
An Equivalence Theorem and A Sequential Algorithm for A-Optimal Experimental Designs on Manifolds

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Preliminaries and Literature Review
2.1. Classical Optimal Experimental Design on Euclidean Space
2.2. Manifold Learning and Manifold Regularization Model
3. Main Results
3.1. The A-Optimality Criterion
3.2. Equivalence Theorem for A-Optimal Designs on Manifolds
- (1)
- The experimental design is A-optimal under the LapRLS model (4), i.e., minimizes ;
- (2)
- The experimental design minimizes
- (3)
- ;
3.3. Sequential Algorithm with Finite Candidate Points
| Algorithm 1 ODOEM with discrete candidate points under the D-optimality criterion. |
|
| Algorithm 2 ODOEM2 with discrete candidate points under the A-optimality criterion. |
|
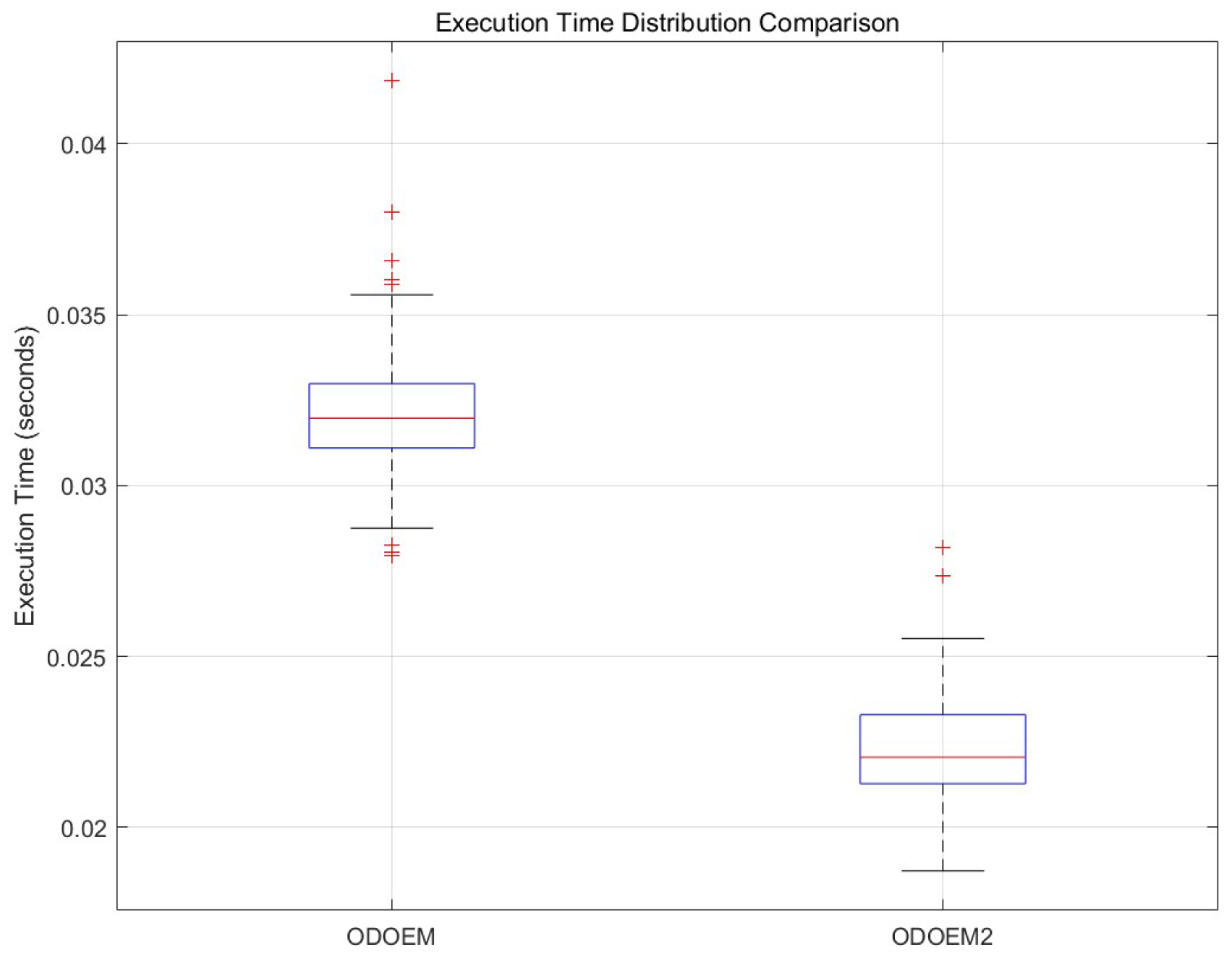
4. Simulation Study
4.1. Synthetic Manifold Datasets
4.2. Real Dataset: Columbia Object Image Library
5. Conclusions
6. Discussion
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kiefer, J.; Wolfowitz, J. The Equivalence of Two Extremum Problems. Can. J. Math. 1960, 12, 363–366. [Google Scholar] [CrossRef]
- Fedorov, V.V. Design of Experiments for Linear Optimality Criteria. Theory Probab. Its Appl. 1971, 16, 189–195. [Google Scholar] [CrossRef]
- Silvey, S.D. Optimal Design; Chapman and Hall: London, UK, 1980. [Google Scholar]
- Pukelsheim, F. Optimal Design of Experiments; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2006. [Google Scholar]
- Roweis, S.T.; Saul, L.K. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Tenenbaum, J.B.; de Silva, V.; Langford, J.C. A Global Geometric Framework for Nonlinear Dimensionality Reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Donoho, D.; Grimes, C. Hessian Eigenmaps: Locally Linear Embedding Techniques for High Dimensional Data. Proc. Natl. Acad. Sci. USA 2003, 100, 5591–5596. [Google Scholar] [CrossRef] [PubMed]
- Coifman, R.; Lafon, S.; Lee, A.; Maggioni, M.; Nadler, B.; Warner, F.; Zuker, S. Geometric Diffusions as a Tool for Harmonic Analysis and Structure Definition of Data: Diffusion Maps. Proc. Natl. Acad. Sci. USA 2005, 102, 7426–7431. [Google Scholar] [CrossRef] [PubMed]
- Belkin, M.; Niyogi, P.; Sindhwani, V. Manifold Regularization: A Geometric Framework for Learning from Labeled and Unlabeled Examples. J. Mach. Learn. Res. 2006, 7, 2399–2434. [Google Scholar]
- Meilă, M.; Zhang, H. Manifold Learning: What, How, and Why. Annu. Rev. Stat. Its Appl. 2024, 11, 393–417. [Google Scholar] [CrossRef]
- He, X. Laplacian Regularized d-optimal Design for Active Learning and its Application to Image Retrieval. IEEE Trans. Image Process. 2010, 19, 254–263. [Google Scholar] [PubMed]
- Chen, C.; Chen, Z.; Bu, J.; Wang, C.; Zhang, L.; Zhang, C. G-optimal Design with Laplacian Regularization. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010; Volume 1, pp. 413–418. [Google Scholar]
- Alaeddini, A.; Craft, E.; Meka, R.; Martinez, S. Sequential Laplacian Regularized V-optimal Design of Experiments for Response Surface Modeling of Expensive Tests: An Application in Wind Tunnel Testing. IISE Trans. 2019, 51, 559–576. [Google Scholar] [CrossRef]
- Li, H.; Del Castillo, E. Optimal Design of Experiments on Riemannian Manifolds. J. Am. Stat. Assoc. 2024, 119, 875–886. [Google Scholar] [CrossRef]
- Jones, B.; Allen-Moyer, K.; Goos, P. A-Optimal versus D-Optimal Design of Screening Experiments. J. Qual. Technol. 2020, 53, 369–382. [Google Scholar] [CrossRef]
- Stallrich, J.; Allen-Moyer, K.; Jones, B. D- and A-Optimal Screening Designs. Technometrics 2023, 65, 492–501. [Google Scholar] [CrossRef]
- Domagni, F.K.; Hedayat, A.S.; Sinha, B.K. D-optimal saturated designs for main effects and interactions in 2k-factorial experiments. Stat. Theory Relat. Fields 2024, 8, 186–194. [Google Scholar] [CrossRef]
- Belkin, M. Problems of Learning on Manifolds. Ph.D. Thesis, The University of Chicago, Chicago, IL, USA, 2003. [Google Scholar]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Jayasumana, S.; Hartley, R.; Salzmann, M.; Li, H.; Harandi, M. Kernel Methods on Riemannian Manifolds with Gaussian RBF Kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2464–2477. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.-H. Machine Learning; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Singh, V.P.; Bokam, J.K.; Singh, S.P. Best-case, worst-case and mean integral-square-errors for reduction of continuous interval systems. Int. J. Artif. Intell. Pattern Recognit. 2020, 17, 17–28. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Wang, Y. An Equivalence Theorem and A Sequential Algorithm for A-Optimal Experimental Designs on Manifolds. Axioms 2025, 14, 436. https://doi.org/10.3390/axioms14060436
Zhang J, Wang Y. An Equivalence Theorem and A Sequential Algorithm for A-Optimal Experimental Designs on Manifolds. Axioms. 2025; 14(6):436. https://doi.org/10.3390/axioms14060436
Chicago/Turabian StyleZhang, Jingwen, and Yaping Wang. 2025. "An Equivalence Theorem and A Sequential Algorithm for A-Optimal Experimental Designs on Manifolds" Axioms 14, no. 6: 436. https://doi.org/10.3390/axioms14060436
APA StyleZhang, J., & Wang, Y. (2025). An Equivalence Theorem and A Sequential Algorithm for A-Optimal Experimental Designs on Manifolds. Axioms, 14(6), 436. https://doi.org/10.3390/axioms14060436