1. Introduction
Magnetic resonance imaging (MRI), a non-invasive imaging technique based on the principle of magnetic resonance, has been widely used in clinical diagnosis [
1,
2,
3]. Compared with other imaging modalities, MRI has unique advantages such as no ionizing radiation, high soft tissue contrast, and multidirectional imaging, particularly in neuroimaging and oncology, where it has an irreplaceable position [
4,
5]. However, long MRI scanning times cause discomfort and unconscious movement of the patient, both of which reduce image quality and raise the cost of the examination, making it difficult to promote its use in emergency medicine and rapid screening. Therefore, shortening the scanning time while guaranteeing image clarity is the main challenge for MRI technology. Early acceleration methods mainly rely on hardware improvement [
6,
7,
8], such as parallel imaging, which can shorten acquisition time with fast sequences, but the equipment is expensive and the effect decreases under high acceleration, which makes it difficult to popularize. Compressed sensing (CS) utilizes the sparse property of images to accelerate imaging and has been widely used in MRI reconstruction [
9,
10], usually processing the data in domains such as wavelet, full-variance, or cosine transforms. However, CS is computationally intensive, and the removal of ringing artifacts is still unsatisfactory at high acceleration rates [
11,
12,
13,
14,
15].
In contrast to traditional methods, deep learning dramatically streamlines MRI reconstruction by learning features end-to-end rather than relying on hand-crafted regularization. It can process large datasets, reduce computational overhead, and better suppress artifacts and detail loss at high acceleration factors [
16,
17]. For example, Schlemper et al. proposed a cascaded reconstruction network with a data-consistency layer in each block, yielding more stable, high-quality results [
18], while KIKI-Net fuses physical priors with deep learning to optimize image–k-space interactions, enhancing accuracy and robustness under rapid acquisition conditions [
19].
While deep learning brings these gains, Transformer-based architectures—celebrated in NLP for their global dependency modeling—have also been adapted to vision tasks [
20,
21]. Unfortunately, the original visual Transformer incurs quadratic complexity with respect to image size, making it impractical for high-resolution MRI reconstruction. Swin-Transformer addresses this by introducing shifted windows and relative position encoding to achieve linear computational scaling and efficiently capture both local and global features [
22]. Restormer further combines multi-head attention with an efficient feed-forward network to model long-range pixel interactions in large images [
23]. Subsequent Swin-based models—SwinIR’s residual Swin blocks and multi-scale feature aggregation [
24], SwinMR’s combinatorial loss for improved texture retention [
25], SwinGAN’s adversarial training for artifact suppression [
26], The HAT network demonstrates the excellent performance of the super-resolution model based on the hybrid attention mechanism by enhancing the information exchange between windows [
27], and CDSCU-Net’s multi-scale pixel-shuffle Swin learning for high-resolution detail recovery [
28]—have all achieved notable gains in natural image and MRI restoration. However, these designs still rely on stacking Swin Transformer blocks (STBs), and thus do not resolve the information-blocking issue between adjacent windows.
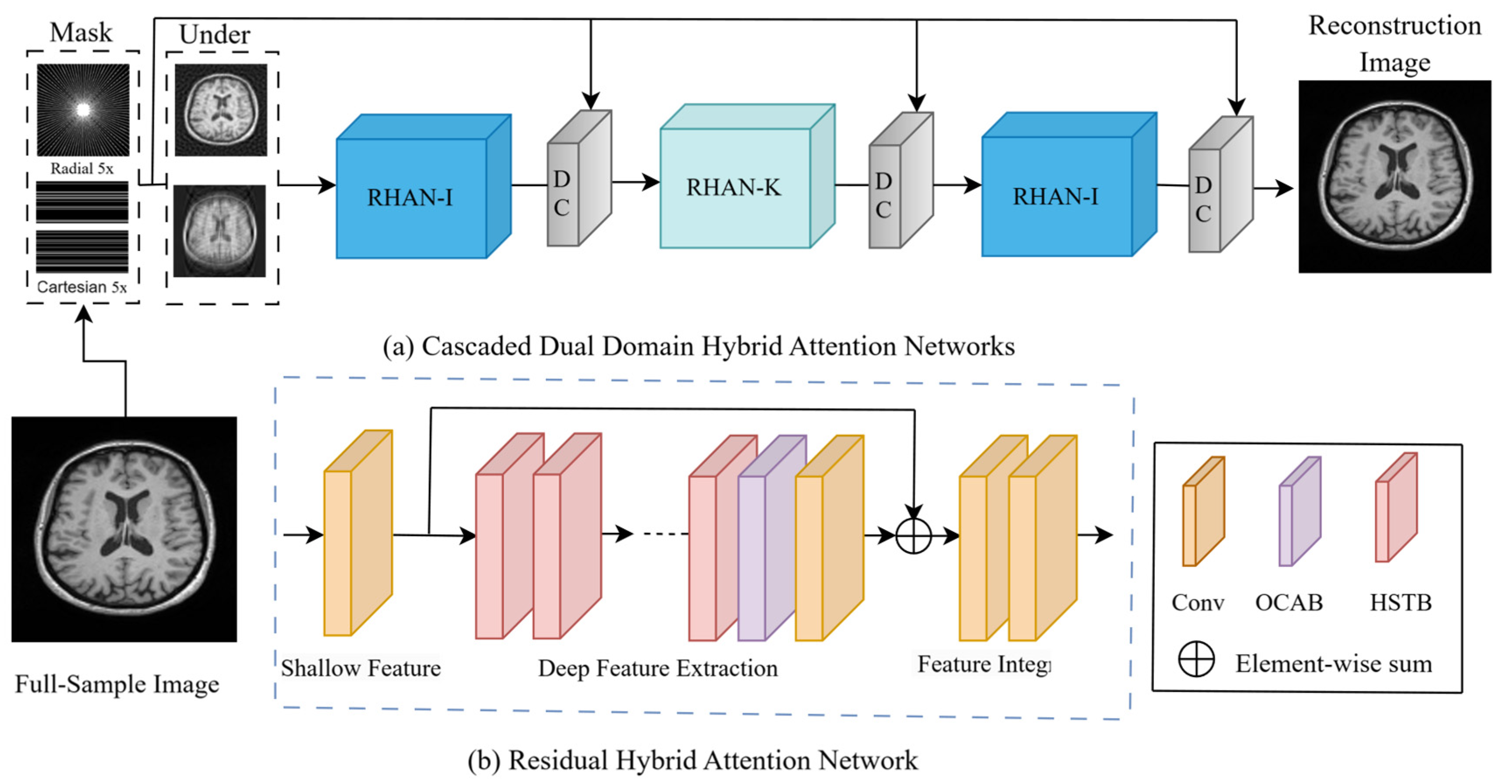
To address these limitations, we propose a cascaded dual-domain hybrid attention network (CDDHAN). CDDHAN fuses spatial- and frequency-domain information through a cascade structure, effectively improving the expressive power of the network. CDDHAN adopts a dual-domain hybrid attention mechanism, which not only captures the image details in the local region but also optimizes the global information through cross-domain feature fusion, thus improving the accuracy and stability of image reconstruction. In addition, the model combines the original K-space data for data consistency (DC) correction, digs deeper into the frequency-domain features through the hybrid attention mechanism, and converts the data back to the null domain to achieve high-quality image reconstruction. Each sub-model is cascaded, and the model transmits and fuses information in the null and frequency domains layer by layer, effectively avoiding the problem of local optimality that may occur in a single-domain model. The experimental results show that CDDHAN has significant performance advantages over traditional MRI reconstruction methods and classical deep learning methods at high acceleration factors.
Overall, our main contributions are four-fold:
A novel cascaded hybrid attention network for fast MRI reconstruction is proposed, as shown in
Figure 1a.
An effective overlapping attention is proposed, that is, a module that can effectively solve the information blocking problem in the existing STBs.
A new hybrid attention module is proposed that can effectively distinguish between different textures and artifacts for better learning image feature information.
Comparative experimental studies using different undersampled trajectories are conducted to verify the effectiveness of the proposed CDDHAN.
The first section of the paper describes the current state of domestic and international research on the more classical MR image reconstruction algorithms;
Section 2 describes our proposed model architecture and its various components;
Section 3 presents the design of the comparison and ablation experiments as well as the related parameter settings;
Section 4 discusses the experimental results; and
Section 5 summarizes the paper and outlines directions for future work.
5. Conclusions
In this paper, we present CDDHAN, a hybrid-attention network for accelerated MRI reconstruction. CDDHAN leverages an alternating spatial- and frequency-domain attention mechanism to accurately capture complex texture features, and incorporates an overlapping-window self-attention module to enhance information exchange and aggregation across windows. Extensive undersampling experiments demonstrate that CDDHAN outperforms state-of-the-art methods in both PSNR and SSIM. Ablation studies further confirm the effectiveness of each component: the hybrid attention module alone yields a 0.36 dB PSNR gain; the addition of a data consistency module provides a further 0.17 dB improvement; and the overlapping-window mechanism, while reducing parameter count, contributes an additional 0.04 dB increase. Overall, these results show that the hybrid attention framework has great potential for accelerated MRI reconstruction. However, the direct applicability of CDDHAN to 3D or multi-coil MRI data still requires further validation, and more work is needed to optimize the balance between computational efficiency and robustness. Therefore, in future research, we will focus on multi-coil reconstruction tasks, fully exploiting the advantages of multi-coil data acquisition to further shorten scan times and improve image SNR. At the same time, we will optimize the model architecture to reduce computational costs and promote the real-time clinical deployment of CDDHAN.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}