1. Introduction
The univariate generalized exponential (GE) is a versatile distribution introduced by [
1] with several interesting properties that can be used quite effectively to analyze lifetime data. It is a good alternative to the usual lifetime distributions as Weibull and Gamma distributions. Although several studies have been conducted on the GE distribution, research on the bivariate GE distributions remains limited.
While the foundational work on bivariate copulas remains essential, the field has seen significant advances in recent years. Contemporary research has largely focused on developing highly flexible models for high-dimensional data, particularly using vine copulas or pair-copula constructions (e.g., [
2]). Bayesian non-parametric copulas using infinite partitions of unity have been introduced to capture both central and tail dependence through stick-breaking priors [
3]. Ref. [
4] developed Dirichlet process mixtures of Archimedean copulas that allow arbitrary dimension and complex dependence patterns. Ref. [
5] proposed approximate Bayesian conditional copulas to incorporate covariate effects into the copula function without fixed parametric forms. Furthermore, ref. [
6] integrated vine copula constructions with Bayesian non-parametric priors to flexibly model high-dimensional conditional dependence structures. Furthermore, there is a growing body of literature on dynamic copula models that allow the dependence structure to evolve over time [
7]. The current work contributes to a parallel stream of research that continues to develop novel bivariate distributions with specific, practical marginals, such as the generalized exponential, to provide flexible and interpretable models for lifetime and reliability data.
In recent years, some representations of bivariate GE distribution have been proposed. Refs. [
8,
9] have introduced a bivariate distribution using the GE and exponential distribution. However, the marginal distributions do not have known forms. Ref. [
10] introduced a singular bivariate generalized exponential distribution (BVGE), whose marginals are GE distributions. The authors present several probabilistics properties, including the maximum likelihood estimation (MLE). Ref. [
11] used the Bayesian approach to estimate the parameters of BVGE. Ref. [
12] considered the Bayesian inference of the unknown parameters of this distribution obtained by using different prior distributions as uniform, gamma distributions and the objective Jeffreys prior. Ref. [
13] also derived an absolute continuous BVGE distribution by using transformation from bivariate exchangeable distribution. The marginals of the proposed BVGE are also GE.
Ref. [
14] introduced an absolutely continuous bivariate generalized exponential distribution by using the method of [
15]. This new distribution was obtained from the bivariate generalized exponential distribution (BVGE) model by removing the singular part. In this case, the marginal distributions are not a generalized exponential.
Besides generalizations, copula functions have become a popular tool for modeling the dependence between multivariate data; see, for example, [
16,
17]. The copula approach allows the construction of unknown bivariate distributions based on known marginals. Ref. [
18] wrote a compendium on copulas, where they presented an updated review on this important subject.
Copula functions have been effectively applied to model the dependence structure of the generalized exponential (GE) distribution, offering flexibility in capturing complex multivariate relationships. Refs. [
19,
20] further contributed to this field by proposing novel methodologies for incorporating copula functions into the modeling of dependent lifetimes with GE marginals, such as the Farlie–Gumbel–Morgensten and Clayton copulas. Their contributions include both classical and Bayesian inference procedures, demonstrating the flexibility and practical relevance of copula-based GE models in survival analysis and reliability studies. The integration of copulas with the GE distribution, as explored by these authors, provides a robust framework for analyzing multivariate non-normal data.
The existing bivariate GE distributions face limitations: rigid dependence structures, singular components, or non-GE marginals, restricting their utility for real-world lifetime data with complex dependencies. To address this, we present four different bivariate generalized exponential distributions obtained by using the Farlie–Gumbel–Morgenstern, Gumbel–Barnett, Clayton, and Frank copulas compounded with GE marginal distributions.
Although copulas are able to capture several different dependence structures of two or more random variables, an incorrect choice of copula may result in a poor fit to the data. To select a more appropriate copula, this paper considers three levels of dependence: weak, moderate, and strong, for each of the BVGE distributions generated. Also, we investigate the performance of the resulting BVGE distributions through a simulation study. We assess fidelity to data generated from bivariate Weibull distributions, a neutral benchmark that avoids favoring any GE-based model.
Given the complexity of the proposed bivariate generalized exponential distributions derived using the Farlie–Gumbel–Morgenstern, Gumbel–Barnett, Clayton, and Frank copulas, obtaining the parameter estimates through traditional analytical methods is not straightforward. The likelihood functions for these models can be complex, making direct maximization challenging. Therefore, a Bayesian approach under non-informative priors and using Markov Chain Monte Carlo (MCMC) methods provides a robust and flexible alternative for parameter estimation. This computational approach allows us to simulate samples from the posterior distributions of the model parameters, providing not only point estimates but also credible intervals that capture the uncertainty in the obtained estimates. To implement this Bayesian analysis, we utilized the OpenBUGS 3.2. [
21] software, which is a powerful and widely used tool for performing MCMC simulations.
Finally, a real-life data (electrical treeing failures) set was used in order to illustrate the usefulness of the proposed distributions.
The paper is organized as follows.
Section 2 introduces copula functions, focusing on the Farlie–Gumbel–Morgenstern, Gumbel–Barnett, Clayton, and Frank copulas.
Section 3 presents the derivation of the bivariate generalized exponential distribution using copulas. In
Section 4, three bivariate models are presented: the BGE, the BVGE, and the the generalized bivariate exponential distribution Block–Basu (BBBGE) distributions.
Section 5 details the Bayesian analysis, including prior distributions for the model parameters.
Section 6 evaluates the performance of the bivariate models through simulations to determine which best captures data characteristics.
Section 7 applies the models to a real-world survival time dataset in electrical engineering. Finally,
Section 8 summarizes the findings and conclusions of the study.
2. Copula Function
Copula functions link marginal distributions to form a joint distribution. For specified univariate marginal distribution functions
, the function
,
,
…,
is defined using a copula function
C, resulting in a multivariate distribution defined via the copula function. It is important to note that any multivariate distribution function
can be written in the form of a copula function [
22]; that is, if
is a joint multivariate distribution function with univariate marginal distribution functions
, there exists a copula function
such that
If
and
denote the joint density and marginal densities of
, respectively, with distribution function
, then the joint density can be written in terms of the copula density and the marginal densities as
where
is the copula density of
C.
Specifically, the dependence between and is equivalent to specifying dependence between and . Thus, the problem reduces to defining a bivariate distribution for two uniform variables; that is, a copula.
Different copula functions introduced in the literature could be used to obtain a bivariate distribution with GE marginals. The first model considered for the study of the dependence structure for two variables is based on the Farlie–Gumbel–Morgenstern (FGM) copula; see, for example, [
23].
In this section, we review some copula-based bivariate models that shall be employed to obtain bivariate generalized exponential distributions.
2.1. Farlie–Gumbel–Morgenstern Copula
The first model considered for the study of dependence structure for two variables is based on the Farlie–Gumbel–Morgenstern (FGM) copula defined by
where
and
and
. Observe that
measures the dependence between two marginals; that is, if
, we have independent random variables. This copula is appropriated to model weak dependence structures.
The association parameter
can take different values depending on the copula, whereas measures of association, such as Pearson’s correlation coefficient that is usually bounded. The parameter
is related to the well-known association coefficients Kendall’s Tau
and Spearman’s Rho
by the equations
The correlation coefficient clearly ranges from to .
Now, for the FGM copula
given in the Equation (
3), the corresponding copula density
is
Let
denote the paired random variables with
,
denoting the corresponding marginal cumulative and density functions, respectively, then the joint cumulative distribution function and density for the random variables
and
become
and
respectively. The bivariate survival function
of the FGM copula is given by
where
and
are the marginal survival functions of
and
, respectively.
2.2. Gumbel–Barnett Copula
The second copula function to be considered for the study of dependence structure for two variables is the Gumbel–Barnett copula [
24], defined by
where
is the dependence parameter restricted to the interval
.
Ref. [
25] showed that the conditional copula of Gumbel–Barnett copula is also a Gumbel–Barnett copula. He also deduced its properties and its importance in applications.
The density of this copula is given by
The corresponding Kendall’s Tau
coefficient is given by
and the Spearman’s Rho
coefficient is given by
Both integrals (
11) and (
12) can be obtained by numerical integration.
In this model, the joint cumulative distribution function for the random variables
and
is given by
and the corresponding joint density function for
and
is given by
The joint survival function for the lifetimes
and
can also be obtained as
2.3. Clayton Copula
A well-known copula is the Clayton copula introduced by [
26]. The Clayton copula is an Archimedean asymmetric copula given by
The density function
of copula (
16) is given by
The Clayton copula has been used to study correlated risks because it exhibits strong left-tail dependence and relatively weak right-tail dependence.
Note that it does not allow negative dependence between the marginal distributions. Moreover, when , we have independence, while implies perfect positive dependence.
The relationship between the parameter
and the Kendall’s Tau
measure is given by
The Spearman’s Rho measure for this copula is very complicated.
The joint cumulative function of the Clayton copula (
16) is given by
and the corresponding joint density function for
and
is given by
The joint survival function based on the Clayton copula can be expressed as
2.4. Frank Copula
Another alternative copula is the Frank copula [
27] that takes the form
with dependence parameter
.
The density function
of the copula (
22) is given by
Unlike the Clayton and Gumbel-Barnett copulas, which are restricted to positive dependence, the Frank copula accommodates both positive and negative dependence. However, it is most appropriate for data that exhibit weak tail dependence.
The relationship between the Frank copula parameter
and the coefficients Kendall’s Tau
, and Spearman’s Rho
are given by the equations
respectively, where
is a Debye function of the
k-th kind.
The joint cumulative function of the Frank copula (
22) is given by
and the corresponding joint density function for
and
is given by
The joint survival function can be expressed as
2.5. Copula Selection Criteria
To ensure that the comparison covers a broad spectrum of dependence structures, we select four classical copula families with distinct tail-dependence properties and overall dependence ranges, commonly found in lifetime data. The selected copulas, FGM, Gumbel–Barnett, Clayton, and Frank, each offer different properties:
FGM copula. It models weak to moderate symmetric dependence (
; no tail dependence), ideal for scenarios where extreme-value dependence is negligible [
16].
Gumbel–Barnett copula. It captures negative and upper-tail dependence, making it suitable for modeling the simultaneous occurrence of large values (late failures), (), rare in survival data but critical for robustness checks.
Clayton copula. It has a strong lower-tail dependence (i.e., when both variables have low values, they are highly correlated for ), suitable for joint early failures (e.g., system shocks).
Frank copula. It is a flexible symmetric dependence (
), accommodating both positive/negative associations without tail dependence [
28]. Its flexibility in the body of the distribution makes it a natural contrast to FGM.
Table 1 compares their properties, and the coming simulation (
Section 6) validates their complementary roles in capturing GE-based dependence.
By including both symmetric, tail-independent families (FGM and Frank) and asymmetric, tail-dependent families (Clayton and Gumbel–Barnett), the current study systematically evaluates model performance under weak versus strong dependence and lower- versus upper-tail behavior.
Furthermore, by comparing these four families, we can empirically determine which dependence structure is the most suitable for the dataset under consideration, providing a comprehensive analysis that is not limited to a single type of association.
3. Bivariate Generalized Exponential Distribution Derived from Copulas
In this section, we construct the bivariate generalized exponential distribution based on the four copulas stated in
Section 2. We derive the bivariate joint survival functions.
Let us assume the marginal generalized exponential distributions
and
with distributions functions given by
and respective marginal densities
Choosing the Farlie–Gumbel–Morgenstern copula yields the joint density function obtained from Equation (
7) as
and the corresponding joint survival function is given by
Now, if we assume the Gumbel–Barnett copula with the generalized exponential marginals Equations (
28) and (
29), then the corresponding bivariate density and survival distributions are given by
and
respectively.
The Clayton copula joint density (
16) results in the bivariate generalized exponential distribution given by
and its joint bivariate survival function has the form
We conclude this section by deriving another bivariate generalized exponential distributions provided by the Frank copula given in Equation (
22). The copula leads to the joint density given by
and the Frank survival function is
4. Bivariate Generalized Exponential Distribution
In order to compare the results obtained via distributions by copula functions introduced in
Section 3, in this section, we recall three bivariate models proposed in the literature: the generalized bivariate exponential distribution (BGE) provided by [
29]; generalized bivariate exponential (BVGE), by [
10]; and the generalized bivariate exponential distribution Block–Basu (BBBGE), by [
14].
4.1. The BVGE Distribution
The BVGE distribution is introduced by [
10], for positive random variables
and
, with the shape parameters
,
,
and the scale parameter
. It has the joint cumulative distribution function
where
,
,
,
. The cumulative distribution function can also be written as
Note that the BVGE distribution has both an absolute continuous part and a singular part. The presence of a singular component implies that .
The corresponding joint density function for
and
obtained from
is given by
The marginals distributions are univariate generalized exponential with
and the conditional distribution of
given
is given by
Ref. [
30] derived the joint moments and the moment generating function for the BVGE.
4.2. The BBBGE Distribution
Block and Basu obtained the bivariate exponential distribution (BBBE) from the Marshall–Olkin bivariate exponential (MOBE) distribution by removing the singular part and retaining only the absolutely continuous part in their article [
31].
The BBBGE distribution ([
14]) has been obtained from the BVGE model by removing the singular part and keeping only the continuous part, which makes Block and Basu’s bivariate generalized exponential distribution an absolutely continuous bivariate distribution and it is a more flexible model than the BBBE model because of the presence of the shape parameter. Hence, the joint probability density function of
can be written as
The bivariate distribution function of
and
is
where
4.3. The BGE Distribution
Ref. [
29] proposed an absolutely continuous bivariate generalized exponential distribution, where
and
are two sequences mutually independent and identical exponential distributed random variables. They assumed that for
,
and
.
The BGE distribution is obtained using the distribution of minimum order statistics of the two independent samples of the ordinary exponential distribution defined above.
The associate joint distribution function is given by
From Equation (
45), by taking
or
, we have that
Therefore, it follows that the marginals of joint distribution function (
45) are GE distributions. A pair
distributed with joint distribution function (
45) is said to have BGE distribution with parameters
and
, denoted by
if it has the joint density function
The joint survival function of
is given by
Ref. [
29] derived a copula function associated with the bivariate generalized exponential (BGE) distribution, defined by Equation (
46), to analyze its dependence structure. Employing Sklar’s Theorem [
22], the copula function is given by
for all
,
and
.
5. Bayesian Analysis
The copula functions and bivariate models derived for GE in
Section 3 and
Section 4 provide different frameworks for bivariate dependence, but their parameters require efficient estimation methods. In this section, we adopt a Bayesian approach, implemented via MCMC methods in OpenBUGS, to estimate these parameters.
For a Bayesian inference, an appropriate prior distribution must be selected for the model parameters, particularly in the absence of expert opinion to inform the prior. Different prior distributions can be used in this study according to all currently available information.
In this paper, we perform the Bayesian estimation of the parameters assuming the absence of information; that is, the choice of priors will not have an influence on posterior. Thus, since
shape and
scale parameters of univariate generalized exponential distribution assume values greater than zero, then we can pre-establish, as usual, a gamma prior distribution with shape and scale hyperparameters
and
,
, respectively, and denoted by
When , , and , the prior distribution becomes vague (non-informative). In practice, these hyperparameters are typically set to 0.1 or 0.01.
Many copula models have parameters (e.g., a dependence parameter in an Archimedean copula) that need to be estimated. For the FGM, Clayton, Frank, and Gumbel–Barnett Archimedean copulas, uniform priors for their dependence parameters can be used. Often, there is no strong prior knowledge about the dependence structure between variables. A uniform prior reflects this uncertainty by assigning equal probability to all plausible values of the dependence parameter within its admissible range. For example,
with
denoting a uniform distribution in the interval
.
A uniform prior over these ranges ensures that no value is favored a priori; that is, it is considered “non-informative”. However, care must be taken to ensure the uniform prior is proper (i.e., defined over a bounded range). For instance, for the Clayton copula, , but an improper uniform prior would lead to an improper posterior. Instead, a proper uniform prior over a reasonable range (e.g., [0, 100]) can be used. Similarly, for the Frank copula, , but a uniform prior over a sufficiently wide symmetric interval (e.g., ) can approximate a weakly informative prior. Furthermore, these priors were chosen to cover plausible ranges while ensuring proper posteriors.
We further assume prior independence among the parameters. Thus, the joint posterior distribution for the vector of parameters
is given by
where
is the joint prior distribution for
,
is the likelihood function and
and
,
is a vector of observed lifetime data.
Because the joint posterior densities implied by the considered four BVGE-copula models admit no closed-form summaries, the Markov Chain Monte Carlo (MCMC) algorithm is a natural choice to obtain the posterior summaries of interest from their distributions. We implement all sampling algorithms in OpenBUGS [
21] for performing Bayesian inference on complex statistical models via Markov Chain Monte Carlo (MCMC) methods. This choice is motivated by OpenBUGS ability to handle complex likelihoods and generate posterior distributions even for non-standard copula models.
6. Simulation
In the previous sections, we considered several copula functions to account for the dependence between two failure times and resulting from different forms of the BBBGE, BVGE, and BGE distributions. This section is intended to test the performance of those bivariate models to assess which one captures more closely the features of the data. Also, we confront the bivariate models with four different copulas presented previously.
In order to illustrate the performance of each distribution for comparison, we consider a simulation study with datasets drawn from the bivariate Weibull distributions for three dependence levels (weak, moderate, and strong). Since the datasets are generated from the Weibull distributions and not from the bivariate distributions from the GE model, the comparison will not favor any of them.
The simulation consists in 10,000 samples from the bivariate Weibull distributions with sample sizes , 60, and 100 considering three levels of correlation.
Bayesian analysis is performed with Markov Chain Monte Carlo (MCMC) methods to obtain the summaries of the posteriors of interest. We use the software OpenBUGS for the MCMC simulation method to run simulations of the marginal posteriors distributions with the goal of estimating the parameters of the models and hence comparing different proposed model structures. For each model and dataset, we ran MCMC chains for 20,000 iterations, following a burn-in period of 5000 iterations to ensure the chains reached their stationary distribution and thinning interval of 10 to reduce autocorrelation. The convergence of the MCMC chains generated was assessed using the Gelman–Rubin diagnostic test. We calculated the potential scale reduction factor (
). For all parameters, we ensured that
, which provides strong evidence that the chains have converged to the target posterior distribution. To compare models, we use the deviances and deviance information criterion (DIC; [
32]), defined as follows:
The deviance is a measure of model fit, defined as
where
C is a constant independent of
and thus cancels in model comparisons and
is the likelihood with
as a vector of unknown parameters of the model.
The DIC criterion defined by [
32] combines fit and complexity computed as
where
is the deviance evaluated at the posterior mean
and
is the effective number of parameters of the model given by
, where
is the posterior deviance measuring the quality of the data fit for the model. A lower DIC value indicates a better-fitting model, balancing goodness-of-fit and model complexity. Note that these values could be negative.
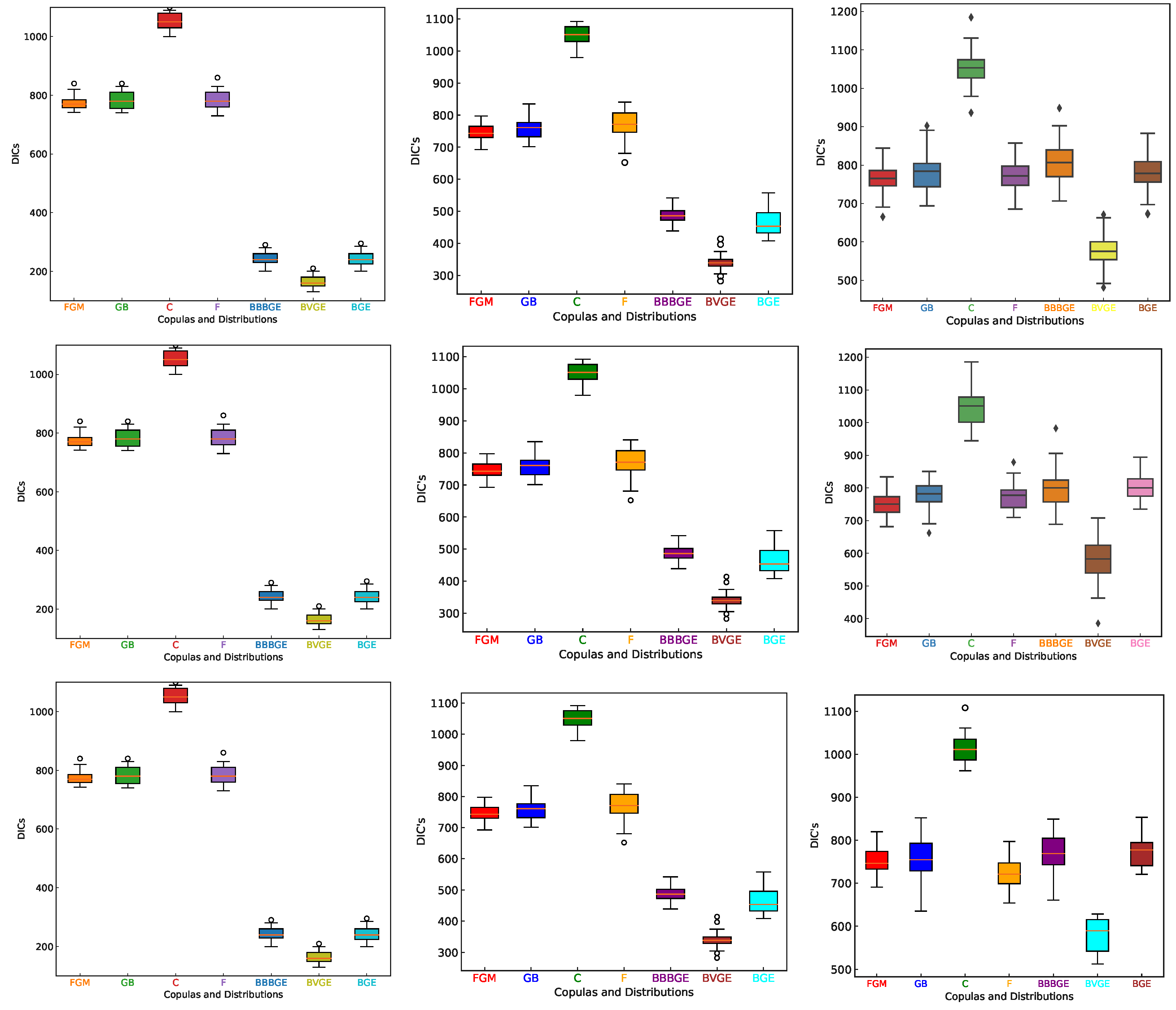
The most plausible choice for modeling the data is that it produces the lowest value for the DIC. In this simulation study, for each sample, the Bayesian analysis was carried out to estimate the unknown parameters of the bivariate models from the copulas distributions, and the DIC values were obtained for each of these distributions where the minimum value will report the corresponding to the best fitted distribution.
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7 present the mean of the posteriori estimate, the credible intervals of 95% and the deviance information criterion (DIC) and deviances for the proposed copulas models by considering the weak, moderate, and strong levels of correlation, respectively.
From the these tables, the analysis of DIC values and 95% Bayesian credible intervals reveals distinct patterns of model performance. Among the copula-based models, the Frank copula consistently yielded the lowest DIC values (mean DIC ranging from 750 to 776 across varying sample sizes), indicating superior model fit, particularly for datasets exhibiting moderate to strong dependence. In contrast, the FGM copula demonstrated the best performance under weak dependence scenarios (
), but its adequacy declined as dependence strength increased. The Clayton copula exhibited the highest DIC values (DIC > 1000), likely attributable to its restrictive lower-tail dependence structure, rendering it less suitable in broader dependence contexts. Regarding the bivariate models, the BVGE model outperformed others in small samples (e.g.,
, DIC between 165 and 430), benefiting from its ability to capture singular components in limited data. However, as the sample size increased, the performance gap between copula-based and bivariate models narrowed, with differences in DIC values falling below 5% for
. Furthermore, posterior credible intervals for the dependence parameters varied considerably across models. The Frank copula yielded the narrowest intervals (width
), indicating precise estimation, while the Clayton copula produced the widest intervals (width
,
), suggesting instability and challenges in parameter estimation.
Table 8 summarizes these trends across dependence levels.
The performance of the models, in terms of estimated DICs, can be checked by
Figure 1 and
Figure 2. Note that the bivariate models performed better than the models composed by using copulas functions for small sample sizes. When the sample sizes increase, the copulas’ and the bivariate models’ performance cannot be distinguished.
After replicating the process 10,000 times, the DIC mean was computed for each bivariate and the proportion of selected model too. The same was carried out for the models that were generated from the copula functions. The best distribution fitted to the datasets generated from the bivariate Weibull dataset will be that one with higher proportion and/or lower DIC mean. The results of the simulations are reported in
Table 9.
It is important to note that the bivariate models performed better for small samples, especially the BVGE model. This superiority of the bivariate models in relation to the copula models decreases when the sample sizes increase, independently of the correlation level. It is important to note that the Clayton copula presented the worst performance in relation to the other.
7. Application to Real-Life Data Set
In this real-life data example, we consider a survival time dataset in electrical engineering (phenomenon known as electrical treeing), introduced by [
33]. The data originate from an experiment investigating the failure of epoxy electrical cable insulation specimens under high-voltage conditions. In this experiment, there is an inception that a defect appears in the material and then after some time, the defect causes failure of the insulation. This study investigates a two-stage failure process:
Inception: A defect (like a crack or void) develops within the epoxy material.
Time to Failure: The time it takes for the developed defect to cause the insulation to fail completely under the applied high voltage.
The data consist of the time
to inception of the defect and the time
of failure.
Table 10 gives the results from this experiment, where 17 items were observed (times are in minutes).
We first calculate the three sample dependence measures between the variables
and
, Pearson’s correlation coefficient, Kendall’s Tau, and Spearman’s Rho.
Table 11 contains these measures and the
Figure 3 presentation the dispersion of the data.
The estimation of the unknown parameters is carried out with the maximum likelihood and Bayesian approaches. We have used the MCMC algorithm to compute the Bayes estimates and also to construct the credible intervals. In
Table 12, we have the posterior mean and 95% credible interval.
Analysis of the posterior estimates, credible intervals, DIC, and deviance metrics reveals significant performance differences across the evaluated models.
The comparative analysis yields three principal findings with both methodological and practical implications. First, the Frank copula emerged as the optimal modeling approach, demonstrating superior performance across all evaluation metrics. With the lowest DIC (409.9) and deviance (405.5) values in the electrical treeing application, it outperformed not only alternative copula models (DIC ranging from +3.3 to +51.8) but also all bivariate generalized exponential distributions. This robust performance suggests that its symmetric dependence structure and absence of tail dependence provide the most appropriate framework for modeling the studied failure processes, particularly given the dataset’s limited size.
Second, the results challenge conventional assumptions about bivariate models’ inherent advantages. While the BGE model showed competitive performance (second-best DIC at 413.2), other bivariate formulations (BVGE, BBBGE) underperformed significantly (DIC > 17 versus Frank), as shown in
Table 13. This pattern indicates that comprehensive dependence modeling through copulas generally provides better fit than rigid parametric bivariate structures, except in specific cases where the BGE’s singular component aligns with the underlying failure mechanism. The Clayton copula’s poor performance (DIC = 461.7) further emphasizes how inappropriate tail dependence assumptions can substantially degrade model quality.
Finally, this study highlights critical sample size considerations. The wide credible intervals observed across all models (average width = 1.8 for dependence parameters) reflect the inherent limitations of observations. While the Frank copula demonstrated relative stability under these conditions, the small magnitude of DIC differences (<5) between top-performing models suggests cautious interpretation.
8. Conclusions
This paper introduced a flexible framework for modeling bivariate lifetime data by developing and evaluating four novel bivariate generalized exponential (BVGE) distributions. These models were constructed using the Farlie–Gumbel–Morgenstern, Gumbel–Barnett, Clayton, and Frank copulas, allowing for the representation of diverse and complex dependence structures that are often encountered in real-world applications but are not adequately captured by existing models. The MCMC implementation presented in OpenBUGS allowed us to compare model fit using DIC and quantify uncertainty through 95% credible intervals.
The simulation study confirmed that tail-dependent copulas (Clayton and Gumbel–Barnett) consistently yield lower DIC values and narrower posterior intervals for the dependence parameter when extreme co-movements occur. In contrast, the Frank copula provided a robust middle-ground fit under moderate association, and the FGM baseline served to demonstrate the consequences of assuming weak dependence.
The primary finding, based on both simulation studies and an application to a real-world dataset of electrical treeing failures, is that the choice of copula is critical for achieving a good model fit. The Frank copula and BGE model demonstrated a significantly superior performance, as evidenced by its substantially lower deviance information criterion (DIC). This result underscores the importance of accounting for asymmetric lower-tail dependence when modeling this type of failure data.
The main contribution of this work is the provision of a robust and well-documented set of tools for practitioners and researchers analyzing bivariate lifetime data. By demonstrating how to construct, estimate (via Bayesian MCMC methods), and compare these models, we offer practical guidance on selecting appropriate copula families based on the nature and strength of joint-failure dependence observed in empirical applications, thereby supporting informed model choice in reliability and survival analysis.
While this study provides valuable insights, it is subject to certain limitations. The current analysis was confined to four specific copulas; other families, such as vine copulas, might offer even greater flexibility. Furthermore, the findings are based on a single real-world dataset, and the performance of these models should be validated on other types of data with different underlying characteristics
Future research could explore several promising directions. An immediate next step would be to explore a wider range of copula families to capture more complex and varied dependence structures. Additionally, extending this framework to accommodate higher-dimensional generalized exponential distributions would represent a significant theoretical and practical contribution. Another important extension involves adapting the methodology to censored data scenarios, which are commonly encountered in reliability studies. Moreover, the development of formal statistical tests for copula selection, beyond reliance on the DIC, would enhance model discrimination and robustness. Finally, applying these models to diverse fields, such as hydrology, finance, or medical survival analysis, would further demonstrate their broad applicability and practical relevance.


 ,
, 



{kind=link}
{kind=link}
{kind=link}