1. Introduction
Community detection (CD) is a method of dividing a complex network into several sub-structures. It is widely accepted that a community should have dense intra-connections and sparse inter-connections [
1]. Most of complex networks imply a community structure [
2,
3,
4,
5]; their vertices are organized into groups, called communities, clusters, or modules. These include the functional structure of the protein networks, relationships in social networks, link relation of web pages on the Internet, cooperative modules in power network systems, and so on. Uncovering the mesoscopic-structure of community in complex networks is helpful for understanding complex systems [
6,
7,
8], where objects are represented as nodes and the relationships among the objects are represented as edges [
1]. Complex networks have characteristics of discrete distribution and dynamic evolution [
9] unlike simple networks such as lattices or random graphs. Thus, simple modeling and analysis based on network topology gradually fails to meet the needs of community detection.
Recent studies have paid much attention to community detection and have developed various algorithms from different perspectives. According to the principle of division, community structures now can be detected through many different methods, such as division-based [
1,
10,
11], cohesion-based [
12,
13], spectral-based [
14,
15], statistical-inference-based [
16,
17], and optimization-based [
18,
19,
20,
21,
22,
23,
24,
25,
26] methods. Recently, the optimization-based methods have drawn steady attention to community detection [
4,
20,
27,
28]. The community detection problem can be translated into an optimization problem [
29], where modularity function Q [
10] is a widely adopted in optimization objective, even if maximizing Q is usually non-deterministic polynomial hard (NP-hard) [
21]. In community structure detection, optimization is based on the monotonic increase and the approximate maximum two characteristics of the Q function [
30]. Although Q functions are limited in resolution [
28] and extreme degradation [
31], they are widely used by researchers. Blondel [
32] and Khadivi et al. [
33] found that the design of multi-level, multi-granularity, and weighted methods can ease resolution limits and extreme degradation. Evolutionary algorithm (EA)-based strategies are effective in optimization approaches [
33]. Compared to other strategies, there are three main advantages. Firstly, EAs are similar to the simulation network evolution process [
34]. Secondly, the multi-level, multi-granularity strategy of EAs can be used to further compensate for resolution limitations and extreme degradation defects based on modular optimization methods [
35]. Thirdly, they are more suitable for solving complex and discrete problems (EAs change their current state to the next state with the strategy adopted, while maintaining some degrees of randomness to ensure the exploration of solution space). However, in the EA-based for CD algorithm, too much fitness calculation and premature convergence of the population are still the main obstacles in the community testing process. In addition, maintaining the diversity of the population and balancing the algorithm convergence is the key issue to improving the performance of EAs [
36].
Thus, researchers have designed a number of algorithms to overcome obstacles [
36]. Recently, the differential evolution (DE) hybrid meta-heuristic-based optimization algorithms of CD research have made great progress [
20,
21,
22,
23,
24,
27,
37,
38]. Typically, the parent’s mutation operator of the DE algorithm is chosen randomly from the population. This is different from other EAs, in which the probability of all individuals being treated as parents is equal. Such a strategy could damage the population diversity [
2,
39,
40,
41]. Therefore, Wang [
40] presented a new differential strategy, whereby individuals in the current population are first sorted according to their fitness and diversity contribution by non-dominant sorting, thus, the promising individuals with better fitness and diversity have a greater opportunity to be selected as parents in order to achieve a good balance between exploration and exploitation. However, the above strategy does not evaluate fitness and diversity information in real time in each generation. If it is used to model the discovery of the community, it may lead to loss of diversity information and be difficult to converge.
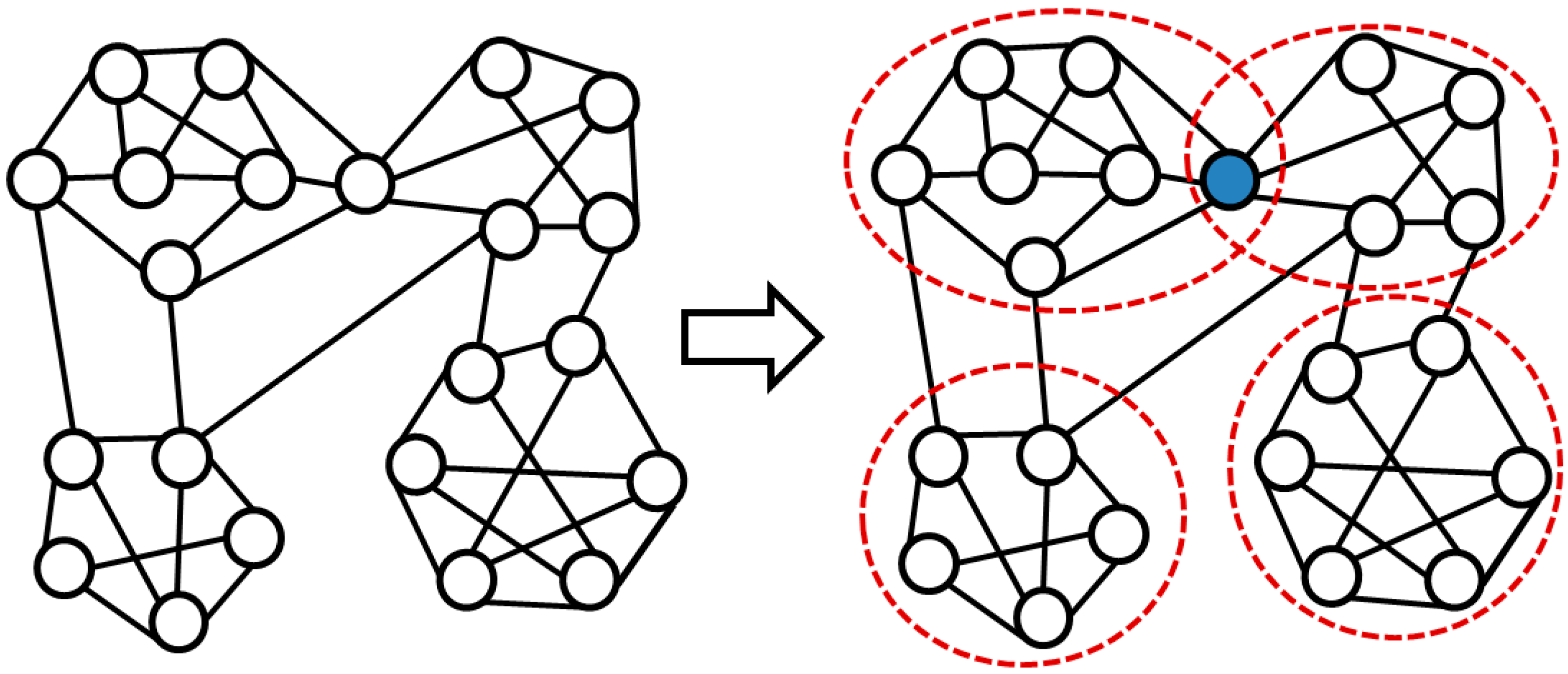
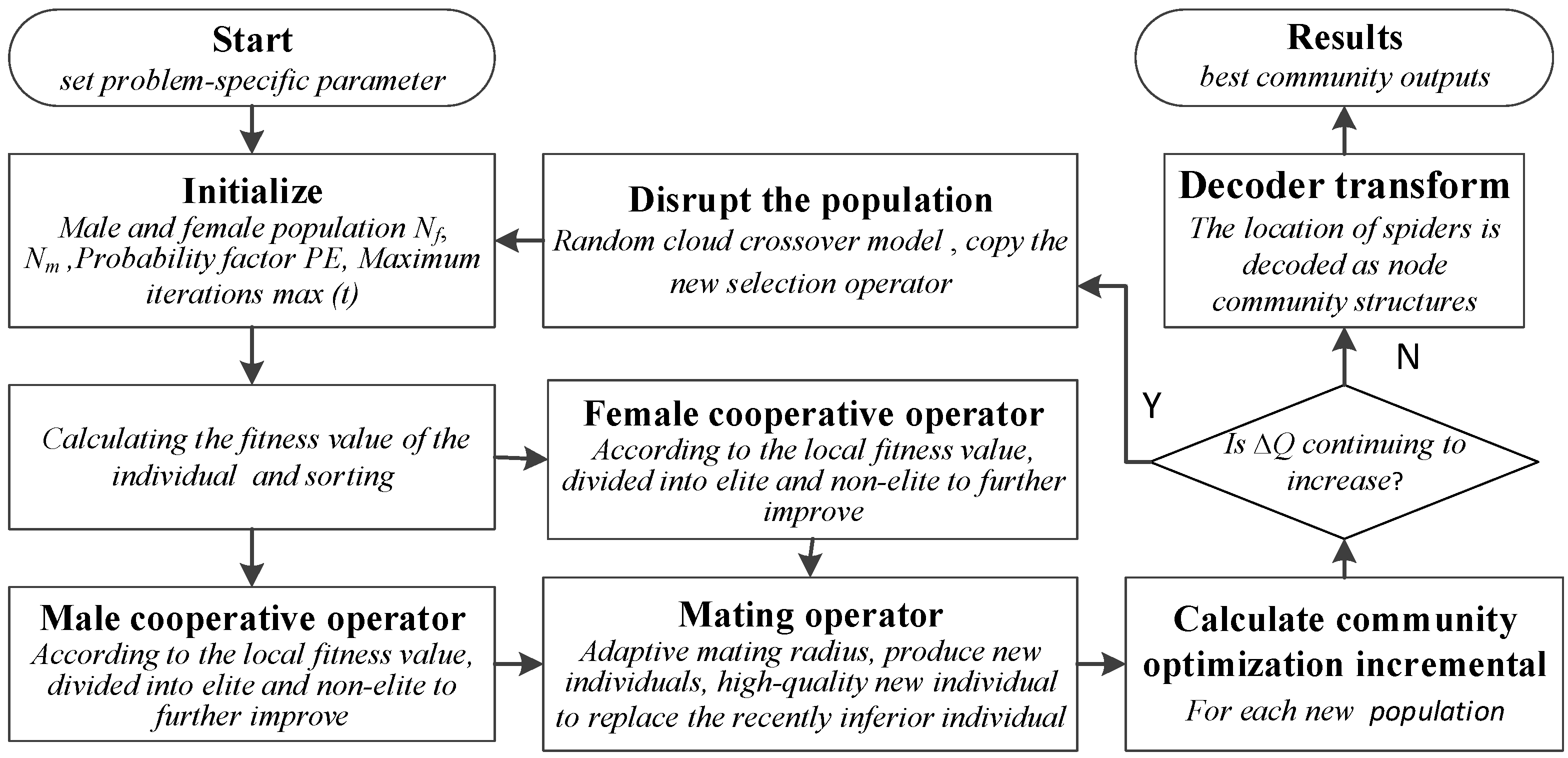
Based on the above analysis and inspiration, this paper proposes a community detection algorithm based on differential evolution using social spider optimization (DESSO/CD). In this algorithm, a new community detection algorithm framework based on social spider optimization (SSO) is presented. In initializing the population process, nodes in the network are initialized as populations in the SSO algorithm. In the cooperative operators’ process, the fitness function of the SSO algorithm is defined according to the local similarity strategy of nodes. The populations are divided into two categories: elite and non-elite based on the fitness value, which further improves the differential evolution strategy of the SSO algorithm (the effect of the strategy corresponds to the hybrid differential evolution scheme proposed in [
40]). At the same time, a random cloud crossover model is adopted to keep the diversity of population. In the mating operator process of DESSO/CD, the mating radius will automatically be adjusted according to the fitness value in the dominant individuals. Each generation of the quality increment of community modularity is used as a criterion for the evolutionary selection operator. This approach promotes the balance between local exploration and global search, while maintaining the diversity of the populations can effectively improve the adaptability and efficiency of the CD algorithm.
Therefore, there are three main contributions of this paper. Firstly, a new community detection algorithm framework based on social spider optimization is presented. Secondly, based on the hybrid meta-heuristic approach, the population in the SSO algorithm is further differentiated. Thirdly, an adaptive mating radius strategy fitted by the fitness value and iterative times is presented.
The rest of the paper is organized as follows. In
Section 2, we first introduce some background knowledge and the framework of the DESSO/CD algorithm. Then, the fitness function and evolution criteria of the proposed algorithm are presented. In
Section 3, the SSO algorithm is described in detail. Our improvements for SSO and the general process steps of the DESSO/CD algorithm are described in
Section 4, and experimental settings and analysis are provided in
Section 5. In
Section 6, the proposed algorithms are analyzed and discussed. The last section concludes this paper and threads some future research issues.
3. Social Spider Optimization Algorithms
Cuevas [
47] proposed the social spider optimization (SSO) algorithm in 2013. SSO is an intelligent swarm-based heuristic differential evolution algorithm, which is based on the simulation of cooperative behavior of social spiders. The SSO algorithm is different from most existing swarm algorithms which model individuals as unisex entities exhibiting virtually the same behavior [
48]. The SSO algorithm has three steps [
47,
48,
49,
50,
51] including initializing the population, cooperative operators, and mating operators. In the SSO algorithm, the search space is modeled as a spider’s web; the optimization of the problem is equivalent to finding the final position of the spider after the collaboration. The fitness value corresponds to the ability of the spider to adapt to the environment. When the SSO solves the problem, the spider position is randomly initialized, and the optimal solution of the problem is obtained through the interaction of female and male internal cooperative movement (evolution of population) and marriage process (each generation produces new individuals to replace inferior individuals). In the evolution of SSO, each individual has the ability to learn at random, as well as learning from parents and the most recent and optimal individual (Formula (7)). These strategies give SSO more flexible parameters, stronger adaptability, and a higher searching efficiency. It can maintain the diversity of the population and obtain better solutions.
Compared to existing EAs, SSO is more competitive [
47,
48,
51,
52]. Cuevas has experimentally tested SSO, considering 19 benchmark functions, and using comparisons with PSO and ABC algorithm performance. Results have confirmed that SSO is more competitive in solving discrete problems. In recent works, SSO has been used to solve different sorts of engineering problems. A multilevel image threshold is proposed based on the SSO algorithm [
51]. The SSO is used in solving high-dimensional dataset clustering [
52]. SSO has shown a better effect in solving the above problems. However, since SSO has only just been proposed, there are few studies related to the applications of the community detection, and further research is needed in terms of algorithm adaptability.
The SSO algorithm simulates the law of spider swarm movement to achieve optimization. In this algorithm, the number of females was controlled at 65–90% of the entire population [
47]. Every spider has a weight according to the fitness value of its solution. A new population of search agents is generated using the mating operator. Male spiders tend to be attracted toward females according to a certain radius. This is called the mating radius. After producing new spiders, their fitness values are calculated and then compared to the worst spider in the population. In each generation, the inferior spiders will be replaced by the latest and most optimal spiders. The steps of SSO algorithm are as follows (the detailed process can be found in [
47]):
3.1. Initializing the Population
Like other evolutionary algorithms, SSO is an iterative process involving a first step of randomly initializing the entire population (female and male). The algorithm begins by initializing the set
S of
N spider positions [
47]. This occurs through initialization of the relevant parameters: population number
N, probability factor
PE, and the number of male and female spiders
and
. The correlation formula is
where
is a downward integer, and
is the random number of (0, 1).
The relationship between the male and female population of the spiders is
where
F and
M represent female and male populations, respectively, and
S is the full spider population.
The formula for randomly generating male and female populations is
where
and
denote the initialized female and male, respectively;
and
denote the upper and lower bounds of the
j dimension, respectively; and
,
,
.
3.2. Cooperative Operators
3.2.1. Female Cooperative Operator
According to the biological behavior of the social-spider, the male population is divided into two classes: dominant and non-dominant male spiders. Females attract or exclude other individuals by vibration, and female spiders can be divided into two groups for individual updates. Their updates are less than or equal to the probability factor, while
PE attracts and vice versa. In reality, the size of a spider is a characteristic manifestation of executive ability. In SSO, each individual (spider) designs a fitness weight
that represents the solution quality (irrespective of gender). Individual updates are conducted by
where
is the random number of the current iteration,
is [0, 1],
;
is an individual nearest to and superior to itself in distance from the individual
;
is the vibration perception of individual
l to individual
v;
is the fitness function of the individual
objective function; and
is the Euclidean distance between the individual
v and the individual
l.
3.2.2. Male Cooperative Operator
Dominant male spiders have better fitness characteristics (usually regarding size) in comparison to non-dominant spiders. Dominant males are attracted to the closest female spider in the communal web. In contrast, non-dominant male spiders tend to concentrate in the center of the male population as a strategy to take advantage of resources that are wasted by dominant males [
47]. According to the size of the fitness ranking, the male individual update can be divided into dominant and non-dominant. Dominant individuals attract the opposite sex so that they are close, and have the ability to gather the middle section of individual male clusters. Individual updates are achieved through
where
indicates the weight in the middle. The male individuals are arranged according to the weight of descending value. If the male has a weight greater than or equal to that of the middle position, it is updated by the dominant individual; otherwise, this occurs through the non-dominant individual. A subset of the population consisting of male-dominated individuals is represented by
TD;
is the closest individual to
, and
is the average weight of the male spider.
3.3. Mating Operator
Mating in a social spider colony is performed by dominant males and female members [
46]. Under such circumstances, when a dominant male
spider (
) locates a set
of female members within a specific range r (range of mating), it mates, forming a new brood
which is generated considering all the elements of the set
that, in turn, has been generated by the union
. Male and female spiders have a generational update after mating to produce new individuals to replace the inferior spider until it meets the conditions. In each of the dominant male mating radii (
r), according to the methods of roulette bets and females after mating to generate new individuals (
). That is,
,
,
,
, and
D is the total number of individuals dominated by the male. If the value of
is larger than that of the worst individual in the population,
is replaced by
. All female individuals are marked in the male mating
radius for the population
. The probability that the female individual
q in
is chosen for marriage by the male individual
is calculated as
Marriage radius
r is calculated as
where
and
are the upper limit and the lower limit of the
jth dimension, respectively.
5. Experiments and Analysis
The framework of a CD algorithm based on SSO is proposed in this paper. There are two major improvements in the SSO algorithm from the specific application of CD. In order to verify the validity of the DESSO/CD algorithm, this section conducts a comparison with the existing algorithms. In order to compare the improved performance of the original SSO, we split the frame into four algorithms according to the different points of the improved SSO algorithm; the CD algorithm based on the original SSO framework (SSO/CD), the CD algorithm based on further differential SSO framework (DSSO/CD), the CD algorithm based on improved marriage radius of the SSO framework (RSSO/CD), and the CD algorithm based on two improved SSO frameworks (DESSO/CD). The other algorithms used for comparison are some evolutionary and non-evolutionary algorithms, including the CD algorithm based on simulated annealing [
19] (an algorithm proposed by Guimerà and Amaral, GA), the CD based on the scatter-based genetic algorithm [
9] (SSGA), the CD based on differential bat algorithm [
9] (Improved Bat Algorithm Based On The Differential Evolutionary Algorithm, BADE), the CD based on hybrid particle swarm optimization (PSO) algorithm [
54], and the CD based on immune discrete differential evolution algorithm [
35] (IDDE). The comparison of the four algorithms (SSO/CD, DSSO/CD, RSSO/CD, and DESSO/CD) is to verify the effect of improving the SSO framework. The comparison of other existing algorithms is to confirm the competitiveness of the DESSO/CD framework.
There are evaluation metrics of accuracy of CD measure. Since the DESSO/CD algorithm uses modular increment as the evolutionary operator selection criteria, in order to avoid the bias error, we also use the normalized mutual information (
NMI) [
55] and modularity Q [
10] functions as the evaluation metrics of accuracy for CD measure, as described in
Section 4.1.
The experimental data set is as follows. In the LFR (Lancichinetti Fortunato Radicchi, LFR) benchmark [
56], 10 randomly generated different sizes of the network, six kinds of real network data sets commonly used in the CD field, and a novel graphical analysis come from the DESSO/CD algorithm for a set of data collected in an online social network (Sina Weibo network) using community detection.
The experimental environment involves a PC with an Intel i7 7700 k 4.2 GHz CPU, 16 GB of memory, and a Windows 7 operating system. The general experimental parameters of this paper are population size
N = 500 (less than the expected number of communities), probability factor
PE = 0.6 [
47], and maximum iteration number
.
5.1. Evaluation Metrics of Accuracy for the CD Measure
The modularity function is defined as
where
represents the possibility of node
i and
. If
is connected, Krone function Δ = 1, or Δ = 0, and the value of
Q is the actual difference between the two proportional expectations. The two ratios are the proportion of the connection edges between the nodes within the network community and the proportion of links between the nodes of community in the random network
Q ∈ (0,1). The closer the
Q value is to 1, the more obvious the network partitioning community is.
The NMI defines the formula as
where
A and
B represent two different communities, respectively,
, and
,
I stands for mutual information, and
H represents the entropy of information. If two communities are divided into the same
A and
B, then
= 1. If the two partitions of
A and
B are more similar, then the
NMI value is closer to 1.
5.2. Experiments on Artificial Data
The LFR benchmark [
56] is an extension of the GN standard network data set, and is an artificial network commonly used in current community discovery. The model is defined as
The parameter meaning of LFR and the initial value of this experiment are shown in
Table 1:
5.2.1. Experiments of Iterations on LFR Networks
SSO/CD, DSSO/CD, RSSO/CD, and DESSO/CD will be compared in the same LFR networks. For the sake of fairness, all parameters in the above four algorithms maintain consistency and the mixing parameters
μ = 0.06 in artificial benchmark networks on the LFR (usually
μ ∈ [0, 3]), and in the meantime the network has obvious community structure characteristics: the smaller the
μ is, the more obvious the characteristics of community structure will be. Other LRF parameters are shown in
Table 1. The accuracy of DC (
NMI) was detected by increasing the number of evolutionary iterations.
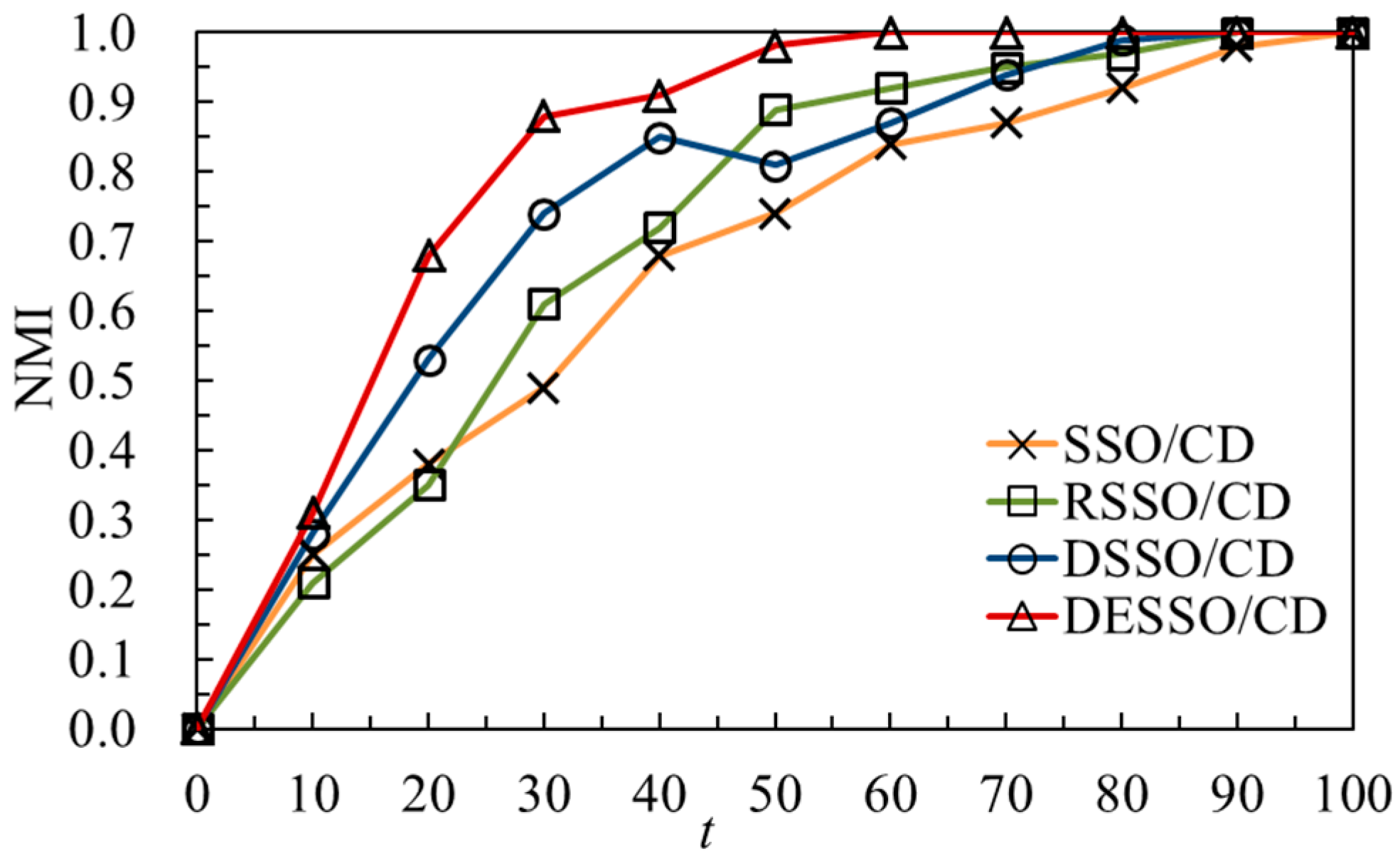
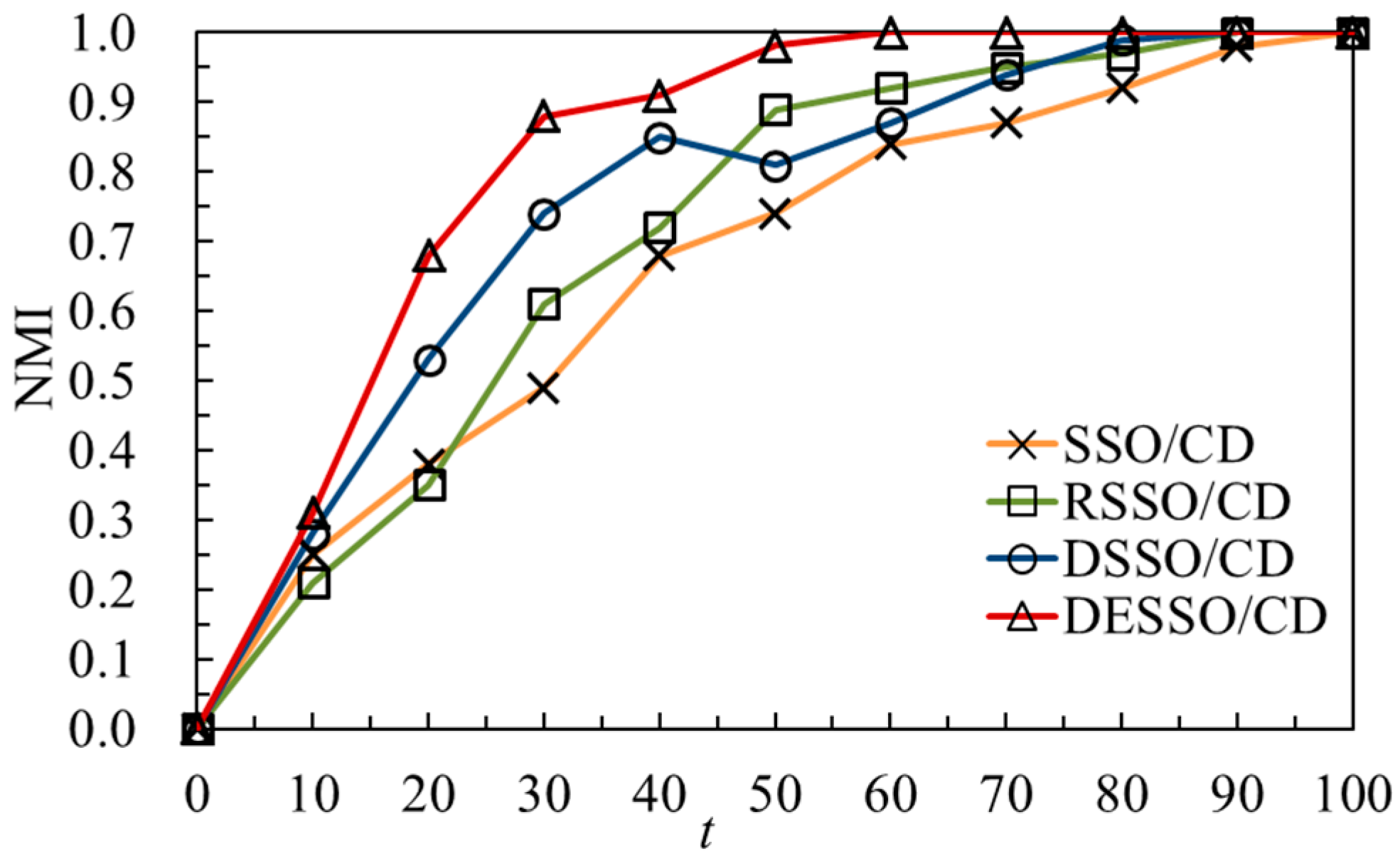
As shown in
Figure 3, the convergence speed of the algorithm between 30–40 generations of DESSO/CD has an obvious oscillation period because of the random cloud crossover model to disrupt the population (
Section 4.1.2). Therefore, it can be concluded that algorithm accuracy and convergence speed improved significantly after mixing the population as described in
Section 4.1.2. This point can also be clearly obtained from the DSSO/CD algorithm for the 50th generation with precision changes. Moreover, in the later stage of the RSSO/CD algorithm, the spider search efficiency will be further improved due to the amplification of elite individual mating and mating radius, and the radius of other individuals being narrow. In addition, RSSO/CD has accelerated the trend of convergence clearly in the 15th generation.
5.2.2. Partitioning Accuracy on LFR Networks
The mixed parameter (
μ) values of the LFR network are adjusted by 0.05 with the changing scale, so that 10 different artificial networks are generated randomly, and then the network can be divided. The algorithm runs 10 times in each network, taking the average of the precision index (
NMI). Changes of
NMI value with increasing
μ value in LFR network are shown in
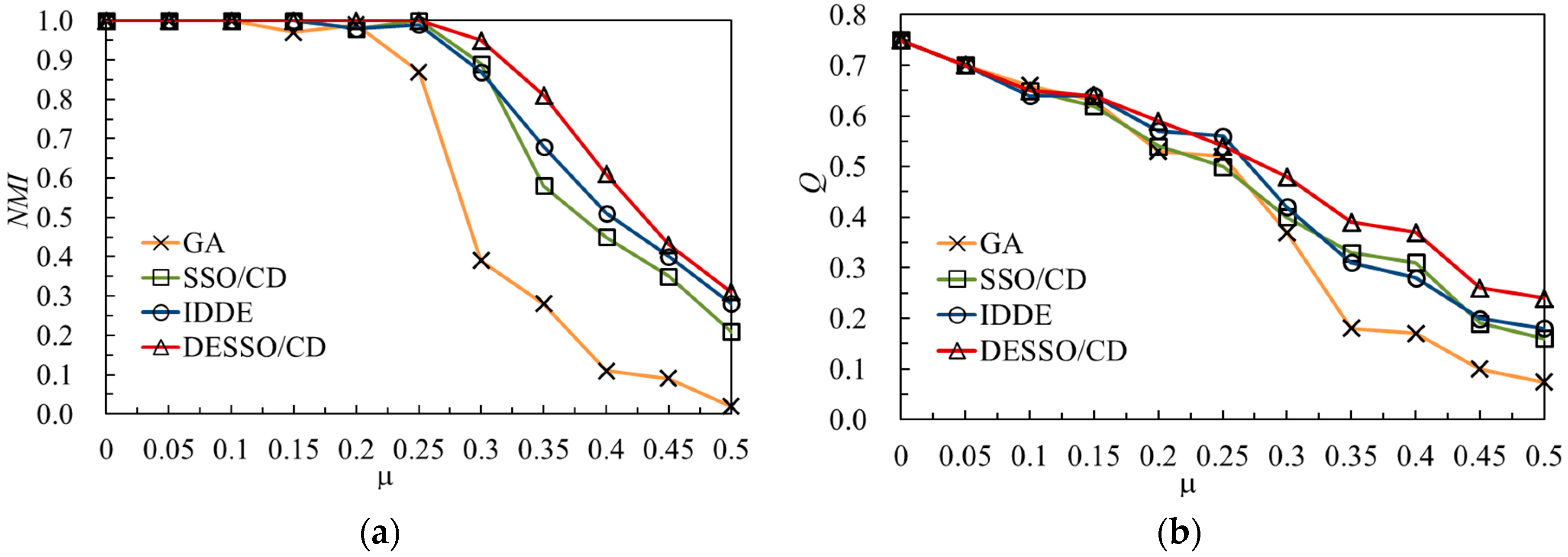
Figure 4a, which indicates that when the network mixed parameter is
μ ∈ [0, 3], the network community structure is relatively clear, and so is the above algorithm. When
μ ≈ 0.3, the
NMI of SSO/CD and IDDE drops more clearly, but DESSO/CD still can hold at 0.95 or so.
In addition, with the increase of
μ, the changes of
Q value index are shown in
Figure 4b. Obviously, the SSO/CD and DESSO/CD algorithms are better than other algorithms, mainly because the two algorithms are based on the growth of Δ
Q for jumping out of circulation. The accuracy of SSO/CD and IDDE is relatively close, that is because the SSO algorithm belongs to differential evolution as IDDE does. In conclusion, the improved DESSO/CD algorithm is more stable and accurate.
5.2.3. Partitioning Speed of LFR Networks
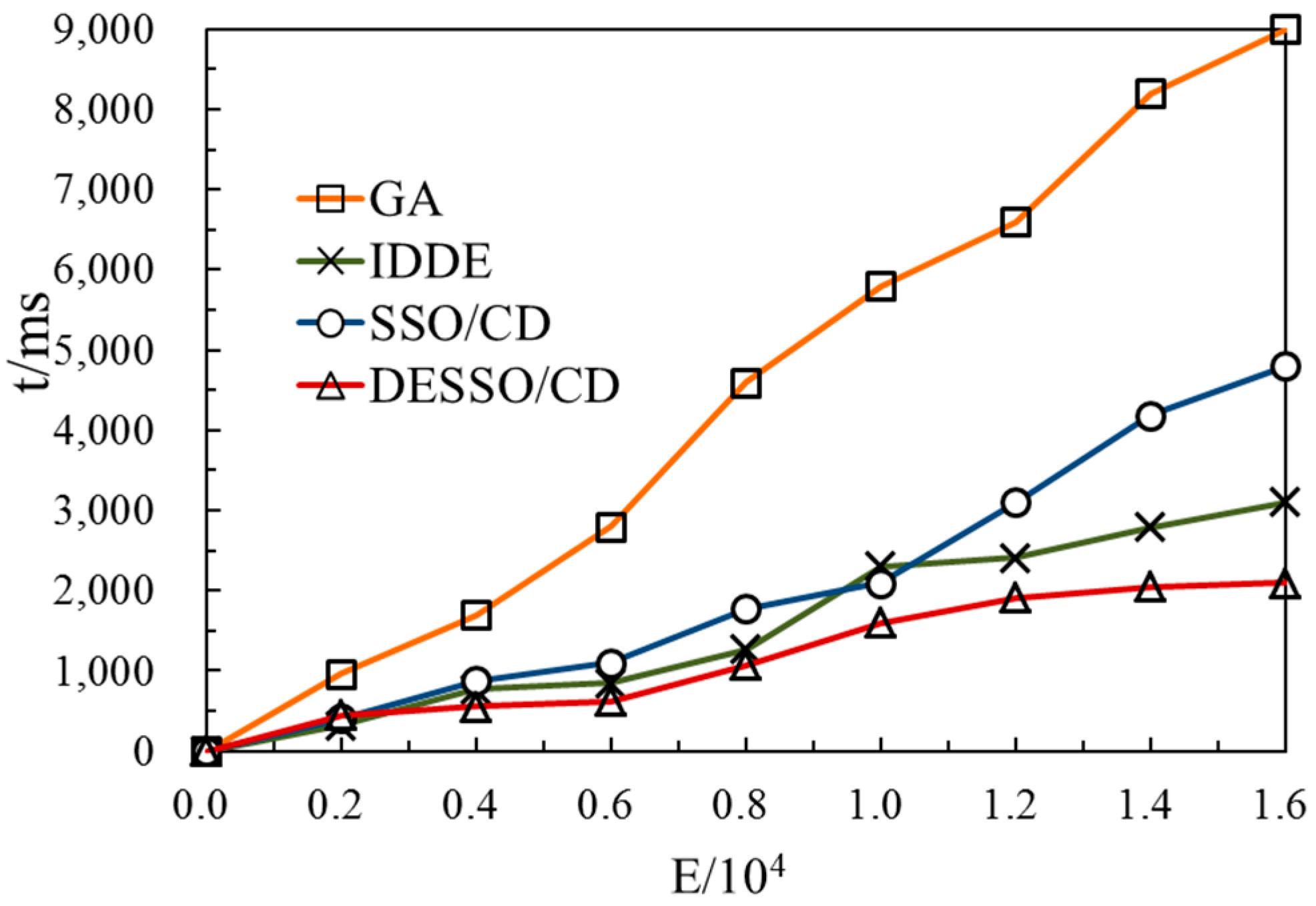
On the LFR benchmark network, with the increase of the number of edges, the data for the execution time of the test algorithm can be obtained, as shown in
Figure 5. The reasons are because the radius of differential evolution strategy and adaptive matching reduces the calculation of the fitness function number as well as the random adjustment of learning mechanism based on a cloud model, which could effectively control the blind search spiders. Therefore, SSO/CD is slightly worse than IDDE in convergence, whereas algorithms based on differential evolution (DESSO/CD, IDDE, SSO/CD) are more efficient than the classical simulated annealing CD algorithm (GA). It can also be concluded that the adjusted DESSO/CD has better convergence.
5.3. Real Network Experiment
In the real network experiment, five groups of real networks are used to compare the precision of the algorithm presented in this study with other existing network algorithms. Moreover, we conduct some simulation and contrast experiments on network data randomly captured from Sina Weibo.
5.3.1. Partitioning Accuracy of Real Networks
The network data used in real network experiments is shown in
Table 2. Amazon and YouTube are relatively complete networks, while the other two networks are relatively simple. In the same data set and experimental environment, each algorithm was repeated 10 times, and some experimental data derived from [
20,
35].
Table 2 and
Table 3 have been marked.
The experimental results are shown in
Table 3. In the karate network, because the network nodes and the connection edges are few, each kind of algorithm can maintain relatively high precision. The standard deviation is also small, so the precision of each algorithm is similar. The edge node and connection are relatively large in the football networks, and differential evolution algorithm (DESSO/CD, BADE, IDDE) can maintain high accuracy. However, in a more complex network, the meta-heuristic algorithm is based on differential evolution (DESSO/CD, BADE) with more obvious advantages. Overall, DESSO/CD runs on a variety of networks with a more stable performance, and better adaptability and accuracy.
5.3.2. Novel Graphical Analysis of Real Social Network Partitioning
Using the method provided by Yibochen [
62], based on Sina Weibo opened by Application Programming Interface (API), we specified an account to capture a set of relational list data under the theme of sports. The experiment captured 517 Weibo accounts and their mutual data. Since the number of communities, the degree of node distribution, clustering coefficients, and other information in the experimental data are unknown, the test can also check the performance of the algorithm without prior information.
IDDE, SSO/CD, and DESSO/CD use the method of the target data classification experiments. The influential leading nodes in the community are detected as described in [
63]. Igraph software is used to zoom in and render the five influential leader nodes, as shown in
Figure 6. The community discovery using the SSO algorithm is better than IDDE, and the improved DESSO/CD is best. As shown in the diagram, the Weibo data captured will be divided into two parts: football and basketball, while each area shows a team based on community division, where the enlarged nodes show the opinion of influential leaders in the community.
7. Conclusions
On the basis of improving the SSO algorithm, this paper proposes a community detection algorithm based on differential evolution using social spider optimization (DESSO/CD). Community detection is achieved by simulating spider cooperative operators, and marriage and operator selection. In this algorithm, nodes in the network are initialized as populations in the SSO algorithm. The similarity of nodes is defined as the local fitness function and the community quality increment is used as the screening criteria for evolutionary operators. Each individual has the ability to learn at random. Meanwhile, the populations are divided into two categories—elite and non-elite—based on the fitness value. Spider populations are further differentiated for cooperation. Since fitness and diversity information is simultaneously considered to select the operators, a good balance between exploration and exploitation can be achieved. A random cloud crossover model is adopted to maintain the diversity of the population. The mating radius will be adjusted automatically according to the fitness value in the dominant individuals. Each generation of the quality increment of community modularity is used as a criterion for the evolutionary selection operator. Thus, this strategy not only ensures the search space of operators, but also reduces the blindness of exploration. On the other hand, the multi-level, multi-granularity strategy of DESSO/CD can be used to further compensate for resolution limitations and extreme degradation defects based on modular optimization methods. It could detect community structure with higher partition accuracy and lower computational cost. Experiments on artificial and real-world networks show the effectiveness and efficiency of DESSO/CD. In comparison with other methods, EA algorithms also confirm that DESSO/CD’s flexibility is better.
DESSO/CD is a method of community detection based on local neighborhood expansion. It has less dependence on parameters, better adaptability, higher efficiency, and shows greater accuracy. This study is competitive and promising. Since the CD approach is based on SSO, the key points are setting of the fitness vectors and the screening criteria for evolutionary operators. This plays a vital role in maintaining the distribution of the population. The organizational dimension of the edges and nodes within the community is diverse. Indeed, the fitness values based on the objective function still result in many contradictions and conflicts in practical operation. However, in the future, we will focus on the application of multidimensional fitness values in the SSO-based CD algorithm and intelligent systems in fuzzy, neutrosophic, inconsistent, and dynamic environments [
64,
65,
66,
67,
68].







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}