
Adaptive Image Matching Using Discrimination of Deformable Objects


Abstract
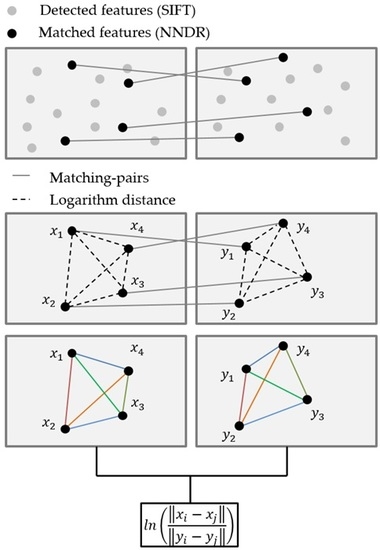
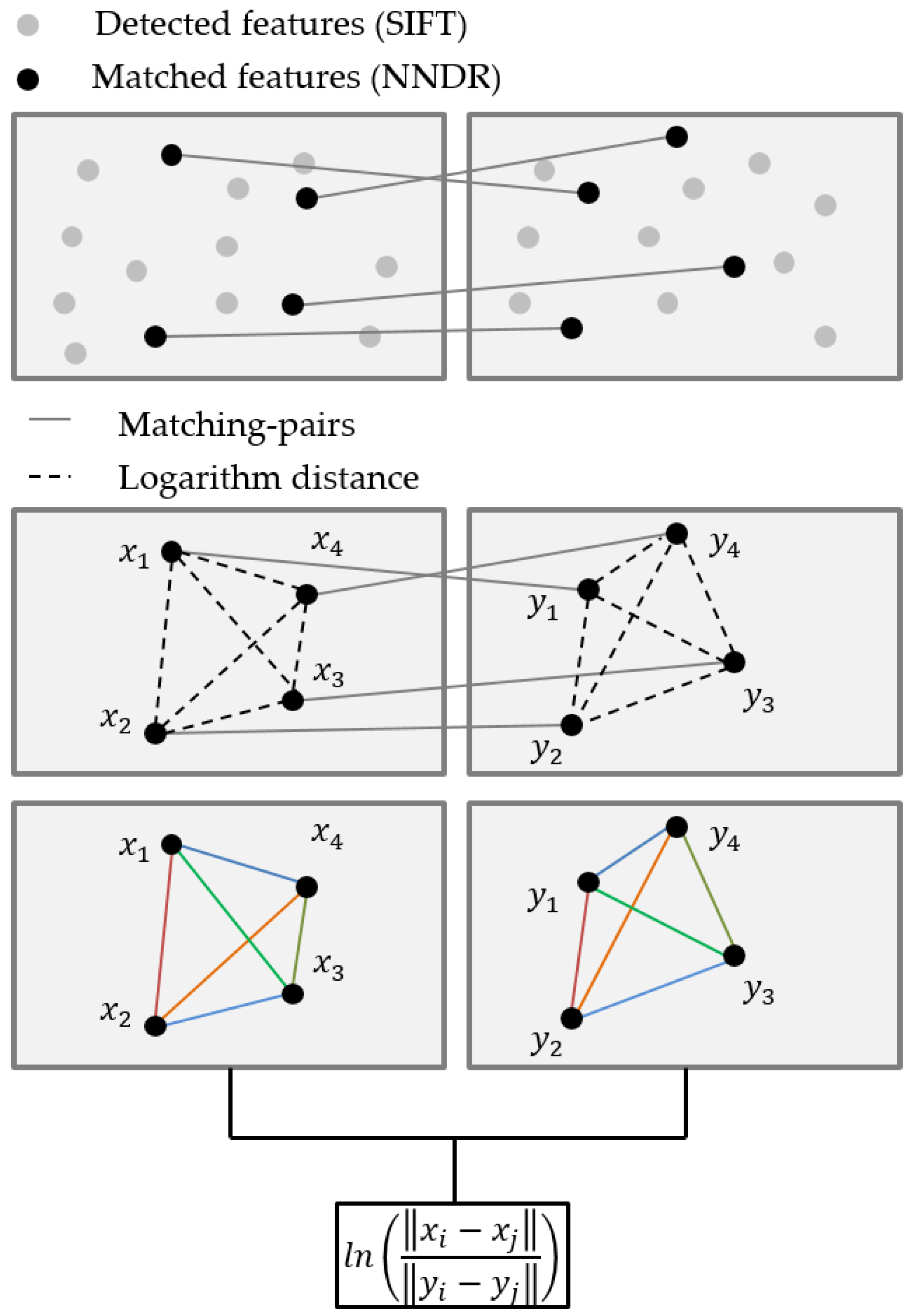
:
1. Introduction
2. Related Works
2.1. Neighborhood-Based Matching
2.2. Statistical-Based Matching
2.3. Deformable Object-Based Matching
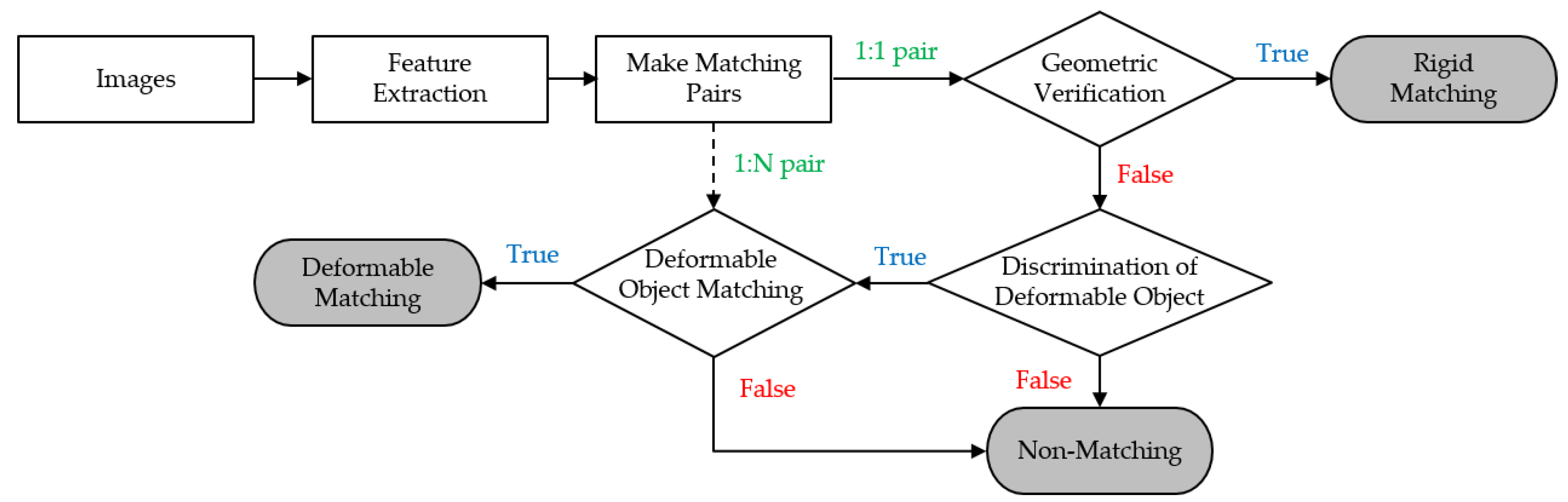
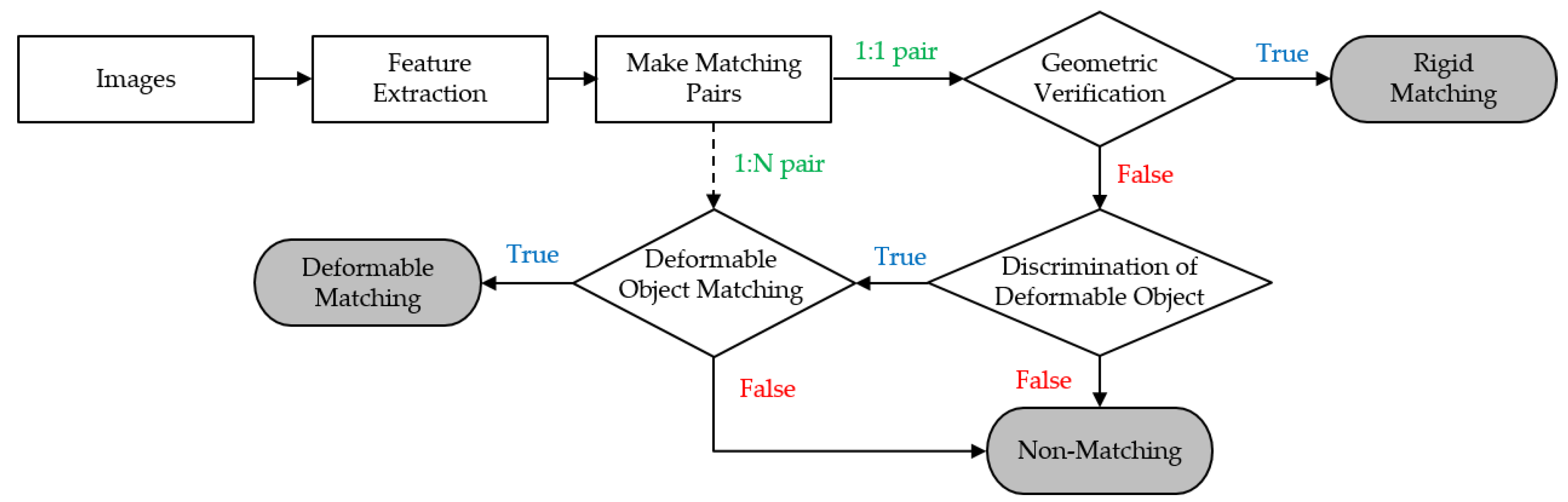
3. Proposed Algorithm
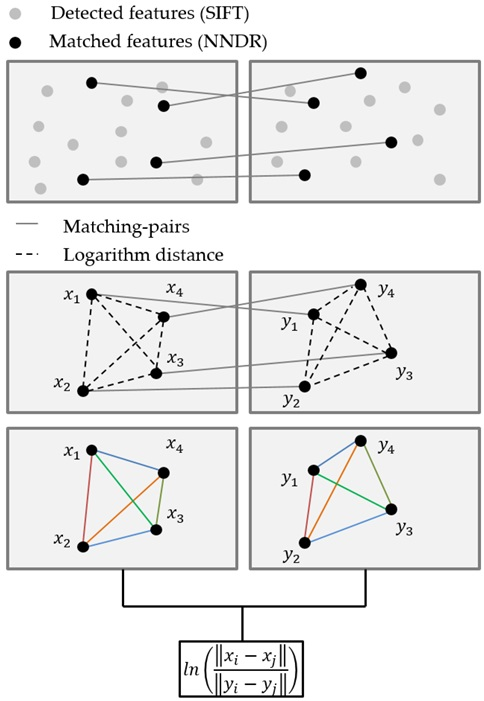
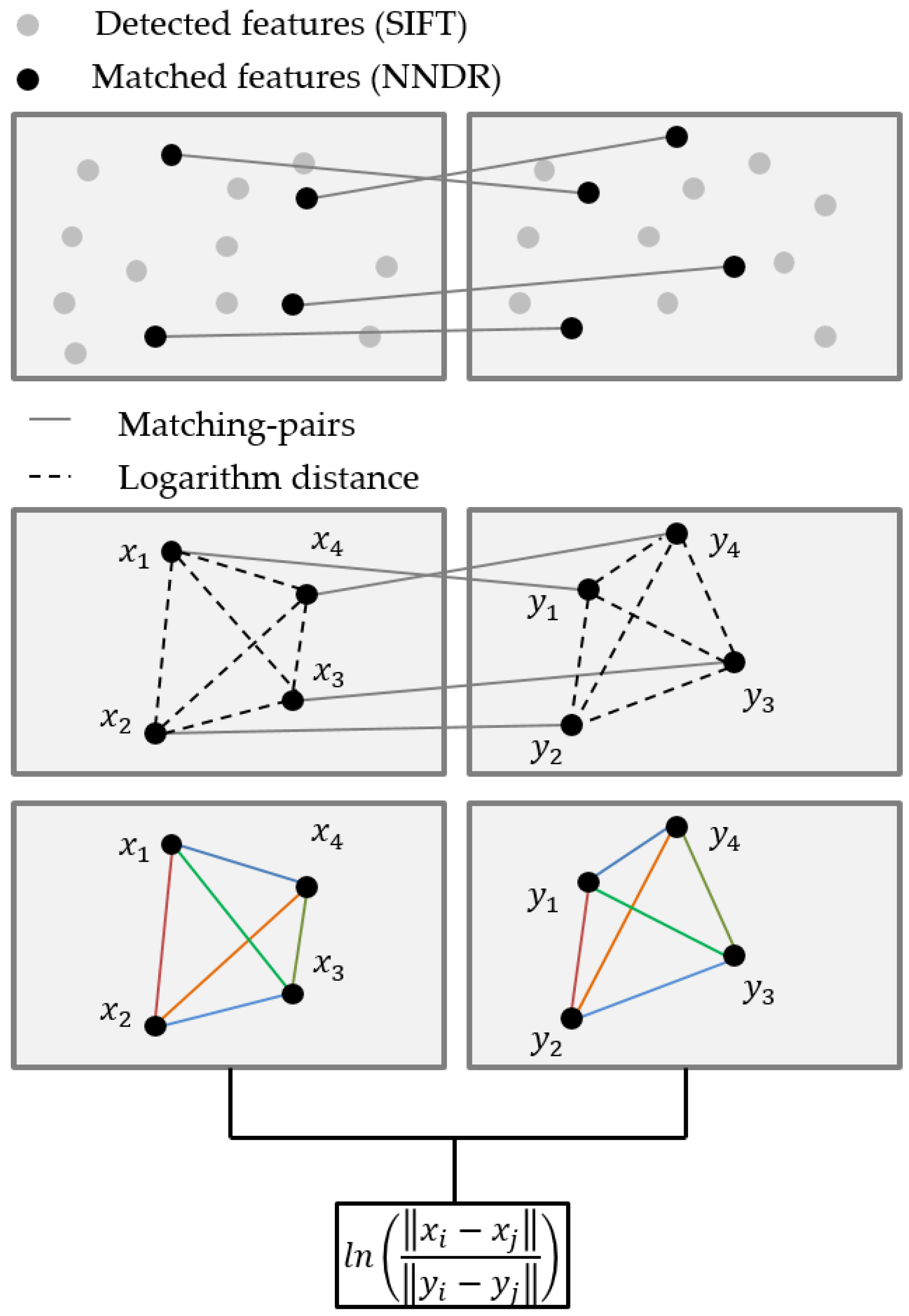
3.1. Feature Detection, and Making a Matched Pair
3.2. Geometric Verification for Rigid Object-Matching
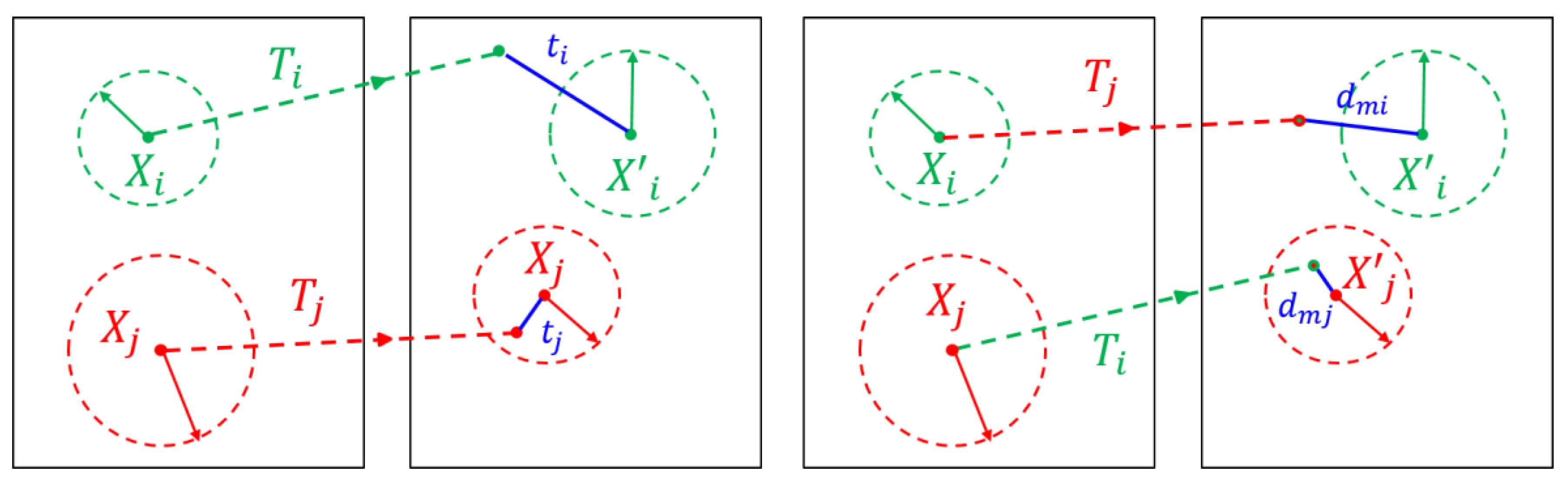
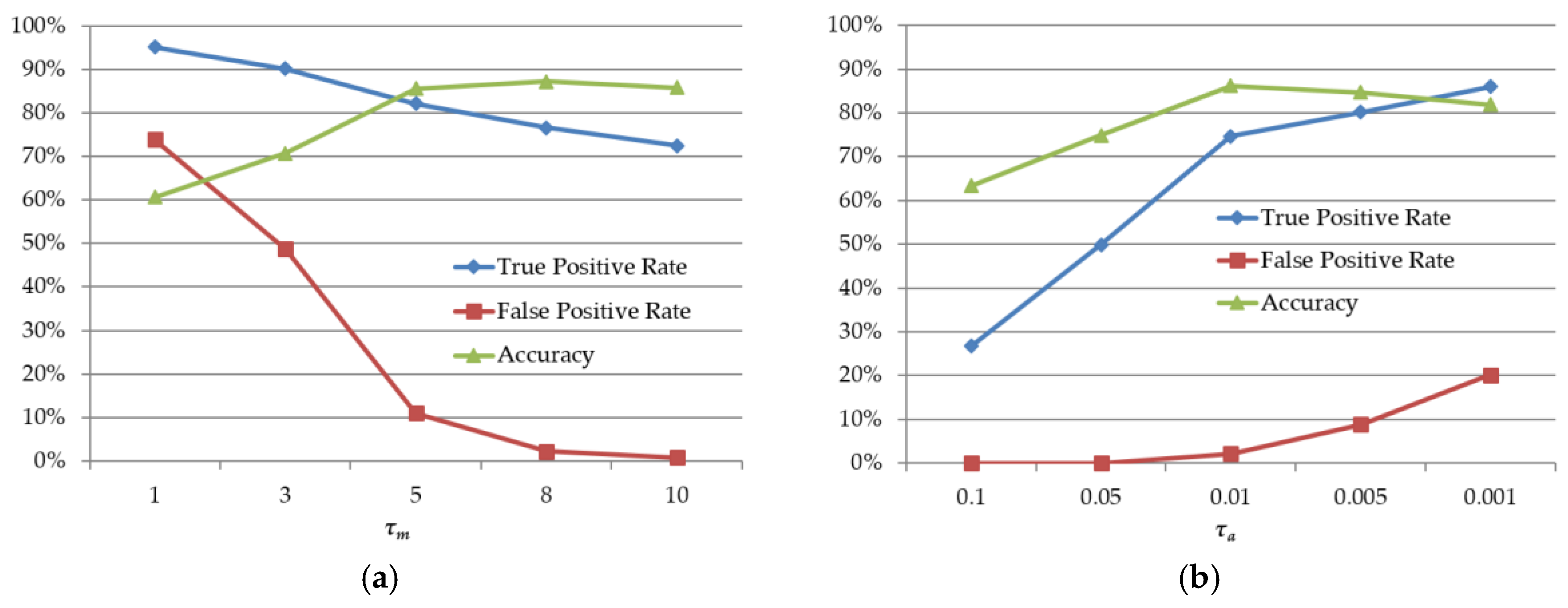
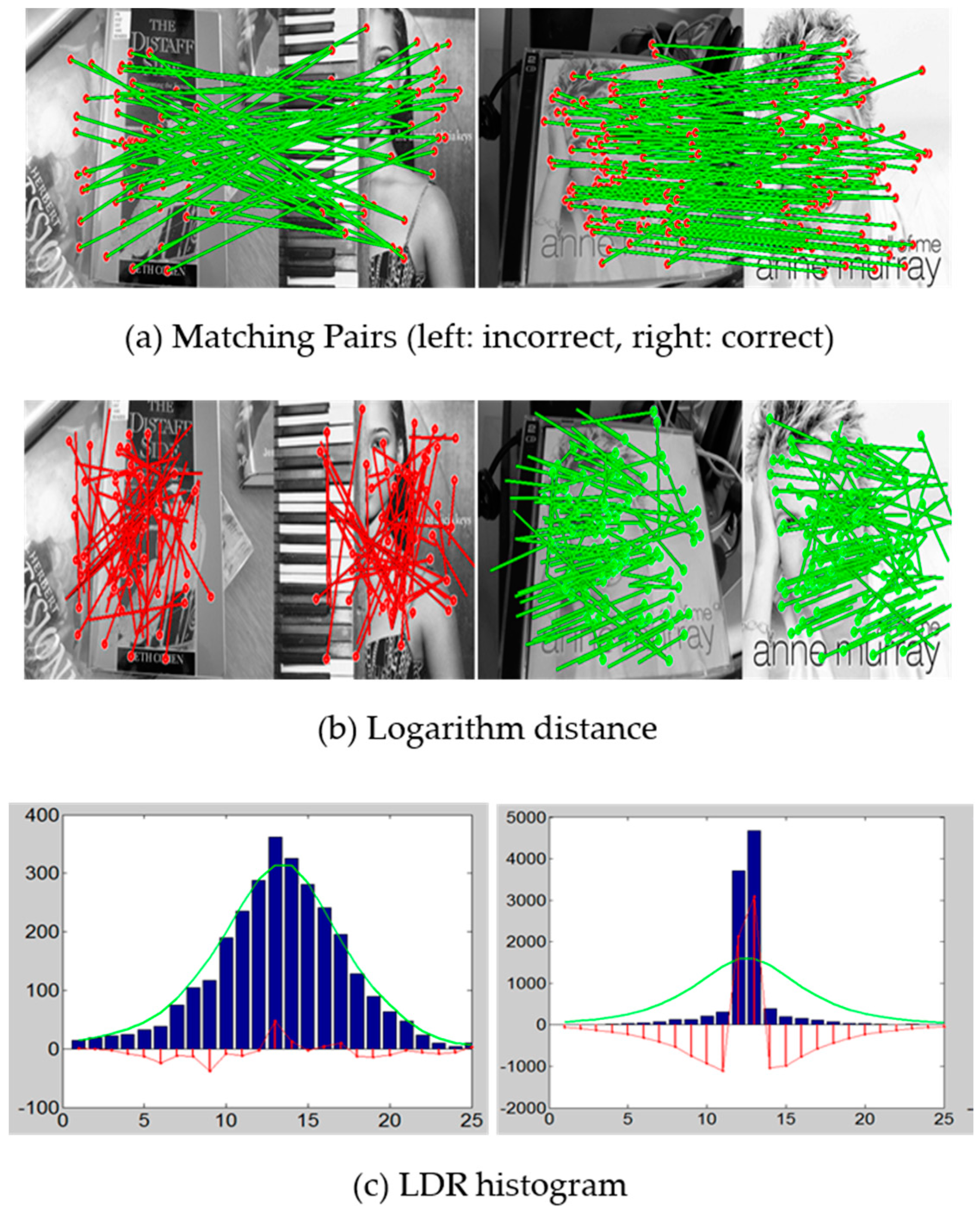
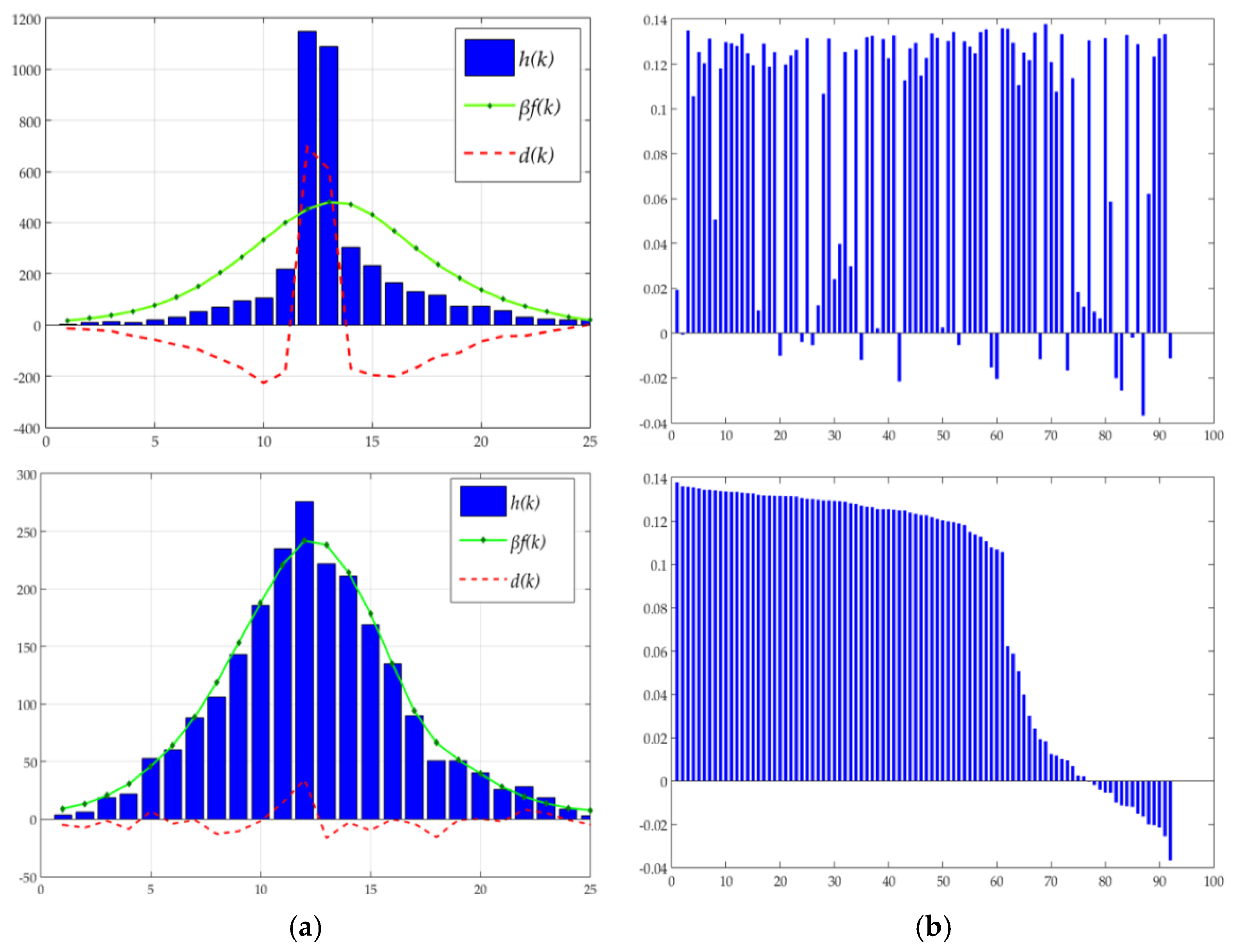
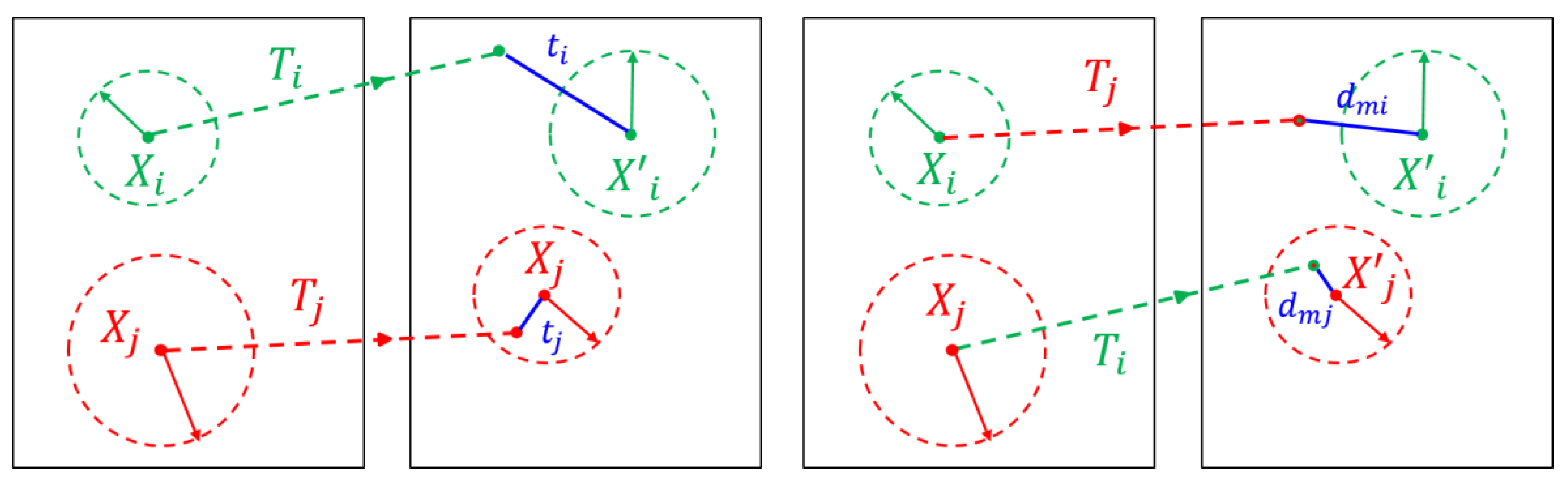
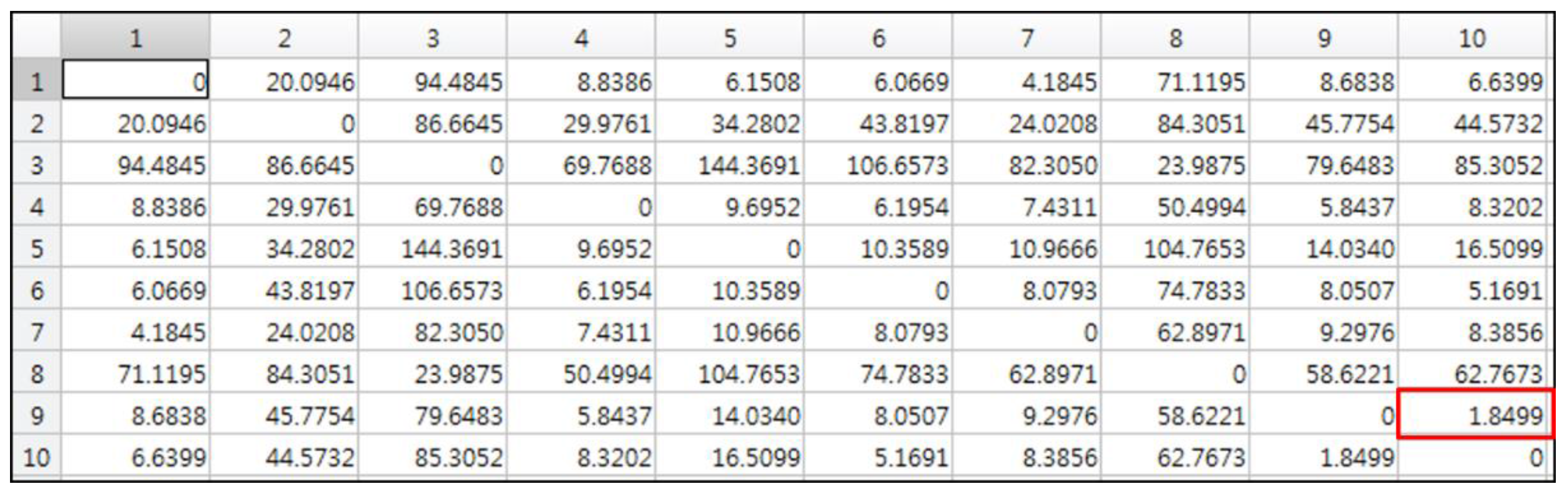
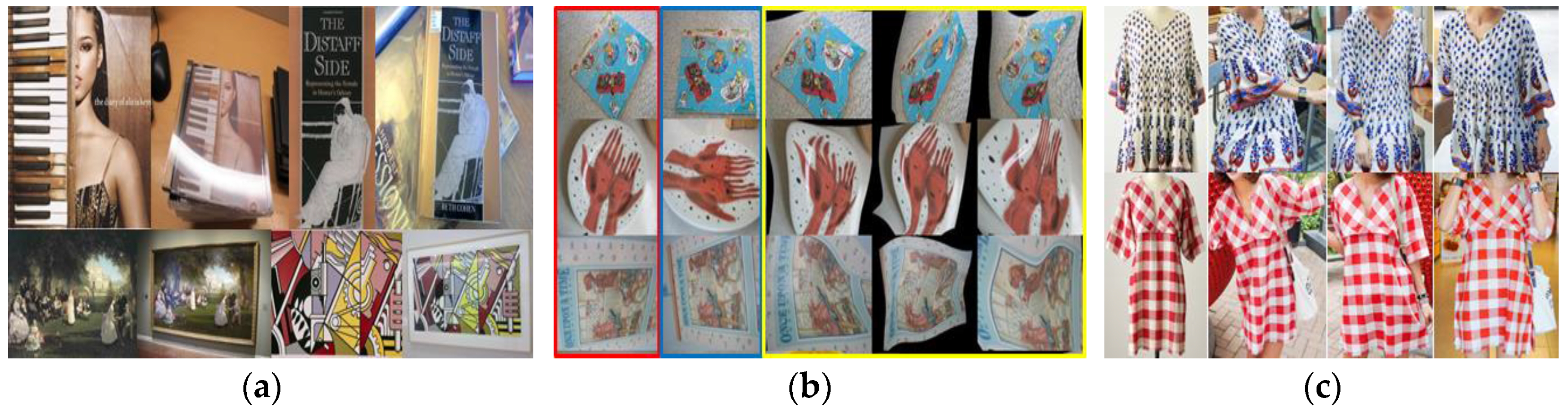
3.3. Discrimination of Deformable Object Images
3.4. Deformable-Object Matching
4. Experiment Results
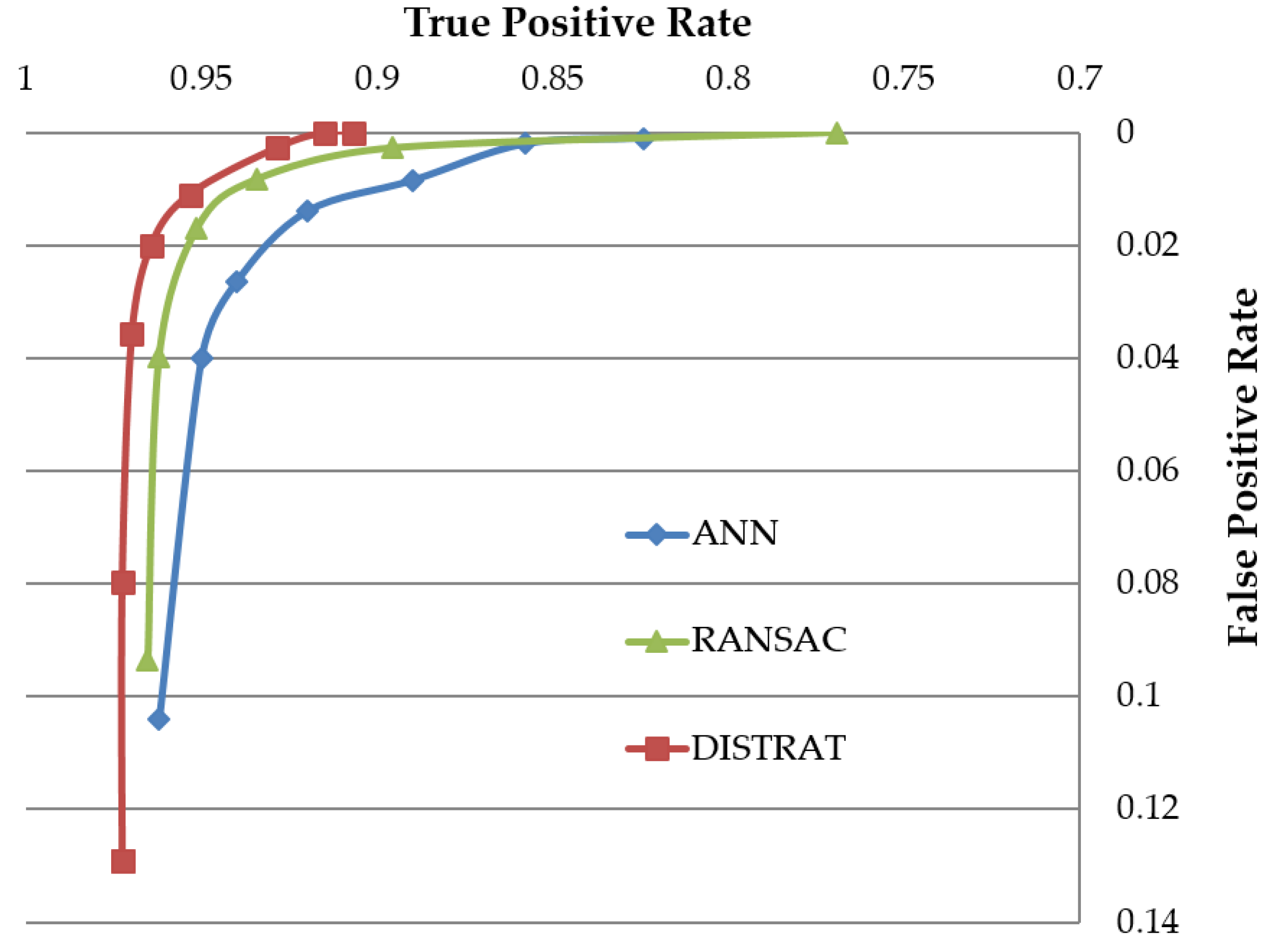
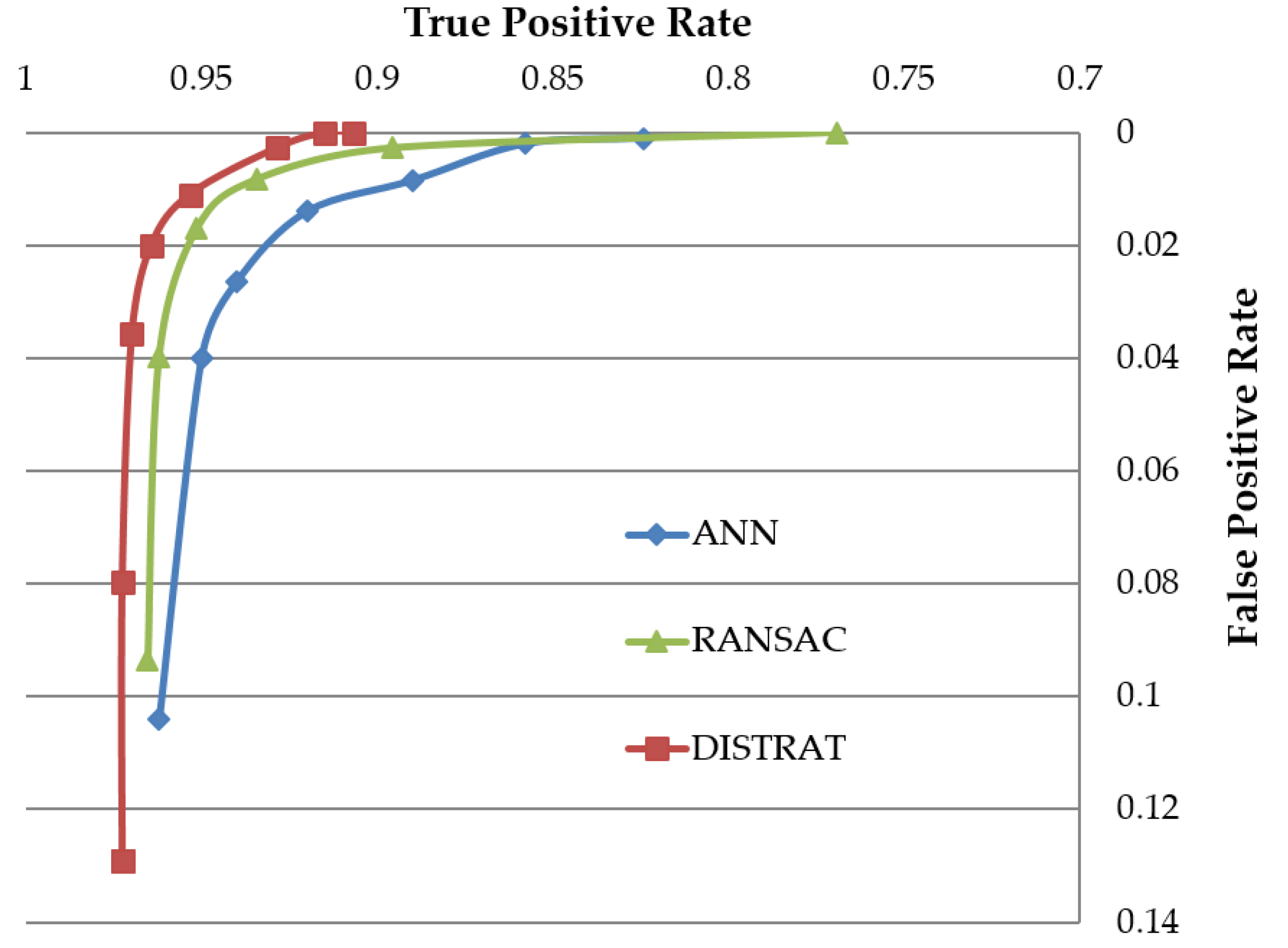
4.1. Geometric Verification Test for Rigid Object Matching
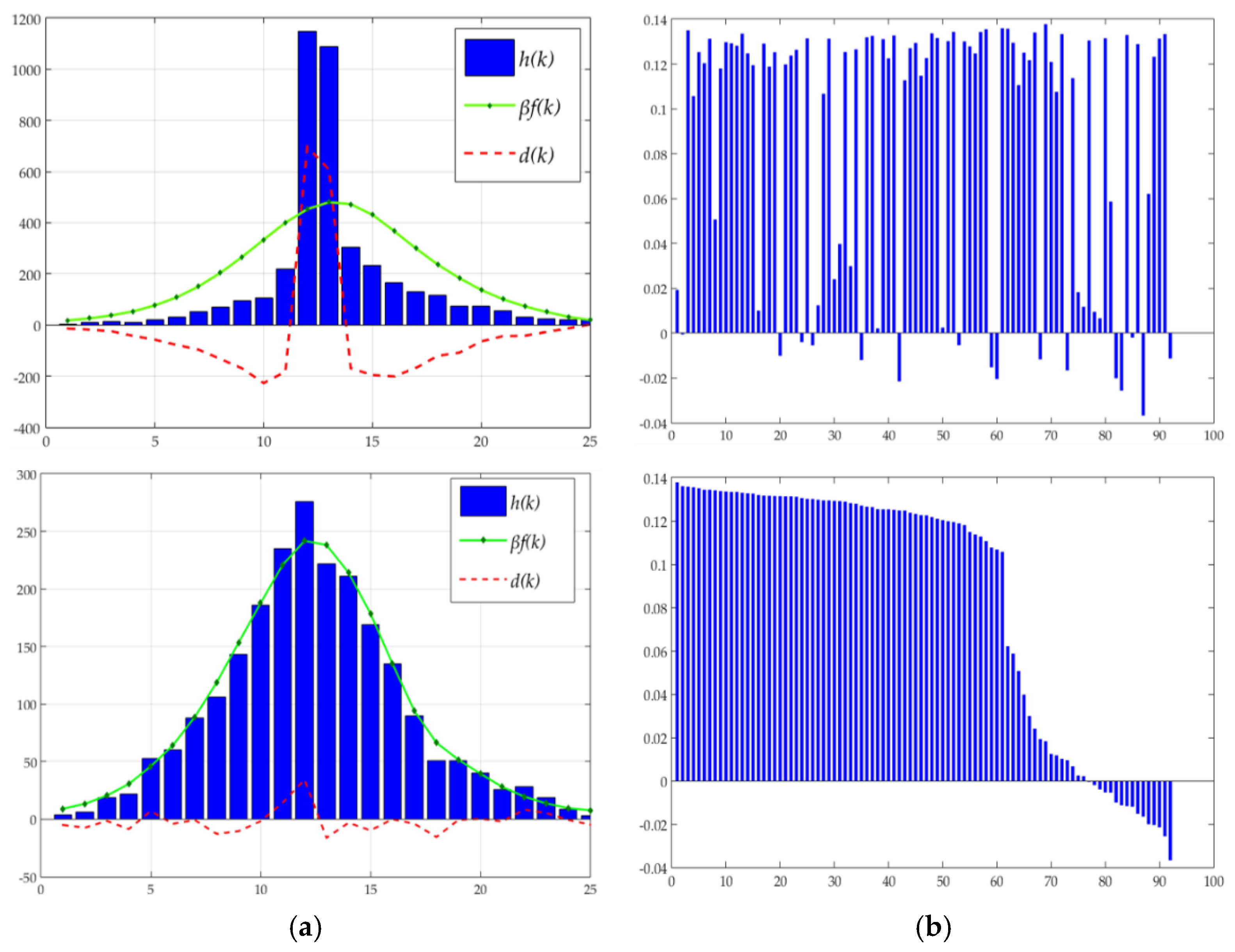
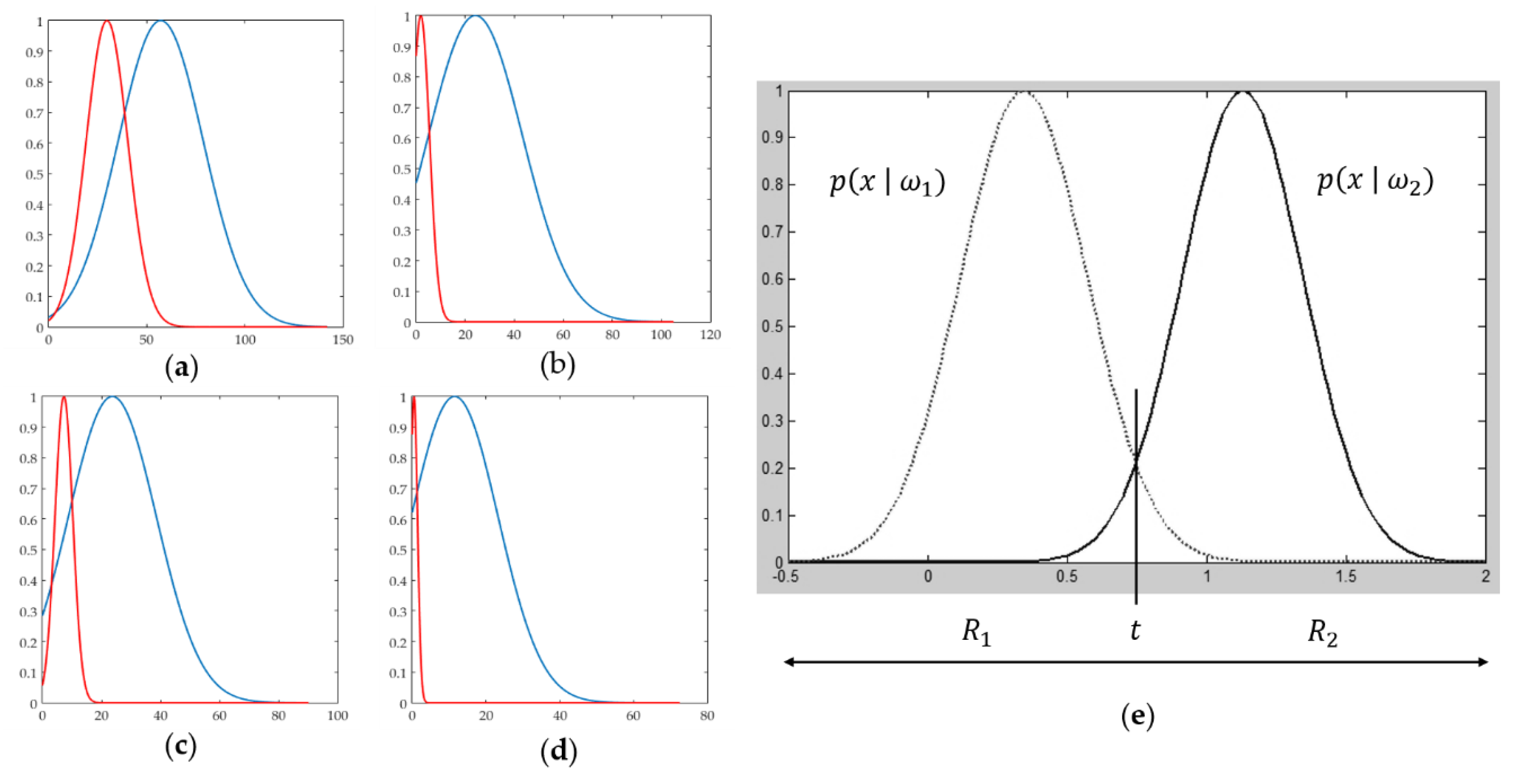
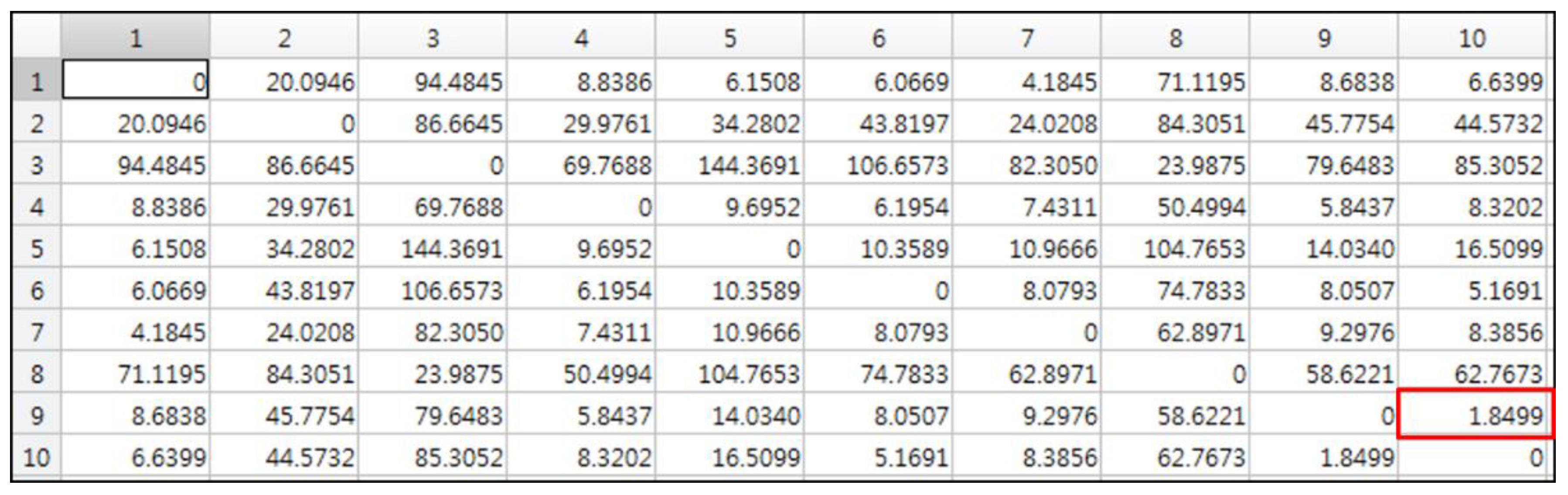
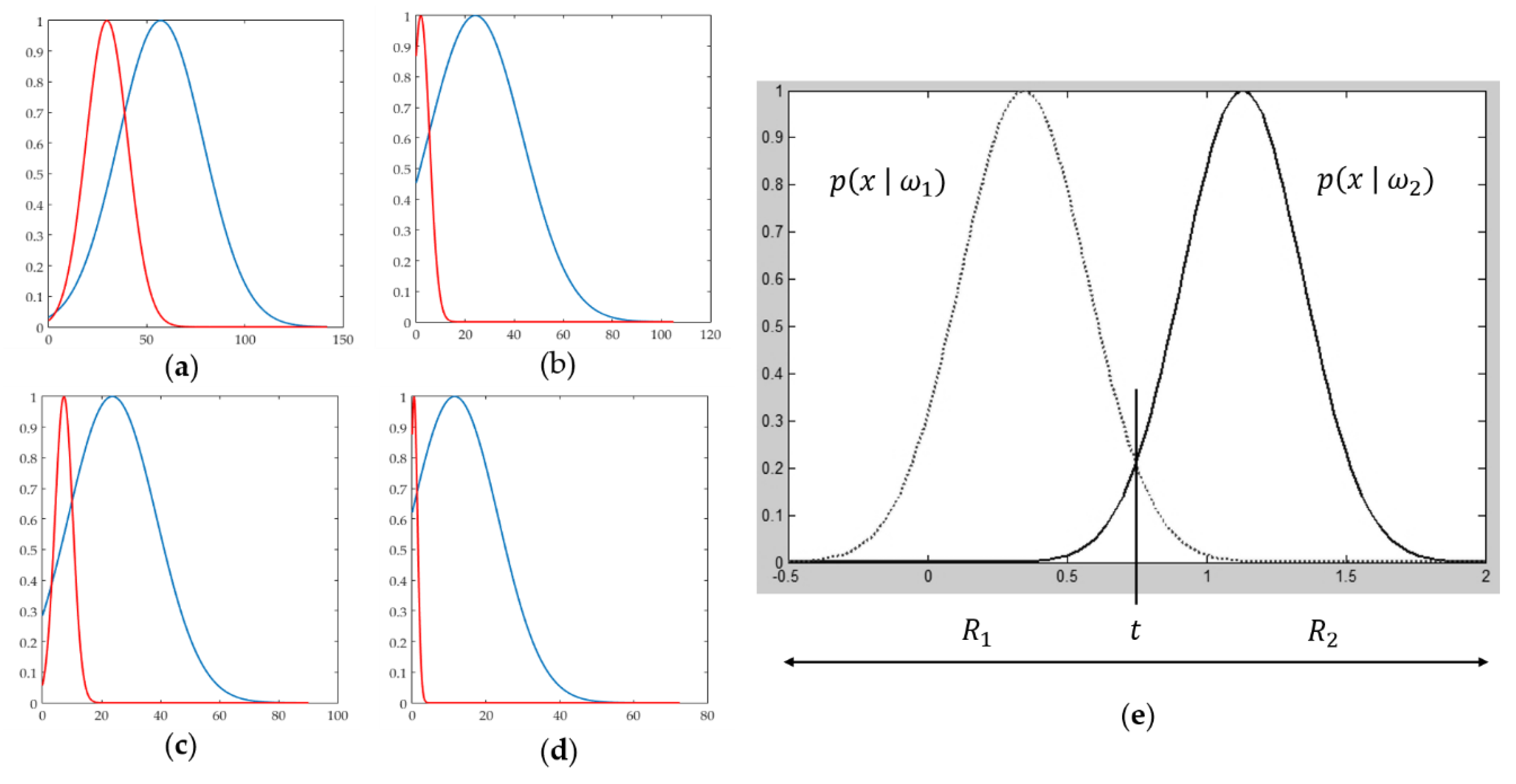
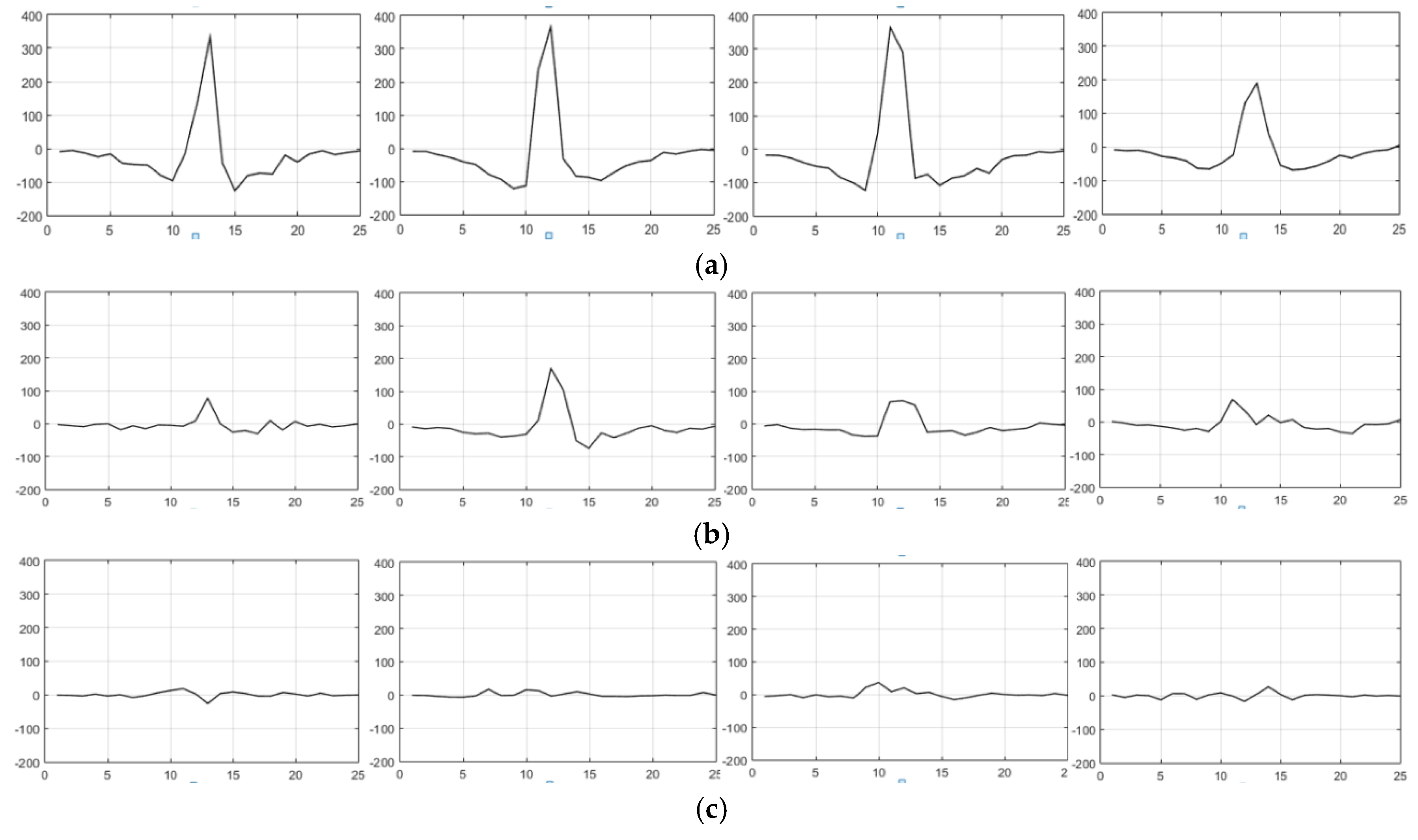
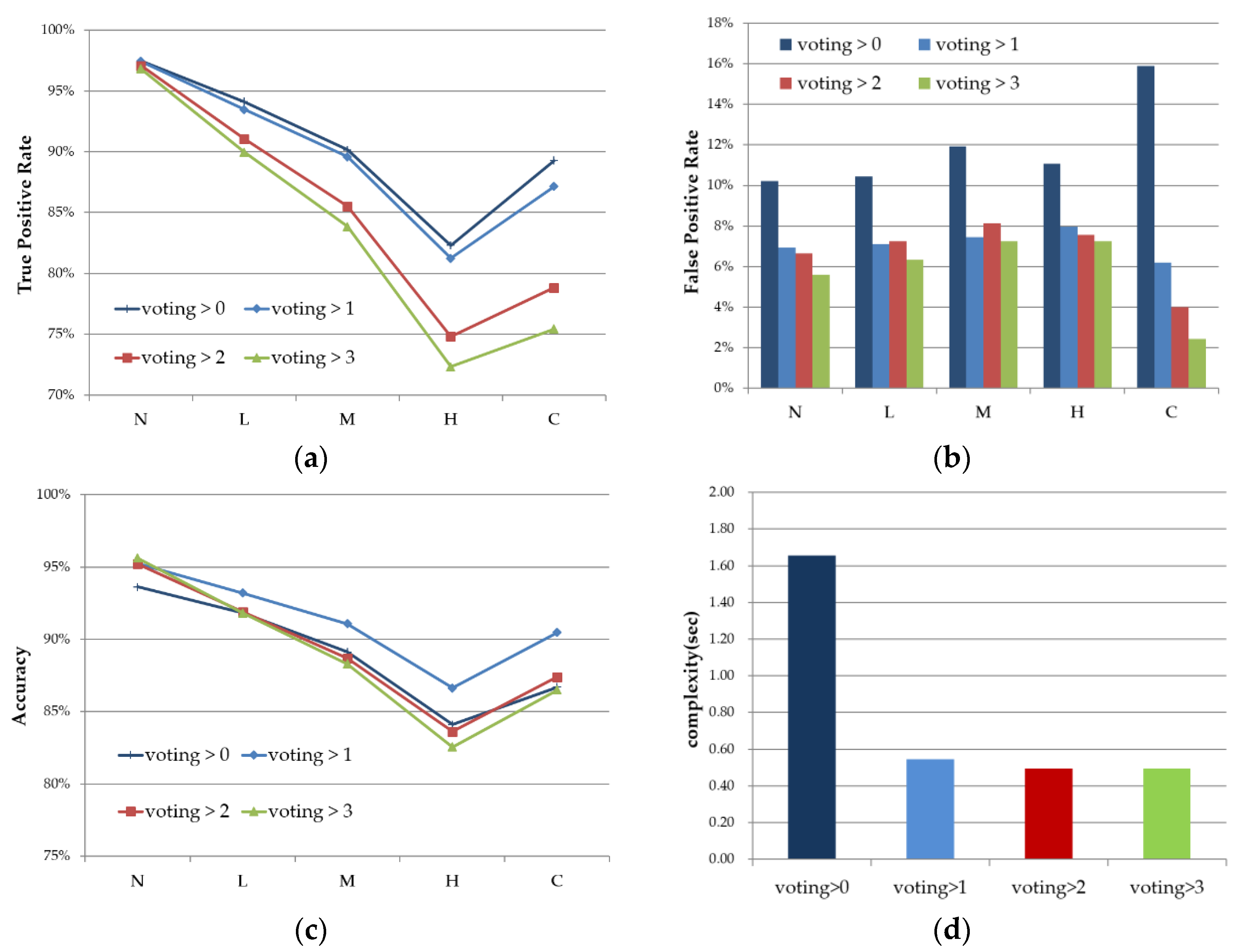
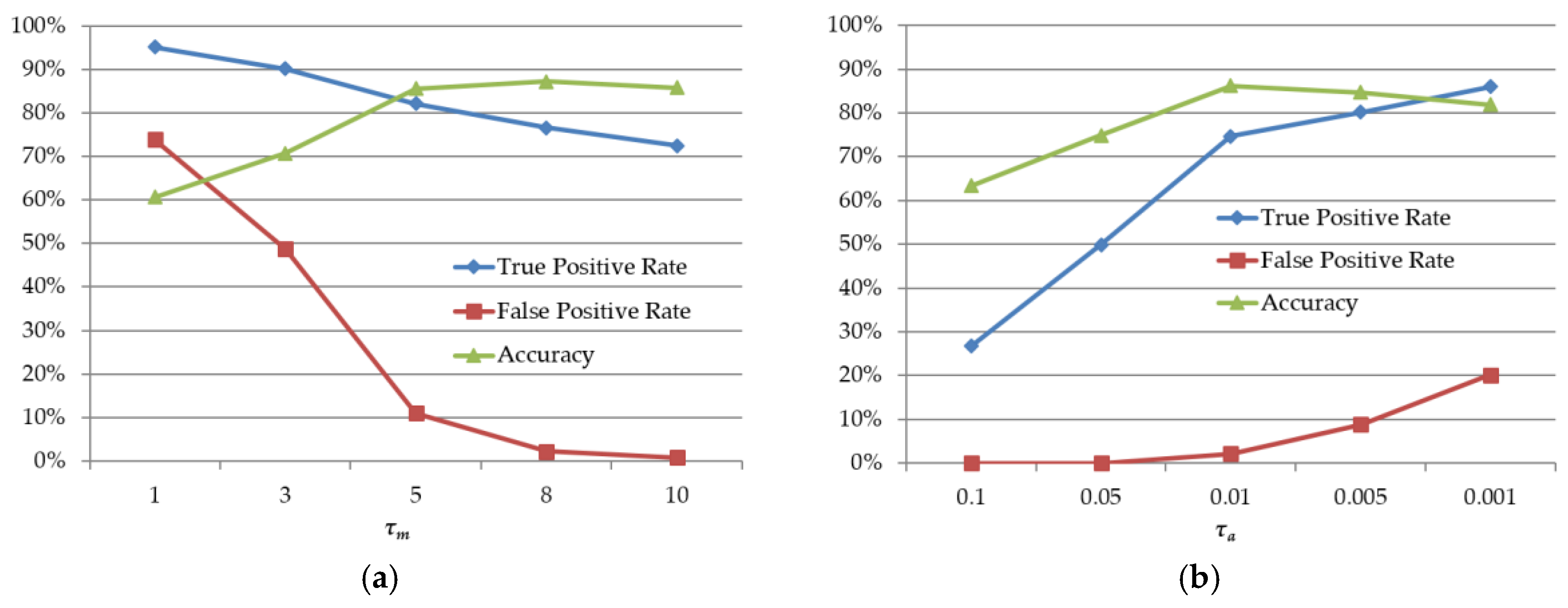
4.2. Discriminating Deformable Objects Using Voting Methods
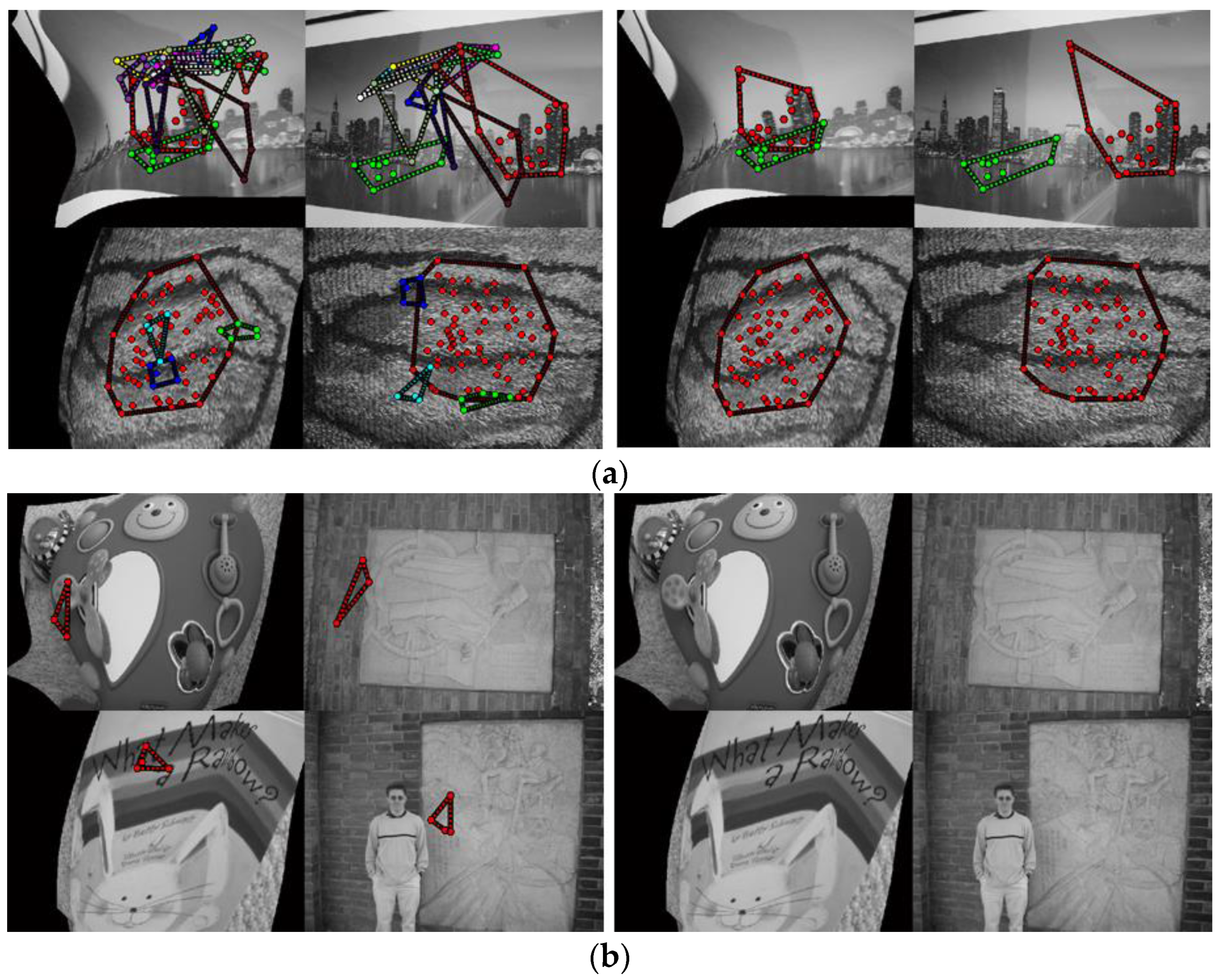
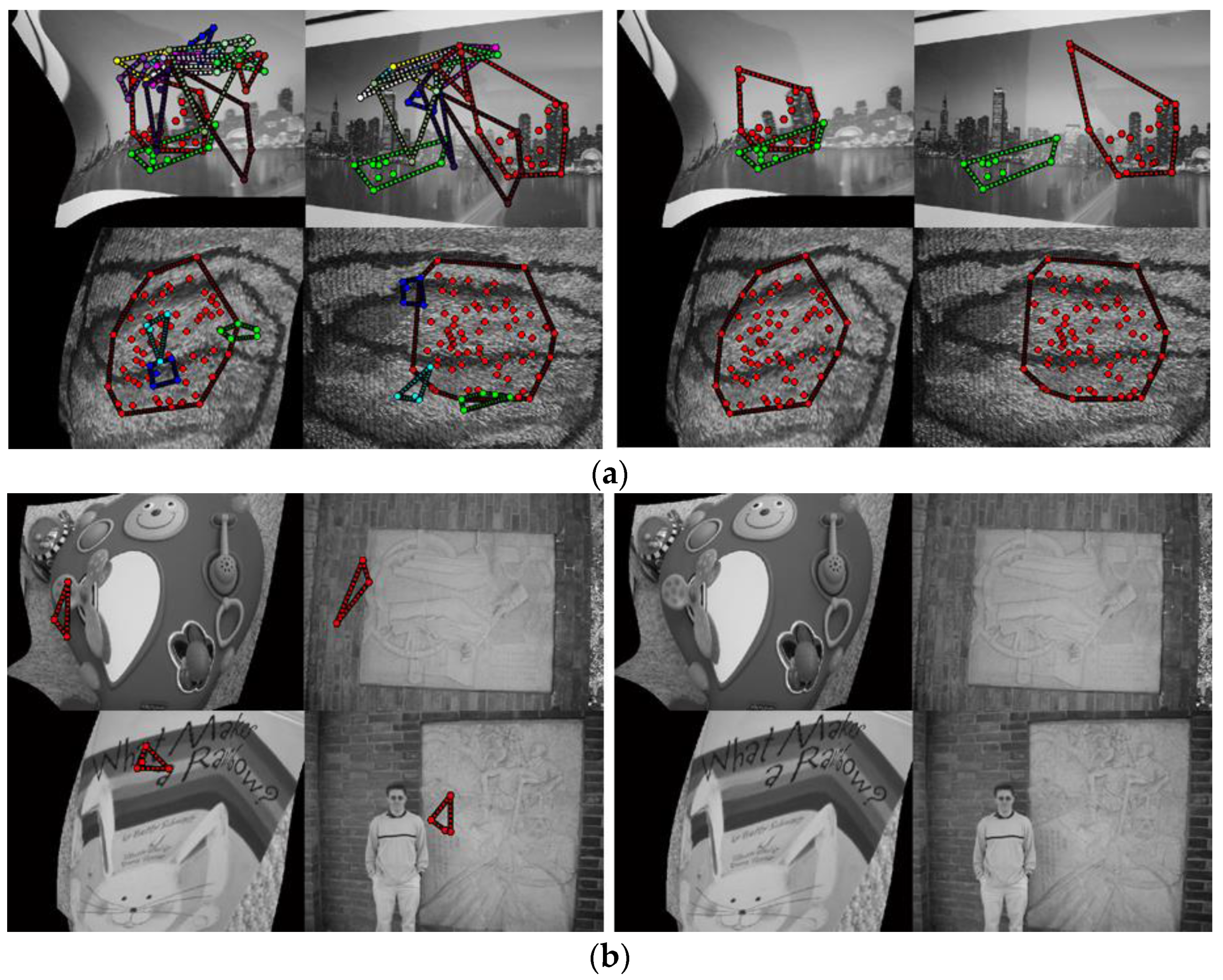
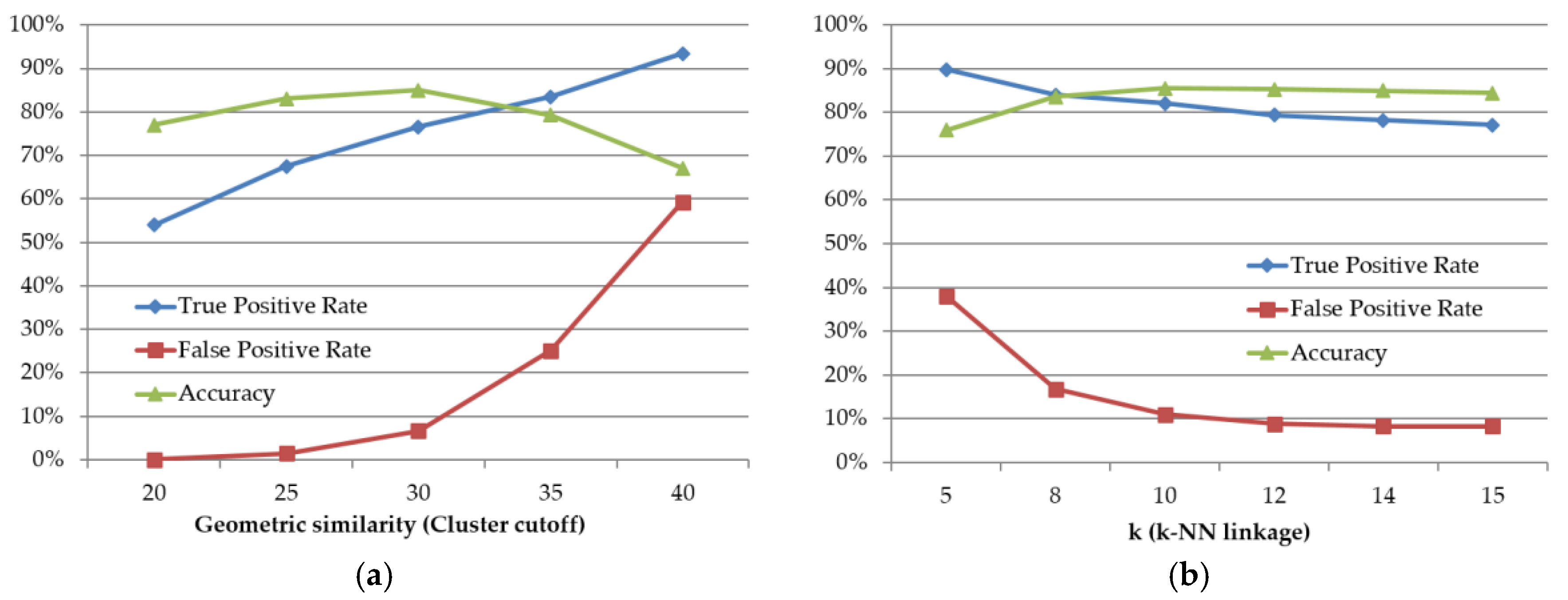
4.3. Deformable Object-Matching Performance Test
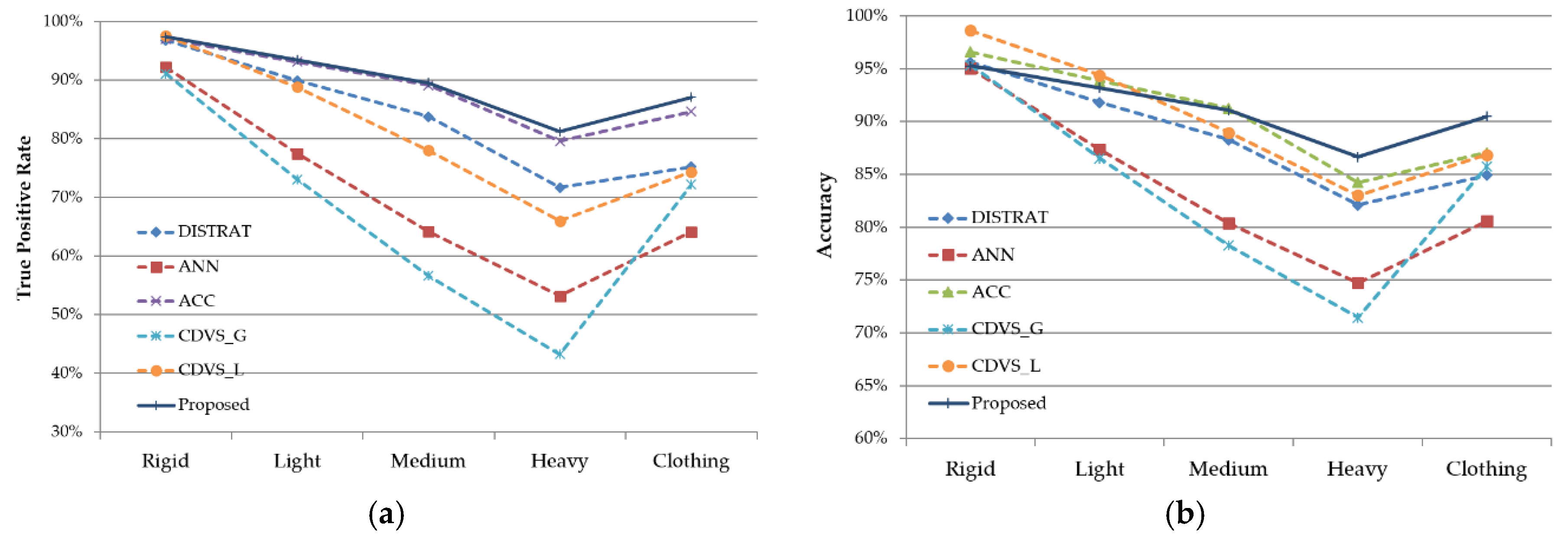
4.4. Performance Evaluation for the Proposed Matching Method
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105.
- Won, I.; Yang, H.; Jang, H.; Jeong, D. Adaptive Matching Method of Rigid and Deformable Object Image using Statistical Analysis of Matching-pairs. J. Inst. Electron. Inform. Eng. 2015, 52, 102–110. [Google Scholar] [CrossRef]
- Liu, S.; Song, Z.; Liu, G.; Xu, C.; Lu, H.; Yan, S. Street-to-shop: Cross-scenario clothing retrieval via parts alignment and auxiliary set. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3330–3337.
- Na, S.; Oh, W.; Jeong, D. A Frame-Based Video Signature Method for Very Quick Video Identification and Location. ETRI J. 2013, 35, 281–291. [Google Scholar] [CrossRef]
- Kahaki, S.; Nordin, M.J.; Ashtari, A.H.; Zahra, S.J. Deformation invariant image matching based on dissimilarity of spatial features. Neurocomputing 2016, 175, 1009–1018. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Lu, G. Contour-Based Corner Detection and Robust Geometric Point Matching Techniques. Ph.D. Thesis, Monash University, Melbourne, Australia, 2008. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Tsai, S.S.; Chen, D.; Takacs, G.; Chandrasekhar, V.; Vedantham, R.; Grzeszczuk, R.; Girod, B. Fast geometric re-ranking for image-based retrieval. In Proceedings of the International Conference on Image Processing (ICIP), Hong Kong, 26–29 September 2010; pp. 1029–1032.
- Lepsøy, S.; Francini, G.; Cordara, G.; Gusmão, D.; Buarque, P.P. Statistical modelling of outliers for fast visual search. In Proceedings of the International Conference Multimedia and Expo (ICME), Barcelona, Spain, 11–15 July 2011; pp. 1–6.
- Duan, L.; Chandrasekhar, V.; Chen, J.; Lin, J.; Wang, Z.; Huang, T.; Girod, B.; Gao, W. Overview of the MPEG-CDVS Standard. IEEE Trans. Image Process. 2016, 25, 179–194. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Hoi, S.C.; Lyu, M.R. Nonrigid shape recovery by Gaussian process regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 1319–1326.
- Pilet, J.; Lepetit, V.; Fua, P. Real-time nonrigid surface detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2009; pp. 822–828.
- Kettani, O.; Ramdani, F.; Tadili, B. An Agglomerative Clustering Method for Large Data Sets. Int. J. Comp. Appl. 2014, 92, 1–7. [Google Scholar] [CrossRef]
- Zhou, F.; Torre, F. Deformable graph matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2922–2929.
- Cho, M.; Lee, J.; Lee, K.M. Feature correspondence and deformable object matching via agglomerative correspondence clustering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Kyoto, Japan, 27 September–4 October 2009; pp. 1280–1287.
- Yang, H.; Won, I.; Jeong, D. On the Improvement of Deformable Object Matching. In Proceedings of the Korea-Japan Joint Workshop on Frontiers of Computer Vision (FCV), Okinawa, Japan, 4–6 February 2014; pp. 1–4.
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comp. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Krystian, M.; Cordelia, S. A Performance Evaluation of Local Descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar]
- Chapelle, O.; Haffner, P.; Vapnik, V.N. Support vector machines for histogram-based image classification. IEEE Trans. Neural Netw. 1999, 10, 1055–1064. [Google Scholar] [CrossRef] [PubMed]
- Zhao, W.; Wu, X.; Ngo, C. On the annotation of web videos by efficient near-duplicate search. IEEE Trans. Multimed. 2010, 12, 448–461. [Google Scholar] [CrossRef]
- Chandrasekhar, V.R.; Chen, D.M.; Tsai, S.S.; Cheung, N.; Chen, H.; Takacs, G.; Reznik, Y.; Vedantham, R.; Grzeszczuk, R.; Bach, J. The Stanford mobile visual search data set. In Proceedings of the Second Annual ACM Conference on Multimedia Systems, Santa Clara, CA, USA, 23–25 February 2011; pp. 117–122.
- Bookstein, F.L. Principal warps: Thin-plate splines and the decomposition of deformations. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 10, 567–585. [Google Scholar] [CrossRef]
- Nister, D.; Stewenius, H. Scalable recognition with a vocabulary tree. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006; pp. 2161–2168.
- Arya, S.; Mount, D.M.; Netanyahu, N.S.; Silverman, R.; Wu, A.Y. An optimal algorithm for approximate nearest neighbor searching fixed dimensions. J. ACM 1998, 45, 891–923. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | TPR | FPR | Accuracy | Matching Time (s) |
|---|---|---|---|---|
| DISTRAT [9] | 83.51% | 6.41% | 88.55% | 0.446 |
| ANN [24] | 70.27% | 3.03% | 83.62% | 0.536 |
| ACC [15] | 86.45% | 6.46% | 89.99% | 3.759 |
| CDVS(Global) [10] | 67.27% | 0.35% | 83.46% | 0.003 |
| CDVS(Local) [10] | 74.94% | 0.28% | 87.33% | 0.005 |
| Proposed | 89.78% | 7.12% | 91.33% | 0.521 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Won, I.; Jeong, J.; Yang, H.; Kwon, J.; Jeong, D. Adaptive Image Matching Using Discrimination of Deformable Objects. Symmetry 2016, 8, 68. https://doi.org/10.3390/sym8070068
Won I, Jeong J, Yang H, Kwon J, Jeong D. Adaptive Image Matching Using Discrimination of Deformable Objects. Symmetry. 2016; 8(7):68. https://doi.org/10.3390/sym8070068
Chicago/Turabian StyleWon, Insu, Jaehyup Jeong, Hunjun Yang, Jangwoo Kwon, and Dongseok Jeong. 2016. "Adaptive Image Matching Using Discrimination of Deformable Objects" Symmetry 8, no. 7: 68. https://doi.org/10.3390/sym8070068
APA StyleWon, I., Jeong, J., Yang, H., Kwon, J., & Jeong, D. (2016). Adaptive Image Matching Using Discrimination of Deformable Objects. Symmetry, 8(7), 68. https://doi.org/10.3390/sym8070068