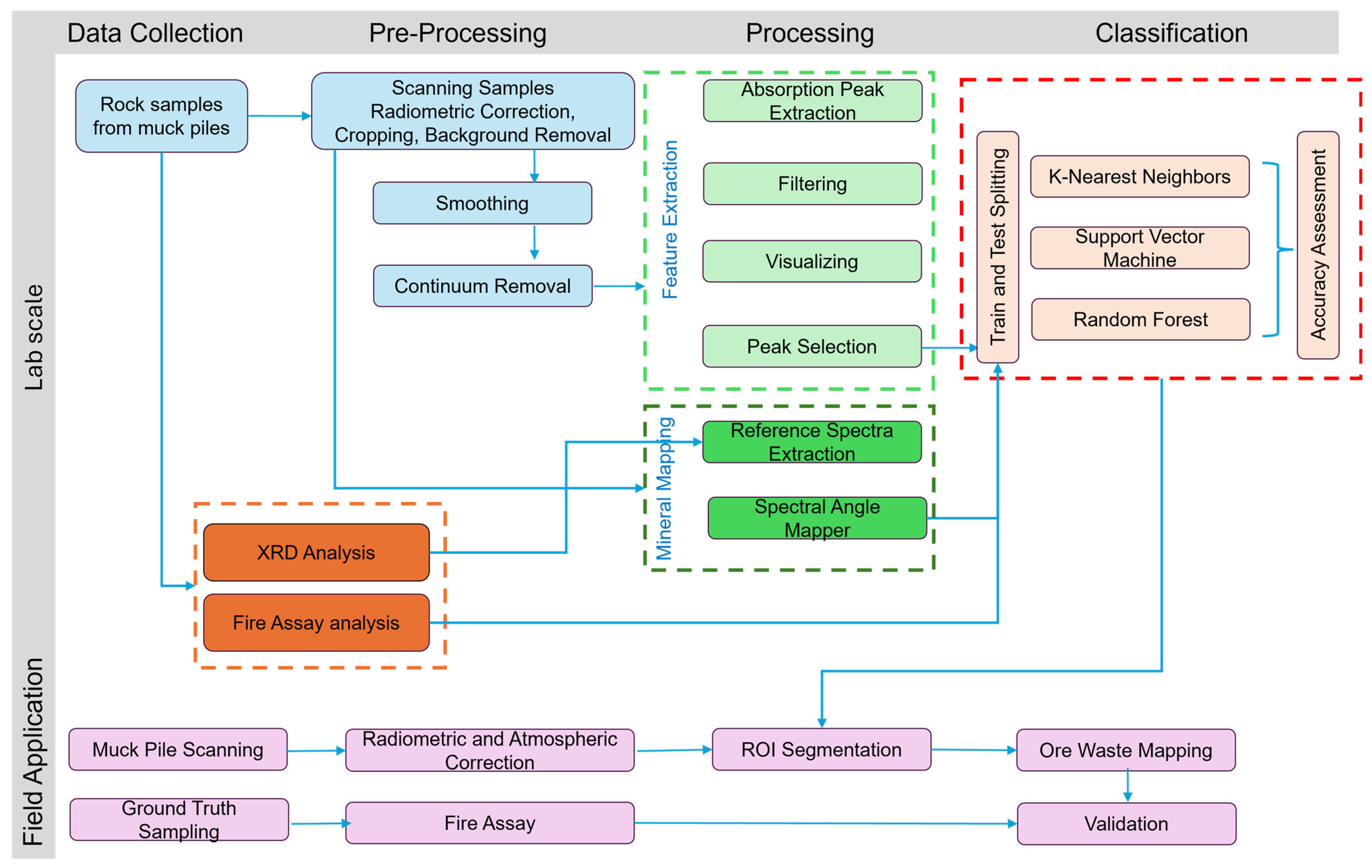
3.1.1. Data-Driven Approach: Results
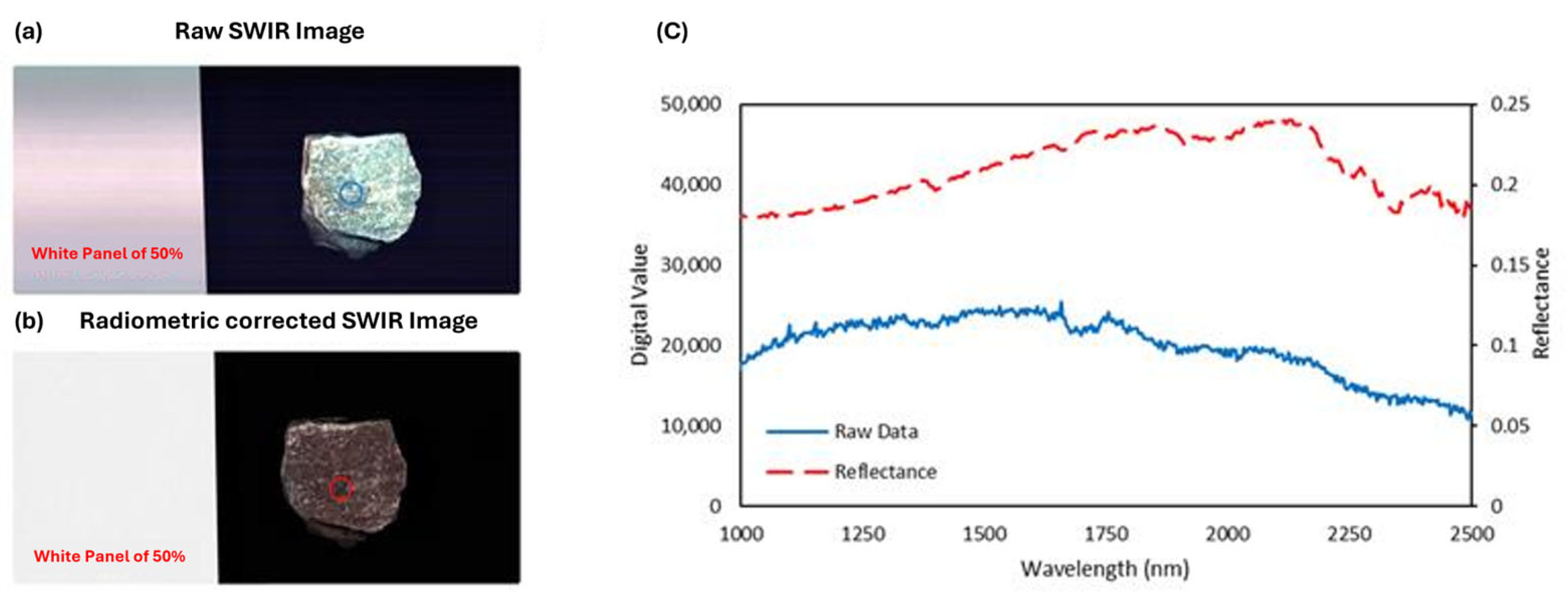
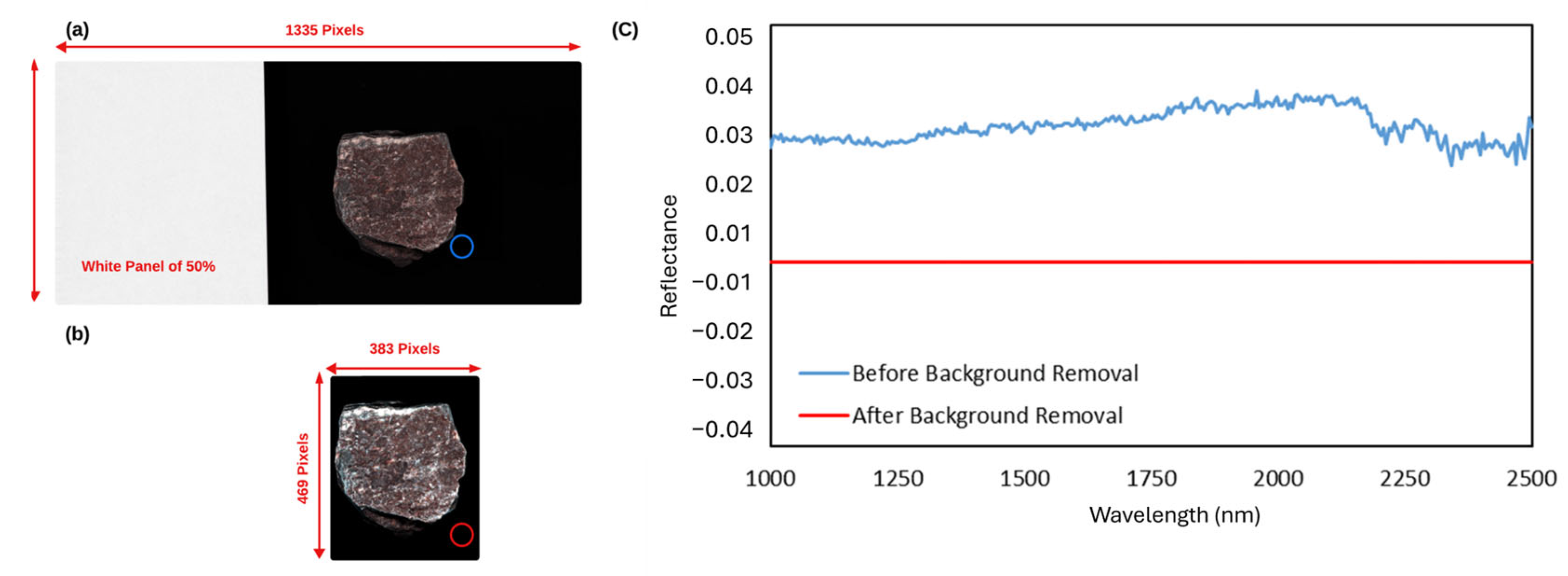
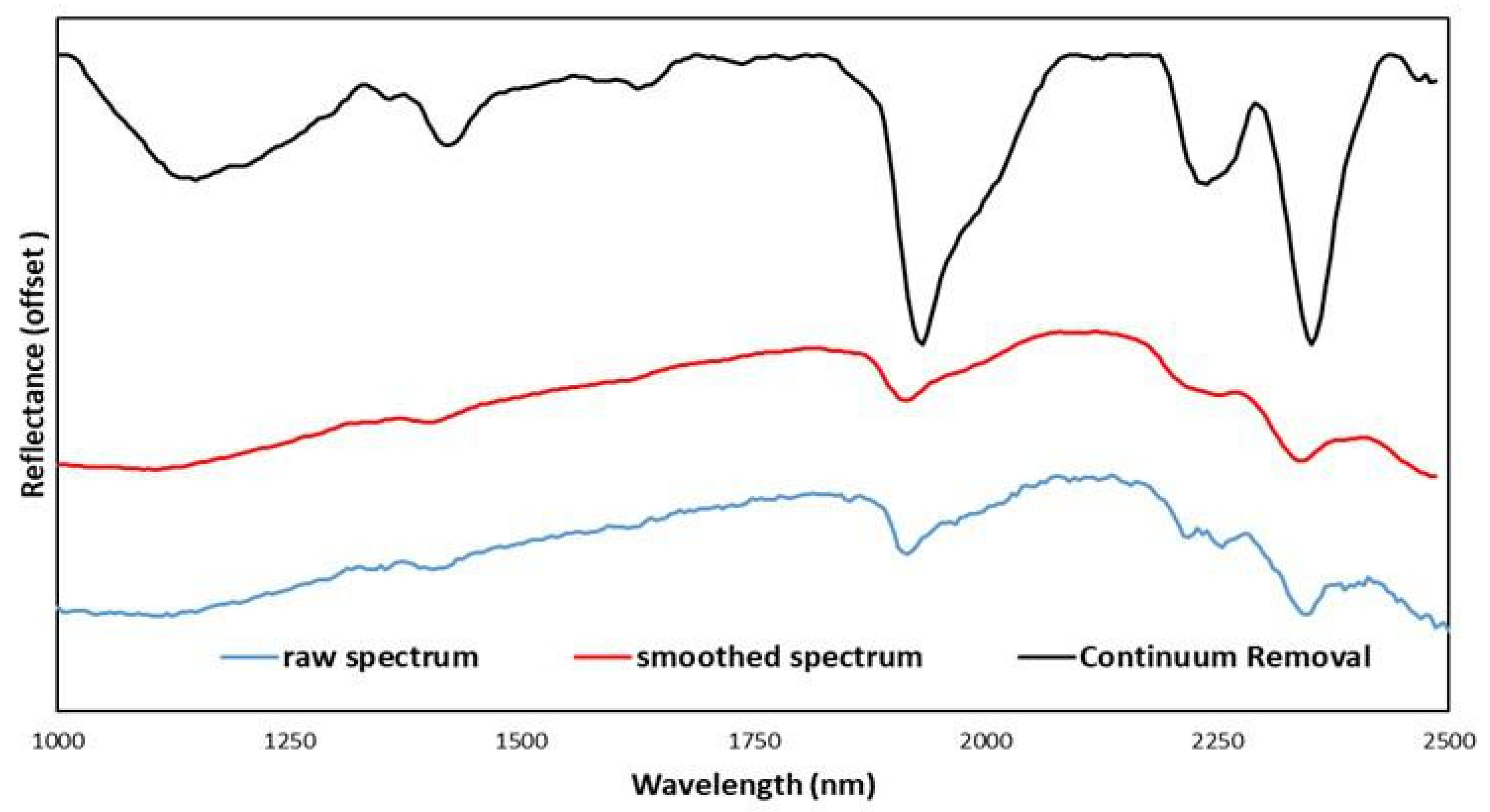
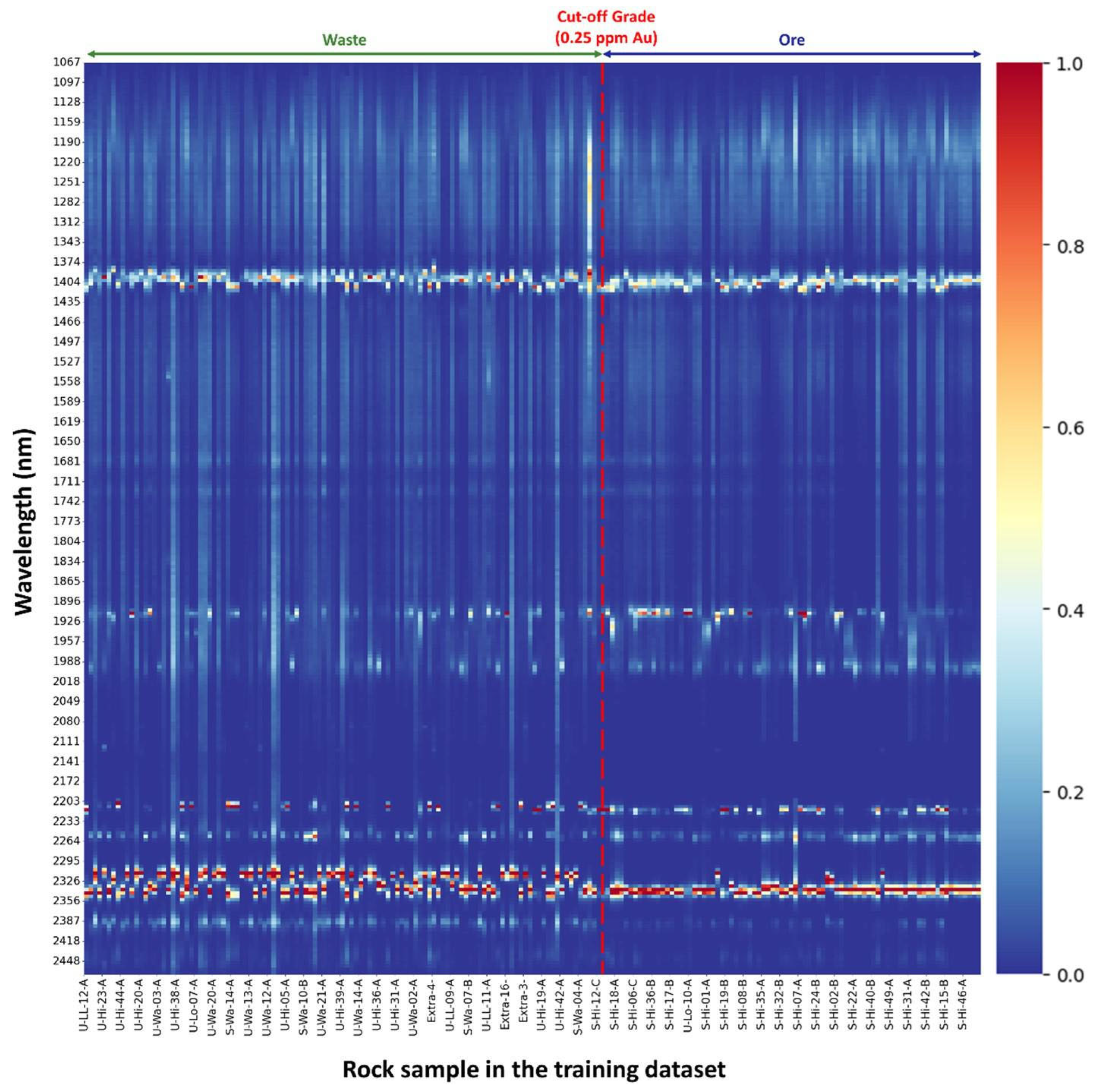
After extracting the main absorption peaks using the proposed FE approach, a heatmap was generated to visualize the distribution of the peaks across all scanned samples. Since the frequencies of the absorption peaks could vary significantly from one wavelength to another, it was impossible to distinguish the existing pattern within a wavelength with lower frequencies when other wavelengths had higher frequency values. To address this issue, we normalized the frequencies of all samples within each wavelength to between 0 and 1, as shown in
Figure 11. The
Y-axis represents all wavelengths, while the
X-axis displays scanned samples sorted from low grade on the left to high grade on the right, with a vertical red line indicating the cut-off grade threshold. Colors on the heatmap signify the normalized frequencies of each extracted absorption peak. The generated heatmap could be used to visually inspect existing patterns within absorption peaks at a specific wavelength to discriminate between ore and waste samples. Notably, four prominent areas are observed around 1916 nm, 2208 nm, 2315 nm, and 2336 nm. It is recognized that these features were extracted based on a limited number of samples tested for the study, and they are only valid for rock samples with a similar mineralogical composition.
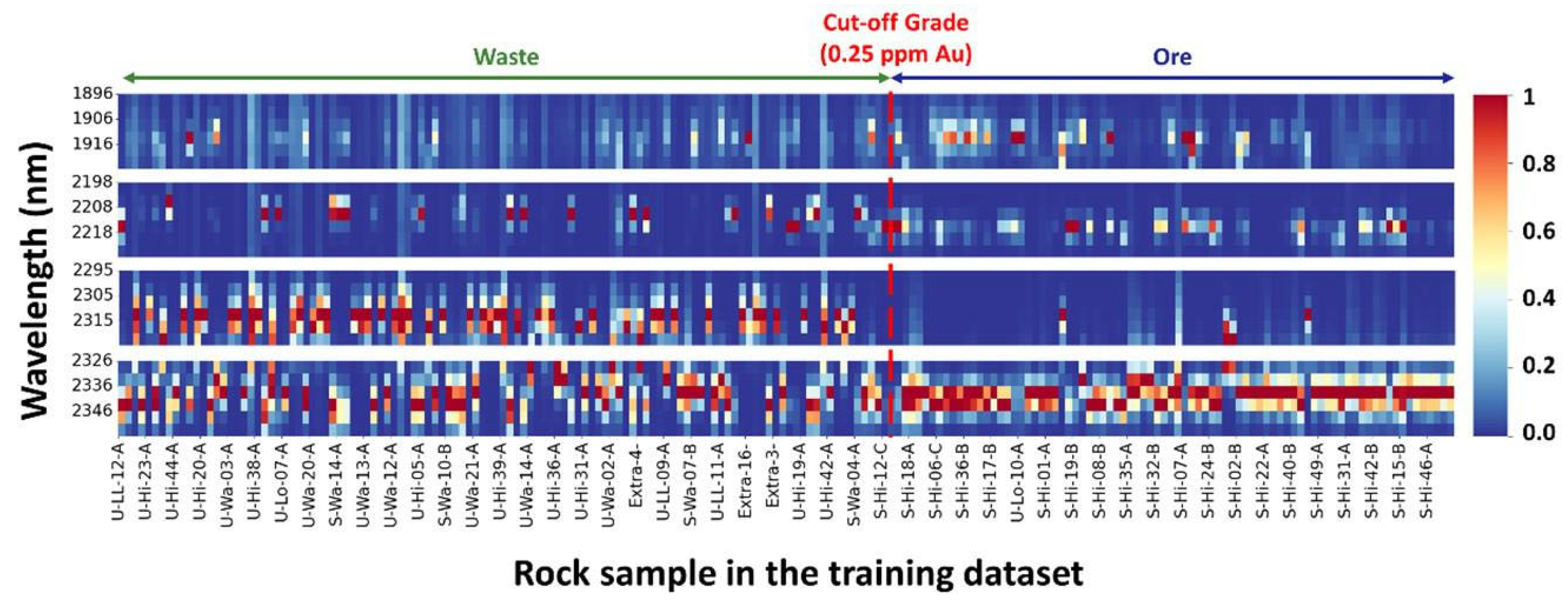
Figure 12 provides a detailed view of these prominent areas, assisting in further analysis and interpretation.
Based on the detailed heatmap shown in
Figure 12, it becomes apparent that certain features, such as those around 1916 nm, show a higher frequency in ore samples compared to waste samples, although the distinction is less evident than what is observed at 2208 nm. At 2208 nm, there is a clear discrimination between ore and waste samples, with waste samples exhibiting higher absorption frequencies. Similarly, at 2310 nm and 2315 nm, there is a noticeable increase in frequencies in some waste samples compared to ore samples. Features at 2336 nm and 2341 nm also show potential for discriminating between ore and waste, although with less certainty than those at 2203 nm, 2208 nm, 2310 nm, and 2315 nm. Notably, while these features may help to distinguish waste samples, they do not exhibit a consistent pattern in ore samples, making it easier to identify waste samples based solely on these features.
However, visually focusing on these extracted absorption peaks may be less helpful in identifying ore samples, as the patterns are less distinct than waste samples. While these features provide valuable insights, additional analysis and techniques may be required to identify ore samples accurately. Therefore, we utilized all extracted spectral absorption features for classification purposes, employing three popular classifiers in the remote-sensing field: RFC, SVC, and KNNC. Subsequently, the outcomes of these classifications will be presented in the following sections, showing how well they can discriminate ore and waste samples.
The classification process was conducted on a dataset of 196 train image samples and 50 test image samples, utilizing the extracted absorption peaks as input features.
Figure 13 displays the classified output using the RFC on the testing dataset. Our analysis indicated that out of the 50 test image samples, 1 sample that was predicted as ore was, in fact, waste (highlighted in purple). Also, four samples were classified as waste, which were actually ore (highlighted in red). Additionally, the classifier accurately predicted 45 samples: 17 ore (highlighted in blue) and 28 waste (highlighted in green).
Similarly,
Figure 14 illustrates the classified output using SVC on the testing dataset. The analysis showed that out of the 50 test samples, 2 samples predicted as ore were, in fact, waste (purple), while 4 samples classified as waste were ore samples (red). Furthermore, the classifier accurately predicted 44 samples, including 17 ore (blue) and 27 waste samples (green).
Lastly,
Figure 15 demonstrates the results obtained from the KNNC applied to the testing dataset. Our examination revealed that, out of the 50 test samples, 4 samples initially classified as ore were waste samples (purple). In comparison, three samples classified as waste by the classifier were ore samples (red). Despite these discrepancies, the KNNC achieved an overall accurate prediction for 43 samples, with 18 correctly identified as ore (blue) and 25 as waste (green). These detailed analyses provide valuable insights into the performance and reliability of each classifier in accurately classifying ore and waste samples.
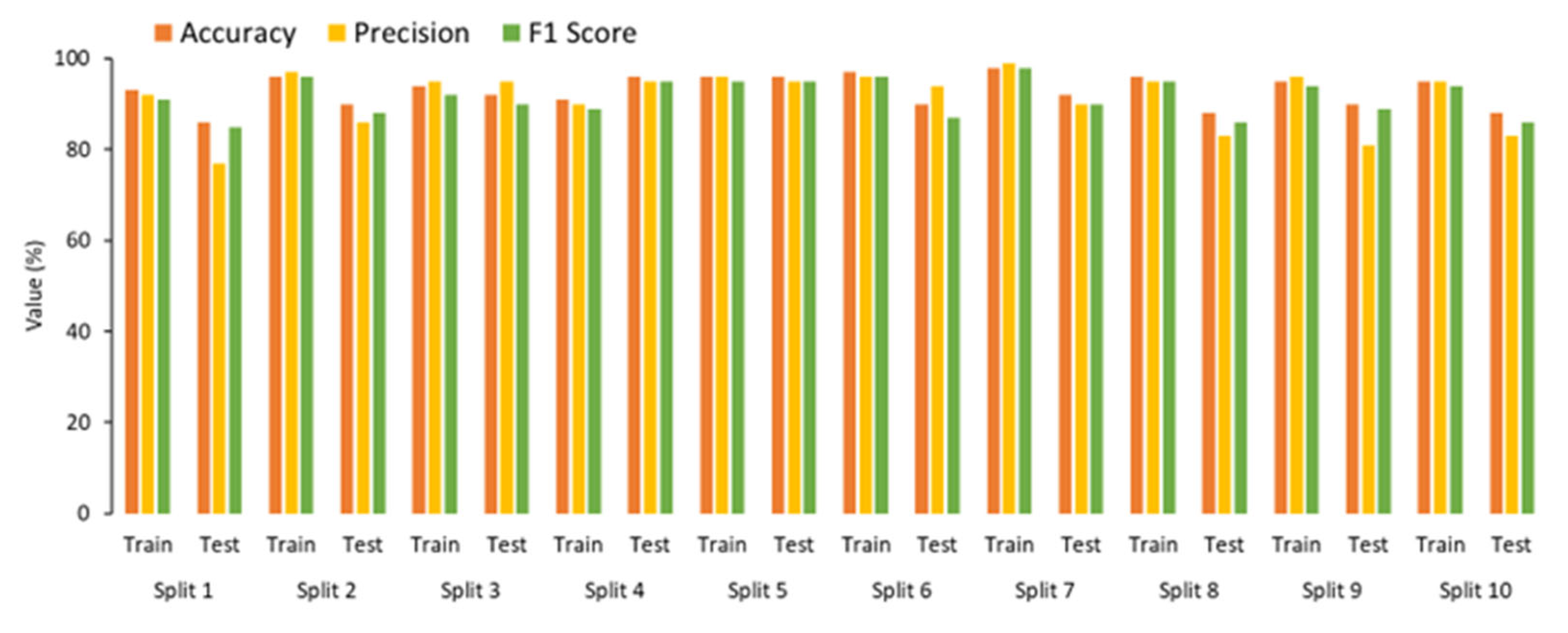
The performance of proposed classifiers was examined through a comprehensive accuracy assessment using accuracy, precision, recall, and F1-score.
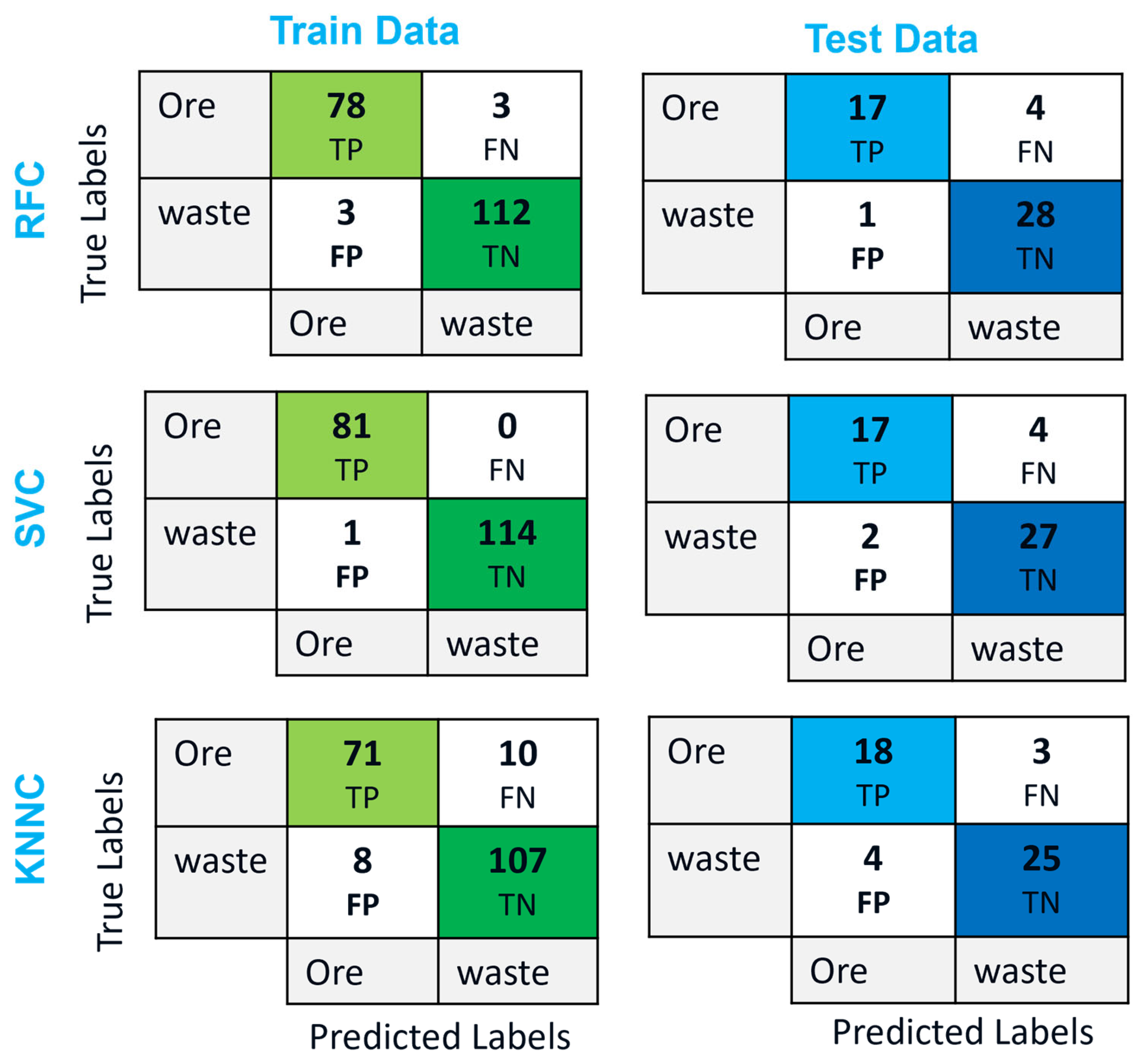
Figure 16 presents confusion matrices for the training and test datasets across three classifiers: RFC, SVC, and KNNC models. Additionally,
Table 5 lists the analysis of overall accuracy, precision, recall, and F1-score metrics for each classifier’s confusion matrix on the testing dataset. These assessments offer valuable insights into the classifiers’ effectiveness in accurately classifying ore and waste samples.
The results’ comparison highlights the proposed method’s effectiveness based on assessment metrics, including overall accuracy, precision, recall, and F1-score. Each metric provides valuable insights into the classifiers’ performance.
Starting with the RFC, it achieved a notable overall accuracy of 0.90, indicating that 90% of the samples were correctly classified. The high precision values for both ore, 0.94, and waste, 0.88, suggest that RFC accurately identified true positive samples for both classes. However, the recall value for ore, 0.81, indicates that some ore samples were incorrectly classified as waste, which might be attributed to a higher false negative rate. Conversely, the recall value for waste, as 0.96, suggests that RFC effectively captured the majority of true waste samples, with a lower false negative rate. The F1-score provides a great balanced measure of the classifier’s performance, with values of 0.87 for ore and 0.95 for waste.
Moving on to SVC, it resulted in an overall accuracy of 0.88, with precision values of 0.94 for ore and 0.90 for waste. Like RFC, SVC exhibited a higher precision for ore, indicating a lower false positive rate for ore samples. The recall values for both ore, 0.81, and waste, 0.93, suggest that SVM effectively captured true positive samples for waste classes like RFC did. The F1-scores for ore and waste were 0.85 and 0.90, respectively, indicating a good balance between precision and recall for both classes.
Lastly, KNNC reached an overall accuracy of 0.86, with precision values of 0.82 for ore and 0.89 for waste. The lower precision for ore suggests a higher false positive rate for ore samples compared to RFC and SVC. However, KNNC exhibited balanced recall values for both ore, 0.86, and waste, 0.86, indicating a relatively consistent performance in capturing true positive samples for both classes. The F1-scores for ore and waste were 0.84 and 0.88, respectively, indicating a good balance between precision and recall for both classes.
Regarding the F1-score and overall accuracy, RFC outperforms both SVC and KNNC, making it a suitable choice if accurately identifying both ore and waste samples is crucial. SVC exhibits higher precision than RFC and KNNC, indicating a better performance in correctly identifying positive samples. Therefore, SVC may be preferred if minimizing false positives is a priority. However, KNNC demonstrates a balanced recall for both ore and waste samples, suggesting reliability in capturing true positive samples for both classes. Thus, KNNC may be suitable if achieving a balance between capturing all positive samples is essential. Generally, while RFC may excel in overall accuracy and F1-score, SVC shows superior precision, and KNNC demonstrates balanced recall.
3.1.4. Knowledge-Based Approach: Results
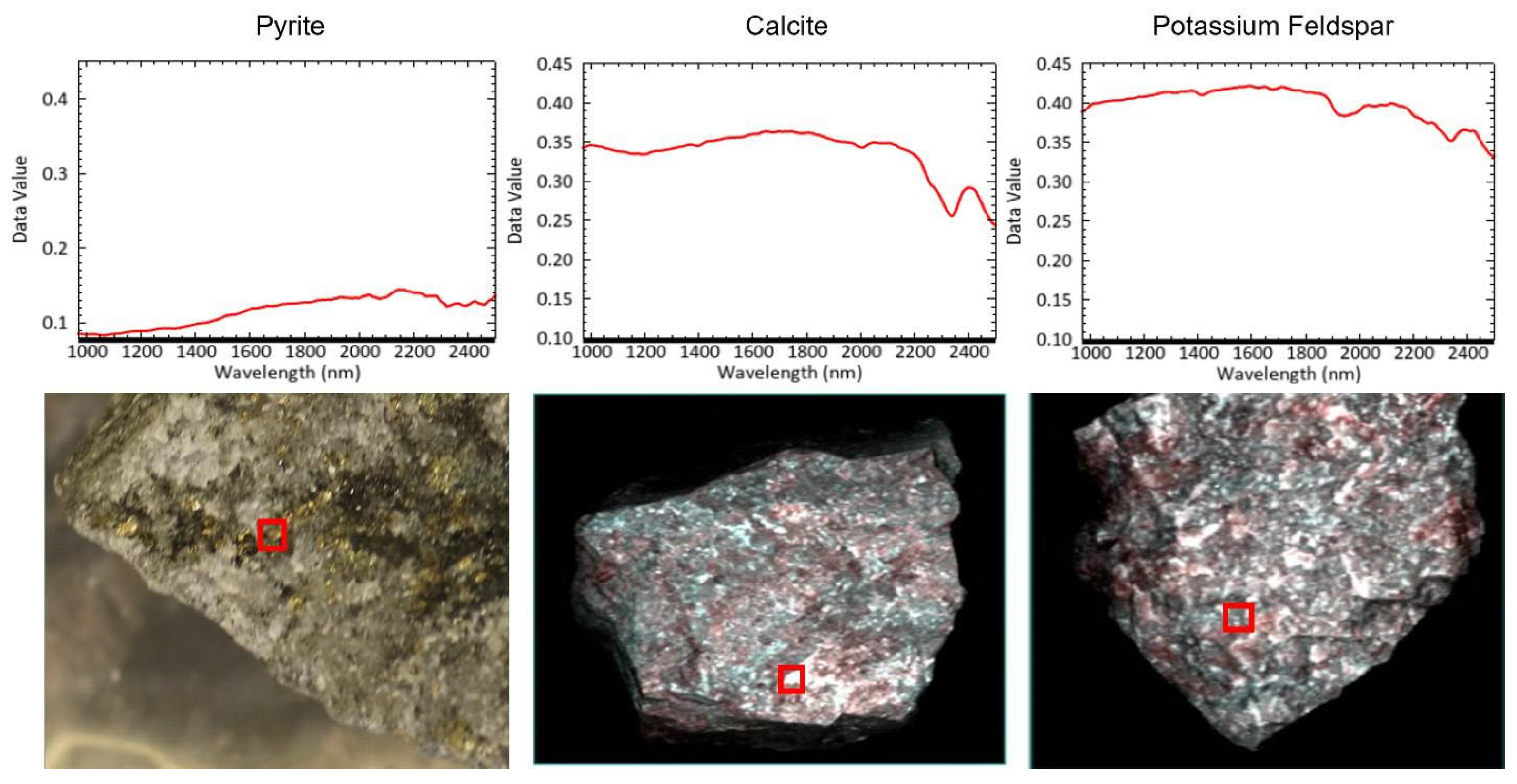
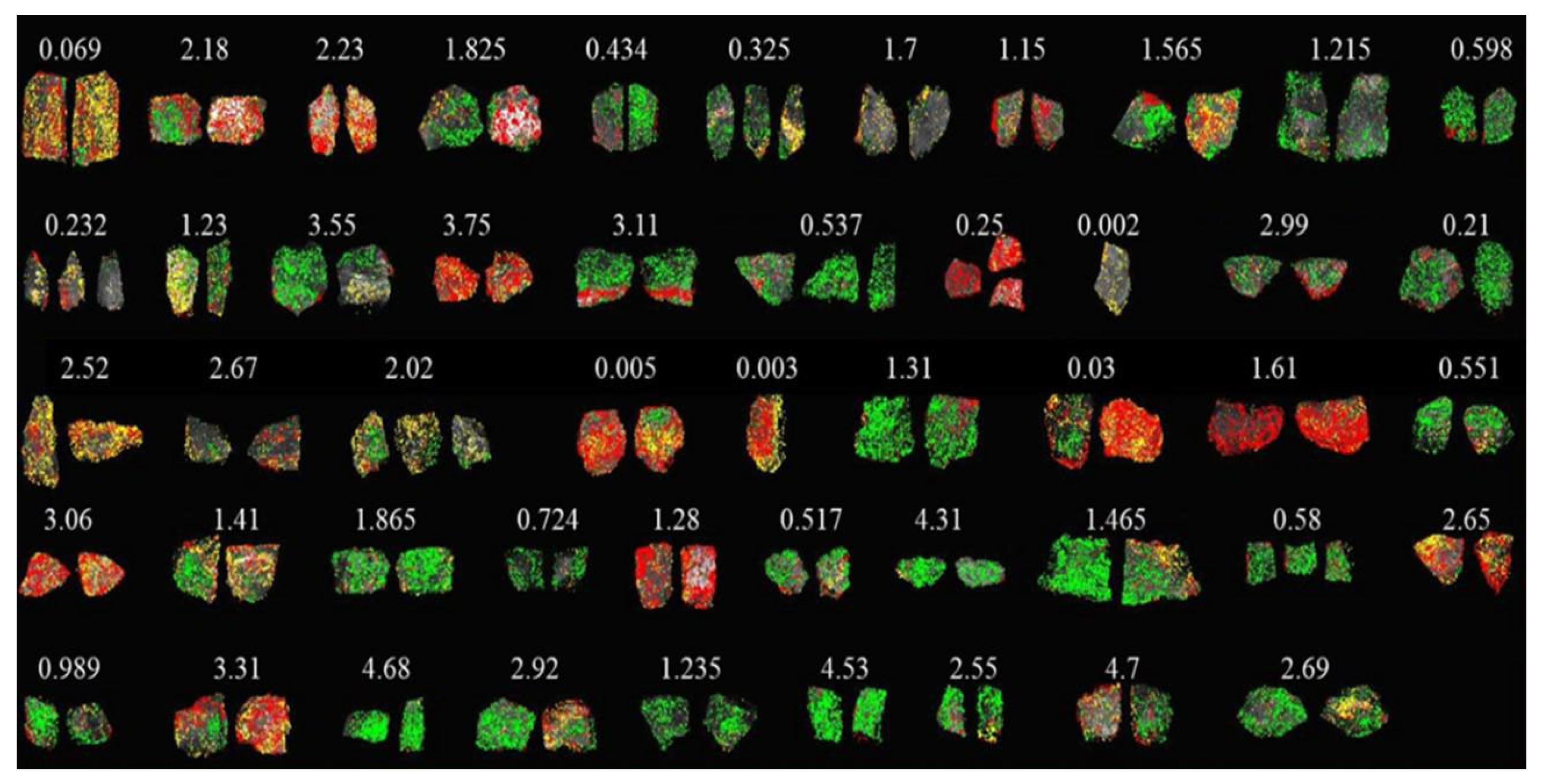
In the MPM approach, the SAM algorithm was applied to all 256 scanned hyperspectral images to classify minerals based on three local reference spectra: pyrite, calcite, and potassium feldspar. These reference spectra were extracted from laboratory-scale analysis and used to identify spectral similarities within the dataset. The MPM output generated by the SAM classification for selected images is shown in
Figure 18. In these images, green pixels represent pyrite, yellow pixels represent calcite, and red pixels represent potassium feldspar. Following mineral classification, the frequency of occurrence of each mineral was calculated for each sample. These mineral abundance values were then used as input features for the classifier in the ore–waste discrimination process.
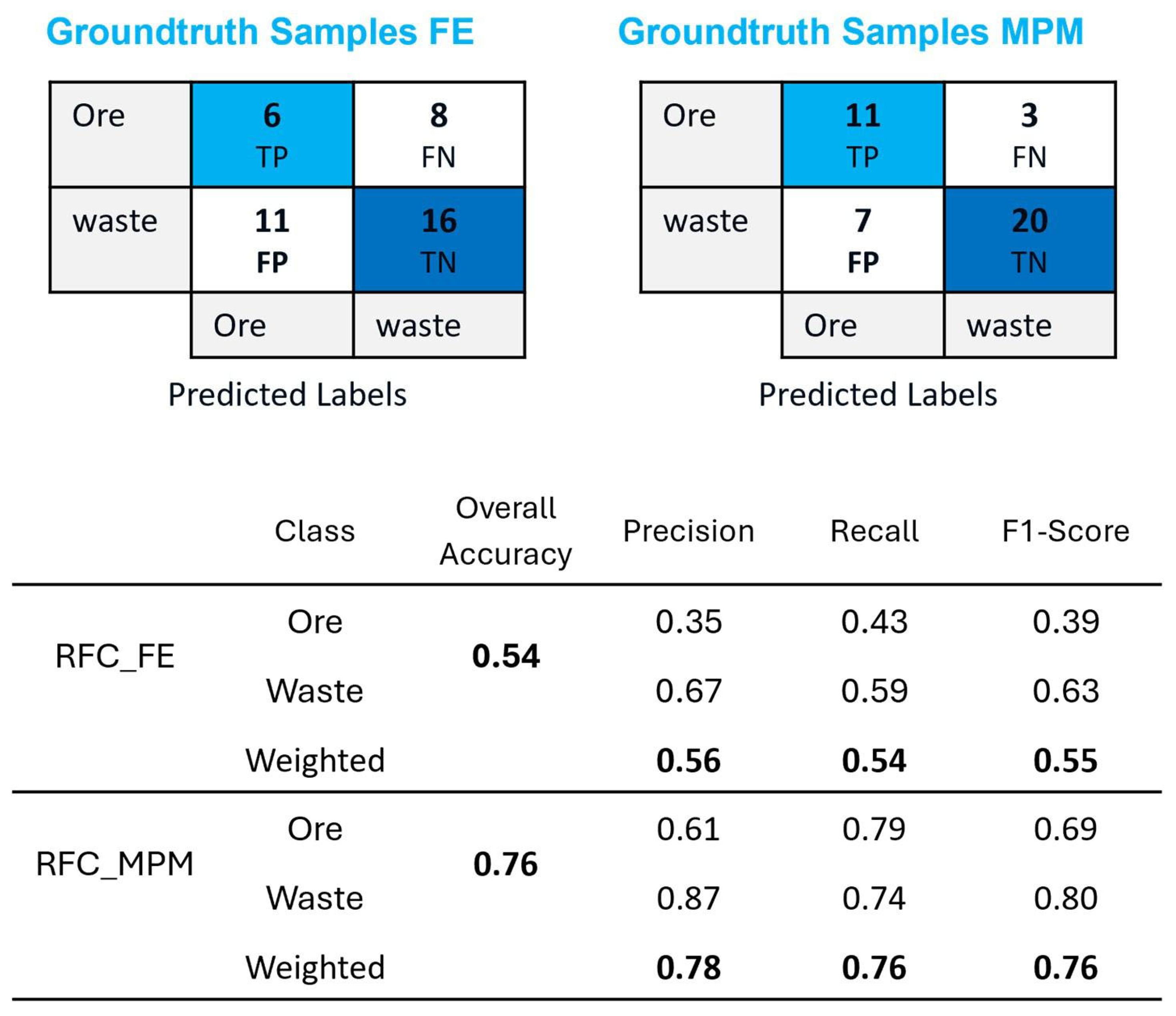
The classification process in the MPM method used the same training and testing datasets as the data-driven approach. Since RFC consistently outperformed SVC and KNNC in terms of overall accuracy and F1-score during the data-driven evaluation, it was identified as the most reliable and effective classifier. As a result, only RFC was selected for use in the MPM approach to ensure optimal performance.
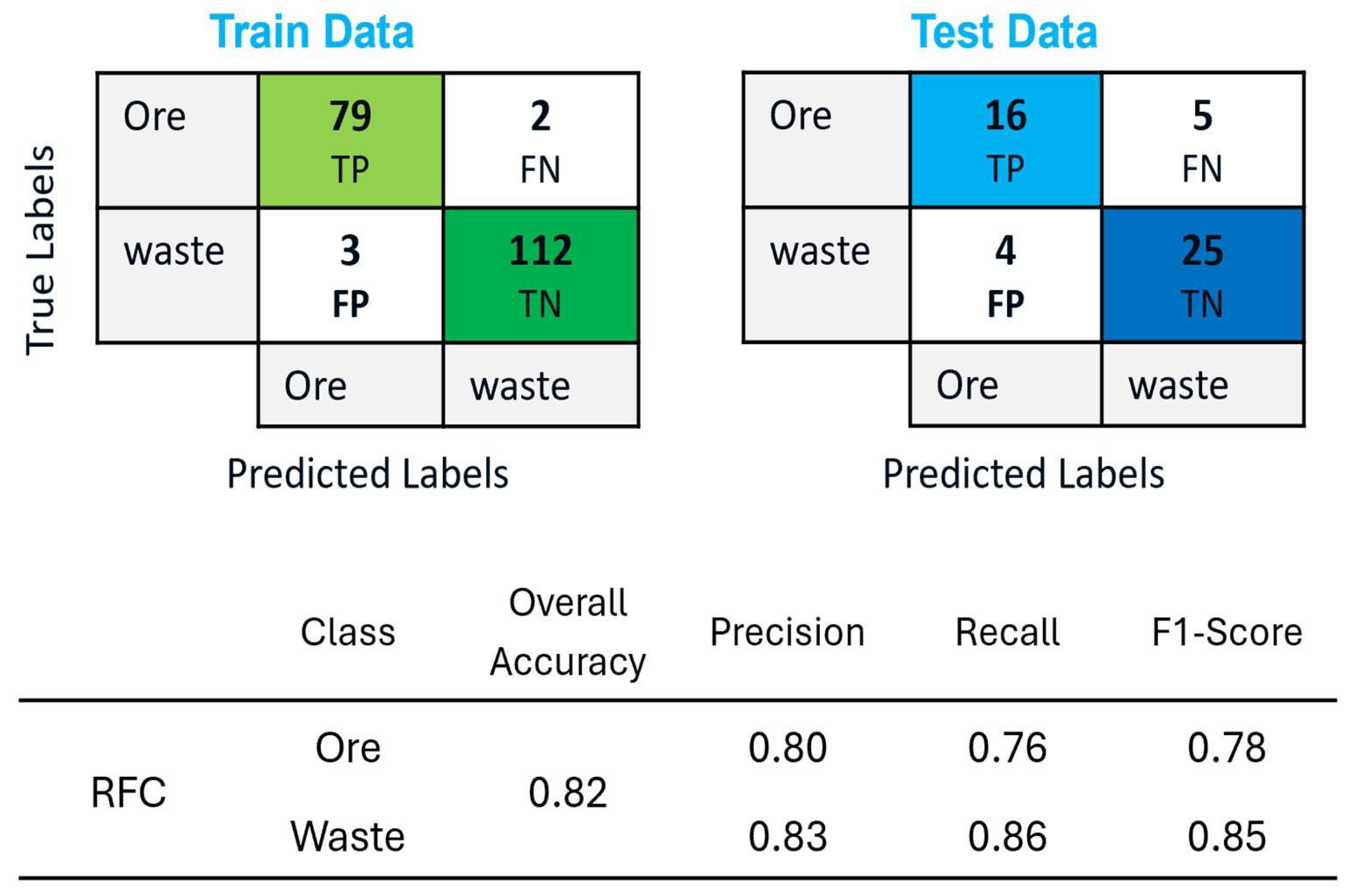
Figure 19 shows the classified output generated by the RFC model on the testing dataset. The results showed that out of the 50 test samples, 41 samples were correctly classified, including 16 ore samples, represented in blue, and 25 waste samples, represented in green. However, four samples were misclassified as ore, shown in purple, when they were actually waste, while five samples classified as waste, shown in red, were actually ore. These results demonstrate the model’s effectiveness in distinguishing ore from waste while also highlighting some misclassification cases, which could be attributed to the spectral similarities between certain ore and waste materials.
Figure 20 presents the confusion matrices for the training and test datasets, along with the accuracy assessment report, to evaluate the performance of RFC in the MPM method for ore–waste discrimination.
The RFC applied in the MPM method achieved an overall accuracy of 0.82, indicating that 82% of the total samples were correctly classified. While slightly lower than the 90% accuracy achieved for RFC in the data-driven approach, this result still demonstrates a strong classification performance in distinguishing ore from waste. For the ore class, RFC obtained a precision of 0.80, meaning that 80% of the samples predicted as ore were actually ore. However, the recall of 0.76 suggests that 24% of the actual ore samples were misclassified as waste. This lower recall value indicates a relatively higher false negative rate, meaning that some ore samples were incorrectly labeled as waste. The F1-score of 0.78 represents the balance between precision and recall for ore classification, highlighting the moderate ability of the model to distinguish ore samples. In contrast, for the waste class, RFC achieved a precision of 0.83, meaning that 83% of the samples predicted as waste were truly waste. The recall value of 0.86 shows that 86% of the actual waste samples were correctly identified, with a relatively lower false negative rate compared to the ore class. The F1-score of 0.85 indicates a strong balance between precision and recall, demonstrating that the model was more effective in classifying waste than ore.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}