
DIaaS: Resource Management System for the Intra-Cloud with On-Premise Desktops

_Park.png)

Abstract
:1. Introduction
2. Related Works
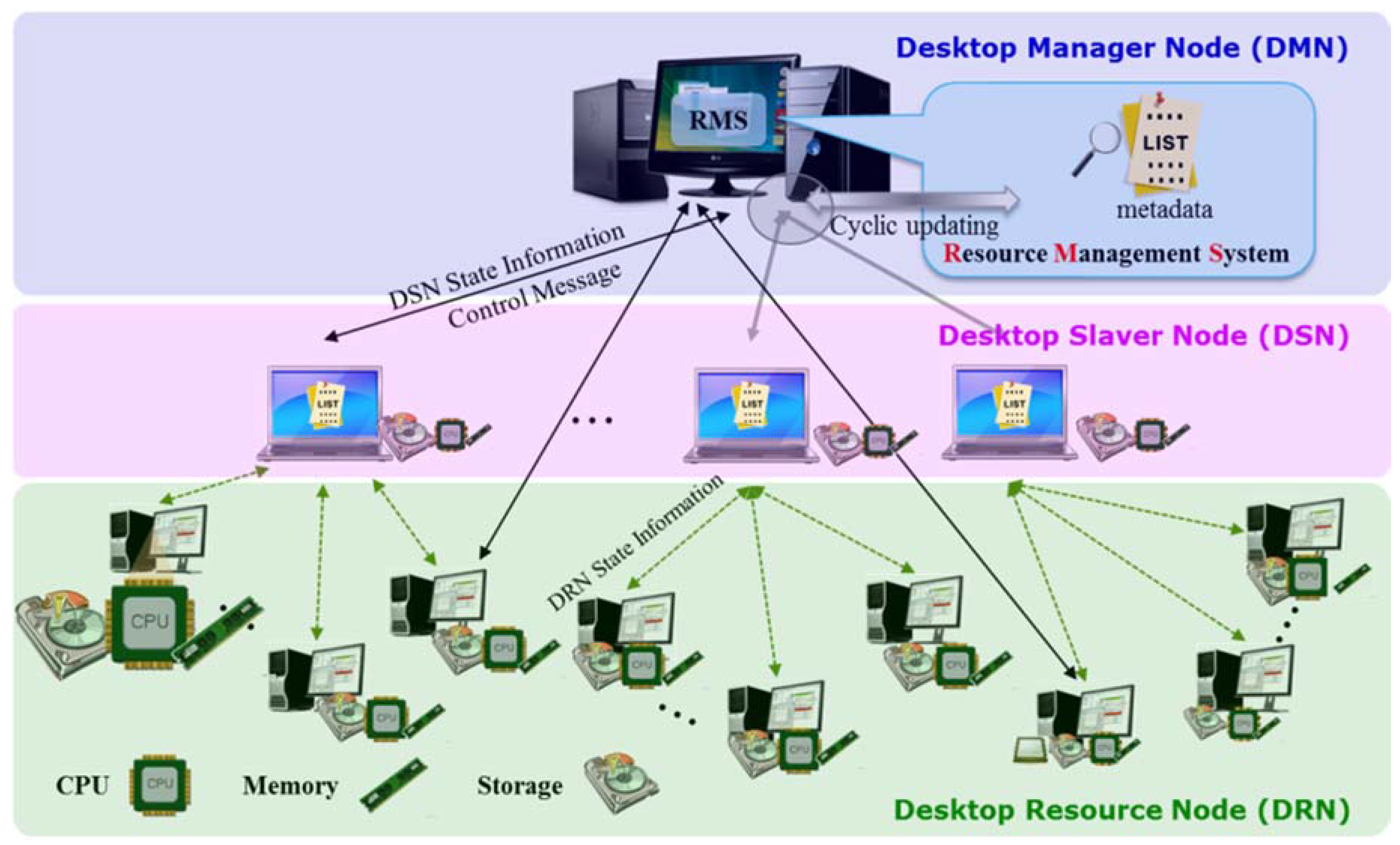
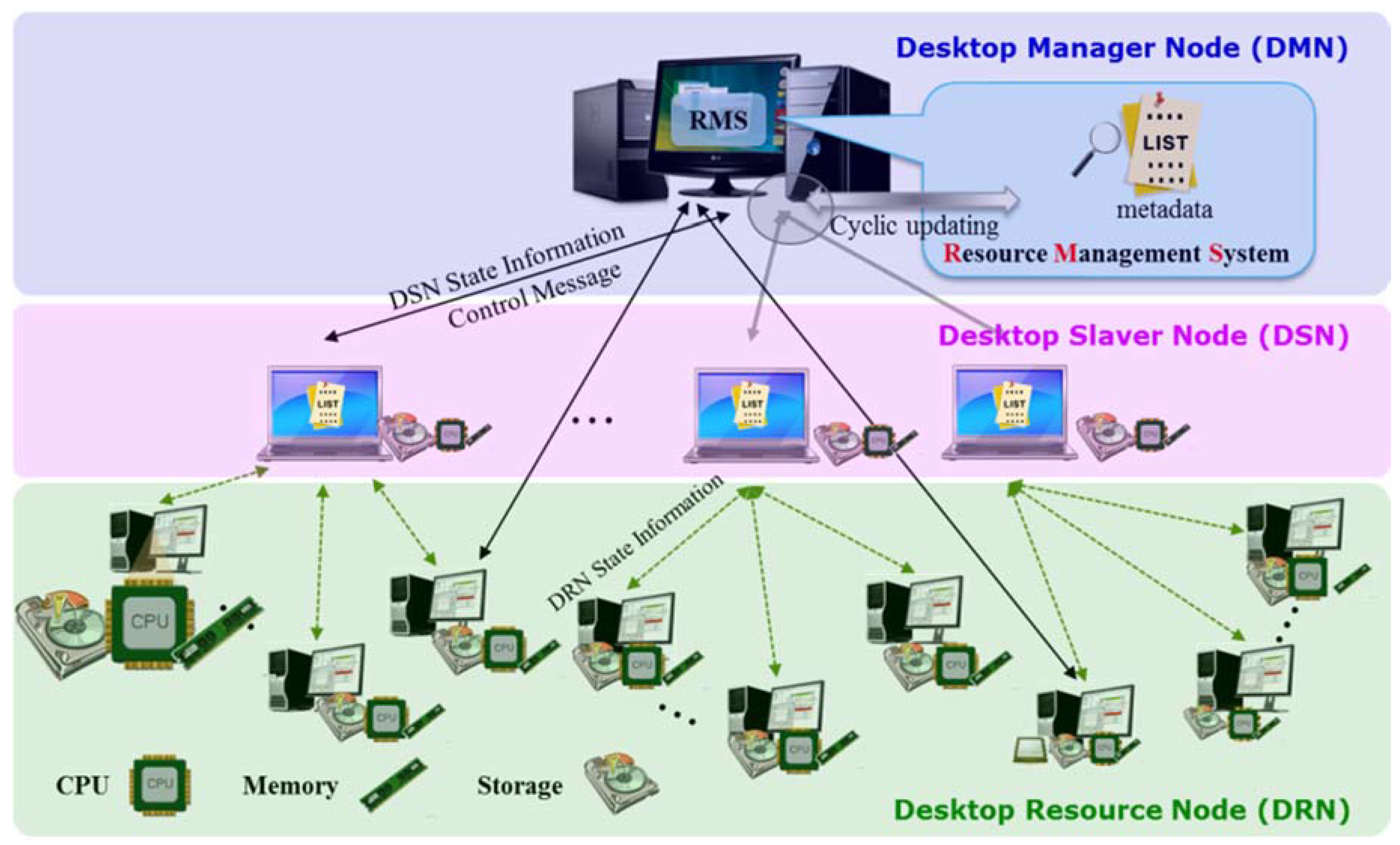
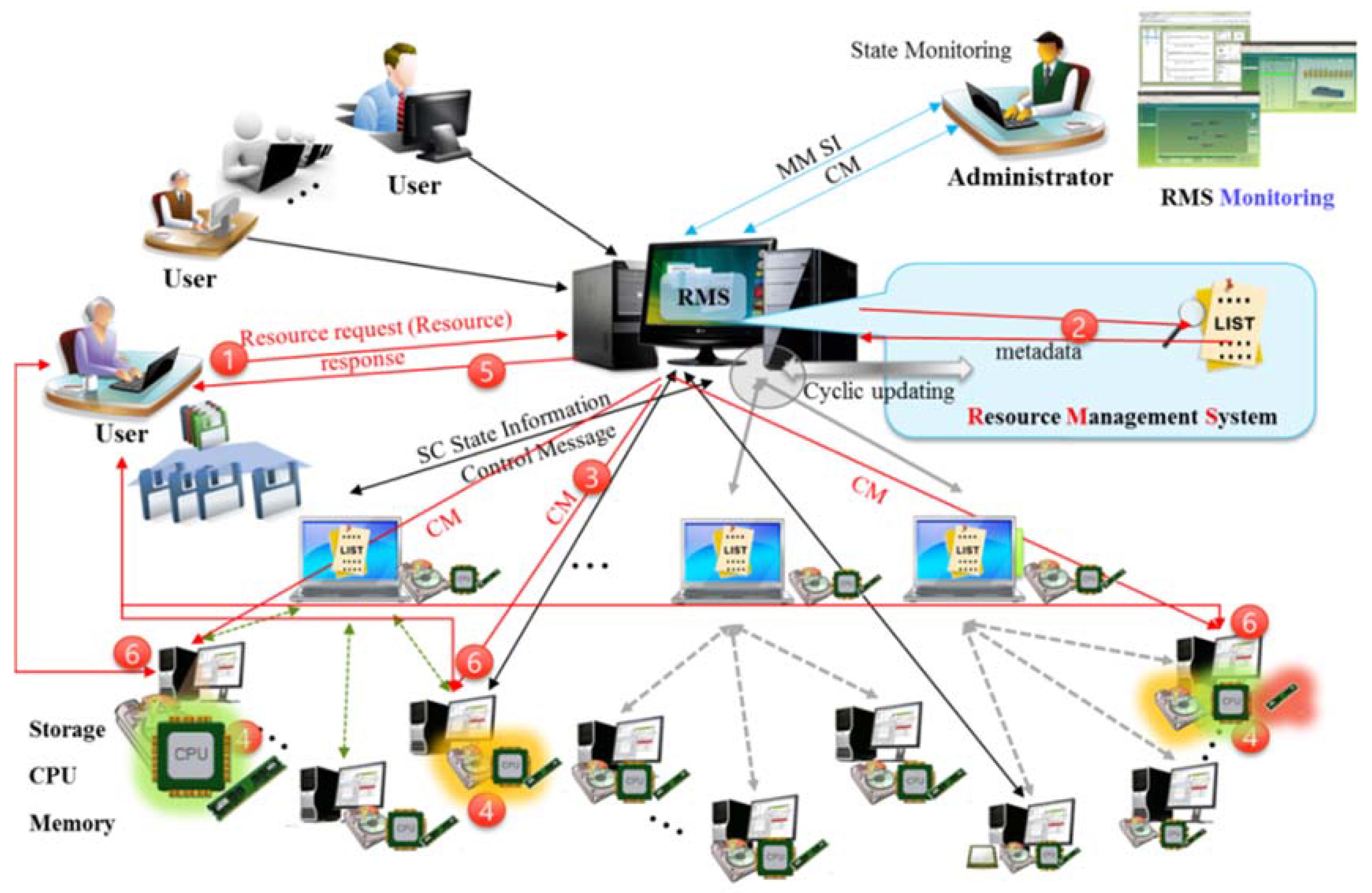
3. On-Premise Intra-Cloud Resource Management Scheme
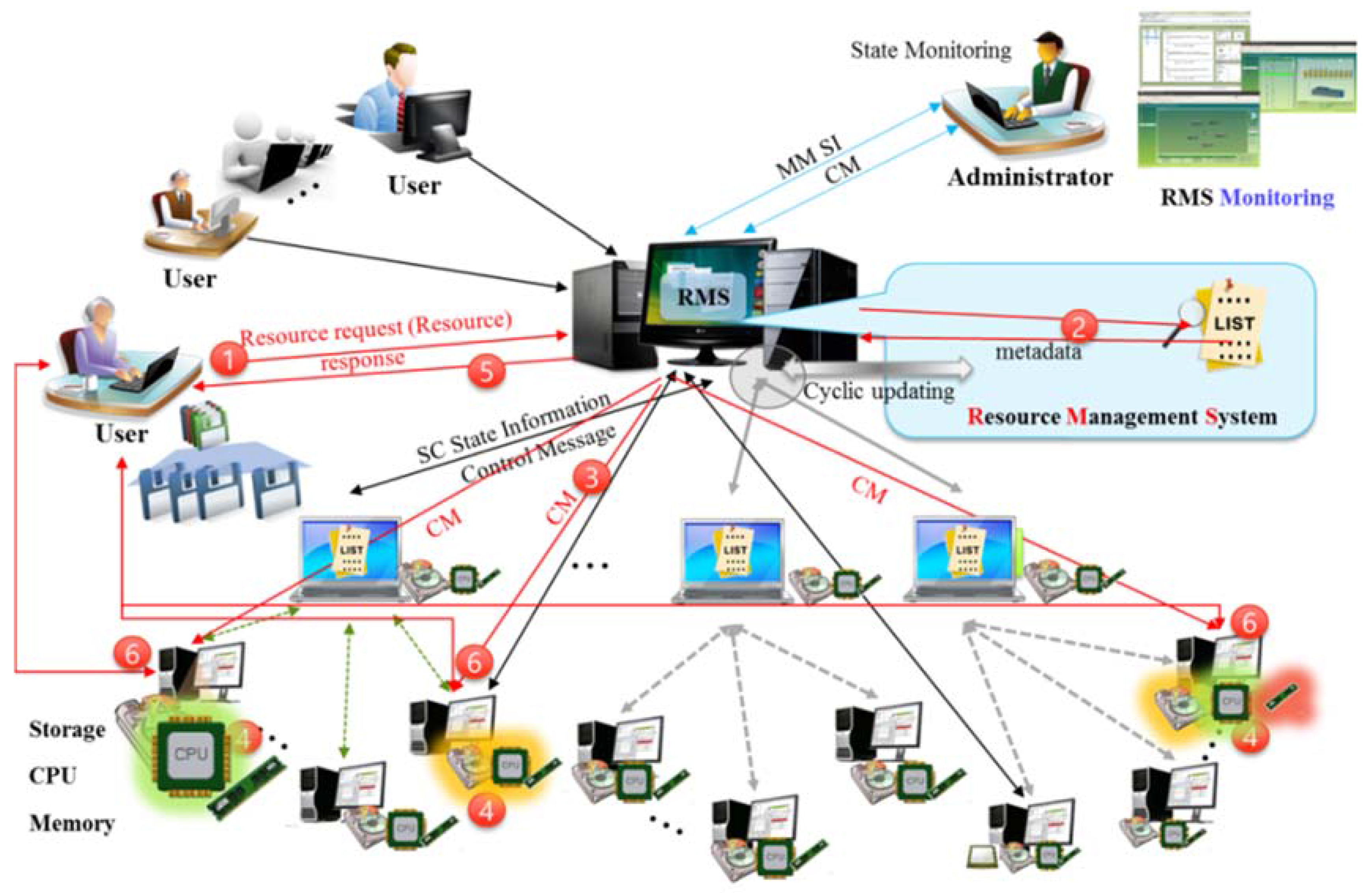
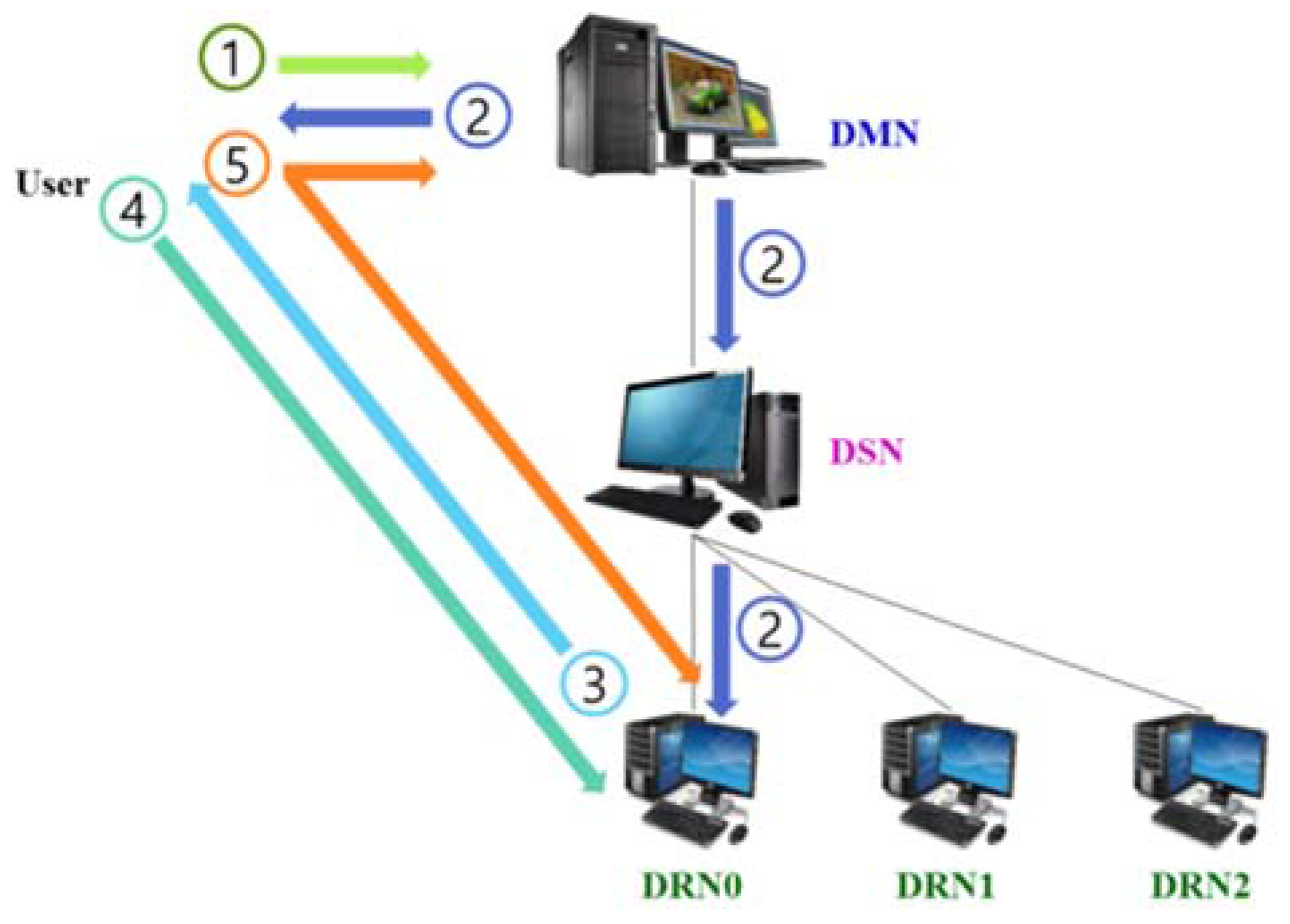
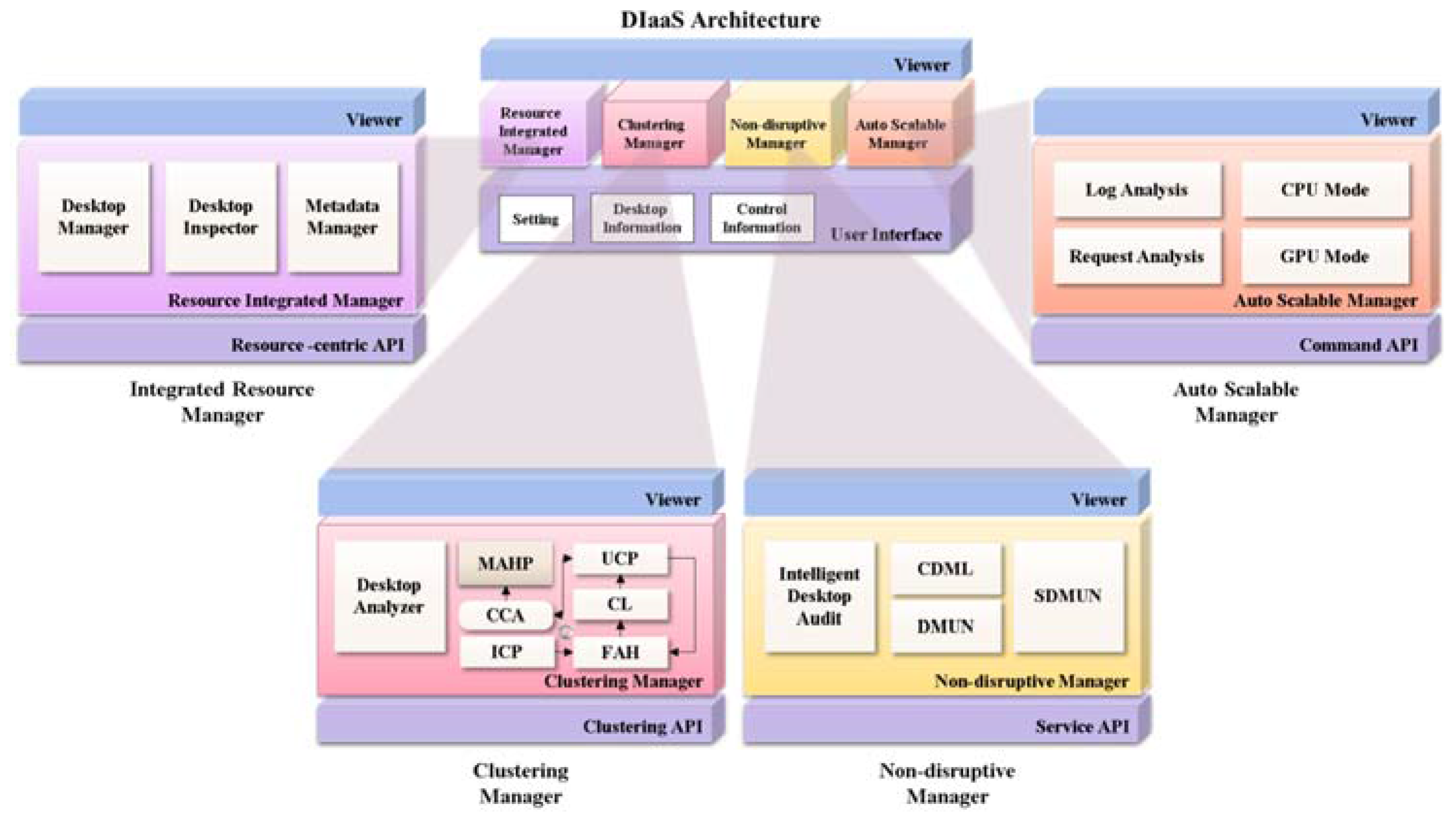
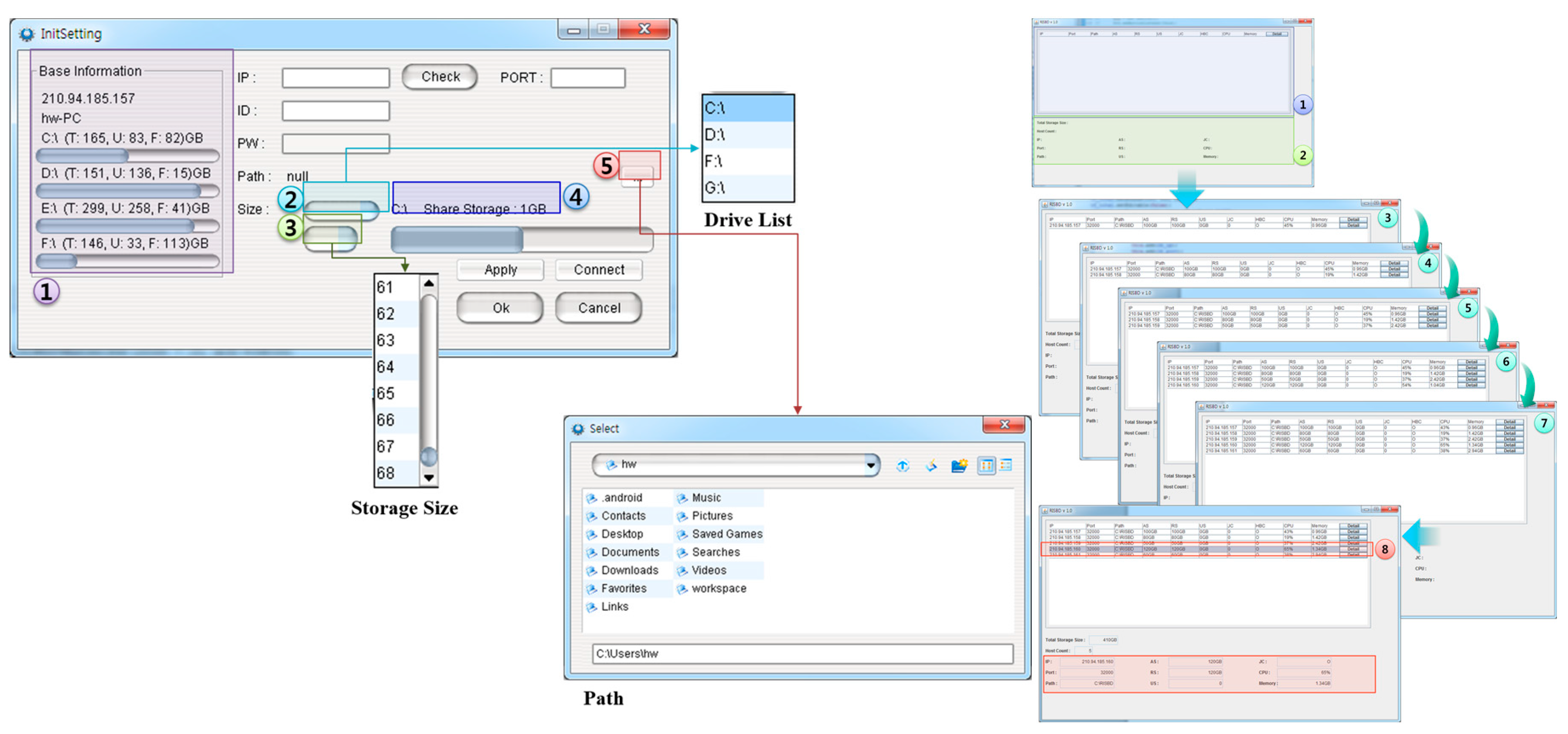
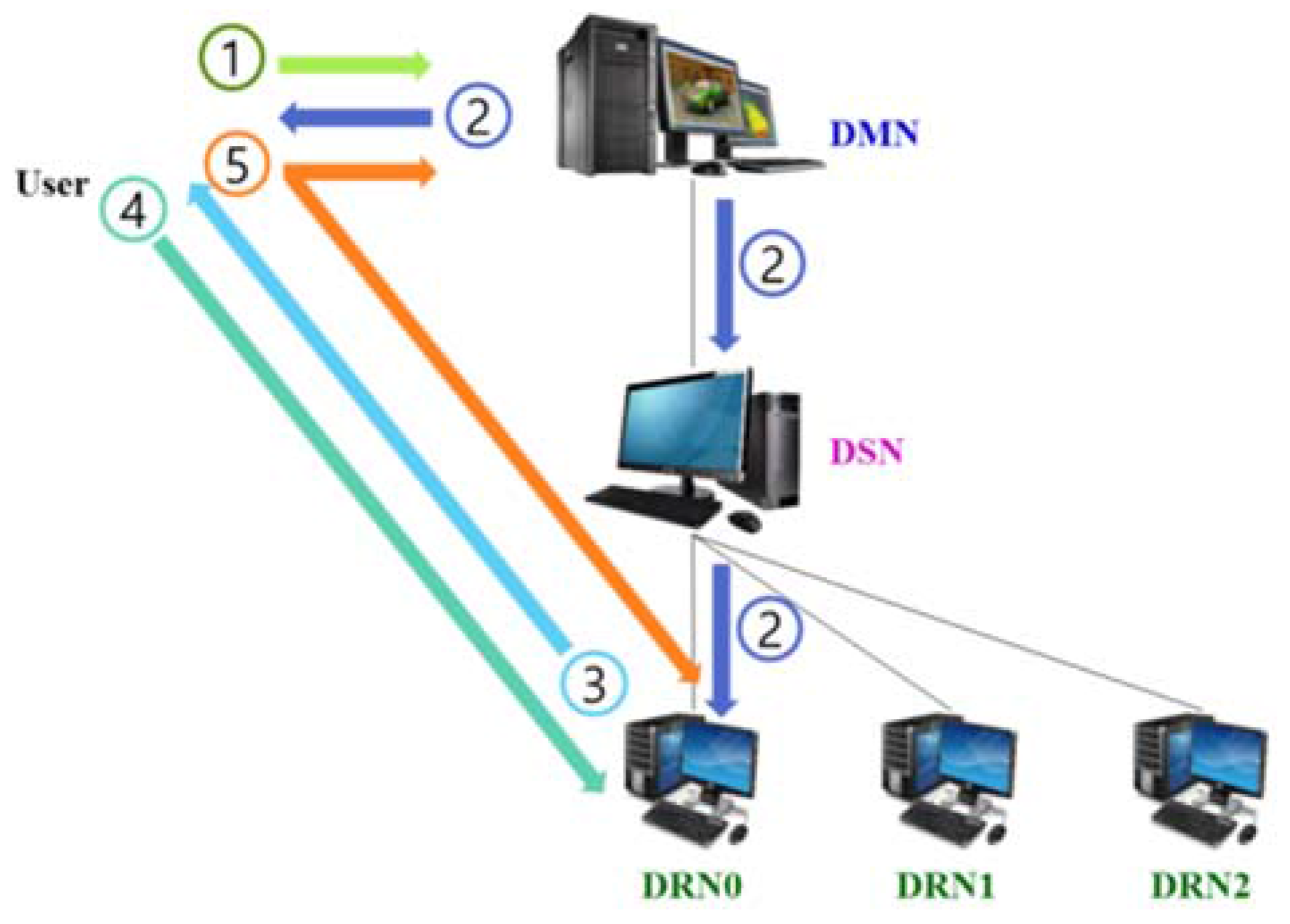
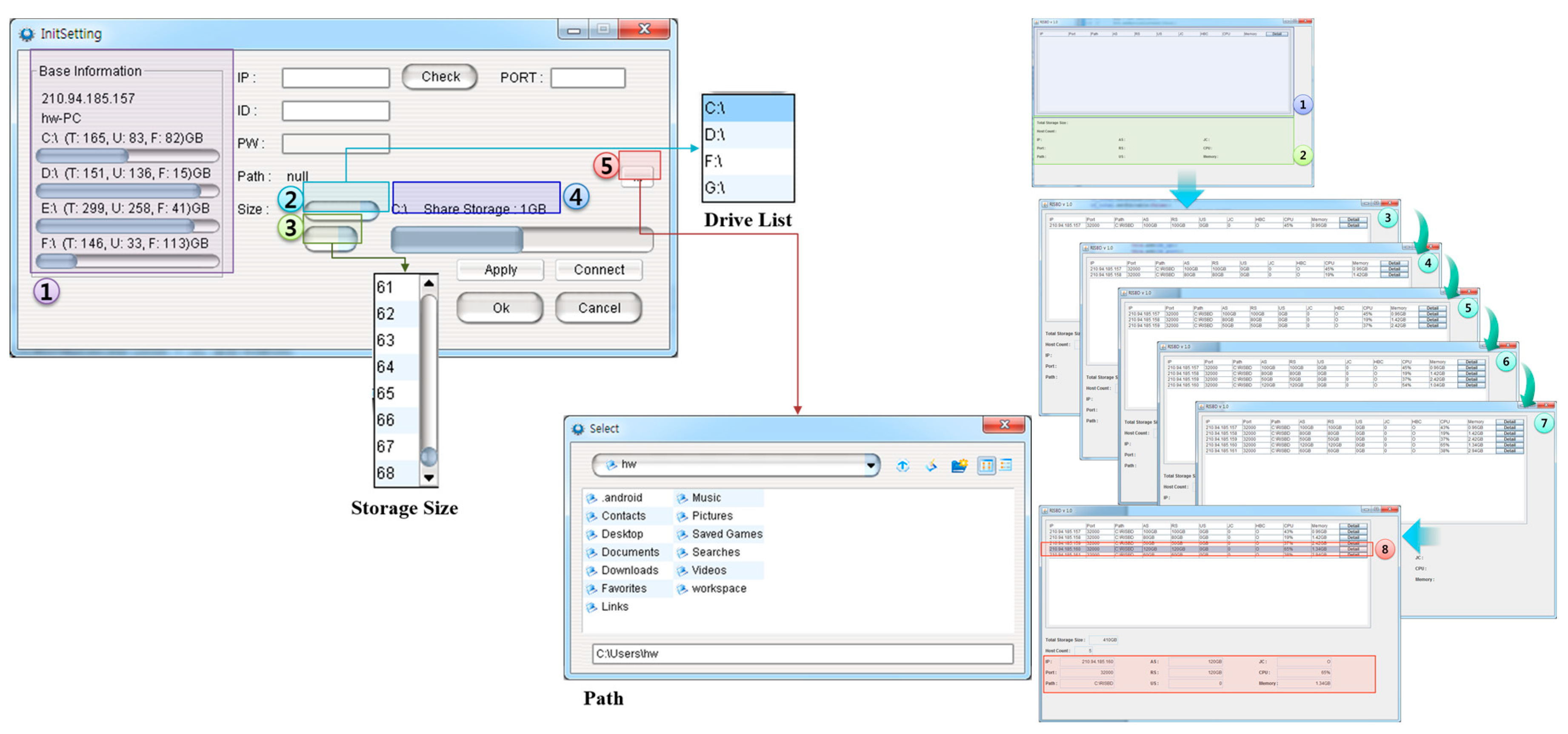
3.1. On-Premise Integrated Resource Management
- Step 1
- The user requests computing or storage resources of the DMN through the client program.
- Step 2
- Using metadata, the DMN resource management system determines whether to accept the request depending on the requested computing and storage size.
- Step 3
- When the request is accepted, the location of the resource to process the job is selected. The selected resource information is sent as a control message through the desktop slave node (DSN) for direct connection with the client program.
- Step 4
- The client information is included in the control message sent to the service resource, and the job performance is prepared.
- Step 5
- The DMN sends the resource information to perform the job as a response message to the client program.
- Step 6
- The client program and the job-performing desktop resource node (DRN) execute the job through a direct connection.
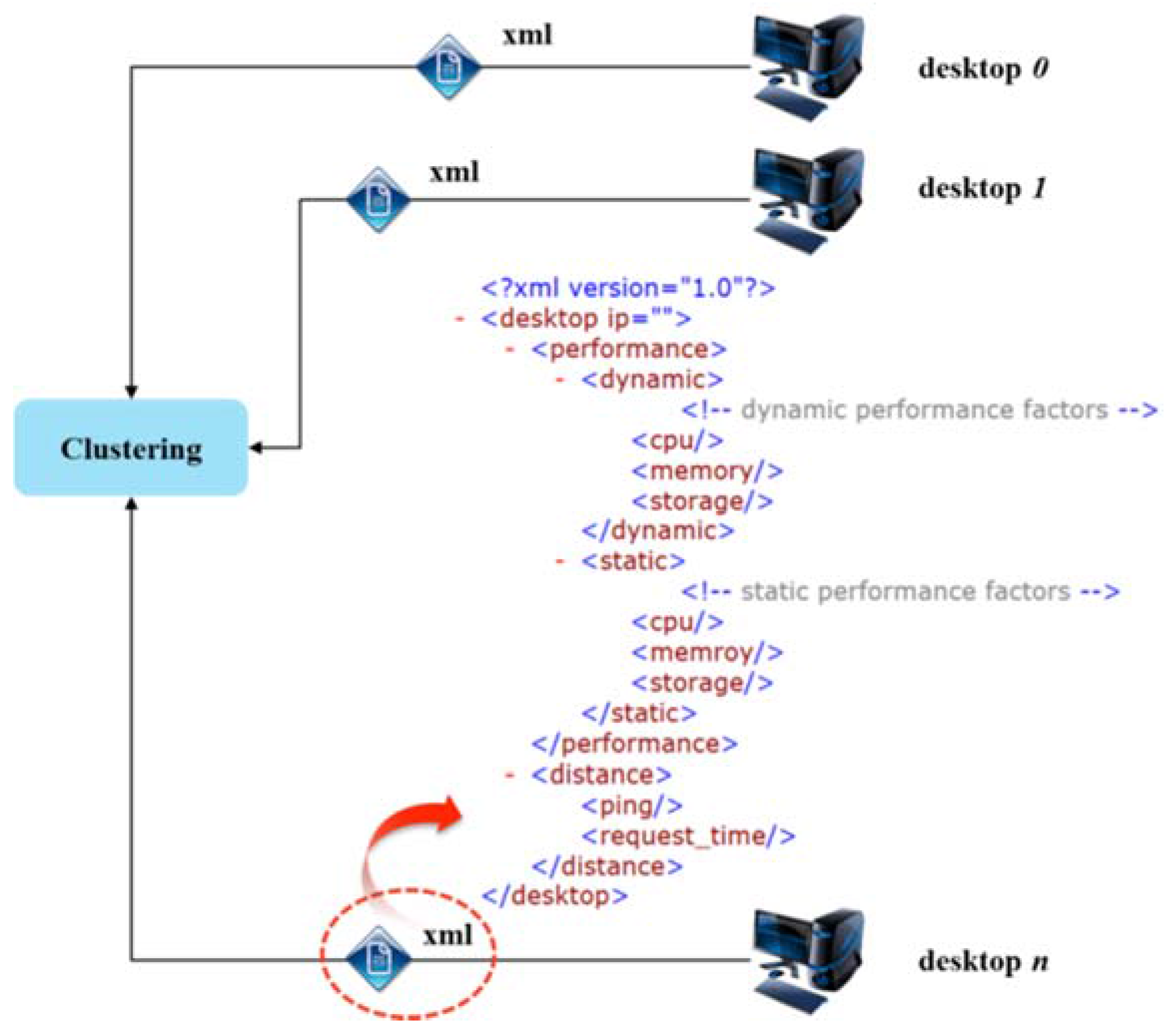
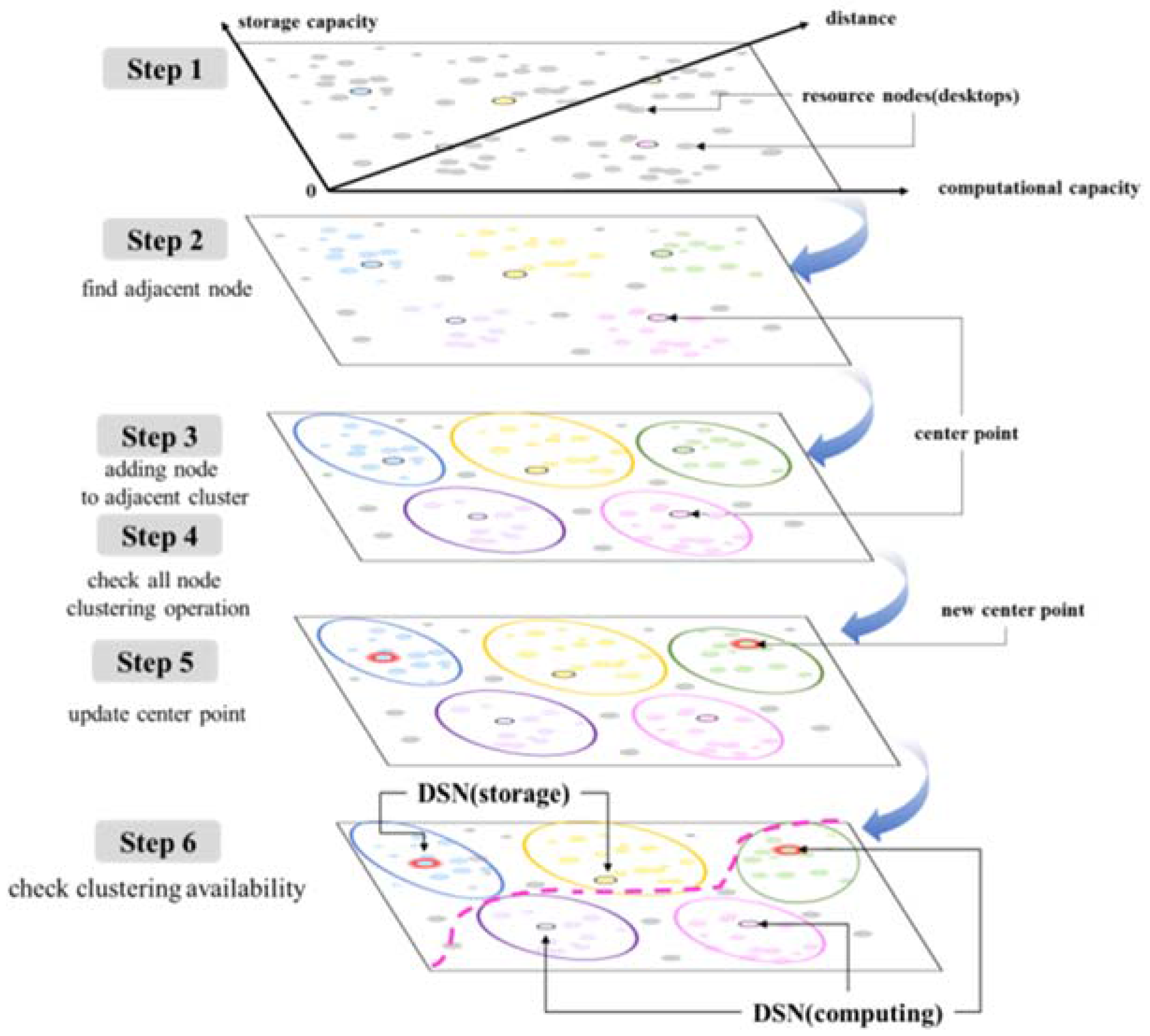
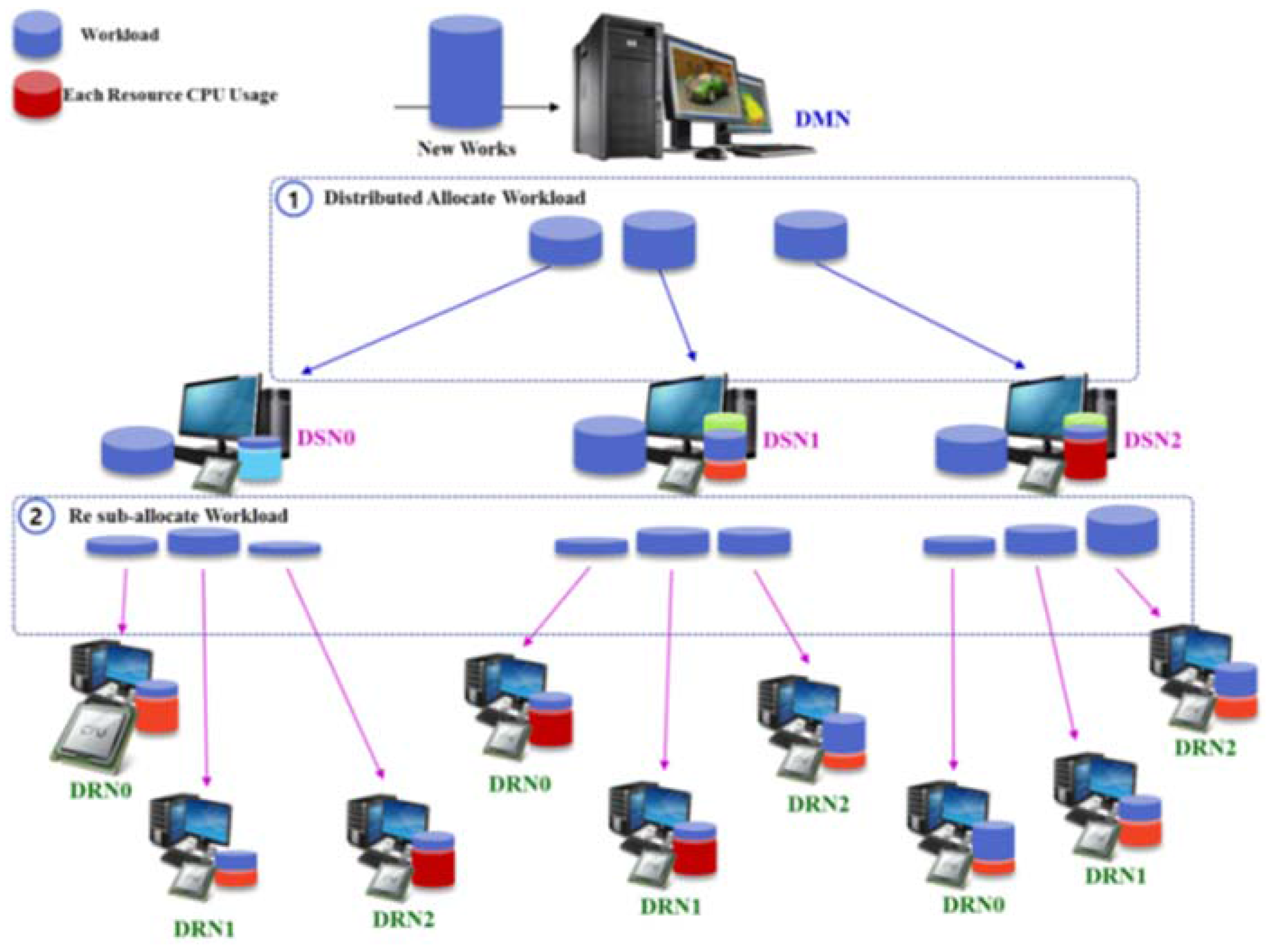
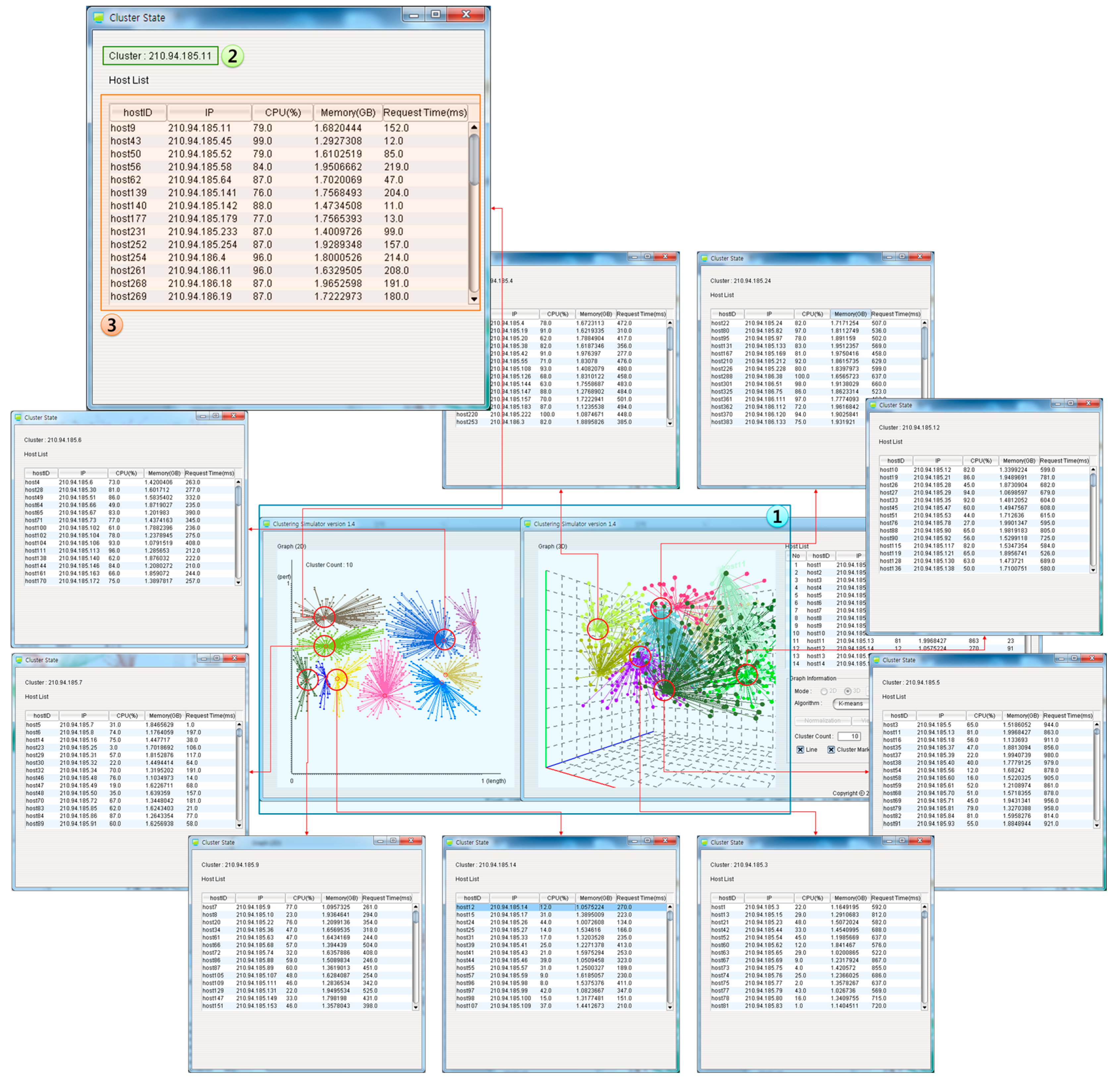
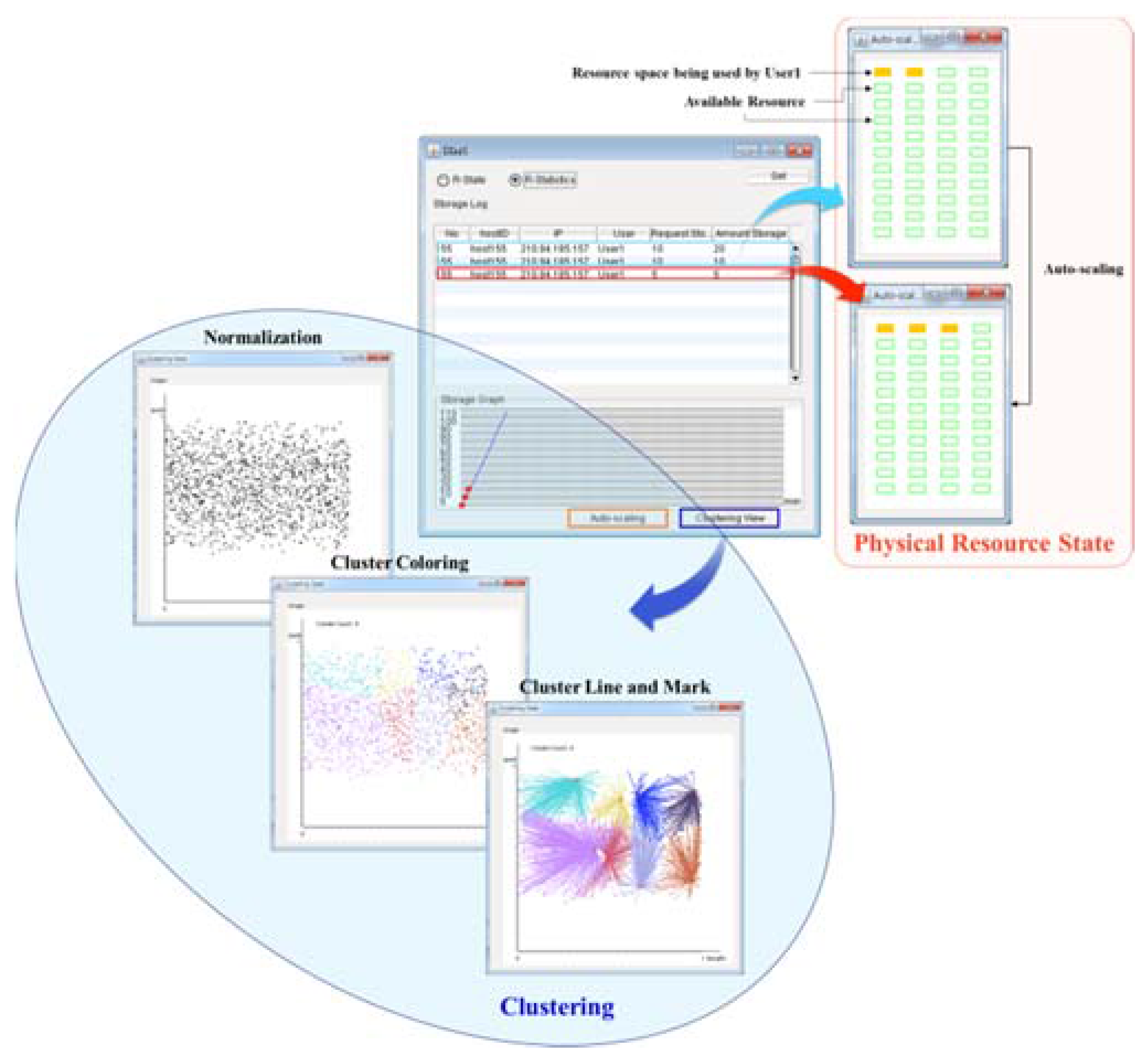
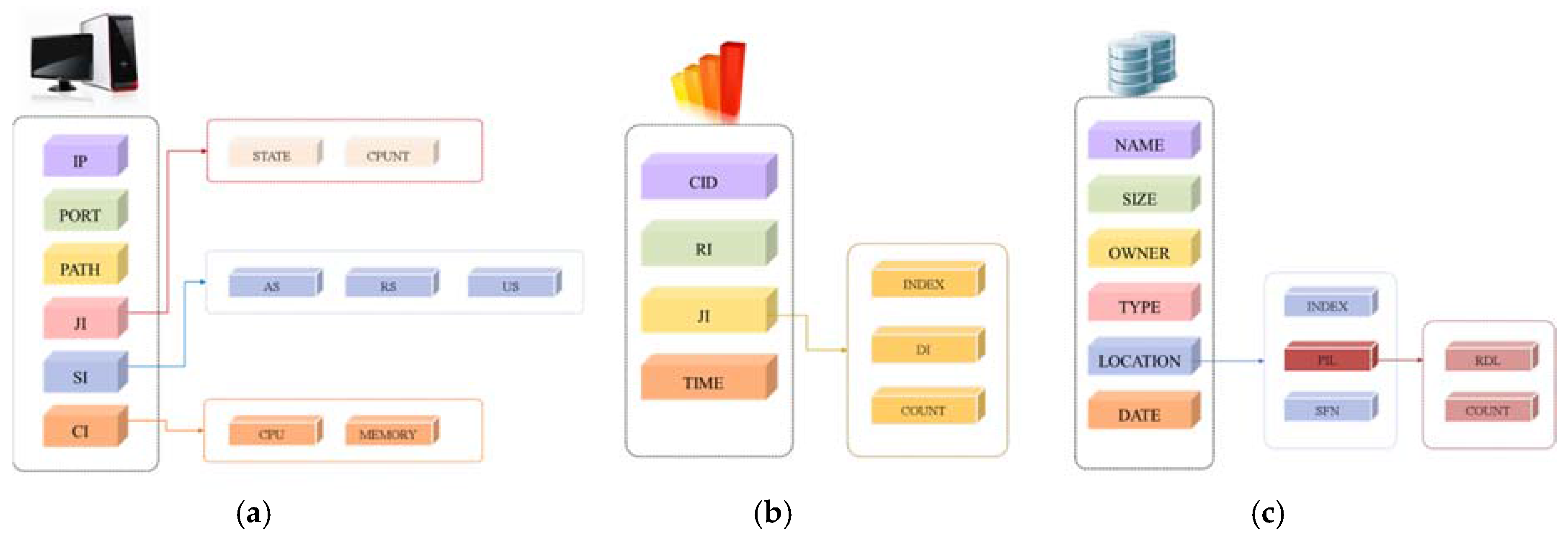
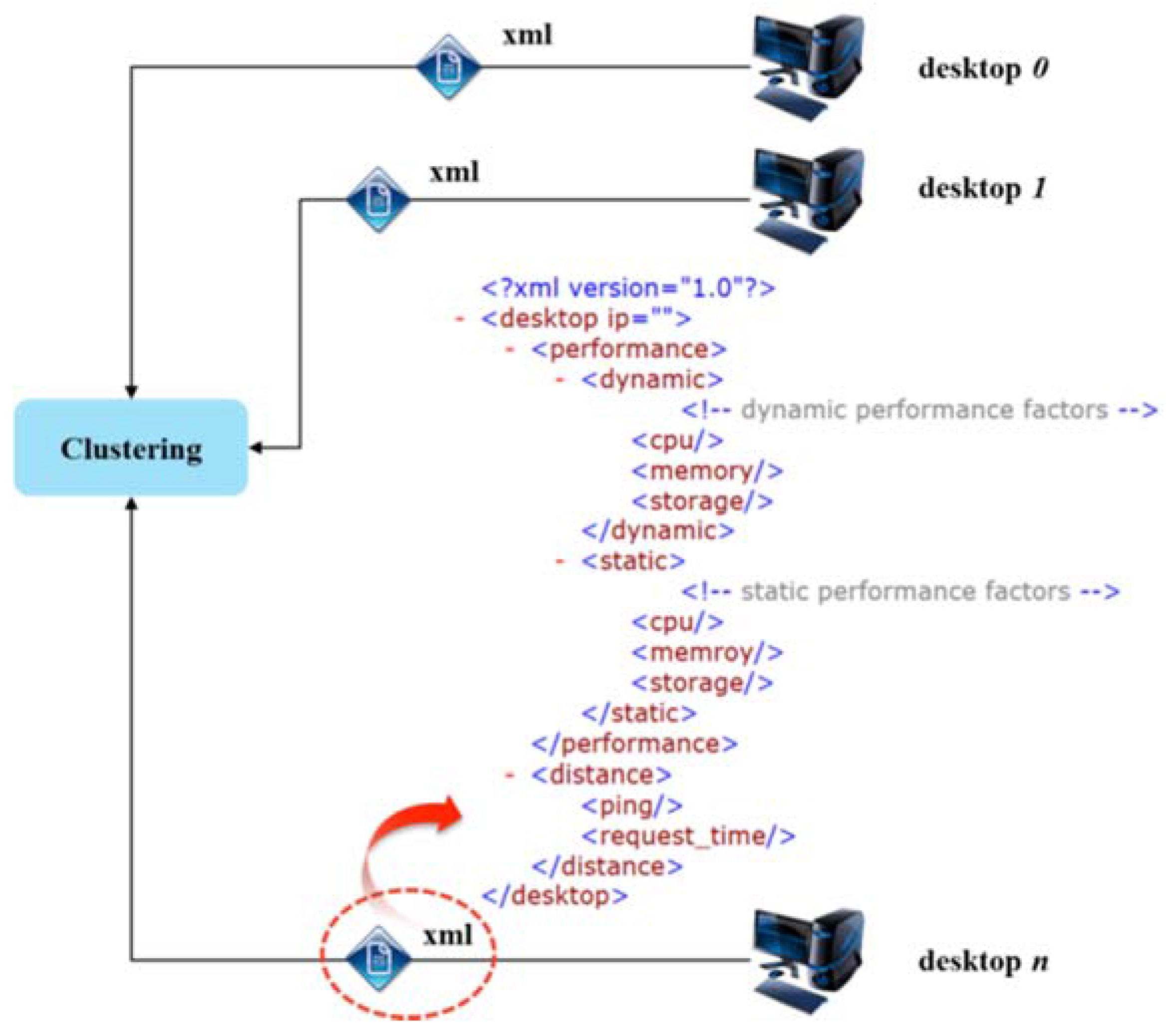
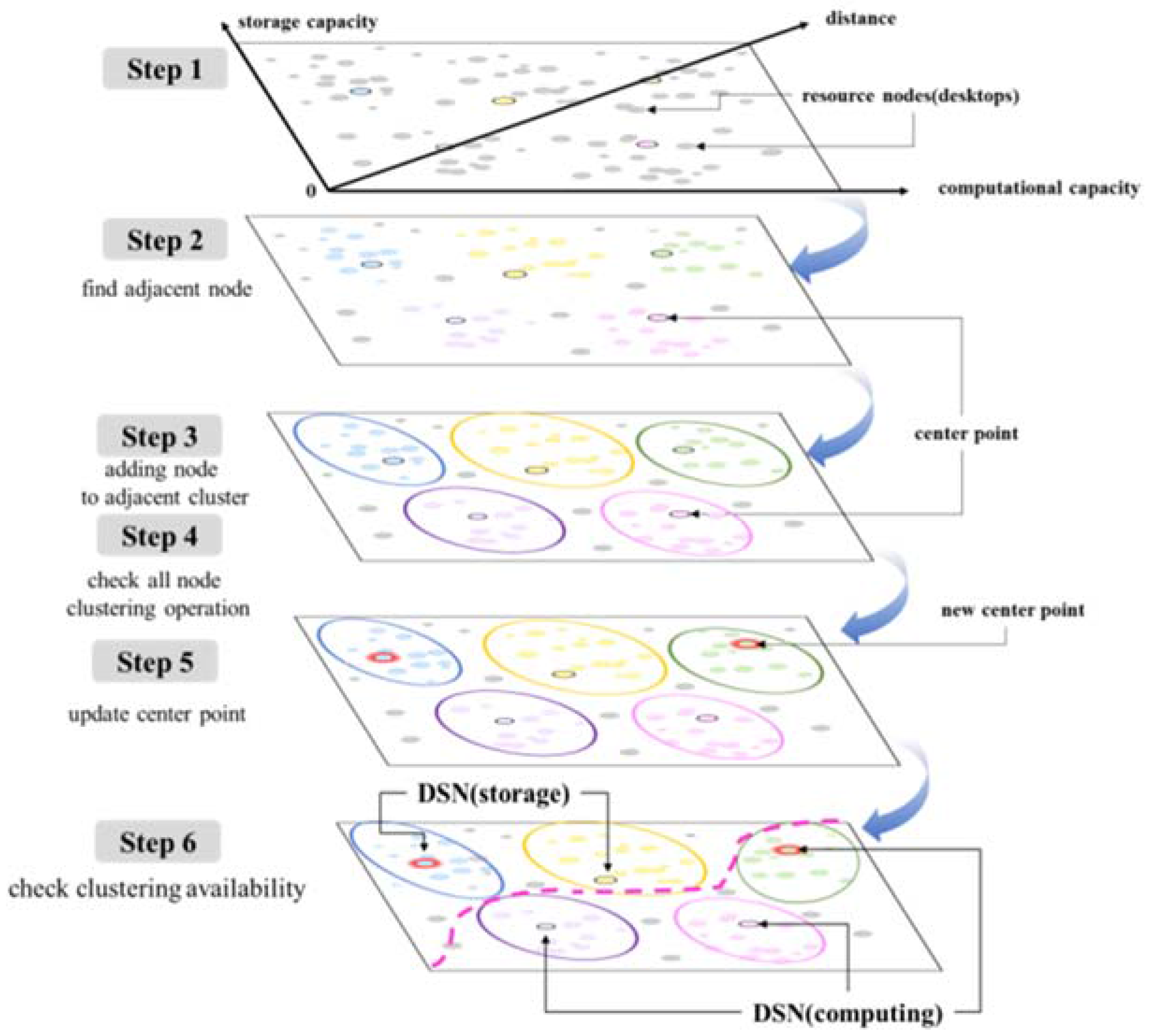
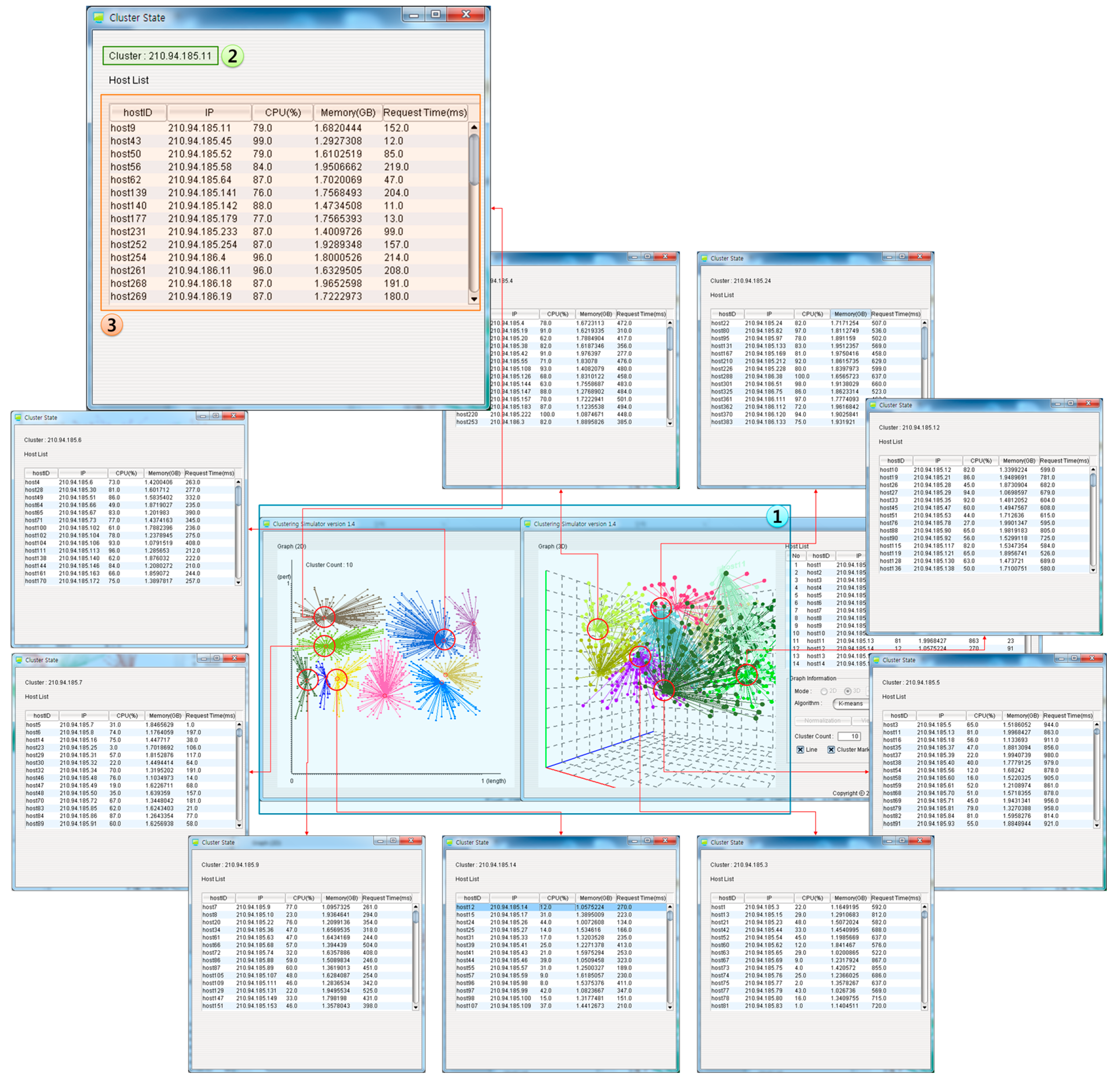
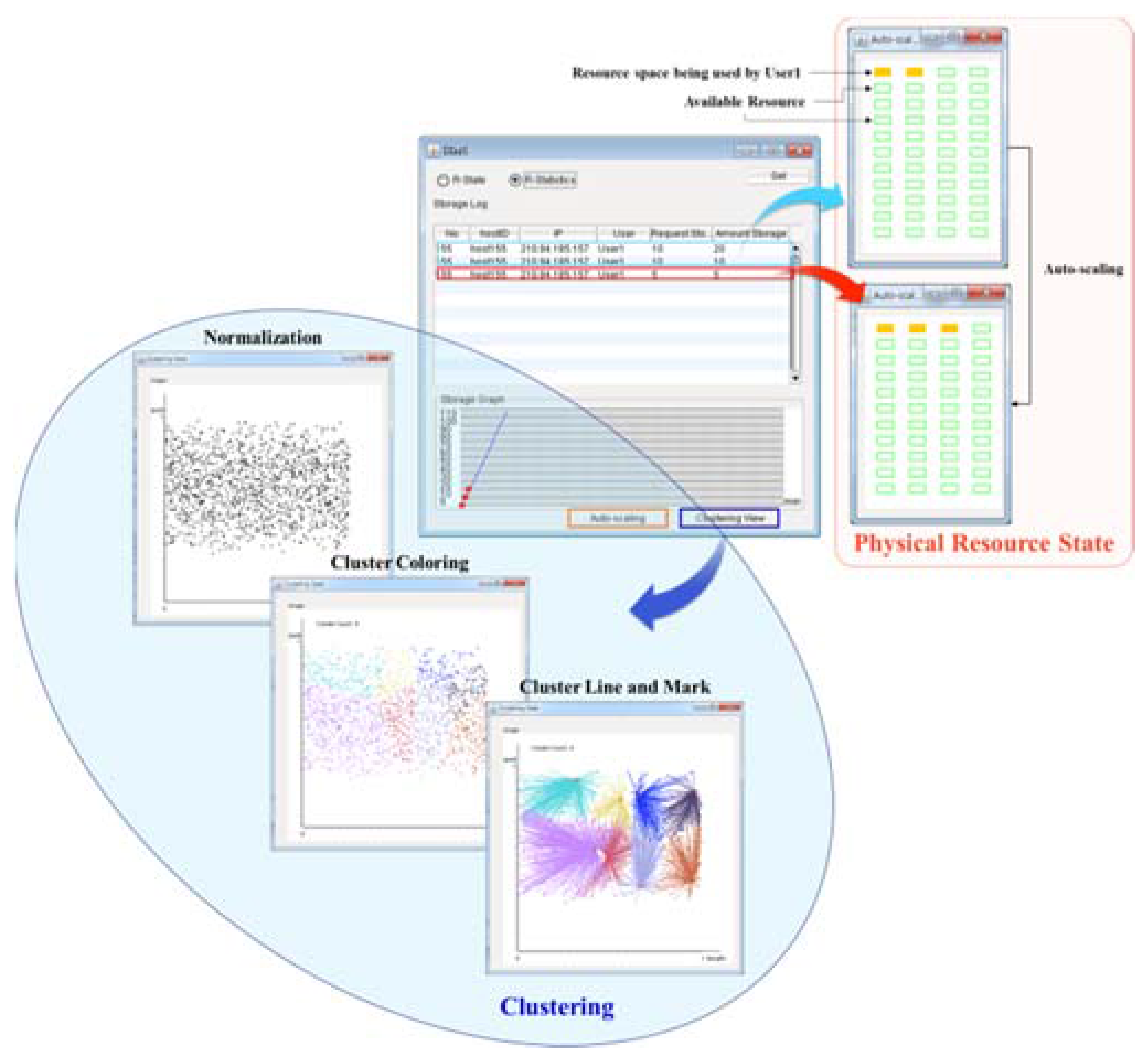
3.2. Clustering Scheme for Integrated Resource Management
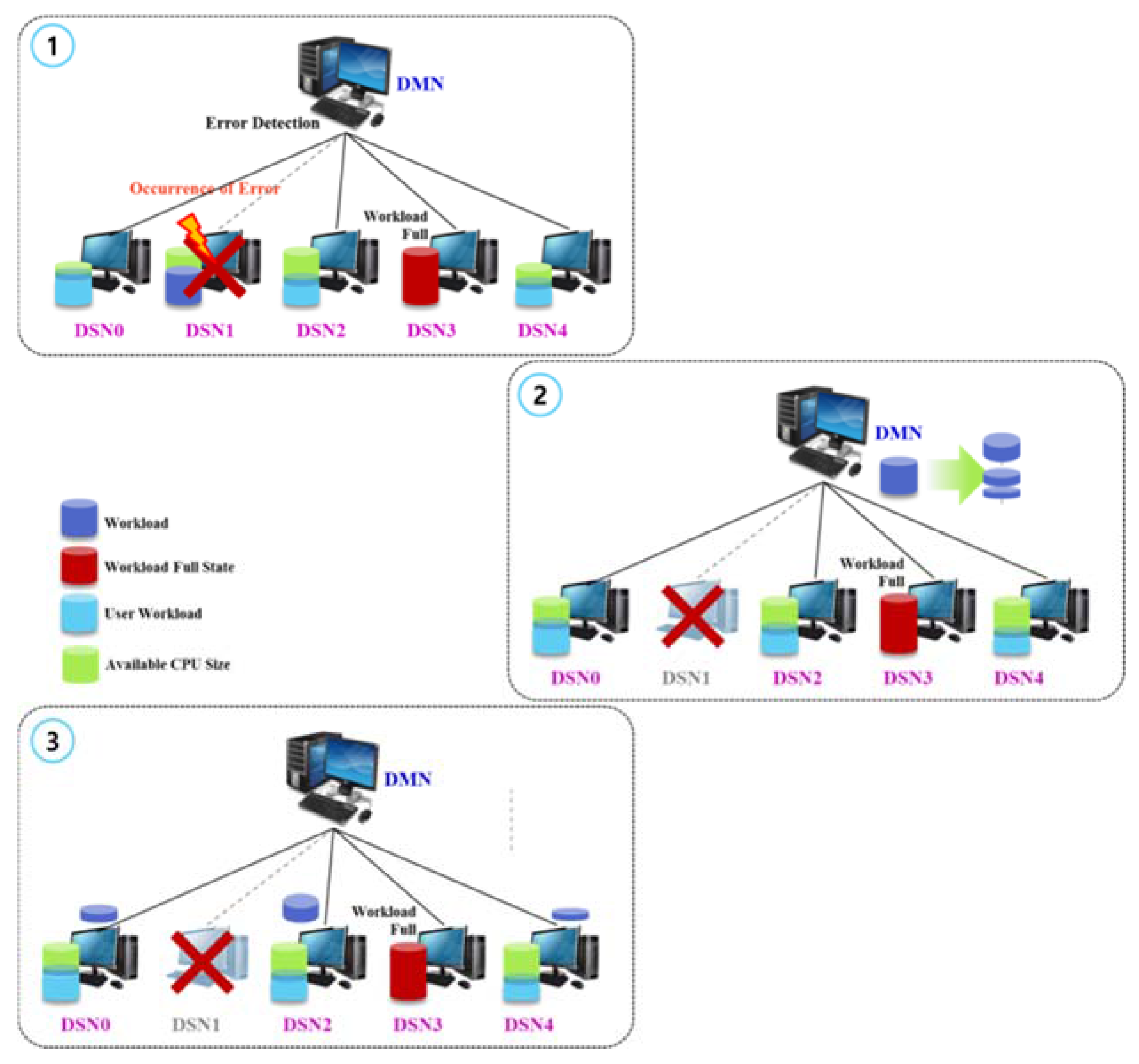
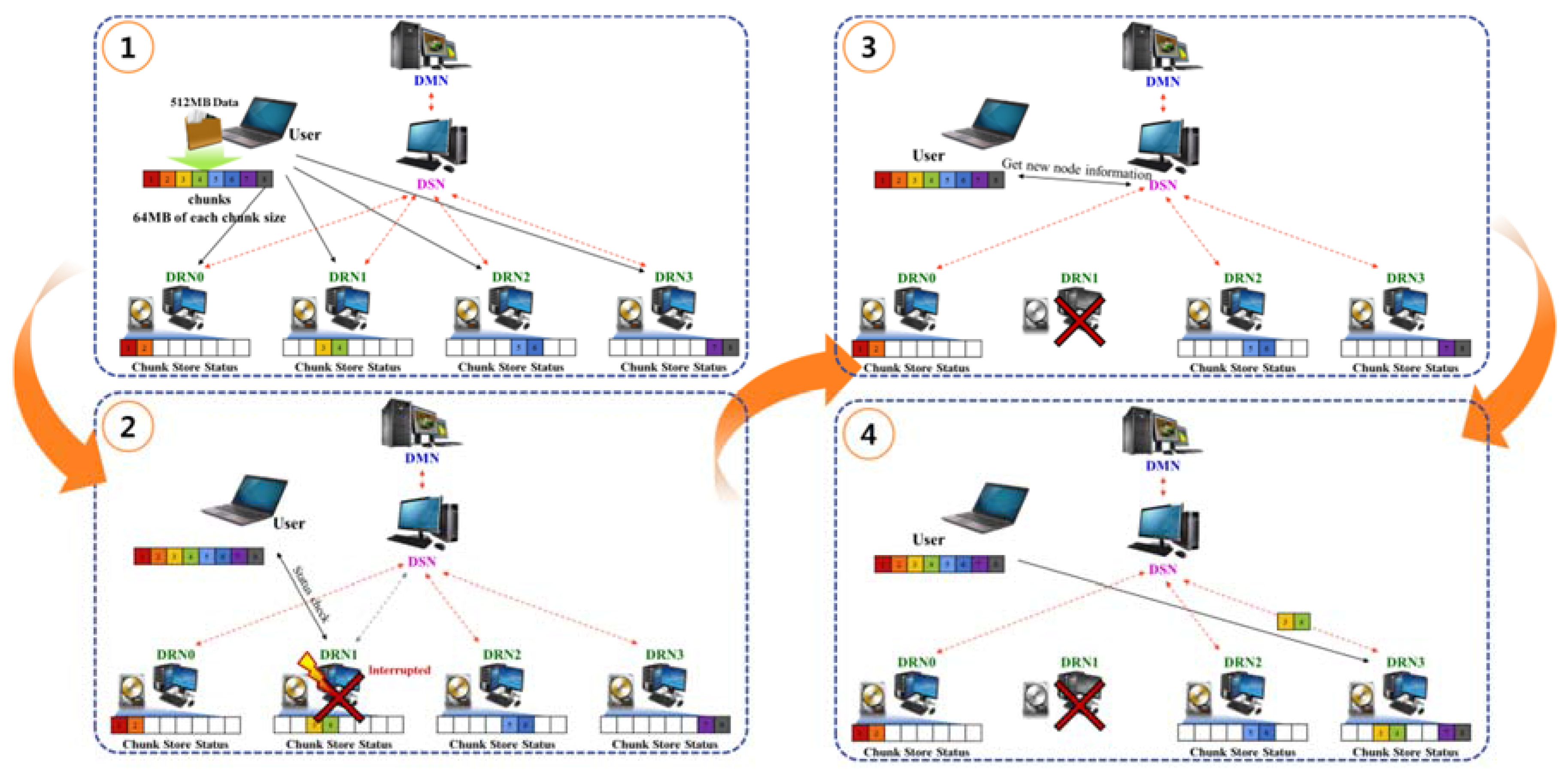
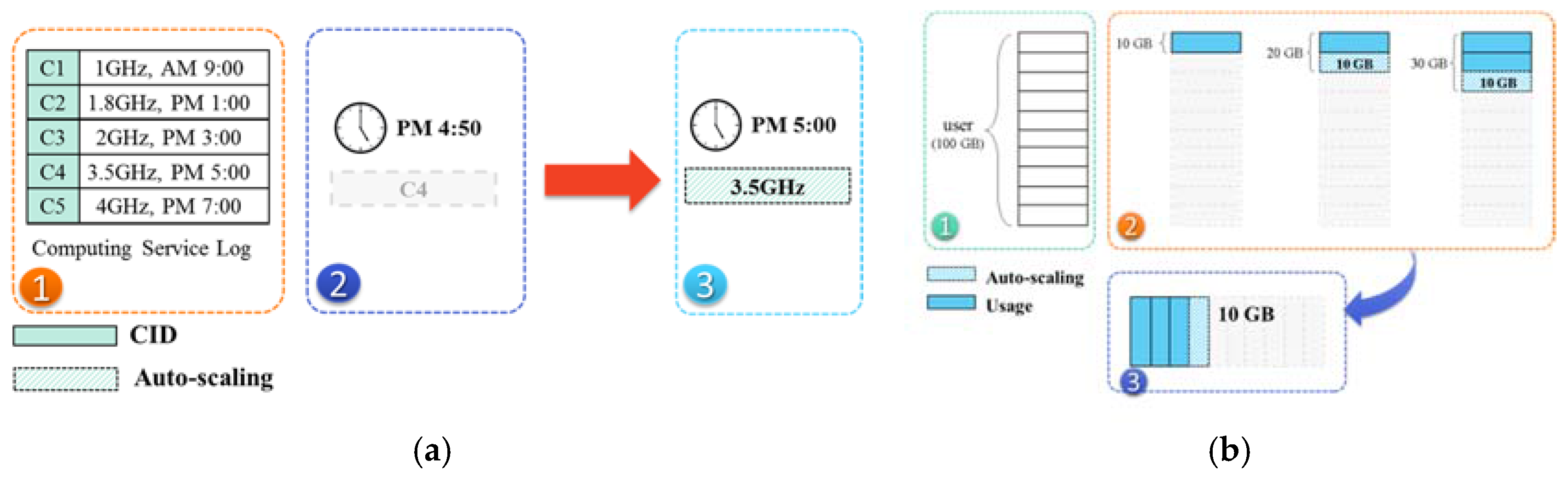
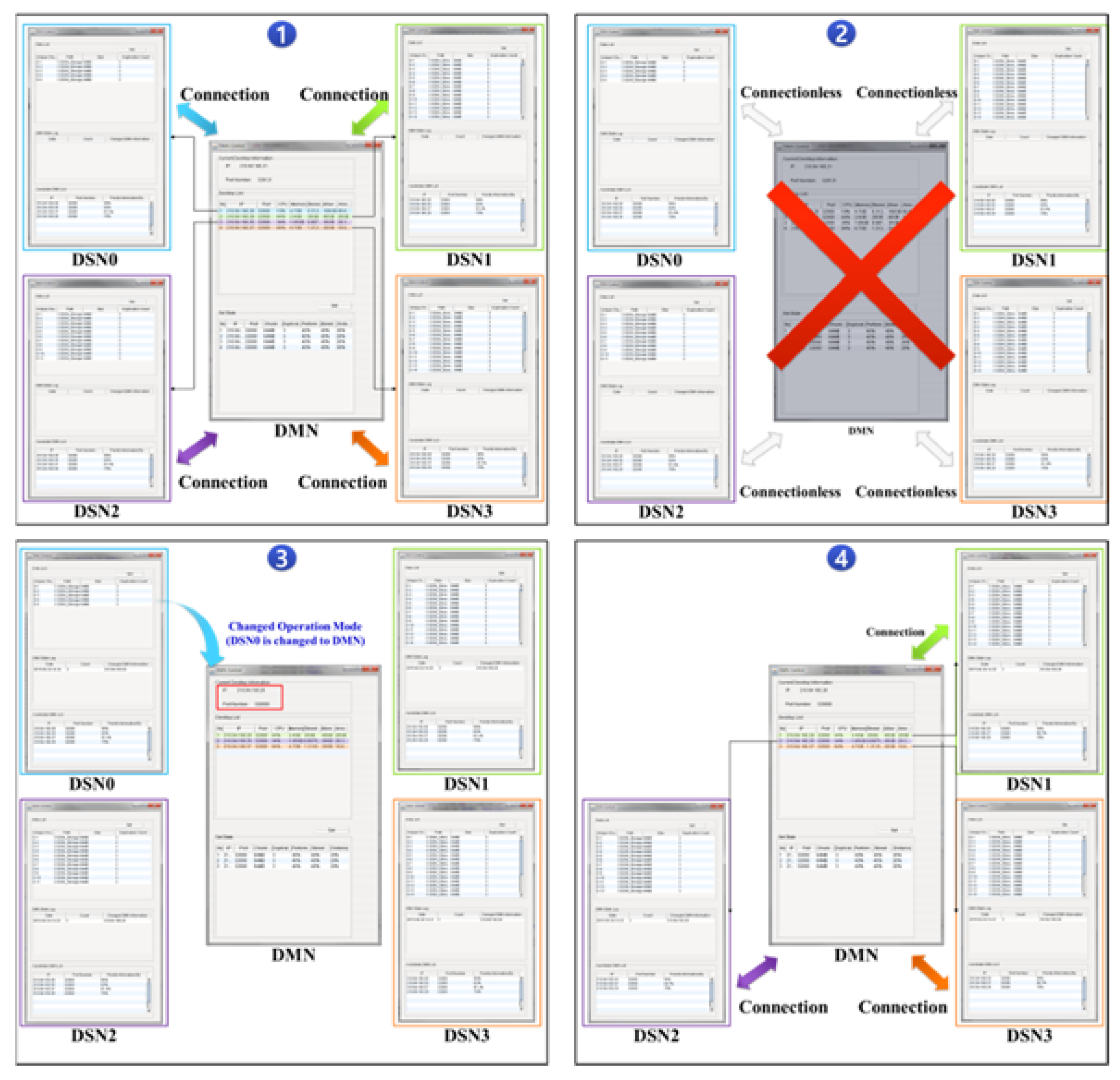
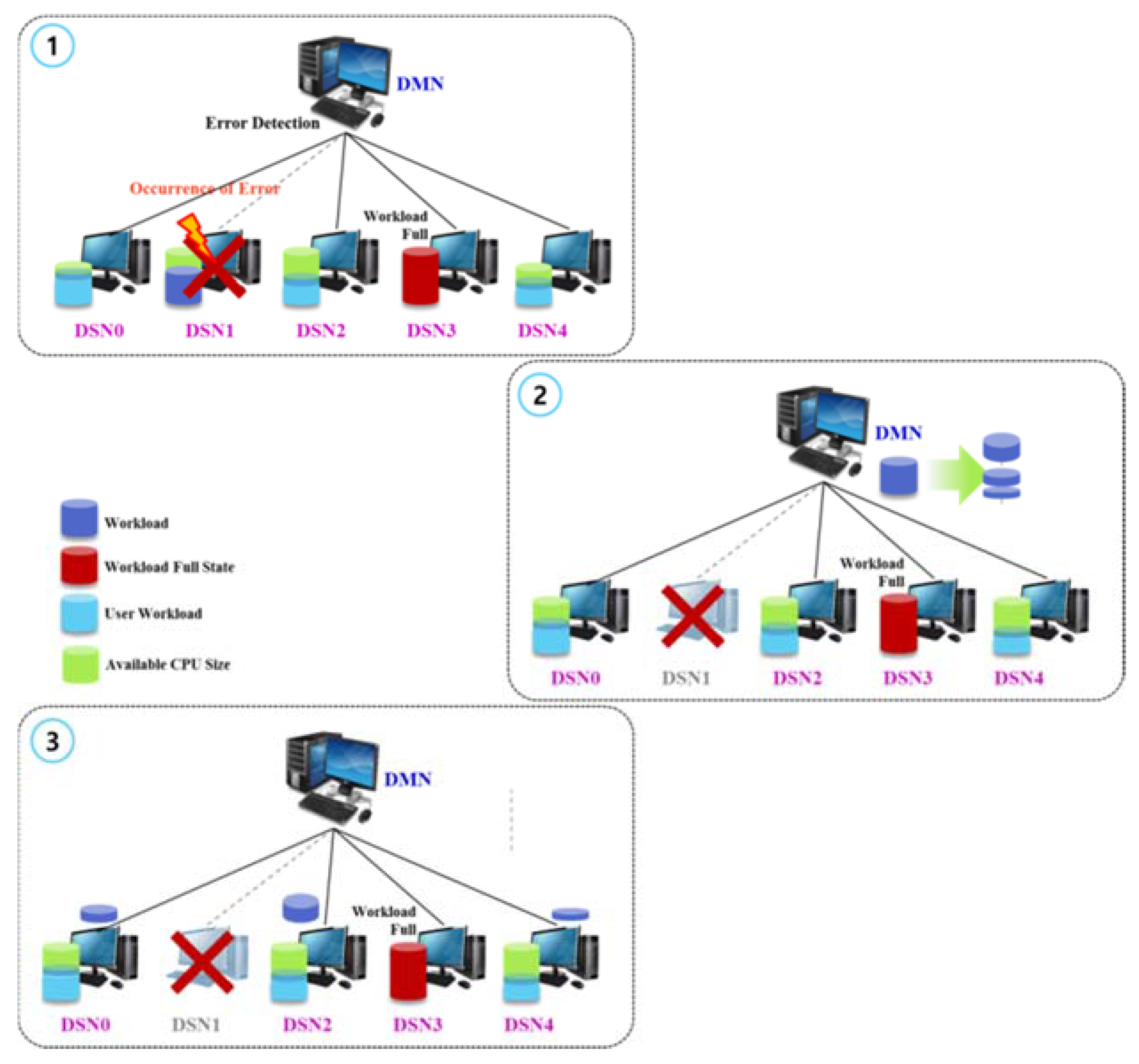
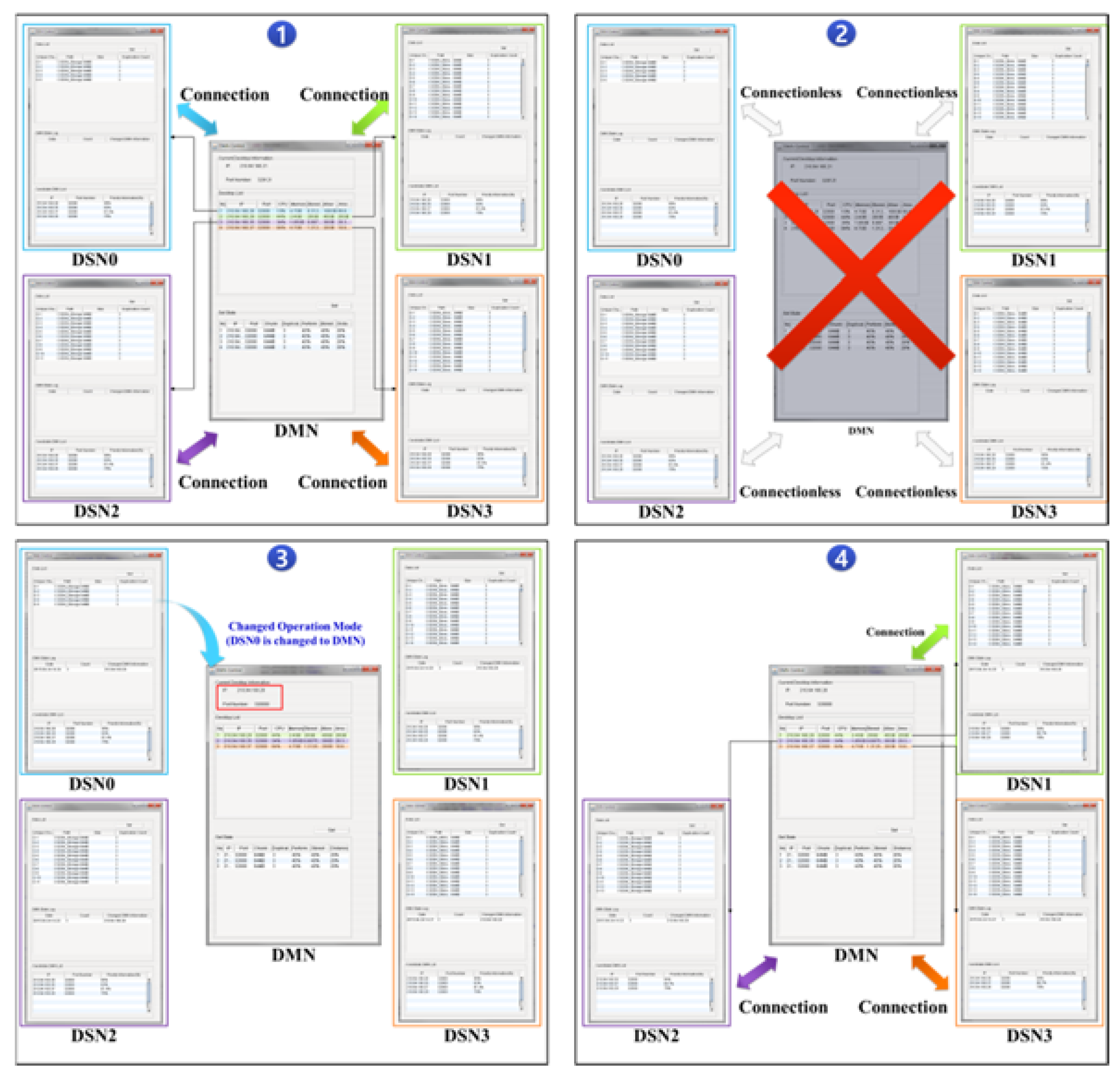
3.3. Nondisruptive Computing and Storage Service Scheme
- Step 1
- The first on-premise resource is specified as the DMN. The added resources are limited to DSN and DRN roles. The same server functions of the DMN are included in the DSN and DRN.
- Step 2
- The DSN and DRN send metadata, including the integrated storage resource settings, as well as CPU and main memory performance information, to the DMN.
- Step 3
- The DMN creates a substitute server candidate list of metadata on the IP address, performance, stored data amount, and distance criteria. The stored data amount is used as the top priority by default to minimize computing waste and network bandwidth due to duplicated internal data.
- Step 4
- The substitute server candidate list metadata are synchronized with the connected desktops, and Steps 1–3 are repeated to add resources.
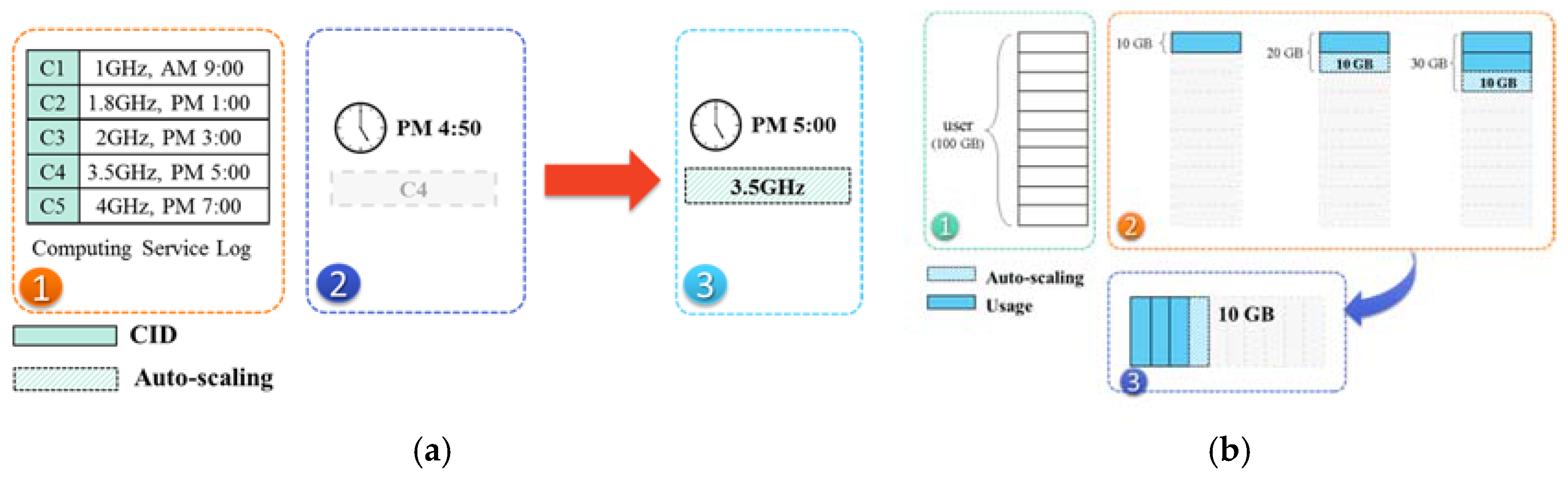
3.4. Auto-Scalable Scheme
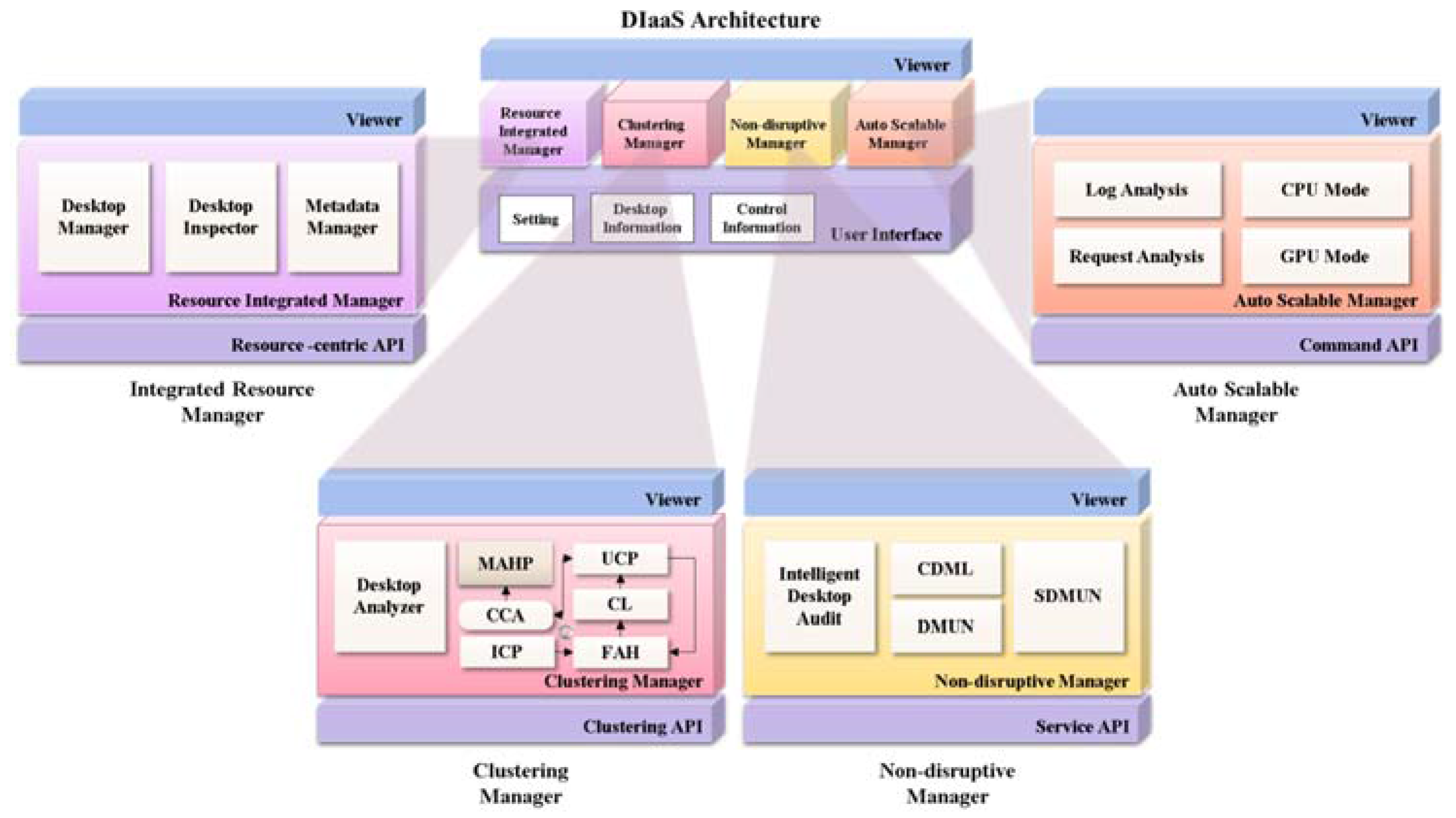
4. Infrastructure as a Service with Desktops (DIaaS) Design
5. DIaaS Implementation
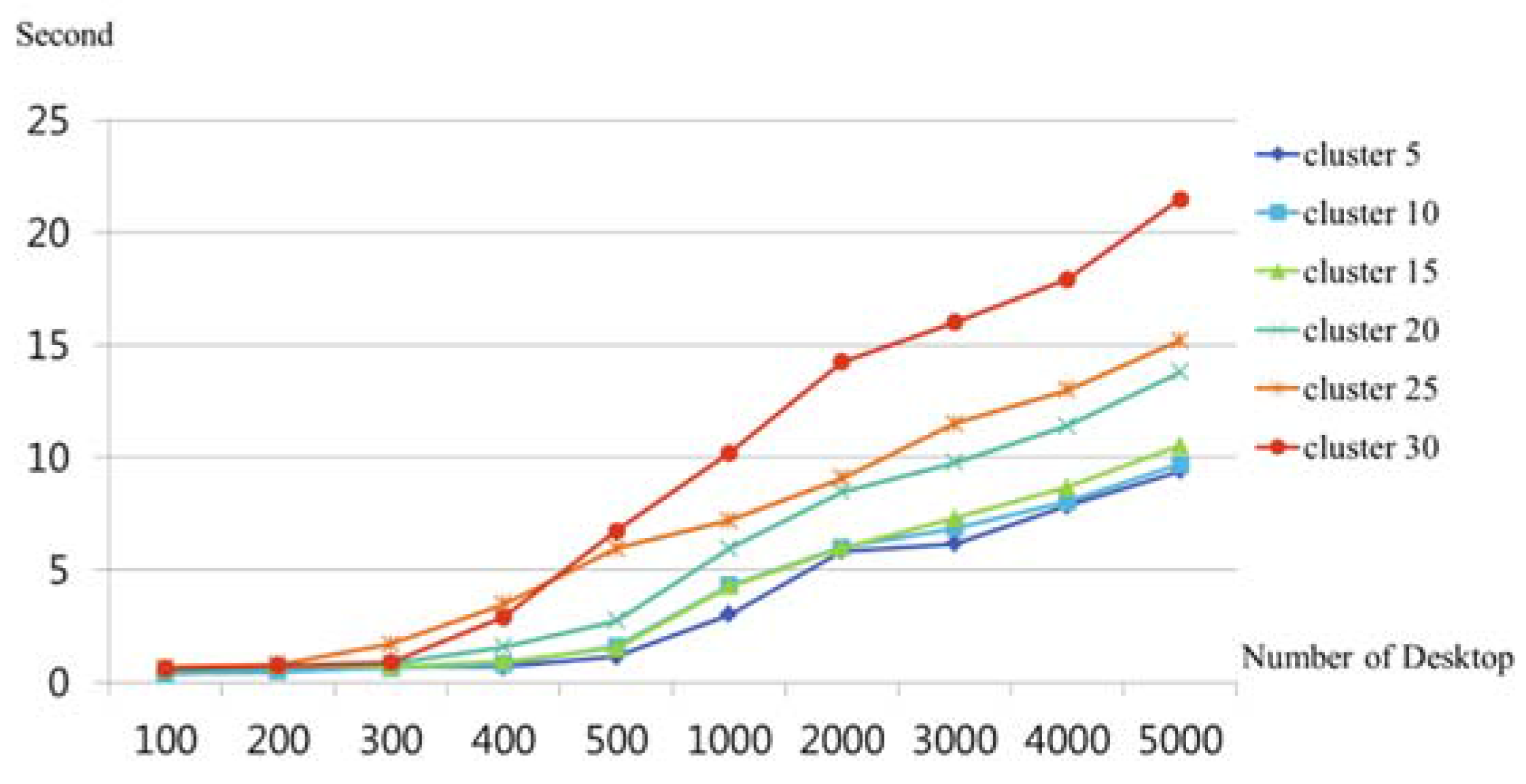
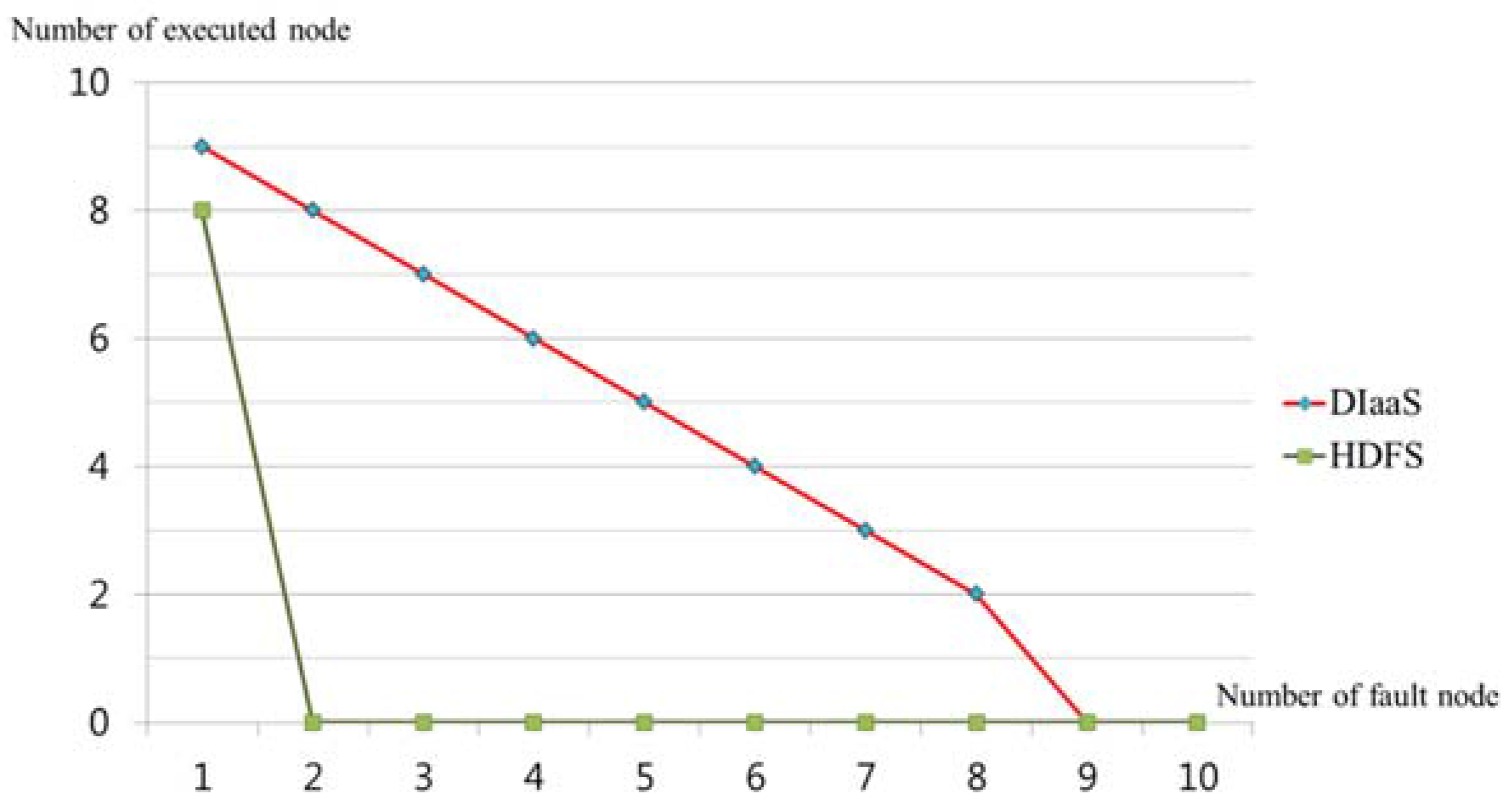
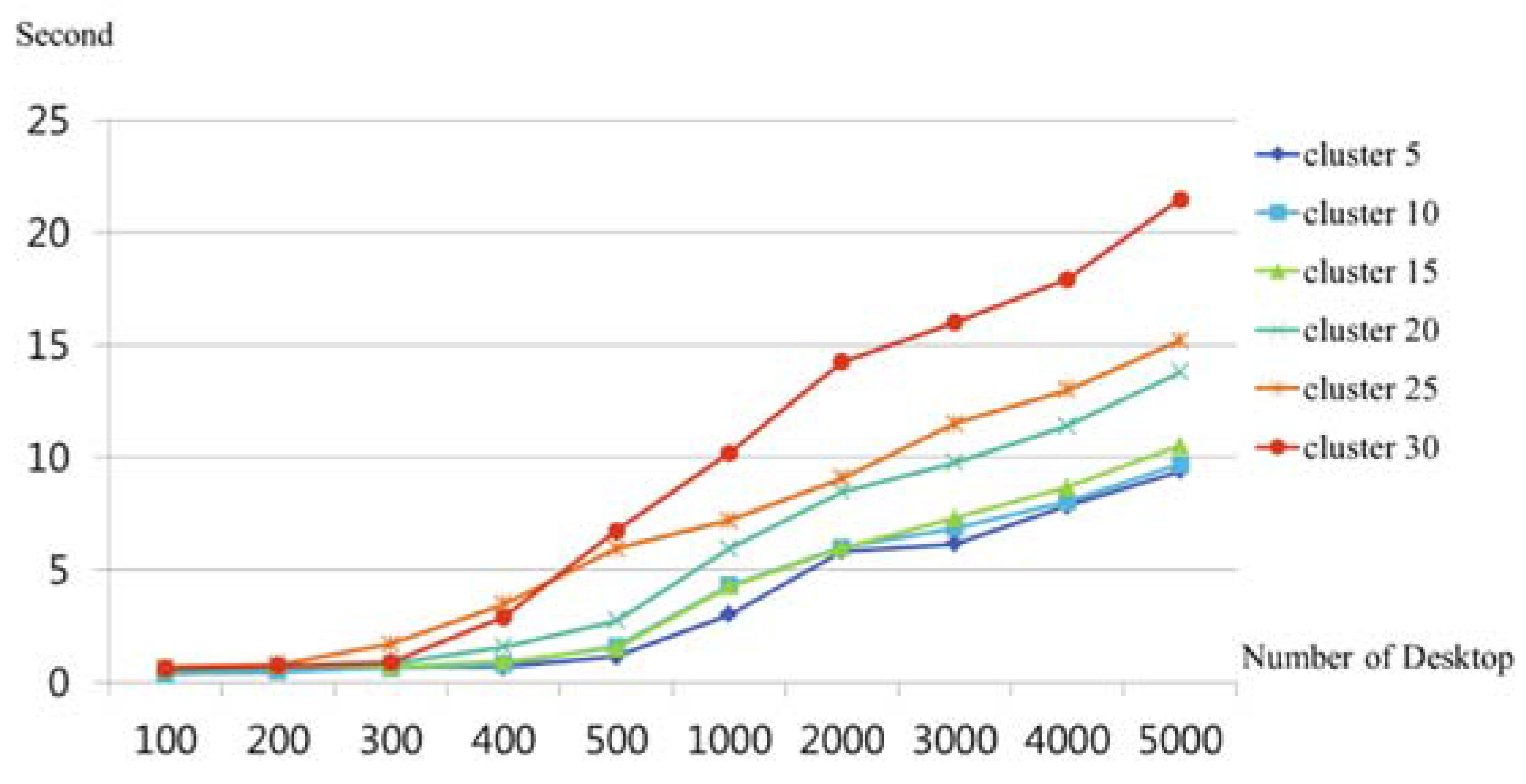
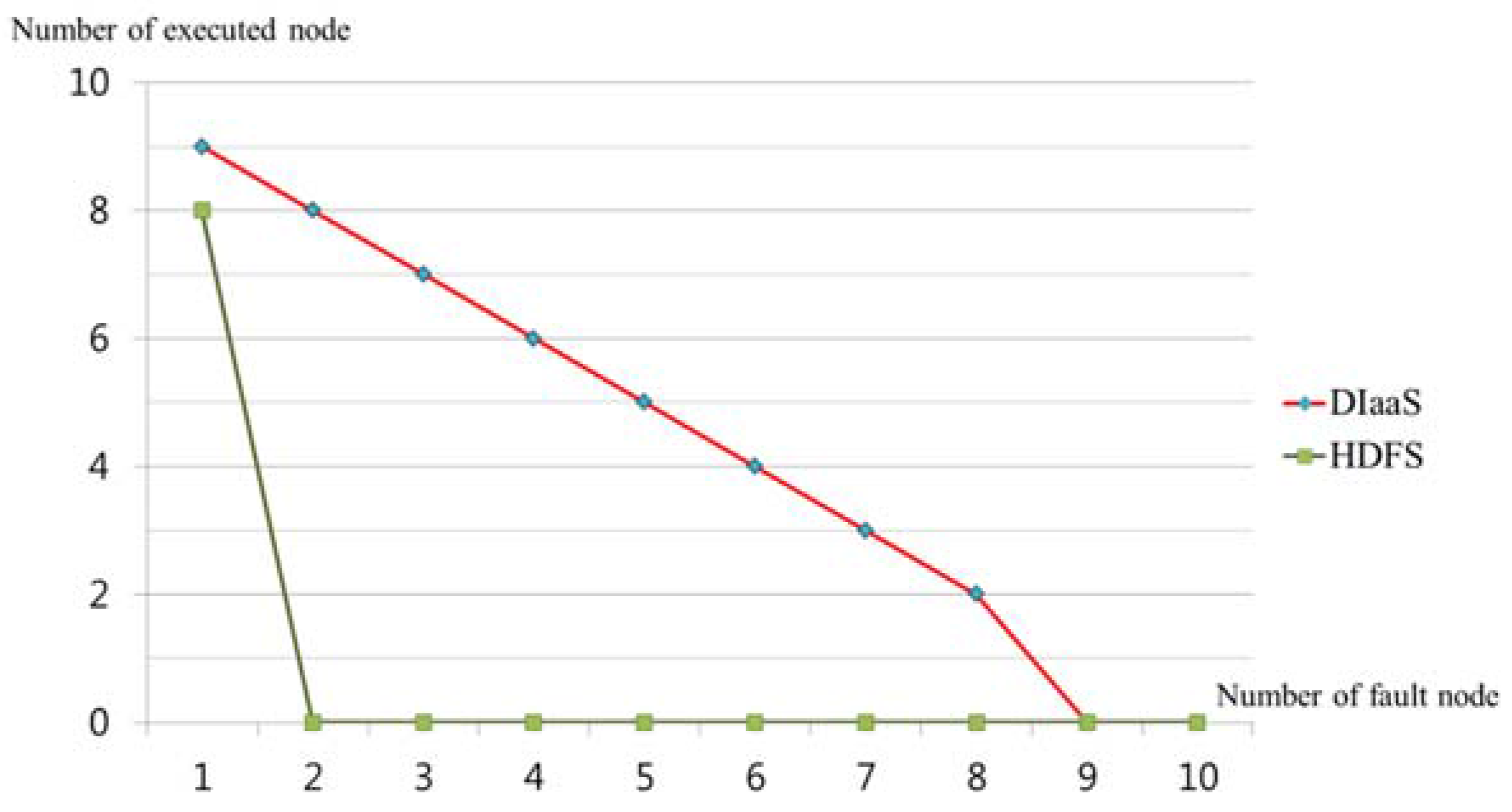
6. Performance Evaluation
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Jeong, Y.-S.; Kim, H.-W.; Jang, H.J. Adaptive resource management scheme for monitoring of CPS. J. Supercomput. 2013, 66, 57–69. [Google Scholar] [CrossRef]
- Jararweh, Y.; Al-Ayyoub, M.; Darabseh, A.; Benkhelifa, E.; Voukc, M.; Rindos, A. Software defined cloud: Survey, system and evaluation. Future Gener. Comput. Syst. 2016, 58, 56–74. [Google Scholar] [CrossRef]
- Vasoya, S.; Gadhavi, L.; Bhatia, J.; Bhavsar, M. Resource provisioning strategies in cloud: A Survey. Int. J. Comput. Sci. Commun. 2016, 7, 12–15. [Google Scholar]
- Alam, M.I.; Pandey, M.; Rautaray, S.S. A comprehensive survey on cloud computing. Int. J. Inf. Technol. Comput. Sci. 2015, 7, 68–79. [Google Scholar] [CrossRef]
- Guzek, M.; Bouvry, P.; Talbi, E.G. A survey of evolutionary computation for resource management of processing in cloud computing. IEEE Comput. Intell. Mag. 2015, 10, 53–67. [Google Scholar] [CrossRef]
- Suralkar, S.; Mujumdar, A.; Masiwal, G.; Kulkarni, M. Review of distributed file systems: Case studies. Int. J. Eng. Res. Appl. 2013, 3, 1293–1298. [Google Scholar]
- Asadianfam, S.; Shamsi, M.; Kashany, S. A review: Distributed file system. Int. J. Comput. Netw. Commun. Secur. 2015, 3, 229–234. [Google Scholar]
- Yadav, J.S.; Yadav, M.; Jain, A. Distributed file system. Int. J. Sci. Res. Educ. 2013, 1, 126–134. [Google Scholar]
- Bera, S.; Misra, S.; Rodrigues, J.J.P.C. Cloud computing applications for smart grid: A survey. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 1477–1494. [Google Scholar] [CrossRef]
- Patel, I.; Shah, B. Survey on resource allocation technique in cloud. Int. J. Sci. Res. 2016, 5, 232–235. [Google Scholar]
- Jackson, J.C.; Vijayakumar, V.; Quadir, M.A.; Bharathi, C. Survey on programming models and environments for cluster, cloud, and grid computing that defends big data. Procedia Comput. Sci. 2015, 50, 517–523. [Google Scholar] [CrossRef]
- Ranjan, R.; Benatallah, B.; Dustdar, S.; Papazoglou, M.P. Cloud resource orchestration programming. IEEE Internet Comput. 2015, 19, 46–56. [Google Scholar] [CrossRef]
- Zhan, Z.-H.; Liu, X.-F.; Gong, Y.-J.; Zhang, J.; Chung, H.S.-H.; Li, Y. Cloud computing resource scheduling and a survey of its evolutionary approaches. ACM Comput. Surv. 2015, 47. [Google Scholar] [CrossRef]
- Jennings, B.; Stadler, R. Resource management in clouds: Survey and research challenges. J. Netw. Syst. Manag. 2015, 23, 567–619. [Google Scholar] [CrossRef]
- Kukade, P.P.; Kale, G. Survey of load balancing and scaling approaches in cloud. Int. J. Emerg. Trends Technol. Comput. Sci. 2015, 4, 189–192. [Google Scholar]
- Motavaselalhagh, F.; Esfahani, F.S.; Arabnia, H.R. Knowledge-based adaptable scheduler for SaaS providers in cloud computing. Hum. Centric Comput. Inf. Sci. 2015, 5. [Google Scholar] [CrossRef]
- Kim, S.; Lee, H.; Kwon, H.; Lee, S. Evaluation model of defense information systems use. J. Converg. 2015, 6, 18–26. [Google Scholar]
- Kar, J.; Mishra, M.R. Mitigating threats and security metrics in cloud computing. J. Inf. Process. Syst. 2016, 12, 226–233. [Google Scholar]
- Kashyap, D.; Viradiya, J. A survey of various load balancing algorithms in cloud computing. Int. J. Sci. Technol. Res. 2014, 3, 115–119. [Google Scholar]
- Park, J.H.; Kim, H.-W.; Jeong, Y.-S. Efficiency sustainability resource visual simulator for clustered desktop virtualization based on cloud infrastructure. Sustainability 2014, 6, 8079–8091. [Google Scholar] [CrossRef]
- Kim, H.-W.; Park, J.H.; Jeong, Y.-S. Human-centric storage resource mechanism for big data on cloud service architecture. J. Supercomput. 2015, 72, 2437–2452. [Google Scholar] [CrossRef]
- Kumbhare, A.G.; Simmhan, Y.; Frincu, M.; Prasanna, V.K. Reactive resource provisioning heuristics for dynamic dataflows on cloud infrastructure. IEEE Trans. Cloud Comput. 2015, 3, 105–118. [Google Scholar] [CrossRef]
- Lingawar, R.P.; Srode, M.V.; Ghonge, M.M. Survey on load-balancing techniques in cloud computing. Int. J. Advent Res. Comput. Electron. 2014, 1, 18–21. [Google Scholar]
- Magalhães, D.; Calheiros, R.N.; Buyya, R.; Gomes, D.G. Workload modeling for resource usage analysis and simulation in cloud computing. Comput. Electr. Eng. 2015, 47, 69–81. [Google Scholar] [CrossRef]
- De Assunçãoa, M.D.; Cardonha, C.H.; Netto, M.A.S.; Cunha, R.L.F. Impact of user patience on auto-scaling resource capacity for cloud services. Future Gener. Comput. Syst. 2016, 55, 41–50. [Google Scholar] [CrossRef]
- Al-Ayyoub, M.; Jararweh, Y.; Daraghmeh, M.; Althebyan, Q. Multi-agent based dynamic resource provisioning and monitoring for cloud computing systems infrastructure. Cluster Comput. 2015, 18, 919–932. [Google Scholar] [CrossRef]
- Tan, Y.; Xia, C.H. An adaptive learning approach for efficient resource provisioning in cloud Services. ACM Sigmetrics Perform. Eval. Rev. 2015, 42, 3–11. [Google Scholar] [CrossRef]
- Yue, T.; Xia, C.H. An Adaptive Learning Approach for Efficient Resource Provisioning in Cloud Services. ACM Sigmetrics Perform. Eval. Rev. 2015, 42, 3–11. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme | Characteristics | Strengths | Weaknesses |
|---|---|---|---|
| NFS/CIFS | File system similar to a local | High-speed save | Less extension, high cost |
| GFS/HDFS | Distributes large-scale files | Low cost | Manual system recovery when errors occur |
| AFS | Low server load balancing Independent operations for local file systems | High scalability and strong security | Less extension |
| OwFS | Saves metadata and data information to “owner” Stable when saving the positions of errors | Low cost | Load-balancing limitation when large-scale files are saved |
| Schemes | Setup Method | Visualization | Clustering Organization | Simulation |
|---|---|---|---|---|
| VCS simulator [24] | Text-based | Text | User-defined | Yes |
| GridSim [25,26] | Modified source code | Chart | None | Yes |
| ClusterSim [27] | Clustering-based | Text | User-defined | Yes |
| CloudSim [28] | Text-based | Text | None | Yes |
| DIaaS | Graph-based | Graph | User-defined | Yes |
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.-W.; Han, J.; Park, J.H.; Jeong, Y.-S. DIaaS: Resource Management System for the Intra-Cloud with On-Premise Desktops. Symmetry 2017, 9, 8. https://doi.org/10.3390/sym9010008
Kim H-W, Han J, Park JH, Jeong Y-S. DIaaS: Resource Management System for the Intra-Cloud with On-Premise Desktops. Symmetry. 2017; 9(1):8. https://doi.org/10.3390/sym9010008
Chicago/Turabian StyleKim, Hyun-Woo, Jaekyung Han, Jong Hyuk Park, and Young-Sik Jeong. 2017. "DIaaS: Resource Management System for the Intra-Cloud with On-Premise Desktops" Symmetry 9, no. 1: 8. https://doi.org/10.3390/sym9010008
APA StyleKim, H.-W., Han, J., Park, J. H., & Jeong, Y.-S. (2017). DIaaS: Resource Management System for the Intra-Cloud with On-Premise Desktops. Symmetry, 9(1), 8. https://doi.org/10.3390/sym9010008