1. Introduction
Competing risk models are valuable tools in survival analysis that address scenarios where individuals or systems face multiple mutually exclusive failure events. In such models, the event of interest is influenced by competing events that can prevent or modify the occurrence of the primary event. Competing risk models enable a more comprehensive understanding of the probabilities and cumulative incidences associated with different failure types. They provide insights into the relative risks and dynamics of competing events over time. These models have diverse applications across various fields, including healthcare, epidemiology, actuarial science, and engineering. By accounting for competing risks, researchers and practitioners can make informed decisions, develop appropriate risk management strategies, and gain a deeper understanding of complex systems’ failure patterns.
For example, in healthcare, competing risk models can be applied to study patient outcomes where different causes (e.g., death from different diseases) might prevent the observation of the event of primary interest, such as disease recurrence (see, e.g., [
1]). In epidemiology, these models allow for the analysis of disease outcomes where various risks, like co-occurring conditions, compete (see, e.g., [
2]). Actuarial science uses them to predict life insurance risks and policy lapses (see, e.g., [
3]), while engineering applies them to assess system reliability where different failure modes compete for priority (see, e.g., [
4]).
Censoring is a widely recognized and effective approach for cost reduction in experimental settings. In the field of reliability and survival analysis, numerous censoring strategies have been developed and employed by researchers. The two primary censoring plans, namely Type-I and Type-II, allow for the control of the overall duration of the experiment and the number of observed failures, respectively.
Progressive Type-II censoring is a censoring scheme that has gained considerable attention in the field of life testing and reliability analysis that was first introduced by [
5,
6]. It is designed to enhance the efficiency of experiments where the objective is to study the lifetimes or failure times of a set of items. In this censoring plan, a predetermined number of failures, denoted as
m, is specified before the experiment begins. The censoring scheme, represented by
, is carefully devised such that the sum of the individual censoring values,
, equals the difference between the total number of items,
n, and the specified number of failures,
m, i.e.,
. Throughout the course of the experiment, items are progressively removed in stages, starting with the elimination of
items after the first failure occurs. This sequential removal process continues until the
mth failure, where the remaining
items are also removed from the experiment. The progressive Type-II censoring scheme holds promise for optimizing the efficiency of experimental designs and has been extensively explored by researchers aiming to extract meaningful insights from reliability and survival analysis. For an excellent overview and in-depth discussions on progressive censoring, interested readers are encouraged to refer to the monograph authored by [
7] (see also [
8,
9]).
Several authors have studied the competing risk models for common lifetime distributions based on progressive Type-II censored data. Ref. [
10] studied the exponential model. Refs. [
11,
12] considered the Weibull model. Refs. [
13,
14,
15,
16] focused on the competing risk data for the Lomax, Kumaraswamy, Burr Type-XII and generalized Rayleigh distributions.
Ref. [
17] analyzed the two-parameter Log-Normal model for hybrid Type-II progressive censored data. Ref. [
18] introduced a competing risk exponential model utilizing a generalized Type I hybrid censoring method. The generalized exponential and the Weibull competing risk models under adaptive Type-II progressive censored data were studied, respectively, by [
16,
19]. Ref. [
20] studied the statistical inference for a class of exponential distributions with Type-I progressively interval-censored competing risk data. Ref. [
21] considered generalized progressive hybrid censoring for Burr XII competing distributions.
Bayesian inference for competing risk models has been explored by [
12,
22] for the Weibull model, and by [
23] for the Gompertz model (see also [
24,
25,
26,
27], among others).
The case of dependent competing risks was studied by [
28] for Marshall–Olkin bivariate Kumaraswamy distribution, and [
29] for the Burr-XII model (see also [
30] among others).
The Dagum distribution, alternatively referred to as Burr Type-III, was initially introduced by [
31] as the third solution to the Burr differential equation, which characterizes the various types of Burr distributions. The Dagum distribution, introduced by [
32], is widely applied in diverse fields such as finance, economics, and hydrology. It is characterized by its flexibility in modeling a wide range of data, particularly those with heavy tails and skewness. The Dagum distribution offers a flexible framework for analyzing data with varying shapes and tail behaviors, making it a valuable tool for researchers and practitioners seeking to understand and model complex phenomena.
The probability density function (pdf) of the two-parameter Dagum distribution, denoted as
, is given by the following expression:
where
and
are both shape parameters. The cumulative distribution function can be expressed in a simple form as follows:
The Dagum distribution is commonly referred to as the inverse Burr distribution. This connection arises from the fact that if a random variable
X follows the Dagum distribution, its reciprocal
follows the Burr Type-XII distribution, or simply the Burr distribution. For a comprehensive examination of the Dagum distribution, interested readers are encouraged to refer to the extensive study conducted by [
33].
Despite the extensive literature on competing risk models under common lifetime distributions, such as exponential and Weibull, there is limited research on the application of the Dagum distribution with progressively Type-II censored data. This work addresses this gap by developing an inferential framework for the Dagum distribution under competing risks and various censoring schemes. Additionally, distributions with finite support such as Kies-style models (see [
34]) could be explored as alternatives to the Dagum model for bounded failure times (see also [
35]).
Moreover, while several heavy-tailed distributions (e.g. Pareto, Weibull, log-normal) have been employed in reliability analysis, the Dagum distribution offers unique advantages that make it especially attractive for modeling component lifetimes under complex censoring schemes. First, unlike the one-parameter Pareto model, whose mean is infinite when the shape parameter does not exceed unity, the Dagum distribution admits finite moments even in pronounced heavy-tail regimes, ensuring well-defined reliability measures [
36]. Second, whereas the Weibull distribution enforces a monotonic hazard and the log-normal produces a strictly increasing-then-decreasing failure rate, the Dagum’s hazard function can assume bathtub, unimodal, or monotonic shapes, thereby capturing a wider range of empirical failure-mechanism behaviors observed in engineering applications [
37]. Third, all key functions of the Dagum model (PDF, CDF, and hazard) have closed-form expressions, which greatly facilitates both classical and Bayesian inference under various types of censoring schemes. These combined features, flexible tail behavior, versatile hazard shapes, and analytic tractability underscore the Dagum distribution’s suitability for competing risks systems, as explored in the present work.
This paper is structured as follows.
Section 2 introduces the competing risk models and their structure for the Dagum distribution.
Section 3 discusses the maximum likelihood estimation of the unknown Dagum parameters, considering both the general case of arbitrary distribution parameters and the special case of a common shape parameter,
. Additionally, a likelihood ratio test procedure for testing the validity of the common shape parameter
is presented.
Section 4 is devoted to the asymptotic confidence intervals based on the Fisher information matrix, along with bootstrap confidence intervals. In
Section 5, we evaluate the performance of our inference procedure through extensive Monte Carlo simulations. Finally, we illustrate the proposed methods with a real data example in
Section 6.
2. Competing Risk Model Description
Suppose there are n units involved in an experiment, and there are K known causes of failure. To implement progressive Type-II censoring, the experiment is conducted until a certain number of failures occur. Let m be the predetermined number of failures.
When the first failure is observed, units under each cause of failure are randomly chosen and progressively removed from the experiment. This process continues until m failures are observed, at which point the remaining units are also removed.
The lifetimes of these units can be represented by independent and identically distributed (i.i.d.) random variables , where indicates the failure cause for each observation, for .
Furthermore, we introduce the indicator variable
as
for
. Then,
, represents the count of units that failed due to cause
k.
For ease of notation, we will show the progressively Type-II censored sample , by .
Let represent the latent failure time of the jth unit under the kth failure mode. In this case, we can determine the actual failure time as the minimum value among , , …, , where j ranges from 1 to m, i.e., , , …, .
Additionally, to avoid identifiability issues in the underlying model, it is often assumed that the failure modes are independent. This means that ’s, representing the latent failure time of the jth unit under the kth failure mode, are also independent and identically distributed for . Furthermore, we assume each follows a Dagum distribution with parameters and .
In this paper, we specifically focus on the case where
, meaning there are two failure modes considered. Hence, for each observation
j,
, where
and
represent the latent failure times under the first and second failure modes, respectively. Moreover, we study the special case of
in more detail. This will enable us to derive a simple formula for the relative risk
through the following remark, which was also derived by [
38,
39].
Remark 1. Let for and , follow , and and let be the number of failures due to failure causes 1 and 2, respectively. Then, and , whereis the relative risk due to failure cause 1. Proof. The result follows by noting that
is the sum of independent Bernoulli random variables
with parameter
p given by the following:
The last integral is equal to one, as the integrand is the pdf of
. □
Figure 1 shows the plot of the pdfs of the Dagum distribution for
,
and
under different causes of failure.
3. Maximum Likelihood Estimation
In this section, we address the construction of the maximum likelihood estimators (MLEs) and the confidence intervals for the unknown parameters of the Dagum distribution using the progressively Type-II competing risks censored data.
We consider two cases, the general case of arbitrary parameters , , and and the special case of . The latter case enables us to present the relative failure risk due to cause 1 in a closed form of Theorem 1. We also discuss the likelihood ratio test for testing the validity of the special case of .
3.1. Estimation of Parameters Under General Case
For a given competing risk sample
, from
distribution, where
,
and
, the likelihood function of
,
,
and
can be expressed as follows (see, e.g., Kundu et al., 2003 [
10]):
where
and
denotes the number of units removed at the
ith failure time.
The log-likelihood function ignoring the additive constant term is given by the following:
Upon differentiating Equation (
2) with respect to
and
, for
we get
and
where
.
The maximum likelihood estimators of the parameters
and
can be found by the simultaneous solution of the system of nonlinear equations
and
for
. However, since there is no closed-form solution for these equations, a numerical method is needed to find the MLEs. In our simulation study and data analysis, in
Section 5 and
Section 6, respectively, we used the Barzilai-Borwein (BB) method for this purpose (see [
40]).
3.2. Estimation of Parameters Under Special Case
If the assumption of a common shape parameter
is valid, then the joint likelihood function can be expressed as follows (see [
9]):
where
.
We define the log-likelihood function as follows:
Hence, we derive the log-likelihood derivatives with respect to
,
and
as follows:
and
for
and
.
Note that under standard regularity conditions, the MLEs are consistent and asymptotically normal. To assess finite-sample properties such as bias and mean squared error, we performed extensive Monte Carlo simulations, as presented in
Section 5.
3.3. Likelihood Ratio Test
To validate the assumption of a common shape parameter
, we need to perform the following hypothesis test using the likelihood ratio test procedure:
The likelihood ratio statistic can be written as
where,
,
and
are the maximum likelihood estimators under the special case and
,
,
and
are the maximum likelihood estimators under the general case. We note that for large sample sizes,
follows the chi square distribution with one degree of freedom. Therefore, the null hypothesis (
4) of common
will be rejected at significance level
if
In
Section 6, we will apply the aforementioned testing procedure to verify the validity of the assumption of a common
in the special case.
4. Asymptotic Confidence Intervals
In this section, we will study the asymptotic confidence intervals of the unknown parameters by inverting the Fisher information matrix which is given by the following:
for the general case and by the following:
for the special case.
The
confidence interval for
is given by
where
is the critical value from the standard normal distribution and
is the first diagonal element of the inverted Fisher information matrix. The asymptotic confidence intervals for the other parameters are given in a similar manner.
In the next two subsections, we will present the second derivative of the log-likelihood function with respect to the parameters for the general and special cases, respectively.
4.1. General Case
The second derivatives of the log-likelihood function in the general case are given by the following:
and
for
and
.
Note that .
4.2. Special Case
The second derivatives of the log-likelihood function in the special case are given by the following:
for
.
and
Note that .
In the next two sections, we will compare the asymptotic confidence intervals with the corresponding bootstrap confidence intervals in terms of the lengths and coverage probabilities. We will see that, generally, asymptotic confidence intervals perform better, particularly for larger sample sizes.
5. Simulation Study
In this section, we evaluated the performance of our proposed method using extensive Monte Carlo simulations. We used the R pseudo-random generator with 10,000 iterations. We set the number of bootstrap iterations to 1000.
We studied both the general case of arbitrary parameter values and the special case of common . Without loss of generality, we considered , , and for the general case and , and for the special case.
We considered different combinations of sample size
, number of failures,
and censoring schemes
R.
Table 1 shows the nine censoring schemes considered in this simulation study. For example,
means
. Note that schemes 1, 4, and 7 are early censoring, whilst schemes 2, 5 and 8 are the conventional Type-II censoring.
For each censoring scheme, we generated a progressively Type-II competing risk censored sample from a Dagum distribution with assumed parameter values using the algorithm of [
41]. We then found the maximum likelihood estimates of the parameters using the method proposed in
Section 3. We employ the Barzilai-Borwein spectral method using the ‘BB’ R package to solve nonlinear equations and determine the maximum likelihood estimates of the parameters. This method offered enhanced performance and consistent convergence in our case, which ultimately provided more accurate and reliable maximum likelihood estimates. The BB algorithm uses an adaptive, derivative-free step size that implicitly captures curvature information, yielding super-linear convergence for a wide class of smooth functions without requiring explicit Hessian evaluations. In our pilot Monte Carlo experiments, the BB method reduced total CPU time compared to Newton–Raphson, while maintaining comparable accuracy.
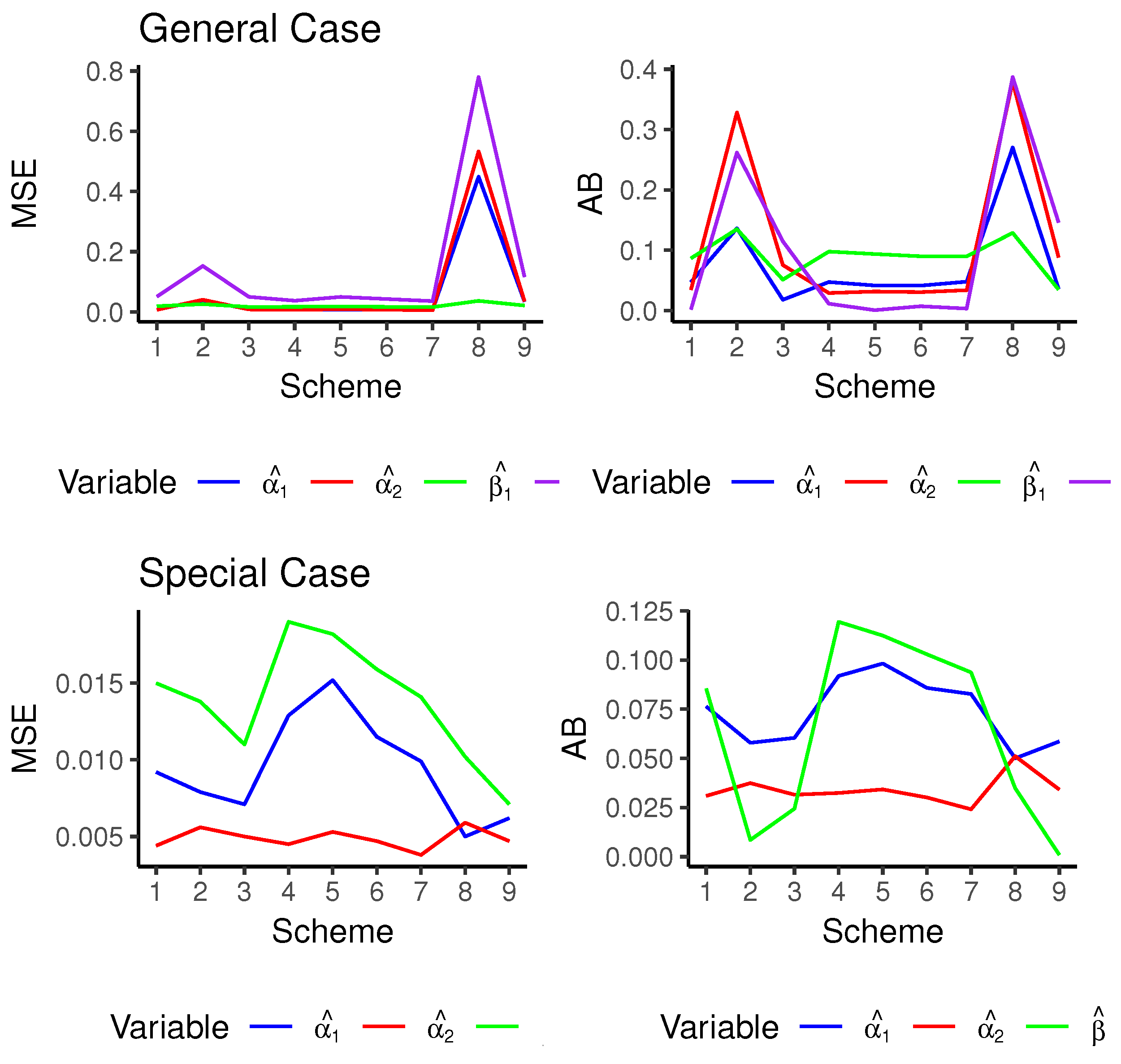
We assess the accuracy of the maximum likelihood estimates (MLEs) by comparing their absolute bias (AB) and mean squared error (MSE). The estimator with the lowest mean squared error is deemed the best. When evaluating different interval estimations, we consider the average interval coverage percentages (CPs).
Table 2 and
Table 3 show the maximum likelihood estimates, the mean squared errors, the absolute biases and the empirical coverage probabilities (approximate and bootstrap) for the estimate of parameters for the general and special cases, respectively. For ease of comparison, the corresponding graphs are depicted in
Figure 2. We observe that the estimation results are generally satisfactory in terms of MSEs and ABs for all censoring schemes. However, censoring schemes 3 and 9, which feature a uniform and smooth censoring of items, relatively outperformed other schemes in terms of both MSE and AB. Moreover, early censoring schemes (1, 4 and 7) performed better than other schemes with respect to the MSE with the same number of
n and
m. Also, note that relative risk due to cause 1 is given by
, meaning that, relatively, more data will be due to cause 2 rather than cause 1, resulting in a better estimate of the parameter
, which is very clear in
Figure 2.
Moreover, both confidence interval methods produce coverage probabilities of more than the nominated levels; however, the approximate confidence intervals performed better than the bootstrap ones.
Though this study focuses on the MLE approach, future work may compare its performance against Bayesian estimators or EM-type algorithms, particularly in the presence of model misspecification or small sample sizes.
6. Numerical Example
In this section, we study two numerical examples to illustrate our proposed inferential procedure for the Dagum Distribution.
Example 1 (Pneumonia data)
The data concerning investigating the impact of hospital-acquired infections in intensive care include a random subsample of 747 patients from the SIR 3 (Spread of Nosocomial Infections and Resistant Pathogens) cohort study conducted at Charité University Hospital in Berlin, Germany (see [
42]). The data are also available in “mvna” R package.
The dataset includes details on pneumonia status at admission, duration of stay in the intensive care unit, and the ICU outcome, which is either hospital death or discharge alive. The competing endpoints are discharge from the unit and death within the unit.
The objective of the study is to examine the impact of pneumonia present at admission on mortality in the unit. Given that pneumonia is a severe illness, it is anticipated that more patients with pneumonia will die compared to those without. Thus, death is the primary event of interest, with discharge serving as the competing event.
Among the 97 patients admitted with pneumonia, 8 were censored before the end of their ICU stay. Therefore, we considered patients with pneumonia present on admission, of which 68 were discharged from hospital (failure cause 1) and 21 were dead (failure cause 2).
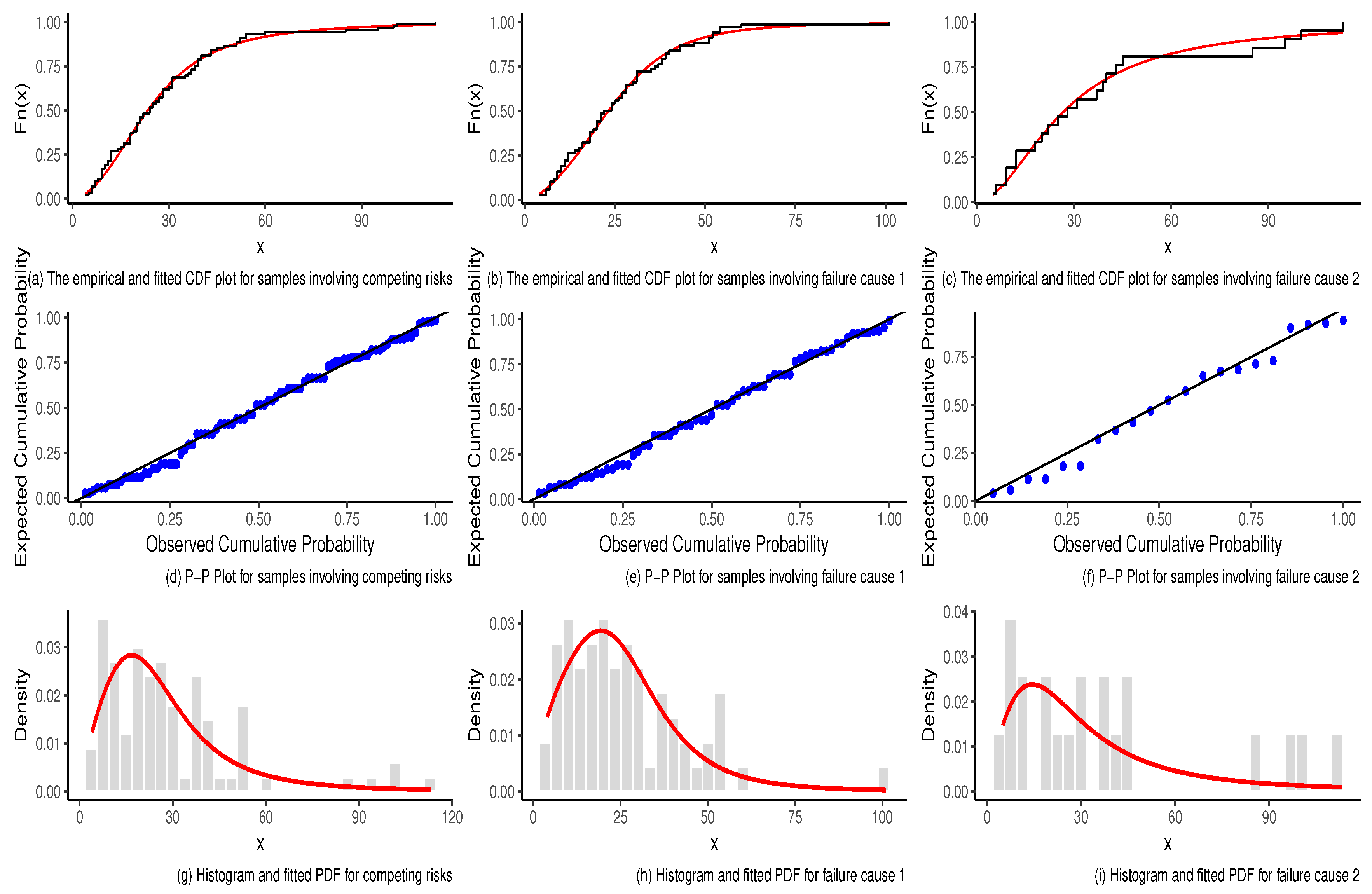
We checked the suitability of fitting the Dagum distribution to the competing risks, failure cause 1 and failure cause 2 data by performing well-known goodness-of-fit tests.
Table 4 provides the estimation of the parameters as well as the values of the Cramér–von Mises goodness-of-fit test statistic (
) and the Kolmogorov–Smirnov statistic (
D) with their corresponding
p-values (in bracket) for the competing risk, failure cause 1 and failure cause 2. Note that
denoted the scale parameter of the general Dagum distribution. All the
p-values are sufficiently large to conclude the suitability of the Dagum distribution to model the failure time data.
Figure 3 depicts the plots of the empirical and fitted Dagum CDF for competing risks, cause 1 and cause 2 for pneumonia data. Additionally, it includes the P-P plot comparing observed cumulative probabilities with expected cumulative probabilities.
We then generated the progressive Type-II censoring data with effective sample size and the late censoring scheme to complete the data. There were data due to failure cause 1 (discharge) and data due to failure cause 2 (death).
The test statistic for testing the null hypothesis
is equal to
with a corresponding
p-value
, which is highly significant. Hence, we used the general model to estimate the unknown parameters.
Table 5 shows the maximum likelihood estimates, the asymptotic confidence intervals and the bootstrap confidence intervals of the unknown parameters
and
under different censoring schemes for the failure causes 1 and 2, respectively. It can be seen that, in most cases, the asymptotic confidence intervals are shorter than the bootstrap confidence intervals, indicating superior performance in terms of length.
Example 2 (Leukemia data)
The dataset pertains to 177 acute leukemia patients who underwent stem cell transplantation. The competing risks are the incidence of relapse and death due to transplant-related complications. After excluding 46 censored cases, the dataset includes 131 patients, with 56 cases of relapse and 75 cases of competing events.
This dataset was analyzed by [
43] to fit a competing risk regression model incorporating covariates such as age, gender, disease phase, and type of transplant. The data are available in “casebase” R package.
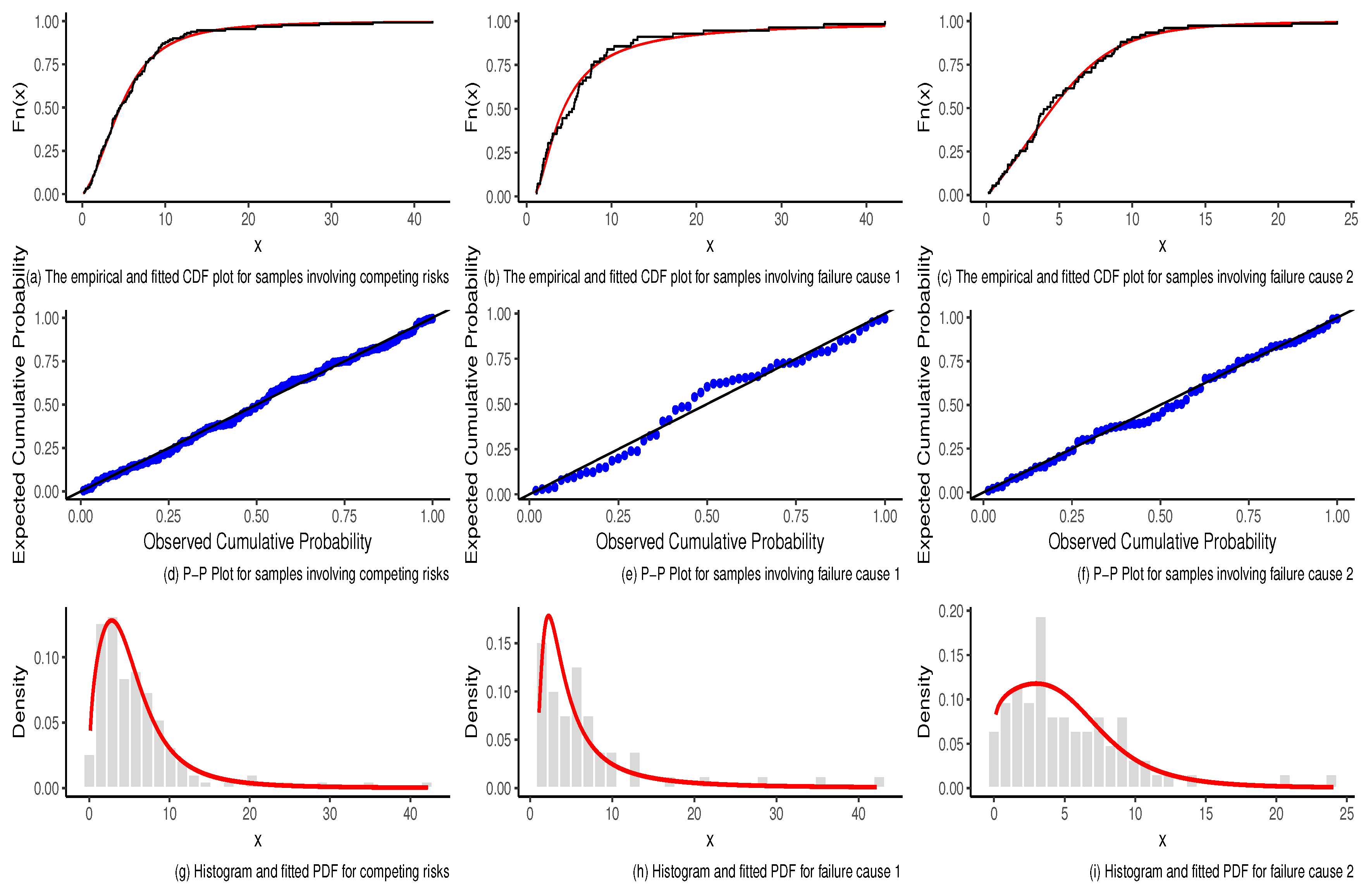
The results of the estimation of the parameters and the goodness-of-fit tests are shown in
Table 6. As observed, the null hypothesis that the data for the failure cause 1, failure cause 2 and competing risk follow a Dagum distribution is not rejected for any of the three test statistics.
Figure 4 depicts the plots of the empirical CDF, fitted Dagum CDF and P-P plot for competing risks, cause 1 and cause 2 for the leukemia data.
Progressive Type-II censoring data were generated with an effective sample size of using the early censoring scheme applied to a complete dataset of size . The resulting data included observations attributed to failure cause 1 (relapse) and observations due to competing events. Note that the sample size is below the conventional threshold for large-sample inference. Therefore, we recommend relying on bootstrap-based intervals to ensure accurate uncertainty quantification.
We test for for the null hypothesis of the equality of shape 2 parameters
and
. The test statistic was found to be
with a
p-value equal to 0.003, indicating a high level of significance. Hence, we considered the general case for estimating the parameters.
Table 7 presents the maximum likelihood estimates and the asymptotic and bootstrap confidence intervals of the unknown parameters when considering various censoring schemes.
It can be seen that, in most cases, the asymptotic confidence intervals are shorter than the bootstrap confidence intervals when estimating and . However, for estimating and , the bootstrap confidence intervals are shorter and thus perform better in terms of length.
As shown in
Table 7, the asymptotic confidence intervals are generally shorter than the bootstrap confidence intervals for estimating
and
, except under the conventional Type-II censoring scheme, where the bootstrap confidence intervals are shorter. For
, the bootstrap confidence intervals consistently outperform the asymptotic confidence intervals across all schemes in terms of length. In contrast, for
, the asymptotic confidence intervals are shorter than the bootstrap confidence intervals under the conventional Type-II censoring scheme and the third smoothing censoring scheme.
7. Concluding Remarks
This paper proposes statistical inference methods to estimate the parameters of the Dagum distribution under progressively Type-II censored data with independent competing risks, including both point and interval estimation. Monte Carlo simulations demonstrate that the proposed methods perform relatively well. The interval estimation obtained from the asymptotic model generally outperforms the bootstrap method. Different censoring schemes affect both point and interval estimation, with early censoring schemes yielding the best results. Moreover, the conventional Type-II censoring scheme performs relatively well. The special case of common shape parameter
yields to a closed form for the reliability parameter
in Remark 1. For a general setting of different values of
and
, the reliability parameter
R is given by the following:
It is evident that a numerical method is required to evaluate this integral. While this paper focuses on the case , extending our methods to systems with more than two failure modes substantially increases the dimensionality of the likelihood functions and, therefore, finding the maximum likelihood estimators becomes more challenging.
For future work, one could consider dependent failure models by fitting a bivariate distribution, such as the bivariate exponential model or bivariate Dagum distribution (see [
44]). Additionally, other censoring schemes, such as hybrid censoring, can be explored.
Moreover, future studies could include the incorporation of covariates using regression models, the development of Bayesian estimation procedures, or the modeling of dependent competing risks via bivariate Dagum or copula-based methods. To enhance reproducibility, the R code used for simulations and data analysis is available upon request.





{kind=link}
{kind=link}
{kind=link}
{kind=link}