

Intelligent Tool-Wear Prediction Based on Informer Encoder and Bi-Directional Long Short-Term Memory



Abstract
1. Introduction
- This study proposed a new and effective tool-wear monitoring and evaluation method. This is the first time that a combination of an informer encoder and the Bi-LSTM model has been used for tool-wear monitoring. The experimental results show that this method is superior to other methods in terms of related evaluation indexes.
- The informer encoder was employed as the global feature extractor for multichannel long-term feature sequences, and computational efficiency was enhanced by employing sparse self-attention.
- The Bi-LSTM module was used to enhance the ability to capture the feature dependence of long-distance time series.
2. Model Theory
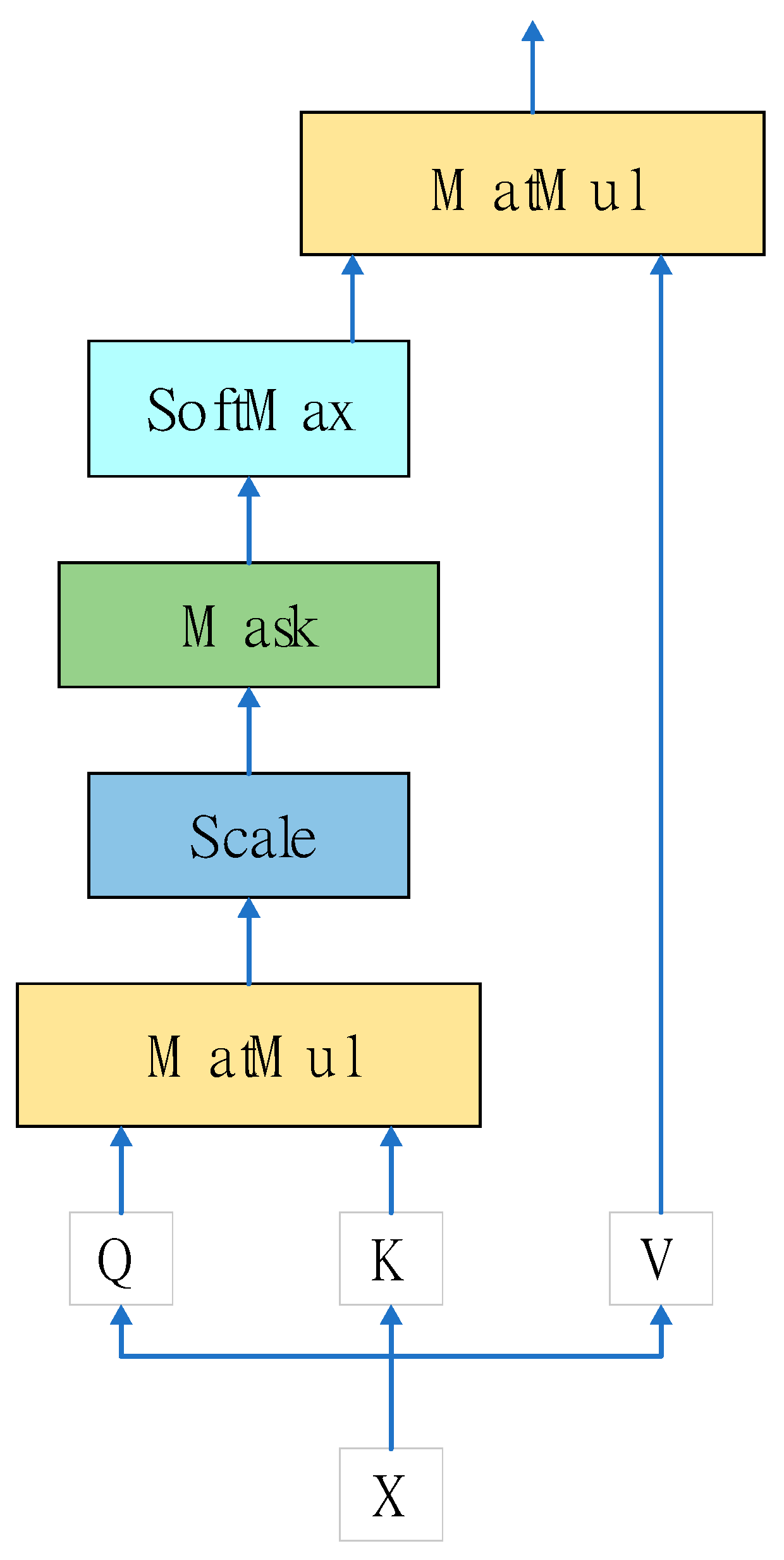
2.1. Scaled Dot-Product Attention
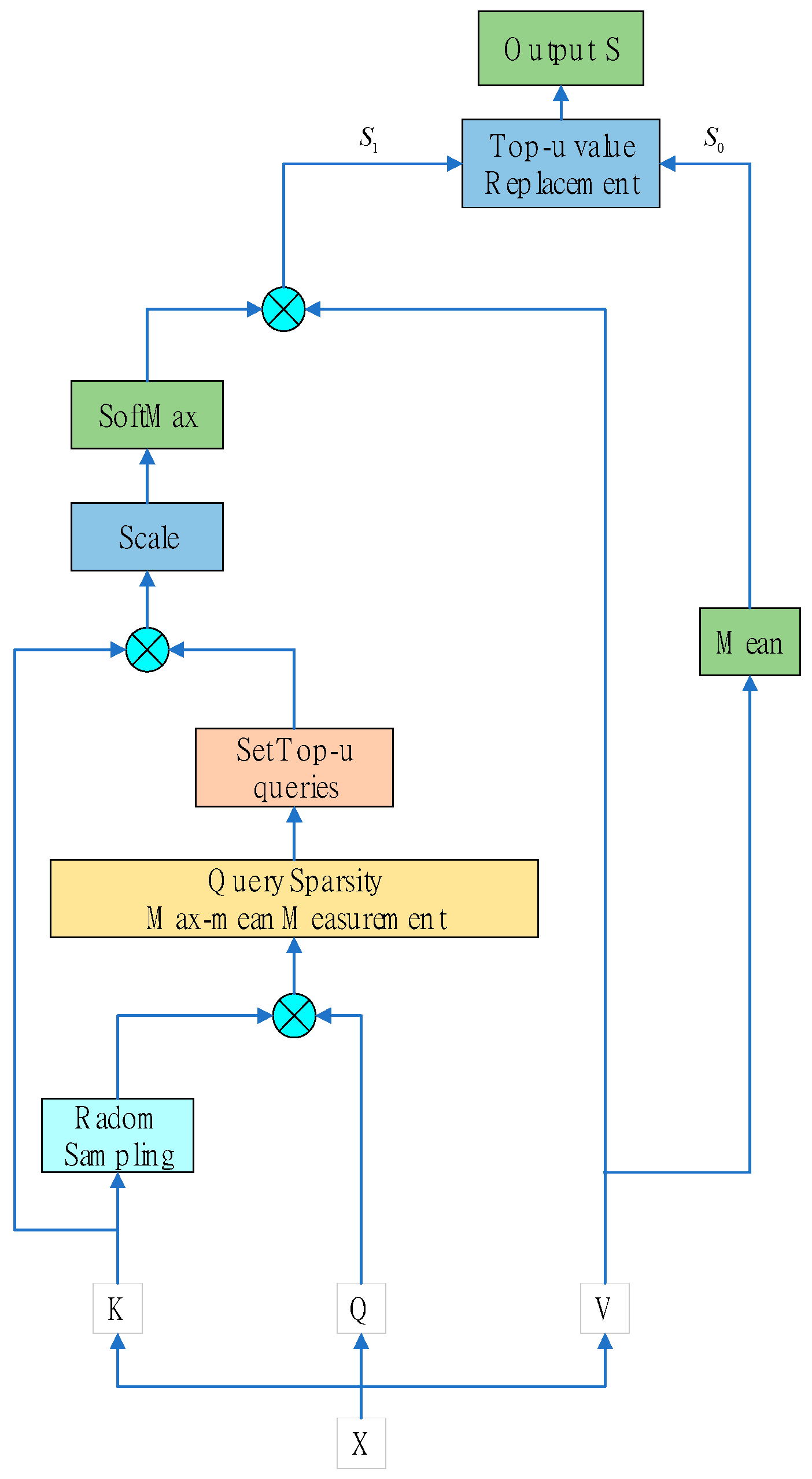
2.2. Prob-Sparse Self-Attention
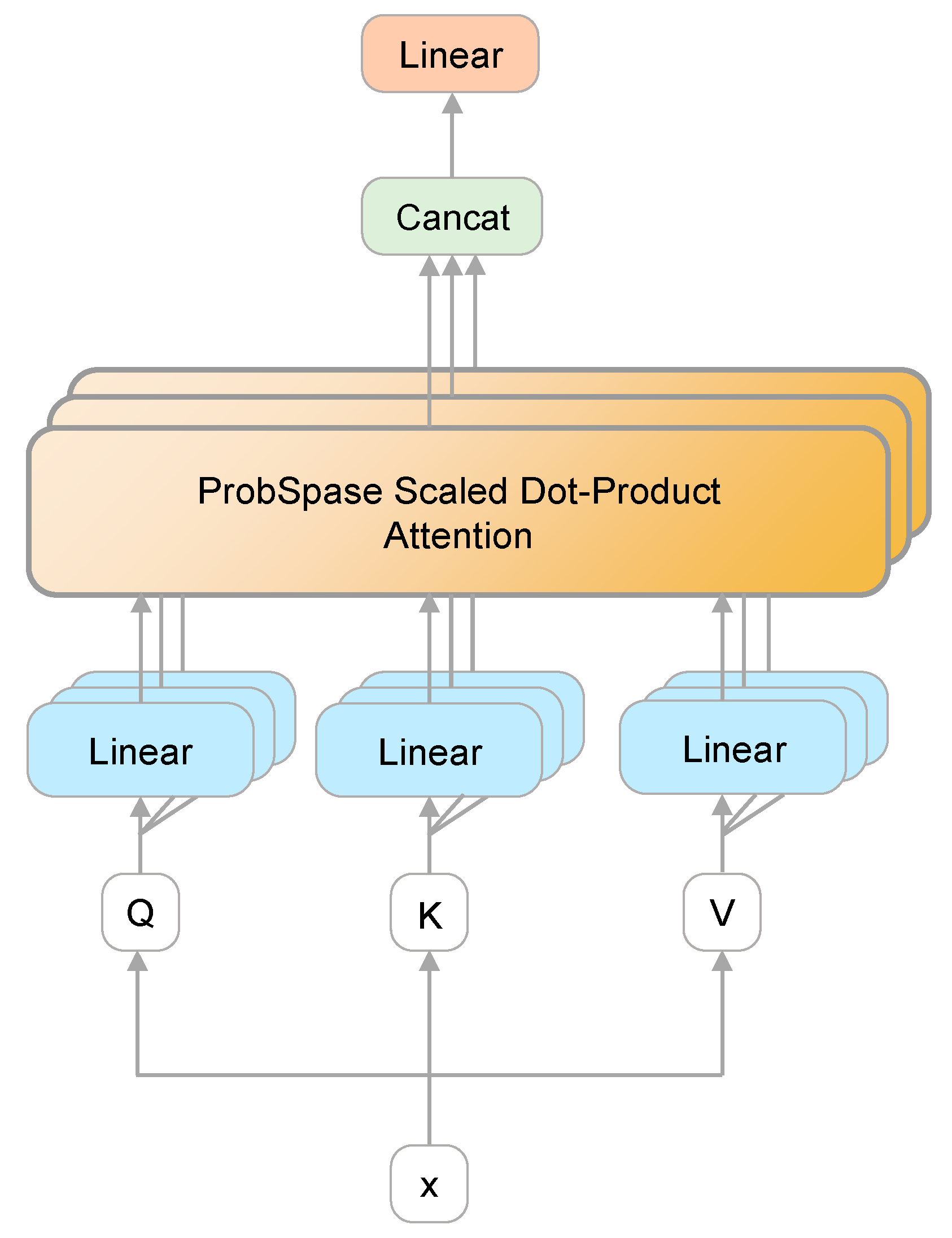
2.3. Informer Encoder
2.3.1. Multi-Head Attention
2.3.2. Position-Wise Feedforward Networks
2.3.3. Residual Connections and Layer Normalization
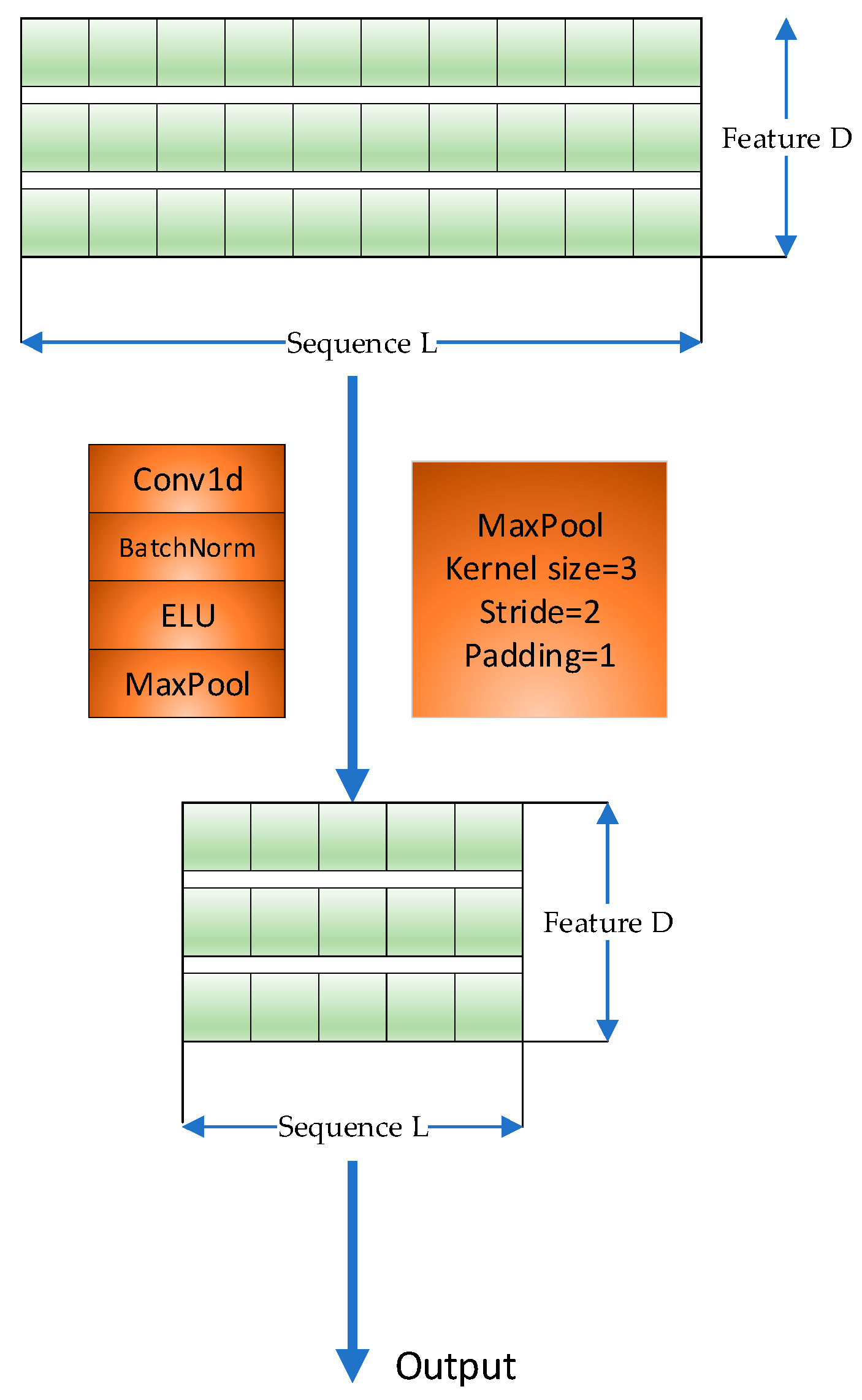
2.4. Distilling Layer
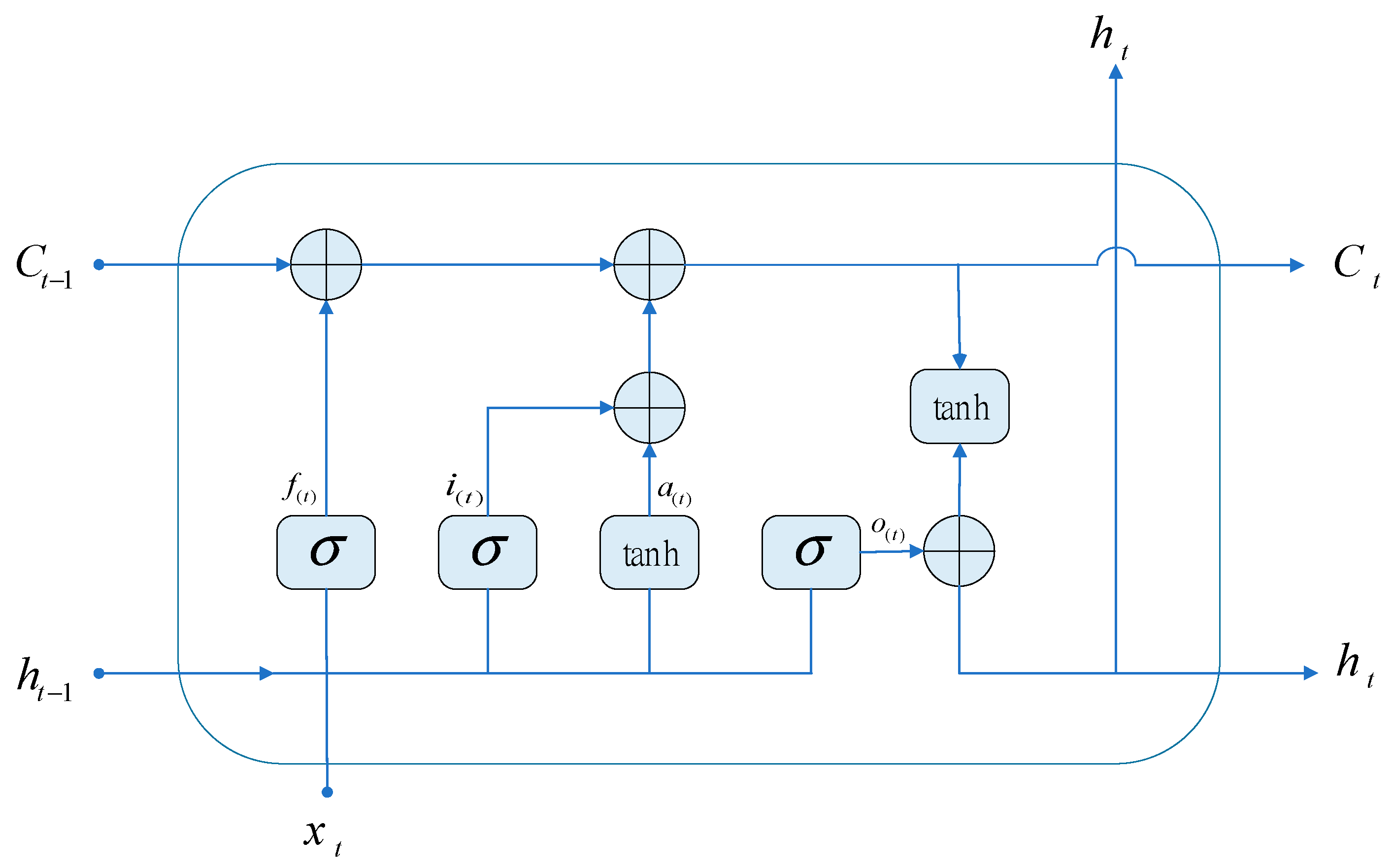
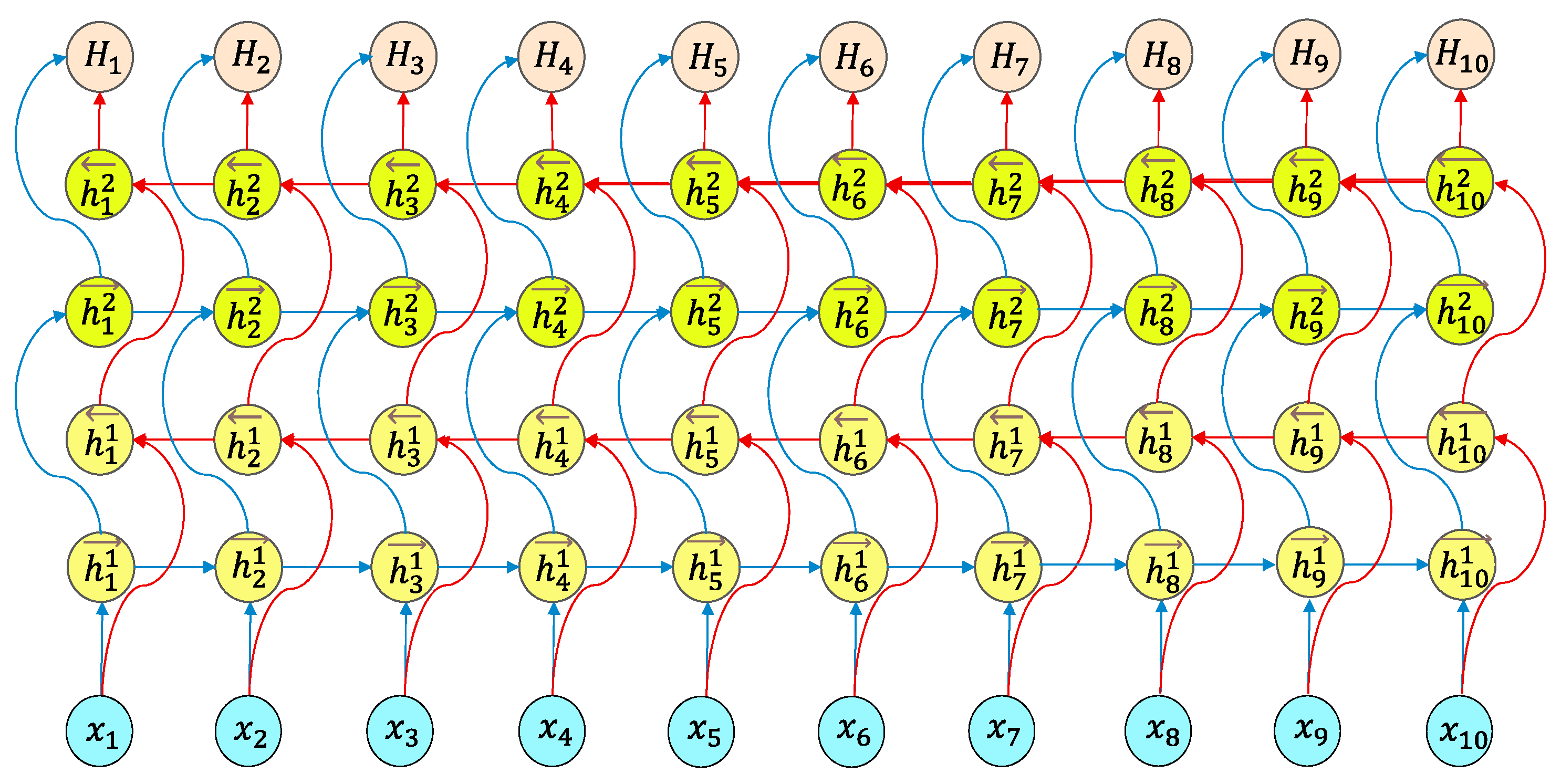
2.5. Bi-Directional Long Short-Term Memory
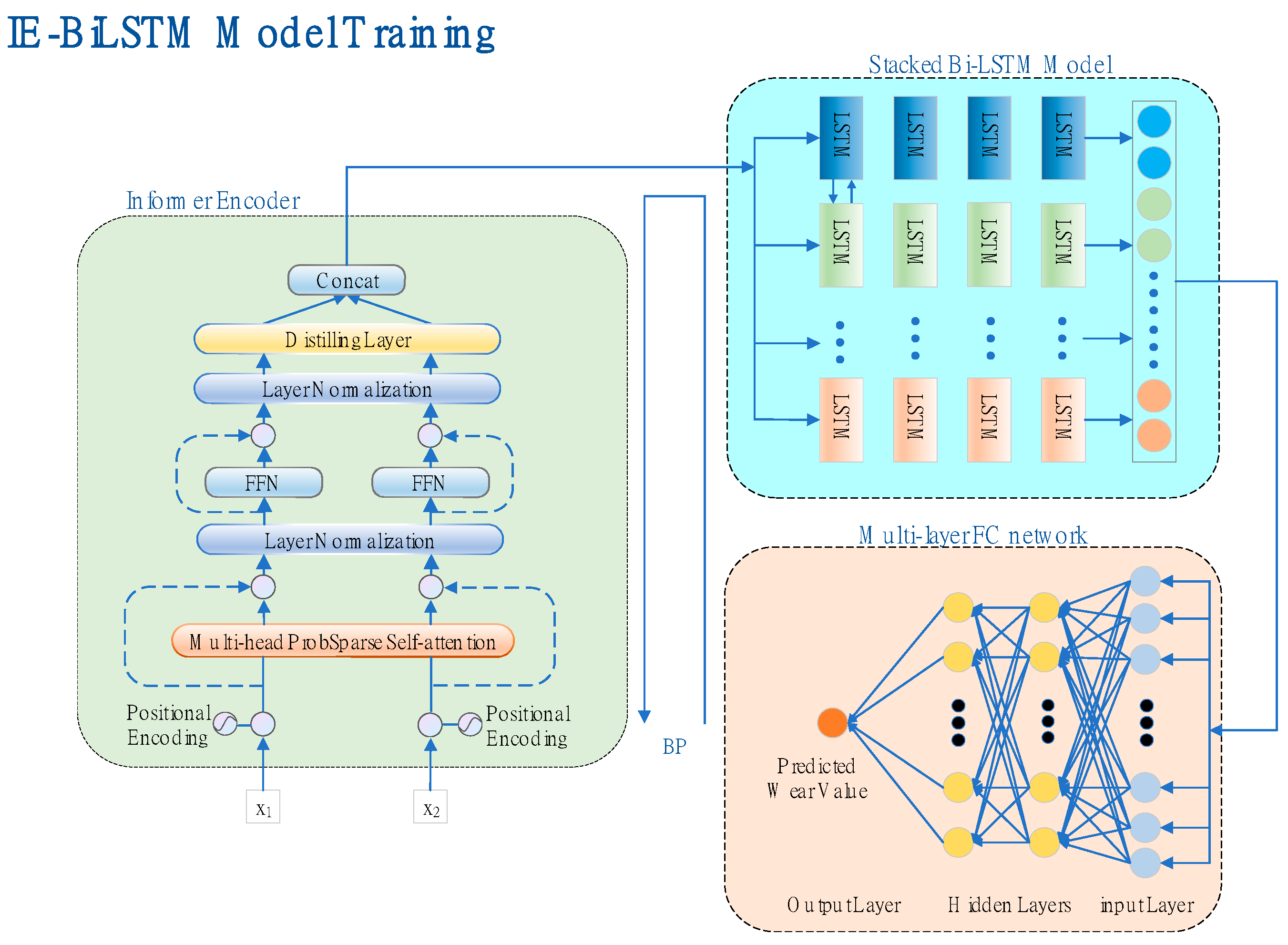
3. Methods: The IE-Bi-LSTM Model
4. Experimental Results
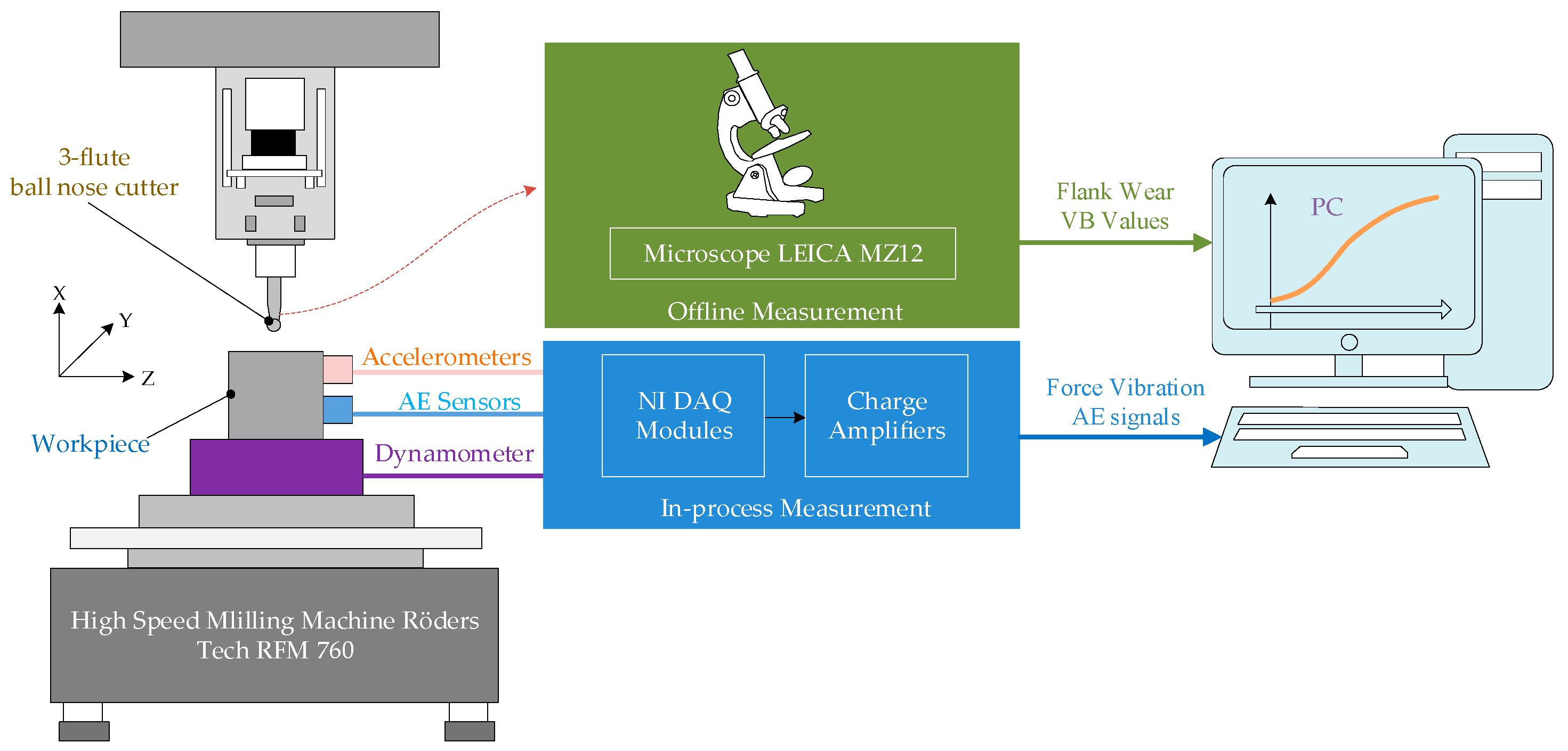
4.1. Dataset Descriptions
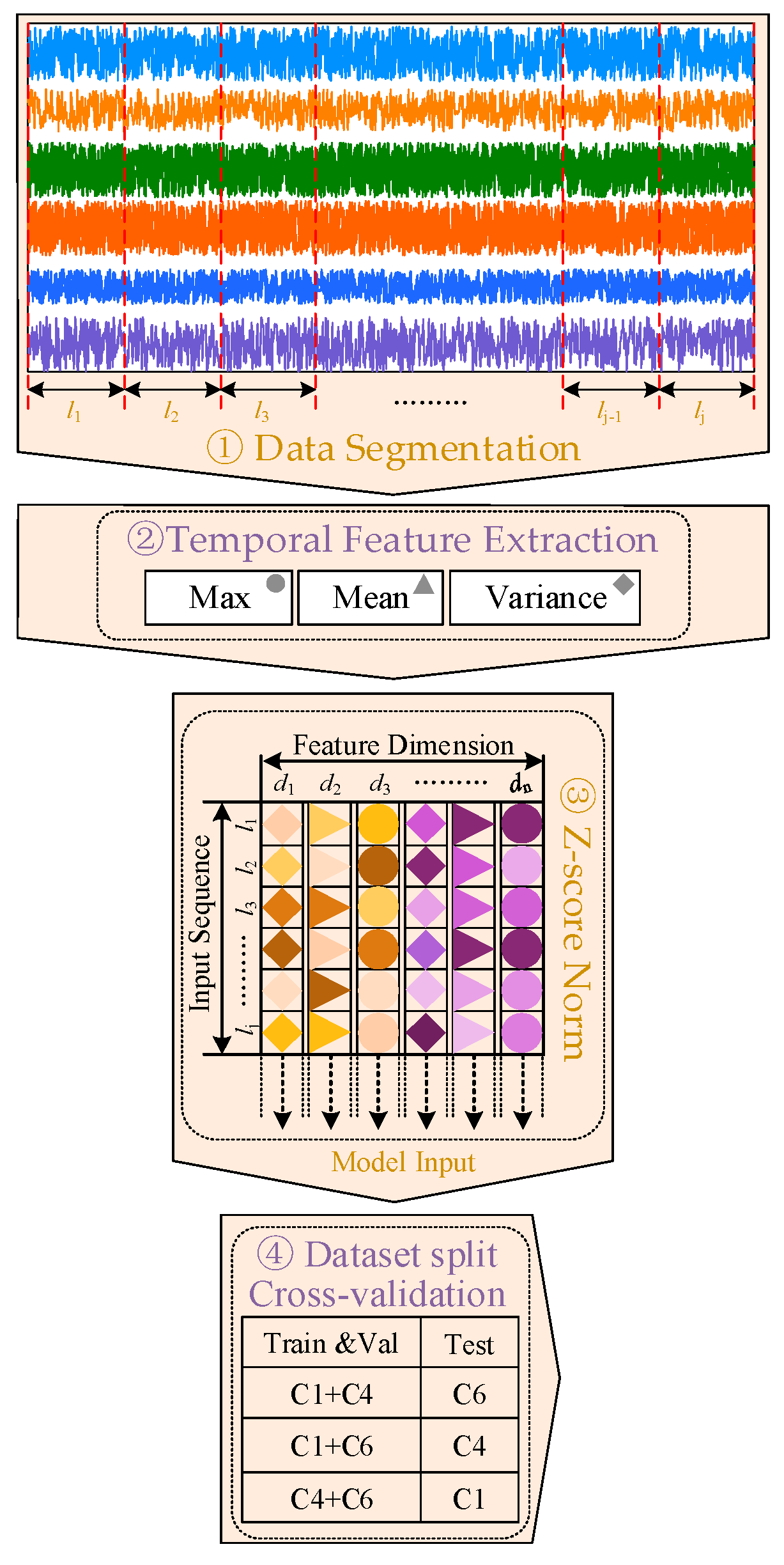
4.2. Data Preprocessing
4.3. Experimental Environment and Hyperparameter Configuration
4.4. Experimental Environment and Hyperparameter Configuration
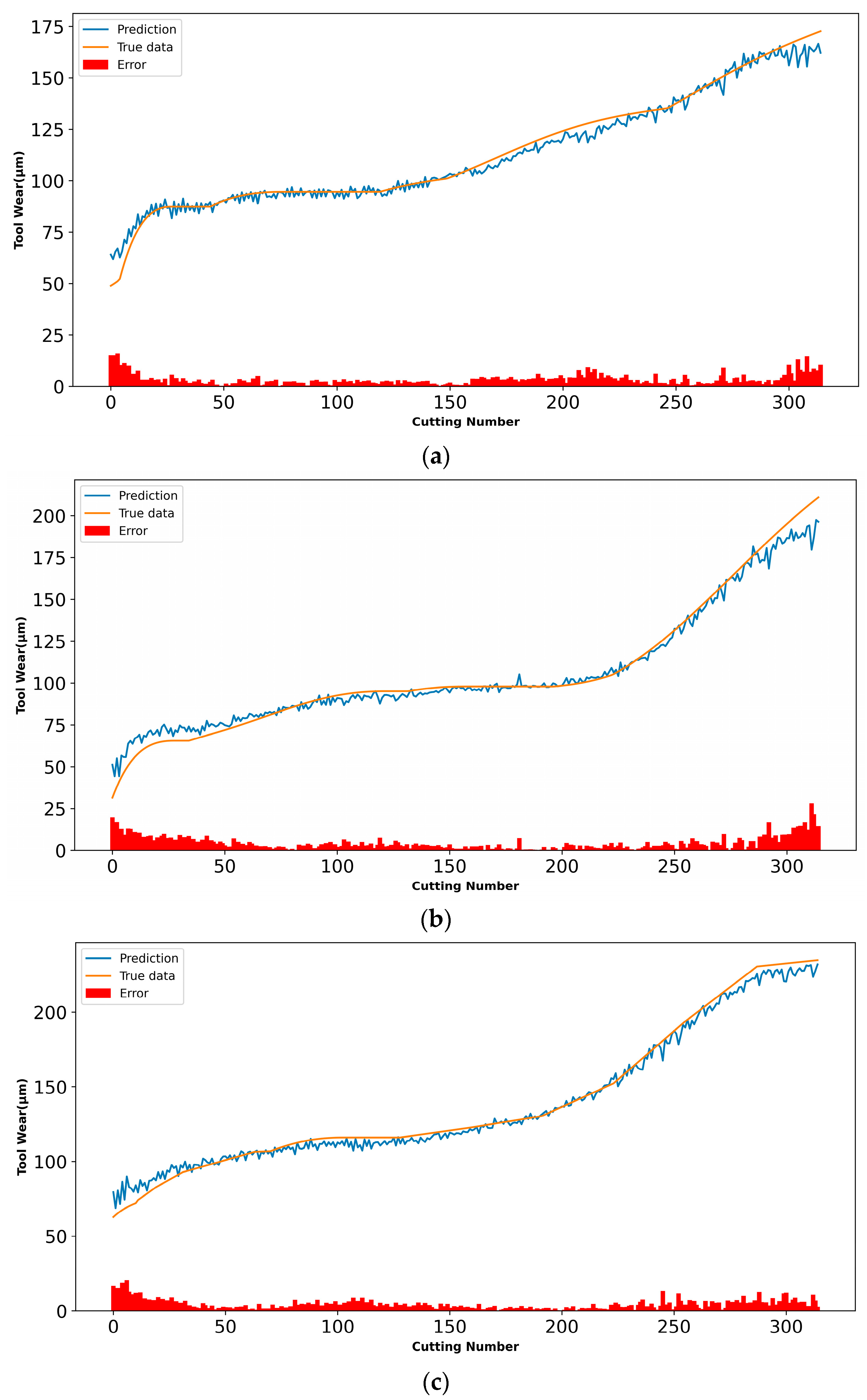
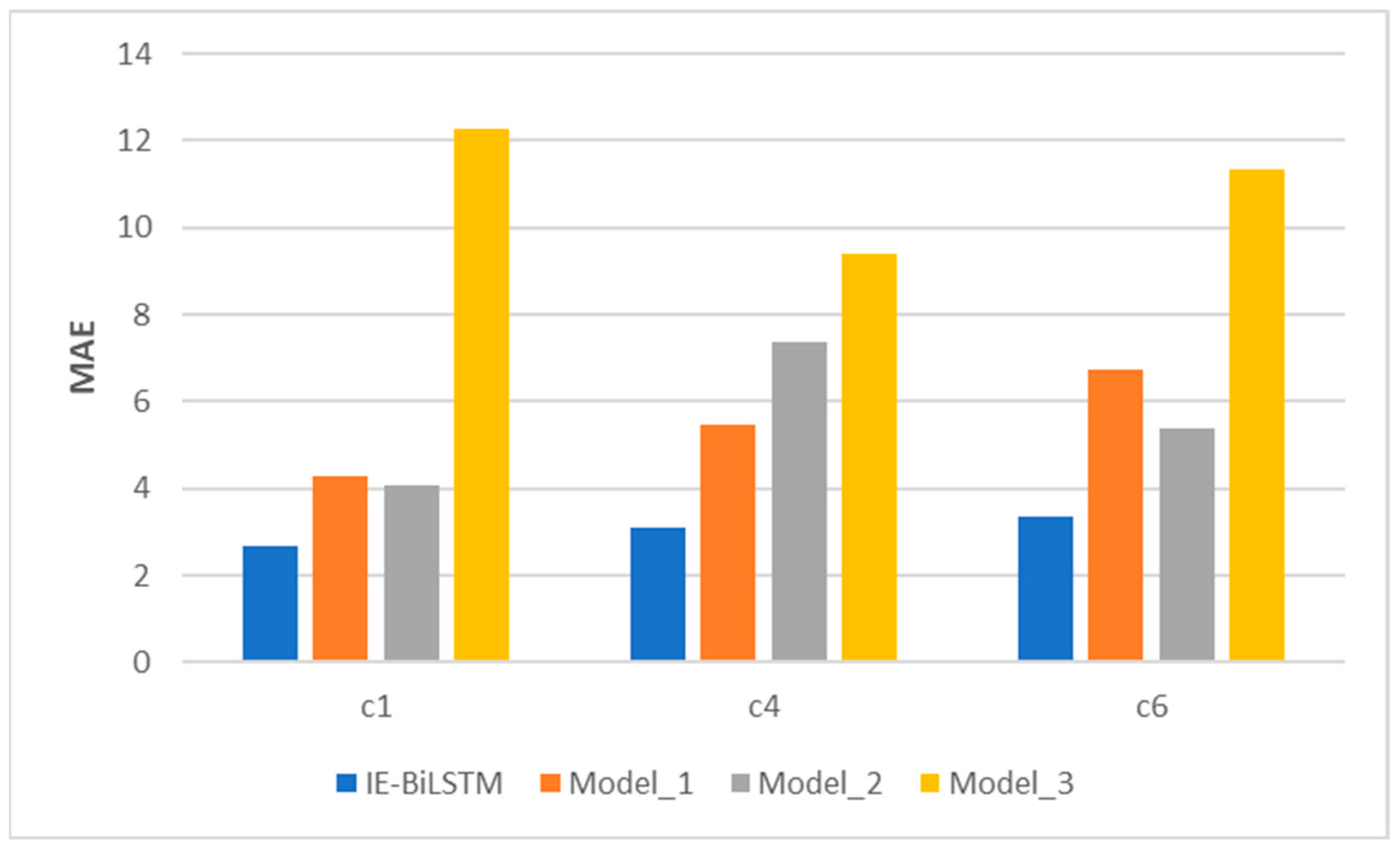
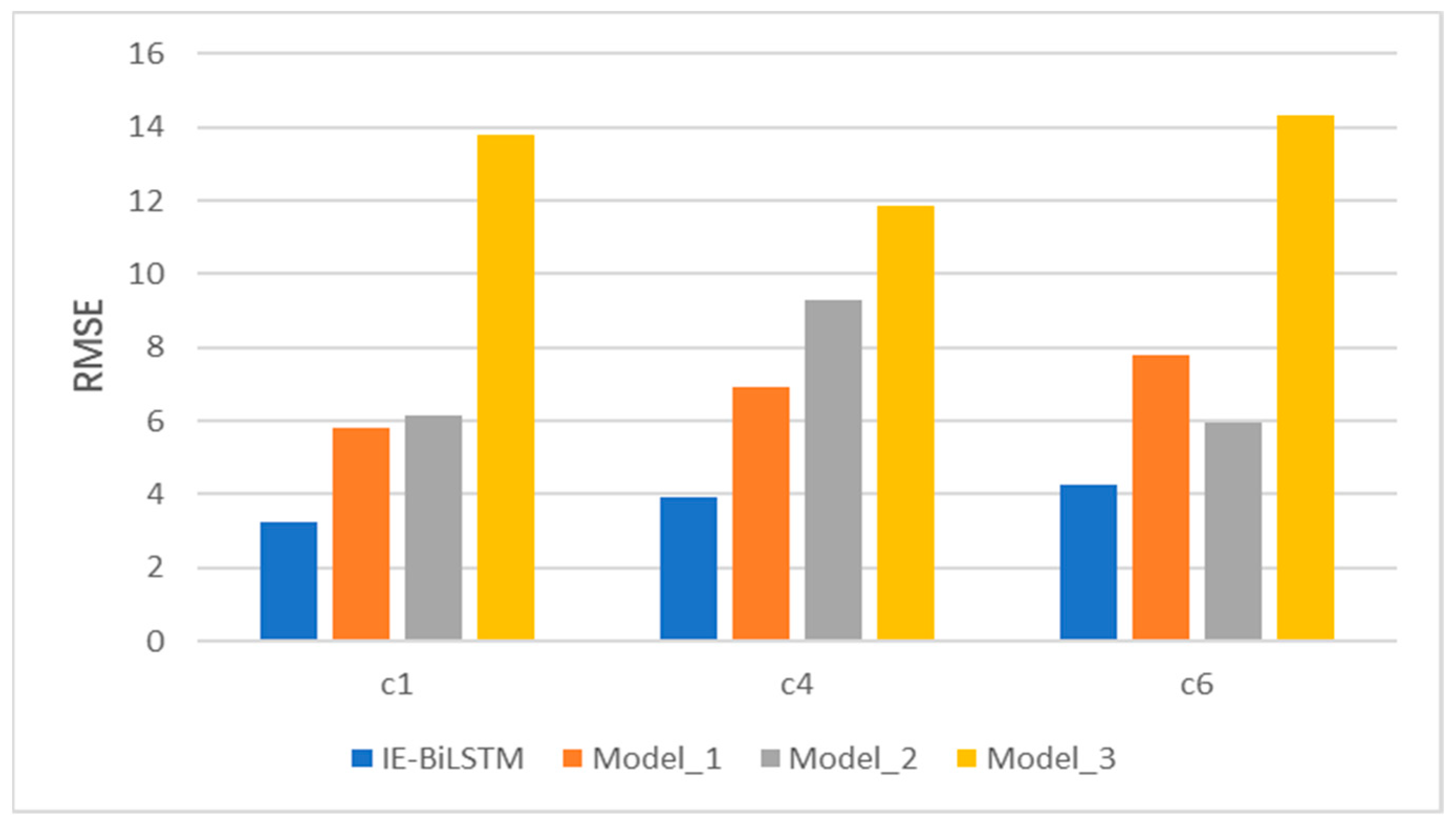
4.5. Experimental Results and Analysis
4.6. Model Module Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Baroroh, D.K.; Chu, C.; Wang, L. Systematic literature review on augmented reality in smart manufacturing: Collaboration between human and computational intelligence. J. Manuf. Syst. 2021, 61, 696–711. [Google Scholar] [CrossRef]
- Yu, H.; Wang, K.; Zhang, R.; Wu, X.; Tong, Y.; Wang, R.; He, D. An improved tool wear monitoring method using local image and fractal dimension of workpiece. Math. Probl. Eng. 2021, 2021, 9913581. [Google Scholar] [CrossRef]
- Kurada, S.; Bradley, C. A review of machine vision sensors for tool condition monitoring. Comput. Ind. 1997, 34, 55–72. [Google Scholar] [CrossRef]
- Li, Y.; Liu, C.; Hua, J.; Gao, J.; Maropoulos, P. A novel method for accurately monitoring and predicting tool wear under varying cutting conditions based on meta-learning. CIRP Ann. 2019, 68, 487–490. [Google Scholar] [CrossRef]
- Duan, J.; Zhang, X.; Shi, T. A hybrid attention-based paralleled deep learning model for tool wear prediction. Expert Syst. Appl. 2023, 211, 118548. [Google Scholar] [CrossRef]
- Lins, R.G.; de Araujo, P.R.M.; Corazzim, M. In-process machine vision monitoring of tool wear for Cyber-Physical Production Systems. Robot. Comput.-Integr. Manuf. 2020, 61, 101859. [Google Scholar] [CrossRef]
- Wang, J.; Xie, J.; Zhao, R.; Zhang, L.; Duan, L. Multisensory fusion based virtual tool wear sensing for ubiquitous manufacturing. Robot. Comput.-Integr. Manuf. 2017, 45, 47–58. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, H. Modelling and prediction of tool wear using LS-SVM in milling operation. Int. J. Comput. Integr. Manuf. 2016, 29, 76–91. [Google Scholar] [CrossRef]
- Shi, D.; Gindy, N.N. Tool wear predictive model based on least squares support vector machines. Mech. Syst. Signal Process. 2007, 21, 1799–1814. [Google Scholar] [CrossRef]
- Atlas, L.; Ostendorf, M.; Bernard, G.D. Hidden Markov models for monitoring machining tool-wear. In Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing, Istanbul, Turkey, 5–9 June 2000; (Cat. No. 00CH37100). pp. 3887–3890. [Google Scholar]
- Zhu, K.; San Wong, Y.; Hong, G.S. Multi-category micro-milling tool wear monitoring with continuous hidden Markov models. Mech. Syst. Signal Process. 2009, 23, 547–560. [Google Scholar] [CrossRef]
- Ertunc, H.M.; Loparo, K.A.; Ocak, H. Tool wear condition monitoring in drilling operations using hidden Markov models (HMMs). Int. J. Mach. Tools Manuf. 2001, 41, 1363–1384. [Google Scholar] [CrossRef]
- Sick, B. On-line and indirect tool wear monitoring in turning with artificial neural networks: A review of more than a decade of research. Mech. Syst. Signal Process. 2002, 16, 487–546. [Google Scholar] [CrossRef]
- Ezugwu, E.O.; Arthur, S.J.; Hines, E.L. Tool-wear prediction using artificial neural networks. J. Mater. Process. Technol. 1995, 49, 255–264. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, W.; Li, H. Tool wear prediction method based on symmetrized dot pattern and multi-covariance Gaussian process regression. Measurement 2022, 189, 110466. [Google Scholar] [CrossRef]
- Liao, X.; Zhou, G.; Zhang, Z.; Lu, J.; Ma, J. Tool wear state recognition based on GWO–SVM with feature selection of genetic algorithm. Int. J. Adv. Manuf. Technol. 2019, 104, 1051–1063. [Google Scholar] [CrossRef]
- Dong, J.; Subrahmanyam, K.; Wong, Y.S.; Hong, G.S.; Mohanty, A.R. Bayesian-inference-based neural networks for tool wear estimation. Int. J. Adv. Manuf. Technol. 2006, 30, 797–807. [Google Scholar] [CrossRef]
- Wang, L.; Mehrabi, M.G.; Kannatey-Asibu, E., Jr. Hidden Markov model-based tool wear monitoring in turning. J. Manuf. Sci. Eng. 2002, 124, 651–658. [Google Scholar] [CrossRef]
- Palanisamy, P.; Rajendran, I.; Shanmugasundaram, S. Prediction of tool wear using regression and ANN models in end-milling operation. Int. J. Adv. Manuf. Technol. 2008, 37, 29–41. [Google Scholar] [CrossRef]
- Sun, H.; Zhang, J.; Mo, R.; Zhang, X. In-process tool condition forecasting based on a deep learning method. Robot. Comput.-Integr. Manuf. 2020, 64, 101924. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, J.; Yan, R.; Mao, K. Machine health monitoring with LSTM networks. In Proceedings of the 2016 10th International Conference on Sensing Technology (ICST), Nanjing, China, 11–13 November 2016; pp. 1–6. [Google Scholar]
- Duan, J.; Duan, J.; Zhou, H.; Zhan, X.; Li, T.; Shi, T. Multi-frequency-band deep CNN model for tool wear prediction. Meas. Sci. Technol. 2021, 32, 65009. [Google Scholar] [CrossRef]
- Sun, C.; Ma, M.; Zhao, Z.; Tian, S.; Yan, R.; Chen, X. Deep transfer learning based on sparse autoencoder for remaining useful life prediction of tool in manufacturing. IEEE Trans. Ind. Inform. 2018, 15, 2416–2425. [Google Scholar] [CrossRef]
- Marani, M.; Zeinali, M.; Songmene, V.; Mechefske, C.K. Tool wear prediction in high-speed turning of a steel alloy using long short-term memory modelling. Measurement 2021, 177, 109329. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, B.; Li, X.; Liu, S.; Yue, C.; Liang, S.Y. An approach for tool wear prediction using customized DenseNet and GRU integrated model based on multi-sensor feature fusion. J. Intell. Manuf. 2022, 1–18. [Google Scholar] [CrossRef]
- Cao, X.; Chen, B.; Yao, B.; He, W. Combining translation-invariant wavelet frames and convolutional neural network for intelligent tool wear state identification. Comput. Ind. 2019, 106, 71–84. [Google Scholar] [CrossRef]
- Huang, Z.; Zhu, J.; Lei, J.; Li, X.; Tian, F. Tool wear predicting based on multi-domain feature fusion by deep convolutional neural network in milling operations. J. Intell. Manuf. 2020, 31, 953–966. [Google Scholar] [CrossRef]
- Cheng, M.; Jiao, L.; Yan, P.; Jiang, H.; Wang, R.; Qiu, T.; Wang, X. Intelligent tool wear monitoring and multi-step prediction based on deep learning model. J. Manuf. Syst. 2022, 62, 286–300. [Google Scholar] [CrossRef]
- Bazi, R.; Benkedjouh, T.; Habbouche, H.; Rechak, S.; Zerhouni, N. A hybrid CNN-BiLSTM approach-based variational mode decomposition for tool wear monitoring. Int. J. Adv. Manuf. Technol. 2022, 119, 3803–3817. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, A.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Liu, H.; Liu, Z.; Jia, W.; Lin, X.; Zhang, S. A novel transformer-based neural network model for tool wear estimation. Meas. Sci. Technol. 2020, 31, 65106. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. Proc. AAAI Conf. Artif. Intell. 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Zong, C.; Nie, J.; Zhao, D.; Feng, Y. Natural language processing and Chinese computing. Commun. Comput. Inf. Sci. 2012, 333, 262–273. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Li, W.; Fu, H.; Han, Z.; Zhang, X.; Jin, H. Intelligent tool wear prediction based on Informer encoder and stacked bidirectional gated recurrent unit. Robot. Comput.-Integr. Manuf. 2022, 77, 102368. [Google Scholar] [CrossRef]
- Li, J.; Wang, T.; Zhang, W. An improved Chinese named entity recognition method with TB-LSTM-CRF. In Proceedings of the 2020 2nd Symposium on Signal Processing Systems, Guangzhou China, 11–13 July 2020; pp. 96–100. [Google Scholar]
- PHM Society: 2010 PHM Society Conference Data Challenge. Available online: https://www.phmsociety.org/competition/phm/10 (accessed on 31 December 2022).
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A new convolutional neural network-based data-driven fault diagnosis method. IEEE Trans. Ind. Electron. 2017, 65, 5990–5998. [Google Scholar] [CrossRef]
- Chan, Y.; Kang, T.; Yang, C.; Chang, C.; Huang, S.; Tsai, Y. Tool wear prediction using convolutional bidirectional LSTM networks. J. Supercomput. 2022, 78, 810–832. [Google Scholar] [CrossRef]
- Qiao, H.; Wang, T.; Wang, P.; Qiao, S.; Zhang, L. A time-distributed spatiotemporal feature learning method for machine health monitoring with multi-sensor time series. Sensors 2018, 18, 2932. [Google Scholar] [CrossRef]
- Liu, H.; Liu, Z.; Jia, W.; Zhang, D.; Wang, Q.; Tan, J. Tool wear estimation using a CNN-transformer model with semi-supervised learning. Meas. Sci. Technol. 2021, 32, 125010. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, D.; Yan, R.; Mao, K.; Shen, F.; Wang, J. Machine health monitoring using local feature-based gated recurrent unit networks. IEEE Trans. Ind. Electron. 2017, 65, 1539–1548. [Google Scholar] [CrossRef]
- Wang, J.; Yan, J.; Li, C.; Gao, R.X.; Zhao, R. Deep heterogeneous GRU model for predictive analytics in smart manufacturing: Application to tool wear prediction. Comput. Ind. 2019, 111, 1–14. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Equipment | Type |
|---|---|
| CNC milling machine | Roders Tech RFM760 |
| Dynamometer | Kistler 9265B |
| Charge amplifier | Kistler 5019A |
| Acoustic emission sensor | Kistler AE sensor |
| Cutters | 3-flute ball carbide milling cutters |
| Data acquisition card | DAQ NI PCI 1200 |
| Abrasion measuring apparatus | LEICA MZ12 microscope |
| Parameter | Value |
|---|---|
| Spindle | 10,400/(r/min) |
| Feed rate | 1555 (mm/min) |
| Depth of cut (y direction, radial) | 0.125 (mm) |
| Depth of cut (z direction, axial) | 0.2 (mm) |
| Sampling rate | 50 (KHz) |
| Workpiece material | Stainless steel (HRC52) |
| Parameters | Learning Rate | Epoch | Batch Size | Dropout |
|---|---|---|---|---|
| Values | 0.001 | 100 | 32 | 0.2 |
| Parameters | Warmup | FC neurons | H | Activation |
| Values | 20 | 64/64/1 | 3 | ReLu |
| Models | Datasets | |||||
|---|---|---|---|---|---|---|
| C1 | C4 | C6 | ||||
| MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| RNN [21] | 13.1 | 15.6 | 16.7 | 20 | 25.5 | 32.91 |
| Bi-LSTM [40] | 12.8 | 14.6 | 10.9 | 14.2 | 14.7 | 17.7 |
| CNN-LSTM [41] | 11.18 | 13.77 | 9.39 | 11.85 | 11.34 | 14.33 |
| Deep-LSTM [21] | 8.3 | 12.1 | 8.7 | 10.2 | 15.2 | 18.9 |
| HLLSTM [40] | 6.6 | 8 | 6 | 7.5 | 7.1 | 8.8 |
| TBNN [31] | 4.294 | 6.116 | / | / | 7.772 | 9.553 |
| CTNN [42] | 3.634 | 5.358 | / | / | 7.531 | 9.209 |
| LF-GRU [43] | 4.2 | 5.4 | 6.9 | 8.3 | 5.8 | 8.2 |
| DH-GRU [44] | 3.7 | 4.66 | 7.07 | 8.73 | 5.08 | 6.94 |
| IE-SBIGRU [36] | 3.694 | 5.056 | 5.189 | 6.884 | 3.398 | 4.527 |
| Proposed model | 2.68 | 3.23 | 3.09 | 3.91 | 3.37 | 4.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, X.; Huang, M.; Liu, Y.; An, Q. Intelligent Tool-Wear Prediction Based on Informer Encoder and Bi-Directional Long Short-Term Memory. Machines 2023, 11, 94. https://doi.org/10.3390/machines11010094
Xie X, Huang M, Liu Y, An Q. Intelligent Tool-Wear Prediction Based on Informer Encoder and Bi-Directional Long Short-Term Memory. Machines. 2023; 11(1):94. https://doi.org/10.3390/machines11010094
Chicago/Turabian StyleXie, Xingang, Min Huang, Yue Liu, and Qi An. 2023. "Intelligent Tool-Wear Prediction Based on Informer Encoder and Bi-Directional Long Short-Term Memory" Machines 11, no. 1: 94. https://doi.org/10.3390/machines11010094
APA StyleXie, X., Huang, M., Liu, Y., & An, Q. (2023). Intelligent Tool-Wear Prediction Based on Informer Encoder and Bi-Directional Long Short-Term Memory. Machines, 11(1), 94. https://doi.org/10.3390/machines11010094