1. Introduction
The advancement of obstacle detection through the fusion of LiDAR and camera data represents a vital area of research aimed at improving the precision of simultaneous localization and mapping (SLAM), as well as for navigation obstacle avoidance. However, the integration of 2D LiDAR and depth cameras for obstacle detection presents significant challenges, including the accurate construction of obstacle contour information within the map, and the mitigation of LiDAR point cloud distortion triggered by movement and vibrations on unstable platforms. Those issues, coupled with the resultant SLAM map drift and scale distortion emanating from point cloud distortion, necessitate further research and investigation.
Jiang [
1] proposed a 2.5D map construction method that utilizes visual features for loop closure detection. López E [
2], on the other hand, implemented an EKF filter that fuses LiDAR, monocular camera, and IMU data to generate a local 2.5D map. Unlike conventional 2D maps, 2.5D maps can provide height information of obstacles, while also allowing for the construction of their outlines. However, in scenarios with complex environments or expansive spaces, 2.5D maps with rich point cloud or elevation information can occupy significant memory space and incur high computational costs, resulting in decreased map accuracy and update frequencies. Consequently, this method is best suited for the construction of local maps for navigation, obstacle avoidance, or quadruped gait adaptation planning, such as Spot [
3] and ANY mal [
4] quadruped robots that perceive terrain and construct local elevation maps centered on the robot for adaptive gait planning and local navigation using a combination of depth cameras and LiDAR fusion. Spot Mini [
5] and Mini Cheetah [
6,
7] quadruped robots, on the other hand, use multiple sets of cameras to sense terrain and construct similar local elevation maps.
Barbosa [
8] fused 2D LiDAR and camera data using a convolutional neural network for segmentation tasks, and improved the obstacle detection accuracy for driving vehicles under adverse weather and strong lighting conditions. Wang [
9] proposed an obstacle detection method based on machine learning and improved VIDAR. Specific types of obstacles were detected using machine learning algorithms, and the improved VIDAR removed unknown obstacles from the image to increase detection speed (average detection time of 0.316 s) and performance (accuracy of 92.7%). Alfred [
10] proposed a pedestrian detection algorithm based on fully convolutional neural networks, which accurately locates pedestrians within a 10–30 m range using fused data from LiDAR and cameras. The fusion method based on deep learning detects and identifies specific types of obstacles through model training. The detection efficiency and accuracy are high, but it is difficult to construct an environmental map. Point cloud fusion and local grid map fusion are still the mainstream fusion methods. Xiao [
11] lowered the cost of 3D obstacle detection by projecting virtual LiDAR data from Kinect camera’s 3D point cloud and fusing it with distance features from Hokuyo LiDAR data. Liu [
12] proposed a metric feature environment representation method based on a 2D occupancy grid and visual feature map, and used a multi-layer optimization strategy to obtain globally consistent environmental maps.
Regardless of the fusion method employed, the motion-induced distortion of LiDAR point clouds remains a critical consideration. The methods commonly utilized to address motion distortion in LiDAR point clouds can be broadly categorized into two main groups. The first category encompasses iterative closest point (ICP) [
13] and velocity estimation ICP (VICP) [
14] methods, which rely on estimation techniques. The ICP method solves the rotation matrix and translation matrix of two frame point clouds through iterative operations, while disregarding the motion of the LiDAR and inevitably introducing random errors. The VICP method estimates the robot’s velocity while performing point cloud matching, but the assumption of constant velocity is difficult to guarantee. The second category involves sensor-assisted methods, which mainly use high-frequency sensor data to interpolate point cloud data and transform each moment’s point cloud into the robot’s base coordinate system through coordinate transformation. This approach includes methods that involve inertial sensor assistance [
15,
16] and odometry to correct motion-induced distortion [
17]. Sun [
18] extracted feature corner points by calculating the curvature of point cloud data, and used a spherical interpolation algorithm to optimize the feature point data based on IMU data, achieving the goal of correcting the distorted point cloud. Huang [
19] proposed a method that combined static and dynamic thresholds to deal with iterative degradation in scenes with less structured information. They also added a local map optimization step to optimize the initial pose and distorted point cloud. Yan [
20] improved the accuracy of visual odometry using homography matrix decomposition, and then used the Lie group form to interpolate distorted LiDAR point cloud data based on visual odometry. Compared with the method of correcting point cloud distortion using IMU data, this method reduces the cost by 40% and only reduces the positioning error by less than 0.1%. The method satisfies the frequency and angular velocity requirements of the inertial sensor, but the local accuracy after the quadratic integration of linear acceleration is poor. Compared to this, the odometer method has better local angle and position measurement accuracy.
The odometer data can be obtained by visual cameras [
21,
22], IMU, encoders, etc. The odometer used in this research is a legged odometry designed in reference [
23], which has the advantages of high accuracy, high frequency, and high robustness.
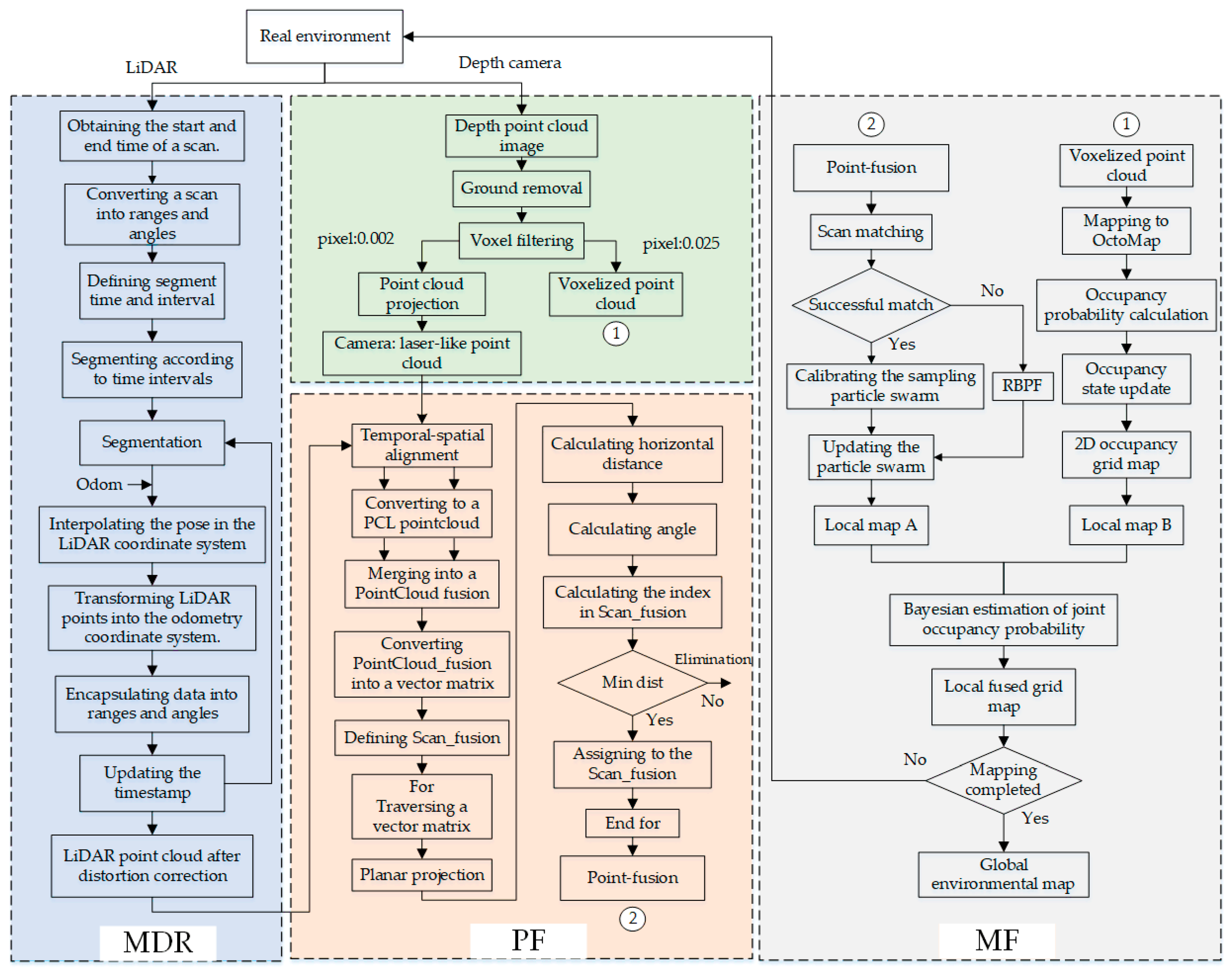
In summary, to address the issues of missing obstacle contours and map drift caused by distorted LiDAR point cloud data in obstacle detection and map building with 2D LiDAR-camera fusion, this study proposed an obstacle detection algorithm that combines point cloud fusion and robot-centered local grid map fusion. Additionally, a LiDAR point cloud distortion correction algorithm based on high-frequency legged odometry is presented. These two algorithms aim to optimize the aforementioned issues. This research mainly completed the following four parts:
- (1)
Completed the joint calibration of the sensors used, as well as the LiDAR and camera.
- (2)
Achieved a motion distortion removal (MDR) method for LiDAR point cloud data based on odometer readings.
- (3)
Presented the obstacle detection algorithms that fuse LiDAR and camera data, which are divided into three sections: (1) a comparison of obstacle detection using a single LiDAR or camera, (2) obstacle detection using the point-fusion (PF) method, and (3) obstacle detection using the point-map fusion (PMF) algorithm.
4. SLAM Map Construction Algorithm Based on LiDAR and Camera Data Fusion
The first step in constructing a map of the perceived environment involves the perception of various obstacle types, such as rectangular prisms, spheres, cylinders and cones. The physical representations of these typical obstacles and their poses are shown in
Figure 10a, from left to right: a rectangular cardboard box, a soccer ball, a cylindrical tube and a conical roadblock.
4.1. SLAM Map Construction Based on a Single Sensor
For the typical obstacles depicted in
Figure 10a, obstacle detection was carried out using both the 2D LiDAR (RPLiDAR_A3) and the RealSense D435 depth camera. The standing height of the robot dog was adjusted when using different sensors. It was ensured that both methods accurately detected the obstacles. The experimental results are presented in
Figure 10b–e.
Figure 10b illustrates the detection results of typical obstacles using LiDAR, with the detection areas of these obstacles being locally magnified to facilitate detailed observation and analysis. In comparison to camera-based detection, the LiDAR exhibited a larger detection range, but was limited to a certain plane. When an obstacle was detected, it appeared as a continuous or intermittent line or scattered points. For example, in the case of the rectangular cardboard box positioned frontally, the detection result formed a continuous straight-line segment. Similarly, for the cylindrical tube, soccer ball and conical roadblock, the detection results manifested as partially continuous segments that resembled ellipses.
The depth image captured by the camera (
Figure 10c) could be directly fused with LiDAR data, due to differences in the data format and characteristics. Therefore, a pre-processing step was employed, where the camera depth point cloud was first filtered with voxel filtering to reduce the number of points and generate a voxel point cloud image that outlined the obstacles. Then, the voxel point cloud data were projected onto a plane to generate laser-like point cloud data. The detection results of obstacles using the laser-like point cloud data are shown in
Figure 10d. Notably, compared with the LiDAR, this approach offers the advantage of adjusting the detection height and angle as needed, while maintaining a constant installation height for the camera. This allows for flexibility in obstacle detection in various scenarios.
The experimental results of using the voxel point cloud based on the OctoMap occupancy grid algorithm to detect obstacles are shown in
Figure 10e. In comparison to the methods shown in
Figure 10b,d, the plane information of obstacles were accurately detected, resulting in a more complete and detailed contour.
4.2. SLAM Map Construction Based on PF Method
The diverse fusion models of sensors have evolved into distributed, centralized and hybrid architectures. From the perspective of structural categories, they can be classified into strategy-level fusion, feature-level fusion and data-level fusion. Due to the high perception ability of the quadruped robot dog in obstacle detection, the requirements for the real-time performance of the structure and the robustness of the system are stringent. Moreover, there are differences in measurement angles, angular resolution, measurement radius, data frequency, and numbers of LiDAR point cloud data and laser-like point cloud data. Therefore, a distributed feature-level fusion was performed between the two. The pseudocode of the fusion algorithm (PF) is presented in Algorithm 1.
| Algorithm 1 Data fusion algorithm for LiDAR point cloud and laser-like point cloud |
| Require: LiDAR point cloud , laser-like point cloud . |
| Ensure: Fusion point cloud . |
| 1: Convert to PCL format and . |
| 2: Merge to PCL Point Cloud . |
| 3: Convert to Vector matrix . |
| 4: Define the max and min angles of as and , Angle resolution , Max and min scanning dist and |
| 5: each |
| 6: Project to the plane to obtain the projection point . |
| 7: |
| 8: |
| 9: |
| 10: |
| 11: |
| 12: |
| 13: |
| 14: |
| 15: |
| 16: |
| 17: |
| 18: |
| 19: |
| 20: return . |
Firstly, the point cloud data of two sensors were transformed into PCL-formatted point cloud data in the world coordinate system. The PCL data were then used to merge the two point cloud data sets into a combined set of three-dimensional coordinate points that were represented as point cloud data in PCL format. These combined point cloud data were expressed in the form of a three-dimensional spatial vector matrix , enabling further processing and analysis.
Subsequently, the vector matrix was iterated, and each vector was projected onto a plane located 10 cm above the ground, as designed based on the step height of the robotic dog in this research. The horizontal distance (dist) from the projection point to the base coordinate system of the quadruped robot dog, as well as the angle formed with the x-axis, were calculated. Then, based on , the current number (ind) of the projection point in the predefined fusion point cloud data array was determined. If a distance value for this already existed, the minimum distance value principle was applied to select the distance value, which was assigned to . This process was repeated for all of the column vectors in the vector matrix. Once all of the column vectors were traversed, the completed array was returned, which represented the fusion point cloud data .
The PF method was used to conduct obstacle detection experiments in different environmental types.
As shown in
Figure 11a, multiple environments containing stacked typical obstacles are shown. These environments consist of rectangular paper boxes labeled as ① and ②, a sphere labeled as ③, another rectangular paper box labeled as ④, and a conical barrier with base labeled as ⑦; the two sensors obtained point clouds information with varying depth distances within their sensing range. For the sphere labeled as ⑥ and the cylindrical barrier labeled as ⑧, as well as the frame-type obstacle environment in
Figure 10b which included benches, chairs and guardrails, the 2D LiDAR either failed to scan or captured minimal feature information. The PF method utilized the minimum distance principle to correctly extract the maximum contour information of the obstacle from the perspective of the LiDAR and camera detection after removing the invalid point cloud.
The PF method enhances the capability to detect obstacles in the forward direction, however it may not accurately construct an obstacle contour map. As shown in
Figure 12, initially, the PF algorithm successfully detected a rectangular cardboard box obstacle (
Figure 11, ④) and constructed a partial contour map. However, as the robot dog moved closer to the obstacle, the camera lost visibility of the cardboard box, and the scanning plane height of the LiDAR was higher than the box. Consequently, on the map, the rectangular box obstacle appeared as a sheet-like planar obstacle.
4.3. SLAM Map Construction Based on PMF Method
The point cloud data fusion method was enhanced to improve the ability to identify obstacle contour information and construct a more comprehensive environment map. The updated approach involved using the LiDAR point cloud after point cloud data fusion was used to construct a local map A, while employing the voxel point cloud to build a local map B. These two maps, A and B, were then subjected to inter-frame fusion using Bayesian estimation theory. It is important to note that both maps A and B needed to be generated with the same map resolution, in order to ensure accurate fusion results.
The pseudocode for the local grid map fusion based on Bayesian estimation is presented in Algorithm 2.
| Algorithm 2 Bayesian Local Grid Map Fusion Algorithm |
| Require: Local grid maps , parameters . |
| Ensure: Global grid map . |
| 1: Initialize global grid map: |
| 2: to do |
| 3: each cell do |
| 4: Compute the occupancy probabilities and for cell in the global grid map and the th local grid map, respectively. |
5: Compute the posterior probability using bayes-rule:
|
| 6: Update the occupancy probability in the global grid map using the posterior probability: |
| 7:
|
| 8: |
| 9: Output the updated global grid map: . |
In the equation, represents the occupancy probability of the ith grid in the global map, while represents the occupancy probability of the ith grid in the nth local fusion map. When computing the posterior probability, the prior probability needed to be used. When updating the global map, all of the grid’s posterior probabilities needed to be updated in order to obtain the correct probability values.
When the quadruped robot dog reached time
, the LiDAR or camera detected obstacles and updated the occupancy probability values of the corresponding grid cells. At this point, it was necessary to fuse the two probability estimates to obtain the occupancy probability
at time
. This process can be represented by Equation (5).
Equations and represent the occupancy probability estimates of the ith grid in the global map based on the LiDAR point cloud and the camera voxel point cloud in the nth local fusion map.
Equation
specifies the occupancy rules, as shown in
Table 2.
As shown in
Figure 13, the local grid map fusion method effectively addressed the problem of missing obstacle contour information shown in
Figure 11, and correctly identified the rectangular cardboard box obstacle.
5. Overall Experiment
This chapter presents a comprehensive experiment divided into two parts. The first part involved conducting an obstacle detection experiment using three different methods: single LiDAR, the PF method, and the PMF method proposed in this study. The second part focused on a map construction experiment using the PMF method in complex laboratory scenarios, with and without MDR links. The experiments were designed to evaluate the performance and effectiveness of the proposed PMF method, in comparison to other methods, in detecting obstacles and constructing maps in different scenarios. The results of these experiments are presented and discussed in the following sections.
5.1. Sensor Information Fusion SLAM Map Construction Experiment
The experimental platform for the quadruped robot dog, as shown in
Figure 14, consisted of several components. The 2D LiDAR (RPLiDAR_A3) was installed above the robot dog’s body, with a router and a protective plate placed underneath it. The router was powered by an external power bank. Additionally, the Intel RealSense D435 camera is installed at the front of the robot, facing downwards at a 15° angle. The relative positions of the LiDAR, camera, and the robot dog’s internal IMU sensors were determined through a multi-sensor joint calibration experiment.
The purpose of this section was to conduct comparative experiments on three different methods, namely, single LiDAR, the PF method and the PMF method proposed in this study, in order to verify the effectiveness of the algorithm. The obstacle detection experiment environment consisted of a closed environment with an experimental table and a blue barrier, which included eight typical obstacles such as stools and chairs, as shown in
Figure 15.
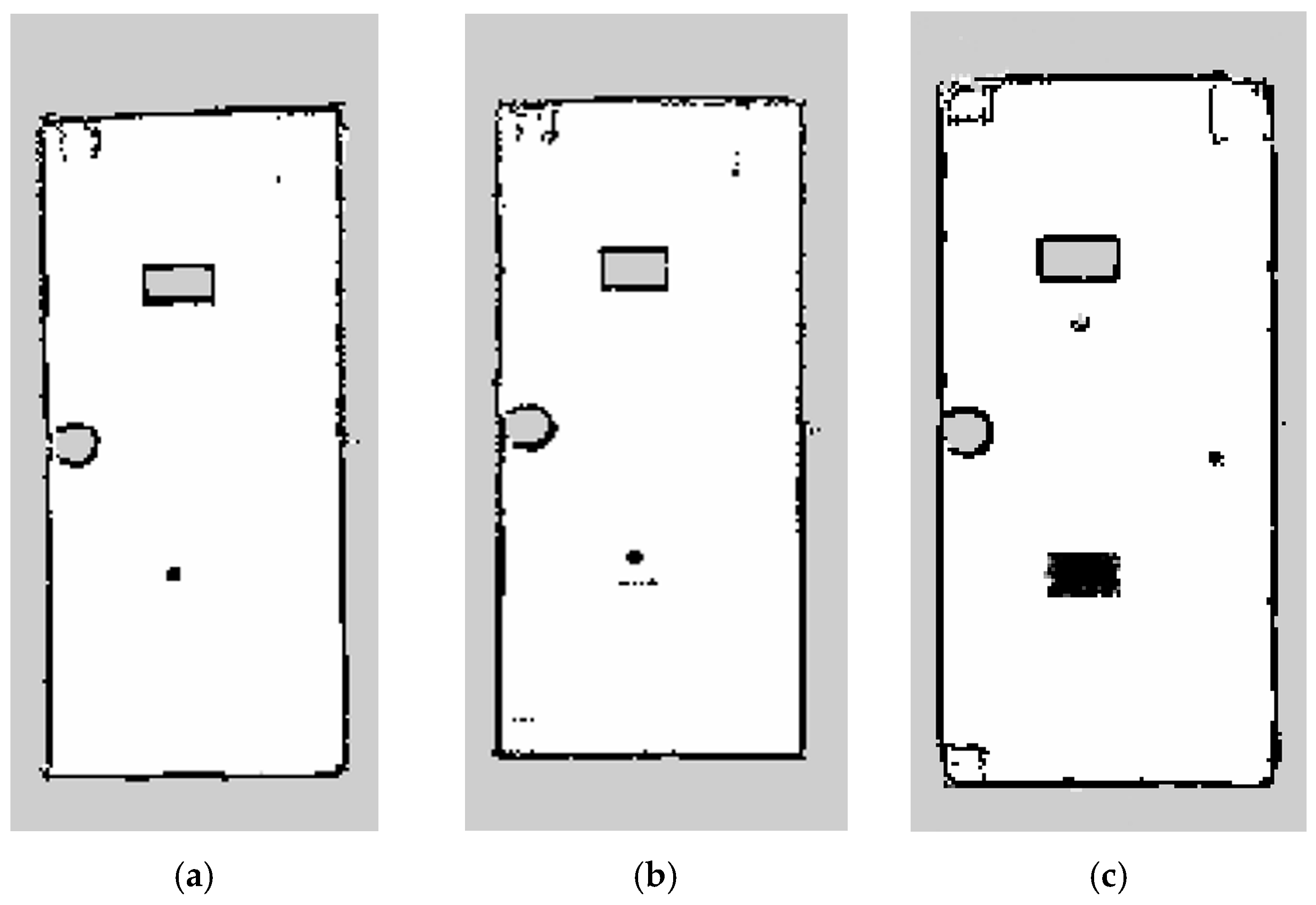
The experimental results, shown in
Figure 16, revealed notable differences among the three methods for obstacle detection. In
Figure 16a, the first method exhibited significant issues with missing obstacle information, resulting in only four obstacles being constructed in the map, with a detection success rate of 50%. Obstacles, such as single stools, chairs, footballs and blue cones below the height of the LiDAR installation, were not constructed in the map. In
Figure 16b, the second method constructed a map with six obstacles and a detection success rate of 75%. However, the football and red cone obstacles were not constructed in the map, and construction of the red cone obstacle with the rectangular cardboard box as the base was inaccurate. In contrast, in
Figure 16c, the third method utilized camera voxel point detection to obtain the three-dimensional contour information of the obstacles. and constructed a local grid map based on the LiDAR point cloud. The method also implemented frame-to-frame local map fusion with the grid mapping algorithm used in
Figure 16b. Therefore, the constructed map was the most complete, with the outer contours of all eight objects accurately represented, and a detection success rate of 100%. Notably, in comparing the results shown in
Figure 16a,b, the third method demonstrates a significant improvement in detection accuracy, with a 50% and 25% increase, respectively.
5.2. SLAM Experiments Performed before and after Motion Distortion
To assess the impact of mitigating motion distortion in the LiDAR point cloud on obstacle detection and SLAM fusion, an experiment was conducted in the environment shown in
Figure 17.
The environment was divided into four distinct areas, labeled as A to D, with the experimental table located in the middle. Area A on the left side comprised obstacles such as cardboard boxes, radiators and chairs, while area B in the middle contained two rectangular cardboard box obstacles. Area C on the right side was populated with obstacles such as stools, rectangular distribution boxes and blue cone obstacles. Area D was an open environment with cylindrical barrels and four chairs as obstacles. Ten sets of key dimension data (outline size, location size of obstacles and overall size of the indoor environment) were selected, taking into consideration the overall size of the environment, the position and size of obstacles, as well as the contours of the obstacles.
The mapping of an open laboratory environment was performed with the use of a quadruped robot dog.
Figure 18 illustrates the experimental outcomes, which revealed that the map generated through the proposed algorithm after motion distortion elimination exhibited significantly reduced drift and distortion issues compared to the map constructed by the fusion algorithm without distortion removal. In
Figure 18a, stacking phenomena and angle distortion occurred at the map boundary marked as number ①. The contours of the three typical obstacles marked with number ② were distorted. The experimental table marked with number ③ was bent. There was a lot of noise and unclear contours in the bench area marked with number ④ and the chair area marked with number ⑤. However, after motion distortion removal, the results in
Figure 18b demonstrate that no stacking phenomenon occurred in area ①, and the angle was right-angled. Additionally, the contours of the three typical obstacles marked with number ② were normal and complete. The experimental table in area ③ was not deformed. The contours of the bench and chair in areas ④ and ⑤ were continuous, and the noise was significantly reduced.
The laser rangefinder (accuracy ±1 mm) was used to measure 10 sets of marked feature sizes, and the average value was measured 10 times as the true value of the size. Then, the corresponding values of the dimensions were measured in the grid map using the measure tool in RVIZ. The measurements were also taken 10 times, and the average value was determined. Next, the relative errors between the measured values of the marked feature dimensions in the environment maps constructed by SLAM before and after removing motion distortion and the true values were calculated, and the error results are shown in
Figure 18c. When using the PMF method for obstacle detection and mapping, the root mean square error (RMSE) value of the mapping without using the MDR algorithm reached 109 mm, while the RMSE value of the mapping using the MDR algorithm was 59 mm, improving the accuracy by about 45.9%.
The MDR algorithm introduced in this research can serve as an integral component of data preprocessing, applicable to both conventional 2D and 3D LiDAR SLAM techniques, as well as LiDAR–visual SLAM methodologies. By optimizing the LiDAR odometer, the precision of the SLAM algorithm was effectively enhanced. This study presented experimental evidence to validate the feasibility of employing various MDR techniques in 2D LiDAR SLAM (specifically the Gmapping algorithm), and compared the performance of LiDAR-camera fusion SLAM (utilizing the PMF algorithm) with or without the inclusion of the MDR link.


 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}