Abstract
Implicit emotions are often expressed through implicit and weak clues between modalities due to the lack of explicit emotional feature words, representing a significant challenge for multimodal sentiment analysis. In order to improve implicit emotion recognition, this paper proposes a multimodal sentiment analysis method that integrates KAN and the modal dynamic fusion mechanism. This method first introduces the KAN structure to construct a modal feature encoder to enhance the emotional expression ability of features. Then, the emotional contribution weight of each modality is calculated using the difference between the unimodal and multimodal sentiment scores, and the cross-attention mechanism guided by the main modality is used for feature fusion. Experiments on four datasets, CH-SIMS, CH-SIMSv2, MOSI, and MOSEI, show that the proposed method significantly outperforms the mainstream model in multiple indicators, especially when dealing with samples with implicit or ambiguous emotional expressions. The results verify the effectiveness of enhancing feature encoding capabilities and utilizing modal asymmetry information in implicit sentiment analysis.
1. Introduction
With the development of social networks and the explosive growth of online video content, people are increasingly expressing their opinions in a variety of ways and forms. Therefore, online platforms are filled with a large amount of data that integrates multiple information formats, such as text, audio, and visual data. These multimodal data often convey rich emotional information, and the analysis and processing of large-scale data often face complex and arduous challenges [1]. Multimodal sentiment analysis (MSA) aims to identify user emotional tendencies by integrating heterogeneous modal data, and has become an important research direction in the field of sentiment analysis [2]. Compared with unimodal sentiment analysis that only focuses on a single modality, MSA emphasizes mining emotional clues from multi-source heterogeneous data such as text, speech, and vision to achieve a deeper portrayal of user emotions [3]. It has important value in the fields of intelligent human–computer interaction, public opinion detection, depression detection, product optimization, etc. [4].
Emotional expressions can be categorized as explicit or implicit. Explicit emotions, such as “I’m happy” or “This is terrible,” contain clear emotional signatures and can be effectively recognized by existing text-based models. However, the lack of explicit emotional feature words in implicit emotional expressions (such as sarcasm and implication) makes it difficult for traditional text-based sentiment analysis models to accurately capture the complete emotional information of a sentence. Implicit emotions can express richer emotional information than explicit emotions, which is particularly important in the current context of the rapid development of the Internet. For example, the identification and analysis of implicit emotions in user comments can help businesses optimize products and improve their responsiveness to user needs. Implicit emotions are usually expressed in a more subtle and non-intuitive way, but recognition efficiency can be improved by combining other modal information. The question of how to accurately capture the implicit emotions contained in multimodal information such as text, audio, and visual media has become a key challenge in multimodal sentiment analysis research. To address this challenge, Huang et al. [5] used a ternary symmetry-based approach to assign equal weight to each modality and model the bidirectional relationship between all modalities. Zhang et al. [6] used text as the dominant modality and guided the audio and visual modalities to interact with it to appropriately adjust the weights of different modalities. Both methods assume that the contribution size between modalities is static, but in actual scenarios, the dominant modality may change dynamically, and visual expressions or voice intonation may carry key emotional clues. Wang et al. [7] used BiLSTM to extract unimodal contextual information to improve feature representation capabilities, but did not break through the limitations of linear representation. Although these methods have achieved promising results, they still fail to address two major technical bottlenecks in current multimodal sentiment analysis research. First, implicit emotions rely on complex nonlinear interactions between modalities, but existing multimodal sentiment analysis methods primarily rely on encoders based on multi-layer perceptrons or standard Transformer modules for unimodal representation learning. These methods struggle to capture the fine-grained nonlinear variations of emotional signals, limiting their expressiveness and interpretability. Second, existing fusion strategies struggle to dynamically balance the contributions of each modality. Most methods treat all modalities symmetrically or apply fixed, context-driven weights. These strategies fail to reflect the dynamic and often asymmetric contributions of modalities, especially in implicit emotional contexts such as sarcasm and innuendo, where different modalities may convey varying degrees of emotional information.
To overcome the above limitations, this paper proposes a multimodal sentiment analysis model based on KANs [8] (Kolmogorov–Arnold Networks) and the dynamic fusion mechanism (KD-MSA) which improves the model’s sentiment recognition performance by enhancing the feature encoding mechanism and dynamic fusion strategy. First, we introduce KAN-enhanced feature encoding. By using adaptive spline basis functions, KAN not only improves the nonlinear expressiveness of unimodal features but also provides interpretability through the explicit form of the basis activation functions. To our knowledge, this is the first attempt to integrate KAN into multimodal sentiment analysis. Second, we propose an asymmetric contribution-aware dynamic fusion mechanism. Unlike existing symmetric or static fusion methods, our method adaptively adjusts the weights of the modalities based on their sentiment consistency and contribution. This design enables the model to enhance the influence of the primary modality while suppressing noisy or redundant modalities, which is particularly beneficial for implicit sentiment understanding.
The main contributions of this paper can be summarized as follows:
- KAN-based feature encoding: We introduce a feature encoder–decoder architecture that replaces the conventional feed-forward network with a KAN module. By leveraging learnable B-spline basis functions, our model captures complex nonlinear relationships that traditional MLP-based encoders fail to represent, thereby improving the expressiveness and interpretability of unimodal sentiment features.
- Sentiment-aware dynamic fusion: We propose a novel cross-fusion strategy guided by dynamically calculated unimodal sentiment weights. Unlike existing static or text-dominant fusion methods, our approach adaptively adjusts modality contributions according to their emotional consistency, effectively suppressing noisy signals and enhancing complementary cues across modalities.
- Integration of multi-head attention: Multi-head attention is incorporated in both unimodal encoding and multimodal fusion stages. This enables the model to capture dependencies from multiple representation subspaces in parallel, improving robustness in handling ambiguous or implicit emotional expressions.
- Comprehensive evaluation with significant improvements: Extensive experiments on two Chinese datasets (CH-SIMS, CH-SIMSv2) and two English datasets (MOSI, MOSEI) demonstrate that our model consistently outperforms strong baselines. Specifically, on CH-SIMSv2, KD-MSA achieves an F1 score of 81.02%, surpassing the best baseline (CENet, 79.63%) by 1.39%. On MOSI, KD-MSA improves the F1 score to 84.87%, a relative gain of 2.64% over MulT. On the large-scale MOSEI dataset, KD-MSA attains an F1 score of 85.89%, exceeding BBFN (85.56%) and MMIM (85.26%), while reducing the MAE to 0.5299, the lowest among all compared models. These results verify the effectiveness and cross-lingual generalization capability of our method.
2. Related Work
In recent years, multimodal sentiment analysis has made significant progress in fusing heterogeneous information to improve the accuracy of sentiment recognition, especially in handling implicit sentiment expressions in complex scenarios. In order to further clarify the positioning and innovations of this study, this section will briefly review existing work from two perspectives: first, the methods for mining and representing modal features in implicit sentiment analysis, and second, the development and evolution of multimodal fusion strategies.
2.1. Implicit Sentiment Analysis
Early research on implicit sentiment analysis mainly focused on rule-based [9,10] and corpus-based [11] methods, which generally used the manual encoding of knowledge and dictionary resources to assist analysis and recognition. Although this method is easy to analyze and understand, it is overly dependent on text language features and vocabulary resources and is not ideal in cross-domain and cross-language sentiment analysis. In order to reduce the reliance on manual annotation resources, researchers began to use deep neural network models to study implicit emotions. The BiLSTM model with multi-polar orthogonal attention [12] adopts orthogonal constraints to maintain the weight differences of neutral words in different contexts, which can effectively handle implicit emotional expressions without emotional word clues. The network model based on bidirectional sequential graph convolution [13] uses graph convolutional neural network to analyze the grammatical structure of text and combines it with BERT to extract text information. However, constructing a sentence dependency tree solely from the perspective of grammatical analysis will result in errors. The dual graph convolutional neural network model [14] jointly considers grammatical structure and semantic relevance and enhances the ability to extract sentiment information by fusing both grammatical information and semantic information. Tian et al. [15] introduced a phrase structure tree and converted the phrase tree into a hierarchical phrase matrix. They extracted grammatical and semantic information through a graph convolutional neural network, effectively solving the problem of irrelevant noise caused by the dependency tree method when modeling.
However, when the text is relatively complex, the above deep-learning-model-based methods will lose some key information. To solve this problem, researchers introduced the attention mechanism into the network layer to filter irrelevant information [16,17,18], thereby improving the performance of implicit sentiment feature capture. Focusing only on text data is not enough to accurately identify implicit emotions. Multimodal information such as human facial expressions and voice also conveys rich emotional information. Studies have shown that using both facial expression features and text features for implicit emotion recognition [19,20,21] can significantly improve the performance of implicit sentiment analysis. Speech features can also effectively make up for the shortcomings of text and visual modalities in capturing emotional information [22]. The acoustic and rhythmic information they carry can provide more subtle emotional clues. However, existing multimodal fusion methods are limited to basic modal mapping, ignoring the differences between modalities and lacking effective fusion of data between modalities.
2.2. Multimodal Fusion Strategy
In order to make full use of the emotional information contained in visual and audio modalities, the multimodal fusion strategy shifts from the simple splicing of modal data to data interaction between modalities. Wang et al. [23] used a text-based multi-head attention mechanism to incorporate textual information when learning emotion-related non-linguistic representations. Zhu et al. [24] designed a text-guided interaction module that processes cross-modal input using a self-attention mechanism and captures complementary non-linguistic information based on the text modality. In addition, in order to reduce the interference of potential sentiment-irrelevant or contradictory information, some studies have introduced methods to maximize mutual information [25] and adaptive representation learning strategies [6] to effectively weaken the impact of redundant noise. At the same time, to enhance the alignment of cross-modal information, contrastive learning is widely used to mine stable and similar representation features between text and other modalities [26,27]. However, non-linguistic information may dominate implicit emotional expression. The above method of statically setting text as the dominant modality will cause the model’s attention to be distracted by the text [28], seriously affecting the accuracy of emotion recognition. In order to adapt to scenarios where the dominant modality changes, researchers have begun to use attention mechanisms [29,30,31,32] and gating mechanisms [33,34] to adjust modal weights. However, these methods do not use emotional expression ability as the basis for weight evaluation, which may result in the overweighting of emotion-irrelevant modalities and fail to fully consider the complementary effect of implicit cues between modalities.
In summary, with the rapid development of artificial intelligence technology, the research on multimodal sentiment analysis has achieved some promising results, but there are still deficiencies in implicit sentiment mining and multimodal dynamic fusion. This paper uses KAN to enhance the emotional expression ability of features. By introducing single-modal sentiment weights, the modal fusion process is guided by emotional expression ability to achieve more targeted dynamic adjustments. In terms of multimodal fusion, cross-fusion modules dominated by each modality are constructed separately, which enhances the prominent expression of the dominant modal features and the organic supplementation of auxiliary modal information.
3. Methodology
3.1. Task Definition
In the MSA task, the input data is a video utterance and the multimodal dataset consists of N labeled utterances, represented as , . Each video utterance contains data from three modalities, namely text (), visual (), and audio () data, where and represent the sequence length and feature dimension of the input modality, respectively. Our goal is to make the model’s predicted sentiment label for fit its true sentiment label .
3.2. Overall Architecture
As shown in Figure 1, our proposed KD-MSA method consists mainly of five core modules: (1) The input representation module extracts low-level features for the three modalities in the video utterance. (2) The unimodal feature encoding module further encodes the text sequence and the low-level visual/audio features to extract high-level features for unimodal sentiment representation. (3) The sentiment weight calculation module uses the decoder to predict the unimodal sentiment and converts it into the sentiment weight by calculating the difference between unimodal and multimodal sentiment scores. (4) The multimodal dynamic fusion module adopts a main modal guidance strategy based on sentiment weight to achieve the enhancement of dominant information and the deep integration of multimodal information. (5) The sentiment classification module outputs the final sentiment polarity.
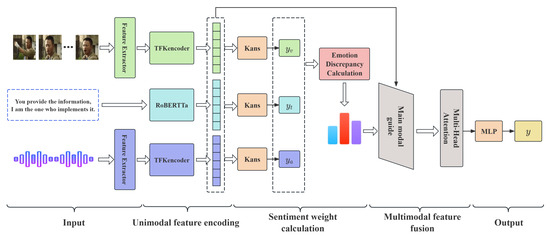
Figure 1.
The overall architecture of KD-MSA. The green, blue, purple, and gray represent the relevant module operations of visual, text, audio, and multimodal fusion.
3.3. Unimodal Feature Extraction
To ensure a fair comparison with state-of-the-art methods, based on previous work, we used the following data preprocessing strategy to extract features of the three modalities.
For the text modality, we used the roberta-base [35] and Chinese-roberta-wwm-ext [36] pre-trained models to convert English and Chinese, respectively, into word embeddings as text modality features. For the visual modality, since individuals mainly express their emotions through facial expressions, we used the OpenFace2.0 toolkit [37] to extract facial expression features as visual modality features. For the audio modality, we used the LibROSA speech toolkit [38] to extract MFCC features as audio modality features. All modal features are aligned with the same semantic segment according to timestamps, ensuring the consistency of multimodal input in the temporal dimension and semantic level to meet the needs of fusion.
After the above processing, the structural characteristics of each dataset are shown in Table 1.

Table 1.
Structural characteristics of each dataset.
3.4. Encoding with KAN
For the text modality, in order to obtain high-level semantic information from the text, we use RoBERTa to encode the text feature vector . Since RoBERTa is composed of multiple layers of Transformer encoders, the last layer brings together the understanding of the text from shallow to deep layers, covering rich and comprehensive contextual information, so we extract the hidden layer state of the last layer as the global semantic representation :
where represents all trainable parameters of the RoBERTa model.
For visual and audio modalities, we designed the TFKencoder encoder based on KAN. KAN innovates the structural design of traditional neural networks, replaces fixed activation functions with learnable spline functions, realizes the dynamic learning of activation functions, and improves the expressiveness and interpretability of the model through parameter optimization and structural adjustment. Figure 2 shows the internal structure of the TFKencoder encoder designed in this paper.
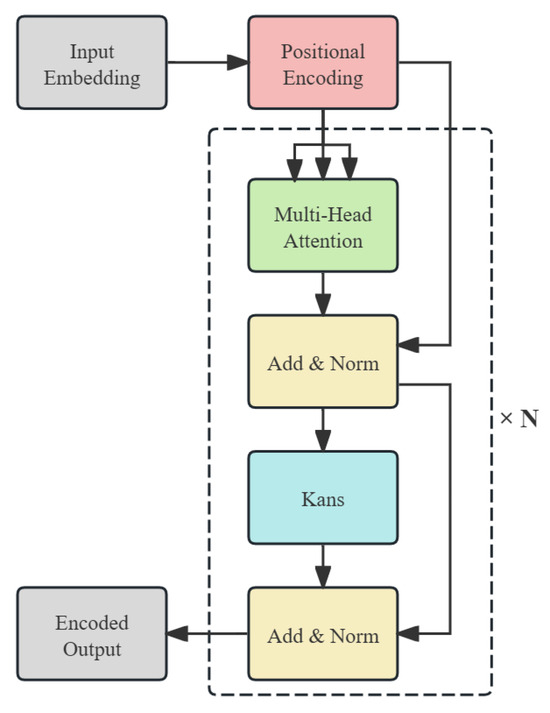
Figure 2.
The structure of the TFKencoder encoder.
In terms of overall structure, the TFKencoder encoder includes key components such as position encoding, a multi-head attention mechanism, residual connection, and a layer normalization module. Significantly different from traditional methods, we creatively replaced the feed-forward network (FFN) used to model nonlinear transformations with a KAN module. Specifically, we abandoned the MLP structure consisting of two linear layers and ReLU and used the KAN structure constructed by B-spline basis functions and learnable linear combination weights to provide stronger nonlinear expression capabilities and better local modeling capabilities. The core calculation process is as follows:
where K represents the number of B-spline basis functions, represents the kth B-spline basis function, and represents the learnable linear combination weight.
The encoder can be stacked in multiple layers to further enhance the representation capability of the model. In each layer, the KAN module processes the features output by the multi-head attention and forms a nonlinear mapping component in the deep structure together with the residual connection. Compared to single-head attention, multi-head attention can focus on input features in different subspaces in parallel, thereby more comprehensively capturing multi-level dependencies and fine-grained semantic cues within the modalities. In this way, facial expressions in the visual modality, and prosody and intonation in the speech modality, can be more fully expressed, avoiding the information limitations that may be caused by a single attention head and providing more discriminative representations for subsequent cross-modal fusion.
Through this structural design, our TFKencoder not only retains the advantages of Transformers in modeling long sequence context information but also combines the powerful representation ability of KANs, so that the model can achieve nonlinear and interpretable local approximation in each input dimension, significantly improving the model’s modeling performance of visual and audio modal emotional features. We use a stacked TFKencoder encoder to capture the global semantic representation :
where and represent all the trainable parameters in TFKencoder.
3.5. Modal Weight Calculation
After encoding the features of the three modalities, we used the decoder constructed by KAN to calculate the unimodal sentiment score. Given that the difference between unimodal and multimodal sentiment scores can reflect the effectiveness of the sentiment information provided by the modality, we further converted the sentiment difference into modal weights and used them to guide the model to pay more attention to modal features with high sentiment consistency during the fusion stage.
Specifically, we designed an independent KAN structure decoder for each modality to map the modality encoding result into the sentiment tendency prediction score :
where . Since the difference between the unimodal sentiment score and the true sentiment label y is negatively correlated with the modality weight, we used an inverse proportional function and normalization operation to convert the sentiment difference into the modal weight :
where and k represents the slope of the inverse proportional function, which is used to scale the sentiment weight.
By introducing modal weights, the model can dynamically adjust the contribution of different modalities in the final fusion, effectively reduce the noise interference caused by weak modalities, and improve the robustness and accuracy of fusion.
3.6. Multimodal Dynamic Fusion
To achieve high-quality emotion fusion based on modal credibility, we designed a main modality-guided multimodal fusion strategy, which combines the cross-modal attention mechanism with the modal weight control mechanism to fully explore the differences in the role of each modality in expressing implicit emotions. The entire module structure is shown in Figure 3. The module mainly consists of four parts: cross-attention fusion, feature enhancement representation, modality ratio control, and multimodal attention output.
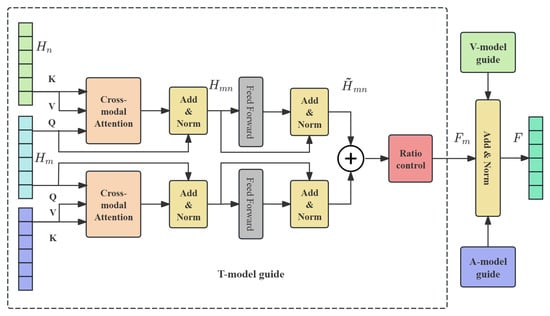
Figure 3.
The architecture of main modality-guided multimodal fusion. The internal structure of the V-model guide and A-model guide modules is consistent with the T-model guide module structure.
We first used cross-attention (CA) to perform two cross-attention calculations with each modality as the main modality (providing the Query vector) and the other two modalities providing the Key and Value vectors. The formula is as follows:
where represents the main mode, , represents the remaining modes, and represents the learnable parameter matrix of the linear projection of query/key/value. In order to avoid the degradation of unimodal representation, the interaction result is residually connected and layer normalized with the main modality:
This process realizes the guided fusion of the main modality to the other modal information. Next, is fed into a feed-forward neural network to further extract deep features, and residual connections and layer normalization are performed again:
This process enhances the sentiment representation guided by the main modality. Next, in order to guide the model to dynamically adjust the influence of different main modalities in the final fusion result, the fusion enhancement feature guided by each main modality is multiplied by its weight :
This weighting mechanism enables quantifiable control over modal contributions, meaning that the fusion results guided by the main modes that are more consistent with the final emotion prediction will be given higher weights. Finally, the fused weighted features guided by the three main modalities are added and layer-normalized to form the fused feature F:
The fusion feature F is further input into the multi-head attention and feed-forward neural network to obtain the dynamic attention output . The multi-head attention mechanism can simultaneously capture the diverse dependencies between cross-modal features. Different attention heads can focus on complementary information in the fused features, thereby strengthening effective interactions while suppressing redundant or noisy signals. This parallel representation learning not only improves the stability of cross-modal information integration, but also enhances the model’s generalization ability when processing implicit emotions.
3.7. Output and Optimization Objectives
In order to simultaneously improve the model’s ability to model the semantic consistency between multimodal representations and the final sentiment classification accuracy, we designed a joint loss function that comprehensively considers both inter-modal correlation estimation and prediction accuracy. This loss function is used to guide the training of the entire model. Algorithm 1 shows the training process of our KD-MSA.
Specifically, in order to guide the model to learn the consistency between the fusion features and the representations of each modality, we introduced the Noise Contrastive Estimation (NCE) framework [39] to calculate the difference between the encoded features , of each modality and the final fusion features as the modality correlation loss :
In order to ensure that the model can output accurate sentiment predictions, we input the final fusion feature into a two-layer MLP to obtain the final sentiment prediction result :
Subsequently, in order to measure the gap between the predicted emotion value and the true emotion label value y, the mean absolute error (MAE) is used as the emotion prediction regression loss :
The total loss used for model training is obtained by weighted addition of the above two losses:
where is a hyperparameter used to balance the importance of sentiment prediction accuracy and modality consistency modeling.
| Algorithm 1: Training Procedure of KD-MSA |
 |
4. Experiments
4.1. Datasets
In order to fully verify the effectiveness and cross-language generalization ability of the proposed model in multimodal sentiment analysis tasks, we conducted experiments on four mainstream multimodal sentiment analysis datasets, namely CH-SIMS [40], CH-SIMSv2 [41], MOSI [42], and MOSEI [43]. These four datasets cover two language environments, Chinese and English, and are widely used in multimodal sentiment intensity regression and classification tasks. They all contain three modalities: text, visual, and audio data. The detailed statistical information of the dataset division is shown in Table 2.
Table 2.
Detailed statistics of the dataset.
CH-SIMS. CH-SIMS is a Chinese multimodal sentiment analysis dataset constructed by the Institute of Automation, Chinese Academy of Sciences. Its corpus is derived from dialogue clips of characters in film and television dramas, with natural content and authentic emotions. During the construction of this dataset, sentence-level segmentation and trimodal synchronous annotation strategies were adopted, and a sentiment consistency scoring mechanism was introduced to ensure the co-occurrence of sentiment between multimodal semantics. The dataset supports multimodal alignment and implicit sentiment modeling research, and is one of the most important benchmark datasets for Chinese multimodal research.
CH-SIMSv2. CH-SIMSv2 is an enhanced version of CH-SIMS, which expands the coverage of video utterances and optimizes the sampling density of visual and speech modalities. This dataset introduces more complex scenes and emotional transition segments, further improving modal diversity and temporal modeling difficulty.
MOSI. MOSI was proposed by Carnegie Mellon University (CMU). The data come from English social media and YouTube bloggers’ opinion videos. This dataset is one of the early benchmarks for English multimodal sentiment analysis, emphasizing sentence-level sentiment expression, and is widely used for model verification and performance comparison.
MOSEI. MOSEI was also released by CMU, being one of the largest and most thematically rich multimodal sentiment corpora. Its corpus covers different speakers, different topics, and multiple emotional states, with a high degree of contextual diversity and speaking-style complexity, and it is widely used in research tasks such as multimodal sentiment intensity and emotion recognition.
4.2. Evaluation Metrics
In order to comprehensively evaluate the performance of the model in the multimodal sentiment analysis task, we used the following four mainstream evaluation indicators to evaluate the model from three dimensions: regression accuracy, relevance, and classification effect.
The mean absolute error (MAE) is used to measure the average absolute deviation between the model prediction results and the true sentiment label. The smaller the MAE value, the stronger the model’s ability to regress sentiment intensity. Pearson correlation (Corr) is used to measure the linear correlation between the prediction result and the true label. The value range is [−1, 1]. This indicator can reflect whether the model prediction trend is consistent with the actual emotional changes. The binary classification accuracy (Acc-2) evaluates the accuracy of the model in positive and negative sentiment discrimination tasks through the sentiment score, and is often used for sentiment polarity analysis. The F1 score (F1) comprehensively considers the precision and recall rate in binary classification tasks, reflects the discrimination ability of the model under unbalanced labels, and is suitable for evaluating the accuracy of sentiment polarity prediction.
4.3. Baselines
In order to verify the effectiveness and advancement of the proposed method, representative methods in the current field of multimodal sentiment analysis were selected as comparison models. These methods cover different technical approaches, including early tensor fusion, attention mechanism methods, and modular decoupling mechanisms, as detailed below:
TFN [44]: This full modal interaction representation is constructed using the tensor product of the three modalities. Although it has a high computational cost, its complete modeling capability has important implications for subsequent research.
LMF [45]: This model was proposed to decompose the multimodal tensor fusion process into a low-rank decomposition to significantly reduce the computational complexity and the number of parameters. The core idea is to capture the potential multimodal coupling representation through tensor factorization while retaining the modal interaction capability.
MulT [31]: This cross-modal attention mechanism was introduced and a multi-layer Transformer encoder was constructed to capture the temporal dependencies between modalities. The modeling of long-distance context and the interaction between non-aligned modalities are significant.
MISA [46]: By decoupling the universal features and unique features of modalities, a joint representation of shared space and specific space was constructed, enhancing the interpretability and generalization ability of the representation.
BBFN [47]: The bimodal bilinear interaction module was introduced to perform layer-by-layer cross-modeling of any modal pair. Its design fully considers the bidirectional interaction mechanism between modalities and uses residual connections to enhance semantic consistency.
MMIM [25]: Based on the mutual information maximization theory, more useful information is retained in the fusion process, and the effectiveness of multimodal fusion is improved through the information bottleneck mechanism.
CubeMLP [48]: This method first reshapes the three modal features into a three-dimensional cube structure, and then learns and maps them through a shared MLP to achieve a good balance between fusion efficiency and expression ability.
CENet [32]: This cross-modal attention mechanism is used to enhance feature interaction, and the fusion robustness is improved by explicitly constructing the inter-modal guidance path. At the same time, the residual learning strategy is introduced to alleviate the information offset problem caused by modal conflict.
4.4. Experimental Settings
The method in this paper was implemented based on the PyTorch (Version 1.9.0) framework, and all experiments were run on a single Huawei Ascend 910B NPU with 64G graphical memory size. For different datasets, we set different hyperparameters. The detailed information regarding the optimal hyperparameters is shown in Table 3.
Table 3.
Hyperparameter settings on different datasets.
The core hyperparameters of the KAN neural network in the modal encoder structure designed in this paper are configured as follows: the order of B-spline is set to 3, indicating that the cubic B-spline is used as the basis function; the number of grid partitions is set to 5 to control the degree of local division of the function; the spline coefficient noise scale is set to 0.1 to control the perturbation degree of spline weight initialization; the domain range of the B-spline basis functions is set to [−1, 1]; and the basic activation function is set to SiLU to provide basic nonlinear mapping capabilities.
4.5. Results and Analysis
4.5.1. Comparison with Baselines
The comparison results between the proposed method and the baseline method on four datasets are shown in Table 4 and Table 5. Analysis of the experimental data in the table shows that, based on the Chinese datasets CH-SIMS and CH-SIMSv2, the method proposed in this paper achieves the best performance in all four evaluation metrics, with particularly significant improvements over existing methods in the Corr and F1 metrics. Based on the English datasets MOSI and MOSEI, our method also achieved the best results. Specifically, on MOSEI, our model further reduced the MAE to 0.5299 and achieved an F1 score of 0.8589, demonstrating optimal performance and validating the model’s robustness and generalization capabilities on cross-lingual corpora with larger scales and more complex modal structures.
Table 4.
Performance comparison on CH-SIMS and CH-SIMSv2. Note: the best result is marked in bold.
Table 5.
Performance comparison on MOSI and MOSEI. Note: the best result is marked in bold.
Furthermore, from a comparative perspective, since MOSEI covers a wide range of diverse corpora in open domains, modal expressions exhibit significant heterogeneity, and the emotional consistency between different modalities is unstable. In this context, traditional methods such as TFN, LMF, and MulT, which adopt fixed fusion strategies, struggle to adapt to dynamic changes between modalities. For example, TFN’s tensor fusion mechanism is sensitive to dimensional changes, LMF’s low-rank approximation limits the modeling ability of nonlinear interactions between modalities, and although MulT introduces a cross-modal attention mechanism, it lacks adaptive control of modal importance. Secondly, although BBFN and MMIM improve fusion depth, they do not consider emotional consistency between modalities, which leads to fusion results being easily affected by conflicting information when emotional expressions are inconsistent (e.g., positive speech but negative text). In contrast, the method proposed in this paper enhances the nonlinear representation capability of unimodal features by constructing a KAN encoder, enabling the model to extract effective emotional cues even when faced with complex semantic structures within a modality. Additionally, the emotion difference-based modal weight calculation mechanism we designed can dynamically identify which modalities contribute more emotional information in the current context, thereby avoiding interference from low-quality modalities in the final judgment. Finally, the main modality-guided cross-fusion strategy further enhances information interaction and collaborative expression between high-value modalities and other modalities, thereby showing significant performance advantages in datasets with high modal difference and high emotional ambiguity such as MOSEI.
4.5.2. Ablation Study and Analysis
In order to verify the effectiveness of each key module in the proposed method, we conducted ablation experiments on the CH-SIMS and MOSI datasets. Specifically, we removed three key modules in turn: (1) the TFKencoder encoder module (TFKE) based on the KAN neural network; (2) the unimodal emotion decoder module (KAND) based on the KAN neural network; and (3) the multimodal fusion module (DWA) based on main modality guidance. The experimental results are shown in Table 6.
Table 6.
Ablation experiment results of key modules on CH-SIMS and MOSI. “w/o” means removing a submodule in KAN-MSA. The top-down sequence indicates that a certain module is missing based on the previous method. The results demonstrate the contribution of each module. Note: the best result is marked in bold.
The analysis of the experimental data in the table shows that after removing the TFKE module used to enhance single-modal features, the model’s Acc-2 based on CH-SIMS decreased by 1.53% and F1 decreased by 1.50%. Based on the MOSI dataset, Acc-2 decreased by 1.53% and F1 decreased by 1.47%. This indicates that the TFKE module effectively enhances the expressive capability of single-modal features. Without this module, the original feature’s expressive capability is limited, thereby affecting the downstream fusion performance. After the TFKE module was removed, the KAND module was further removed. The model’s Acc-2 based on CH-SIMS dropped by another 0.22%, and F1 dropped by another 0.49%. Based on MOSI, Acc-2 and F1 dropped by 0.76% and 0.79%, respectively. KAND decodes unimodal features for sentiment difference calculation. When this modality is missing, the accuracy of the sentiment difference calculation decreases, which ultimately affects the allocation of modal weights. This shows that the KAND module is crucial to the calculation of modal weights. After removing the DWA module on the basis of missing the TFKE module and the KAND module, the model performance is further reduced. Based on CH-SIMS, Acc-2 dropped by 3.28% and F1 dropped by 3.42%. Based on MOSI, Acc-2 dropped by 2.29% and F1 dropped by 2.29%. Due to the lack of dynamic weight guidance in the fusion process, the inter-modal feature fusion degenerates into a static average, resulting in redundant or noisy information participating in the fusion, which reduces the model’s emotion recognition ability. In summary, although the ablation experiments were not performed on all datasets, we intentionally selected one Chinese dataset (CH-SIMS) and one English dataset (MOSI) to provide cross-lingual evidence. This design ensures that the observed improvements are not language-specific but rather generalizable. Together with the complete benchmark results reported in Table 4 and Table 5, the ablation study strongly supports the effectiveness of each module.
4.5.3. Example Analysis
To further verify and demonstrate the interpretability of our method in implicit sentiment analysis and the fusion contributions of different modalities, we selected two challenging examples from the CH-SIMS dataset for analysis. Because the CH-SIMS dataset not only annotates multimodal sentiment scores but also annotates each unimodal sentiment score, it can more intuitively demonstrate the role of modal contributions in the multimodal fusion process, as shown in Table 7.
Table 7.
Case study examples with sentiment scores from different modalities and model predictions.
For case 1, it is potentially ironic. Although the text expresses a strong positive sentiment, the real sentiment is negative, which shows that it is difficult to accurately judge the implicit sentiment tendencies of individuals by relying solely on text. KD-MSA adjusts the dominant modality and suggests that facial expressions and voice intonation can better reflect the true sentiment. After incorporating visual and audio information, it outputs a predicted value close to the actual sentiment intensity and successfully identifies the implicit sentiment. Similarly, for case 2, the text conveys a strong negative sentiment, but the real sentiment is positive. KD-MSA assigns the visual modality as the dominant one and ultimately achieves the accurate prediction of a positive sentiment. In addition, compared with the method that does not employ sentiment-aware weights, the sentiment scores predicted by KD-MSA are closer to the true values, indicating that the introduction of sentiment weighting enables the model to capture sentiment information more comprehensively and reduce the interference of noisy signals.
5. Conclusions and Future Work
This paper proposes a multimodal implicit sentiment analysis method that integrates KAN and a modal asymmetry perception fusion mechanism. Aiming to address the problem of traditional implicit sentiment analysis methods being unable to extract sufficient sentiment information, a modal encoder based on KAN is proposed to reduce the impact of noise and enhance the sentiment expression ability of features. In order to improve the efficiency of implicit emotion recognition, multimodal features are introduced to provide more comprehensive emotion information. Different from the existing methods that generally adopt static fusion or treat each modality equally, this study starts from the asymmetry of emotional contribution between modalities, dynamically allocates modal weights by calculating the emotion difference between single modality and multimodality features, and then guides the cross-attention fusion mechanism driven by the main modality, achieving more targeted and dynamic feature fusion. The experimental results based on four datasets show that the proposed method outperforms the existing mainstream models in multiple indicators, indicating that introducing multimodal features and effectively utilizing asymmetric information between modalities can help to improve the model’s ability to recognize implicit emotions.
In the future, we will further improve and expand this study based on the following aspects:
- (1)
- Although this paper has achieved asymmetry modeling at the modal level, it has not yet considered more fine-grained modal differences, such as local asymmetry in the temporal dimension or at the semantic segment level. Next, we plan to extend the dynamic fusion mechanism to the local level to more accurately characterize the contribution changes of different modalities in different semantic segments.
- (2)
- We will try to introduce external knowledge resources, such as metaphor knowledge bases, emotional common sense graphs, etc., to enhance the model’s perception of implicit emotional clues, which play an important complementary role in low-resource modalities such as visual media and speech.
- (3)
- The modal asymmetric fusion strategy proposed in this paper will be extended to other implicit sentiment task analyses, such as sarcasm recognition and racial discrimination recognition, to further verify the universality and extensibility of the method.
Author Contributions
Conceptualization, Z.H. and Q.Z.; methodology, Z.H. and Z.L.; software, Z.H. and Z.L.; validation, Q.Z. and Z.Z.; formal analysis, Q.Z. and Z.Z.; investigation, Z.Z.; resources, Z.L.; data curation, Z.H. and R.J.; writing—original draft preparation, Z.H. and Z.L.; writing—review and editing, Z.L., Z.Z. and R.J.; visualization, Z.H.; supervision, Z.Z. and R.J.; project administration, Z.Z. and R.J.; funding acquisition, Z.L. and R.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Program of China, grant number 2022YFB3103600.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- Zhang, C.; Yang, Z.; He, X.; Deng, L. Multimodal Intelligence: Representation Learning, Information Fusion, and Applications. IEEE J. Sel. Top. Signal Process. 2020, 14, 478–493. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 423–443. [Google Scholar] [CrossRef]
- Wu, T.; Peng, J.; Zhang, W.; Zhang, H.; Tan, S.; Yi, F.; Ma, C.; Huang, Y. Video sentiment analysis with bimodal information-augmented multi-head attention. Knowl.-Based Syst. 2022, 235, 107676. [Google Scholar] [CrossRef]
- Zhang, H.; Li, M.; Zhang, J. Implicit Sentiment Analysis for Chinese Texts based on Multimodal Information Fusion. Comput. Eng. Appl. 2025, 179–190. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, J.; Tang, Z.; Lin, J.; Chen, C.Y.C. TMBL: Transformer-based multimodal binding learning model for multimodal sentiment analysis. Knowl.-Based Syst. 2024, 285, 111346. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Yin, G.; Liu, K.; Liu, Y.; Yu, T. Learning Language-guided Adaptive Hyper-modality Representation for Multimodal Sentiment Analysis. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; pp. 756–767. [Google Scholar] [CrossRef]
- Wang, Y.; Lu, C.; Chen, Z. Multimodal sentiment analysis model with cross-modal text-information enhancement. J. Comput. Appl. 2024, 1–10. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Hou, T.Y.; Tegmark, M. KAN: Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2404.19756. [Google Scholar]
- Turney, P.; Neuman, Y.; Assaf, D.; Cohen, Y. Literal and Metaphorical Sense Identification through Concrete and Abstract Context. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; Barzilay, R., Johnson, M., Eds.; pp. 680–690. [Google Scholar]
- Liao, J.; Wang, S.; Li, D. Identification of fact-implied implicit sentiment based on multi-level semantic fused representation. Knowl.-Based Syst. 2019, 165, 197–207. [Google Scholar] [CrossRef]
- Gandy, L.; Allan, N.; Atallah, M.; Frieder, O.; Howard, N.; Kanareykin, S.; Koppel, M.; Last, M.; Neuman, Y.; Argamon, S. Automatic identification of conceptual metaphors with limited knowledge. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013; AAAI Press: Washington, DC, USA, 2013. AAAI’13. pp. 328–334. [Google Scholar]
- Wei, J.; Liao, J.; Yang, Z.; Wang, S.; Zhao, Q. BiLSTM with Multi-Polarity Orthogonal Attention for Implicit Sentiment Analysis. Neurocomputing 2020, 383, 165–173. [Google Scholar] [CrossRef]
- Fu, L.; Liu, S. A Syntax-based BSGCN Model for Chinese Implicit Sentiment Analysis with Multi-classification. In Proceedings of the 2022 IEEE 16th International Conference on Application of Information and Communication Technologies (AICT), Washington DC, USA, 12–14 October 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. DualGCN: Exploring Syntactic and Semantic Information for Aspect-Based Sentiment Analysis. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 7642–7656. [Google Scholar] [CrossRef]
- Tian, J.; Ai, F. Aspect-Level Sentiment Analysis Based on Enhanced Syntactic Information and Multi-feature Graph Convolutional Fusion. J. Front. Comput. Sci. Technol. 2025, 19, 738–748. [Google Scholar]
- Zhou, X.; Wan, X.; Xiao, J. Attention-based LSTM network for cross-lingual sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; pp. 247–256. [Google Scholar]
- Zhang, J.; Zhang, L.; Shen, F.; Tan, H.; He, Y. Implicit Sentiment Analysis Based on RoBERTa Fused with BiLSTM and Attention Mechanism. Comput. Eng. Appl. 2022, 58, 142–150. [Google Scholar]
- Ma, Y.; Yu, L.; Tian, S.; Qian, M.; Zhang, L. Metaphorical Aspect Sentiment Analysis Based on RoBERTa and Attention Mechanism. J. Chin. Comput. Syst. 2023, 44, 2236–2241. [Google Scholar] [CrossRef]
- Shutova, E.; Kiela, D.; Maillard, J. Black Holes and White Rabbits: Metaphor Identification with Visual Features. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Knight, K., Nenkova, A., Rambow, O., Eds.; pp. 160–170. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, M.; Guo, T.; Peng, C.; Saikrishna, V.; Xia, F. In Your Face: Sentiment Analysis of Metaphor with Facial Expressive Features. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Chen, M.; Ubul, K.; Xu, X.; Aysa, A.; Muhammat, M. Connecting Text Classification with Image Classification: A New Preprocessing Method for Implicit Sentiment Text Classification. Sensors 2022, 22, 1899. [Google Scholar] [CrossRef] [PubMed]
- Fan, X.; Yang, X.; Zhang, L.; Ye, Q.; Ye, N. Emotion recognition based on visual and auditory information. J. Nanjing Univ. (Nat. Sci.) 2021, 57, 309–317. [Google Scholar] [CrossRef]
- Wang, D.; Guo, X.; Tian, Y.; Liu, J.; He, L.; Luo, X. TETFN: A text enhanced transformer fusion network for multimodal sentiment analysis. Pattern Recognit. 2023, 136, 109259. [Google Scholar] [CrossRef]
- Zhu, C.; Chen, M.; Zhang, S.; Sun, C.; Liang, H.; Liu, Y.; Chen, J. SKEAFN: Sentiment knowledge enhanced attention fusion network for multimodal sentiment analysis. Inf. Fusion 2023, 100, 101958. [Google Scholar] [CrossRef]
- Han, W.; Chen, H.; Poria, S. Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; Moens, M.F., Huang, X., Specia, L., Yih, S.W.T., Eds.; pp. 9180–9192. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, Y.; Zhang, W.; Liu, Y.; Yang, C.; Lian, Z.; Hu, S. AMOA: Global Acoustic Feature Enhanced Modal-Order-Aware Network for Multimodal Sentiment Analysis. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; Calzolari, N., Huang, C.R., Kim, H., Pustejovsky, J., Wanner, L., Choi, K.S., Ryu, P.M., Chen, H.H., Donatelli, L., Ji, H., et al., Eds.; pp. 7136–7146. [Google Scholar]
- Lin, R.; Hu, H. Multimodal Contrastive Learning via Uni-Modal Coding and Cross-Modal Prediction for Multimodal Sentiment Analysis. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; pp. 511–523. [Google Scholar] [CrossRef]
- Feng, X.; Lin, Y.; He, L.; Li, Y.; Chang, L.; Zhou, Y. Knowledge-Guided Dynamic Modality Attention Fusion Framework for Multimodal Sentiment Analysis. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024. [Google Scholar]
- Zhang, Y.; Zhang, H.; Liu, Y.; Liang, K.; Wang, Y. Multimodal Sentiment Analysis Based on Bidirectional Mask Attention Mechanism. Data Anal. Knowl. Discov. 2023, 7, 46–55. [Google Scholar]
- Wang, Y.; He, J.; Wang, D.; Wang, Q.; Wan, B.; Luo, X. Multimodal transformer with adaptive modality weighting for multimodal sentiment analysis. Neurocomputing 2024, 572, 127181. [Google Scholar] [CrossRef]
- Tsai, Y.H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal Transformer for Unaligned Multimodal Language Sequences. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D., Màrquez, L., Eds.; pp. 6558–6569. [Google Scholar] [CrossRef]
- Wang, D.; Liu, S.; Wang, Q.; Tian, Y.; He, L.; Gao, X. Cross-Modal Enhancement Network for Multimodal Sentiment Analysis. IEEE Trans. Multimed. 2023, 25, 4909–4921. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, L.; Zhang, L.; Lü, X. Multimodal Sentiment Analysis Method Based on Cross-Modal Attention and Gated Unit Fusion Network. Data Anal. Knowl. Discov. 2024, 8, 67–76. [Google Scholar]
- Mengara Mengara, A.G.; Moon, Y.k. CAG-MoE: Multimodal Emotion Recognition with Cross-Attention Gated Mixture of Experts. Mathematics 2025, 13, 1907. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Wang, S.; Hu, G. Revisiting Pre-Trained Models for Chinese Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, Online, 16–20 November 2020; pp. 657–668. [Google Scholar]
- Baltrusaitis, T.; Zadeh, A.; Lim, Y.C.; Morency, L.P. OpenFace 2.0: Facial Behavior Analysis Toolkit. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 59–66. [Google Scholar] [CrossRef]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. SciPy 2015, 2015, 18–24. [Google Scholar]
- Gutmann, M.; Hyvärinen, A. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; Teh, Y.W., Titterington, M., Eds.; Volume 9, Proceedings of Machine Learning Research, pp. 297–304. [Google Scholar]
- Yu, W.; Xu, H.; Meng, F.; Zhu, Y.; Ma, Y.; Wu, J.; Zou, J.; Yang, K. CH-SIMS: A Chinese Multimodal Sentiment Analysis Dataset with Fine-grained Annotation of Modality. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J., Eds.; pp. 3718–3727. [Google Scholar] [CrossRef]
- Liu, Y.; Yuan, Z.; Mao, H.; Liang, Z.; Yang, W.; Qiu, Y.; Cheng, T.; Li, X.; Xu, H.; Gao, K. Make Acoustic and Visual Cues Matter: CH-SIMS v2.0 Dataset and AV-Mixup Consistent Module. In Proceedings of the 2022 International Conference on Multimodal Interaction, Bengaluru, India, 7–11 November 2022; Association for Computing Machinery: New York, NY, USA, ICMI ’22; pp. 247–258. [Google Scholar] [CrossRef]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. Multimodal Sentiment Intensity Analysis in Videos: Facial Gestures and Verbal Messages. IEEE Intell. Syst. 2016, 31, 82–88. [Google Scholar] [CrossRef]
- Bagher Zadeh, A.; Liang, P.P.; Poria, S.; Cambria, E.; Morency, L.P. Multimodal Language Analysis in the Wild: CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Gurevych, I., Miyao, Y., Eds.; pp. 2236–2246. [Google Scholar] [CrossRef]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor Fusion Network for Multimodal Sentiment Analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; Palmer, M., Hwa, R., Riedel, S., Eds.; pp. 1103–1114. [Google Scholar] [CrossRef]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Bagher Zadeh, A.; Morency, L.P. Efficient Low-rank Multimodal Fusion With Modality-Specific Factors. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Gurevych, I., Miyao, Y., Eds.; pp. 2247–2256. [Google Scholar] [CrossRef]
- Hazarika, D.; Zimmermann, R.; Poria, S. MISA: Modality-Invariant and -Specific Representations for Multimodal Sentiment Analysis. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; Association for Computing Machinery: New York, NY, USA, 2020. MM ’20. pp. 1122–1131. [Google Scholar] [CrossRef]
- Han, W.; Chen, H.; Gelbukh, A.; Zadeh, A.; Morency, L.p.; Poria, S. Bi-Bimodal Modality Fusion for Correlation-Controlled Multimodal Sentiment Analysis. In Proceedings of the 2021 International Conference on Multimodal Interaction, Montréal, QC, Canada, 18–22 October 2021; Association for Computing Machinery: New York, NY, USA, 2021. ICMI ’21. pp. 6–15. [Google Scholar] [CrossRef]
- Sun, H.; Wang, H.; Liu, J.; Chen, Y.W.; Lin, L. CubeMLP: An MLP-based Model for Multimodal Sentiment Analysis and Depression Estimation. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; Association for Computing Machinery: New York, NY, USA, 2022. MM’22. pp. 3722–3729. [Google Scholar] [CrossRef]
- Mao, H.; Yuan, Z.; Xu, H.; Yu, W.; Liu, Y.; Gao, K. M-SENA: An Integrated Platform for Multimodal Sentiment Analysis. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Dublin, Ireland, 22–27 May 2022; Basile, V., Kozareva, Z., Stajner, S., Eds.; pp. 204–213. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).