3577. [Google Scholar] [CrossRef]
- Zhang, G.H.; Xing, K.Y. Memetic social spider optimization algorithm for scheduling two-stage assembly flowshop in a distributed environment. Comput. Ind. Eng. 2018, 125, 423–433. [Google Scholar] [CrossRef]
- De-ming, L.; Tian, W. An improved shuffled frog leaping algorithm for the distributed two-stage hybrid flow shop scheduling. J. Control Decis. Mak. 2021, 36, 241–248. [Google Scholar]
- Ya-ling, C.; De-ming, L. An imperialist competition and cooperation algorithm for distributed two-stage assembly flow shop scheduling. J. Control Theory Appl. 2021, 38, 1957–1967. [Google Scholar]
- Aghezzaf, E.H. Production planning and warehouse management in supply networks with inter-facility mold transfers. Eur. J. Oper. Res. 2007, 182, 1122–1139. [Google Scholar] [CrossRef]
- Song Ming, Z.; GuiXing, Y. Slipper industry interconnection platform—Shared mold app. J. Bohai Rim Econ. Outlook 2019, 4, 72–73. [Google Scholar] [CrossRef]
- Zhang, H.J.; Yan, Q.; Wen, Z.H. Information modeling for cyber-physical production system based on digital twin and Automation ML. Int. J. Adv. Manuf. Technol. 2020, 107, 1927–1945. [Google Scholar] [CrossRef]
- Lee, E.A.; Seshia, S.A. Introduction to Embedded Systems—A Cyber-Physical Systems Approach; lulu.com: Morrisville, NC, USA, 2011; p. 4. [Google Scholar]
- Mahmoodjanloo, M.; Tavakkoli-Moghaddam, R.; Baboli, A.; Bozorgi-Amiri, A. Dynamic Distributed Job-Shop Scheduling Problem Consisting of Reconfigurable Machine Tools. In Proceedings of the IFIP WG 5.7 International Conference on Advances in Production Management Systems (APMS), Novi Sad, Serbia, 30 August–3 September 2020. [Google Scholar]
- Hosseini, S.; Khaled, A.A.; Vadlamani, S. Hybrid Imperialist Competitive Algorithm, Variable Neighborhood Search, and Simulated Annealing for Dynamic Facility Layout Problem. Neural Comput. Appl. 2014, 25, 1871–1885. [Google Scholar] [CrossRef]
- Sangaiah, A.K.; Khanduzi, R. Tabu search with simulated annealing for solving a location–protection–disruption in hub network. Appl. Soft Comput. 2022, 114, 108056. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- Lambora, A.; Gupta, K.; Chopra, K. Genetic Algorithm- A Literature Review. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019. [Google Scholar]
- Zhang, K.; XT Peng, X. Reheating Furnace Temperature Optimization Based on the Inver-Over Operator Genetic Algorithm. J. Jiangnan Univ. 2013, 12, 677–681. [Google Scholar]
- Li, P.; Yang, Y.X.; Du, X.Y.; Qu, X.H.; Wang, K.Y.; Liu, B.; IEEE. Iterated Local Search for Distributed Multiple Assembly No-wait Flowshop Scheduling. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Donostia-San Sebastián, Spain, 5–8 June 2017. [Google Scholar]
- Li, Y.L.; Li, X.Y.; Gao, L.; Meng, L.L. An improved artificial bee colony algorithm for distributed heterogeneous hybrid flowshop scheduling problem with sequence-dependent setup times. Comput. Ind. Eng. 2020, 147, 106638. [Google Scholar] [CrossRef]
- Jialin, H.; Yaya, Z.; Xingsheng, G. Distributed Assembly Permutation Flowshop Scheduling Problem Based on Modified Biogeography-Based Optimization Algorithm. J. East China Univ. Sci. Technol. (Nat. Sci. Ed.) 2020, 46, 758–769. [Google Scholar] [CrossRef]
- Li, W.H.; Chen, X.L.; Li, J.Q.; Sang, H.Y.; Han, Y.Y.; Du, S.B. An improved iterated greedy algorithm for distributed robotic flowshop scheduling with order constraints. Comput. Ind. Eng. 2022, 164, 107907. [Google Scholar] [CrossRef]
- Qingyong, Z.; Haoran, W.; Deming, L. Novel imperialist competitive algorithm for distributed parallel machine scheduling problem. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2019, 47, 86–91. [Google Scholar]
- Pei, S.; Zhao, J.; Zhang, N.; Guo, M. Methodology on developing an assessment tool for intralogistics by considering cyber-physical production systems enabling technologies. Int. J. Comput. Integr. Manuf. 2019, 32, 406–412. [Google Scholar] [CrossRef]
- Talkhestani, B.A.; Jazdi, N.; Schloegl, W.; Weyrich, M. Consistency check to synchronize the Digital Twin of manufacturing automation based on anchor points. Procedia CIRP 2018, 72, 159–164. [Google Scholar] [CrossRef]
- Song, Y.; Wei, L.; Yang, Q.; Wu, J.; Xing, L.; Chen, Y. RL-GA: A Reinforcement Learning-based Genetic Algorithm for Electromagnetic Detection Satellite Scheduling Problem. Swarm Evol. Comput. 2023, 77, 101236. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1. Procedure |
| 2. Set Parameters (N_t, N_t1, N_t2, N_t3, N_job, N_sku, N_k, N_p, N_m, N, M) |
| 3. Input Solution Matrix |
| 4. %%Job-SKU allocation%% |
| 5. For i = 1: N_job |
| 6. If J(i) is null and i ≤ M |
| 7. J(i) = SKU(i) % Assign product SKU(i) to job J(i) % |
| 8. Else if i > M |
| 9. J(i) = randi ([1 M],1) % Randomly assign product SKU to job J(i) % |
| 10. End if |
| 11. End for |
| 12. %%Job-factory allocation and initial scheduling%% |
| 13. For t = 1: N_t |
| 14. For i = 1: N_job |
| 15. h(i)= randi ([1 P],1) % Randomly assign factory p to job J(i) % |
| 16. End for |
| 17. Calculate total quantity Q(p,j,t),U(p,j,w,t), I(w,j,t), V(w,j,c,t)in period t. |
| 18. Sum production quantity Q(p,j,t) = Sum transportation quantity U(p,j,w,t). |
| 19. Sum transportation quantity V(w,j,c,t) = Sum order demand d(c,j,t) of customers. |
| 20. Required production quantity Q(p,j,t) ≤ Total production capacity in period t. |
| 21. End for |
| 22. %%mold allocation and mold routing %% |
| 23. wz_mj = [1111] % Initial position of 4 sets of molds |
| 24. For t = 1: N_t |
| 25. If (t = =1) |
| 26. For i = 1: N_t1 |
| 27. If h(i) ≠ p1 |
| 28. Transfer mold from factory p1 to factory of h(i). |
| 29. Record the new location of the factory where the mold is located. |
| 30. Calculate the arrival time of mold AT(p,i,q). |
| 31. End if |
| 32. End for |
| 33. End if |
| 34. For i = N_t1 + 1: N_job |
| 35. If h(i)_mj = Empty %if the factory of h(i) has no mold |
| 36. For p = 1:N_p |
| 37. If wz_mj(p, t) ≠ Empty %if the factory P(p) has mold in period t |
| 38. Transfer mold from factory P(p) to factory of h(i). |
| 39. Record the new location of the factory where the mold is located. |
| 40. Calculate the arrival time of mold AT(p,i,q). |
| 41. End if |
| 42. End for |
| 43. End if |
| 44. End for |
| 45. End for |
| 47. %%Production Scheduling %% |
| 48. For t = 1: N_t |
| 49. For j = 1: N_job |
| 50. For p = 1: N_p |
| 51. If AT(p,j,q) ≤ ST(p,j) %The mold should arrive at the factory before production start% |
| 52. Completion time CT(p,j,t) in factory p = Starting time + Production time in phase one and assembly time in phase two. |
| 53. Else if CT(p,j,t)-D(j,t) > 0 |
| 54. The order delay time T(j) = the completion time CT(p,j,t)—the delivery time D(j,t) |
| 55. End if |
| 56. The order delay time T(j) = 0. |
| 57. End for |
| 58. End for |
| 59. End for |
| 60. End Procedure |
| Parameter | Parameter Range | Parameter | Parameter Range |
|---|---|---|---|
| 122 | 5 | ||
| 10 | 150 | ||
| [3, 4, 1] | 2 | ||
| 40 | 150 | ||
| [0.3 0.3 0.3 0.3 0.3; 0.4 0.4 0.4 0.4 0.4; 0.2 0.2 0.2 0.2 0.2] | [0 4 5; 4 0 3; 5 3 0] | ||
| [0.1 0.1 0.1 0.1 0.1; 0.1 0.1 0.1 0.1 0.1; 0.1 0.1 0.1 0.1 0.1] | [0 60 70; 60 0 65; 70 65 0] | ||
| [96 98 97 96 99; 86 88 87 86 89; 85 85 86 85 87] | [1 4 6 3; 4 1 7 3; 5 4 1 3] | ||
| Because the relationship between the distribution warehouse and the customer is fixed (one-to-one), take the fixed value of 2 | [0 0 0 0 0; 0 0 0 0 0; 0 0 0 0 0] | ||
| t1: [5 0 0 0 0; 0 4 0 0 0; 0 0 5 0 0; 0 0 0 0 0] t2: [0 0 0 0 6; 4 0 0 0 0; 0 5 0 0 0;0 0 0 5 0] t3: [0 0 0 0 0;0 0 0 0 0; 0 0 0 0 0; 0 0 6 0 0] | |||
| GA Parameters | SA Parameters | ICA Parameters | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 0.9 | 0.1 | 0.2 | 100 | 10 | 0.85 | 100 | 10 | 1.5 | 0.2 | 0.2 |
| No. | Transfer Cost and Time | GA | ICA | SA | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Optimal Profit | Delay Time (h) | Calculation Time (s) | Optimal Profit | Delay Time (h) | Calculation Time (s) | Optimal Profit | Delay Time (h) | Calculation Time (s) | ||
| 1 | 5mc4mt | 2235 | 0.3 h | 62.15 s | 2229 | 0.3 h | 61.31 s | 2269 | 0.3 h | 76.95 s |
| 2 | 25mc4mt | 2197 | 1.5 h | 67.59 s | 2191 | 1.5 h | 60.17 s | 2058 | 0.3 h | 75.2 s |
| 3 | 45mc4mt | 2085 | 1.5 h | 61.16 s | 2149 | 0.3 h | 60.33 s | 2032 | 1.5 h | 72.67 s |
| 4 | 65mc4mt | 2095 | 0.3 h | 62.98 s | 2095 | 0.3 h | 57.78 s | 2016 | 0 h | 73.9 s |
| 5 | 75mc4mt | 1860 | 0.3 h | 58.84 s | 2024 | 0.3 h | 59.73 s | 1932 | 0.3 h | 71.45 s |
| 6 | 25mc6mt | 2182 | 3 h | 62.43 s | 2142 | 3.5 h | 65.24 s | 2060 | 2.5 h | 75.804 s |
| 7 | 45mc6mt | 2082 | 3.5 h | 63.21 s | 2122 | 3 h | 60.53 s | 2000 | 3 h | 74.49 s |
| 8 | 25mc8mt | 2105 | 7.8 h | 62.04 s | 2122 | 9 h | 59.21 s | 1980 | 8.6 h | 76.3 s |
| 9 | 45mc8mt | 1988 | 5.3 h | 63.64 s | 2062 | 9 h | 61.09 s | 1937 | 8.2 h | 77.45 s |
| Diff | Lwr | Upr | Adjusted p-Value | |
|---|---|---|---|---|
| GA-ICA | 13.6 | −20.20229 | 47.40229 | 0.5846945 |
| GA-SA | −40.2 | −74.00229 | −6.39771 | 0.0173309 |
| ICA-SA | −53.8 | −87.60229 | −19.99771 | 0.0014349 |
| Diff | Lwr | Upr | Adjusted p-Value | |
|---|---|---|---|---|
| GA-ICA | 5.763 | 3.226744 | 8.299256 | 1.63 × e−05 |
| GA-SA | 21.960 | 19.423744 | −24.496256 | 0.00 × e+00 |
| ICA-SA | 16.197 | 13.660744 | 18.733256 | 0.00 × e+00 |
| No. | Mold Transfer Cost and Time | Optimal Profit | Gross Margin | Delay Time (h) | Before and After Optimization |
|---|---|---|---|---|---|
| 1 | 5mc4mt | 2235 | 45.8% | 0.3 h | After |
| 2 | 25mc4mt | 2197 | 45.0% | 1.5 h | |
| 3 | 45mc4mt | 2085 | 42.7% | 1.5 h | |
| 4 | 65mc4mt | 2095 | 42.9% | 0.3 h | |
| 5 | 75mc4mt | 1860 | 38.1% | 0.3h | |
| 6 | 25mc6mt | 2182 | 42.2% | 3 h | |
| 7 | 45mc6mt | 2082 | 41.0% | 3.5 h | |
| 8 | 25mc8mt | 2105 | 40.6% | 7.8 h | |
| 9 | 45mc8mt | 1988 | 40.7% | 5.3 h | |
| 10 | 0mc0mt | 1152 | 23.6% | 11.3 h | Before |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Ma, C.; Huang, Y. An Internet of Things-Based Production Scheduling for Distributed Two-Stage Assembly Manufacturing with Mold Sharing. Machines 2024, 12, 310. https://doi.org/10.3390/machines12050310
Liu Y, Ma C, Huang Y. An Internet of Things-Based Production Scheduling for Distributed Two-Stage Assembly Manufacturing with Mold Sharing. Machines. 2024; 12(5):310. https://doi.org/10.3390/machines12050310
Chicago/Turabian StyleLiu, Yin, Cunxian Ma, and Yun Huang. 2024. "An Internet of Things-Based Production Scheduling for Distributed Two-Stage Assembly Manufacturing with Mold Sharing" Machines 12, no. 5: 310. https://doi.org/10.3390/machines12050310
APA StyleLiu, Y., Ma, C., & Huang, Y. (2024). An Internet of Things-Based Production Scheduling for Distributed Two-Stage Assembly Manufacturing with Mold Sharing. Machines, 12(5), 310. https://doi.org/10.3390/machines12050310