1. Introduction
With the progress of science and technology, artificial intelligence, autonomous vehicles, and the internet of things are becoming ingrained in our daily lives. In recent years, many applications have utilized unmanned aerial vehicles (UAVs) to perform specific tasks, such as water pollution detection, object detection, livestock monitoring, crop monitoring, and building appearance inspection. Untreated trash has always been ubiquitous, especially on riversides and coastlines, significantly affecting many species’ natural habitats and quality of life. The first significant civilizations originated from riversides. Rivers transport things and provide fresh water for crops and people near the river. However, many rivers are now polluted by trash and untreated garbage, affecting the environment.
To improve the quality of life and protect the species from trash pollution, we developed a trash detection system based on UAVs that detects garbage and sends trash information to government officials. The proposed system can help officials monitor the riverine efficiently. In particular, this study assembles UAVs for riverine garbage detection. We built an exclusive garbage detector, and the images obtained from the UAVs’ cameras were stitched and sent to a video streaming server, allowing government officials to check waste information efficiently from the real-time multi-camera stitching images.
In [
1], the authors collected data from TrashNet [
2], the trash annotations in context (TACO) dataset [
3], the drinking waste classification dataset [
4], and other photos from the internet. The object detection system detected trash successfully in complex backgrounds using a simple background dataset. In [
5], the authors created the HAIDA (nickname of the National Taiwan Ocean University) dataset [
6], which includes the TACO dataset and the simple aerial trash dataset with 1834 images. They developed a UAV trash detector and a real-time monitoring system for sea coast and beach usage, successfully detecting trash in several scenarios. In [
7], the authors proposed an effective data augmentation method called “circulate shift for convolutional neural networks”, which can deal with a data limit. In [
8], the authors proposed the you only look once version 5s (YOLOv5s) model and built a trash detector. The model successfully detected five categories: battery, orange peel, waste paper, paper cups, and bottles. In [
9], the authors proposed an unsupervised depth image stitching framework, including unsupervised coarse image alignment and image reconstruction. This framework successfully stitched the images and performed well. In [
10], the authors proposed an edge-based weight minimum error seam method to overcome the limitations caused by parallax and video stitching. In addition, they used a trigonometric-ratio-based image match algorithm to reduce computational complexity. In [
11], to prevent the optimization from being affected by poor feature matches, the authors proposed a method to distinguish between correct and false matches and encapsulate the false match elimination scheme and their optimization into a loop. The main component of their method is a unified video stitching and stabilization optimization that computes stitching and stabilization simultaneously rather than performing each individually. In [
12], the authors combined the scale-invariant feature transform (SIFT) [
13] and the speed-up robust features (SURF) [
14] algorithms for better image stitching results. Adapting the above concepts, we developed a UAV riverine detector and achieved dynamic image stitching from UAV cameras.
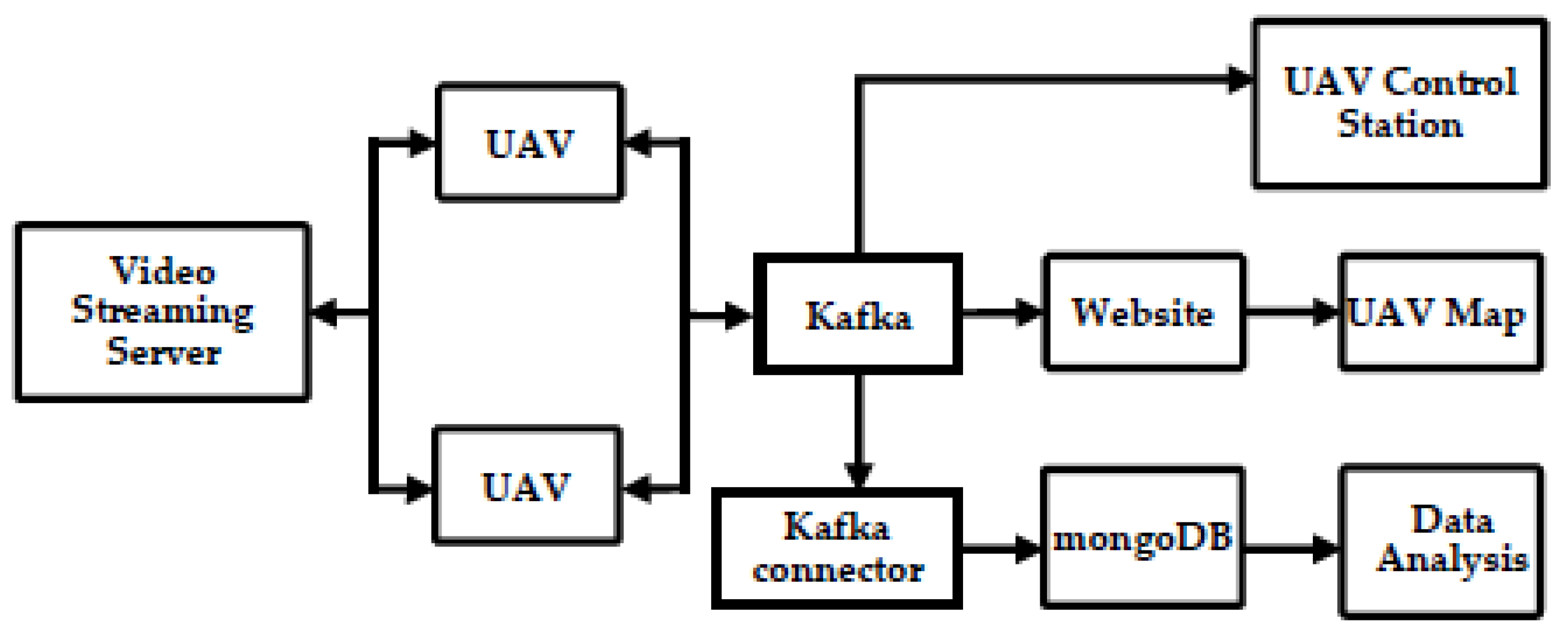
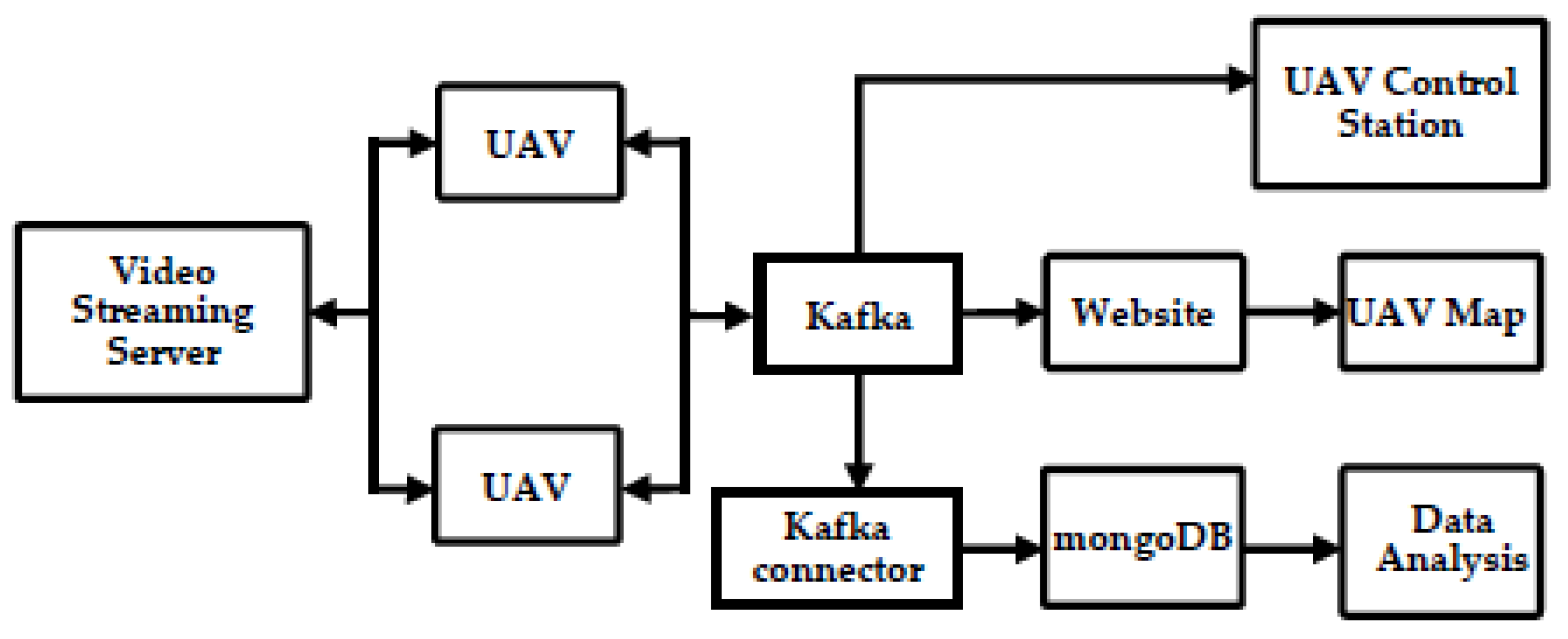
In this study, we built an intelligent system of UAVs and collected images for our riverine waste dataset, the riverine waste dataset. A riverine waste detector based on the YOLO object detection algorithms was proposed. We compared various algorithms, tuned the parameters, and evaluated the model to obtain the best performance and lowest error. Dynamic image stitching from UAV cameras based on the SIFT algorithm was applied. We utilized Kafka to receive and transmit data and used MongoDB to store the data [
5]. A video streaming server was used to obtain the images from the UAVs. An exclusive website was built to present the aerial photographs, while a UAV control station was built for emergencies.
2. System Description
There are ten parts in the real-time UAV riverine waste monitoring system, as shown in
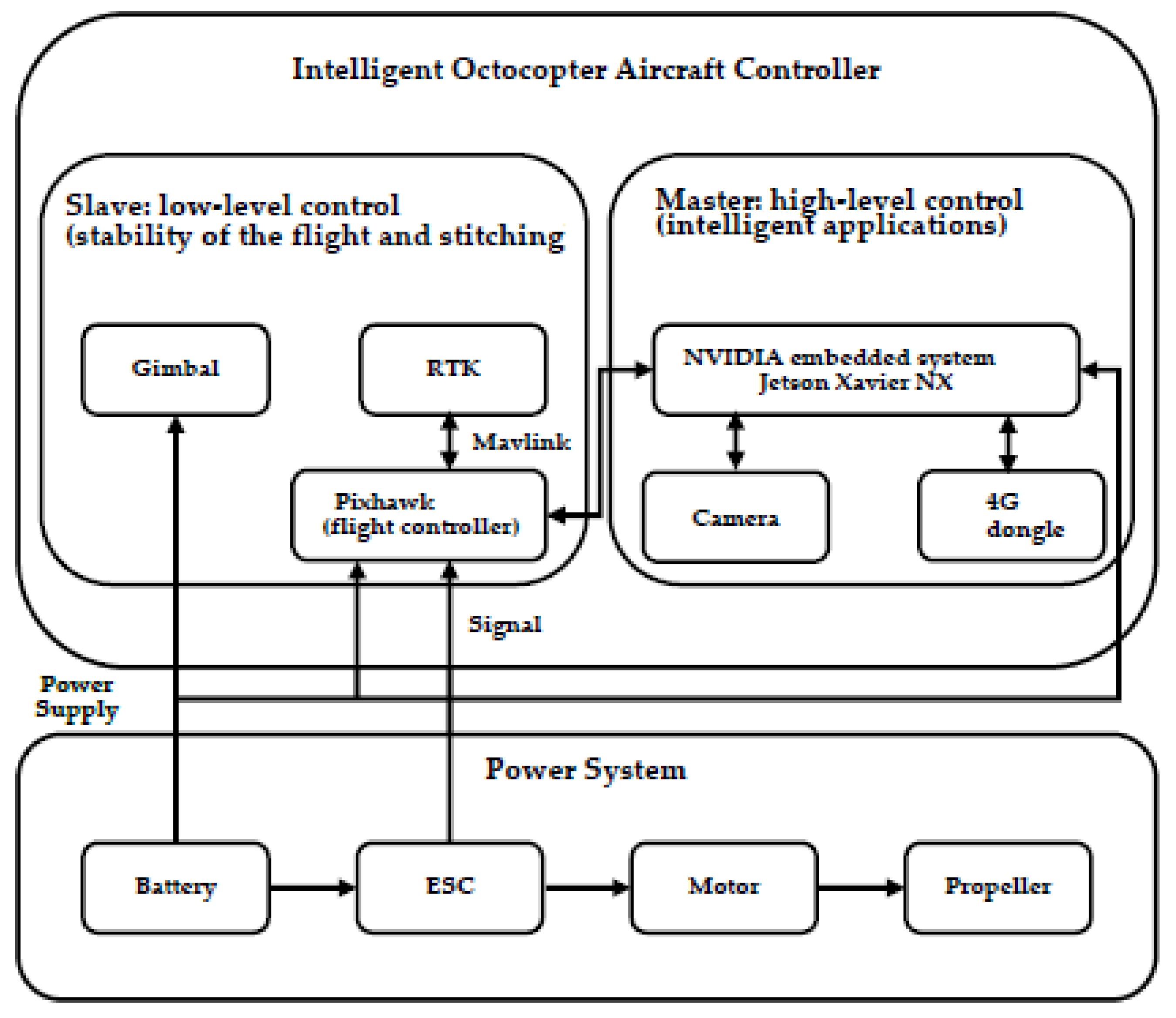
Figure 1. The UAV systems are divided into the quadcopter aircraft controller, octocopter aircraft controller, and power system. The intelligent quadcopter and octocopter aircraft controllers utilize Pixhawk [
15] to achieve flight stability. The intelligent octocopter aircraft controller assembles the gimbal to achieve image stitching stability and uses real-time kinematic positioning (RTK) to achieve precise positioning. The power system supplies the power to the UAVs and gimbal.
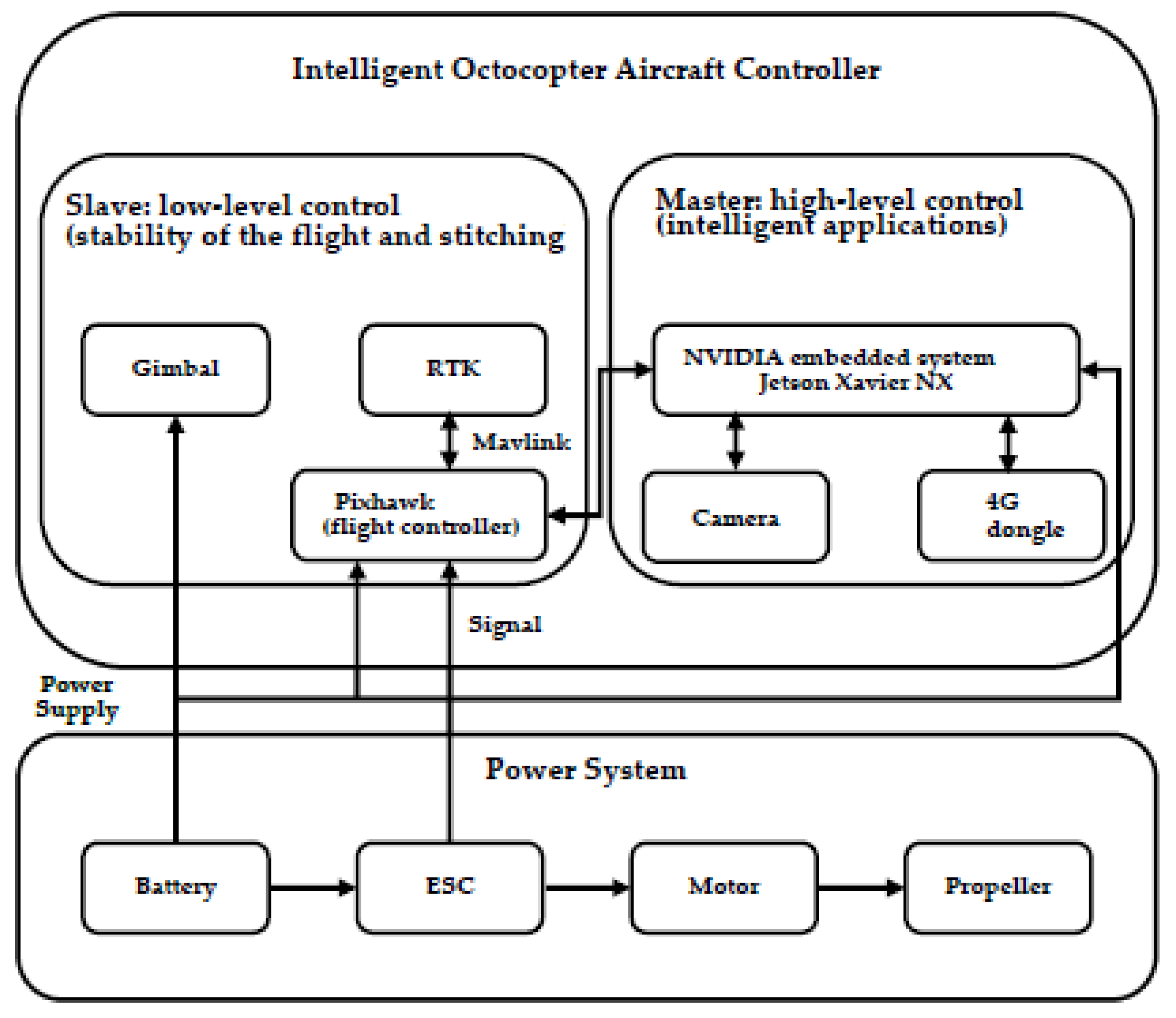
Figure 2 shows the architecture of the octocopter aircraft system.
The slave of the octocopter aircraft controller assembles an extra gimbal to achieve high-quality images and replaces the global positioning system (GPS) module with RTK to achieve precise positioning. The masters of the quadcopter and octocopter aircraft controllers perform high-level control, including detecting riverine waste and sending flight commands to the slave. The quadcopter (
Figure 3) and the octocopter (
Figure 4) aircraft controllers utilize the Pixhawk flight controller. The quadcopter aircraft controller is equipped with the Ublox M8N GPS [
16] module to achieve flight stability. In contrast, the octocopter aircraft controller is equipped with the Holybro F9P RTK [
17] module to achieve higher flight stability and precise positioning. The position error of the Holybro F9P RTK module is 0.3 m, and the error of the Ublox M8N GPS module is about 3 to 5 m. The PID controller of the quadcopter and the octocopter aircraft are auto-tuned. The limitation of the wind force scale for the proposed UAV system is 4. The maximum wind speed that the UAV can be operated is 8 m/s.
The quadcopter and octocopter aircraft controllers are equipped with the embedded NVIDIA system Jetson Xavier NX [
18] as the UAV onboard computers, that can perform high-level computational detection. This study needs to make the UAV system perform image processing, control, and monitoring of various information of the UAV that requires many calculations. The NVIDIA Jetson Xavier NX has many advantages, including its small size, being lightweight, and fast computing speed, and can provide up to 21 trillion operations, achieving excellent performance in real-time computation. Combined with peripheral equipment, drone automation can be realized. The quadcopter and octocopter aircraft controllers are equipped with the SJCAM 5000x [
19] webcam and the Huawei E8372 4G dongle [
20], respectively. The webcam is attached to the Tarot T2-2D gimbal [
21]. The camera’s field of view (FOV) is 120°, and the frames per second (FPS) of 1080 p video is 60. The camera has built-in Wi-Fi and anti-shake digital stabilization, and the ground sample distance (GSD) is 2 mm/px at a 5 m height. For the UAVs’ riverine waste detection mission, we need to measure the coordinates and set the waypoints for the UAVs in advance. Consequently, the UAVs can detect the riverine waste along the riverbank.
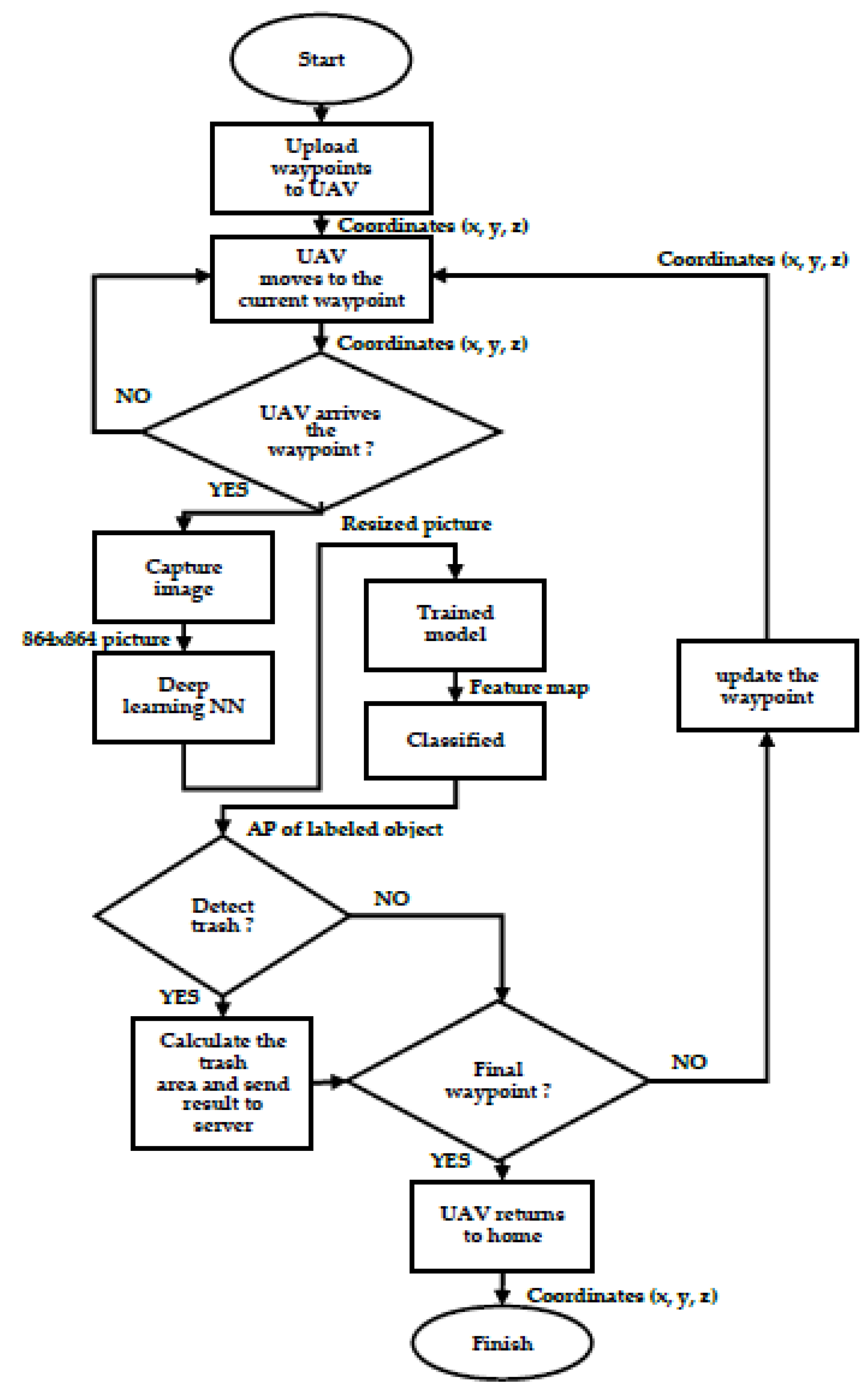
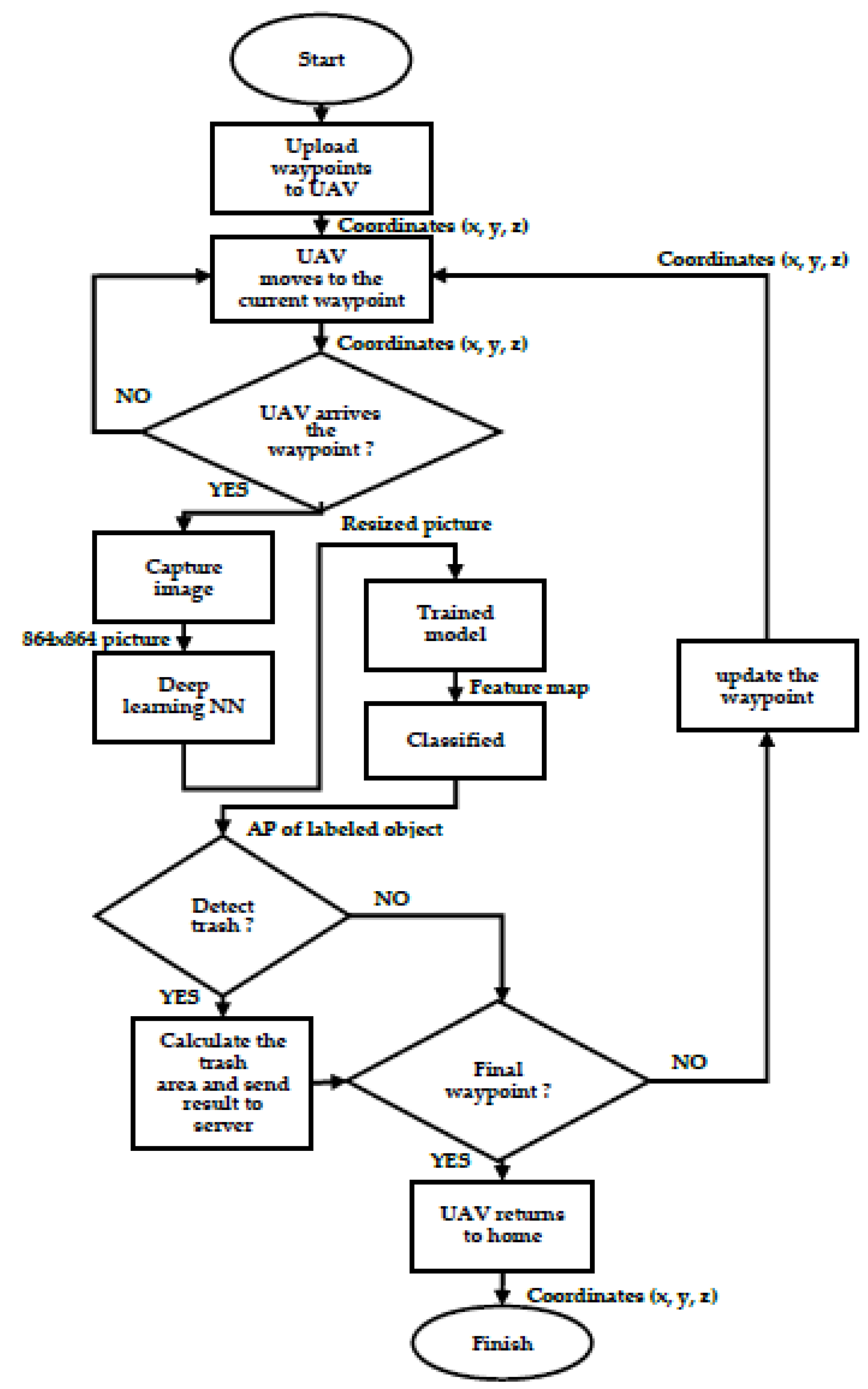
Figure 5 shows the flowchart of a UAV’s waste detection process. A preplanned path with waypoint coordinates is uploaded to the UAV onboard computer. The UAV flies to the waypoint and captures an image. The image is then sent to the deep learning neural networks for object identification. The classified image with labels is checked by its AP value. If there is garbage, the trash area is calculated and the result is sent to the ground control center. Finally, the UAV’s position is checked; if it is the ending point, the mission is accomplished; otherwise, it moves to the next waypoint and repeats the steps until it reaches the ending position.
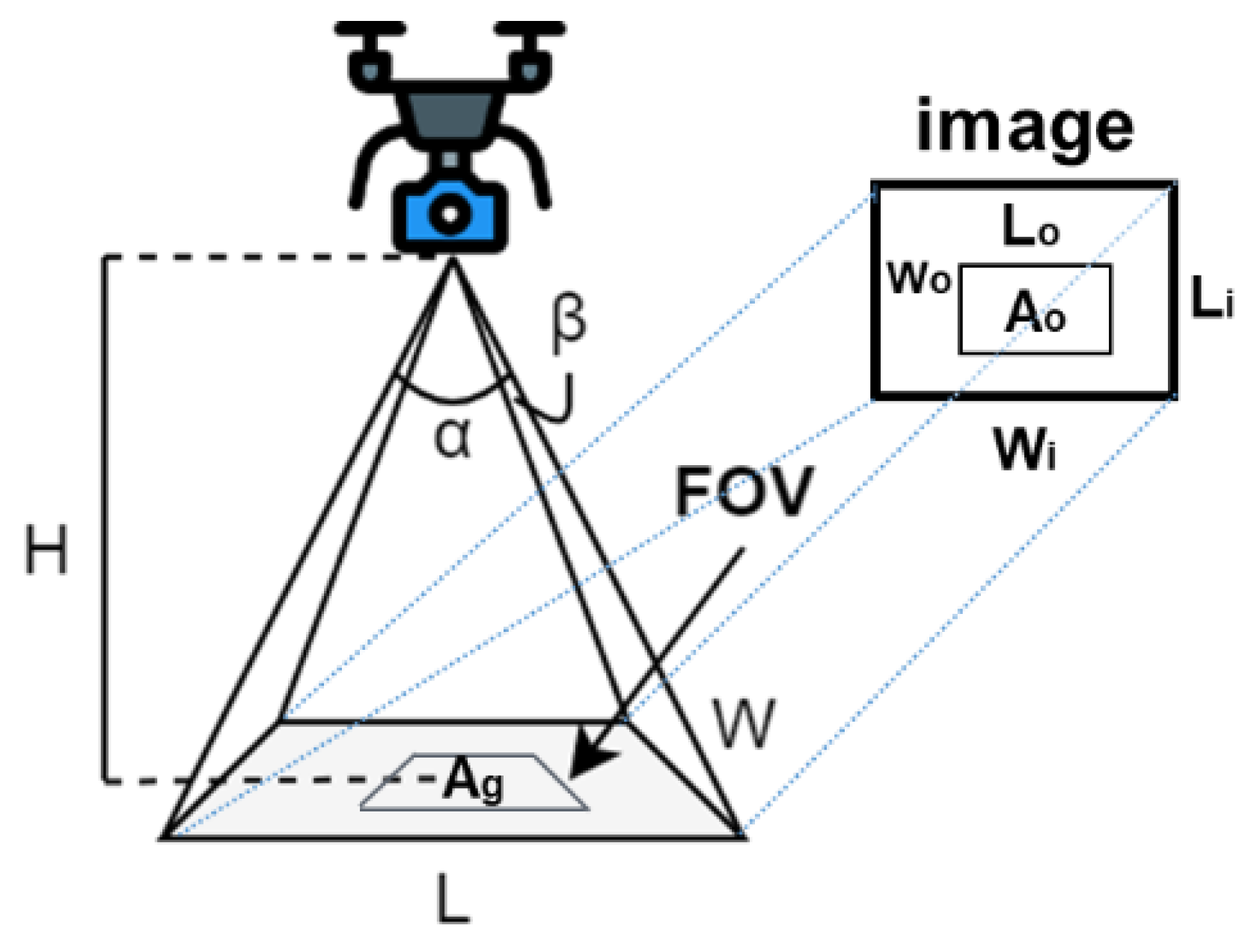
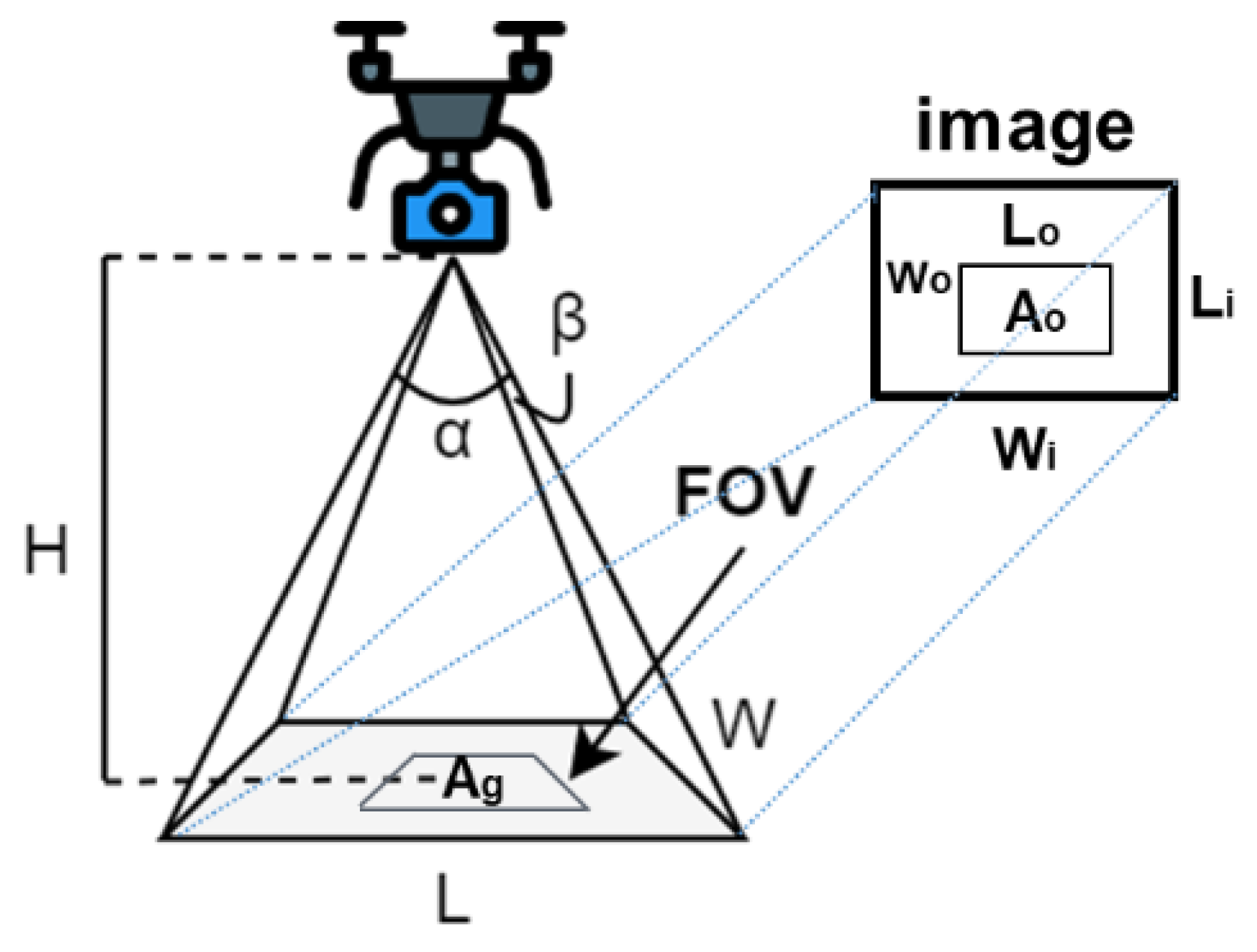
For the UAVs’ dynamic image stitching mission, we set the UAVs’ flight speed to 1 m/s; the UAVs were separated by 4 m. We can calculate the riverine waste pollution area using Equations (1) to (4), where
are the camera’s horizontal and vertical angle of view;
H is the UAV’s height;
L and
W are the lengths of the camera’s horizontal and vertical view;
Wi and
Li are the width and height of the camera’s image; and
Wo and
Lo are the width and height of the detected riverine waste in the picture, respectively;
Ao is the detected riverine waste’s area in the image; and
Ag is the area of the detected riverine waste in the real world, as shown in
Figure 6.
In the riverine waste monitoring system, the detector detects the riverine waste and calculates the riverine waste pollution area; then, the image is transmitted to the server. This process produces several streaming data. Therefore, we need to set up a suitable information-fusing system for streaming, analyzing, and storing data. Four methods are integrated to build a compelling message queuing system: file transfer, shared database, remote procedure invocation, and messaging. The file transfer is performed through the processor to monitor a folder; if the source produces a file in a folder, the processor captures this file from that folder. Given that the file transfer method has high latency, the file transfer method does not fit our information-fusing system. In the shared database method, applications can use the exact synchronized storage location concurrently. The shared database performs poorly due to the difficulty in defining the boundaries between the same data. For the remote procedure invocation method, a client addresses the demand while the server replies. The disadvantage of this procedure lies in all applications being coupled and the difficulty in integration. The messaging method is asynchronous, which can deal with tightly coupled applications. In this method, the transmitter does not need to wait for a receiver. Further, an application can be developed efficiently in a real-time riverine waste inspection system.
There are several message queuing (MQ) systems, such as Kafka [
22], RabbitMQ [
23], RocketMQ [
24], ActiveMQ [
25], and Pulsar [
26]. In [
27], the authors compared the performance of these systems and tested the throughput in three scenarios, including the numbers of partitions, producers and consumers, and message size. The throughput refers to the number of bytes per time transmitted through the queueing system. Kafka achieved the highest throughput among these queuing systems. Therefore, we selected Kafka as the message queuing system and utilized a Kafka broker to deal with messages from the UAVs. The UAVs’ flight data stream is collected; each UAV produces one partition with one replica. Riverine waste data—detected by the UAVs—is collected, and all the UAVs send the data to the same partition. The UAVs’ real-time maps consume the collected data to monitor the status of each UAV and the area polluted by the riverine waste. The Kafka configuration in the UAV riverine waste monitoring system can be found in our previous work [
5].
In different operating systems, a web service is the best way to exchange data between applications. Therefore, we utilized the Python 3.10 web framework Django [
28], using the hypertext transfer protocol in the UAVs’ riverine waste inspection system to develop a website running on a computer to facilitate client queries. A real-time UAV riverine waste map was created using a JavaScript library Leaflet [
29] for interactive maps with the Django website and Kafka broker to develop a riverine waste pollution monitoring system. Consumers can access information from Kafka via the web service. The riverine waste data (e.g., the position of the UAVs and the area of the riverine waste, which the UAVs obtain) are shown in the riverine waste map.
In the design of the video streaming server, the UAV utilizes 4G communication to transmit the video stream to the server and then release it. Multiple users can subscribe to a video streaming server at 30 FPS (frames per second) through a website. The UAVs first fly to the waypoint and subsequently use the onboard camera’s current altitude and FOV (field of view) to calculate where the UAVs should detect garbage and avoid double detection. Finally, the UAVs send the image back to the server. In addition, the UAVs continuously send real-time video streams to the server while the server simultaneously receives images from the drone’s camera and stitches them together. ZeroMQ [
30] is a socket-based concurrency framework featuring intra-process, inter-process, and transmission control protocol (TCP) communication. On the other hand, ImageZMQ [
31] is a Python application programming interface (API) for video streaming built on top of the ZeroMQ framework. We leverage the ImageZMQ API with automatic image resizing methods, an automatic reconnection mechanism, and JPEG compression [
32] to adapt to varying network conditions.
In the automatic reconnection mechanism, we set the timeout to 1.8 s. This value is determined by trial and error, depending on the network conditions of the server and the UAVs. The UAVs will automatically reconnect to the video streaming server if the disconnection time exceeds the timeout. Through trial and error, the UAVs record the number of timeouts that occur and use this to automatically resize the appropriate image size, with more timeouts resulting in a smaller image size, before sending the video stream to the server. In the waste detection mission, the UAVs continuously receive messages from Kafka topics to check for commands from the control station. Each UAV uses a partition in the topic. If the UAV encounters an emergency, we can issue commands through the UAV control station, allowing the UAV to perform landing or RTL or other actions.
In [
33], a performance comparison of seven databases, three SQL (Oracle, MySQL, MsSQL) and four NoSQL (Mongo, Redis, GraphQL, Cassandra), was performed. In experiments, NoSQL databases are faster than SQL databases, among which Mongo performs best. Therefore, we selected Mongo as our database for its excellent performance and schema-free data storage. In Mongo, a collection is created to store the documents. The trash document sent by the UAV contains the identity of the UAV, the time that riverine waste is detected, the latitude position of the riverine litter, and the area of the riverine waste. We used Kafka as the data streaming platform in the waste monitoring system. It must be noted that the data must be accessed and stored in the database. Further, we built the Kafka connector that consumes the data with batch processing from Kafka and transfers the data into the database. The Kafka configuration in the UAV riverine waste monitoring system can be found in our previous work [
5].
3. Image Classification
There are a variety of algorithms for image classification, including the backpropagation neural network (BPNN) [
34], support vector machine (SVM) [
35], and Hopfield neural network [
36]. In 2012, an extensive deep convolutional neural network (CNN) called AlexNet [
37] showed excellent performance on the ImageNet [
38] large-scale visual recognition challenge (ILSVRC), marking the start of the broad use and development of CNN models such as VGGNet [
39], GoogLeNet [
40], ResNet [
41], and DenseNet [
42]. In [
43], the authors compared the classification accuracy and speed of the four classification algorithms, including k-nearest neighbors (KNN) [
44], SVM, BPNN, and CNN. CNN has the best classification accuracy for handwriting digit recognition. In the past few years, deep learning has been proven to be a significantly powerful tool because of its ability to process large amounts of data used for image recognition, video recognition, imagery analysis, and classification. One of the most popular neural networks in image classification is CNN. CNN can design some weights based on the different objects in the image and then distinguish them from each other. CNN requires very little pre-processing of data compared to other deep learning algorithms. The CNN algorithm is based on various steps structured in a specific workflow, including input image, convolutional layer, pooling layer, and fully connected layer for classification.
The convolutional layer is the first layer in the CNN, responsible for the feature extraction of the input images. Convolution is an operation comprising two steps: sliding and inner product. The image obtained after convolution is called a feature map, which uses a filter to slide on the input image and continue to perform the matrix inner product. A pooling layer is usually applied after a convolutional layer, and is responsible for reducing the size of the convolved feature map to reduce computational expense. There are three types of pooling: average pooling, max pooling, and sum pooling. We mainly utilized max pooling, where the filter selects the largest element from the region of the feature map. After extracting features and reducing the image parameters from the convolution layer and max pooling, the feature information will be passed to the fully connected layer. The fully connected layers in a neural network are those where all the inputs from one layer are connected to every activation unit of the next layer; each connection has its own independent and different weight. Consequently, it will result in the fully connected layer taking in a variety of computations.
3.1. Image Recognition Algorithm
In recent years, artificial intelligence has been applied to many tasks. Object detection is also the most popular part of deep learning. It can be used in various aspects, such as license plate recognition, autonomous driving, product defect detection, and medical image recognition. There are many tasks related to image recognition. Accordingly, the target detection framework is divided into two-stage and one-stage methods.
Two-stage: In object detection, the general method involves first selecting objects; the process of selecting objects is called region proposal. The chosen objects’ sizes may differ, so the object detection may only be classified or include feature extraction and classification. The two-stage method needs to find the region proposal first before performing detection. The classic two-stage method is the faster region-based convolutional neural network (Fast R-CNN).
One-stage: A common problem with the two-stage method is that too many objects are selected for real-time computing. The one-stage method operates the object position detection and recognition in one step. The neural network can detect the object’s position and recognize the object simultaneously. While the one-stage method is faster than the two-stage method, its recognition accuracy is not on a par with the latter. Recognition accuracy is still within an acceptable range in the one-stage method. Therefore, the one-stage method is currently more developed and used on mobile devices. The classic one-stage methods are YOLO and single-shot detector (SSD).
In this study, we selected the YOLO algorithm as the waste detecting algorithm. In July 2021, YOLOR-D6 ranked first in the real-time object detection benchmark on the common objects in context (COCO) dataset. A better tradeoff can be found based on speed and accuracy [
45]. In YOLOv4 [
46], the authors proposed two neural networks, named cross-stage partial (CSP) Darknet53 and CSPResNeXt50, as a backbone to operate quickly and compute optimizations in parallel. The authors found that the CSPResNeXt50 is suitable for classification, while the CSPDarknet53 is suitable for object detection. In YOLOv4, the authors proposed the path aggregation network (PANet) and spatial pyramid pooling (SPP) as the neck instead of the feature pyramid network (FPN). The PANet is modified by the FPN, which adds one more layer that can accurately store spatial information. It can correctly locate pixel points and form masks. On the other hand, there are more channels where the amount of calculations will increase. The SPP extracts features and connects them for deeper depth features.
In [
47], the authors compared various activation functions, including rectified linear unit (ReLU), swish, and mish. The mish activation function outperforms all the other activations. Mish is bounded below and unbounded above; its range is in
. It avoids saturation, which generally causes training to slow down drastically due to near-zero gradients, resulting in strong regulation effects and reduced overfitting.
The intersection over union (IoU) loss [
48] was proposed for the bounding box regression loss function in 2016. The authors proposed GIoU loss [
49] in 2019, and DIoU loss [
50] and CIoU loss [
51] in 2020. The CIoU loss considers the overlap area, point distance, and aspect ratio, making its convergence accuracy higher than GIoU. In GIoU, the DIoU can be used instead of IoU in the NMS algorithm, which is DIoU-NMS. The NMS has four bounding boxes, and the DIoU-NMS has five in the same scenario. Therefore, the authors utilized CIoU loss and DIoU-NMS in YOLOv4. The formula for DIoU-NMS is shown in Equation (6).
is the classification confidence,
is the threshold of the DIoU-NMS, and M is the bounding box with the highest confidence. Compared to the IoU loss, GIoU loss, DIoU loss, CIoU loss, and CIoU loss, the DIoU—NMS in YOLOv3, CIoU loss with the DIoU—NMS can improve the average precision.
YOLOV4-tiny [
46] is the compressed version of YOLOv4. The CSPOSANet is modified by CSPNet and VoVNet [
52]. VoVNet consists of a one-shot aggregation (OSA) module that aggregates all the layers before the last layer. In YOLOv4-tiny, the network structure is less complicated than in YOLOv4, and the parameters are reduced so that the training and detection are faster than in YOLOv4. The inference time in YOLOv4-tiny can reach 371 FPS (frames per second). On the other hand, YOLOv4-tiny-3l utilizes three YOLO heads to detect large objects, medium objects, and small objects. YOLOv4-tiny-3l can reach a higher accuracy and precision than YOLOv4-tiny on the COCO dataset.
In 2021, the BottleneckCSP module was proposed to extract the features on the feature maps in YOLOv5 [
53]. It can reduce the repetition of gradient information in the optimization process of CNNs. The authors of [
53] adjusted the width and depth of BottleneckCSP and developed four models called YOLOv5s, YOLOv5m, YOLOv5L, and YOLOv5x. YOLOv5s has the smallest size and model parameters of the four structures. Conversely, YOLOv5x has the biggest size and model parameters of the four structures. The focus module was proposed, which slices the image before the image input enters the backbone. It can extract four times as many features as without the focus module in exchange for four times the amount of computation. For example, our input image size is 864 × 864 × 3; using the focus module, the output size becomes 432 × 432 × 12, as shown in
Figure 7. Comparison of the modern YOLO includes YOLOv3, YOLOv4, and YOLOv5. Regarding average precision, YOLOv4 achieves the best performance on the COCO dataset in the experiment. In terms of inference time, YOLOv5s is better than YOLOv4. When the batch size is adjusted to 36, the inference time can reach 140 FPS.
3.2. Dataset
We need to collect data in advance to train the model for riverine waste detection. In data mining, we utilize the TACO dataset, drinking waste classification dataset, TrashNet, HAIDA trash dataset, and the images collected by the UAVs. We collected 2595 images and divided them into one class (11,318 garbage objects) and 876 negative samples. We also split the data into two categories (7488 garbage objects and 3830 bottle objects) for classification. The data we used and collected is called the riverine waste dataset. The TACO dataset is a dataset of waste from beaches and streets, but the trash is small. The drinking waste classification dataset is full of drinking waste and is divided into four classes (cans, plastic bottles, glass bottles, and milk bottles). We utilized TrashNet, which comprises 2527 images and is divided into six categories (glass, paper, cardboard, plastic, metal, and trash). UAVs collected the HAIDA trash dataset at different heights, and the data are divided into two classes (garbage and bottles). We also downloaded some riverine waste images from the internet, no matter whether the waste was large or small. Most of the data were taken from different places such as Kibera, Indonesia, Manila, etc. We also collected riverine waste images using UAVs; negative samples were also collected.
Data augmentation is a method that increases the amount of data. Many data augmentation algorithms have been proposed, such as mixup [
54], cutmix [
55], cutout [
56], mosaic [
46], attentive cutmix [
57], random erasing [
58], dropout [
59], and DropBlock [
59]. The first data augmentation method used for YOLOv4 is mosaic. The mosaic data augmentation method merges four images into one. This method allows the mode to learn how to recognize smaller objects and increase batch size in training, as shown in
Figure 8. The bounding boxes in
Figure 8 are the objects to be learned by the neural networks.
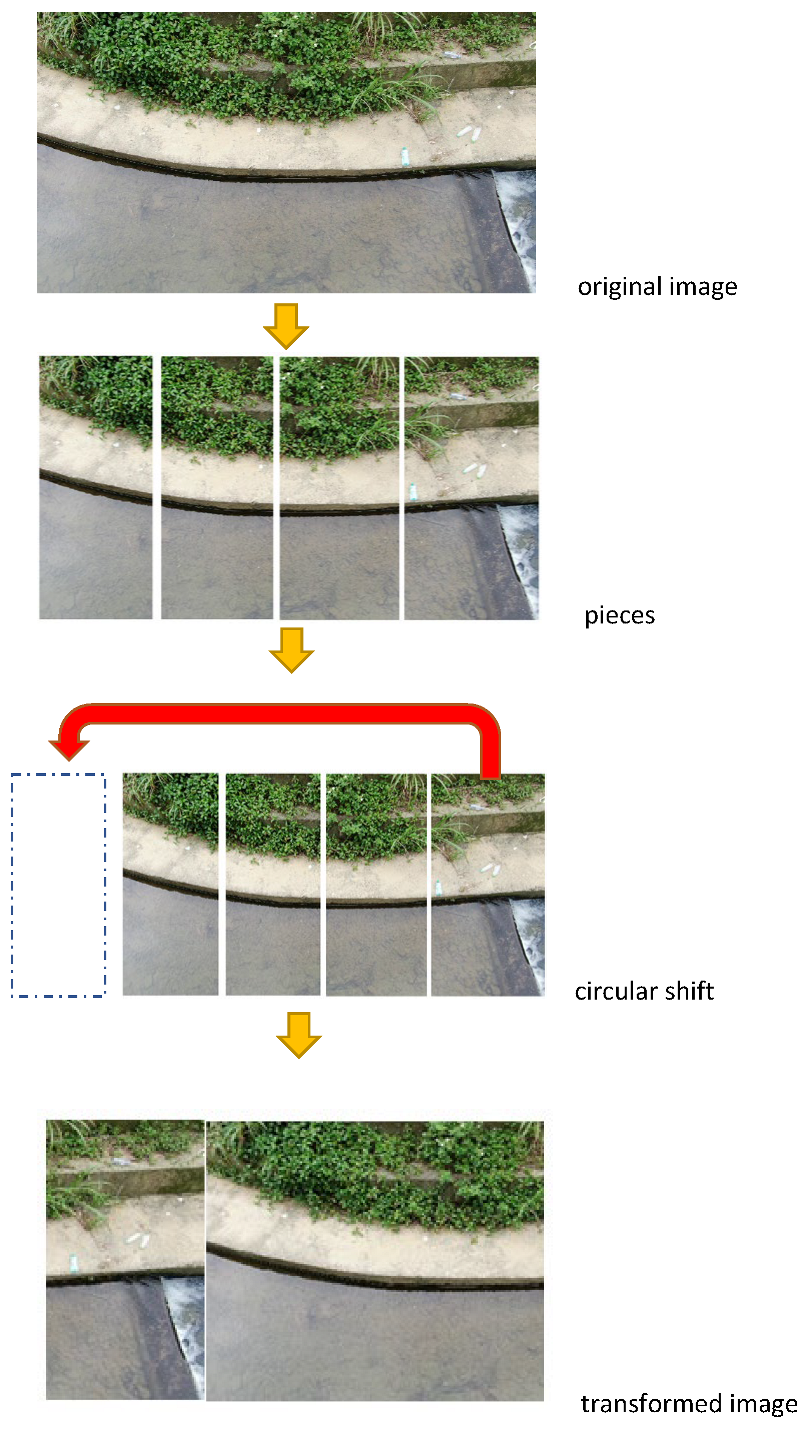
The circular shift method [
7] cuts the original image proportionally, shifts the last image to the first position, and transforms all the images into a new one. With different networks, including VGG16, ResNet, SqueezeNet, and DenseNet, utilizing the original and circular shift datasets can achieve higher performance in VGG16, ResNet, and DenseNet. The operation steps include the original dataset, circular shift, and the combination of crop, rotation, and flip. These steps will repeat until the image transforms into the original image, as shown in
Figure 9.
Regularization is used to reduce the error and over-complexity of machine learning, commonly known as generalization error. In the training process, the model produces many parameters that may cause overfitting. Therefore, there are various regularization methods to avoid model overfitting and help the model reduce the parameters to promote generalization. Regularization methods include dropout, DropBlock, L1 regularization [
60], and L2 regularization [
61]. In the model we trained, if the model has too many parameters and too few training data, it is easy for the model to have overfitting. Therefore, dropout can ignore a feature randomly to reduce the parameters that can make the model utilize its generalization. It only depends a little on some local features, bringing out overfitting. The DropBlock method is a form of structured dropout where the features in a contiguous region of the feature map are dropped together. Dropout is widely utilized in fully connected layers and performs well. However, it is not suitable for convolutional layers because the features are spatially related to each other. DropBlock can address the features being spatially associated with each other and reduce the dependence on features.
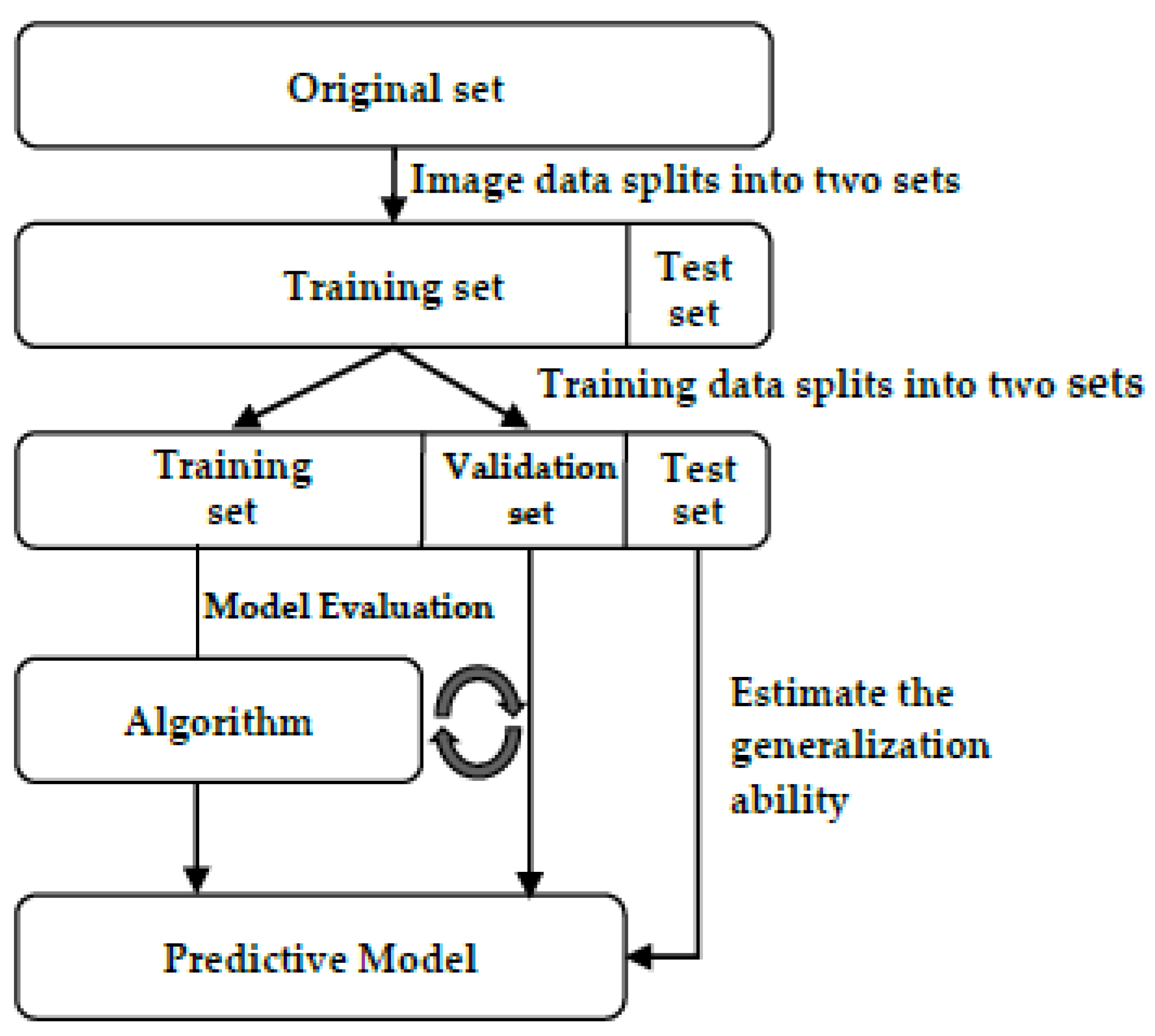
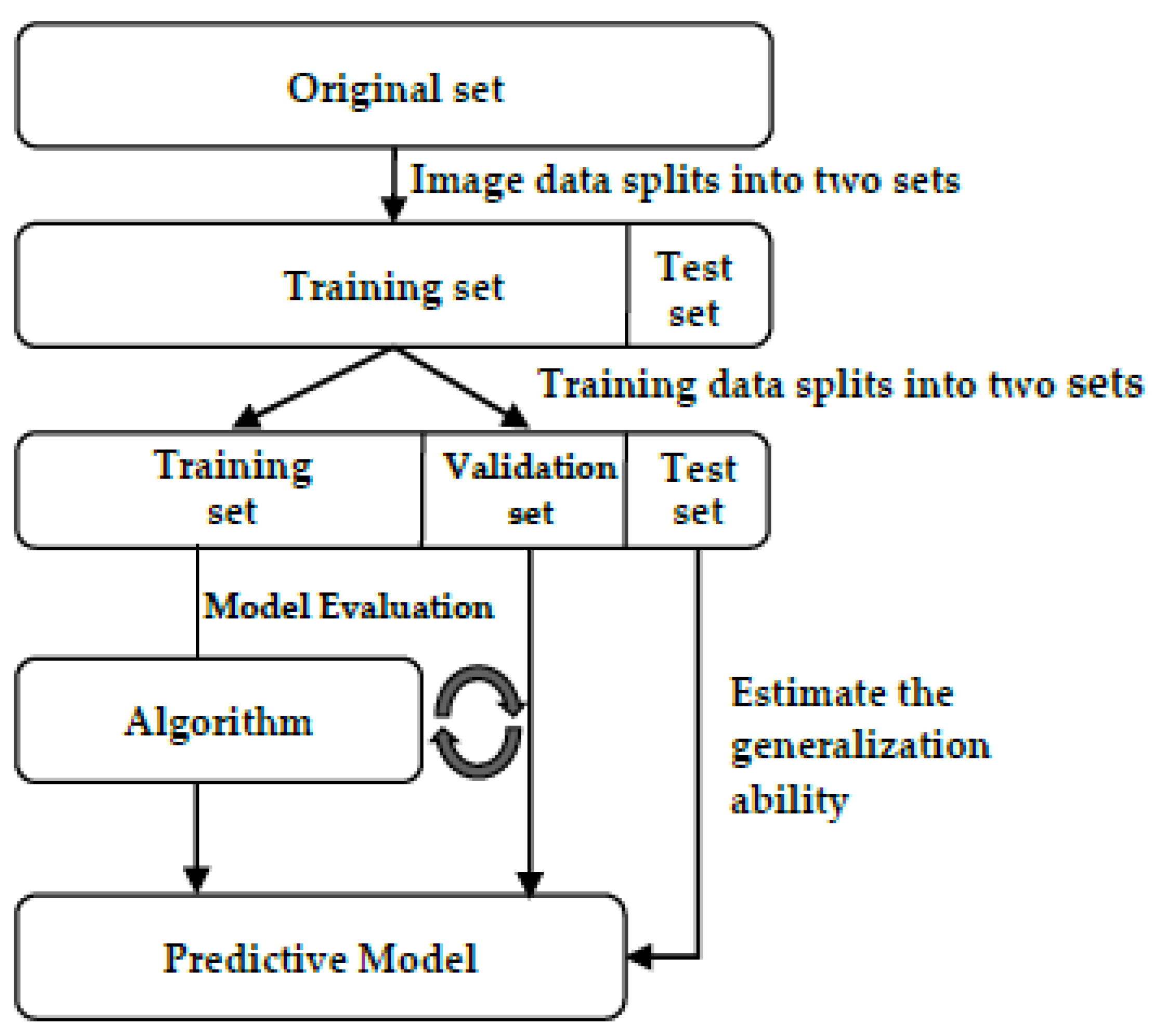
After collecting the data, we need to evaluate the model and verify the generalization ability of the model to independent test data. If we reuse the test set, which means the test set is part of the training set, it can easily lead to overfitting. Several methods can be used to split the data and verify the model, including the hold-out method [
62], k-fold cross-validation, nested k-fold cross-validation, repeated k-fold validation, stratified k-fold validation, and group k-fold validation [
63]. The hold-out method splits the dataset into training and test sets, and the training set splits again and produces a validation set. The training set is used to fit the different models, while the validation set is used for the model evaluation. The test set is used for estimating the generalization ability of the model. A diagram of the hold-out method is shown in
Figure 10.
The k-fold cross-validation method splits the data into k equal parts, meaning the same model is trained k times. The k-1 fold is the training set for the training, and the remaining fold is used for validation. Finally, the loss of the k times is summed up and averaged, which is considered the final result. The nested k-fold cross-validation method is modified by k-fold cross-validation and is divided into two parts: the outer loop and the inner loop. The inner loop tunes the hyperparameters and chooses the best parameters. Then, the model is trained with the best hyperparameters, and the generalization ability is estimated in the outer loop. Repeated k-fold cross-validation means to repeat n times. Every time it is repeated, it splits the data. Then, the k-fold cross-validation is performed, and the best performance is selected. Each fold is split in proportion to the category. In this study, we divided the data into two classes. The proportion is about 1:2, so the ratio of the two classes in each fold must also be 1:2. This method, useful for unbalanced data, is modified from the stratified k-fold cross-validation method. It prevents continuous data from resulting in overfitting. When the data are split in this method, it selects each block from the data and is randomly set as validation. The cross-validation methods are accurate and can prevent model overfitting. On the other hand, the computation time is more than for the hold-out method. Compared to the methods we mentioned, the hold-out method has a simple way to split the data and prevent model overfitting. In this study, the training set accounts for 70 percent of the collected data, the validation set accounts for 20 percent, and the test set accounts for 10 percent.
3.3. Training
There are several learning rate decay methods, including poly, random, and steps. The poly method adjusts the learning rate with every training step, as shown in Equation (7). The random method gives the learning rate randomly for every training step, as shown in Equation (8). The steps method decays the learning at specified steps. For example, we set the specified step to 8000 and 9000, the decay ratio as 0.01, and the initial learning rate as 0.05. In the step set at 8000, the learning rate was adjusted to 0.005, while in the step at 9000, the learning rate was adjusted to 0.0005.
A comparison of the state-of-the-art (SOTA) object detection algorithms is shown in
Table 1. This study focuses on FPS and AP50 (Val). The YOLOv4-tiny-3l model can achieve 75.4% AP50 (Val). This performance is the best in this model, and its inference time of 175 FPS is good. YOLOv5m reaches 74.4% AP50 (Val), close to YOLOv5s. However, its inference time is lower than YOLOv5s. Hence, this study compared the performance of YOLOv4-tiny-3l and YOLOv5s on a test set.
The results show that the confidence scores of YOLOv4-tiny-3l are higher than those of YOLOv5s in the same frame, as shown in
Figure 11 and
Figure 12. While both did not miss trash, only YOLOv4-tiny has false detection, as shown in
Figure 13 and
Figure 14. Therefore, this study selected YOLOv5s as the riverine waste detection algorithm and proposed improving YOLOv5s for better performance.
For the hyperparameter tuning for YOLOv5s, we adjusted the input size, filter size, iterations, learning rate, activation function, mosaic, learning rate decay, and dropout method. When the input size is 864 × 864, the number of iterations is 13,000, the learning rate is 0.005, and the decay steps are at 8000 and 9000, with the mish activation function and without mosaic data augmentation, the AP50 (Val) can reach 78.2%. If we add a dropout layer in YOLOV5s, when we use DropBlock and cover 50% of the features, the AP50 (Val) drops to 74.5%. If it covers 30% of the features, the AP50 (Val) is 76.2%, as shown in
Table 2.
After tuning the hyperparameters, we modified the structure of YOLOv5s to achieve a higher performance in detecting riverine waste. Therefore, we proposed the improved YOLOv5s-i, improved YOLOv5s-ii, and improved YOLOv5s-iii. The improved YOLOv5s-i adds eleven additional convolutional layers in the neck, including four filters for 32 convolutional layers, six for 64 convolutional layers, and one for 128 convolutional layers. The AP50 (Val) improves by 78.6% in the improved YOLOv5s-I. Improved YOLOv5s-ii adds fifteen additional convolutional layers in the neck, including four filters for 32 convolutional layers, ten for 64 convolutional layers, and one for 128 convolutional layers. The AP50 (Val) improves by 79.3% in the improved YOLOv5s-ii. Improved YOLOv5-iii adds 22 additional layers in the neck, including five filters for 32 convolutional layers, fifteen for 64 convolutional layers, and two for 128 convolutional layers. The AP50 (Val) improves by 79.6% in the improved YOLOv5s-iii. Based on the improved YOLOv5s-ii and improved YOLOv5s-iii, we found that adding more layers did not significantly improve the AP50 (Val). To verify this conjecture, we added 27 additional layers in the neck, including five filters with 32 convolutional layers, fifteen filters with 64 convolutional layers, and four filters with 128 convolutional layers. The AP50 (Val) drops to 78.1%.
Finally, the improved YOLOv5s-iii was selected as the riverine waste detection algorithm. The hold-out method was used to split the riverine waste dataset first. It split the data into 70% for the training set, 20% for validation, and 10% for the test set. We used a test set to verify the proposed structure. Notably, the improved YOLOv5s-iii performed well. The confidence scores of the improved YOLOv5s-iii increased by 20% in the test set, as shown in
Figure 15.
4. Image Stitching
Image stitching is performed when images have overlapping areas. Image stitching methods can be classified into region-based and feature-based image stitching.
Region-based image stitching: This method is divided into two parts. One part of the region-based image stitching method is applied in the space domain, and the other is in the frequency domain. In the space domain, the method is used to select an area in the overlapping areas as a template and search for the blocks of another image. The most relevant areas are the matching areas. In the frequency domain, images are transformed by discrete Fourier transform. Then, the correlation function of the space domain is obtained by inverse Fourier transform, and the best matching areas to the correlation function are calculated.
Feature-based image stitching: This method finds the features in the scale space by the extrema value detection and then positions the features. The feature description obtains the matching areas and stitches the images. Feature-based image stitching is a commonly utilized method because its computational cost is lower than the region-based image stitching method. Therefore, several algorithms have been proposed, including the SIFT, SURF, and ORB.
In [
64], the authors compared the three methods: SIFT, SURF, and ORB. According to their tests, the stitching results of the three methods are similar. The most significant difference lies in the computation: the SIFT algorithm takes the most computing time because it extracts the most features. On the other hand, the ORB algorithm takes the least amount of computing time. In this study, the SIFT algorithm is used as the image stitching method. Although the SIFT algorithm spends more computing time for stitching, it can extract more features to stitch images, and the computing time is acceptable for the proposed system. There are four steps for feature detection in SIFT [
13], including the extrema value detection in scale space, keypoint localization, orientation assignment, and keypoint description. An image in scale space is similar to the image people see in the real world but is in the computer vision space. It presents far, near, clear, and blurred images using the Laplace of Gaussian (LoG) function. In scale space, the difference of Gaussian (DoG) function is used for determining the extrema value. Equation (9) is the Laplace of Gaussian function, and Equation (10) is the difference of Gaussian function.
After using the difference of Gaussian function to determine the extrema value, the value is not necessarily a true extrema value because it may be a discrete point. Therefore, the Taylor series is used to find a real extrema value, named the keypoint, as shown in Equation (11). It eliminates boundary responses that include low-contrast or poorly positioned points using a Hessian matrix, as shown in Equation (12). The Hessian matrix is used to calculate curvatures, as shown in Equation (13).
is the largest value, and
is the smallest value. If the curvature is less than ten, the keypoints may be close to the boundary and can be eliminated.
To let the onboard computer obtain these keypoints, we need to provide keypoint orientation, which means converting them to vectors. Equation (14) shows how the gradient values of keypoints is calculated. Equation (15) shows how the orientation of keypoints is calculated.
Before this step, each keypoint can receive three messages, including position (x, y), scale , and orientation . Then, the vectors in eight directions are counted, and the main direction for the keypoint is determined. If several directions differ by less than 20%, the main directions can be more than one direction. When the image is rotated, the main direction is used to correct the right direction; the vectors will not change.
The SURF algorithm is a further optimization of the SIFT algorithm. SURF is faster than SIFT and can achieve real-time implementation of applications. It utilizes a box filter instead of a Laplace of Gaussian filter, which can reduce a significant amount of computation time; hence, SURF is fast. SURF utilizes Hessian matrix determinant approximation instead of the difference of Gaussian function calculation. In addition, it uses box filters to simplify the Gaussian filters. SURF uses Harr wavelet features in the field of counted feature points instead of gradient histograms. In a circle with a radius of 6s, s is the scale of the feature point. The sum of the horizontal Harr wavelet and the vertical Harr wavelet features of all points in the 60-degree sector is calculated. Then, it is rotated at 60 degrees until it turns a circle. Finally, the maximum value is used as the main direction of the feature point. Before this step, each keypoint can receive four messages, including the sum of the horizontal values, the sum of the vertical values, the absolute value of the sum of horizontal values, and the absolute value of the sum of vertical values.
In oriented FAST and rotated Brief (ORB) [
65], FAST is used to detect the keypoints, and Brief is used to describe the keypoints—both have good performance and low computation. FAST gives a pixel
in an array, compares the brightness of
with a circle of 16 pixels around it, and then classifies the pixels into three categories: brighter than
, darker than
and similar to
. If more than eight pixels are brighter or darker than
,
is selected as a keypoint. The original FAST method cannot have orientation. Therefore, ORB assigns an orientation to each keypoint depending on how the intensity level around the keypoint changes. The Brief descriptor is used to describe the keypoints. It utilizes a bit string, a binary intensity test set that describes the image patch. ORB uses rotation-aware Brief to deal with Brief’s matching; its performance degrades dramatically for rotation beyond a few degrees.
5. Experiments and Results
The parameters used in this study are listed in
Table 3 and
Table 4. Image stitching is a complex problem when the object is moving, or the scene is changing. The light, image quality, and many factors affect the image stitching result. Therefore, image stitching is divided into static and dynamic scenes.
Static scene: A static scene does not mean that the scene is not changing. It usually refers to the cameras being sedentary. The background does not move; conventional methods can find moving objects, and camera images can be stitched.
Dynamic scene: A dynamic scene means that the scene changes constantly, including the background and the objects. It is difficult to stitch images from moving cameras.
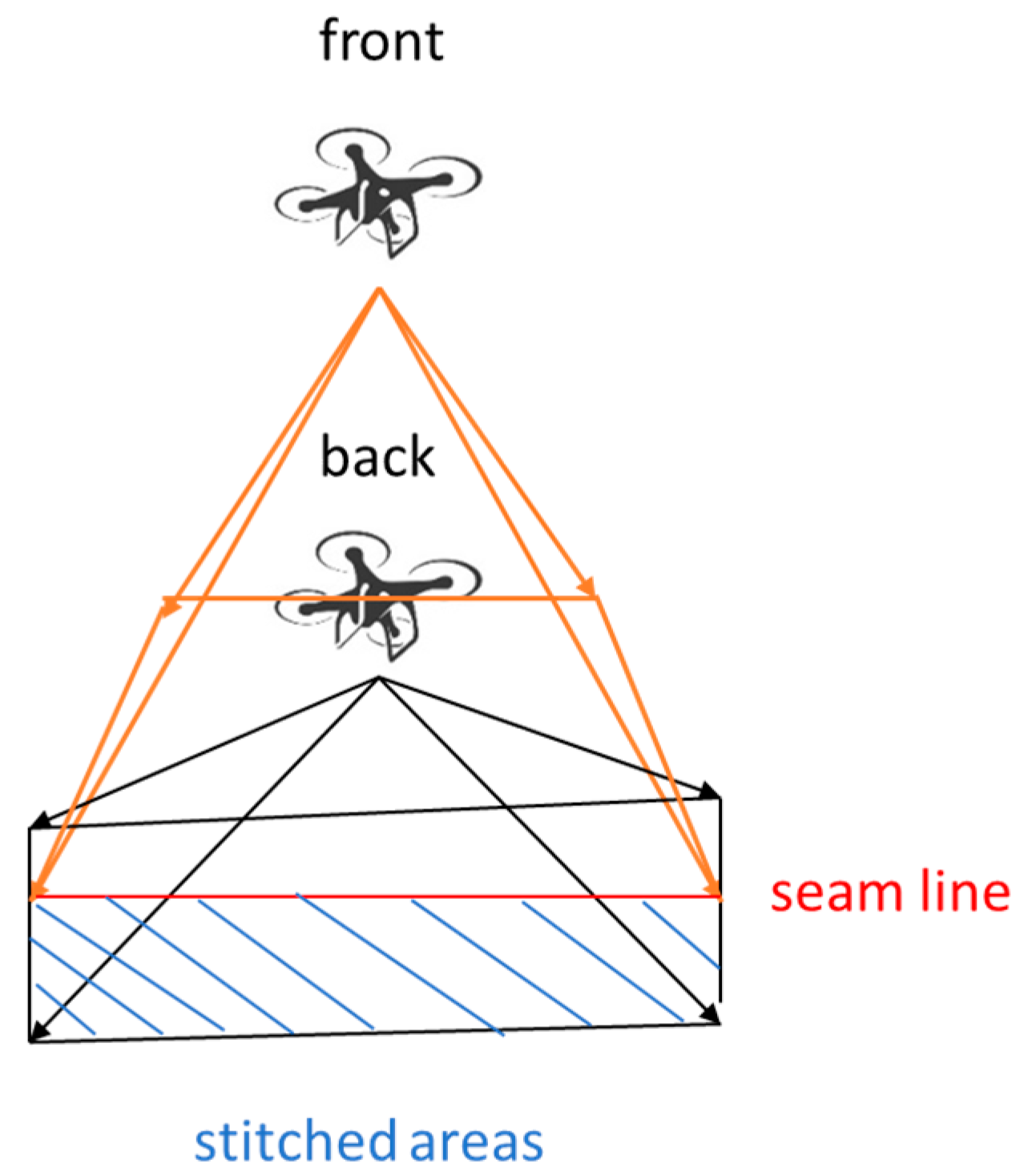
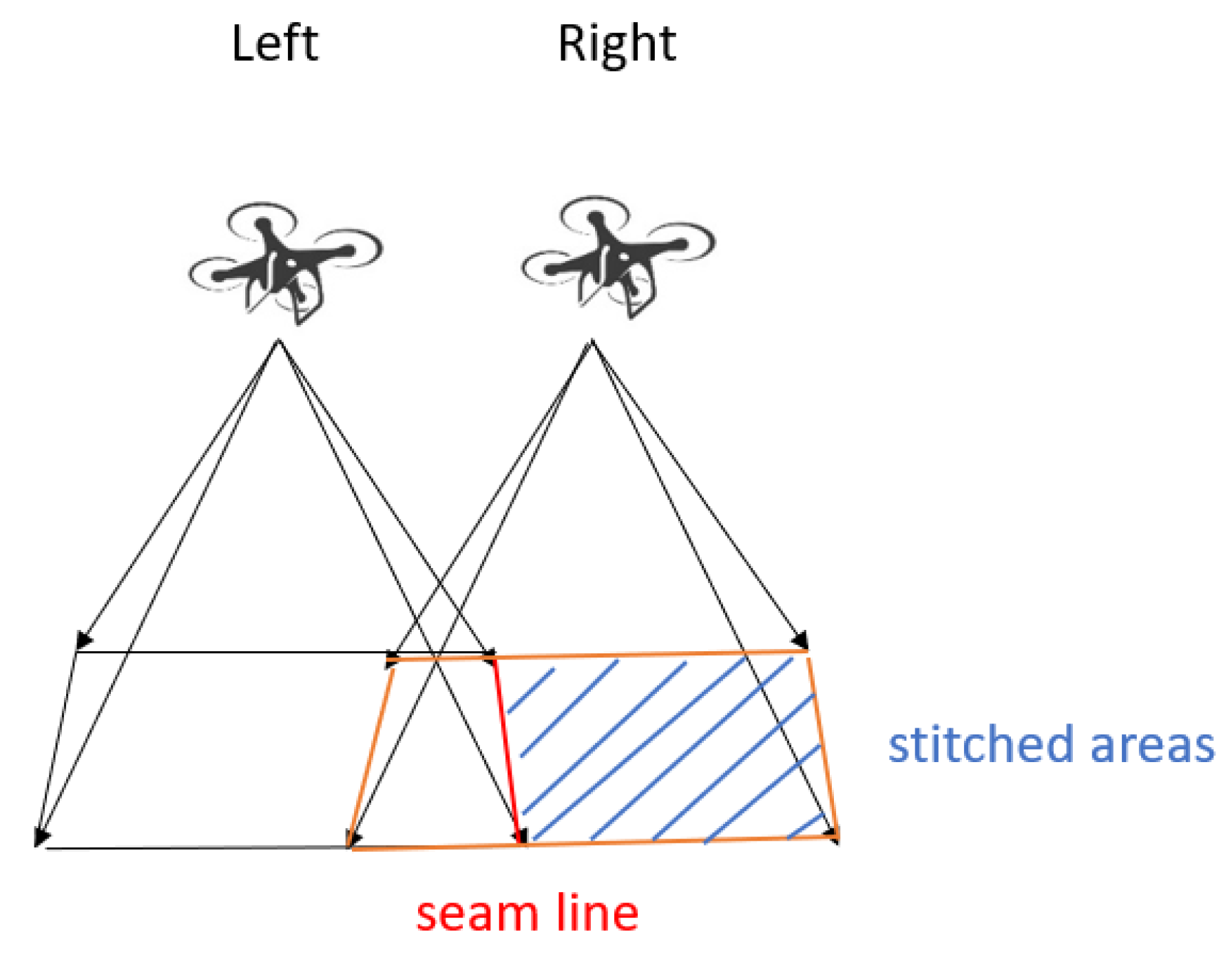
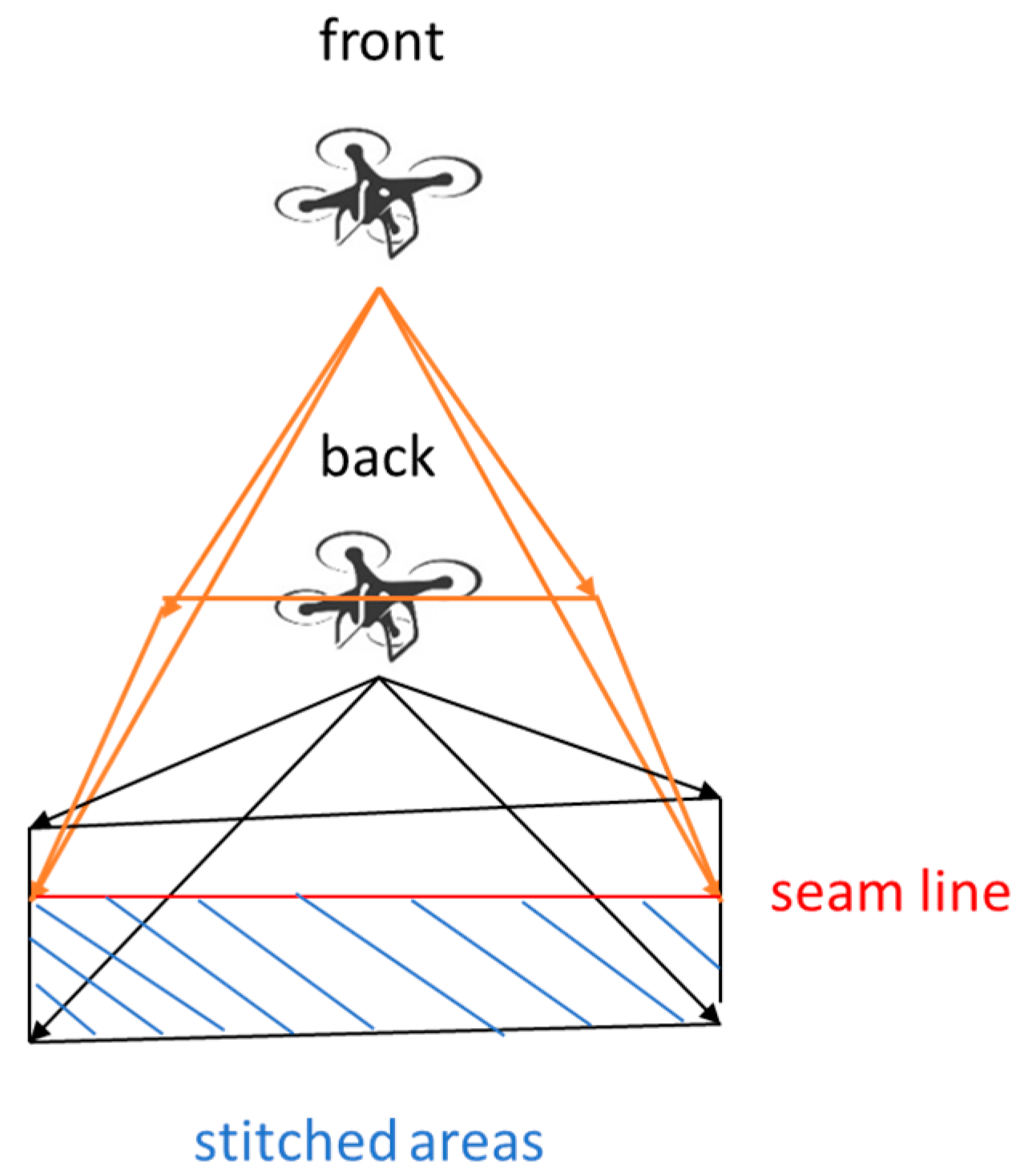
In [
66], the authors proposed that on each side of the seam line, only the image from the camera’s image must be selected to address the failure rate and computing time of dynamic scene stitching. For example, if two images are stitched, and the left camera’s image of the right seam line does not move, the right camera’s image is selected for stitching. If the overlapping area is enough, the images can be stitched. Therefore, we selected this stitching method. The image on the left side does not change, and the right side image is used for stitching, as shown in
Figure 18. If the cameras’ positions are at the front and back, the front side image does not change, and the back side image is selected for stitching, as shown in
Figure 19.
There are three scenes in our test environment: (1) the National Taiwan Ocean University (NTOU) campus; (2) the Tianliao River, based on the Keelung Bureau of Environmental Protection and the Society of Wilderness’s suggestions; and (3) the Keelung River. We utilized the embedded NVIDIA system NX on the UAVs to realize real-time detection and sent the image from the UAVs’ cameras to the ground station server for stitching. In the riverbank inspection mission, if the UAVs encountered an emergency, we could give a command to let the UAVs land, return, or perform other operations through the UAV control station.
5.1. Scene 1: NTOU Campus
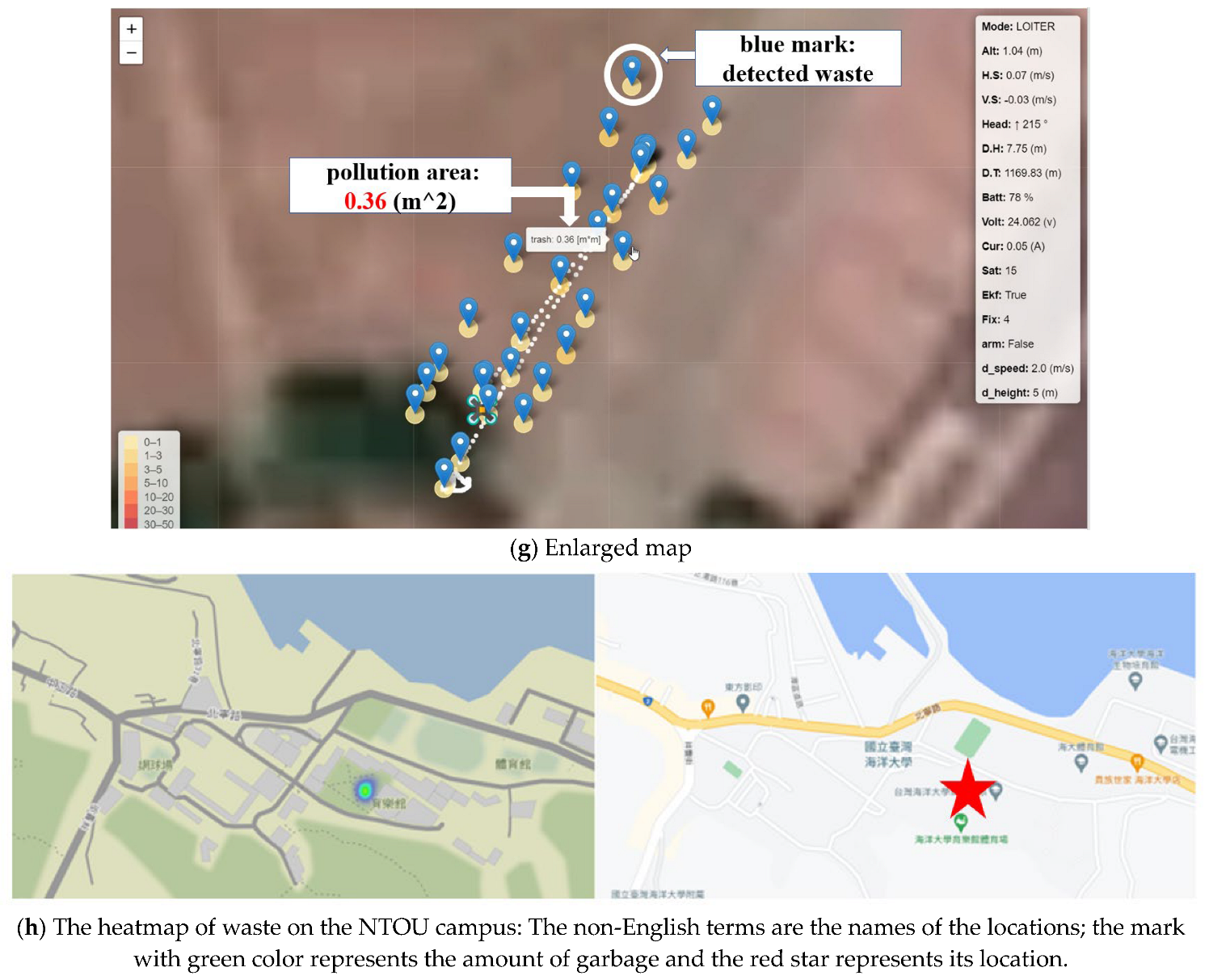
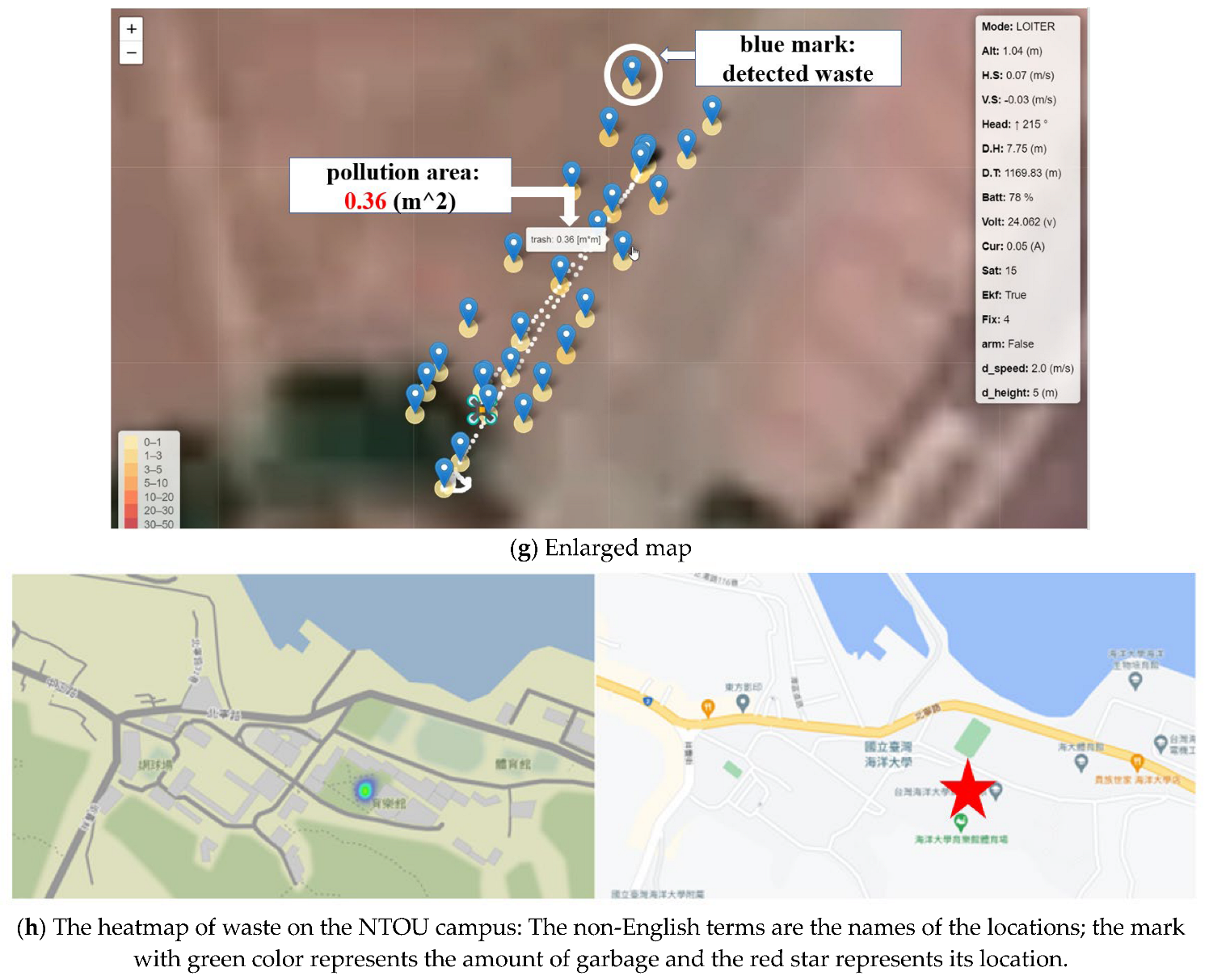
In the riverbank inspection, the waste was divided into one class (garbage) and two classes (garbage and bottle). First, we put some plastic bags and bottles on the campus. We set the UAVs’ height to five meters and speed to 1 m/s. For one-class detection, the confidence scores for garbage detection are high (54.81%, 90.31%, 95.1%, 98%, 98.86%), as shown in
Figure 20a. For the two classes, the confidence scores for garbage and bottles are still high (80.03%, 94.12%, 98.2%), as shown in
Figure 20b. However, they are slightly lower than the one-class case. In image stitching, UAVs hovered first and then tried to find the maximum distance for effective stitching, as shown in
Figure 20c–e. When the distance between the UAVs exceeded six meters and the image overlap area was less than 30%, the stitching results were bad. The real-time detection data and the pollution area were indicated on the ground station monitor, as shown in
Figure 20f,g. Each blue dot in
Figure 20f is the waypoint of the flight trajectory; it contains the coordinates of the location and garbage information. Detailed information is shown in
Figure 20g. After analysis, the waste location is indicated on the heatmap, as shown in
Figure 20h. Garbage information can be successfully demonstrated at the ground station (control center). Government officials can check pollution information from the real-time images provided by our riverbank inspection system. The officials can move the cursor by using the computer mouse and pointing at the blue dot on the computer screen. Then, the garbage size and coordinates will appear on the screen, as shown in
Figure 20f,g. In addition, the areas of the detected debris are also shown in
Figure 20a,b on the left side of the pictures; they are indicated as “trash: 1.47 m
2” and “trash: 1.43 m
2”, respectively. The proposed system can reduce labor spent on garbage inspection a lot.
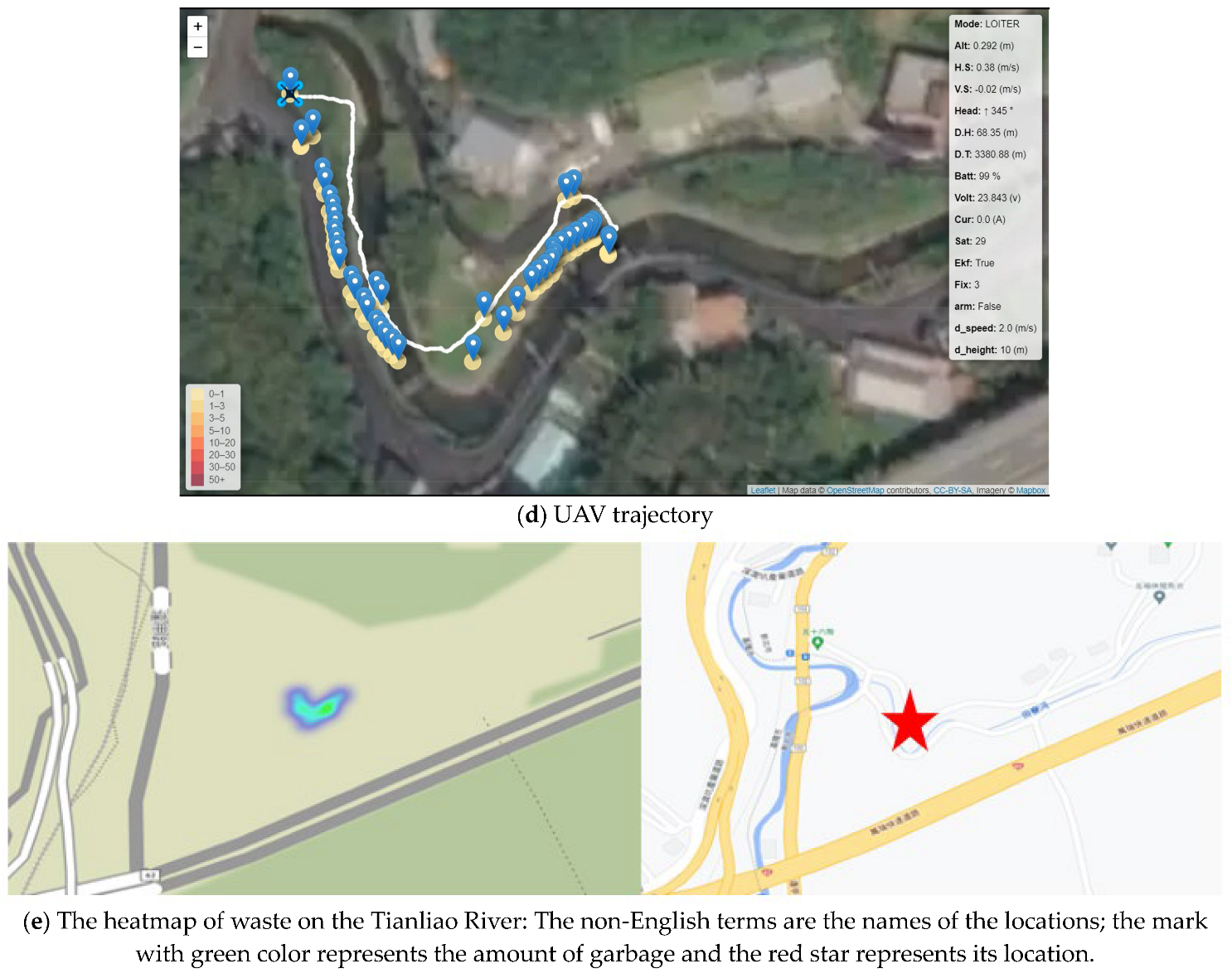
5.2. Scene 2: Tianliao River
At the Tianliao River, some garbage and bottles are stuck in stones. The UAVs’ height was about 5 m above the riverbank, the speed was about 1 m/s, and UAVs were separated by 4 m. In riverine waste detection, the detector could recognize two classes well when tested in NTOU. Therefore, we only tested two-class detection in the Tianliao River, as shown in
Figure 21b, and all garbage was identified. On the day of the test, the wind speed reached 6 m/s to 8 m/s, and the UAVs’ heights differed, making the size of both cameras’ images different. Further, the gimbal and UAVs were unstable due to the strong wind. Although the result is not remarkable, the images could still be stitched, as shown in
Figure 21c. The trajectories of the UAVs are shown in
Figure 21d; each blue dot represents a location with garbage information on it. The heatmap of waste is shown in
Figure 21e. The area of the detected debris is shown in
Figure 21b on the left side of the picture; it is indicated as “trash: 0.35 m
2”. The confidence rates of the detected debris are shown in
Figure 21b (62.04%, 40.51%, 38.47%, 62.34%).
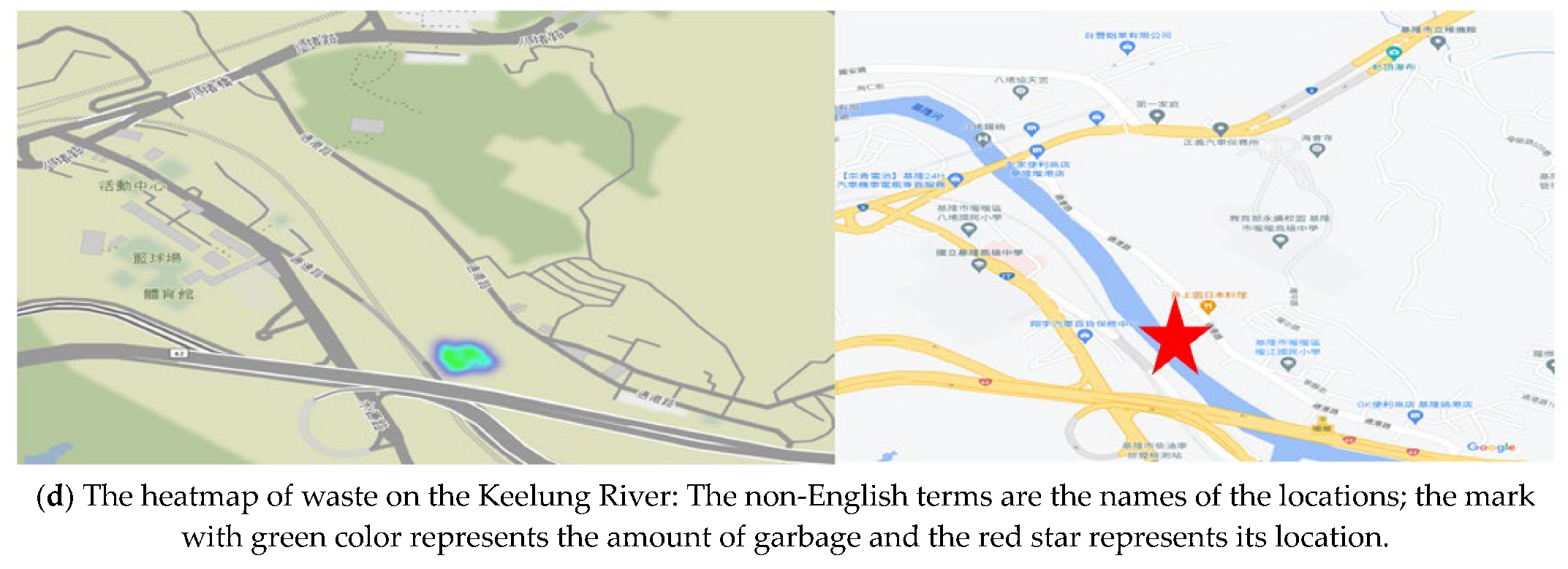
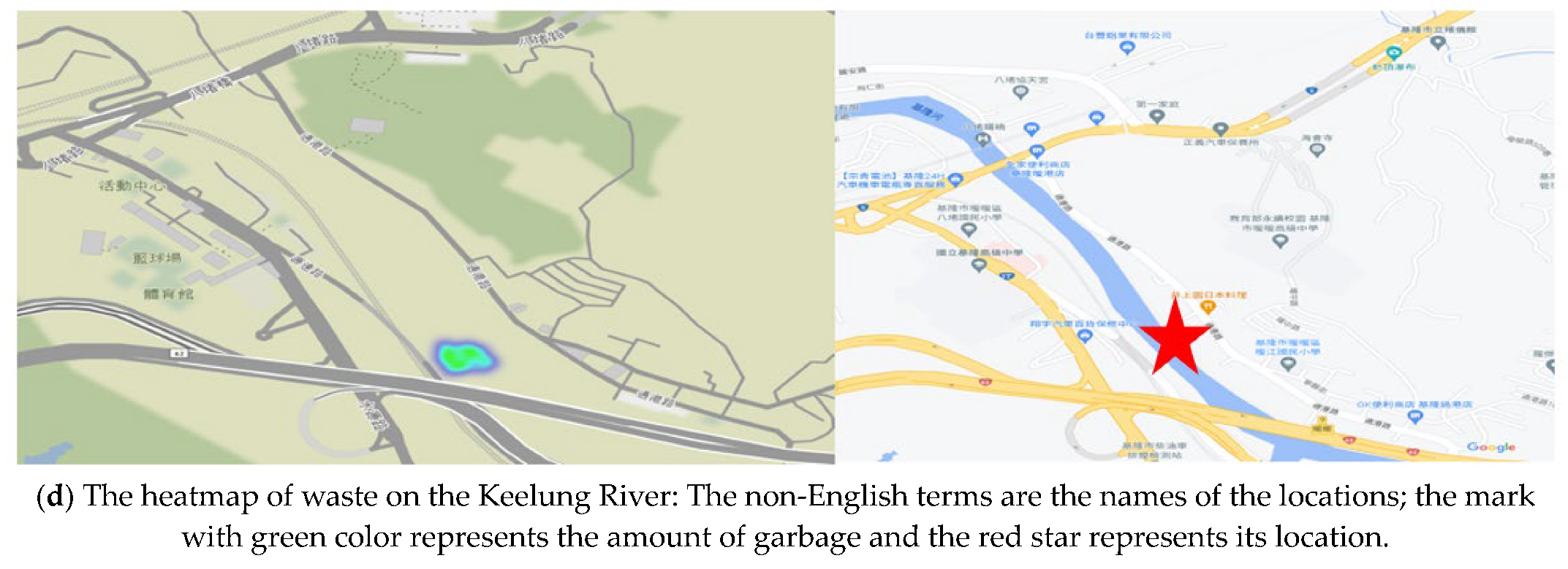
5.3. Scene 3: Keelung River
In the Keelung River test, we set the UAVs’ height to about 5 m above the riverbank, the speed was about 1 m/s, and the UAVs were separated by 5 m. In riverine waste detection, some small garbage could be detected. The confidence scores are high, as shown in
Figure 22b. For image stitching, we set the UAVs farther away from each other. Images can be stitched, as shown in
Figure 22c. The heatmap of waste is shown in
Figure 22d. The area of the detected debris is shown in
Figure 22b on the left side of the picture; it is indicated as “trash: 0.02 m
2”. The confidence rates of the detected debris are shown in
Figure 22b (62.83%, 95.18%).
Table 5 demonstrates the effectiveness of the proposed trash inspection system by summarizing the detected results from three different scenes. The experimental results show that if the background of the test field is complex, there are undetected objects. To overcome this problem, more training images are needed. The position accuracy is good in the three scenes. This is because the RTK system is used in the proposed UAV system.
6. Conclusions
In waste detection, we found that the improved YOLOv5s-iii is better than YOLOv5s and YOLOv4-tiny-3l after tuning the hyperparameters and modifying the YOLOv5s model. When we tested it on rivers, we also found that the confidence scores with one class were better than the confidence scores with two classes. In the Tianliao River, the waste detector could still detect two classes (garbage and bottles) in an unknown scene. The detector sometimes misses a small amount of waste because the wind is too strong, making the camera gimbal shake and become unstable. In this case, the captured image is blurred and unable to be classified. Another reason is that the altitude of the UAV is too high, which makes the object too small to be identified. To overcome these problems, low-altitude flight is performed. The drawback is that the detection area is also reduced. Thus, this study proposed multiple UAVs and image stitching to cover a wide area on the inspected riversides. For better resolution and inspection of the captured garbage image, the UAV must fly at a low altitude but this will reduce the cover area of the camera. In this study, the UAV altitude is about 5 m, and the ground range of one image frame is about 10 m wide. To make the inspection task more intelligent, we apply two UAVs in parallel flights so that they can cover one side of the riverbank in a flight. Both UAVs can fly along the preplanned path automatically. The images from the two UAVs are stitched and sent to the ground control center in real time. The inspector at the control center can check the image of one side of the river immediately. If we only use one UAV, the UAV needs to fly two times on one side of the river; this is inconvenient for the UAV operator and makes the inspection task less intelligent. In the Keelung River, some false detection occurred. The waste detector misidentified reflective waves as garbage. In image stitching, the SIFT algorithm’s computation is extensive. We utilized the seam line method to stitch the image, which reduced the computation time and achieved real-time image stitching. Although the cameras kept moving and several factors affected the image stitching results, including the light, quality of image, the UAVs’ height and speed, and vibrations of the UAVs, image stitching could still be performed for moving carriers. Information on garbage, location, and area size could be successfully transmitted to the ground station via the message queuing system. Further, the heatmap of waste can be provided on a monitor in real time. Moreover, the proposed UAV system is capable of performing riverbank inspection. Government officials can check garbage information from the inspection system’s real-time images. The proposed system can reduce the labor spent on garbage inspection a lot. In addition, riverside pollution can be further controlled. In the future, we can modify the model to detect more classes of riverine waste and utilize more UAVs to increase the detected areas and efficiency. Furthermore, precise positioning and UAV formation flight are essential. Precise positioning can help UAVs to relocate their position in a robust wind environment. Better UAV formations can make the image stitching smoother and allow stitching of a wide area of images captured by UAVs simultaneously. Dynamic image stitching is very difficult in this study. Although we used the same type of camera, color differences exist in the same object on two camera images. These differences make many feature points unable to be matched. Further improvements will be made in upcoming studies. In addition, there were objects undetected in the field tests. To overcome this problem, more training samples are needed in future work.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}