1. Introduction
Efficiency analysis is one of the main methods of studying economic growth rate and determining the causes of economic growth. Stochastic frontier analysis is a common method of efficiency analysis, which is widely used in economics, management, and other fields. Aigner et al. [
1], Meeusen and Broeck [
2] and Battese and Corra [
3] have proposed the stochastic frontier analysis (SFA), which is based on the deterministic production frontier model proposed by Aigner and Chu [
4], and adds a random error term (denoted as
v) so that the frontier production function also has randomness. It is usually assumed that this error term is an ordinary white noise error term and obeys a normal distribution. Generally,
u is used to represent the technical inefficiency term, assuming that it is non-negative and independent of
v. The stochastic frontier function can be expressed as
, where
denotes the functional form of the production function, typically specified as a Cobb–Douglas function.
The most obvious difference between the stochastic frontier model and the general econometric model is that there is a composite error term
. In order to estimate the parameters contained in the error term and calculate the technical efficiency, it is necessary to make more detailed assumptions on the distribution of the error term. Battese and Corra [
3] assume that
u obeys a half normal distribution, which is the most commonly adopted assumption in stochastic frontier models. Meeusen and Broeck [
2] assume that
u obeys exponential distribution, which has good properties and is often used. Greene [
5,
6] proposes the Gamma distribution hypothesis of the inefficiency term
u, but it has been questioned. Stevenson [
7] proposes the truncated normal distribution assumption of
u. In our paper, the most commonly used half normal distribution hypothesis is used for model estimation. Stochastic frontier analysis is a common method for efficiency measurement. After a long period of development, a series of theoretical innovations on stochastic frontier model setting and estimation and technical efficiency estimation and inference have emerged.
In the era of big data, data sets are often massive and diverse. However, in practical applications, the amount of data collected or generated by people is often not enough to provide accurate models for estimation and prediction. For example, when using stochastic frontier analysis to analyze the production efficiency of production units, the analysis performance depends on a large amount of labeled data, but obtaining sufficient labeled data to train the model is usually expensive and time-consuming. Moreover, the data collected or generated by people generally exist in high-dimensional form, so using stochastic frontier analysis requires us to consider the problem that the amount of data is too small and the data is high-dimensional.
In order to solve the problem that the amount of data is too small, researchers have begun to consider integrating different but related data sets to improve the accuracy of parameter estimation and prediction. The idea of transfer learning is to find relevant data sets from existing domains and reduce data set bias by learning in new target domains. So far, transfer learning has been widely used in various fields such as computer science [
8], health care [
9] and power security [
10], which fully proves the effectiveness of transfer learning.
High-dimensional data analysis has attracted people’s attention for a long time in the past, and many effective methods have been proposed. The Elastic Net developed by Zou and Hastie [
11] is a very efficient and practical method. Elastic Net is a hybrid regularization technique that has gained significant attention due to its remarkable ability to handle high-dimensional data, address collinearity, and select relevant features. In addition, Jia and Yu [
12] and Yuan and Lin [
13] establish the theoretical properties of the Elastic Net, such as statistical consistency and convergence rate, which provided a solid foundation for its practical application. Similar to transfer learning, high-dimensional data analysis often encounters the challenge of limited sample size, where the number of samples is significantly smaller than the data dimension. Therefore, people began to apply transfer learning to high-dimensional problems.
In order to achieve this goal, Bastani [
14] adopts transfer learning in the context of high-dimensional problems, mainly focusing on estimation and prediction in high-dimensional linear models. Following the traditional framework of transfer learning, Bastani [
14] operates under the assumption that there is a certain degree of similarity between the target model and the source model. If the similarity condition is violated, negative transfer may occur, which means that the increase in sample size will actually lead to worse training and prediction results of the model. Notably, Bastani [
14] assumes that the objective model is high-dimensional, while ensuring that the size of the source data is much larger than the dimension. In addition, the study only considers a single source model and does not explore scenarios involving multiple sources. As a way of further improvement, Li et al. [
15] consider multiple sources, with both the source and target models situated in high-dimensional settings. Based on the work of Li et al. [
15,
16], the concept of transfer learning is extended to high-dimensional generalized linear models. They introduce an algorithm-free method to identify transferable sources in the source detection context, and always select transferable sources to prevent negative transfer.
Building on the research of Bastani [
14] and Li et al. [
15], Meng et al. [
17] introduce a novel two-step transfer learning algorithm for cases where the transferable domain is known. This algorithm employs the Elastic Net penalty in both the transfer and debiasing steps. In addition, when the transferable source is unknown, a new algorithm for detecting the transferable source through the Elastic Net is also proposed. Furthermore, based on the high-dimensional model, Chen et al. [
18] add the constraints of prior knowledge and study robust transfer learning. Finally, through experiments, it is proved that it is feasible to use transfer learning for high-dimensional models with linear constraints, and the performance of the model is greatly improved. When the transferable source is unknown, a constrained transferable source detection algorithm is proposed. The above high-dimensional problems are mostly based on linear regression models. For high-dimensional stochastic frontier models, Qingchuan and Shichuan [
19] pioneered the use of the Alasso penalty method to select variables in stochastic frontier models, and achieved good results.
As far as we know, no one has applied the Elastic Net to the stochastic frontier model. Inspired by the work of Meng et al. [
17] and Qingchuan and Shichuan [
19], we explore the use of the Elastic Net in high-dimensional stochastic frontier models to perform variable selection and address multicollinearity issues, and further apply this approach in a transfer learning framework. To enhance the accuracy of coefficient estimation and improve overall model performance, we are additionally inspired by Chen et al. [
18]. According to the prior knowledge, we add equality and inequality constraints to limit the coefficient estimation to a certain range.
This paper proposes transfer learning of high-dimensional stochastic frontier model via Elastic Net. To improve the accuracy of coefficient estimation and enhance model performance, inspired by Chen et al. [
18], we incorporate equality and inequality constraints based on prior knowledge to restrict the coefficient estimates within a certain range. The following are the innovations of this paper:
- (1)
When the transferable source domain is known, we propose a high-dimensional stochastic frontier transfer learning algorithm via Elastic Net.
- (2)
When the transferable source domain is unknown, we design a transferable source detection algorithm.
- (3)
When some prior knowledge is known, we add linear constraints to the model so that the coefficient estimation is reduced to a certain range and the coefficient estimation is improved.
The rest of this paper is organized as follows. In
Section 1, we first briefly review the stochastic frontier model and transfer learning. Then we introduce the Elastic Net stochastic frontier model with transfer learning based on known transferable sources and unknown transferable sources in
Section 2. Next, we perform extensive simulations in
Section 3 and one real data experiment in
Section 4. Finally, we summarize our paper in
Section 5.
2. Methodology
2.1. High-Dimensional Stochastic Frontier Model via Elastic Net
This paper studies the following stochastic frontier models
where
represents the frontier production function,
v is the bilateral random error term, and
u represents the technical inefficiency term. Formula (
1) uses the Cobb–Douglas production function. The stochastic frontier model based on Cobb–Douglas production function and logarithm is
For the sake of convenience, let
and
, then the Formula (
2) can be expressed as
where
and
.
Although Formula (
3) is similar to the ordinary linear model, the perturbation term
is asymmetric due to the introduction of the non-negative term
u. This asymmetry allows for the identification of the existence and distribution of
u. We assume that
,
, and that
v and
u are mutually independent and also independent of the explanatory variables. Based on these assumptions, the log-likelihood function can be derived as follows [
20]:
where
,
, and
. The function
denotes the cumulative distribution function of the standard normal distribution.
Compared with the ordinary linear model, the log-likelihood function in Formula (
4) introduces a nonlinear term to reflect the presence of inefficiency. Ordinary linear models typically assume that the error term follows a symmetric normal distribution, and their likelihood functions involve only the exponential of the squared residuals. In stochastic frontier models, however, the residual is decomposed into white noise and an inefficiency term, which is assumed to follow a half-normal distribution. Consequently, Formula (
4) includes the nonlinear term
, which characterizes the asymmetry in the residual distribution.
This difference has an important influence on the optimization process. First, the likelihood function no longer has a closed-form solution, requiring numerical methods for parameter estimation. Second, the nonlinear term may lead to numerical instability—especially when approaches 1, causing to become nearly zero, which results in a loss of precision in the logarithmic term. Therefore, stabilization techniques are necessary in practical optimization. Finally, the inclusion of the additional parameters and increases the dimensionality of the optimization problem, making the estimation process more complex.
In general, we use maximum likelihood estimation for parameter estimation but typically do not account for cases where the number of features exceeds the number of samples. To this end, we add regularization terms to achieve feature selection and address the collinearity problem. For convenience, we define
as the negative log-likelihood function for the
i-th observation. The resulting optimization problem can be expressed as
If we have some prior knowledge of the parameters before the estimation, we can incorporate linear equality and inequality constraints. This transforms Formula (
5) into the following constrained optimization problem:
Among them,
and
are the penalty parameters, and
are vectors that are set according to the actual situation. The Formula (
5) can be used to select parameters by
, and the collinearity problem can be solved by
.
We now provide a more detailed introduction to the linear constraints to enhance readability. If we know some prior knowledge of the parameters before the estimation, such as
,
and
, where
is a real number, then we can use this knowledge to construct a linear constraint. Specifically, the following matrix is constructed:
The inequality constraint is , and the equality constraint is .
Here, we discuss the linear constraints derived from prior knowledge and the regularization terms and . The regularization terms are considered soft constraints, which influence the objective function through penalty terms, thereby contributing to structural selection and preventing overfitting during model training. In contrast, linear constraints are hard constraints that typically originate from domain-specific prior knowledge. While regularization helps control model complexity and enhance interpretability, linear constraints enforce parameter feasibility based on the actual problem setting. The two types of constraints are complementary in nature.
In addition, to solve the optimization problem in Formula (
6), we refer to the framework proposed by Zou et al. [
11] and introduce several modifications. First, the Elastic Net penalty term in the original problem is equivalently reformulated as a standard Lasso problem. Following Lemma 1 in Zou et al. [
11], an extended data set is constructed to achieve this transformation. As a result, the original problem is converted into a minimization problem with an
penalty. The Lasso solution path is then computed on the extended data set using a standard Lasso algorithm, and the final solution to the original problem is recovered through variable transformation.
The choice of penalty parameters has a significant impact on the estimation. Here, we take the Formula (
5) as an example to briefly illustrate the selection of the penalty parameters
and
. The same strategy can be applied to determine the penalty parameters in other parts of the model.
By introducing the mixing parameter
, the optimization problem becomes
where
and
. Given a fixed
and a sequence candidate values
, we use five-fold cross validation to find the optimal
. The process involves randomly dividing the sample data into five subsets, using one subset as the validation set and the remaining subsets as the training set for each iteration. For each candidate value
(
), the model is trained on the training set and evaluated on the validation set. The value of
that minimizes the mean absolute error (
) across all validation sets is selected as the final penalty parameter.
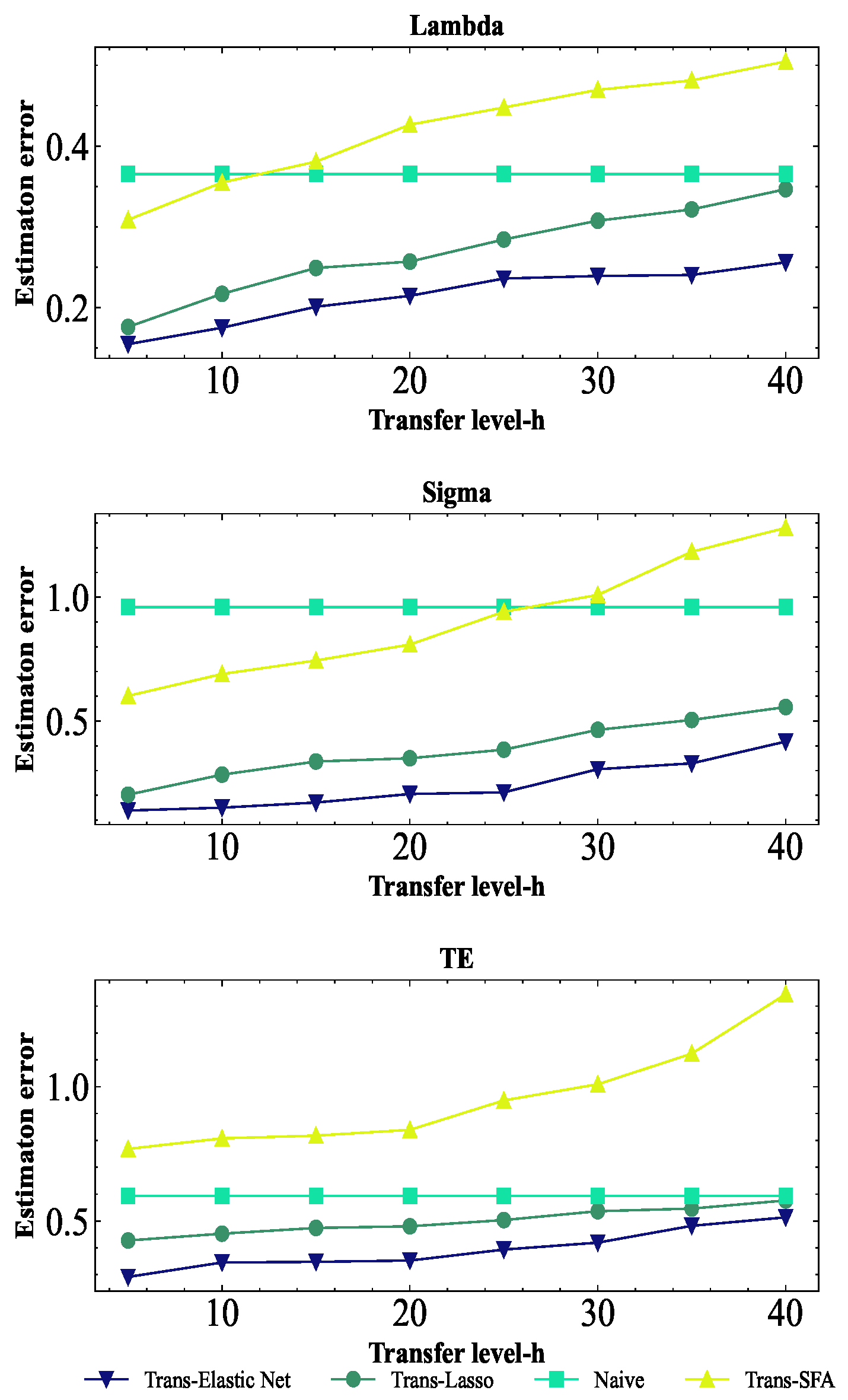
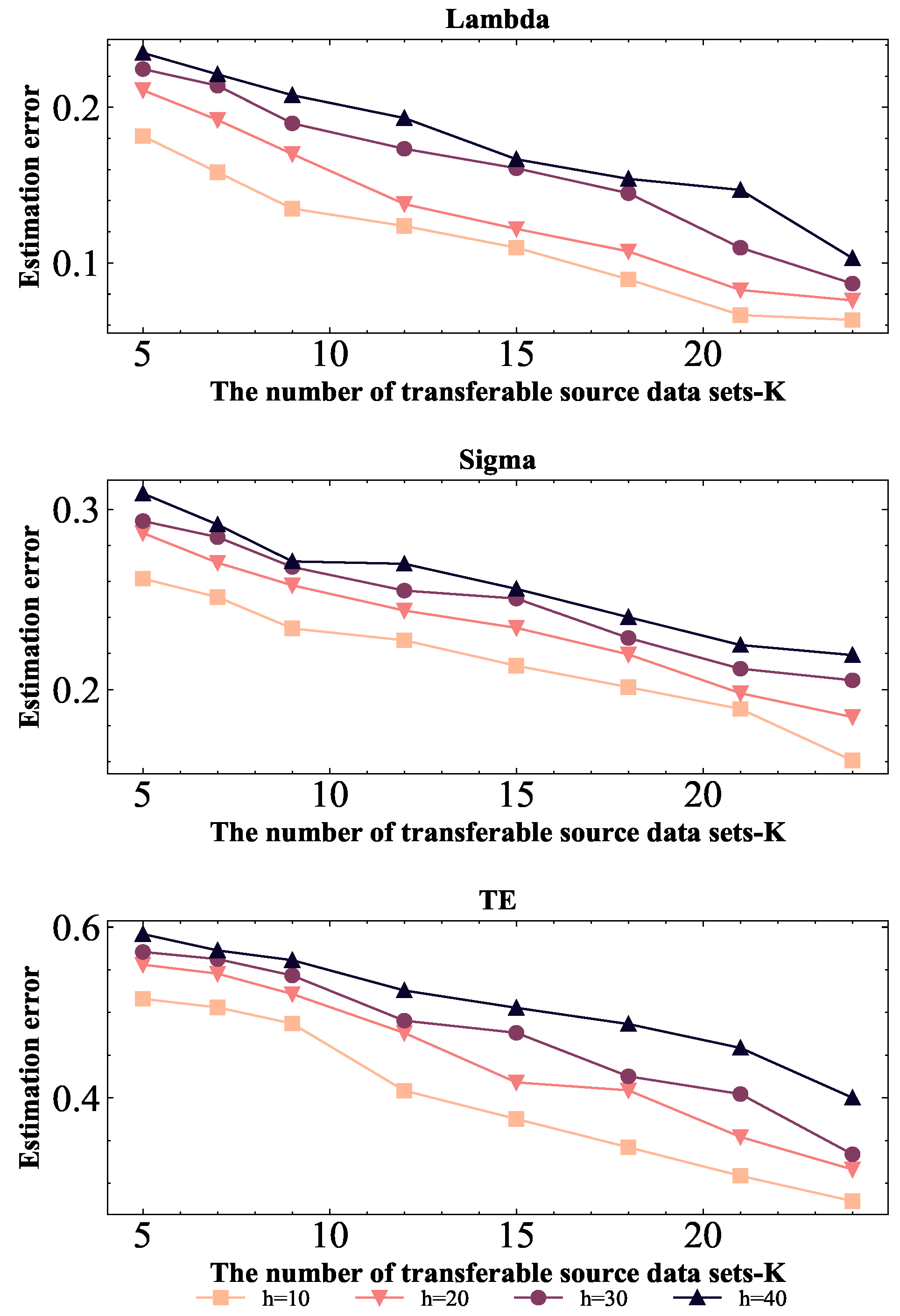
When the sample size of the target data is large, the above constraint variable selection method has achieved good results, but when the sample size of the target data is small, the variable selection effect is not ideal. In this case, it is necessary to use transfer learning technology to transfer data from similar distributed source data sets.
2.2. Transfer Learning of High-Dimensional Stochastic Frontier Model via Elastic Net
Transfer learning usually has two domains: source domain and target domain, respectively. The target domain, which has limited data or labels, is the focus of learning, while the source domain contains abundant data or rich label information. Although the source and target domains may differ in data distribution, they share certain similarities. The purpose of transfer learning is to transfer knowledge from the source domain to the target domain to complete model learning.
Suppose that the target data
, where the
ith target data is defined as
, comes from the following stochastic frontier model
Then the target model is constructed:
Assume that there are
K source data sets
. And the
kth source data set is represented as
, where
and
. The
kth source data set of the
jth data is represented as
. The source data comes from the stochastic frontier model:
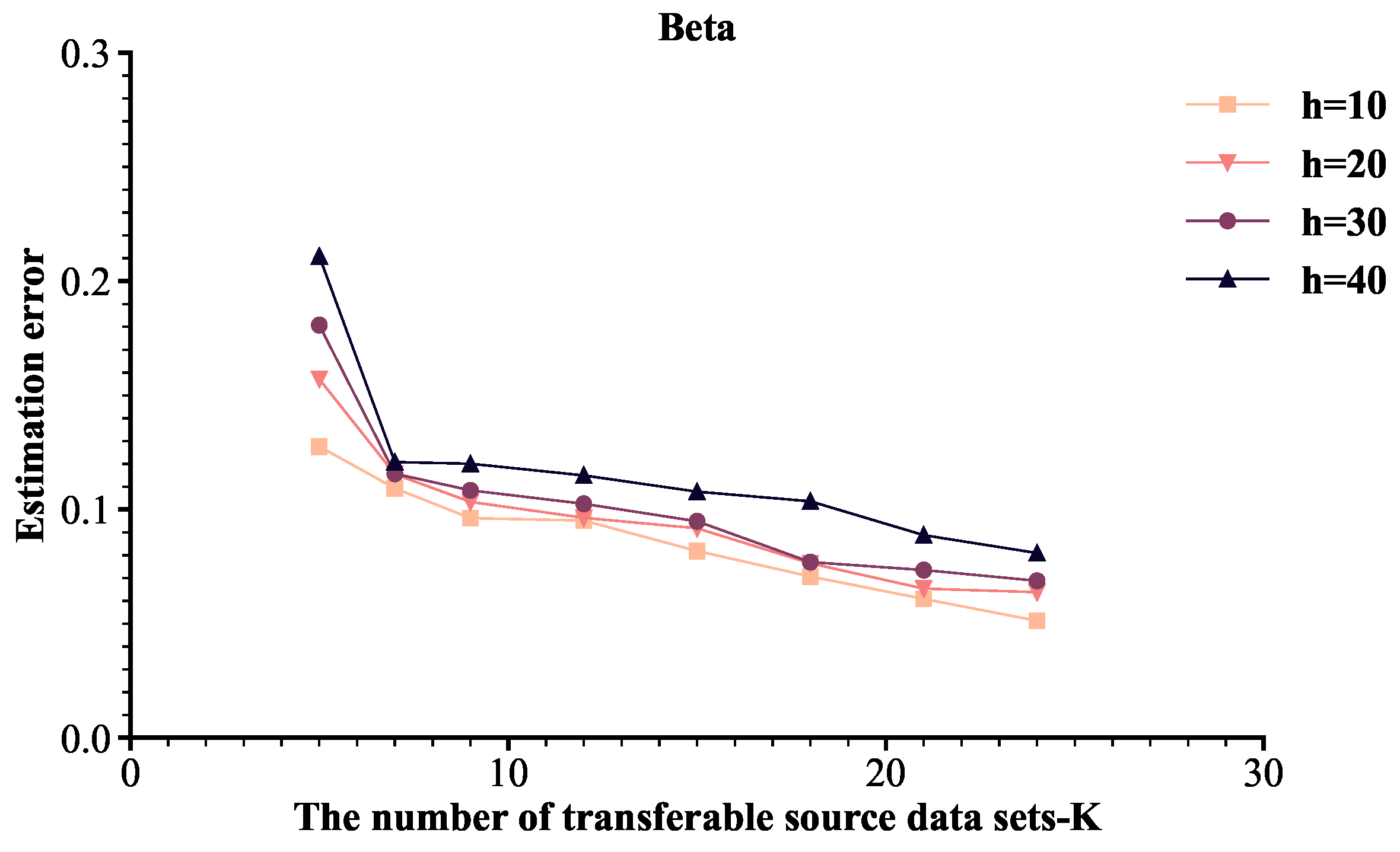
In this paper, we refer to source data sets that meet a predefined similarity condition as transferable sources. Only the information from these transferable sources is utilized to enhance the coefficient estimation for the target data. This restriction is reasonable, as it ensures that the incorporated information is sufficiently relevant and consistent with the target domain, thereby improving the accuracy and robustness of the estimation. In contrast, if the similarity between the source and target domains is insufficient, incorporating source data may degrade performance rather than improve it.
We now define a transferable source. Given any positive threshold , let denote the parameter vector of the target model, and let denote the parameter vector of the kth source model. Define the difference as . If , the k-th source is considered transferable. The index set of all transferable sources is then defined as .
This paper studies how to perform transfer learning on high-dimensional stochastic frontier models with known and unknown transferable sources, and how to perform transfer learning on high-dimensional stochastic frontier models with linear constraints.
2.2.1. Known Transferable Sources and No Constraints
Suppose there is a set of transferable sources
, where the sample size is
. Firstly, the target data and transferable data are brought into the log-likelihood function with regularization term to obtain
where
.
Next, the target data is brought into the log-likelihood function with regularization term to obtain
where
.
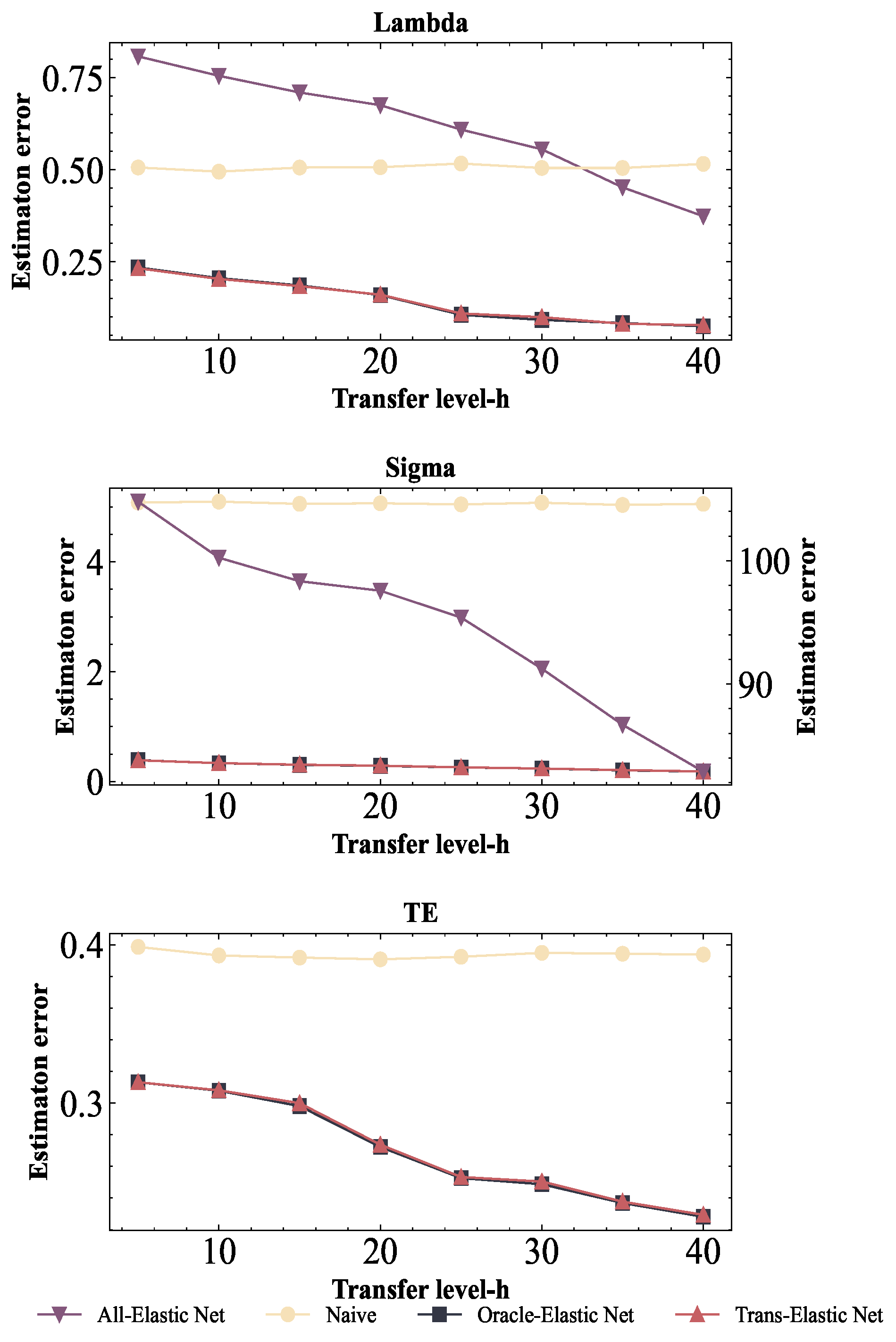
The penalty parameters , , and are obtained by cross validation. In order to help readers easily understand the algorithm, the -Trans algorithm is shown in Algorithm 1.
The transfer learning algorithm proposed below is an improvement of the two-step transfer learning framework introduced by Chen et al. [
18]. The main difference lies in the use of a different likelihood function. The practicability and effectiveness of the original algorithm have been demonstrated in their paper.
| Algorithm 1: -Trans |
Input: Target data , transferable source data , penalty parameter , , and Output: The estimated coefficient vector 3 Calculate: 4 Output: |
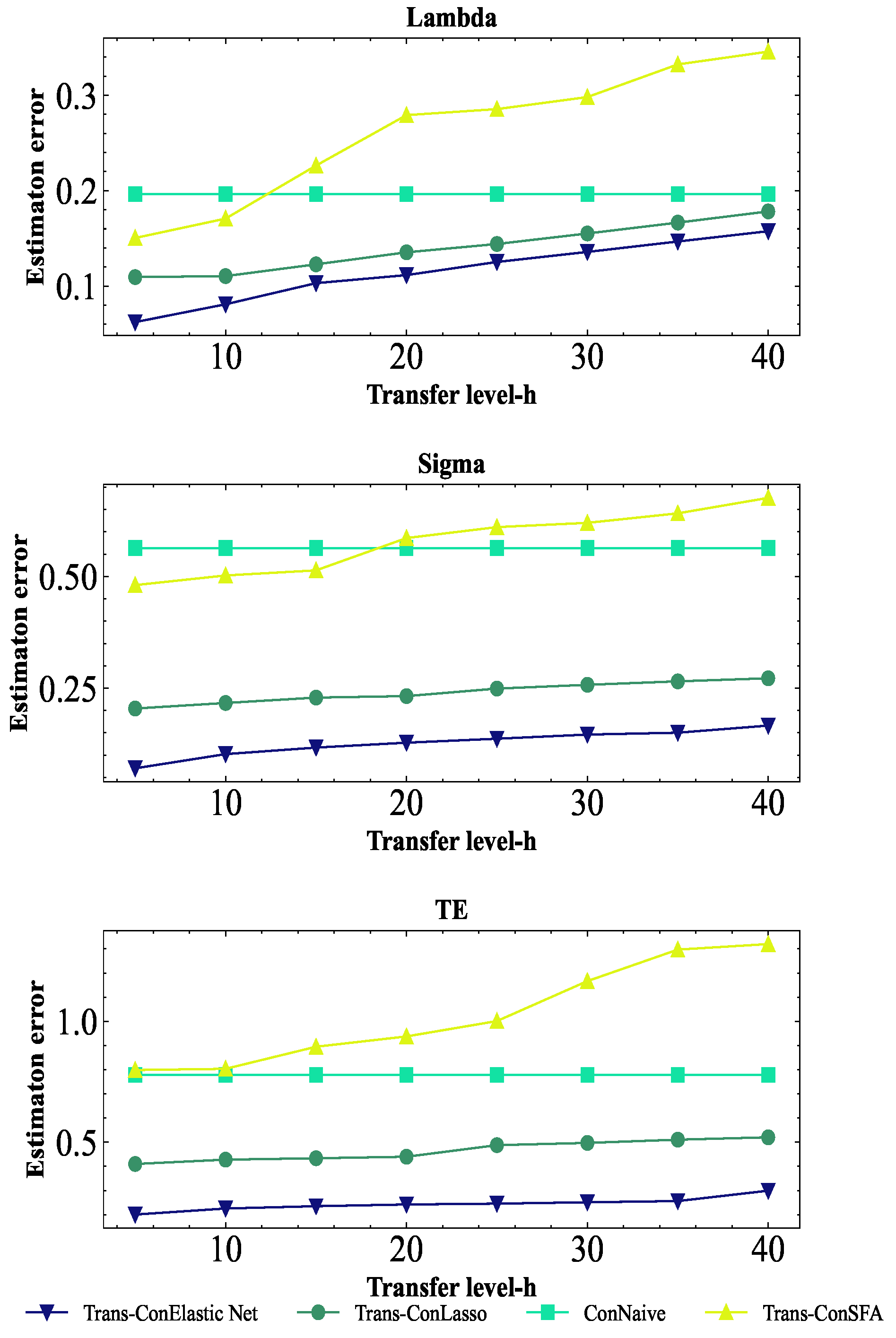
2.2.2. Known Transferable Sources and Linear Constraints
If we have some prior knowledge about the parameter of the stochastic frontier model, then we can add linear equations and inequality constraints to transfer learning. Similar to the above, is also estimated by a two-step method, but constraints are added in the solution process.
It is still assumed that the transferable source
is known, where the sample size is expressed as
. Firstly, the target data and transferable data are brought into the log-likelihood function with regularization terms and linear constraints to obtain
:
where
.
Secondly, the target data is brought into the log-likelihood function with regularization terms and constraints to obtain
:
where
.
Similarly, we can obtain the penalty parameters
,
,
and
by cross validation. The
-ConTrans algorithm is shown in Algorithm 2.
| Algorithm 2: -ConTrans |
Input: Target data , transferable source data , penalty parameter , , and , constraint parameter Output: The estimated coefficient vector 3 Calculate: 4 Output: |
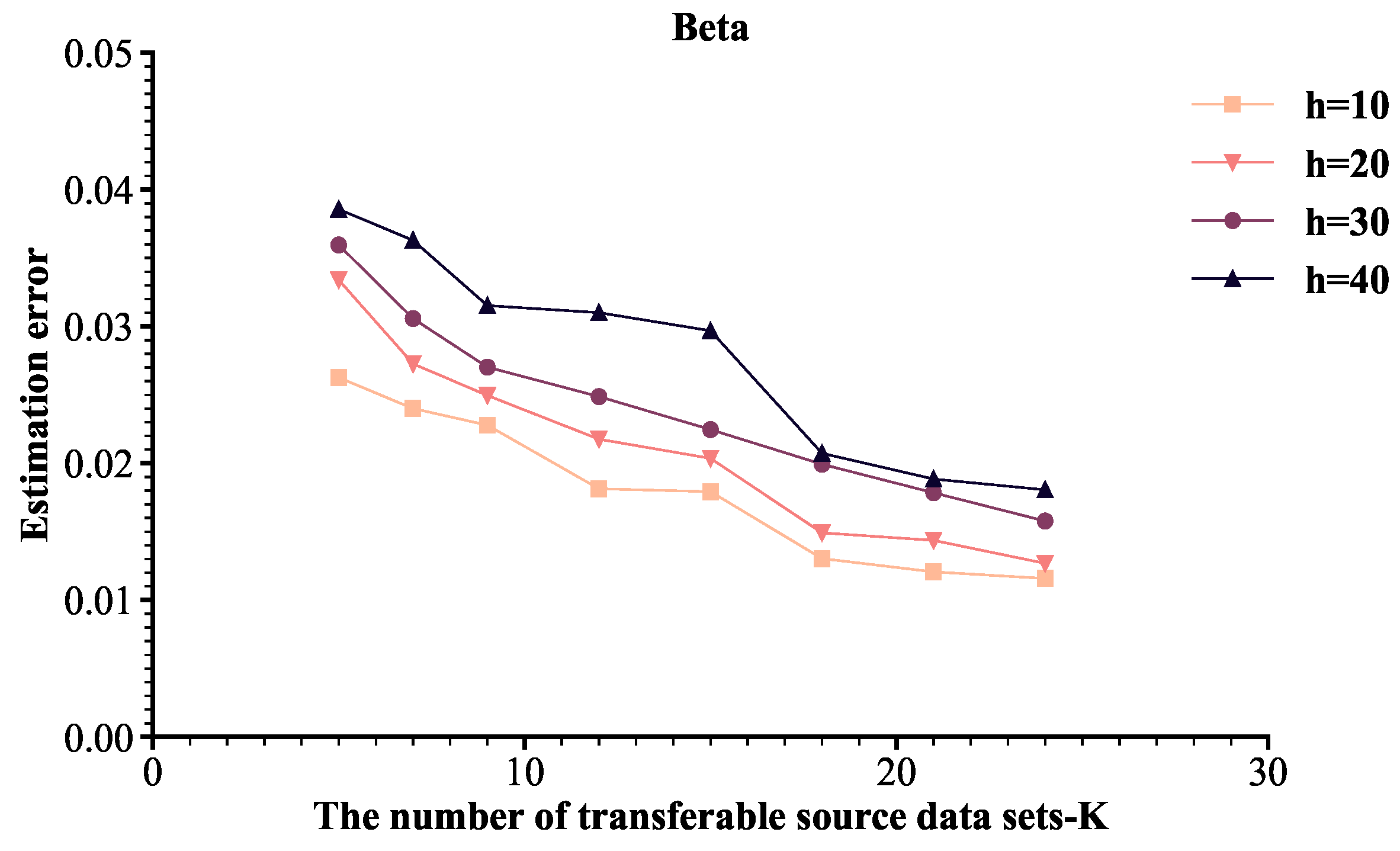
2.2.3. Unknown Transferable Sources and Linear Constraints
When the transferable source is unknown, the consequences of not running the transferable source detection is unimaginable. In order to solve this problem, this paper implements a transferable source detection algorithm based on the constrained Elastic Net stochastic frontier model, which detects the data set that can be transferred from the source data set, and the unconstrained situation is the same. The penalty parameters and are obtained by cross validation. For the sake of convenience, the transferable source detection algorithm first divides the target data set into five parts . It runs the migration step on each source domain and every four fold target data. Then the average error of the residual fold of the objective function is calculated. For the target data of every four folds, we use the constrained regularized stochastic frontier model to fit and calculate the error of the remaining folds. Then the average error is calculated as the baseline. Finally, these two errors are compared against a threshold: source domains with errors greater than the threshold are discarded, while those with errors less than the threshold are added to the collection .
For convenience, we assume that
can be divided into five parts. The average error of the
rth fold of the target data
is
The specific algorithm is shown in Algorithm 3. It should be noted that Algorithm 3 does not require the input of
h. And we add some constraints to the algorithm to limit the inclusion of non-transferable source domains.
| Algorithm 3: -ConTrans Detection |
Require: Target data , all all source data , penalty parameters , a constant , constraint parameter Ensure: The estimated coefficient vector and transferable source data sets
- 1:
Transferable source detection: Divide into five sets of equal size as - 2:
for to 5 do - 3:
fit the Stochastic frontier model of Elastic Net with and penalty parameters , - 4:
running step 1 in Algorithm 2 with and for , - 5:
calculate the error with , for - 6:
end for - 7:
, - 8:
- 9:
-Trans: running Algorithm 2 with - 10:
Output: and
|
Algorithm 3 relies on the unknown constant
, which determines the threshold for selecting transferable source data. Without knowing the true value of
, a larger value may lead to an overestimation of
, while a smaller value may result in an underestimation. Following Liu [
21], we determine
by running an additional round of cross-validation. Although this increases computational cost, it is an effective approach for solving practical problems.
2.3. Technical Efficiency
When using the stochastic frontier model for analysis, in addition to estimating all model parameters, we also need to estimate the technical efficiency. In this paper, we mainly rely on the JLMS method proposed by James Jondrow et al. [
22] to obtain the technical efficiency
by calculating
:
where
,
,
and
.
is the probability density function of standard normal distribution,
is the cumulative distribution function of standard normal distribution. By using maximum likelihood estimation, we can not only obtain the estimator
but also
and
, and bring them into the above formula to obtain the estimation of technical efficiency.
4. Real Data
The real data come from the Farm Accountancy Data Network (FADN), which is maintained and enhanced by EU member states, and is available at
http://ec.europa.eu/agriculture/rica/, accessed on 1 May 2025. We choose the data from the year 2013 for analysis. Python 3.8.10 is used to remove outliers and missing values, perform logarithmic transformation and normalization, select appropriate features, and conduct other preprocessing steps. After handling missing values and outliers and performing feature engineering, a data set consisting of 101 features is prepared. We use total output as the dependent variable, the total input, the total agricultural utilization area, the total labor input as the dependent variable. The test data exhibit strong collinearity, which is very suitable for our model. The target and source data sets are divided by economic scale. The data with an economic scale of EUR
are used as the target domain, totaling 19 samples. The data with economic scales of EUR
, EUR
, EUR
and
EUR 5000,000 are used as the source domain, containing 84, 131, 132, and 74 samples, respectively. We believe that the influence of total input and total agricultural utilization area among the independent variable on the total output of the dependent variable is always positive. This is a prior knowledge available before estimation, so the constraint is set to
. Using Algorithm 3, we find that data sets with economies of EUR
, EUR
and EUR
can be migrated.
Since prior knowledge is specified before estimation, it is inevitable that some correct and practical prior knowledge may be omitted, or incorrect and irrelevant prior knowledge may be included. Other prior knowledge about the coefficients may influence the final results, but such knowledge is not as evident as that of the two variables mentioned above. To avoid the risk of poor outcomes caused by the incorrect introduction of prior knowledge, we conservatively apply only the constraint .
In order to prove the repeatability of our method, we perform five-fold cross-validation analyses on the data and record the average prediction error across the five folds as the final comparative prediction error. The prediction error of each fold is defined by .
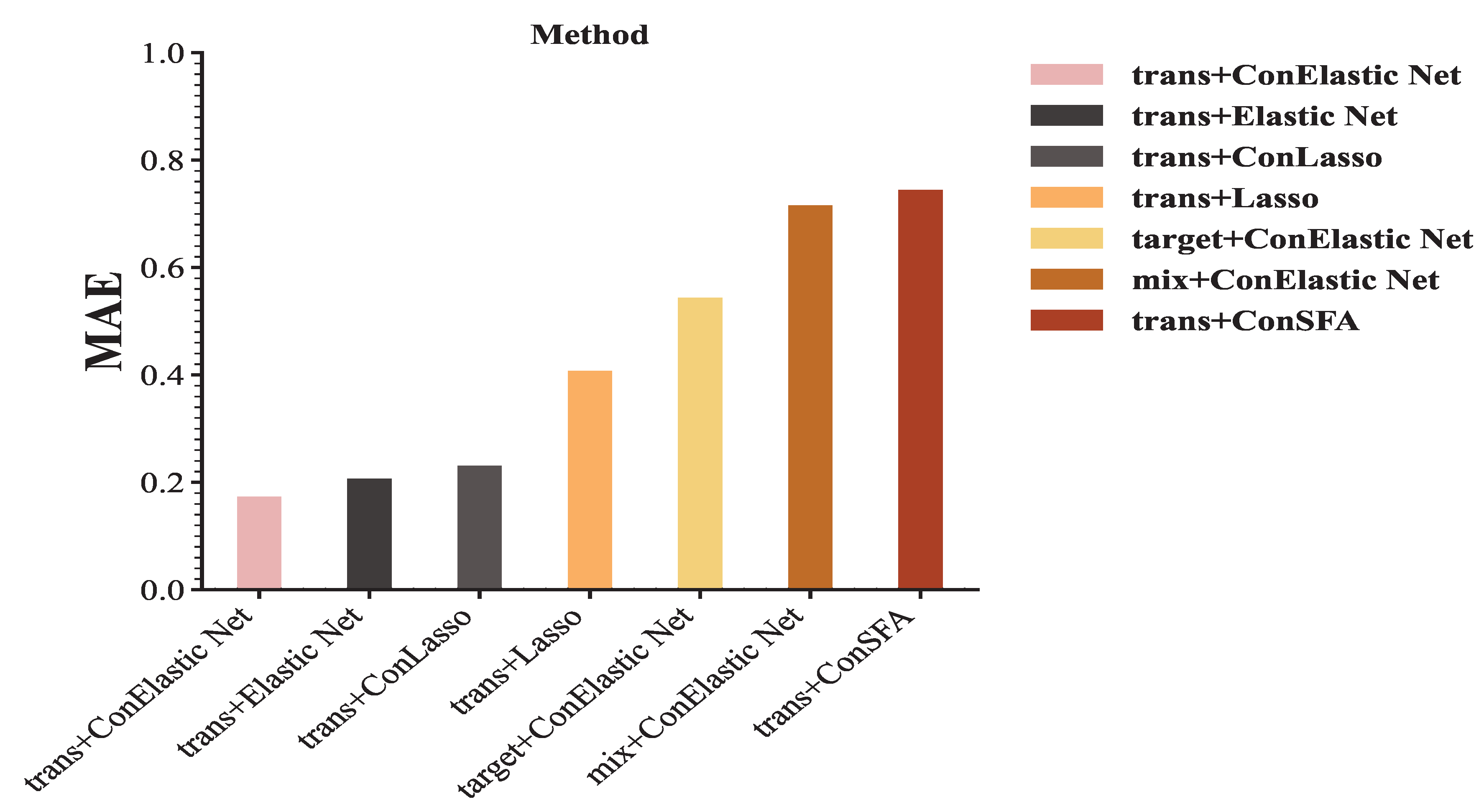
We use the Elastic Net stochastic frontier model with or without linear constraints, the Lasso stochastic frontier model, and the ordinary stochastic frontier model for testing. The results after transfer are shown in
Figure 12. The various methods are explained below:
trans+ConElastic Net: Elastic Net stochastic frontier model with transferable source data and target data under added constraints.
trans+Elastic Net: Elastic Net stochastic frontier model with transferable source data and target data without adding constraints.
trans+ConLasso: Lasso stochastic frontier model with transferable source data and target data under added constraints.
trans+Lasso: Ordinary stochastic frontier model with transferable source data and target data without adding constraints.
target+ConElastic Net: Elastic Net stochastic frontier model with only target data under linear constraints.
mix+ConElastic Net: Elastic Net stochastic frontier model with all data under added constraints.
trans+ConSFA: Ordinary stochastic frontier model with transferable source data and target data under linear constraints.
As shown in
Figure 12, trans+conElastic Net achieves the lowest MAE, followed by trans+Elastic Net, which proves the effectiveness of our proposed algorithm. The MAE under constrained conditions is lower than that under unconstrained conditions. Across all methods, this indicates that incorporating prior knowledge during coefficient estimation is beneficial to the estimation results. When all data are used directly for stochastic frontier analysis, a large MAE is observed, further highlighting that the absence of transferable source detection can lead to significant estimation errors.
From
Table 1, we can see that trans + conElastic Net achieves the lowest standard deviation, and the standard deviation of trans + Elastic Net ranks second, only after trans + ConLasso, indicating that our method is both accurate and stable. We use trans + conElastic Net as the benchmark method for the paired
t-test. The results show that, except for the
p-values of trans + Elastic Net and trans + ConLasso, the
p-values of all other methods reach the significance level
, which directly indicates that this method is significantly better than most of the comparison methods in terms of error performance. Combining the results of
, standard deviation, and the paired
t-test, we conclude that our proposed method performs best among the seven candidate methods from multiple perspectives, demonstrating strong practicality and robustness.
5. Discussion
From the above experiments, it can be seen that the transfer learning of the high-dimensional stochastic frontier model via Elastic Net is feasible and effective. Firstly, in the presence of high-dimensional and collinear data, our model outperforms the Lasso stochastic frontier model and ordinary stochastic frontier model. Secondly, adding constraints to the model, that is, incorporating some prior knowledge, can restrict the parameter estimation within a certain range, making the estimation more accurate. Third, transfer learning is used to transfer knowledge from similar source data in the case of limited target data, in order to improve the accuracy of parameter estimation and the performance of prediction. Experiments show that transfer learning is indeed feasible for the high-dimensional stochastic frontier model based on Elastic Net, and greatly improves the performance of the model. Moreover, the effectiveness of both algorithms is demonstrated by simulation experiments and real cases for the scenarios where the transferable source is known and where it is unknown. This study also often observes the phenomenon of negative transfer learning, that is, the negative impact on the final result, which is still very common in transfer learning. How to reduce or avoid the phenomenon of negative transfer learning is a problem for further research in the future. Whether transfer learning can be used for other statistical learning methods will also continue to be studied in the future.
Although the proposed algorithm performs well in numerical simulation and empirical research, it lacks theoretical proof to support its effectiveness. A potential research direction is to provide statistical inference and confidence intervals for the parameters estimated by the proposed method. This will enhance the interpretability and applicability of the algorithm. In addition, extending the existing framework and theoretical analysis to other models is a worthwhile avenue of exploration. Evaluating the applicability of the proposed methods to different models may offer insights into their versatility and potential improvements in various transfer learning scenarios.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}