1. Introduction
The selection of vital explanatory variables is one of the most important parts of statistics. For this reason, significant progress has been made in the penalty regression method, which performs parameter estimation and variable selection simultaneously. The Lasso method [
1] and its derivatives, such as fused Lasso [
2], adaptive Lasso [
3], elastic network [
4], etc., can be used to select variables and estimate coefficients of the model simultaneously, which is favored by many researchers. At the same time, due to its simplicity of solution, it also plays an important role in practical applications. The
norm can also be used as a penalty term in the process of variable selection, but because its non-convexity solution is difficult to obtain, various algorithms are proposed and applied, for example, the Smoothed L0 (SL0) algorithm [
5]. Tibshirani et al. [
6] proposed the method of generalized Lasso. By designing the selection matrix, the generalized Lasso could be transformed into Lasso and adaptive Lasso. Moreover, the proof of its properties and the design of solving algorithm are given. However, both of the methods mentioned above are based on the least squares method. As we know, the least squares method does not have good robustness. In statistics, outliers refer to measured values that deviate from the mean by more than twice the standard deviation. When there are abnormal observations in a sample, the final estimations of coefficients in the model obtained using the least squares method are often greatly deviated. In a regression setting, the robustness of the estimator is closely related to the choice of loss function. Therefore, we consider choosing one robust loss to replace the least squares. Penalty robust regression, combining different loss functions and different penalty functions, has attracted significant attention and seen considerable development, for example, penalty regression based on Huber loss [
7], Minimum Absolute Deviation (LAD)-Lasso [
8], and penalty quantile regression [
9]. Although these existing penalty regressions can yield robust parameter estimators, their robustness (such as breakdown point and impact function) has not been well characterized. To this end, a suitable variable selection process based on exponential squared loss is presented [
10] and has proven to satisfy the
consistent and oracle properties. It also has better robustness and numerical performance than the penalty regression method mentioned above. Therefore, in this paper, the least squares component of the generalized Lasso is replaced by the exponential squared loss when constructing the objective model based on the method of a penalized likelihood framework [
11], and the objective function of the model used in the later part is obtained.
In practical applications, there are many cases where we can obtain some information about the real model in advance, which is called prior information. The traditional way of using prior knowledge is via the Bayes method. We can also take advantage of prior information by setting constraints on parameters. For example, in the studies by Fan, Zhang, and Yu [
12], the sum of all portfolio ratios is 1, which is a linear equation constraint. In this case, the problem of choosing the portfolio with the maximum return is transformed into a linear regression problem with a lasso penalty term and linear constraint. The shape of the non-parametric regression has some conditional restrictions [
13], which requires adding linear inequality constraints to the coefficients to solve the regression problem. To solve the problems in the above application scenarios, corresponding models are respectively established. In addition, variable selection methods based on least squares [
14] and robust quantile loss [
15] under linear constraints are respectively established. Their studies also provide solution algorithms for the corresponding models and numerical simulation studies. However, these authors neither conducted simulations under outliers nor specifically described the robustness of their models. Moreover, variable selection methods based on quantile loss may experience reduced efficiency when normally distributed data are involved [
16]. In this paper, for the convenience of studying the problem, we integrate the prior information into the variable selection model in the form of linear constraints, so as to build an optimization model under linear constraints. It is advisable to incorporate prior information into the objective model through linear constraints.
Based on the discussion above, we use the exponential squared loss function and generalized Lasso penalty to construct the objective model, and then incorporate it into the linear constraint conditions of prior information to build the following equation:
where
is the response variable,
is the design matrix, and
is the parameter vector. Penalty matrix
is the matrix which is be chosen by real application. The choice of the punishment matrix
D can vary, such as different forms of Lasso punishment, including Lasso, adaptive lasso, or fused lasso.
,
,
, and
can be determined based on prior information.
and
are tuning parameters.
means
-norm of one vector.
In fact, the above model is an optimization problem of non-convex function under linear constraints, and it is often difficult to solve such a problem directly. Therefore, we aim to transform the model into a more tractable form before attempting to solve it. X. Wang et al. [
10] showed that the exponential squared loss can be approximated via Taylor expansion, transformed into a quadratic model, and then solved by the Batch Size Gradient Descent (BSGD) method. Based on this, we first transform the model into a quadratic programming problem with linear constraints, then solve its dual model, and finally solve the dual problem using the coordinate descent method. Solving the dual problem is preferred because coordinate descent is significantly more efficient when applied to the dual problem than to the original quadratic programming problem [
14]. The main contributions of this paper lie in the following aspects:
- (i)
In terms of computing, an effective algorithm is designed in this paper. The original non-convex model is transformed, then parameters ( and ) in the model are selected using established criteria, and finally, coefficients are estimated by the designed algorithm.
- (ii)
In terms of theory, based on the research work of some scholars, a formula for calculating model degrees of freedom is developed to measure model complexity.
- (iii)
In terms of robustness, three sets of simulated data with different outliers are designed in this paper. The results obtained by the model on these three sets of data are in line with expectations, which indicates that the model has the ability to resist noise points or outliers.
This paper is organized as follows. In
Section 2, we elaborate on the construction method of our model, derive its dual form, and calculate the degrees of freedom. In
Section 3, we present the parameter selection method and establish the solution algorithm of the model. In
Section 4, we design two sets of experiments: numerical simulation and real-data experimentation. Finally, we summarize and discuss this paper.
2. Methodology
This section covers several topics related to the proposed method. Firstly, we discuss some basic contents of exponential squared loss function. Then, a robust variable selection method with linear constraints is constructed on the basis of this loss function. Next, this problem is transformed into a quadratic programming formulation with linear constraints. Afterwards, the dual form of the transformed quadratic programming problem is derived, along with the Karush–Kuhn–Tucker (KKT) conditions of its dual solution, which is the optimality criteria for constrained nonlinear programming problems. Finally, the degrees of freedom related to model complexity are discussed.
2.1. Exponential Squared Loss Function
In the design of the variable selection method, the choice of loss function often determines the robustness. The exponential squared loss function enhances robustness against outliers by imposing an exponential decay on the gradient magnitude for large residuals. Unlike the squared error loss, whose gradient grows linearly with residuals, the exponential squared loss suppresses the influence of large errors through its multiplicative exponential term. This bounded gradient ensures that outliers contribute minimally to parameter updates, while smaller residuals retain near-quadratic behavior for efficient learning. Exponential squared loss has been shown to perform well as a loss function in AdaBoost for classification problems [
17]. Specifically, AdaBoost (Adaptive Boosting), a well-known ensemble learning algorithm for classification that iteratively adjusts sample weights and combines weak classifiers through weighted majority voting, demonstrated enhanced robustness against label noise when employing this loss function. In the regression field, X. Wang et al. [
10] used exponential squared loss to design a noise-resistant variable selection method, which also performed well. In energy management systems, the exponential squared loss function can be used to make robust estimates of signal states with errors [
18]. In this paper, we also use this loss function to construct a robust model with linear constraints.
The exponential squared loss function has the following form:
In (
4),
, which represents one regression residual.
is a tuning parameter, whose numerical value determines the robustness in the estimation of coefficients. Under large
conditions (usually greater than 10), the
is approximately equal to
, leading the estimators to closely resemble least squares methods in limiting cases. When
is small, observations with large absolute values of
t will lead to large losses of
, which diminishes their impact to
parameter estimation. Therefore, selecting a smaller
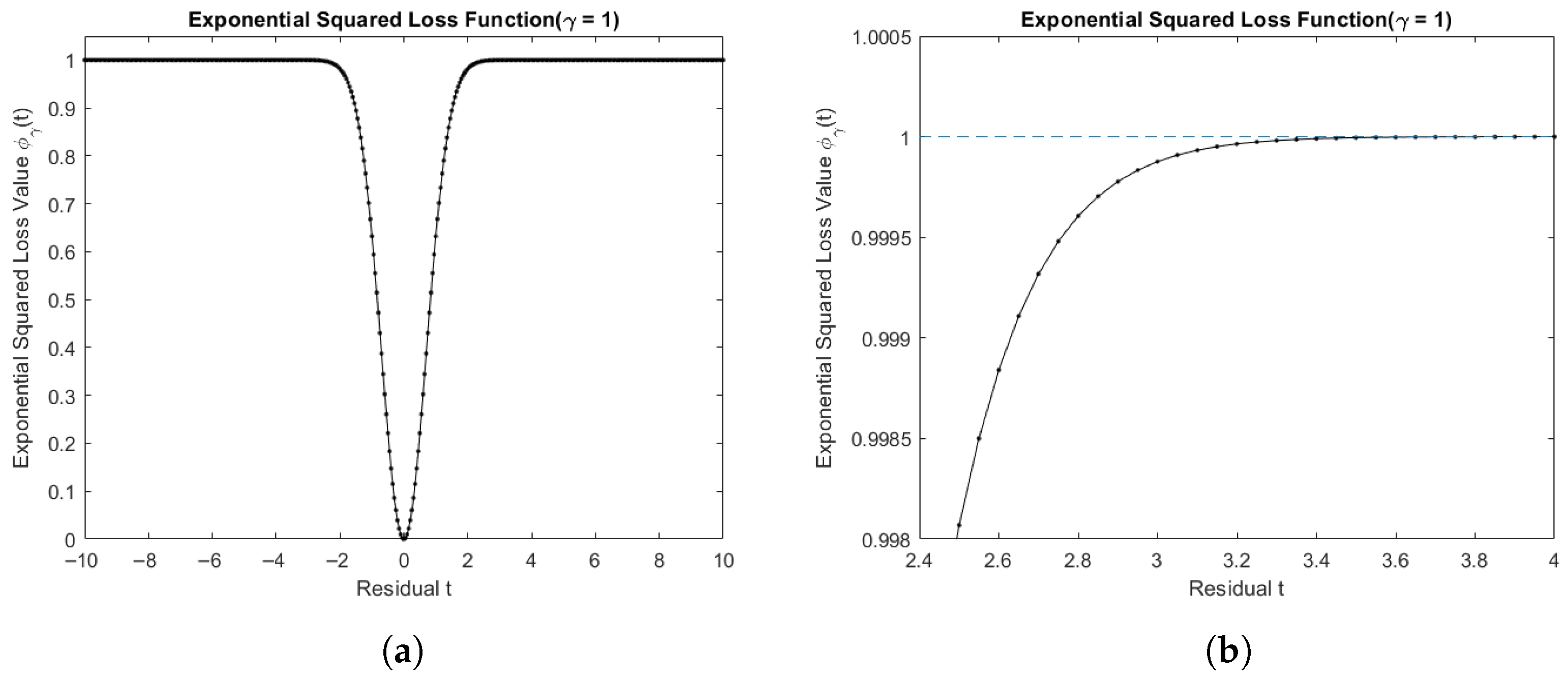
value limits the impact of an outlier on the estimators; this comes at the cost of decreased estimator responsiveness to data variations. We use the following two images to intuitively explain why the exponential squared loss function is of certain robustness.
Firstly, we consider
as a small fixed value. When there are noise points or abnormal data in the samples, the absolute value of residual
t tends to be larger. From
Figure 1a,b, we can see that the value of the exponential squared loss function gradually approaches 1 as the absolute value of residual
t increases, which would have a small impact on the estimation of
. In contrast, as the absolute value of the residual
t increases, the least squares loss function will result in a larger loss value, which leads to an inaccurate estimation of
.
When the value of is significantly high, we can consider . According to the theorem of infinitesimal substitution of equal values, we can determine that . This approximation implies that the exponential squared is analogous to the least squares loss.
In conclusion, the selection of the parameter in the exponential squared loss function should be guided by the statistical properties of the data and the desired robustness–efficiency trade-off.
2.2. Penalized Exponential Squared Loss with Linear Constraints
The idea of model construction is as follows: Firstly, we design a general unconstrained variable selection method based on exponential squared loss and generalized Lasso penalty. Then, prior information is incorporated into the variable selection method as constraints. Finally, variable selection is reformulated as a constrained optimization problem. Notably, we mainly consider the case where prior information exists as linear constraints.
The model we built is as follows:
where
,
,
.
is a matrix that is chosen based on the application.
,
,
, and
can be determined based on prior information.
represents the
-norm of a vector. We know that the existence of a constant term has no effect on the solution of an optimization model. Therefore, we remove the constant term in Equation (
5), and the model is changed into the following form:
Equation (
8) contains the non-convex term
. As a result, the computational complexity of finding a numerical solution is high, making the programming process challenging. For this reason, we consider applying some transformation to Equation (
8) to turn it into a form that can be easily processed. The basic idea behind this transformation is Taylor expansion. This strategy has also been employed in prior research [
7,
10,
18]. Specifically, we use the Taylor formula to expand the exponential squared function in Equation (
8). By discarding terms above the second order, we convert the exponential squared function into a quadratic form.
Let
Assuming that
is the initial estimate of the coefficients for the explanatory variables, we can obtain this value using various methods, such as via an MM-estimator (multiple M-estimator, a robust regression method involving two M-estimation steps), a least squares estimator, and so on. It is obtained by solving the objective function with only the loss function (
) and no penalty term, so
is valid. We can use Taylor’s formula to expand (11) at
to get
Substituting Equation (
12) into (8), the model can be transformed into the following form:
where
is the Hessian matrix of
at
. Formulas (13) to (15) are quadratic programming problems with linear constraints, which are easier to solve than the original model. Next, we consider removing the constant term
from Equation (
13), which is independent of optimization. Simultaneously, we also consider the processing of the Hessian matrix, so as to further simplify the model.
The Hessian matrix is represented as
. According to the previous statement, the following is true:
can be calculated using the following formula:
is a Jacobian matrix.
is a diagonal matrix,
, where
. Existing research [
18] shows that for the model defined by Equations (13)–(15) to attain its maximum, matrix
Q must be negative definite. Let
Therefore,
. At the same time,
is a diagonal matrix. Based on the algebraic theory, if all
, then
is a positive definite matrix, which makes
Q negative. However, when there are outliers or contaminated data, some residuals will be too large and the corresponding diagonal elements will be negative. Therefore, we need to relax the condition of
as follows:
in (16) is a small negative number, such as −0.01, which is selected according to the specific situation of the problem. If (16) is true in the study, we also believe that the second-order condition of the optimization problem is satisfied.
We now rearrange Equation (
13): since it serves as the optimization objective function, its constant term does not affect the solution. Therefore, we remove the constant term from (13). Then, we rewrite (13) as follows:
Substituting the above discussion of the Hessian matrix into (17), we obtain
Finally, we get
where
The above is equivalent to
In this way, (20)–(22) is the model we will solve later in the paper, which is much easier to handle than the previous model (13)–(15).
2.3. The Dual Problem and KKT Conditions
We adopted a methodology similar to Hu et al. [
14] for processing model (20)–(22). However, there is a difference between (20) and their model, which lies in the values of the variables
S and
r. In their study,
S and
r are
which are obviously different from (18) and (19).
The aim of our research is to analyze the model (20)–(22). First, we derive the primal problem’s dual form. Then, we analyze the dual solution’s properties through its KKT conditions. Next, we present a proposition that establishes the relationship between the dual problem and the primal model. Finally,
Section 3 develops a coordinate descent algorithm for the dual model.
We introduce a new variable
into (20). The model can be transformed into the following form:
The Lagrangian equation of the above model is as follows:
where
,
, and
are Lagrange multipliers. Each of the
is non-negative for
. Therefore, the resulting Lagrangian dual function is as follows:
Boyd and Vandenberghe [
19] have discussed the duality problem under convex optimization in detail. Since matrix
S is positive definite, Equation (
23) is convex. Moreover, all constraints are linear, so the model including (23)–(26) is a convex optimization problem. We know that the primal model minimization is equivalent to the dual problem maximization.
We can divide
L into the sum of two functions. One is related to
and another is only concerned with
z:
Minimizing
L is equivalent to minimizing both
and
simultaneously. When
takes the minimum value, the corresponding value of parameter
is
The result of minimizing
is
where
is the
∞-norm of
u. The dual model of the original problem obtained is
where
We transform the original problem into its dual form because coordinate descent is more efficient on the dual than on the primal problem. The KKT conditions for the dual model are given below:
where
,
and
. When
or
is known, the KKT conditions above can be simplified. Firstly, we need to define two boundary sets for the dual problem:
and
. Both sets are related to
. By substituting Equation (
7) into the KKT conditions above, we obtain
In fact, the primal model also has two similar boundary sets, which have been discussed in some studies [
14], so this paper will not go into detail.
Here, we provide a proposition that describes the uniqueness of the solution.
Proposition 1. If S is positive definite, then and are unique, where .
The proof of Proposition 1 is as follows.
Considering the model including (20)–(22), the objective function (20)’s Hessian matrix is
Since
S is positive definite, we can determine that (20) is a strictly convex function.
Assuming that both
and
are the minimizers of the model including (20) and (21), where
, then we have
At the same time, we know
Let
; it is easy to know that
satisfies all of the linear constraints. Therefore, we have
where the equality holds only when
. This is inconsistent with the requirements of
. Therefore,
is unique. In the meantime, since
, we can determine that
is also unique.
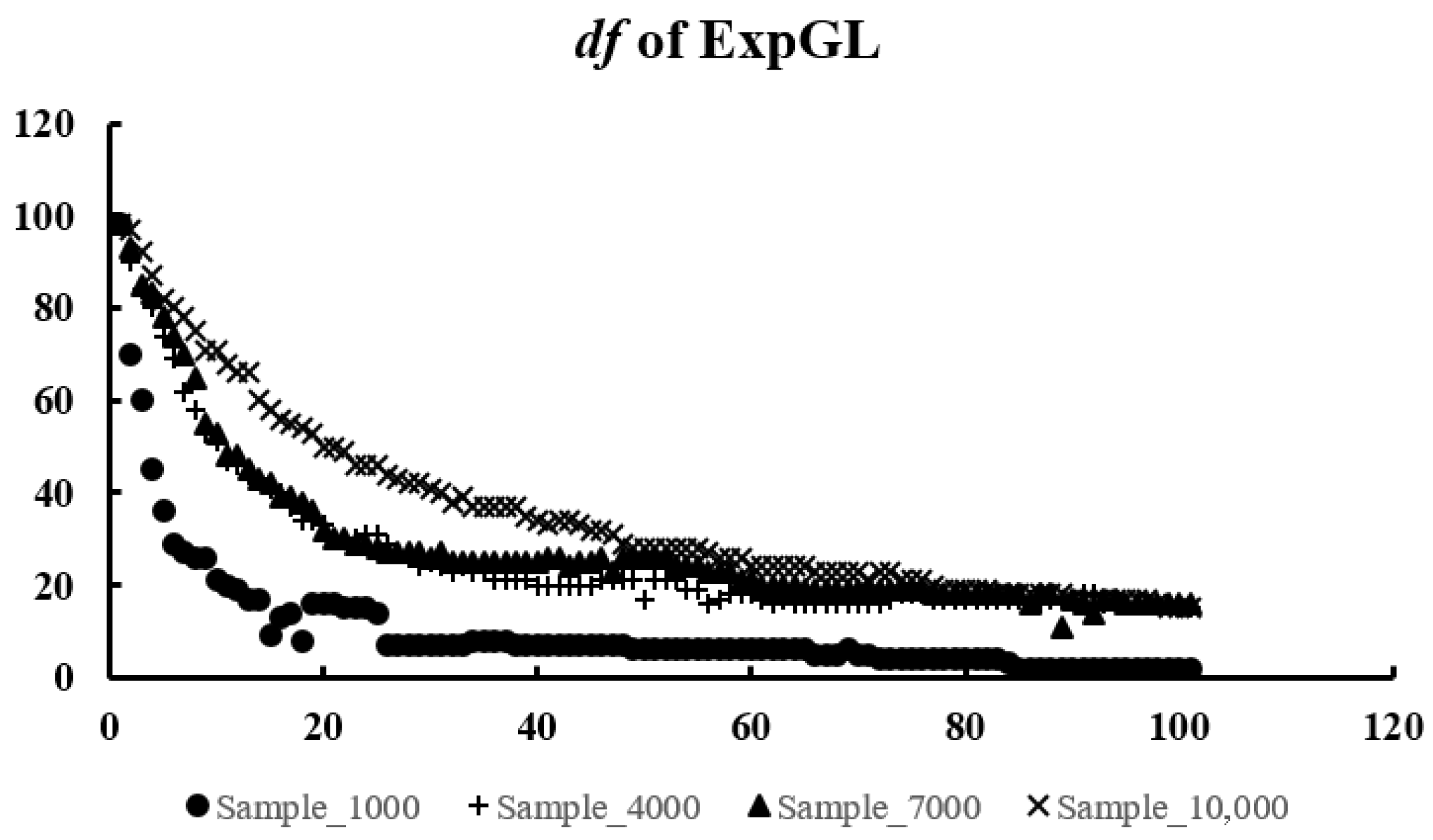
2.4. Degrees of Freedom
The degrees of freedom actually introduce a measure of the complexity of a model. We know that the same problem may admit multiple modeling approaches. It is not possible to directly compare the results of each model, because the number of parameters in each model is not the same. However, the results of different models can be compared at the same degrees of freedom, which can be used for model selection and assessment.
When studying the theory of unbiased risk estimation, Stein [
20] proposed a method to calculate the degrees of freedom. Later, on the basis of Stein’s work, Efron [
21] studied a new estimation method, which can be reduced to Stein’s estimate formula in some cases. We assume that
,
are independent of each other. Here, the superscript “T” denotes the transpose; the notation
denotes that
Y has a normal distribution with mean
and variance
, where
I is the identity matrix. Let
, where
g is a statistical model. The degree of freedom of the model can be calculated by the following formula:
The above formula can be interpreted as indicating that predictive performance improves with increasing model complexity. As a result, stronger correlation emerges between the observed samples and the predicted data. Ultimately, it leads to higher degrees of freedom. When
Y is normally distributed, there is
. If
is a continuously differentiable function of
Y, then we have
which is Stein’s estimate. In order to apply the above theory, we need to prove that
is a continuous and almost differentiable function of
Y. In fact, according to Hu et al. [
14], we can prove that given
,
is continuous and
satisfies a uniformly Lipschitz condition. We give three lemmas in the following text. Based on these and Hu et al. [
14], we derive the formula for calculating degrees of freedom for the dual problem.
Lemma 1. For any fixed λ, there is a set , whose measure is zero. For , there is always a neighbourhood where and are constant.
Lemma 2. For any fixed λ, is a continuous function about Y.
Lemma 3. For any fixed and , is uniformly Lipschitz.
Then, we can obtain the following theorem.
Theorem 1. Assuming that Y is a random vector consisting of independent random variables, each has a normal distribution. For any matrices D, C, E and any scalar , we can obtain the formula for the degrees of freedom. Here, denotes the matrix D with the rows or columns associated with u removed, and is defined analogously. 3. Choice of Tuning Parameter and Algorithm Designing
In this section, the coordinate descent method is used to solve the dual model. However, there are other parameters in the model besides , such as and . Therefore, we also need to introduce corresponding methods for the selection of and .
3.1. Selection of
The selection of
determines the robustness of coefficient estimations, or in other words, the sensitivity to outliers. Following X. Wang et al. [
10], we obtain a
selection method according to sample data, which can bypass prior identification and processing of outliers. In the meantime, the value of
obtained by this method is of high efficiency and robustness. This approach can be broken down into the following two steps:
1. Determining the set of outliers in the sample
Let . First, we calculate . Next, we obtain . Finally, we can determine the set of outliers as follows: . Let , .
2. Updating
is essentially minimizing the
on the set
, where
det() is the determinant and
, where
In this way, we can obtain an estimate of .
3.2. Updating
Hu et al. [
14] proposed the coordinate descent method for the dual model of a quadratic programming problem under linear constraints. Taking their work into consideration, we first define a few new matrices as follows:
Before we give the coordinate descent algorithm for the dual problem
the calculation formula of the primal solution can be given:
The four steps of the coordinate descent method are given below:
1. The initial value of can be given by a robust estimate such as the MM estimator. At the same time, we set the initial values of u and as the zero vectors.
2. Update every component of u. We define the current kth component to be and the latest estimate of as . First, calculate . Then, update . Finally, we can obtain .
3. Update every component of . We define the current kth component to be and the latest estimate of as . First, calculate . Then, update . Finally, we can obtain .
4. Calculate the value of
P using Equation (
27) to check for convergence. If the value of
P in (27) obtained over two consecutive times satisfies the convergence condition, we stop the iteration and output the estimation of
. Otherwise, repeat 2–3 until convergence.
3.3. Choice of
First, we determine the interval for selecting
. Then, we select an appropriate length and obtain a series of
values from the interval, which is called as set
R. For any
, we calculate the degrees of freedom and the
value using the following formula:
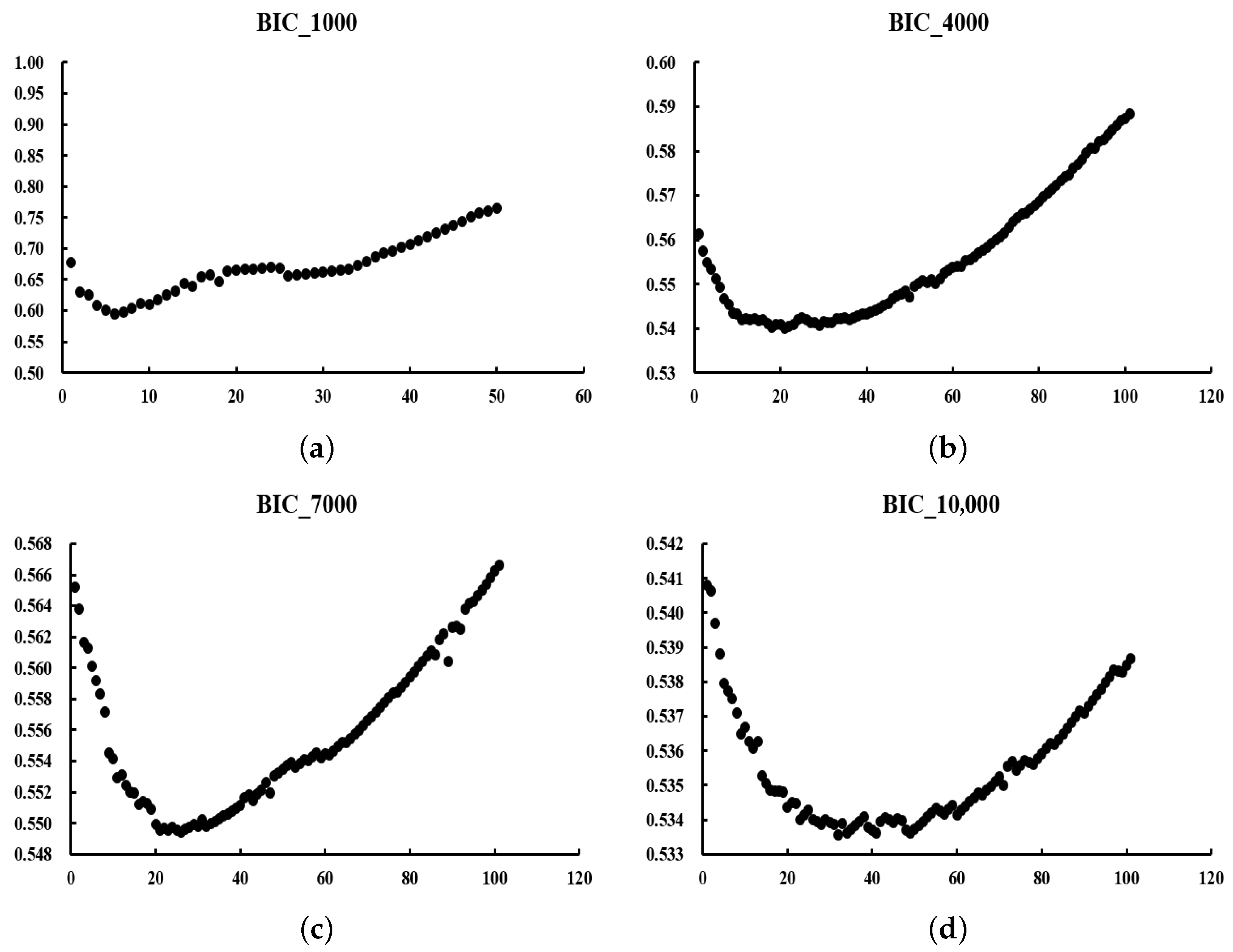
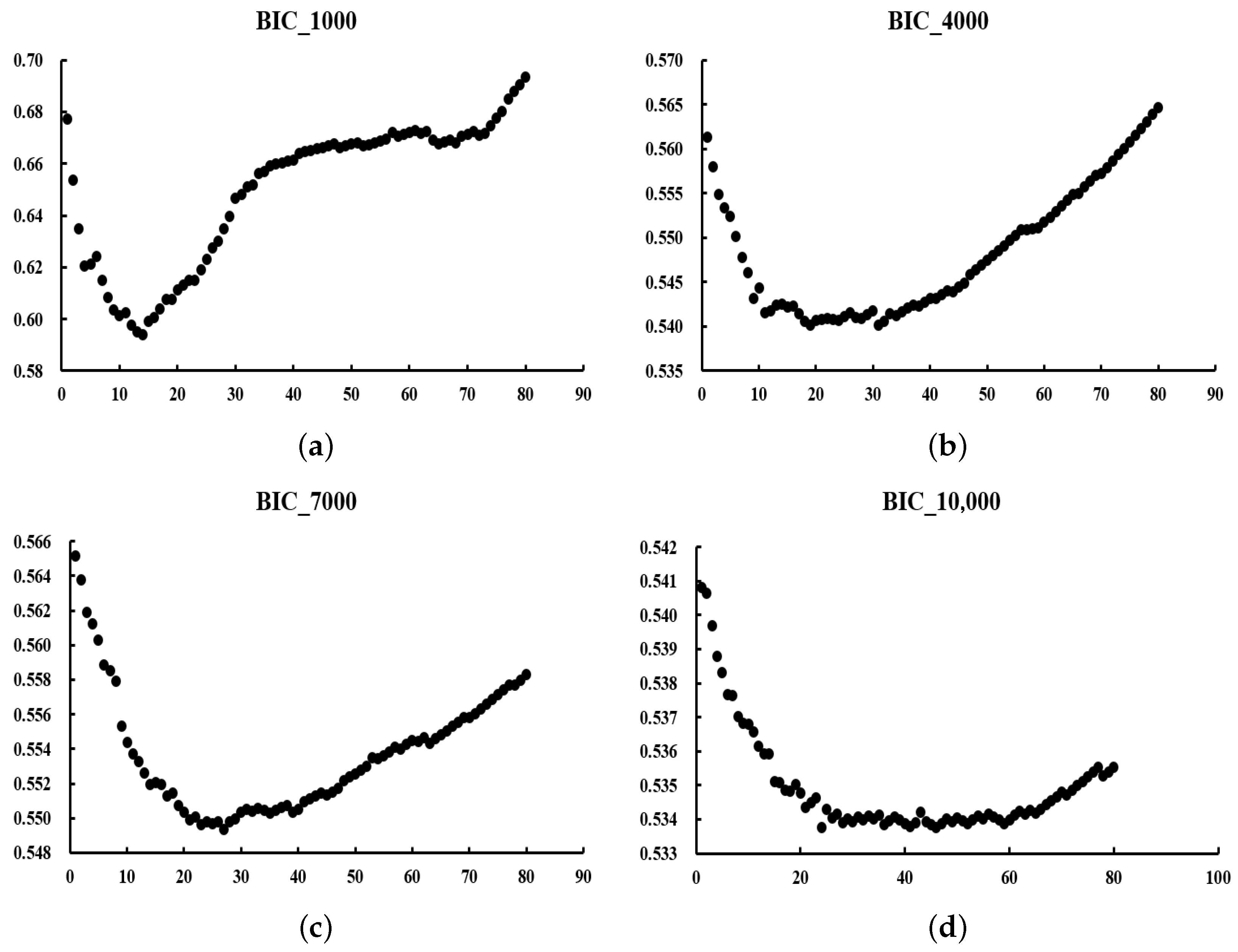
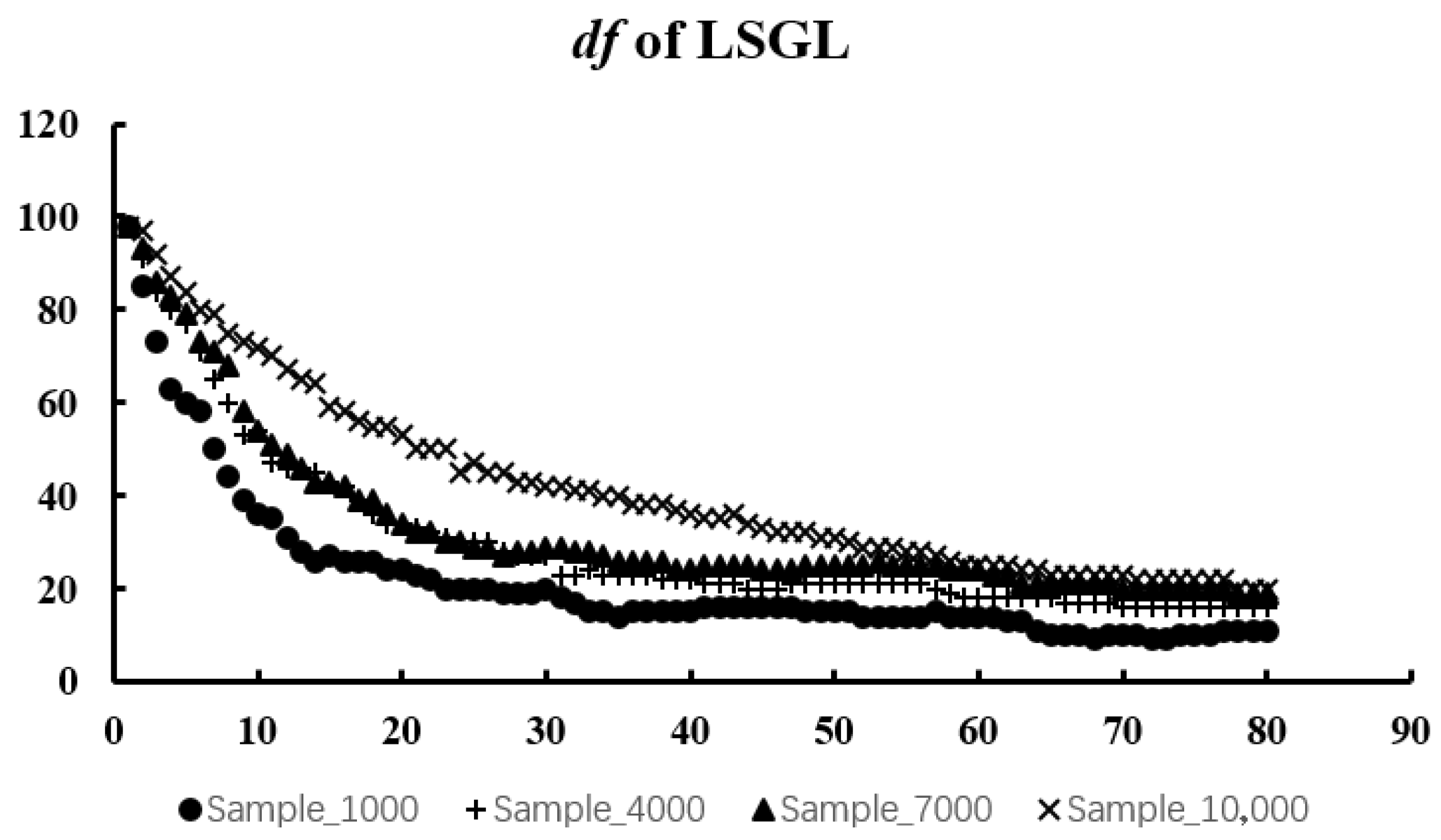
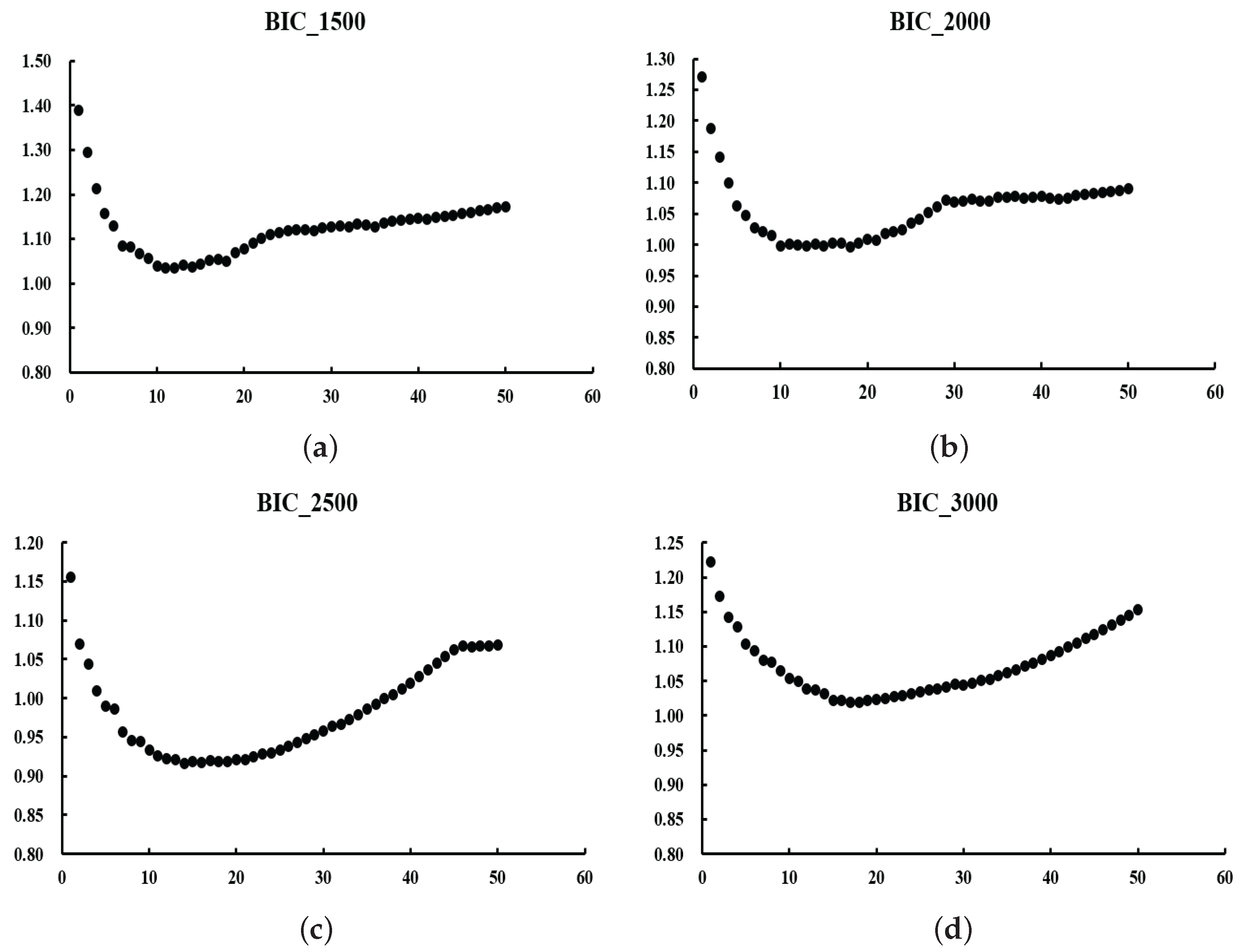
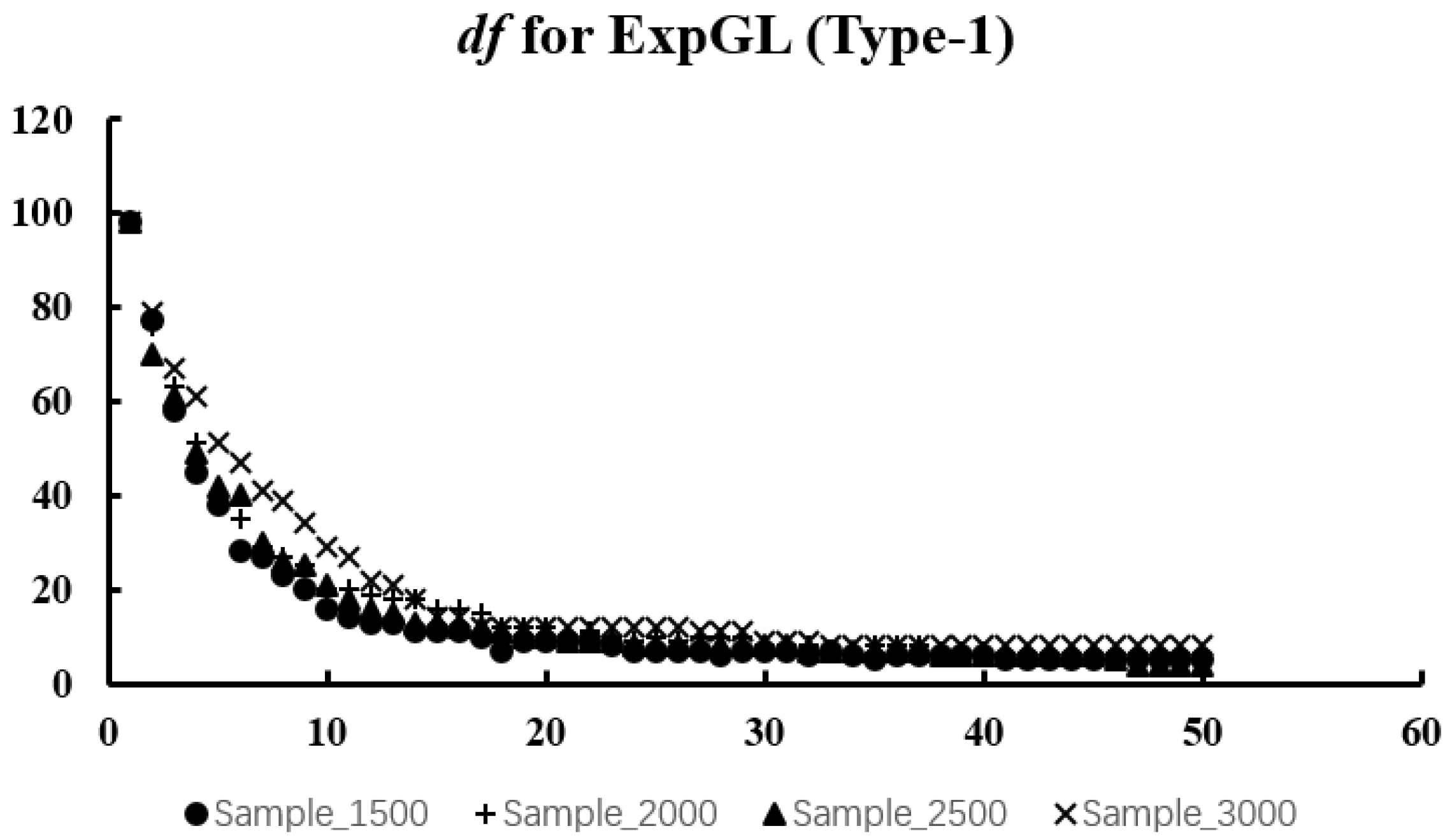
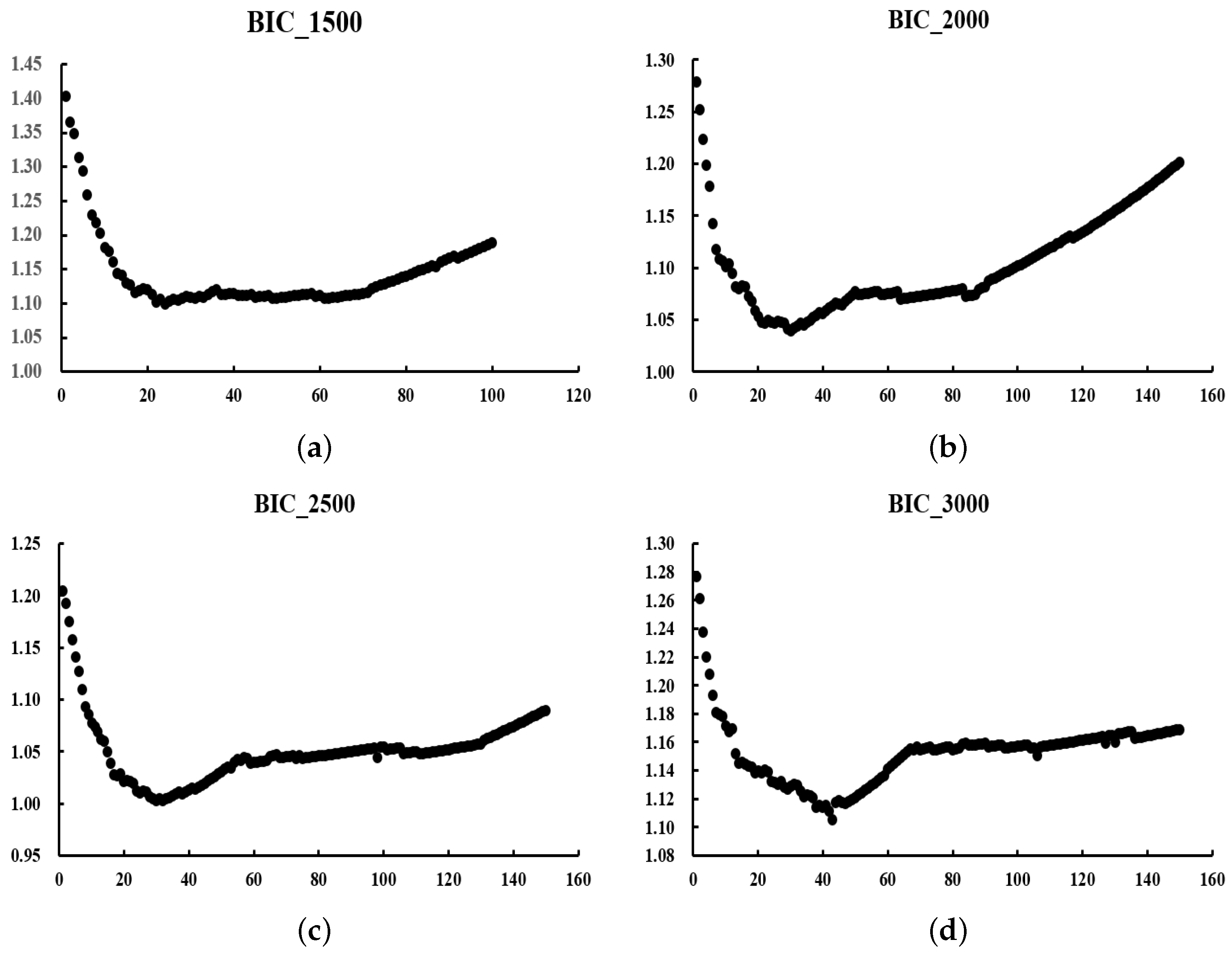
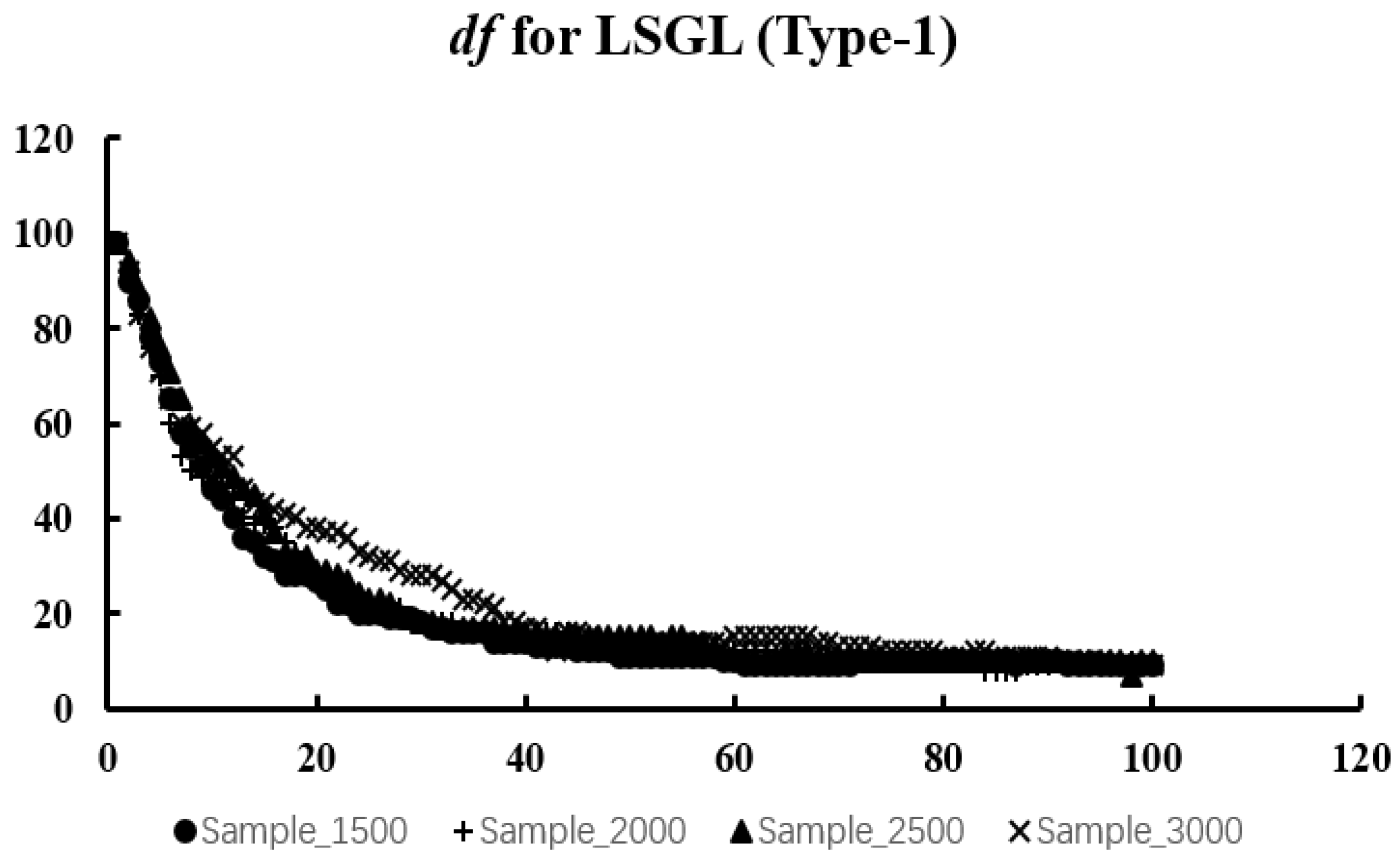
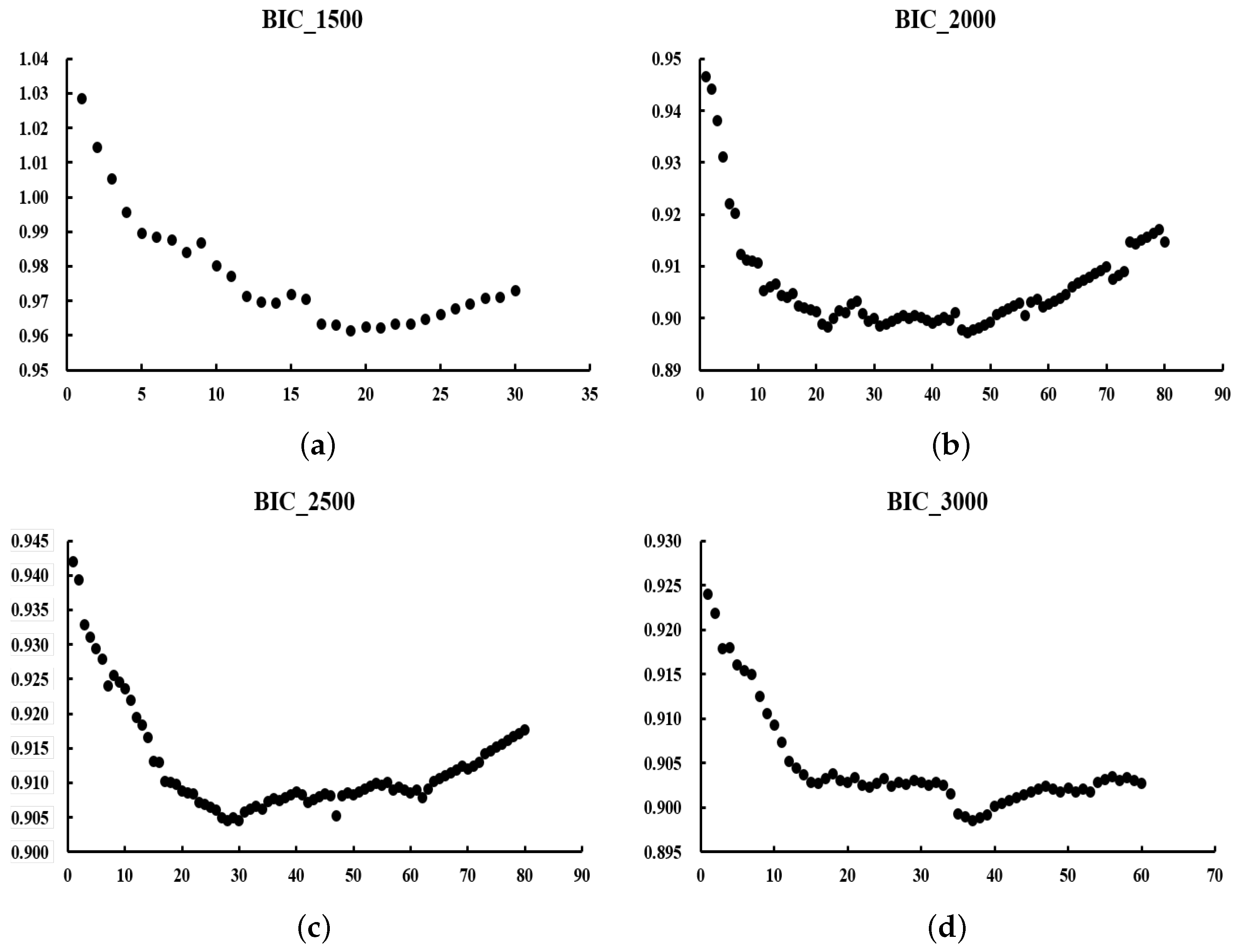
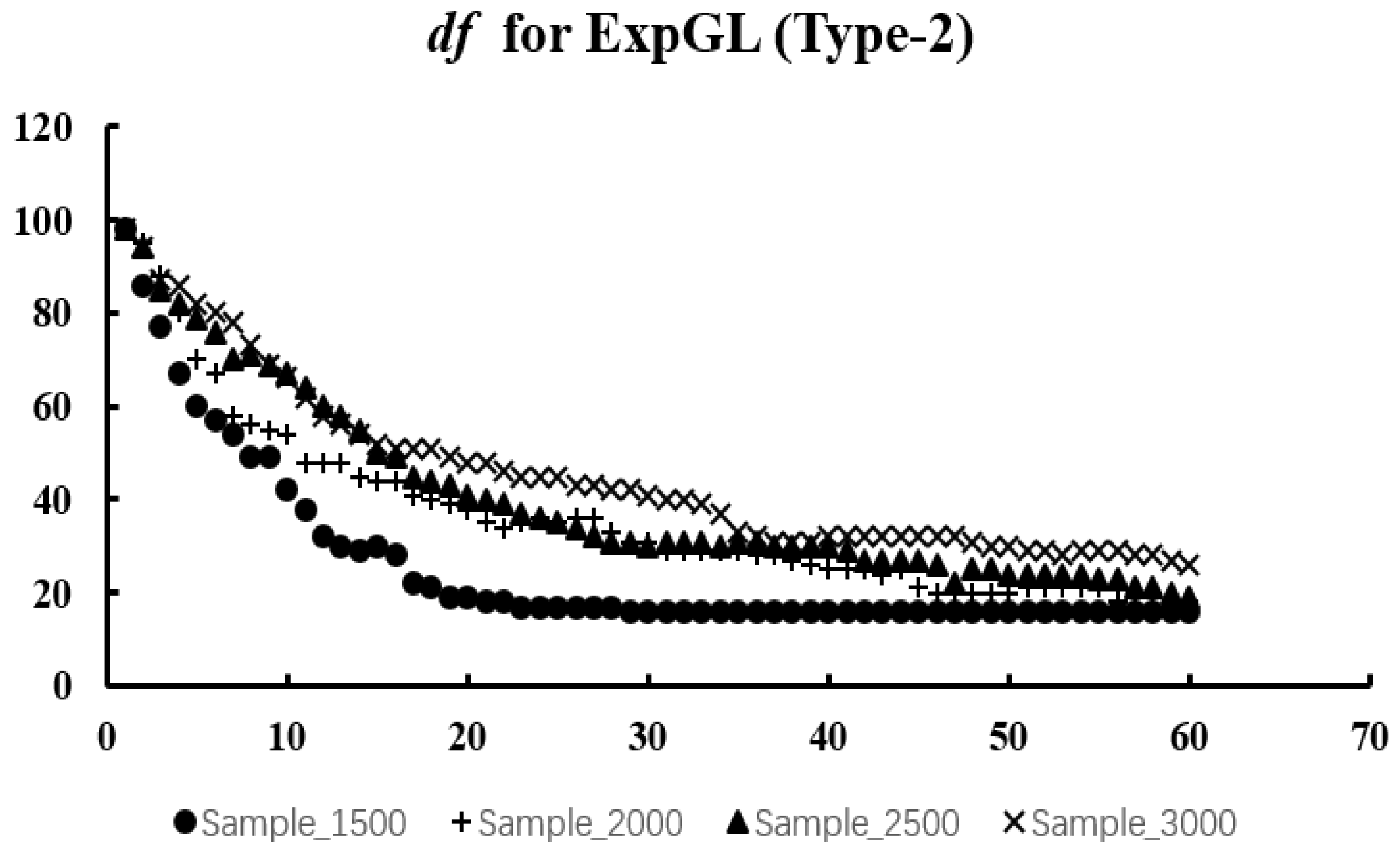
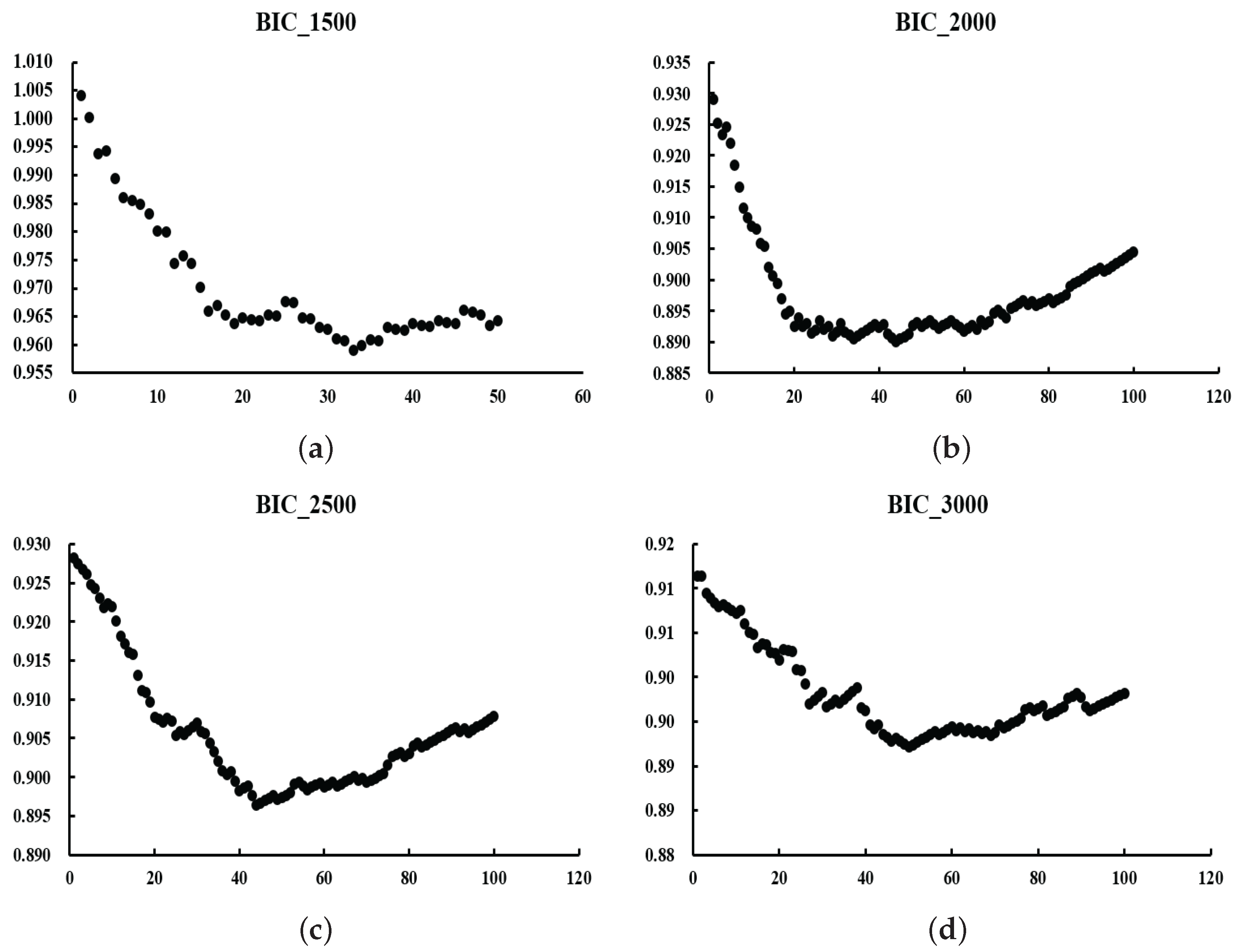
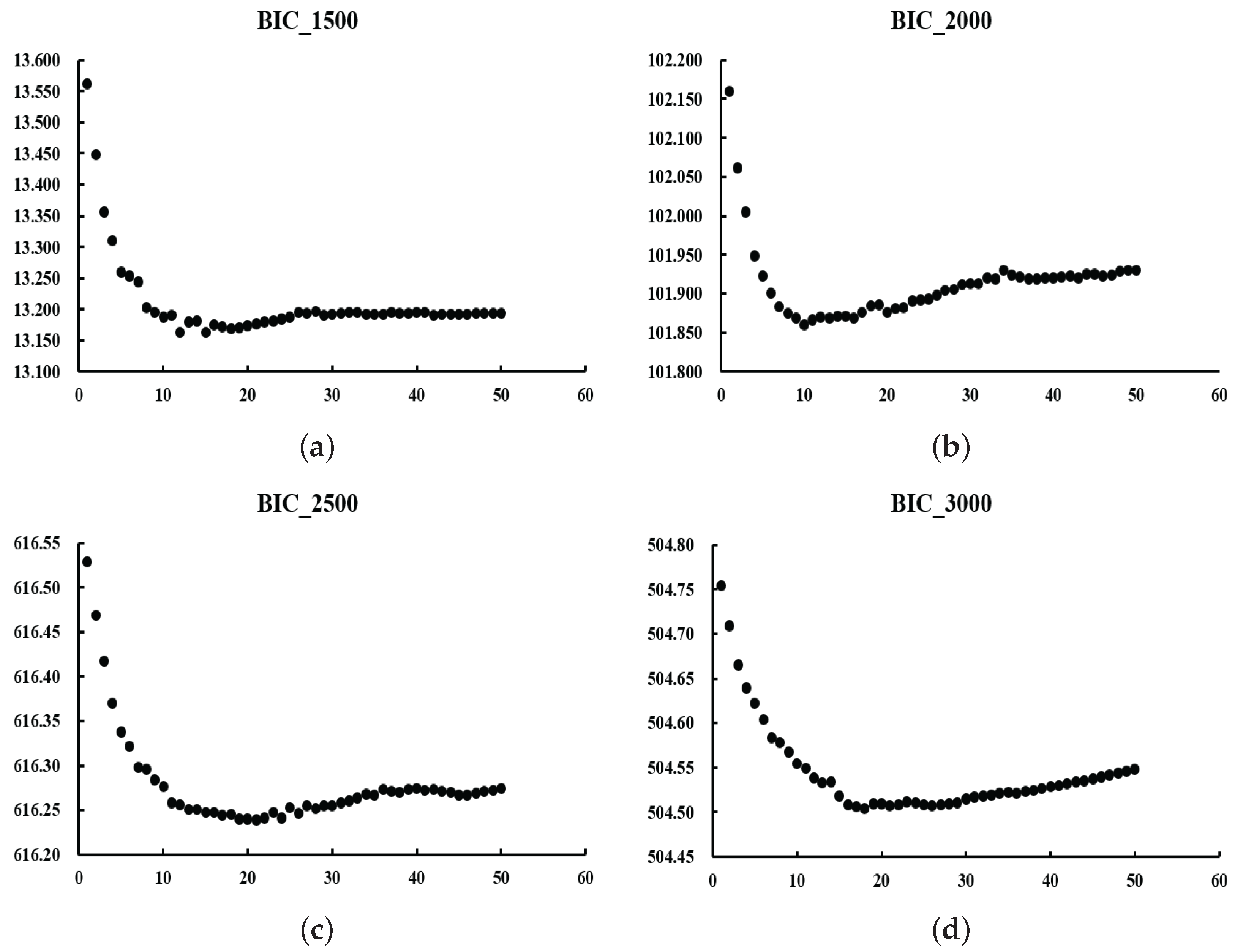
We expect to obtain a U-shaped curve of values. The at the curve’s lowest point represents the optimal value. The reason for choosing the criterion is that it requires less computation than the optimal value obtained by cross-validation.
In the next section, we will discuss numerical simulations and real-data experiments using the algorithm given in this section.
5. Discussion
The main purpose of this paper is to design a robust variable selection method combining prior information. In order to ensure robustness, that is, to resist the influence of certain abnormal or noise points, we chose the exponential squared loss function as the loss under a penalized likelihood framework. Simultaneously, in order to obtain a more realistic model, we considered adding some prior information to the variable selection method through linear constraints. Finally, we constructed an optimization problem with the linear constraints. Since the objective function is non-convex, it is not easy to deal with. Therefore, we employed Taylor expansion to transform the model into a more tractable quadratic programming problem. Then, in order to deal with the transformed model more easily by using the coordinate descent method, we obtained the dual form of the quadratic programming problem first. Finally, the estimation of the final coefficient was obtained by applying the coordinate descent method to the dual problem. Note that some parameter selections were involved in the process, but we will not repeat them here.
After the algorithm was obtained, numerical simulations and real-data experiments were carried out. The experimental results show that the performance of our method without outliers is not significantly different from that of LSGL, but the latter is easier to operate. When outliers are present, our method significantly outperforms LSGL. In the third outlier scenario, LSGL is no longer effective, but our method maintains satisfactory performance. Our method demonstrates effective handling of outliers in the predictors, outliers in the response, as well as scenarios involving both. These results suggest that our method is indeed robust. Furthermore, as established in the work of X. Wang et al. [
10], the breakdown point (BP) is fundamentally determined by the breakdown point of the initial estimate and the tuning parameter
. The results of the real-data experiments show that the coefficients estimated by our method meet the linear constraints set previously, and the sparse model can be obtained by compressing variables. In other words, both numerical simulations and real-data experiments show that our method conforms to the expectations established.
So far, there is little research on the oracle properties of variable selection models under linear constraints. For future research, in addition to the model proposed in this paper, we intend to uniformly prove the oracle properties of all variable selection models proposed so far under linear constraints, for example, variable selection models based on least squares loss under linear constraints, variable selection models based on quantile loss under linear constraints, and so on.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}