
A Fine-Tuning Method via Adaptive Symmetric Fusion and Multi-Graph Aggregation for Human Pose Estimation


Abstract
1. Introduction
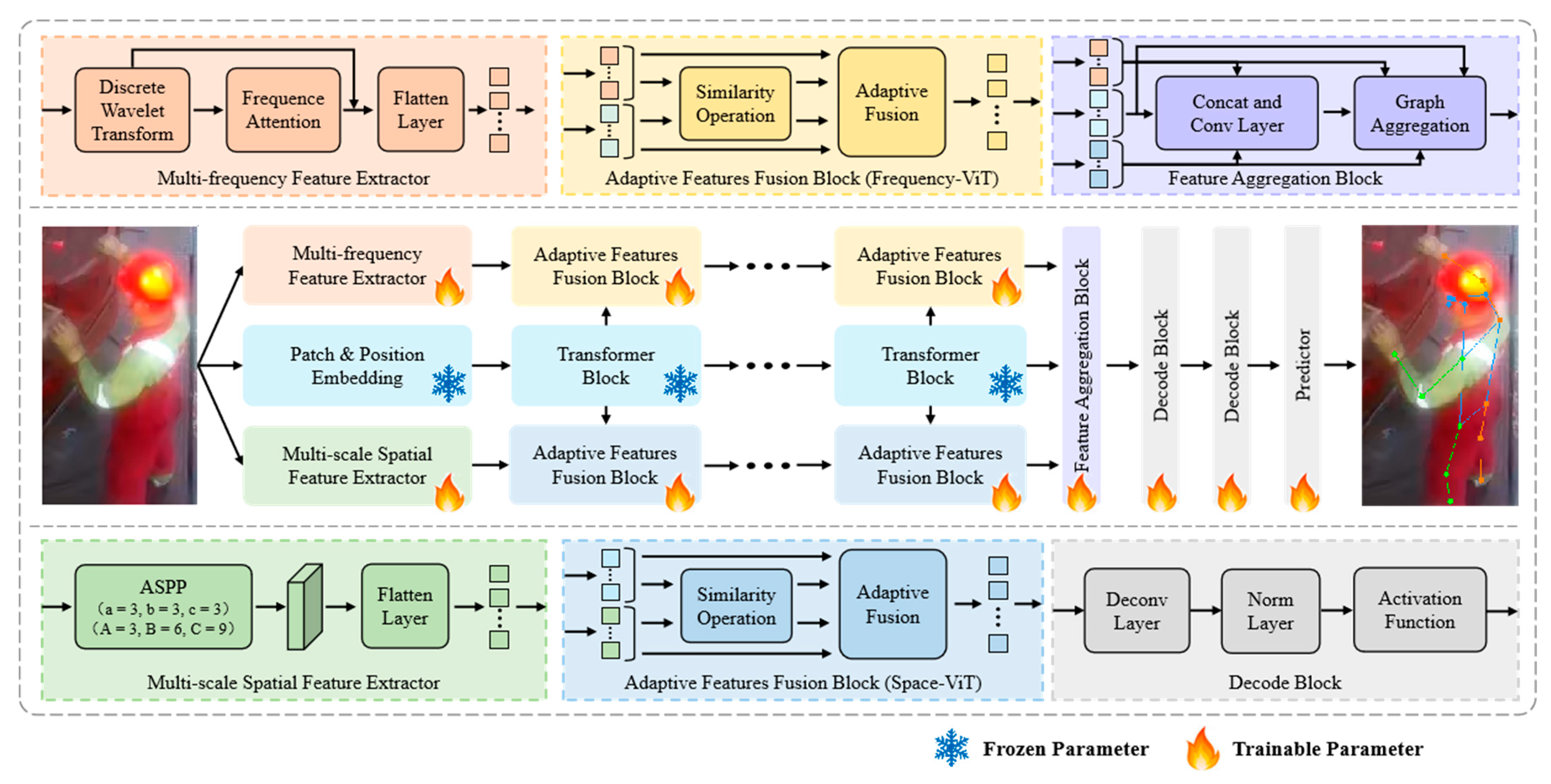
- Since the ViT model focuses on capturing global features while ignoring local detail information, we use discrete wavelet convolution and atrous spatial pyramid pooling. This introduces frequency features and multi-scale spatial features to improve the model’s ability to capture local details, texture information, and spatial information. This also improves the model’s anti-interference ability, as well as its generalization and robustness in high-interference environments.
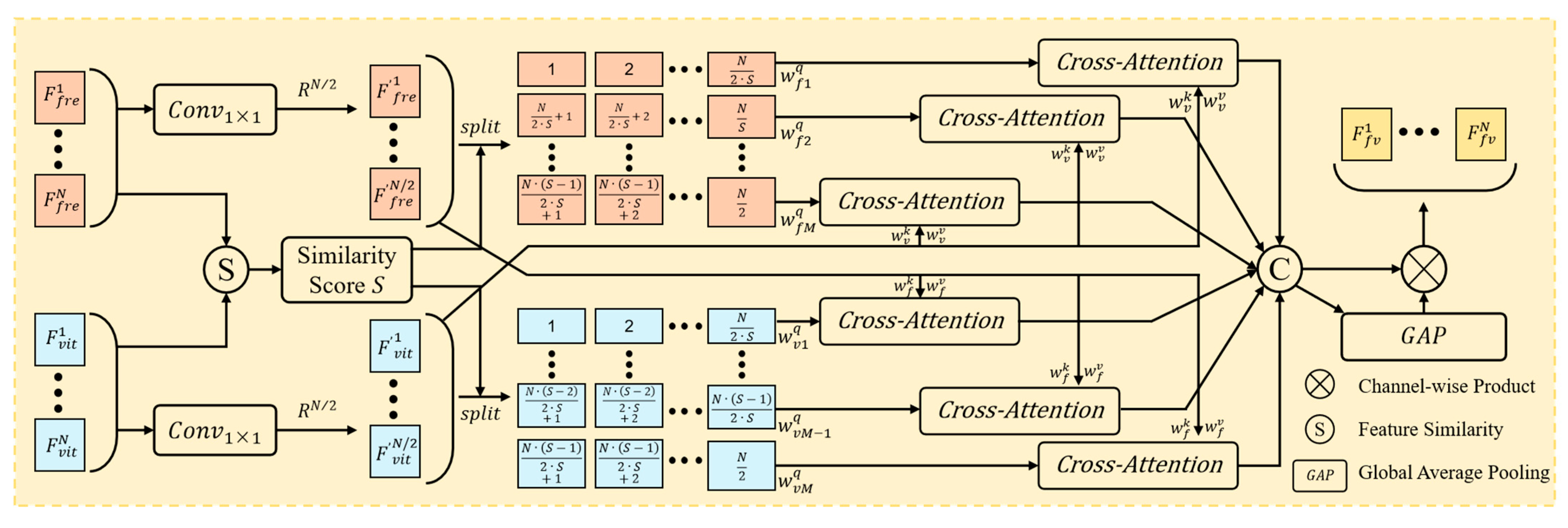
- To address the issues of insufficient and excessive feature fusion, this study suggests an adaptive symmetric feature fusion strategy. We analyze the similarity between the newly introduced features and the pre-trained model features. The number of blocks of the two feature types is dynamically and symmetrically adjusted. And the cross-attention mechanism is used to fuse the features of each block with the global features of another feature type, achieving the optimal feature fusion effect while minimizing resource consumption.
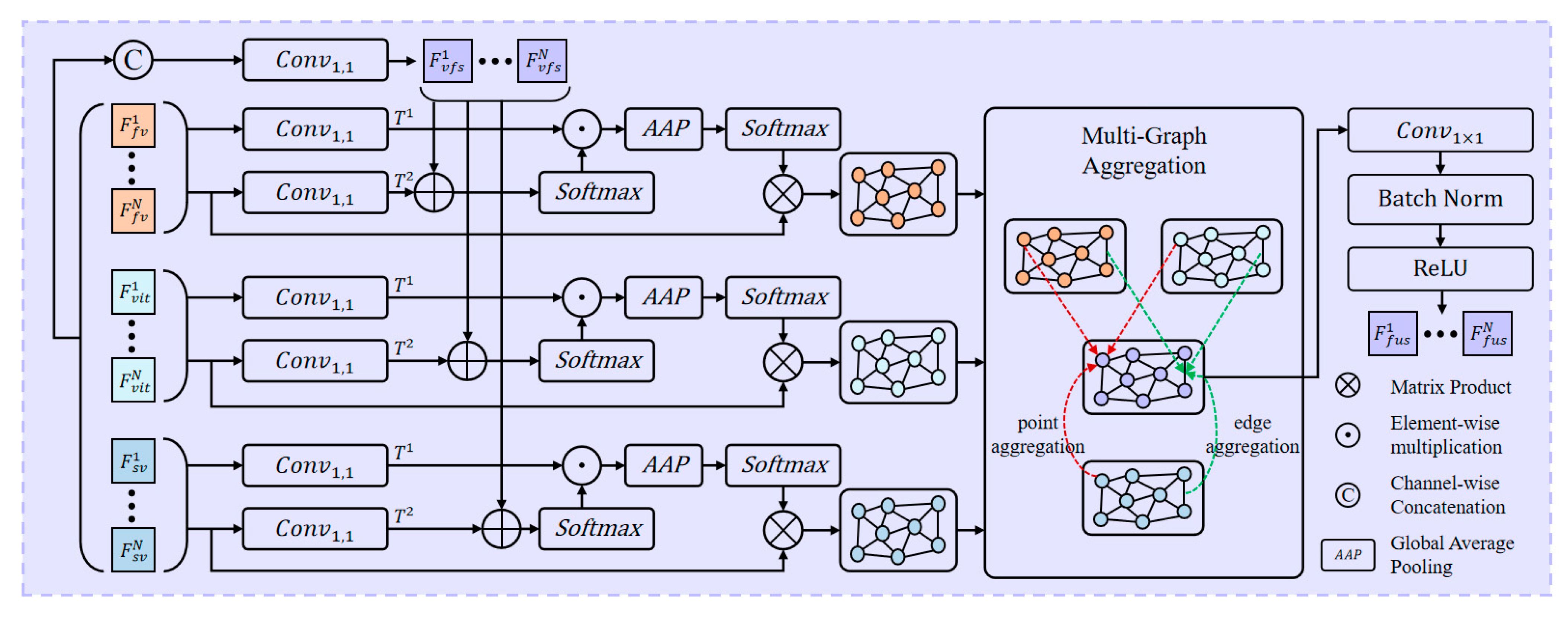
- To effectively achieve the deep fusion of ViT global features, frequency domain features, and spatial features, this paper suggests a multi-graph aggregation method. This method constructs a graph structure for each feature and achieves the structural fusion of the three graphs through point and edge attention mechanisms. This approach aims to capture the consistency and complementary of information between different features for maintaining the integrity of each piece of information.
- The human pose estimation method proposed in this paper was verified on the COCO dataset and the self-built high-blur dataset. Compared with existing methods, this method achieves significant improvement in performance, confirming the excellent anti-interference ability of our method.
2. Related Work
2.1. Human Pose Estimation Method
2.2. ViT Fine-Tuning Method
3. Method
3.1. Network Structure
3.2. Adaptive Symmetric Feature Fusion
3.3. Multi-Graph Feature Aggregation
3.4. Loss Function
4. Experiment
4.1. Dataset Introduction
4.2. Evaluation Indicators
4.3. Experimental Environment and Parameter Configuration
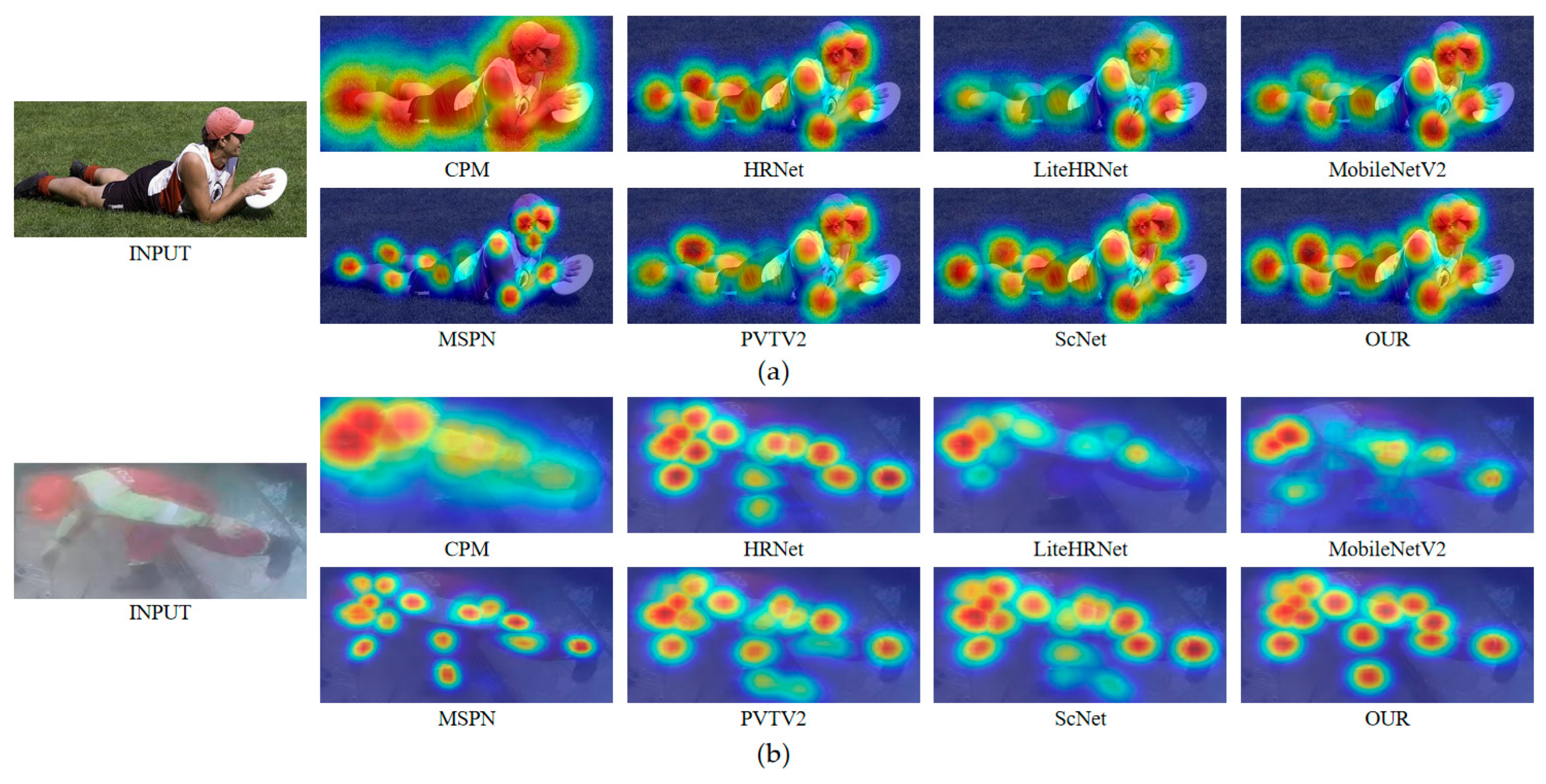
4.4. Comparative Experiment
4.5. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, J.; Qiu, K.; Peng, H.; Fu, J.; Zhu, J. Ai coach: Deep human pose estimation and analysis for personalized athletic training assistance. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 374–382. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 143–152. [Google Scholar]
- Difini, G.M.; Martins, M.G.; Barbosa, J.L.V. Human pose estimation for training assistance: A systematic literature review. In Proceedings of the Brazilian Symposium on Multimedia and the Web, Belo Horizonte, Brazil, 5–12 November 2021; pp. 189–196. [Google Scholar]
- Gkioxari, G.; Arbeláez, P.; Bourdev, L.; Malik, J. Articulated pose estimation using discriminative armlet classifiers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3342–3349. [Google Scholar]
- Wren, C.R.; Azarbayejani, A.; Darrell, T.; Pentland, A.P. Pfinder: Real-time tracking of the human body. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 780–785. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-alone self-attention in vision models. Adv. Neural Inf. Process. Syst. 2019, 32–44. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30–40. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Pictorial structures for object recognition. Int. J. Comput. Vis. 2005, 61, 55–79. [Google Scholar] [CrossRef]
- Eichner, M.; Ferrari, V. Better appearance models for pictorial structures. In Proceedings of the British Machine Vision Conference, London, UK, 7–10 September 2009. [Google Scholar]
- Freifeld, O.; Weiss, A.; Zuffi, S.; Black, M.J. Contour people: A parameterized model of 2D articulated human shape. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 639–646. [Google Scholar]
- Yang, Y.; Ramanan, D. Articulated pose estimation with flexible mixtures-of-parts. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 1385–1392. [Google Scholar]
- Yang, Y.; Ramanan, D. Articulated human detection with flexible mixtures of parts. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2878–2890. [Google Scholar] [CrossRef]
- Achilles, F.; Ichim, A.-E.; Coskun, H.; Tombari, F.; Noachtar, S.; Navab, N. Patient MoCap: Human pose estimation under blanket occlusion for hospital monitoring applications. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2016: 19th International Conference, Athens, Greece, 17–21 October 2016; Proceedings, Part I 19. Springer: Cham, Switzerland, 2016; pp. 491–499. [Google Scholar]
- Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Sun, X.; Shang, J.; Liang, S.; Wei, Y. Compositional human pose regression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2602–2611. [Google Scholar]
- Rogez, G.; Weinzaepfel, P.; Schmid, C. Lcr-net: Localization-classification-regression for human pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3433–3441. [Google Scholar]
- Luvizon, D.C.; Tabia, H.; Picard, D. Human pose regression by combining indirect part detection and contextual information. Comput. Graph. 2019, 85, 15–22. [Google Scholar] [CrossRef]
- Wei, S.-E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII 14. Springer: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. Human pose estimation via convolutional part heatmap regression. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VII 14. Springer: Cham, Switzerland, 2016; pp. 717–732. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5386–5395. [Google Scholar]
- Yang, S.; Quan, Z.; Nie, M.; Yang, W. Transpose: Keypoint localization via transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11802–11812. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.-T.; Zhou, E. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11313–11322. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. Hrformer: High-resolution vision transformer for dense predict. Adv. Neural Inf. Process. Syst. 2021, 34, 7281–7293. [Google Scholar]
- Fang, H.-S.; Li, J.; Tang, H.; Xu, C.; Zhu, H.; Xiu, Y.; Li, Y.-L.; Lu, C. Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 7157–7173. [Google Scholar] [CrossRef]
- Jia, M.; Tang, L.; Chen, B.-C.; Cardie, C.; Belongie, S.; Hariharan, B.; Lim, S.-N. Visual prompt tuning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 709–727. [Google Scholar]
- Yu, B.X.; Chang, J.; Wang, H.; Liu, L.; Wang, S.; Wang, Z.; Lin, J.; Xie, L.; Li, H.; Lin, Z. Visual tuning. ACM Comput. Surv. 2024, 56, 1–38. [Google Scholar] [CrossRef]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual instruction tuning. Adv. Neural Inf. Process. Syst. 2023, 36, 34892–34916. [Google Scholar]
- Zaken, E.B.; Ravfogel, S.; Goldberg, Y. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv 2021, arXiv:2106.10199. [Google Scholar]
- Bu, Z.; Wang, Y.-X.; Zha, S.; Karypis, G. Differentially private bias-term only finetuning of foundation models. arXiv 2023, arXiv:2210.00036. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. ICLR 2022, 1, 3. [Google Scholar]
- Valipour, M.; Rezagholizadeh, M.; Kobyzev, I.; Ghodsi, A. Dylora: Parameter efficient tuning of pre-trained models using dynamic search-free low-rank adaptation. arXiv 2022, arXiv:2210.07558. [Google Scholar]
- Gao, Y.; Shi, X.; Zhu, Y.; Wang, H.; Tang, Z.; Zhou, X.; Li, M.; Metaxas, D.N. Visual prompt tuning for test-time domain adaptation. arXiv 2022, arXiv:2210.04831. [Google Scholar]
- Herzig, R.; Abramovich, O.; Ben Avraham, E.; Arbelle, A.; Karlinsky, L.; Shamir, A.; Darrell, T.; Globerson, A. Promptonomyvit: Multi-task prompt learning improves video transformers using synthetic scene data. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 6803–6815. [Google Scholar]
- Zhang, J.-W.; Sun, Y.; Yang, Y.; Chen, W. Feature-proxy transformer for few-shot segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 6575–6588. [Google Scholar]
- Wang, S.; Chang, J.; Wang, Z.; Li, H.; Ouyang, W.; Tian, Q. Fine-grained retrieval prompt tuning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 2644–2652. [Google Scholar]
- Gan, Y.; Bai, Y.; Lou, Y.; Ma, X.; Zhang, R.; Shi, N.; Luo, L. Decorate the newcomers: Visual domain prompt for continual test time adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 7595–7603. [Google Scholar]
- Nie, X.; Ni, B.; Chang, J.; Meng, G.; Huo, C.; Xiang, S.; Tian, Q. Pro-tuning: Unified prompt tuning for vision tasks. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 4653–4667. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, T.; Yu, M.; Sun, J.; Ye, W.; Wang, C.; Zhang, S. Stacking networks dynamically for image restoration based on the plug-and-play framework. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIII 16. Springer: Cham, Switzerland, 2020; pp. 446–462. [Google Scholar]
- Ermis, B.; Zappella, G.; Wistuba, M.; Rawal, A.; Archambeau, C. Continual learning with transformers for image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3774–3781. [Google Scholar]
- Pan, J.; Lin, Z.; Zhu, X.; Shao, J.; Li, H. St-adapter: Parameter-efficient image-to-video transfer learning. Adv. Neural Inf. Process. Syst. 2022, 35, 26462–26477. [Google Scholar]
- Chen, Z.; Duan, Y.; Wang, W.; He, J.; Lu, T.; Dai, J.; Qiao, Y. Vision transformer adapter for dense predictions. arXiv 2022, arXiv:2205.08534. [Google Scholar]
- Chen, S.; Ge, C.; Tong, Z.; Wang, J.; Song, Y.; Wang, J.; Luo, P. Adaptformer: Adapting vision transformers for scalable visual recognition. Adv. Neural Inf. Process. Syst. 2022, 35, 16664–16678. [Google Scholar]
- Zhang, J.O.; Sax, A.; Zamir, A.; Guibas, L.; Malik, J. Side-tuning: A baseline for network adaptation via additive side networks. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: Cham, Switzerland, 2020; pp. 698–714. [Google Scholar]
- Sung, Y.-L.; Cho, J.; Bansal, M. Lst: Ladder side-tuning for parameter and memory efficient transfer learning. Adv. Neural Inf. Process. Syst. 2022, 35, 12991–13005. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer vision–ECCV 2014: 13th European conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part v 13. Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Li, B.; Tang, S.; Li, W. LMFormer: Lightweight and multi-feature perspective via transformer for human pose estimation. Neurocomputing 2024, 594, 127884. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Name | Configuration |
|---|---|---|
| Software | OS | Ubuntu20.04 |
| Python | 3.10 | |
| CUDA | 12.1 | |
| Pytorch | 2.3.1 | |
| Hardware | CPU | Intel(R) Xeon(R) Gold 6430 (Intel, Santa Clara, CA, USA) |
| GPU | Nvidia A800 (NVIDIA, Santa Clara, CA, USA) | |
| Parameters | Image size | 256 × 192 |
| Epochs | 100 | |
| Batch size | 64 | |
| Optimizer | AdamW | |
| Learning rate | 0.0005 | |
| Weight decay | 0.0001 | |
| Pre-trained model parameters | ≈632 M |
| Dataset | |||||
|---|---|---|---|---|---|
| COCO Dataset | 77.1 | 78.5 | 78.1 | 79.3 | 79.0 |
| Self-built Dataset | 66.5 | 68.2 | 67.9 | 69.1 | 68.6 |
| Method | AP/% | AP50/% | AP75/% | AR |
|---|---|---|---|---|
| CPM | 62.2 | 85.9 | 70.5 | 68.3 |
| HRNet | 75.0 | 90.1 | 82.3 | 80.4 |
| LiteHRNet | 67.0 | 87.6 | 75.0 | 72.7 |
| MobileNetV2 | 63.7 | 86.3 | 70.7 | 70.0 |
| MSPN | 76.1 | 90.0 | 82.8 | 82.0 |
| PVTV2 | 72.9 | 89.8 | 80.6 | 78.3 |
| SCNet | 72.5 | 89.6 | 80.2 | 77.9 |
| Hrformer | 73.8 | 90.4 | 81.2 | 79.3 |
| TokenPose | 75.8 | 90.3 | 82.5 | 80.9 |
| TransPose | 74.2 | 89.6 | 80.8 | 79.5 |
| LMFormer [49] | 68.9 | 88.3 | 76.4 | 74.7 |
| OUR | 79.3 | 92.0 | 85.7 | 84.2 |
| Method | AP/% | AP50/% | AP75/% | AR |
|---|---|---|---|---|
| CPM | 52.0 | 73.2 | 60.3 | 57.2 |
| HRNet | 64.9 | 79.4 | 70.8 | 67.0 |
| LiteHRNet | 54.6 | 74.9 | 65.7 | 64.9 |
| MobileNetV2 | 54.3 | 75.1 | 65.3 | 64.8 |
| MSPN | 65.2 | 79.9 | 71.5 | 68.0 |
| PVTV2 | 65.5 | 80.3 | 72.0 | 68.7 |
| SCNet | 60.4 | 78.4 | 66.5 | 65.4 |
| OUR | 69.1 | 81.8 | 73.3 | 71.8 |
| Multi-Frequency Feature | Multi-Scale Spatial Feature | Adaptive Symmetric Feature Fusion | Multi-Graph Feature Aggregation | AP/% | AP50/% | AP75/% | AR |
|---|---|---|---|---|---|---|---|
| 78.0 | 90.2 | 84.2 | 83.3 | ||||
| √ | 78.4 | 90.8 | 84.7 | 83.5 | |||
| √ | √ | 78.4 | 91.0 | 84.7 | 83.6 | ||
| √ | √ | √ | 78.4 | 91.1 | 84.8 | 83.6 | |
| √ | 78.6 | 91.3 | 85.0 | 83.6 | |||
| √ | √ | 78.7 | 91.5 | 85.1 | 83.8 | ||
| √ | √ | √ | 78.9 | 91.5 | 85.3 | 83.9 | |
| √ | √ | 78.8 | 91.3 | 85.3 | 83.9 | ||
| √ | √ | √ | 79.1 | 91.7 | 85.6 | 84.0 | |
| √ | √ | √ | √ | 79.3 | 92.0 | 85.7 | 84.2 |
| Multi-Frequency Feature | Multi-Scale Spatial Feature | Adaptive Symmetric Feature Fusion | Multi-Graph Feature Aggregation | AP/% | AP50/% | AP75/% | AR |
|---|---|---|---|---|---|---|---|
| 66.7 | 77.9 | 70.8 | 68.7 | ||||
| √ | 68.2 | 79.9 | 72.0 | 69.9 | |||
| √ | √ | 68.5 | 80.7 | 72.6 | 70.4 | ||
| √ | √ | √ | 68.6 | 80.9 | 72.8 | 70.8 | |
| √ | 66.9 | 78.2 | 71.4 | 68.7 | |||
| √ | √ | 67.2 | 78.6 | 71.7 | 69.2 | ||
| √ | √ | √ | 67.2 | 78.7 | 71.8 | 69.4 | |
| √ | √ | 68.4 | 80.3 | 72.3 | 70.3 | ||
| √ | √ | √ | 69.0 | 81.2 | 72.9 | 71.0 | |
| √ | √ | √ | √ | 69.1 | 81.8 | 73.3 | 71.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Y.; Liu, Z.; Jiang, B.; Dai, T.; Lian, Y. A Fine-Tuning Method via Adaptive Symmetric Fusion and Multi-Graph Aggregation for Human Pose Estimation. Symmetry 2025, 17, 1098. https://doi.org/10.3390/sym17071098
Shi Y, Liu Z, Jiang B, Dai T, Lian Y. A Fine-Tuning Method via Adaptive Symmetric Fusion and Multi-Graph Aggregation for Human Pose Estimation. Symmetry. 2025; 17(7):1098. https://doi.org/10.3390/sym17071098
Chicago/Turabian StyleShi, Yinliang, Zhaonian Liu, Bin Jiang, Tianqi Dai, and Yuanfeng Lian. 2025. "A Fine-Tuning Method via Adaptive Symmetric Fusion and Multi-Graph Aggregation for Human Pose Estimation" Symmetry 17, no. 7: 1098. https://doi.org/10.3390/sym17071098
APA StyleShi, Y., Liu, Z., Jiang, B., Dai, T., & Lian, Y. (2025). A Fine-Tuning Method via Adaptive Symmetric Fusion and Multi-Graph Aggregation for Human Pose Estimation. Symmetry, 17(7), 1098. https://doi.org/10.3390/sym17071098