Abstract
In this work, we address the problem of improving the classification performance of machine learning models, especially in the presence of noisy and outlier data. To this end, we first innovatively design a generalized adaptive robust loss function called . Intuitively, can improve the robustness of the model by selecting different robust loss functions for different learning tasks during the learning process via the adaptive parameter . Compared with other robust loss functions, has some desirable salient properties, such as symmetry, boundedness, robustness, nonconvexity, and adaptivity, making it suitable for a wide range of machine learning applications. Secondly, a new robust semi-supervised learning framework for pattern classification is proposed. In this learning framework, the proposed robust loss function and capped -norm robust distance metric are introduced to improve the robustness and generalization performance of the model, especially when the outliers are far from the normal data distributions. Simultaneously, based on this learning framework, the Welsch manifold robust twin bounded support vector machine (WMRTBSVM) and its least-squares version are developed. Finally, two effective iterative optimization algorithms are designed, their convergence is proved, and their complexity is calculated. Experimental results on several datasets with different noise settings and different evaluation criteria show that our methods have better classification performance and robustness. With the Cancer dataset, when there is no noise, the classification accuracy of our proposed methods is and , respectively. When the Gaussian noise is , the classification accuracy of our proposed methods is and , respectively, demonstrating that our method has satisfactory classification performance and robustness.
1. Introduction
Data collecting and reasonable processing are becoming increasingly crucial as modern computer technology advances. As an excellent machine learning tool, support vector machine (SVM) [1,2,3] has been widely used in bioinformatics, computer vision, data mining, robotics, and other fields in recent years. The main idea behind SVM classification based on statistical learning theory and optimization theory is to construct a pair of parallel hyperplanes to maximize the minimum distance between two classes of samples. SVMs implement the structural risk minimization (SRM) principle in addition to empirical risk minimization. Although SVM can achieve good classification performance, it needs to solve a large-scale quadratic programming problem (QPP), and learning it takes a lot of time, which seriously hinders the application of SVM in large-scale classification tasks [4]. Furthermore, when dealing with complicated data, the simple SVM model would run into various issues, which will stymie its development and practical implementation, such as the “XOR” problem.
To overcome the difficulties brought by SVM to solve a QP problem, Jayadeva et al. [5] proposed a twin support vector machine (TSVM) for pattern classification based on generalized eigenvalue approximation support vector machine (GEPSVM). Since TSVM solves two smaller QPP problems instead of a single large QPP problem, it can theoretically learn four times faster than a standard SVM. The main goal of TSVM is to find two parallel hyperplanes, each of which is as close as possible to the corresponding class in the sample data, while being as far away from the other classes as possible. Further, to overcome the problem that TSVM only considers empirical risk minimization without considering the principle of structural risk minimization, Shao et al. [6] proposed a twin bounded support vector machine (TBSVM) by introducing two regularization terms. Compared with TSVM, a significant advantage of TBSVM is the principle of structural risk minimization, which embodies the essence of statistical learning theory, so this improvement can improve the classification performance of TSVM. In recent years, some TSVM-based variant algorithms have been proposed for pattern classification tasks, such as least squares twin support vector machine (LSTSVM) [4], recursive projection twin support vector machine (RPTSVM) [7], pinball twin support vector machine (Pin-TSVM) [8], sparse pinball twin support vector machine (SPTWSVM) [9], least squares recursive projection twin support vector machine (LSRPTSVM) [10], fuzzy twin support vector machine (FBTSVM) [11], and so on, which greatly promoted the development of TSVM.
It is well known that distance metrics play a crucial role in many machine learning algorithms [12]. Although the above algorithms show good performance in pattern classification, it is worth noting that most of them adopt the -norm distance metric, whose squaring operation will exaggerate the impact of outliers on model performance. To effectively alleviate the impact of the -norm distance metric on the robustness of the algorithm, the -norm distance metric c with bounded derivative has received extensive attention and research in many fields of machine learning in recent years [13,14,15,16,17,18]. For example, Zhu et al. [13] proposed 1-norm SVM (1-SVM) based on an SVM learning framework. Mangasarian [14] proposed an exact -norm support vector machine based on unconstrained convex differentiable minimization. Gao [15] developed a new 1-norm least squares TSVM (NELSTSVM). Ye et al. [16] proposed a -norm distance minimization-based robust TSVM. Yan et al. [17] proposed 1-norm projection TSVM (1-PTSVM), and so on. As mentioned earlier, the -norm is a better alternative to the squared -norm in terms of enhancing the robustness of the algorithm. However, when the outliers are large, the existing classification methods based on -norm distance often cannot achieve satisfactory classification results.
Recently, more and more researchers have paid attention to the capped -norm and achieved some excellent research results [19,20,21,22,23,24]. Research shows that capped -norm is considered to be a better approximation of -norm and more robust than -norm. In general, the capped -norm is considered to be a better approximation of the -norm, with stronger robustness than the -norm. Some excellent algorithms based on capped -norm have been proposed for robust classification tasks. For example, Wang et al. [25] proposed a new robust TSVM (CTSVM) by applying capped -norm. CTSVM retains the advantages of TSVM and improves the robustness of classification. The experimental results on multiple datasets show that the CTSVM algorithm has good robustness and effectiveness to outliers. The capped -norm metrics are neither convex nor smooth, which makes them difficult to optimize. There are two general strategies for solving nonconvex optimization problems. The first strategy is to design efficient algorithms, such as the bump process algorithm and the abnormal path algorithm. The second strategy is to smooth the metric function to reduce the complexity of the algorithm. To overcome the shortcomings of capped -norm, many scholars proposed capped -norm for robust learning [26,27]. Zhang et al. [28] proposed a new large-scale semi-supervised classification algorithm based on ridge regression and capped -norm loss function. It is worth noting that by setting the appropriate p-value, the capped -norm and capped -norm are special forms of capped -norm: when or , the capped -norm corresponds to the capped -norm or capped -norm. These algorithms show that the capped distance metric is robust against outliers. However, there are few extensions and related applications of the capped -norm for twin support vector machine.
In the current scenario, although data collection is easy, obtaining labeled data is difficult [29]. To address this issue, researchers have proposed semi-supervised learning (SSL) [29], which uses less labeled data and more unlabeled data to build more reliable classifiers. Graph-based SSL algorithms are a significant branch of SSL. The learning strategy involves first forming edges by connecting points between labeled and unlabeled data points and then creating a graph from these edges that represents the similarity between samples. Manifold regularization-based SSL [30] is one of the graph-based SSL methods that preserve the manifold structure to improve the discriminative property of the data [31]. The learning strategy involves mining the geometric distribution information of the data and representing it in the form of regularization terms. The reference [31] first introduced MR to SSL by proposing the Laplace support vector machine (Lap-SVM) and Laplace regularized least squares (Lap-RLS). Qi et al. [32] developed a Laplace TSVM (LapTSVM) based on a pair of non-parallel hyperplanes of TSVM. Although the classifier’s generalization performance is improved, the method’s parameter adjustment may be impacted by different datasets, and it may not be able to handle large-scale problems effectively due to high computational complexity. Xie et al. [33] propose a novel Laplacian -norm least squares twin support vector machine (Lap-LSTSVM). The experimental results on both synthetic and real-world datasets show that Lap-LSTSVM outperforms other state-of-the-art methods and can also deal with noisy datasets [34,35].
To summarize, prior research on improving the TBSVM classification performance while considering robustness and discriminability is limited. In response, we introduce the WMRTBSVM and WMLSRTBSVM models. Specifically, we replace the hinge loss term in TBSVM with the -norm, and we replace the second term in TBSVM with the Welsch Loss with p-power. This improves the model’s classification performance and robustness. Furthermore, we incorporate a manifold structure into the model to further enhance its classification performance and discriminability. The main contributions of this paper are summarized as follows:
- (1)
- A generalized adaptive robust loss function called is innovatively designed. Intuitively, can improve the robustness of the model by selecting different robust loss functions for different learning tasks during the learning process via the adaptive parameter . Compared with other robust loss functions, has some desirable salient properties, such as symmetry, boundedness, robustness, nonconvexity, and adaptivity.
- (2)
- A novel robust manifold learning framework for semi-supervised pattern classification is proposed. In this learning framework, the proposed robust loss function and capped -norm robust distance metric are introduced to improve the robustness and generalization performance of the model, especially when the outliers are far from the normal data distributions.
- (3)
- Two effective iterative optimization algorithms are designed for solving our methods by the half-quadratic (HQ) optimization algorithm, and the convergence of the algorithms is demonstrated.
- (4)
- Experimental results on artificial and benchmark datasets with different noise settings and different evaluation criteria show that our methods have better classification performance and robustness.
In Section 2, we introduce the formulas involved in TBSVM and manifold regularization since our model is based on these two approaches. In Section 3, we present a novel robust manifold learning framework for semi-supervised pattern classification. Finally, we discuss experiments and conclusions in Section 4 and Section 5, respectively.
The structure of the rest of this paper is as follows: In Section 2, as our model is based on TBSVM and manifold regularization, in order to improve our formulas and their derivation, we will introduce the formulas involved in TBSVM and manifold regularization, respectively. In Section 3, we present a novel robust manifold learning framework for semi-supervised pattern classification. Finally, in Section 4 and Section 5, we discuss experiments and conclusions.
2. Related Works
This section presents a review of related works, which include TBSVM and manifold regularization. The binary classification problem in the n-dimensional real vector space is considered. All vectors are represented as columns. Given a training dataset , where is the input and is the corresponding output for . T is composed of positive class and negative class samples, where m = + . The data samples from class i form the data matrix , where each column represents a sample. represents all positive class samples (i.e., ), and represents all negative classes (i.e., ).
2.1. TBSVM
In this subsection, we provide a brief review of the twin bounded support vector machine (TBSVM). The optimization objective of TBSVM is to ensure that each hyperplane is as close as possible to the samples in the corresponding class and as far away as possible from the samples in the other class. For the linear case, TBSVM defines two nonparallel hyperplanes:
To improve the classification ability of TSVM and realize the principle of structural risk minimization, an improved version of TSVM named TBSVM is obtained by introducing an -regularization term based on TSVM:
and
To avoid the impact of singular problems caused by inverse matrices, positive scales and are introduced, where and are small positive constants, and 0 and I represent the zero vector matrix and the identity matrix, respectively, on the appropriate dimension. Therefore, based on the dual theory, we can obtain the dual problem of (2) and (3):
and
where represent regularization parameters, and are vectors of ones, and and are slack vectors. The prime superscript T is used to transform column vectors into row vectors, and the matrices and . The dual problems are revised as and , which are Lagrange multipliers. By solving (4) and (5), two nonparallel hyperplanes can be obtained:
A new data point is then assigned to the positive or negative class, depending on which of the two hyperplanes (1) it lies closest to, i.e.,
where is the absolute value operation, means the -norm for , when , is written as for brevity.
2.2. Manifold Regularization
In this subsection, we briefly review graph-based semi-supervised learning (SSL). Manifold regularization (MR) is one of the graph-based SSL methods, whose learning strategy is to mine the geometric distribution information of the data and represent it in the form of regularization terms. In [30], the authors point out that data distributions on manifolds are often complex and may exhibit nonlinear structures, and traditional methods may not be able to effectively capture their intrinsic structures and characteristics. Based on this, the authors propose a regularization method based on the Laplacian graph. On the basis of ensuring smoothness, the method maintains the Euclidean distance relationship of the original data sample as far as possible, enabling it to better reflect the distribution of data in the manifold space.
Consider a binary semi-supervised classification problem in the n-dimensional real space . The set of training data is represented by , where , dataset are the labeled data with corresponding labels , and dateset are the unlabeled data with corresponding labels , where represent the whole dateset. We model as a graph , is the adjacency matrix of graph ,
denotes the similarity between examples and , where represents the k nearest neighbors of . Based on the adjacency matrix , the Laplacian matrix of the graph can be computed by , where .
In RKHS, the optimization of manifold regularization can be written as follows:
where denotes the empirical risks on the labeled data , which also denote the loss function. and are non-negative regularization parameters. is the regularization term to prevent overfitting. is the smoothness term, which can be expressed as:
3. Main Contributions
In this section, we begin by outlining the key motivation behind our proposed model. We then present the model formulation and describe its components in detail. Finally, we provide a convergence analysis of the proposed model in Section 3.3.
3.1. Generalized Adaptive Robust Loss Function
To improve the robustness, classification performance, and generalization ability of the TBSVM framework, we propose a new robust loss function called the generalized adaptive robust loss function . The loss function is symmetric and has bounded non-negativity. The is defined for any as follows:
where is the power parameter, and c is a trade-off parameter that penalizes outliers.
Remark 1.
When , the -Loss will degenerate into Welsch Loss [36]. That is, Welsch Loss is a special case of -Loss.
Property 1.
has boundedness, non-negativity, symmetry, lack of smoothness, and non-convexity. Secondly, its value is limited to a constant and does not increase, which ensures better robustness and desirability of the loss function.
In Figure 1, we compare the robustness of different loss functions, namely -loss, -loss, Welsch loss, and (), against outliers. As shown in the figure, the Welsch Loss with -power (red curves) is the most robust, highlighting its effectiveness in suppressing the impact of noisy outliers on the model performance. In Figure 2, we plot the loss curve of the Welsch Loss with -power under different values of the parameter . We observe that as decreases (from 4 to 2, 1, and ), the function becomes narrower while remaining symmetric and bounded, further demonstrating its suitability for handling noise and outliers.
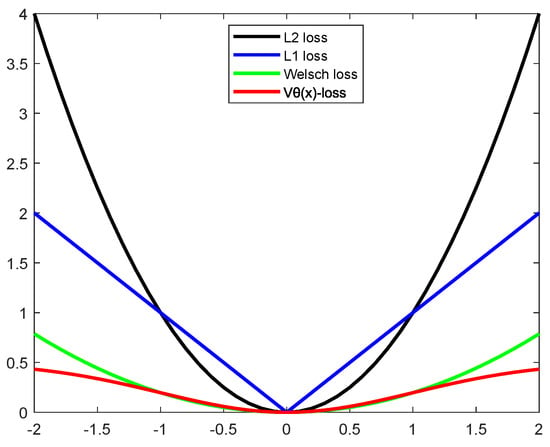
Figure 1.
loss vs. loss vs. Welsch loss vs. −loss.
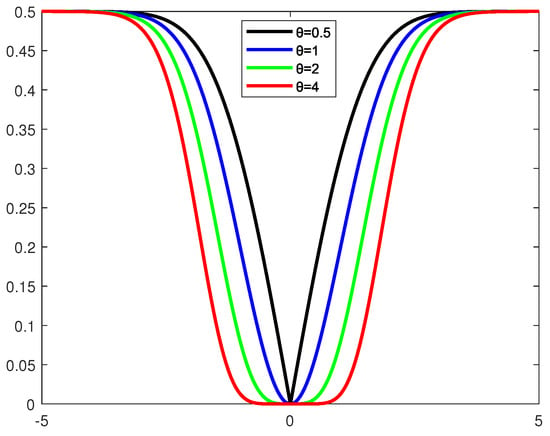
Figure 2.
Welsch Loss with −power under different .
3.2. Our Method
In this subsection, we present our model and provide an explanation of it. For the binary classification task, we aim to find a pair of optimal classification hyperplanes to separate the positive and negative samples. Specifically, we consider a pair of constrained optimization problems:
and
where, , and are positive regularization parameters, while c is an adjustment parameter that controls the degree of penalty for outliers. As stated in (6):
and
where refers to the Graph Laplacian matrix. D is a diagonal matrix associated with W, where the diagonal element is . The vector equals , while equals , where represents all training data, including labeled and unlabeled data and e is an appropriate vector. Thus, the primary problem of (8) and (9) can be written as:
and
Since the two terms are quite similar, we can solve one of them and obtain a solution for the other in a similar manner. For the purpose of illustration, let us consider solving (10) in two parts:
Then, we can rewrite the Formula (10) as:
where . We define a convex function
From the theory of conjugate functions, we obtain:
Then, we obtain:
Thus, the (10) and (11) can be rewritten as:
and
where , . To optimize the objective function smoothly, we introduce concave duality, as illustrated in Lemma 1 [37,38].
Lemma 1.
Let be a continuous nonconvex function, suppose is a map with range Ξ. We assume that a concave function exists defined on Ξ, such that holds.
Therefore, the nonconvex function can be expressed as:
According to concave duality, is the concave dual of given as:
In addition, the minimum value to the right is as follows:
Based on the Lemma 1, we give a non-convex function make any arbitrary ,
Assuming that , we obtain
Based on (23), the first term of (17) and (18) can be rewritten as:
and
Let . By Formula (19), the first term of (17) can be expressed as:
Therefore, the nonconvex dual function of given as:
By optimizing for (27):
Finally, the objective function (17) first term can be further written as:
where
Therefore, Formula (17) can be rewritten as:
Similarly, Formula (18) can be rewritten as:
The objective functions (30) and (31) are solved by learning optimal classifiers through alternative optimization algorithms. We calculate the gradient of the function with respect to , expressed as:
If , we fix and :
Similarly, if , we fix and :
To understand the relationship between parameters more clearly, we set the distance from sample to the hyperplane as X. If and almost equals 0, then the sample is considered an outlier and is discarded. Furthermore, is similar to . When the variables and are fixed to solve the classifier-related parameters , , , and , the optimization problem (30) and (31) can be written as:
and
Let be an diagonal matrix, and be an diagonal matrix. The optimization problem (35) and (36) can be rewritten as:
and
The corresponding Lagrange function of the above optimization problem (37) can be rewritten as:
where is a Lagrange multiplier, we derive the Lagrange function about and and obtain the following Karush–Kuhn–Tucker (KKT) conditions.
Let
Thus, we have
Further, we can get
where I is an identity matrix of appropriate dimensions. According to matrix theory, it can be easily proved that is a positive definite matrix. Therefore, we have
Furthermore, we can obtain the dual problem of (8) as follows:
Similarly, the dual problem of (9) can be written as:
where is the Lagrange multiplier and the augmented vector
Once vectors and are obtained, a new data point is then assigned to the positive or negative class, depending on which the two hyperplanes it lies closest to, i.e.,
where is the absolute value operation, means the -norm for , when , is written as for brevity.
Based on the above discussion, our algorithm will be presented in Algorithm 1.
| Algorithm 1 Solving WMRTBSVM |
|
To improve the computational power of WMTBSVM, we further propose the least squares version of WMTBSVM.
and
Like (37) and (38) in WMTBSVM, (48) and (49) can be rewritten as follows:
and
By bringing the equality constraint into the objective function,
and
The solution of (52) can be expressed as:
where H, F,Z, , E, and D are the same as those of WMTBSVM.
Once vectors and are obtained, a new data point is then assigned to the positive or negative class, depending on which of the two hyperplanes it lies closest to, i.e.,
where is the absolute value operation; means that the -norm for , when , is written as for brevity. Based on the above discussion, our algorithm will be presented in Algorithm 2.
| Algorithm 2 Solving WMLSRTBSVM |
|
3.3. Convergence Analysis
In this subsection, we prove the convergence of the proposed algorithms (see Appendix A).
3.4. Complexity Analysis
In this section, we briefly analyze the complexity of our proposed Algorithms 1 and 2. We know that computational complexity is mainly determined by matrix multiplication and matrix inversion. In Algorithms 1 and 2, assuming the size of the dataset is , where there are and positive and negative samples, respectively, and and .
In (44) and (47), and . The computational costs of matrix multiplication are both , while the computational cost of matrix inversion is . Therefore, the upper bound of the total computational cost of Algorithm 1 is , where T is the number of iterations, which is usually less than 10 in similar algorithms to our model. In addition, in our experiment, the number of samples m is generally much larger than the dimension of samples n, so the total computational cost of Algorithm 1 is .
In (53), the computational costs of matrix multiplication are and , respectively, and the computational cost of matrix inversion is . Therefore, the upper bound of the total computational cost of Algorithm 2 is , where . Consequently, the total computational cost of this algorithm is .
4. Experimental Results and Analysis
In this section, we test the performance of our proposed model. For a fair comparison, we implemented six classification algorithms in MATLAB R2021a. The experimental environment consisted of a Windows 11 machine (CPU: Intel Core i5; RAM: 16.00 GB; OS: 64-bit Windows 11).
4.1. Experimental Setting
To validate and evaluate the validity and reliability of our proposed model, we compared WM-TBSVM and WM-LSTBSVM with other related methods, including twin support vector machine (TSVM), twin bounded support vector machine (TBSVM), least squares twin support vector machine (LSTSVM), WMRTBSVM, and WMLSRTBSVM. Furthermore, the conventional accuracy () was used to measure the classification performance of all algorithms, which is defined as follows:
where TP and TN denote the true positive and true negative, respectively, and FP and FN denote the false positive and false negative, respectively. The higher the ACC value, the better the model value.
In the experiment, data preprocessing is carried out first. We divided the dataset into a training dataset and a test dataset, and all sample data were normalized to reduce the difference in features among different samples. In order to overcome the randomness of the test results, the experimental parameters were selected by 10-fold cross-validation, each dataset was tested 10 times, and the classification accuracy was averaged 10 times. In order to obtain the best generalization ability, the parameters involved in the experiment were selected as follows:
The value range of the is , = , and is .
4.2. General Experimental Results
In order to verify the classification performance of the proposed method and other related algorithms in a noise-free setting, we ran them on twelve UCI datasets from the UCI Machine Learning Repository. We split each dataset into a training set and a testing set with a sample ratio of 7:3. That is, in each experiment, we randomly selected 70% points of both classes at a time as the training set and the rest as the testing set. In addition, we used the grid method with 10-fold cross-validation to find the optimal parameters. The process was repeated 10 times. The general experimental results are shown in Table 1, with the best results for each testing set shown in bold. Here, ACC is the average classification accuracy in the testing set, and “time (s)” represents the average running time in the testing set in seconds obtained by each algorithm according to the optimal parameters.

Table 1.
Experimental results on UCI datasets without noise.
UCI datasets: Australian, Balance, Backnote, Cancer, German, Hepat, Pima Indian (Pima), QSAR, Spect, Vote, Wisconsin diagnostic breast cancer (WDBC), and Wholesale. See Table 2 for details of the twelve UCI datasets.
Table 2.
Characteristics of UCI Datasets.
As shown in Table 1, we observe that the classification accuracy of WMRTBSVM and WMLSRTBSVM is generally higher than that of other methods. Additionally, the classification accuracy of CTSVM is generally higher than that of TSVM, TBSVM, and LSTBSVM. CTSVM, WMRTBSVM, and WMLSRTBSVM all contain capped norm distances. In general, LSTBSVM and WMLSRTBSVM have shorter running times, but WMLSRTBSVM has higher classification accuracy. Based on this, we can objectively conclude that the use of a capped -norm distance metric in the TBSVM framework can improve classification performance, and the addition of the Welsch Loss with p-power can further enhance classification performance.
4.3. Convergence Analysis
In Section 3.3, we theoretically proved that the iterative optimization algorithm we designed is convergent. In this section, we conducted experiments on the Cancer dataset to further verify its convergence. As shown in Figure 3, the value of the objective function decreases with each iteration. In addition, the algorithm reached the optimal value in less than 10 iterations on the Cancer dataset. This also proves the feasibility and effectiveness of our algorithm.
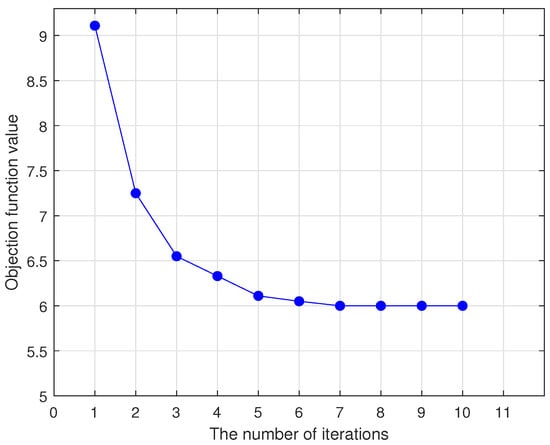
Figure 3.
Convergence of WMTBSVM.
4.4. Robustness Analysis
We conducted experiments on both artificial datasets and UCI datasets in a noisy environment. The dataset includes one synthetic dataset and twelve benchmark datasets from the UCI Machine Learning Repository. Please refer to Figure 4 and Table 2 for details on the artificial and UCI datasets.
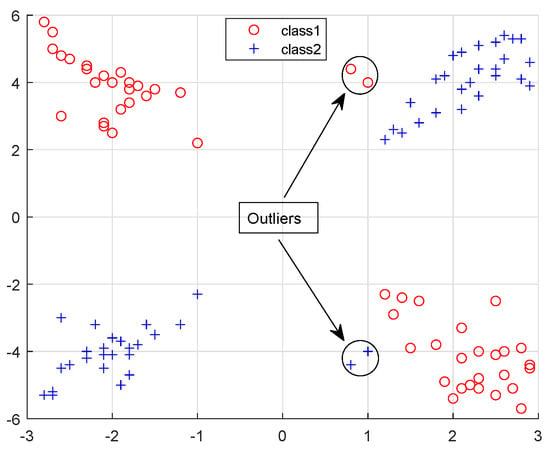
Figure 4.
Distribution of artificial datasets with outliers.
Artificial datasets The dataset consists of 104 two-dimensional points, with 52 samples in each class. These points are generated by disturbing points located on two intersecting planes, where each plane corresponds to a class of data. We used “∘” and “+” to distinguish between the two classes. To test the effect of outliers on classification performance, we added four outliers to the dataset, two of which belong to class , and two belong to class . This is illustrated in Figure 4.
In order to visually evaluate the classification performance and robustness differences between WMRTBSVM, WMLSRTBSVM, and the other four algorithms, we conducted experiments on artificial datasets with four outliers. The experimental results are shown in Figure 5.
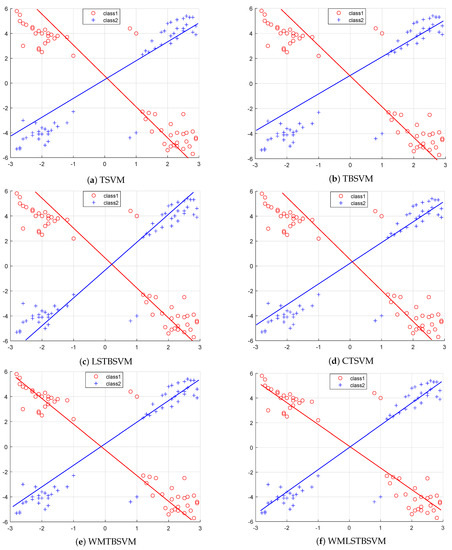
Figure 5.
The classification performance of six algorithms on the artificial datasets.
From the results depicted in Figure 5, we can see intuitively that WMRTBSVM and WMLSRTBSVM have better performance. The accuracy of six algorithms (TBSVM, LSTBSVM, CTSVM, WMRTBSVM, and WMLSRTBSVM) were , , , , , and , respectively. These results indicate that WMRTBSVM and WMLSRTBSVM can deal with outliers better than other methods after the introduction of outliers. Additionally, the classification effect of CTSVM is also good, which may neutralize the negative impact of outliers due to the capped -norm distance. Experimental results demonstrate that WMRTBSVM and WMLSRTBSVM have good classification accuracy after introducing outliers, which may be due to the use of capped -norm distance. The robustness of WMRTBSVM and WMLSRTBSVM to outliers has been demonstrated effectively.
In addition, we also evaluated the robustness of WMRTBSVM and WMLSRTBSVM by introducing Gaussian noise of , , and in the UCI datasets. Table 3, Table 4 and Table 5 show the experimental results on the dataset with , , and Gaussian noises, respectively.
Table 3.
Experimental results on UCI datasets with noise.
Table 4.
Experimental results on UCI datasets with noise.
Table 5.
Experimental results on UCI datasets with noise.
Table 3, Table 4 and Table 5 present the comparison of the 6 algorithms on the 12 UCI datasets with , and Gaussian noise, respectively. The experimental results reveal that the classification accuracy of each algorithm decreases after the introduction of noise. However, in most cases, WMTBSVM and WMLSTBSVM display higher classification accuracy than other algorithms, particularly when the noise surpasses . Moreover, LSTBSVM and WMLSTBSVM demonstrate less runtime. Overall, WMTBSVM and WMLSTBSVM are superior to the other four algorithms in terms of accuracy and robustness. This implies that WMTBSVM and WMLSTBSVM are robust learning algorithms that facilitate the classification of noise-contaminated samples.
Based on the results shown in Figure 6, we observe that the accuracy of the six algorithms decreases to varying degrees as noise increases from to , , and . This indicates that the algorithms’ robustness is impacted by the number of noise points. However, our proposed models, WMTBSVM (represented by the red curve) and WMLSTBSVM (represented by the blue curve), maintain the highest accuracy. Even when noise points reach , our algorithms still show clear advantages over the others. In the smaller datasets (a: , c: , and d: ), the CTSVM (represented by the magenta curve), WMTBSVM (represented by the red curve), and WMLSTBSVM (represented by the blue curve) curves show relatively smooth variations. This may be attributed to the truncation loss used in the algorithms. The performance of the three truncation-based algorithms was also good in the larger datasets (b: , e: , and f: ). However, overall, WMTBSVM and WMLSTBSVM showed the best performance, likely due to their use of Welsch Loss with p-power.
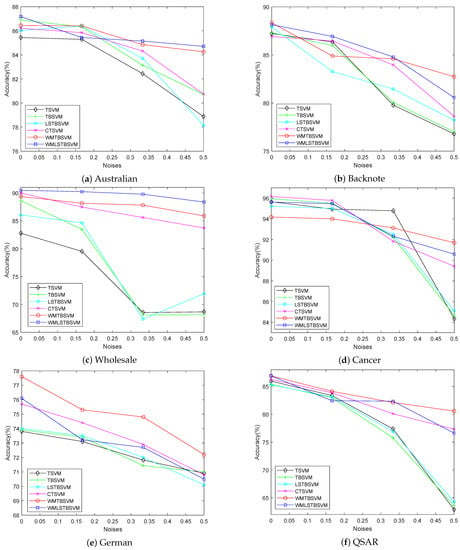
Figure 6.
Accuracies of six algorithms via different noises.
4.5. Statistical Analysis
This section describes the analysis of the significant differences among the seven algorithms on the 12 UCI datasets using the Friedman test [39]. The Friedman test is a simple, safe, and robust non-parametric test that assumes the null hypothesis that all algorithms have the same performance. If the null hypothesis is rejected, we can perform a post-hoc test of the Nemeny test [39]. We calculated the average ranking and accuracy of the seven algorithms on the ten datasets, and the results are presented in Table 6.
Table 6.
Average accuracy and ranks of seven algorithms with Gaussian kernel on UCI datasets with different proportions of unlabeled samples.
To begin with, taking Gaussian kernel datasets with unlabeled samples as an example, we calculate the Friedman statistic variable by using the following formulation:
where k is the number of algorithms, N is the number of UCI datasets, and is the average rank of the jth algorithm on the employed datasets. Notice that and in our paper. Furthermore, according to the distribution with degrees of freedom, we have
where obeys the F-distribution with and degrees of freedom. In addition, for , we obtain . Obviously, the value of is greater than ; thus, we can reject the null hypothesis. From Table 6, we see that the average ranking of WMTBSVM and WMLSTBSVM was much lower than the rest of the algorithms, which means that our WMTBSVM and WMLSTBSVM are more effective than the other algorithms.
Furthermore, we compared the seven algorithms in pairs using the Nemenyi post-hoc test. The difference in performance between the two algorithms was significant when the average rank difference between the two algorithms was larger than the critical value; otherwise, the difference was not significant. By dividing the Studentized range statistic by , we obtain . Therefore, we calculate the critical difference by the following formula:
From Figure 7, we see that WMTBSVM and WMLSTBSVM perform significantly better than TSVM, TBSVM, LSTBSVM, and CTSVM. It can further be seen that there is no significant difference between the proposed methods WMTBSVM and WMLSTBSVM, as the difference is smaller than the CD value. Therefore, through statistical analysis, it can be a safe conclusion that the proposed methods WMTBSVM and WMLSTBSVM have better performance.
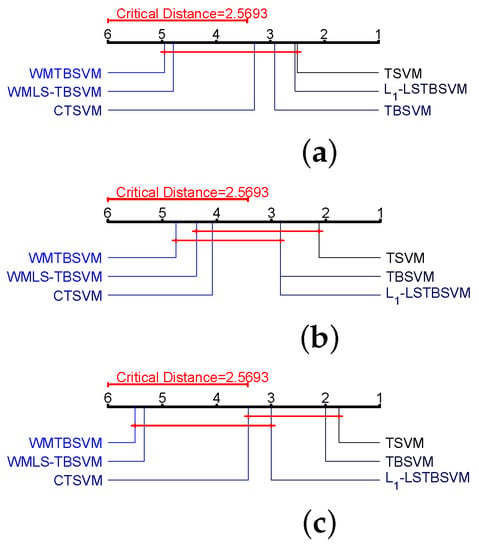
Figure 7.
Visualization of post-hoc tests for data from Table 6. (a) Gaussian kernel with unlabeded samples. (b) Gaussian kernel with unlabeled samples. (c) Gaussian kernel with unlabeled samples.
5. Conclusions
In this paper, a generalized adaptive robust loss function is designed. has several significant and satisfactory characteristics, such as symmetry, boundedness, and non-convexity. By setting appropriate parameters to improve the adaptability and robustness of WMTBSVM, we achieve better generalization performance and robustness. Secondly, we introduce the capped -norm distance measure into WMRTBSVM to improve the generalization performance and robustness of the model. This is done by setting appropriate p and upper bound parameter values, especially when the outliers are far from the normal data distribution. We also add MR into WMTBSVM to improve the discriminability and classification ability of our model. To improve the computational efficiency of WMRTBSVM, we use the least square method to obtain WMLSRTBSVM. Two effective iterative optimization algorithms are designed, and theoretical support is given for both WMRTBSVM and WMLSRTBSVM. We mainly conducted accuracy test experiments on manual datasets and UCI datasets. The experimental results show that WMRTBSVM and WMLSRTBSVM have better classification performance and robustness. In future work, we hope to apply WMRTBSVM and WMLSRTBSVM to multi-classification tasks to further study their performance and our theoretical work. We also plan to study how to combine our method with sparse kernel SVM to develop better performance and faster algorithms. In addition, we designed the generalized adaptive robust loss function , which we hope can be combined with other loss functions to further improve the adaptability and robustness of the correlation algorithms. Ultimately, we hope that can be applied to ensemble learning to deal with unbalanced datasets.
Author Contributions
B.M.: writing—original draft, conceptualization, writing—reviewing and editing, software, data curation. G.Y.: writing—original draft, supervision, validation, project administration, funding acquisition. J.M.: writing—original draft, conceptualization, writing—reviewing and editing, software, data curation. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Natural Science Foundation of Ningxia Provincial of China (No. 2022AAC03260, No. 2023AAC02053), in part by the Key Research and Development Program of Ningxia (Introduction of Talents Project) (No. 2022BSB03046), in part by the Fundamental Research Funds for the Central Universities (No. 2021KYQD23, No. 2022XYZSX03), in part by the National Natural Science Foundation of China (No. 11861002).
Institutional Review Board Statement
Not Applicable.
Informed Consent Statement
Not Applicable.
Data Availability Statement
All of the benchmark datasets used in our numerical experiments are from the UCI Machine Learning Repository, and are available at http://archive.ics.uci.edu/ml/ (accessed on 21 March 2023).
Conflicts of Interest
There are no conflict of interest in this study.
Appendix A. Convergence Analysis
Lemma A1.
For any scalar t, when , inequality holds.
Proof.
Let , find the first derivative of , respectively:
and
If and , then and is only point that . Note that , thus when and , then . Thus , which indicates holds. □
Lemma A2.
For any nonzero vectors α, β, when , the following inequality holds.
Proof.
According to Lemma A1, we obtain:
⇒
⇒
□
Theorem A1.
Proof.
Recall our framework
where , . When is smaller than , the above equation is equivalent to:
Suppose is the solution of the th iteration of the algorithm, based on (47) we have:
At the kth iteration:
≤
Which is equality:
≤
Based on Lemma A2, we obtain:
Lemma A3.
For all positive real number a and b, the following inequality holds:
Proof.
Recall our framework
where , . First we consider the , and we first define two functions
Based on conjugate function theory, there exists a convex conjugate function of the convex function in :
where
Because the conjugate function of a convex function’s conjugate function is the convex function itself, we have
Let , and define a convex function ,
which is equivalent to
In (A18), by is convex, then we can obtain a minimum solution by derivation. Define , where , due to , we have:
When , there exists a minimum solution in the right hand of the above equation, i.e.,
Combining the Formulas (A19) and (A20):
where . Then, we can say that Algorithm 1 will converge to a local minimum solution of . For , in the th iteration, we have:
With Lemma A3, we set
then, we can easily obtain the following inequality:
Combining (A22) and (A24), we can obtain
Then, we can say that Algorithm 1 will converge to a local minimum solution of . For
Define the Lagrangian function of (A26) as , with the KKT condition of (A26), we have:
We substitute the in (33) into the above equation:
Combining (A28) and (47), we obtain:
Similarly, we obtain the Lagrangian function of Formula (A29):
Then, we can say that Algorithm 1 will converge to a local minimum solution of . Furthermore, we can say that Algorithm 1 will converge to a local minimum solution of J. □
References
- Brown, M.P.; Grundy, W.N.; Lin, D.; Cristianini, N.; Sugnet, C.W.; Furey, T.S.; Ares, M., Jr.; Haussler, D. Knowledge-based analysis of microarray gene expression data by using support vector machines. Proc. Natl. Acad. Sci. USA 2000, 97, 262–267. [Google Scholar] [CrossRef] [PubMed]
- Ma, S.; Cheng, B.; Shang, Z.; Liu, G. Scattering transform and LSPTSVM based fault diagnosis of rotating machinery. Mech. Syst. Signal Process. 2018, 104, 55–170. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Kumar, M.A.; Gopal, M. Least squares twin support vector machines for pattern classification. Expert Syst. Appl. 2009, 36, 7535–7543. [Google Scholar] [CrossRef]
- Jayadeva, N.; Khemchandani, R.; Chandra, S. Twin support vector machines for pattern classification. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 905–910. [Google Scholar] [CrossRef]
- Shao, Y.H.; Zhang, C.H.; Wang, X.B.; Deng, N.Y. Improvements on twin support vector machines. IEEE Trans. Neural Netw. 2011, 22, 962–968. [Google Scholar] [CrossRef]
- Chen, X.; Yang, J.; Ye, Q.; Liang, J. Recursive projection twin support vector machine via within-class variance minimization. Pattern Recognit. 2011, 44, 2643–2655. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, Z.; Pan, X. A novel twin support-vector machine with pinball loss. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 359–370. [Google Scholar] [CrossRef]
- Tanveer, M.; Tiwari, A.; Choudhary, R.; Jalan, S. Sparse pinball twin support vector machines. Appl. Soft Comput. 2019, 78, 164–175. [Google Scholar] [CrossRef]
- Shao, Y.H.; Deng, N.Y.; Yang, Z.M. Least squares recursive projection twin support vector machine for classification. Pattern Recognit. 2012, 45, 2299–2307. [Google Scholar] [CrossRef]
- Chen, S.G.; Wu, X.J. A new fuzzy twin support vector machine for pattern classification. Int. J. Mach. Learn. Cybern. 2018, 9, 1553–1564. [Google Scholar] [CrossRef]
- Hou, Y.Y.; Li, J.; Chen, X.B.; Ye, C.Q. Quantum adversarial metric learning model based on triplet loss function. arXiv 2023, arXiv:2303.08293. [Google Scholar] [CrossRef]
- Zhu, J.; Rosset, S.; Tibshirani, R.; Hastie, T. 1-norm support vector machines. Adv. Neural Inf. Process. Syst. 2003, 16. [Google Scholar]
- Mangasarian, O.L.; Bennett, K.P.; Parrado-Hernández, E. Exact 1-Norm Support Vector Machines via Unconstrained Convex Differentiable Minimization. J. Mach. Learn. Res. 2006, 7, 1517–1530. [Google Scholar]
- Gao, S.; Ye, Q.; Ye, N. 1-Norm least squares twin support vector machines. Neurocomputing 2011, 74, 3590–3597. [Google Scholar] [CrossRef]
- Ye, Q.; Zhao, H.; Li, Z.; Yang, X.; Gao, S.; Yin, T.; Ye, N. L1-Norm distance minimization-based fast robust twin support vector k-plane clustering. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 4494–4503. [Google Scholar] [CrossRef]
- Yan, H.; Ye, Q.; Zhang, T.A.; Yu, D.J.; Yuan, X.; Xu, Y.; Fu, L. Least squares twin bounded support vector machines based on L1-norm distance metric for classification. Pattern Recognit. 2018, 74, 434–447. [Google Scholar] [CrossRef]
- Hazarika, B.B.; Gupta, D. 1-Norm random vector functional link networks for classification problems. Complex Intell. Syst. 2022, 8, 3505–3521. [Google Scholar] [CrossRef]
- Jiang, W.; Nie, F.; Huang, H. Robust dictionary learning with capped L1-norm. In Proceedings of the 24th International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Nie, F.; Huo, Z.; Huang, H. Joint capped norms minimization for robust matrix recovery. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Wu, M.J.; Liu, J.X.; Gao, Y.L.; Kong, X.Z.; Feng, C.M. Feature selection and clustering via robust graph-laplacian PCA based on capped L1-norm. In Proceedings of the 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Kansas City, MO, USA, 13–16 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1741–1745. [Google Scholar]
- Zhao, M.; Chow, T.W.; Zhang, H.; Li, Y. Rolling fault diagnosis via robust semi-supervised model with capped L2,1-norm regularization. In Proceedings of the IEEE International Conference on Industrial Technology, Toronto, ON, Canada, 22–25 March 2017; pp. 1064–1069. [Google Scholar]
- Xiang, S.; Nie, F.; Meng, G.; Pan, C.; Zhang, C. Discriminative least squares regression for multiclass classification and feature selection. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1738–1754. [Google Scholar] [CrossRef]
- Nie, F.; Wang, X.; Huang, H. Multiclass capped Lp-norm SVM for robust classifications. In Proceedings of the 32th AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018. [Google Scholar]
- Wang, C.; Ye, Q.; Luo, P.; Ye, N.; Fu, L. Robust capped L1-norm twin support vector machine. Neural Netw. 2019, 114, 47–59. [Google Scholar] [CrossRef]
- Ma, X.; Ye, Q.; Yan, H. L2,p-norm distance twin support vector machine. IEEE Access 2017, 5, 23473–23483. [Google Scholar] [CrossRef]
- Ma, X.; Liu, Y.; Ye, Q. P-Order L2-Norm Distance Twin Support Vector Machine. In Proceedings of the 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 617–622. [Google Scholar]
- Zhang, L.; Luo, M.; Li, Z.; Nie, F.; Zhang, H.; Liu, J.; Zheng, Q. Large-scale robust semisupervised classification. IEEE Trans. Cybern. 2018, 49, 907–917. [Google Scholar] [CrossRef] [PubMed]
- Chapelle, O.; Scholkopf, B.; Zien, A. Semi-supervised learning. IEEE Trans. Neural Netw. 2009, 20, 542. [Google Scholar] [CrossRef]
- Belkin, M. Problems of Learning on Manifolds. Ph.D. Thesis, The University of Chicago, Chicago, IL, USA, 2003. [Google Scholar]
- Rossi, L.; Torsello, A.; Hancock, E.R. Unfolding kernel embeddings of graphs: Enhancing class separation through manifold learning. Pattern Recognit. 2015, 48, 3357–3370. [Google Scholar] [CrossRef]
- Qi, Z.; Tian, Y.; Shi, Y. Laplacian twin support vector machine for semi-supervised classification. Neural Netw. 2012, 35, 46–53. [Google Scholar] [CrossRef]
- Xie, X.; Sun, F.; Qian, J.; Guo, L.; Zhang, R.; Ye, X.; Wang, Z. Laplacian Lp-norm least squares twin support vector machine. Pattern Recognit. 2023, 136, 109192. [Google Scholar] [CrossRef]
- Wen, J.; Lai, Z.; Wong, W.K.; Cui, J.; Wan, M. Optimal feature selection for robust classification via L2,1-norms regularization. In Proceedings of the Twenty-Second International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 517–521. [Google Scholar]
- Wang, H.; Nie, F.; Huang, H. Learning robust locality preserving projection via p-order minimization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; AAAI Press: Washington, DC, USA, 2015; pp. 3059–3065. [Google Scholar]
- Ke, J.; Gong, C.; Liu, T.; Zhao, L.; Yang, J.; Tao, D. Laplacian Welsch Regularization for Robust Semisupervised Learning. IEEE Trans. Cybern. 2020, 52, 164–177. [Google Scholar] [CrossRef]
- Yuan, C.; Yang, L.-M. Capped L2,P-norm metric based robust least squares twin support vector machine for pattern classification. Neural Netw. 2021, 142, 457–478. [Google Scholar] [CrossRef] [PubMed]
- Kwak, N. Principal component analysis based on L1-norm maximization. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1672–1680. [Google Scholar] [CrossRef] [PubMed]
- Demi<i>s</i>ˇar, J.; Schuurmans, D. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).