
A Bridge Defect Detection Algorithm Based on UGMB Multi-Scale Feature Extraction and Fusion
Abstract
1. Introduction
- (1)
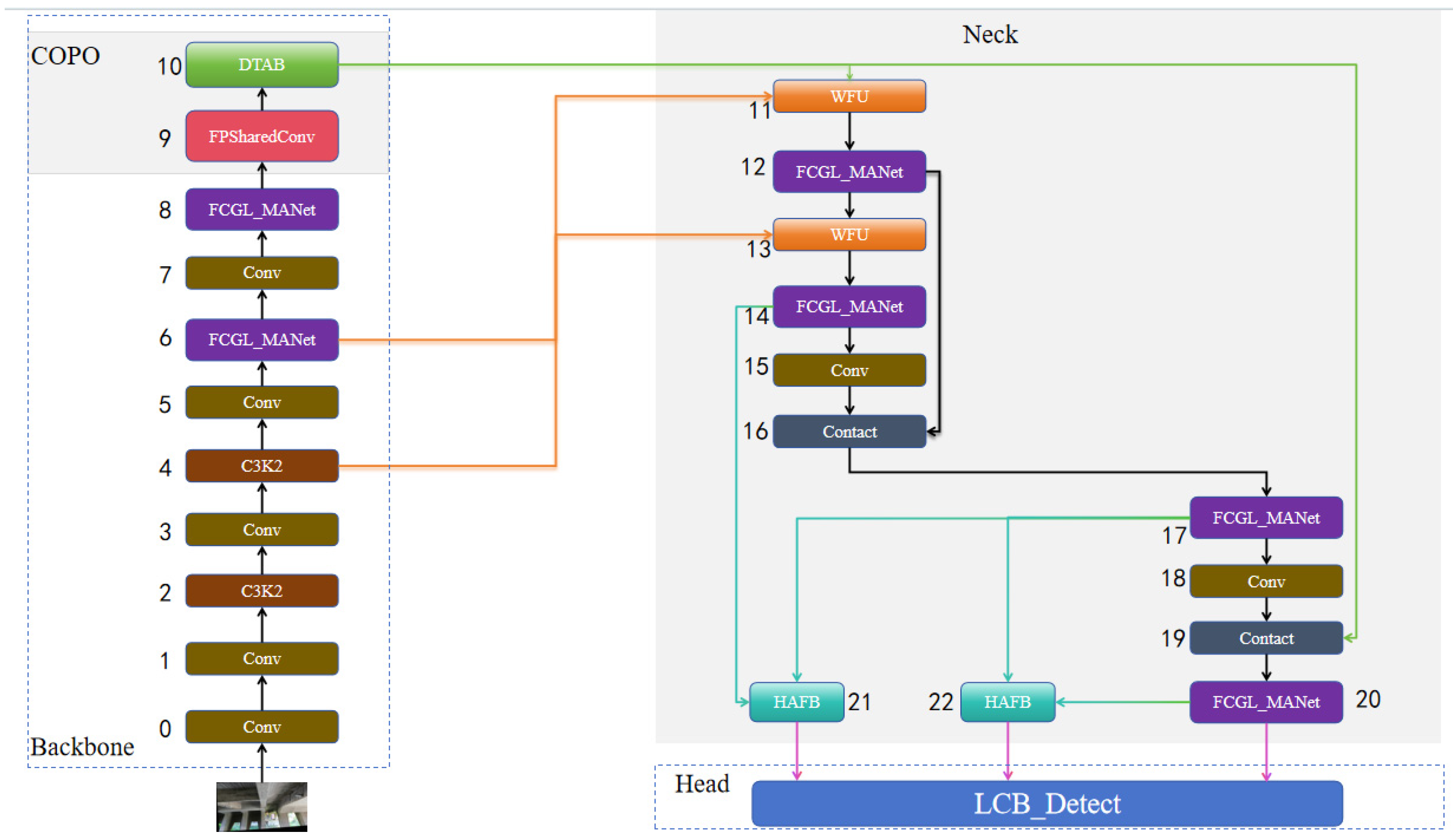
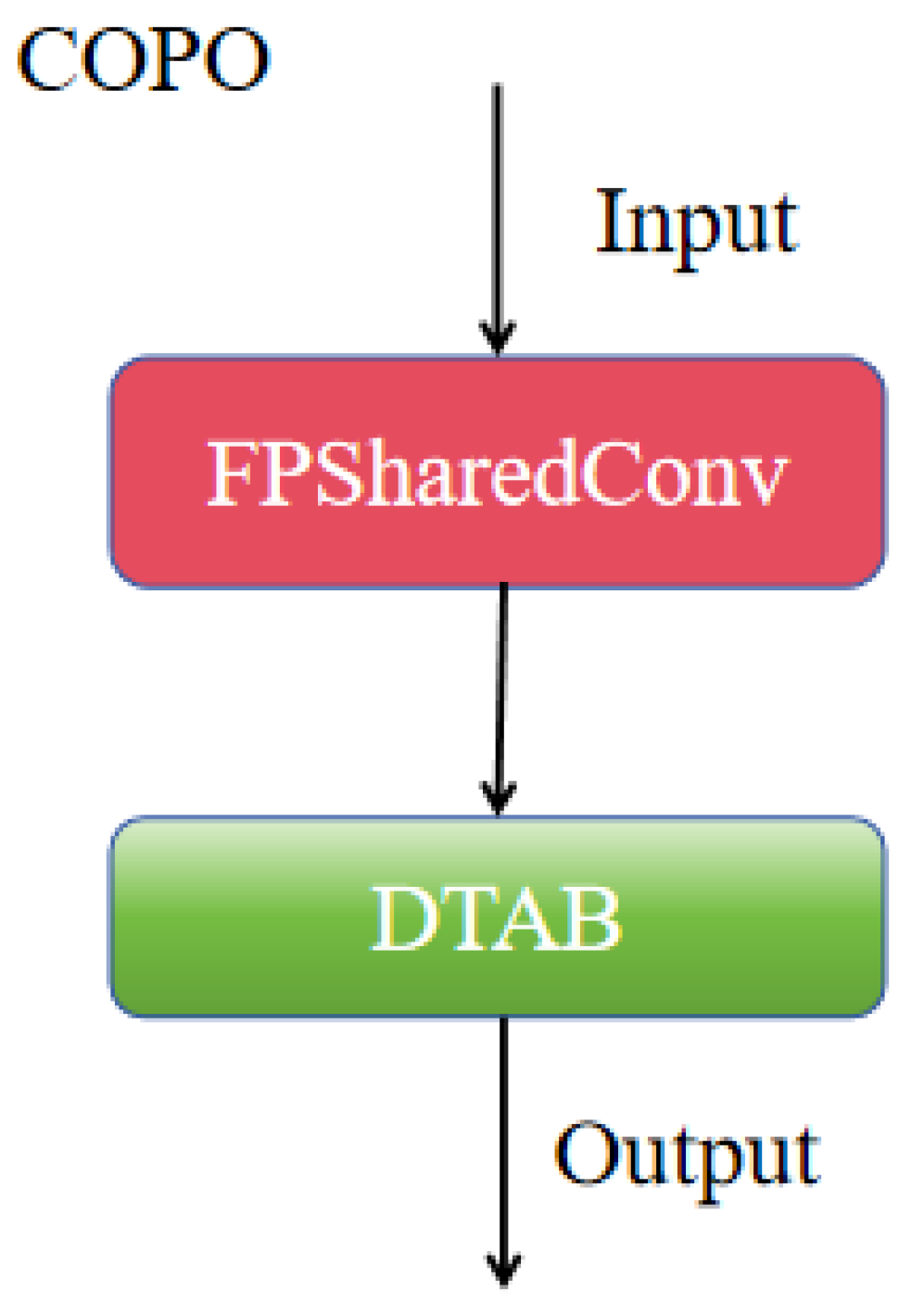
- Collaborative Optimization Module (COPO): The designed COPO module incorporates the proposed FPSharedConv and DATB modules to capture multi-scale feature information as well as local and global feature information. This collaborative optimization module expands the receptive field while enhancing feature learning capabilities, effectively improving the detection capability for multi-scale targets.
- (2)
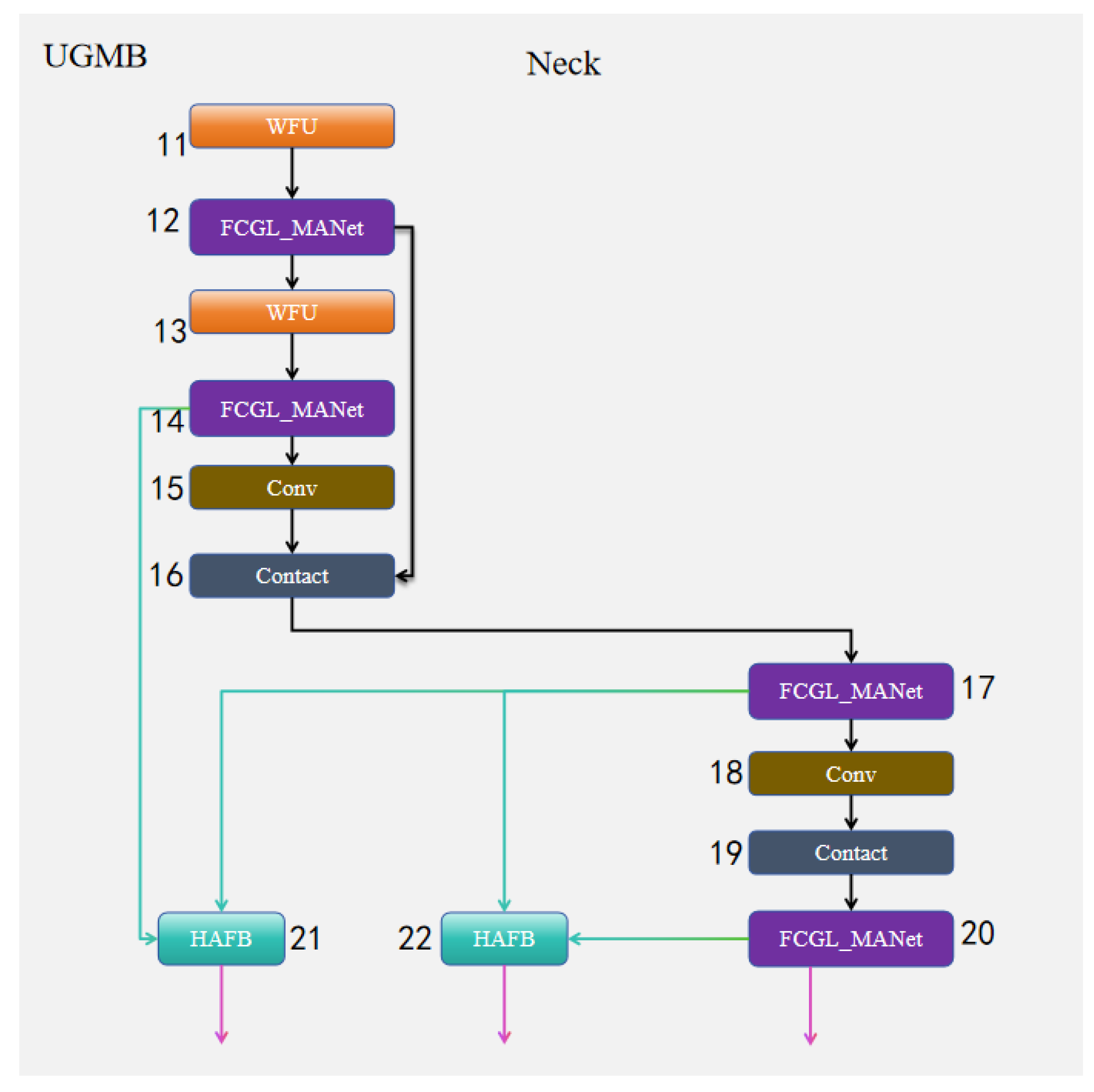
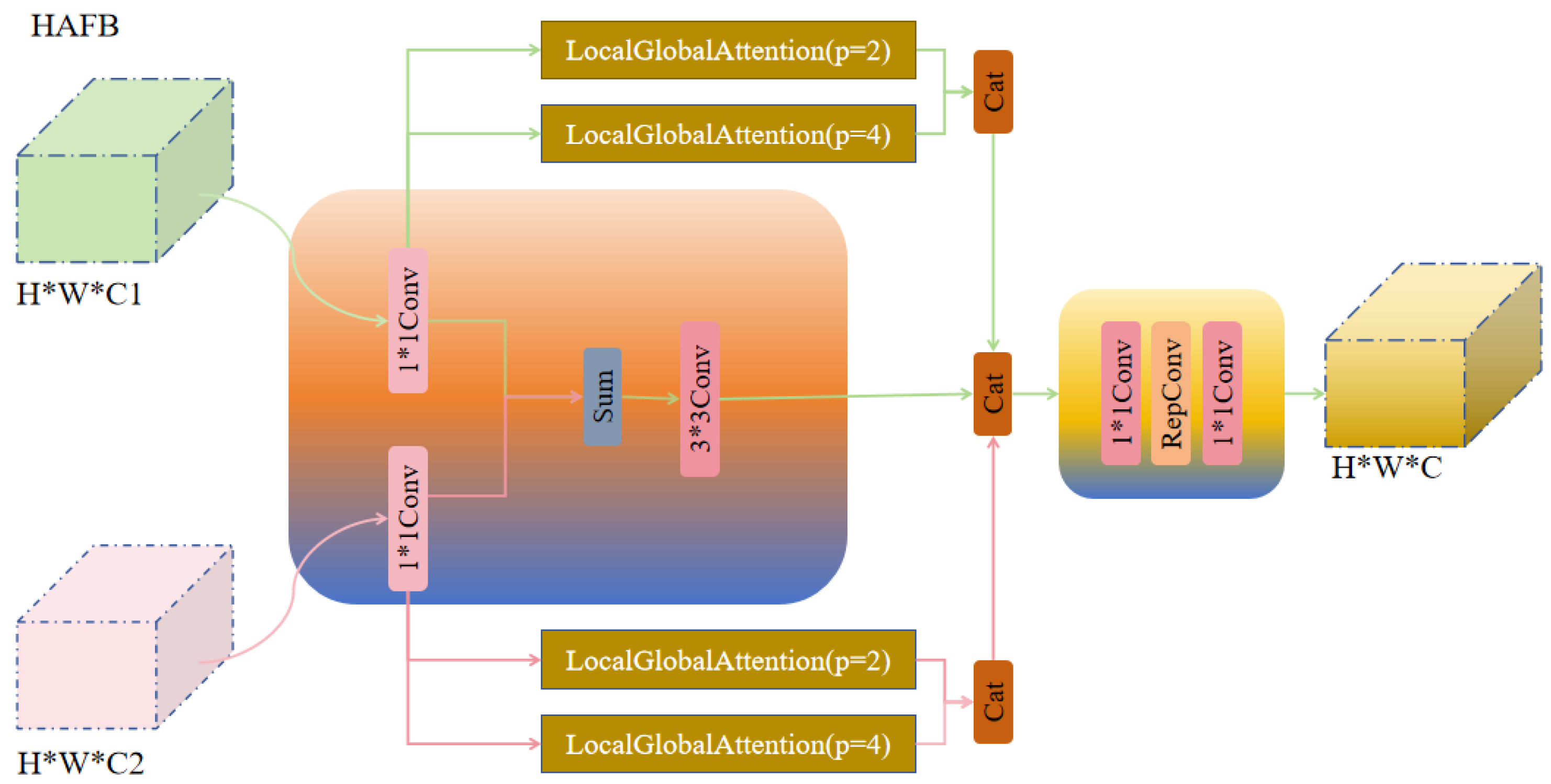
- UGMB Feature Pyramid Module: The proposed UGMB module combines multi-scale feature fusion, local feature enhancement, and global attention mechanisms to strengthen feature representation capabilities, thereby improving the detection accuracy and computational efficiency of the model.
- (3)
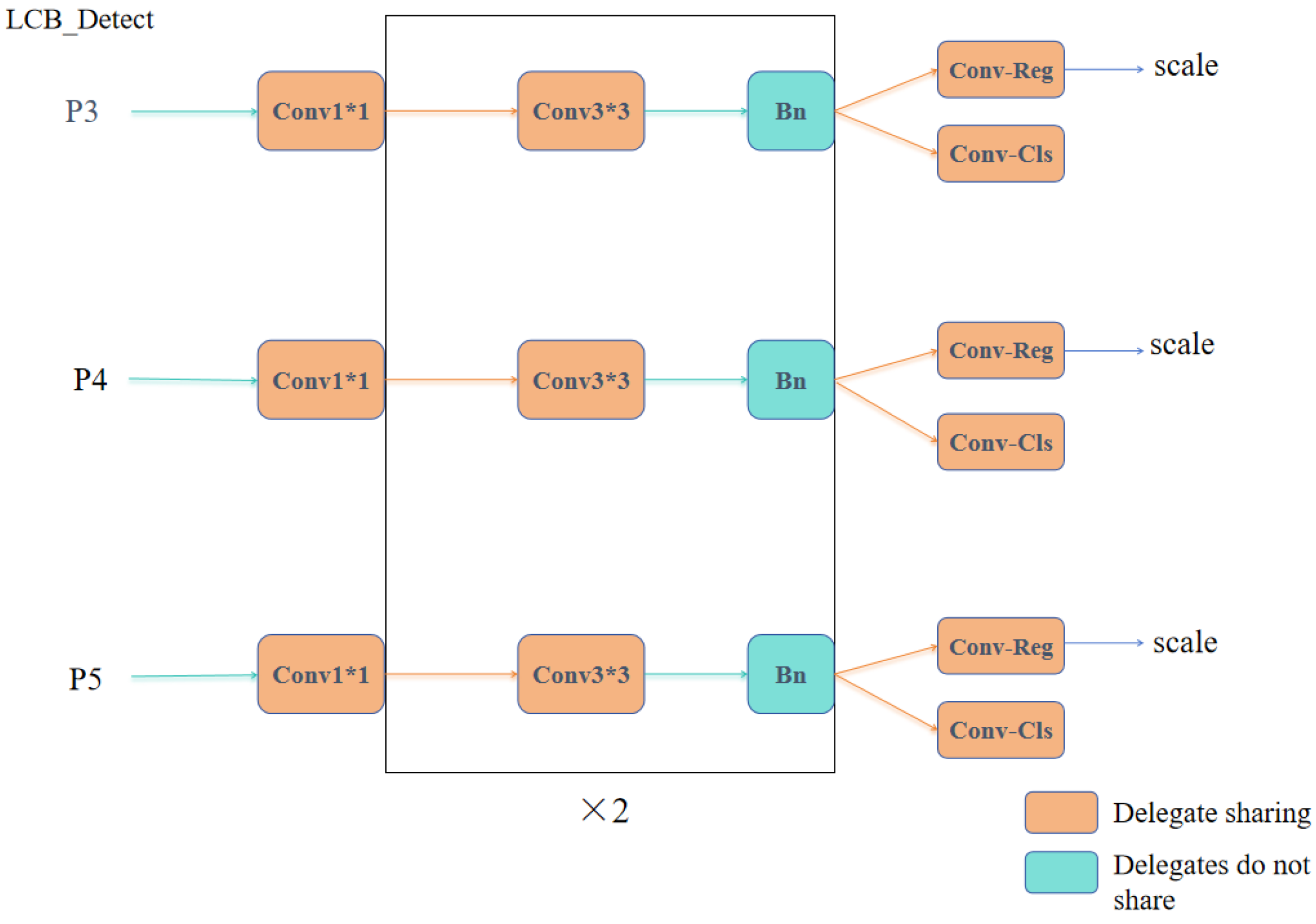
- LCB_Detect Module: This module employs a lightweight shared convolution architecture to achieve cross-layer parameter sharing, reducing computational redundancy. It combines independent batch normalization to differentiate normalization across multi-scale feature maps, decouples the classification and regression branches, and introduces dynamic scale factors and the DFL mechanism. These optimizations enhance the detection head’s performance in terms of lightweight adaptability, multi-scale capability, and robustness in complex scenarios.
2. YOLOv11 Model
3. AMSF-Pyramid-YOLOv11n Model
3.1. COPO Cooperative Optimization Module
3.2. UGMB Feature Pyramid Module
3.3. LCB_Detect Optimized Lightweight Detection Head
4. Analysis of Experimental Results
4.1. Datasets and Experimental Environments
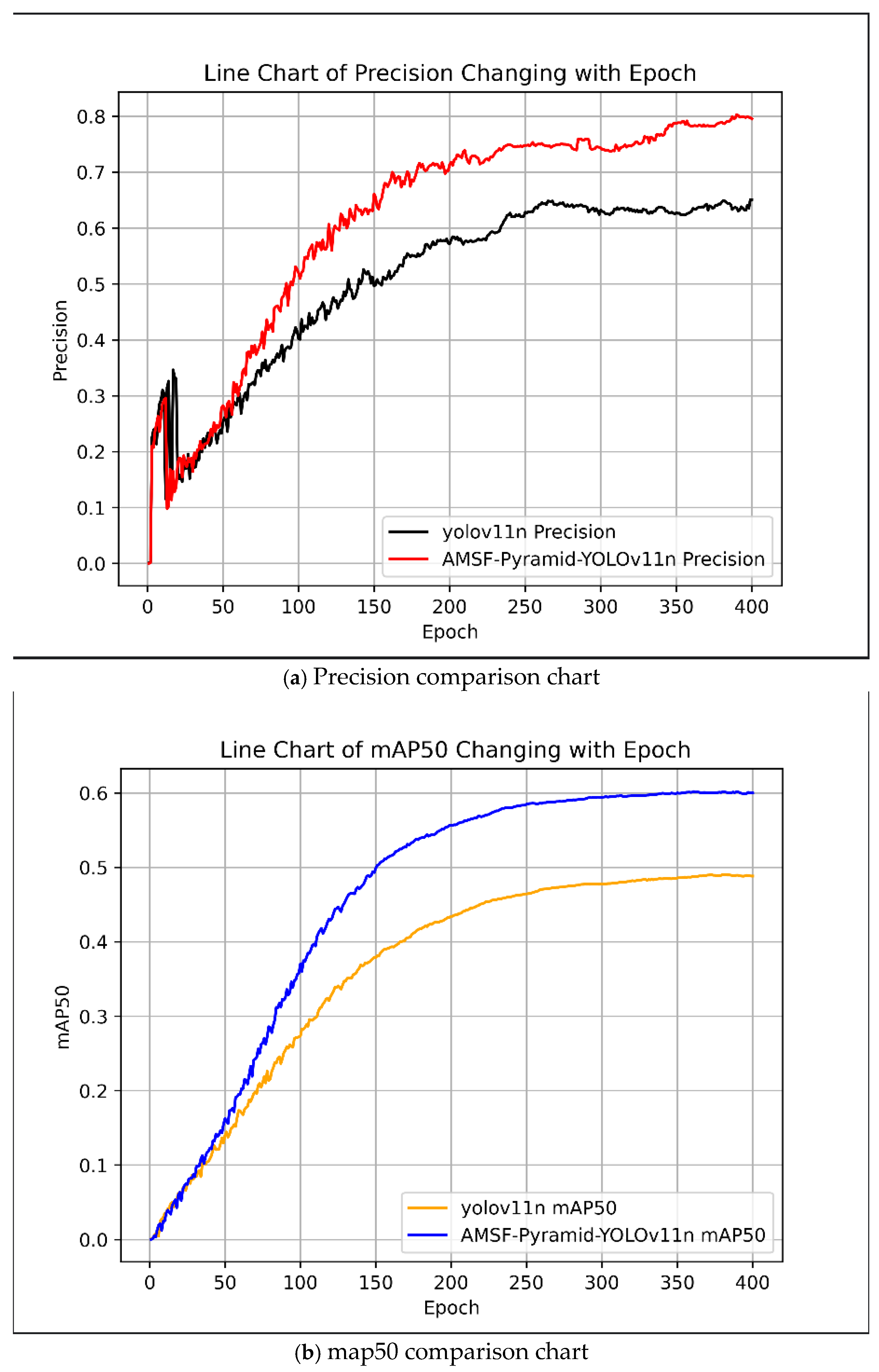
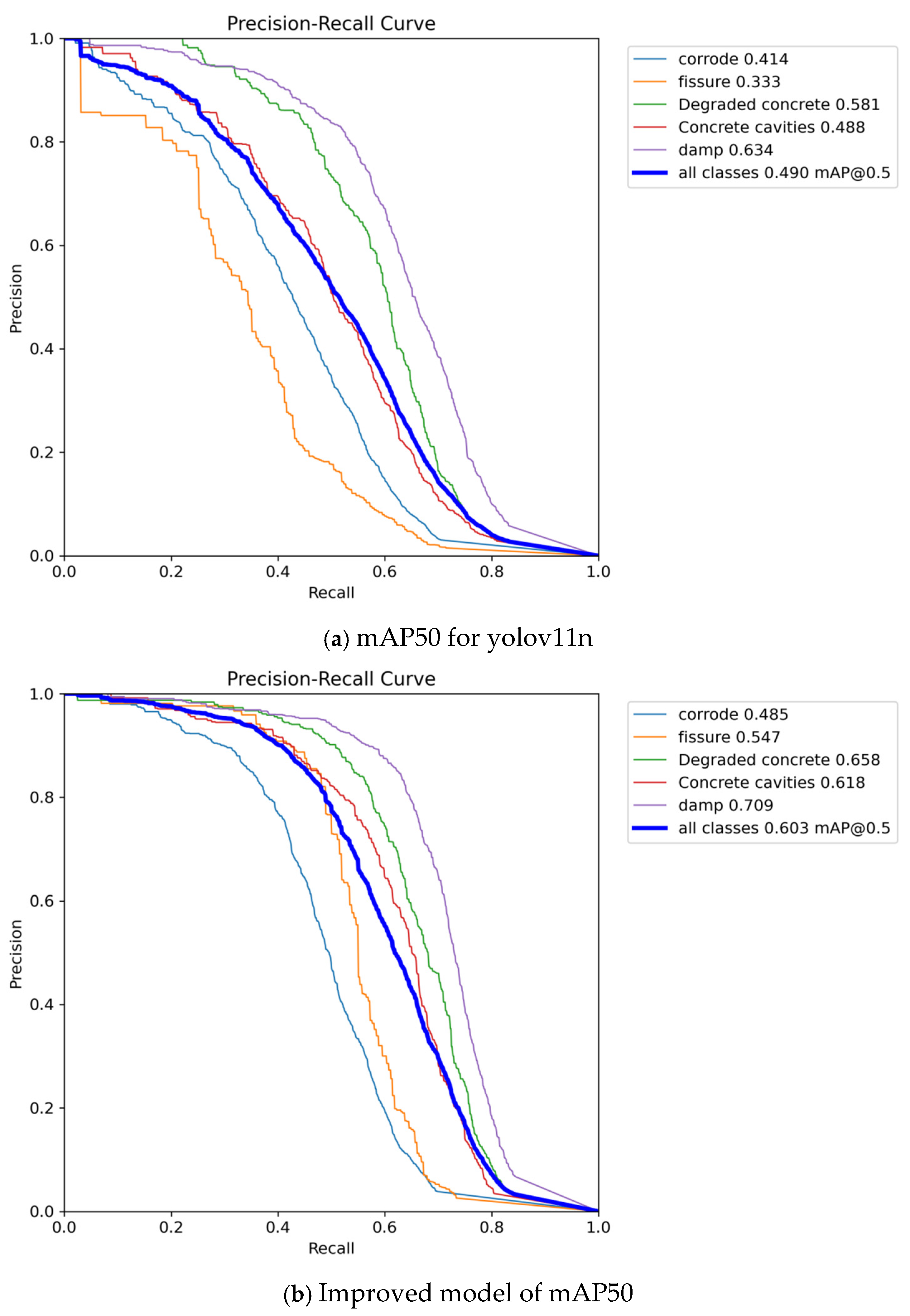
4.2. Comparative Experiments
Comparative Experiments on Improved Effects
4.3. Ablation Experiments
4.4. Generalization Validation
4.5. Visualization of Inspection Results
5. Summary and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dirmeier, J.; Paterson, J. Renewal and Rejuvenation of Aging Infrastructure. In Routes/Roads; World Road Association (PIARC): Paris, France, 2022; Volume 394. [Google Scholar]
- Ye, H.W.; Huang, R.S.; Liu, J.L.; Wang, Y.Q.; Huang, X.J. Analysis of the continuous collapse process of South Korea’s Seongsu Bridge. World Bridges 2021, 49, 87–93. [Google Scholar]
- GR, A.N.; Adarsh, S.; Muñoz-Arriola, F. Introducing a climate, demographics, and infrastructure multi-module workflow for projected flood risk mapping in the greater Pamba River Basin, Kerala, India. Int. J. Disaster Risk Reduct. 2024, 112, 104780. [Google Scholar] [CrossRef]
- Deng, L.; Wang, W.; Yu, Y. State-of-the-art review on the causes and mechanisms of bridge collapse. J. Perform. Constr. Facil. 2016, 30, 04015005. [Google Scholar] [CrossRef]
- Deng, Z.; Huang, M.; Wan, N.; Zhang, J. The current development of structural health monitoring for bridges: A review. Buildings 2023, 13, 1360. [Google Scholar] [CrossRef]
- Fernandez, I.; Berrocal, C.G.; Almfeldt, S.; Rempling, R. Monitoring of new and existing stainless-steel reinforced concrete structures by clad distributed optical fibre sensing. Struct. Health Monit. 2023, 22, 257–275. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, S.; Huang, Y.; Li, H. Robust multitask compressive sampling via deep generative models for crack detection in structural health monitoring. Struct. Health Monit. 2024, 23, 1383–1402. [Google Scholar] [CrossRef]
- Rao, A.S.; Nguyen, T.; Le, S.T.; Palaniswami, M.; Ngo, T. Attention recurrent residual U-Net for predicting pixel-level crack widths in concrete surfaces. Struct. Health Monit. 2022, 21, 2732–2749. [Google Scholar] [CrossRef]
- Flah, M.; Suleiman, A.R.; Nehdi, M.L. Classification and quantification of cracks in concrete structures using deep learning image-based techniques. Cem. Concr. Compos. 2020, 114, 103781. [Google Scholar] [CrossRef]
- Tang, H.; Xie, Y. Deep transfer learning for connection defect identification in prefabricated structures. Struct. Health Monit. 2023, 22, 2128–2146. [Google Scholar] [CrossRef]
- Sohaib, M.; Arif, M.; Kim, J.M. Evaluating YOLO Models for Efficient Crack Detection in Concrete Structures Using Transfer Learning. Buildings 2024, 14, 3928. [Google Scholar] [CrossRef]
- Zhang, C.; Karim, M.M.; Qin, R. A multitask deep learning model for parsing bridge elements and segmenting defect in bridge inspection images. Transp. Res. Rec. 2023, 2677, 693–704. [Google Scholar] [CrossRef]
- Luo, K.; Kong, X.; Zhang, J.; Hu, J.; Li, J.; Tang, H. Computer vision-based bridge inspection and monitoring: A review. Sensors 2023, 23, 7863. [Google Scholar] [CrossRef]
- Campbell, L.E.; Connor, R.J.; Whitehead, J.M.; Washer, G.A. Benchmark for evaluating performance in visual inspection of fatigue cracking in steel bridges. J. Bridge Eng. 2020, 25, 04019128. [Google Scholar] [CrossRef]
- Fukuoka, T.; Fujiu, M. Detection of bridge damages by image processing using the deep learning transformer model. Buildings 2023, 13, 788. [Google Scholar] [CrossRef]
- Chen, Y.; Yuan, X.; Wang, J.; Wu, R.; Li, X.; Hou, Q.; Cheng, M.-M. YOLO-MS: Rethinking multi-scale representation learning for real-time object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 4240–4252. [Google Scholar] [CrossRef]
- Lu, Y.F.; Gao, J.W.; Yu, Q.; Li, Y.; Lv, Y.-S.; Qiao, H. A cross-scale and illumination invariance-based model for robust object detection in traffic surveillance scenarios. IEEE Trans. Intell. Transp. Syst. 2023, 24, 6989–6999. [Google Scholar] [CrossRef]
- Huang, L.; Huang, W. RD-YOLO: An effective and efficient object detector for roadside perception system. Sensors 2022, 22, 8097. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Li, S.-F.; Gao, S.-B.; Zhang, Y.-Y. Pose-guided instance-aware learning for driver distraction behavior recognition. J. Image Graph. 2023, 28, 3550–3561. [Google Scholar] [CrossRef]
- Hu, K.; Shen, C.; Wang, T.; Xu, K.; Xia, Q.; Xia, M.; Cai, C. Overview of Temporal Action Detection Based on Deep Learning. Artif. Intell. Rev. 2024, 57, 26. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Yeh, I.-H.; Chen, P.-Y.; Hsieh, J.-W. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Lau, K.W.; Po, L.M.; Rehman, Y.A.U. Large Separable Kernel Attention: Rethinking the Large Kernel Attention Design in CNN. arXiv 2023, arXiv:2309.01439. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhou, L.; Zhou, Y.; Corso, J.J.; Socher, R.; Xiong, C. End-to-end dense video captioning with masked transformer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8739–8748. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zhang, Y.; Qiu, Q.; Liu, X.; Fu, D.; Liu, X.; Fei, L.; Cheng, Y.; Yi, L.; Hu, W.; Zhuge, Q. First Field-Trial Demonstration of L4 Autonomous Optical Network for Distributed AI Training Communication: An LLM-Powered Multi-AI-Agent Solution. arXiv 2025, arXiv:2504.01234. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Zhou, Y.; Ding, G.; Sun, J. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Korban, M.; Li, X. Semantics-enhanced early action detection using dynamic dilated convolution. Pattern Recognit. 2023, 140, 109595. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Z.; Zuo, W. Rethinking Transformer-Based Blind-Spot Network for Self-Supervised Image Denoising. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; Volume 39, pp. 4788–4796. [Google Scholar]
- Li, W.; Guo, H.; Liu, X.; Liang, K.; Hu, J.; Ma, Z.; Guo, J. Efficient face super-resolution via wavelet-based feature enhancement network. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, Australia, 28 October–1 November 2024; pp. 4515–4523. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Xu, S.; Zheng, S.; Xu, W.; Xu, R.; Wang, C.; Zhang, J.; Teng, X.; Li, A.; Guo, L. Hcf-net: Hierarchical context fusion network for infrared small object detection. In Proceedings of the 2024 IEEE International Conference on Multimedia and Expo (ICME), IEEE, Niagra Falls, ON, Canada, 15–19 July 2024; pp. 1–6. [Google Scholar]
- Flotzinger, J.; Rösch, P.J.; Braml, T. dacl10k: Benchmark for semantic bridge damage segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 8626–8635. [Google Scholar]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. arXiv 2012, arXiv:1504.08083. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Khanam, R.; Hussain, M. What is YOLOv5: A deep look into the internal features of the popular object detector. arXiv 2024, arXiv:2407.20892. [Google Scholar]
- Varghese, R.; Sambath, M. Yolov8: A novel object detection algorithm with enhanced performance and robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Feng, Y.; Huang, J.; Du, S.; Ying, S.; Yong, J.-H.; Li, Y.; Ding, G.; Ji, R.; Gao, Y. Hyper-yolo: When visual object detection meets hypergraph computation. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 47, 2388–2401. [Google Scholar] [CrossRef]
- Bianchi, E.; Hebdon, M. COCO-Bridge 2021+ Dataset. University Libraries, Virginia Tech. Dataset. 2021. Available online: https://data.lib.vt.edu/articles/dataset/COCO-Bridge_2021_Dataset/16624495/1 (accessed on 30 April 2025).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bridge Defect Category | Number of Samples | Proportion |
|---|---|---|
| corrode | 17,593 | 40.18% |
| fissure | 2511 | 5.73% |
| Degraded concreate | 5534 | 12.64% |
| Concreate cavities | 6164 | 14.08% |
| damp | 11,985 | 27.37% |
| The Name of the Parameter | Parameter Value |
|---|---|
| Epochs | 400 |
| Batch_size | 16 |
| Image_size | 640 × 640 |
| patience | 100 |
| works | 16 |
| Initial learning rate | 0.01 |
| Final learning rate | 0.01 |
| Weight-Decay | 0.0005 |
| Method | P(%) | R(%) | mAP @0.5(%) | mAP @0.5:0.95(%) | Parameters | Gflops |
|---|---|---|---|---|---|---|
| Faster R-CNN [38] | 43.52 | 34.88 | 31.66 | - | - | 200 |
| SSD [39] | 45.99 | 35.355 | 35.57 | - | - | 30.7 |
| CenterNet [40] | 54.6 | 39.9 | 52.0 | - | - | - |
| YOLOv5n [41] | 62.4 | 43.0 | 46.7 | 21.0 | 2,182,639 | 5.8 |
| YOLOv5s [41] | 72.3 | 51.3 | 58.5 | 27.5 | 7,815,551 | 18.7 |
| YOLOv8n [42] | 65.8 | 45.3 | 49.7 | 22.9 | 3,157,200 | 8.9 |
| YOLOv11n [19] | 65.0 | 44.7 | 49.0 | 23.4 | 2,624,080 | 6.6 |
| YOLOv11s [19] | 73.9 | 53.0 | 60.1 | 31.1 | 9,458,752 | 21.7 |
| YOLOv12n [43] | 54.8 | 38.3 | 40.7 | 18.9 | 2,602,288 | 6.7 |
| YOLOv12s [43] | 71.1 | 51.6 | 57.8 | 29.6 | 9,284,096 | 21.7 |
| Hyper-YOLO [44] | 67.2 | 47.1 | 51.4 | 24.7 | 3,621,759 | 9.5 |
| AMSF-Pyramid-YOLOv11n | 79.1 | 53.0 | 60.3 | 30.5 | 6,021,560 | 11.9 |
| A | B | C | D | P(%) | R(%) | mAP @0.5(%) | mAP @0.5:0.95(%) | Gflops |
|---|---|---|---|---|---|---|---|---|
| √ | × | × | × | 66.7 | 45.7 | 50.2 | 25.1 | 10.4 |
| × | √ | × | × | 69.1 | 47.0 | 52.3 | 25.2 | 6.3 |
| × | × | √ | × | 72.9 | 52.2 | 57.7 | 29.0 | 7.8 |
| × | × | × | √ | 67.8 | 47.5 | 52.7 | 25.4 | 6.2 |
| √ | √ | × | × | 68.2 | 46.5 | 51.4 | 26.0 | 10.2 |
| √ | × | √ | × | 68.6 | 46.8 | 52.9 | 27.1 | 10.5 |
| √ | × | × | √ | 65.6 | 47.4 | 51.0 | 25.1 | 10.3 |
| × | √ | √ | × | 73.0 | 50.8 | 57.1 | 27.9 | 8.2 |
| × | √ | × | √ | 68.3 | 47.7 | 53.3 | 25.1 | 7.0 |
| × | × | √ | √ | 69.2 | 49.0 | 53.6 | 25.4 | 9.1 |
| √ | √ | √ | × | 77.4 | 52.6 | 59.5 | 29.8 | 12.2 |
| √ | √ | × | √ | 70.4 | 48.2 | 53.0 | 25.7 | 10.3 |
| × | √ | √ | √ | 60.7 | 39.2 | 41.9 | 20.4 | 5.3 |
| √ | × | √ | √ | 70.4 | 45.7 | 51.5 | 25.6 | 10.4 |
| √ | √ | √ | √ | 79.1 | 53.0 | 60.3 | 30.5 | 11.9 |
| a | b | c | P(%) | R(%) | mAP @0.5(%) | mAP @0.5:0.95(%) | Gflops |
|---|---|---|---|---|---|---|---|
| √ | × | × | 71.5 | 49.0 | 55.2 | 27.0 | 8.5 |
| × | √ | × | 65.8 | 45.8 | 51.0 | 23.8 | 7.8 |
| × | × | √ | 65.7 | 47.62 | 51.11 | 24.7 | 7.1 |
| × | √ | √ | 67.1 | 44.8 | 49.0 | 24.1 | 7.6 |
| √ | × | √ | 70.5 | 49.3 | 52.4 | 26.5 | 9.7 |
| √ | √ | × | 69.2 | 49.0 | 53.6 | 25.4 | 10.1 |
| √ | √ | √ | 79.1 | 53.0 | 60.3 | 30.5 | 11.9 |
| Algorithm | P(%) | R(%) | mAP @0.5(%) | mAP @0.5:0.95(%) | FPS |
|---|---|---|---|---|---|
| YOLOV11n | 19.0 | 13.6 | 15.9 | 5.95 | 198.3 |
| AMSF-Pyramid-YOLOv11n | 22.2 | 16.6 | 17.7 | 6.08 | 85.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Tian, C.; Zhang, A.; Liu, Y.; Gao, G.; Zhuang, Z.; Yin, T.; Zhang, N. A Bridge Defect Detection Algorithm Based on UGMB Multi-Scale Feature Extraction and Fusion. Symmetry 2025, 17, 1025. https://doi.org/10.3390/sym17071025
Zhang H, Tian C, Zhang A, Liu Y, Gao G, Zhuang Z, Yin T, Zhang N. A Bridge Defect Detection Algorithm Based on UGMB Multi-Scale Feature Extraction and Fusion. Symmetry. 2025; 17(7):1025. https://doi.org/10.3390/sym17071025
Chicago/Turabian StyleZhang, Haiyan, Chao Tian, Ao Zhang, Yilin Liu, Guxue Gao, Zhiwen Zhuang, Tongtong Yin, and Nuo Zhang. 2025. "A Bridge Defect Detection Algorithm Based on UGMB Multi-Scale Feature Extraction and Fusion" Symmetry 17, no. 7: 1025. https://doi.org/10.3390/sym17071025
APA StyleZhang, H., Tian, C., Zhang, A., Liu, Y., Gao, G., Zhuang, Z., Yin, T., & Zhang, N. (2025). A Bridge Defect Detection Algorithm Based on UGMB Multi-Scale Feature Extraction and Fusion. Symmetry, 17(7), 1025. https://doi.org/10.3390/sym17071025