1. Introduction
Machinery plays a major role in the national economy and composes the core of the whole industrial field. The traditional manufacturing industry is constantly undergoing innovation, and advanced progress has been made as a result of the industrial revolution. This increased use of science and technology has led to the development of big data analysis, cloud computing, and artificial intelligence. To guarantee that mechanical productivity meets the requirements of modern industry and everyday life, mechanical equipment development is continuously moving towards complexity, integration, continuity, and intelligence [
1,
2,
3]. Modern industrial machinery is produced by large-scale production systems, has rich performance indicators, and consists of a variety of mechanical components, which means that the failure of small parts can cause entire production lines, or even production plants, to stop working and producing. These failures can cause huge economic losses, can waste resources, and can even threaten the lives of staff when immediate fault diagnosis is not performed. Early health-monitoring of mechanical systems is crucial to identifying failure sources, replacing degraded mechanical components, and troubleshooting faults in a timely manner; completing these tasks can effectively reduce the risk of accidents, decrease maintenance costs, and limit hazard potential [
4,
5,
6].
Gearboxes are devices used for transmitting motion and power and are often preferred for constant-speed applications in mechanical equipment due to their compact structures, fixed transmission ratios, and simple disassembly and installation procedures. However, due to the complexity of gearing and the fact that gearboxes often work under harsh conditions, such as high speeds and heavy loads, their primary components, such as gears, shaft systems, and bearings, usually experience varying degrees of wear and are prone to damage [
7]. In the past century, many scholars and studies from around the world have focused on the special challenges associated with science and industrial technology regarding the development of original techniques for analyzing complex machinery, such as oil analysis, noise detection, vibration analysis, and non-destructive testing. Research regarding vibration-detection technology began before studies involving the other techniques; therefore, this technology is much more mature, and its application potential is the most extensive [
8,
9,
10].
Common signal processing methods used for feature extraction for different damage and failure types include principal component analysis (PCA) techniques, classical modal analysis techniques, convolutional neural networks (CNNs), and singular-value decomposition (SVD) algorithms [
11]. Previously published research regarding the methods and theory of performing feature extraction with signal analysis has effectively improved fault-feature identification and provided feasible bases for gearbox failure identification and integrity assessment. The parallel-factor decomposition model—which was first proposed in the 1970s but not used for many years due to computer storage and computing power limitations—has gained significant attention in recent decades as a new signal-processing method because of its good performance, in addition to being widely used in fields such as environmental science, clinical medicine, and image processing fields [
12,
13,
14]. Parallel-factor analysis methods are most commonly used for 3D fluorescence spectroscopy within the environmental science and resource utilization disciplines. The theory behind the parallel-factor method has been improved and its associated techniques have gradually matured alongside its expansion into fields outside of chemistry [
15]. Sidropoulos developed direct sequence–code division multiple access (DS–CDMA) systems by applying the parallel-factor theory to signal processing [
16]. Liang [
17] proposed a new blind model by using the parallel-factor (PARAFAC) code division of multiple-access systems for blind signal detection in CDMA systems. Yang [
18] used the tensor singular spectrum to analyze the underdetermined observed signals for blind source separation.
In recent years, scholars have begun to investigate PARAFAC methods for degradation monitoring of mechanical systems. Zhang et al. [
19] established the parallel-factor algorithm for integrity assessments of wind turbines. The fault information acquired by the data acquisition and monitoring system was used to conduct effective wind farm condition monitoring. Wang [
20] used the PARAFAC method to reconstruct multi-source bearing fault signals. Fault-condition classification of engineering systems was achieved by combining principal component analysis with the alternating least squares method. In general, matrix decomposition is not unique unless a constraining condition, such as orthogonality, the Toeplitz condition, or the constant mode, is imposed. However, these harsh constraints are not satisfied in practical applications. A new method must be sought to solve this problem. Unlike traditional 2D signal processing methods, the PARAFAC method can decompose 3D and multidimensional signals to obtain unique solutions under relatively loose constraints. The PARAFAC analysis method can uncover the underlying structure and reflect the essential characteristics of high-dimensional data and can therefore efficiently utilize multi-channel signals for fault detection. Therefore, research regarding the use of a PARAFAC-based method for mechanical fault diagnosis was conducted during this study.
In light of the above, it is urgent to develop theories and methods for mechanical fault diagnosis under non-stationary operating conditions to ensure that modern industrial production processes achieve intelligence, digital monitoring and diagnostic prediction. This issue has become a technical limitation and is a recognized challenge when applying fault-diagnosis technology to key mechanical equipment in engineering practice. This paper focuses on intelligent techniques of vibration signal analysis. The goal of this paper is to propose an intelligent hybrid method, based on parallel-factor theory for the adaptive diagnosis of nonstationary fault modes, that uses adaptive particle swarm optimization (APSO) with a support vector machine (SVM) to improve fault-diagnosis intelligence and accuracy.
2. Optimized Hybrid PARAFAC–APSO–SVM Model
2.1. Parallel Factors Model
The essence of the PARAFAC structure is the low-order multi-decomposition process of the multi-dimensional matrices that represent multiple linear models. The parallel-factor decomposition theory is described next.
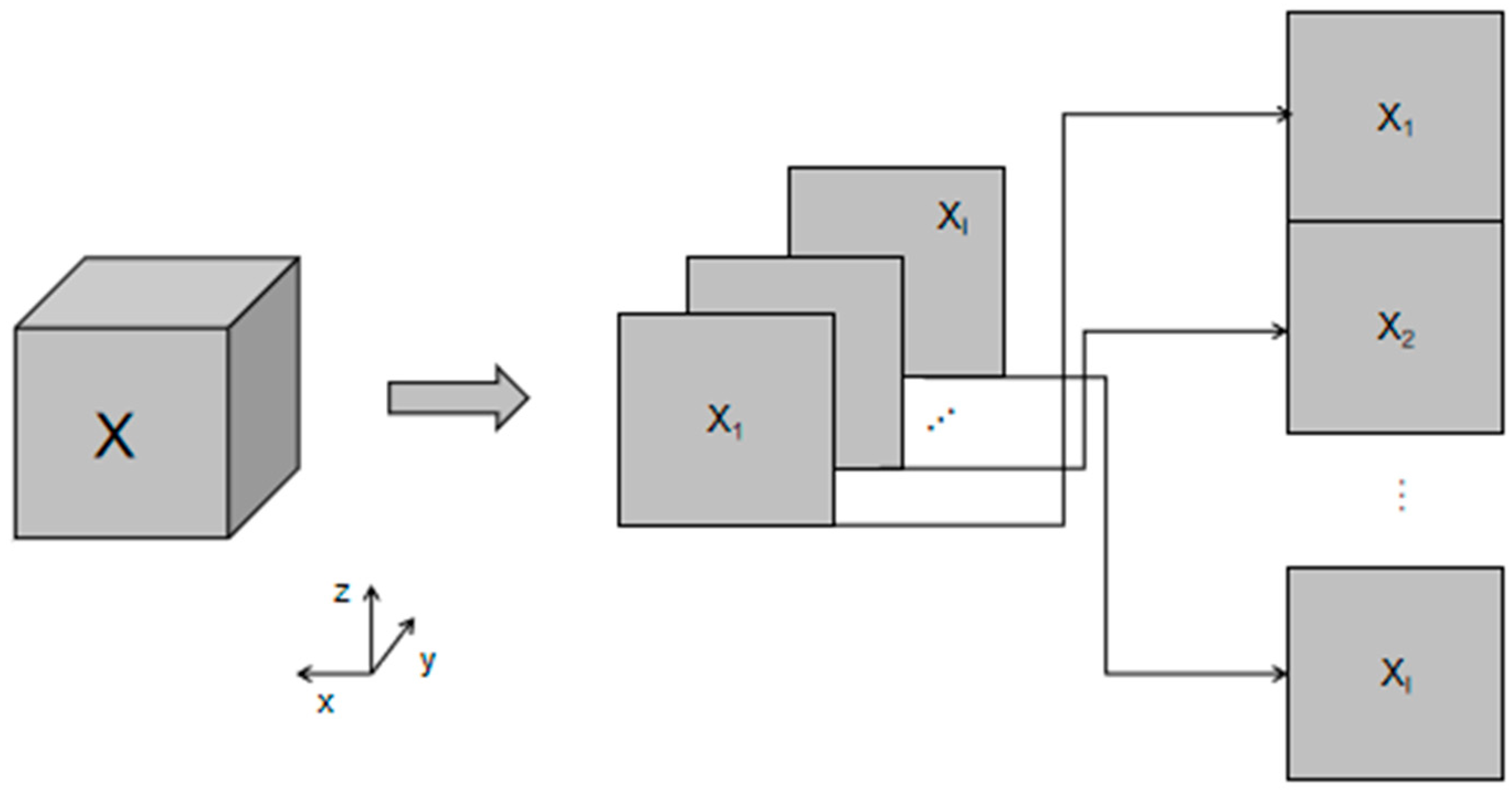
The three-dimensional matrix,
, was subjected to PARAFAC decomposition with scalar expressions, as shown in Equation (1):
In Equation (1), the variable ranges are p
… M. The 2D moments,
, are the loading matrices of the PR multi-level model. The sets
,
,
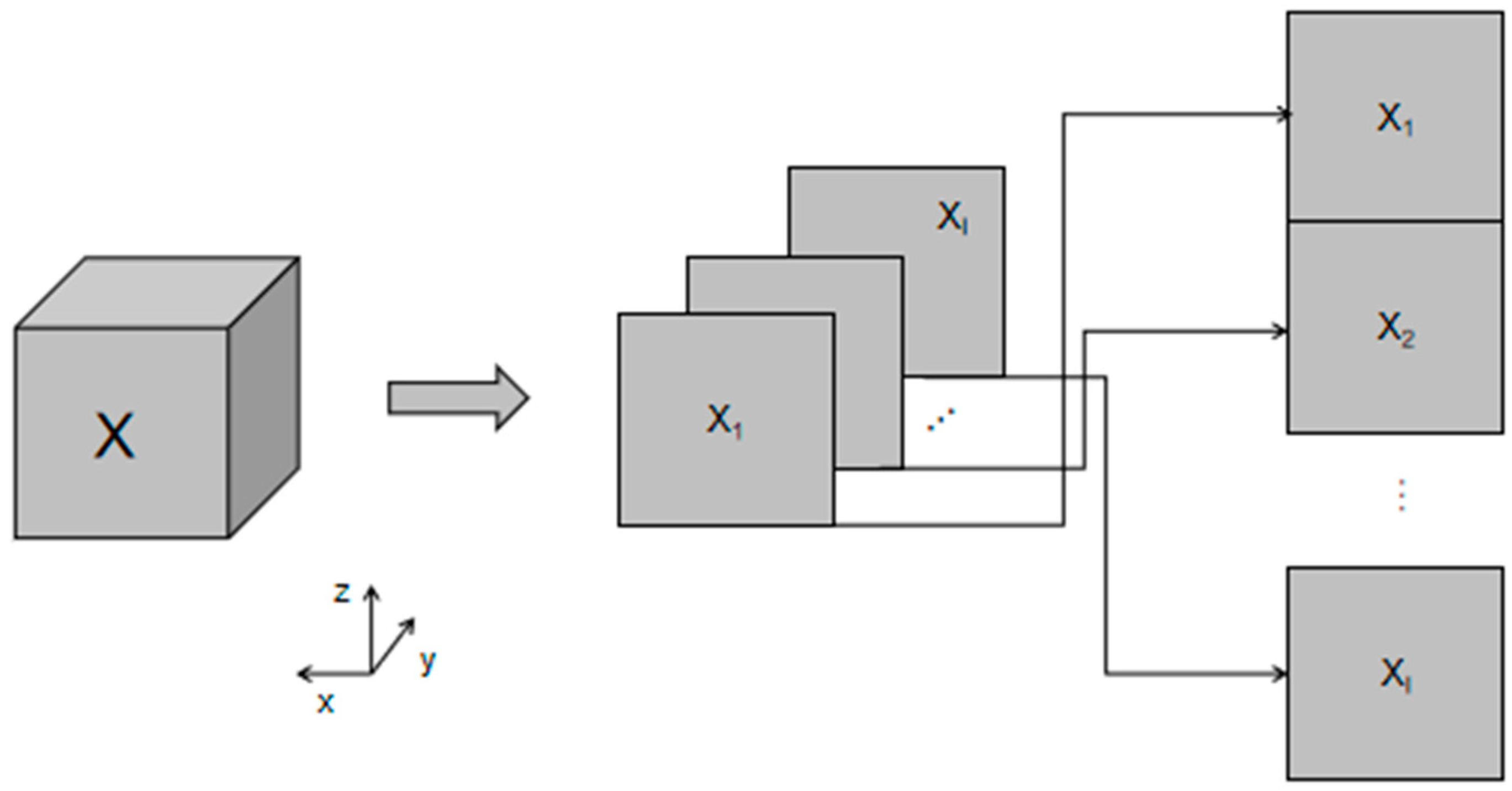
are noise matrices. The low-order multi-decomposition process was enlarged to a higher dimension. The number of dimensions increased, which caused the degrees of freedom of the elements in the matrix to also increase. The abstraction process became much more complicated. Only 3D matrices were investigated during this study. In practice, the 3D model can also be used to intercept profiles from different directions by using the 2D set matrix, which is equivalent to the 3D-model representation.
Figure 1 presents the 2D set matrix along the
x-axis direction within the PARAFAC model.
The primary formula used in the PARAFAC model is expressed in Equation (2):
In Equation (2), the set
is the element of the pth row of extracted matrix A and is constructed as a diagonal sub-matrix. The parallel-factor model has significant advantages over 2D matrix decomposition in that it allows the fuzzy decompositions of the column and scale to be unique in the absence of any other constraints. In terms of the discriminating conditions of the PARAFAC set, the definition of the k-order matrix is introduced as the rank of set A. Set A consists of independent columns when, and only when, the total number of columns is at least equal to r, which is defined below:
The parameter k is the number of independent column vectors in set matrix A. The required condition for the order of set matrix A is .
There is only one solution for the three sub-matrices of the PR decomposition after both the scale and column transformations. It is required that the k-orders of matrices A, B, and C satisfy
. The sufficient condition for discriminability of the multi-decomposition PARAFAC model is presented as follows:
2.2. Support Vector Machine Theory
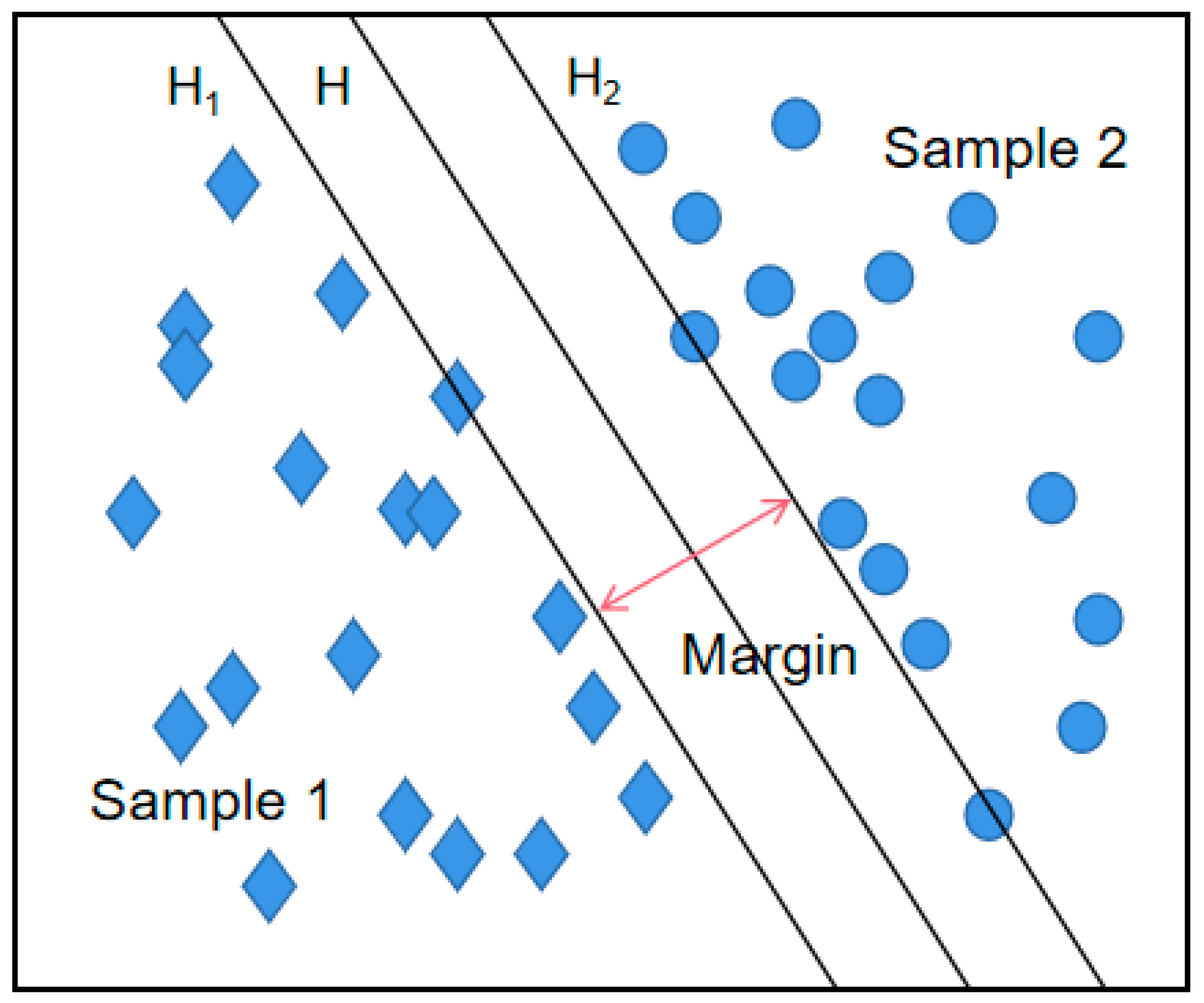
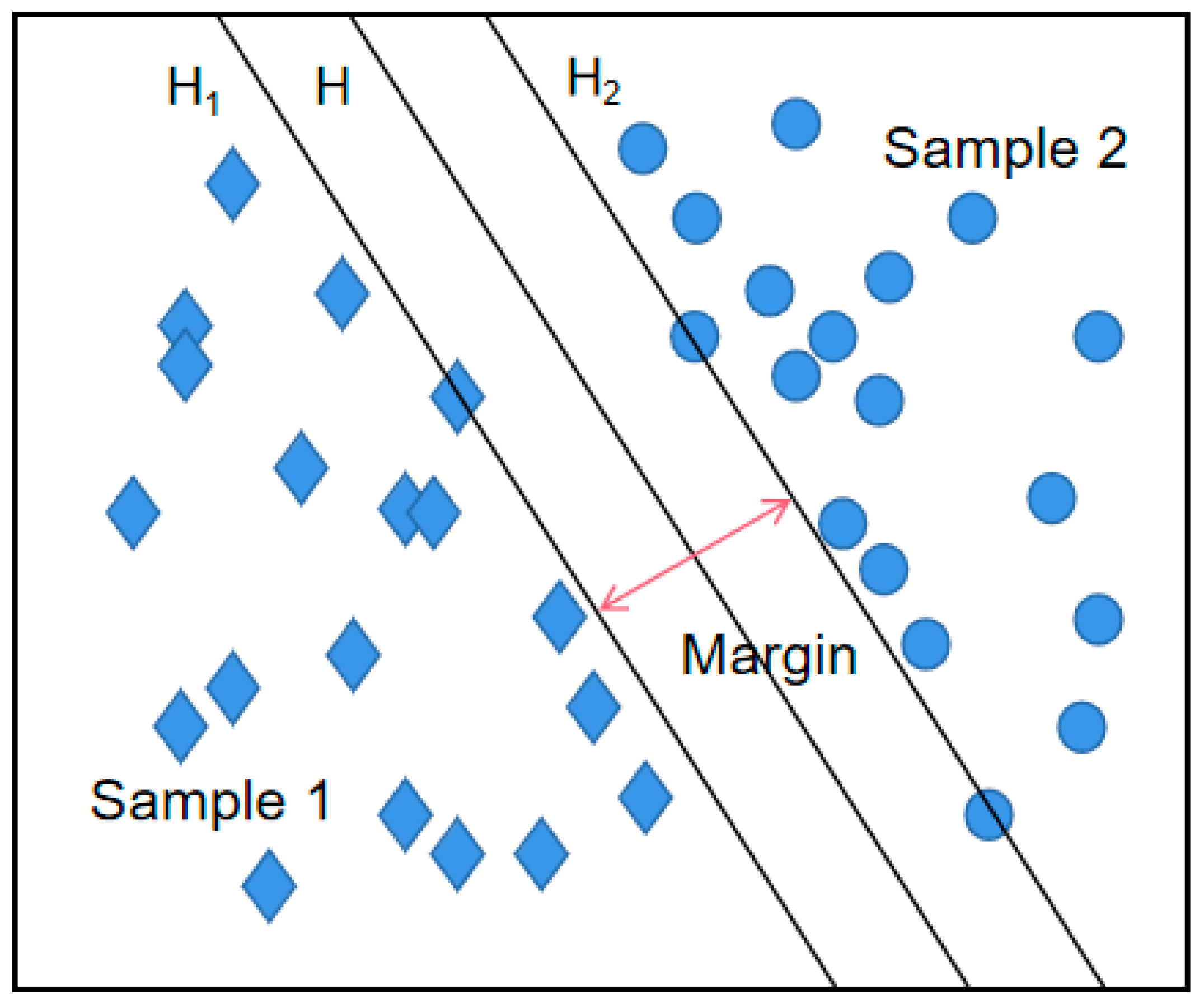
Support vector machines were invented as a result of the binary classification problem, which was proposed as a linear classifier model to construct binary feature spaces with the maximum interval. The interval between the training data sets is maximized by establishing a divided hyperplane using optimization theory, as shown in
Figure 2.
The training data set is supposed to be
. The input data and learning objectives in the classification problem are given as
and
, respectively. The multiple features included in the input data construct the feature space according to
. The updated objectives are bi-category objectives:
. The hyperplane exists and is regarded as the decision boundary in the feature space in which the input data are located, and the updated optimization objectives are divided into two classes. The distance from the geometric location of any data point to the hyperplane is greater than or equal to 1. The decision boundary is defined according to Equation (5):
The condition that the separation line correctly classifies all the sample data as one of two types satisfies the separation interval. Therefore, Equation (5) can be transformed into
At this point, the classification interval margin is equal to . The optimal hyperplane is constructed by a transformation into a minimum problem with constraints. We first assume that a hyperplane has a parameter that is a geometric interval between the plane and the data set. The constraint function is used to control the geometric interval. When the geometric interval is smaller, the hyperplane is better. Thus, the problem of finding the optimal plane can be transformed into the problem of finding its constraint optimization problem by finding the minimum values of variables and b to produce the minimum value of parameter . The final classification hyperplane, which is obtained after training the sample data, is determined by the sample data points at the limit surface, i.e., the training sample points on H1 and H2 are called support vectors.
The disadvantage of using the hard-margin SVM to solve linear non-separable problems is that it easily generates classification errors. Therefore, a loss function based on margin maximization is introduced in the proposition of a novel optimization method. To find the maximum interval and minimize the number of misclassifications or serious classification errors, the objective function must be adjusted by introducing a slack variable,
, to reduce the constraint and by adding a penalty factor,
, to balance the
values, which control the optimization tendency. The SVM expression can then be obtained, as shown below:
A nonlinear SVM can be obtained by mapping the original input data into the high-dimensional feature space by using a nonlinear function in a linear SVM. However, the nonlinear SVM has some optimization problems. By introducing the Lagrange function, Equations (7) and (8) can be transformed into a dyadic expression according to the Karush–Kuhn–Tucker (KKT) theory:
In Equations (9) and (10), the parameter
is the KKT multiplier that the Lagrange multiplier uses to impose the inequality constraint. The Gaussian radial basis kernel is universally applicable, so it was chosen as the kernel function. The unique parameter
must be set up according to Equation (11):
The objective function can thus be ultimately expressed by Equation (12):
2.3. Improved APSO Algorithm
The traditional particle swarm algorithm finds the optimal particles by learning from the particles’ historical experience
and population experience
; this algorithm has been widely used because of its high computational speed and robustness. The important SVM parameters,
and
, must be optimized to establish the optimal decision boundaries of the 3D feature space in an SVM.
is used to control the penalties of the misclassified training examples and
is the kernel function parameter. A new particle-velocity updating strategy for PSO is proposed according to the definition of the core PSO search formula:
In Equations (13) and (14),
and
represent the particle velocity and generation, respectively. The variable representing the inertia weight
decreases linearly with successive iterations;
and
are the learning factors;
and
are mutually independent, arbitrary numbers between 0 and 1. The particles of the APSO algorithm are updated to pursue the optimal values of the particles in the neighborhood and to update their velocities. The distances between a specific particle and other particles are computed one-by-one during each iteration;
lmn represents the distance between the
particle and the
particle. The maximum value of
lmn is
lmax. The specific value
can also be obtained. The value of the threshold
is adaptively adjustable according to the number of cycles;
is defined below:
In Equation (15),
is the cycle index with a maximum value of
. When
is equal to 0.9 and
is less than
, the
particle is supposed to be near the
particle. The velocity of the particle is refreshed by an updated learning factor c
3, and a random parameter, r
3. Equation (13) can then be rewritten as
If is greater than 0.9 or if is greater than , then Equation (13) is used to refresh the particle velocity.
Conventional PSO applies the inertia weights along with linear reduction to alter the step length in the search process, which causes the optimization toward the extreme point to gradually converge. A shortcoming of conventional PSO is that it is prone to falling into local optima. An improved PSO algorithm, the APSO algorithm, is proposed to address the drawback of local convergence without the optimization inherent to the conventional PSO. The weights,
, of the APSO algorithm decrease according to an S-shaped function so that
changes dynamically. At the beginning of the optimization search when using the APSO algorithm, the original value of
is set as a large value to facilitate global optimization. At the end of the optimization search process,
is evaluated as a smaller value so it can conduct the optimization search process. This improved strategy for updating
in the APSO algorithm is achieved by the definition below:
2.4. SVM Optimization with the APSO Algorithm
The APSO algorithm primarily optimizes the penalty coefficients of SVM functions and the parameters of kernel functions, that is, a slack variable, , which reduces the constraint, and a penalty factor, , which determines the penalty degree for the model complexity and fitting bias. These two variables have significant impacts on the SVM regression model. Values that are both too large and too small can affect the system’s generalization performance. The kernel function parameters precisely define the structure of the high-dimensional space. The optimal parameters must be selected to ensure the generalization capability of the system. The standard for determining the optimal parameters of an SVM classifier is based on there being the same number of iterations for both the improved and non-improved SVM. The higher the SVM correction rate, the better the parameters. The optimal parameters are selected based on higher SVM classification correction rates.
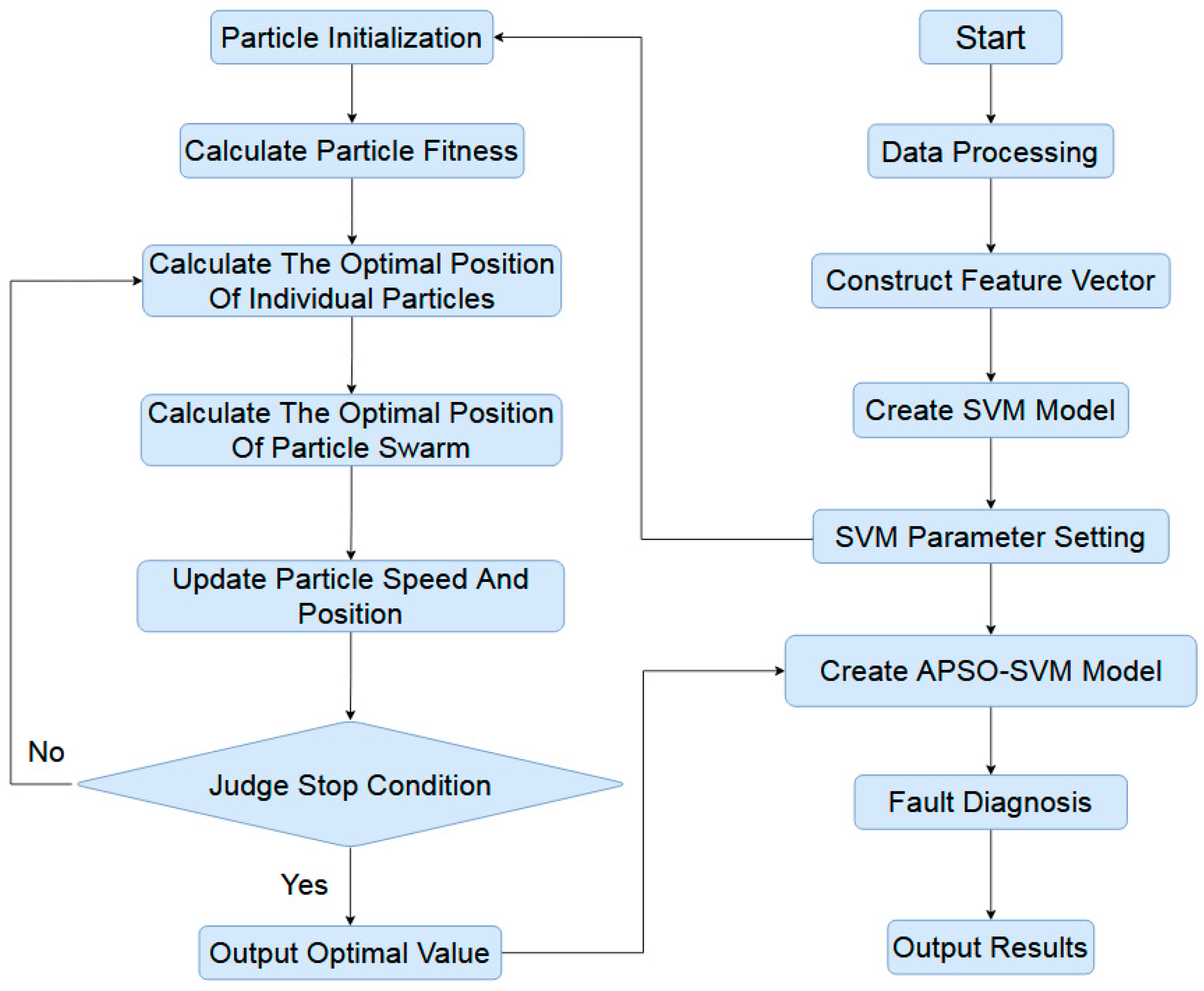
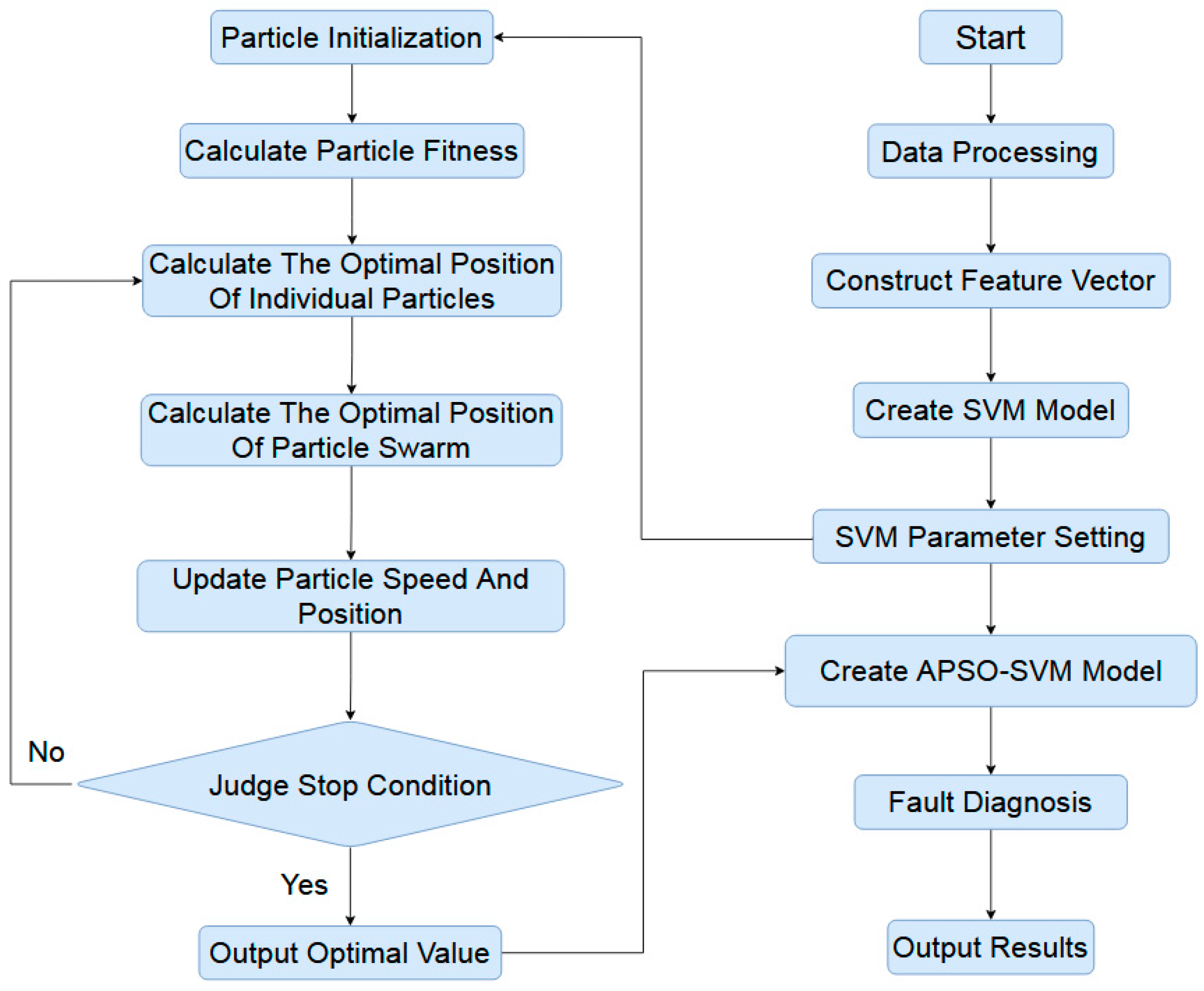
A flowchart depicting the use of the APSO algorithm to optimize the SVM classifiers is shown in
Figure 3. The procedure consists of five primary steps.
The parameters in the APSO algorithm are initialized; these include the number of particles, the initial particle positions, the number of evolutionary generations, the acceleration factor, and the maximum loop value.
The fitness values of the particles are computed and compared based on a given objective function. The APSO algorithm uses the objective function in Equation (9) as a self-adjusting fitness function.
The fitness values of the individual particles with optimal positions are obtained and the optimal positions of all the particles are refreshed.
The fitness values for the local optimal positions of the particles are compared to the fitness value of the particle’s global optimal position to obtain the new global optimal particle positions.
Equations (13)–(16) are used to refresh the velocities and positions of the particles. If the loop has finished or the accuracy requirement has been met, the optimal values are output and substituted into the SVM. Otherwise, the conditional requirement has not been met, and the process returns to Step (2) and continues from there.
3. Experimental System for the Gearbox
Five fault modes
were set up for a gearbox system to simulate gearbox failure; these fault modes consist of a normal gear mode
and four broken gear modes
. Four sizes of gear cracks were selected for the experimental testing system to simulate the gearbox fault conditions. The geometric features and dimensions of the gear cracks included maximum depth
, width
, thickness
, and angle
values of
,
,
, and
, respectively. There was no loading force on the input shaft of the gearbox during the experiment. The geometric gear-crack parameters for the five fault modes are described in
Table 1.
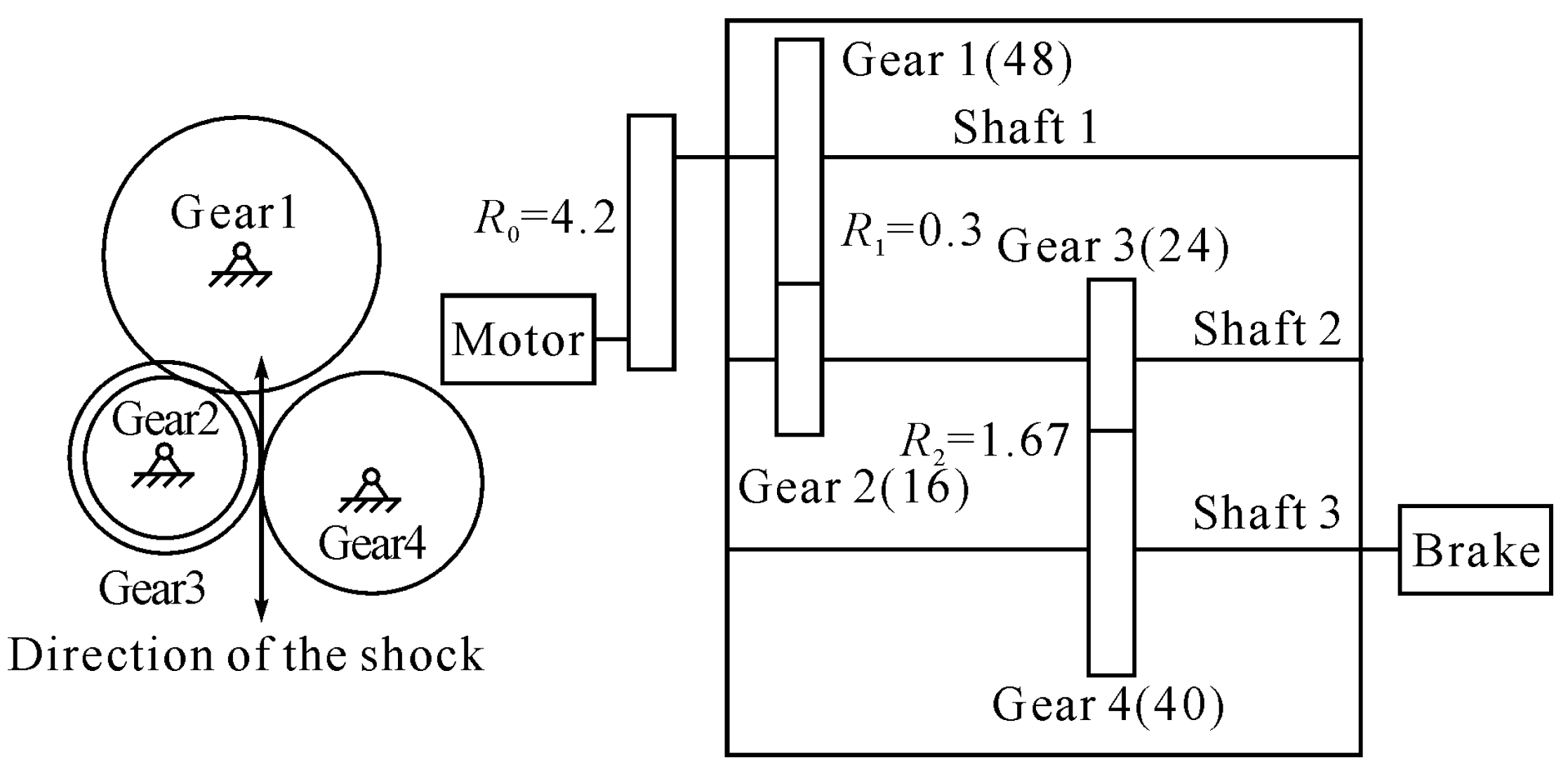
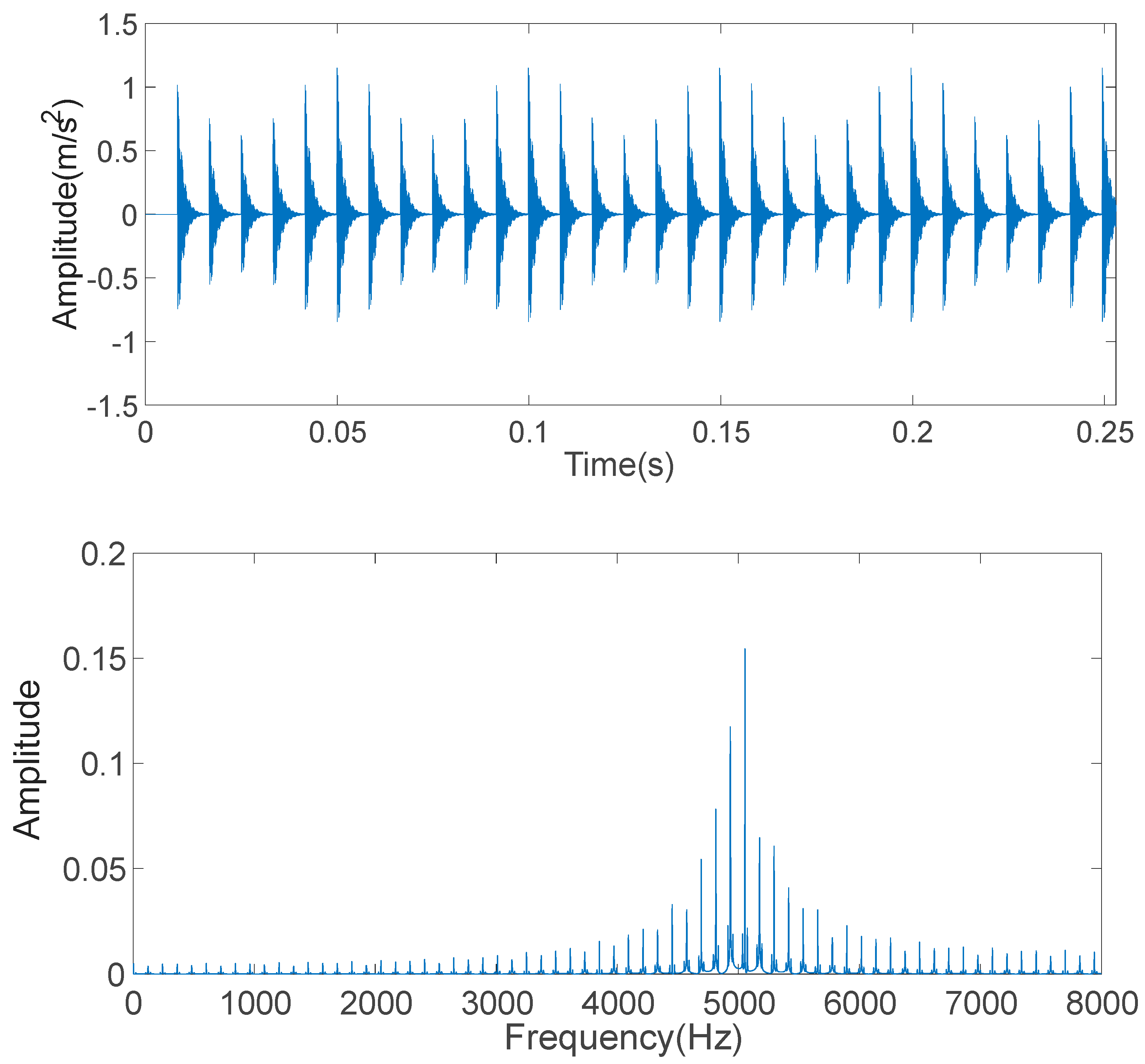
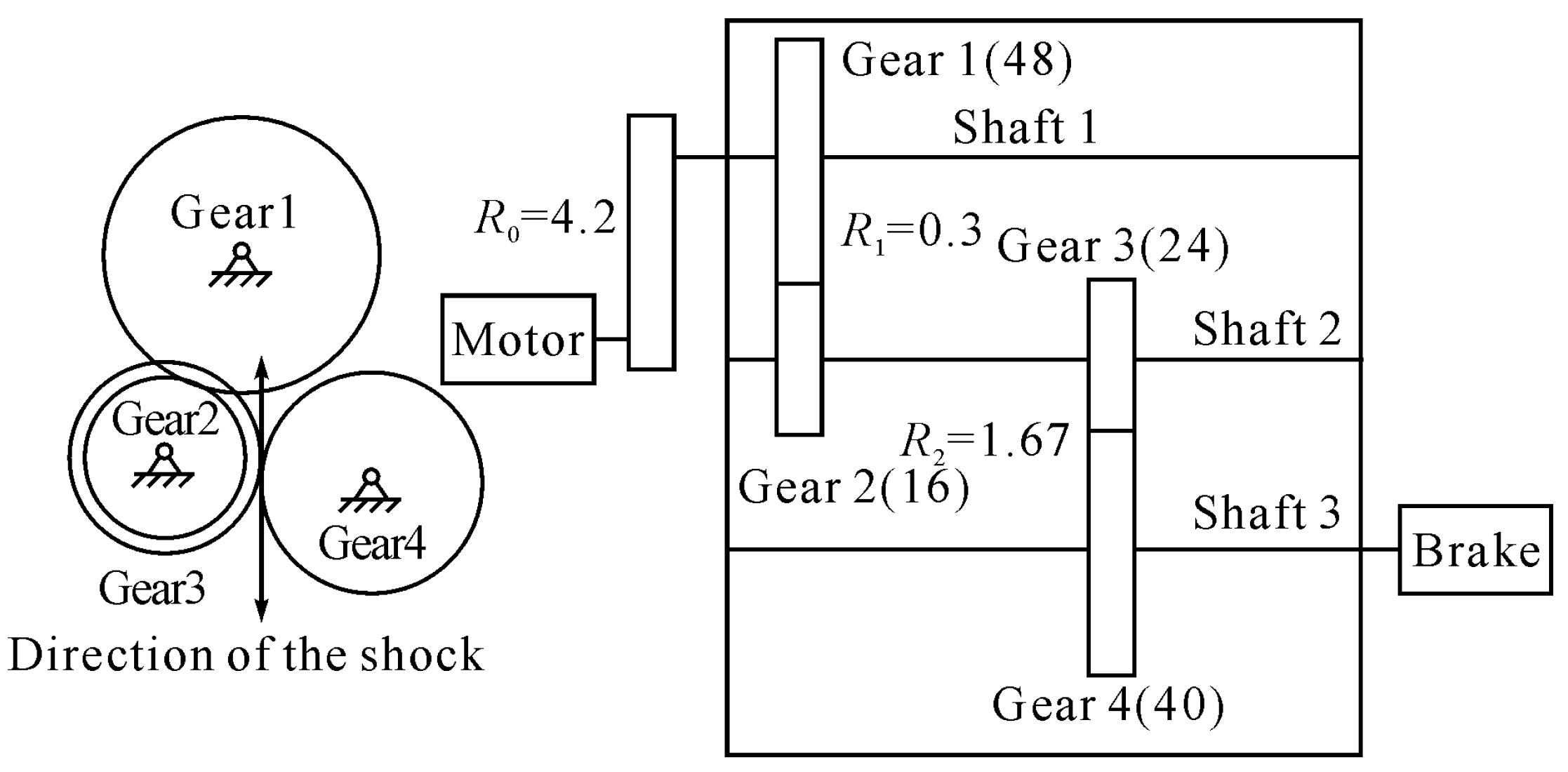
As shown in
Figure 4, the dynamic acceleration of the gearbox system was excited by the vertical meshing mechanics of Gear 3 and Gear 4. Sensors placed vertically are more sensitive to this failure mode than sensors placed horizontally, and they can collect more comprehensive data of the outer cast of the gearbox. Gears 3 and 4 were chosen to simulate actual failure modes in industrial applications. It was difficult to determine which gear failed first. Based on existing experimental research, Gear 3 was chosen to simulate gear failure by cracking during the experimental procedure.
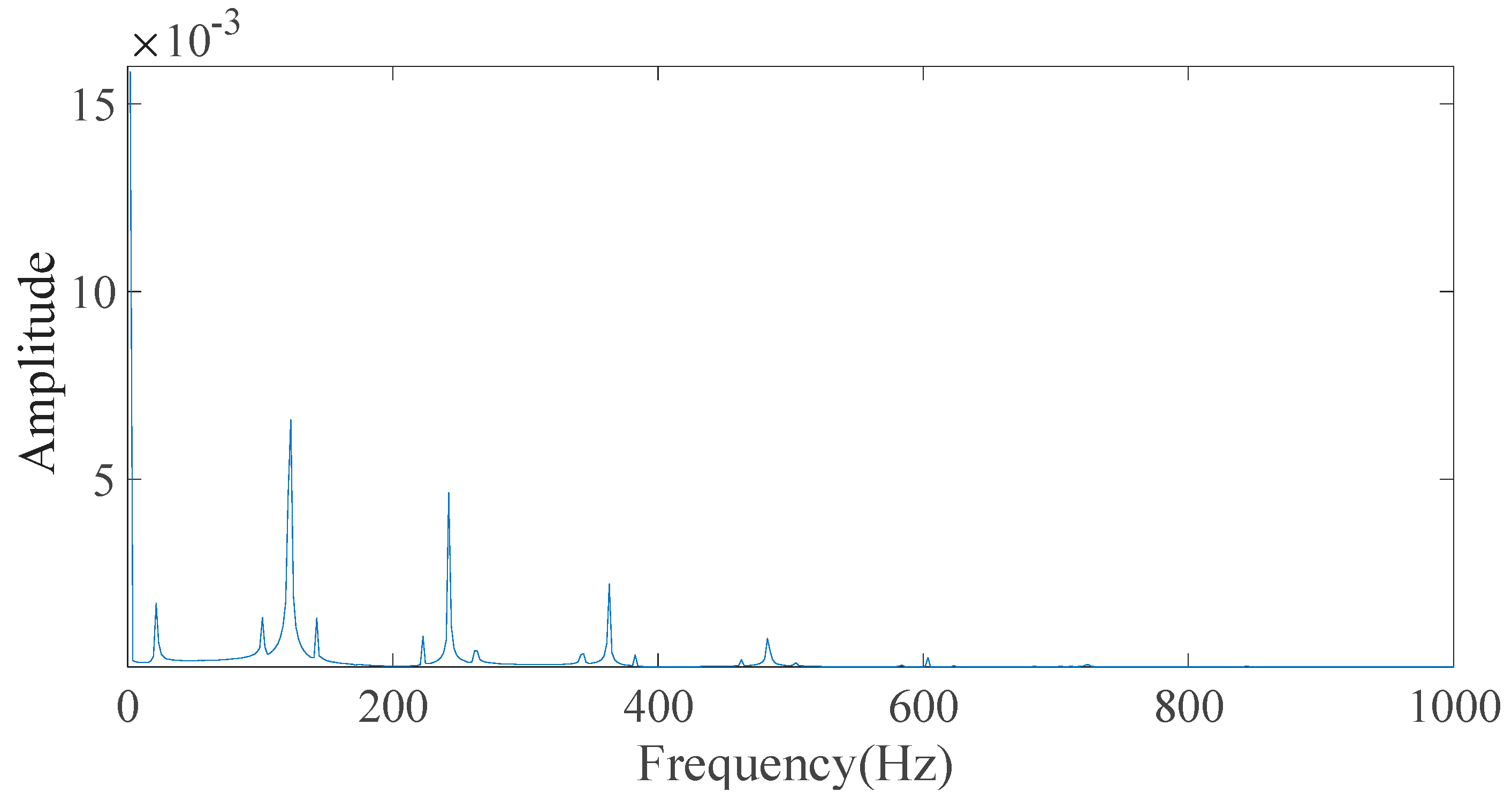
The experimental motor speed was chosen to be 2800 r/min, which caused the sampling frequency to be 12,800 Hz. Initial condition parameters, such as the safety factor (1.15) and the number of teeth in each gear, were set up. The angular velocities and characteristic frequencies of the shafts and gears inside the gearbox were calculated based on the drive ratio between the drive motor and the driven gears and the rotational speed of the drive motor. In
Table 2,
indicates the speed of the first shaft that is mounted with the first gear,
indicates the speed of the second shaft that is mounted with the second and third gears,
indicates the speed of the third shaft that is mounted with the fourth gear,
is the meshing frequency of the first and second gears, and
is the meshing frequency of the third and fourth gears.
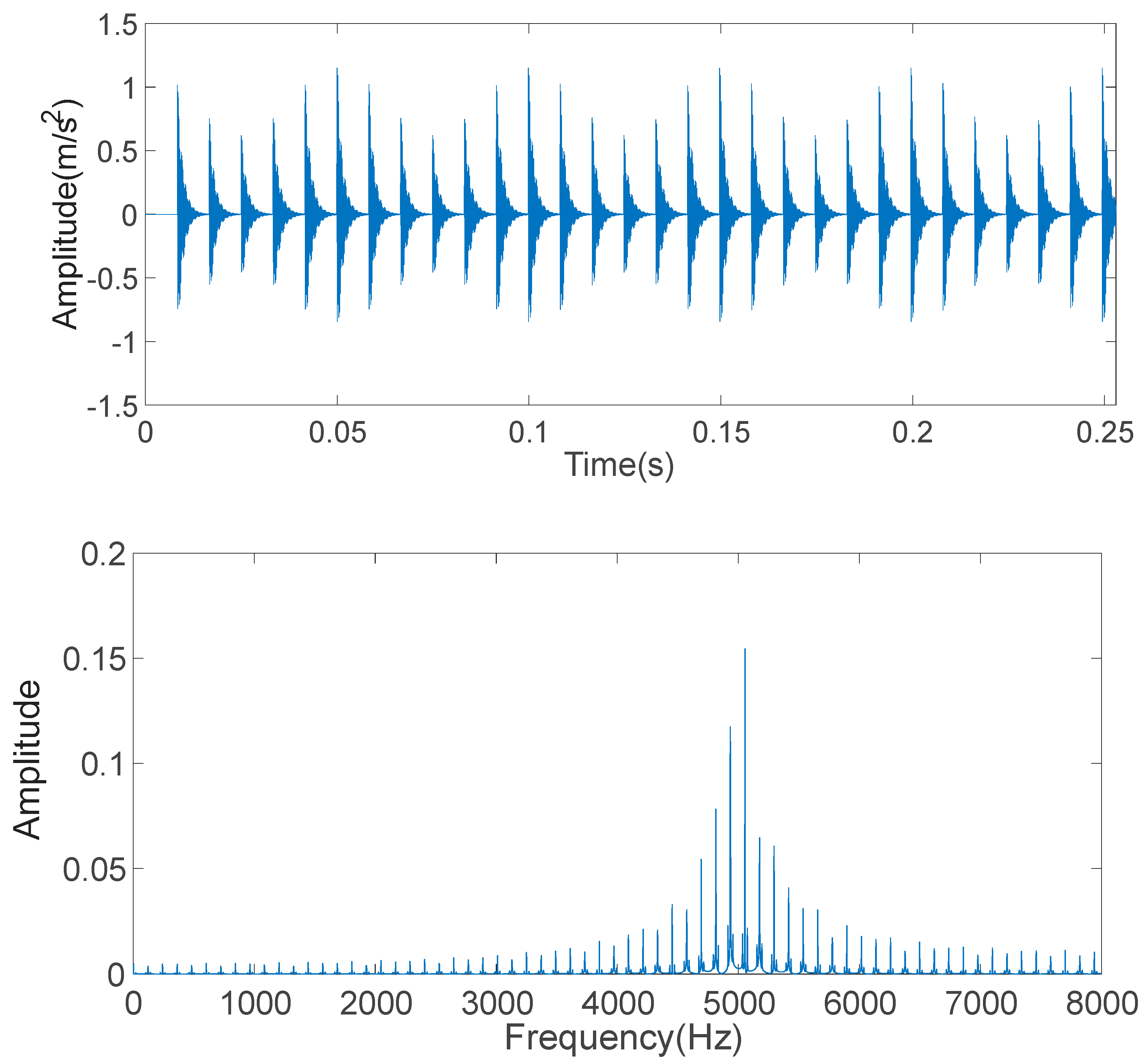
The vibration-signal acquisition system used for gearbox fault diagnosis in this study is displayed in
Figure 5. Accelerometers (352C67-PCB) were installed on the gearbox cast. The vertical and horizontal components of the vibration signals were collected with a dynamic simulator (Spectra Quest). The vibration data were transmitted to a computer via a digital signal processor. The vibration signals of both data channels were synchronously acquired and analyzed using the proposed method.
5. Conclusions
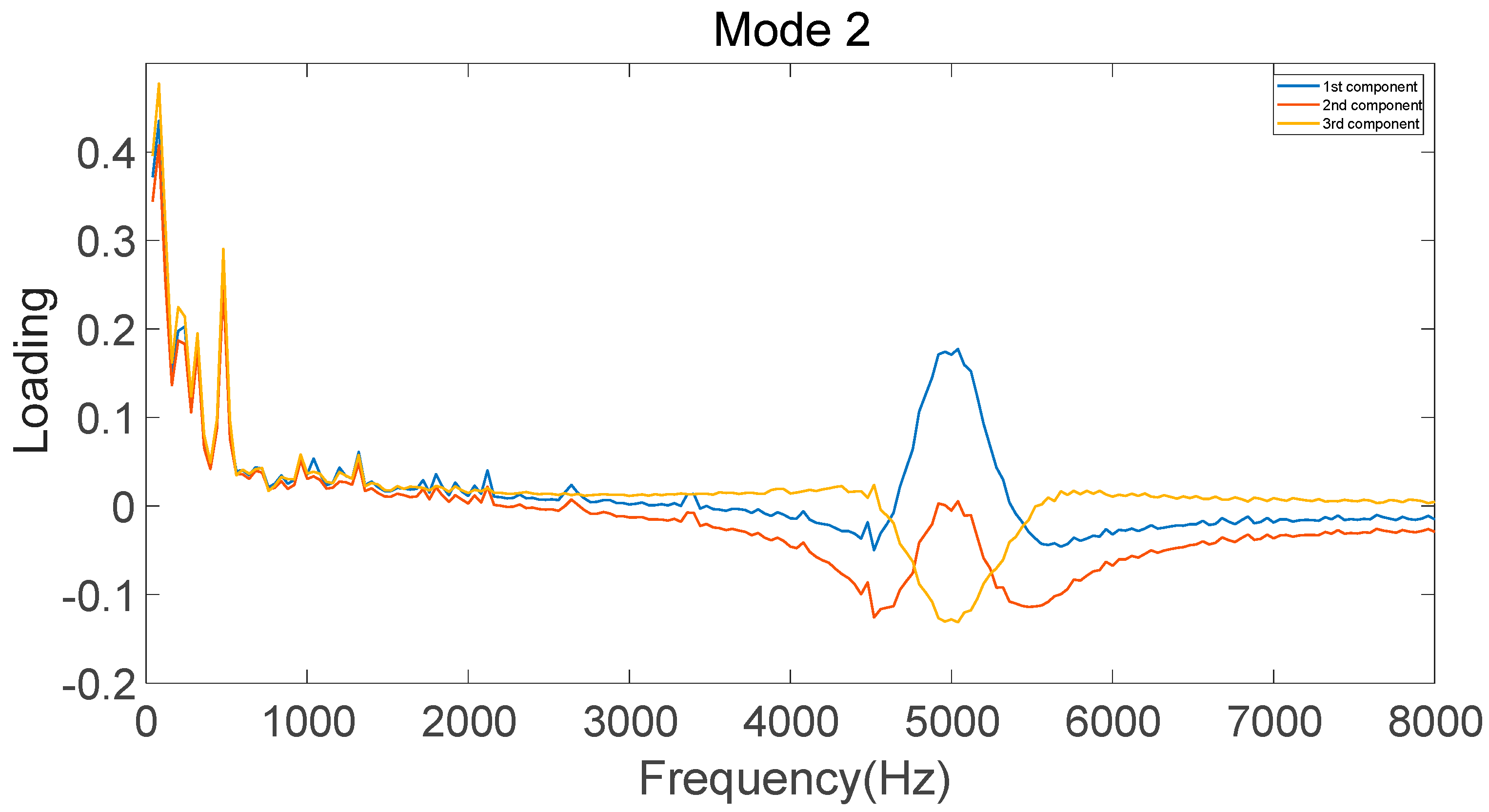
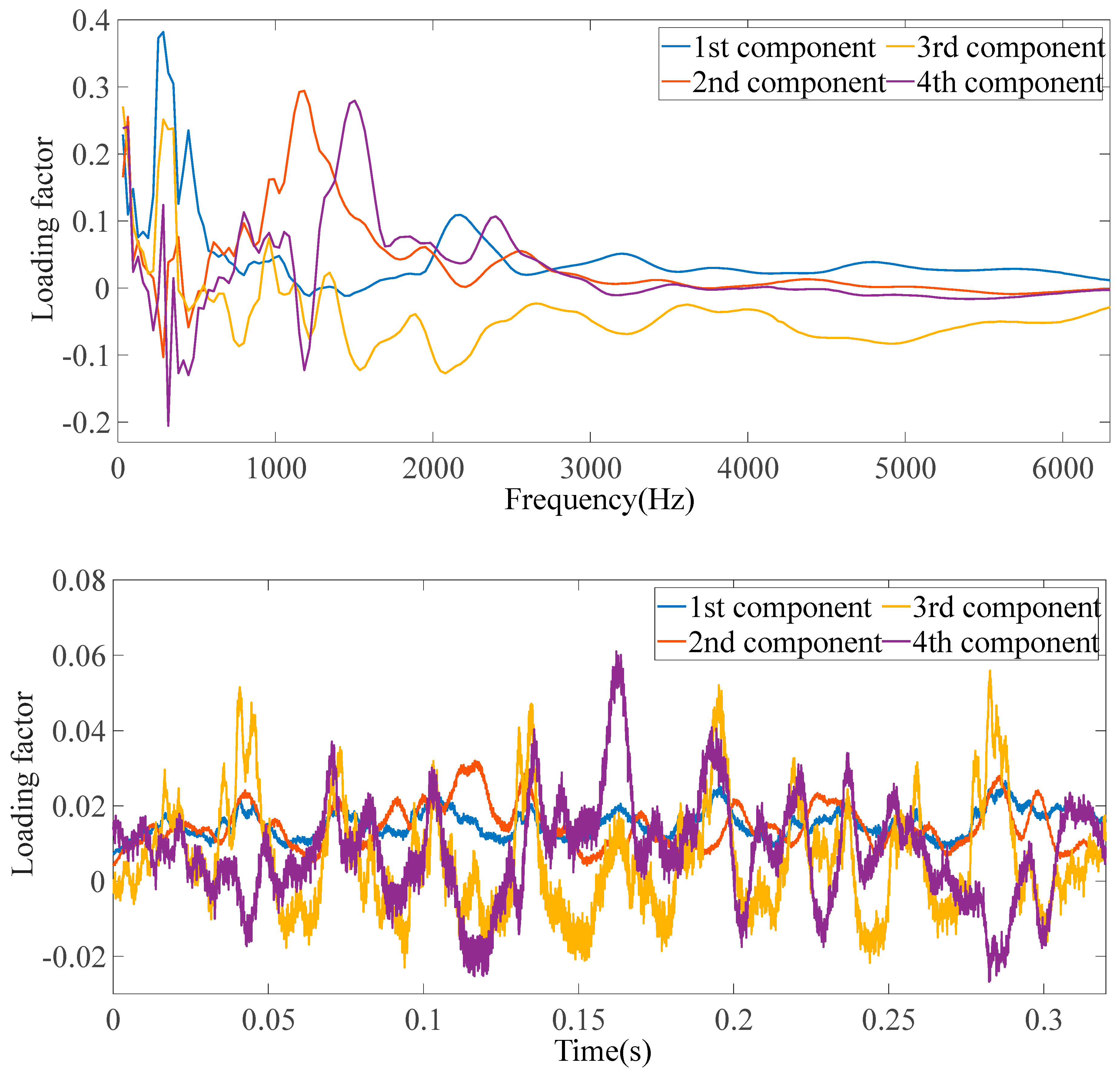
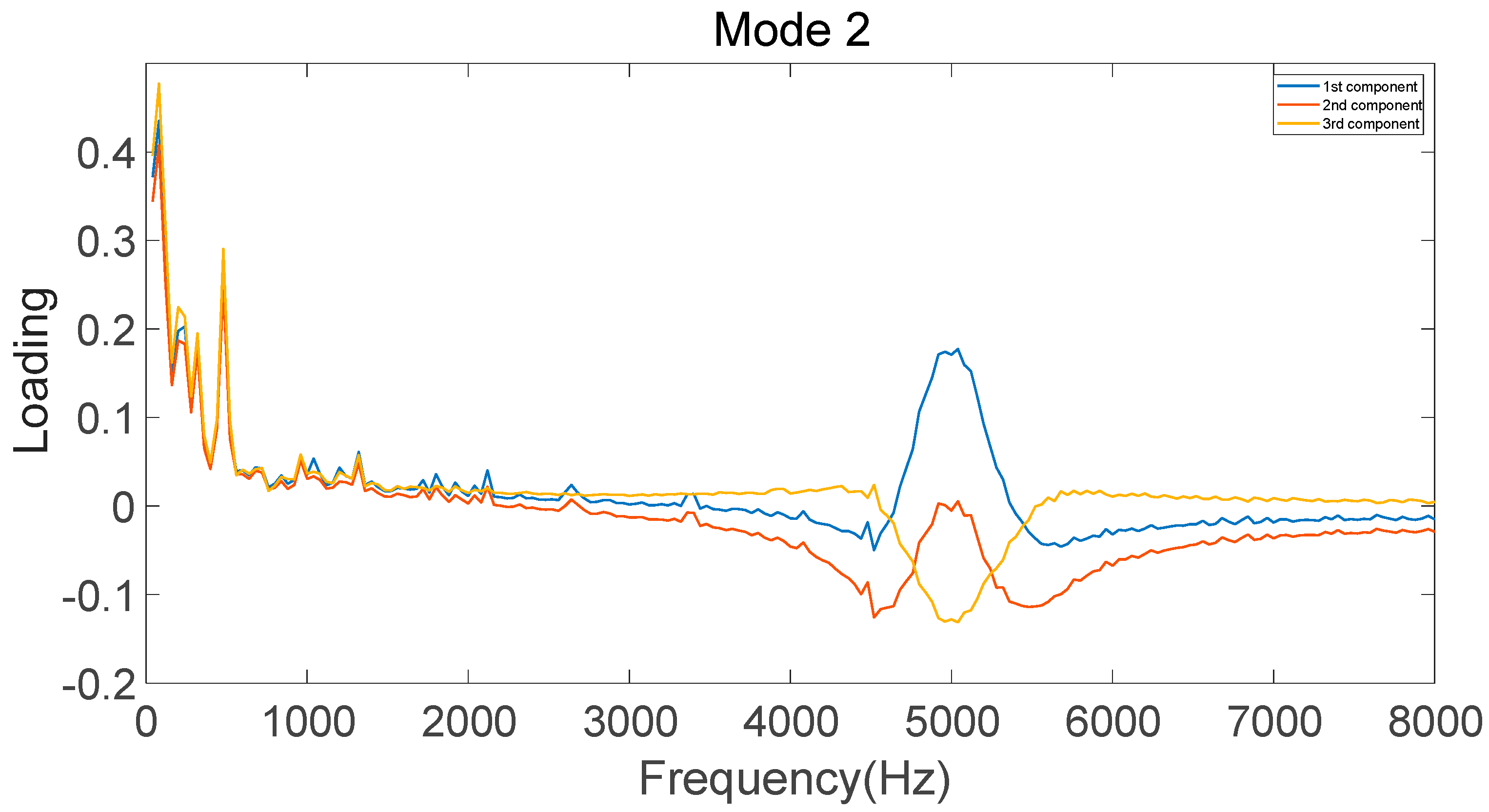
In this study, the parallel-factor multi-level decomposition theory was investigated with the goal of proposing a hybrid method for multi-channel, multi-scale data mining. Compared to traditional dimensionality reduction methods, parallel factor models retain more signal fault information, thereby improving the accuracy of fault feature extraction.
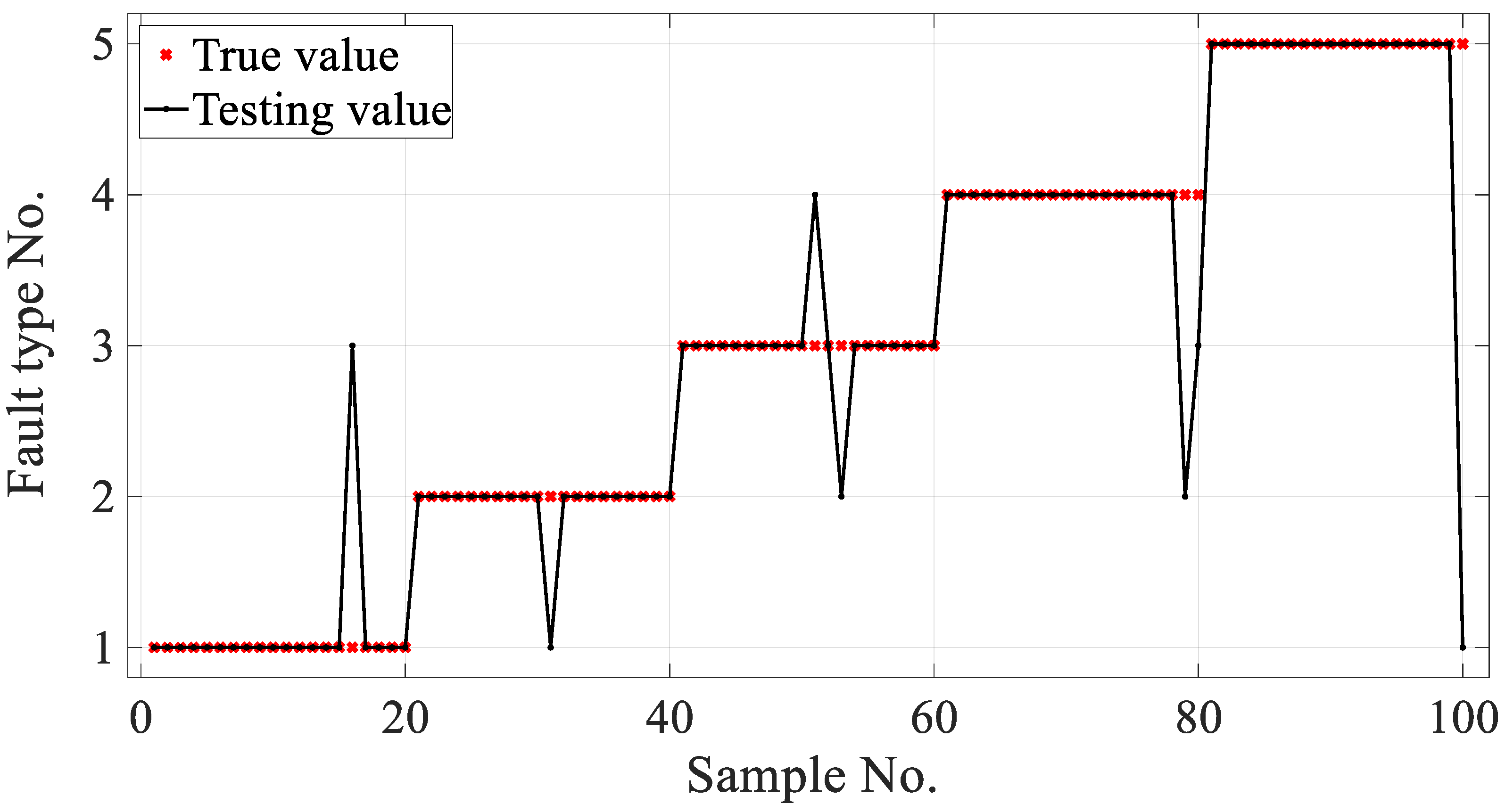
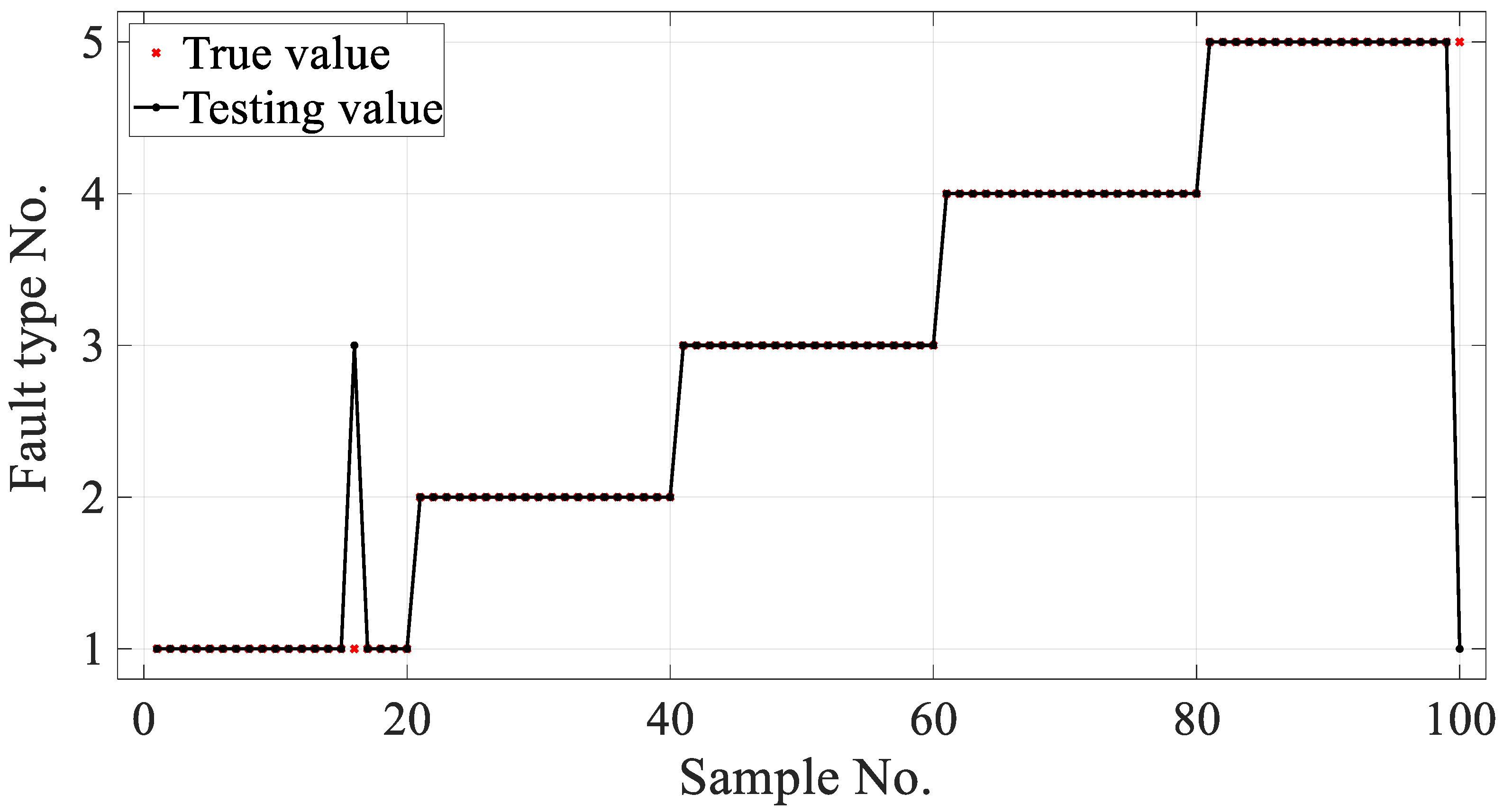
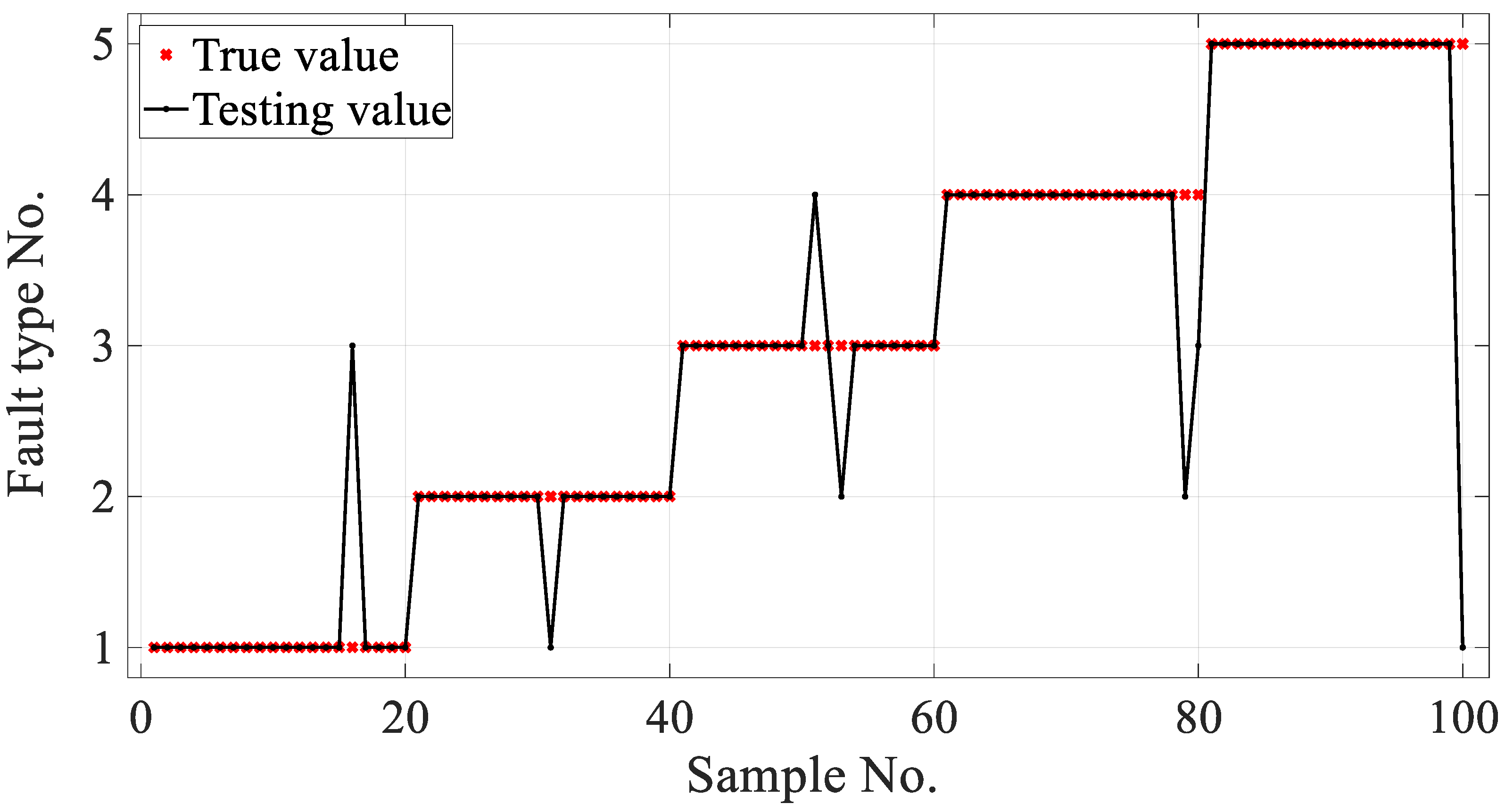
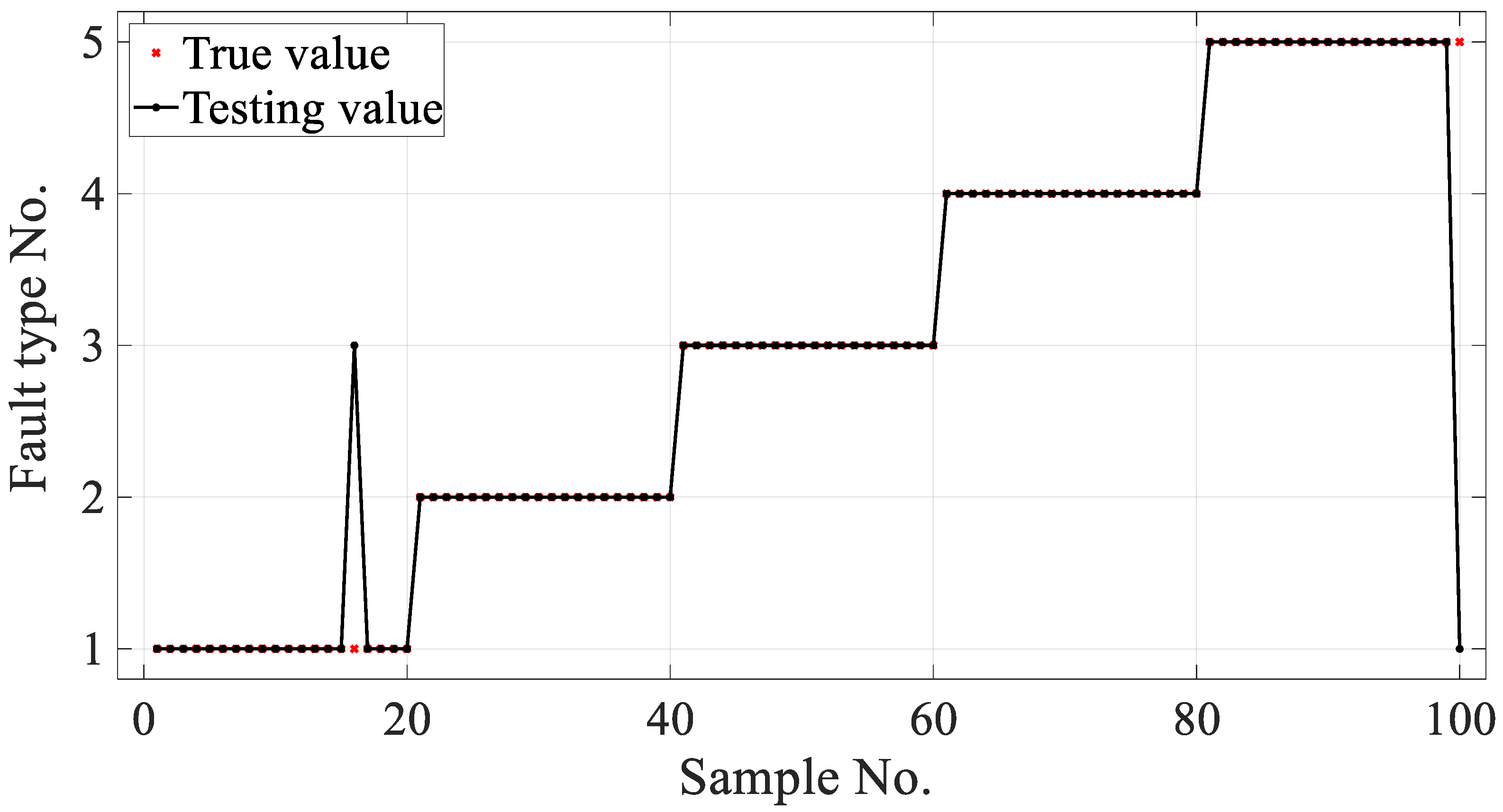
A larger classification correction rate for the condition monitoring of gear failures in a gearbox was achieved by using the developed PARAFAC–APSO–SVM classifier. The parameters of a traditional SVM were optimized using APSO to improve the recognition of different gearbox failure modes. In future work, it will be necessary to improve the reliability and robustness of the classifier for use in complex industrial applications.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}