1. Introduction
Let
be positive integers and
. We call a real fourth-order
-dimensional tensor
a biquadratic tensor. This is different from [
1]. Denote
. If for all
and
, we have
then we say that
is weakly symmetric. If furthermore for all
and
, we have
then we say
is symmetric. In fact, all the biquadratic tensors in [
1] are symmetric biquadratic tensors in this paper. We denote the set of all biquadratic tensors in
by
, the set of all weakly symmetric biquadratic tensors in
, by
, and the set of all symmetric biquadratic tensors in
, by
, respectively. Then
,
, and
are all linear spaces.
A biquadratic tensor
is called positive semi-definite if for any
and
,
Here, ∘ represents the vector outer product. This means that the
th element of
is the product of the corresponding vector elements
. The tensor
is called an SOS (sum-of-squares) biquadratic tensor if
can be written as a sum of squares. A biquadratic tensor
is called positive definite if for any
and
,
In [
2], bi-block tensors were studied. A bi-block tensor may have an order higher than 4, but its dimension is uniformly
n. We recall that a tensor
with
is called a cubic tensor [
3]. Hence, bi-block tensors are special cubic tensors. On the other hand, biquadratic tensors are not cubic tensors. Thus, they are different.
Biquadratic tensors arise in solid mechanics [
4,
5], statistics [
6,
7], quantum physics [
8], spectral graph theory [
9], and polynomial theory [
10,
11]. In the next section, we review such application background of biquadratic tensors. In particular, we point out that the covariance tensors in statistics and Riemann curvature tensor in relativity theory are both biquadratic tensors that are weakly symmetric, but not symmetric in general. This motivates us to consider nonsymmetric biquadratic tensors and study possible conditions and algorithms for identifying positive semi-definiteness and definiteness of such biquadratic tensors.
In the study of strong ellipticity condition of the elasticity tensor in solid mechanics, in 2009, Qi, Dai and Han [
12] introduced M-eigenvalues for symmetric biquadratic tensors. In
Section 3, we extend this definition to nonsymmetric biquadratic tensors by symmetrizing them.
In
Section 4, we present a Gershgorin-type theorem for biquadratic tensors. We introduce diagonally dominated biquadratic tensors and strictly diagonally dominated biquadratic tensors. Then, we show that diagonally dominated biquadratic tensors are positive semi-definite, and strictly diagonally dominated biquadratic tensors are positive definite.
In
Section 5, we introduce Z-biquadratic tensors, M-biquadratic tensors, strong M-biquadratic tensors,
-biquadratic tensors, and B-biquadratic tensors. We show that M-biquadratic tensors and symmetric
-biquadratic tensors are positive semi-definite, and that strong M-biquadratic tensors and symmetric B-biquadratic tensors are positive definite. A Riemannian LBFGS method for computing the smallest M-eigenvalue of a general biquadratic tensor is presented in
Section 6. Convergence analysis of this algorithm is also given there. Numerical results are reported in
Section 7. Some final remarks are made in
Section 8.
2. Application Backgrounds of Biquadratic Tensors
2.1. The Covariance Tensor in Statistics
The covariance matrix is a key concept in statistics and machine learning. It is a square matrix that contains the covariances between multiple random variables. The diagonal elements represent the variances of each variable, reflecting their individual dispersion. The off-diagonal elements represent the covariances between pairs of variables, indicating their linear relationships. The covariance matrix is symmetric and positive semi-definite, providing a comprehensive view of the interdependencies among variables. However, when the variable takes the form of a matrix, the corresponding covariance matrix transforms into a covariance tensor.
We let
be a random matrix with each element being a random variable. We denote the mean and variance of the element
as
and
(
), respectively. The covariance with another element
is denoted as
. Subsequently, it is formulated as a fourth-order covariance tensor. The fourth-order covariance tensor was proposed in [
6] for portfolio selection problems and in [
7] for group identification, respectively.
For any random matrix
, its fourth-order covariance tensor is defined as
, where
Then
is a weakly symmetric biquadratic tensor, which may be nonsymmetric.
Proposition 1. The fourth-order covariance tensor defined in (
2)
is positive semi-definite. Proof. For any
and
, we have
Here,
. This completes the proof. □
We let
represent the
tth observed matrix data for
. We assume that each
is an independent and identically distributed (iid) sample of the random matrix
. Then the estimated mean is
, where
. A natural estimate for the covariance can be formulated as
, where
Proposition 2. The fourth-order covariance tensor defined in (
3)
is a positive semi-definite biquadratic tensor. Proof. This result can be proven similar with that of Proposition 1, and for brevity, we omit the detailed proof here. □
2.2. The Elasticity Tensor in Solid Mechanics
The field equations for a homogeneous, compressible, nonlinearly elastic material in two or three dimensions, pertaining to static problems in the absence of body forces, can be formulated as follows [
4]:
Here,
(with
or
) represents the displacement field,
denotes the coordinate of a material point in its reference configuration, and
. Given
or
,
signifies the elasticity tensor and
The tensor of elastic moduli is invariant with respect of permutations of indices as follows [
5]:
For hyperelastic materials
also has the property
The elasticity tensor is the most well-known tensor in solid mechanics and engineering [
13]. The above equations are strongly elliptic if and only if for any
and
, (
1) holds. Several methods were proposed for verifying strongly ellipticity of the elasticity tensor [
2,
14,
15,
16].
In solid mechanics, the Eshelby tensor is also a biquadratic tensor. The Eshelby inclusion problem is one of the hottest topics in modern solid mechanics [
17].
In 2009, Qi, Dai, and Han [
12] proposed an optimization method for tackling the problem of the strong ellipticity and also to give an algorithm for computing the most possible directions along which the strong ellipticity can fail. Subsequently, a practical method for computing the largest M-eigenvalue of a fourth-order partially symmetric tensor was proposed by Wang et al. [
18]. Later, in [
15,
16], bounds of M-eigenvalues and strong ellipticity conditions for elasticity tensors were provided.
2.3. The Riemann Curvature Tensor in Relativity Theory
In the domain of differential geometry, the Riemann curvature tensor, or the Riemann–Christoffel tensor (named after Bernhard Riemann and Elwin Bruno Christoffel), stands as the preeminent method for describing the curvature of Riemannian manifolds [
19]. This tensor assigns a specific tensor to each point on a Riemannian manifold, thereby constituting a tensor field. Essentially, it serves as a local invariant of Riemannian metrics, quantifying the discrepancy in the commutation of second covariant derivatives. Notably, a Riemannian manifold possesses zero curvature if and only if it is flat, meaning it is locally isometric to Euclidean space.
We let
be a Riemannian manifold, and
be the space of all vector fields on
M. The Riemann curvature tensor is defined as a map
by the following formula:
where ∇ is the Levi–Civita connection,
is the Lie bracket of vector fields. It turns out that the right-hand side actually only depends on the value of the vector fields
at a given point. Hence,
R is a (1,3)-tensor field. By using the tensor index notation and the Christoffel symbols, we have
where
are Christoffel symbols of the first kind. For convenience, we could also write
as
.
We denote
as the Riemann curvature tensor. Then it is a biquadratic tensor. The curvature tensor has the following symmetry properties [
8]:
By
for all
and
, the Riemann curvature tensor is a weakly symmetric biquadratic tensor, and it may not be symmetric.
2.4. Bipartite Graphs and Graph Matching
Bipartite matching, or bipartite graph matching, is a fundamental problem in graph theory and combinatorics. It involves finding an optimal way to pair nodes from two disjoint sets in a bipartite graph, ensuring that no two pairs share nodes from the same set. This problem arises in various real-world scenarios, such as job assignment, task scheduling, and network flow optimization [
9].
We consider a bipartite graph with two subgraphs and , where and are disjoint sets of points with , , and , are sets of edges. The bipartite graph matching aims to find the best correspondence (also referred to as matching) between and with the maximum matching score. Specifically, we let be the assignment matrix between and , i.e., if is assigned to and otherwise. Two edges and are considered matched if and only if . Namely, is assigned to and is assigned to .
We let
be the matching score between
and
, where higher values indicate greater matching likelihood. Then
is a biquadratic tensor. Here,
denotes the affinity tensor [
9] that encodes pairwise similarity through a fusion of complementary metrics, combining edge-based geometric and attribute similarities with node-level features as well as higher-order topological relationships and local neighborhood structure. We assume that
. We let
denote the vector of all ones. The graph matching problem can be formulated as
It is commonly assumed that
and
, i.e.,
is both weakly symmetric and nonnegative.
Adjacency tensors and Laplacian tensors are basic tools in spectral hypergraph theory [
20,
21]. Given a bipartite graph, the corresponding adjacency tensors and Laplacian tensors can also be formulated as biquadratic tensors.
2.5. Biquadratic Polynomials and Polynomial Theory
Given a biquadratic tensor , the biquadratic polynomial constitutes a significant branch within the realm of polynomial theory.
In 2009, Ling et al. [
11] studied the biquadratic optimization over unit spheres,
Then they presented various approximation methods based on semi-definite programming relaxations. In 2012, Yang and Yang [
22] studied the biquadratic optimization with wider constrains. They relaxed the original problem to its semi-definite programming problem, discussed the approximation ratio between them, and showed that the relaxed problem is tight under some conditions. In 2016, O’Rourke et al. [
23] subsequently leveraged the theory of biquadratic optimization to address the joint signal-beamformer optimization problem and proposed a semi-definite relaxation to formulate a more manageable version of the problem. This demonstrates the significance of investigating biquadratic optimization.
One important problem in polynomial theory is Hilbert’s 17th Problem. In 1900, German mathematician David Hilbert listed 23 unsolved mathematical challenges proposed at the International Congress of Mathematicians. Among these problems, Hilbert’s 17th Problem stands out as it relates to the representation of polynomials. Specifically, Hilbert’s 17th Problem asks whether every nonnegative polynomial can be represented as a sum of squares (SOS) of rational functions. The Motzkin polynomial is the first example of a nonnegative polynomial that is not an SOS. Hilbert proved that in several cases, every nonnegative polynomial is an SOS, including univariate polynomials, quadratic polynomials in any number of variables, bivariate quartic polynomials (i.e., polynomials of Degree 4 in two variables) [
24]. In general, a quartic nonnegative polynomial may not be represented as an SOS, such as the Robinson polynomial and the Choi–Lam polynomial. Very recently, Cui, Qi, and Xu [
10] established that despite being four-variable quartic polynomials, all nonnegative biquadratic polynomials with
can be expressed as the sum of squares of three quadratic polynomials. The key technique is that an
biquadratic polynomial can be expressed as a tripartite homogeneous quartic polynomial of
variables.
If
is a nonnegative diagonal biquadratic tensor, then we have
which is an SOS expression. In the following, we present a sufficient condition for the nonnegative biquadratic polynomial to be SOS.
Proposition 3. Given a biquadratic tensor with and the biquadratic polynomial . We suppose that there exist factor matrices for such that , i.e., , then f can be expressed to be an SOS.
Proof. We suppose that
. Then for any
and
, we have
which is an SOS. This completes the proof. □
In fact, the nonnegative diagonal biquadratic tensor
may be rewritten as
where
contains exactly one nonzero entry, specifically located at the
th position.
We consider a radar datacube collected over
L pulses with
N fast time samples per pulse in
M spatial bins. The biquadratic tensor in [
23] could be written as
where
is the spatiodoppler response matrix,
Q is the number of independent clutter patches. If
is in the real field, then
satisfies the assumptions in Proposition 3.
3. Eigenvalues of Biquadratic Tensors
We suppose that
. A real number
is called an M-eigenvalue of
if there are real vectors
such that the following equations are satisfied. For
,
for
,
and
Then
and
are called the corresponding M-eigenvectors. M-eigenvalues were introduced for symmetric biquadratic tensors in 2009 by Qi, Dai and Han [
12], i.e., for
,
for
,
Subsequently, several numerical methods, including the WQZ method [
18], semi-definite relaxation method [
11,
22], and the shifted inverse power method [
25,
26], were proposed. It is easy to see that if
is symmetric, then (
5) and (
6) reduce to the definition of M-eigenvalues in Equations (
8) and (
9) in [
12]. Hence, we extend M-eigenvalues and M-eigenvectors to nonsymmetric biquadratic tensors by symmetrizing these tensors.
We have the following theorem.
Theorem 1. We suppose that . Then always have M-eigenvalues. Furthermore, is positive semi-definite if and only if all of its M-eigenvalues are nonnegative, is positive definite if and only if all of its M-eigenvalues are positive.
Proof. We consider the optimization problem
The feasible set is compact. The objective function is continuous. Thus, an optimizer of this problem exists. Furthermore, the problem satisfies the linear independence constraint qualification. Hence, at the optimizer, the optimal conditions hold. This implies that (
5) and (
6) hold, i.e., an M-eigenvalue always exists. By (
5) and (
6), we have
Hence,
is positive semi-definite if and only if all of its M-eigenvalues are nonnegative,
is positive definite if and only if all of its M-eigenvalues are positive. □
We let
, where
is referred to as
M-identity tensor in [
27,
28]. In the following proposition, we see that
acts as the identity tensor for biquadratic tensors.
Proposition 4. We suppose that is a biquadratic tensor and let be an arbitrary real number that need not be an eigenvalue of . Then (resp. ) is an M-eigenvalue of (resp. if and only if μ is an M-eigenvalue of .
Proof. By the definitions of M-eigenvalues and , we have the conclusion. □
We suppose that
. Then we call
diagonal entries of
for
and
. The other entries of
are called off-diagonal entries of
. If all the off-diagonal entries are zeros, then
is called a diagonal biquadratic tensor. If
is diagonal, then
has
M-eigenvalues, which are its diagonal elements, with corresponding vectors
and
, where
is the
ith unit vector in
and
is the
jth unit vector in
, as their M-eigenvectors. However, different from cubic tensors, in this case,
may have some other M-eigenvalues and M-eigenvectors. In fact, for a diagonal biquadratic tensor
, (
5) and (
6) have the following forms: for
,
and for
,
We now present an example with .
Example 1. A diagonal biquadratic tensor may possess M-eigenvalues that are distinct from its diagonal elements. We suppose that , , , and . Then by Equations (
11)
and (
12)
, we haveWe let and . We suppose that are nonzero numbers. Otherwise, if any of these numbers are zero, the eigenvalue shall be equal to one of the diagonal elements. Then we have an M-eigenvalue and the corresponding M-eigenvectors satisfyandFor instance, if and , we have , which is not a diagonal element of , and the corresponding M-eigenvectors satisfy . We let . Then its diagonal entries form an rectangular matrix .
By (
11) and (
12), we have the following proposition.
Proposition 5. We suppose that is a diagonal biquadratic tensor, then has M-eigenvalues, which are its diagonal elements , with corresponding vectors and as their M-eigenvectors. Furthermore, though may have some other M-eigenvalues, they are still in the convex hull of some diagonal entries.
Proof. When
and
, we may verify that (
11) and (
12) hold with
. This shows the first conclusion.
Furthermore, we let
,
, and
. Here,
is composed of the rows
and columns
of
. Then Equations (
11) and (
12) can be reformulated as
Here,
and
. Therefore, given the index sets
and
, as long as
and
are in the convex hull of
and
, respectively, then there is an M-eigenvalue in the convex hull of the entries in
.
This completes the proof. □
We have the following theorem for biquadratic tensors.
Theorem 2. A necessary condition for a biquadratic tensor to be positive semi-definite is that all of its diagonal entries are nonnegative. A necessary condition for to be positive definite is that all of its diagonal entries are positive. If is a diagonal biquadratic tensor, then these conditions are sufficient.
Proof. We let
and
Then
for
and
. This leads to the first two conclusions. If
is a diagonal biquadratic tensor, then
The last conclusion follows. □
4. Gershgorin-Type Theorem and Diagonally Dominated Biquadratic Tensors
RWe rcall that for square matrices, there is a Gershgorin theorem from which we may show that (strictly) diagonally dominated matrices are positive semi-definite (definite). These have been successfully generalized to cubic tensors [
21,
29]. Then, can these be generalized to nonsymmetric biquadratic tensors? To answer this question, we have to understand the “rows” and “columns” of a biquadratic tensor.
We suppose that
. Then
has
m rows. In the
ith row of
, there are
n diagonal entries
for
, and totally
entries
and
for
and
. We use the notation
. We let
if
is an off-diagonal entry, and
if
is a diagonal entry. Then, in the
ith row, the diagonal entry
has the responsibility to dominate the
entries
,
,
and
for
and
. Therefore, for
and
, we define
If
is weakly symmetric, then (
13) reduces to
If
is symmetric, then (
13) reduces to
For M-eigenvalues, here we have the following theorem, which generalizes the Gershgorin theorem of matrices to biquadratic tensors.
Theorem 3. We suppose that . We let for and be defined by Equation (
13).
Then any M-eigenvalue λ of lies in one of the following m intervals:for , and one of the following n intervals:for . Proof. We suppose that
is an M-eigenvalue of
, with M-eigenvectors
and
. We assume that
is the component of
with the largest absolute value. From (
5), we have
for
. The other inequalities of (
14) and (
15) can be derived similarly.
This completes the proof. □
In the symmetric case, the inclusion intervals and bounds of M-eigenvalues are presented in [
15,
16,
28,
30]. Here, Theorem 3 covers both the symmetric the nonsymmetric cases.
If the entries of
satisfy
for all
and
, then
is called a diagonally dominated biquadratic tensor. If the strict inequality holds for all these
inequalities, then
is called a strictly diagonally dominated biquadratic tensor.
We suppose that
. Then Equation (
16) can be simplified as
for all
and
.
Corollary 1. A diagonally dominated biquadratic tensor is positive semi-definite. A strictly diagonally dominated biquadratic tensor is positive definite.
Proof. This result follows directly from Theorems 1 and 3. □
5. B-Biquadratic Tensors and M-Biquadratic Tensors
Several structured tensors, including
-tensors, B-tensors, Z-tensors, M-tensors, and strong M-tensors have been studied. See [
21] for this. It has been established that even-order symmetric
-tensors and even-order symmetric M-tensors are positive semi-definite, even-order symmetric B-tensors and even-order symmetric strong M-tensors are positive definite [
21,
31]. We now extend such structured cubic tensors and the above properties to biquadratic tensors.
We let
. We suppose that for
and
, we have
and for
and
, we have
Then we say that
is a
-biquadratic tensor. If all strict inequalities hold in (
18) and (
19), then we say that
is a B-biquadratic tensor.
A biquadratic tensor in is called a Z-biquadratic tensor if all of its off-diagonal entries are nonpositive. If is a Z-biquadratic tensor, then it can be written as , where is the identity tensor in , and is a nonnegative biquadratic tensor. By the discussion in the last section, has an M-eigenvalue. We denote as the largest M-eigenvalue of . If , then is called an M-biquadratic tensor. If , then is called a strong M-biquadratic tensor.
If
and is nonnegative, it follows from Theorem 6 of [
27] that
, where
is the M-spectral radius of
, i.e., the largest absolute value of the M-eigenvalues of
. Checking the proof of Theorem 6 of [
27], we may find that this is true for
,
and
B being nonnegative. If
is nonnegative but not symmetric, this conclusion is still an open problem at this moment.
The following proposition is a direct generalization of Proposition 5.37 of [
21] for cubic tensors to biquadratic tensors.
Proposition 6. We suppose is a Z-biquadratic tensor. Then
- (i)
is diagonally dominated if and only if is a -biquadratic tensor;
- (ii)
is strictly diagonally dominated if and only if is a B-biquadrtic tensor.
Proof. By the fact that all off-diagonal entries of
are nonpositive, for all
and
, we have
Therefore, (
16) and (
18) are equivalent.
If
is diagonally dominated, then (
16) holds true. Hence, (
18) also holds. Since the left hand side of (
19) is nonnegative, and the right hand side is nonpositive, we have that (
19) holds.
On the other hand, we suppose that
is a
-biquadratic tensor. Then (
18) holds, thus (
16) holds true.
Similarly, we could show the last statement of this proposition. This completes the proof. □
By Proposition 4, we have the following proposition.
Proposition 7. An M-biquadratic tensor is positive semi-definite. A strong M-biquadratic tensor is positive definite.
Proof. We suppose that
, where
,
is the identity tensor in
, and
is a nonnegative biquadratic tensor. It follows from Proposition 4 that every M-eigenvalue of
satisfies
where
is an M-eigenvalue of
. This combined with Theorem 1 shows the first statement of this proposition.
Similarly, we could show the last statement of this proposition. This completes the proof. □
Proposition 8. We let be a Z-biquadratic tensor. is positive semi-definite if and only if it is an M-biquadratic tensor. Similarly, is positive definite if and only if it is a strong M-biquadratic tensor.
Proof. The necessity part follows from Proposition 7. We now demonstrate the sufficiency aspect.
Let
Then
is nonnegative. Furthermore, by Proposition 4, we have
Here, the last inequality follows from the fact that
is positive semidefinite and all the M-eigenvalues are nonnegative. This shows that
is an M-biquadratic tensor.
Similarly, we could show the last statement of this proposition. This completes the proof. □
We let be a biquadratic tensor and let and be two positive diagonal matrices. The transformed tensor is defined componentwise by . The following corollary is an immediate consequence of Proposition 8.
Corollary 2. We let be a Z-biquadratic tensor. If all diagonal entries of are nonnegative and there exist two positive diagonal matrices and such that is diagonally dominated, then is an M-biquadratic tensor. Similarly, if all diagonal entries of are positive and there exist two positive diagonal matrices and such that is strictly diagonally dominated, then is a strong M-biquadratic tensor.
Proof. By Corollary 1,
is positive semi-definite. By Theorem 7 in [
32], an M-eigenvalue of
is also an M-eigenvalue of
. Therefore,
is also positive semi-definite. This result follows directly from Proposition 8.
Similarly, we could show the last statement of this corollary. This completes the proof. □
We let
. For any
, we denote
as a biquadratic tensor in
, where
if
and
, and
otherwise. Then for any nonzero vectors
and
, we have
where
with
if
and
otherwise.
Similar with Theorem 5.38 in [
21] for cubic tensors, we could establish the following interesting decomposition theorem.
Theorem 4. We suppose is a symmetric -quadratic tensor, i.e., for and , we haveThen either is a diagonal dominated symmetric M-biquadratic tensor itself, or it can be decomposed aswhere is a diagonal dominated symmetric M-biquadratic tensor, s is a nonnegative integer, , , , , and . If is a symmetric B-quadratic tensor, then either is a strictly diagonal dominated symmetric M-quadratic tensor itself, or it can be decomposed as (
22)
with being a strictly diagonal dominated symmetric M-biquadratic tensor. Proof. For any given symmetric
-quadratic tensor
, we define
If
, then
itself is already a Z-biquadratic tensor. It follows from Proposition 6 that
is a diagonally dominated symmetric Z-biquadradtic tensor. Furthermore, it follows from (
21) that
Namely, all diagonal elements of
are nonnegative. By virtue of Corollary 2,
is a symmetric M-biquadratic tensor itself.
If
, we denote
,
By (
23), we have
and
. We let
. Now we claim that
is still a
-biquadratic tensor. In fact, we have
where
is the number of nonzero elements in
, and the first inequality follows from (
21). By the symmetry of
, we know that if
for some
, then
,
, and
are also in
. Thus, for any
,
Therefore, we have
Thus, we complete the proof of the claim that
is still a
-biquadratic tensor.
We continue the above procedure until the remaining part is an M-tensor. It is not hard to find out that with for any . Similarly, we can show the second part of the theorem for symmetric B-biquadratic tensors. □
Based on the above theorem, we show the following result.
Corollary 3. A symmetric -biquadratic tensor is positive semi-definite, and a symmetric B-biquadratic tensor is positive definite.
Proof. The results follow directly from Theorem 4 and the fact that the sum of positive semi-definite biquadratic tensors are positive semi-definite. Furthermore, the sum of a positive definite biquadratic tensor and several positive semi-definite biquadratic tensors are positive definite. □
6. A Riemannian LBFGS Method for Computing the Smallest M-Eigenvalue of a Biquadratic Tensor
We let
denote the multilinear form. Similarly, we define the contracted forms
and
. We consider the following two-unit-sphere constrained optimization problem:
Since the linearly independent constraint qualification is satisfied, every local optimal solution must satisfy the KKT conditions:
Here, we simplify the above equations by taking into account the constraints
and
. By multiplying
and
at both hand sides of the first two equations of (
25), we have
Thus, (
25) is equivalent to the definitions of M-eigenvalues in (
5)–(
7) with
. In other words, every KKT point of (
24) corresponds to an M-eigenvector of
with the associated M-eigenvalue given by
. Moreover, the smallest M-eigenvalue and its corresponding M-eigenvectors of
are associated with the global optimal solution of (
24). As established in Theorem 1, the smallest M-eigenvalue can be utilized to verify the positive semidefiniteness (definiteness) of
.
For convenience, we let
and denote
Then the gradient of
is given by
Under the constraints
and
, the gradient simplifies to
Therefore, the definitions of M-eigenvalues in (
5)–(
7) are also equivalent to
Furthermore, it can be validated that
Consequently, the partial gradients
and
inherently reside in the tangent spaces of their respective unit spheres. This geometric property provides fundamental motivation for our selection of the optimization model (
24), as it naturally aligns with the underlying manifold structure of the problem.
6.1. Algorithm Framework
Next, we present a Riemannian LBFGS (limited memory BFGS) method for solving (
24). At the
kth step, the LBFGS method generate a search direction as
where
is the quasi-Newton matrix. Notably, the LBFGS method approximates the BFGS method without explicitly storing the dense Hessian matrix
. Instead, it uses a limited history of updates to implicitly represent the Hessian or its inverse. This could be done in the two-loop recursion [
33]. To establish theoretical convergence guarantees, we impose the following essential conditions:
and
Here,
are predefined parameters. These conditions may not always hold for the classic LBFGS method. Consequently, when the descent Condition (
27) or (
28) is not satisfied, we adopt a safeguard strategy by setting the search direction as
. Namely
The classic LBFGS method was originally developed for unconstrained optimization problems. However, our optimization Model (
24) involves additional two unit sphere constraints. To address this challenge while maintaining the convergence properties of LBFGS, we employ a modified approach inspired by Chang et al. [
34]. Specifically, we incorporate the following Cayley transform, which inherently preserves the spherical constraints:
Here,
represents the step size, which is determined through a backtracking line search procedure to ensure the Armijo condition is satisfied, i.e.,
where
a predetermined constant that controls the descent amount. The stepsize
is determined through an iterative reduction process, starting from an initial value
and gradually decrease by
until the condition specified in Equation (
32) is satisfied. Here,
is the decrease ratio.
The Riemannian LBFGS algorithm terminates when the following stopping condition is satisfied:
where
are small positive tolerance parameters approaching zero.
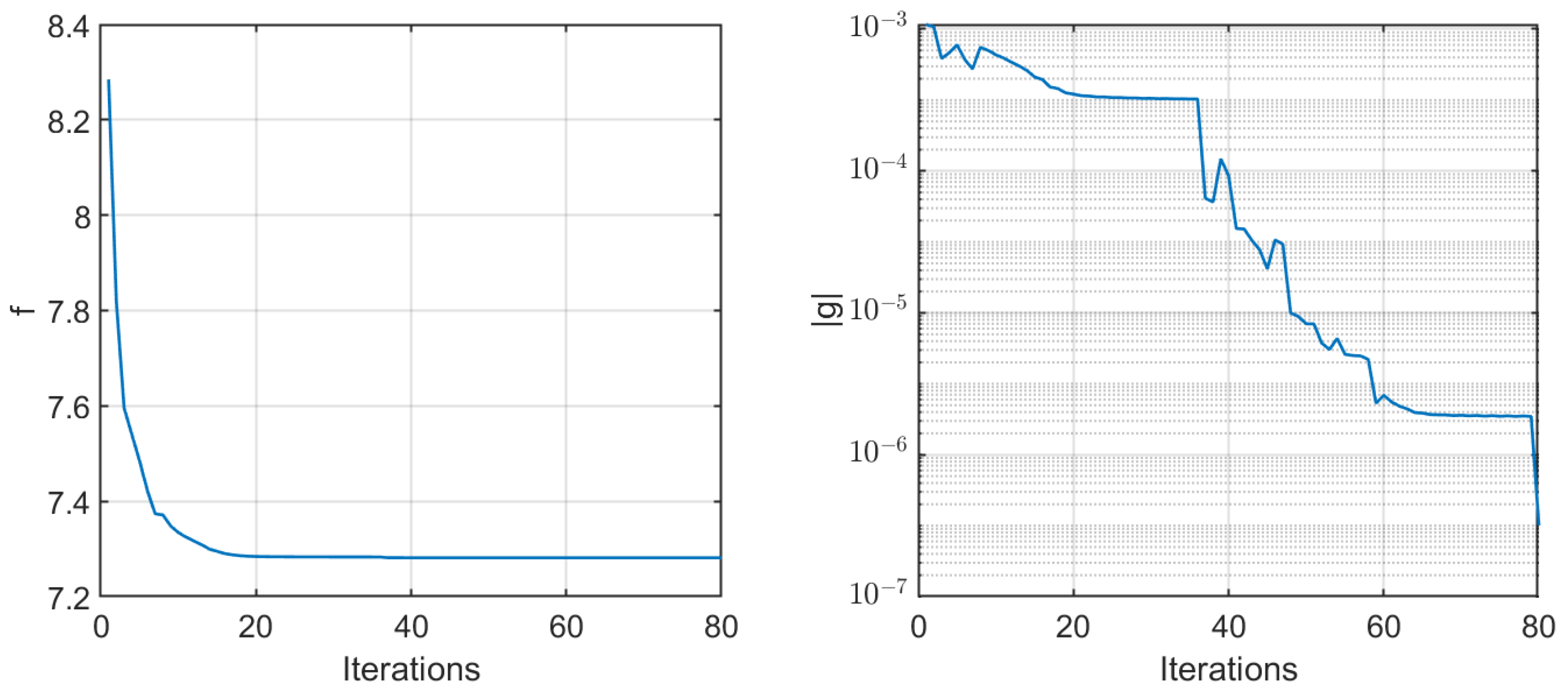
We present the Riemannian LBFGS method for computing M-eigenvalues of biquadratic tensors in Algorithm 1.
| Algorithm 1 A Riemannian LBFGS method for computing M-eigenvalues of biquadratic tensors |
Require:, , . The parameters , ,
, and are required in Equations ( 29)–( 33). - 1:
for do - 2:
Compute using ( 26) and then determine the descent direction by ( 29). - 3:
Compute the stepsize through a backtracking procedure until ( 32) is satisfied. - 4:
Update and by ( 30) and ( 31), respectively. - 5:
if The stopping criterion ( 33) is reached then - 6:
Stop. - 7:
end if - 8:
end for - 9:
Output: and
|
6.2. Convergence Analysis
We now establish the convergence analysis of Algorithm 1. Our Riemannian LBFGS method is specifically designed for solving optimization Problem (
24) that is constrained on the product of two unit spheres. This setting differs from existing Riemannian LBFGS methods that primarily address optimization problems constrained to a single unit sphere [
34], as well as classic LBFGS methods developed for unconstrained optimization Problems [
33].
We begin with several lemmas.
Lemma 1. We let be a sequence generated by Algorithm 1. We consider the descent direction defined by (
29).
For any positive constants and , Conditions (
27)
and (
28)
hold. Proof. We consider the two choices of the descent direction
as defined in (
29).
If , the conclusions of this lemma follow directly by setting and .
If the descent direction
is selected according to the LBFGS method, then both the conditions (
27) and (
28) must be satisfied.
Combining the both cases, the proof is completed. □
Lemma 2. The objective function in (
24),
its gradient vector and Hessian matrix, are bounded on any feasible set of (
24).
Namely, there exists a positive constant M such thatfor any satisfying and . Proof. Under the conditions that
and
,
,
and
are all polynomial functions over
. Then it follows from
is a compact set such that (
34) holds. □
Lemma 3. We let be a sequence generated by Algorithm 1. We let and , where is the decrease ratio in the Armijo line search. Then for all , the stepsize that satisfies (
32)
is lower bounded, i.e., Proof. Following from Lemma 4.3 in [
34], for any
satisfying
, it holds that
and
Therefore, we have
for any
. By the backtracking line search rule, we have
for all
k. This completes the proof. □
We now prove that the objective function in (
24) converges to a constant value, and any limit point is a KKT point.
Theorem 5. We let be a sequence generated by Algorithm 1. Then we haveFurthermore, the objective function monotonously converges to a constant value andNamely, any limit point of Algorithm 1 is a KKT point of Problem (
24),
which is also an M-eigenpair of the biquadratic tensor . Proof. It follows from Lemma 3 that
Combining with Lemma 1 derives (
35). In other words, the objective function
is monotonously decreasing. Lemma 2 shows that
is lower bounded. Therefore,
monotonously converges to a constant value
.
Furthermore, summing the both hand sides of (
35) over
k gives
Therefore, we have
which implies
.
This completes the proof. □
Before demonstrating the sequential global convergence, we first present the following lemma.
Lemma 4. We let be a sequence generated by Algorithm 1. Then there exist two positive constants such thatHere, and . Proof. By Theorem 4.6 in [
34], we have
Therefore, we have
Here, the last inequality follows from
. This shows the left inequality in (
37) holds.
Furthermore, by Lemma 4.7 in [
34], we have
Therefore, we have
This completes the proof. □
Now we are ready to present the global convergence of the sequence produced by Algorithm 1.
Theorem 6. We let be a sequence generated by Algorithm 1. Then we have the following result:Namely, sequence converges globally to a limit point . Furthermore, is an M-eigenvector of with the corresponding eigenvalue . Proof. By Theorem 5 and Lemma 4, we may deduce the sufficient decrease property
and the gradient lower bound for the iterates gap
Both the objective function and the constraints in (
24) are semi-algebraic functions that satisfy the KL property [
35]. Therefore, it follows from Theorem 1 in [
35] that (
38) holds. In other words,
is a Cauchy sequence, and it converges globally to a limit point
.
This completes the proof. □





{kind=link}
{kind=link}