1. Introduction
In this paper, we adopt the standard notation for a real Hilbert space . The inner product on is denoted by , and the associated norm is represented by . Let H denote a nonempty, closed, and convex subset of , and let T, be two nonlinear operators. The operator is called
- (i)
λ-Lipschitzian if there exists a constant
, such that
- (ii)
- (iii)
α-inverse strongly monotonic if there exists a constant
, such that
- (iv)
r-strongly monotonic if there exists a constant
, such that
- (iv)
Relaxed cocoercive if there exist constants
and
, such that
It is evident that the classes of -inverse strongly monotonic and r-strongly monotonic mappings are subsets of the class of relaxed cocoercive mappings; however, the reverse implication does not hold.
Example 1. Let and . Clearly, is a Hilbert space with norm induced by the inner product . Define the operator by .
We demonstrate that T is relaxed cocoercive with and . Specifically, we aim to verify that for all ,First, note that , andCombining the terms, for all , we see thatIndeed, putting , we conclude thatbecause for all . Thus, T is relaxed cocoercive. Since for all , we conclude that there is no positive constant α, such that (3) holds. Thus, the operator T is not α-inverse strongly monotonic. Also, it is not an r-strongly monotonic. The theory of variational inequalities, initially introduced by Stampacchia [
1] in the context of obstacle problems in potential theory, provides a powerful framework for addressing a broad spectrum of problems in both pure and applied sciences. Stampacchia’s pioneering work revealed that the minimization of differentiable convex functions associated with such problems can be characterized by inequalities, thus establishing the foundation for variational inequality theory. The classical
variational inequality problem (
VIP) is commonly stated as follows:
Find such thatwhere is a given operator. The
VI (
5) and its solution set are denoted by
VI and
, respectively.
Lions and Stampacchia [
2] further expanded this theory, demonstrating its deep connections to other classical mathematical results, including the Riesz–Fréchet representation theorem and the Lax–Milgram lemma. Over time, the scope of variational inequality theory has been extended and generalized, becoming an indispensable tool for the analysis of optimization problems, equilibrium systems, and dynamic processes in a variety of fields. The historical development of variational principles, with contributions from figures such as Euler, Lagrange, Newton, and the Bernoulli brothers, highlights their profound impact on the mathematical sciences. These principles serve as the foundation for solving maximum and minimum problems across diverse disciplines such as mechanics, game theory, economics, general relativity, transportation, and machine learning. Both classical and contemporary studies emphasize the importance of variational methods in solving differential equations, modeling physical phenomena, and formulating unified theories in elementary particle physics. The remarkable versatility of variational inequalities stems from their ability to provide a generalized framework for tackling a wide range of problems, thereby advancing both theoretical insights and computational techniques.
Consequently, the theory of variational inequalities has garnered significant attention over the past three decades, with substantial efforts directed towards its development in various directions [
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17]. Building on this rich foundation, Noor [
18] introduced a significant extension of variational inequalities known as the
general nonlinear variational inequality (
GNVI), formulated as follows:
The
GNVI (
6) and its solution set are denoted by
GNVI and
, respectively. It has been shown in Ref. [
18] that problem (
6) reduces to
VI, where
(the identity operator). Furthermore, the
GNVI problem can be reformulated as a general nonlinear complementarity problem:
Find such thatwhere is the dual cone of a convex cone H in . For , where m is point-to-point mapping, problem (7) corresponds to the implicit (quasi-)complementarity problem. A wide range of problems arising in various branches of pure and applied sciences have been studied within the unified framework of the
GNVI problem (
6) (see Refs. [
1,
19,
20,
21]). As an illustration of its application in differential equation theory, Noor [
22] successfully formulated and studied the following third-order implicit obstacle boundary value problem:
Find such that on where is an obstacle function and is a continuous function. The projection operator technique enables the establishment of an equivalence between the variational inequality VI and fixed-point problems, as follows:
Lemma 1. Let be a projection (which is also nonexpansive). For given , the conditionis equivalent to . This implies thatwhere is a constant. Applying this lemma to the
GNVI problem (
6), Noor [
18] derived the following equivalence result, which establishes a connection between the
GNVI and fixed-point problems:
Lemma 2. Let be a projection (which is also nonexpansive). A function satisfies the GNVI problem (6) if and only if it satisfies the relationwhere is a constant. This equivalence has played a crucial role in the development of efficient methods for solving
GNVI problems and related optimization problems. Noor [
22] showed that the relation (
8) can be rewritten as
which implies that
where
is a nonexpansive operator and
denotes the set of fixed points of
S.
Numerous iterative methods have been proposed for solving variational inequalities and variational inclusions [
22,
23,
24,
25,
26,
27,
28,
29,
30,
31]. Among these, Noor [
22] introduced an iterative algorithm based on the fixed-point formulation (
9) to find a common solution to both the general nonlinear variational inequality
GNVI and the fixed-point problem. The algorithm is described as follows:
where
,
, and
.
The convergence of this algorithm was established in [
22] under the following conditions:
Theorem 1. Let be a relaxed cocoercive and λ-Lipschitzian mapping, be a relaxed cocoercive and -Lipschitzian mapping, and be a nonexpansive mapping such that . Define as the sequence generated by the algorithm in (10), with real sequences , , and , where . Suppose the following conditions are satisfiedwhereThen, converges strongly to a solution . Noor’s algorithm in (
10) and its variants have been widely studied and applied to variational inclusions, variational inequalities, and related optimization problems. These algorithms are recognized for their efficiency and flexibility, contributing significantly to the field of variational inequalities. However, there remains considerable potential for developing more robust and broadly applicable iterative algorithms for solving
GNVI problems. Motivated by the limitations of existing methods, we propose a novel Picard-type iterative algorithm designed to address general variational inequalities and nonexpansive mappings:
where
and
. Algorithm (
11) cannot be directly derived from (
10) because the update rule for
differs fundamentally. In the first algorithm,
is updated as
whereas in the second algorithm, the update for
follows a direct convex combination of previous iterates:
This structural difference in the
update step leads to different iterative behaviors, making it impossible to derive (
11) directly from (
10).
Building on these methodological advances, recent research has significantly deepened our understanding of variational inequalities by offering innovative frameworks and solution techniques that address real-world challenges.
The literature has seen significant advancements in variational inequality theory through seminal contributions that extend its applicability to diverse practical problems. Nagurney [
32] laid the groundwork by establishing a comprehensive framework for modeling complex network interactions, which has served as a cornerstone for subsequent research in optimization and equilibrium analysis. Also, it is interesting to see a collection of papers presented in the book [
33], mainly from the 3rd International Conference on Dynamics of Disasters (Kalamata, Greece, 5–9 July 2017), offering valuable strategies for optimizing resource allocation under emergency conditions. More recently, Fargetta, Maugeri, and Scrimali [
34] expanded the scope of variational inequality methods by formulating a stochastic Nash equilibrium framework to analyze competitive dynamics in medical supply chains, thereby addressing challenges in healthcare logistics.
These developments underscore the dynamic evolution of variational inequality research and its capacity to address complex, real-world problems. In this context, the new Picard-type iterative algorithm proposed in our study builds upon these advances by relaxing constraints on parameter sequences, ultimately providing a more flexible and efficient approach for solving general variational inequalities.
In
Section 2, we establish a strong convergence result (Theorem 2) for the proposed algorithm. Unlike Noor’s algorithm, which requires specific conditions on the parametric sequences for convergence, our algorithm eliminates this requirement while maintaining strong convergence properties. Specifically, Theorem 2 refines the convergence criteria in Theorem 1, leading to broader applicability and enhanced theoretical robustness. Furthermore, Theorem 3 demonstrates the equivalence in convergence between the algorithms in (
10) and (
11), highlighting their inter-relationship and the efficiency of our approach. The introduction of the Collage–Anticollage Theorem 4 within the context of variational inequalities marks a significant innovation, offering a novel perspective on transformations related to the
GNVI problem discussed in (
6). To the best of our knowledge, this theorem is presented for the first time in this setting. Additionally, Theorems 5 and 6 explore the continuity of solutions to variational inequalities, a topic rarely addressed in the existing literature. These contributions extend the theoretical framework established by Noor [
22], offering new insights into general nonlinear variational inequalities. Beyond theoretical advancements, we validate the practical utility of the proposed algorithm by applying it to convex optimization problems and real-world scenarios.
Section 3 provides a modification of the algorithm for solving convex minimization problems, supported by numerical examples. In
Section 4, we demonstrate the algorithm’s applicability in real-world contexts, including machine learning tasks such as classification and regression. Comparative analysis shows that our algorithm consistently converges to optimal solutions in fewer iterations than the algorithm in (
10), highlighting its superior computational efficiency and practical advantages.
The development of the main results in this paper relies on the following lemmas:
Lemma 3 ([
35]).
Let for be non-negative sequences of real numbers satisfyingwhere and . Then, . Lemma 4 ([
36]).
Let for be non-negative real sequences satisfying the following inequalitywhere for all , , and . Then, . 2. Main Results
Theorem 2. Let be a relaxed cocoercive and -Lipschitz operator, be a relaxed cocoercive and -Lipschitz operator, and be a nonexpansive mapping such that . Let be an iterative sequence defined by the algorithm in (11) with real sequences , . Assume the following conditions holdwhereThen, the sequence converges strongly to with the following estimate for each ,where Proof. Let
be a solution to
. Then,
Using (
11), (
15), and the assumptions that
and
S are nonexpansive operators, we obtain
Since
T is a relaxed
cocoercive and
-Lipschitzian operator,
or equivalently
where
is defined by (
14).
Since
g is a relaxed
cocoercive and
-Lipschitzian operator,
where
L is defined by (
13).
Combining (
16), (
17), and (
18), we have
and from (
12) and (
14), we know that
(see
Appendix A).
It follows from (
11), (
15), and the nonexpansivity of the operators
S and
that
Using the same arguments above gives us the following estimates
where
.
Combining (
19)–(
21), we obtain
As
,
for all
and
, we have
for all
. Using this fact in (
22), we obtain
which implies
Taking the limit as
, we conclude that
. □
Theorem 3. Let , H, T, g, S, L, and δ be defined as in Theorem 2, and let the iterative sequences and be generated by (10) and (11), respectively. Assume the conditions in (12) hold, and , , and . Then, the following assertions are true: (i)
If converges strongly to , then also converges strongly to 0. Moreover, the estimate holds for all ,Furthermore, the sequence converges strongly to .(ii)
If the sequence is bounded and , then the sequence converges strongly to 0. Additionally, the estimate holds for all Moreover, the sequence converges strongly to . Proof. (i) Suppose that
converges strongly to
. We aim to show that
converges strongly to 0. Using (
1), (
2), (
4), (
10), (
11), and (
15), we deduce the following inequalities
as well as
Combining these inequalities, we get
Since
,
,
and
, for all
, we have
By applying the inequalities in (
24) to (
23), we derive the following result
Define
,
, and
, for all
. Given the assumption
, it follows that
. It is straightforward to verify that (
25) satisfies the conditions of Lemma 3. By applying the conclusion of Lemma 3, we obtain
. Furthermore, we note the following inequality for all
,
Taking the limit as
, we conclude that
, since
(ii) Let us assume that the sequence
is bounded and
. By Theorem 2, it follows that
. We now demonstrate that the sequence
converges strongly to
. Utilizing results from (
1), (
2), (
4), (
10), (
11), and (
15), we derive the following inequalities:
From the proof of Theorem 2, we know that
Combining (
26)–(
29), we obtain
Since
,
,
and
, for all
, we have
Applying the inequalities in (
31) to (
30) gives
Now, we define the sequences
,
for all
. Note that
.
Since the sequence
is bounded, there exists
such that
for all
. For any
, since
converges to 0 and
, there exists
such that
for all
. Consequently,
for all
, which implies
, i.e.,
. Thus, inequality (
32) satisfies the requirements of Lemma 4, and by its conclusion, we deduce that
. Since
and
it follows that
. □
After establishing the strong convergence properties of our proposed algorithm in Theorems 2 and 3, we now present additional results that further illustrate the robustness and practical applicability of our approach. In the following theorems, we first quantify the error estimate between an arbitrary point and the solution via the operator , and then we explore the relationship between and its approximation .
Specifically, Theorem 4 provides rigorous bounds linking the error to the distance between any point and a solution , thereby offering insights into the stability of the method. Building on this result, Theorem 5 establishes an upper bound on the distance between the fixed point of the exact operator and that of its approximation . Finally, Theorem 6 delivers a direct error bound in terms of a prescribed tolerance , which is particularly useful for practical implementations.
Theorem 4. Let , H, T, g, S, L, and δ be as defined in Theorem 2, and suppose the conditions in (12) are satisfied. Then, for any solution and for any , the following inequalities hold:where the operator is defined as . Proof. From equation (
9), we know that
. If
, inequality (
33) is trivially satisfied. On the other hand, if
for all
, we have
as well as
Inserting (
35) and (
36) into (
34), we obtain
or equivalently
On the other hand, we have
By employing similar arguments as in (
34)–(
36), we deduce
or equivalently
Combining the bounds derived from (
34)–(
36), we finally arrive at
which completes the proof. □
Transitioning from error estimates for the exact operator, Theorem 5 shifts the focus to the interplay between the original operator and its approximation . This theorem establishes an upper bound for the distance between their respective fixed points, thus providing a measure of how closely the approximation tracks the behavior of the exact operator. The theorem is stated as follows:
Theorem 5. Let T, g, S, Φ
, L, and δ be as defined in Theorem 4. Assume that is a map with a fixed point . Further, suppose the conditions in (12) are satisfied. Then, for a solution , the following holds Proof. By (
9), we know that
. If
, then inequality (
37) is directly satisfied. If
, then using the same arguments as in the proof of Theorem 4, we obtain
as well as
Combining (
38)–(
40), we derive
Simplifying further, this yields
which completes the proof. □
Finally, Theorem 6 extends this analysis by providing a direct error bound in terms of a prescribed tolerance . This result is particularly valuable for practical implementations, as it offers a clear metric for the performance of the approximating operator in approximating the fixed point of . The theorem is formulated as follows:
Theorem 6. Let T, g, S, Φ
, , L, and δ be as defined in Theorem 5. Let be a map with a fixed point . Suppose the conditions stated in (12) hold. Additionally, assume thatfor some fixed . Then, for a fixed point , such that , the following inequality holds Proof. Let
. From (
38)–(
40), we have
Then, using this inequality, as well as (
37) and (
41), we obtain
which had to be proven. □
3. An Application to the Convex Minimization Problem
Let
be a Hilbert space,
H be a closed and convex subset of
, and
be a convex function. The problem of finding the minimums of
f is referred to as the convex minimization problem, which is formulated as follows
Denote the set of solutions to the minimization problem (
42) by
ℵ. The minimization problem (
42) can equivalently be expressed as a fixed-point problem:
A point is a solution to the minimization problem if and only if , where is the metric projection, denotes the gradient of the Fréchet differentiable function f, and is a constant.
Moreover, the minimization problem (
42) can also be reformulated as a variational inequality problem:
A point is a solution to the minimization problem if and only if satisfies the variational inequality for all .
Now, let
be a nonexpansive operator, and let
represent the set of fixed points of
S. If
, then for any
, the following holds:
since
is both the solution to the problem (
42) and a fixed point of
S.
Based on these observations, if we set
(the identity operator) and
in the iterative algorithm (
11), we derive the following algorithm, which converges to a point that is both a solution to the minimization problem (
42) and a fixed point of
S:
where
,
.
Theorem 7. Let S, L, and δ be defined as in Theorem 2 and . Let be a convex mapping such that its gradient is a relaxed cocoercive and λ-Lipschitz mapping from H to . Assume that . Define the iterative sequence by the algorithm in (43) with real sequences , . In addition to the condition (12) in Theorem 2, assume the following condition is satisfiedThen, the sequence converges strongly to , and the following estimate holds Proof. Set
and
in Theorem 2. The mapping
g is 1-Lipschitzian and a relaxed
cocoercive for every
, satisfying the condition (
44). Consequently, by Theorem 2, it follows that
. □
Example 2. Letdenote a real Hilbert space equipped with the norm , where for . Additionally, the set is a closed and convex subset of . Now, we consider a function defined by , where . The solution to the minimization problem (42) is the zero vector, for f. From [
37] (Theorem 2.4.1, p. 167)
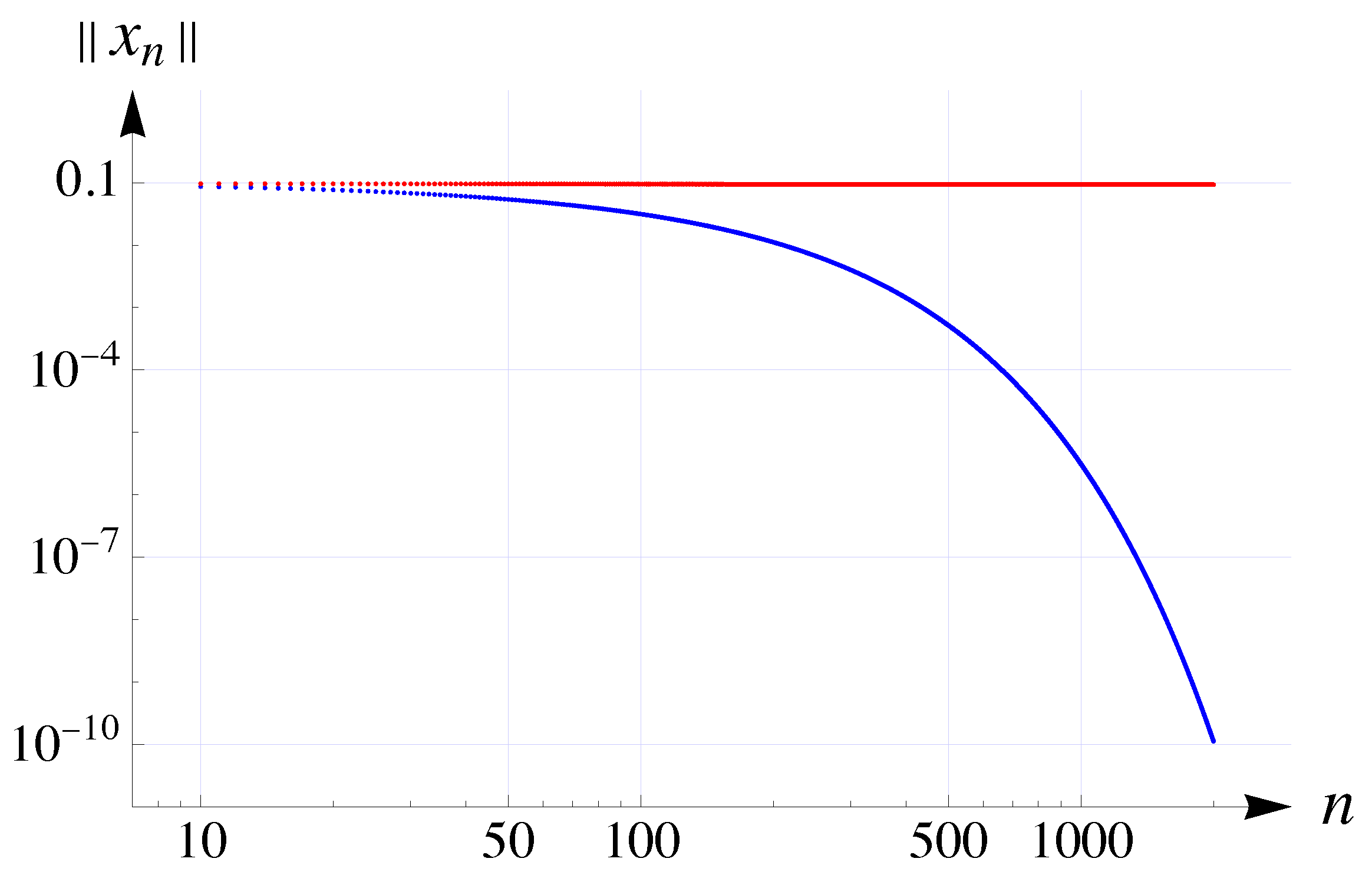
, the Fréchet derivative of f at a point is , which is unique. For , we havefrom which we deduceThis means that is a relaxed cocoercive operator. Additionally, since is a 14-Lipschitz function. Let be defined by . The operator S is nonexpansive sinceMoreover, . Based on assumptions (12) and (44), we set , , and . Consequently, we calculate and , which yields . Also, we have . It is evident that these parameter choices satisfy conditions (12) and (44). Next, let for all n. To ensure clarity, we denote a sequence of elements in the Hilbert space H as , where . Under these notations, the iterative algorithms defined in (43) and (11) are reformulated as follows:andwhere is defined by , when , and , when . Let the initial point for both iterative processes be the sequence . From Table 1 and Table 2, as well as from Figure 1, it is evident that both algorithms (45) and (46) converge strongly to the point . Furthermore, the algorithm in (45) exhibits faster convergence compared to the algorithm in (46). As a prototype, consider the mapping Φ
, , be defined asand . With these definitions, the results of Theorems 4, 5, and 6 can be straightforwardly verified. All computations in this example were performed using Wolfram Mathematica 14.2.
4. Numerical Experiments
In this section, we adapt and apply the iterative algorithm (
11) within the context of machine learning to demonstrate the practical significance of the theoretical results derived in this study. By doing so, we highlight the real-world applicability of the proposed methods beyond their theoretical foundations. Furthermore, we compare the performance of algorithm (
11) with algorithm (
10), providing additional support for the validity of the theorems presented in previous sections.
Our focus is on the framework of loss minimization in machine learning, employing two novel projected gradient algorithms to solve related optimization problems. Specifically, we consider a regression/classification setup characterized by a dataset consisting of
m samples and
d attributes, represented as
, with corresponding outcomes (labels)
Y. The optimization problem is formulated as follows:
Using the
-projection operator
(onto the positive quadrant),
,
,
, and
, we define two iterative algorithms:
and
where
,
, and
. To compute the optimal value of the step size
, a backtracking algorithm is employed. All numerical implementations and simulations were carried out using
Matlab, Ver. R2023b.
The real-world datasets used in this study are:
- +
Aligned Dataset (in Swarm Behavior): Swarm behavior refers to the collective dynamics observed in groups of entities such as birds, insects (e.g., ants), fish, or animals moving cohesively in large masses. These entities exhibit synchronized motion at the same speed and direction while avoiding mutual interference. The Aligned dataset comprises pre-classified data relevant to swarm behavior, including 24,017 instances with 2400 attributes (see
https://archive.ics.uci.edu/ml/index.php (accessed on 14 February 2025)).
- +
COVID-19 Dataset: COVID-19, an ongoing viral epidemic, primarily causes mild to moderate respiratory infections but can lead to severe complications, particularly in elderly individuals and those with underlying conditions such as cardiovascular disease, diabetes, chronic respiratory illnesses, and cancer. The dataset is a digitized collection of patient records detailing symptoms, medical history, and risk classifications. It is designed to facilitate predictive modeling for patient risk assessment, resource allocation, and medical device planning. This dataset includes 1,048,576 instances with 21 attributes (see
https://datos.gob.mx/busca/dataset/informacion-referente-a-casos-covid-19-en-mexico (accessed on 14 February 2025)).
- +
Predict Diabetes Dataset: Provided by the National Institute of Diabetes and Digestive and Kidney Diseases (USA), this dataset contains diagnostic metrics for determining the presence of diabetes. It consists of 768 instances with 9 attributes, enabling the development of predictive models for diabetes diagnosis (see
https://www.kaggle.com/datasets (accessed on 14 February 2025)).
- +
Sobar Dataset: The Sobar dataset focuses on factors related to cervical cancer prevention and management. It includes both personal and social determinants, such as perception, motivation, empowerment, social support, norms, attitudes, and behaviors. The dataset comprises 72 instances with 20 attributes (see
https://archive.ics.uci.edu/ml/index.php (accessed on 14 February 2025)).
The methodology for dataset analysis and model evaluation was carried out as follows:
All datasets were split into training and testing subsets. During the analysis, we set the tolerance value (i.e., the difference between two successive function values) to and capped the maximum number of iterations at . To evaluate the performance of algorithms on these datasets, we recorded the following metrics:
Function values ;
The norm of the difference between the optimal function value and the function values at each iteration, i.e., ;
Computation times (in seconds);
Prediction and test accuracies, measured using root mean square error (rMSE).
The results and observations are as follows:
Function Values: In
Figure 2, the function values
for the evaluated algorithms are presented.
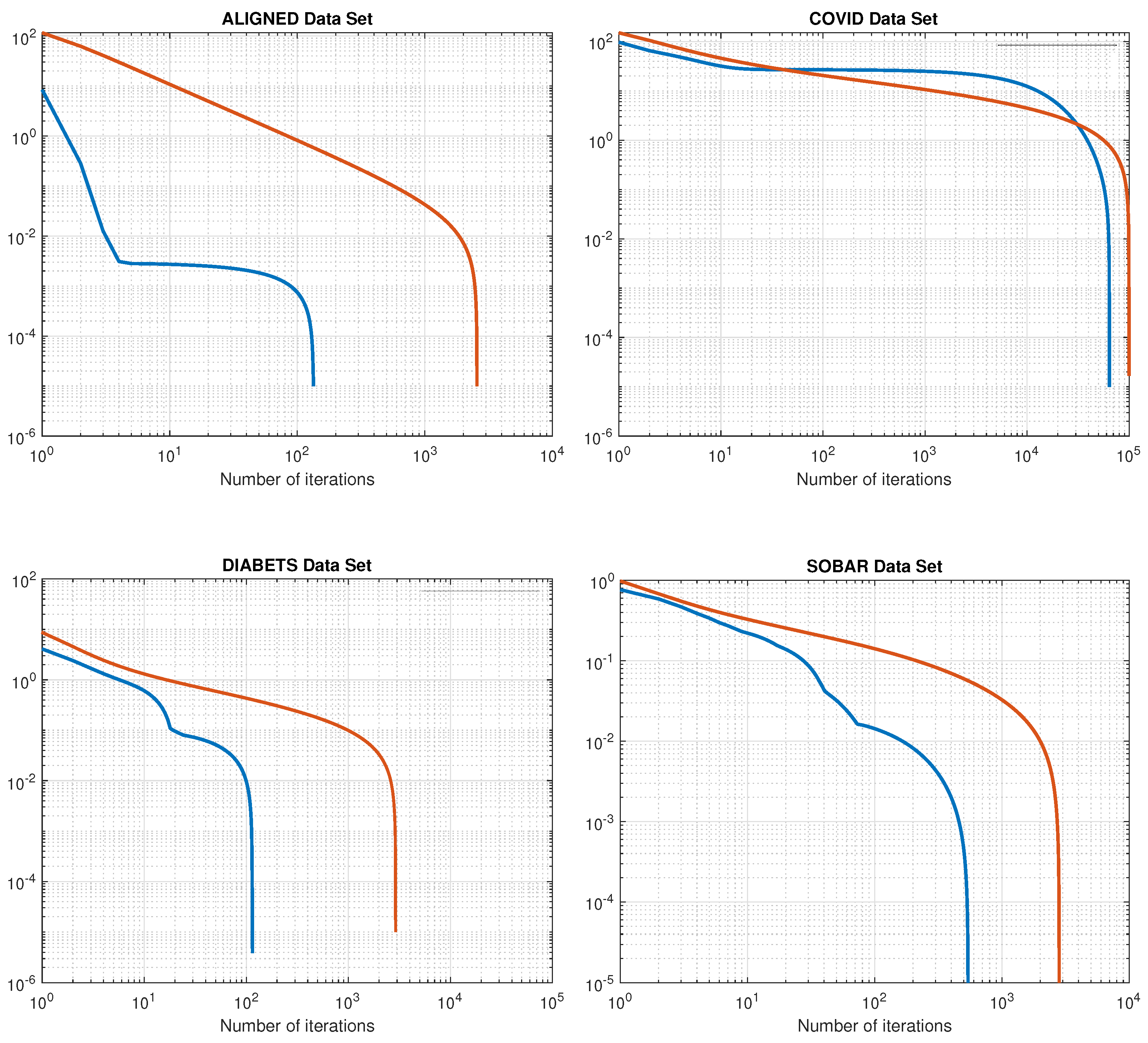
Convergence Analysis:
Figure 3 demonstrates the convergence performance of the algorithms in terms of
.
Prediction Accuracy:
Figure 4 show cases the prediction accuracy (rMSE) achieved by the algorithms during the testing phase.
The results, as illustrated in
Figure 2,
Figure 3 and
Figure 4 and summarized in
Table 3, clearly indicate that algorithm (
47) outperforms algorithm (
48) in terms of efficiency and accuracy.
Table 3 clearly demonstrates that algorithm (
47) yields significantly better results than algorithm (
48) across various datasets. In terms of the number of iterations, (
47) converges in far fewer steps (for example, 135 versus 2559 for the Aligned dataset and 116 versus 10,480 for the Diabetes dataset) and achieves the same or lower minimum
F values, resulting in superior outcomes. Moreover, (
47) shows slightly lower training errors (rMse) and, in most cases—with the exception of COVID-19, where (
48) achieves a marginally better test error—comparable or improved test errors (rMse2). Most importantly, the training time for (
47) is significantly shorter across all datasets (for instance, 6.28 s versus 118.14 s for the Aligned dataset and 0.022 s versus 2.83 s for the Diabetes dataset), which confers an advantage in computational efficiency. Overall, these results demonstrate that algorithm (
47) not only converges faster but also delivers better performance in terms of both accuracy and computational cost compared to algorithm (
48).







{kind=link}
{kind=link}
{kind=link}
{kind=link}