A Novel Single-Valued Neutrosophic Set Similarity Measure and Its Application in Multicriteria Decision-Making


Abstract
1. Introduction
2. Preliminaries
2.1. Neutrosophic Sets
2.2. Single-Valued Neutrosophic Set
2.3. Dempster–Shafer Evidence Theory
2.4. A Correlation Coefficient
3. A New Similarity Measures for SNVS
- Step 1: According to A and B, two groups of BPAs and can be obtained by Equation (22);
- Step 3: The similarity measure can be obtained as:
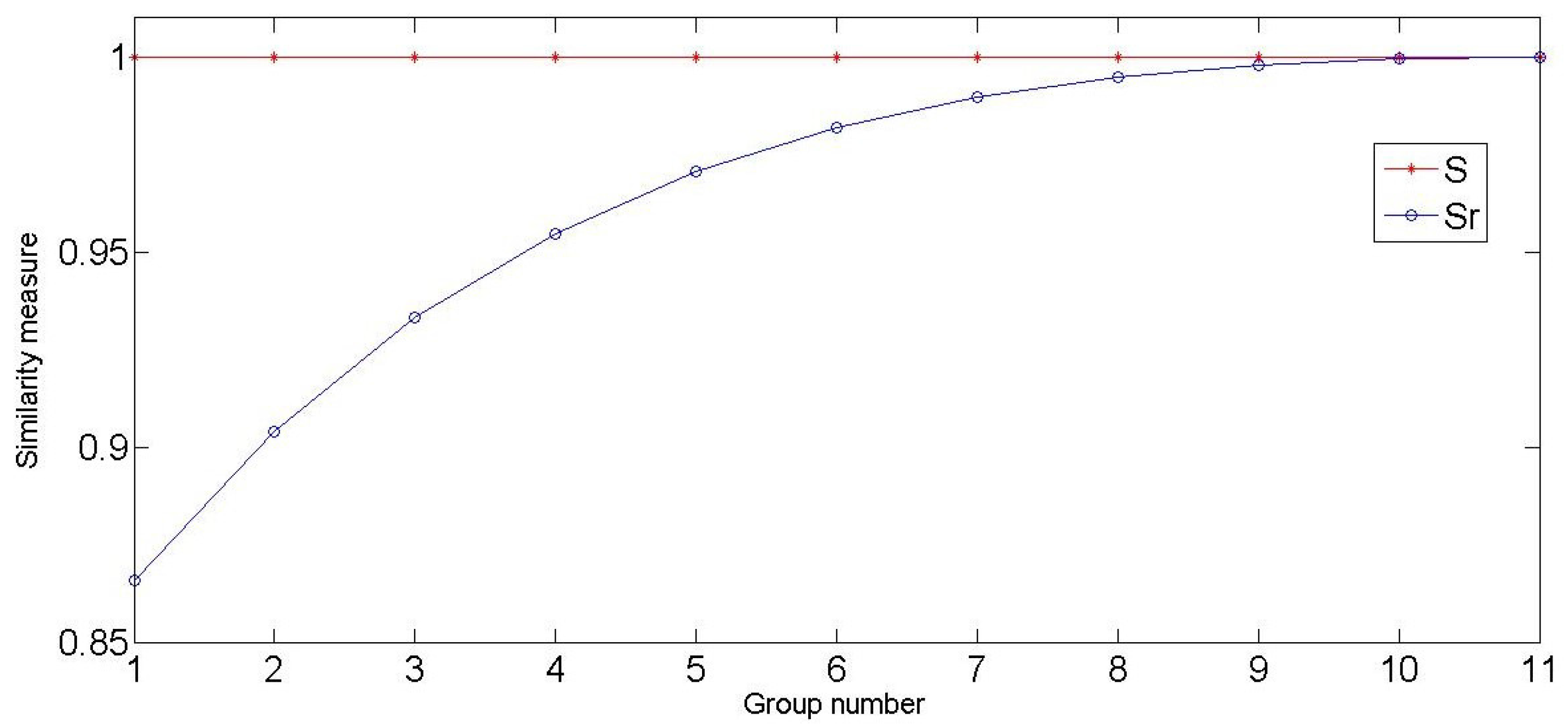
4. Test and Analysis
5. Multicriteria Decision-Making
- Step 1: can be obtained by Equation (12). The computing results are:
- Step 2: Correlation measure between each alternative and the ideal alternative were calculated by the method proposed in Section 3. The results are as follows:
- Step 3: According to the results in the second step, the ranking order of four alternatives is:
- Step 2: According to SVNS of the real testing samples B, can be obtained by Equation (12). Additionally, correlation measure between each fault diagnosis problem and the sample were calculated by the method we proposed in Section 3 and that of Ye [5] individually. Therefore, the two method ranking order of all faults is as follows:
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Smarandache, F. A Unifying Field in Logics: Neutrosophic Logic. Philosophy 1999, 8, 1–141. [Google Scholar]
- Wang, H.; Smarandache, F.; Sunderraman, R.; Zhang, Y.Q. Interval Neutrosophic Sets and Logic: Theory and Applications in Computing; Infinite Study: Hexis, AZ, USA, 2005. [Google Scholar]
- Wang, H.; Smarandache, F.; Zhang, Y.; Sunderraman, R. Single valued neutrosophic sets. Rev. Air Force Acad. 2010, 17, 10–14. [Google Scholar]
- Zhang, H.Y.; Wang, J.Q.; Chen, X.H. Interval neutrosophic sets and their application in multicriteria decision making problems. Sci. World J. 2014, 2014, 645953. [Google Scholar] [CrossRef] [PubMed]
- Ye, J. A multicriteria decision-making method using aggregation operators for simplified neutrosophic sets. J. Intell. Fuzzy Syst. 2014, 26, 2459–2466. [Google Scholar]
- Ye, J. Multicriteria decision-making method using the correlation coefficient under single-valued neutrosophic environment. Int. J. Gen. Syst. 2013, 42, 386–394. [Google Scholar] [CrossRef]
- Peng, J.J.; Wang, J.Q.; Wang, J.; Zhang, H.Y.; Chen, X.H. Simplified neutrosophic sets and their applications in multi-criteria group decision-making problems. Int. J. Syst. Sci. 2016, 47, 2342–2358. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, J.; Chen, X. An outranking approach for multi-criteria decision-making problems with interval-valued neutrosophic sets. Neural Comput. Appl. 2016, 27, 615–627. [Google Scholar] [CrossRef]
- Liu, P.; Wang, Y. Multiple attribute decision-making method based on single-valued neutrosophic normalized weighted Bonferroni mean. Neural Comput. Appl. 2014, 25, 2001–2010. [Google Scholar] [CrossRef]
- Guo, Y.; Cheng, H.D. New neutrosophic approach to image segmentation. Pattern Recognit. 2009, 42, 587–595. [Google Scholar] [CrossRef]
- Broumi, S.; Smarandache, F. Correlation coefficient of interval neutrosophic set. Appl. Mech. Mater. 2013, 436, 511–517. [Google Scholar] [CrossRef]
- Guo, Y.; Sengur, A. A novel color image segmentation approach based on neutrosophic set and modified fuzzy c-means. Circuits Syst. Signal Process. 2013, 32, 1699–1723. [Google Scholar] [CrossRef]
- Ma, Y.X.; Wang, J.Q.; Wang, J.; Wu, X.H. An interval neutrosophic linguistic multi-criteria group decision-making method and its application in selecting medical treatment options. Neural Comput. Appl. 2016, 1–21. [Google Scholar] [CrossRef]
- Ye, J. Single-valued neutrosophic similarity measures based on cotangent function and their application in the fault diagnosis of steam turbine. Soft Comput. 2017, 21, 1–9. [Google Scholar] [CrossRef]
- Ji, P.; Zhang, H.Y.; Wang, J.Q. A projection-based TODIM method under multi-valued neutrosophic environments and its application in personnel selection. Neural Comput. Appl. 2016, 1–14. [Google Scholar] [CrossRef]
- Fatimah, F.; Rosadi, D.; Hakim, R.F.; Alcantud, J.C.R. Probabilistic soft sets and dual probabilistic soft sets in decision-making. Neural Comput. Appl. 2017, 1–11. [Google Scholar] [CrossRef]
- Alcantud, J.C.R.; Santos-García, G. A New Criterion for Soft Set Based Decision Making Problems under Incomplete Information; Technical Report; Mimeo: New York, NY, USA, 2015. [Google Scholar]
- Majumdar, P.; Samanta, S.K. On similarity and entropy of neutrosophic sets. J. Intell. Fuzzy Syst. Appl. Eng. Technol. 2014, 26, 1245–1252. [Google Scholar]
- Zadeh, L.A. A simple view of the Dempster-Shafer theory of evidence and its implication for the rule of combination. AI Mag. 1986, 7, 85–90. [Google Scholar]
- Jiang, W.; Xie, C.; Luo, Y.; Tang, Y. Ranking Z-numbers with an improved ranking method for generalized fuzzy numbers. J. Intell. Fuzzy Syst. 2017, 32, 1931–1943. [Google Scholar] [CrossRef]
- Jiang, W.; Wei, B.; Tang, Y.; Zhou, D. Ordered visibility graph average aggregation operator: An application in produced water management. Chaos 2017, 27, 023117. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.B.; Xu, D.L. Evidential reasoning rule for evidence combination. Artif. Intell. 2013, 205, 1–29. [Google Scholar] [CrossRef]
- Chin, K.S.; Fu, C. Weighted cautious conjunctive rule for belief functions combination. Inf. Sci. 2015, 325, 70–86. [Google Scholar] [CrossRef]
- Wang, J.; Xiao, F.; Deng, X.; Fei, L.; Deng, Y. Weighted evidence combination based on distance of evidence and entropy function. Int. J. Distrib. Sens. Netw. 2016, 12, 3218784. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, Y. Iterative Approximation of Basic Belief Assignment Based on Distance of Evidence. PLoS ONE 2016, 11, e0147799. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Han, D.; Han, C.; Cao, F. A novel approximation of basic probability assignment based on rank-level fusion. Chin. J. Aeronaut. 2013, 26, 993–999. [Google Scholar] [CrossRef]
- Yang, Y.; Han, D. A new distance-based total uncertainty measure in the theory of belief functions. Knowl. Based Syst. 2016, 94, 114–123. [Google Scholar] [CrossRef]
- Deng, X.; Xiao, F.; Deng, Y. An improved distance-based total uncertainty measure in belief function theory. Appl. Intell. 2017, 46, 898–915. [Google Scholar] [CrossRef]
- Jiang, W.; Zhuang, M.; Xie, C.; Wu, J. Sensing Attribute Weights: A Novel Basic Belief Assignment Method. Sensors 2017, 17, 721. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Hu, L.; Guan, X.; Han, D.; Deng, Y. New conflict representation model in generalized power space. J. Syst. Eng. Electron. 2012, 23, 1–9. [Google Scholar] [CrossRef]
- Jiang, W.; Zhan, J. A modified combination rule in generalized evidence theory. Appl. Intell. 2017, 46, 630–640. [Google Scholar] [CrossRef]
- Mo, H.; Lu, X.; Deng, Y. A generalized evidence distance. J. Syst. Eng. Electron. 2016, 27, 470–476. [Google Scholar] [CrossRef]
- Dong, J.; Zhuang, D.; Huang, Y.; Fu, J. Advances in multi-sensor data fusion: Algorithms and applications. Sensors 2009, 9, 7771–7784. [Google Scholar] [CrossRef] [PubMed]
- Yang, F.; Wei, H. Fusion of infrared polarization and intensity images using support value transform and fuzzy combination rules. Infrared Phys. Technol. 2013, 60, 235–243. [Google Scholar] [CrossRef]
- Jiang, W.; Xie, C.; Zhuang, M.; Shou, Y.; Tang, Y. Sensor Data Fusion with Z-Numbers and Its Application in Fault Diagnosis. Sensors 2016, 16, 1509. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Liu, W.; Miller, P.; Zhou, H. An evidential fusion approach for gender profiling. Inf. Sci. 2016, 333, 10–20. [Google Scholar] [CrossRef]
- Islam, M.S.; Sadiq, R.; Rodriguez, M.J.; Najjaran, H.; Hoorfar, M. Integrated Decision Support System for Prognostic and Diagnostic Analyses of Water Distribution System Failures. Water Resour. Manag. 2016, 30, 2831–2850. [Google Scholar] [CrossRef]
- Jiang, W.; Xie, C.; Zhuang, M.; Tang, Y. Failure Mode and Effects Analysis based on a novel fuzzy evidential method. Appl. Soft Comput. 2017, 57, 672–683. [Google Scholar] [CrossRef]
- Zhang, X.; Deng, Y.; Chan, F.T.S.; Adamatzky, A.; Mahadevan, S. Supplier selection based on evidence theory and analytic network process. J. Eng. Manuf. 2016, 230, 562–573. [Google Scholar] [CrossRef]
- Deng, Y. Deng entropy. Chaos Solitons Fractals 2016, 91, 549–553. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, W.; Zhang, J. Zero-sum matrix game with payoffs of Dempster-Shafer belief structures and its applications on sensors. Sensors 2017, 17, 922. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Mahadevan, S.; Deng, X. Reliability analysis with linguistic data: An evidential network approach. Reliab. Eng. Syst. Saf. 2017, 162, 111–121. [Google Scholar] [CrossRef]
- Jiang, W.; Wei, B.; Zhan, J.; Xie, C.; Zhou, D. A visibility graph power averaging aggregation operator: A methodology based on network analysis. Comput. Ind. Eng. 2016, 101, 260–268. [Google Scholar] [CrossRef]
- Jousselme, A.L.; Grenier, D.; Bossé, É. A new distance between two bodies of evidence. Inf. Fusion 2001, 2, 91–101. [Google Scholar] [CrossRef]
- Jiang, W. A Correlation Coefficient of Belief Functions. Available online: http://arxiv.org/abs/1612.05497 (accessed on 2 February 2017).
- Ye, J. Fault diagnosis of turbine based on fuzzy cross entropy of vague sets. Expert Syst. Appl. 2009, 36, 8103–8106. [Google Scholar] [CrossRef]


{kind=link}
| Group Number | A | B | S [6] | |
|---|---|---|---|---|
| 1 | <1 0 0> | <0 0 0> | 0.8660 | 1 |
| 2 | <1 0 0> | <0.1 0 0> | 0.9042 | 1 |
| 3 | <1 0 0> | <0.2 0 0> | 0.9333 | 1 |
| 4 | <1 0 0> | <0.3 0 0> | 0.9549 | 1 |
| 5 | <1 0 0> | <0.4 0 0> | 0.9707 | 1 |
| 6 | <1 0 0> | <0.5 0 0> | 0.9820 | 1 |
| 7 | <1 0 0> | <0.6 0 0> | 0.9897 | 1 |
| 8 | <1 0 0> | <0.7 0 0> | 0.9948 | 1 |
| 9 | <1 0 0> | <0.8 0 0> | 0.9979 | 1 |
| 10 | <1 0 0> | <0.9 0 0> | 0.9995 | 1 |
| 11 | <1 0 0> | <1 0 0> | 1 | 1 |
| Group Number | A | B | S [6] | |
|---|---|---|---|---|
| 1 | <0.6 0.2 0.8> | <0.3 0.1 0.4> | 0.9862 | 1 |
| 2 | <0.7 0.8 0.2> | <0.6 0.8 0.1> | 0.9965 | 0.9935 |
| 3 | <0.2 0.1 0.5> | <0.2 0.1 0.5> | 1 | 1 |
| 4 | <0.9 0.8 0.7> | <0.1 0.2 0.1> | 0.8440 | 0.9379 |
| (Fault Knowledge) | (0.01–0.39 f) | (0.4–0.49 f) | (0.51–0.99 f) | (3–5 f) | (Odd Times of f) | (High Frequency > 5 f) | |||
|---|---|---|---|---|---|---|---|---|---|
| (unbalance) | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> | <0.85 0.15 0> | <0.04 0.02 0.94> | <0.04 0.03 0.93> | <0 0 1> | <0 0 1> |
| (pneumatic force couple) | <0 0 1> | <0.03 0.28 0.69> | <0.9 0.3 0.88> | <0.55 0.15 0.3> | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> | <0.08 0.05 0.87> |
| (offset center) | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> | <0.3 0.28 0.42> | <0.40 0.22 0.38> | <0.08 0.05 0.87> | <0 0 1> | <0 0 1> |
| (oil-membrane oscillation) | <0.09 0.22 0.89> | <0.78 0.04 0.18> | <0 0 1> | <0.08 0.03 0.89> | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> |
| (radial impact friction of rotor) | <0.09 0.03 0.88> | <0.09 0.02 0.89> | <0.08 0.04 0.88> | <0.09 0.03 0.88> | <0.18 0.03 0.79> | <0.08 0.05 0.87> | <0.08 0.05 0.87> | <0.08 0.04 0.88> | <0.08 0.04 0.88> |
| (symbiosis looseness) | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> | <0.18 0.04 0.78> | <0.12 0.05 0.83> | <0.37 0.08 0.55> | <0 0 1> | <0.22, 0.06, 0.72> |
| (damage of antithrust bearing) | <0 0 1> | <0 0 1> | <0.08 0.04 0.88> | <0.86 0.07 0.07> | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> |
| (surge) | <0 0 1> | <0.27 0.05 0.68> | <0.08 0.04 0.88> | <0.54 0.08 0.38> | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> |
| (looseness of bearing block) | <0.85, 0.08, 0.07> | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> | <0.08 0.04 0.88> | <0 0 1> |
| (non-uniform bearing stiffness) | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> | <0 0 1> | <0.77 0.06 0.17> | <0.19 0.04 0.7> | <0 0 1> | <0 0 1> |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, W.; Shou, Y. A Novel Single-Valued Neutrosophic Set Similarity Measure and Its Application in Multicriteria Decision-Making. Symmetry 2017, 9, 127. https://doi.org/10.3390/sym9080127
Jiang W, Shou Y. A Novel Single-Valued Neutrosophic Set Similarity Measure and Its Application in Multicriteria Decision-Making. Symmetry. 2017; 9(8):127. https://doi.org/10.3390/sym9080127
Chicago/Turabian StyleJiang, Wen, and Yehang Shou. 2017. "A Novel Single-Valued Neutrosophic Set Similarity Measure and Its Application in Multicriteria Decision-Making" Symmetry 9, no. 8: 127. https://doi.org/10.3390/sym9080127
APA StyleJiang, W., & Shou, Y. (2017). A Novel Single-Valued Neutrosophic Set Similarity Measure and Its Application in Multicriteria Decision-Making. Symmetry, 9(8), 127. https://doi.org/10.3390/sym9080127