
Symmetric Dual-Phase Framework for APT Attack Detection Based on Multi-Feature-Conditioned GAN and Graph Convolutional Network

 ,
,
Abstract
1. Introduction
1.1. Advanced Persistent Threat
1.2. Problem Statement
- Class imbalance in datasets: Research indicates that class imbalance occurs when the prevalence of one class significantly exceeds that of another within a dataset. A critical pain point in detecting APT attacks lies in the overwhelming complexity of network traffic data, where attack-class traffic typically constitutes less than one-hundredth (or even lower proportions) of benign traffic volumes. This asymmetry severely skews classifiers towards majority classes, consequently diminishing the detection model’s sensitivity to APT attacks and impairing its capacity to identify latent attack threats. Deep learning models designed to uncover underlying APT attack patterns require both sufficient sample quantities and rationally distributed class structures to effectively learn discriminative features and generate accurate classifications. Consequently, substantial disparities in class distributions not only degrade the model’s detection performance metrics (e.g., precision–recall trade-offs) but also undermine its generalization capability when confronted with novel or mutated APT attack variants [7,8].
- Limitations of non-intelligent feature extraction: APT attacks exhibit three intrinsic characteristics: high stealthiness, behavioral complexity, and prominent cross-spatiotemporal patterns. Their anomalous patterns manifest not only through multi-scale temporal distribution but also across multilayer network hierarchies, demonstrating highly dynamic inter-feature correlations. This has rendered the feature extraction process for APT detection more complex. Traditional detection methods primarily rely on static features, such as rule-based or signature-based identification techniques, which determine malicious behavior by matching known attack patterns. However, these methods exhibit limitations when dealing with APT attacks, particularly due to the highly dynamic nature of APT. Different stages of an APT attack may employ varying strategies and techniques, making it difficult for fixed static features to comprehensively cover the entire attack chain, thereby reducing detection effectiveness. Consequently, more intelligent and efficient feature extraction methods are required [9].
- Graph representation learning: Malicious behaviors in APT attacks typically involve intricate interactions among multiple IP addresses and ports. Compared with conventional methods that merely analyze isolated data points, graph-structured detection approaches for APT attacks have demonstrated superior efficacy in capturing multi-hop attack dependencies. Nevertheless, constructing logically coherent and computationally efficient graph structures persists as a critical challenge in contemporary research. As a universal representation formalism, graphs provide systematic, high-level abstractions that capture complex relational patterns across network entities. This contrasts sharply with flat data structures, in which semantic fragmentation limits anomaly detection capabilities. The inherent topological properties of graphs (e.g., node centrality, community structures) enable richer semantic representations specifically tailored for APT detection scenarios. Therefore, the application of graph representation learning methods for network attack detection still necessitates certain innovations [10].
1.3. Solutions
1.3.1. Proposed Methodology
- Phase 1: Perform feature cleansing and standardization on network traffic dataset features using feature engineering, followed by applying information gain techniques.
- Phase 2: Propose a data generation model MF-CGAN. We enhance the conditional generative adversarial networks (CGANs) framework by incorporating conditional features that guide data generation, developing a multi-feature-conditioned generative adversarial network to generate minority-class samples for class imbalance mitigation.
- Phase 1: Leverage convolutional neural networks (CNNs)-based feature extraction with a multi-scale convolution strategy, deploying varying kernel sizes to holistically capture hierarchical data features. Subsequently, integrate a channel attention mechanism to prioritize pivotal feature representations, thereby significantly enhancing the model’s discriminative capacity for critical characteristics.
- Phase 2: Construct graph structures by establishing edge connections to organize homogeneous nodes into local graphs, thereby achieving graph-based representation of data structures. The preliminary features extracted via CNN are transferred as augmented inputs to a graph convolutional network (GCN), enabling graph-structured feature fusion. The GCN leverages graph convolution operations to aggregate adjacent node features at the topological level, which facilitates high-throughput information propagation and deep reinforcement of node embeddings.
1.3.2. Scientific Basis of Solutions
1.3.3. Contributions of This Paper
- To address class imbalance in network traffic datasets, this study proposes the MF-CGAN model, a novel symmetric two-stage data reconstruction model combining feature engineering and CGAN. The model optimizes both preprocessing and data balancing by first refining raw network traffic data into discriminative representations and subsequently generating synthetic minority-class samples. This dual-stage approach demonstrates significant improvements in preprocessing efficiency and class distribution equilibrium, providing a robust foundation for downstream analysis and model training.
- To address challenges in graph representation learning, this study proposes the MC-GCN model, a novel framework for APT attack detection. The MC-GCN innovatively integrates two core components to construct a flexible and efficient detection architecture. By enhancing the accuracy of APT attack identification, the model simultaneously achieves a significant reduction in false positive rates. Experimental validation across diverse scenarios demonstrates that the proposed method outperforms state-of-the-art detection approaches in performance metrics, offering a more advanced solution for APT attack detection.
- To address limitations in non-intelligent feature extraction, this study proposes an intelligent network traffic analysis framework that integrates spatial multi-scale perception and dynamic channel optimization. Specifically, the framework combines multi-scale convolution with channel attention mechanisms to enhance traffic processing and feature extraction. Unlike traditional paradigms that directly input statistical features, the method constructs a spatiotemporal mapping mechanism for traffic data: raw traffic sequences are transformed into image-like 2D tensors via IP session clustering and a sliding time window (50 × 50 frame structure). This representation effectively inherits the spatial representation advantages of CNN in image recognition.
- This study proposes a new method for network traffic classification by constructing a highly effective GCN model. Experimental results demonstrate that the proposed approach achieves significant improvements in both overall detection rate and classification performance under class imbalance, providing a robust solution for complex traffic analysis scenarios.
2. Related Work
2.1. Data Imbalance and Oversampling-Based Methodologies
2.2. Feature-Based Methodologies
2.2.1. Deep Feature Extraction and Sequence Modeling
2.2.2. Attention Mechanism-Based Methodologies
2.3. Graph Neural Network (GNN)-Based Methodologies
3. Materials and Methods
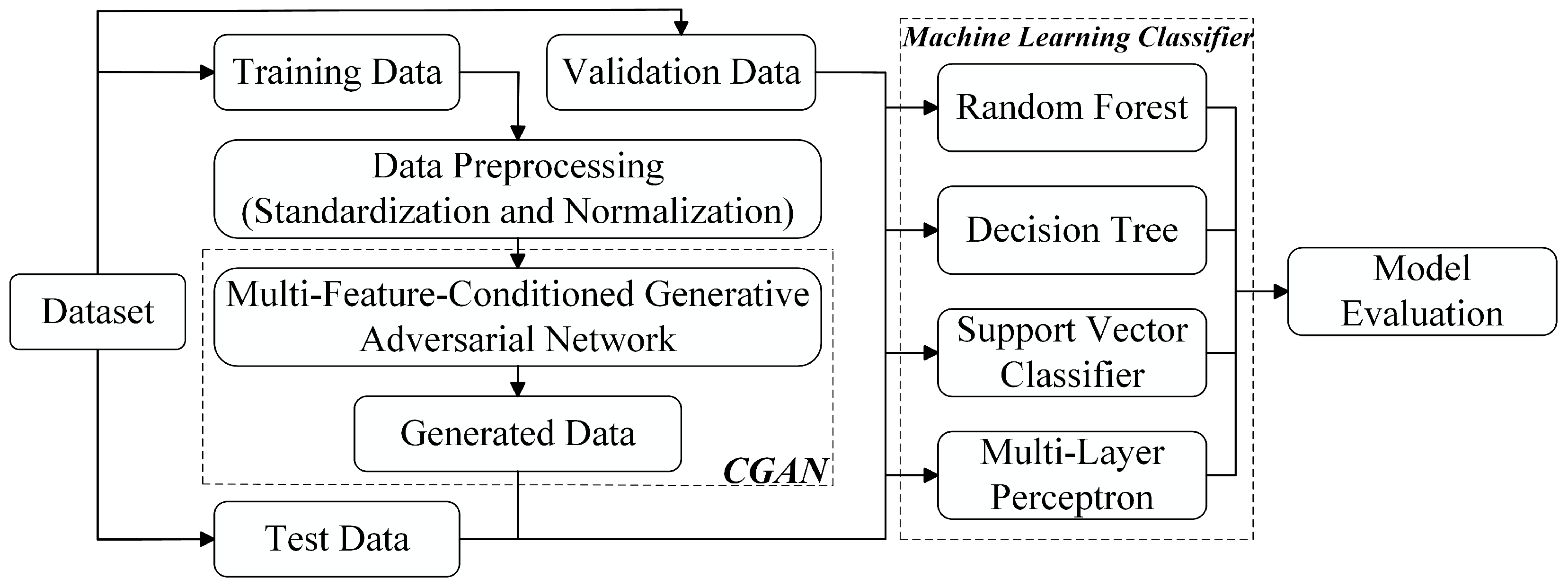
3.1. Data Reconstruction
3.1.1. Dataset
3.1.2. Feature Engineering
- Stratified random sampling: Given the substantial volume of the CIC-IDS2017 dataset (comprising millions of records), processing the complete dataset would demand prohibitively high computational resources. To address this challenge, stratified random sampling was implemented in our experiments, with a sampling ratio of frac = 0.2 applied to each file. This strategy ensures a balanced distribution of data across distinct classes while maintaining statistical representativeness. Stratified sampling helps to avoid bias by preserving the original class proportions, allowing the model to learn from both majority and minority classes, thus mitigating overfitting and improving generalization.
- Data processing: The merged dataset underwent comprehensive preprocessing through three core operations. First, all NaN/missing values, infinite values, constant features, and duplicate entries were systematically removed to ensure data cleanliness. Second, multimodal standardization was executed to resolve feature-scale discrepancies: each feature was normalized to a zero-mean and unit variance distribution; nominal data were converted into ordinal integers; individual samples were scaled to unit norms; median values were eliminated from feature columns; and interquartile range (IQR) scaling between the 1st and 3rd quartiles was applied. Finally, a binary encoding scheme assigned labels 0 and 1 to benign and anomalous traffic instances, respectively, establishing a foundation for supervised learning tasks.
- Feature selection: Three correlation coefficients—Pearson’s linear correlation, Kendall’s tau, and Spearman’s rank correlation [38]—were employed to quantify inter-feature dependencies. Features exhibiting correlation coefficients exceeding the 0.95 threshold were systematically eliminated to mitigate multicollinearity-induced information redundancy. Furthermore, feature columns demonstrating constant values in ≥ samples and those with zero variance (i.e., constant features where all samples share identical values) were rigorously excluded. Through this iterative feature screening and dimensionality reduction pipeline, a refined 50-dimensional feature subspace was ultimately derived for experimental modeling, optimally balancing discriminative power and computational efficiency.
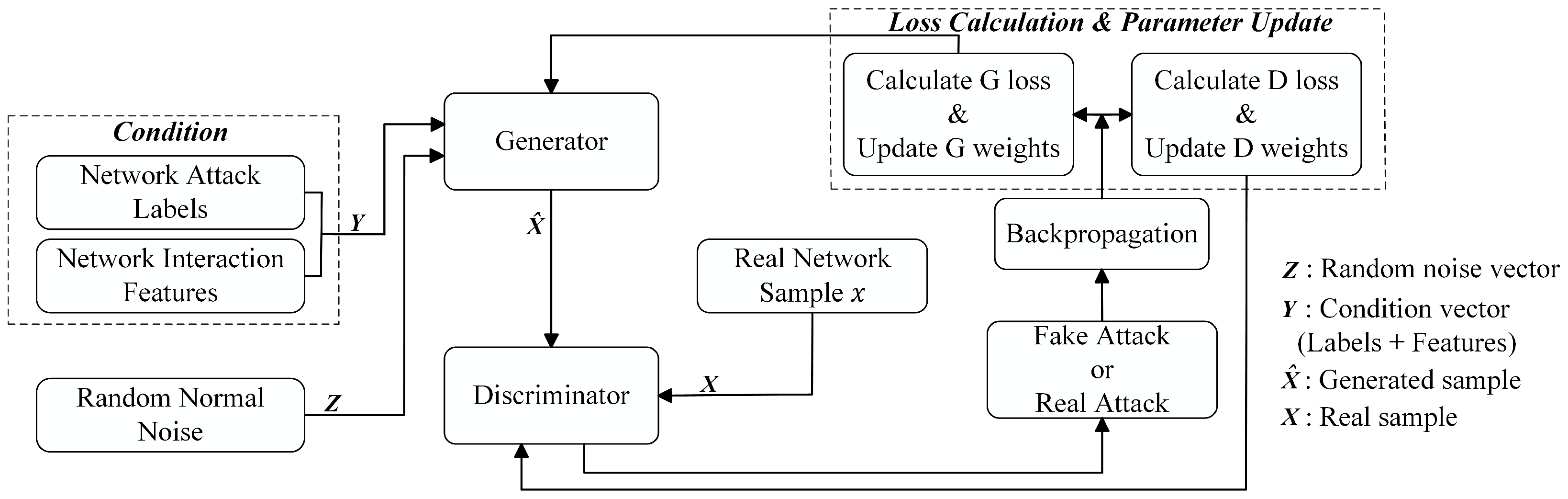
3.1.3. Conditional Generative Adversarial Network
- Learning rate decay: gradually decreasing the learning rate helps avoid overshooting during optimization, facilitating smoother convergence.
- Batch normalization: applied to stabilize the training process and prevent mode collapse, ensuring that both the generator and discriminator improve over time.
3.1.4. Data Reconstruction via MF-CGAN
3.2. APT Attack Detection via Feature Enhancement and Graph Neural Networks
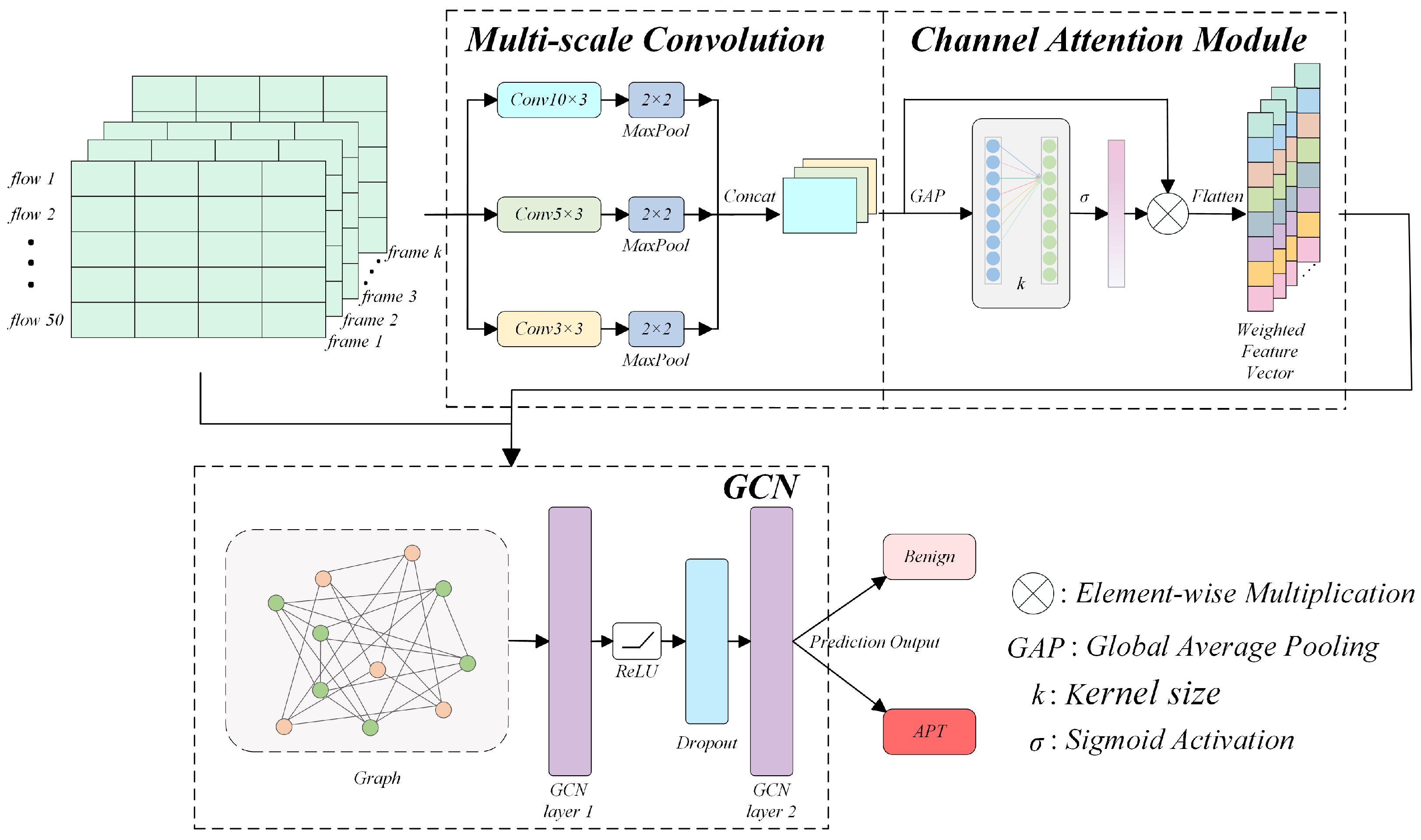
3.2.1. Model Architecture
- Phase 1: Frame construction from network traffic data: The balanced network traffic dataset processed during the data reconstruction phase is grouped by IP addresses and aggregated into frames of size m × n (m = 50; n = 50), where m denotes the number of flow entries per frame and n represents the feature count per flow entry.
- Phase 2: Multi-scale feature extraction with channel attention: The constructed frames are fed into multi-scale convolutional layers equipped with convolutional kernels of varying sizes. Through multi-level convolutional operations, multi-grained network traffic features are extracted to generate feature maps. A channel attention mechanism is then introduced to dynamically weight feature channels, producing refined feature vectors that highlight salient characteristics per frame.
3.2.2. Multi-Scale Convolution
3.2.3. Channel Attention Mechanism
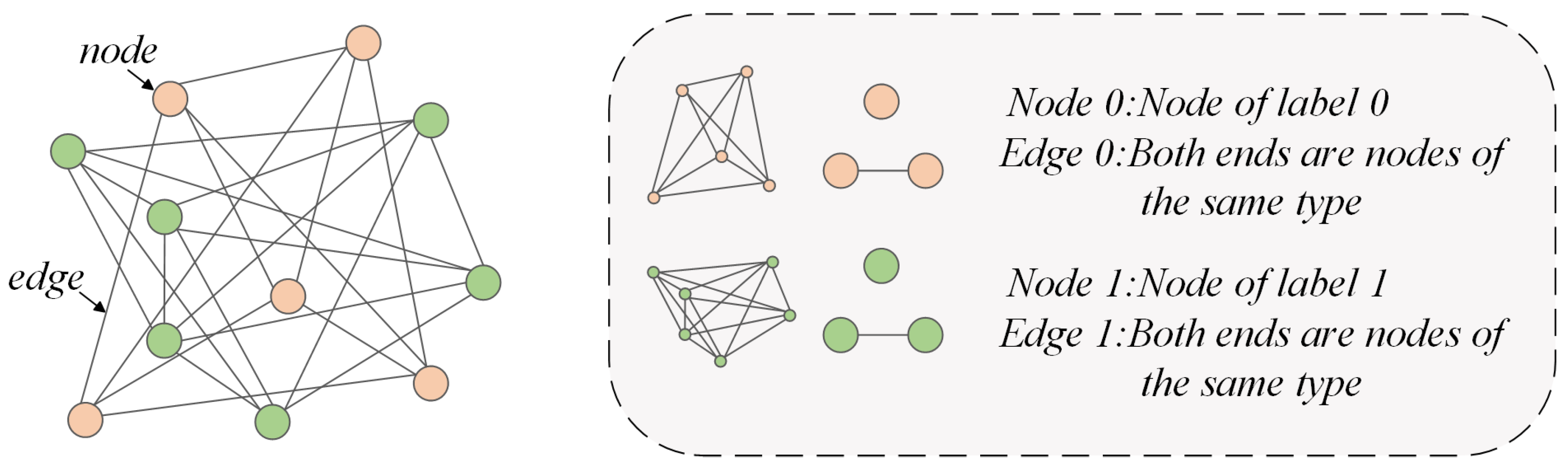
3.2.4. Graph Convolutional Network
3.3. Time and Space Complexity
3.3.1. MF-CGAN (Multi-Feature-Conditioned Generative Adversarial Network)
3.3.2. MC-GCN (Multi-Scale Graph Convolutional Network)
4. Experimental Analysis and Results
4.1. Experimental Setup and Model Training
4.1.1. Hyperparameter Definitions
4.1.2. Sensitivity Analysis of Hyperparameters
- Learning rate: We tested learning rates from to . The model performed optimally at a learning rate of 0.005, with lower rates leading to slower convergence and higher rates causing instability in training.
- Batch size: Batch sizes of 32, 64, and 128 were evaluated. A batch size of 32 provided the best trade-off between training time and model accuracy, while larger batch sizes (64 and 128) did not lead to significant improvements in performance.
- Number of layers: We experimented with the number of layers in the model, from 3 to 6 layers. The performance did not improve beyond four layers, suggesting that the model achieves stable performance with this configuration.
4.2. Experimental Evaluation
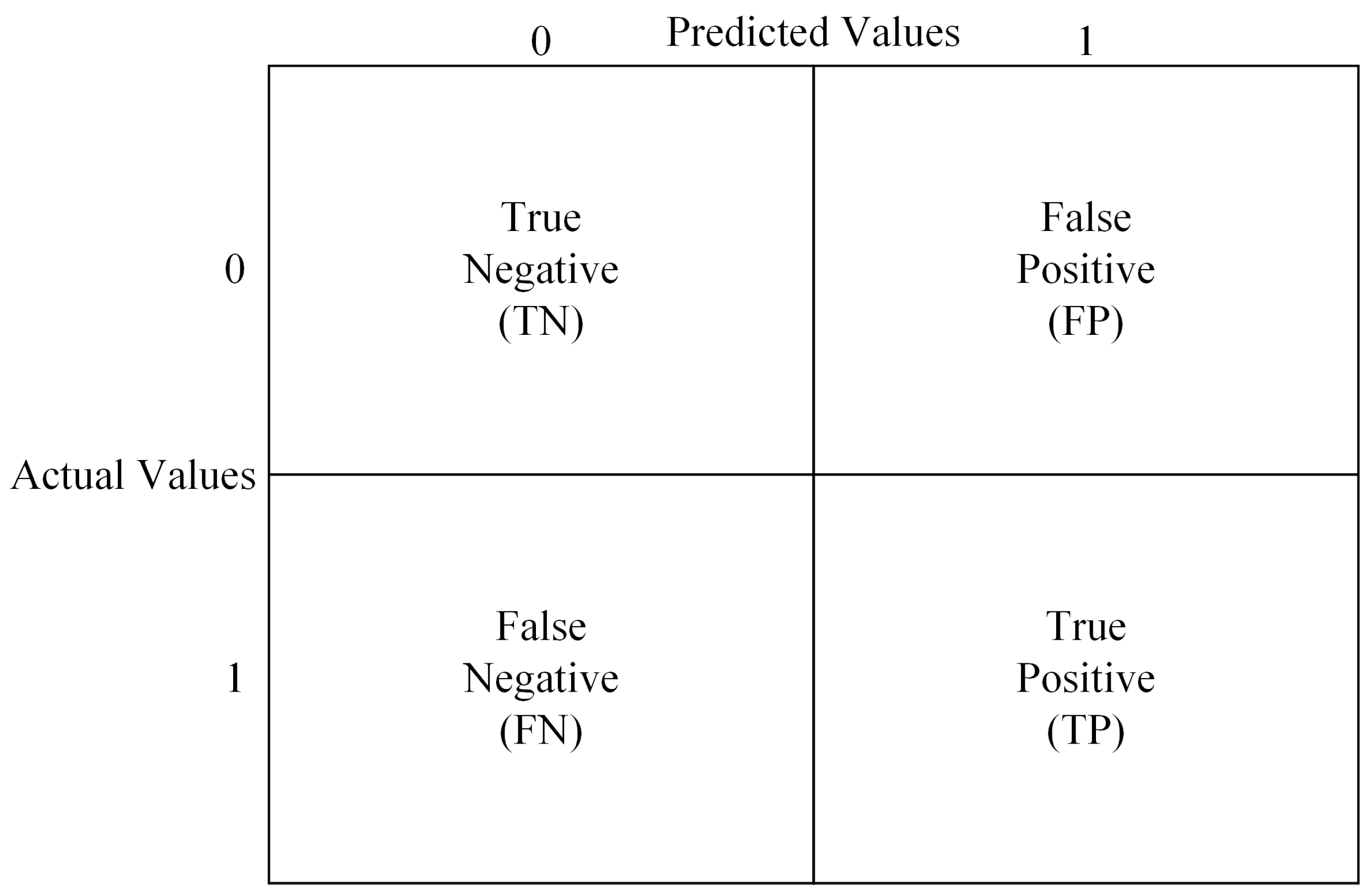
4.2.1. Confusion Matrix
4.2.2. Evaluation Metrics
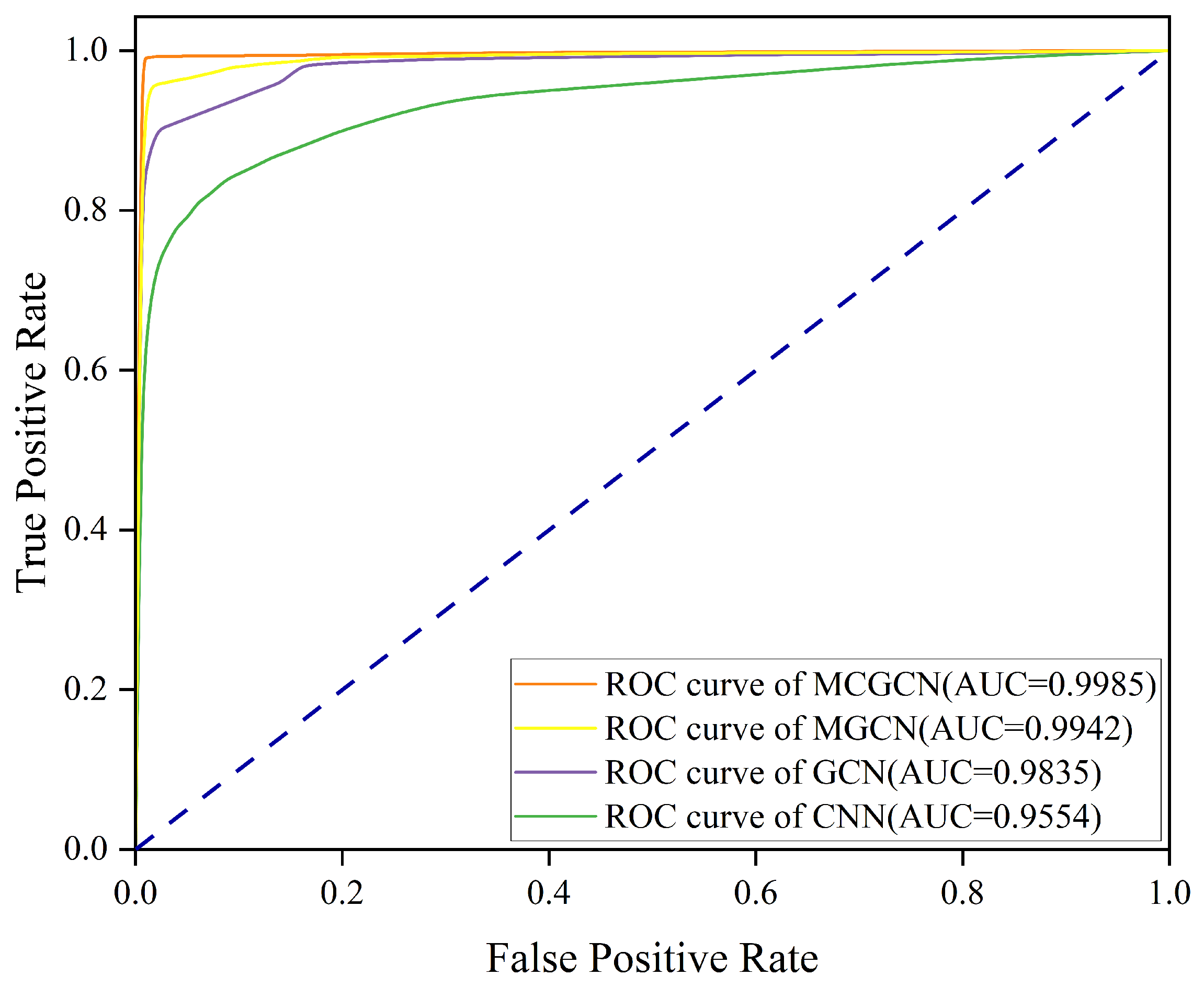
4.2.3. AUC-ROC Analysis
4.3. Experimental Results Analysis
4.3.1. Experimental Results of Data Reconstruction
4.3.2. Experimental Results of MC-GCN Model
4.4. Ablation Studies
4.4.1. Ablation Study of MF-CGAN
4.4.2. Ablation Study of MC-GCN Model
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alshamrani, A.; Myneni, S.; Chowdhary, A.; Huang, D. A survey on advanced persistent threats: Techniques, solutions, challenges, and research opportunities. IEEE Commun. Surv. Tutor. 2019, 21, 1851–1877. [Google Scholar] [CrossRef]
- Talib, M.A.; Nasir, Q.; Nassif, A.B.; Mokhamed, T.; Ahmed, N.; Mahfood, B. APT beaconing detection: A systematic review. Comput. Secur. 2022, 122, 102875. [Google Scholar] [CrossRef]
- Cole, E. Advanced Persistent Threat: Understanding the Danger and How to Protect Your Organization; Newnes: Oxford, UK, 2012. [Google Scholar]
- Sharma, A.; Gupta, B.B.; Singh, A.K.; Saraswat, V.K. Advanced persistent threats (apt): Evolution, anatomy, attribution and countermeasures. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 9355–9381. [Google Scholar] [CrossRef]
- Malik, V.; Khanna, A.; Sharma, N. Advanced Persistent Threats (APTs): Detection Techniques and Mitigation Strategies. Int. J. Glob. Innov. Solut. (IJGIS) 2024. [Google Scholar] [CrossRef]
- Van Duong, L.; Nikolaevich, T.V.; Do, H.; Long, N.Q.D.; Hoang, N.Q. Detecting APT attacks based on network flow. Int. J. Emerg. Trends Eng. Res. 2020, 8, 3134–3139. [Google Scholar] [CrossRef]
- Sauber-Cole, R.; Khoshgoftaar, T.M. The use of generative adversarial networks to alleviate class imbalance in tabular data: A survey. J. Big Data 2022, 9, 98. [Google Scholar] [CrossRef]
- Akbar, K.A.; Wang, Y.; Islam, M.S.; Singhal, A.; Khan, L.; Thuraisingham, B. Identifying tactics of advanced persistent threats with limited attack traces. In Proceedings of the Information Systems Security: 17th International Conference, ICISS 2021, Patna, India, 16–20 December 2021; Proceedings 17. Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 3–25. [Google Scholar] [CrossRef]
- Xuan, C.D.; Cuong, N.H. A novel approach for APT attack detection based on feature intelligent extraction and representation learning. PLoS ONE 2024, 19, e0305618. [Google Scholar] [CrossRef]
- Bilot, T.; El Madhoun, N.; Al Agha, K.; Zouaoui, A. Graph neural networks for intrusion detection: A survey. IEEE Access 2023, 11, 49114–49139. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 139–144. [Google Scholar] [CrossRef]
- Lee, J.H.; Park, K.H. GAN-based imbalanced data intrusion detection system. Pers. Ubiquitous Comput. 2021, 25, 121–128. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy-ICISSP, Funchal, Portugal, 22–24 January 2018; Volume 1, pp. 108–116. [Google Scholar] [CrossRef]
- Lin, Z.; Shi, Y.; Xue, Z. Idsgan: Generative adversarial networks for attack generation against intrusion detection. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Chengdu, China, 16–19 May 2022; Springer International Publishing: Cham, Switzerland, 2022; pp. 79–91. [Google Scholar] [CrossRef]
- Zheng, M.; Li, T.; Zhu, R.; Tang, Y.; Tang, M.; Lin, L.; Ma, Z. Conditional Wasserstein generative adversarial network-gradient penalty-based approach to alleviating imbalanced data classification. Inf. Sci. 2020, 512, 1009–1023. [Google Scholar] [CrossRef]
- Mirza, M. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar] [CrossRef]
- Dlamini, G.; Fahim, M. DGM: A data generative model to improve minority class presence in anomaly detection domain. Neural Comput. Appl. 2021, 33, 13635–13646. [Google Scholar] [CrossRef]
- Lee, J.H.; Park, K.H. AE-CGAN model based high performance network intrusion detection system. Appl. Sci. 2019, 9, 4221. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, X.; Wang, D.; Sui, Q.; Yang, C.; Li, H.; Li, Y.; Luan, T. A CE-GAN based approach to address data imbalance in network intrusion detection systems. Sci. Rep. 2025, 15, 7916. [Google Scholar] [CrossRef] [PubMed]
- Douzas, G.; Bacao, F. Effective data generation for imbalanced learning using conditional generative adversarial networks. Expert Syst. Appl. 2018, 91, 464–471. [Google Scholar] [CrossRef]
- Yeo, M.; Koo, Y.; Yoon, Y.; Hwang, T.; Ryu, J.; Song, J.; Park, C. Flow-based malware detection using convolutional neural network. In Proceedings of the 2018 International Conference on Information Networking (ICOIN), Chiang Mai, Thailand, 10–12 January 2018; pp. 910–913. [Google Scholar] [CrossRef]
- Sun, P.; Liu, P.; Li, Q.; Liu, C.; Lu, X.; Hao, R.; Chen, J. DL-IDS: Extracting Features Using CNN-LSTM Hybrid Network for Intrusion Detection System. Secur. Commun. Netw. 2020, 2020, 8890306. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Soman, K.P.; Poornachandran, P. Applying convolutional neural network for network intrusion detection. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; pp. 1222–1228. [Google Scholar] [CrossRef]
- Hassan, M.M.; Gumaei, A.; Alsanad, A.; Alrubaian, M.; Fortino, G. A hybrid deep learning model for efficient intrusion detection in big data environment. Inf. Sci. 2020, 513, 386–396. [Google Scholar] [CrossRef]
- Gautam, S.; Henry, A.; Zuhair, M.; Rashid, M.; Javed, A.R.; Maddikunta, P.K.R. A composite approach of intrusion detection systems: Hybrid RNN and correlation-based feature optimization. Electronics 2022, 11, 3529. [Google Scholar] [CrossRef]
- Zhang, K.; Zheng, R.; Li, C.; Zhang, S.; Wu, X.; Sun, S.; Yang, J.; Zheng, J. SE-DWNet: An Advanced ResNet-Based Model for Intrusion Detection with Symmetric Data Distribution. Symmetry 2025, 17, 526. [Google Scholar] [CrossRef]
- Manocchio, L.D.; Layeghy, S.; Lo, W.W.; Kulatilleke, G.K.; Sarhan, M.; Portmann, M. Flowtransformer: A transformer framework for flow-based network intrusion detection systems. Expert Syst. Appl. 2024, 241, 122564. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, L. Intrusion detection model based on improved transformer. Appl. Sci. 2023, 13, 6251. [Google Scholar] [CrossRef]
- Ibrahim, N.; Shehmir, S.; Yadav, A.; Kashef, R. A Transformer-Based Model for Network Intrusion Detection: Architecture, Classification Heads, and Transformer Blocks. In Proceedings of the International IOT, Electronics and Mechatronics Conference; Springer Nature: Singapore, 2024; pp. 149–163. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar] [CrossRef]
- Do Xuan, C.; Dao, M.H.; Nguyen, H.D. APT attack detection based on flow network analysis techniques using deep learning. J. Intell. Fuzzy Syst. 2020, 39, 4785–4801. [Google Scholar] [CrossRef]
- Zhou, J.; Xu, Z.; Rush, A.M.; Yu, M. Automating botnet detection with graph neural networks. arXiv 2020, arXiv:2003.06344. [Google Scholar] [CrossRef]
- Wang, H.; Wan, L.; Yang, X. Defending Graph Neural Networks Against Backdoor Attacks via Symmetry-Aware Graph Self-Distillation. Symmetry 2025, 17, 735. [Google Scholar] [CrossRef]
- Ding, Q.; Li, J. AnoGLA: An efficient scheme to improve network anomaly detection. J. Inf. Secur. Appl. 2022, 66, 103149. [Google Scholar] [CrossRef]
- Ren, W.; Song, X.; Hong, Y.; Lei, Y.; Yao, J.; Du, Y.; Li, W. APT Attack Detection Based on Graph Convolutional Neural Networks. Int. J. Comput. Intell. Syst. 2023, 16, 184. [Google Scholar] [CrossRef]
- Xuan, C.D.; Nguyen, T.T. A novel approach for APT attack detection based on an advanced computing. Sci. Rep. 2024, 14, 22223. [Google Scholar] [CrossRef]
- Nguyen, H.C.; Xuan, C.D.; Nguyen, L.T.; Nguyen, H.D. A new framework for APT attack detection based on network traffic. J. Intell. Fuzzy Syst. 2023, 44, 3459–3474. [Google Scholar] [CrossRef]
- Lewis-Beck, M.S.; Bryman, A.; Liao, T.F. Encyclopedia of Social Science Research Methods; Sage Publishing: New York, NY, USA, 2004; pp. 1143–1144. [Google Scholar] [CrossRef]
- Riyaz, B.; Ganapathy, S. A deep learning approach for effective intrusion detection in wireless networks using CNN. Soft Comput. 2020, 24, 17265–17278. [Google Scholar] [CrossRef]
- Bakhshi, T.; Ghita, B. Anomaly detection in encrypted internet traffic using hybrid deep learning. Secur. Commun. Netw. 2021, 2021, 5363750. [Google Scholar] [CrossRef]
- Halbouni, A.; Gunawan, T.S.; Habaebi, M.H.; Halbouni, M.; Kartiwi, M.; Ahmad, R. CNN-LSTM: Hybrid deep neural network for network intrusion detection system. IEEE Access 2022, 10, 99837–99849. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Method | Dataset(s) | Imbalance Handling | Limitation |
|---|---|---|---|---|---|
| Lee et al. [12] | 2021 | GAN-based (CGAN) | NSL-KDD, CIC-IDS2017 | GAN-based data augmentation | Data redundancy, model instability |
| Yang et al. [19] | 2025 | GAN-based (CE-GAN) | CIC-IDS2017, UNSW-NB15 | GAN-based data augmentation | High complexity, training cost |
| Gautam et al. [25] | 2022 | Feature-based (Hybrid RNN + Correlation) | NSL-KDD, UNSW-NB15, CIC-IDS2017 | Hybrid feature optimization | High computational demand |
| Zhang et al. [26] | 2025 | Attention-based (SE-DWNet) | CSE-CIC-IDS2018, ToN-IoT | Symmetric data distribution | Slow inference, complexity |
| Manocchio et al. [27] | 2024 | Attention-based (FlowTransformer) | CIC-IDS2017, IoT datasets | Global average pooling (GAP) | Poor performance in NIDS, suboptimal in data imbalance |
| Xuan et al. [36] | 2024 | GNN-based (Graph-based APT Detection) | UNSW-NB15, CSE-CIC-IDS2018 | Graph-based sampling and GCN | Limited dataset adaptability |
| Ren et al. [35] | 2023 | GNN-based (GCN for APT Detection) | ToN-IoT, NSL-KDD | Graph-based data augmentation | Slow training time, high resource consumption |
| Proposed MC-GCN | 2025 | Hybrid (MF-CGAN + GCN + Multi-scale CNN) | CIC-IDS2017 | MF-CGAN-based synthetic data generation | - |
| Day | Attack Type(s) | Attack Details | Size |
|---|---|---|---|
| Monday | Benign Traffic | – | 11 G |
| Tuesday | Brute Force Attacks | SFTP, SSH | 11 G |
| Wednesday | DoS, Heartbleed | Slowloris, Slowhttptest, Hulk, GoldenEye | 13 G |
| Thursday | Web, Infiltration | Web BForce, XSS, SQL Injection, Dropbox, Cool Disk | 7.8 G |
| Friday | DDoS, Botnet, Scan | LOIT, ARES Botnet, PortScan | 8.3 G |
| Parameter | Generator | Discriminator |
|---|---|---|
| Learning rate | 0.0005 | 0.0005 |
| Epochs | 2000 | 2000 |
| Optimizer | SGD | SGD |
| Layers | 4 | 4 |
| Input layer neurons | 33 | 35 |
| Layer 1 neurons | 128 | 512 |
| Layer 2 neurons | 256 | 256 |
| Layer 3 neurons | 512 | 128 |
| Layer 4 neurons | 34 | 1 |
| Output layer neurons | 35 | 1 |
| Batch size | 128 | 128 |
| Random noise dimension | 32 | – |
| Activation | ReLU | ReLU |
| Parameter | Value |
|---|---|
| Learning rate | 0.005 |
| Epochs | 200 |
| Optimizer | Adam |
| Loss function | Cross-entropy |
| Batch size | 32 |
| Activation | ReLU |
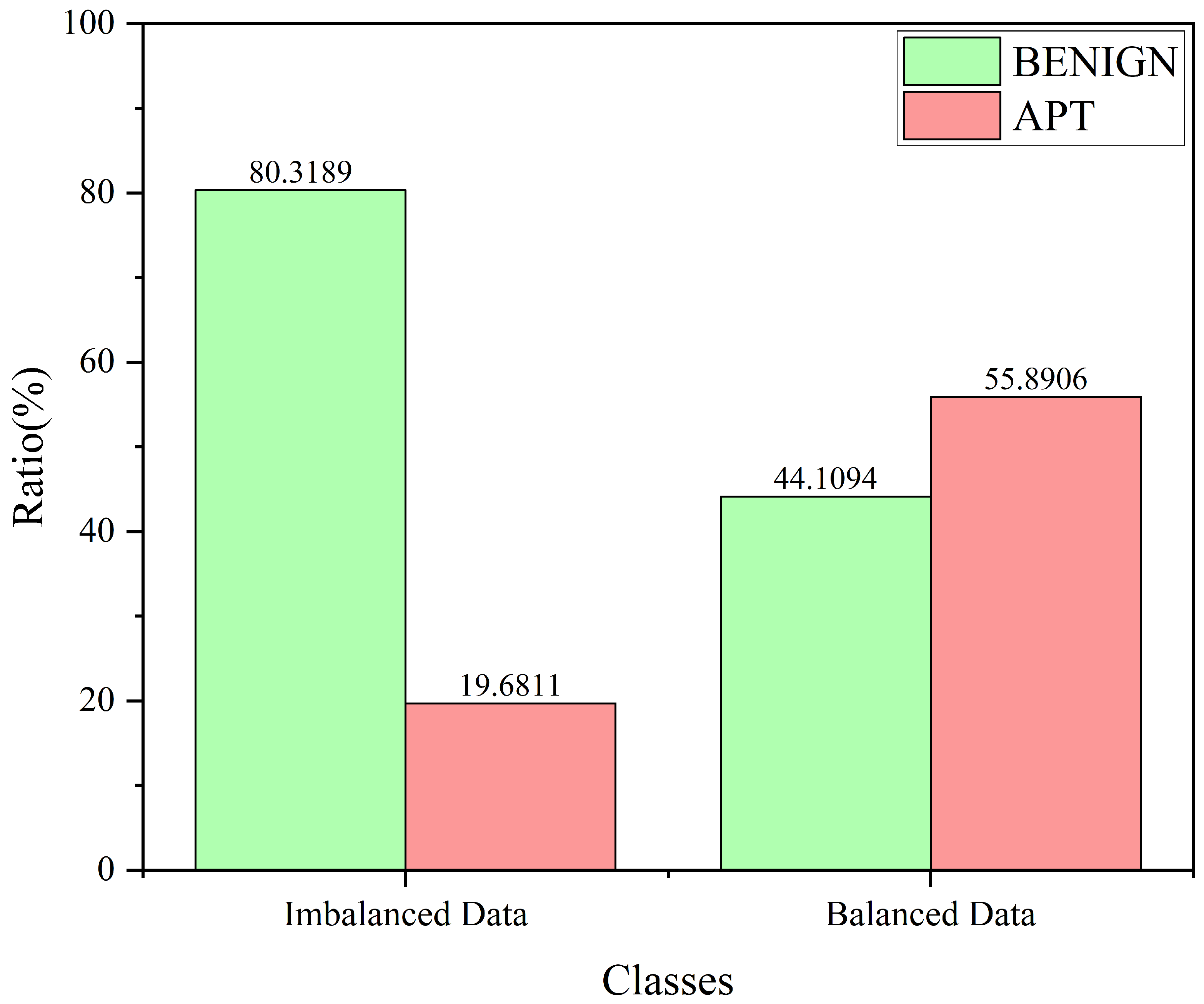
| Class | Original Count | Original Ratio (%) | Balanced Count | Balanced Ratio (%) |
|---|---|---|---|---|
| BENIGN | 2,271,311 | 80.3189 | 227,132 | 44.1094 |
| DoS_Hulk | 230,124 | 8.1377 | 67,965 | 13.1989 |
| PortScan | 158,804 | 5.6157 | 60,549 | 11.7587 |
| DDoS | 128,025 | 4.5273 | 57,688 | 11.2031 |
| DoS_GoldenEye | 10,293 | 0.3640 | 26,351 | 5.1174 |
| FTPPatator | 7935 | 0.2806 | 20,382 | 3.9582 |
| SSHPatator | 5897 | 0.2085 | 15,265 | 2.9645 |
| DoS_slowloris | 5796 | 0.2050 | 14,793 | 2.8728 |
| DoS_Slowhttptest | 5499 | 0.1945 | 14,169 | 2.7516 |
| Bot | 1956 | 0.0692 | 4982 | 0.9675 |
| Web_Attack_Brute_Force | 1507 | 0.0533 | 3826 | 0.7430 |
| Web_Attack_XSS | 652 | 0.0231 | 1659 | 0.3222 |
| Infiltration | 36 | 0.0013 | 80 | 0.0155 |
| Web_Attack_Sql_Injection | 21 | 0.0007 | 61 | 0.0118 |
| Heartbleed | 11 | 0.0004 | 27 | 0.0052 |
| Class | RF | DT | SVC | MLP | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | Prec. | Rec. | F1 | Prec. | Rec. | F1 | |
| Bot | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.97 | 0.99 | 0.98 | 1.00 | 1.00 | 1.00 |
| DDoS | 0.98 | 1.00 | 0.99 | 0.98 | 1.00 | 0.99 | 0.98 | 0.94 | 0.96 | 0.98 | 1.00 | 0.99 |
| DoS_GoldenEye | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 0.98 | 0.99 | 1.00 | 1.00 | 1.00 |
| DoS_Hulk | 1.00 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.90 | 0.98 | 0.93 | 0.96 | 0.92 | 0.94 |
| DoS_Slowhttptest | 0.99 | 1.00 | 1.00 | 0.98 | 0.99 | 0.99 | 0.93 | 0.94 | 0.93 | 0.88 | 0.97 | 0.92 |
| DoS_slowloris | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| FTPPatator | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Heartbleed | 1.00 | 0.81 | 0.90 | 0.50 | 0.73 | 0.60 | 0.07 | 0.73 | 0.13 | 0.88 | 0.64 | 0.74 |
| Infiltration | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| PortScan | 0.98 | 1.00 | 0.99 | 0.98 | 0.99 | 0.99 | 0.98 | 0.97 | 0.98 | 0.98 | 1.00 | 0.99 |
| SSHPatator | 0.73 | 0.80 | 0.76 | 0.73 | 0.73 | 0.73 | 1.00 | 0.15 | 0.25 | 0.69 | 0.95 | 0.80 |
| Web_Attack_Brute_Force | 1.00 | 0.50 | 0.67 | 0.57 | 0.67 | 0.62 | 0.04 | 0.67 | 0.08 | 0.00 | 0.00 | 0.00 |
| Web_Attack_Sql_Injection | 0.47 | 0.33 | 0.38 | 0.42 | 0.42 | 0.42 | 0.34 | 0.98 | 0.50 | 0.78 | 0.04 | 0.07 |
| Web_Attack_XSS | 0.98 | 1.00 | 0.99 | 0.99 | 0.99 | 0.99 | 0.95 | 1.00 | 0.98 | 0.99 | 1.00 | 0.99 |
| Balancing Method | RF | DT | SVC | MLP |
|---|---|---|---|---|
| SMOTEENN | 99.59 | 99.41 | 98.08 | 98.96 |
| Borderline-SMOTE | 99.70 | 99.56 | 97.50 | 99.01 |
| SVMSMOTE | 99.72 | 99.48 | 97.77 | 99.01 |
| MF-CGAN | 99.77 | 99.70 | 99.28 | 99.42 |
| Reference | Method | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Riyaz B et al. [39] | CNN | 86.46 | 77.94 | 91.06 | 93.84 |
| Bakhshi T et al. [40] | CNN-GRU | 90.17 | 92.34 | 91.24 | 92.05 |
| Ding Q et al. [34] | GCN | 99.24 | 98.50 | 98.62 | 98.72 |
| Halbouni A et al. [41] | CNN-LSTM | 99.64 | 99.56 | 99.70 | 99.60 |
| Our proposed method | MC-GCN | 99.87 | 99.87 | 99.88 | 99.87 |
| Method | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Original | 94.70 | 98.75 | 74.22 | 84.75 |
| MF-CGAN | 99.87 | 99.87 | 99.88 | 99.87 |
| Model | AvgAcc | 95% Confidence Interval |
|---|---|---|
| MC-GCN | 0.99712 | (0.99632, 0.99879) |
| MGCN | 0.982387 | (0.97741, 0.98742) |
| GCN | 0.978474 | (0.97353, 0.98341) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Dong, Y.; Zheng, C.; Dai, H.; Wang, J.; Ning, L.; Liang, Q. Symmetric Dual-Phase Framework for APT Attack Detection Based on Multi-Feature-Conditioned GAN and Graph Convolutional Network. Symmetry 2025, 17, 1026. https://doi.org/10.3390/sym17071026
Liu Q, Dong Y, Zheng C, Dai H, Wang J, Ning L, Liang Q. Symmetric Dual-Phase Framework for APT Attack Detection Based on Multi-Feature-Conditioned GAN and Graph Convolutional Network. Symmetry. 2025; 17(7):1026. https://doi.org/10.3390/sym17071026
Chicago/Turabian StyleLiu, Qi, Yao Dong, Chao Zheng, Hualin Dai, Jiaxing Wang, Liyuan Ning, and Qiqi Liang. 2025. "Symmetric Dual-Phase Framework for APT Attack Detection Based on Multi-Feature-Conditioned GAN and Graph Convolutional Network" Symmetry 17, no. 7: 1026. https://doi.org/10.3390/sym17071026
APA StyleLiu, Q., Dong, Y., Zheng, C., Dai, H., Wang, J., Ning, L., & Liang, Q. (2025). Symmetric Dual-Phase Framework for APT Attack Detection Based on Multi-Feature-Conditioned GAN and Graph Convolutional Network. Symmetry, 17(7), 1026. https://doi.org/10.3390/sym17071026