1. Introduction
In many scientific disciplines, such as genomics, finance, and medical research, comparing the variability structures of multiple groups plays a crucial role in understanding group differences. In multivariate data analysis, these structures are often characterized by covariance matrices, which capture not only the spread of variables but also their mutual relationships. Before conducting comparisons of mean vectors using techniques such as the Hotelling
test or MANOVA, it is essential to verify whether the covariance matrices across groups are homogeneous [
1,
2].
The assumption of homogeneity of covariance matrices, often referred to as the multivariate version of the Behrens–Fisher problem, underlies the validity of many multivariate hypothesis tests. Violations of this assumption can lead to misleading statistical conclusions. For this reason, testing the equality of covariance matrices is a fundamental problem in multivariate statistics [
1].
Classical methods, such as Box’s M test [
3], have long been used to assess the equality of covariance matrices. However, this test requires that the sample size be larger than the number of variables, and it is highly sensitive to outliers. As high-dimensional datasets have become increasingly common in modern research, especially when the number of variables
p exceeds the sample size n, the limitations of classical approaches have become more pronounced.
In recent years, several methods have been proposed for application in high-dimensional settings. Notable among them are the tests developed by Schott [
4], Srivastava and Yanagihara [
5], and Li and Chen [
6], which are based on Frobenius norms of covariance matrix differences. Additionally, Yu [
7] introduced a permutation-based approach that does not rely on any distributional assumptions and has shown promising results for multi-sample high-dimensional comparisons.
Despite these advances, the existing methods still suffer from a major limitation: they are not robust to outliers. This study addresses this gap by proposing a novel test statistic that is applicable in high-dimensional settings and remains reliable even in the presence of outliers. Our approach is based on minimum regularized covariance determinant (MRCD) estimators [
8] and utilizes a permutation-based framework, eliminating the need for distributional assumptions. The proposed method was evaluated through extensive simulation studies and a real data application to demonstrate its type-1 error control, power, and robustness.
The rest of the paper is organized as follows.
Section 2 introduces the tests used to test the homogeneity of covariance matrices in high-dimensional data in the literature. In
Section 3, we introduce the MRCD estimators.
Section 4 introduces the proposed test procedure.
Section 5 presents a simulation study to compare the type-1 error control, power, and robustness properties of the proposed approach with the
statistic proposed by Yu [
7].
Section 6 exemplifies the use of the proposed approach with a real data application.
Section 7 introduces the R function developed to apply the proposed approach in real data studies. Finally,
Section 8 presents a discussion.
2. Literature Review
The homogeneity of variances is an important issue for inferential statistics [
1,
4]. In univariate mean tests (
t-test or ANOVA), unequal variances are referred to as the univariate Behrens–Fisher problem. Similarly, in the Hotelling
and MANOVA methods used for the comparison of multivariate mean vectors, there is an assumption that the variance–covariance matrices of the groups are equal [
1,
2]. This assumption is called the homogeneity assumption, and not meeting this assumption is called the multivariate Behrens–Fisher problem. Hypotheses about the equality of covariance matrices are established as follows:
where
is the covariance matrix of the
group, and
is the number of groups. To test these hypotheses, let us draw samples with sample sizes of
units from multivariate normal distributions. Let the sample covariance matrices of these samples be
, respectively. Accordingly, we can use the test statistic to test the null hypothesis given in (1):
where
When
, we reject the null hypothesis [
1,
2]. However, the test statistic given in Equation (2) can be only used for low-dimensional data where
and the samples come from multivariate normal distribution [
3].
In addition to hypothesis testing procedures, recent studies have focused on improving covariance matrix estimation in high-dimensional settings. Among these, shrinkage-based estimators have attracted particular attention due to their ability to produce well-conditioned covariance estimates when the number of variables exceeds the sample size. Ledoit and Wolf [
9] introduced a linear shrinkage estimator that combines the sample covariance matrix with a structured target to stabilize estimation. Similarly, Schäfer and Strimmer [
10] proposed a shrinkage approach particularly suited to applications in genomics and functional data analysis. Although our study focuses on hypothesis testing, incorporating such estimation techniques can improve the reliability of test statistics in challenging high-dimensional scenarios.
Several tests have been proposed to test hypotheses about the equality of covariance matrices in high-dimensional data [
4,
5,
6,
7,
11]. Schott [
4] and Srivastava and Yanagihara [
5] have suggested tests to compare any two covariance matrices based on the Frobenius norm. Similarly, Li and Chen [
6] proposed a test statistic based on Frobenius norm to test the hypothesis about the equality of two covariance matrices of two independent high-dimensional groups. Their test statistic is given in Equation (5).
where, under the assumption that
, we can calculate the
and
values as follows:
Li and Chen [
6] defined the asymptotic distribution of
statistic under the null hypothesis
as follows:
This test proposed by Li and Chen [
6] can test the null hypothesis given in (1) when the number of groups is two. To solve this problem, Wang [
11] proposed to divide the null hypothesis given in (1) into
pieces and to use the
statistic defined in Equation (5) to test these hypotheses. For this purpose, we can rewrite the null hypothesis in (1) as
, where the
and
hypotheses can be written as follows:
Because there are g − 1 comparisons, we use the Bonferroni correction. Accordingly, the test is performed according to the largest of the calculated statistics by absolute value. If the null hypothesis cannot be rejected according to this statistic, then that the null hypothesis given by (1) cannot be rejected.
Yu [
7] suggested a permutation test to compare covariance matrices and to test the null hypothesis in Equation (1) in high-dimensional datasets. Let
be the sample covariance matrix of the
group
. The pooled covariance matrix can be calculated as follows:
If the mean vectors of the groups are zero vectors,
can be used for the pairwise comparison of the covariance matrices of the
and
groups. We can define
as follows:
where
are non-zero eigenvalues of the matrix
, and
is a diagonal matrix and has the same diagonal elements as
. Yu [
7] proposed the following test statistic:
Because the distribution of the
statistic is not known, Yu [
7] proposed using a permutation approach to obtain the sampling distribution of the test statistic. Detailed information is available in [
7].
All of the approaches introduced above are sensitive to outliers in the dataset since they are based on classical estimations. This study aims to propose a test statistic to compare the covariance matrices of
-independent groups in high-dimensional data contaminated with outliers. The proposed test statistic is based on the minimum regularized covariance determinant (MRCD) estimations introduced in
Section 3. Details of these estimations are given in
Section 4.
3. MRCD Estimators
Outliers in multivariate data can significantly distort classical estimates of location and dispersion. The minimum covariance determinant (MCD) estimator is a robust alternative that is less sensitive to outliers. This makes it ideal to estimate the location and scatter parameters in contaminated data. However, MCD estimates cannot be used in high-dimensional data where the number of variables exceeds the sample size . This limitation restricts its applicability in high-dimensional data.
Boudt et al. [
8] proposed minimum regularized covariance determinant (MRCD) estimators of location and scatter parameters without being affected by outliers in high-dimensional data. The MRCD estimator retains the good breakdown point properties of the MCD estimator [
8,
12].
To compute MRCD estimates, we first standardized the data using the median and
as the univariate location and scatter estimators [
13], and then used the
target matrix. This
matrix was symmetric and positive definite. The regularized covariance matrix of any subset
obtained from the standardised
data was computed as follows:
where
is the regularization parameter,
is the consistency factor defined by Croux and Haesbroeck [
14], and
MRCD estimations are obtained from the subset
, which is obtained by solving the minimization problem given by Equation (14).
where
is the set of all subsets with size
in the data. Finally, the MRCD location and scatter estimators were obtained as given in Equations (15) and (16).
where
and
are the eigenvalues and eigenvector matrices of
, respectively. Also,
was calculated as follows:
More detailed information on the MRCD estimators can be found in [
8]. In this study, we used the “
rrcov” package in R software for calculations regarding the MRCD estimators [
15]. When using this package, we assumed that we knew the outlier rate of the data. We also preferred to use the default values of the regularization parameter (rho) and the target matrix. This function automatically calculates these values from the dataset.
4. Proposed Test Statistic
To test the equality of covariance matrices in high-dimensional data, the test statistics given by Equations (10) and (11) have been shown to be more successful than alternative methods [
7]. However, since these test statistics are based on classical covariance matrices, they are affected by outliers in the dataset. Moreover, the
matrix used in these test statistics is a diagonal matrix consisting of the
covariance matrix. Therefore, it only considers the variances of the variables and excludes the relationships among the variables.
In this study, to test the null hypothesis given by (1) in contaminated high-dimensional data, we propose using the MRCD estimators introduced in
Section 2 instead of the classical estimators in the test statistics given by Equations (10) and (11). We also recommend using the
matrix directly instead of the
matrix to take the relationships among the variables into account in the test statistics. In the proposed approach, the
matrix can be calculated by using spectral decomposition as follows:
where
is the diagonal eigenvalue matrix of
, and
is the orthogonal eigenvector matrix. We calculated the
matrix based on the MRCD estimations, as given in Equation (20).
where
is the MRCD covariance matrix of the
group
.
If the mean vectors of the groups are zero vector,
can be used for pairwise comparison of the covariance matrices of the
and
groups as follows:
where
are the non-zero eigenvalues of the matrix
, and
is calculated as given in Equation (20). We propose the following test statistic to test the null hypothesis given in (1):
Because the distribution of the
statistic is not known, we can use a permutation approach to obtain the sampling distribution of the test statistic as proposed by Yu [
7]. For this purpose, we propose the following Algorithm 1 to test the null hypothesis:
| Algorithm 1: Robust test for comparison of covariance matrices |
Let be the observation vector in the group . Combine all observation vectors to the data . Randomly distribute the observations in the data into groups such that there are observations in the group. After this operation, let represent the observations in the group. For each group, calculate the MRCD covariance matrices based on the observations and calculate the statistic given by Equation (22). Let us denote this statistic as . Repeat steps (i)–(iii) times and calculate the statistics at each step. Calculate the p-value as follows:
|
When the p-value is lower than the significance level, the null hypothesis given by (1) is rejected, indicating that the covariance matrices are not homogeneous.
If the mean vectors are not equal to the zero vectors, then the test statistic given by Equality (22) is defined as follows:
where
,
, and
is the transpose operator. Here,
is calculated as given in Equation (20), and
is the MRCD location estimation of the
group.
Lemma 1. Let be the number of test statistics computed from randomly sampled permutations (without replacement) that are more extreme than the observed test statistic . Then, the p-value defined asis a consistent estimator under the null hypothesis and converges to the true significance level as , provided that the permutation distribution approximates the true null distribution. □
This formulation aligns with the permutation-based inference strategy described by Yu [
7] and is widely used in the literature for high-dimensional testing problems. Although alternatives, such as
have been proposed [
16] to avoid zero
p-values and improve small-sample behavior, we did not observe any zero
p-values in our simulation settings. Thus, the classical estimator
remains practically appropriate and computationally efficient in our context.
The test we propose can test whether the covariance matrices of high-dimensional independent groups are equal or not without being affected by outliers in the dataset. Moreover, since it is a permutation test, it does not require any distributional assumption.
The proposed test statistic integrates a robust covariance estimation approach (MRCD) with a permutation-based inference strategy. This design grants the test several important theoretical properties:
Nonparametric nature: The test does not require multivariate normality. Its null distribution is derived empirically via permutation of the group labels. Under the null hypothesis and assuming exchangeability, this ensures exact control of type-1 error in finite samples.
Robustness to outliers: Unlike the
TMYU test, the
TMMRCD test based on MRCD estimations is robust to outliers in data. The MRCD estimator, while not affine equivariant due to the use of a fixed regularization matrix, offers strong resistance to outliers. It guarantees a minimum eigenvalue bounded away from zero when the regularization parameter is applied, resulting in a 100% implosion breakdown value [
8]. Though not maximally robust in all directions, this feature provides practical protection against severe contamination.
Finite sample validity: Since permutation testing is used, type-1 error control holds in finite samples, making the procedure reliable even for small sample sizes, provided that the group labels are exchangeable.
Asymptotic behavior: Although a formal proof of asymptotic consistency is beyond the scope of this paper, the simulation results show that the type-1 error rates stabilize near the nominal level as the sample size increases. This is consistent with findings from the permutation test literature.
High-dimensional applicability: Unlike Box’s M test, which fails in high-dimensional contexts, TMMRCD remains valid and operational. This makes it suitable for applications such as gene expression analysis, where the number of variables often exceeds the sample size.
These properties make a robust and flexible tool for covariance matrix comparison in challenging data environments.
5. Simulation Study
In this section, we perform simulation studies to compare our statistics with the
statistic proposed by Yu [
7] and the
statistic suggested by Box [
3]. Since the
statistic can only be used for low-dimensional data, it is not included in the comparisons for high-dimensional data. In the simulation studies, we compared the test statistics according to the type-1 error, power, and robustness performance. The significance level was
for all tests. Although these test statistics can measure the covariance matrix of two or more groups, only three group covariance matrices were compared in the simulation studies. In other words, each test evaluated the null hypothesis
.
In the simulation study, the sample sizes of the groups were taken as equal to each other. Accordingly, the sample sizes were taken as 10, 30, and 60. The number of variables was determined as 5, 10, 50, 100, and 300. Therefore, both low-dimensional and high-dimensional data were included in the dataset used in simulation studies. In each step of the simulation study, the number of trials was taken as 1000 repetitions.
5.1. Comparisons of Type-1 Error Rates
To investigate the type-1 error performance of our proposed test, we compared the rejection rates when the null hypothesis which was true. Similar to the simulation study used by Yu [
7], the diagonal elements of the
matrix were
and its non-diagonal elements were
. In order for the null hypothesis to be true, we defined the other covariance matrices as
.
We generated datasets under two scenarios: multivariate normal distribution and mixed distributions. We give details about these scenarios below. To make more precise comparisons in terms of type-1 error, the average relative error (ARE) values were calculated for each statistic. The ARE values indicate the deviation of the test statistic from the nominal significance level of type-1 proportions and were calculated as given in Equation (25).
where
is the number of type-1 error rates calculated for each statistic in the table,
is the number of type-1 error rates, and
is the nominal significance level used in the testing process. In this study, we used the significant level
as 5%. We can say that the test statistic with the smallest ARE value had a higher performance in terms of the type-1 error rate.
Scenario 1: We generated datasets from multivariate normal distribution. For this purpose, the mean vectors were set as
without any loss of generality. Accordingly, observations in each group were randomly generated from
such that the sample sizes were
. We tested the null hypothesis
which is true in this case. The obtained results are presented in
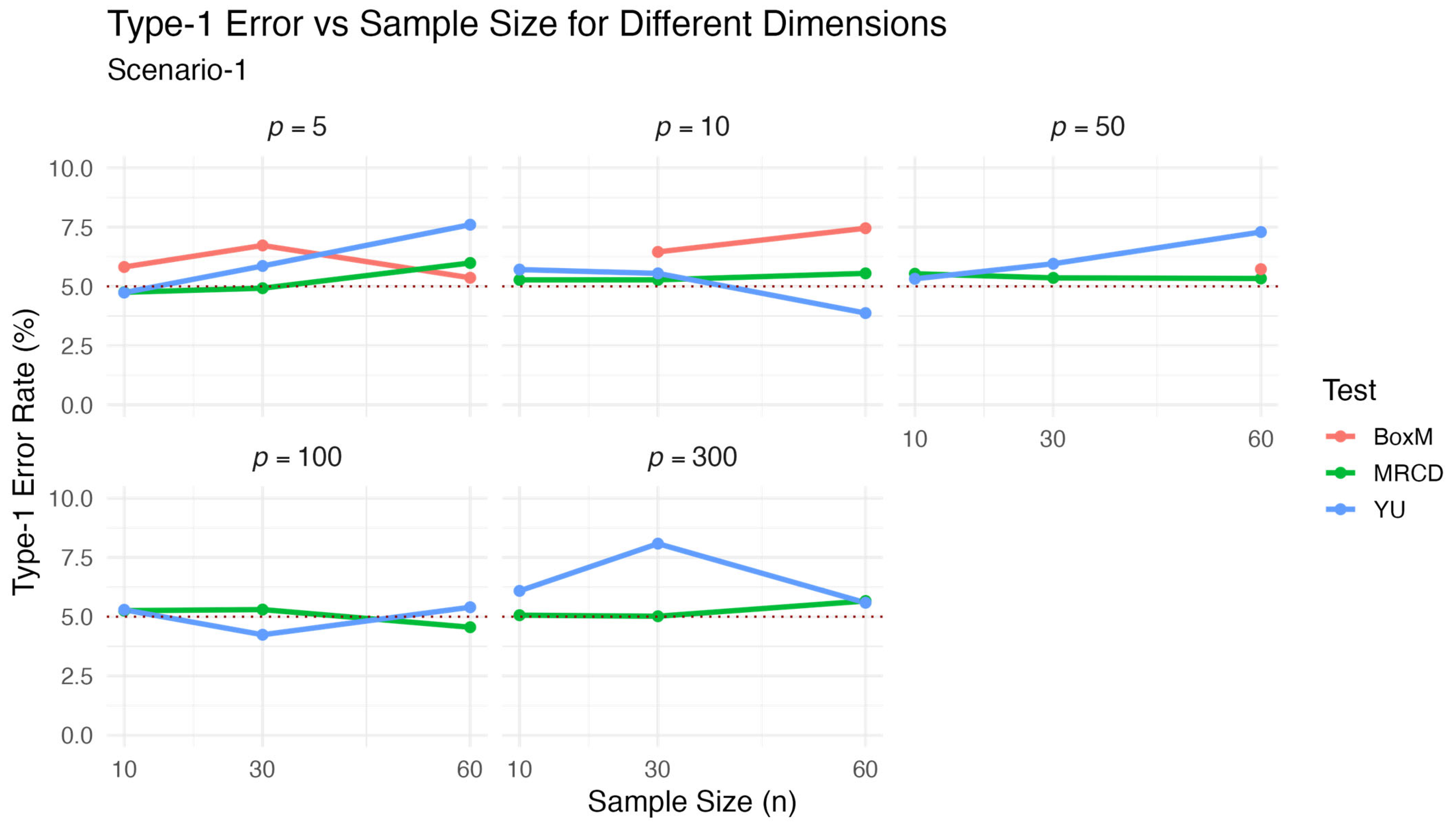
Table 1 and visualized in
Figure 1.
The results presented in
Table 1 and illustrated in
Figure 1 show the behaviors of the three test statistics in terms of type-1 error control under various sample sizes and dimensional settings. The proposed
test consistently yielded rejection rates that were closest to the nominal 5% level across all considered scenarios. This accuracy is reflected in its notably lower average relative error (ARE) compared to the alternative methods. In contrast,
tended to deviate from the nominal level, especially for higher values of
, while Box’s M test was applicable only in low-dimensional settings and exhibited greater variability. The graphical representation reinforces these numerical findings and highlights the comparative advantage of the proposed test in controlling the type-1 error rate under Scenario 1.
After the datasets were generated in this way, we tested the null hypothesis
, which is actually true. The
,
and
values used here correspond to those given in Scenario 1. The results are presented in
Table 2 and visualized in
Figure 2.
The simulation results under the mixed distributed data are summarized in
Table 2 and visualized in
Figure 2. The
statistic continued to exhibit robust performance in controlling the type-1 error rate, yielding rejection rates that remained consistently close to the nominal level across all combinations of n and
p. This is reflected in the lowest ARE value (6.254) among the three methods. The
test also performed reasonably well in this setting, with moderate deviations from the nominal 5% level, particularly at higher dimensions. In contrast, the classical Box’s M test showed severe inflation of type-1 error rates under the mixed distribution, with values exceeding 25% in all applicable scenarios. For this reason, the Box M test was excluded from
Figure 2 to improve the readability and visual interpretability of the results.
In both
Figure 1 and
Figure 2, the horizontal dashed line represents the nominal 5% significance level; test statistics with values closer to this line are considered more accurate in terms of type-1 error control.
5.2. Comparison of Powers
To examine the power performance of the proposed approach, we compared the rejection rates when the null hypothesis was false. Similar to the simulation design used by Yu [
7], the
matrix was defined as shown in
Section 5.1. However, we defined
and
to ensure the null hypothesis was false. Datasets were generated under two different scenarios: multivariate normal distribution and mixed.
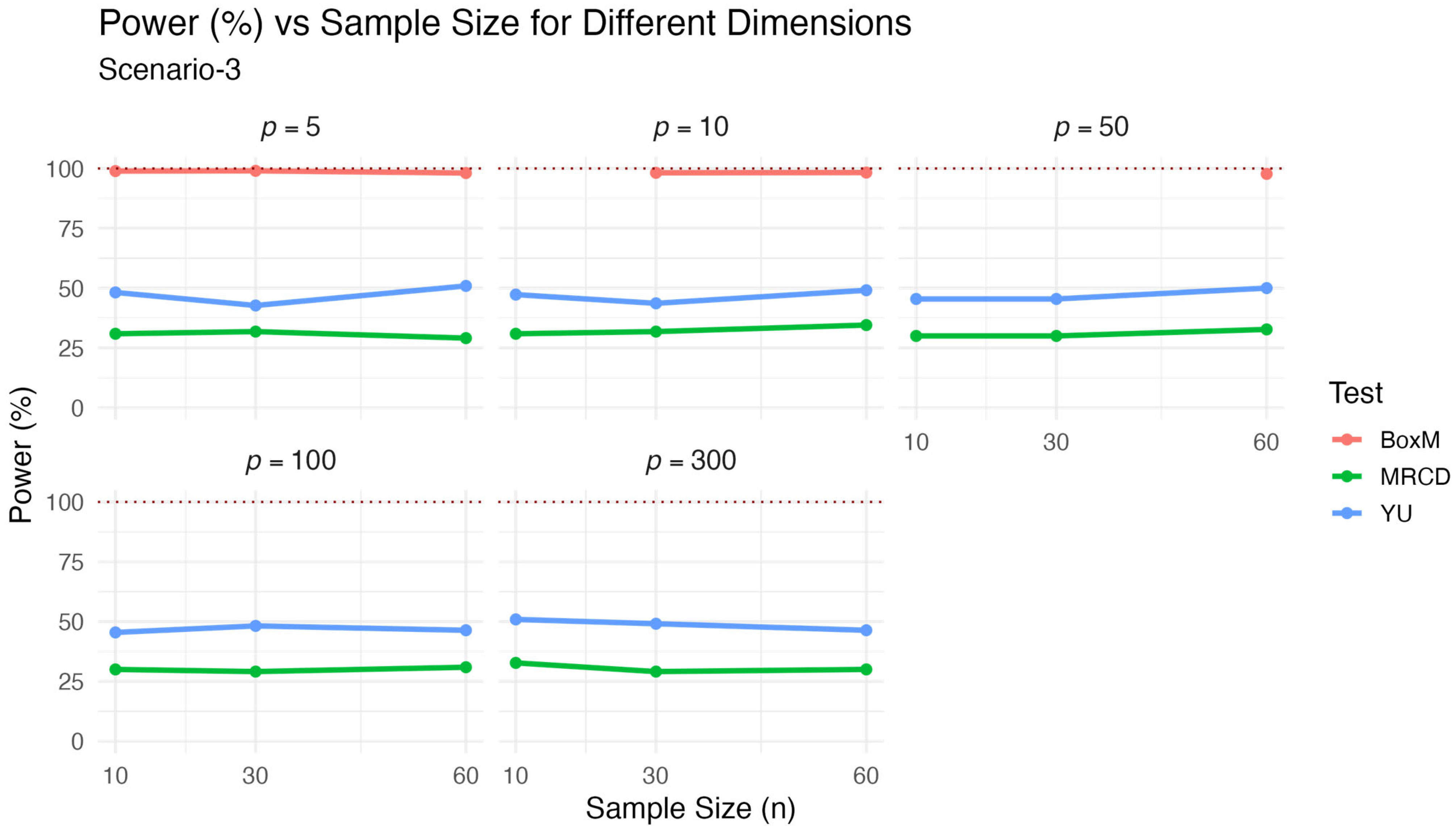
Scenario 3: We generated datasets from a multivariate normal distribution. For this purpose, the mean vectors were set as
without any loss of generality. Accordingly, observations in each group were randomly generated from
such that the sample sizes were
. We tested the null hypothesis
, which is false. The power performance of the test statistics under multivariate normal distribution is presented in
Table 3 and visualized in
Figure 3.
As expected, the classical Box’s M test yielded the highest power values across all scenarios, often exceeding 95%. However, this high power comes at the cost of poor type-1 error control in high-dimensional or non-normal data, as shown in previous results. The test exhibited moderately high power, typically ranging between 43% and 51%, and remained relatively stable across dimensions. The proposed test demonstrated the lowest power values among the three, generally around 30%, but still consistent across varying sample sizes and dimensions. These results reflect the classical trade-off between power and robustness: while is more conservative, it provides strong type-1 error control even in contaminated or non-normal data settings. Therefore, although its power is slightly lower, it offers a more reliable alternative when robustness is essential.
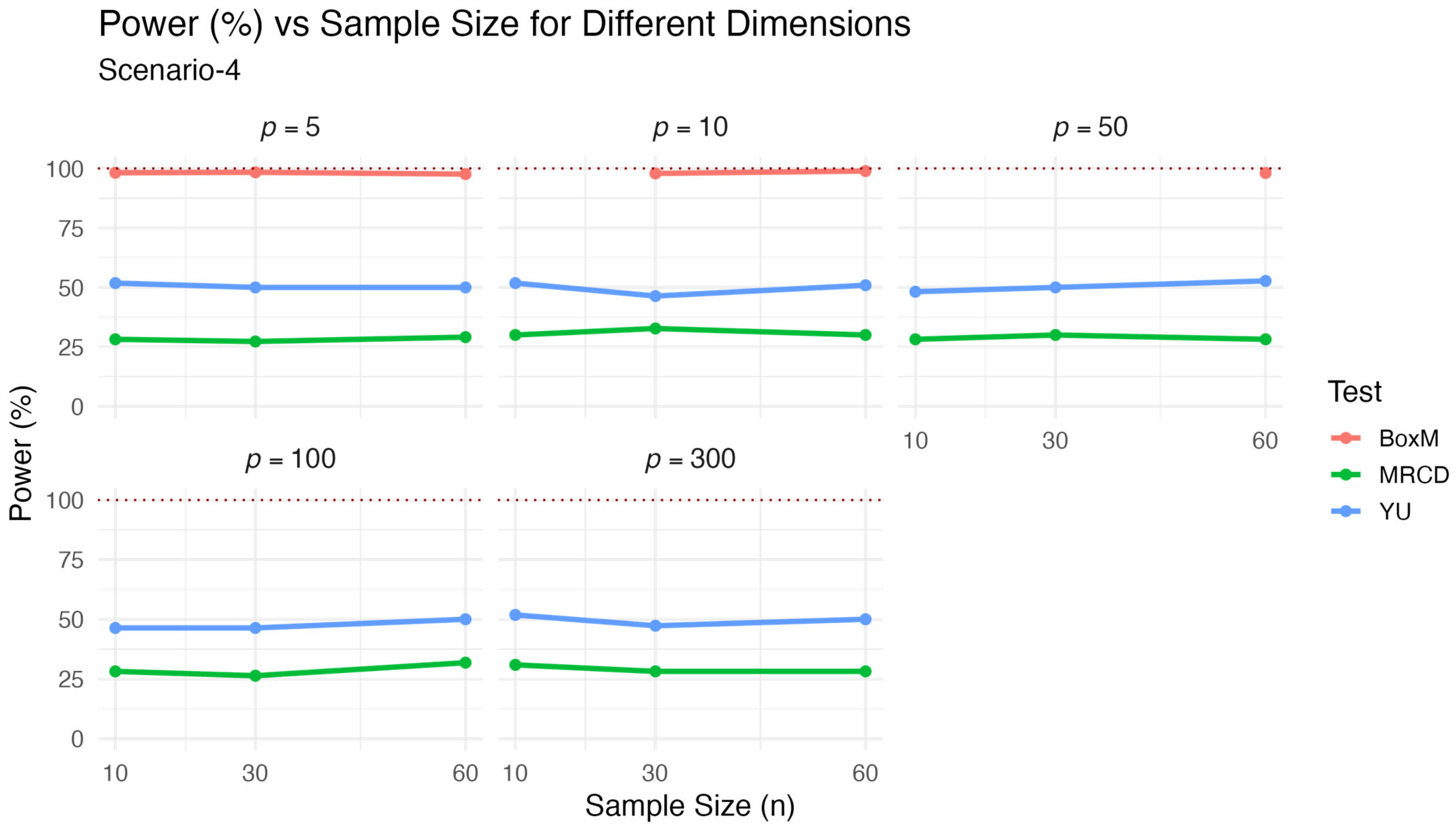
Scenario 4: In this scenario, we generated observations as defined in Scenario 2. Unlike in Scenario 2, the
matrices were different from each other here. After the datasets were generated in this way, we tested the null hypothesis
which is actually false. The
p,
and
values used here were as given in Scenario 3. The results are presented in
Table 4 and visualized in
Figure 4.
The results for Scenario 4, which involved mixed distributed data under the alternative hypothesis, are presented in
Table 4 and visualized in
Figure 4. Similar to the previous scenario, Box’s M test showed the highest power values, often exceeding 97%, but its known sensitivity to distributional deviations limits its practical reliability. The
test maintained stable and moderately high power across varying dimensionalities and sample sizes, typically around 50%. The proposed
test again demonstrated lower power, generally between 26% and 32%, but its behavior remained consistent across the simulation settings. These results align with the classical robustness–power trade-off, where
prioritizes robustness and type-1 control over maximizing power. While the power of the proposed test was lower in this contaminated data scenario, its performance did not substantially deteriorate, suggesting resilience under non-ideal conditions.
5.3. Comparisons of Robustness
In order to examine the robustness of the proposed approach to outliers, we first contaminated the dataset and then calculated the rejection rates of the null hypothesis, which is true. The observations generated here can be categorized as regular and outliers. Here, too, the data were contaminated with two different scenarios. In each case, the covariance matrices were generated as those given in
Section 5.1.
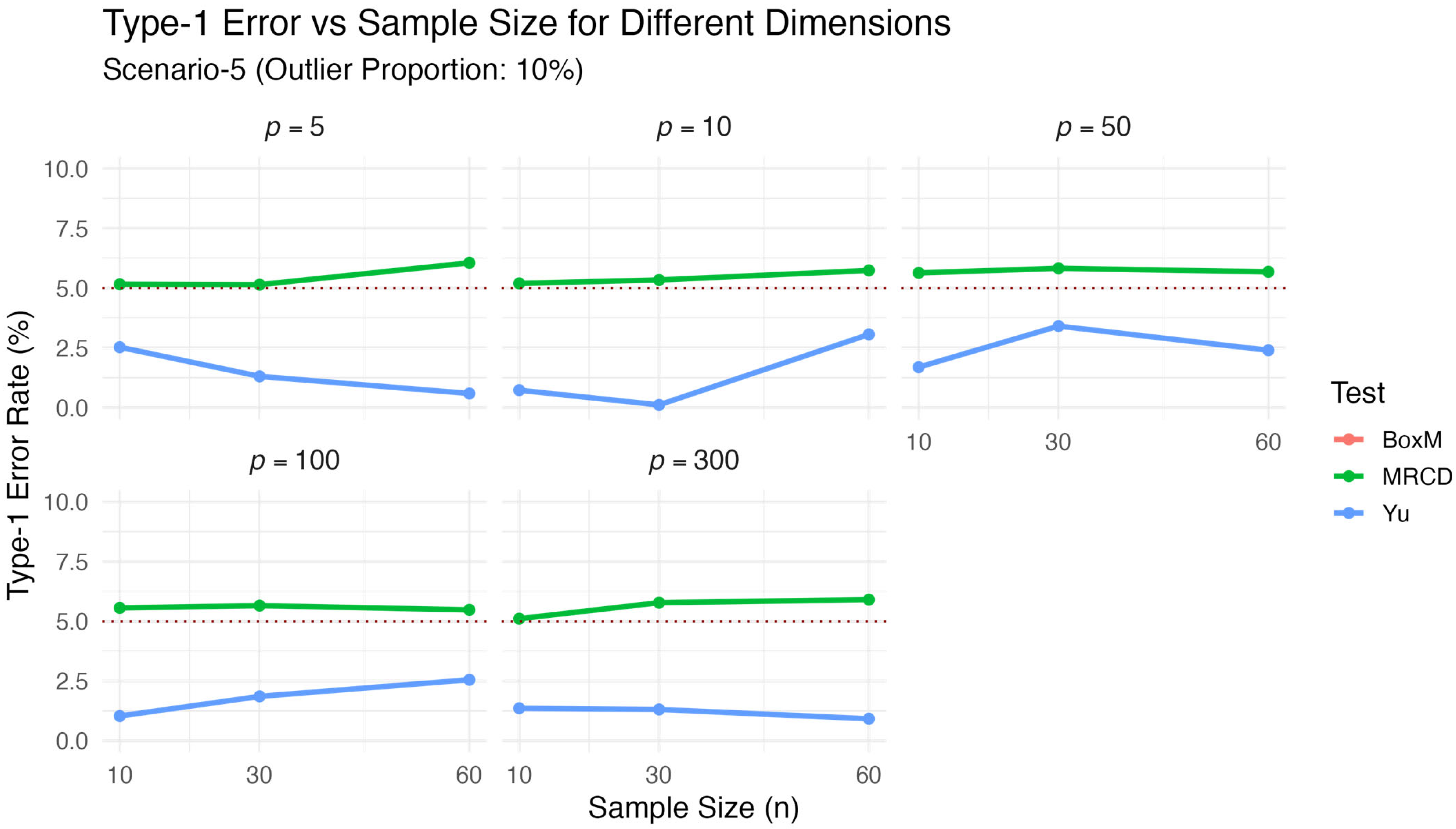
Scenario 5: We generated datasets from a multivariate normal distribution. To generate regular observations, we set the mean vectors as without any loss of generality. Accordingly, regular observations in each group were randomly generated from . The proportion of regular observations in the data was , where denotes the contamination rate. In Scenario 5, we used and 25 for sensitivity analysis. Outliers were generated from multivariate normal distributions , with the following group-specific mean vectors:
Although the mean vectors of the outliers differed among the groups, the covariance matrices remained identical, ensuring that the null hypothesis remained true even under contamination. Finally, we tested the null hypothesis
which holds in reality. The results for
are presented in
Table 5 and visualized in
Figure 5. Similarly, the results for
are presented in
Table 6 and visualized in
Figure 6.
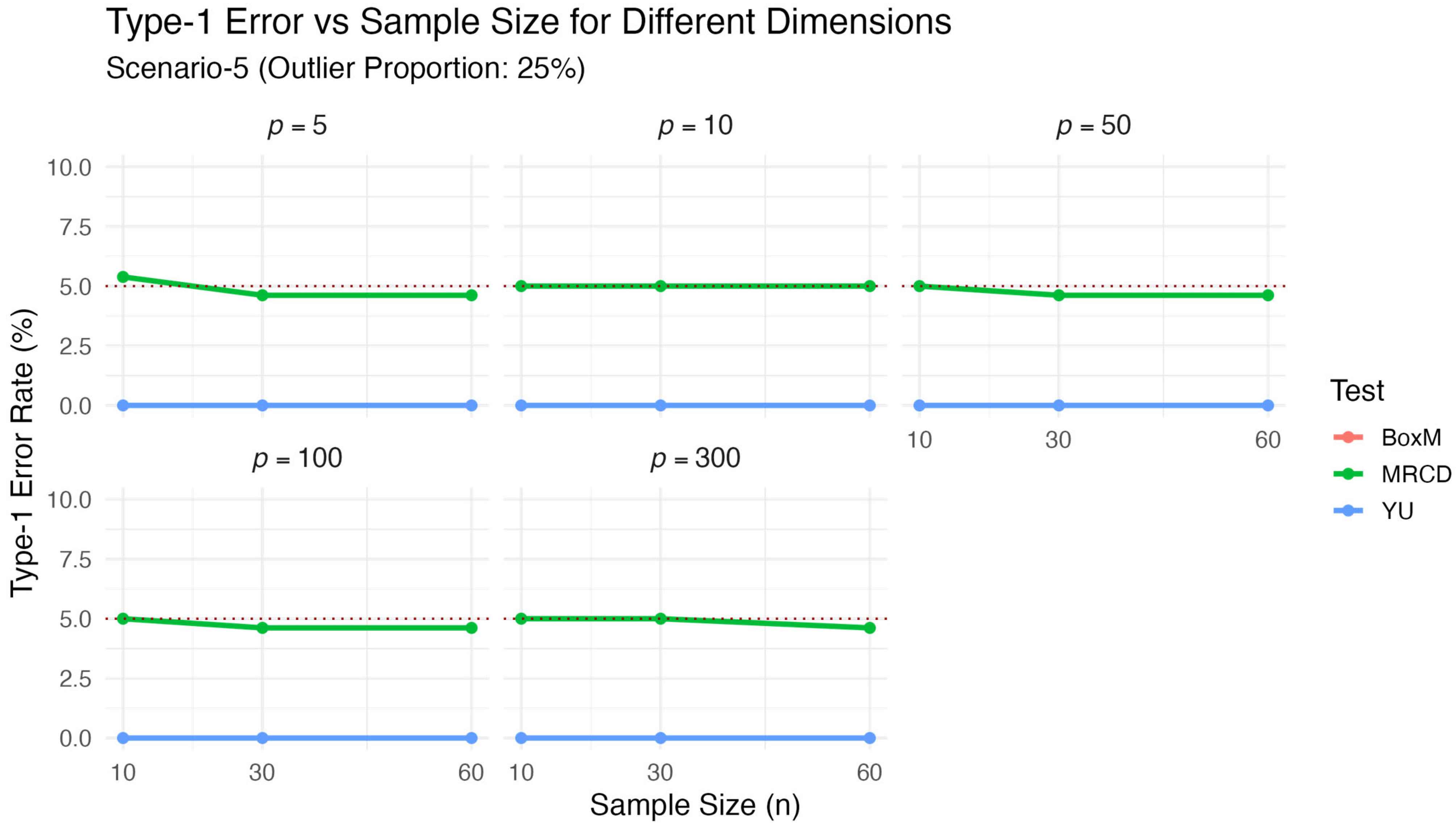
The results of Scenario 5 given in
Table 5 and
Table 6 and visualized
Figure 5 and
Figure 6, explore the sensitivity of the test statistics to outlier contamination by comparing the results obtained under 10% and 25% contamination levels. When benchmarked against the clean data scenario (Scenario 1;
Table 1 and
Figure 1), a clear pattern emerges: as the proportion of contamination increased, the performance of the classical Box’s M and
tests deteriorated significantly, while the proposed
test remained stable. Specifically, under 10% contamination, Box’s M exhibited severely inflated type-1 error rates (ARE = 522.667), and
also showed poor robustness (ARE = 66.855). This effect became even more pronounced under 25% contamination, where Box’s M failed entirely (ARE = 672.444) and
consistently returned zero
p-values, indicating excessive conservatism or breakdown. In contrast,
maintained type-1 error rates remarkably close to the nominal 5% level across all contamination levels, with decreasing ARE values as contamination increased (11.002 at 10% vs. 4.103 at 25%). This stable performance under increasing contamination levels confirms that the MRCD estimator is effective in identifying and limiting the impact of outliers. Overall, the results clearly demonstrate that the proposed
test provided strong robustness and reliability when the data included outliers.
Scenario 6: All observation values in this scenario were initially generated as described in Scenario 2. To contaminate the data, we modified the last observation vector in each group: the last observation in group 1 was multiplied by −5, in group 2 by 5, and in group 3 by 15. This approach introduced group-specific outliers of varying magnitude, which resulted in different contamination rates depending on the group sample sizes. Importantly, the null hypothesis
remained valid in this setting. The impact of these structured outliers on the performance of the test statistics was evaluated, and the results are presented in
Table 7 and
Figure 7.
Table 7 and
Figure 7 present the robustness performance of the test statistics under Scenario 6, in which structured outliers of varying magnitude were introduced to each group. As expected, the proposed
test maintained type-1 error rates close to the nominal 5% level across all combinations of n and
p. This stability is confirmed by the lowest ARE value (5.522) among the three methods. In contrast,
displayed substantial variability and inflated rejection rates, particularly for small sample sizes and moderate dimensional settings. The classical Box’s M test was severely affected by the contamination, with type-1 error rates exceeding 98% in nearly all configurations, yielding an extremely large ARE value of 1885.582. These findings confirm that the
test is highly robust to structured outliers, whereas both
and Box’s M failed to provide reliable control over the type-1 error under contaminated conditions.
6. Real Data Example
In this section, as in the simulation study, we analyze a real dataset to compare the performance of the proposed test statistic with the
statistic proposed by Yu [
7]. In this scenario, we used the dataset available at the NCBI website under the code GSE57275. This dataset includes 14 observations and 45281 genes (variables). In addition, these 14 observations are divided into three different groups.
These groups are called the controlled, infected, and infected-medication groups. The infected group consists of chips GSM1378192, GSM1378193, GSM1378194, and GSM1378195, resulting in a total of four observations in the first group. The infected-medication group consists of chips GSM1378196, GSM1378197, GSM1378198, GSM1378199, and GSM1378200. Finally, the control group consists of chips GSM1378201, GSM1378202, GSM1378203, GSM1378204, and GSM1378205. Therefore, there were five observations in both the second and third groups.
We tested whether the covariance matrices of these high-dimensional groups were equal or not and compared the test statistics. For this purpose, we also examined how the test statistics were affected as the ratio increased by determining different gene (variable) numbers. For this purpose, p values were chosen as 5, 20, 100, 300, 400, and 500. At all stages, the first p genes in the data were selected.
To examine the sensitivity of the test statistics to outliers, after performing the test process for clean data, we multiplied the last observation row in the first (infected) group by 10 and repeated this test process by creating an outlier in the dataset. Thus, we can see whether this outlier changed the decision made by the test statistics. The results are given in
Table 8.
According to
Table 8, the
and
statistics failed to reject the null hypothesis
when there were no outliers in the data
. The
statistic, however, rejected the null hypothesis when we added outliers to the data
. Accordingly, it is concluded that the outliers in the data changed the decision of the
statistic, indicating that this statistic is sensitive to outliers in data. On the other hand, the
statistic still failed to reject data contaminated with outliers. Therefore, we can say that the outliers in the data had no effect on the decision of the
statistic and that this statistic is robust to outliers.
7. Software Availability
We constructed the function RobPer_CovTest() in the R package entitled “MVTests” to perform the proposed robust permutational test on real datasets. This function needs four arguments: The data matrix is assigned to the argument x, and the grouping vector of observations is assigned to the argument group. The permutation number is assigned to the argument N (default of N = 100). Finally, the argument alpha, which takes a value between 0.5 and 1 (default of alpha = 0.75), can be used to determine the trimming parameter. The function obtains the p-value, the value, and the values. Due to this function, all researchers can use our proposed test statistics without being affected by outliers to compare covariance matrices in high-dimensional data. Researchers can install this package from GitHub by using the following code block:
install.packages(“devtools”)
devtools::install_github(“hsnbulut/MVTests”)
8. Conclusions
Classical methods cannot be used to test the equality of covariance matrices in high-dimensional settings because the classical covariance matrix becomes singular, making its determinant zero and inverse undefined. Several alternative methods have been proposed in the literature to address this problem, as summarized in
Section 2. However, these proposed tests are used for high-dimensional data, they are not robust to outliers in the data. To overcome this limitation, this study proposes a new test statistic,
, designed to compare covariance matrices in high-dimensional data while being resistant to outlier effects.
The performance of the proposed test was evaluated through an extensive simulation study focusing on its type-1 error control, statistical power, and robustness. In the simulation study, it was observed that the proposed approach had a lower ARE value in terms of type-1 than the
statistic proposed by Yu [
7]. Accordingly, it can be said that the proposed approach is more successful in terms of type-1 error rate. Although
exhibited higher statistical power,
remained competitive. Importantly, the robustness comparisons reveal that
maintained a low ARE under contamination while the
statistic became highly sensitive to outliers and yielded inflated rejection rates.
Although
does not permit closed-form distribution under the null or alternative hypotheses due to its permutation-based structure, its asymptotic consistency can be justified empirically and theoretically. Under the null hypothesis, permutation-based tests are known to control the type-1 error asymptotically [
17]. Under the alternative hypothesis, the proposed test statistic diverged from its permutation distribution as the group differences in covariance increased, thereby leading to the power converging to 1 as the sample size increased. This behavior is supported by the simulation results reported in
Table 1,
Table 2,
Table 3 and
Table 4.
To further compare their practical performance, we applied both test statistics to a real gene expression dataset. In these analyses, both the
and
statistics failed to reject the null hypothesis on clean data. However, when the data were contaminated, the
statistic no longer failed to reject the null hypothesis, while
maintained the same decision without being affected by the outliers. This real data example shows that the proposed test can be used on high-dimensional data without being affected by outliers. For a concise summary of the key differences among the proposed test
, the
statistic, and Box’s M test, we refer the reader to the comparative table provided in
Table A2 in
Appendix A.Finally, to support real-world applications, we implemented the proposed test as an R function in the MVTests package. In conclusion, we believe that the proposed approach can contribute to the literature not only theoretically but also practically.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}