1. Introduction
Non-negative integer-valued (NNIV) time series are the subject of numerous research studies (see, among the more recently published, e.g., [
1,
2,
3,
4,
5,
6]) on the modeling and analysis of count time series. In the class of NNIV series, some of the frequently used models are the so-called integer-valued autoregressive (INAR) processes (see, among the more recently published, e.g., [
7,
8,
9,
10,
11,
12,
13,
14]). Our main motivation in this study is to introduce an integer-valued process based on the autoregressive principle, which would have a more general form than ordinary INAR-based time-series models. The proposed generalization can be viewed in the next two different aspects:
The first motive is the formation of the NNIV stochastic model based on a principle similar to that of the so-called Split-BREAK process, introduced by Stojanović et al. [
15,
16] and later also discussed by Jovanović et al. [
17] and Ljajko et al. [
18]. The Split-BREAK process is proposed there as a stochastic model intended for the description and analysis of time series with accentuated and persistent fluctuations, whereby different forms of continuous stochastic distributions (such as Gaussian, Laplace and Cauchy) are used as its innovations. Therefore, the model proposed here is based on similar ideas, i.e., it describes pronounced fluctuations in count time-series dynamics.
Another motive is the use, as innovation series, of NNIV distributions known as power-series (PS) distributions. These distributions represent a very general class of NNIV stochastic distributions, to which many well-known distributions belong as special cases (see, for instance, Stojanović et al. [
19,
20,
21]).
In this way, a first-order integer-valued Split-BREAK process (abbr. INSB(1) process) is proposed here. It is worth pointing out that this model, similar to the Split-BREAK process with continuous-type distributions, can be seen as a generalization of some well-known count time-series models, such as INAR-based models. Also, as will be explained further, it can be applied to the examination of more pronounced fluctuations in some real-world time series. The definition and the basic features of the INSB(1) process are described in next section,
Section 2. Then, some of the more important stochastic features of this process are presented in
Section 3. The next section,
Section 4, is devoted to a recent estimation technique called probability-generating function (PGF) estimation method. For the estimators thus obtained, asymptotic properties and efficiency, under some regulatory conditions, are also analyzed.
Section 5 presents Monte Carlo simulations of the PGF estimators for some specific innovations, such as the Poisson and geometric distributions, which can be seen as special cases of PS-distributed innovation series. In both cases, the asymptotic properties of the obtained estimates are examined. The application of the INSB(1) process in modeling the dynamics and empirical distribution of some real-world time series, namely, the numbers of traffic accidents and forest fires, is described in
Section 6. Also, the INSB(1) model is compared here with the ordinary INAR(1) model and is shown that the proposed model has the same or even better efficiency and forecasting accuracy. Finally,
Section 7 provides some concluding details.
2. Definition and Structure of the INSB(1) Process
Similarly as in Stojanović et al. [
19,
20,
21], we firstly introduce the independent identically distributed (i.i.d.) time series with power-series (PS) distribution.
Definition 1. The i.i.d. integer-valued time series , , is PS-distributed if its probability mass distribution (PMF) is as follows:where is discrete set of values of the series ; is the mass function; is the (unknown) parameter; andis the increasing function, which converges on some interval . As is shown in
Table 1, for certain choices of functions
and
, Equation (
1) gives some of the most well-known types of discrete distributions. Notice that the condition
holds for them, which will henceforth be assumed to be satisfied, in order to examine the zero-inflation property of our model. Furthermore, using some simple calculations (see, e.g., [
19]) for the mean and variance of the random variables (RVs)
, one obtains
where
.
Furthermore, if we define the over-dispersion index
, then inequality
holds if and only if
,
. Thus, the series
is over-dispersed if and only if
is a convex function on
. Finally, the PGF of the first order of PS-distributed RVs
can be obtained as follows:
Clearly, the above sum converges when
and allows for the simple calculation PGFs of some specific PS distributions, as also presented in
Table 1. Below is a definition of the INSB(1) process, as well as some basic notes about it.
Definition 2. Let be the probability space, expanded by some filtration , where is the set of time indices. The INSB(1) process is represented by the following time series, defined on an expanded basis :
is the i.i.d. time series with PS distribution, given by Equation (1). is a series of martingale means given by recurrence relation:where is a (unknown) parameter; is the binomial thinning operator, where are mutually independent (and also independent of X) Bernoulli RVs, with ; andis the noise indicator with critical value . is a basic INSB series given by the additive decomposition Note that in a practical interpretation, the filtration
is a set of “information” about some (real-world) time series at time
t. Thus, PS-distributed RVs
are
-adaptive, for each
, and constitute the deviation (noise) component of the INSB(1) process. On the contrary, series
is
-adaptive and represents the predictive and stability component of the INSB(1) process. Finally, the parameter
is the critical value of the reaction, which indicates the importance of the earlier realizations of
for the inclusion of its current values in Equation (
3). In other words, when
, the martingale mean
does not exceed its previous value
, and the basic INSB series
, given by Equation (
5), is then realized with "low" fluctuation. Otherwise, the case
indicates a pronounced fluctuation in the series
. In this way, the critical value
determines not only the fluctuation intensity of the basic series
but also the stochastic structure of the INSB(1) process, which represents a certain generalization of some well-known integer time-series models. For instance, according to Equation (
4), larger values of
c imply that
. Thus, Equation (
3) becomes
, that is,
, where “as” means “almost surely”. According to Equation (
5), the series
is then reduced to the innovation series
. On the other hand, when
, it follows that
, and the structure of the series
, as well as
, is then the same as with first-order integer-valued autoregressive (abbr. INAR(1)) models.
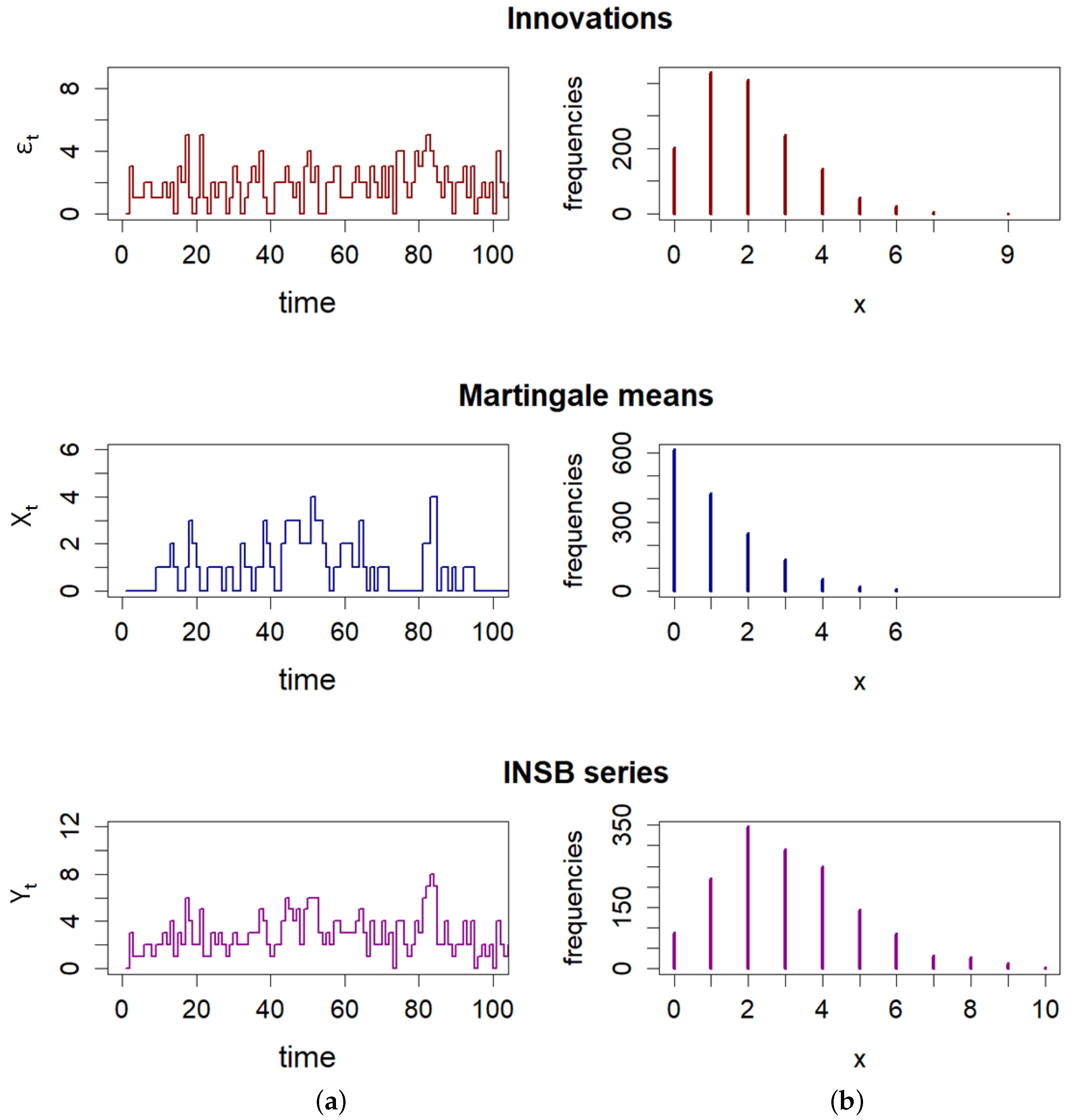
Figure 1 shows realizations of all mentioned INSB series, where as PS-distributed innovations, the Poisson distribution with parameter
is taken. It is easy to see that the series
of martingale means has the most pronounced zero inflation, which will be formally confirmed further on.
3. Main Properties of the INSB(1) Process
Here, some stochastic features of the INSB(1) process are examined. The following statement gives the integer-valued moving average representation of the infinite order (abbr. INMA representation) of corresponding series of this process.
Theorem 1. Suppose that PS-innovations , given by Equation (1), have finite first moment , which is uniformly bounded on . Then, the INSB(1) series , defined by Equation (3), has an INMA representation:where , . Similarly, series , defined by Equation (5), has a representation:where both sums above converge almost surely. Proof. Using a similar procedure to that in Stojanović et al. [
19] (see Theorem 2.1), it can be proved that RVs
are mutually uncorrelated with the mean and variance, respectively,
where
and
is the cumulative distribution function (CDF) of RVs
. Further, according to assumptions of the theorem, there is an
such that
Based on that and independence of RVs
and
, for each
, it follows that
where the sum above converges uniformly on
. In addition, as
,
is a monotone and bounded sequence, the Abelian criterion for convergence of infinite sums implies that
Moreover, the above convergence is uniform on
, and using Theorem 2.1 in Alzaid and Al-Osh [
22], it follows that inequality (
9) is sufficient for the equality
where
is the PGF of RVs
,
is the PGF of RVs
, while
and
are vectors of (unknown) parameters. Furthermore, the above product absolutely converges for every
, so using the bijective correspondence between PGFs and PMFs of arbitrary RVs, it follows that Equation (
10) is equivalent to the INMA
representation in Equation (
6).
To prove the almost sure convergence in Equation (
6), note that using Equation (3), for any
, it holds that
Now, let us consider a random event:
where
According to Equation (
12), for any
, one obtains
From here, using the probability continuity property and the definition of the thinning operator, for events
, we obtain
By applying again the property of continuity of probability and convergence of the product in Equation (
10), it follows that
that is, the sum in Equation (
6) converges almost surely. Similarly, using the definition of the series
, given by Equation (
5), the almost sure convergence in Equation (
7) is proved. □
Remark 1 (PGFs of the INSB series).
By applying a procedure similar to the previous theorem, as well as some general facts about PGFs of non-negative stationary integer-valued time series (see, e.g., [20]), explicit expressions for the PGFs of the INSB(1) process can be obtained. Namely, using Equations (5), (10) and (11), the first-order PGFs of the series and areFurthermore, suppose that , , and , , , are the overlapping blocks of series and , respectively. The replacement in Equation (12) and some calculations give the r-dimensional PGFs of random vectors and as follows: Also, it is worth noting that by using realizations of the (only) observable series , that is, the second-order PGF , the parameter estimators of the INSB(1) process will be obtained (see Section 4, below). Based on the previous theorem, the following statement concerns the mean, variance and correlation structure of INSB series.
Theorem 2. Assume that the conditions of Theorem 1 hold, as well as that series and , given by Equations (3) and (5), respectively, have second-order finite moments. Then, both of these series are strictly stationary and ergodic. The mean and variance for the series are, respectively,and the autocorrelation function (ACF) is , Similarly, for the series , it isand its ACF is Additionally, both sums in their INMA(∞) representations, given by Equations (6) and (7), converge in the mean-square sense. Proof. Using Equation (
6) and the well-known features of the binomial thinning operator (see, e.g., Kella & Löpker [
23]), for the mean of the series
, one obtains
Analogously, the variance of this series is obtained as follows:
From here, by substituting Equations (
8) for the mean value (
) and variance (
) of the series
, and after some computations, Equations (
15) are obtained. Finally, according to Equation (
12), the ACF of the series
is obtained from the equalities
Note that previously proven facts imply that RVs
have finite moments up to the second order. Then, using again Equation (
12) and features of the binomial thinning, one obtains
Thus, the mean-square convergence of the sum in Equation (
6) holds. Finally, the statement for the series
can be proved in a completely analogous way. □
According to the previous theorem, in the non-trivial case , the inequalities , obviously hold. Therefore, the basic INSB series has a weaker correlation than , i.e., compared with the correlation of INAR-based models. Also, by applying the previous results, the over-dispersion conditions for INSB series can be described as follows.
Remark 2 (
Over-dispersion conditions)
. Recall that the over-dispersion of the PS series depends on the function . Namely, Equations (2) imply that if and only if , On the other hand, the over-dispersion conditions of the series are weaker, because Equations (8) imply that holds if and only ifThereafter, using Theorem 2, that is, Equations (15), it is obtained thatso the over-dispersion conditions are the same for both series and . Finally, Equation (16) implies that if and only if According to the inequality , , it follows that Thus, over-dispersion of the series implies over-dispersion for , that is, has weaker over-dispersion conditions than .
The Markov properties of the INSB(1) series, their marginal distributions and the properties of zero inflation are discussed below.
Theorem 3. Let be the PS-distributed series, with the PMF given by Equation (1). The martingale mean series , defined by Equation (3), is a homogeneous Markov process with one-step transition probabilities: Similarly, series , given by Equation (5), is a Markov process with transition probabilities:where andis the PMF of the series , . Proof. Using Equations (
3) and (
4), as well as the definition of conditional probabilities and binomial thinning, for the conditional distribution of
on a given
, one obtains
where
is the PMF of binomial distribution
. From here, Equation (
17) is directly obtained.
On the other hand, notice that for the series
, it is valid that
where using conditional probabilities, the PMF of the series
is obtained as follows:
It can easily be seen that the last obtained equality is equivalent to Equation (
19). According to this, for the conditional distribution of
on a given
, one obtains
which proves Equation (
18), as well as the theorem completely. □
Remark 3 (
Distributional properties)
. Note that the first summand in Equation (17) exists if and only if martingale means pass from the state to the non-increasing state . In addition, the transition probabilities given by Equations (17) and (18) give the marginal PMFs of the INSB series and :Finally, using the PGFs of the INSB series and , given by Equations (13), the PMFs of these two series can also be expressed as follows: In a similar way to INAR processes with zero inflation (see, e.g., Li et al. [
24,
25]), the distribution of zero lengths of INSB(1) processes is examined below. For this purpose, recall that we have assumed that the condition
is satisfied and observe the distribution of zero “runs”, as the number of zeros occurrences between two distinct non-zero values. The following statement gives the expected lengths of zeros in INSB(1) model.
Theorem 4. The expected lengths of zero runs for the series and are, respectively,where and is the proportion of zeros in the RVs . Proof. Using Equation (
17), as well as Equation (
1) for the PS distributions family, the probabilities of transitions from zero to zero and from zero to non-zero values of the series
are obtained as follows:
It can easily be seen (see, e.g., Stojanović et al. [
21]) that zero lengths of the series
have a geometric distribution with parameter
. Therefore, the expected length of zero is
and from here the first equality in Equations (
22) immediately follows. Similarly, according to Equation (
18) and using the same procedure as the previous one, the second equality in (
22) is easily obtained. □
Remark 4 (
Zero-inflation properties)
. Based on the previous results, the proportions of zeros in the INSB series can be easily computed. Indeed, using the definition of series and , given by Definition 1 and Theorem 1, one obtainsFrom here, we obtaini.e., RVs have a more pronounced zero inflation than . On the other hand, using the PGFs of the series and , that is, Equations (13) and (21), the zero proportions of these two series are Note that these proportions are products of convex combinations of values , , and constant 1. Since the function is monotonically increasing, it follows thatand this implies Thus, the basic INSB series has a less pronounced zero inflation compared with the other mentioned series. Finally, martingale means have the most pronounced zero inflation and can be an adequate stochastic model in the fitting real-world series with pronounced zero values. 4. Parameter Estimation Procedure
Due to the specific structure of the INSB(1) process, its parameter estimation procedure is more complex compared with most known count time-series models. For instance, according to Equation (
20), it follows that the (only) observable series
has an INAR(1) structure, but with 1-dependent innovations
. Therefore, the conditional mean of this series is
and it depends on realizations of (unobservable) noise indicator
. Thus, some of the widely used estimation methods, e.g., conditional last squares (CLS) method [
26], as well as conditional maximum likelihood (CML) method [
27], cannot be used here. Moreover, according to Theorem 2 and Equations (
15) and (
16), it is clear that even some moment-based estimation methods, i.e., the well-known Yule–Walker (YW) estimators [
28], cannot simply obtain the above (see
Section 6).
In order to obtain efficient parameter estimators of the INSB(1) process, an estimation technique called probability-generating function (PGF) method is examined here. It is worth to notice that some general results of PGF estimation theory were given in Esquivel [
29]. Thereafter, some more specific PGF estimation procedures were recently examined in Stojanović et al. [
19,
20,
21], as well as in Cadena et al. [
30]. Also, it can be emphasized that the main idea of the PGF method is close to the empirical characteristic function (ECF) estimation method introduced by Yu [
31]. Similar to the ECF method, the goal of the PGF method is minimizing the “distance” between the theoretical PGF of the series
, given by Equation (
14), and its appropriate empirical PGF (of order
:
where
and
is a finite realization of the basic INSB(1) series
. Since the stationarity and ergodicity of the series
was proved in Theorem 2, it follows that
where
is the true value of unknown parameters
. Hence,
is an unbiased estimator of
. In addition, the PGF
is well defined on the set
, so the objective function can be given as follows:
where
and
is a weight function, integrable on
. Then, PGF estimators are usually obtained through minimization of the objective function given by Equation (
24), with respect to parameters
. More precisely, PGF estimates are solutions to the equation
where
is a parameter space of the regular and stationary INSB(1) process. In order to solve Equation (
26), some of the numerical integration procedures can be used, which is described in the next section,
Section 5. Similar to Stojanović et al. [
20], the following statement examines the strict consistency and asymptotic normality (AN) of PGF estimators of the INSB(1) process under certain regulatory conditions.
Theorem 5. Let be the true value of the parameter θ and , , be solutions to Equation (26). Additionally, assume that the following regularity conditions hold:
and , for T large enough.
The functionhas a unique minimum at the point . is a non-zero matrix uniformly bounded by some positive and w-integrable function .
is a regular matrix.
Then, is a strictly consistent and AN estimator of the parameter θ.
Proof. To prove the statement of theorem, we use a procedure based on some general results related to PGF estimators, described in Stojanović et al. [
20]. First, the consistency of the estimator
should be checked. As the INSB(1) series
is ergodic, Equation (
24) and the strong law of large numbers (SLLN) give
Furthermore, by assumption
, the set
is a compact, with
belonging to its interior. Therefore, the continuous functions
and
are bounded on compacts
and
, respectively, so that for some
is valid:
According to this and similarly as in Stojanović et al. [
20], it follows that
which, along with Equation (
27), implies that
Thus,
converge almost surely and uniformly to
. According to this, as well as assumption
and Theorem 2.1 in Newey and McFadden [
32], one obtains
that is,
is a strictly consistent estimator of the parameter
.
In order to prove the property of AN for
, note that the partial derivatives up to the first two orders of the function
are continuous functions. Therefore, they can then be differentiated under the integral sign, as follows:
From here, taking the mean values at
, one obtains
where
According to assumption
, for the function
, it is valid that
where
is some matrix norm on
. Therefore, it follows that
and using Equations (
30) and SLLN, it is obtained that
Further, according to Equations (
23) and (
28), the gradient of function
is as follows:
where
and
holds. Using some general facts on ECF theory (see, e.g., [
30,
31]), absolute summability of covariance
,
of the series
is sufficient for a non-zero finite value:
According to Theorem 2, for each
, it is valid that
so the central limit theorem for stationary processes [
33], as well as Equations (
32) and (
33), gives
where “
d” means the convergence in distribution.
On the other hand, according to the Taylor expansion of the function
at
, it follows that
From here, using assumption
and the equality
, one obtains
Finally, Equations (
31), (
34) and (
35) give
and the theorem is fully proved. □
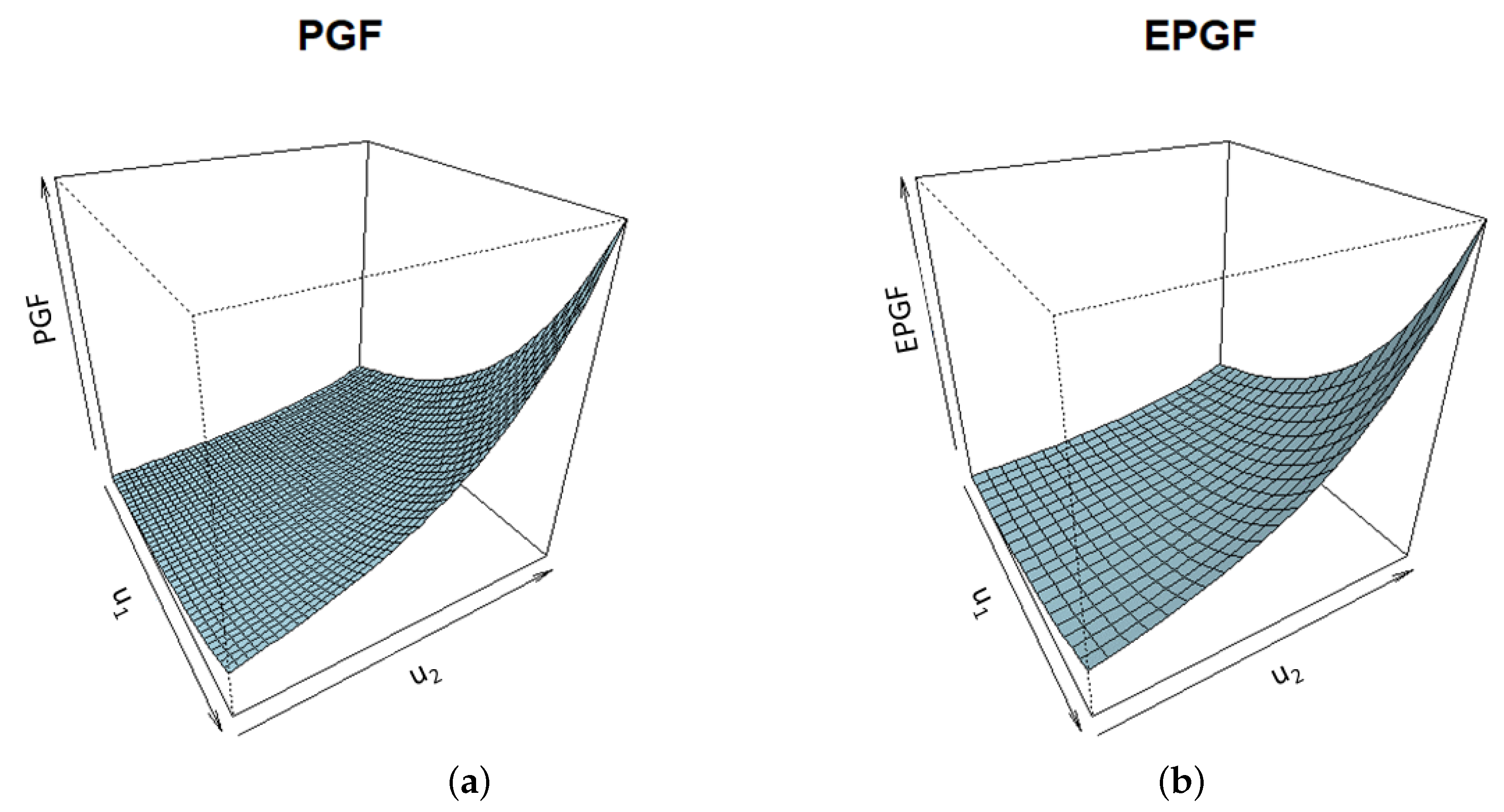
Remark 5. Using similar considerations as in ECF estimation theory (see, e.g., Yu [31]), the PGF estimators of the (true) parameter can be calculated using the realization of a two-dimensional random vector . In that case, the objective function is given as a double integral that can be approximately calculated by applying some well-known cubature formulas (see the next section, Section 5). To this end, the two-dimensional PGF of the basic INSB(1) series should be determined. By replacing in Equation (14) and using Equation (13), this PGF can be obtained in the following way:where Figure 2 shows, as an illustration, the theoretical and empirical PGFs of the series with geometrically distributed PS innovations. 5. Numerical Simulations
In this part, numerical simulations of the PGF estimation procedure for the unknown parameters
of the INSB(1) process were performed. To that aim, as mentioned earlier, different PS-distributed innovations
can be considered. For some practical reasons, related to the application of the INAR(1) process that will be further explained, two different PS-distributions of the innovations
were examined, one with a Poisson distribution and the other with a geometric distribution. Using Monte Carlo simulations, samples of length
were generated in both cases, based on 500 independent realizations of the PS series
. According to that, by applying Equations (
3) and (
5), respectively, the series of martingale means
and the basic INSB series
were then generated. In that way, the realizations
of the INSB-based series
were obtained, on which the PGF method could be applied.
The estimators of parameters
were calculated by minimizing the double integral
where
is the weight function, and
is the two-dimensional PGF of the INSB(1) series
. For some specific PS-distributed innovations, this PGF can be obtained after some computation, by using Equation (
36). In that way, for PS innovations with Poisson distribution, one obtains
while for PS innovations with geometric distribution, it follows that
where
It is worth mentioning that these PGFs are not obtained in closed form, but they can be easily approximated by finite
k-terminal products and with arbitrary precision.
After that, the integral in Equation (
37) is approximately calculated using the cubature formula:
where
are the cubature nodes and
are the weight coefficients. In this case, the Gaussian cubature formulas with
nodes were used, where two-dimensional weights are based on the Gegenbauer orthogonal polynomials, i.e.,
where
. Obviously, these cubatures reduce to the well-known Gauss–Chebyshev cubatures of the first type (when
), Gauss–Chebyshev cubatures of the second type (when
) and Gauss–Legendre cubatures (when
). These cubatures were calculated within software package “Orthogonal polynomials” in Wolfram Mathematica language, authorized by Cvetković and Milovanović [
34]. Thereafter, minimization of the objective function given by Equation (
37) was performed using the box-constrained optimization procedure “nlminb” [
35] in the statistical programming language R. At the same time, realizations of a uniform distribution
were taken as the initial values of the parameters.
Table 2 presents the summary statistics of the thus obtained PGF estimates, that is, their minimums (Min.), mean values (Mean), maximums (Max.), as well as the mean squared estimation errors (MSEEs), for all proposed weights and both innovation distributions considered. Additionally, the values of the objective functions
are given, as reference errors in the estimation. Regarding to the results presented, it is seen that the PGF procedure provides efficient parameter estimates, with similar properties, for both innovation series
. Notice that slightly smaller estimation errors are observed with weight
. This is expected, because this weight emphasizes points around the coordinate origin. On the contrary, somewhat larger errors in the estimation are observed with weight
, which “forces” ends of the interval
. Finally, when
, Gauss–Legendre orthogonal polynomials with weight
are obtained. Their accuracy is also satisfactory, and due to their simplicity, similarly to what is reported in Stojanović et al. [
19,
21], they will be used in some practical applications of the PGF method.
In addition,
Table 2 contains the AN test results, where Anderson–Darling normality test was performed. The test statistic, denoted as AD, as well as the corresponding
p-values, were calculated using the procedure from the software package “nortest” [
36], within the statistical programming language R (version 4.3.2). According to the values thus obtained, it is easy to see that the property of AN is verified for most PGF estimates of parameters
, at the significance level of
. At the same time, it is worth emphasizing that estimates of critical value
c can be simply obtained from the estimates of parameter
and the equality
6. Application of the Model
Some practical applications of the INSB process in real-world data modeling are discussed here, taking two sets of actual data. The first series, named Series A, represents the number of traffic accidents with a fatal outcome in the Republic of Serbia, collected according to the official statistics of the Office for Information Technologies and Egoverment [
37], in the period from 1 January 2015 to 31 December 2021. The second one (Series B) represents the number of forest fires in Evros, one of the largest regional units of the Republic of Greece, with data taken from the official website of the Hellenic Fire Service [
38], from 1 January 2019 to 31 December 2021. In that way, count time series of lengths
and
, respectively, were obtained, and their dynamics are shown in
Figure 3.
Summary statistics of both series are shown in
Table 3, where their specific descriptive characteristics can already be observed. For instance, with Series A, a slight over-dispersion is noticeable. Using the previous theoretical results, it appears that its dynamics can be modeled by an INSB(1) process with Poisson-distributed innovations
. Namely, in this case,
holds, and according to Equation (
15) in Theorem 2, the over-dispersion index is
On the other hand, when Series B is observed, it is noticeable that the over-dispersion is much more pronounced, as are the properties of zero inflation. Thus, it appears that geometrically distributed PS innovations can be used to model its dynamics.
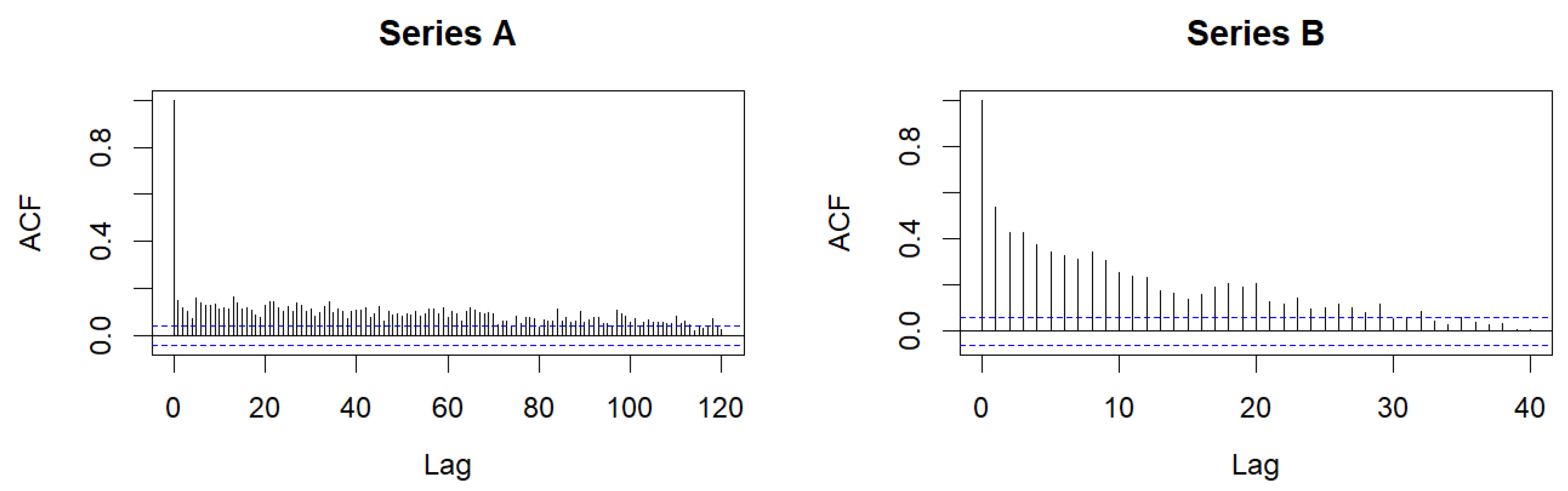
Further, the augmented Dickey–Fuller (ADF) test was conducted, with the alternative hypothesis that the observed series are stationary, which was confirmed in both cases. Also, the estimated values of the autocorrelation functions (ACFs) of both series are decreasing, as is shown in
Figure 4. In addition, it is noticeable that the decrease in both ACFs, especially for Series A, is slower than in the case of the regular INAR(1) process. In accordance with previous theoretical results, primarily Theorem 2, this suggests the possibility of modeling the dynamics of both series with the INSB(1) procedure.
On the other hand, the weak correlation in Series A indicates the possibility that the hypothesis of the absence of correlation in the members of this time series is valid here. Therefore, the following null hypotheses are tested here:
where
and
are the
kth-order correlations of the series
and
, respectively. Using the results given by Dalla et al. [
39], the above hypotheses are tested using the robust statistics
where
and
are estimated
kth correlations of the above series, respectively.
Alternatively, the absence of correlation in the series
and
is also tested, via the hypotheses
where
and
are the appropriate
kth-order correlations. Like previously, the statistics used for testing are
For all the above statistics, the following convergences hold:
where
and
are the RVs with chi-square distributions.
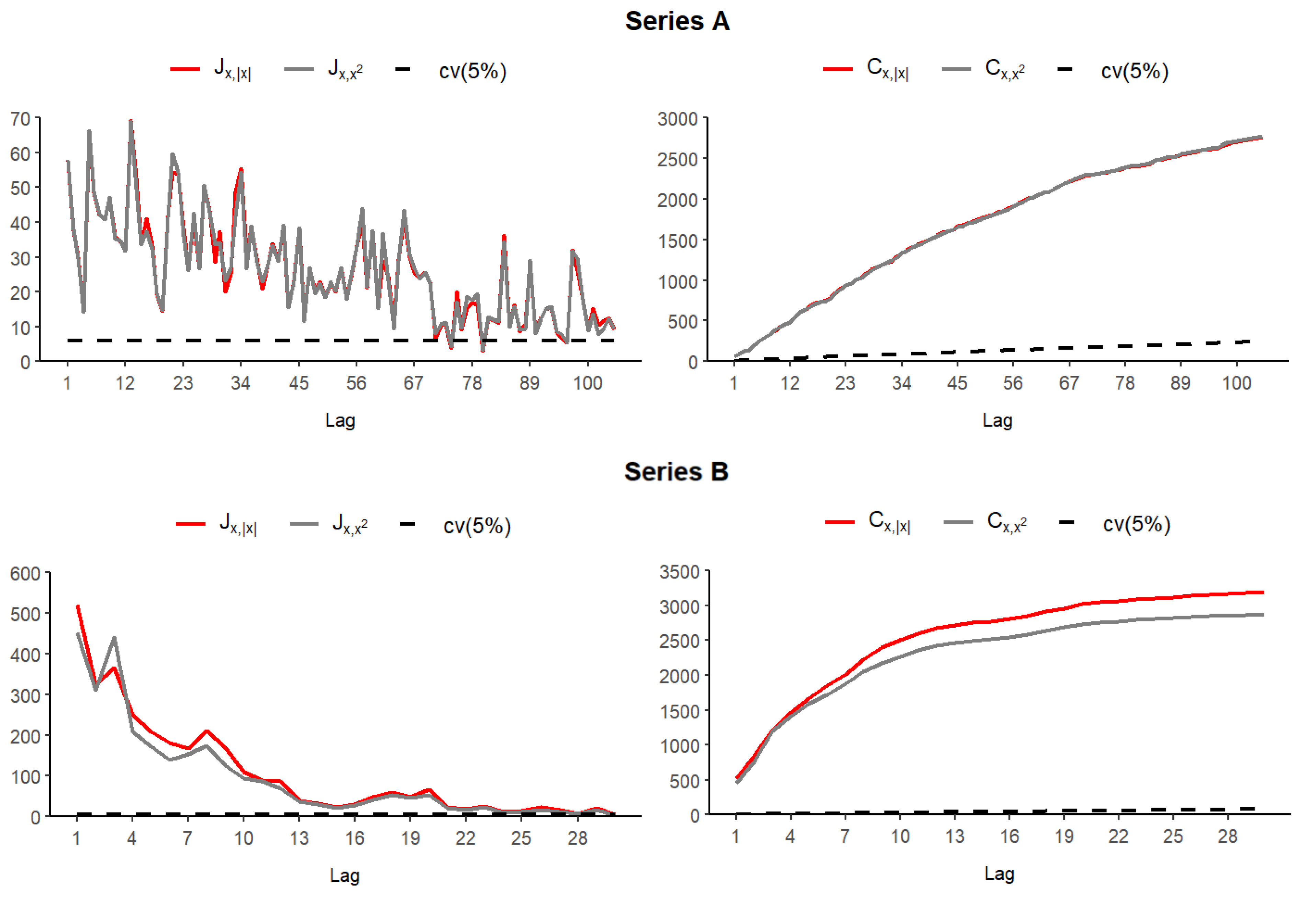
Figure 5 reports the test results of both observed series, at the significance level
(showed with dashed lines), obtained using the function “iid.test()“ within the R-package “testcorr“.
In the case of individual testing, it is obvious that the null hypothesis is rejected up to a certain correlation lag. Specifically, with Series A, the i.i.d. property appears for the first time when , where the appropriate p-values of the statistics and are equal to 0.144 and 0.114, respectively. Similarly, with Series B, the first i.i.d. case is when . On the other hand, following the cumulative tests, it is clear that the null hypothesis of non-correlation of the observed series does not hold at any level. Thus, the assumption about their possible modeling using the INSB(1) process can be justified.
To compare INSB(1) modeling with INAR(1) process modeling, both of these stochastic models were formed based on the observed data. First, by applying equality
where
the INAR(1) model was constructed, whose parameters
can be estimated using some well-known procedures. Here, the CLS estimation method was applied, based on the minimization of the function
and the CLS-estimates
,
, same as in the regression procedure, are easily computed by differentiating Equation (
39) and equating it to zero. Notice that in the case of the PS distributions family, by using the estimator
, estimates of the parameter
a can be also easily determined (see, c.f.
Table 1). Hence, for the Poisson and geometric distributions, the corresponding estimates are
and
, respectively. By applying some basic results of CLS theory [
40], the asymptotic properties of the CLS estimators obtained in this way can be proven. The results of this estimation procedure are given in the upper part of
Table 4.
Taking as initial values the estimates obtained from the previous CLS procedure, the PGF method is then applied. PGF estimates of parameters
are calculated using the previously described estimation procedure, that is, by minimizing the double integral given by Equation (
37). In doing so, Gauss–Legendre orthogonal polynomials with weight
are used, and the estimated values for both series, along with the corresponding estimated standard errors, are also presented in
Table 4. Additionally, parameter estimates of critical value
c can be computed using Equation (
38), and for Series A and B, these values are
and
, respectively. Accordingly, this means that both series can be equally modeled by the regular INAR(1) or INSB(1) model, although the INSB(1) model appears to have slightly better fitting capabilities.
To confirm this fact, the efficiency of fitting is analyzed for both stochastic models and both of the mentioned estimation procedures. For this purpose, using previously obtained estimated parameter values, 500 Monte Carlo simulations of INAR(1) and INSB(1) time series are generated, while the efficiency of the fit to the real-world data used here is checked using the MSEE statistics and Akaike’s information criterion (AIC). Their average values, as well as the values of objective function
, are presented in the middle part of
Table 4. It is worth noting that fitting statistics, as well as the estimated parameter values, are close for both series, i.e., for both estimation methods and both stochastic models. However, it is noticeable that the fitting errors are slightly less when the INSB(1) model is applied. This is somewhat more emphasized in the case of Series B, for which it can be concluded that the INSB(1) process represents a more suitable stochastic fitting model. Some of the aforementioned facts can also be observed in the above plots of
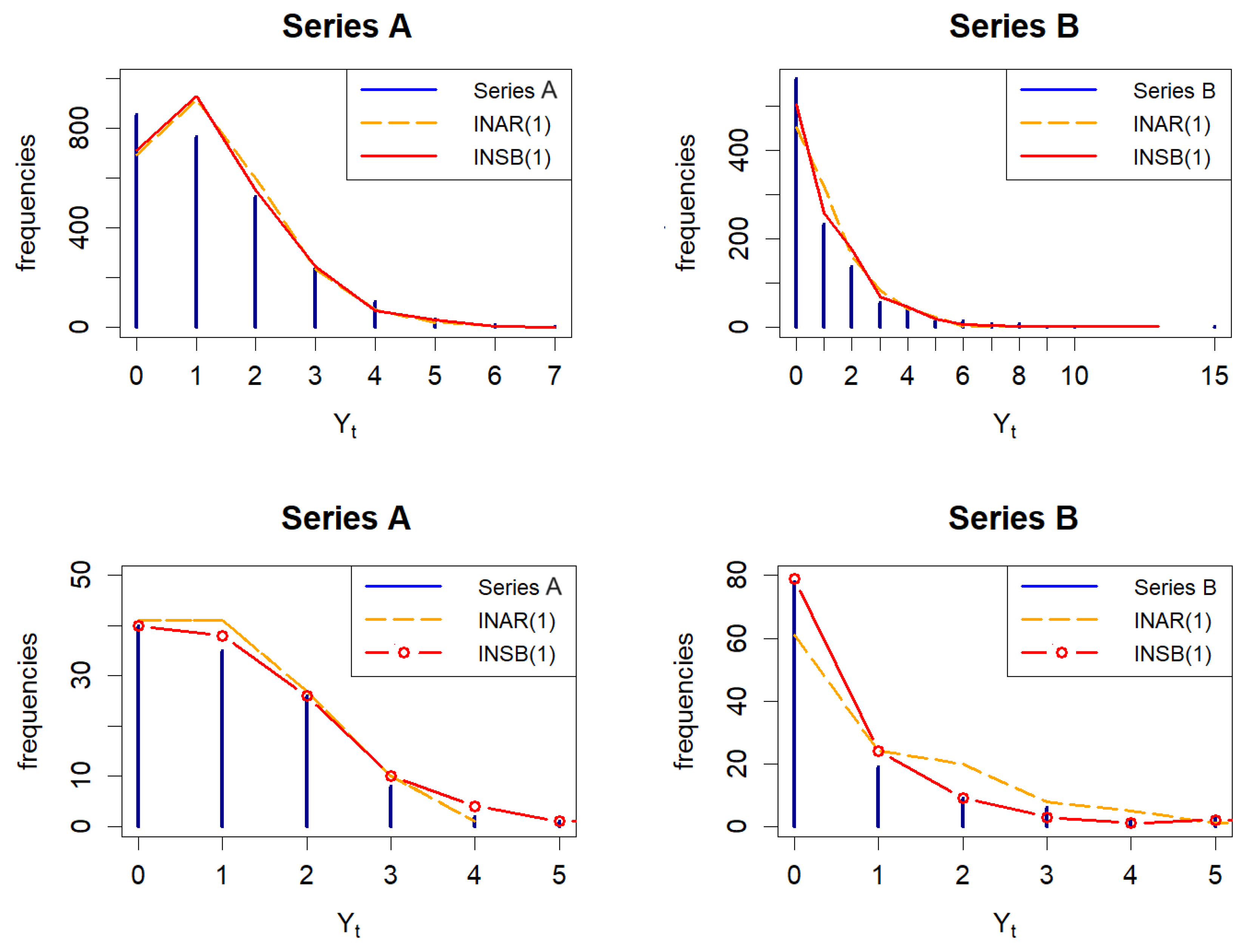
Figure 4, where the empirical and fitted frequencies of both time series (as well as both stochastic models) are shown.
Finally, for both of these models, the analysis of forecast accuracy based on them is examined. To this end, the time interval from 1 January 2023 to 30 April 2023 was taken as the horizon of the forecast length (
). The testing procedure was carried out using a one-tailed Diebold–Marian
o test of predictive accuracy [
41]. More precisely, the null hypothesis was that the INAR(1) and INSB(1) models have the same predictive accuracy, while the alternative hypothesis was that the INSB(1) model has better accuracy. The test statistic, labeled DM, as well as the corresponding
p-values, were calculated within the package “forecast” [
42] in the statistical programming language R and are presented in the lower part of
Table 4. Based on this, it can be seen that the INSB(1) model has better forecast accuracy, which is in accordance with the previous results obtained. As an illustration, the lower diagrams in
Figure 6 show the frequency distribution of both models, based on forecast data.
7. Conclusions
A novel count time-series model, named INSB(1) process, is presented here. Using the general form of PS-distributed innovations, as well as the noise indicator series, this stochastic model can be viewed as a generalization of some related models, primarily the INAR(1) processes. The key properties of the proposed model, as well as the procedure for estimating its parameters based on probability-generating functions (PGF method), were discussed in detail. Through Monte Carlo simulations, the consistency of PGF estimators, as well as a practical application of the INSB(1) process in real-world data fitting, was examined. In order to verify the effectiveness of the proposed model, it was applied in fitting distributions and for forecasting two accident-based real-world time series: the number of serious traffic accidents and the number of forest fires. At the same time, the INSB(1) model was also compared with the regular INAR(1) model. Based on the obtained results, that is, the fitting errors and DM-statistics presented in the previous section, the proposed model has the same or even better fitting possibilities with the observed data. According to the above, the better characteristics of the INSB model can be observed, especially in the prediction of future values of the considered time series.
Let us notice that as members of the PS distributions family, two special cases of the INSB(1) model, with Poisson-distributed and geometrically distributed innovations, were considered. For both, the fitting procedures were examined in various aspects, as well as prediction accuracy. The obtained results indicate the appropriateness of the proposed model, which at the same time represents a motivation for further research. This can be conducted, for instance, in defining a higher-order INSB processes or, similar to the General Split-BREAK (GSB) model, to use some other discrete-type stochastic distribution as the innovation series. Finally, it should be mentioned that there are integer-valued distributions that do not belong to the family of PS distributions, which may be a limitation of the proposed model.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}