
FAMNet: A Lightweight Stereo Matching Network for Real-Time Depth Estimation in Autonomous Driving


Abstract
1. Introduction
- (1)
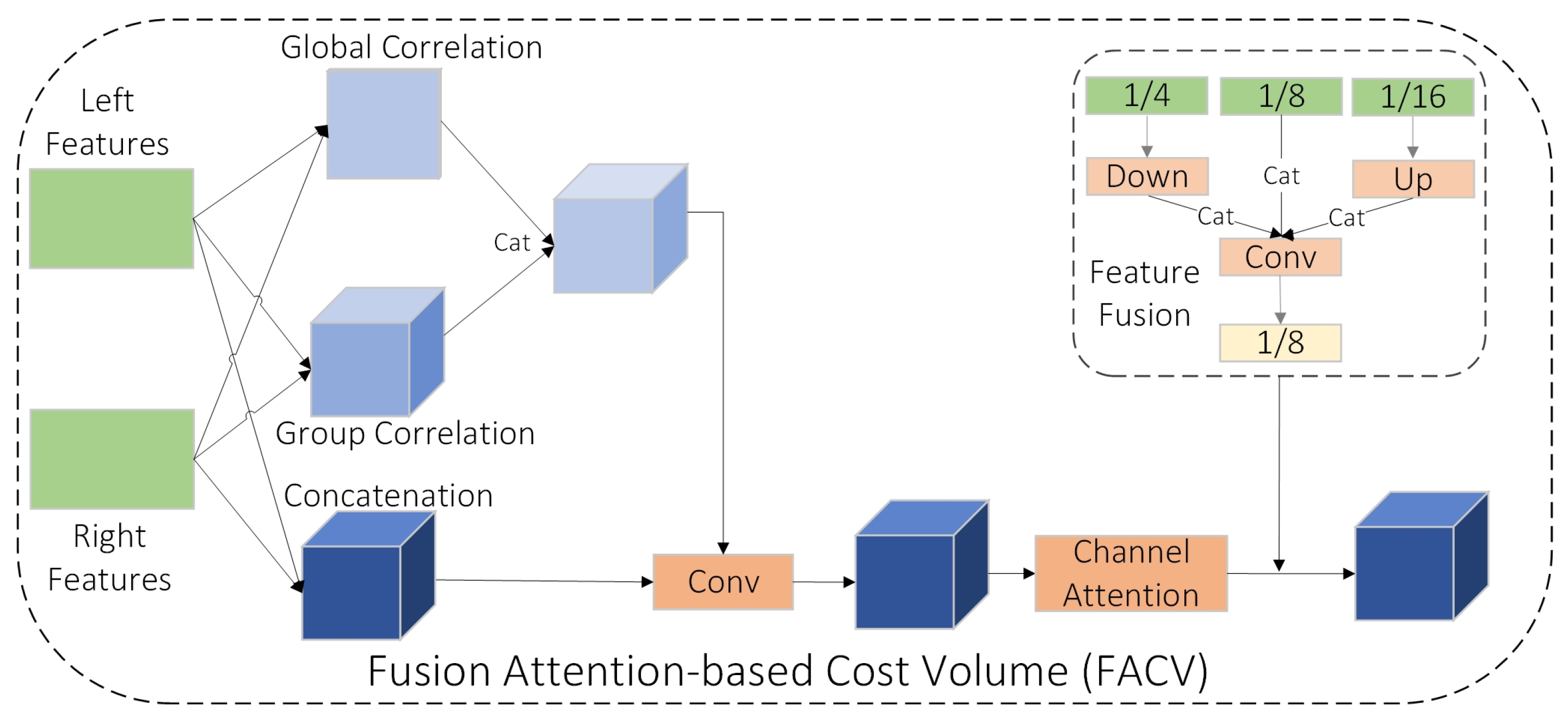
- We propose FACV, which integrates multi-scale correlation, attention-guided fusion, and channel reweighting to construct compact and informative cost volumes with reduced reliance on 3D convolutions.
- (2)
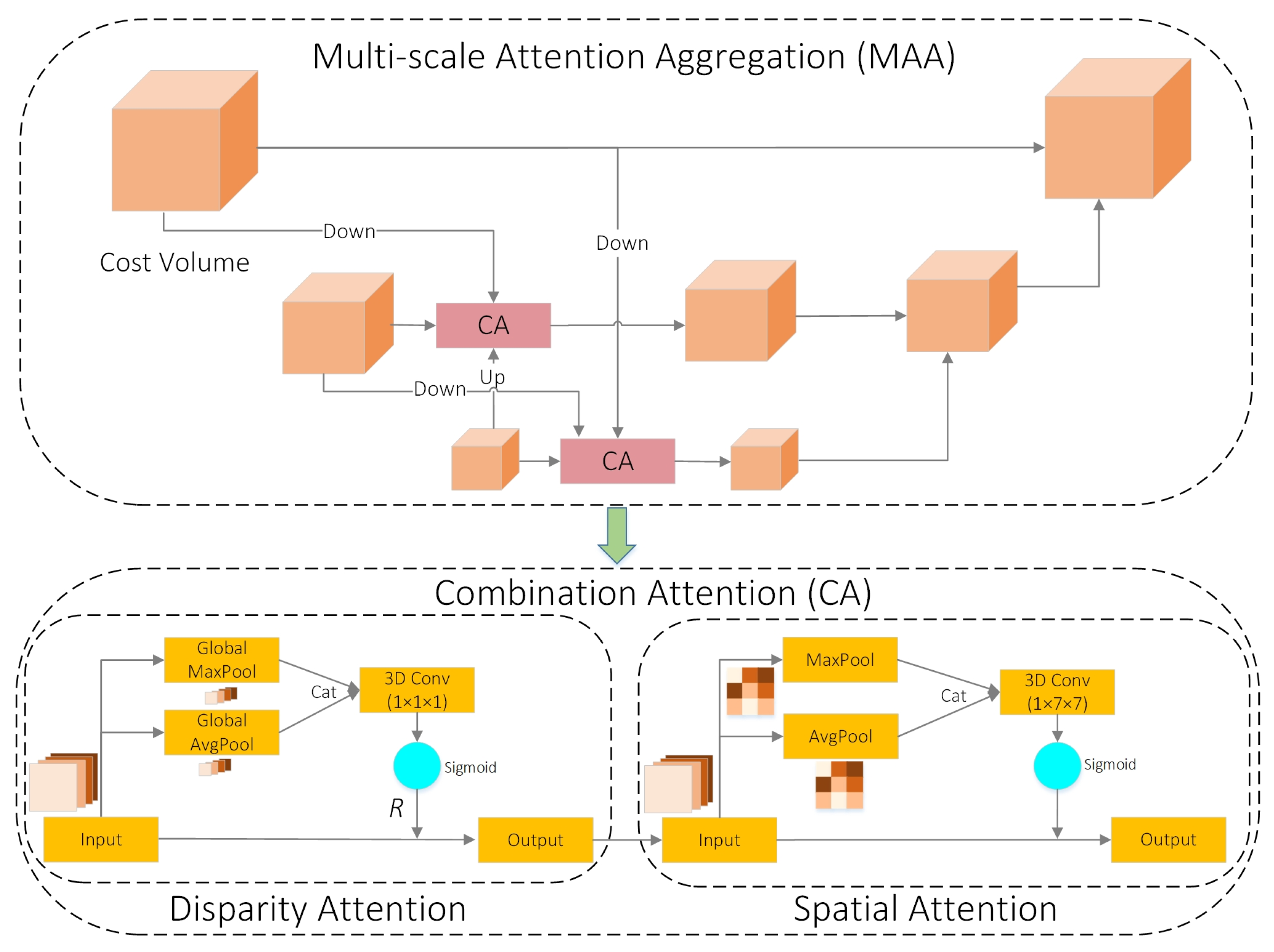
- We introduce MAA, which combines pyramid-based hierarchical cost aggregation and dual-path attention to enhance disparity estimation with minimal computational cost.
- (3)
- We develop a lightweight and real-time stereo matching network, FAMNet, to achieve a favorable balance between accuracy, efficiency, and cross-domain generalization, demonstrating its feasibility for practical deployment in autonomous driving scenarios.
2. Related Work
2.1. End-to-End Stereo Matching Network
2.2. Real-Time Stereo Matching Network
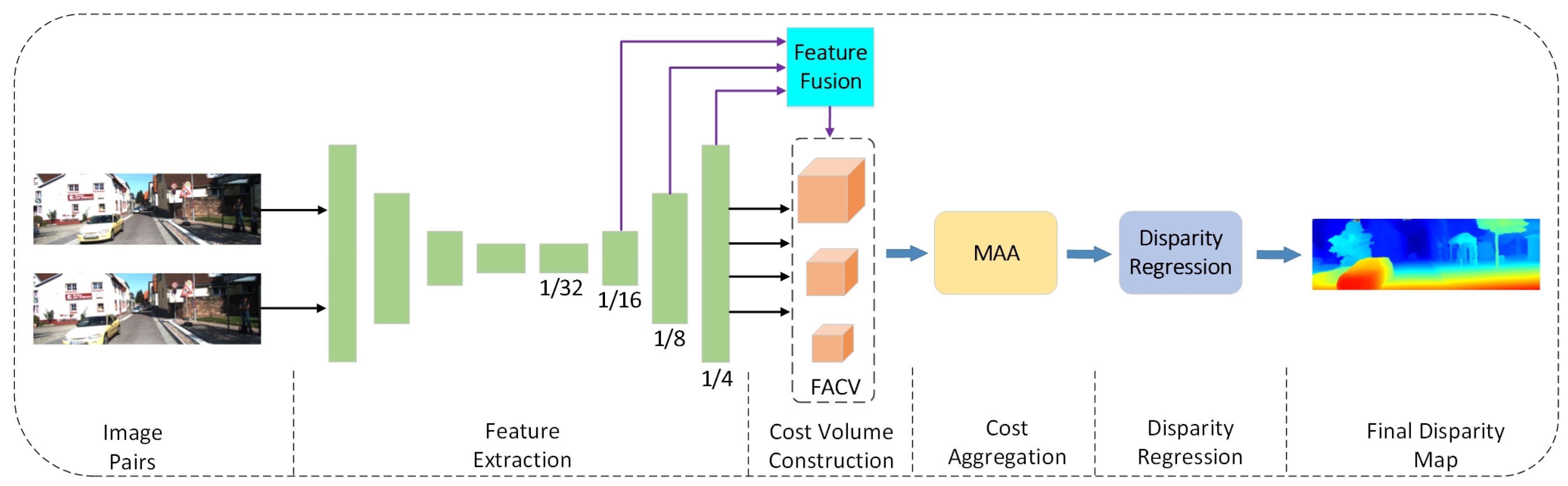
3. Method
3.1. FACV—Fusion Attention-Based Cost Volume
3.2. MAA—Multi-Scale Attention Aggregation
3.3. Disparity Regression and Loss Function
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Ablation Analysis
4.4. Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| FAMNet | Fusion Attention Multi-Scale Network |
| FACV | Fusion Attention-Based Cost Volume |
| MAA | Multi-Scale Attention Aggregation |
| GRU | Gate Recurrent Unit |
| GPU | Graphics Processing Unit |
| GwcNet | Group-Wise Correlation Network |
| CFNet | Cascade and Fused Cost Volume-Based Network |
| ACVNet | Attention Concatenation Volume Network |
| BGNet | Bilateral Grid Network |
| GAnet | Guided Aggregation Network |
| AANet | Adaptive Aggregation Network |
| GCNet | Geometry and Context Network |
| PSMNet | Pyramid Stereo Matching Network |
| IGEV | Iterative Geometry-Encoding Volume |
References
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. Deepdriving: Learning affordance for direct perception in autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Biswas, J.; Veloso, M. Depth camera based localization and navigation for indoor mobile robots. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Alhaija, H.; Mustikovela, S.K.; Mescheder, L.; Geiger, A.; Rother, C. Augmented reality meets computer vision: Efficient data generation for urban driving scenes. Int. J. Comput. Vis. 2011, 126, 961–972. [Google Scholar] [CrossRef]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Guo, X.; Yang, K.; Yang, W.; Wang, X.; Li, H. Group-wise correlation stereo network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, F.; Prisacariu, V.; Yang, R.; Torr, P.H.S. Ga-net: Guided aggregation net for end-to-end stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Xu, G.; Cheng, J.; Guo, P.; Yang, X. Attention concatenation volume for accurate and efficient stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Lipson, L.; Teed, Z.; Deng, J. Raft-stereo: Multilevel recurrent field transforms for stereo matching. In Proceedings of the International Conference on 3D Vision, Prague, Czech Republic, 1–3 December 2021. [Google Scholar]
- Xu, G.; Wang, X.; Ding, X.; Yang, X. Iterative geometry encoding volume for stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Xu, G.; Wang, X.; Zhang, Z.; Cheng, J.; Liao, C.; Yang, X. IGEV++: Iterative multi-range geometry encoding volumes for stereo matching. arXiv 2024, arXiv:2409.00638. [Google Scholar] [CrossRef] [PubMed]
- Liao, L.; Zeng, J.; Lai, T.; Xiao, Z.; Zou, F.; Fujita, H. Stereo matching on images based on volume fusion and disparity space attention. Eng. Appl. Artif. Intell. 2024, 136, 108902. [Google Scholar] [CrossRef]
- Lu, Y.; He, X.; Zhang, Q.; Zhang, D. Fast stereo conformer: Real-time stereo matching with enhanced feature fusion for autonomous driving. Eng. Appl. Artif. Intell. 2025, 149, 110565. [Google Scholar] [CrossRef]
- Tahmasebi, M.; Huq, S.; Meehan, K.; McAfee, M. DCVSMNet: Double cost volume stereo matching network. Neurocomputing 2025, 618, 129002. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Bhar, S.F.; Alhashim, I.; Wonka, P. AdaBins: Depth estimation using adaptive bins. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, Z.; Liu, X.; Drenkow, N.; Ding, A.; Creighton, F.X.; Taylor, R.H.; Unberath, M. Revisiting stereo depth estimation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Khamis, S.; Fanello, S.; Rhemann, C.; Kowdle, A.; Valentin, J.L.; Izadi, S. Stereonet: Guided hierarchical refinement for real-time edge-aware depth prediction. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xu, H.; Zhang, J. Aanet: Adaptive aggregation network for efficient stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, Y.; Lai, Z.; Huang, G.; Wang, B.; Maaten, L.; Campbell, M.; Weinberger, K.Q. Anytime stereo image depth estimation on mobile devices. In Proceedings of the IEEE International Conference on Robotics and Automation, Montreal, BC, Canada, 20–24 May 2019. [Google Scholar]
- Duggal, S.; Wang, S.; Ma, W.; Hu, R.; Urtasun, R. Deeppruner: Learning efficient stereo matching via differentiable patchmatch. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Xu, B.; Xu, Y.; Yang, X.; Jia, W.; Guo, Y. Bilateral grid learning for stereo matching networks. In Proceedings of the IEEE International Conference on Computer Vision, Virtual, 19–25 June 2021. [Google Scholar]
- Bangunharcana, A.; Cho, J.W.; Lee, S.; Kweon, I.S.; Kim, K.S.; Kim, S. Correlate-and-excite: Real-time stereo matching via guided cost volume excitation. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]
- Xu, G.; Zhou, H.; Yang, X. CGI-Stereo: Accurate and real-time stereo matching via context and geometry interaction. arXiv 2023, arXiv:2301.02789. [Google Scholar]
- Jiang, X.; Bian, X.; Guo, C. Ghost-Stereo: GhostNet-based cost volume enhancement and aggregation for stereo matching networks. arXiv 2024, arXiv:2405.14520. [Google Scholar]
- Pan, B.; Jiao, J.; Pang, J.; Cheng, J. Distill-then-prune: An efficient compression framework for real-time stereo matching network on edge devices. In Proceedings of the IEEE International Conference on Robotics and Automation, Yokohama, Japan, 13–17 May 2024. [Google Scholar]
- Guo, X.; Zhang, C.; Zhang, Y.; Zheng, W.; Nie, D.; Poggi, M.; Chen, L. Light Stereo: Channel boost is all you need for efficient 2D cost aggregation. arXiv 2025, arXiv:2406.19833v3. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE International Conference on Computer Vision, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE International Conference on Computer Vision, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the IEEE International Conference on Com puter Vision, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Guo, X.; Zhang, C.; Lu, J.; Duan, Y.; Wang, Y.; Yang, T.; Zhu, Z.; Chen, L. OpenStereo: A comprehensive benchmark for stereo matching and strong baseline. arXiv 2023, arXiv:2312.00343. [Google Scholar]
- Cheng, J.; Liu, L.; Xu, G.; Wang, X.; Zhang, Z.; Deng, Y.; Zang, J.; Chen, Y.; Cai, Z.; Yang, X. MonSter: Marry monodepth to stereo unleashes power. arXiv 2025, arXiv:2501.08643. [Google Scholar] [CrossRef]
- Yang, J.; Wu, C.; Wang, G.; Xu, R.; Zhang, M.; Xu, Y. Guided aggregation and disparity refinement for real-time stereo matching. Signal Image Video Process. 2024, 18, 4467–4477. [Google Scholar] [CrossRef]
- Wu, Z.; Zhu, H.; He, L.; Zhao, Q.; Shi, J.; Wu, W. Real-time stereo matching with high accuracy via spatial attention-guided upsampling. Appl. Intell. 2023, 53, 24253–24274. [Google Scholar] [CrossRef]
- Shen, Z.; Dai, Y.; Rao, Z. CFNet: Cascade and fused cost volume for robust stereo matching. In Proceedings of the IEEE International Conference on Computer Vision, Virtual, 19–25 June 2021. [Google Scholar]
- Scharstein, D.; Hirschmüller, H.; Kitajima, Y.; Krathwohl, G.; Nešic, N.; Wang, X.; Westling, P. High-resolution stereo datasets with subpixel-accurate ground truth. In Proceedings of the German Conference on Pattern Recognition, Cham, Switzerland, 2–5 September 2014. [Google Scholar]
- Schöps, T.; Schönberger, J.L.; Galliani, S.; Sattler, T.; Schindler, K.; Pollefeys, M.; Geiger, A. A multi-view stereo benchmark with high-resolution images and multi-camera videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Scene Flow EPE (px) | KITTI 2015 | Runtime (ms) | |
|---|---|---|---|---|
| D1-all (%) | EPE (px) | |||
| Baseline | 0.89 | 2.59 | 0.73 | 19 |
| Baseline + FACV | 0.74 | 1.64 | 0.65 | 25 |
| Baseline + MAA | 0.72 | 1.61 | 0.64 | 26 |
| Baseline + FACV + MAA (Ours) | 0.62 | 1.49 | 0.59 | 31 |
| Model | KITTI 2012 | KITTI 2015 | Platform | Runtime (ms) | |||
|---|---|---|---|---|---|---|---|
| 3px-noc (%) | 3px-all (%) | D1-bg (%) | D1-fg (%) | D1-all (%) | |||
| Accuracy | |||||||
| GANet-deep [7] | 1.19 | 1.60 | 1.48 | 3.46 | 1.81 | Tesla P40 | 1800 |
| PSMNet [5] | 1.49 | 1.89 | 1.86 | 4.62 | 2.32 | Titan X | 410 |
| GwcNet [6] | 1.32 | 1.70 | 2.21 | 6.16 | 2.11 | Titan X | 320 |
| GCNet [4] | 1.77 | 2.30 | 1.37 | 3.16 | 2.87 | Titan X | 900 |
| IGEV-Stereo [10] | 1.12 | 1.44 | 1.38 | 2.67 | 1.59 | RTX 3090 | 180 |
| Raft-Stereo [9] | 1.30 | 1.66 | 1.58 | 3.05 | 1.82 | RTX 6000 | 380 |
| CFNet [33] | 1.23 | 1.58 | 1.54 | 3.56 | 1.88 | Tesla V100 | 180 |
| ACVNet [8] | 1.13 | 1.47 | 1.37 | 3.07 | 1.65 | RTX3090 | 250 |
| OpenStereo [36] | 1.00 | 1.26 | 1.28 | 2.26 | 1.44 | - | 290 |
| MonSter [37] | 0.84 | 1.09 | 1.13 | 2.81 | 1.41 | RTX 3090 | 450 |
| Speed | |||||||
| StereoNet [21] | 4.91 | 6.02 | 4.30 | 7.45 | 4.83 | Titan X | 15 |
| AnyNet [23] | 2.20 | 2.66 | - | - | 2.71 | RTX 2080TI | 27 |
| AANet [22] | 1.91 | 2.42 | 1.99 | 5.39 | 2.55 | Tesla V100 | 62 |
| BGNet [25] | 1.77 | 2.15 | 2.07 | 4.74 | 2.51 | RTX 2080TI | 25 |
| Fast-ACVNet [8] | 1.68 | 2.13 | 1.82 | 3.93 | 2.17 | RTX 3090 | 39 |
| CoEx [26] | 1.55 | 1.93 | 1.79 | 3.82 | 2.13 | RTX 2080TI | 27 |
| GADR-Stereo [38] | - | - | 1.80 | - | 2.11 | RTX 3090 | 31 |
| SAGU-Net-fr [39] | 1.55 | 1.55 | 1.70 | 3.79 | 2.05 | RTX 3090 | 35 |
| Ghost-Stereo [28] | 1.45 | 1.80 | 1.71 | 3.77 | 2.05 | RTX3090 | 37 |
| LightStereo-M [30] | 1.56 | 1.91 | 1.81 | 3.22 | 2.04 | RTX3090 | 23 |
| FAMNet (Ours) | 1.53 | 1.81 | 1.72 | 3.43 | 2.06 | RTX 3090 | 31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Tong, Q.; Yan, N.; Liu, X. FAMNet: A Lightweight Stereo Matching Network for Real-Time Depth Estimation in Autonomous Driving. Symmetry 2025, 17, 1214. https://doi.org/10.3390/sym17081214
Zhang J, Tong Q, Yan N, Liu X. FAMNet: A Lightweight Stereo Matching Network for Real-Time Depth Estimation in Autonomous Driving. Symmetry. 2025; 17(8):1214. https://doi.org/10.3390/sym17081214
Chicago/Turabian StyleZhang, Jingyuan, Qiang Tong, Na Yan, and Xiulei Liu. 2025. "FAMNet: A Lightweight Stereo Matching Network for Real-Time Depth Estimation in Autonomous Driving" Symmetry 17, no. 8: 1214. https://doi.org/10.3390/sym17081214
APA StyleZhang, J., Tong, Q., Yan, N., & Liu, X. (2025). FAMNet: A Lightweight Stereo Matching Network for Real-Time Depth Estimation in Autonomous Driving. Symmetry, 17(8), 1214. https://doi.org/10.3390/sym17081214