Abstract
A modified method for better superpixel generation based on simple linear iterative clustering (SLIC) is presented and named BSLIC in this paper. By initializing cluster centers in hexagon distribution and performing k-means clustering in a limited region, the generated superpixels are shaped into regular and compact hexagons. The additional cluster centers are initialized as edge pixels to improve boundary adherence, which is further promoted by incorporating the boundary term into the distance calculation of the k-means clustering. Berkeley Segmentation Dataset BSDS500 is used to qualitatively and quantitatively evaluate the proposed BSLIC method. Experimental results show that BSLIC achieves an excellent compromise between boundary adherence and regularity of size and shape. In comparison with SLIC, the boundary adherence of BSLIC is increased by at most 12.43% for boundary recall and 3.51% for under segmentation error.
1. Introduction
Although superpixels were firstly described as over-segmentations by Ren and Malik in 2003, they have still not been exactly defined [1,2]. Generally, a superpixel can be treated as the set of pixels that are similar in location, color, texture, etc. Superpixels can capture image redundancy and transform pixel-level computing into a region-level operation [3], which can greatly reduce the complexity of subsequent image processing tasks. Superpixel segmentation has become an important pre-processing step in various image processing applications, such as image segmentation [4,5,6,7,8,9], saliency detection [10,11,12] and classification [13,14].
Existing superpixel segmentation methods can be classified into three major categories: the spectral-graph-based method, the gradient-ascent-based method and the optimization-theory-based method. The spectral-graph-based method is an optimal procedure to globally minimize the graph-based objective functions [15]. This method treats image pixels as the nodes of graph and sets the edge weights of the graph proportional to the affinities between neighboring pixels [3]. Shi and Malik proposed the Normalized Cut (NCut) criterion for graph segmenting [16]. Although NCut generates superpixels of a similar size and compact shapes [3], its complexity brings a heavy burden into the computation works. Felzenszwalb and Huttenlocher (FH) [17] is another typical spectral-graph-based algorithm, which has a complexity of [18] and is faster than NCut. However, the superpixels generated by FH are very irregular in size and shape. The gradient-ascent-based method forms superpixels by updating the clustering of pixels in the direction of gradient ascent until a certain convergence criterion is met [3]. Mean Shift (MS) [19] and Quick Shift (QS) [20] are two gradient-ascent-based methods. They have complexities of and ( is a small constant) respectively, and the superpixels generated by them are still irregular in shape [3]. Turbopixel [21] is another gradient-ascent-based algorithm, which can provide more regular superpixels and shorten the processing time to [3]. The optimization-theory-based method formulates the image segmentation as a minimization problem of energy function, which is derived from image information. SuperPB [22] and SEEDS [15] are two classical methods based on optimization theories. SuperPB generates superpixels by minimizing two pseudo-boolean functions, and its computing speed is independent from the superpixels number. SEEDS is a two-stage method, which firstly segments the image into coarse superpixels and then refines the boundaries. The energy function of SEEDS is established based on the color similarity and histogram of the initial superpixels. Thus, SEEDS features an excellent compromise between accuracy and efficiency.
SLIC (Simple Linear Iterative Clustering) is the most widely used superpixel method. Essentially, it is a local k-means clustering method [3], and does not belong to the above three categories. SLIC groups pixels into perceptually meaningful regions in a five-dimensional feature space, which is defined by the CIELAB color space and the pixel coordinates. Compared with the above-mentioned methods, SLIC has several advantages. Firstly, SLIC has lower complexity. For image pixels, the complexity of SLIC is just . Secondly, SLIC can generate superpixels with compact, regular size and shape. Moreover, SLIC is simple to use and understand [3,23].
Figure 1 displays the segmentation results of SEEDS, SuperPB, SLIC and Turbopixel. Numbers of the generated superpixels are the same or approximate. The edges that cannot be extracted by superpixels are labelled with a white dotted line. It can be observed from the first row that SEEDS possesses the worst regularity in size and shape. Turbopixel is much better than SEEDS, but still worse than SuperPB and SLIC. The second row is the partial enlarged images for the region containing image edges. It is observed that SEEDS owns higher boundary adherence, while the other three methods cluster more pixels of slender rod and sky into one superpixel. Segmentation results suggest that SLIC provides a relatively better compromise between boundary adherence and regularity. However, the boundary adherence of the superpixels generated by it still needs to be improved.
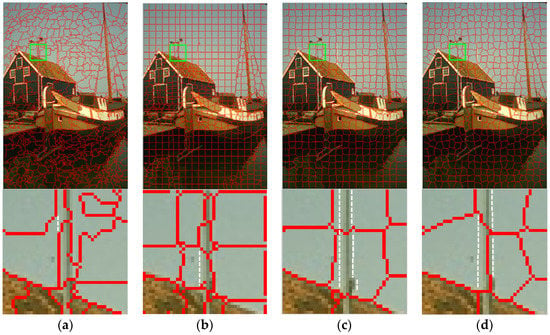
Figure 1.
Superpixel segmentation results of four algorithms. (a) SEEDS; (b) SuperPB; (c) simple linear iterative clustering (SLIC); (d) Turbopixels. The second row is the partial enlarged superpixels defined by the green rectangles.
In this paper, based on SLIC, an improved superpixel method is proposed to achieve an excellent compromise between boundary adherence and the regularity of size and shape. Boundaries and regions are two affinitive cues for humans to perform segmentation [24]. As the small regions in an image domain, superpixels rely on region information more than boundary information. In order to efficiently align the SLIC superpixels to image edges and obtain better segmentation results, a global usage of boundary and region information is conducted. In contrast to the previous method, which utilizes multi-scale boundary information to segment a specific image region instead of the whole scene [25], this paper adopts a simple edge detecting algorithm to obtain the complete boundary information. Herein, the modified SLIC is expressed as BSLIC, where B stands for the boundary term. The advantages of BSLIC are summarized as follows: First, the modified method features competitive boundary adherence, which can be validated by qualitative and quantitative experiments on databases BSDS500 [26]. Second, BSLIC, which only modifies two steps of SLIC, is very simple to use and understand. Third, the superpixels generated by BSLIC have good compactness and regularity in size and shape, which is an effective inheritance from SLIC.
The rest of the paper is organized as follows: Section 2 provides an overview of the algorithm. Section 3 introduces the proposed BSLIC algorithm, including the distribution of cluster centers, the initialization of edge centers and the distance measurement. Section 4 shows the experimental results and necessary discussions. Finally, Section 5 concludes the paper.
2. Overview of BSIC
BSLIC is essentially a k-means clustering method. The data points of BSLIC are vectors that describe the features of image pixels. In fact, spectral clustering [27] and subspace clustering [28] are also capable of implementing the clustering of image pixels. However, the memory of these two kinds of methods are demanding. Both the spectral clustering and the subspace clustering method have to compute the affinity matrix of data points, which is an matrix for an image with pixels. For images with moderate resolution, such as , the affinity matrix would take up more than memory cells. As a pre-processing step, superpixels should be fast to compute, memory-efficient and simple to use. So, in our BSLIC, the k-means method is chosen to implement the clustering of image pixels.
Figure 2 illustrates the flow chart of BSLIC. In BSLIC, two kinds of cluster centers, “plane center” and “edge center” are initialized. We first initialize plane centers (red dots) in a hexagon distribution. For each plane center, an edge pixel within its local searching region is initialized as an edge center, and these are marked by green dots. A canny operator, the most widely used edge detecting algorithm, is utilized to obtain the boundary information, and the boundary term is then incorporated into the local k-means clustering. For each iteration, the pixel-wise distance is dependent on the boundary term. If there exists an edge pixel along the straight line connecting the two pixels, the distance is set as Inf; otherwise, it is calculated as the weighted sum of color and space Euclidean distance. The iterating process is terminated when the residual error is less than 5%, and the iterating time is often no more than 10 [2].
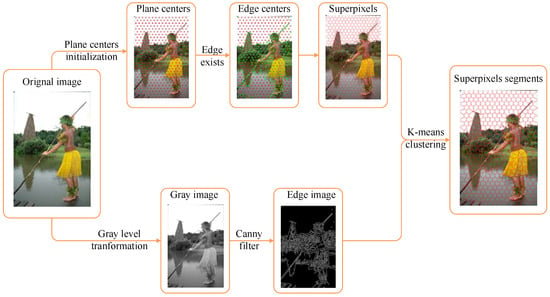
Figure 2.
The flow chart of the proposed BSLIC algorithm.
3. Algorithm of BSLIC
The SLIC algorithm has been described by [3] in detail. In this section, only the differences between BSLIC and SLIC are presented. The BSLIC algorithm is different from SLIC in the following three aspects: initializing cluster centers in hexagon rather than square distribution, additionally choosing some specific edge pixels as cluster centers, incorporating boundary term into the distance measurement during k-means clustering. The technical details are discussed below.
3.1. Distribution of Cluster Centers
In SLIC, the initialized cluster centers are squarely distributed as shown in Figure 3a. Centers , , , , , , , and are sampled with an interval of pixels. Rectangles in a black solid line are initialized superpixels. Given the number of image pixels and the desired superpixels number , the interval can be obtained as:
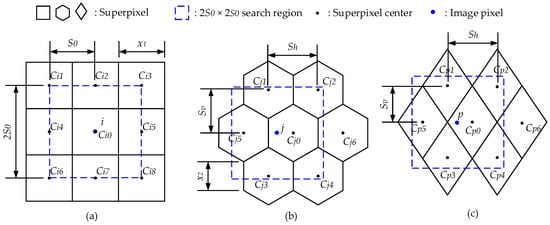
Figure 3.
Distribution of Cluster Centers. (a) Square distribution; (b) Hexagon distribution; (c) Diamond distribution.
Square superpixels display central symmetry, but the regions containing the image edges are generally asymmetric. In order to improve the boundary adherence of superpixels across image edges, the symmetry properties of superpixels are reduced from central symmetry to axial symmetry. Both hexagons and diamonds display axial symmetry. Below, the initializing centers in hexagon and diamond distributions are discussed.
Figure 3b displays the geometric sketch of a hexagon distribution. Centers , , , , , and are sampled at intervals of pixels in the horizontal direction, and pixels in the vertical direction. Hexagons in the black solid line are superpixels. To make the hexagon superpixel equal to the square superpixel in area, side lengths of the square and hexagon should follow the mathematical relationship:
where and are the side lengths of the square and hexagon, and is obtained by:
For a hexagon distribution, the horizontal and vertical intervals are given as:
Combining Equations (2)–(5), and are obtained as:
For diamond distribution, which is displayed in Figure 3c, its horizontal and vertical intervals are equal to that of the hexagon distribution.
SLIC performs k-means clustering within the local region of pixels. For a square distribution, there are at most nine adjacent superpixels within the local region. Pixel in Figure 3a depicts this. The local searching region of is marked by the rectangle in the blue dotted line, there exist nine adjacent superpixels (, , , , , , , and ) in the scope. This means that, at most, nine distance calculations are needed for the assignment of one pixel. The complexity for each iteration of the clustering is 9. Compared with square distribution, the hexagon distribution has a lower complexity of 6 for one iteration of the clustering. As shown in Figure 3b, there are six adjacent superpixels (, , , , and ) in the local searching scope of pixel . The complexity of the diamond distribution is also 6, which is displayed in Figure 3c.
Performing k-means clustering in a limited size, rather than the whole image domain, is the key point to speed up the SLIC algorithm because it largely reduces the number of distance calculations. By initializing cluster centers in the hexagon or diamond distribution, the number of distance calculations can decrease by 3. With the same sample intervals, cluster centers initialized in the hexagon distribution are the same as that of the diamond distribution. In other words, the superpixel segmentation results of the hexagon distribution are the same as that of the diamond distribution. In our work, cluster centers are initialized in the hexagon distribution.
3.2. Initialization of Edge Centers
The superpixels across the ground truth edges, which are called the edge-across superpixels, are the root cause of under segmenting. Edge-across superpixels are displayed in Figure 4c,d. Their cluster centers are initialized in the hexagon and square distribution respectively. The white and red solid lines describe the image edges and the superpixels’ boundaries. Each closed region in a red solid line represents a superpixel. The edge-across superpixels are denoted as , and the accurate superpixels are denoted as , which refers to the superpixels that exactly align to the ground truth edges. The subscript plays the role of counting the superpixels. It is found that the edge-across and accurate superpixels have a similar size. As shown in Figure 4c, the edge-across superpixels and have 67 and 101 pixels, while the accurate superpixels , and have 99, 122 and 126 pixels. For images with a resolution of , regions in size (approximately 67 pixels) are hardly different from regions in (approximately 126 pixels). In order to improve the boundary adherence of edge-across superpixels, the area of edge-across superpixels should be decreased.
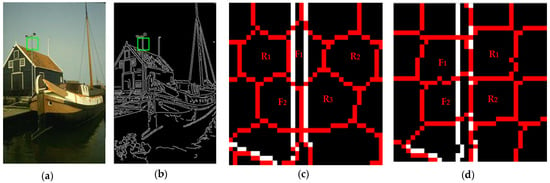
Figure 4.
Edge-across superpixels. (a) Original image with slender rod; (b) Edge image with canny filter operator; (c) Partial enlarged superpixels with only plane centers initialized in hexagon distribution; (d) Partial enlarged superpixels with only plane centers initialized in square distribution.
Edge-across superpixels are the small regions containing image edges, while the edges are the place where discontinuity in intensity or color happens. For an edge-across superpixel, pixels located in two sides of the edge are very dissimilar. To assign these pixels two superpixels, the exact edge pixels are chosen as cluster centers. Centers initialized from edge pixels are called “edge center”, and those that are initialized in a uniform geometric distribution are called “plane center”. The two kinds of cluster centers are illustrated in Figure 5. Edge center is determined by the following rules:
- If there exist image edges in the searching region of plane center (like ), choose a median edge pixel as the edge center (like );
- If there is no image edge within the region (like ), no edge center is generated;
- To avoid any noisy pixel being chosen as cluster center, modify the edge center to the lowest gradient position in the corresponding local neighborhood;
- Edge center is introduced to reduce the negativity of edge-across superpixels. It is necessary to keep it near to the image edges. During the 10 iterations, edge centers remain unalterable, and only plane centers are updated to the mean value.
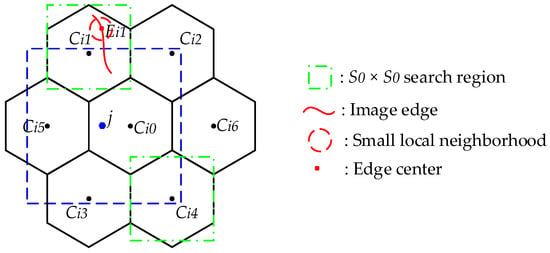
Figure 5.
Plane center and edge center. Dots in solid black , , , , , and are “plane center”; Square in solid red is “edge center”.
Superpixel segmentation results with initialized edge centers are displayed in Figure 6. Compared with Figure 4c, the edge-across superpixel is successfully transformed into the accurate superpixel in Figure 6a, which can improve boundary adherence to some degree. However, when it comes to square distribution, there is no apparent decrease in area for edge-across superpixels and , as shown in Figure 4d and Figure 6b.
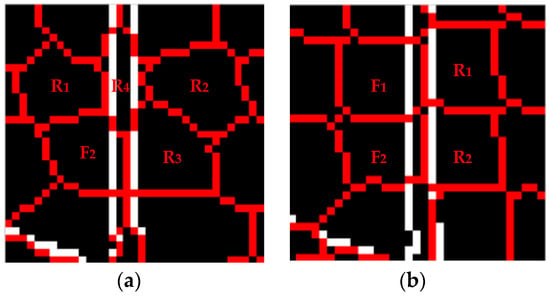
Figure 6.
Partial enlarged superpixels segmentation with edge cluster centers initialized. (a) Plane centers initialized in a hexagon distribution; (b) Plane centers initialized in a square distribution.
We owe the better segmentation results of Figure 6a to the asymmetry of the edge-across superpixel. For small regions without image details, such as edges and texture, the pixels possess high similarity with others. These small regions can be described as possessing local symmetry to some degree. However, this is inconsistent for edge-across superpixels, the pixels of which are located on two sides of the edge and are very dissimilar. Edge-across superpixels are asymmetrical in the local region. Compared with superpixels initialized in square distribution, the hexagon distribution reduces the central and axial symmetry. Moreover, initializing edge centers largely destructs the horizontal and vertical symmetry of the initialized superpixels.
3.3. Distance Measurement
From Figure 4c to Figure 6a, there is no apparent decrease in the area of edge-across superpixel . This part introduces an available method to reduce the area of . In SLIC, the distance between pixels is defined as the weighted sum of color and spatial Euclidean distance. For the pixels that are similar in spatial locations and color but belong to different objects, such as pixels and shown in Figure 7a, SLIC tends to assign them to one superpixel. Setting a large value for the distance between and is an effective way to assign and to different superpixels.
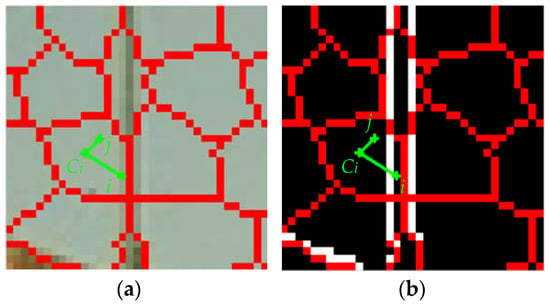
Figure 7.
Boundary term incorporation. (a) Partial enlarged superpixels on original image; (b) Partial enlarged superpixels on logical edge image.
Herein, the given pair of pixels is connected by straight line over the image domain. The boundary term is incorporated by checking the presence of image edge along the straight line. Figure 7 illustrates this process. The edge image, which is obtained by a canny operator, is a binary image. In fact, any existing edge detecting algorithms, such as Sobel, Robert, etc., are suitable for the work. Our problem is transformed into checking if there exists a nonzero element along the straight line. If it exists, such as pixel and center shown below, the distance would be Inf. Otherwise, like and , the distance would be calculated as the weighted sum of color and spatial Euclidean distance. The modified distance equation can be described as follows:
where and are color and spatial Euclidean distances. Parameter is the weighting factor. It is suggested that should be in the range of [1, 40] in CIELAB color space [3].
Superpixel segmentation results are shown in Figure 8 with boundary term incorporated. Compared with Figure 6a, our distance measurement successfully transforms the edge-across superpixel into accurate superpixel , realizing a further progress in improving boundary adherence.
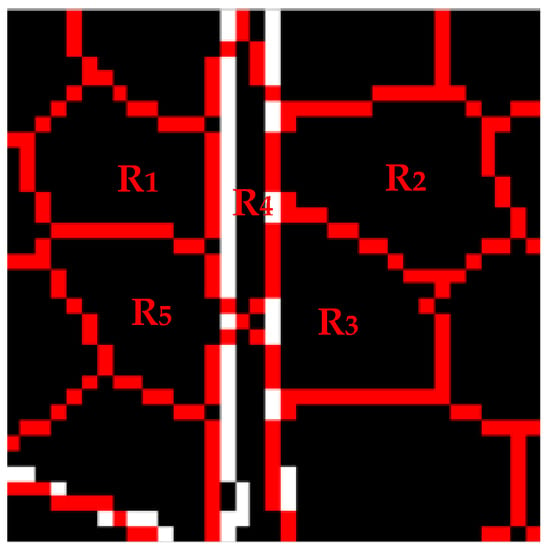
Figure 8.
Superpixels segmentation result with modified distance calculation.
4. Experimental Results
In this section, we first discuss some important issues of BSLIC, including the iterating process and the effects of parameters. Then the evaluation of the BSLIC is presented together with other four algorithms. Qualitative and quantitative experimental results are all displayed, and necessary comparison is carried out to validate the competitive performance of BSLIC.
4.1. BSLIC Superpixels
The iterating process of BSLIC is displayed in Figure 9. Figure 9a shows the superpixels with only plane centers initialized, in which the superpixels have good axial symmetry in both the horizontal and vertical directions. Figure 9b is the superpixels with edge centers initialized. It is obvious that the axial symmetry of the edge-cross superpixels is destroyed. Figure 9c,d are the first and final iterating results. Compared to the final results, the first iteration has already aligned to the true boundaries in the whole picture.

Figure 9.
BSLIC iterating process. (a) Superpixels with only plane centers; (b) Superpixels with both plane and edge centers; (c) First iterating result of BSLIC; (d) Final segmentation result of BSLIC.
The norm is adopted to compute the residual error between two iterations. In BSLIC, the iteration of k-means clustering is not terminated until the residual error of the cluster centers is less than 5%. In the simulation experiments, we found that small changes of superpixel segmentation results happened after five or six iterations. Figure 10 displays the change curve of residual error against iterating times. After 10 or fewer times, the residual error becomes convergent, which is consistent with the empirical data in [3].
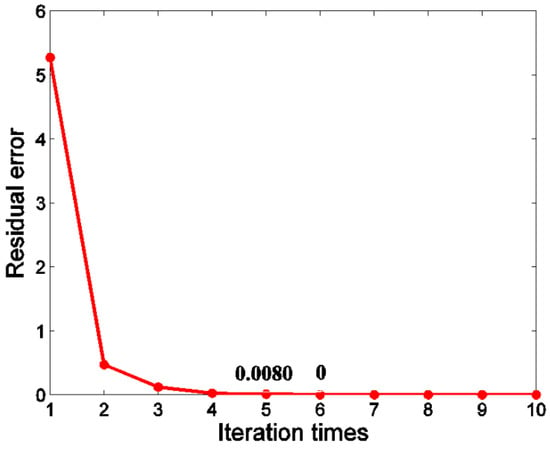
Figure 10.
Change curve of residual error against iterating times.
Figure 11 shows the BSLIC segmentation results with different and . It is indicated that larger achieves better regularity for superpixels, and smaller achieves better adherence to image boundaries. Our explanation for this is that the spatial distance plays a key role when is large, like 40, so the superpixels obey the geometric distribution in the image plane. In contrast, when is small, the superpixels mainly obey the color distribution. To achieve a compromise on superpixels regularity and boundary adherence, is usually set as 15. For parameter , it is obvious that larger aligns to more detailed boundaries. Considering the running time of the algorithm, it is appropriate for to be in the range [100, 2500] for images.

Figure 11.
BSLIC superpixels segmentation results. Superpixels number , weighting factor . (a) BSLIC segments when ; Column (b) BSLIC segments when ; Column (c) BSLIC segments when .
4.2. Qualitative Comparisons
We compare BSLIC with four other methods: SEEDS, SuperPB, SLIC and Turbopixels. All the 500 images of dataset BSDS500 are segmented by these five methods. As the superpixels are segmented to give a description of features for a subsequent image processing task, they cannot be too small in size. Herein, we maintain the size of a superpixel larger than 80, which is nearly in size. For images in resolution, when the number of superpixels exceeds 2000, the generated superpixels are approximately an average size of 77. Therefore, during the experiments, takes its value at intervals of 100 from 50 to 2500. Weighting factor is within the range of .
Figure 12 displays part of the experimental results. The number of superpixels is the same or approximate in every row. Column (a) gives a qualitative presentation for BSLIC segmentations over the whole image domain. The superpixels are compact and uniform hexagons in shape, which is benefits from initializing centers in the hexagon distribution. The superpixels are also regular in size, which is attributed to the locality of k-means clustering. Although SLIC segmentations over the whole image domain are not displayed here, it is necessary to mention that both SLIC and BSLIC superpixels are regular and compact in size and shape. Columns (b)–(f) provide the partial enlarged results of the solid rectangle tagged regions, which contain image edges. Compared with the other four methods, BSLIC superpixels achieve higher adherence to image edges. For the other four methods, we draw conclusions as follows: (1) SEEDS is highly irregular in size and shape; (2) SuperPB has high regularity and compactness in both size and shape, but it lacks flexibility when it comes to the regions containing edges; (3) SLIC and Turbopixel have an equal regularity in size and shape, but their boundary adherences are lower than BSLIC.

Figure 12.
Part of experimental results. (a) BSLIC segments; (b) Partial enlarged superpixels of BSLIC; (c) Partial enlarged superpixels of SEEDS; (d) Partial enlarged superpixels of SuperPB; (e) Partial enlarged superpixels of SLIC; (f) Partial enlarged superpixels of Turbopixles.
4.3. Quantitative Comparisons
The performance metrics of superpixel segmentation methods are different from that of image segmentation and other visual tasks [29]. Recall is a professional index in information retrieval. Boundary recall (BR) was first adopted to measure the accuracy of image segmentation in [1]. Under segmentation error (UE) is another metric to measure the error rate of image segmentation. BR and UE are widely used to measure the boundary adherence of superpixels, which can be demonstrated by [3,15,21,22]. BR and UE measure the boundary adherence in boundary-wise and region-wise situations, respectively. BR is the fraction of ground truth edges that are retrieved by superpixel boundaries within a small neighboring region. The radius of the neighboring region is denoted as , which is equal to 1 or 2 in the work. UE is the fraction of superpixel regions across ground truth edge. To represent the image more faithfully, high BR and low UE are usually expected. Given the set of superpixel boundaries , and the set of ground truth edges , where refer to the ground truth edge images, BR can be expressed as
where the operator denotes the size of an element in pixels, is 5 on average in database BSDS500. UE can be expressed as
where is the image pixels, is the number of segments for one ground truth image, is one segment for superpixel segmentation results.
As the rounding operation is done when calculating the horizontal and vertical intervals, and the initialized centers are updated as the lowest gradient position in a corresponding local neighborhood, the numbers of actually generated superpixels are not equal to . Figure 13 displays the UE curves against . Obviously, BSLIC has lower UE than in the other methods. According to the obtained UE, the boundary adherence can be sorted from high to low as: BSLIC > SEEDS > SuperPB > SLIC > Turbopixels. Figure 14a,b displays the BR curves with radius of neighborhood respectively. It is observed that BSLIC produces a uniform increase for BR when compared with SuperPB, SLIC and Turbopixels. BSLIC is a little bit inferior to SEEDS in boundary recall. However, BSLIC has apparent advantages over SEEDS in the regularity and compactness in size and shape.
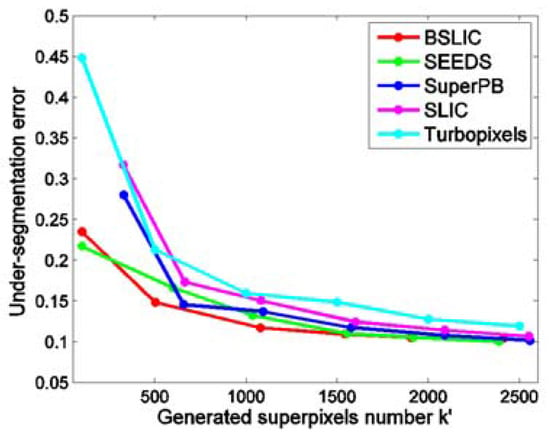
Figure 13.
Under segmentation error.
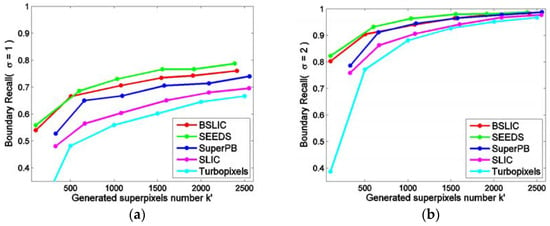
Figure 14.
Boundary recall. (a) ; (b) .
BSLIC is a modified SLIC method, and a specific comparison between the two methods are conducted. The experimental data are listed in Table 1 and Table 2. Table 1 is the data of with . The generated number of superpixels is set in the range of , and is . For boundary recall, Table 1 shows that BSLIC can achieve at most a 6.23%, 8.56% and 12.43% increase when is 5, 15 and 30. For under segmentation error, Table 2 shows that BSLIC can achieve at most a 1.46%, 2.77% and 3.51% decrease when is 5, 15 and 30.

Table 1.
Experimental data of .
Table 2.
Experimental data of under segmentation error .
5. Conclusions
This paper presents a superpixel method that achieves an excellent compromise between the boundary adherence and the regularity in size and shape. By initializing cluster centers in a hexagon distribution and initializing the “edge center” as an exact edge pixel, the symmetry properties of superpixels are evidently reduced, which can effectively improve the boundary adherence of edge-across superpixels. With the boundary term being incorporated into the distance calculation of clustering, the boundary adherence of superpixels generated by BSLIC is further improved. Compared with SLIC, the segmentation quality of BSLIC is increased by at most 12.43% for boundary recall and 3.51% for under segmentation error. Based on local k-means clustering, BSLIC superpixels are more regular in size and more compact in shape than the state-of-art methods. One of our future research projects is to apply the BSLIC method to the two-stage semantic image segmentation models.
Acknowledgments
This research is supported by the Fundamental Research Funds for the Central Universities of China (No. JB160409) and the open foundation of State Key Laboratory for Manufacturing Systems Engineering (No. sklms201511).
Author Contributions
Hai Wang and Xiongyou Peng conceived and designed the experiments; Xiongyou Peng performed the experiments; Hai Wang and Xiongyou Peng analyzed the data; Yan Liu contributed analysis tools; Xue Xiao wrote the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ren, X.; Malik, J. Learning a classification model for segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Nice, France, 13–16 October 2003.
- Veksler, O.; Boykov, Y.; Mehrani, P. Superpixels and Supervoxels in an Energy Optimization Framework. In Proceedings of the European Conference on Computer Vision-Part V (ECCV Part V), Crete, Greece, 5–11 September 2010.
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Susstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Wu, X.M.; Chang, S.F. Segmentation using superpixels: A bipartite graph partitioning approach. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012.
- Gonzalo-Martín, C.; Lillo-Saavedra, M.; Menasalvas, E.; Fonseca-Luengo, D.; García-Pedrero, A.; Costumero, R. Local optimal scale in a hierarchical segmentation method for satellite images. J. Intell. Inf. Syst. 2016, 46, 517–529. [Google Scholar] [CrossRef]
- Schick, A.; Bauml, M.; Stiefelhagen, R. Improving foreground segmentations with probabilistic superpixel Markov random Fields. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition Workshop (CVPR Workshop), Providence, RI, USA, 16–21 June 2012.
- O, N.K.; Kim, C. Unsupervised Texture Segmentation of Natural Scene Images Using Region-based Markov Random Field. J. Signal Process. Syst. 2016, 83, 423–436. [Google Scholar] [CrossRef]
- Ayvaci, A.; Soatto, S. Motion segmentation with occlusions on the superpixel graph. In Proceedings of the IEEE International Conference on Computer Vision Workshop (ICCV Workshop), Kyoto, Japan, 27 September–4 October 2009.
- Lee, T.; Fidler, S.; Levinshtein, A.; Sminchisescu, C.; Dickinson, S. A Framework for Symmetric Part Detection in Cluttered Scenes. Symmetry 2015, 7, 1333–1351. [Google Scholar] [CrossRef]
- Fu, K.; Gong, C.; Yang, J.; Zhou, Y.; Gu, I.Y.H. Superpixel based color contrast and color distribution driven salient object detection. Signal Process.-Image 2013, 28, 1448–1463. [Google Scholar] [CrossRef]
- Xie, Y.; Lu, H.; Yang, M.H. Bayesian Saliency via Low and Mid-Level Cues. IEEE Trans. Image Process. 2013, 22, 1689–1698. [Google Scholar] [PubMed]
- Peng, H.; Bing, L.; Ling, H.; Hu, W.; Xiong, W.; Maybank, S.J. Salient object detection via structured matrix decomposition. IEEE Trans. Pattern Anal. 2016, 99, 796–802. [Google Scholar] [CrossRef] [PubMed]
- Feng, J.; Cao, Z.; Pi, Y. Polarimetric Contextual Classification of PolSAR Images Using Sparse Representation and Superpixels. Remote Sens. 2014, 6, 7158–7181. [Google Scholar] [CrossRef]
- Garcia-Pedrero, A.; Rodríguez-Esparragón, D.; Gonzalo-Martín, C.; Ibarrola, E.; Lillo-Saavedra, M.; Marcello, J. Automatic identification of shrub vegetation of the Teide National Park. In Proceedings of the International Work Conference on Bio-Inspired Intelligence (IWOBI), San Sebastian, Spain, 10–12 June 2015.
- Bergh, M.V.D.; Boix, X.; Roig, G.; Capitani, B.; Gool, L.V. Seeds: Superpixels extracted via energy-driven sampling. Int. J. Comput. Vis. 2015, 111, 1–17. [Google Scholar]
- Shi, J.; Malik, J. Normalized Cuts and Image Segmentation. IEEE Trans. Pattern Anal. 2000, 22, 888–905. [Google Scholar]
- Pedro, F.; Felzenszwalb, P.F.; Daniel, P.H. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar]
- Thomas, H.C.; Charles, E.L.; Ronald, L.R.; Clifford, S. Introduction to Algorithms, 3rd ed.; The MIT Press: Cambridge, MA, USA, 2009; pp. 43–45. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean Shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Vedaldi, A.; Soatto, S. Quick Shift and Kernel Methods for Mode Seeking. In Proceedings of the European Conference on Computer Vision-Part IV (ECCV Part IV), Marseille, France, 12–18 October 2008.
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. TurboPixels: Fast Superpixels Using Geometric Flows. IEEE Trans. Pattern Anal. 2009, 31, 2290–2297. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Hartley, R.; Mashford, J.; Burn, S. Superpixels via Pseudo-Boolean Optimization. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011.
- Liu, Y.J.; Yu, C.C.; Yu, M.J.; He, Y. Manifold SLIC: A Fast Method to Compute Content-Sensitive Superpixels. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016.
- Fowlkes, C.; Martin, D.; Malik, J. Learning affinity functions for image segmentation: Combining patch-based and gradient-based approaches. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Madison, WI, USA, 16–22 June 2003.
- Garcia-Pedrero, A.; Gonzalo-Martin, C.; Fonseca-Luengo, D.; Lillo-Saavedra, M. A GEOBIA methodology for fragmented agricultural landscapes. Remote Sens. 2015, 7, 767–787. [Google Scholar] [CrossRef]
- The Berkeley Segmentation Dataset and Benchmark. Available online: https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/bsds/ (accessed on 24 November 2016).
- Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Peng, X.; Tang, H.; Zhang, L.; Zhang, Y.; Xiao, S. A Unified Framework for Representation-Based Subspace Clustering of Out-of-Sample and Large-Scale Data. IEEE Trans. Neural Netw. 2016, 27, 2499–2512. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.Y.; Tuzel, O.; Ramalingam, S.; Chellappa, R. Entropy rate superpixel segmentation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011.
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).