1. Introduction
With the rapid growth of internet technology, it has become very easy to download media such as pictures, images, and audio or video files. This makes media data not only easy to transmit but also easy to copy and distribute. Therefore, pirates can easily record and distribute copyright-protected material without paying the appropriate compensation to the owner. Thus, a legal issue arises such that some media need to be protected against unauthorized use or operations. Data hiding and encryption are two effective and prevalent means of privacy protection and secret communication.
Data hiding has attracted considerable research interest in recent years [
1,
2,
3]. By this technique, secret data can be embedded into a cover medium, and later the embedded data can be extracted from the marked medium for various purposes. Hong et al. [
1] proposed a novel data-embedding method using adaptive pixel pair matching. Hussain et al. [
2] introduced a hybrid data hiding method combining the right-most digit replacement (RMDR) with an adaptive least significant bit (ALSB) for digital images. Hong et al. [
3] proposed a new data hiding technique for absolute moment block truncation coding (AMBTC) compressed image based on quantization level modification. However, for most data hiding systems, during the data hiding operation the cover medium has been distorted and hence, after data extraction, the cover medium cannot be recovered to its original state. Such permanent distortion is unacceptable and the exact recovery of the original cover medium is prerequisite in some sensitive applications like medical, defense, legal matters, artwork, and so on. To solve this problem, reversible data hiding (RDH), also known as lossless or invertible data hiding, is proposed to exactly recover both the hidden data and the cover medium. Explicitly, with the RDH, not only the hidden data but also the cover medium can be exactly recovered from the marked medium.
Several RDH techniques have been introduced [
4,
5,
6,
7,
8,
9,
10]. In 2003, Tian [
4] proposed a reversible data hiding method using the difference expansion technique, where one bit is embedded into the difference of two successive pixels. In 2006, Ni et al. [
5] introduced a novel RDH system based on histogram shifting by utilizing the minimum and maximum points of the image histogram; data are concealed by shifting the histogram. In 2007, Thodi and Rodriguez [
6] proposed a different technique by expanding the prediction errors. In 2010, Luo et al. [
7] presented a new reversible data hiding process by adopting an additive interpolation error expansion technique, which provides very small falsification and a comparatively high capability. Moreover, to improve performance, many techniques have been proposed for typical reversible data hiding approaches [
8,
9,
10].
In some applications of data hiding, the embedded carriers are further encrypted to prevent the carrier from being analyzed to expose the existence of the embedding [
11,
12]. In 2007, Lian et al. [
11] proposed a video encryption and watermarking scheme based on H.264, the advanced video coding (AVC) codec, where media data are encrypted and partially watermarked. In 2010, Cancellaro et al. [
12] presented a commutative watermarking and ciphering scheme where a watermarked image is further encrypted to increase the security of the system.
Most of the existing reversible data-hiding systems are only suitable for unencrypted covers. However, for maintaining confidentiality or protecting privacy, in many fields—like medicine, the military, and the law—a content owner may demand to encrypt the original images. Meanwhile, without knowing the encryption key and the plaintext content, a channel administrator or an inferior assistant may need to insert some additional information within the encrypted images. As an authorized receiver, it is essential that hidden information can be extracted and the original cover can be recovered error-free without any loss or distortion after image decryption and data extraction. Reversible data hiding in encrypted images (RDH-EI) gratifies these requirements.
The existing RDH-EI methods can be classified into two categories: “vacating room before encryption (VRBE)” and “vacating room after encryption (VRAE)”. In VRBE, the content owner creates room for embedding data in the cover image before encryption [
13,
14]. As VRBE requires the content owner to do an extra preprocessing before content encryption, so this method might be impractical. In this sense, the VRAE method is more practical. In VRAE methods, the original content is encrypted by the content owner, and the data-hider embeds the additional information by modifying a small part of the encrypted data [
15,
16,
17,
18,
19,
20,
21,
22,
23]. The VRAE methods can be further divided into two categories: joint method and separable method.
In joint methods [
15,
16,
17,
18,
19,
20], with an encrypted image containing additional data, a receiver may first decrypt it using the encryption key, and then extract the embedded data and recover the original image from the decrypted image using the data-hiding key. In 2011, Zhang [
15] proposed a novel reversible data hiding technique in encrypted images. In 2012, Hong et al. [
16] improved Zhang’s technique by using a side match technique. Zhang’s and Hong’s systems were further enhanced with other techniques [
17,
18]. In these systems, the encrypted image is divided into blocks, and the spatial correlation in the block cannot fully reflect the smoothness of natural images, especially when the block size is small. In 2014, Li et al. [
19] introduced a new scheme where a random diffusion strategy is used for embedding and accurate prediction is used to measure the smoothness. In 2014, Wu and Sun [
20] proposed a different joint RDH system based on prediction error. However, the smoothness calculation from using prediction error fails to perform well.
Nevertheless, in joint methods, the embedded data can only be extracted before image decryption. In other words, a receiver having a data-hiding key but no encryption key cannot extract any information. Moreover, when the payload is high, it is not possible to get error-free extracted bits with all these joint methods. To overcome these problems, a separable reversible data-hiding scheme is required.
In separable methods [
20,
21,
22,
23], with an encrypted image containing additional data, if a receiver has the data-hiding key, he can extract the additional bits from the marked encrypted image directly, while if the receiver has the encryption key, he can decrypt the received data which is similar to the original one. When, the receiver has both the data-hiding and encryption keys, he can extract the additional bits and recover the original image perfectly. However, in [
20] prediction error is used for separable method too which causes worse performance. Moreover, in [
21] data cannot be extracted precisely and the original image cannot be recovered perfectly especially when the payload is high. Beyond that, many parameters assumed in [
21] make it a little complicated for implementation. Qian et al. [
22] proposed a novel scheme of RDH in encrypted images using distributed source coding (DSC) where the low-density parity check (LDPC) encoding and source decoding are used which make the system’s complexity much higher. Xiao et al. [
23] proposed a separable RDH technique in encrypted images based on pixel value ordering (PVO) where homomorphism encryption is used for image encryption.
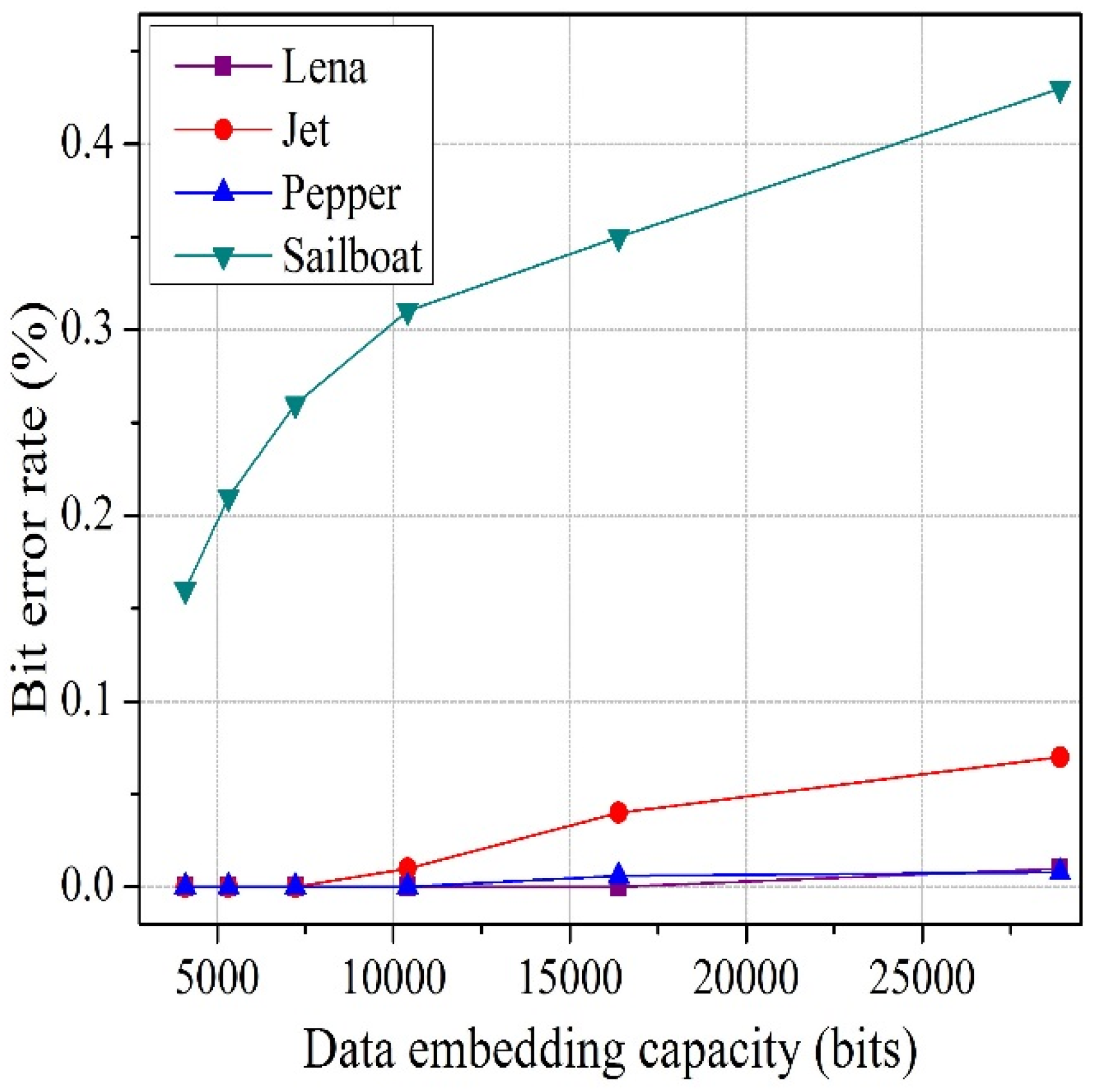
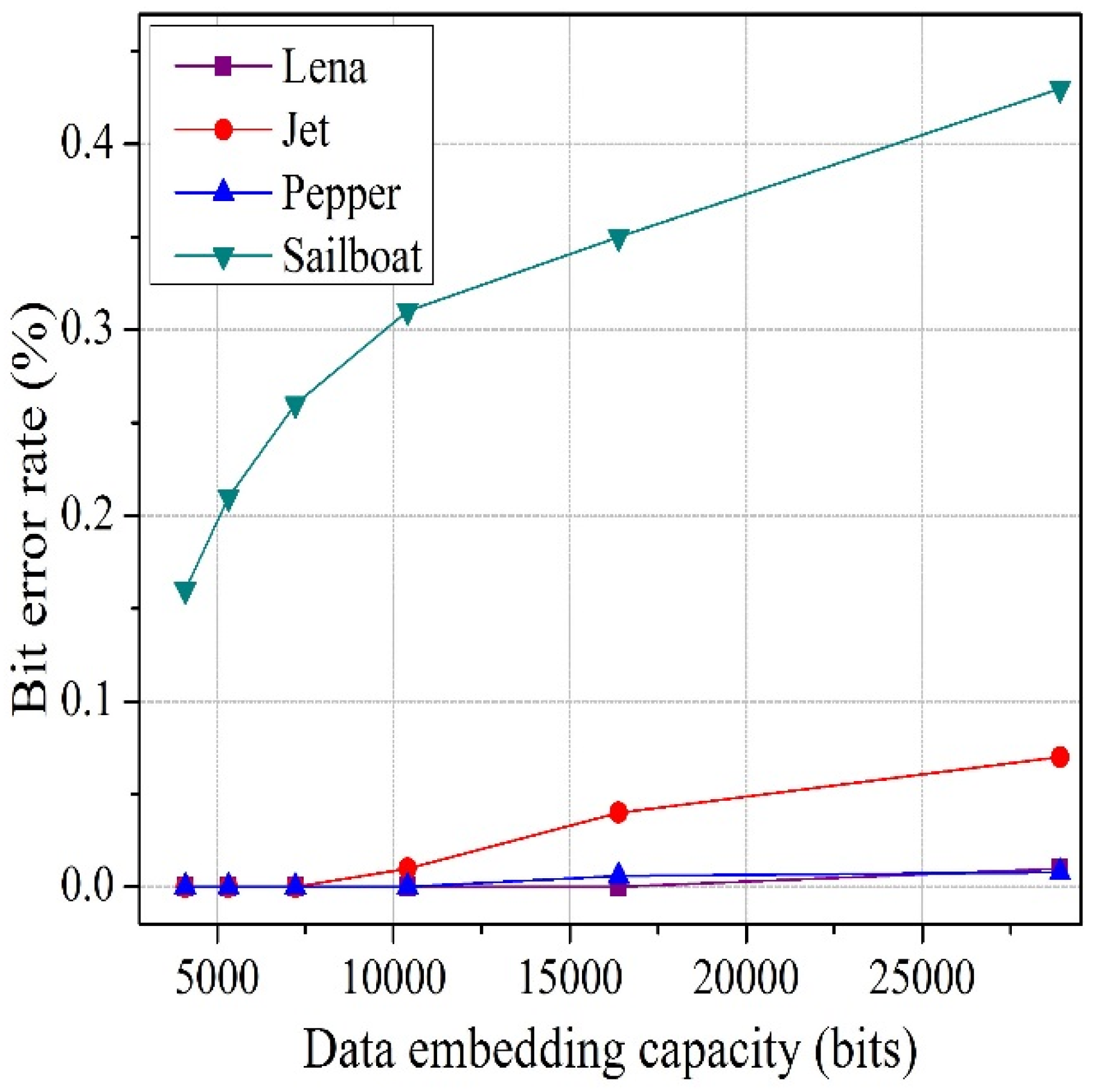
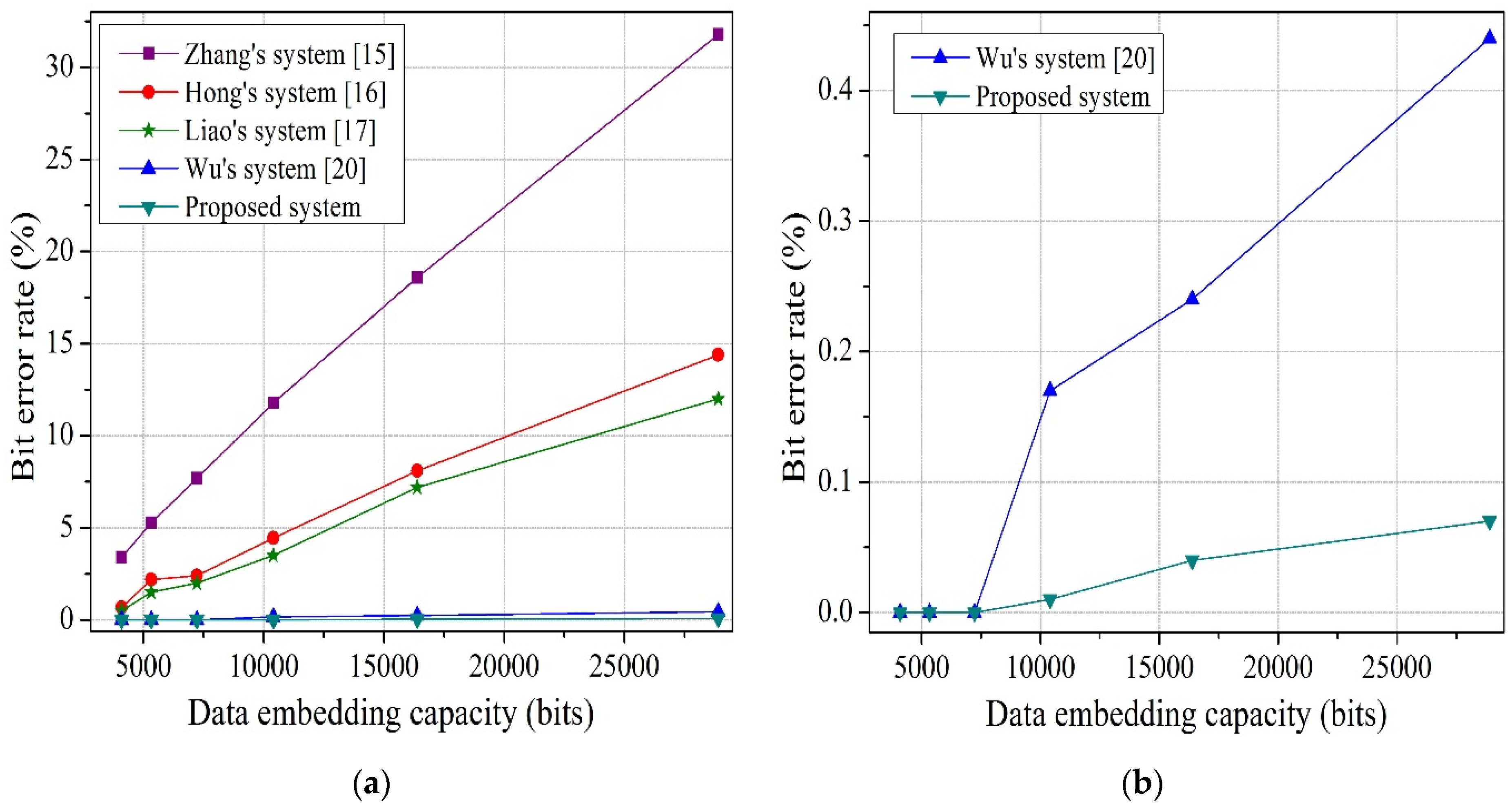
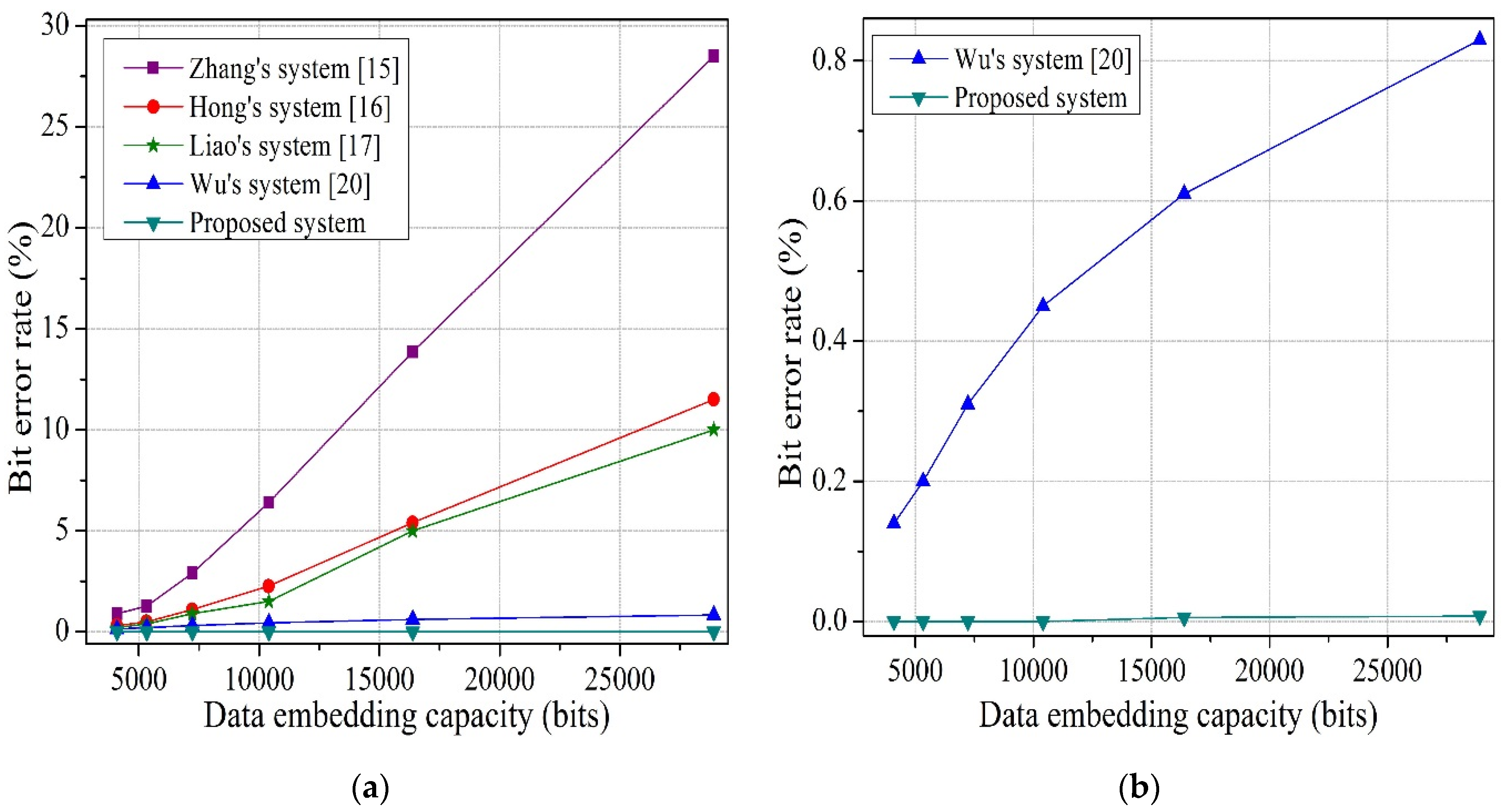
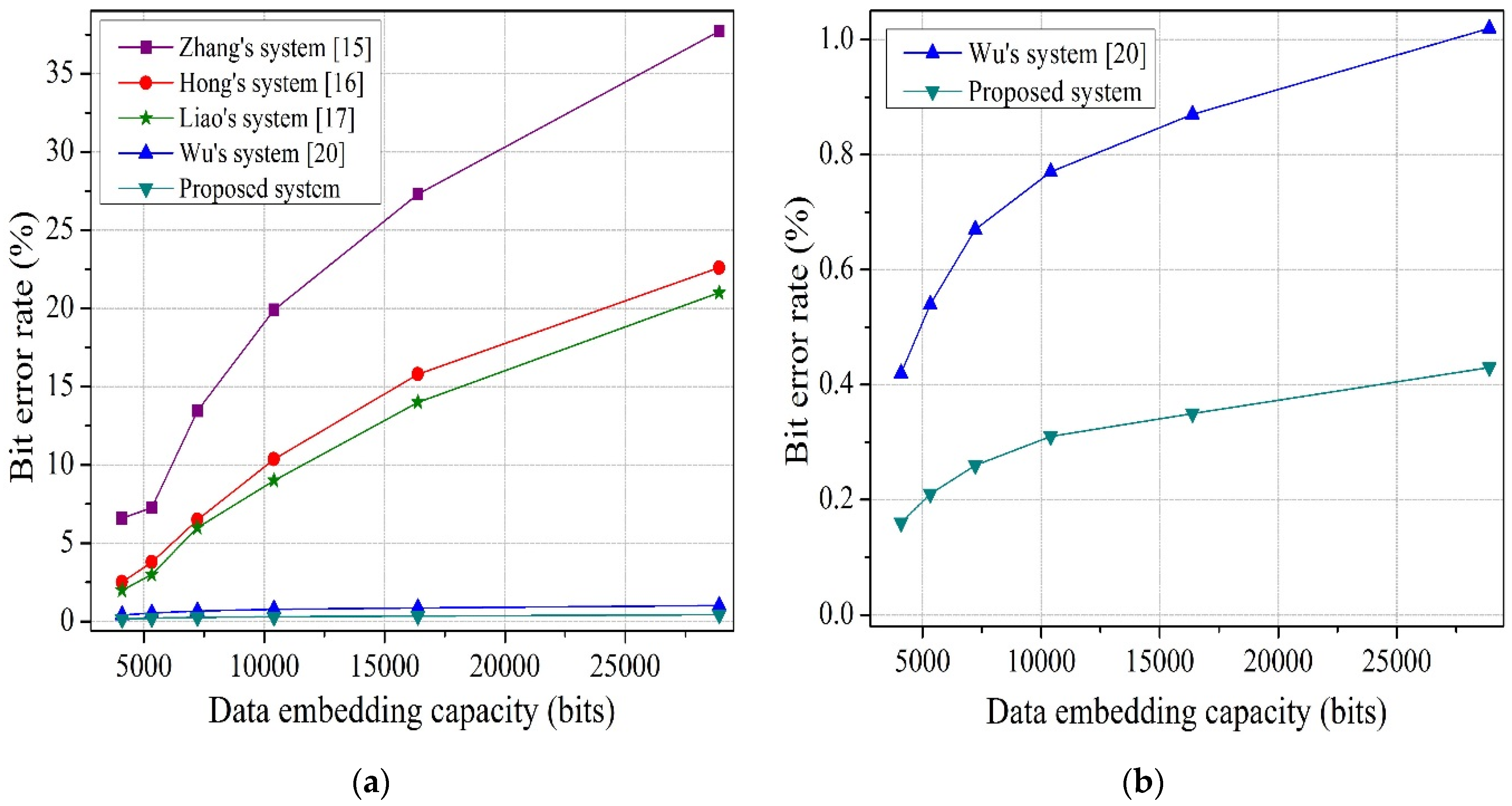
To solve the above-mentioned issues in both joint and separable methods, we propose an improved joint and separable RDH technique in this paper. For joint method, the encrypted image is divided into four sets, instead of blocks, and two sets can be used for data hiding. Therefore, the embedding capacity increases. In addition, we consider the actual value of pixels in preference to an estimated value, and exploit the absolute difference between neighboring pixels, rather than prediction error, to calculate fluctuation for both joint and separable method. By avoiding block division and prediction error, we fully use the spatial correlation property of a natural image, which helps to reduce the bit error rate (BER). For this reason, performance of the proposed system is superior to the performance of other systems. Additionally, before hiding the data, we encrypt the information bits to further increase the security of the system.
The rest of this paper is organized as follows. Related work is described in
Section 2. Then, the proposed joint and separable data hiding systems are discussed in
Section 3 and
Section 4, respectively. After that, the experimental results are presented in
Section 5. Finally, the conclusion is in
Section 6.
2. Related Work
In this section, we explain the important and related results of the referenced papers to be compared with our research. Zhang [
15], encrypted the original host image by using an encryption key. The pixels in the original host image are decomposed into bits and a random sequence is determined by an encryption key using standard stream cipher. The exclusive-or results of original bits and pseudo-random bits are calculated to encrypt the original image. Then, the encrypted image is divided into non-overlapping blocks sized
s ×
s, and according to the data-hiding key, each block is divided into two sets,
S0 and
S1, pseudo-randomly. Each block is capable of carrying one bit. If the bit to be inserted is 0, then the three least significant bits (LSBs) of each pixel in set
S0 are flipped. On the other hand, if the bit to be inserted is 1 then the three LSBs of each pixel in set
S1 are flipped. Thus, the embedding process is done. For data extraction and image recovery, the receiver first decrypts the embedded encrypted image. Then, the decrypted image is partitioned into non-overlapping blocks sized
s ×
s. According to the data-hiding key, the pixels of each block are divided into two sets,
S0 and
S1, pseudo-randomly in the same way as before. For each decrypted block, two new blocks,
B0 and
B1, are obtained. In
B0, all three LSBs of each pixel in
S0 are flipped, and in
B1, all three LSBs of the pixels in
S1 are flipped. One of
B0 and
B1 is the original block, and the other is the three LSBs flipped block. To determine which one is the original block, Zhang [
15] proposed a fluctuation function
fZ to calculate the smoothness of
B0 and
B1 as follows:
where
p(
u,
v) ∈
Bc for c = 0, 1.
In [
16], Hong et al. ameliorated data the extraction and image recovery part based on Zhang’s method. Firstly, they proposed a new function as (2) where more pixels are considered to reduce the bit error rate.
Secondly, data extraction and image recovery is done according to the descending order of the absolute smoothness difference between two candidate blocks. Finally, side match technique is used to achieve a much lower error rate.
In order to further reduce the error rate, Liao et al. [
17] introduced a new more precise function to calculate the fluctuation of each image block. They employed two, three, or four neighboring pixels according to the location of each pixel. Furthermore, the data embedding ratio is also considered in this technique.
In these systems [
15,
16,
17], the encrypted image is divided into blocks and the spatial correlation in the block cannot fully reflect the smoothness of natural images, especially when the block size is small. The constraint and centralization of local pixels will cause unreliability in the fluctuation measurement, which is based on the smoothness of natural images. Therefore, in the proposed work, we thoroughly avoid the idea of block division to reduce the bit error rate.
Based on prediction error, Wu and Sun [
20] proposed two RDH techniques: joint and separable. In joint method, they divided the encrypted image into two sets:
TQual and
TForb, according to the data-hiding key. Then, only pixels in
TQual, which are about half of the encrypted image, are used for data embedding. For inserting information in data hiding, pixels in
TQual are divided into groups, and each group is composed of
m pixels. One bit of information can be embedded in one group. For data extraction and image recovery, the receiver first decrypts the embedded encrypted image. Then, the decrypted image is divided into two sets:
TQual and
TForb. The pixels in
TQual are retrieved and divided into groups, and the
d-th group contains
m pixels, denoted as
P(
u,
d) for
u = 1, 2,…,
m. For each pixel, an estimated pixel,
PEst(
u,
d), is calculated by using four neighboring pixels and a flipped pixel,
PFlip(
u,
d), is determined by flipping the
t-th bit of
P(
u,
d). Then, for the smoothness calculation, the prediction error
PE and flipped prediction error
PEFlip, respectively, are calculated by using the following equations:
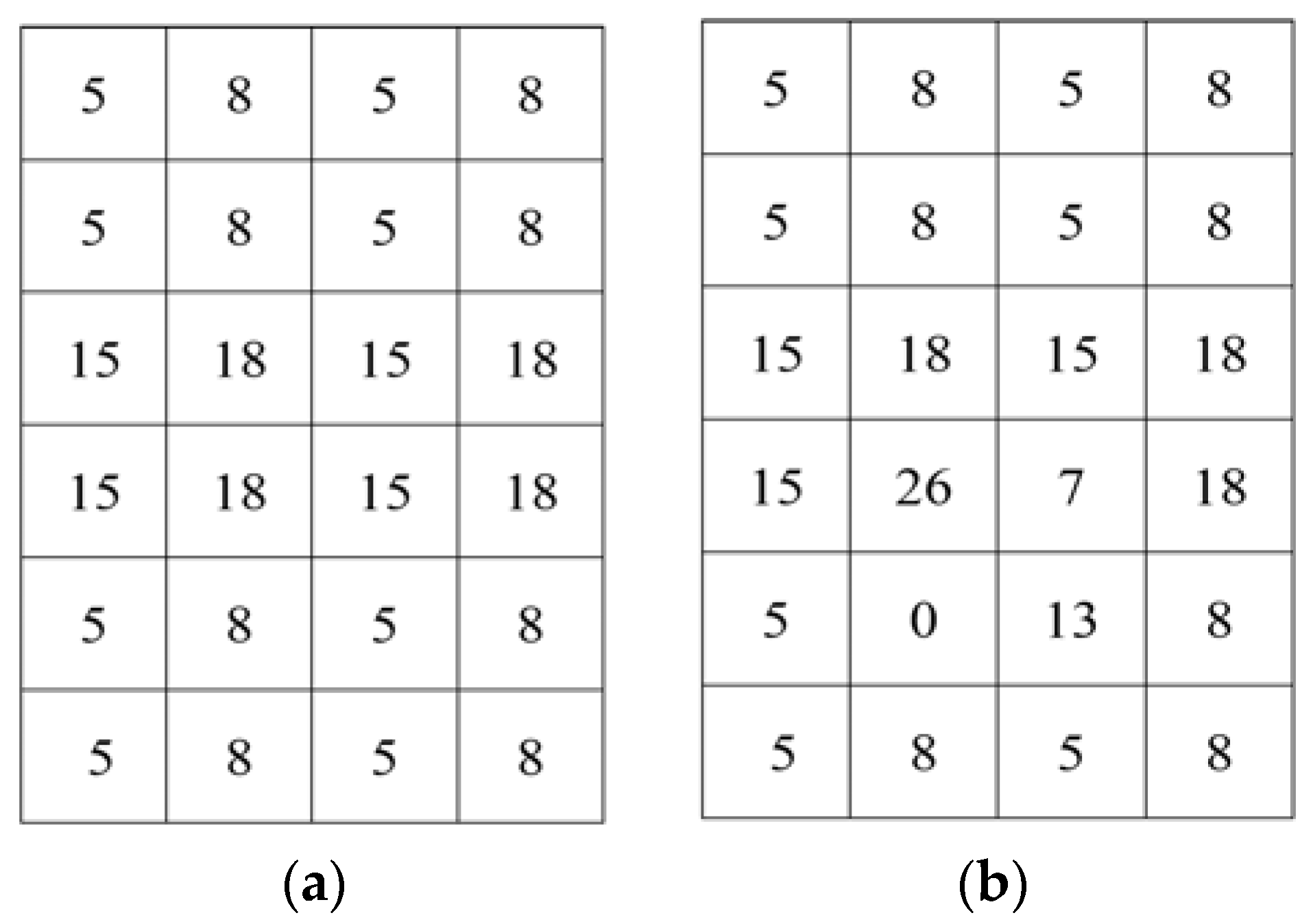
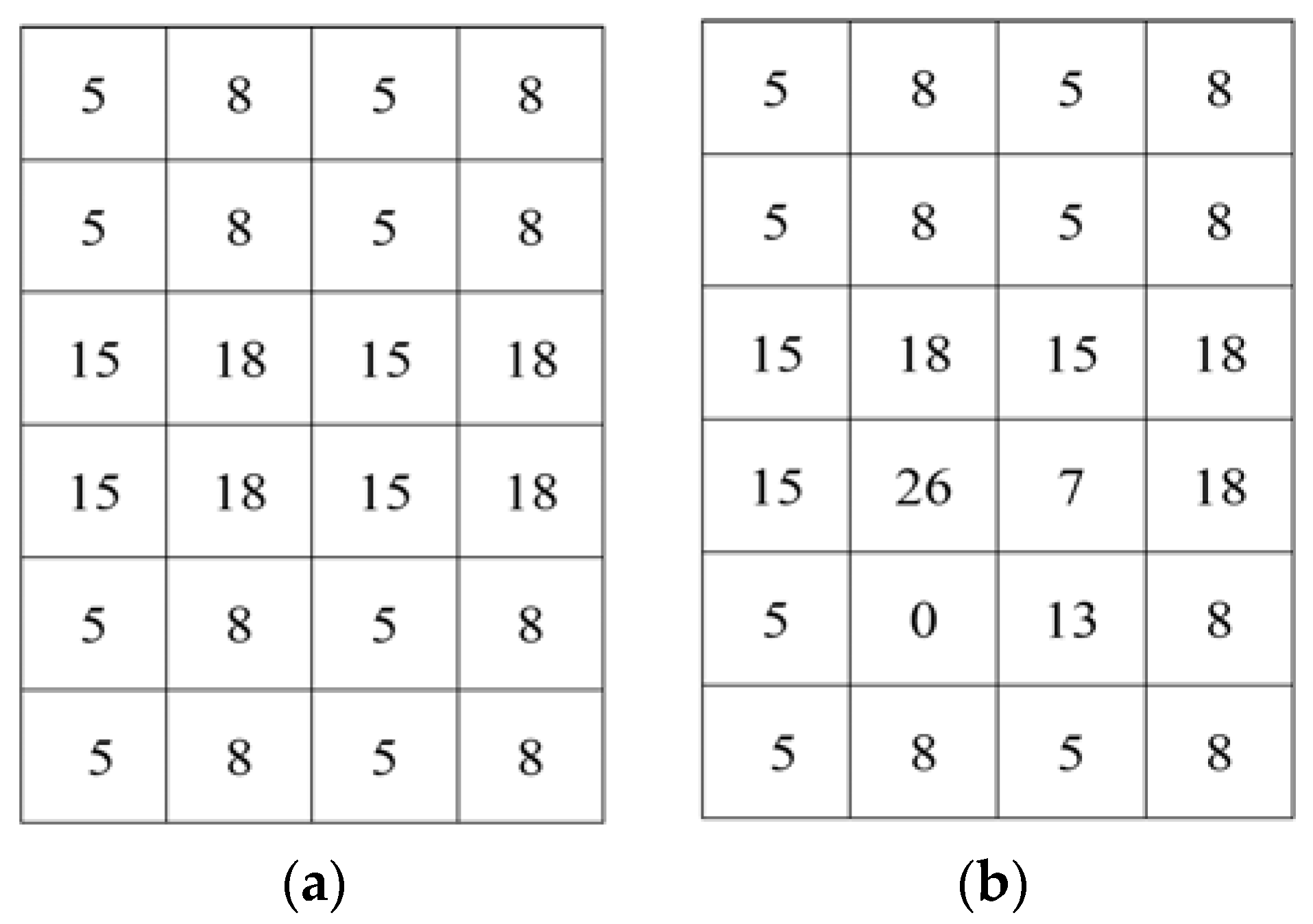
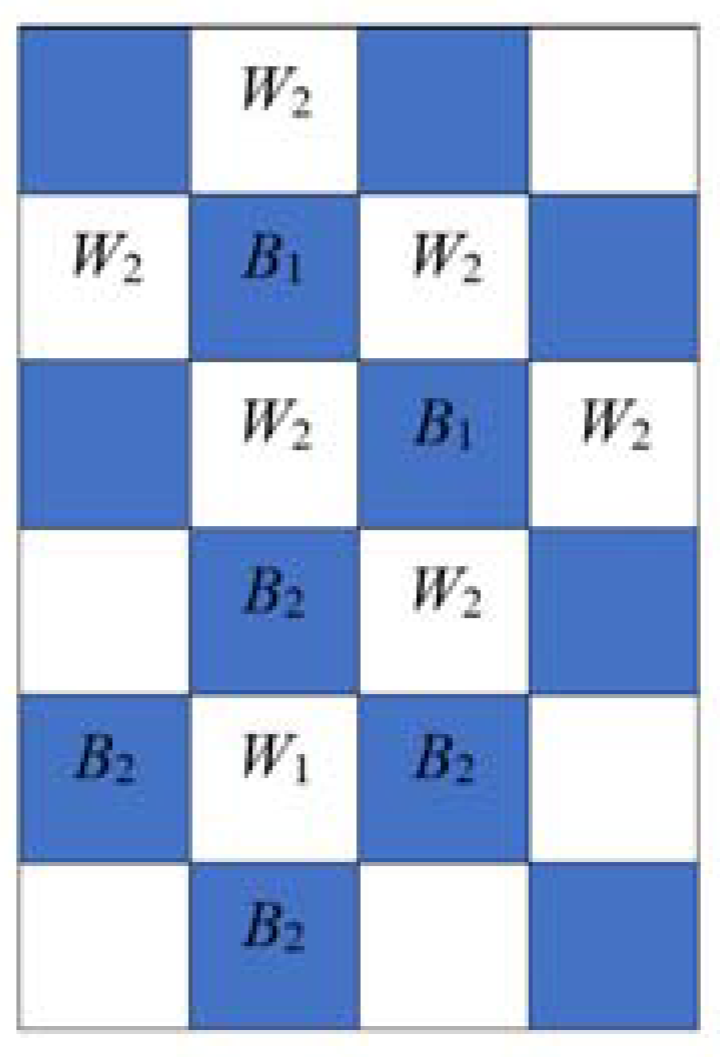
The estimated values in the prediction error in (3) and (4) are not good metrics, since the estimated value is different from the actual value. The smoothness calculation from using the prediction error leads to a worsened bit error rate. For this calculation, it is required to estimate the selected pixel by using four neighboring pixels of that pixel before calculating the prediction error. If the neighboring pixels are changed during the data embedding process, the pixel estimation will be failed and the prediction error calculation will be unsuccessful too. For example, let us consider the
Figure 1a,b as the original image and embedded image, respectively. From
Figure 1b, it is seen that some pixels and their neighboring pixels are changed due to embedding data. In this circumstance, the pixel from the neighboring pixels cannot be estimated accurately. For instance, let pixel 0 at position (5, 2) (
Figure 1b) be the selected pixel. As their neighboring pixels {26, 13} are also changed, so it is not possible to estimate the value of that pixel from the neighboring pixels. So, the main constraint of prediction error is that the neighboring pixels cannot be changed which ultimately decreases the embedding rate. Therefore, in the proposed work, to reduce the bit error rate and increase the embedding rate, we use the absolute difference of neighboring pixels, instead of prediction error, for the smoothness calculation for both joint and separable methods.
In [
21], Zhang introduced a separable RDH-EI method where the encrypted bits are compressed to accommodate the additional bits,
S. Using a data-hiding key, the data-hider pseudo-randomly permutes and divides the encrypted image into groups with size of
L. The
M LSB-planes of each group are compressed with a matrix sized (
M·
L-
S) × (
M·
L) and vacated room is used to embed data. As the additional bits are embedded in LSBs of the encrypted images, they can be extracted directly from the encrypted marked image by using a data-hiding key. On the receiver side, the marked encrypted image is decrypted and a total of 8-
M most significant bits (MSB) of pixels are obtained. The receiver then estimates the
M LSBs by the MSBs of neighboring pixels. By comparing the estimated bits with the vectors in the coset corresponding to the extracted vectors, the receiver can recover the original bits of the
M LSBs. However, Zhang’s technique is little complicated and data cannot be extracted precisely and the original image cannot be recovered perfectly especially when the payload is high.
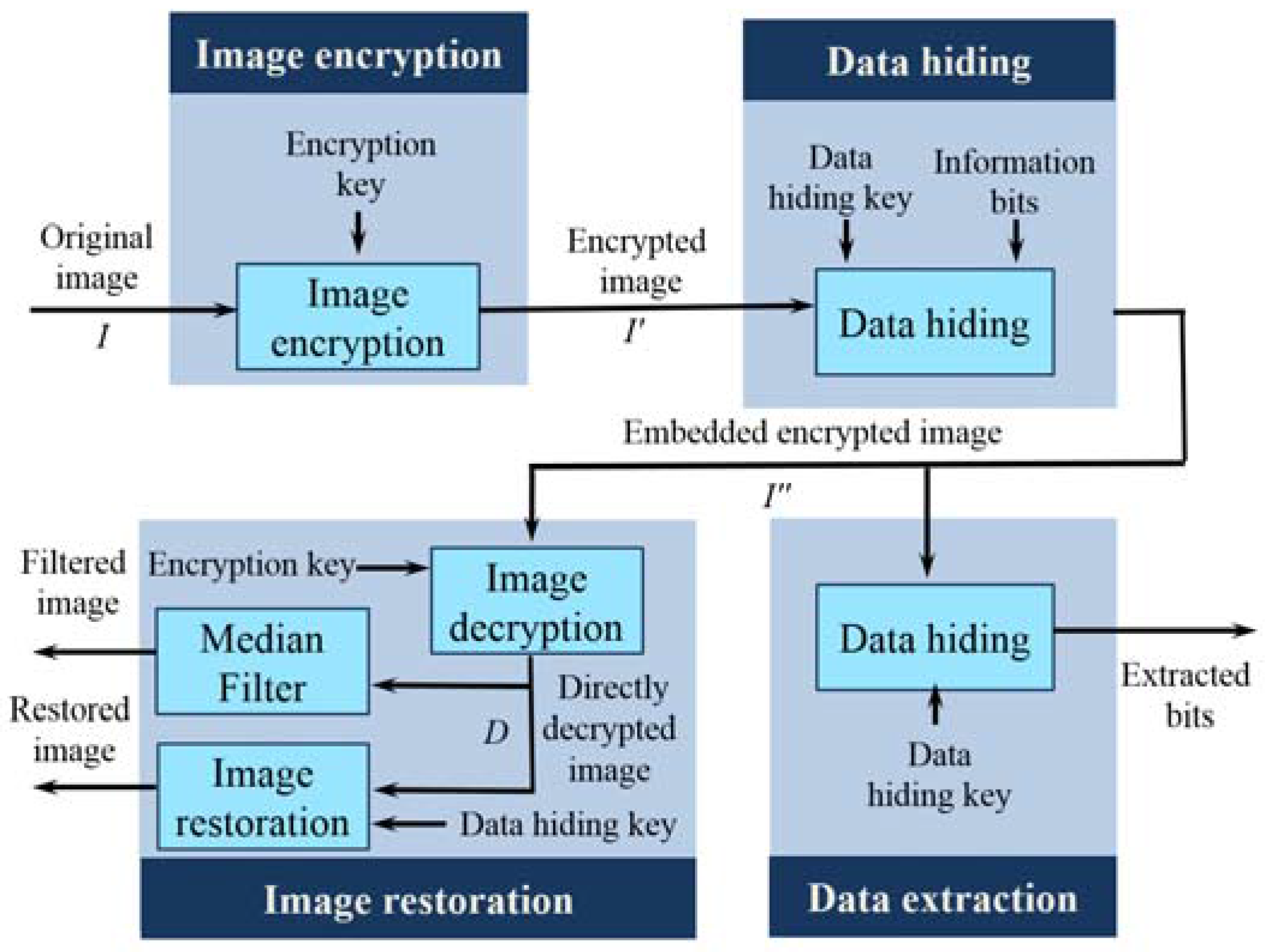
4. The Proposed Separable Data Hiding System
In the joint data hiding system, data extraction and image restoration are inseparable as they are extremely related. If someone has the data-hiding key but not the encryption key, he cannot extract the embedded information bits from the embedded encrypted image.
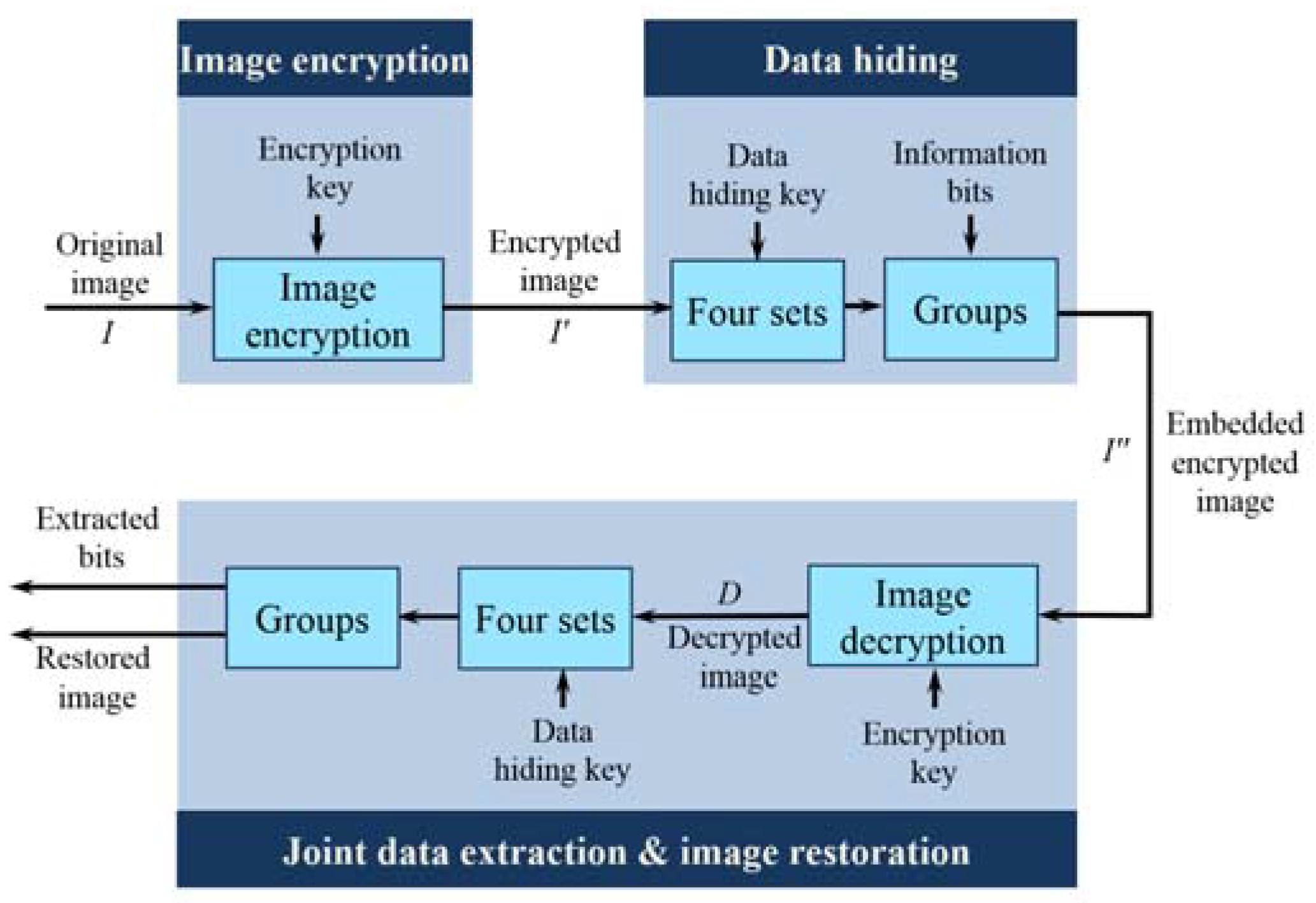
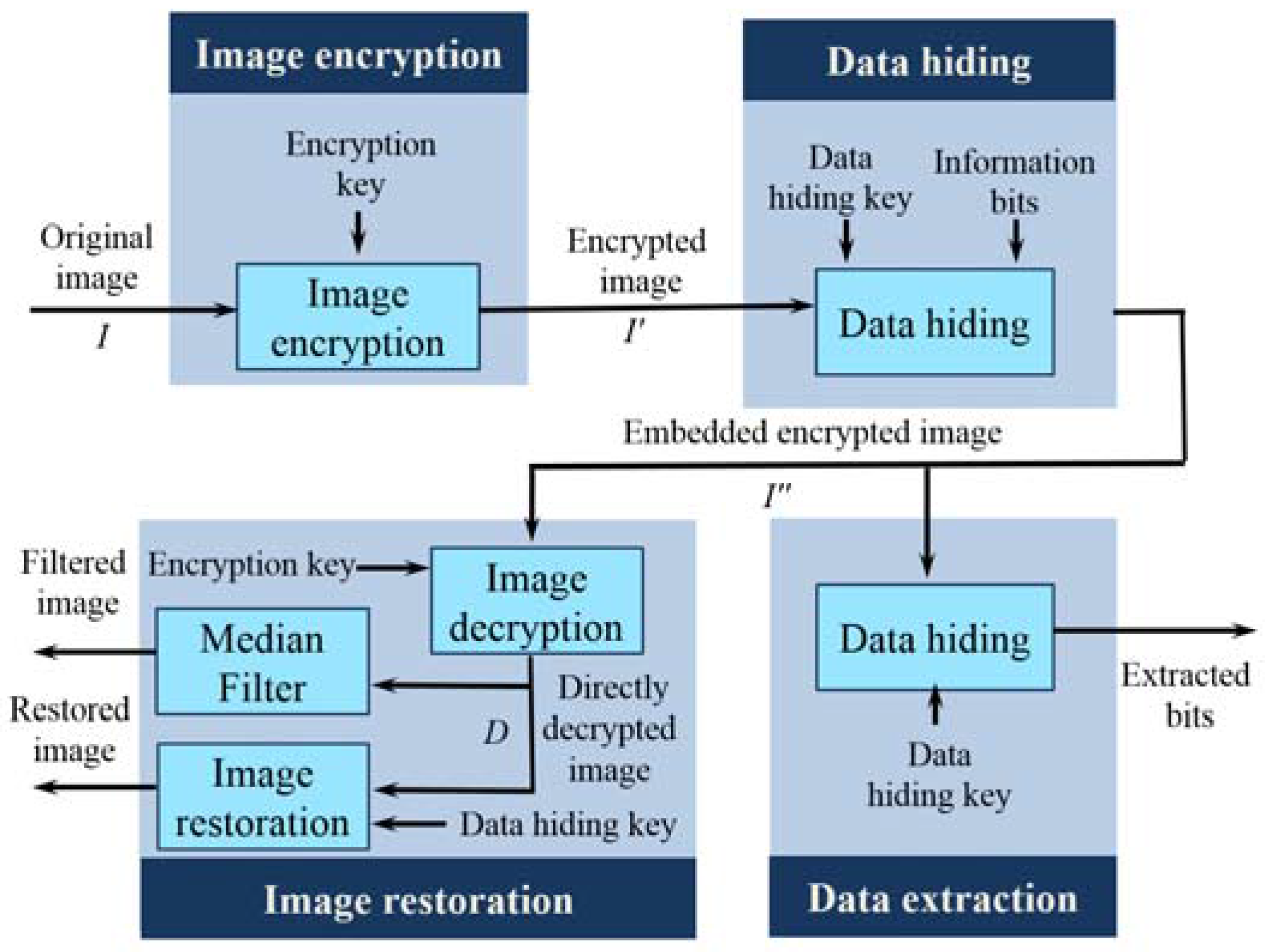
In this section, we present a separable reversible data hiding system in encrypted images, where data extraction and image restoration are separable. There are four phases: image encryption, data hiding, data extraction, and image restoration is demonstrated in
Figure 6. In the proposed scheme, the original image is encrypted using an encryption key and the additional data are embedded into the encrypted image with the aid of a data-hiding key. With an encrypted image containing additional data, if the receiver has only the data-hiding key, he can extract the additional data though he does not know the image content. When, he has only the encryption key, he can decrypt the received data and obtain a filtered decrypted image similar to the original one, but cannot extract the embedded additional data. If the receiver has both the data-hiding key and the encryption key, he can extract the additional data and restore the original image without any error. In the proposed system, to calculate the fluctuation, we have exploited the real value of pixels and the absolute difference between adjacent pixels in place of an estimated value and prediction error, respectively. Herein, data extraction must be carried out before image decryption.
4.1. Image Encryption
In the image encryption phase, by using an encryption key, a content owner encrypts the original uncompressed image to obtain an encrypted image. The encryption procedure is the same as that in the joint system.
4.2. Data Hiding
In data hiding phase, a data hider embeds additional information bits into the encrypted image, I’. The detailed embedding steps are as follows.
Step 1: Before embedding, Q bits of information are permuted by using the data-hiding key; let A(1), A(2),…, A(Q) be the permuted information bits to be embedded.
Step 2: Then, according to the data-hiding key, the data hider pseudo-randomly selects Q pixels from the encrypted image. The selection process is the same as that in the data hiding phase of the joint system. Let I’(1), I’(2),…, I’(Q), be the Q selected pixels in the encrypted image.
Step 3: The t th bits of the I’(1), I’(2),…, I’(Q), pixels are collected, where t ≥ 7. Then, the information bits are embedded by replacing the t th bits of the corresponding selected pixels with A(1), A(2),…, A(Q). Herein, the information bits are concealed in the most significant bits or the second most significant bits. Then, the embedded encrypted image I” is sent to the receiver.
4.3. Data Extraction
In this phase, we consider that the receiver only has the data-hiding key. With the aid of data-hiding key, the receiver extracts the embedded information bits by adopting following steps.
Step 1: The receiver pseudo-randomly selects Q pixels from the embedded encrypted image according to the data-hiding key as did in the data hiding phase. Let I”(1), I”(2),…, I”(Q), be the Q selected pixels in the embedded encrypted image.
Step 2: The
t th bits of
I”(1),
I”(2),…,
I”(
Q) pixels are collected and these bits are the permuted extracted information bits. Let
E(1),
E(2),…,
E(
Q) be the extracted bits. The
t th bits can be extracted by using following equation
Step 3: By exploiting the data-hiding key, the permuted extracted bits E(1), E(2),…, E(Q) are inverse permuted to get the actual information bits.
Note that, because of the pseudo-random pixel selection and permutation of information bits, any attacker without the data-hiding key cannot obtain the pixel locations, and therefore cannot extract the embedded data. Furthermore, although the receiver having the data-hiding key can successfully extract the embedded data, he cannot get any information about the original image content.
4.4. Image Restoration
In the image restoration phase, we consider two cases: (1) the receiver only has the encryption key; and (2) the receiver has both the data hiding and encryption keys.
When the receiver has the encryption key but does not know the data-hiding key, undoubtedly, he cannot extract the embedded data without data-hiding key. However, the original image content can be roughly restored. To do this, receivers first generate a random sequence, Ri,j,k according to the encryption key using a standard stream cipher. Then, a bitwise XOR of I” and R is performed to decrypt the encrypted image. Since some most significant bits or second-most significant bits are modified in the separable method, it introduces salt-and-pepper noise on the directly decrypted image. Then, a median filtering is applied to the directly decrypted image to suppress the noise, and a filtered decrypted image is obtained.
When the receiver has both the data hiding and encryption keys, he can extract the embedded bits and resort the encrypted image to the original version. The detailed steps are as follows.
Step 1: With the aid of data-hiding key, pixels with hidden bits are selected and by fetching the t th bit of the corresponding chosen pixel, embedded bits are extracted. By using the data-hiding key, the extracted bits are inverse permuted to get the actual information bits.
Step 2: A random sequence, Ri,j,k is obtained according to the encryption key using a standard stream cipher. These bits are utilized to decrypt the encrypted image and directly decrypted image, D is obtained. In the directly decrypted image, only the t th bits of the Q specific pixels may differ from the original.
Step 3: From the directly decrypted image, the receiver pseudo-randomly chooses Q pixels by using the data-hiding key. Let D(1), D(2),…, D(Q), be the Q selected pixels in the directly decrypted image.
Step 4: By setting the t th bit as 0 and 1, two possible values of D(d) are achieved. Let D0(d) and D1(d) be the two possible values of D(d), respectively.
Step 5: The fluctuation function of
D0(
d) and
D1(
d) are calculated as follows
By comparing f0(d) and f1(d), image restoration can be performed. If f0(d) < f1(d), then D0(d) will be the original pixel. Otherwise, D1(d) will be the original pixel. When Q original pixels are obtained, the original image is restored.
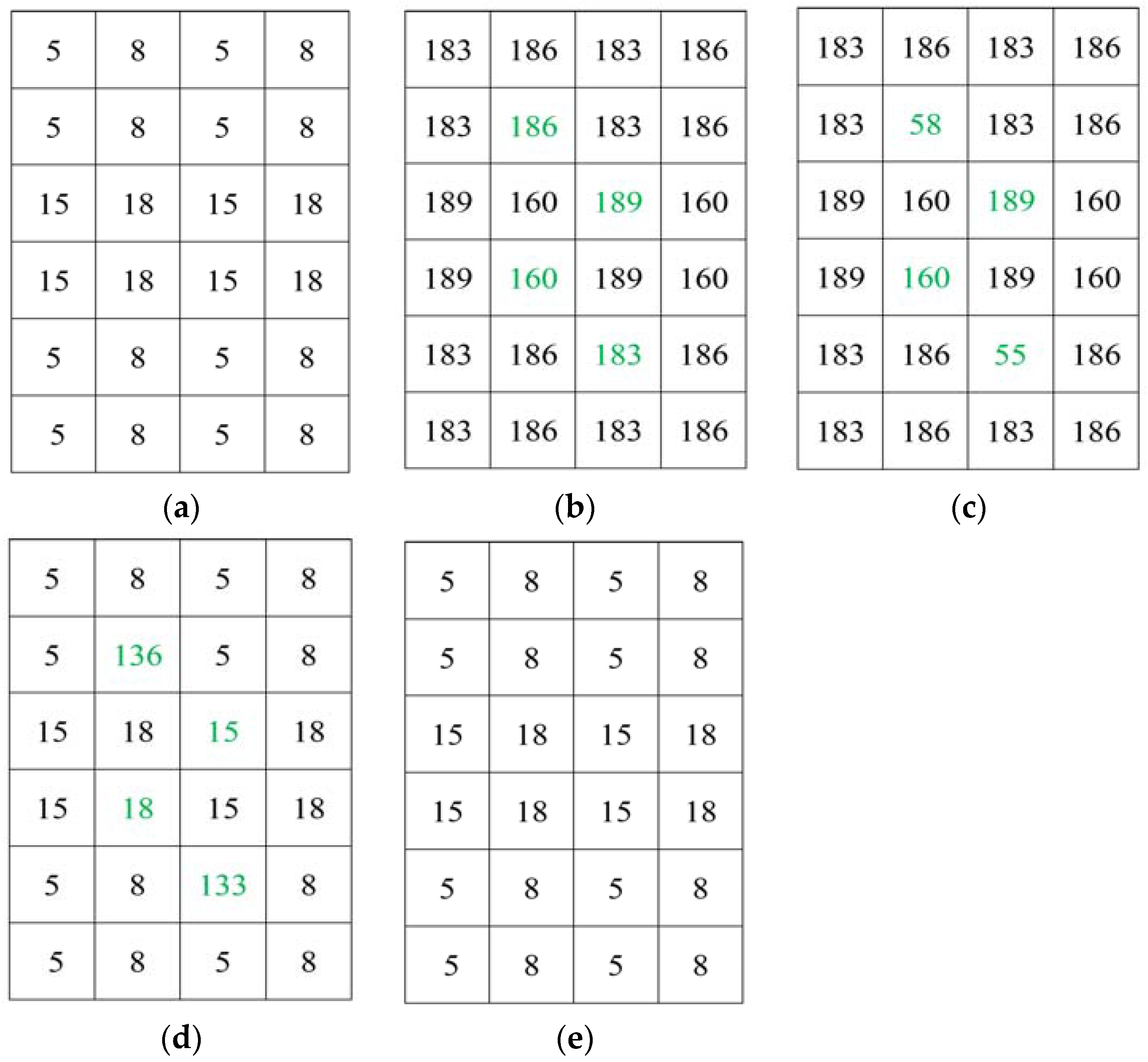
4.5. An Example of the Proposed Separable Data Hiding System
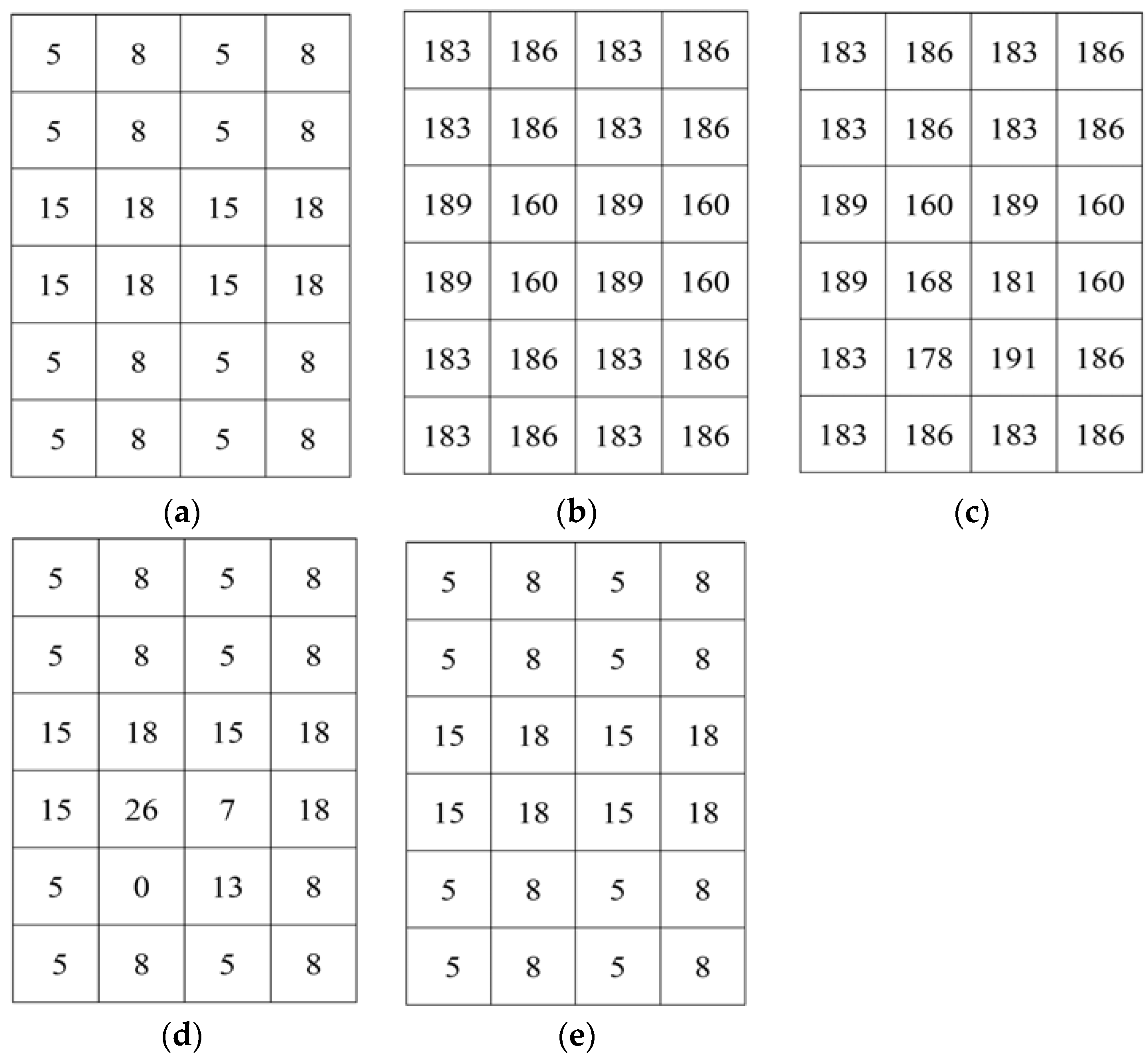
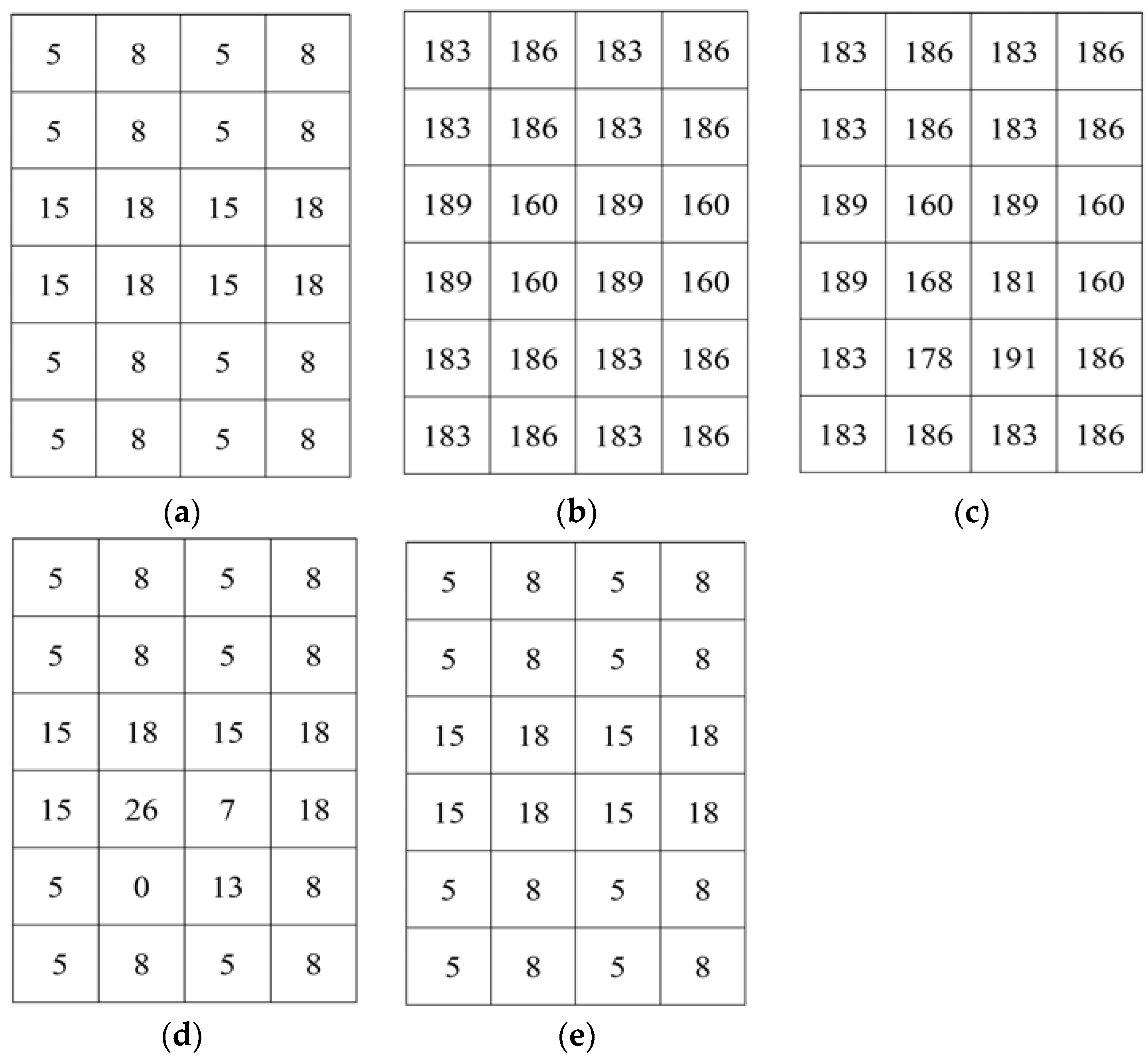
To illustrate our proposed separable data hiding system, a simple example is included. Let
I be the original image of size 4 × 6, as shown in
Figure 7a. First, by using the encryption key,
I is encrypted and encrypted image
I’ is obtained, as demonstrated in
Figure 7b. Then, the information bits can be embedded into
I’ and it is considered that the four bits to be embedded are 1001, and after permutation the permuted bits are
A = 0110. Let
Q selected pixels be {186,189,160,183} that are marked with green in
Figure 7b. The most significant bits of the pixels are collected and replaced with
A = 0110. Thus, the embedded encrypted image is obtained, as shown in
Figure 7c. In the separable method, we can extract the data from the embedded encrypted image. To extract the hidden bits, we need to collect
Q pixels {58,189,160,55} and fetch the
t = 8 th bit by using (14). Then, the extracted bits are permuted to get the original information. For image restoration, first the embedded encrypted image is decrypted. The directly decrypted image (
Figure 7d) is similar to original except some pixels. Then, we collect the pixels {136,15,18,133} from the directly decrypted image. By setting the
t th bit as 0 and 1, two possible values of each pixel are achieved. Let us consider two possible cases of the pixel 136, which are
t = 0,
D0 = 8 and
t = 1,
D1 = 136. The fluctuation of
D0 and
D1 is calculated from (15) and (16), respectively. After calculation, we get
f0 = 16 and
f1 = 508. As
f0 <
f1, then
D0 = 8 will be the original pixel. Therefore, we will restore the original pixels and collect them to restore the original image, as demonstrate in
Figure 7e.












{kind=link}
{kind=link}
{kind=link}
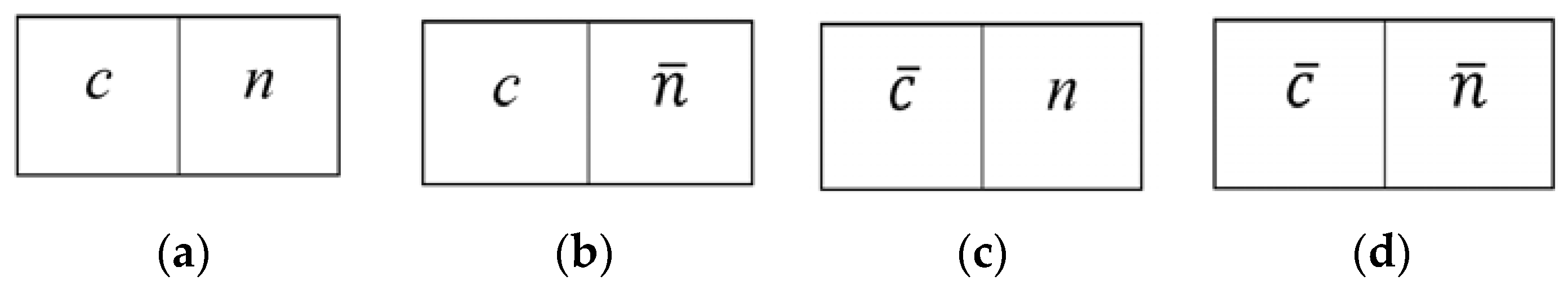{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}