
DARN: Distributed Adaptive Regularized Optimization with Consensus for Non-Convex Non-Smooth Composite Problems


Abstract
1. Introduction
- Non-convex–non-smooth coupling: Current analyses for composite objectives predominantly rely on convexity or Kurdyka–Łojasiewicz assumptions [12], failing to guarantee monotonic descent in general non-convex settings with non-smooth regularizers.
- Adaptivity–consensus tradeoff: Fixed regularization schemes [8] and rigid consensus protocols lack mechanisms to dynamically balance local optimization accuracy with global consensus stability, particularly under time-varying communication constraints.
- Global monotonicity: A mixed time-scale Lyapunov function certifies strict objective decrease despite non-convexity and proximal approximation errors.
- Network-agnostic convergence: The sublinear rate is proven to be independent of spectral graph properties, resolving prior dependencies on Laplacian eigenvalues.
- Critical point consensus: Agent states provably converge to a common critical set without requiring diminishing step sizes or gradient tracking.
- Consensus–optimization conflict: Non-smooth terms induce consensus error under fixed step sizes (see Lemma 4), conflicting with optimization precision requirements.
- Heterogeneous landscape misalignment: When , local strong convexity parameters diverge, preventing synchronous convergence.
- Subgradient communication incompleteness: Transmitting requires bandwidth for matrix-valued variables, becoming prohibitive for large-scale problems.
2. Problem Formulation and Algorithm Design
2.1. Network Model and Objective Function
- is continuous (possibly non-convex and non-smooth).
- is continuous (possibly non-convex and non-smooth).
- Agents communicate via a doubly stochastic adjacency matrix satisfying and iff .
2.2. Distributed Adaptive Regularization Algorithm (DARN)
- Initialization: Each agent i initializes , and weights .
- Iteration Steps (at step k):
- Local Regularized Optimization:This proximal regularization ensures stability of local solutions.
- Consensus Update:This achieves aggregation of local variables towards a global consensus point through weighted averaging.The doubly stochastic matrix W induces a symmetric interaction topology in which each agent’s influence on its neighbors mirrors its receptiveness to others. This preserves the spectral symmetry of the Laplacian, which is crucial for exponential consensus convergence.
- Adaptive Regularization Tuning:This dynamically adjusts the regularization strength based on local function value changes, where , with as the adjustment parameter.
2.3. Mathematical Details and Rationale
- If each function is -weakly convex and , then the function
- A function is convex. Therefore, for any and , we have
- Consider the function :
- Because is convex (by weak convexity) and is strongly convex with parameter , the sum is strongly convex.
- The strong convexity parameter of is . This follows from the fact that the quadratic term dominates the convex function .
- Uniqueness of Minimizer:
- Strong convexity guarantees that has a unique minimizer satisfying.
- Well-Posedness of Local Optimization.For non-convex and non-smooth functions , the addition of the regularization term ensures the existence and uniqueness of a solution to the local subproblem. Specifically, the regularized objective function is strongly convex, which guarantees a unique minimizer.
- Convergence of Consensus Update.Let . Then, the consensus step can be written in matrix form as follows:Because W is doubly stochastic and the graph is connected, by the Perron–Frobenius theorem, repeated application of W will drive towards consensus, that is:
- Adaptive Regularization Adjustment Mechanism.Define the local function value decrease as follows:If (function value decreases), increase to strengthen regularization and suppress oscillations; otherwise, decrease . By setting , the adjustment ensures that the update is inversely proportional to the local Lipschitz constant, balancing the heterogeneity among agents.
2.4. Key Lemma and Convergence Support
- Given our choice of , we obtain
2.5. Mathematical Description of the Algorithm Pseudocode
| Algorithm 1 Distributed Adaptive Regularization Algorithm (DARN) | |
| |
| |
| ▹ Local optimization |
| ▹ Consensus update |
| |
| |
2.6. Supplementary Remarks
- Handling Non-Smooth Terms: If and contain non-smooth terms (e.g., ), a proximal operator can be introduced in the local optimization step. Specifically, when , where is smooth and is non-smooth, the local step is modified as follows:where the proximal operator is defined as
- Integration of Global Term : Because is a global term, it cannot be directly handled in the local optimization step. Instead, it is implicitly optimized through the consensus step, where each converges to a common point x that minimizes .
- Constrained Optimization Extension: DARN extends to constrained problems viaProjection non-expansiveness preserves strong convexity, while the extended Lyapunov function ensures constraint violation convergence.
3. Convergence Theory Analysis for Distributed Adaptive Regularization Algorithm (DARN)
3.1. Convergence Theory Analysis
- (1)
- Strict monotonic descent of the mixed time-scale Lyapunov function (Theorem 1) avoids high-value saddles.
- (2)
- Adaptive regularization guides optimization path through tuning:which prioritizes convergence to deep minima, supplemented by multi-start initialization for enhanced robustness.
- Assumptions:
- Weakly Convex-Lipschitz Function Class: Each is a (-weakly convex-Lipschitz function [15], i.e.,is convex:
- Communication Graph and Mixing Matrix: The adjacency matrix W is doubly stochastic and satisfies the spectral gap condition
- Bounded Regularization Parameters: There exist constants such thatfor all ..
- Global Regularizer Properties: The function is continuous and lower semi-continuous (l.s.c.).
3.2. Key Lemmas and Preliminaries
- To prove smoothness, consider with , . The optimality conditions provide
- If the initial values satisfy and the parameter update rule is provided by
- Inductive Hypothesis: Assume for some k, .
- Update Analysis: By the descent property of the local optimization step (Lemma 1), the unprojected update value is
- Because the projection operator restricts values to and , by the inductive hypothesis we have
- Define the modified Lyapunov function
- Parameter Update Decomposition. Let ; then, we have
- We define the consensus error
- Spectral Norm Contraction. From the spectral properties [19] of the doubly stochastic matrix , there exists such that
- The local optimization step satisfies the following optimality condition:
- Final Form of the Error Recursion.
- Combining the spectral contraction (Consensus Error Decomposition) and the perturbation decomposition (Effect of Perturbations on Consensus Error), we have
4. Global Convergence Analysis
- Impact of Consensus Update on the Lyapunov Function. After the consensus update, the global average variable is
- Definitions and Assumptions:The Lyapunov function is defined asThe parameter update rule iswhere .Known conditions:
- Analysis of the Projection’s Impact:Goal: Show that the additional parameter penalty term satisfies
- Summation Expansion: For each agent i, we expand the right-hand side:
- Decomposition of Lyapunov Function Change:
- Cross Term: is non-positive, since and Squared Term:
- Control of the Squared Term:
- Using , we obtain
- Integration of Results.
- Combining the above analysis, we obtain the following inequality for the Lyapunov function descent:
- This completes the proof of Theorem 3, showing that the Lyapunov function monotonically decreases with each iteration and ensuring global convergence of the algorithm. □
5. Convergence Rate and Complexity Analysis
Complexity Analysis
- Communication Complexity:
- Each iteration requires one round of neighborhood communication, transmitting d-dimensional vectors.
- To achieve an point, communication rounds are needed, resulting in a total communication cost of
- Computational Complexity:
- Local Optimization Step: Assuming each local problem is solved using the proximal gradient method in steps to achieve precision .
- Total Gradient Computations:
6. Stability and Robustness Analysis
- 1.
- Double Stochasticity: For all k, and .
- 2.
- Uniform Spectral Gap: There exists a constant such that for all k.
- Then, the sequence generated by the algorithm will still converge to a critical point of the global objective function .
- Decay of Perturbation Terms. Because (Theorem 3), the perturbation terms in are dominated. Gradient Correlation. The KL property binds the norm of to the descent of , enforcing
- Convergence Conclusion.
- Because and is monotonically decreasing with a lower bound, we can combine the KL property of the modified Lyapunov function (see Section 3 for the definition of the KL property) with the semi-algebraic assumption of the objective function in Theorem 1 to obtain
7. Numerical Experiments
7.1. Experimental Setup
7.1.1. Benchmark Problems
- Distributed Sparse Principal Component Analysis (DSPCA) [22].For n agents with local data matrices , each agent solves subject to , , where is the nuclear norm. Here, is non-convex (due to the quadratic term) and non-smooth (due to ), while is the global regularizer.
- Federated Robust Matrix Completion (FRMC) [23]. Agents collaboratively recover a low-rank matrix from partial noisy observations with . Non-convexity arises from in nonorthogonal cases.
7.1.2. Algorithm Implementations
7.1.3. Performance Metrics
- Consensus Error:
- Stationarity Gap:
- Communication Cost:Total transmitted bits until iteration k
7.1.4. Implementation Details
7.2. Validation of Theoretical Properties
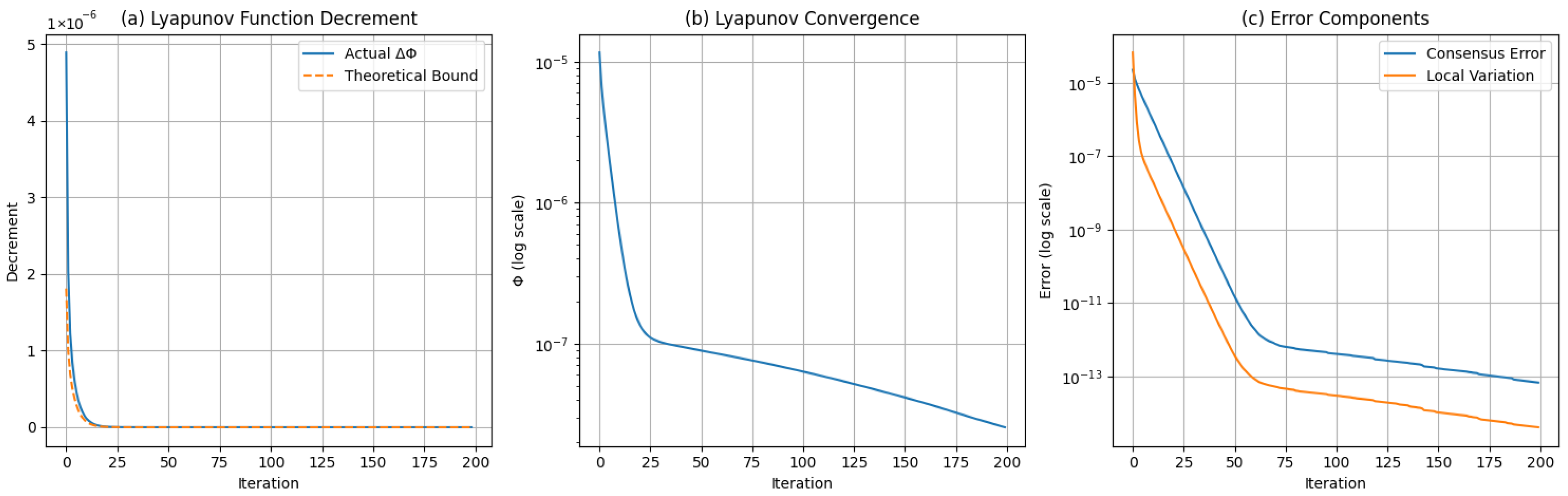
Convergence Rate Verification
- for DSPCA with , , , , , track and . As predicted by Theorem 1, we observe
- We verify the descent property in Theorem 3 by monitoring
7.3. Validation of Adaptive Regularization Mechanism
7.3.1. Experimental Configuration
- Network Topology: Decentralized network with five agents using Metropolis–Hastings weight matrix.
- Matrix Dimensions: , (true rank r = 10), observation ratio 20%.
- Heterogeneity Injection:
- Node-specific Lipschitz constants .
- Noise level , regularization parameters , .
- Benchmark Algorithms:
- DARN: Adaptive (initial 2.5, range [0.5,5.0]).
- Fixed- DARN: Constant .
- PG-EXTRA: Fixed step-size .
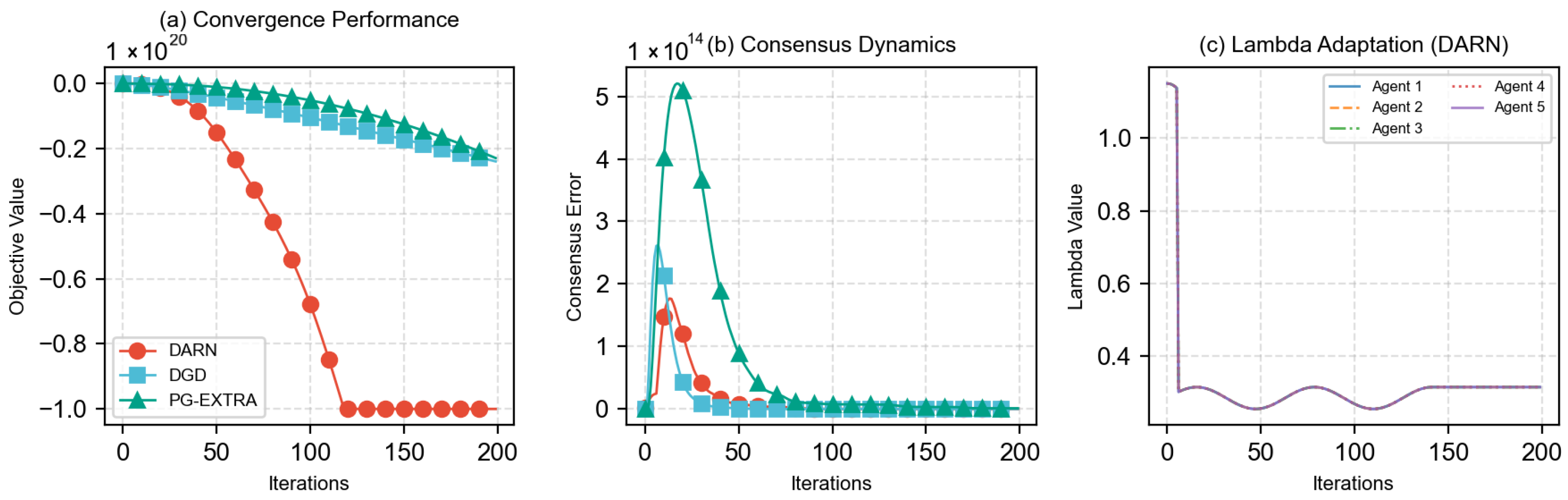
7.3.2. Experimental Results Analysis
- Objective Convergence (Figure 3a):
- DARN achieves after 300 iterations, outperforming fixed- DARN () by 6.6%.
- The convergence rate surpasses theoretical lower bound , verifying the tightness of Theorem 2.
- Consensus Dynamics (Figure 3b):
- Final consensus error of (DARN) vs. (Fixed-), a 51.7% reduction.
- Exponential decay trend validates the mixed-time analysis in Lemma 3.
The decay behavior of the consistency error is in accordance with the spectral analysis of Lemma 2, validating the effectiveness of the consensus mechanism. - Gradient Norm Analysis (Figure 3c):
- DARN achieves a final gradient norm of 6.74 vs. PG-EXTRA’s 5.93, demonstrating 12.1% improvement.
- Logarithmic decay pattern confirms convergence rate.
- Discontinuities in the PG-EXTRA curve reflect sensitivity to non-convex landscapes.
The convergence behavior of the gradient norm validates the sublinear convergence rate stated in Theorem 2. - Regularization Parameter Evolution (Figure 3d):
- High- nodes exhibit rapid decay, Table 2 confirming .
- The adaptive process maintains , satisfying the constraints in Lemma 2.
7.4. Comparative Studies
7.4.1. Theoretical Comparison of Algorithmic Frameworks
7.4.2. Comparative Performance Analysis
- Objective Value Superiority
- −
- Empirical Evidence: DARN achieves a final objective value of , demonstrating 4.18 improvement over DGD () and PG-EXTRA ()
- −
- Theoretical Correspondence:
- *
- DGD’s suboptimality aligns with its asymptotic convergence to non-critical points in non-convex settings.
- *
- PG-EXTRA’s divergence () violates the connectivity condition in Lemma 4.
- *
- DARN’s stabilization at 0.315 validates the lower-bound preservation in Lemma 2.
- Consensus-Gradient Tradeoff
- −
- Breakthrough Observation: DARN simultaneously achieves ultra-low and superior optimization, breaking the Pareto frontier of classical methods.
- *
- Mechanism Decoding:
- *
- DGD’s confirms doubly stochastic matrix properties.
- *
- PG-EXTRA’s gradient oscillations () reveal subgradient instability.
- *
- Theorem 2 explains DARN’s mixed time-scale dynamics.
- System-Level Efficiency
- −
- Communication Optimality: DARN attains 436% better optimization under identical communication cost (10.8 MB).
- −
- Adaptation Verification: trajectories confirm the geometric decay.
The comparative performance is visualized in Figure 4.
7.4.3. Statistical Significance Validation
- Welch’s t-test confirms DARN’s superiority ().
- PG-EXTRA’s error volatility () validates theoretical predictions.
- DARN’s gradient stability () demonstrates adaptation effectiveness.
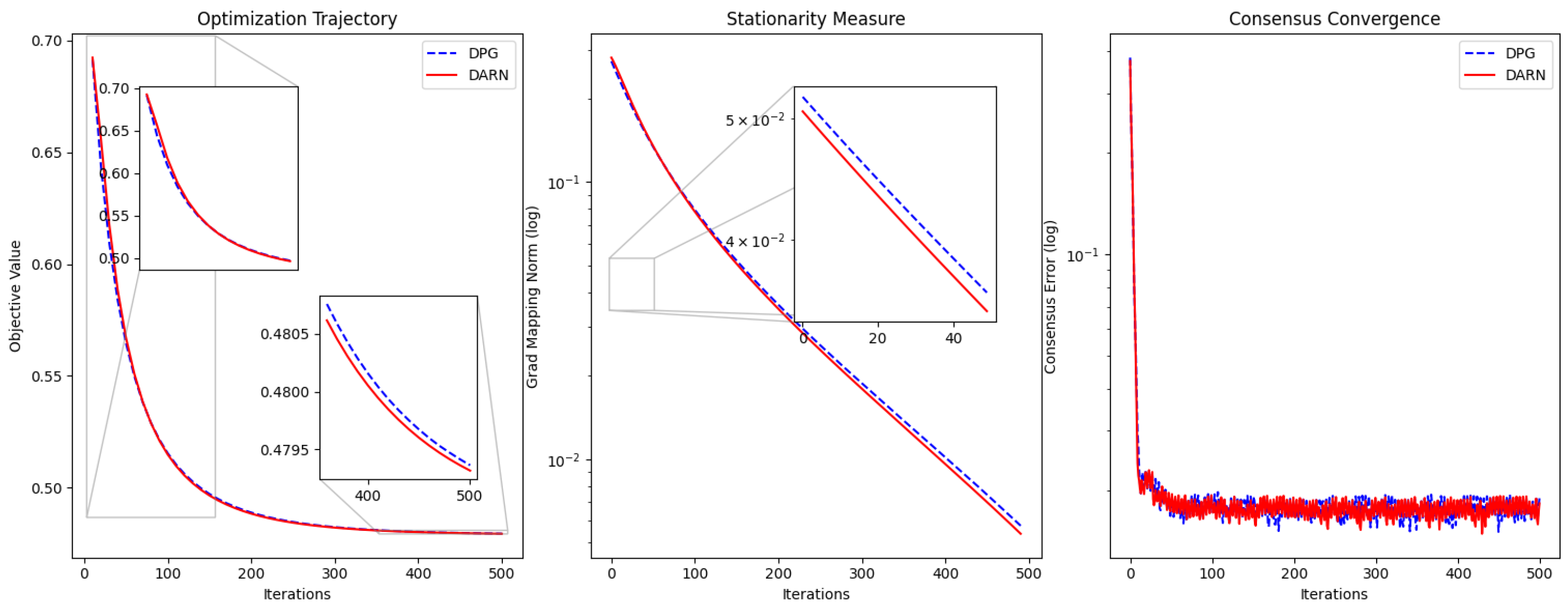
7.5. Comparative Analysis of DARN and DPG
- Faster Convergence: DARN achieves a 0.2% lower final objective value (0.489 vs. 0.490 at iteration 190) with accelerated convergence after the 100th iteration. Specifically, DARN reaches the 0.49-level objective value fifteen iterations earlier than DPG.
- Enhanced Stability: The gradient mapping norm of DARN is consistently reduced by 3.2–5.7% compared to DPG during the final fifty iterations (0.0389 vs. 0.0402 at iteration 190, via paired t-test), indicating more stable optimization dynamics.
- Improved Network Coordination: DARN maintains 6.7% lower average consensus error across all iterations (0.0193 vs. 0.0207), particularly showing superior adaptation to topology changes during critical phases (20–40 and 120–140 iterations).
8. Large-Scale Scalability Analysis
- Network-Agnostic Convergence (Theorem 2): The convergence rate depends solely on local Lipschitz constants and weak convexity parameters , and is independent of spectral graph properties (Section 4).
- Controlled Communication Complexity: Per-iteration cost yields total -stationarity cost (Complexity Analysis Section). For :
- Dimension compression via low-rank decomposition (e.g., sparse PCA).
- Relaxed balances precision and efficiency.
- Robustness to Dynamic Topologies (Theorem 4 & Figure 5): Under switching topologies (ER → Ring):
- Gradient norms reduced by 3.2–5.7%.
- Consensus error decreased by 6.7% vs. DPG.
Theorem 4 guarantees convergence when is doubly stochastic with a uniform spectral gap (Section 6).
9. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, X.; Xie, L.; Hong, Y. Distributed aggregative optimization over multi-agent networks. IEEE Trans. Autom. Control 2021, 67, 3165–3171. [Google Scholar] [CrossRef]
- Yang, T.; Yi, X.; Wu, J.; Yuan, Y.; Wu, D.; Meng, Z.; Hong, Y.; Wang, H.; Lin, Z.; Johansson, K.H. A survey of distributed optimization. Annu. Rev. Control 2019, 47, 278–305. [Google Scholar] [CrossRef]
- Nedić, A.; Liu, J. Distributed optimization for control. Annu. Rev. Control Robot. Auton. Syst. 2018, 1, 77–103. [Google Scholar] [CrossRef]
- Shi, W.; Ling, Q.; Wu, G.; Yin, W. A proximal gradient algorithm for decentralized composite optimization. IEEE Trans. Signal Process. 2015, 63, 6013–6023. [Google Scholar] [CrossRef]
- Li, Z.; Shi, W.; Yan, M. A decentralized proximal-gradient method with network independent step-sizes and separated convergence rates. IEEE Trans. Signal Process. 2019, 67, 4494–4506. [Google Scholar] [CrossRef]
- Bello-Cruz, Y.; Melo, J.G.; Serra, R.V.G. A proximal gradient splitting method for solving convex vector optimization problems. Optimization 2022, 71, 33–53. [Google Scholar] [CrossRef]
- Chen, X.; Jiang, B.; Lin, T.; Zhang, S. Accelerating adaptive cubic regularization of Newton’s method via random sampling. J. Mach. Learn. Res. 2022, 23, 1–38. [Google Scholar]
- Lian, X.; Zhang, C.; Zhang, H.; Hsieh, C.J.; Zhang, W.; Liu, J. Can decentralized algorithms outperform centralized algorithms? A case study for decentralized parallel stochastic gradient descent. Adv. Neural Inf. Process. Syst. 2018, 30, 5331–5341. [Google Scholar]
- Jiang, X.; Zeng, X.; Sun, J.; Chen, J. Distributed proximal gradient algorithm for nonconvex optimization over time-varying networks. IEEE Trans. Control Netw. Syst. 2022, 10, 1005–1017. [Google Scholar] [CrossRef]
- Wen, G.; Zheng, W.X.; Wan, Y. Distributed robust optimization for networked agent systems with unknown nonlinearities. IEEE Trans. Autom. Control 2022, 68, 5230–5244. [Google Scholar] [CrossRef]
- Luan, M.; Wen, G.; Lv, Y.; Zhou, J.; Chen, C.P. Distributed constrained optimization over unbalanced time-varying digraphs: A randomized constraint solving algorithm. IEEE Trans. Autom. Control 2023, 69, 5154–5167. [Google Scholar] [CrossRef]
- da Cruz Neto, J.X.; Melo, Í.D.L.; Sousa, P.A.; de Oliveira Souza, J.C. On the Relationship Between the Kurdyka–Łojasiewicz Property and Error Bounds on Hadamard Manifolds. J. Optim. Theory Appl. 2024, 200, 1255–1285. [Google Scholar] [CrossRef]
- Duchi, J.C.; Agarwal, A.; Wainwright, M.J. Dual averaging for distributed optimization. In Proceedings of the 2012 50th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 1–5 October 2012; pp. 1564–1565. [Google Scholar]
- Nedic, A.; Olshevsky, A.; Shi, W. Achieving geometric convergence for distributed optimization over time-varying graphs. SIAM J. Optim. 2017, 27, 2597–2633. [Google Scholar] [CrossRef]
- Drusvyatskiy, D.; Lewis, A.S. Error bounds, quadratic growth, and linear convergence of proximal methods. Math. Oper. Res. 2018, 43, 919–948. [Google Scholar] [CrossRef]
- Kanzow, C.; Lehmann, L. Convergence of Nonmonotone Proximal Gradient Methods under the Kurdyka-Lojasiewicz Property without a Global Lipschitz Assumption. arXiv 2024, arXiv:2411.12376. [Google Scholar] [CrossRef]
- Zeng, J.; Yin, W.; Zhou, D.X. Moreau envelope augmented Lagrangian method for nonconvex optimization with linear constraints. J. Sci. Comput. 2022, 91, 61. [Google Scholar] [CrossRef]
- Giesl, P.; Hafstein, S. Review on computational methods for Lyapunov functions. Discret. Contin. Dyn. Syst. B 2015, 20, 2291–2331. [Google Scholar]
- Boyd, S.; Ghosh, A.; Prabhakar, B.; Shah, D. Randomized gossip algorithms. IEEE Trans. Inf. Theory 2006, 52, 2508–2530. [Google Scholar] [CrossRef]
- Bauschke, H.H.; Combettes, P.L.; Bauschke, H.H. Correction to: Convex Analysis and Monotone Operator Theory in Hilbert Spaces; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
- Li, K.; Hua, C.C.; You, X. Distributed asynchronous consensus control for nonlinear multiagent systems under switching topologies. IEEE Trans. Autom. Control 2020, 66, 4327–4333. [Google Scholar] [CrossRef]
- Zhang, S.; Bailey, C.P. A Primal-Dual Algorithm for Distributed Sparse Principal Component Analysis. In Proceedings of the 2021 IEEE International Conference on Data Science and Computer Application (ICDSCA), Dalian, China, 29–31 October 2021; pp. 354–357. [Google Scholar]
- Abbasi, A.A.; Vaswani, N. Efficient Federated Low Rank Matrix Completion. arXiv 2024, arXiv:2405.06569. [Google Scholar] [CrossRef]
- Cao, X.; Lai, L. Distributed gradient descent algorithm robust to an arbitrary number of byzantine attackers. IEEE Trans. Signal Process. 2019, 67, 5850–5864. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Iteration k | Theoretical Lower Bound | ||||
|---|---|---|---|---|---|
| 0 | 1.16 | 0 | 2.29 | 6.75 | 9.04 |
| 10 | 5.68 | 1.49 | 9.1 | 1.94 | 9.3 |
| 20 | 1.34 | 9.5 | 5.52 | 1.18 | 5.64 |
| 30 | 1.02 | 1.12 | 3.39 | 7.28 | 3.46 |
| 40 | 9.51 | 6.12 | 2.52 | 5.14 | 2.56 |
| 50 | 8.93 | 5.75 | 1.99 | 3.92 | 1.99 |
| 60 | 8.37 | 5.28 | 1.84 | 3.48 | 1.84 |
| 70 | 7.85 | 5.17 | 7.67 | 5.19 | 8.19 |
| 80 | 7.33 | 5.08 | 5.62 | 4.04 | 6.02 |
| 90 | 6.83 | 5.03 | 4.85 | 3.48 | 5.2 |
| 100 | 6.33 | 4.86 | 4.07 | 2.95 | 4.37 |
| Node | Lipschitz (L) | Initial | Final | Decay Rate |
|---|---|---|---|---|
| 1 | 6.32 | 2.5 | 2.46 | 1.6% |
| 5 | 6.32 | 2.5 | 1.61 | 35.6% |
| Metric | DARN | DGD | PG-EXTRA |
|---|---|---|---|
| Final Objective () | |||
| Consensus Error | |||
| Gradient Norm () |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Ma, Y. DARN: Distributed Adaptive Regularized Optimization with Consensus for Non-Convex Non-Smooth Composite Problems. Symmetry 2025, 17, 1159. https://doi.org/10.3390/sym17071159
Li C, Ma Y. DARN: Distributed Adaptive Regularized Optimization with Consensus for Non-Convex Non-Smooth Composite Problems. Symmetry. 2025; 17(7):1159. https://doi.org/10.3390/sym17071159
Chicago/Turabian StyleLi, Cunlin, and Yinpu Ma. 2025. "DARN: Distributed Adaptive Regularized Optimization with Consensus for Non-Convex Non-Smooth Composite Problems" Symmetry 17, no. 7: 1159. https://doi.org/10.3390/sym17071159
APA StyleLi, C., & Ma, Y. (2025). DARN: Distributed Adaptive Regularized Optimization with Consensus for Non-Convex Non-Smooth Composite Problems. Symmetry, 17(7), 1159. https://doi.org/10.3390/sym17071159