1. Introduction
In recent years, the use of censored samples to draw inferences about populations of interest has increased in the context of reliability studies and life-testing experiments. This trend may be attributed to advancements in modern technology, which have led to the production of more reliable products. To investigate the reliability of such products, it is not practical for researchers to wait for all items under test to fail. Instead, they can gather information from a portion of these items by terminating the experiment before all failures occur. In this case, the acquired sample is referred to as a censored sample. This approach is highly effective for saving money, time, and human resources. The statistical literature describes various censoring strategies, typically classified as single-stage or multi-stage censoring plans. In single-stage censoring, the experiment concludes after reaching a predetermined number of failures or a specified duration, similar to Type-I and Type-II censoring schemes. In these plans, no withdrawals are permitted before the designated endpoint. On the other hand, multi-stage censoring plans allow for the removal of certain items that are still working from the test at any point, rather than only at the end. One of the most common multi-stage censoring plans is progressive Type-II censoring. For more information, refer to Aggarwala and Balakrishnan [
1] and Balakrishnan and Cramer [
2]. Several modifications have been introduced to generalize the progressive Type-II censoring plan.
For example, Ng et al. [
3] suggested an adaptive Type-II progressive censoring (AT-2PC) scheme which allowed the progressive Type-II censoring plan to be derived as a special case. This procedure allows experimenters to conclude the investigation when the testing time exceeds a predetermined boundary. They also noted that the AT-2PC plan functions efficiently in statistical deductions when the total time of the test is not a considerable issue. However, if the test teams are highly reliable, the testing duration may become too long, causing the AT-2PC plan to fall short of guaranteeing an appropriate overall test length. This scheme has been used in several investigations, including those by Al-Essa et al. [
4], Elshahhat and Nassar [
5], Lv et al. [
6], Dutta et al. [
7], Alqasem et al. [
8], and Almuhayfith [
9]. To address this problem, Yan et al. [
10] suggested an improved Type-II adaptive progressive censoring (IT2-APC) plan, which is particularly advantageous when the duration of the test is a critical factor. The IT2-APC plan offers two significant benefits. First, it generalizes several existing plans, including but not limited to the progressive Type-II censoring and AT-2PC plans. Second, it confirms that the experiment ends within a determined time frame. The following is a detailed discussion of how to collect the IT2-APC sample. We assume there are
n items undergoing a test with a predetermined number of failures,
m. The test follows a progressive censoring pattern, denoted as
, and involves a pair of threshold times,
and
, where
. Let
represent the failure time of item
. After obtaining
, the researcher randomly selects
of the remaining items and removes them from the test. Similarly, at
,
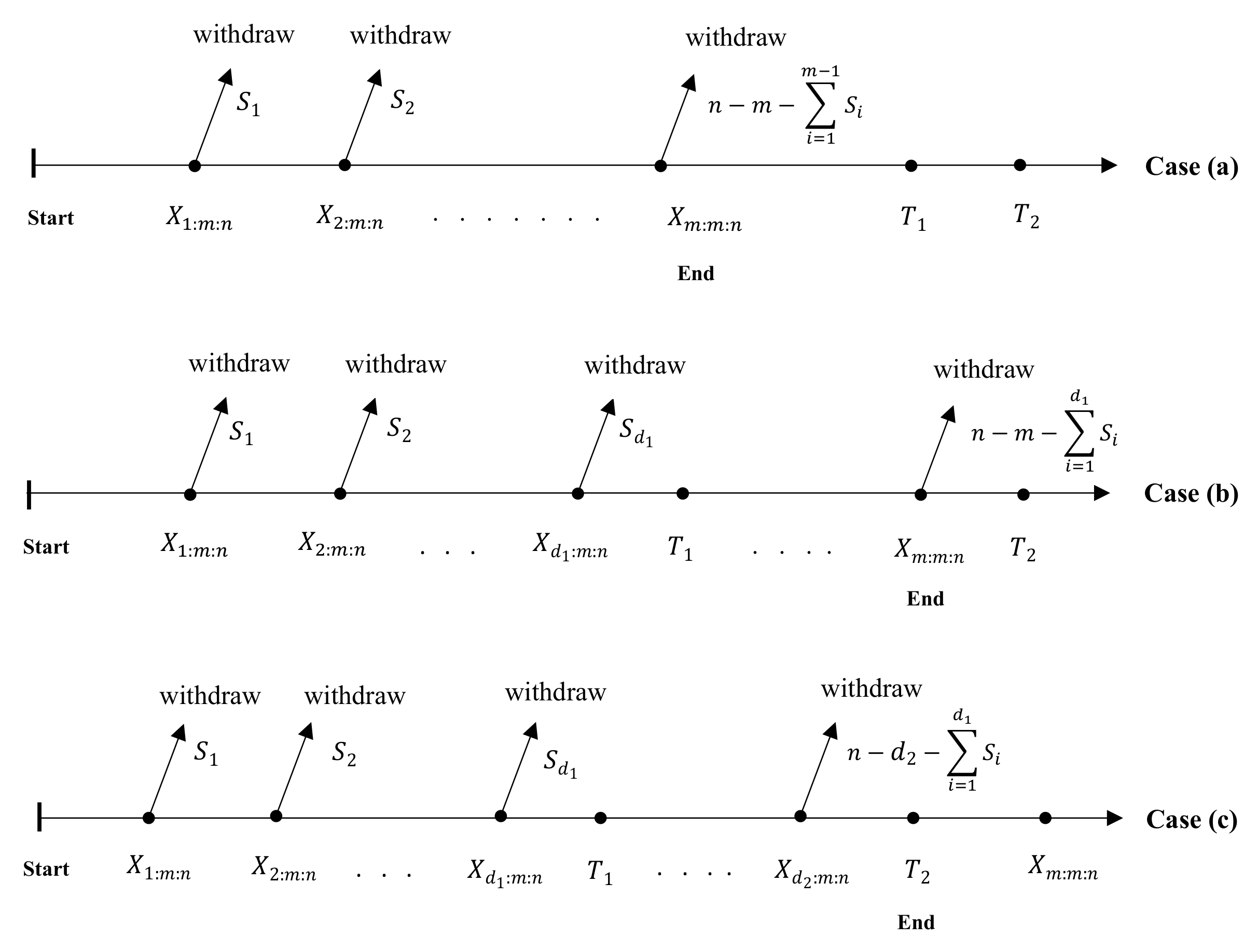
of the remaining items are selected and removed from the test, and so on. Under the IT2-APC plan, we can stop the experiment in one of the following three cases:
- (a)
If , stop the test at . This scenario represents the case of a progressively Type-II censored sample.
- (b)
If , stop the test at . In this case, the removal pattern is updated by setting , where represents the number of items that failed before . This scenario illustrates the case of the AT-2PC sample.
- (c)
If , stop the test at with the understanding that the removal pattern is updated by setting , where represents the number of items that failed before . After reaching , all remaining items are removed from the test. This scenario illustrates the case of the IT2-APC sample.
Many authors have used the IT2-APC scheme to study estimation concerns for certain lifetime models—for example, the Burr Type-III distribution by Asadi et al. [
11], the Weibull distribution by Nassar and Elshahhat [
12], a Weibull competing risk model by Elshahhat and Nassar [
13], a logistic–exponential distribution by Dutta et al. [
14], a Chen distribution by Zhang and Yan [
15], an inverted Lomax distribution by Alotaibi et al. [
16], a Weibull–exponential distribution by Alotaibi et al. [
17], and the Kumaraswamy-G family of distributions by Irfan et al. [
18], among others. For an observed IT2-APC sample,
), where
is the realization of
, with the progressive censoring scheme
. As a result, the joint likelihood function of the observed data can be expressed in the following general form:
where
C is a constant,
and
are the probability density function (PDF) and the cumulative distribution function (CDF) of any lifetime model, and the different values of
,
,
, and
are presented in
Table 1. The detailed experimental procedures for the various cases of the IT2-APC plan are illustrated in
Figure 1.
In reliability analyses, it is essential to assume that the population being studied follows a probability distribution that accurately describes its characteristics. In this study, we assume that the population of interest follows the inverse XLindley (IXL) distribution. The IXL distribution, suggested by Beghriche et al. [
19], functions as an inverse version of the XLindley (XL) distribution. Let the random variable
Y follow the XL distribution. By applying the transformation
, we conclude that the random variable
X follows the IXL distribution. It can be represented as
, where
is a scale parameter. The PDF and the CDF corresponding to the random variable
X are written as
and
respectively.
Beghriche et al. [
19] investigated the key characteristics of the IXL distribution and noted that its hazard rate function (HRF) can be used to model data exhibiting an upside-down bathtub shape. The reliability function (RF) and the HRF, at time point
, of the IXL distribution can be expressed, respectively, as
and
We are motivated to complete the current work for many reasons: (1) The significance of the IXL distribution in modeling reliability data with heavy-tailed behavior and non-monotonic hazard rates. These characteristics make it particularly suitable for high-reliability systems where the failure modes evolve over time, such as in electronic components or medical survival data. Unlike traditional inverted distributions, as shown later in the data analysis section, we compared the IXL distribution and several inverted lifetime models, specifically thirteen inverted models, encompassing both classical inverted models and recently introduced inverted distributions. The findings revealed that the IXL distribution offers a superior fit based on several goodness-of-fit criteria. (2) The IT2-APC scheme offers notable flexibility, which has been recognized in recent studies for its effectiveness in balancing the test duration and estimation accuracy, particularly for highly reliable products. For example, Yan et al. [
10] showed that the IT2-APC scheme shortens the testing time by adaptively removing units based on pre-specified thresholds,
and
. This approach has proven more efficient than traditional progressive Type-II censoring or AT-2PC plan failures. Such adaptability makes the IT2-APC scheme well suited to practical reliability applications, where extended testing periods are often infeasible. While recent studies have explored censored inferences for other inverted distributions, such as the inverted Weibull (IW) distribution by Kazemi and Azizpoor [
20] and the inverted Lindley (IL) distribution by Abushal and AL-Zaydi [
21], no research has yet addressed the IXL distribution under the IT2-APC scheme or any other censoring framework. Beghriche et al. [
19] focused on classical estimation for the IXL distribution but did not consider Bayesian inference, interval estimation, or analyses of the RF and the HRF. Moreover, comparisons with competing inverted models in terms of the goodness-of-fit have not been investigated, limiting the ability of practitioners to justify the use of the IXL distribution in reliability modeling.
This study aims to address several unresolved challenges in the field of reliability testing and statistical estimation. Specifically, it focuses on evaluating the parameters of the IXL distribution, including its RF and HRF, under the IT2-APC scheme, which is crucial for high-reliability testing scenarios. A significant gap exists in the current literature regarding Bayesian estimation methods and the construction of both ACIs and credible intervals for the IXL distribution. Moreover, although the IXL distribution is often described as flexible, there is a lack of empirical comparisons with other inverted distributions. This highlights the need for a comprehensive comparative analysis to validate the IXL model’s performance and justify its adoption in real-world reliability applications. In this study, we consider two estimation methods, namely (1) maximum likelihood estimation, as a classical method, and (2) the Bayesian estimation method. These methods are applied to estimating both the model parameters and the two reliability indicators, namely the RF and the HRF. Collectively, these three quantities will be referred to as the unknown parameters. Accordingly, the objectives of the study can be summarized as follows:
- 1.
Estimate the unknown parameters of the model using both maximum likelihood and Bayesian estimation methods, providing a comprehensive comparison through point estimates, two approximate confidence intervals (ACIs), and two credible intervals;
- 2.
Assess the accuracy and efficiency of the proposed estimation methods under the IT2-APC scheme through an extensive simulation study;
- 3.
Compare the IXL distribution with several competing inverted lifetime models to evaluate and demonstrate its superior performance using various goodness-of-fit measures;
- 4.
Validate the practical applicability and relevance of the IXL model and the IT2-APC plan by analyzing a real-world reliability dataset, thereby illustrating their utility in real-life reliability strategies.
The rest of this study is classified as follows:
Section 2 investigates the classical point and interval estimates of the unknown parameters. The Bayes point and credible intervals of the various unknown parameters are illustrated in
Section 3.
Section 4 shows the simulation setup, as well as the numerical findings. One real dataset is explored in
Section 5.
Section 6 concludes this paper.
2. Classical Point and Interval Estimations
This section presents the maximum likelihood estimates (MLEs) of the unknown parameters , the RF, and the HRF. Additionally, two ACIs are provided: the first uses the normal approximation of the MLEs, designated as ACIs-NA, and the second uses the normal approximation of the log-transformed MLEs, designated as ACIs-NL. A key aspect in calculating the interval estimates for the RF and the HRF is determining the variance in their MLEs. This study uses the delta method to estimate these necessary variances.
Take an IT2-APC sample from the IXL population, denoted by
), with the removal scheme
. Then, after ignoring the constant terms, the likelihood function can be formulated using (
1)–(
3) as
where
. The natural logarithm of (
6), denoted by
, follows
After differentiating (
7) with respect to
and setting the result equal to zero, we obtain the following nonlinear normal equation:
where
It is noted that the MLE of the unknown parameter
, denoted as
, cannot be obtained explicitly because of the complex form of the resulting normal equation. To address this issue, we use the Newton–Raphson method to compute the MLE
numerically from (
8). After obtaining the MLE
, we apply the invariance property of the MLE to computing the MLEs for the RF and the HRF. These estimates can be derived based on (
4) and (
5), respectively, as follows:
and
In addition to calculating the point estimates of the unknown parameters, it is important to examine their interval estimates. The normal approximation of the MLE allows us to obtain such intervals.
In this study, we estimate the variance in the MLE
by inverting the observed Fisher information matrix. To perform this, we first compute the second-order derivative of the log-likelihood function in (
7) as
where
Then, we can obtain the estimated variance in the MLE
as
where
in (
11) is computed at
.
On the other hand, the delta method is applied to obtain the estimated variances for the MLEs of the RF and the HRF, denoted by
and
, respectively. According to this approach, the estimated variances can be computed as
where
and
where
.
Then, at a
confidence level, the ACIs-NA of the unknown parameters
, the RF, and the HRF can be computed as
where
is the upper
percentile point obtained from the standard normal distribution. In addition, the
ACIs-NL of the various unknown parameters can be obtained as
To evaluate both the point and
interval frequentist estimates of
,
, or
, we recommend implementing the ’
’ package, proposed by Henningsen and Toomet [
22].
Theorem 1. For the IXL distribution, at least one exists satisfying the score equation , implying the existence of an MLE.
Proof. Consider the score function . We show that has a solution in .
As ,
.
, where .
.
, , so if . Thus, , similarly for . Hence, .
As ,
.
.
, , so . Thus, .
Since is continuous (, are continuous, ), and as , as , exists such that . The second derivative (see Theorem 2.2) confirms this is a maximum. □
Theorem 2. For the IXL distribution, under the conditions in Theorem 2.1, the MLE is unique.
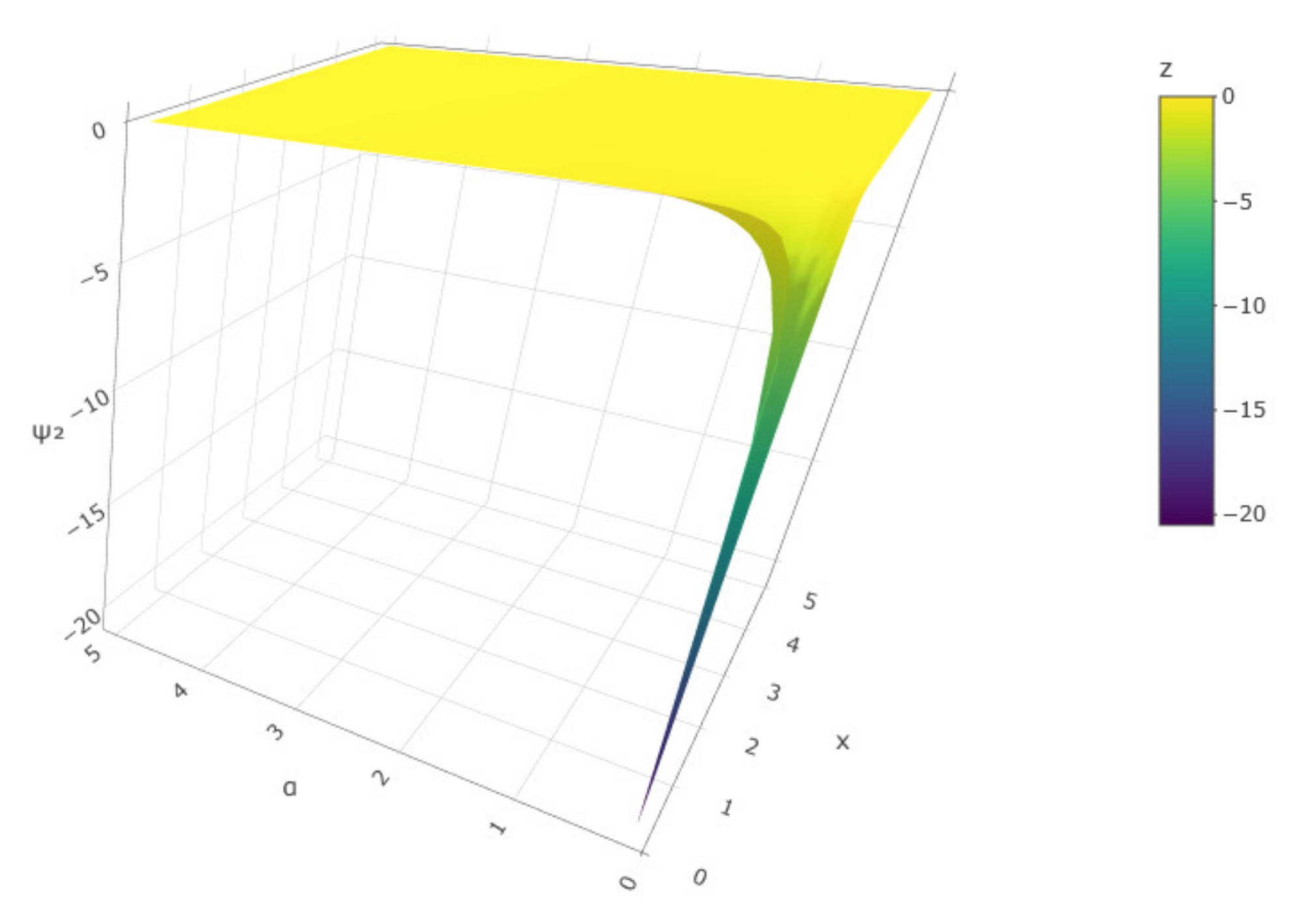
Proof. To show that the MLE is unique, we prove the log-likelihood is strictly concave, i.e.,
. Let
. Then, one can see the following from (
9):
- 1.
The first term in .
- 2.
The second term .
- 3.
For the censoring terms in
, one can easily see from
in (
10) that
and the squared term in
is non-positive. Let
. The first part in
K is positive. The sign of the second part depends on
. It is simple to see that
if
, and
for
. As shown in
Figure 2, the function
is always negative, which is due to the dominance of the positive term in
K and the squared term in
.
Thus, , implying strict concavity. Hence, is strictly decreasing and has a unique root, and is the unique MLE. □
3. Bayesian Point and Interval Estimations
In the field of reliability studies, the ability to integrate prior knowledge is highly advantageous. It enables us to integrate existing knowledge or thoughts about the unknown parameters into the investigation. This inclusion of prior knowledge serves as a foundation for a different type of parametric inference known as Bayesian inference, which has garnered considerable attention as a strong and useful option for frequent estimation approaches. This section focuses on the Bayesian estimation of the unknown parameters of the IXL distribution using the IT2-APC sample. We analyze the point estimations for the various parameters using the squared error loss function. This loss function is widely adopted in Bayesian analyses because of its simplicity and analytical convenience. Specifically, it leads to a closed-form solution for the Bayes estimator, which corresponds to the posterior mean. In the context of reliability studies, the symmetric nature of the squared error loss function ensures that both overestimation and underestimation are treated equally. This property is especially valuable in practical applications such as maintenance scheduling and risk evaluation, where balanced and unbiased parameter estimates are essential. Additionally, we explore two types of Bayesian interval estimates: Bayes credible intervals (BCIs) and highest posterior density (HPD) credible intervals.
To begin with the Bayesian estimation, we need to represent our knowledge of the unknown parameter
through its prior distribution. One common approach is to use the conjugate prior distribution. However, by examining the likelihood function in (
6), it becomes clear that there is no conjugate prior available for the unknown parameter
. In this case, we take advantage of the flexibility of the gamma distribution and use it as a prior distribution for
, expressed in the following form:
The gamma prior is employed in our Bayesian investigation for several critical reasons: (1) The gamma prior distribution shows considerable flexibility, as it can take various shapes, e.g., exponential, right-skewed, or approximately symmetric, contingent upon its shape parameter. This inherent flexibility facilitates the substantial incorporation of prior knowledge regarding the unknown parameter of interest. (2) Given that the unknown parameter of the IXL distribution is non-negative, the gamma prior distribution constitutes a natural choice, as it is solely determined for positive values. This feature guarantees that the prior knowledge conforms to the physical limitation associated with the unknown parameter. (3) The hyper-parameters of the gamma prior distribution (shape and scale) can be intuitively interpreted in relation to prior knowledge, such as the prior mean and variance, thereby facilitating the specification and illustration of the prior settings. (4) The gamma prior distribution is broadly employed in Bayesian reliability investigations due to its compatibility with lifetime data and capability to deliver powerful and interpretable results. (5) Furthermore, it does not introduce additional complexity into the posterior distribution or computational challenges, particularly when employing the MCMC methods. Given the observed IT2-APC data
, the posterior distribution of the unknown parameter
can be expressed as given, after combining the likelihood function in (
6) with the prior distribution in (
12):
where
is defined as
In light of the posterior distribution in (
13), we can write the Bayes estimator of the unknown parameter
under the squared error loss function as
Similarly, the Bayes estimators of the RF and the HRF can be obtained using (
13), respectively, as
and
where
and
are as defined in (
4) and (
5), respectively. It is evident that obtaining the Bayes estimators in (
14)–(
16) for the various parameters is challenging due to the complex form of the posterior distribution. To address this issue and obtain the necessary estimates, we use the Markov chain Monte Carlo (MCMC) technique to generate random samples from the posterior distribution in (
13). We then utilize these samples, along with the squared error loss function, to compute the Bayes estimates for
, the RF, and the HRF. The BCIs and the HPD credible intervals can be also obtained in this case.
To implement the MCMC technique, it is essential to assess whether the posterior distribution of the random variable
aligns with any well-known distribution. This evaluation is crucial for determining the appropriate MCMC algorithm to use. It is evident from (
13) that the posterior distribution does not correspond to any well-known statistical distribution. Therefore, we will utilize the Metropolis–Hastings (MH) algorithm to acquire the necessary samples from the posterior distribution (
13). To acquire samples using the M-H algorithm, we utilize the normal distribution as a proposal density. The following steps are used to generate samples from the posterior distribution in (
13):
- Step 1.
Set and put , where is the MLE of .
- Step 2.
Simulate a candidate from .
- Step 3.
Compute the acceptance ratio:
- Step 4.
Simulate u from the unit uniform distribution.
- Step 5.
Take the candidate by setting if ; otherwise, set .
- Step 6.
Obtain the RF and the HRF as
and
- Step 7.
Set .
- Step 8.
Repeat the approach from steps 2 to 7, M times.
- Step 9.
Use the generated samples to construct the sequence
Based on the squared error loss function, the Bayes estimates of
, the RF, and the HRF can be computed, after a burn-in period
B, respectively, as
where
. On the other hand, to obtain both the BCIs and the HPD credible intervals, we first sort the sequence
as
,
, and
. Thus, the
BCIs for
, the RF, and the HRF are as follows:
respectively. In addition, the
HPD credible intervals of
, the RF, and the HRF are given by
respectively, while
is selected to achieve, for example, in the case of
, the following:
where
is the greatest integer that does not exceed
j.
Theorem 3. Let the posterior distribution for a parameter , given the observed data with , be defined as displayed in (13). Using a normal proposal distribution , where is the proposed state, is the variance, and the proposals are rejected, the M-H algorithm generates a Markov chain with as its stationary distribution if (1) for all , and (2) is continuous on . Proof. The M-H algorithm accepts a proposed state
with the probability
Since
for
, the acceptance probability can be simplified into
For , set .
- (a)
Stationarity. The chain satisfies a detailed balance if
. For
, the transition probability is
. If
, then
since
. The case
is symmetric. For
,
, preserving stationarity.
- (b)
Positivity. For : The term , , , , and since . Thus, .
- (c)
Continuity. Since , , the exponential, and logarithmic terms are continuous for , and is continuous, and is continuous.
- (d)
Convergence. For , and , so the chain is irreducible. Aperiodicity holds since . Thus, the chain converges to .
□
5. Communication Transceiver Data Analysis
An airborne communication transceiver (ACT) is a device designed for aircraft communication, enabling crew and ground-based air traffic control through a built-in intercom. Of course, to focus on showcasing the utility of the proposed IXL model and proving practical applications of the suggested estimation techniques, this section highlights the analysis of forty active repair times (in hours) of an ACT. This dataset was first provided by Jorgensen [
24] and has been reanalyzed by Elshahhat et al. [
25], Alotaibi et al. [
26], Alotaibi et al. [
27], and Nassar et al. [
28]; see
Table 15.
Before proceeding forward, from the full ACT data, we examine the efficiency and adaptability of the proposed IXL model by comparing its behavior with that of twelve other inverted lifetime distributions from the literature, namely the following:
- (1)
The inverted exponential (IE(
)) by Keller et al. [
29];
- (2)
The IW (IW(
)) by Ramos et al. [
30];
- (3)
The inverted gamma (IG(
)) by Glen [
31];
- (4)
The inverted Chen (IC(
)) by Srivastava and Srivastava [
32];
- (5)
The INH (INH(
)) by Tahir et al. [
33];
- (6)
The inverted Lomax (IL(
)) by Kleiber and Kotz [
34];
- (7)
The inverted Kumaraswamy (IK(
)) by Abd Al-Fattah et al. [
35];
- (8)
The inverted exponentiated Pareto (IEP(
)) by Abouammoh and Alshingiti [
36];
- (9)
The exponentiated inverted exponential (EIE(
)) by Fatima and Ahmad [
37];
- (10)
The generalized inverted exponential (GIE(
)) by Abouammoh and Alshingiti [
36];
- (11)
The alpha-power inverted exponential (APIE(
)) by Ünal et al. [
38];
- (12)
The generalized inverted half-logistic (GIHL(
)) by Potdar and Shirke [
39];
- (13)
The inverted Pham (IPham(
)) by Alqasem et al. [
40].
Now, several metrics are utilized to compare the fits of the IXL distribution and its competitors, namely (i) Akaike (
), (ii) consistent Akaike (
), (iii) Bayesian (
), (iv) Hannan–Quinn (
), (v) Anderson–Darling (
), (vi) Cramér–von Mises (
), and (vii) Kolmogorov–Smirnov (
) criteria, with the
value. In
Table 16, these measures (i)–(vii) are assessed using the MLEs (together with related standard errors (St.Errs)) of
and
. It is clear from
Table 16 that the proposed IXL distribution has the lowest values of all of the specified metrics, except for the highest
value. Therefore, we recommend that the IXL model proposed in this study is more appropriate than the others. One key advantage of the IXL model is that although it involves only a single parameter, the analysis of the dataset demonstrates that it outperforms several widely used two-parameter models. This highlights its flexibility and usefulness, particularly in the context of censored data, where working with models that contain many parameters can be challenging. The simplicity of the IXL model makes it especially attractive in complex settings, where a lower number of parameters is preferred.
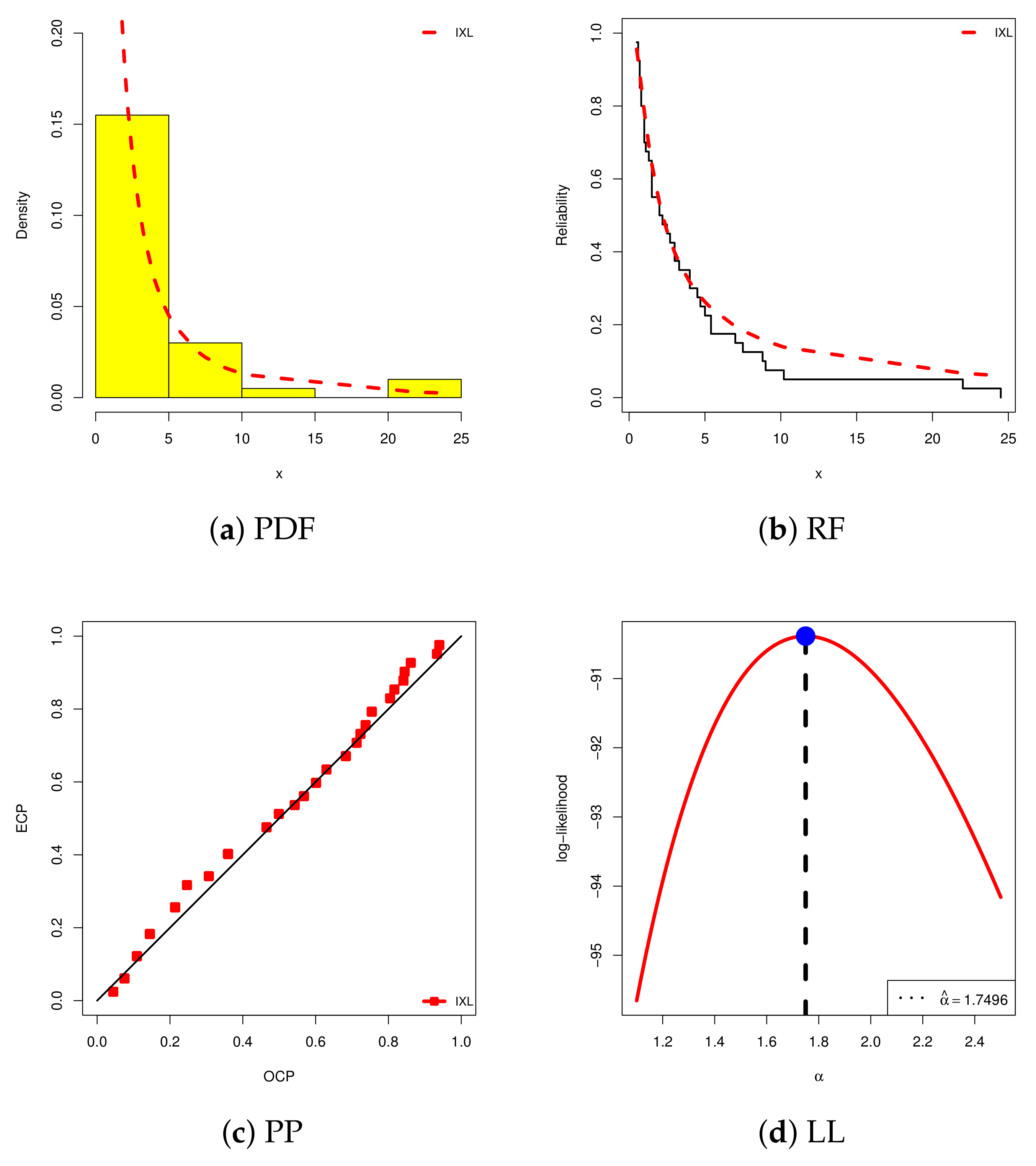
In
Figure 5, we employ four visual aids to examine the superiority of the newly formed IXL model, namely (i) the estimated PDF, (ii) the estimated RF, (iii) the estimated probability–probability (PP), and (iv) the log-likelihood (LL). This confirms that the IXL model under investigation is the best option and reflects the computational information provided in
Table 16. Additionally, from
Figure 5d, the frequentist estimate of
exists and is unique, as well as being chosen as the initial guess in all subsequent evaluations.
From
Table 15, based on different levels of
and
three IT2-APC samples (with
) are obtained; see
Table 17. Because prior knowledge on the IXL model from the collection of the ACT data is unavailable, the Bayes estimates, in addition to their BCI/HPD interval estimates of
,
, or
(at
), are obtained using the gamma improper prior. By simulating 40,000 MCMC iterations and discarding the first of them as 10,000 burn-ins, following the M-H steps, the Bayes point and interval estimates are computed. For each artificial sample and for each unknown quantity, the point estimations (including the maximum likelihood and Bayes MCMC methods) with their St.Errs and the interval estimations (including the 95% ACIs-NA, ACIs-NL, BCIs, and HPD intervals) with their interval lengths (ILs) are obtained; see
Table 18. It is clear from
Table 18 that the estimates we obtained for
,
, or
using the maximum likelihood and Bayes approaches are very close to each other. The same pattern is also achieved when comparing the calculated asymptotic interval estimates with those created from the credible interval estimates. Moreover, in terms of the minimum St.Err and IL values, the point and interval estimates created using the Bayes MCMC framework behaved better than the others.
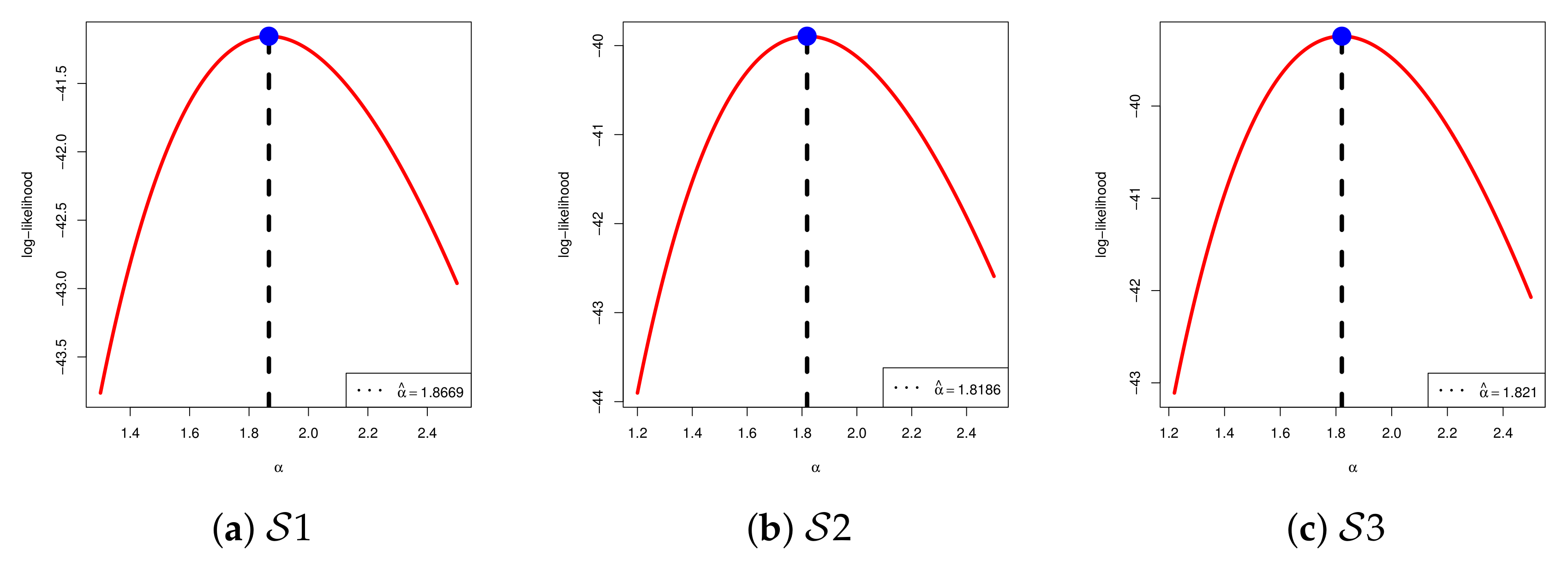
To demonstrate the existence and uniqueness of the MLE of
offered, for
the log-likelihood curves shown in
Figure 6 illustrate that the MLE of
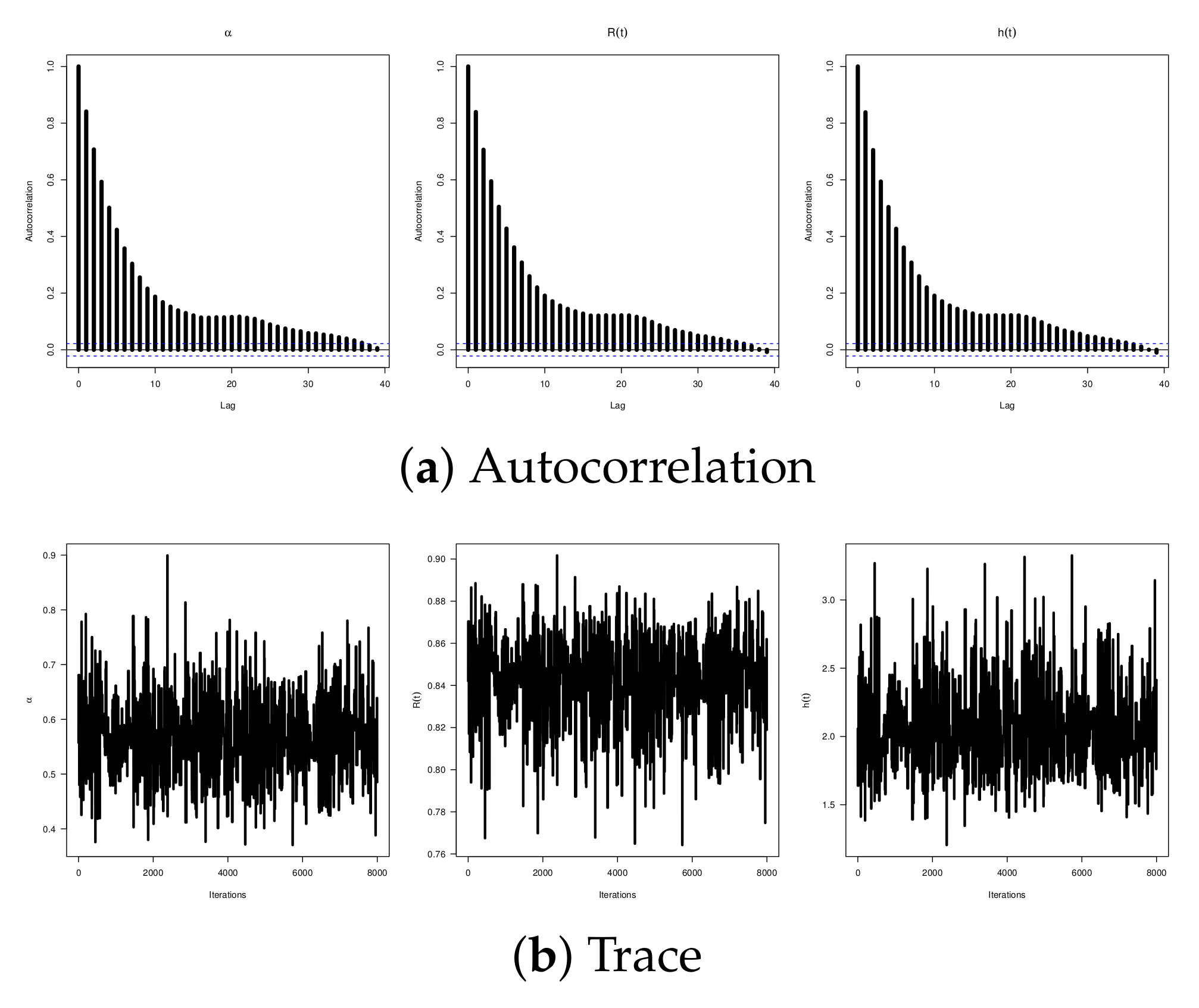
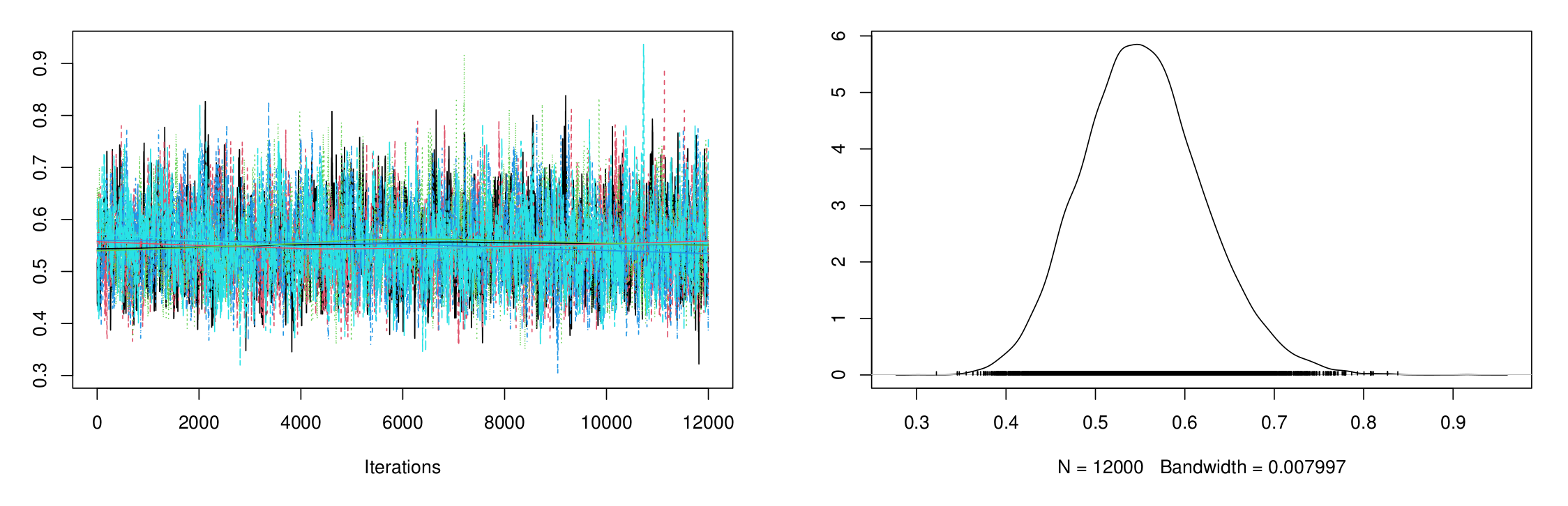
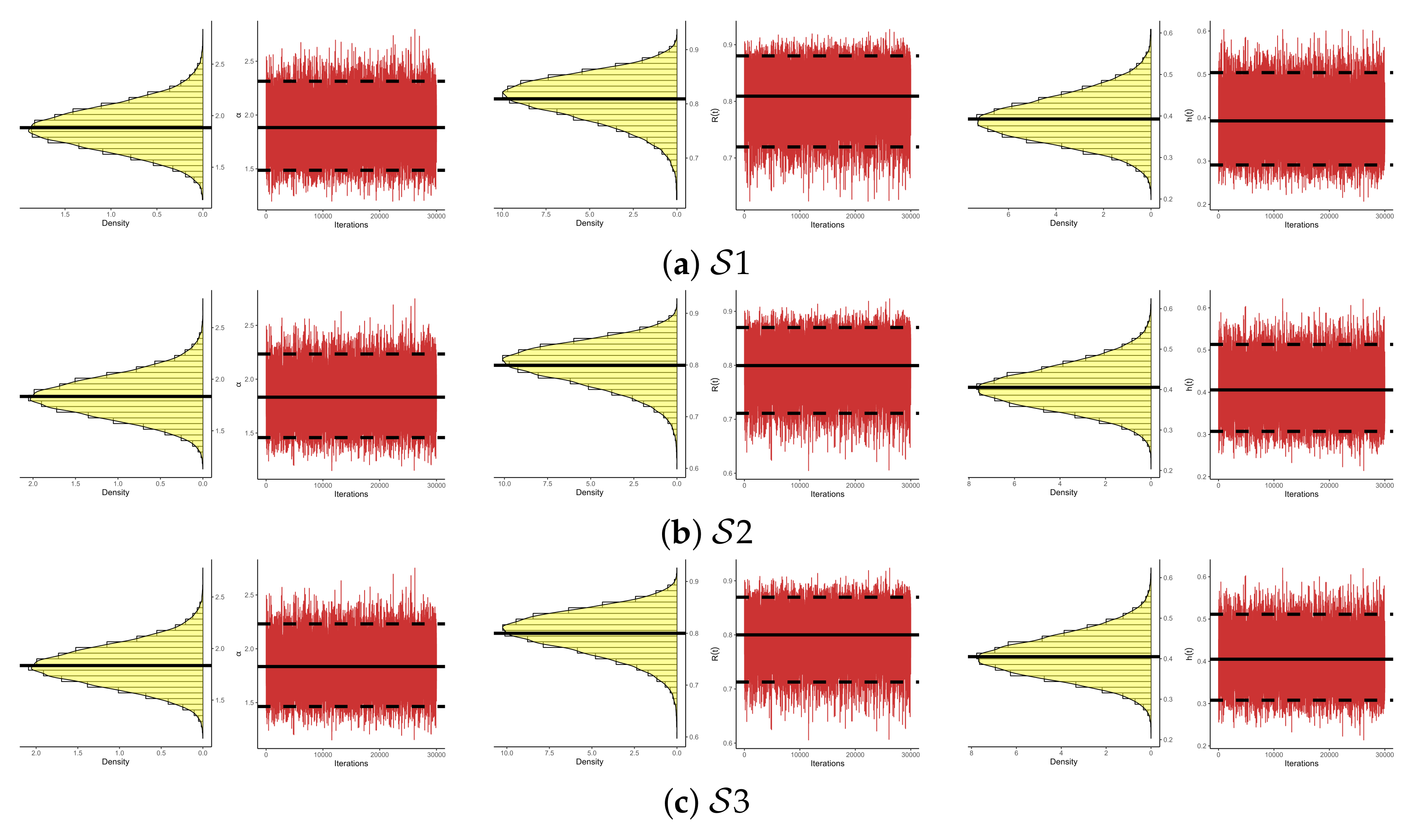
exists and is unique. On the other hand, to assess the convergence of the 30,000 MCMC iterations of
,
, and
retained, both the trace and trace density for each parameter (using
) are depicted in
Figure 7. To distinguish them, the solid and dashed lines represent the Bayes point and BCI estimates, respectively. It reveals that the MCMC technique converges well, and the recommended burn-in sample size is enough. Furthermore, it also indicates that the 30,000 iterations of
and
collected are symmetrical, while those of
are negatively skewed.
To sum up, the ACT system produces bounded or skewed reliability data, making it well suited to the flexible inferential methodologies proposed in our study. Applying the IXL lifespan model within a Bayesian framework enables more accurate modeling of the uncertainty and failure risk, which is critical for reliability and safety assessments in aerospace systems.
6. Concluding Remarks
In this study, point and interval estimates of the scale parameter, the reliability function, and the failure rate function of the inverse XLindley distribution lifetime model are explored under the presence of an improved Type-II adaptive progressive censoring plan. The maximum likelihood method, a conventional approach, is used to estimate the unknown parameters, and two approximate interval estimations are tested using normal approximations of the acquired estimates. Bayesian estimations, on the other hand, incorporate a gamma prior and the squared error loss function. Due to the complex nature of the posterior distribution, Bayes estimates are obtained through sampling using the Metropolis–Hastings algorithm. Additionally, two credible interval estimates are provided. To compare the point estimates obtained using both the classical and Bayesian methodologies, as well as the four interval estimation procedures, a simulation study is carried out using various sampling plans that account for different effective numbers of failures, removal patterns, and threshold times. Based on the findings, we found that the Bayes estimates with informative priors outperform the classical estimates in terms of their minimum root mean square error and mean relative absolute bias. An identical outcome was observed for interval estimations using the interval width and coverage probability criteria. The highest posterior density credible intervals outperformed the Bayes credible intervals, and both were superior to the two classical interval estimates. Finally, the proposed methods were applied to analyzing an actual dataset containing the active repair durations of an airborne communication transceiver. This investigation demonstrated the efficiency of the inverse XLindley distribution across a variety of commonly used models. As a direction for future study, it would be useful to examine Bayesian estimations for the inverse XLindley distribution under asymmetric loss functions, such as the LINEX and general entropy loss functions. These loss functions are mainly suitable for reliability analyses where the costs of overestimation and underestimation may vary. Another possible approach in future research is to explore the estimation challenges for the inverse XLindley distribution in more complex environments, such as scenarios involving numerous reasons for failure, or under accelerated life-testing conditions.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}