Detection of Double-Compressed H.264/AVC Video Incorporating the Features of the String of Data Bits and Skip Macroblocks



Abstract
:1. Introduction
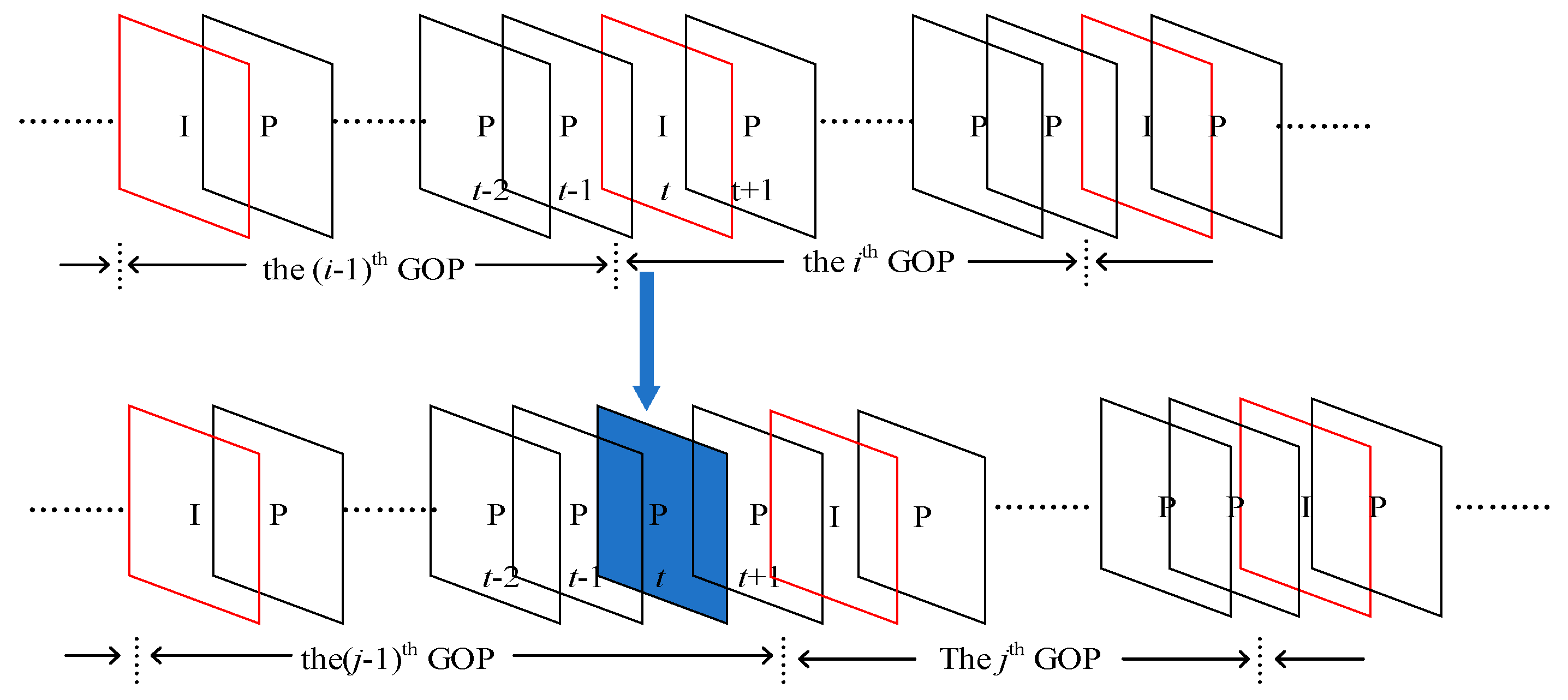
2. Periodic Artifacts for Double-Compressed H.264/AVC Videos
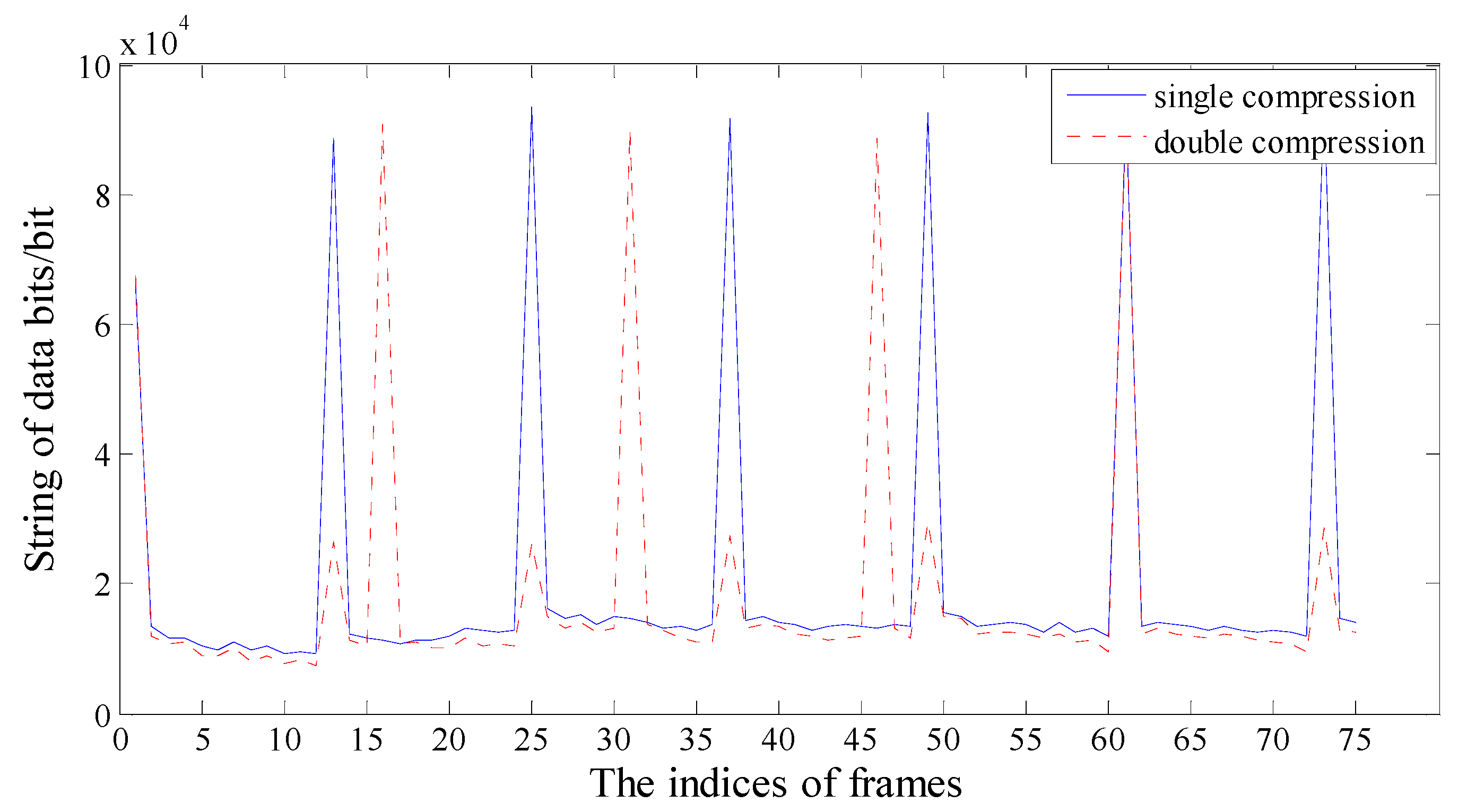
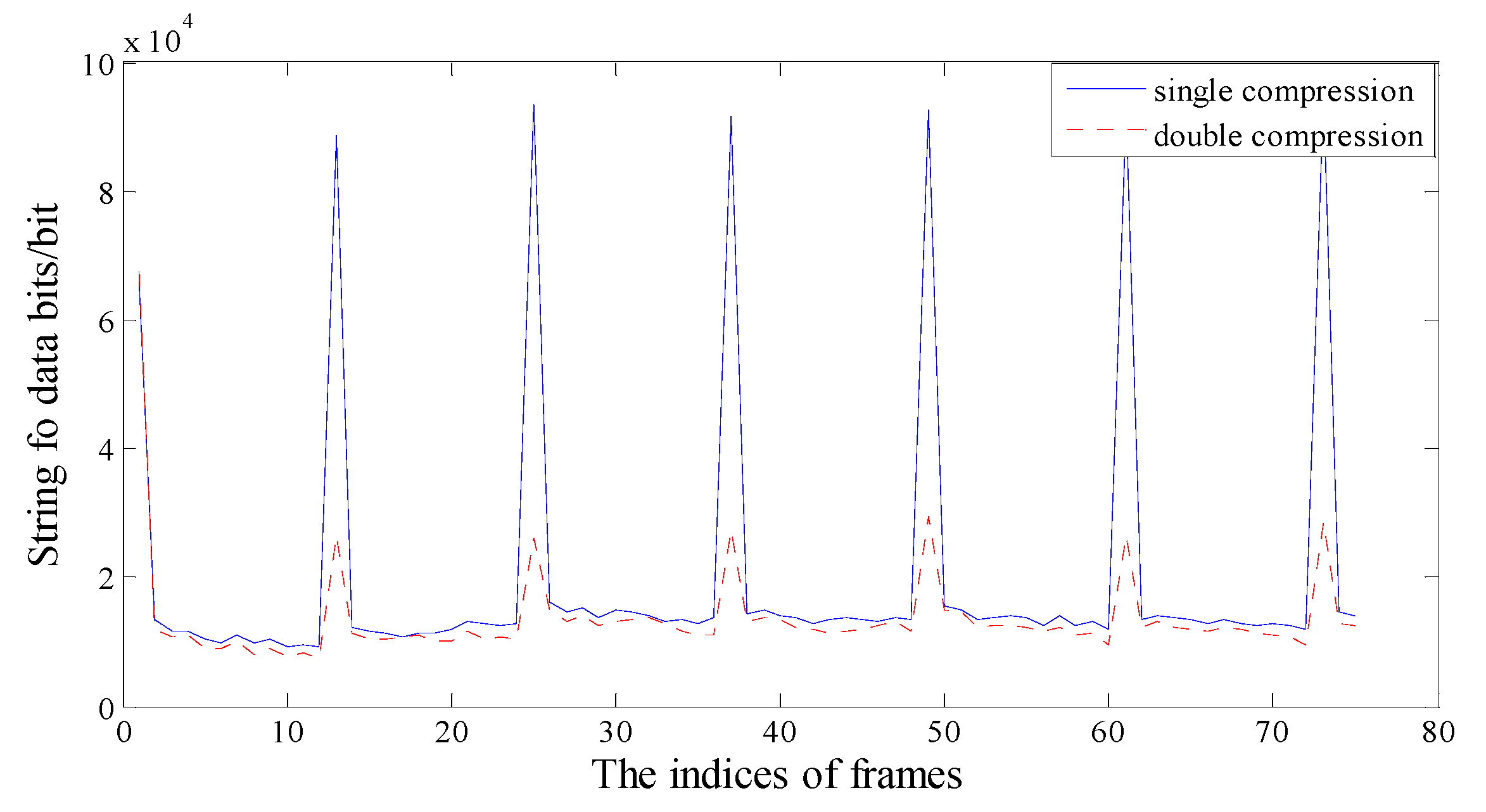
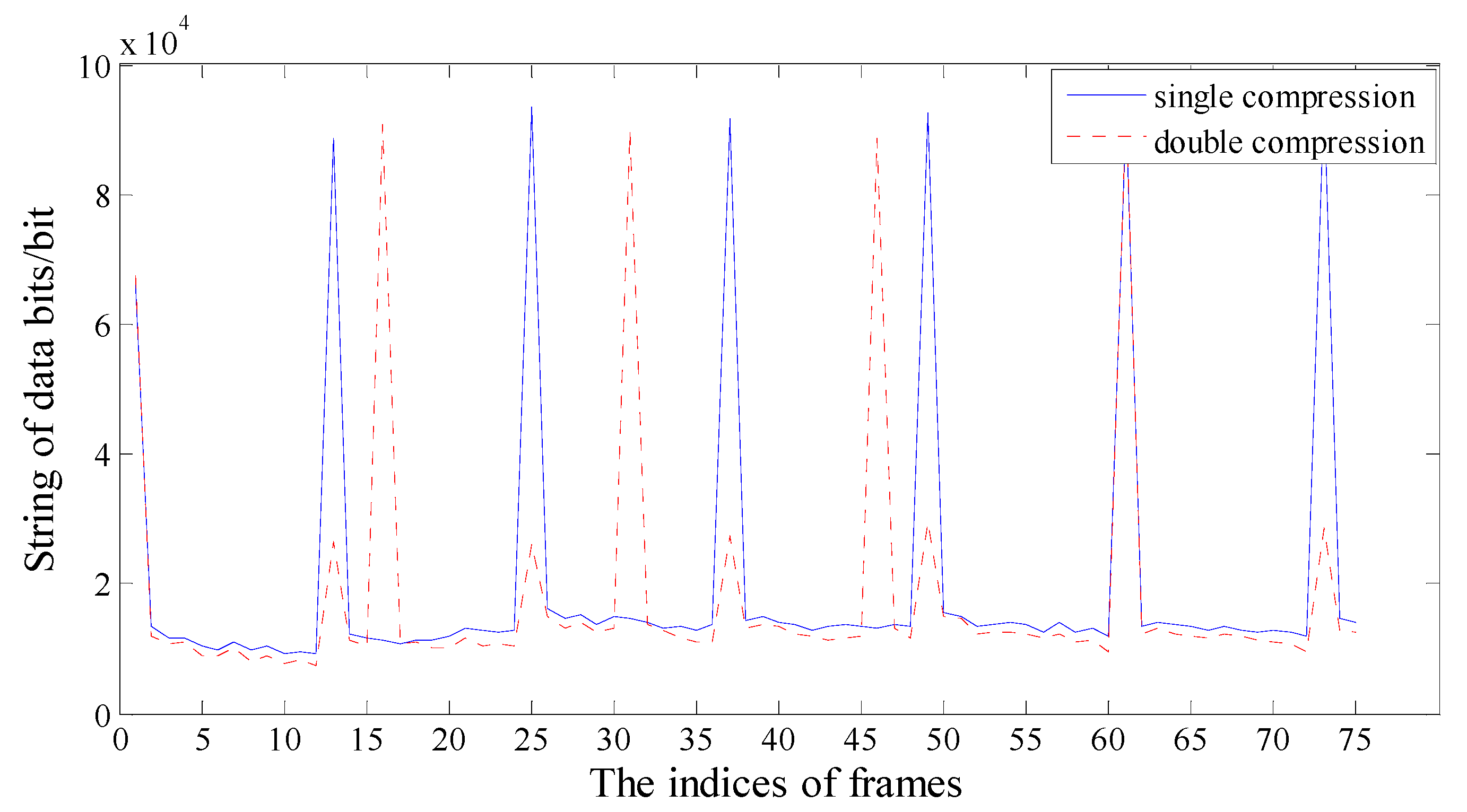
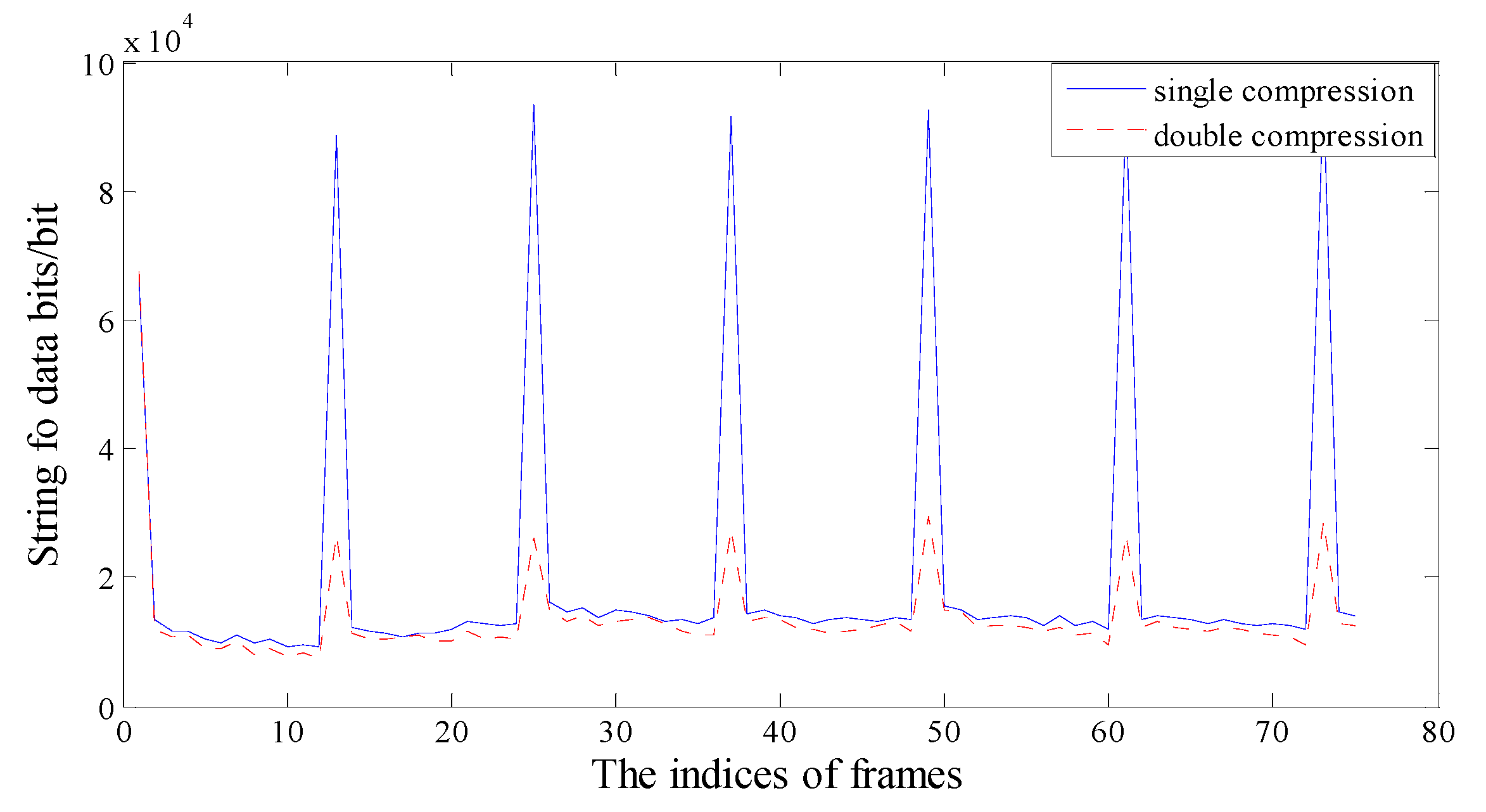
2.1. Periodic Artifact in the P-Frame String of Data Bits
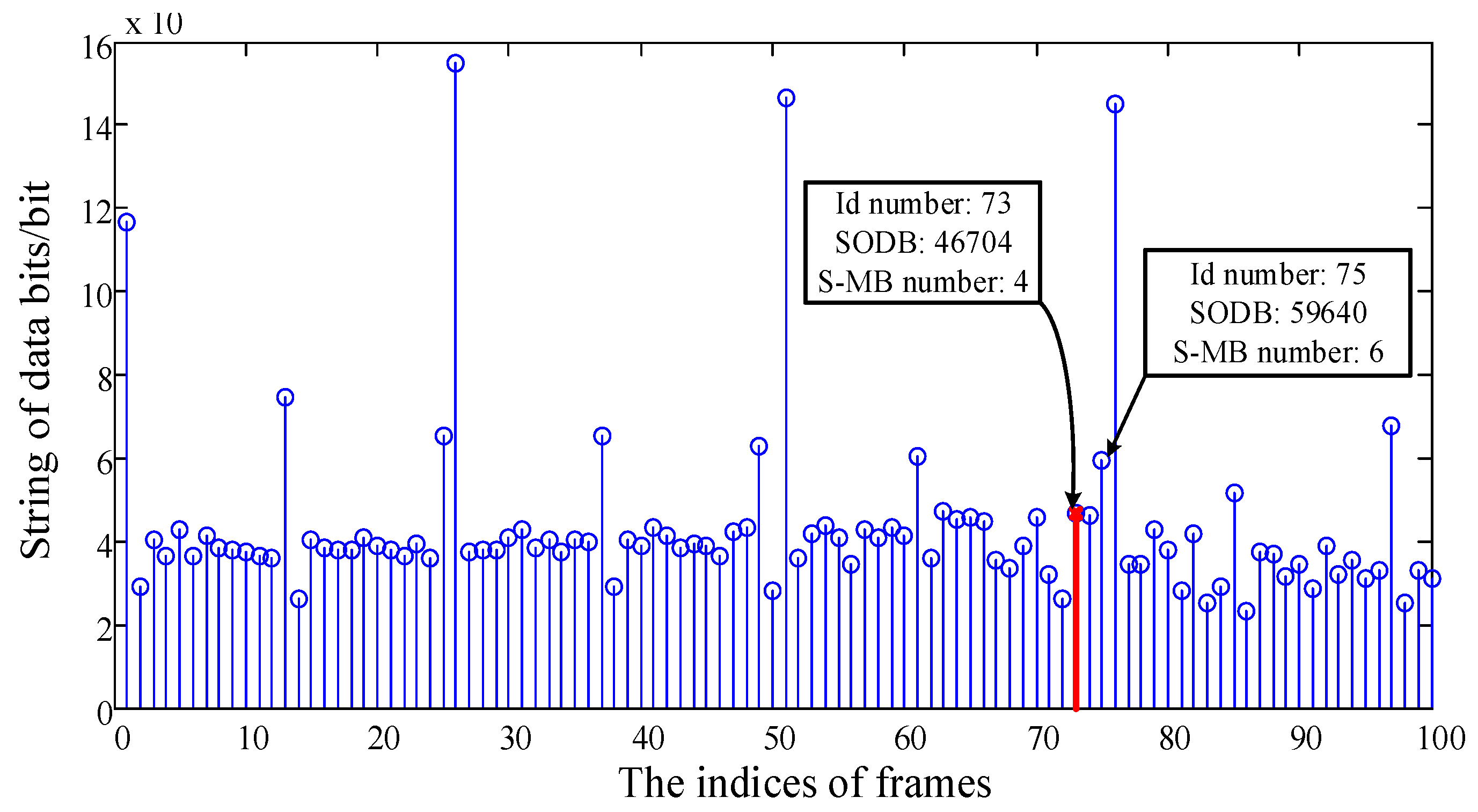
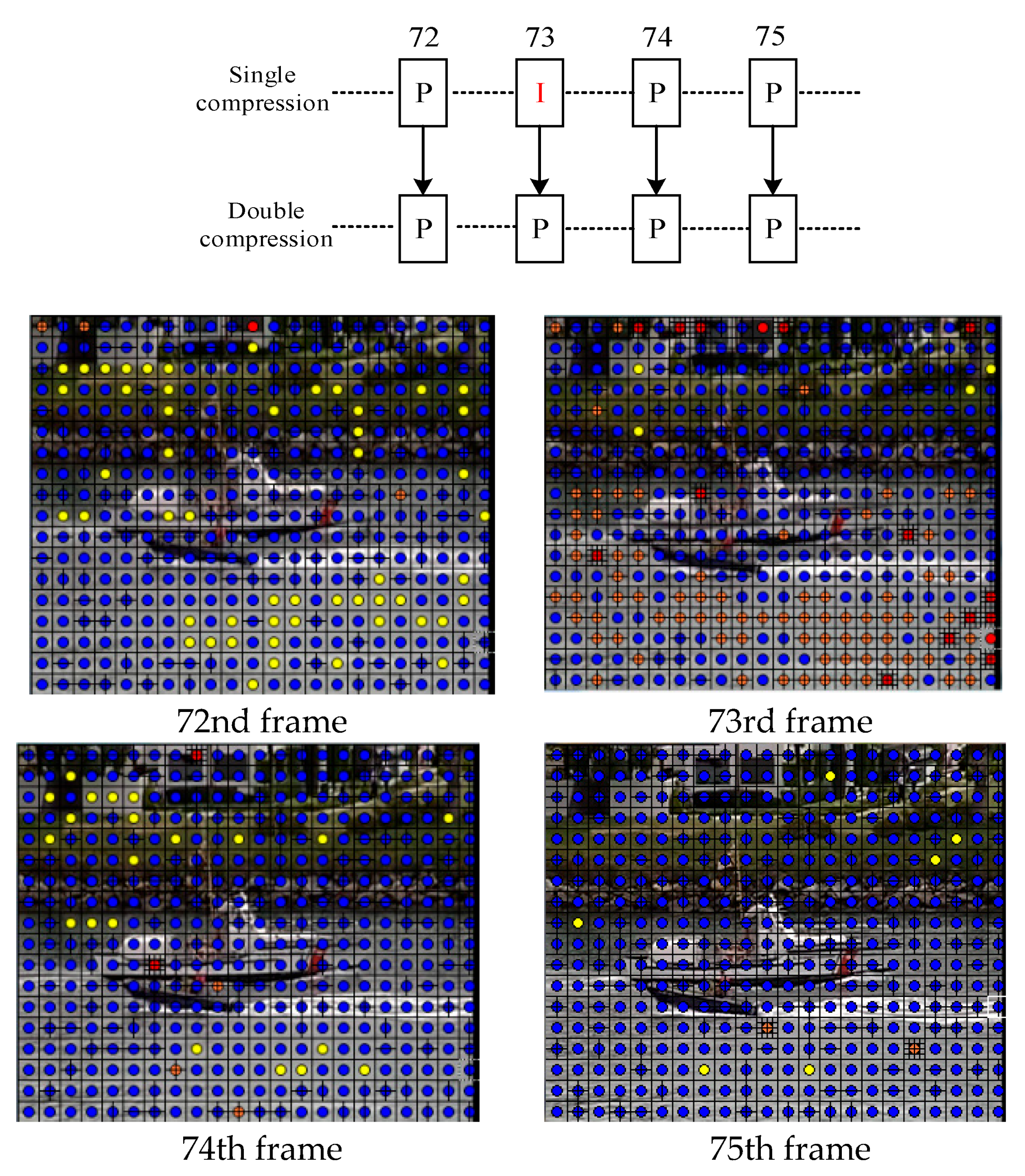
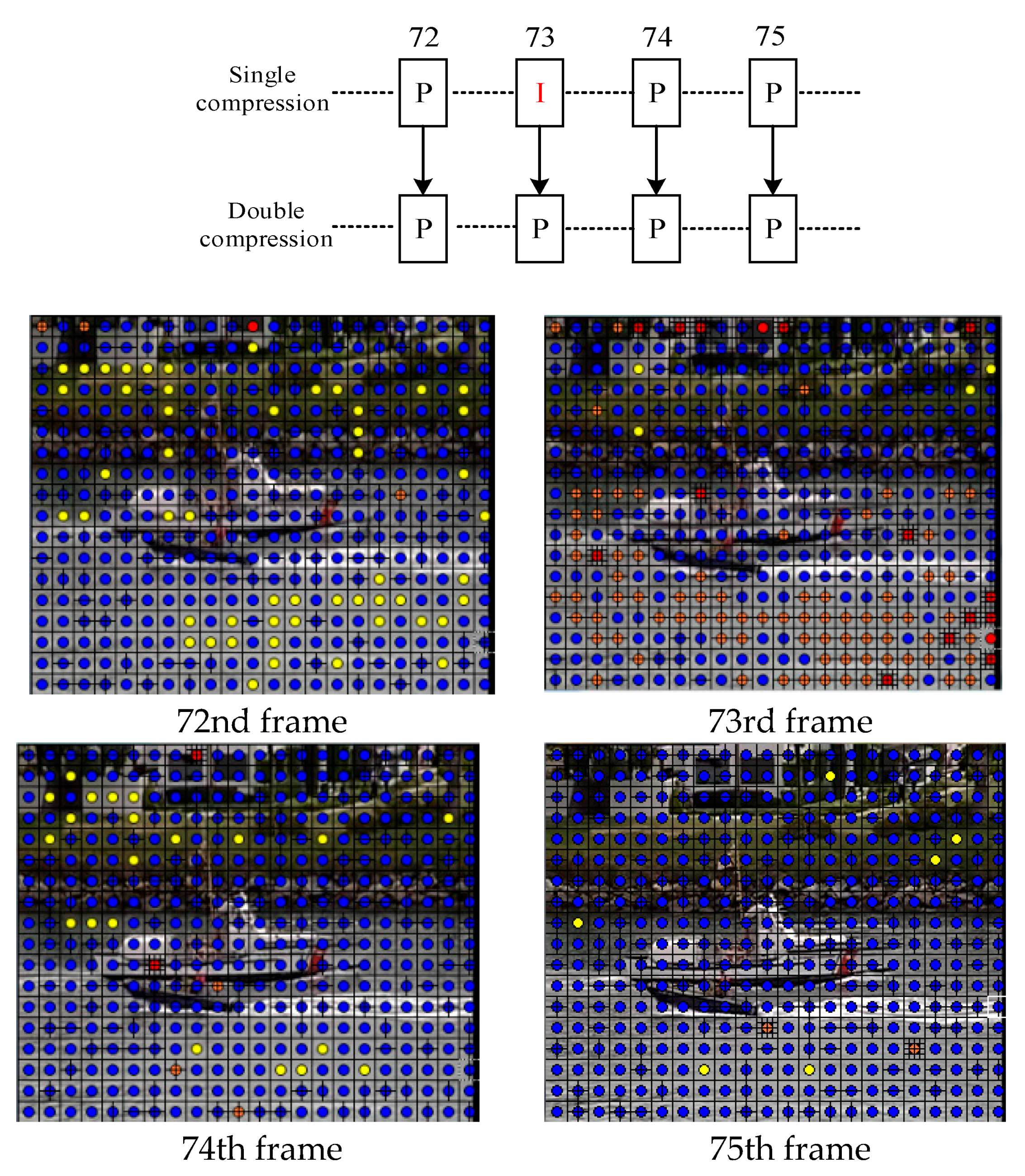
2.2. Periodic Feature of Skip Macroblocks for Double-Compressed H.264/AVC Videos
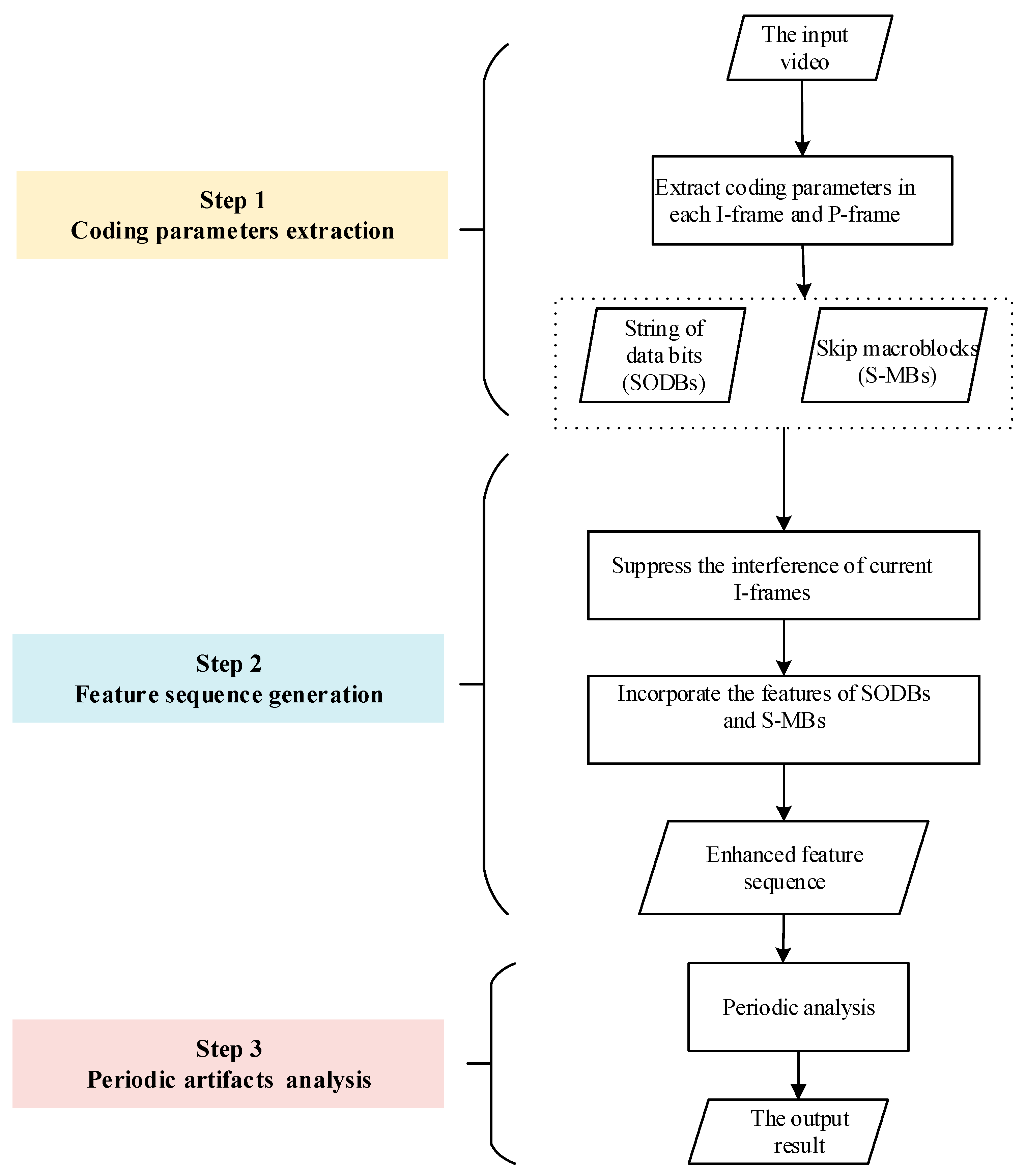
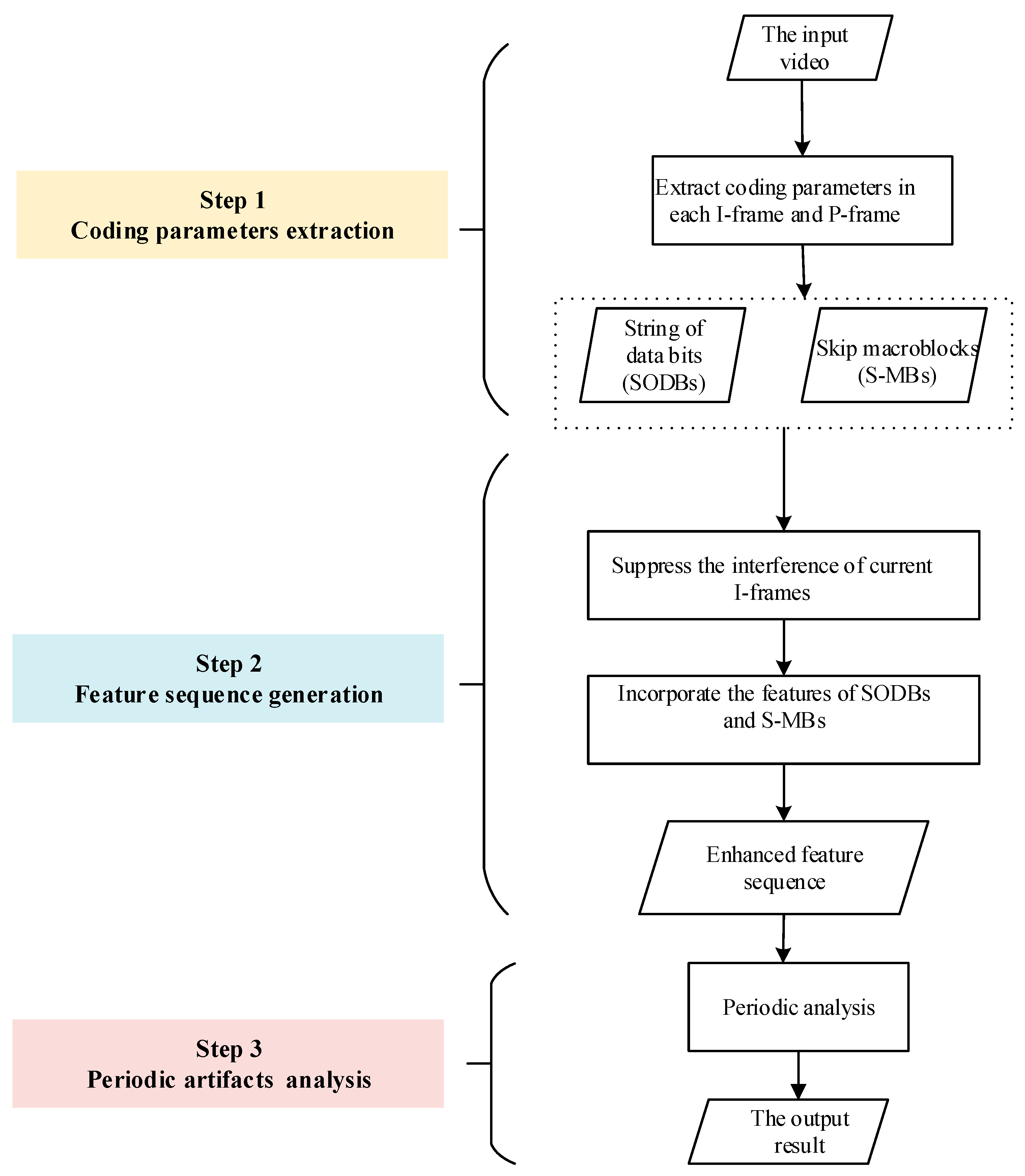
3. Proposed Method
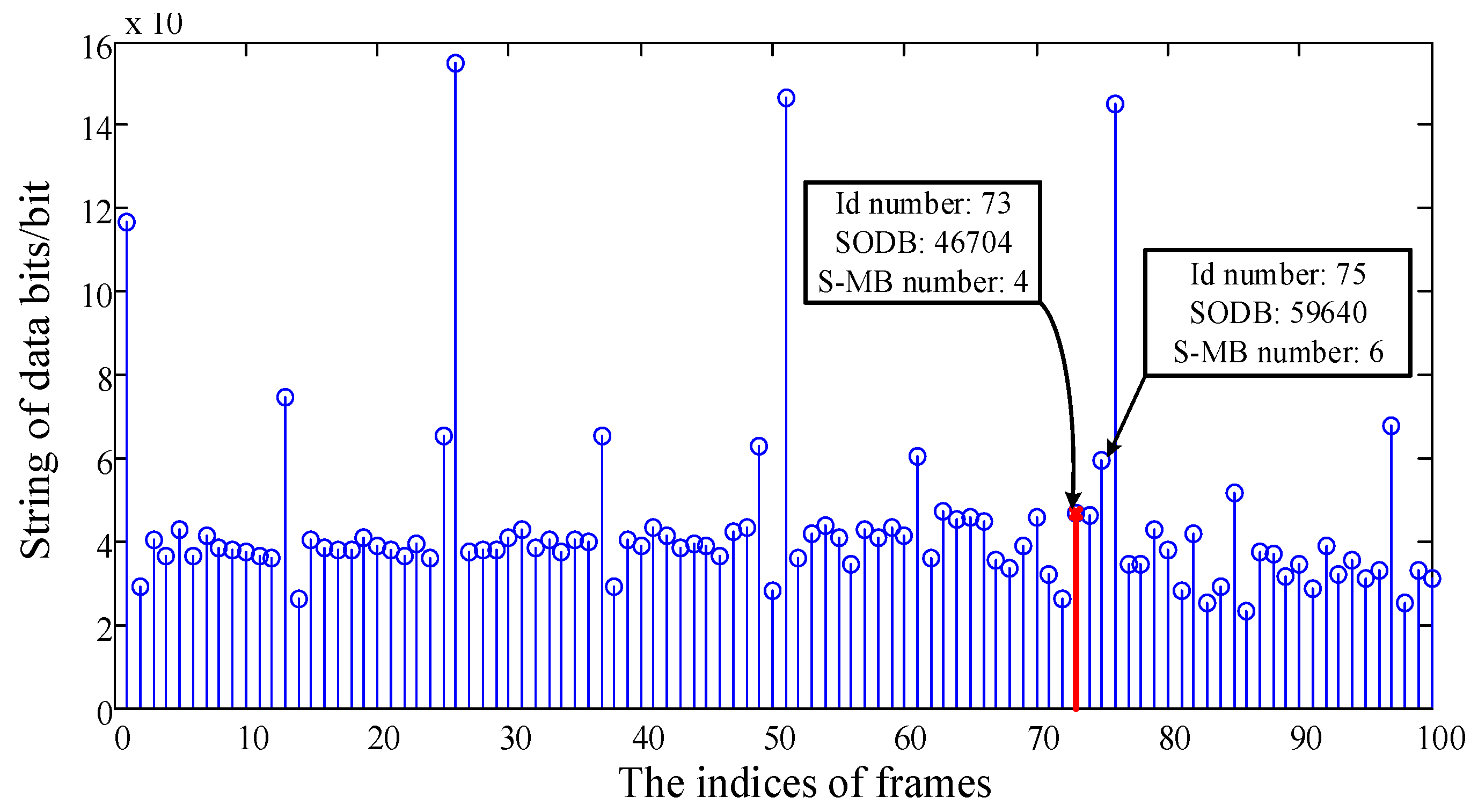
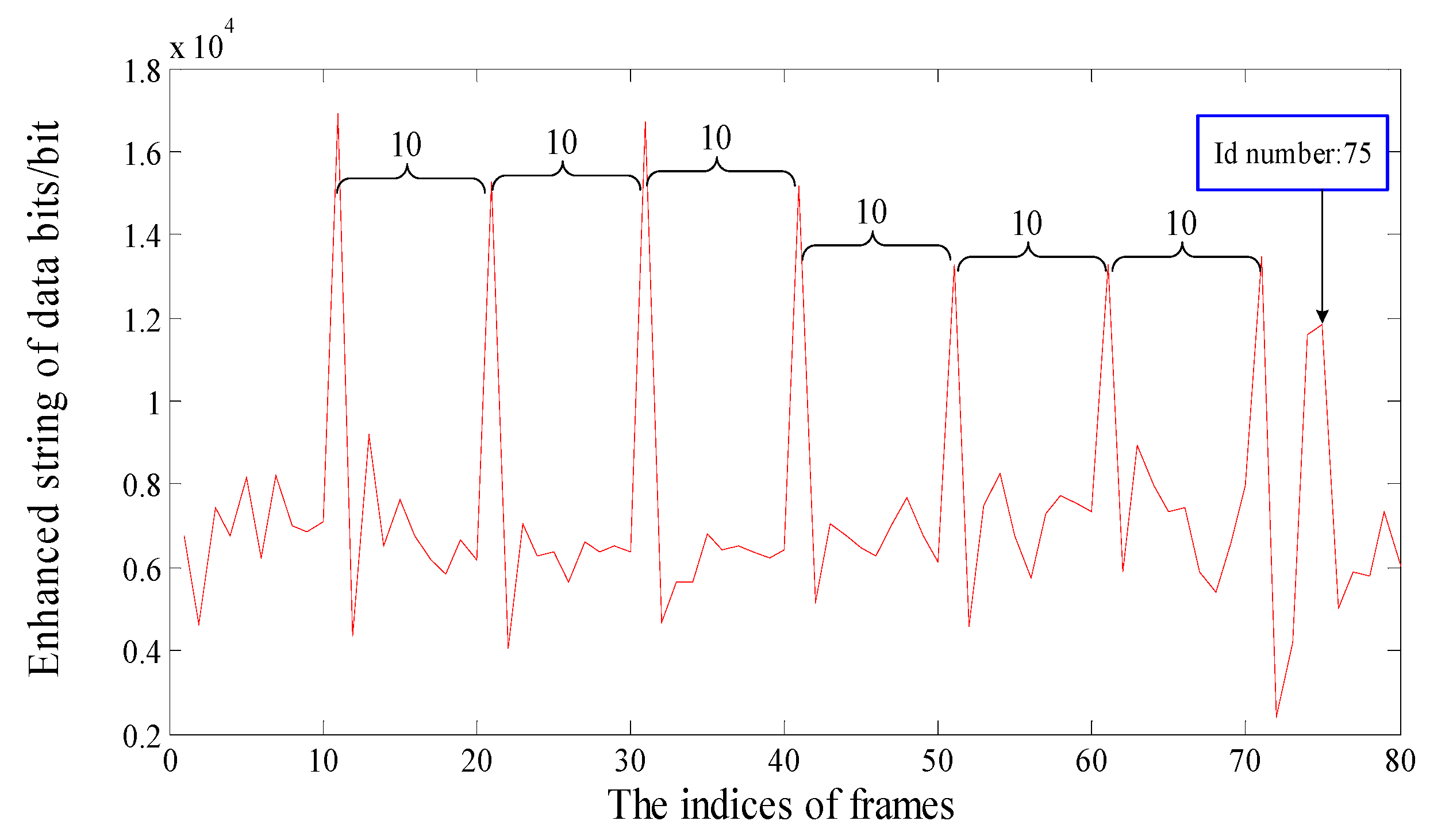
3.1. Generation of the Feature Sequence
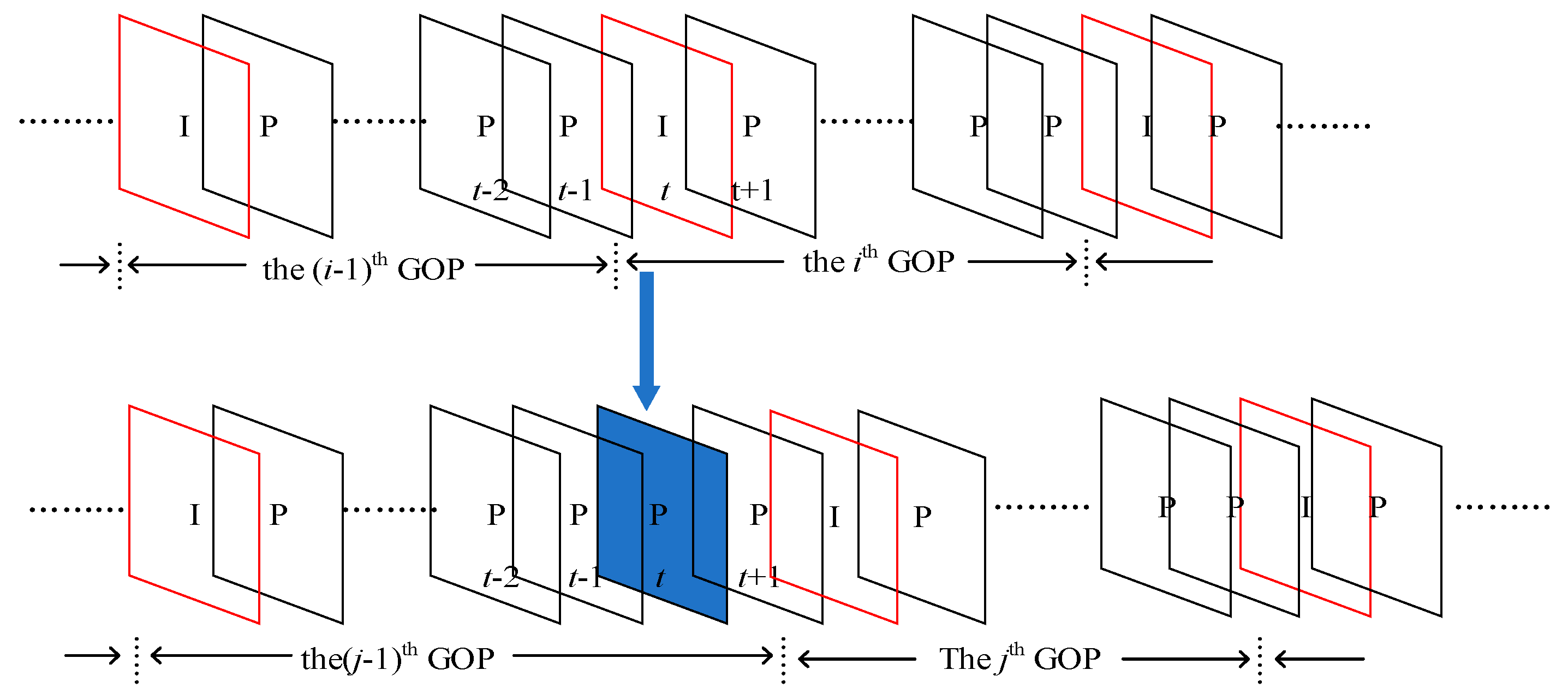
3.2. Detection of Double Compression and Estimation of the Primary GOP Size
| Algorithm 1. Pseudo code of double-compressed video detection and primary GOP size estimation. |
| Input: video sequence {Ft, t = 1, 2, …, T}, the last GOP size G2, and threshold TΛ 1: Count string of data bits (SODB) of each frame Ft, denote Dt 2: Count total number of macroblocks and number of skip macroblocks (S-MB), denote Nt and St, respectively 3: for t = 1 to T do 4: εt = Nt / St 5: if mod(t, G2) = 1 6: Dt = (Dt-1 + Dt+1)/2 7: Et = Dt /εt 8: else Et =εt Dt 9: end If 10: end for 11: for m = 2 to do 12: 13: end for 14: if [max1(Λm) – max2(Λm)] > TΛ 15: R = 1 16: 17: else R = 0 18: end if Output: the double-compression indicator R (1 for double compressed and 0 for single compressed), and estimated primary GOP size in case of R = 1 |
4. Experimental Results
4.1. Test Dataset
4.2. Detection Results for the Double Compression
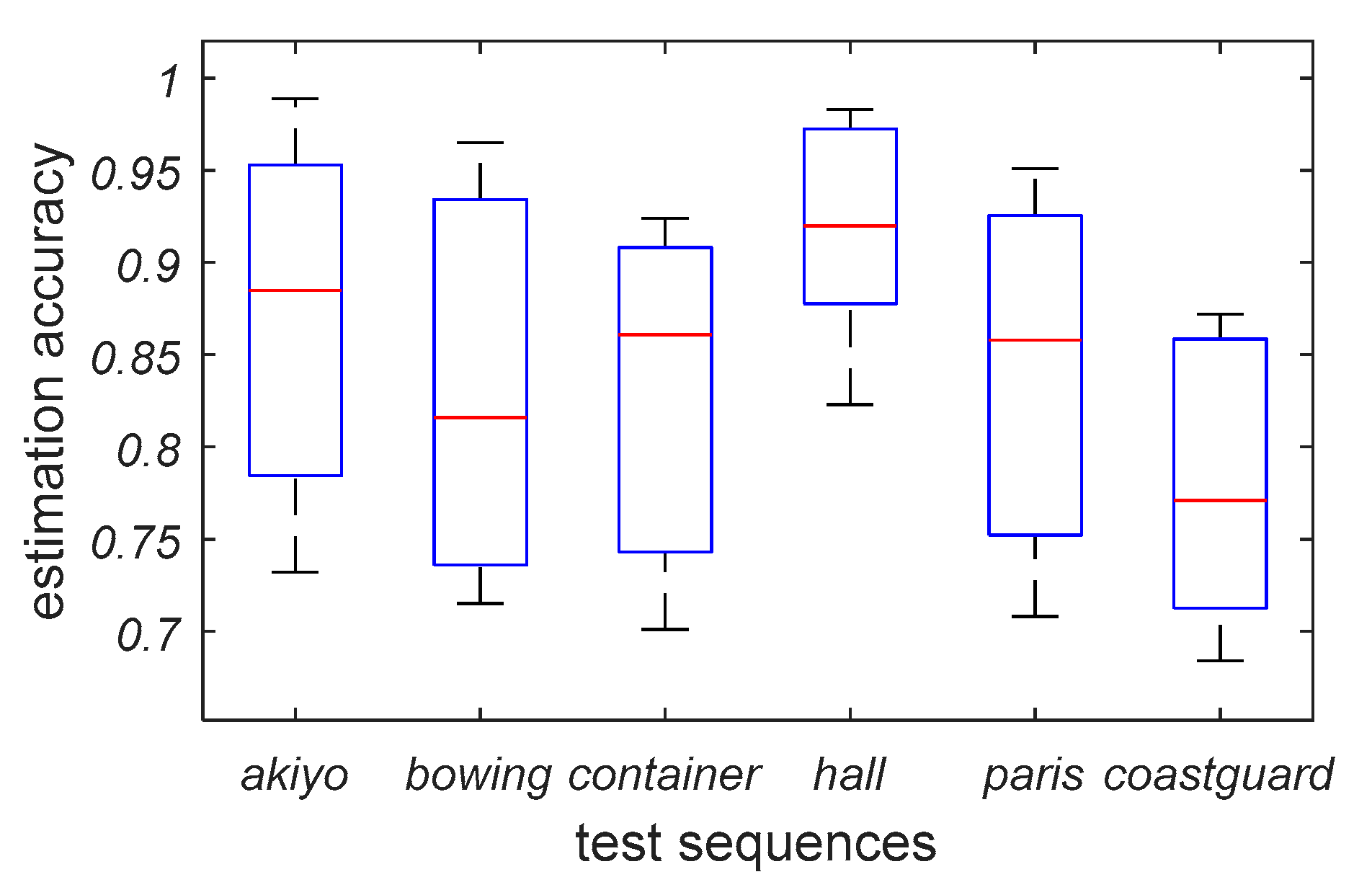
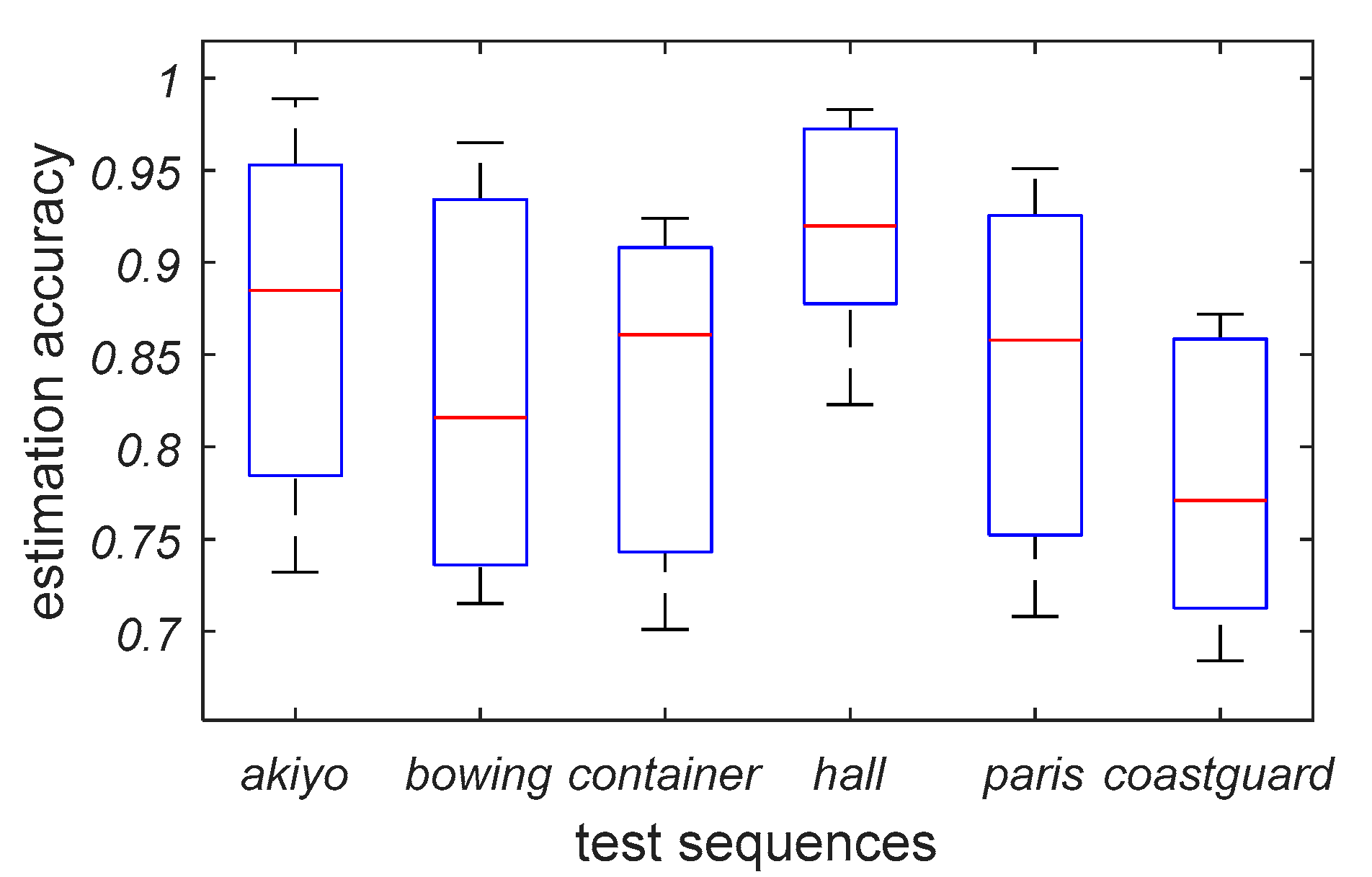
4.3. Performance for Primary GOP Size Estimation
4.4. Time-Efficiency Evaluation
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wang, X.; Pang, K.; Zhou, X.; Zhou, Y.; Li, L.; Xue, J. A visual model-based perceptual image hash for content authentication. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1336–1349. [Google Scholar] [CrossRef]
- Qin, C.; Chen, X.; Ye, D.; Wang, J.; Sun, X. A novel image hashing scheme with perceptual robustness using block truncation coding. Inf. Sci. 2016, 361–362, 84–99. [Google Scholar] [CrossRef]
- Qin, C.; Chen, X.; Luo, X.; Zhang, X.; Sun, X. Perceptual image hashing via dual-cross pattern encoding and salient structure detection. Inf. Sci. 2018, 423, 284–302. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, S.; Qian, Z.; Feng, G. Reference sharing mechanism for watermark self-embedding. IEEE Trans. Image Process. 2011, 20, 485–495. [Google Scholar] [CrossRef] [PubMed]
- Qin, C.; Ji, P.; Zhang, X.; Dong, J.; Wang, J. Fragile image watermarking with pixel-wise recovery based on overlapping embedding strategy. Signal Process. 2017, 138, 280–293. [Google Scholar] [CrossRef]
- Yao, H.; Wang, S.; Zhang, X.; Qin, C.; Wang, J. Detecting image splicing based on noise level inconsistency. Multimed. Tools Appl. 2017, 76, 12457–12479. [Google Scholar] [CrossRef]
- Thai, T.H.; Cogranne, R.; Retraint, F.; Doan, T.N.C. JPEG quantization step estimation and its applications to digital image forensics. IEEE Trans. Inf. Forensics Secur. 2017, 12, 123–133. [Google Scholar] [CrossRef]
- Li, H.; Luo, W.; Qiu, X.; Huang, J. Image forgery localization via integrating tampering possibility maps. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1240–1252. [Google Scholar] [CrossRef]
- Tew, Y.; Wong, K.S. An overview of information hiding in H.264/AVC compressed video. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 305–319. [Google Scholar] [CrossRef]
- Bestagini, P.; Fontan, M.; Milani, S.; Barni, M.; Piva, A.; Tagliasacchi, M.; Tubaro, K.S. An overview on video forensics. In Proceedings of the IEEE 2012 20th European Signal Processing Conference, Bucharest, Romania, 27–31 August 2012; pp. 1229–1233. [Google Scholar]
- Piva, A. An overview on image forensics. ISRN Signal Process. 2013, 2013, 1–22. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Ohm, J.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Su, Y.; Xu, J. Detection of double-compression in MPEG-2 videos. In Proceedings of the International Workshop on Intelligent Systems and Applications (ISA), Wuhan, China, 22–23 May 2010; pp. 1–4. [Google Scholar]
- Wang, W.; Farid, H. Exposing digital forgeries in video by detecting double quantization. In Proceedings of the 11th ACM Workshop on Multimedia and Security, Princeton, NJ, USA, 7–8 September 2009; pp. 39–48. [Google Scholar]
- Chen, W.; Shi, Y.Q. Detection of double MPEG compression based on first digit statistics. In Proceedings of the International Workshop on Digital Watermarking, Newark, DE, USA, 8–10 October 2009; pp. 16–30. [Google Scholar]
- Sun, T.; Wang, W.; Jiang, X. Exposing video forgeries by detecting MPEG double compression. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 1389–1392. [Google Scholar]
- Jiang, X.; Wang, W.; Sun, T.; Shi, Y.Q.; Wang, S. Detection of double compression in MPEG-4 videos based on markov statistics. IEEE Signal Process. Lett. 2013, 20, 447–450. [Google Scholar] [CrossRef]
- Wang, W.; Farid, H. Exposing digital forgeries in video by detecting double MPEG compression. In Proceedings of the 8th Workshop on Multimedia and Security, Geneva, Switzerland, 26–27 September 2006; pp. 37–47. [Google Scholar]
- Aghamaleki, J.A.; Behrad, A. Inter-frame video forgery detection and localization using intrinsic effects of double compression on quantization errors of video coding. Signal Process. Image Commun. 2016, 47, 289–302. [Google Scholar] [CrossRef]
- Stamm, M.C.; Lin, W.S.; Liu, K.J.R. Temporal forensics and anti-forensics for motion compensated video. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1315–1329. [Google Scholar] [CrossRef]
- Vazquez-Padin, D.; Fontani, M.; Bianchi, T.; Comesana, P.; Piva, A.; Barni, M. Detection of video double encoding with GOP size estimation. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Tenerife, Spain, 2–5 December 2012; pp. 151–156. [Google Scholar]
- He, P.; Jiang, X.; Sun, T.; Wang, S. Double compression detection based on local motion vector field analysis in static-background videos. J. Vis. Commun. Image Represent. 2016, 35, 55–66. [Google Scholar] [CrossRef]
- Bestagini, P.; Milani, S.; Tagliasacchi, M.; Tubaro, S. Codec and GOP Identification in Double Compressed Videos. IEEE Trans. Image Process. 2016, 25, 2298–2310. [Google Scholar] [CrossRef] [PubMed]
- STAC: Web Platform for Algorithms Comparison through Statistical Tests. Available online: http://tec.citius.usc.es/ (accessed on 7 December 2017).
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Holm, S. A simple sequentially rejective multiple test procedure. Scand. J. Stat. 1979, 6, 65–70. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Setting Values |
|---|---|
| c1 | MPEG-2(libavcodec), MPEG-4(libavcodec), H.264/AVC |
| R1 | {300, 500, 700, 900, 1100}(kbps) |
| G1 | 10, 15, 30, 40 |
| c2 | H.264/AVC |
| R2 | {300, 500, 700, 900, 1100}(kbps) |
| G2 | 9, 16, 33, 50 |
| R2 | Methods | 300 | 500 | 700 | 900 | 1100 | |
|---|---|---|---|---|---|---|---|
| R1 | |||||||
| 300 | He et al. | 0.997 | 0.999 | 0.999 | 0.997 | 0.992 | |
| Stamm et al. | 0.965 | 0.980 | 0.945 | 0.888 | 0.809 | ||
| Vazquez-Padin et al. | 0.875 | 0.991 | 0.997 | 0.996 | 0.999 | ||
| Proposed | 0.985 | 0.999 | 0.998 | 0.992 | 0.998 | ||
| 500 | He et al. | 0.860 | 0.987 | 0.999 | 0.994 | 0.994 | |
| Stamm et al. | 0.832 | 0.927 | 0.962 | 0.925 | 0.900 | ||
| Vazquez-Padin et al. | 0.489 | 0.922 | 0.940 | 0.976 | 0.968 | ||
| Proposed | 0.909 | 0.981 | 0.999 | 0.997 | 0.995 | ||
| 700 | He et al. | 0.763 | 0.836 | 0.983 | 0.983 | 0.990 | |
| Stamm et al. | 0.727 | 0.793 | 0.873 | 0.900 | 0.892 | ||
| Vazquez-Padin et al. | 0.549 | 0.750 | 0.870 | 0.926 | 0.915 | ||
| Proposed | 0.794 | 0.886 | 0.979 | 0.985 | 0.992 | ||
| 900 | He et al. | 0.671 | 0.711 | 0.899 | 0.955 | 0.984 | |
| Stamm et al. | 0.633 | 0.706 | 0.784 | 0.836 | 0.871 | ||
| Vazquez-Padin et al. | 0.540 | 0.605 | 0.732 | 0.885 | 0.852 | ||
| Proposed | 0.723 | 0.774 | 0.815 | 0.967 | 0.986 | ||
| 1100 | He et al. | 0.616 | 0.620 | 0.776 | 0.833 | 0.916 | |
| Stamm et al. | 0.568 | 0.622 | 0.741 | 0.719 | 0.780 | ||
| Vazquez-Padin et al. | 0.451 | 0.564 | 0.579 | 0.818 | 0.837 | ||
| Proposed | 0.597 | 0.677 | 0.797 | 0.864 | 0.944 | ||
| G2 | Methods | 9 | 16 | 33 | 50 | |
|---|---|---|---|---|---|---|
| G1 | ||||||
| 10 | He et al. | 0.934 | 0.922 | 0.928 | 0.908 | |
| Stamm et al. | 0.892 | 0.857 | 0.854 | 0.811 | ||
| Vazquez-Padin et al. | 0.794 | 0.855 | 0.853 | 0.841 | ||
| Proposed | 0.927 | 0.954 | 0.932 | 0.906 | ||
| 15 | He et al. | 0.921 | 0.916 | 0.924 | 0.918 | |
| Stamm et al. | 0.892 | 0.857 | 0.854 | 0.811 | ||
| Vazquez-Padin et al. | 0.749 | 0.855 | 0.853 | 0.841 | ||
| Proposed | 0.921 | 0.918 | 0.910 | 0.922 | ||
| 30 | He et al. | 0.892 | 0.882 | 0.895 | 0.868 | |
| Stamm et al. | 0.827 | 0.812 | 0.811 | 0.768 | ||
| Vazquez-Padin et al. | 0.721 | 0.817 | 0.818 | 0.769 | ||
| Proposed | 0.854 | 0.894 | 0.914 | 0.883 | ||
| 40 | He et al. | 0.885 | 0.804 | 0.889 | 0.838 | |
| Stamm et al. | 0.850 | 0.707 | 0.776 | 0.727 | ||
| Vazquez-Padin et al. | 0.726 | 0.742 | 0.803 | 0.770 | ||
| Proposed | 0.894 | 0.824 | 0.876 | 0.842 | ||
| Methods | Rank |
|---|---|
| Proposed | 1.439 |
| He et al. | 1.744 |
| Stamm et al. | 3.390 |
| Vazquez-Padin et al. | 3.427 |
| Control Method | Comparative Method | Holm p-Value | Result |
|---|---|---|---|
| Proposed | He et al. | 0.285 | H0 is accepted |
| Proposed | Stamm et al. | 0.000 | H0 is rejected |
| Proposed | Vazquez-Padin et al. | 0.000 | H0 is rejected |
| Sequence | akiyo | bowing | container | hall | paris | coastguard | |
|---|---|---|---|---|---|---|---|
| R2 (kbps) | |||||||
| 300 | 0.732 | 0.715 | 0.701 | 0.823 | 0.708 | 0.684 | |
| 500 | 0.802 | 0.743 | 0.757 | 0.896 | 0.767 | 0.722 | |
| 700 | 0.885 | 0.816 | 0.861 | 0.920 | 0.858 | 0.771 | |
| 900 | 0.941 | 0.924 | 0.903 | 0.969 | 0.917 | 0.854 | |
| 1100 | 0.989 | 0.965 | 0.924 | 0.983 | 0.951 | 0.872 | |
| G1(G2) | 10(9) | 10(16) | 10(33) | 15(9) | 15(16) | 15(33) | 30(9) | 30(16) | 30(33) | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Sequence | |||||||||||
| akiyo | 142 | 127 | 125 | 133 | 123 | 125 | 135 | 126 | 122 | 129 | |
| coastguard | 207 | 196 | 180 | 207 | 210 | 172 | 222 | 199 | 177 | 197 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, H.; Song, S.; Qin, C.; Tang, Z.; Liu, X. Detection of Double-Compressed H.264/AVC Video Incorporating the Features of the String of Data Bits and Skip Macroblocks. Symmetry 2017, 9, 313. https://doi.org/10.3390/sym9120313
Yao H, Song S, Qin C, Tang Z, Liu X. Detection of Double-Compressed H.264/AVC Video Incorporating the Features of the String of Data Bits and Skip Macroblocks. Symmetry. 2017; 9(12):313. https://doi.org/10.3390/sym9120313
Chicago/Turabian StyleYao, Heng, Saihua Song, Chuan Qin, Zhenjun Tang, and Xiaokai Liu. 2017. "Detection of Double-Compressed H.264/AVC Video Incorporating the Features of the String of Data Bits and Skip Macroblocks" Symmetry 9, no. 12: 313. https://doi.org/10.3390/sym9120313
APA StyleYao, H., Song, S., Qin, C., Tang, Z., & Liu, X. (2017). Detection of Double-Compressed H.264/AVC Video Incorporating the Features of the String of Data Bits and Skip Macroblocks. Symmetry, 9(12), 313. https://doi.org/10.3390/sym9120313