
Prognosis Essay Scoring and Article Relevancy Using Multi-Text Features and Machine Learning


Abstract
:1. Introduction
2. Related Work and Literature Review
2.1. Background
2.2. Literature Review
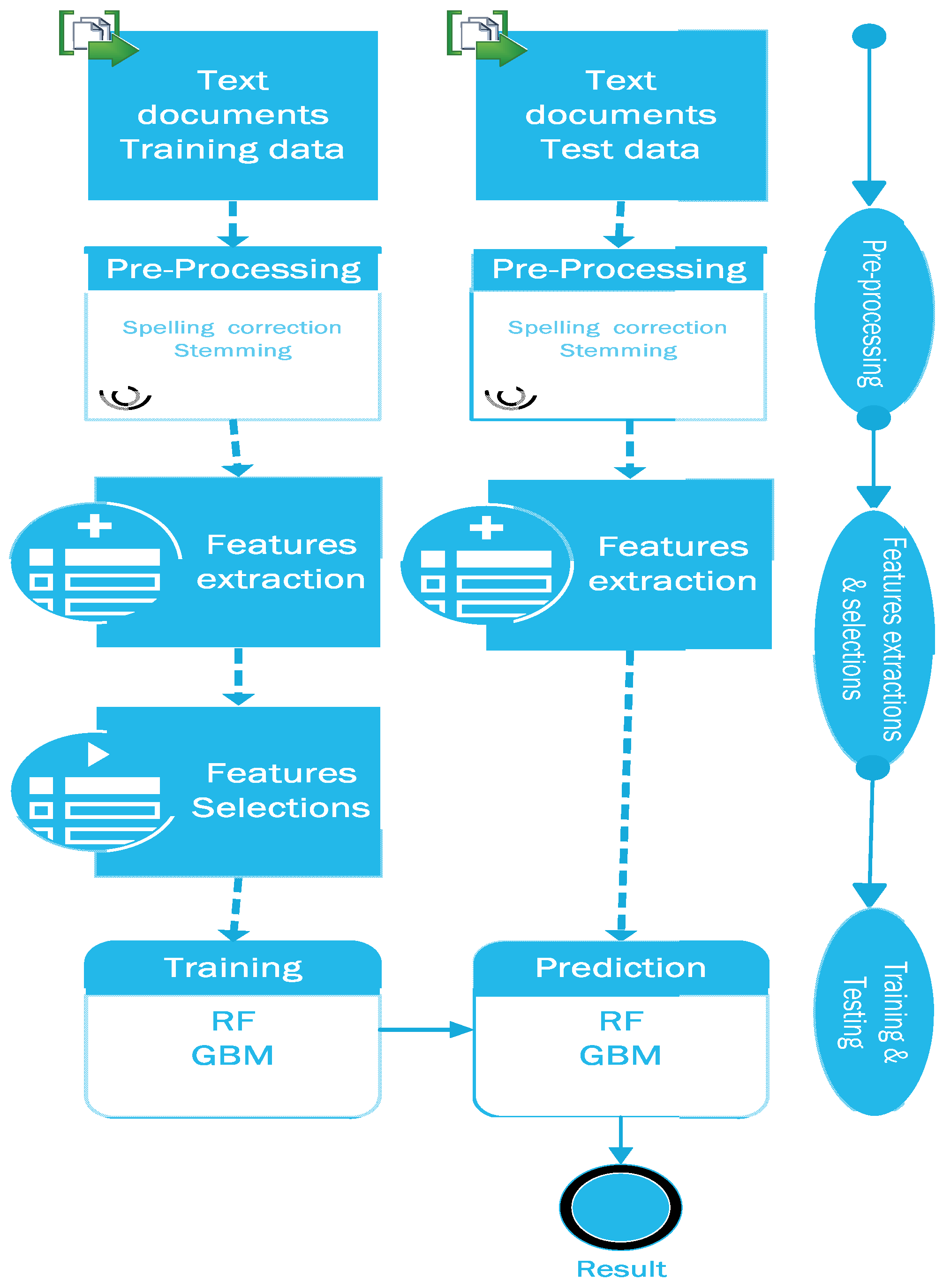
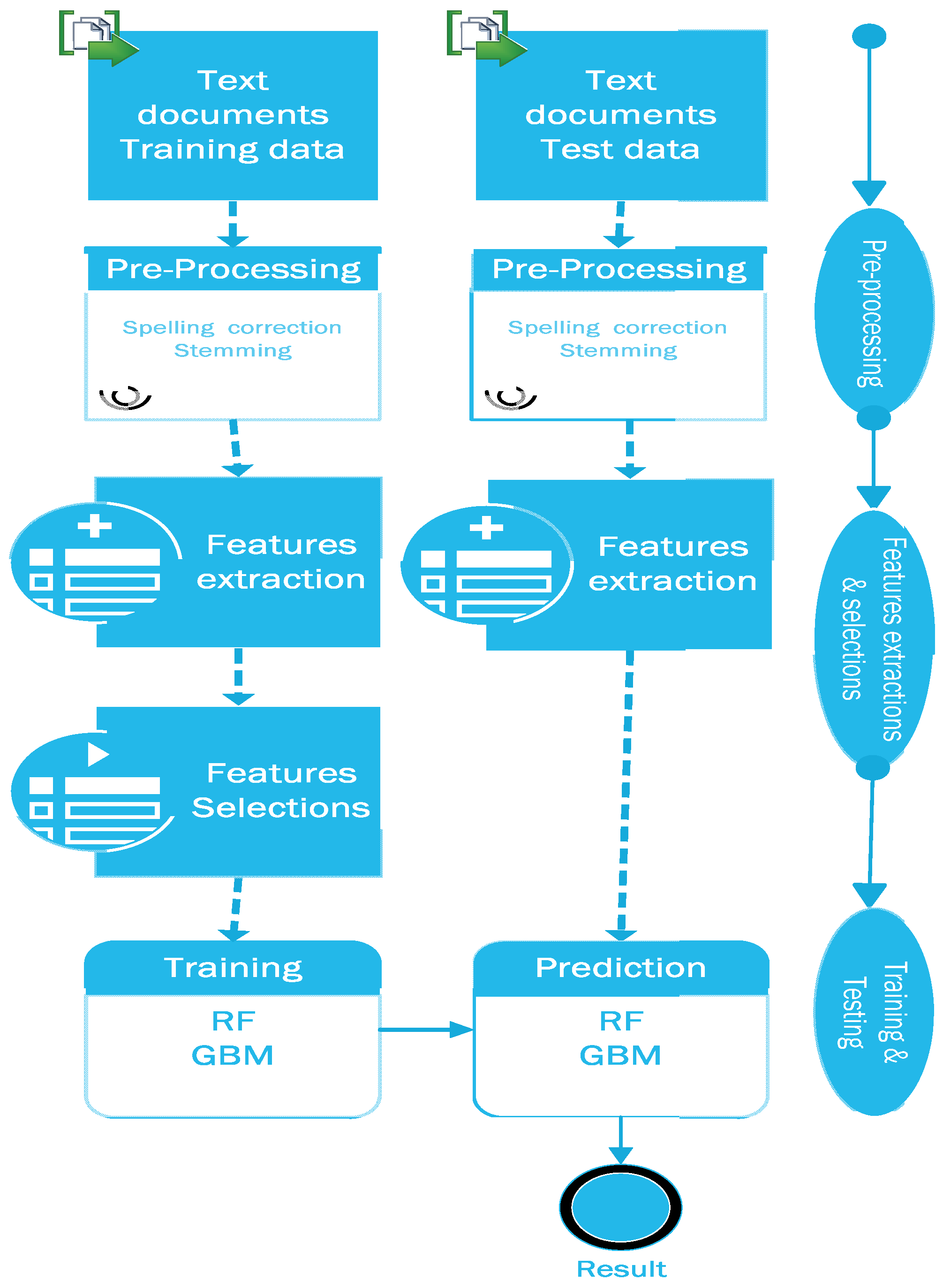
3. Proposed System Architecture
3.1. Data Sets
3.2. Preprocessing
3.3. Feature Extraction and Selection
3.3.1. N-Grams
3.3.2. Regular Expression
- ((type)|(kind)|(brand)) of vinegar
- ((concentr)|( \w?h)|(acid)) (\w+ ){0,5}vinegar
- vinegar (\w+ )?((concentr)|(acid))
- know (\w+ )?vinegar (\w+ )?((us)|(need))
3.3.3. Word2vec
3.3.4. Text Statistics
3.3.5. Feature Selection
| Algorithm 1. Boruta Algorithm |
| 1: procedure 2: Input // Original features 3: Output // Relative features from original features 4: O //Original features matrix 5: S //Shadow features matrix 6: J = [O S] // Merging the features 7: Z = RandomForest(J) //Applying RF and get Z score 8: for (Z←1 to n) do // n is number of total features 9: if (Sz > Max (Oz)) then //comparing the Z score 10: Rel-F←Xz // Related Features 11: else 12: if (Sz < Min (Oz)) then 13: N-Rel-F←Xz // Non related features, drop it. 14: end if 15: end if 16: end for 17: end procedure |
3.4. Training the Model
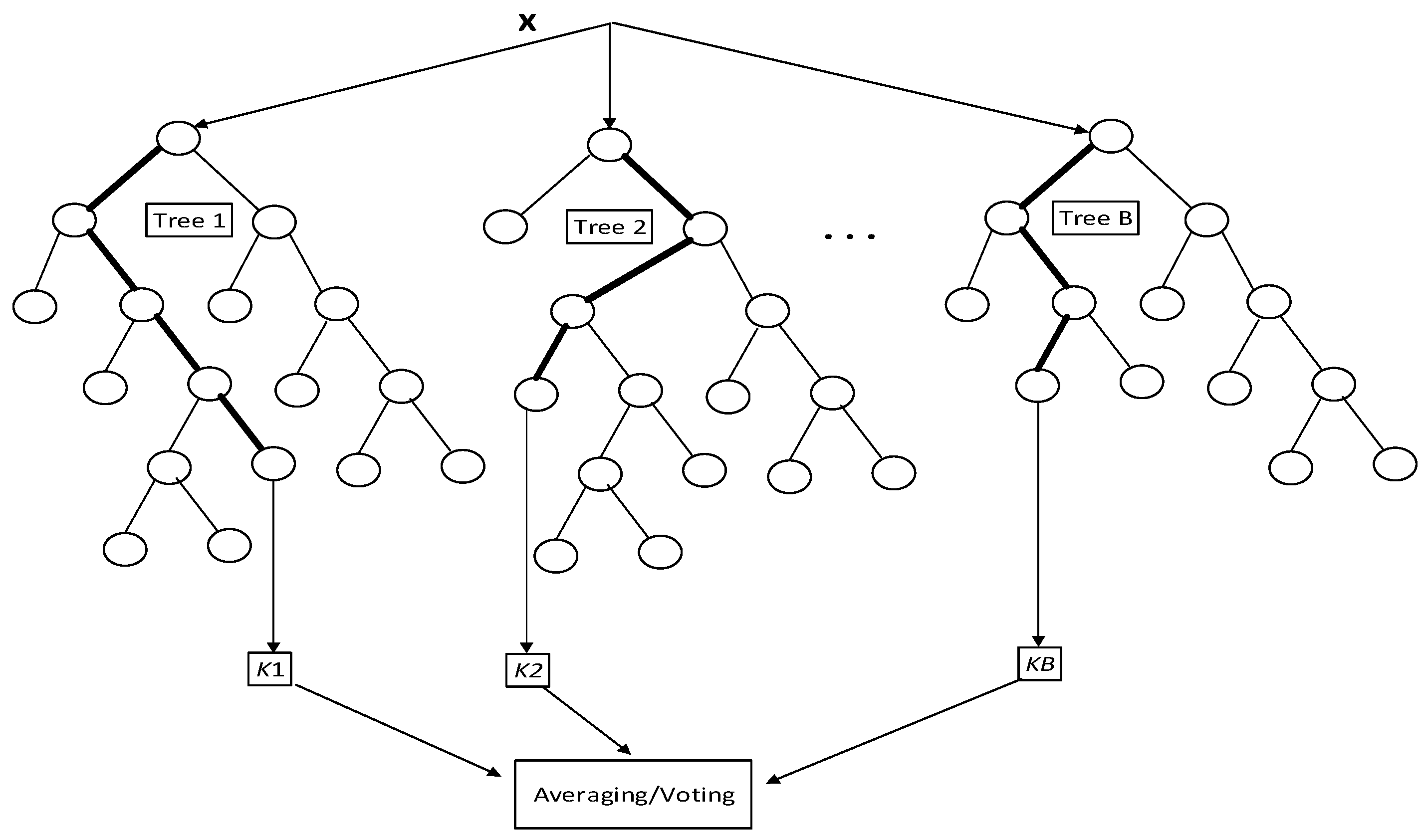
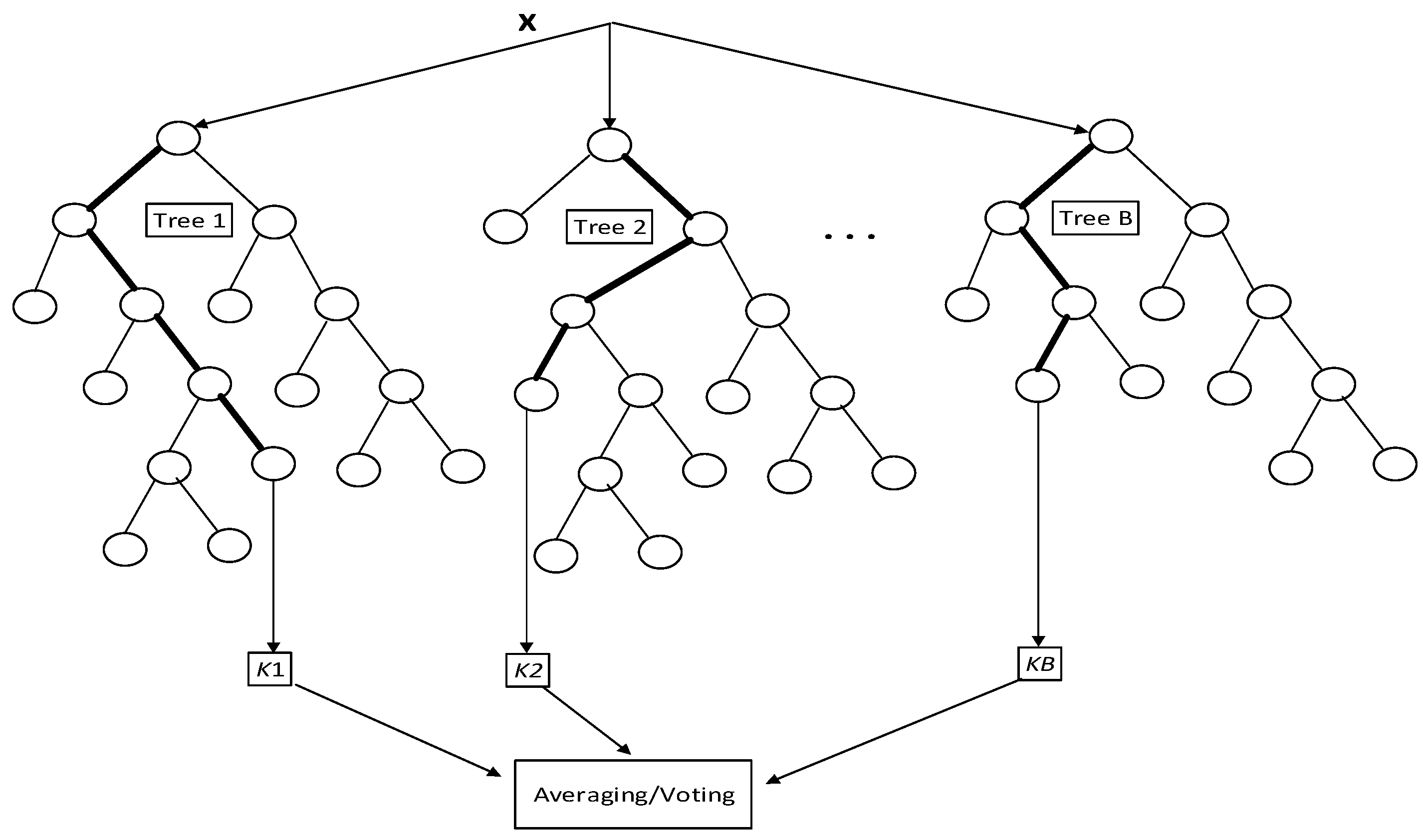
3.4.1. Random Forest
| Algorithm 2. Random Forest |
| 1: for b = 1 to B: // b is initial tree to build forest B (a) Draw a bootstrap sample Z of size N from the training data i.e., relative features. (b) Grow a random forest tree Tb to the bootstrapped data, by re-cursively repeating the following steps for each terminal node of the tree, until the minimum node size nmin is reached. i. Select m variables at random from the p variables. ii. Pick the best variable/split-point among the m. iii. Split the node into two daughter nodes. 2: Output the ensemble of trees {Tb}1B. 3: To find the prediction on this trained data at point x with regression mode Regression: |
3.4.2. Gradient Boosting Machine
| Algorithm 3. Gradient Boosting Machine |
| 1: procedure 2: input data (x, y)Ni = 1 3:number of iterations M 4: choice of the loss-function Ψ(y, f) 5: choice of the base-learner model h(x, θ) 6: initialize with a constant 7: for t = 1 to M do 8: compute the negative gradient gt(x) 9: fit a new base-learner function h(x, θt) 10: find the best gradient descent step-size ρt: ρt = 11: update the function estimate: 13: end procedure |
3.4.3. Rational of Combining RF and GBM
4. Experiment
5. Result and Discussion
- Correspondence in mean and standard deviations of the distributions of scores of human graders to that of the essay scoring system.
- Correlation, weighted kappa and percent agreement.
- Degree of difference between human–human agreement and automated–human agreement by the same agreement metrics.
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Brown, J.C.; Bokor, J.R.; Crippen, K.J.; Koroly, M.J. Translating current science into materials for high school via a scientist–teacher partnership. J. Sci. Teach. Educ. 2014, 25, 239–262. [Google Scholar] [CrossRef]
- Nicol, D. E-assessment by design: Using multiple-choice tests to good effect. J. Furth. High. Educ. 2007, 31, 53–64. [Google Scholar] [CrossRef]
- Mitchell, T.; Russell, T.; Broomhead, P.; Aldridge, N. Towards Robust Computerised Marking of Free-Text Responses. In Proceedings of the 6th CAA Conference, Loughborough University, London, UK, July 2002.
- Butcher, P.G.; Jordan, S.E. A comparison of human and computer marking of short free-text student responses. Comput. Educ. 2010, 55, 489–499. [Google Scholar] [CrossRef]
- Datta, R.; Joshi, D.; Li, J.; Wang, J.Z. Image retrieval: Ideas, influences, and trends of the new age. ACM Comput. Surv. (CSUR) 2008, 40, 5. [Google Scholar] [CrossRef]
- Wilson, T.D. Recent trends in user studies: Action research and qualitative methods. Inf. Res. 2000, 5, 5-3. [Google Scholar]
- Mehmood, A.; Choi, G.S.; Feigenblatt, O.F.; Park, H.W. Proving ground for social network analysis in the emerging research area “Internet of Things”(IoT). Scientometrics 2016, 109, 185–201. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013. [Google Scholar]
- Kursa, M.B.; Rudnicki, W.R. Feature selection with the Boruta package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mob. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Tandalla, L. Scoring Short Answer Essays. ASAP Short Answer Scoring Competition–Luis Tandalla’s Approach. 2012. Available online: https://kaggle2.blob.core.windows.net/competitions/kaggle/2959/media/TechnicalMethodsPaper.pdf (accessed on 17 September 2016).
- Ramachandran, L.; Cheng, J.; Foltz, P. Identifying patterns for short answer scoring using graph-based lexico-semantic text matching. In Proceedings of the Tenth Workshop on Innovative Use of NLP for Building Educational Applications, Denver, CO, USA, 04 June 2015; pp. 97–106.
- Joachims, T.A. Probabilistic of the Rocchio Algorithm with TFIDF for Text Categorization. In Proceedings of the 14th Internationa1 Conference on Machine Learning (ICML’97), Nasvile, TN, USA, 1997.
- Manning, C.D.; Raghavan, P.; Schutze, H. Introduction to Information Retrieval; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining data with random forests: A survey and results of new tests. Pattern Recognit. 2011, 44, 330–349. [Google Scholar] [CrossRef]
- BUhlmann, P.; Hothorn, T. Boosting algorithms: Regularization, prediction and model fitting. Stat. Sci. 2007, 22, 477–505. [Google Scholar] [CrossRef]
- Page, E.B. Computer grading of student prose, using modern concepts and software. J. Exp. Educ. 1994, 62, 127–142. [Google Scholar] [CrossRef]
- Mason, O.; Grove-Stephensen, I. Automated Free Text Marking with Paperless School. In Proceeding of the 6th Conference, Loughborough University, London, UK, July 2002; pp. 213–219.
- Foltz, P.W.; Laham, D.; Landauer, T.K. The intelligent essay assessor: Applications to educational technology. Interact. Multimedia Electron. J. Comput.-Enhanc. Learn. 1999, 1, 939–944. [Google Scholar]
- Mayfield, E.; Rose, C.P. LightSIDE: Open source machine learning for text accessible to non-experts. In Invited Chapter in the Handbook of Automated Essay Grading; Routledge Academic Press: Abingdon, Oxon, UK, 2013. [Google Scholar]
- Williams, R.; Dreher, H. Automatically grading essays with Markit\copyright. J. Issues Inf. Sci. Inf. Technol. 2004, 1, 693–700. [Google Scholar]
- Attali, Y.; Burstein, J. Automated essay scoring with e-rater® V.2. J. Technol. Learn. Assess. 2006, 4. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.800.4773&rep=rep1&type=pdf (accessed on 17 September 2016). [Google Scholar] [CrossRef]
- Schultz, M.T. The IntelliMetric Automated Essay Scoring Engine-A Review and an Application to Chinese Essay Scoring. In Handbook of Automated Essay Evaluation: Current Applications and New Directions; Shermis, M.D., Burstein, J.C., Eds.; Routledge: New York, NY, USA, 2013; pp. 89–98. [Google Scholar]
- Rich, C.S.; Schneider, M.C.; D’Brot, J.M. Applications of automated essay evaluation in West Virginia. In Handbook of Automated Essay Evaluation: Current Applications and New Directions; Shermis, M.D., Burstein, J., Eds.; Routledge: New York, NY, USA, 2013; pp. 99–123. [Google Scholar]
- Shermis, M.D.; Hamner, B. Contrasting state-of-the-art automated scoring of essays: Analysis. In Annual National Council on Measurement in Education Meeting; National Council on Measurement in Education: Vancouver, BC, Canada, 2012; pp. 14–16. [Google Scholar]
- Page, E.B. The imminence of grading essays by computer. Phi Delta Kappan 1966, 47, 238–243. [Google Scholar]
- Rudner, L.M.; Liang, T. Automated essay scoring using Bayes’ theorem. J. Technol. Learn. Assess. 2002, 1. Available online: http://ejournals.bc.edu/ojs/index.php/jtla/article/viewFile/1668/1512 (accessed on 17 September 2016). [Google Scholar]
- Christie, J.R. Automated essay marking-for both style and content. In Proceedings of the Third Annual Computer Assisted Assessment Conference, Loughborough University, Loughborough, UK, June 1999.
- Thomas, P.; Haley, D.; DeRoeck, A.; Petre, M. E-assessment using latent semantic analysis in the computer science domain: A pilot study. In Proceedings of the Workshop on eLearning for Computational Linguistics and Computational Linguistics for eLearning, Geneva, Switzerland, 28 August 2004; Association for Computational Linguistics: Stroudsburg, PA, USA; pp. 38–44.
- Islam, M.M.; Hoque, A.L. Automated essay scoring using generalized latent semantic analysis. In Proceedings of the 2010 13th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 23–25 December 2010; pp. 358–363.
- Baker, R.S.; Yacef, K. The state of educational data mining in 2009: A review and future visions. JEDM 2009, 1, 3–17. [Google Scholar]
- Romero, C.; Ventura, S.; Pechenizkiy, M.; Baker, R.S. (Eds.) Handbook of Educational Data Mining; CRC Press: Boca Raton, FL, USA, 2010.
- Pena-Ayala, A. Educational data mining: A survey and a data mining-based analysis of recent works. Exp. Syst. Appl. 2014, 41, 1432–1462. [Google Scholar] [CrossRef]
- Kim, J.; Shaw, E.; Xu, H.; Adarsh, G.V. Assisting Instructional Assessment of Undergraduate Collaborative Wiki and SVN Activities. In Proceedings of the 5th International Conference on Educational Data Mining (EDM), Chania, Greece, June 19–21 2012.
- Lopez, M.I.; Luna, J.M.; Romero, C.; Ventura, S. Classification via Clustering for Predicting Final Marks Based on Student Participation in Forums. In Proceedings of the 5th International Conference on Educational Data Mining (EDM), Chania, Greece, June 19–21 2012; pp. 148–151.
- Malmberg, J.; Jarvenoja, H.; Jarvela, S. Patterns in elementary school students′ strategic actions in varying learning situations. Instr. Sci. 2013, 41, 933–954. [Google Scholar] [CrossRef]
- Gobert, J.D.; Sao Pedro, M.A.; Baker, R.S.; Toto, E.; Montalvo, O. Leveraging educational data mining for real-time performance assessment of scientific inquiry skills within microworlds. JEDM 2012, 4, 111–143. [Google Scholar]
- Rodrigues, F.; Oliveira, P. A system for formative assessment and monitoring of students’ progress. Comput. Educ. 2014, 76, 30–41. [Google Scholar] [CrossRef]
- Zupanc, K.; Bosnic, Z. Advances in the Field of Automated Essay Evaluation. Informatica 2015, 39, 383. [Google Scholar]
- ASAP-SAS. Scoring Short Answer Essays. ASAP Short Answer Scoring Competition System Description, 2012. Available online: http://www.kaggle.com/c/asap-sas/ (accessed on 17 September 2016).
- Uysal, A.K.; Gunal, S. A novel probabilistic feature selection method for text classification. Knowl.-Based Syst. 2012, 36, 226–235. [Google Scholar] [CrossRef]
- Uysal, A.K.; Gunal, S. The impact of preprocessing on text classification. Inf. Process. Manag. 2014, 50, 104–112. [Google Scholar] [CrossRef]
- Norvig, P. How to Write a Spelling Corrector. Available online: http://norvig.com/spell-correct.html (accessed on 17 September 2016).
- Porter, M. Porter Stemming Algorithm. Available online: http://tartarus.org/martin/PorterStemmer/ (accessed on 17 September 2016).
- Dara, J.; Dowling, J.N.; Travers, D.; Cooper, G.F.; Chapman, W.W. Evaluation of preprocessing techniques for chief complaint classification. J. Biomed. Inf. 2008, 41, 613–623. [Google Scholar] [CrossRef] [PubMed]
- Vicient, C.; Sanchez, D.; Moreno, A. An automatic approach for ontology-based feature extraction from heterogeneous textual resources. Eng. Appl. Artif. Intell. 2013, 26, 1092–1106. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Y.; Feng, L.; Zhu, X. Novel feature selection method based on harmony search for email classification. Knowl.-Based Syst. 2015, 73, 311–323. [Google Scholar] [CrossRef]
- Yang, B.; Zhang, Y.; Li, X. Classifying text streams by keywords using classifier ensemble. Data Knowl. Eng. 2011, 70, 775–793. [Google Scholar] [CrossRef]
- Yang, Y.; Pedersen, J.O. A comparative study on feature selection in text categorization. ICML 1997, 97, 412–420. [Google Scholar]
- Nilsson, R.; Pena, J.M.; Bjorkegren, J.; Tegner, J. Consistent feature selection for pattern recognition in polynomial time. J. Mach. Learn. Res. 2007, 8, 589–612. [Google Scholar]
- Pandey, U.; Chakravarty, S. A survey on text classification techniques for e-mail filtering. In Proceedings of the 2010 Second International Conference on Machine Learning and Computing (ICMLC), Banglore, India, 9–11 Febuary 2010; pp. 32–36.
- Deng, X.B.; Ye, Y.M.; Li, H.B.; Huang, J.Z. An improved random forest approach for detection of hidden web search interfaces. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; Volume 3, pp. 1586–1591.
- Bissacco, A.; Yang, M.H.; Soatto, S. Fast human pose estimation using appearance and motion via multi-dimensional boosting regression. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8.
- Hutchinson, R.A.; Liu, L.P.; Dietterich, T.G. Incorporating Boosted Regression Trees into Ecological Latent Variable Models. AAAI 2011, 11, 1343–1348. [Google Scholar]
- Pittman, S.J.; Brown, K.A. Multi-scale approach for predicting fish species distributions across coral reef seascapes. PLoS ONE 2011, 6, e20583. [Google Scholar] [CrossRef] [PubMed]
- Johnson, R.; Zhang, T. Learning nonlinear functions using regularized greedy forest. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 942–954. [Google Scholar] [CrossRef] [PubMed]
- Shermis, M.D.; Burstein, J. Handbook of Automated Essay Evaluation: Current Applications and New Directions; Routledge: New York, NY, USA, 2013. [Google Scholar]
- Guthrie, D.; Allison, B.; Liu, W.; Guthrie, L.; Wilks, Y. A closer look at skip-gram modelling. In Proceedings of the 5th international Conference on Language Resources and Evaluation (LREC-2006), Genoa, Italy, 24–26 May 2006; pp. 1–4.

{kind=link}
{kind=link}
| Essay Text | If I was to replicate the experiment, I would need to know the amount of vinegar in each container, the size of the containers, and what was used to weigh the samples. | ||
| After preprocessing, the features will be extracted. | |||
| Regular Expression | f0 | f1 | f2 |
| 1 | 1 | 0 | |
| Unigram | if | i | of … |
| 1 | 2 | 2 … | |
| Bigram | if_i | i_was | was_to … |
| 1 | 1 | 1 … | |
| Statistics | Number of words | Number of sentences | Average sentences |
| 33 | 2 | 16.5 | |
| Word2vec | if | i | was … |
| Cosine similarity scores of vectors with this word. | Cosine similarity scores of vectors with this word. | Cosine similarity scores of vectors with this word. | |
| Subject with Set Numbers | Training Set Size | Test Set Size |
|---|---|---|
| Science (Set#1,2,10) | 4590 | 1529 |
| Biology (Set#5,6) | 3592 | 1197 |
| English Language Arts (Set#3,4) | 3465 | 1209 |
| English (Set#7,8,9) | 5396 | 1797 |
| Research Articles | Training Set Size | Test Set Size |
|---|---|---|
| Internet of Things (IoT) | 653 | 162 |
| Non-IoT | 162 | 41 |
| Value of Kappa | Strength of Agreement |
|---|---|
| <0.20 | Poor |
| 0.21–0.40 | Fair |
| 0.41–0.60 | Moderate |
| 0.61–0.80 | Good |
| 0.81–1.00 | Very good |
| Set Number | Tandalla | AutoP | Proposed |
|---|---|---|---|
| 1 | 0.85 | 0.86 | 0.87 |
| 2 | 0.77 | 0.78 | 0.81 |
| 3 | 0.64 | 0.66 | 0.78 |
| 4 | 0.65 | 0.70 | 0.77 |
| 5 | 0.85 | 0.84 | 0.86 |
| 6 | 0.88 | 0.88 | 0.79 |
| 7 | 0.69 | 0.66 | 0.72 |
| 8 | 0.62 | 0.63 | 0.70 |
| 9 | 0.84 | 0.84 | 0.86 |
| 10 | 0.78 | 0.79 | 0.83 |
| Overall | 0.77 | 0.78 | 0.80 |
| Proposed | Human | |||
|---|---|---|---|---|
| - | 0 | 1 | 2 | 3 |
| 0 | 1795 | 525 | 112 | 31 |
| 1 | 215 | 1398 | 78 | 41 |
| 2 | 17 | 49 | 1122 | 22 |
| 3 | 15 | 18 | 23 | 271 |
| PGSN-IoT | Proposed | |||
|---|---|---|---|---|
| Predict-ive | Predict+ive | Predict-ive | Predict+ive | |
| Predict-ive | 2 | 38 | 4 | 25 |
| Predict+ive | 9 | 154 | 10 | 164 |
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mehmood, A.; On, B.-W.; Lee, I.; Choi, G.S. Prognosis Essay Scoring and Article Relevancy Using Multi-Text Features and Machine Learning. Symmetry 2017, 9, 11. https://doi.org/10.3390/sym9010011
Mehmood A, On B-W, Lee I, Choi GS. Prognosis Essay Scoring and Article Relevancy Using Multi-Text Features and Machine Learning. Symmetry. 2017; 9(1):11. https://doi.org/10.3390/sym9010011
Chicago/Turabian StyleMehmood, Arif, Byung-Won On, Ingyu Lee, and Gyu Sang Choi. 2017. "Prognosis Essay Scoring and Article Relevancy Using Multi-Text Features and Machine Learning" Symmetry 9, no. 1: 11. https://doi.org/10.3390/sym9010011
APA StyleMehmood, A., On, B.-W., Lee, I., & Choi, G. S. (2017). Prognosis Essay Scoring and Article Relevancy Using Multi-Text Features and Machine Learning. Symmetry, 9(1), 11. https://doi.org/10.3390/sym9010011