



A Deep Learning Model Applied to Optical Image Target Detection and Recognition for the Identification of Underwater Biostructures


Abstract
:1. Introduction
2. Related Work
2.1. Underwater Image Enhancement
2.1.1. Underwater Target Detection
2.1.2. Target Detection Algorithm Based on Deep Learning
- (1)
- The R-CNN-series algorithm is a classical algorithm based on a recommended region. It first estimates the last frame containing the target through the region recommendation method, then uses CNN to perform a feature extraction operation, and finally inputs the data to the detector for classification and positioning. In 2014, Girshick et al. [20] proposed the R-CNN detection algorithm [21], which firstly uses target detection and the segmentation of a deep neural network CNN and then applies transfer learning to improve network performance. Girshick et al. [22] further improved the R-CNN network. They proposed a FASTR-CNN network, which combined feature extraction and detection with ROI and a multi-task loss function; they also tested its speed and found that the training speed was significantly improved. In the same year, Ren Shaoqing et al. [23] proposed the well-known Faster R-CNN, which offered a region proposal network (RPN) instead of the traditional region selection method. The feature graph after convolution was shared and integrated into a network. The end-to-end training of the detection algorithm was realized for the first time.
- (2)
- Regression-based detection algorithms mainly include the SSD series and YOLO series, which directly set the last frame on the input image and perform regression operations on the target in stand-through feature extraction. In 2016, Redmon et al. proposed YOLO, a single pipeline network viewed only once, to directly perform regression operations on BBO in the grid and predict the target’s coordinate information and category probability. This network dramatically improved the speed of target detection, reaching a real-time detection rate of 45 FPS. In the following year, Redmon et al. made improvements based on the YOLO algorithm and proposed the YOLOv2 algorithm, which introduced batch normalization (BN) [24]. The anchor frame mechanism and the pass-through operation improved the detection performance of the network. In 2018, Redmon et al. [25] proposed the YOLOv3 algorithm based on YOLOv2. YOLOv3 used DarkNet-53 as the master of the thousand networks, which is composed of multiple ResNet stacks, making the depth of the entire network up to 152 layers. Moreover, multi-scale fusion was adopted in the prediction network, which further improved the feature extraction capability of the network.
2.2. Our Contributions
3. Methods and Materials
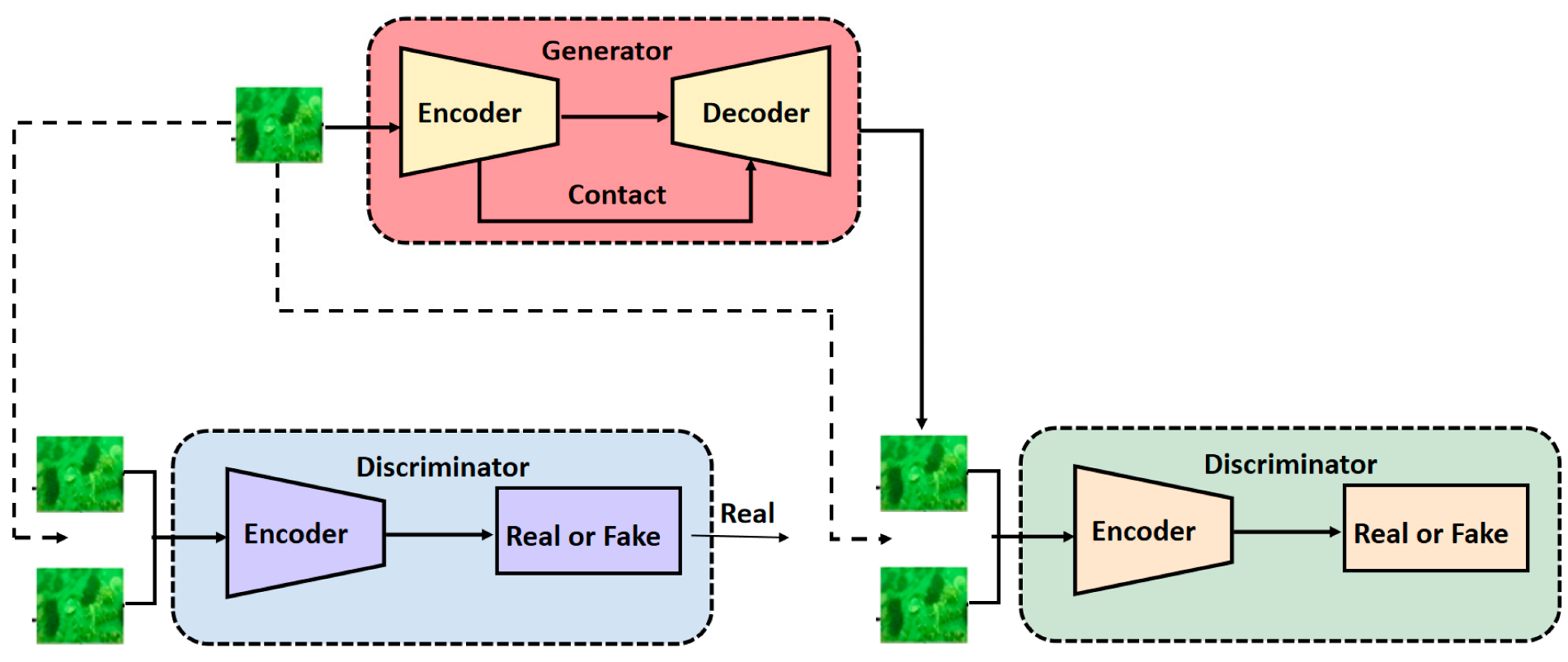
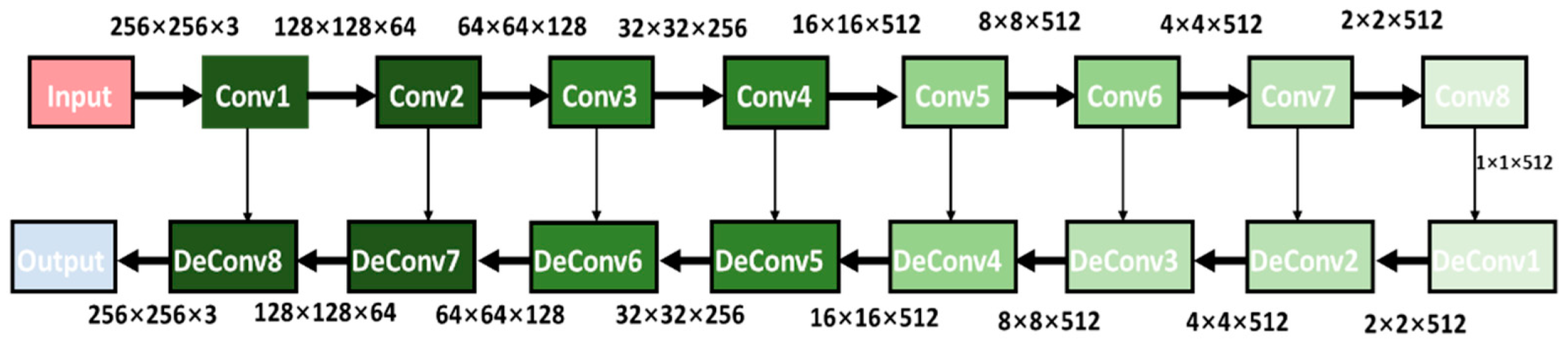
3.1. Underwater Image Enhancement Based on a Generative Adversarial Network
Establishment of Underwater-Style Transfer Dataset
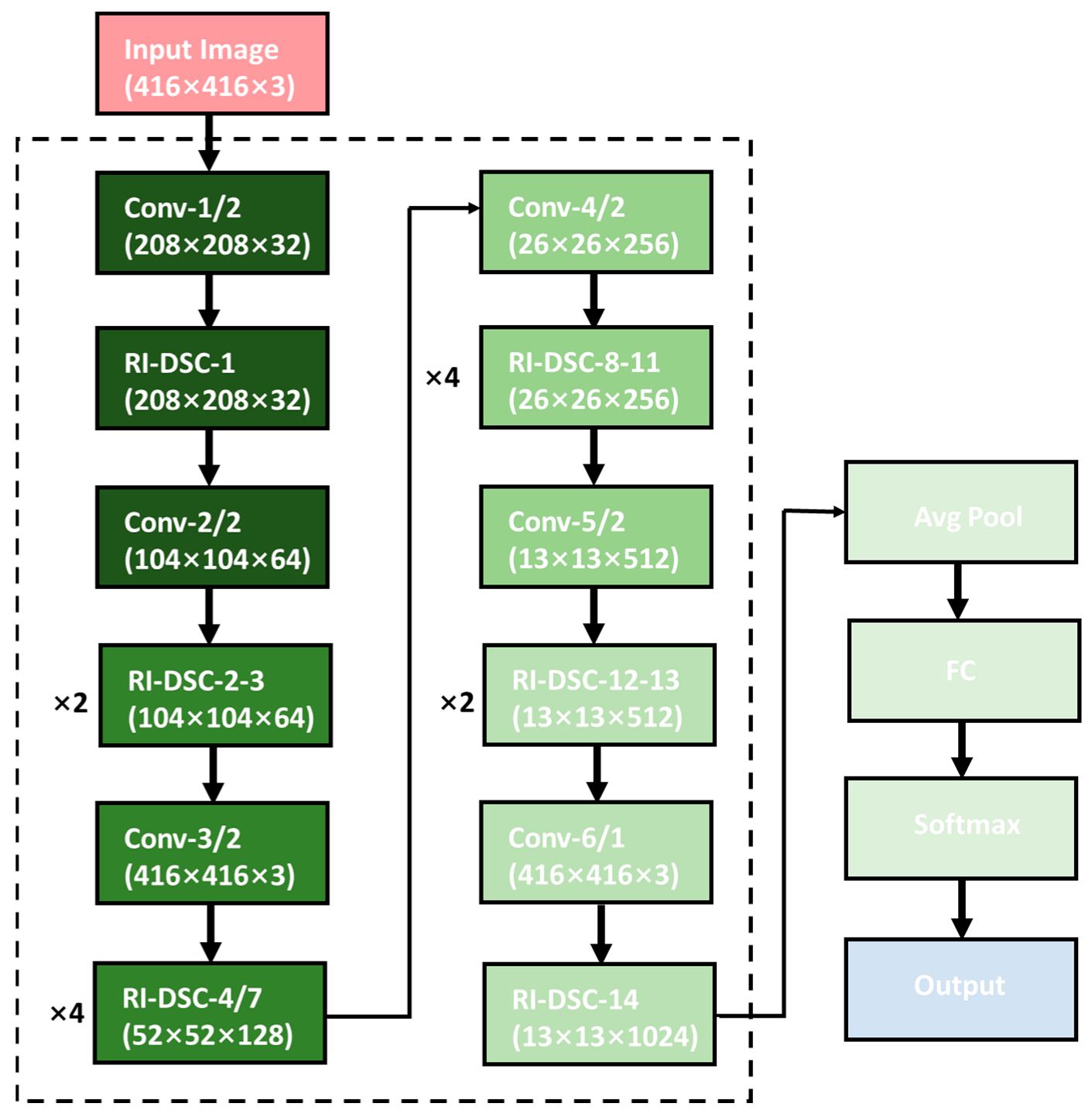
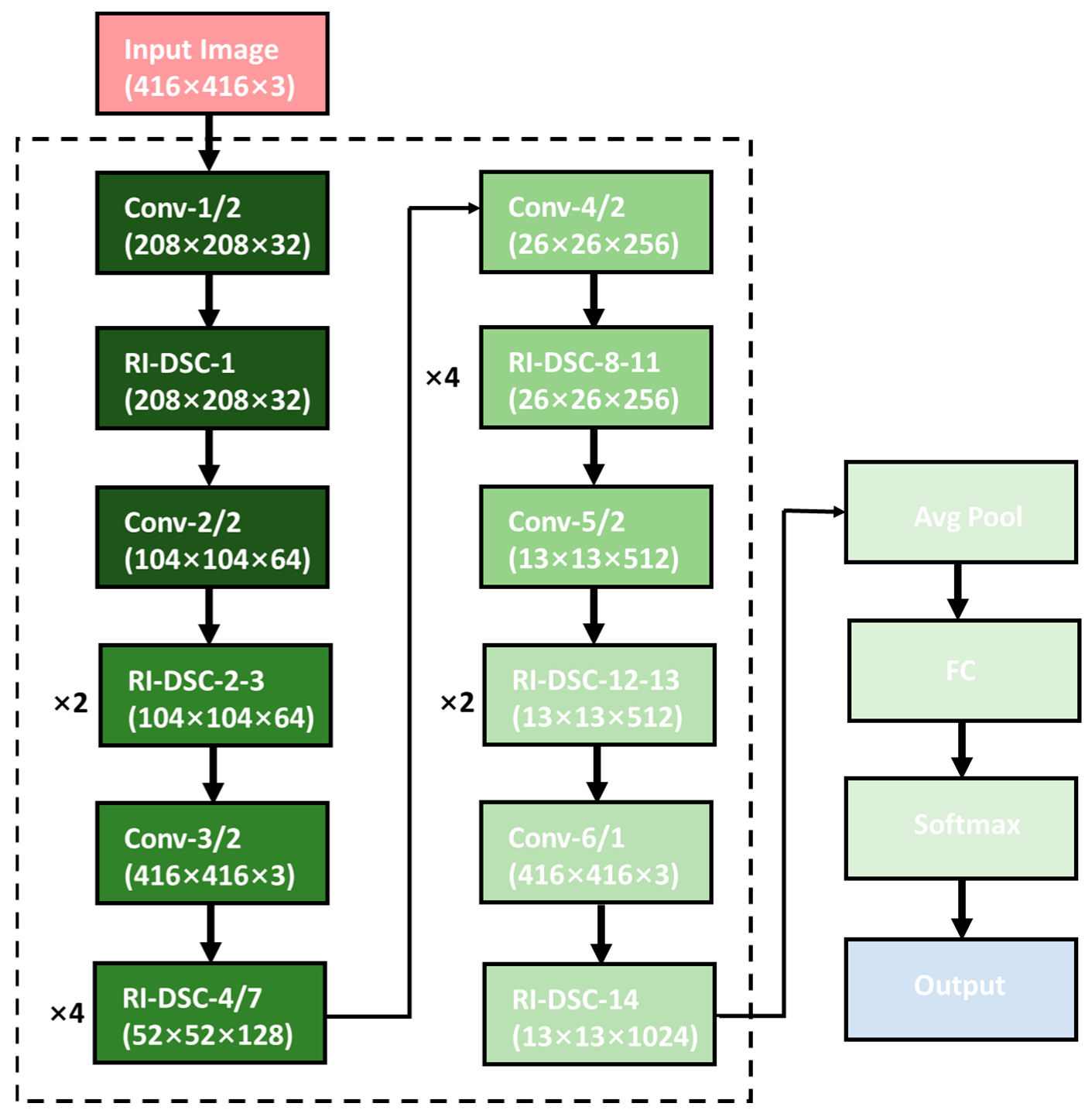
3.2. YOLOv3-Based Lightweight Detection Model
3.2.1. UW_YOLOv3 Trunk Network Establishment
3.2.2. UW_YOLOv3 Prediction Network Establishment
- (1)
- HRNet can always maintain high-resolution features and will not lose feature details due to down-sampling operations, nor will it be unable to fully represent all upper-level information due to up-sampling recovery features.
- (2)
- The HRNet feature fusion method can make predictions more accurate. In this network, different scale fusions are used many times, and low-resolution high-level semantic information is used to improve the capability of the high-resolution feature representation.
3.2.3. UW_YOLOv3 Network Construction
- (1)
- The standard 3 × 3 convolution was replaced with a profoundly separable network, significantly compressing the network model;
- (2)
- Inception was introduced for multi-scale feature extraction to improve the feature-extraction capability of the convolutional layer;
- (3)
- A reset structure was adopted so that the network only learned residuals and speed-up training;
- (4)
- The parallel connection mode of HRNet was used to improve the expression ability of the high-resolution features of the network.
3.3. Data Network Parameter Transfer Based on Transfer Learning
3.3.1. Transfer Learning
3.3.2. Design and Implementation of Parameter Transfer Algorithm
- (1)
- An underwater biological classification dataset was constructed. The acquisition of tags in the biological classification dataset was much easier than in the underwater target detection dataset. There were many seafood image data with corresponding labels on the Internet. In this paper, many sea cucumbers and sea urchins were extracted from Google and Baidu, respectively. Crawling scallop images were screened. Finally, a dataset of three seafood categories was obtained, including 10,230 images: 3105 sea urchin images, 3715 sea cucumber images, and 3410 scallop images.
- (2)
- The parameter migration of the ImageNet classification network was due to VGG16. The parameter space was ample, and it was easy to overfit and slow to converge when using the constructed seafood classification dataset to train the VGG16 network directly. Therefore, this paper firstly initialized the seafood classification network by using the parameters obtained by VGG16 training on the ImageNet dataset, and then carried out the first parameter migration.
- (3)
- The network was fine-tuned. The parameters of the first 15 layers of the initialized VGG16 network were fixed and the last layer was fine-tuned.
- (4)
- Several iterations were performed on the seafood dataset, restoring the learning rate of the first 15 layers and the trained VGG16.
- (5)
- Parameter migration was performed for the marine classification network. The model parameters obtained in the previous step initialized the backbone network of the underwater target detection network and carried out the second parameter migration.
4. Experiments and Results
4.1. Underwater Image Enhancement Based on a Generative Adversarial Network
4.2. Yolov3-Based Lightweight Detection Model
4.3. Data Network Parameter Transfer Based on Transfer Learning
5. Discussion
- (1)
- To solve the problem of underwater image degradation, an underwater image enhancement method based on a generative adventure network was proposed and implemented to establish an underwater-style migration dataset by combining MSRCR and DehazeNet.
- (2)
- Aiming to solve the problem of insufficient real-time detection of the YOLOv3 algorithm in embedded devices, the lightweight network model UW_YOLOv3 was designed by improving the structure of its backbone network and predictive network. In the trunk network, a deep convolution separable network was introduced to replace the standard convolution, a 1 × 1 convolution was introduced to increase the network width, and a 20-layer trunk network was built by using this unit to replace DarkNet-53. This was introduced to the predictive network to improve the traditional feature fusion method so that the network always maintained the capability of high-resolution feature representation. The experimental results showed that the number of parameters of the improved backbone network was only 20% of the original, which achieved the purpose of being lightweight, and the detection speed doubled to 98.1 FPS while maintaining a detection accuracy of 58.1%. The detection accuracy of the improved predictive network was improved by 3.7%. Compared with other algorithms, the lightweight UW_YOLOv3 network designed in this paper dramatically improved the detection speed at the expense of a small part of the accuracy, and its 61.8% accuracy and 80.2 FPS detection speed met the requirements of practical engineering applications.
- (3)
- Given the small in-sample problem caused by the difficulty of the large-scale acquisition of underwater images, a solid supervised underwater target detection method was proposed and implemented in a small-sample scenario. The idea of transfer learning was used to realize the transfer of seafood classification knowledge to underwater target detection knowledge and improve the convergence speed and detection accuracy of the detection network. The data augmentation of an underwater image was completed using a spatial variation network, which strengthened the robustness of the detection network in the targeting of spatial transformation. This solved the problem of the network model being easy to overfit under the condition of small samples.
6. Conclusions
- (1)
- Due to the influence of a complex underwater environment, accurate underwater image data are seriously lacking. Although data amplification can increase a part of the data in this paper, it is still much lower in order of magnitude than the above-ground database, which significantly limits the accuracy of underwater target detection. At the same time, this paper has not considered the fuzzy problem of dynamic robot images, which affects the accuracy of underwater target detection in practice. In subsequent underwater target detection technologies, more attention should be paid to the study of data quantity and quality, and the problem of non-target occlusion in underwater target detection should be further studied.
- (2)
- The high-resolution network-holding model was introduced into the underwater lightweight model prediction network to maintain the feature expression ability of a high resolution, which improves the detection ability of small targets to a certain extent. However, there is still an issue of the partial detection of large targets, and the positioning deviation is significant, especially for some targets that account for more than 30%. Therefore, we need to investigate a detection method that accounts for a relatively large target.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Henke, B.; Vahl, M.; Zhou, Z. Removing color cast of underwater images through non-constant color constancy hypothesis. In Proceedings of the 2013 8th International Symposium on Image and Signal Processing and Analysis, Trieste, Italy, 4–6 September 2013; pp. 20–24. [Google Scholar]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing underwater images and videos by fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar]
- Hu, X.; Yang, L.; Zhao, Z.; Liu, J.; Yang, X.; Sun, C.; Chen, S.; Li, B.; Zhou, C. Real-time detection of uneaten feed pellets in underwater images for aquaculture using an improved YOLO-V4 network. Comput. Electron. Agric. 2021, 185, 106135. [Google Scholar] [CrossRef]
- Li, C.-Y.; Guo, J.-C.; Cong, R.-M.; Pang, Y.-W.; Wang, B. Underwater image enhancement by dehazing with minimum information loss and histogram distribution prior. IEEE Trans. Image Process. 2016, 25, 5664–5677. [Google Scholar] [CrossRef] [PubMed]
- Land, E.H. The retinex theory of color vision. Sci. Am. 1977, 237, 108–129. [Google Scholar] [CrossRef] [PubMed]
- Hu, G.; Wang, K.; Peng, Y.; Qiu, M.; Shi, J.; Liu, L. Deep learning methods for underwater target feature extraction and recognition. Comput. Intell. Neurosci. 2018, 2018, 1214301. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Wang, T.; Dong, J.; Yu, H. Underwater image enhancement via extended multi-scale retinex. Neurocomputing 2017, 245, 1–9. [Google Scholar] [CrossRef]
- Zhao, M.; Liu, X.; Liu, H.; Wong, K.K.L. Super-resolution of cardiac magnetic resonance images using laplacian pyramid based on generative adversarial networks. Comput. Med. Imaging Graph. 2020, 80, 101698. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; Fu, X.; Chen, F.; Wong, K.K.L. Prediction Christian of fetal weight at varying gestational age in the absence of ultrasound examination using ensemble learning. Artif. Intell. Med. 2020, 102, 101748. [Google Scholar] [CrossRef] [PubMed]
- Zhao, M.; Wei, Y.; Wong, K.K.L. A generative adversarial network technique for high-quality super-resolution reconstruction of cardiac magnetic resonance images. Magn. Reson. Imaging 2022, 85, 153–160. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Zhuang, P.; Huang, Y.; Liao, Y.; Zhang, X.-P.; Ding, X. A retinex-based enhancing approach for single underwater image. In Proceedings of the 2014 IEEE International Conference on Image Processing, Paris, France, 27–30 October 2014; pp. 4572–4576. [Google Scholar]
- Chiang, J.Y.; Chen, Y.C. Underwater image enhancement by wavelength compensation and dehazing. IEEE Trans. Image Process. 2012, 21, 1756–1769. [Google Scholar] [CrossRef]
- Peng, Y.T.; Cosman, P.C. Underwater image restoration based on image blurriness and light absorption. IEEE Trans. Image Process. 2017, 26, 1579–1594. [Google Scholar] [CrossRef] [PubMed]
- Ali, R.; Hardie, R.C.; Narayanan, B.N.; Kebede, T.M. IMNets: Deep learning using an incremental modular network synthesis approach for medical imaging applications. Appl. Sci. 2022, 12, 5500. [Google Scholar] [CrossRef]
- Zhao, X.; Jin, T.; Qu, S. Deriving inherent optical properties from background color and underwater image enhancement. Ocean. Eng. 2015, 94, 163–172. [Google Scholar] [CrossRef]
- Yamashita, A.; Fujii, M.; Kaneko, T. Color registration of underwater images for underwater sensing with consideration of light attenuation. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Rome, Italy, 10–14 April 2007; pp. 4570–4575. [Google Scholar]
- Mukherjee, K.; Gupta, S.; Ray, A.; Phoha, S. Symbolic analysis of sonar data for underwater target detection. IEEE J. Ocean. Eng. 2011, 36, 219–230. [Google Scholar] [CrossRef]
- Elberink, S.O. Target graph matching for building reconstruction. Proc. Laserscanning 2009, 9, 49–54. [Google Scholar]
- Hsiao, Y.H.; Chen, C.C.; Lin, S.I.; Lin, F.-P. Real-world underwater fish recognition and identification, using sparse representation. Ecol. Inform. 2014, 23, 13–21. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. Available online: https://arxiv.org/abs/1804.02767 (accessed on 8 April 2018).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Filter | Size | Output | Calculated Quantities/106 | Number of Arguments |
|---|---|---|---|---|---|
| Conv2d | 32 | 3 × 3 | 416 × 416 | 299.04 | 864 |
| Conv2d | 64 | 3 × 3/2 | 208 × 208 | 1594.88 | 18,432 |
| Conv2d | 32 | 1 × 1 | ×1 = 1772.09 | ×1 = 20,480 | |
| Conv2d | 64 | 3 × 3 | |||
| Residual | 208 × 208 | ||||
| Conv2d | 128 | 3 × 3/2 | 104 × 104 | 1594.88 | 73,728 |
| Conv2d | 64 | 1 × 1 | ×2 = 3544.18 | ×2 = 163,840 | |
| Conv2d | 128 | 3 × 3 | |||
| Residual | 104 × 104 | ||||
| Conv2d | 256 | 3 × 3/2 | 52 × 52 | 1594.88 | 294,912 |
| Conv2d | 128 | 1 × 1 | ×8 = 14,176.00 | ×8 = 2,621,440 | |
| Conv2d | 256 | 3 × 3 | |||
| Residual | 52 × 52 | ||||
| Conv2d | 512 | 3 × 3/2 | 26 × 26 | 1594.88 | 1,179,648 |
| Conv2d | 256 | 1 × 1 | ×8 = 14,176.00 | ×8 = 10,485,760 | |
| Conv2d | 512 | 3 × 3 | |||
| Residual | 26 × 26 | ||||
| Conv2d | 1024 | 3 × 3/2 | 13 × 13 | 1594.88 | 4,817,592 |
| Conv2d | 512 | 1 × 1 | ×4 = 7088.04 | ×4 = 20,971,520 | |
| Conv2d | 1024 | 3 × 3 | |||
| Residual | 13 × 13 | ||||
| Sum | DarkNet-53 structure | 48,960.11 | 40,549,216 | ||
| Image | Original Image | MSRCR | MSRCR + DehazeNet | Methods |
|---|---|---|---|---|
| Entropy | 6.35 | 6.48 | 7.18 | 7.26 |
| Standard deviation | 20.4 | 23.6 | 36.0 | 38.4 |
| Algorithm | Trunk Network | AP50 | AP75 | FPS |
|---|---|---|---|---|
| Faster RCNN-600 | ResNcl-101 | 75.6 | 62.7 | 5.1 |
| SSD-512 | VGGNet-16 | 66.5 | 51.6 | 39.3 |
| YOLOv3-416 | DarkNet-53 | 71.9 | 53.5 | 48.7 |
| YOLOv3-tiny-4l6 | DarkNet-tiny | 53.9 | 38.1 | 96.5 |
| UW_YOLOv3-4l6 | RI-DSC | 61.8 | 49.3 | 80.2 |
| UW_YOLOv3-224 | RI-DSC | 54.1 | 39.7 | 156.9 |
| Method | Sea Urchin | Scallop | Sea Cucumber | MAP (%) |
|---|---|---|---|---|
| ImageNet Parameters of the Migration | 84.6 | 44.7 | 64.9 | 64.7 |
| Classification of Seafood Parameters of the Migration | 84.8 | 48. 4 | 69.4 | 67.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, H.; Dai, Y.; Zhu, Z.; Liu, R. A Deep Learning Model Applied to Optical Image Target Detection and Recognition for the Identification of Underwater Biostructures. Machines 2022, 10, 809. https://doi.org/10.3390/machines10090809
Ge H, Dai Y, Zhu Z, Liu R. A Deep Learning Model Applied to Optical Image Target Detection and Recognition for the Identification of Underwater Biostructures. Machines. 2022; 10(9):809. https://doi.org/10.3390/machines10090809
Chicago/Turabian StyleGe, Huilin, Yuewei Dai, Zhiyu Zhu, and Runbang Liu. 2022. "A Deep Learning Model Applied to Optical Image Target Detection and Recognition for the Identification of Underwater Biostructures" Machines 10, no. 9: 809. https://doi.org/10.3390/machines10090809
APA StyleGe, H., Dai, Y., Zhu, Z., & Liu, R. (2022). A Deep Learning Model Applied to Optical Image Target Detection and Recognition for the Identification of Underwater Biostructures. Machines, 10(9), 809. https://doi.org/10.3390/machines10090809