
Cross-Scenario Interpretable Prediction of Coal Mine Water Inrush Probability: An Integrated Approach Driven by Gaussian Mixture Modeling with Manifold Learning and Metaheuristic Optimization
Abstract
1. Introduction
- A novel GMM-based data augmentation method that precisely models multimodal hydrological parameter distributions, overcoming the statistical distortion of traditional techniques and generating geomechanically consistent datasets.
- A robust WOA-XGBoost optimization strategy that globally tunes the hyperparameters, ensuring superior prediction accuracy and stability compared to those of local optimization approaches in high-dimensional feature spaces.
- Integration of the SHAP framework to provide quantitative, transparent interpretability of water inrush predictions, offering critical insights into the nonlinear synergistic effects of key factors and facilitating data-driven engineering decisions.
- Validation of an integrated framework’s real-world applicability and robustness in complex deep mining environments, demonstrating a significant paradigm shift toward data-driven dynamic regulation for water-associated hazard prevention and control.
2. Algorithmic Principles
2.1. Data Augmentation Based on Gaussian Mixture Model
2.2. ISOMAP Feature Extraction
- (1)
- Construct the weighted neighborhood graph G. Given a set of sample points and a target dimension d, use the Euclidean distance d(i,j) as the measure of distance between points. If two sample points are each other’s k-nearest neighbors, connect nodes i and j with an edge whose length is d(i,j). Otherwise, the distance between the samples is considered infinite.
- (2)
- Estimate the geodesic distance matrix. Approximate the true geodesic distance between two points on the manifold structure by calculating the shortest path dG(i,j) between points on the neighborhood graph G using Dijkstra’s algorithm.
- (3)
- Construct a low-dimensional embedding. Employ the multidimensional scaling (MDS) algorithm to embed RD into a low-dimensional space Rd, beginning with the construction of the ISOMAP kernel through the inner product matrix:where , is the centering matrix, I is the identity matrix, and J is the matrix with all elements equal to one.
- (4)
- Eigenvalue decomposition. The singular value decomposition of GC is given byIn the equation, is the diagonal matrix composed of eigenvalues, and is the matrix formed by the corresponding eigenvectors. By selecting the top d eigenvalues and their corresponding eigenvectors Md, the calculation formula for the low-dimensional matrix Y that represents the new coordinate values mapped to the d-dimensional space is given by
- (5)
- Validating dimensionality reduction. Introduce the KNN reconstruction error to assess the efficacy of the reduction, measuring the data’s reconstructive capability post-embedding. The calculation Formula (10) is as follows. A smaller value indicates superior preservation of local neighborhood structure and reduced information loss during reconstruction.Here, N represents the total number of samples, xi denotes the true high-dimensional vector of the i-th data point, and is the reconstructed point obtained by inversely aggregating its neighbors in the low-dimensional space.
2.3. WOA-XGBOOST
- (1)
- WOA
- (2)
- XGBoost Algorithm
- (3)
- WOA-XGBoost Model Prediction Process
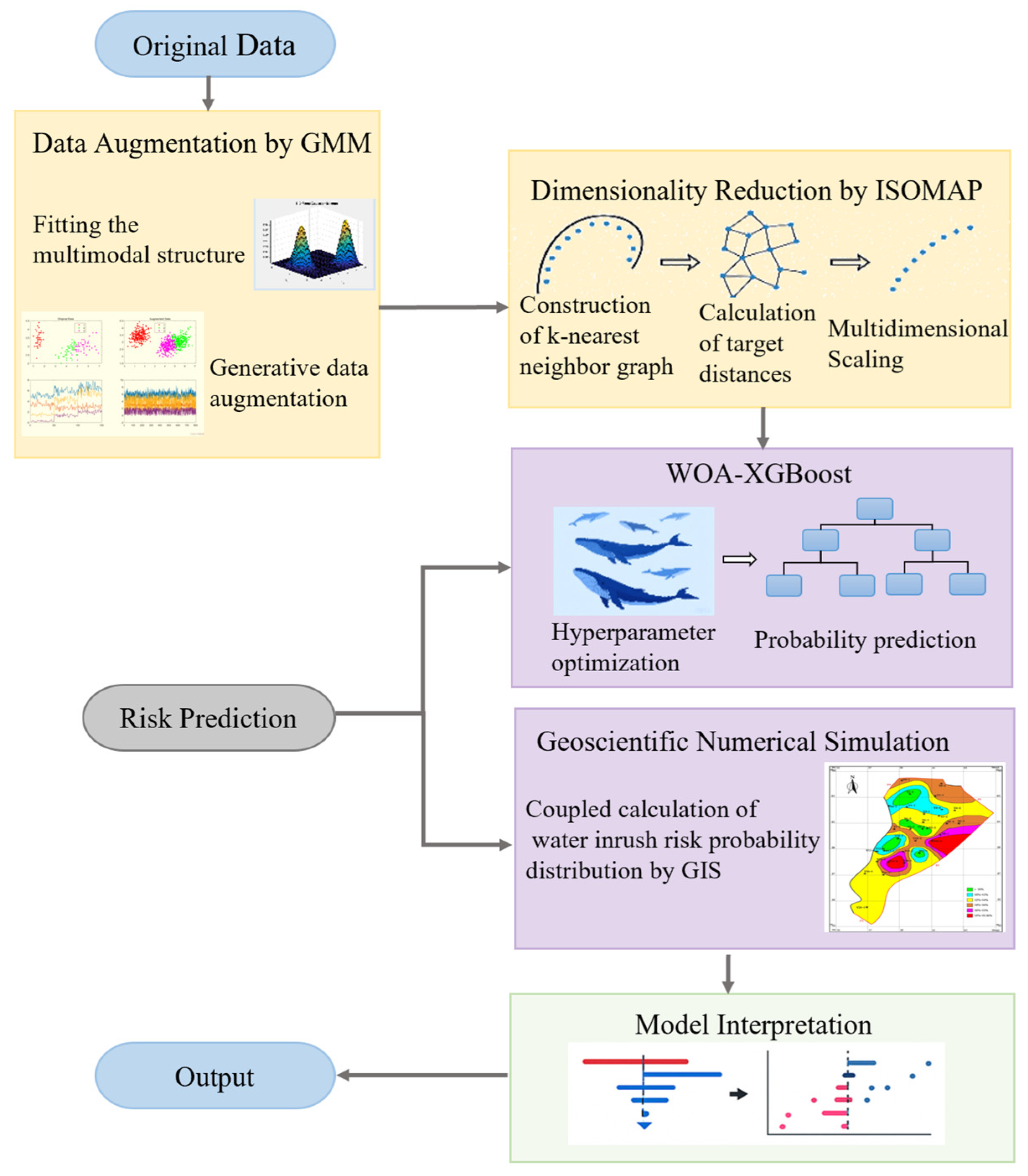
3. Model Construction
4. Engineering Case Studies
4.1. Selection and Processing of Sample Data
4.2. Model Application
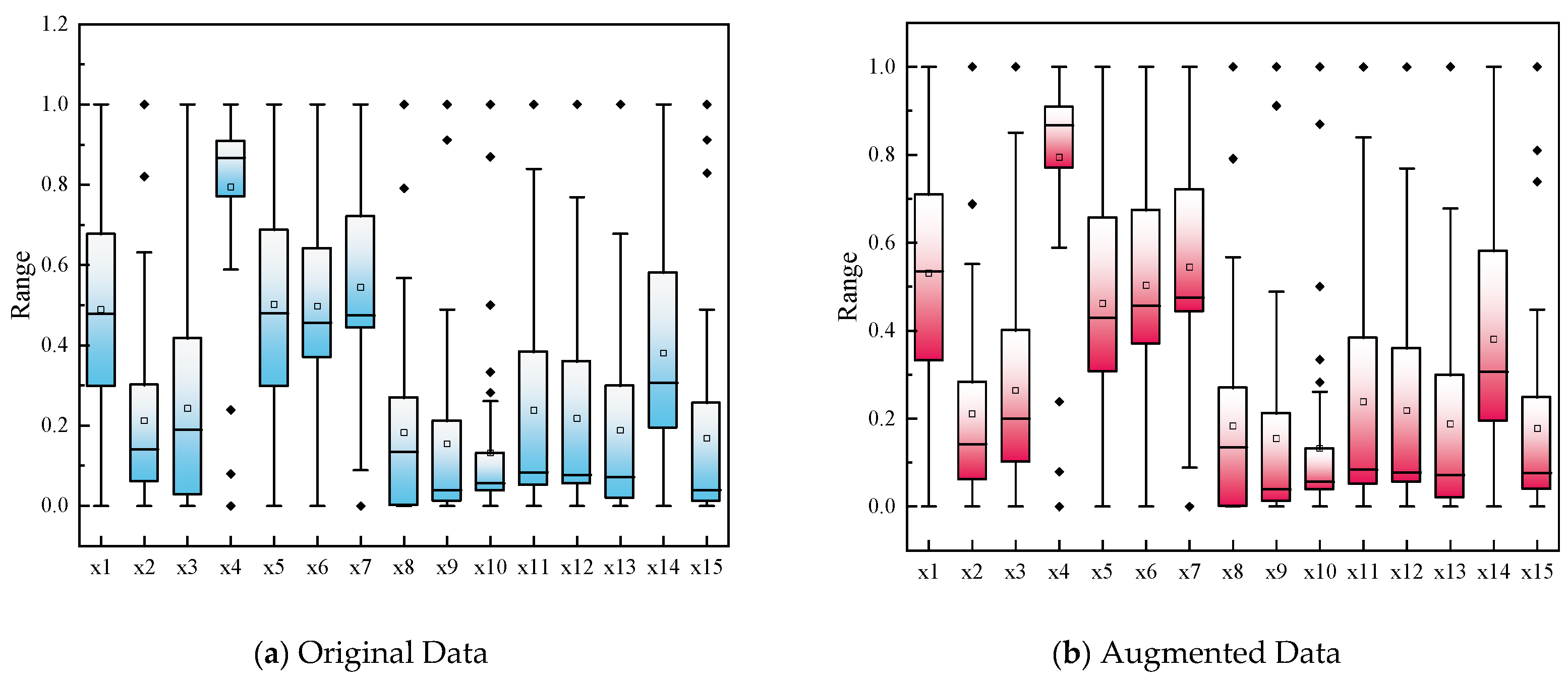
4.2.1. Data Augmentation Results
4.2.2. Extraction of Key Factors
- (1)
- Determination of Optimal Dimension d and Nearest Neighbors k
- (2)
- Presentation of Results Before and After Dimensionality Reduction
4.2.3. Comparative Analysis
4.3. Model Interpretability Analysis
4.4. Method Verification and Application
5. Discussion
6. Conclusions
- (1)
- The GMM-based augmentation strategy effectively expands limited samples of water inrush data. Box plots and KL divergence (all < 0.07) confirm the statistical integrity of the augmented dataset, ensuring distributional similarity and robustness in learning.
- (2)
- ISOMAP successfully reduced 15 input features to 9, improving feature compactness and eliminating redundancy. After dimensionality-reduction, the average gray relational degree increased by 14.9%. Compared with PCA, LLE, and t-SNE, ISOMAP exhibited the lowest KNN residual error (0.41), supporting its application in revealing the underlying symmetrical manifold structures of the data.
- (3)
- The proposed GMM-ISOMAP-WOA-XGBoost model significantly outperformed three baselines in all metrics. The RMSE, MAPE, MAE, and MBE were reduced by up to 60.6%, 73.1%, 65.6%, and 62.1%, respectively. The confidence intervals further supported the statistical reliability of these gains. Validation at the Yangcheng Coal Mine showed R2 > 0.9, indicating strong model generalizability, even with small or incomplete datasets.
- (4)
- SHAP-based interpretability tools highlighted the most influential features. The model offers a transparent and interpretable risk decision tool that aligns with current trends in explainable AI (XAI) for geosciences. Compared to traditional black-box models, the framework balances accuracy, transparency, and data-efficiency, making it suitable for practical deployment.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dong, S.; Fan, M.; Guo, X.; Liu, Y.; Guo, K.; Ji, Z.; Li, C.; Xue, X. Characteristics and prevention and control techniques of typical water hazards in coal mines in Shaanxi Province. J. China Coal Soc. 2024, 49, 902–916. [Google Scholar]
- Gai, Q.; Gao, Y.; Zhang, X.; He, M. A New Method for Evaluating Floor Spatial Failure Characteristics and Water Inrush Risk Based on Microseismic Monitoring. Rock Mech. Rock Eng. 2024, 57, 2847–2875. [Google Scholar] [CrossRef]
- Kong, H.-Q.; Zhang, N. Risk assessment of water inrush accident during tunnel construction based on FAHP-I-TOPSIS. J. Clean. Prod. 2024, 449, 141744. [Google Scholar] [CrossRef]
- Liu, Y.; Ji, M.; Wang, Y.; Liu, G.; Gu, P.; Wang, Q. Fractal mechanical model of variable mass seepage in karst collapse column of mine. Phys. Fluids 2024, 36, 022031. [Google Scholar] [CrossRef]
- Wang, W.; Cui, X.C.; Qi, Y.; Xue, K.L.; Liu, J.; Zuo, C. Research on the evaluation model of emergency rescue capability of coal mine water penetration accident. Sci. Rep. 2025, 15, 6462. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Wang, H.R.; Li, X.P.; Qi, Y.; Cui, X.C.; Bai, C.H. Prediction model of water inrush risk level of coal seam floor based on KPCA-DBO-SVM. Sci. Rep. 2025, 15, 10393. [Google Scholar] [CrossRef]
- Li, B.; Xiang, X.; Wu, Q.; Wang, J.; Zeng, Y.; Li, T. Comparison of multiple methods for identifying water sources of mine water inrush and quantitative analysis of mixed water sources based on isotope theory. Earth Sci. Inform. 2025, 18, 26. [Google Scholar] [CrossRef]
- Ji, Y.; Yu, L.; Wei, Z.; Ding, J.; Dong, D. Research Progress on Identification of Mine Water Inrush Sources: A Visual Analysis Perspective. Mine Water Environ. 2025, 44, 3–15. [Google Scholar] [CrossRef]
- Shen, S.; Li, H.; Chen, W.; Wang, X.; Huang, B. Seismic Fault Interpretation Using 3-D Scattering Wavelet Transform CNN. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8028505. [Google Scholar] [CrossRef]
- Liu, F.; Wang, Y.; Kou, M.; Liang, C. Applications of Microseismic Monitoring Technique in Coal Mines: A State-of-the-Art Review. Appl. Sci. 2024, 14, 1509. [Google Scholar] [CrossRef]
- Liu, J.; Zhao, Y.; Tan, T.; Zhang, L.; Zhu, S.; Xu, F. Evolution and modeling of mine water inflow and hazard characteristics in southern coalfields of China: A case of Meitanba mine. Int. J. Min. Sci. Technol. 2022, 32, 513–524. [Google Scholar] [CrossRef]
- Zheng, Q.; Wang, C.; Yang, Y.; Liu, W.; Zhu, Y. Identification of mine water sources using a multi-dimensional ion-causative nonlinear algorithmic model. Sci. Rep. 2024, 14, 3305. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Bai, Q.; Han, P. A review of water rock interaction in underground coal mining: Problems and analysis. Bull. Eng. Geol. Environ. 2023, 82, 157. [Google Scholar] [CrossRef]
- An, P.; Li, M.; Ma, S.; Zhang, J.; Huang, Z. Analysis of the thickness of the outburst prevention layer in karst tunnels under the control of compressive faults. Tunn. Undergr. Space Technol. 2024, 147, 105710. [Google Scholar] [CrossRef]
- Chun’an, T.; Liexian, T.; Lianchong, L.I.; Changwen, L.I. Centrifugal loading method of RFPA for the failure process analysis of rock and soil structure. Chin. J. Geotech. Eng. 2007, 29, 71–76. [Google Scholar]
- de Graaf, I.E.M.; Sutanudjaja, E.H.; van Beek, L.P.H.; Bierkens, M.F.P. A high-resolution global-scale groundwater model. Hydrol. Earth Syst. Sci. 2015, 19, 823–837. [Google Scholar] [CrossRef]
- Zhou, S.W.; Zhuang, X.Y.; Rabczuk, T. Phase-field modeling of fluid-driven dynamic cracking in porous media. Comput. Methods Appl. Mech. Eng. 2019, 350, 169–198. [Google Scholar] [CrossRef]
- Yin, H.; Zhang, G.; Wu, Q.; Yin, S.; Soltanian, M.R.; Thanh, H.V.; Dai, Z. A Deep Learning-Based Data-Driven Approach for Predicting Mining Water Inrush From Coal Seam Floor Using Microseismic Monitoring Data. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4504815. [Google Scholar] [CrossRef]
- Gai, Q.; He, M.; Gao, Y.; Lu, C. A two-dimensional model test system for floor failure during automatic roadway formation mining without pillars above confined water. Eng. Fail. Anal. 2024, 162, 108369. [Google Scholar] [CrossRef]
- Li, N.; Du, W. Enhanced Methods for Evaluating Water-inrush Risk from Underlying Aquifers: Incorporating Dynamic Weight Theory and Uncertainty Analysis Model. Water Resour. Manag. 2024, 38, 4615–4631. [Google Scholar] [CrossRef]
- Wang, W.; Cui, X.C.; Qi, Y.; Xue, K.L.; Liang, R.; Sun, Z.P.; Tao, H.J. Mine water inrush source discrimination model based on KPCA-ISSA-KELM. PLoS ONE 2024, 19, e0299476. [Google Scholar] [CrossRef]
- Liang, Z.; Li, H.; Tang, J. The description technology of three dimensional space for fault and its fracture development zone. Fault Block Oil Gas Field 2022, 29, 496–501. [Google Scholar]
- Chen, W.; Zhang, S.; Li, R.; Shahabi, H. Performance evaluation of the GIS-based data mining techniques of best-first decision tree, random forest, and naive Bayes tree for landslide susceptibility modeling. Sci. Total Environ. 2018, 644, 1006–1018. [Google Scholar] [CrossRef]
- Kia, M.B.; Pirasteh, S.; Pradhan, B.; Mahmud, A.R.; Sulaiman, W.N.A.; Moradi, A. An artificial neural network model for flood simulation using GIS: Johor River Basin, Malaysia. Environ. Earth Sci. 2012, 67, 251–264. [Google Scholar] [CrossRef]
- Zheng, Q.; Wang, C.; Pang, L. Overburden and surface subsidence with slicing paste filling mining in thick coal seams. Front. Earth Sci. 2023, 10, 1027816. [Google Scholar] [CrossRef]
- Zheng, Q.; Wang, C.; Zhu, Z. Research on the prediction of mine water inrush disasters based on multi-factor spatial game reconstruction. Geomech. Geophys. Geo-Energy Geo-Resour. 2024, 10, 41. [Google Scholar] [CrossRef]
- Li, Z.-Q.; Nie, L.; Xue, Y.; Li, W.; Fan, K. Model Testing on the Processes, Characteristics, and Mechanism of Water Inrush Induced by Karst Caves Ahead and Alongside a Tunnel. Rock Mech. Rock Eng. 2025, 58, 5363–5380. [Google Scholar] [CrossRef]
- Isniarno, N.F.; Aziz, G.; Iswandaru, I. Hydrological monitoring in open PIT mining areas using geodatabase attribute in Geographic Information Systems (GIS). In Proceedings of the International Conference on Innovation in Engineering and Vocational Education 2019 (ICIEVE 2019), PTS 1-4, Bandung, Indonesia, 26 November 2019. [Google Scholar]
- Kim, S.-M.; Choi, Y.; Suh, J.; Oh, S.; Park, H.-D.; Yoon, S.-H.; Go, W.-R. ArcMine: A GIS extension to support mine reclamation planning. Comput. Geosci. 2012, 46, 84–95. [Google Scholar] [CrossRef]
- Naidu, G.; Ryu, S.; Thiruvenkatachari, R.; Choi, Y.; Jeong, S.; Vigneswaran, S. A critical review on remediation, reuse, and resource recovery from acid mine drainage. Environ. Pollut. 2019, 247, 1110–1124. [Google Scholar] [CrossRef]
- Li, W.; Wang, Y.; Ye, Z.; Liu, Y.A.; Wang, L. Development of a mixed reality assisted escape system for underground mine- based on the mine water-inrush accident background. Tunn. Undergr. Space Technol. 2024, 143, 105471. [Google Scholar] [CrossRef]
- Shao, J.; Zhang, Q.; Zhang, W. Evolution of mining-induced water inrush disaster from a hidden fault in coal seam floor based on a coupled stress-seepage-damage model. Geomech. Geophys. Geo-Energy Geo-Resour. 2024, 10, 78. [Google Scholar] [CrossRef]
- Huang, L.; Li, J.; Hao, H.; Li, X. Micro-seismic event detection and location in underground mines by using Convolutional Neural Networks (CNN) and deep learning. Tunn. Undergr. Space Technol. 2018, 81, 265–276. [Google Scholar] [CrossRef]
- Xu, J.; Zheng, L.; Lan, H.; Zuo, Y.; Li, B.; Tian, S.; Tian, Y. Research on an identification model for mine water inrush sources based on the HBA-CatBoost algorithm. Sci. Rep. 2024, 14, 23508. [Google Scholar] [CrossRef] [PubMed]
- Almeida, J.; Soares, J.; Lezama, F.; Limmer, S.; Rodemann, T.; Vale, Z. A systematic review of explainability in computational intelligence for optimization. Comput. Sci. Rev. 2025, 57, 100764. [Google Scholar] [CrossRef]
- Janousek, J.; Gajdos, P.; Radecky, M.; Snasel, V. Gaussian Mixture Model Cluster Forest. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 1019–1023. [Google Scholar]
- Zhang, J.; Zhu, Z.; Zou, J. Supervised Gaussian Process Latent Variable Model Based on Gaussian Mixture Model. In Proceedings of the 2017 International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Shenzhen, China, 15–17 December 2017; pp. 124–129. [Google Scholar]
- Hajihosseinlou, M.; Maghsoudi, A.; Ghezelbash, R. A semi-supervised learning framework for intelligent mineral prospectivity mapping: Incorporation of the CatBoost and Gaussian mixture model algorithms. J. Geochem. Explor. 2025, 274, 107755. [Google Scholar] [CrossRef]
- Yao, X.; Su, K.; Zhang, H.; Zhang, S.; Zhang, H.; Zhang, J. Remaining useful life prediction for lithium-ion batteries in highway electromechanical equipment based on feature-encoded LSTM-CNN network. Energy 2025, 323, 135719. [Google Scholar] [CrossRef]
- Liu, Y.; Li, P.; Liu, Y. Penalized empirical likelihood estimation and EM algorithms for closed-population capture-recapture models. Stat. Comput. 2025, 35, 25. [Google Scholar] [CrossRef]
- Tseng, J.C.-H.; Tsai, B.-A.; Chung, K. Sea surface temperature clustering and prediction in the Pacific Ocean based on isometric feature mapping analysis. Geosci. Lett. 2023, 10, 42. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Z.; Lin, Y. Multi-Cluster Feature Selection Based on Isometric Mapping. IEEE-CAA J. Autom. Sin. 2022, 9, 570–572. [Google Scholar] [CrossRef]
- Qiu, Y.; Zhou, J.; Khandelwal, M.; Yang, H.; Yang, P.; Li, C. Performance evaluation of hybrid WOA-XGBoost, GWO-XGBoost and BO-XGBoost models to predict blast-induced ground vibration. Eng. Comput. 2022, 38, 4145–4162. [Google Scholar] [CrossRef]
- Wu, Y.; Sang, W.; Cao, X.; He, L. Research on the Parameter Prediction Model for Fully Mechanized Mining Equipment Selection Based on RF-WOA-XGBoost. Appl. Sci. 2025, 15, 732. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Key Control Indicators | Unit | Evaluation Criteria |
|---|---|---|---|
| X1 | Inclined Length | m | Actual width of the working face |
| X2 | Aquifer Water Pressure | MPa | Actual water pressure value |
| X3 | Monthly Advancement Distance of Working Face | m | Actual advancement distance of the working face |
| X4 | Aquiclude Thickness | m | Actual thickness of the aquiclude |
| X5 | Depth of Floor Damage | m | Actual depth of floor damage |
| X6 | Percentage of Sandstone in the Aquiclude | None | Actual percentage of sandstone in the aquiclude |
| X7 | Percentage of Mudstone in the Aquiclude | None | Actual percentage of mudstone in the aquiclude |
| X8 | Percentage of Limestone in the Aquiclude | None | Actual percentage of limestone in the aquiclude |
| X9 | Mining Height of Working Face | m | Actual mining height of the working face |
| X10 | Fault Displacement | m | Actual displacement value |
| X11 | Mining Depth of Working Face | m | Actual coal seam mining depth |
| X12 | Water Temperature | °C | Actual water temperature value |
| X13 | Strike Length of Working Face | m | Actual strike length of the working face |
| X14 | Coal Seam Dip Angle | ° | Actual coal seam dip angle |
| X15 | Coal Seam Thickness | m | Actual thickness of the coal seam |
| d | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| k | ||||||||||
| 2 | 0.154 | 0.116 | 0.093 | 0.071 | 0.056 | 0.051 | 0.049 | 0.051 | 0.046 | |
| 3 | 0.204 | 0.123 | 0.098 | 0.060 | 0.051 | 0.047 | 0.044 | 0.041 | 0.042 | |
| 4 | 0.250 | 0.131 | 0.096 | 0.086 | 0.067 | 0.061 | 0.050 | 0.049 | 0.049 | |
| 5 | 0.277 | 0.174 | 0.119 | 0.093 | 0.068 | 0.058 | 0.053 | 0.048 | 0.050 | |
| 6 | 0.248 | 0.147 | 0.120 | 0.077 | 0.069 | 0.056 | 0.050 | 0.049 | 0.049 | |
| 7 | 0.241 | 0.163 | 0.106 | 0.082 | 0.075 | 0.064 | 0.055 | 0.051 | 0.051 | |
| 8 | 0.246 | 0.154 | 0.108 | 0.080 | 0.068 | 0.058 | 0.057 | 0.055 | 0.054 | |
| 9 | 0.276 | 0.184 | 0.131 | 0.095 | 0.077 | 0.061 | 0.062 | 0.060 | 0.057 | |
| 10 | 0.262 | 0.174 | 0.118 | 0.088 | 0.070 | 0.067 | 0.065 | 0.061 | 0.059 | |
| Method | Type | KNN Residual |
|---|---|---|
| ISOMAP | Nonlinear | 0.41 |
| Autoencoder | Nonlinear | 0.47 |
| t-SNE | Nonlinear | 0.55 |
| LLE | Nonlinear | 0.58 |
| MDS | Linear | 0.62 |
| PCA | Linear | 0.68 |
| RMSE | MAPE | MAE | MBE | |
|---|---|---|---|---|
| BPNN | 0.896 ± 0.043 | 0.479 ± 0.038 | 0.805 ± 0.045 | 0.567 ± 0.029 |
| SVR | 0.871 ± 0.039 | 0.442 ± 0.035 | 0.774 ± 0.044 | 0.541 ± 0.024 |
| XGboost | 0.803 ± 0.035 | 0.408 ± 0.033 | 0.701 ± 0.031 | 0.512 ± 0.024 |
| PSO-XGboost | 0.805 ± 0.042 | 0.414 ± 0.035 | 0.725 ± 0.037 | 0.524 ± 0.025 |
| DBO-XGboost | 0.814 ± 0.044 | 0.423 ± 0.033 | 0.748 ± 0.035 | 0.529 ± 0.022 |
| WOA-XGboost | 0.764 ± 0.041 | 0.372 ± 0.029 | 0.691 ± 0.033 | 0.425 ± 0.025 |
| KPCA-DBO-SVR [6] | 0.492 ± 0.031 | 0.207 ± 0.022 | 0.406 ± 0.024 | 0.313 ± 0.022 |
| GMM-WOA-XGboost | 0.453 ± 0.034 | 0.187 ± 0.016 | 0.394 ± 0.027 | 0.190 ± 0.018 |
| GMM-ISOMAP-WOA-XGboost | 0.301 ± 0.026 | 0.100 ± 0.011 | 0.238 ± 0.019 | 0.161 ± 0.015 |
| ISOMAP-WOA-XGboost | 0.504 ± 0.037 | 0.213 ± 0.018 | 0.482 ± 0.031 | 0.275 ± 0.021 |
| Improvement vs. WOA-XGboost | 60.6% | 73.12% | 65.56% | 62.12% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Q.; Wang, C. Cross-Scenario Interpretable Prediction of Coal Mine Water Inrush Probability: An Integrated Approach Driven by Gaussian Mixture Modeling with Manifold Learning and Metaheuristic Optimization. Symmetry 2025, 17, 1111. https://doi.org/10.3390/sym17071111
Zheng Q, Wang C. Cross-Scenario Interpretable Prediction of Coal Mine Water Inrush Probability: An Integrated Approach Driven by Gaussian Mixture Modeling with Manifold Learning and Metaheuristic Optimization. Symmetry. 2025; 17(7):1111. https://doi.org/10.3390/sym17071111
Chicago/Turabian StyleZheng, Qiushuang, and Changfeng Wang. 2025. "Cross-Scenario Interpretable Prediction of Coal Mine Water Inrush Probability: An Integrated Approach Driven by Gaussian Mixture Modeling with Manifold Learning and Metaheuristic Optimization" Symmetry 17, no. 7: 1111. https://doi.org/10.3390/sym17071111
APA StyleZheng, Q., & Wang, C. (2025). Cross-Scenario Interpretable Prediction of Coal Mine Water Inrush Probability: An Integrated Approach Driven by Gaussian Mixture Modeling with Manifold Learning and Metaheuristic Optimization. Symmetry, 17(7), 1111. https://doi.org/10.3390/sym17071111