1. Introduction
The advent of large language models (LLMs) has profoundly reshaped the landscape of natural language processing (NLP), demonstrating remarkable capabilities in multilingual understanding and generation [
1,
2]. A cornerstone of their multilingual prowess lies in the ability to represent words and concepts from different languages within a shared or alignable semantic space, facilitating cross-lingual transfer for various downstream tasks [
3,
4,
5]. Despite the remarkable achievements of LLMs, the quality of their underlying cross-lingual representations, particularly for low-resource or typologically distant languages, remains critically dependent on effective methods for aligning semantic spaces [
6]. A fundamental challenge obstructing robust cross-lingual transfer, especially in unsupervised or low-resource scenarios, is the pervasive issue of structural asymmetry (non-isomorphism) between the embedding spaces of different languages [
7]. This asymmetry arises not only from inherent linguistic differences but also from disparities in training data quality and domain, which are amplified for underrepresented languages. However, as we probe the geometric properties of these high-dimensional representations, the interplay between
symmetry and
asymmetry emerges as a critical factor influencing model performance, particularly in unsupervised settings [
8,
9].
Historically, cross-lingual representation methods like Bilingual Word Embeddings (BWEs) rely on the
isomorphism assumption [
10]. This posits structural
symmetry: Word geometries (e.g., semantic distances and angles) are preserved across languages, typically via an orthogonal transformation. This presumed symmetry simplifies the learning problem, allowing for effective mapping strategies, particularly using offline methods that align pre-trained monolingual embeddings [
11,
12]. While this assumption holds reasonably well for closely related languages with similar linguistic structures and substantial data overlap, its validity diminishes significantly when dealing with distant language pairs [
13,
14]. Consequently, applications relying on cross-lingual alignment, such as unsupervised machine translation for low-resource pairs, bilingual lexicon induction for specialized domains, or zero-shot cross-lingual transfer in critical tasks (e.g., public health information access), face significant performance degradation or even failure when the underlying isomorphism assumption is violated [
15]. This performance gap highlights the urgent need for unsupervised methods specifically designed to handle structural asymmetry.
Increasing evidence points toward inherent
structural asymmetry, or
non-isomorphism, between embedding spaces, especially for languages that are typologically distant or culturally divergent [
16]. This asymmetry arises from fundamental differences in linguistic structures (syntax, morphology), variations in cultural conceptualizations reflected in language use, and disparities in the size and domain distribution of the monolingual corpora used for training [
17,
18]. Such asymmetry manifests as inconsistencies in the geometric neighborhoods and relational structures within the embedding spaces, rendering the simple symmetric mapping assumption inadequate. Consequently, unsupervised methods predicated on isomorphism often experience a sharp decline in performance when confronted with these asymmetric realities [
19]. Addressing this structural asymmetry is crucial for building truly robust multilingual systems, especially in low-resource scenarios where parallel data, the traditional remedy via supervised joint training [
20,
21], is scarce.
Existing attempts to mitigate this asymmetry challenge in unsupervised settings often involve iterative refinement [
22] or leveraging synthetic parallel data generated by unsupervised machine translation systems for joint training [
23]. While the latter approach moves toward joint learning, potentially better accommodating asymmetry, it introduces a dependency on the quality of the synthetic data, which can be noisy and error-prone, particularly for distant language pairs where translation itself is challenging [
24]. The approaches, whether reliant on the fragile isomorphism assumption or the noisy output of unsupervised MT systems, severely constrain the practical deployment of robust multilingual NLP solutions, particularly for the vast majority of language pairs lacking abundant parallel resources. This motivates the need for alternative unsupervised joint training paradigms that can directly handle structural asymmetry without relying on potentially flawed synthetic supervision or the overly strong symmetry assumption.
In this paper, we propose a novel unsupervised joint training methodology specifically designed to navigate the complexities of asymmetric, non-isomorphic embedding spaces. Our core idea is to bypass the need for explicit parallel corpora or synthetic data by mining weak bilingual signals directly from large monolingual corpora. We introduce a dynamic programming algorithm, incorporating nearest-neighbor search within the embedding space, to identify and extract parallel phrase segments across the two monolingual datasets. These mined phrases, while not perfectly parallel sentences, provide valuable anchor points for concurrently training BWEs in a shared space. We jointly optimize embeddings using monolingual context (e.g., skip-gram) and cross-lingual phrase alignments. This fosters shared representations respecting cross-lingual correspondences, even under structural asymmetry. This method directly confronts the asymmetry challenge by learning the alignment implicitly during training, rather than assuming symmetry beforehand or relying on noisy external components.
Our contributions are as follows: (1) We introduce an unsupervised joint training framework for BWEs that operates solely on monolingual corpora, directly addressing the low-resource challenge. (2) We propose a dynamic programming-based phrase-mining technique to extract bilingual signals, offering a novel alternative to synthetic data generation for unsupervised joint training. (3) Through extensive experiments on both closely related and distant language pairs (representing varying degrees of structural asymmetry), we demonstrate empirically that our method significantly outperforms existing unsupervised approaches, particularly in challenging non-isomorphic scenarios, thereby effectively mitigating the negative impact of structural asymmetry in cross-lingual representation learning. We believe this approach offers valuable insights into handling inherent data and structural asymmetries, a pertinent challenge highlighted by this special issue.
3. Methodology
Our objective is to learn high-quality BWEs in an unsupervised manner, effectively navigating the challenges posed by structural asymmetry (non-isomorphism) between language embedding spaces, particularly in low-resource settings. Our approach operates solely on monolingual corpora from a source language
and a target language
, denoted as
and
respectively. The overall process, depicted in
Figure 1, involves three key stages: unsupervised initialization, parallel phrase mining, and unsupervised joint training.
3.1. Unsupervised Initialization of BWEs
Before joint training can commence, we need an initial estimate of the cross-lingual alignment. This initial step provides a starting point for the nearest-neighbor search crucial for our phrase-mining algorithm. We employ a state-of-the-art unsupervised offline mapping technique to establish this initial foundation. Let
and
be the pre-trained monolingual word embedding matrices for the source and target languages, respectively, where
and
are the vocabulary sizes and
d is the embedding dimension. These are typically trained using algorithms FastText [
28] on
and
.
We adopt the robust self-learning approach, which aims to find transformation matrices
and
that align the spaces. The core idea often involves optimizing a criterion:
where
is the
i-th row of the transformed source matrix,
is the
j-th row of the transformed target matrix,
indicates likely translation pairs, and
is a similarity function measuring the similarity between two vectors
and
, commonly, cosine similarity
is used. The summation
iterates over all possible pairs of words in the source and target vocabularies. A common solution involves the SVD of
, yielding orthogonal transformations
and
. Let
and
represent the initial
d-dimensional embeddings aligned in a common space.
3.2. Parallel Phrase Mining via Dynamic Programming
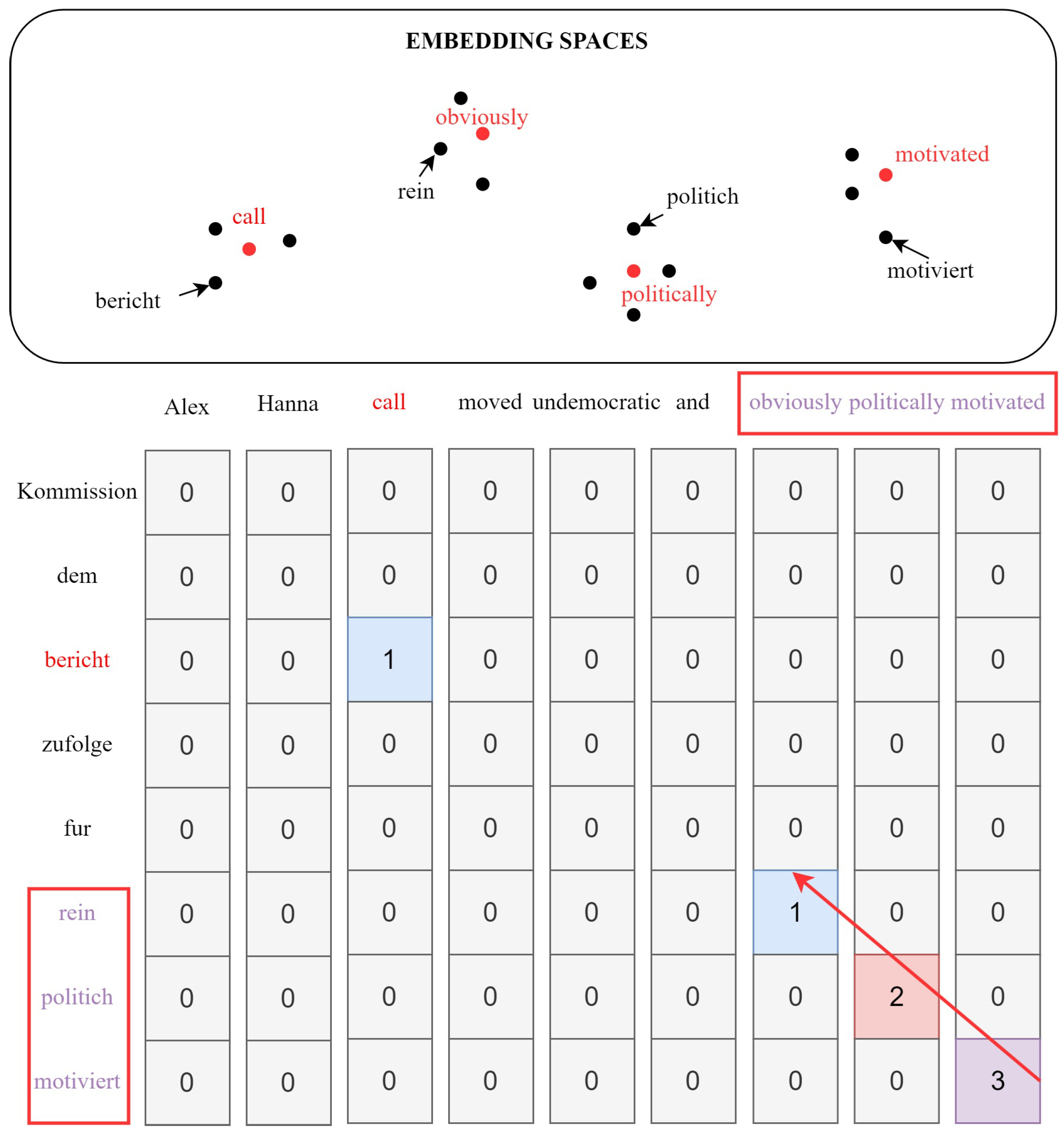
This stage extracts weak bilingual signals by identifying continuous text segments in and that are likely translations, based on word similarity in the “current” embedding space. Consider segments from and from . Let and be the current embeddings (initially ).
Similarity Criterion: We define a binary similarity function
using nearest neighbors:
where
is the
i-th word in a source language text segment,
is the
j-th word in a target language text segment,
is the embedding vector of the source word
from the current source embedding matrix
,
is the embedding vector of the target word
from the current target embedding matrix
,
is the set of the
k nearest neighbors of
e within
based on cosine similarity
, and
k is a parameter. The
indicates that the words
and
are considered potential mutual translation candidates based on their current embedding proximity.
Dynamic Programming: We compute a matrix
that stores the length of the longest contiguous similar sequence ending at
. The transition is as follows:
with base cases
and
. An illustration is in
Figure 2.
Phrase Extraction: We find entries (minimum length, e.g., 3) and extract the corresponding source phrase and target phrase . These pairs form the set .
Discussion on Validity of Mined Phrases: A critical challenge in mining bilingual phrase segments from monolingual corpora lies in distinguishing valid cross-lingual alignments from coincidental similarities. Due to the high dimensionality and potential structural asymmetry of embedding spaces, especially between typologically distant languages, isolated word-level nearest neighbor matches can be unreliable. To address this, our method enforces two criteria, as follows: (1) a minimum length threshold ensures that only sufficiently long continuous segments are extracted, filtering out spurious matches; and (2) a mutual nearest neighbor check guarantees that word pairs exhibit consistent similarity in both directions. These constraints significantly reduce noise in the mined bilingual signals, ensuring that the resulting phrases provide meaningful supervision for unsupervised joint training.
3.3. Unsupervised Joint Training Framework
We jointly optimize
and
using monolingual corpora (
) and mined phrases,
P. The combined objective is as follows:
where
balances the cross-lingual signal,
is the combined loss function minimized during joint training,
is the monolingual loss for the source language,
is the monolingual loss for the target language,
is the cross-lingual loss function (defined below) evaluated using source embeddings
, target embeddings
, and the mined phrase pairs
P.
Monolingual Objective (): We use skip-gram with negative sampling (SGNS):
where
are embeddings for the center, context, and negative sample words,
is the sigmoid function,
is the number of negative samples, and
is the noise distribution.
Cross-lingual Objective (): For each mined phrase pair
, let
be the set of implicitly aligned word pairs identified during DP. The loss maximizes their similarity:
This pulls aligned word embeddings closer.
Optimization and Normalization: Minimize
using SGD (or Adam). Apply embedding normalization and mean centering periodically during training [
39] for stability.
Handling Structural Asymmetry: Unlike traditional unsupervised methods that assume isomorphic embedding spaces, our approach explicitly addresses non-isomorphism through two design choices, as follows: (1) The dynamic programming mining step identifies bilingual segments without relying on symmetric neighborhood structures, avoiding biases toward language-pair-specific isomorphism. (2) The joint training framework iteratively refines embeddings in a shared space, allowing asymmetric adjustments to accommodate linguistic divergences. This eliminates the need for restrictive orthogonality constraints common in mapping-based methods.
This joint framework learns alignment dynamically from mined signals combined with monolingual context, making it adaptable to structural asymmetries without assuming strict isomorphism. The complete unsupervised training procedure integrates the initialization, mining, and joint learning steps.
4. Experimental Settings
This section details the datasets, implementation parameters, evaluation protocols, and baseline methods used to assess the performance of our proposed unsupervised joint training approach for BWEs.
4.1. Datasets and Preprocessing
Monolingual Corpora: We utilized large monolingual corpora extracted from Wikipedia for our primary experiments, ensuring comparability with many previous studies. Additionally, to test robustness across different data sources and potential domain mismatch (reflecting real-world asymmetry), we also conducted experiments using corpora derived from Common Crawl. Following common practice [
22,
30], we used the “WikiExtractor” tool to obtain plain text from Wikipedia dumps. For each language, we used approximately 100 million words (or a comparable amount based on typical dataset sizes in the literature) for training the embeddings.
Language Pairs: We evaluated our method on six language pairs, categorized by linguistic distance, to investigate performance under varying degrees of expected structural asymmetry:
Closely related: English–German (En-De), English–Italian (En-It), German-Italian (De-It). These pairs are expected to exhibit relatively higher structural symmetry.
Distant: English–Russian (En-Ru), English–Turkish (En-Tr), English–Chinese (En-Zh). These pairs are typologically more distant and are expected to exhibit greater structural asymmetry (non-isomorphism).
All experiments involving English use it as the source language unless otherwise specified (e.g., De-It).
Preprocessing: Standard text preprocessing steps were applied, including tokenization (using the Moses tokenizer scripts), lowercasing, and the removal of rare words (e.g., keeping words occurring at least five times). We constructed vocabulary sizes appropriate for each language pair, ensuring coverage of evaluation dictionaries.
4.2. Implementation Details
Monolingual Embeddings: We used the FastText [
28] implementation to train the initial 300-dimensional monolingual embeddings on the preprocessed corpora. We used a window size of 5, as well as 10 negative samples, training for 5 epochs.
Initialization for Our Method: The initial alignment for our unsupervised joint training framework (Stage 1 in
Section 3.1) was obtained using the robust self-learning unsupervised mapping method [
30], specifically using their publicly available implementation with default settings. We also experimented with other initializations as reported in the ablation studies.
Phrase-Mining Parameters: For the dynamic programming phrase mining (
Section 3.2), we set the number of nearest neighbors
for the similarity check (Equation in
Section 3.2) and the minimum phrase length threshold
.
Joint Training Parameters: Our joint training framework (
Section 3.3) was implemented by building upon standard embedding training procedures. We used the Adam optimizer with a learning rate tuned on a held-out validation set (or a standard default like 0.001). The skip-gram objective within the joint training used a window size of 5 and 5 negative samples. The weight for the cross-lingual loss term
was set based on preliminary experiments (e.g.,
). The joint training ran for a fixed number of iterations or epochs (e.g., 5 epochs over the effective combined data). Normalization and mean centering were applied periodically as suggested in [
39]. The primary results reported use a single pass of phrase mining followed by joint training, unless specified as iterative.
4.3. Evaluation Tasks and Metrics
We evaluated the learned BWEs on intrinsic and extrinsic tasks:
- 1.
Bilingual Lexicon Induction (BLI): This is the primary intrinsic evaluation.
Dataset: We used the standard test dictionaries provided by MUSE [
22], which contain 1500 source words and their translations for training and 5000 for testing (we used the test split).
Protocol: For a source word embedding, we retrieved its nearest neighbor in the target embedding space using cosine similarity. We evaluated using Accuracy@1 (P@1), i.e., the percentage of source words whose retrieved nearest neighbor is the correct translation according to the dictionary. We report average accuracies across all test words.
- 2.
Downstream Task Evaluation: We assessed the utility of the BWEs in three cross-lingual transfer scenarios, following protocols similar to [
17]:
Cross-lingual Natural Language Inference (XNLI): We trained a classifier (e.g., a BiLSTM with attention) on the English MultiNLI training data and evaluated its zero-shot performance on the translated XNLI test sets for the target languages, using the learned BWEs as input features.
Cross-lingual Document Classification (CLDC): We trained a document classifier (e.g., averaging BWEs + linear SVM) on the English portion and tested its zero-shot performance on target language documents.
Cross-lingual Information Retrieval (CLIR): We represented queries (English) and documents (target languages) by averaging the embeddings of their constituent words (after stopword removal). We ranked documents based on cosine similarity to the query.
- 3.
Unsupervised Machine Translation (UMT): We initialized the embedding layer of a standard Transformer model with the learned BWEs and trained a UNMT system following [
39].
4.4. Baseline Methods
We compared our proposed method against representative state-of-the-art approaches:
Supervised Mapping:
Mapper [
43]: Learns a linear projection using a seed dictionary (we used 1k or 5k pairs for supervised runs).
VecMap (Supervised) [
27]: The supervised variant of VecMap, using a seed dictionary.
Unsupervised Offline Mapping: These methods rely on the isomorphism assumption.
VecMap (Unsupervised) [
30]: Robust self-learning approach. (Used for our initialization).
MUSE (Adversarial + Refinement) [
22]: Adversarial training followed by Procrustes refinement.
Unsupervised Joint Training:
Fusion [
44]: Combines offline mapping with joint training on synthetic data from UNMT.
For all baselines, we utilized publicly available code and default parameters where possible. Crucially, all methods (including ours and baselines) were trained using the “same” preprocessed monolingual corpora and vocabularies for each language pair to ensure fair comparison. For supervised baselines requiring seeds, we used standard bilingual dictionary pairs.
6. Conclusions
In this paper, we systematically addressed the critical challenge of learning high-quality Bilingual Word Embeddings (BWEs) in unsupervised settings, with a focus on mitigating the pervasive issue of structural asymmetry between embedding spaces of typologically diverse languages. Structural asymmetry, particularly pronounced in distant language pairs and exacerbated by domain mismatches in monolingual corpora, has been shown to degrade the performance of traditional unsupervised methods reliant on the isomorphism assumption in bilingual lexicon induction (BLI) tasks. To overcome these limitations, we proposed a novel unsupervised joint training framework that circumvents the need for parallel corpora or synthetic data, operating solely on monolingual texts.
Our approach leverages a dynamic programming algorithm to mine parallel phrase segments directly from monolingual corpora. By exploiting nearest-neighbor relationships in the evolving embedding space, the algorithm identifies contiguous blocks of semantically related words, generating robust, data-driven bilingual signals. These mined phrases guide the concurrent optimization of source and target embeddings within a shared space, enabling the model to learn cross-lingual alignments dynamically while preserving monolingual structure. Extensive experiments across six language pairs (en-de, en-it, de-it, en-ru, en-tr, en-zh) demonstrated significant improvements over state-of-the-art methods. On BLI tasks, our framework achieved 74.15% accuracy@1 for English–German (en-de) and 74.33% accuracy@1 for English–Italian (en-it) on Wikipedia Corpora. For cross-lingual natural language inference (XNLI), our method attained 58.6% test accuracy on average, surpassing unsupervised offline mapping baselines by 11.82%.
The contributions of this work are threefold. First, we introduced an unsupervised joint training framework that explicitly addresses structural asymmetry without relying on synthetic data or external resources, achieving competitive performance even for distant language pairs like English–Turkish. Second, our dynamic programming-based phrase-mining technique provides a scalable alternative to conventional synthetic data generation, reducing computational overhead compared to back-translation-based methods. Third, we validated the effectiveness of our approach across diverse corpora, including clean (Wikipedia) and noisy (Common Crawl) domains, demonstrating robustness to data quality variations.
Despite these advancements, the proposed framework has limitations. The dynamic programming algorithm’s time complexity scales quadratically with sentence length, limiting its applicability to longer texts. Additionally, while our method excels in aligning lexical semantics, it does not explicitly model syntactic structures, potentially affecting performance in tasks requiring fine-grained grammatical transfer. Future work will focus on optimizing the algorithm’s efficiency via approximate nearest-neighbor search and integrating syntactic constraints into the alignment process. Furthermore, extending this framework to multilingual settings and exploring semi-supervised variants with minimal seed lexicons could further bridge the gap between unsupervised and fully supervised performance.
Meanwhile, our method’s design is extensible to multilingual and low-resource scenarios. Similar to multilingual joint training paradigms [
45,
46], our phrase-mining algorithm could be adapted to mine multi-view alignments across multiple monolingual corpora, leveraging shared embedding spaces for distant languages. Further, the minimal reliance on external resources (only monolingual corpora) aligns with low-resource settings [
47]. For languages with extreme data scarcity, subword-enhanced initialization (e.g., FastText) combined with our phrase mining could mitigate lexical sparsity—an avenue for future exploration.
By directly addressing the challenges of structural asymmetry in cross-lingual representation learning, this work advances the feasibility of unsupervised methods for low-resource language pairs, offering a practical pathway toward equitable multilingual NLP systems.





{kind=link}
{kind=link}
{kind=link}