

Semi-Supervised Learning with Entropy Filtering for Intrusion Detection in Asymmetrical IoT Systems


Abstract
1. Introduction
- We introduce an entropy-based uncertainty filtering mechanism calculated dynamically to identify uncertain predictions. This technique ensures only confident predictions are used during the initial supervised training phase.
- We use a self-training model that leverages high-confidence uncertain predictions as pseudo-labeled samples for semi-supervised retraining. This enables the model to improve its generalization using additional unlabeled or low-confidence data.
- We evaluate the proposed model across three IoT intrusion detection datasets: RT-IoT2022, CICIoT2023, and CICIoMT2024. The datasets include up to 34 attack types, providing a comprehensive benchmark for multiclass intrusion detection in IoT environments. Additionally, we compare our proposed model with existing models.
- We present a detailed evaluation of semi-supervised classifiers for cyberattack detection, including per-class performance analysis to highlight each model’s strengths and limitations in classifying diverse attack types.
2. Related Works
3. Methodology
3.1. Datasets
3.1.1. RT-IoT2022
3.1.2. CICIoT2023
3.1.3. CICIoMT2024
3.2. Proposed Model Components
3.2.1. Training and Testing Classifiers
3.2.2. Entropy-Based Uncertainty Detection
3.2.3. Self-Training of Classifiers
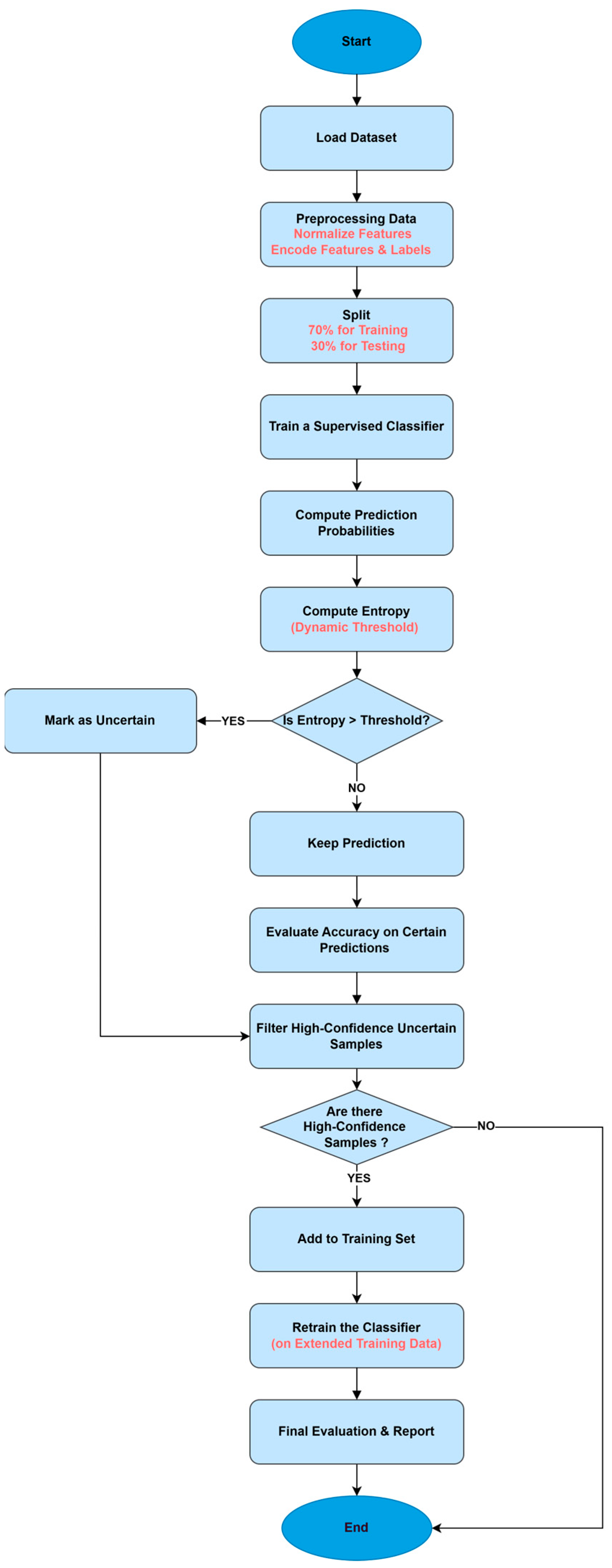
3.3. Proposed Model Flow of Operations
4. Results and Discussion
4.1. Experimental Environment
4.2. Classifiers Parameters
4.2.1. DT
4.2.2. GBC
4.2.3. RF
4.2.4. XGBoost
4.2.5. XRT
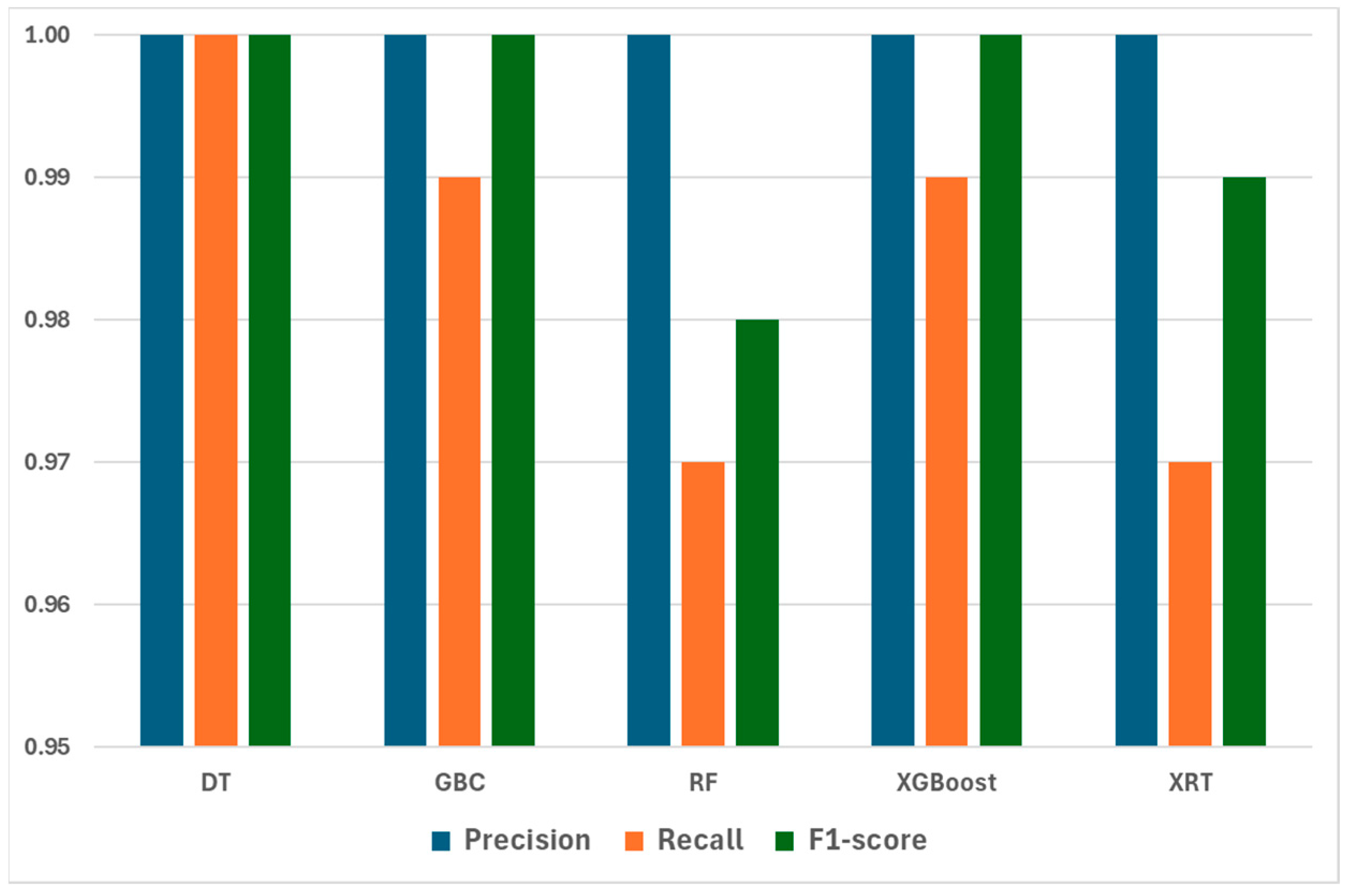
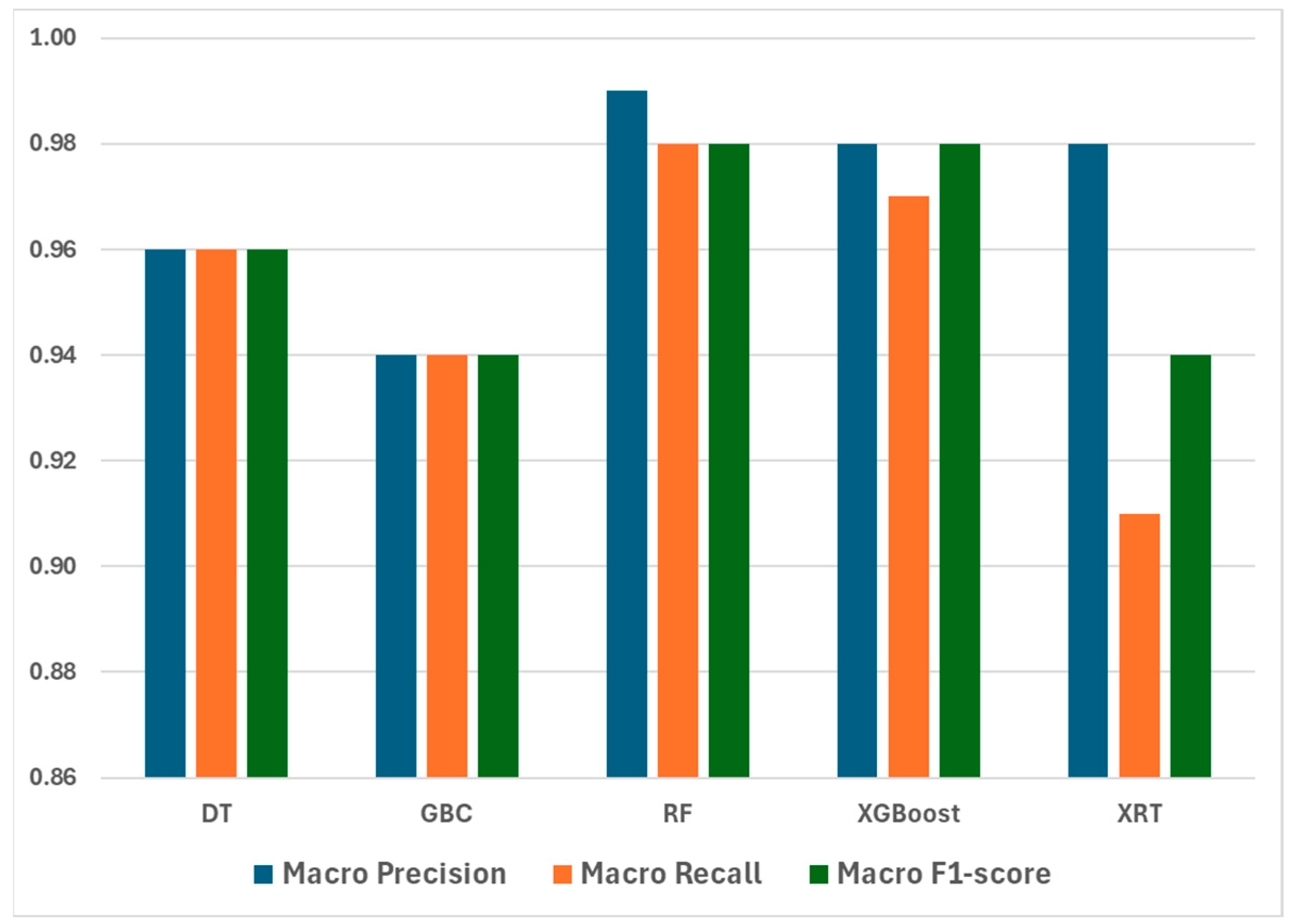
4.3. Result of RT-IoT2022 Dataset
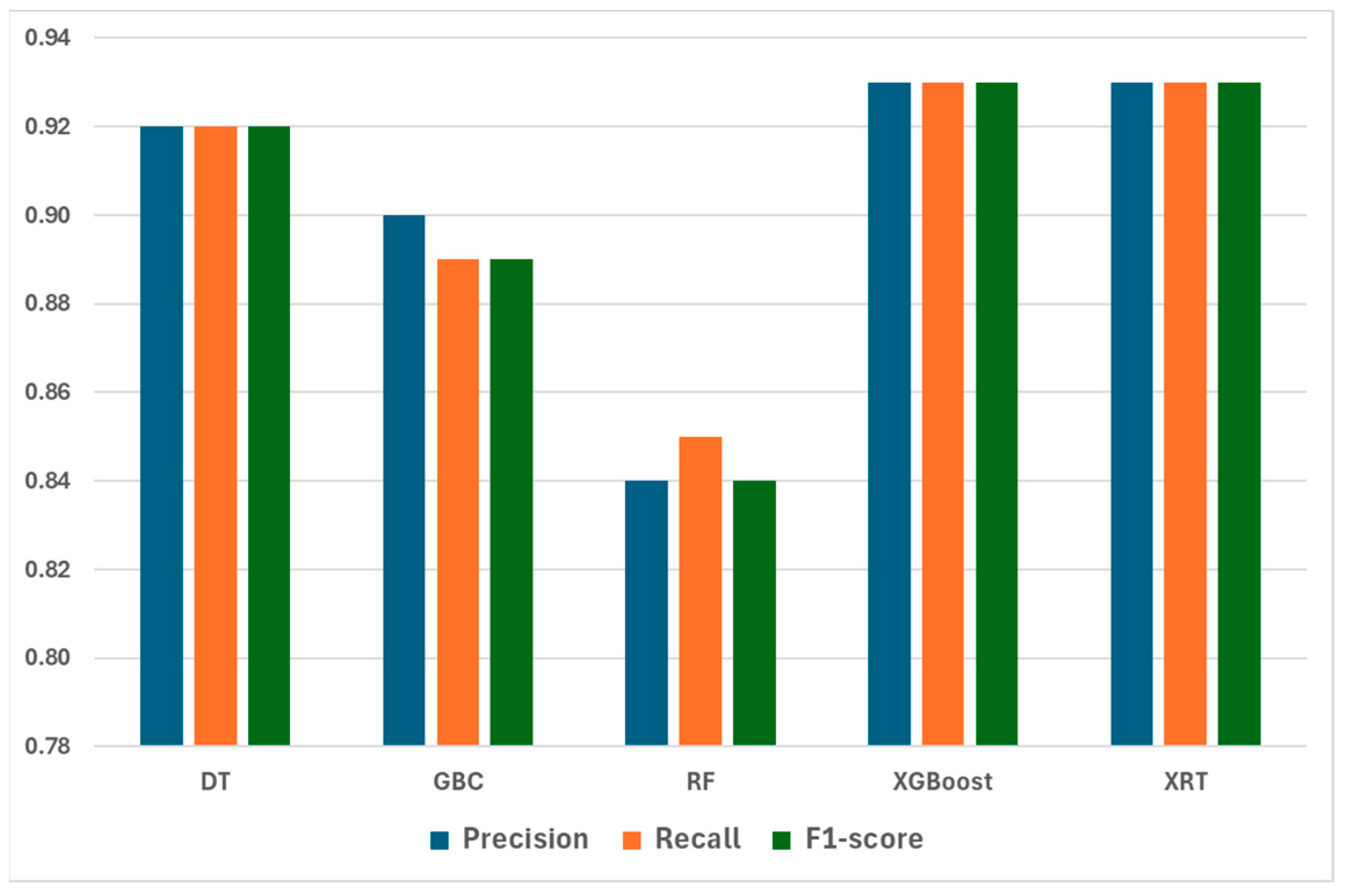
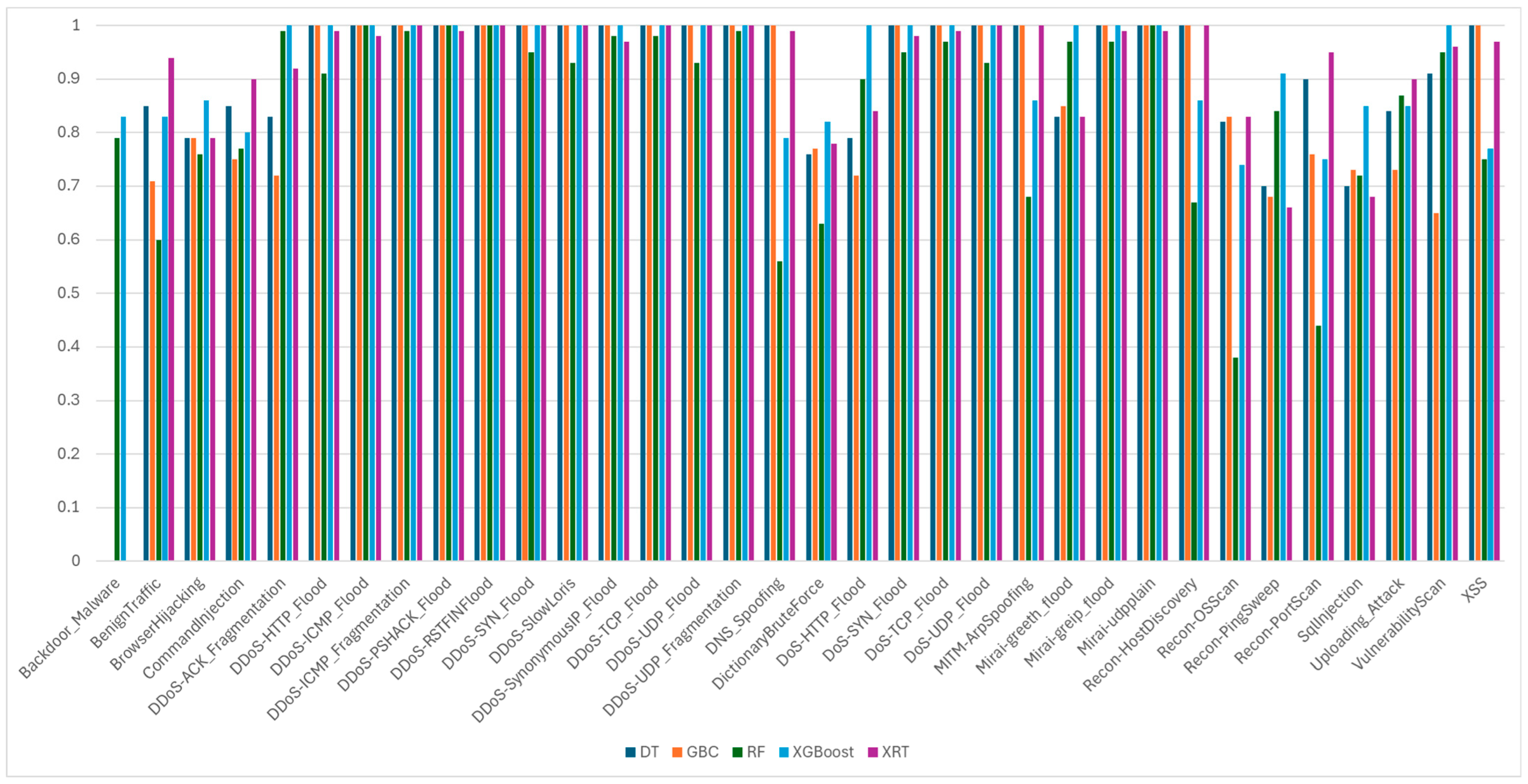
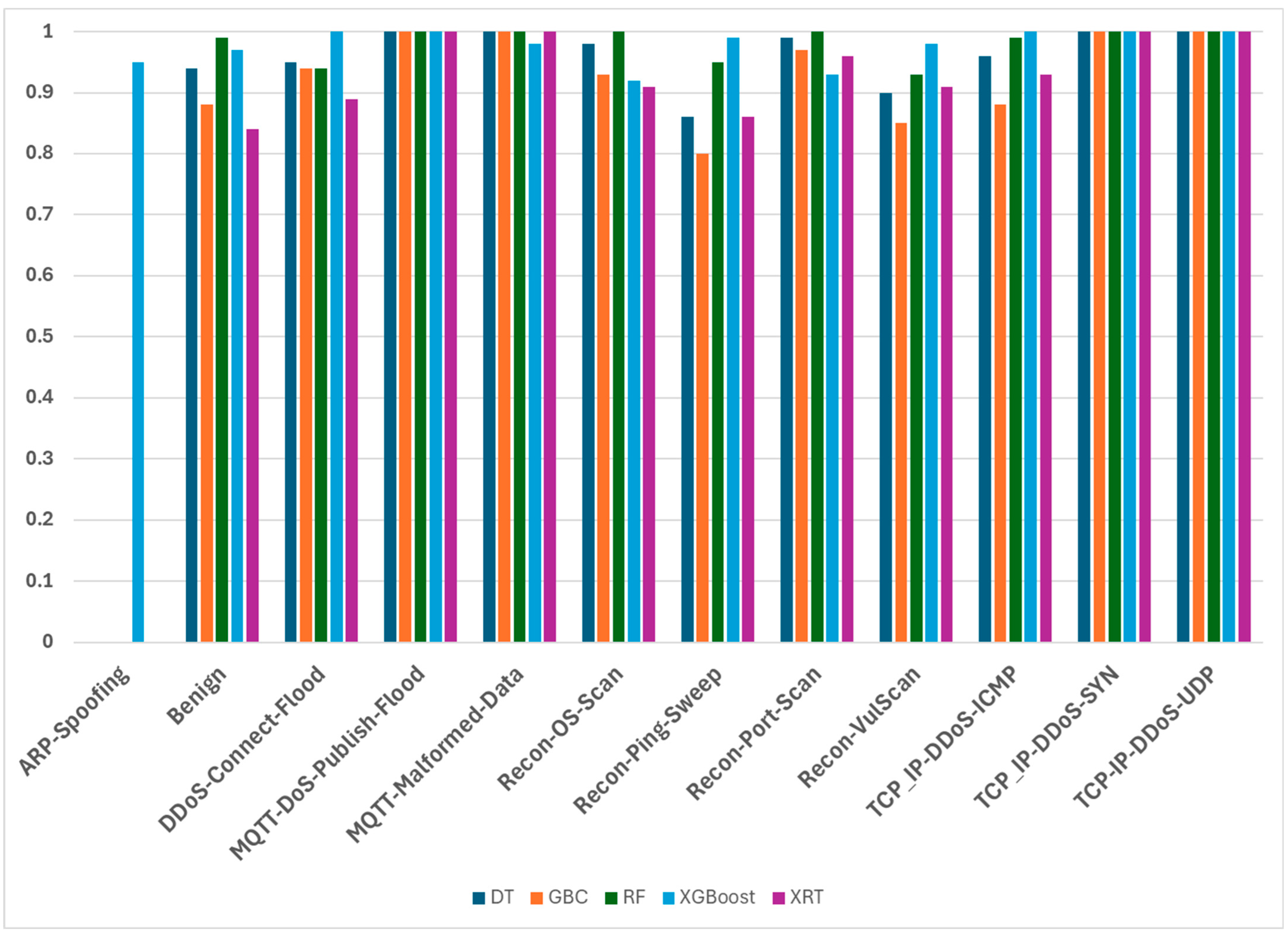
4.4. Result of CICIoT2023 Dataset
4.5. Result of CICIoMT2024 Dataset
4.6. Comparative Evaluation with Existing Work
4.7. Computation Time Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shen, M.; Gu, A.; Kang, J.; Tang, X.; Lin, X.; Zhu, L.; Niyato, D. Blockchains for Artificial Intelligence of Things: A Comprehensive Survey. IEEE Internet Things J. 2023, 10, 14483–14506. [Google Scholar] [CrossRef]
- Humayun, M.; Tariq, N.; Alfayad, M.; Zakwan, M.; Alwakid, G.; Assiri, M. Securing the Internet of Things in Artificial Intelligence Era: A Comprehensive Survey. IEEE Access 2024, 12, 25469–25490. [Google Scholar] [CrossRef]
- Torre, D.; Chennamaneni, A.; Jo, J.; Vyas, G.; Sabrsula, B. Toward Enhancing Privacy Preservation of a Federated Learning CNN Intrusion Detection System in IoT: Method and Empirical Study. ACM Trans. Softw. Eng. Methodol. 2025, 34, 1–48. [Google Scholar] [CrossRef]
- Goulart, A.; Chennamaneni, A.; Torre, D.; Hur, B.; Al-Aboosi, F.Y. On Wide-Area IoT Networks, Lightweight Security and Their Applications—A Practical Review. Electronics 2022, 11, 1762. [Google Scholar] [CrossRef]
- Ficili, I.; Giacobbe, M.; Tricomi, G.; Puliafito, A. From Sensors to Data Intelligence: Leveraging IoT, Cloud, and Edge Computing with AI. Sensors 2025, 25, 1763. [Google Scholar] [CrossRef] [PubMed]
- Sinha, S. State of IoT 2024; Technical Report; IoT Analytics GmbH: Hamburg, Germany, 2024. [Google Scholar]
- Xu, B.; Sun, L.; Mao, X.; Ding, R.; Liu, C. IoT Intrusion Detection System Based on Machine Learning. Electronics 2023, 12, 4289. [Google Scholar] [CrossRef]
- Tariq, N.; Asim, M.; Al-Obeidat, F.; Zubair Farooqi, M.; Baker, T.; Hammoudeh, M.; Ghafir, I. The Security of Big Data in Fog-Enabled IoT Applications Including Blockchain: A Survey. Sensors 2019, 19, 1788. [Google Scholar] [CrossRef]
- Khazane, H.; Ridouani, M.; Salahdine, F.; Kaabouch, N. A Holistic Review of Machine Learning Adversarial Attacks in IoT Networks. Future Internet 2024, 16, 32. [Google Scholar] [CrossRef]
- Rahman, M.; Al Shakil, S.; Mustakim, M.R. A survey on intrusion detection system in IoT networks. Cyber Secur. Appl. 2025, 3, 100082. [Google Scholar] [CrossRef]
- Kumar, S.V.N.S.; Selvi, M.; Kannan, A.; Doulamis, A.D. A Comprehensive Survey on Machine Learning-Based Intrusion Detection Systems for Secure Communication in Internet of Things. Comput. Intell. Neurosci. 2023, 2023, 8981988. [Google Scholar] [CrossRef]
- Abdulganiyu, O.H.; Tchakoucht, T.A.; Saheed, Y.K. A systematic literature review for network intrusion detection system (IDS). Int. J. Inf. Secur. 2023, 22, 1125–1162. [Google Scholar] [CrossRef]
- Mohy-Eddine, M.; Guezzaz, A.; Benkirane, S.; Azrour, M. An efficient network intrusion detection model for IoT security using K-NN classifier and feature selection. Multimedia Tools Appl. 2023, 82, 23615–23633. [Google Scholar] [CrossRef]
- Awajan, A. A Novel Deep Learning-Based Intrusion Detection System for IoT Networks. Computers 2023, 12, 34. [Google Scholar] [CrossRef]
- Muneer, S.; Farooq, U.; Athar, A.; Raza, M.A.; Ghazal, T.M.; Sakib, S.; Madhukumar, A.S. A Critical Review of Artificial Intelligence Based Approaches in Intrusion Detection: A Comprehensive Analysis. J. Eng. 2024, 2024, 3909173. [Google Scholar] [CrossRef]
- Sharma, B.; Sharma, L.; Lal, C.; Roy, S. Explainable artificial intelligence for intrusion detection in IoT networks: A deep learning based approach. Expert Syst. Appl. 2024, 238, 121751. [Google Scholar] [CrossRef]
- Ozkan-Okay, M.; Akin, E.; Aslan, Ö.; Kosunalp, S.; Iliev, T.; Stoyanov, I.; Beloev, I. A Comprehensive Survey: Evaluating the Efficiency of Artificial Intelligence and Machine Learning Techniques on Cyber Security Solutions. IEEE Access 2024, 12, 12229–12256. [Google Scholar] [CrossRef]
- Elghalhoud, O.; Naik, K.; Zaman, M.; Manzano, R. Data Balancing and CNN based Network Intrusion Detection System. In Proceedings of the 2023 IEEE Wireless Communications and Networking Conference (WCNC), Glasgow, UK, 26–29 March 2023; IEEE: New York, NY, USA; pp. 1–6. [Google Scholar]
- Aljumah, A. IoT-based intrusion detection system using convolution neural networks. PeerJ Comput. Sci. 2021, 7, e721. [Google Scholar] [CrossRef]
- Udurume, M.; Shakhov, V.; Koo, I. Comparative Analysis of Deep Convolutional Neural Network—Bidirectional Long Short-Term Memory and Machine Learning Methods in Intrusion Detection Systems. Appl. Sci. 2024, 14, 6967. [Google Scholar] [CrossRef]
- Phong, L.T.; Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-Preserving Deep Learning via Additively Homomorphic Encryption. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1333–1345. [Google Scholar] [CrossRef]
- Talpini, J.; Sartori, F.; Savi, M. Enhancing trustworthiness in ML-based network intrusion detection with uncertainty quantification. J. Reliab. Intell. Environ. 2024, 10, 501–520. [Google Scholar] [CrossRef]
- Sarantos, P.; Violos, J.; Leivadeas, A. Enabling semi-supervised learning in intrusion detection systems. J. Parallel Distrib. Comput. 2025, 196, 105010. [Google Scholar] [CrossRef]
- Sharmila, B.S.; Nagapadma, R. Quantized autoencoder (QAE) intrusion detection system for anomaly detection in resource-constrained IoT devices using RT-IoT2022 dataset. Cybersecurity 2023, 6, 1–15. [Google Scholar] [CrossRef]
- Neto, E.C.P.; Dadkhah, S.; Ferreira, R.; Zohourian, A.; Lu, R.; Ghorbani, A.A. CICIoT2023: A Real-Time Dataset and Benchmark for Large-Scale Attacks in IoT Environment. Sensors 2023, 23, 5941. [Google Scholar] [CrossRef]
- Dadkhah, S.; Neto, E.C.P.; Ferreira, R.; Molokwu, R.C.; Sadeghi, S.; Ghorbani, A.A. CICIoMT2024: A benchmark dataset for multi-protocol security assessment in IoMT. Internet Things 2024, 28, 101351. [Google Scholar] [CrossRef]
- Sama, N.U.; Ullah, S.; Kazmi, S.M.A.; Mazzara, M. Cutting-Edge Intrusion Detection in IoT Networks: A Focus on Ensemble Models. IEEE Access 2025, 13, 8375–8392. [Google Scholar] [CrossRef]
- Elzaghmouri, B.M.; Jbara, Y.H.F.; Elaiwat, S.; Innab, N.; Osman, A.A.F.; Ataelfadiel, M.A.M.; Zawaideh, F.H.; Alawneh, M.F.; Al-Khateeb, A.; Abu-Zanona, M. A Novel Hybrid Architecture for Superior IoT Threat Detection through Real IoT Environments. Comput. Mater. Contin. 2024, 81, 2299–2316. [Google Scholar] [CrossRef]
- Albalwy, F.; Almohaimeed, M. Advancing Artificial Intelligence of Things Security: Integrating Feature Selection and Deep Learning for Real-Time Intrusion Detection. Systems 2025, 13, 231. [Google Scholar] [CrossRef]
- Gheni, H.Q.; Al-Yaseen, W.L. Two-step data clustering for improved intrusion detection system using CICIoT2023 dataset. e-Prime 2024, 9, 100673. [Google Scholar] [CrossRef]
- Becerra-Suarez, F.L.; Tuesta-Monteza, V.A.; Mejia-Cabrera, H.I.; Arcila-Diaz, J. Performance Evaluation of Deep Learning Models for Classifying Cybersecurity Attacks in IoT Networks. Informatics 2024, 11, 32. [Google Scholar] [CrossRef]
- Erskine, S.K. Real-Time Large-Scale Intrusion Detection and Prevention System (IDPS) CICIoT Dataset Traffic Assessment Based on Deep Learning. Appl. Syst. Innov. 2025, 8, 52. [Google Scholar] [CrossRef]
- Shebl, A.; Elsedimy, E.I.; Ismail, A.; Salama, A.A.; Herajy, M. DCNN: A novel binary and multi-class network intrusion detection model via deep convolutional neural network. EURASIP J. Inf. Secur. 2024, 2024, 36. [Google Scholar] [CrossRef]
- Akar, G.; Sahmoud, S.; Onat, M.; Cavusoglu, Ü.; Malondo, E. L2D2: A Novel LSTM Model for Multi-Class Intrusion Detection Systems in the Era of IoMT. IEEE Access 2025, 13, 7002–7013. [Google Scholar] [CrossRef]
- Alqahtani, A.; Alsulami, A.A.; Alqahtani, N.; Alturki, B.; Alghamdi, B.M. A Comprehensive Security Framework for Asymmetrical IoT Network Environments to Monitor and Classify Cyberattack via Machine Learning. Symmetry 2024, 16, 1121. [Google Scholar] [CrossRef]
- Bajenaid, A.; Khemakhem, M.; Eassa, F.E.; Bourennani, F.; Qurashi, J.M.; Alsulami, A.A.; Alturki, B. Towards Robust SDN Security: A Comparative Analysis of Oversampling Techniques with ML and DL Classifiers. Electronics 2025, 14, 995. [Google Scholar] [CrossRef]
- Venne, S.; Clarkson, T.; Bennett, E.; Fischer, G.; Bakker, O.; Callaghan, R. Automated Ransomware Detection using Pattern-Entropy Segmentation Analysis: A Novel Approach to Network Security. Authorea 2024. [Google Scholar] [CrossRef]
- Zhang, K.; Wang, Y.; Li, O.; Hao, S.; He, J.; Lan, X.; Yang, J.; Ye, Y.; Zakariah, M. Improved self-training-based distant label denoising method for cybersecurity entity extractions. PLoS ONE 2024, 19, e0315479. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Year | Techniques | Datasets | Accuracy |
|---|---|---|---|---|
| [27] | 2024 | ERT, KNN, XGB, SVM, GB, DT and RF | RT-IoT2022 | ERT = 99.7% KNN = 99.4% XGB = 99.6% SVM = 99.2% GB = 99.6% DT = 99.5% RF = 99.6% |
| [28] | 2024 | BLSTM, GRU, and CNN | RT-IoT2022 | Proposed model = 99.62% |
| [29] | 2025 | GR, CFS, Pearson, SU, IG, PCA, ANN, TabNet and DNN | RT-IoT2022 | ANN + Pearson + PCA = 99.7% TabNet + Pearson + PCA = 99.3% DNN + Pearson + PCA = 99.6%. |
| [3] | 2025 | CNN | RT-IoT 2022, CIC IoT 2023, CIC IoMT 2024, TON-IoT, IoT-23, BoT-IoT, and EdgeIIoT. | Average accuracy of 99.47% on RT-IoT 2022 93.96% on CIC IoT 2023, 95.63% on CIC IoMT 2024 99.63% on the TON-IoT 99.99% on IoT-23 100.00% on BoT-IoT 89.12% on EdgeIIoT. |
| [30] | 2024 | GSK, MLP, and AE | CIC IoT 2023 | Binary classification: MLP = 99.26% AE = 98.76% Multi classification: MLP = 97.46% AE = 83.81% |
| [31] | 2024 | CNN, LSTM, and DNN | CIC IoT 2023 | CNN = 99.10% (multiclass) and 99.40% (binary). LSTM = 85.98% (multiclass) and 99.36% (binary). DNN = 99.02% (multiclass) and 99.38% (binary). |
| [32] | 2025 | DT, SVM, MLP, CNN, RNN and ANN | CIC IoT 2023 | DLMIDPSM achieves an accuracy rate of above 85% and a precision rate of 99%. |
| [26] | 2024 | ADA, LR, DNN, and RF | CICIoMT2024 | Accuracy of binary class: ADA = 99.6% LR = 99.5% DNN = 99.6% RF = 99.6% Multiclass: ADA = 42.2% LR = 72.7% DNN = 72.9% RF = 73.3% |
| [33] | 2024 | DCNN | CICIoT2023, CICIDS-2017 and CICIoMT2024 | Accuracy of binary and multiclass: CICIoT2023—99.5%( binary) and 99.25% (multiclass). CICIDS-2017—99.96% (binary) and 99.96% (multiclass). CICIoMT2024—99.98% (binary) and 99.86% (multiclass). |
| [34] | 2025 | LSTM | CICIoMT2024 | An accuracy rate of 98% |
| Class | Description | Benign/Attack |
|---|---|---|
| Thing Speak-LED | Controlling LED through ThingSpeak. | Benign |
| Wipro Bulb | A WiFi-enabled smart bulb communicating with a mobile device for remote control. | |
| MQTT Publish | MQTT protocol used in IoT communications. | |
| DoS SYN Hping | DoS SYN Flood attack generated using hping. | Attack |
| ARP Poisoning | Address Resolution Protocol (ARP) Spoofing attack. | |
| NMAP UDP Scan | An attack uses a UDP scan using Nmap, a network scanning tool. | |
| NMAP TCP Scan | An attack uses a TCP scan using Nmap, a network scanning tool. | |
| NMAP XMAS Tree Scan | Nmap XMAS tree scan attack. | |
| NMAP OS Detection | An attack using Nmap’s OS detection scan. | |
| NMAP FIN Scan | Nmap FIN scan attack. | |
| DDoS Slow Loris | DDoS attack using Slow Loris. | |
| Metasploit Brute-Force SSH | Brute-Force attack on SSH login using Metasploit. |
| Category | Subcategory | Description |
|---|---|---|
| Benign Traffic | - | Normal IoT traffic |
| DDoS | RST FIN Flood | Sends a tremendous number of packets with RST and FIN flags to exhaust system resources. |
| ICMP Fragmentation | Sends fragmented ICMP packets to overwhelm parsing systems. | |
| PSHACK Flood | Uses PUSH and ACK TCP flags in high volume to exhaust resources. | |
| TCP Flood | Overwhelms a target with TCP packets to exhaust system resources. | |
| UDP Fragmentation | Uses large, fragmented UDP packets to consume bandwidth. | |
| UDP Flood | Overwhelms a target with UDP packets to exhaust system resources. | |
| SYN Flood | Floods with TCP SYN packets without completing handshakes, exhausting connections. | |
| HTTP Flood | Floods HTTP requests targeting application layer servers. | |
| ACK Fragmentation | Uses fragmented ACK packets to bypass security and exhaust resources. | |
| ICMP Flood | Floods with ICMP (ping) packets to exhaust connections. | |
| Synonymous IP Flood | Sends spoofed TCP SYN packets with identical source/destination IPs to drain resources. | |
| Slow Loris | Keeps connections open by sending partial HTTP requests and exhausting web server resources. | |
| Reconnaissance | Host Discovery | Scans the network to find active hosts. |
| OS Scan | Attempts to determine the operating system of a host. | |
| Vulnerability Scan | Uses automated tools to identify weaknesses in hosts | |
| Port Scan | Identifies open ports on devices | |
| Ping Sweep | Send ICMP (ping) requests across a subnet to detect live hosts. | |
| Spoofing | DNS Spoofing | Alters DNS responses to redirect victims to malicious sites. |
| MITM ARP Spoofing | Sends fake ARP messages to intercept traffic between devices | |
| DoS | TCP Flood | Uses a single source to overwhelm the target by sending a high volume of TCP packets. |
| UDP Flood | Uses a single source to overwhelm the target by sending a high volume of UDP packets. | |
| HTTP Flood | A single source sends excessive HTTP requests. | |
| SYN Flood | A single source SYN flood targeting TCP handshakes. | |
| Mirai | Greip Flood | Uses GRE protocol with spoofed IPs to flood a victim. |
| UDP Plain | Send repetitive UDP packets to disrupt targets. | |
| Greeth Flood | Floods using GRE packets with Ethernet header spoofing. | |
| Brute-Force | Dictionary Brute-Force | Attempts to guess credentials using a dictionary of common passwords. |
| Web-Based | SQL Injection | Injects malicious SQL into input fields to manipulate databases. |
| Command Injection | Executes system-level commands through vulnerable input. | |
| Uploading Attack | Uploads malicious files to exploit vulnerable servers. | |
| XSS | Inject scripts into web pages to steal data or hijack sessions. | |
| Browser Hijacking | Modifies browser settings to redirect traffic or display ads. | |
| Backdoor Malware | Installs software to maintain unauthorized access. |
| Category | Subcategory | Description |
|---|---|---|
| Benign Traffic | - | Normal IoT traffic |
| DDoS | SYN Flood | Described in CICIoT2023 |
| ICMP Flood | Described in CICIoT2023 | |
| UDP Flood | Described in CICIoT2023 | |
| Reconnaissance | Ping Sweep | Described in CICIoT2023 |
| Vulnerability Scan | Described in CICIoT2023 | |
| OS Scan | Described in CICIoT2023 | |
| Port Scan | Described in CICIoT2023 | |
| MQTT | Malformed Data | Sends corrupted MQTT packets to crash the broker. |
| DoS Publish Flood | Publishes large volumes of messages to MQTT topics from one device. | |
| DDoS Publish Flood | Publishes large volumes of messages to MQTT topics on multiple devices. | |
| Spoofing | ARP Spoofing | Sends falsified ARP messages to redirect traffic through a malicious device. |
| Dataset | Number of Classes | Min Possible Entropy Value | Max Possible Entropy Value |
|---|---|---|---|
| RT-IoT2022 | 12 | ~0.0 | ~3.58 |
| CICIoT2023 | 34 | ~0.0 | ~5.09 |
| CICIoMT2024 | 12 | ~0.0 | ~3.58 |
| Model | Selected Entropy Threshold | ||
|---|---|---|---|
| RT-IoT2022 | CICIoT2023 | CICIoMT2024 | |
| DT | 0.008 | 0.0171 | 0.0952 |
| GBC | 0.1081 | 0.7916 | 0.3995 |
| RF | 0.0407 | 1.0545 | 0.1207 |
| XGBoost | 0.0188 | 0.5584 | 0.1665 |
| XRT | 0.0368 | 0.8088 | 0.2529 |
| Model | Selected Entropy Threshold | Supervised Training (Certain Predictions Accuracy) | Semi-Supervised Retraining (Overall Accuracy) |
|---|---|---|---|
| DT | 0.0080 | 1.00 | 1.00 |
| GBC | 0.1081 | 1.00 | 0.99 |
| RF | 0.0407 | 1.00 | 0.97 |
| XGBoost | 0.0188 | 1.00 | 0.99 |
| XRT | 0.0368 | 1.00 | 0.97 |
| Model | Selected Entropy Threshold | Supervised Training (Certain Predictions Accuracy) | Semi-Supervised Retraining (Overall Accuracy) |
|---|---|---|---|
| DT | 0.0171 | 0.92 | 0.92 |
| GBC | 0.7916 | 1.00 | 0.89 |
| RF | 1.0545 | 0.96 | 0.85 |
| XGBoost | 0.5584 | 1.00 | 0.93 |
| XRT | 0.8088 | 0.99 | 0.93 |
| Model | Selected Entropy Threshold | Supervised Training (Certain Predictions Accuracy) | Semi-Supervised Retraining (Overall Accuracy) |
|---|---|---|---|
| DT | 0.0952 | 0.98 | 0.96 |
| GBC | 0.3995 | 1.00 | 0.94 |
| RF | 0.1207 | 1.00 | 0.98 |
| XGBoost | 0.1665 | 1.00 | 0.97 |
| XRT | 0.2529 | 1.00 | 0.91 |
| Model | RT-IoT2022 | CICIoT2023 | CICIoMT2024 |
|---|---|---|---|
| DT | 0.9987 | 0.9259 | 0.9770 |
| GBC | 0.9956 | 0.90 | 0.97 |
| RF | 0.9584 | 0.8488 | 0.8895 |
| XGBoost | 0.9951 | 0.9277 | 0.9759 |
| XRT | 0.9763 | 0.9344 | 0.9043 |
| Work | Year | Techniques | Dataset | Classification Type | Training Type | Best Reported Accuracy |
|---|---|---|---|---|---|---|
| [27] | 2024 | ERT, KNN, XGB, SVM, GB, DT, RF | RT-IoT2022 | Multiclass | Supervised | Accuracy of 99.7% (ERT), F1-Scores of 95% (XGBoost and RF). |
| [28] | 2024 | BLSTM, GRU, CNN | RT-IoT2022 | Multiclass | Deep Learning | Accuracy of 99.62%, F1-scores of 99.61% |
| [29] | 2025 | ANN, TabNet, DNN + PCA + FS | RT-IoT2022 | Multiclass | Deep Learning | Accuracy of 99.7%, F1-scores of 99.6% |
| [3] | 2025 | CNN | RT-IoT2022, CICIoT2023, CICIoMT2024 | Multiclass | Deep Learning | Accuracy of 99.47%—F1-scores of 97.31% (RT); Accuracy of 93.96%—F1-scores of 77.63% (CICIoT); Accuracy of 95.63%—F1-scores of 95.16% (CICIoMT) |
| [30] | 2024 | GSK, MLP, AE | CICIoT2023 | Binary, Multiclass | Deep Learning | Accuracy of 97.46%, F1-scores of 97% (multiclass) |
| [31] | 2024 | CNN, LSTM, DNN | CICIoT2023 | Binary, Multiclass | Deep Learning | Accuracy of CNN = 99.10%, DNN = 99.02%, LSTM = 85.98% F1-scores of CNN = 99.05%, DNN = 98.95%, LSTM = 84.03% (Multiclass) |
| [32] | 2025 | DT, SVM, MLP, CNN, RNN, ANN | CICIoT2023 | Binary, Multiclass | Deep Learning | >85% |
| [26] | 2024 | ADA, LR, DNN, RF | CICIoMT2024 | Binary, Multiclass | Machine Learning | Accuracy of 73.3%, F1-scores of 55.1% (multiclass, RF) |
| [33] | 2024 | DCNN | CICIoT2023, CICIoMT2024 | Binary, Multiclass | Deep Learning | Accuracy and F1-scores of 99.25% (CICIoT), Accuracy and F1-scores of 99.86% (CICIoMT) (multiclass) |
| [34] | 2025 | LSTM | CICIoMT2024 | Binary, Multiclass | Deep Learning | Accuracy and F1-scores of 98% |
| (Proposed) | 2025 | Semi-Supervised Tree-Based + Entropy Filtering | RT-IoT2022, CICIoT2023, CICIoMT2024 | Multiclass | Semi-Supervised | RT-IoT2022: 100% (DT), 99% (XGB) CICIoT2023: 93% (XGB/XRT) CICIoMT2024: 98% (RF), 98% (XGB) |
| Model | Time in Microseconds |
|---|---|
| DT | 0.15 |
| GBC | 17.35 |
| RF | 12.51 |
| XGBoost | 6.04 |
| XRT | 15.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alturki, B.; Alsulami, A.A. Semi-Supervised Learning with Entropy Filtering for Intrusion Detection in Asymmetrical IoT Systems. Symmetry 2025, 17, 973. https://doi.org/10.3390/sym17060973
Alturki B, Alsulami AA. Semi-Supervised Learning with Entropy Filtering for Intrusion Detection in Asymmetrical IoT Systems. Symmetry. 2025; 17(6):973. https://doi.org/10.3390/sym17060973
Chicago/Turabian StyleAlturki, Badraddin, and Abdulaziz A. Alsulami. 2025. "Semi-Supervised Learning with Entropy Filtering for Intrusion Detection in Asymmetrical IoT Systems" Symmetry 17, no. 6: 973. https://doi.org/10.3390/sym17060973
APA StyleAlturki, B., & Alsulami, A. A. (2025). Semi-Supervised Learning with Entropy Filtering for Intrusion Detection in Asymmetrical IoT Systems. Symmetry, 17(6), 973. https://doi.org/10.3390/sym17060973