
An Intrusion Detection Method Based on Symmetric Federated Deep Learning in Complex Networks

Abstract
1. Introduction
2. Related Work
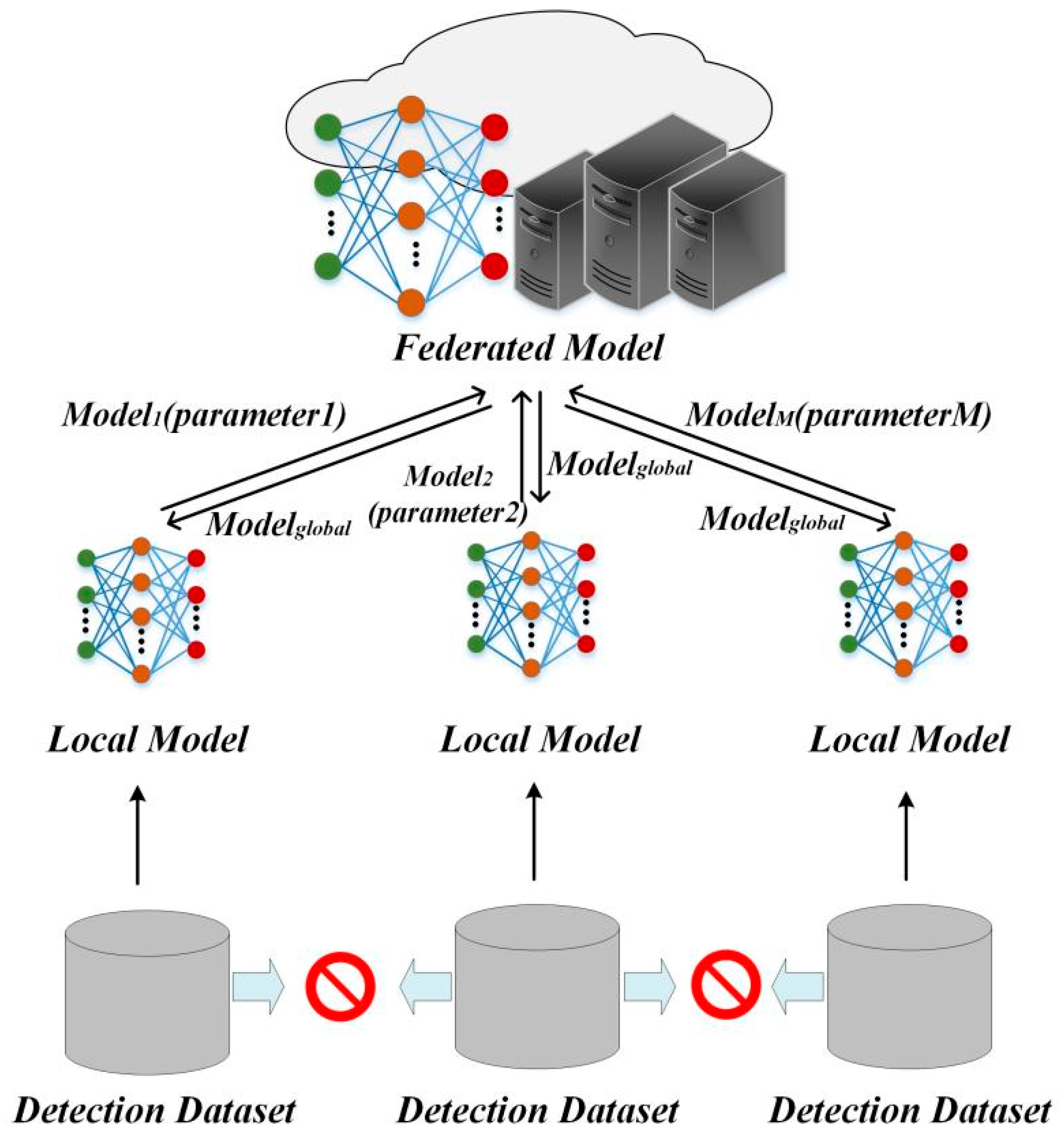
3. System Architecture
4. IDS Method
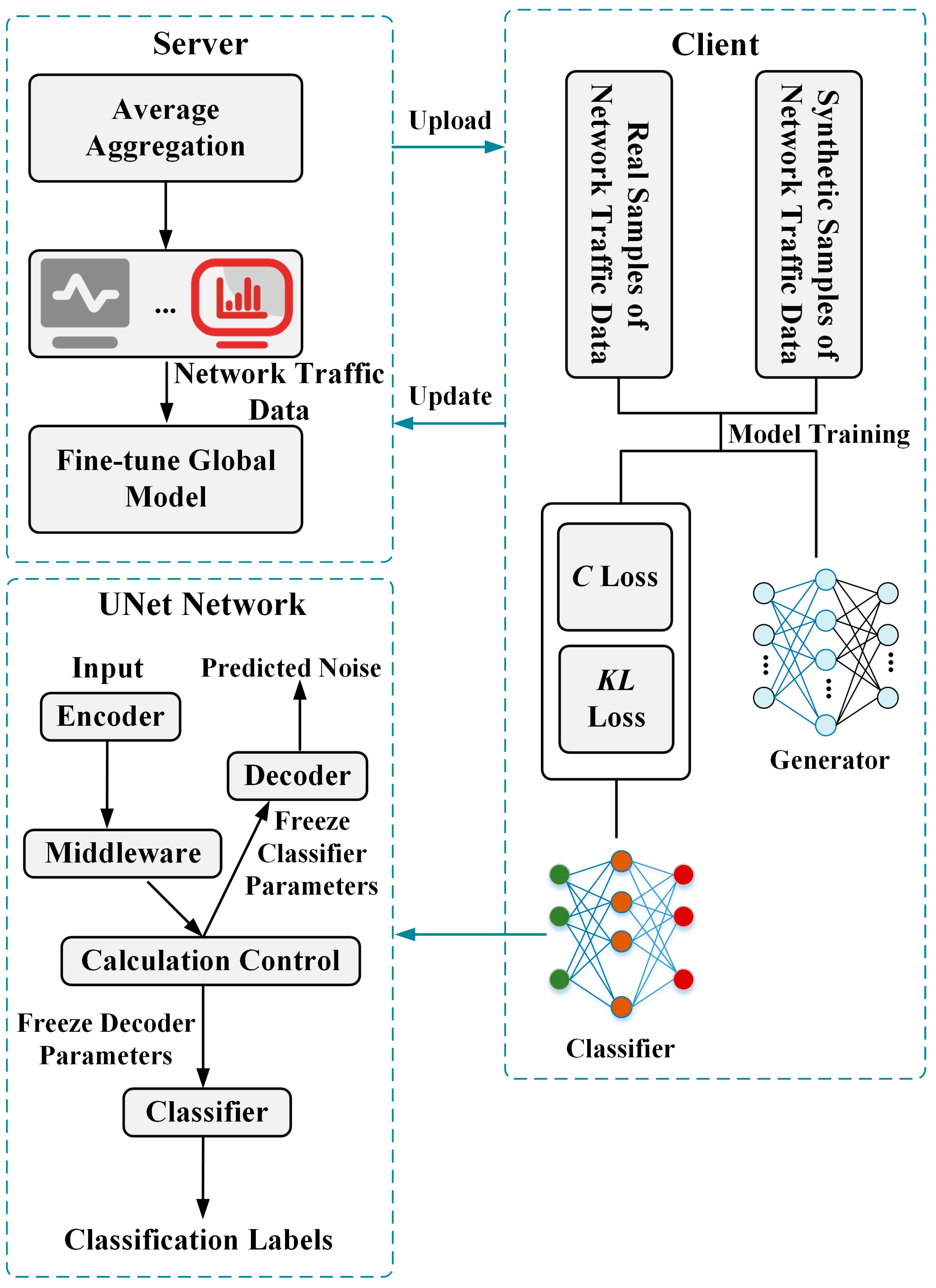
4.1. Symmetric Deep Learning
- Given a time step lh, add noise to the original traffic data d0 to generate data d1.
- Calculate the loss: Use the current UNet network parameters to predict the noise and calculate the loss between the predicted noise and the actual added noise, that is, , where is the parameter of the UNet network except for the “classifier” module, is the image after adding noise at step lh, and l is the category label.
- Backpropagation and parameter update: Calculate the gradient through backpropagation and update the network parameters using the optimizer.
- Repeat the above steps until the predetermined number of training rounds is reached. The goal is to optimize the UNet network’s ability to predict noise and learn richer feature representations of the images.
4.2. Federated Knowledge Distillation Algorithm
4.3. Discussion
- Explore symmetric networks to optimize network intrusion detection
- Explore federated learning to optimize network intrusion detection
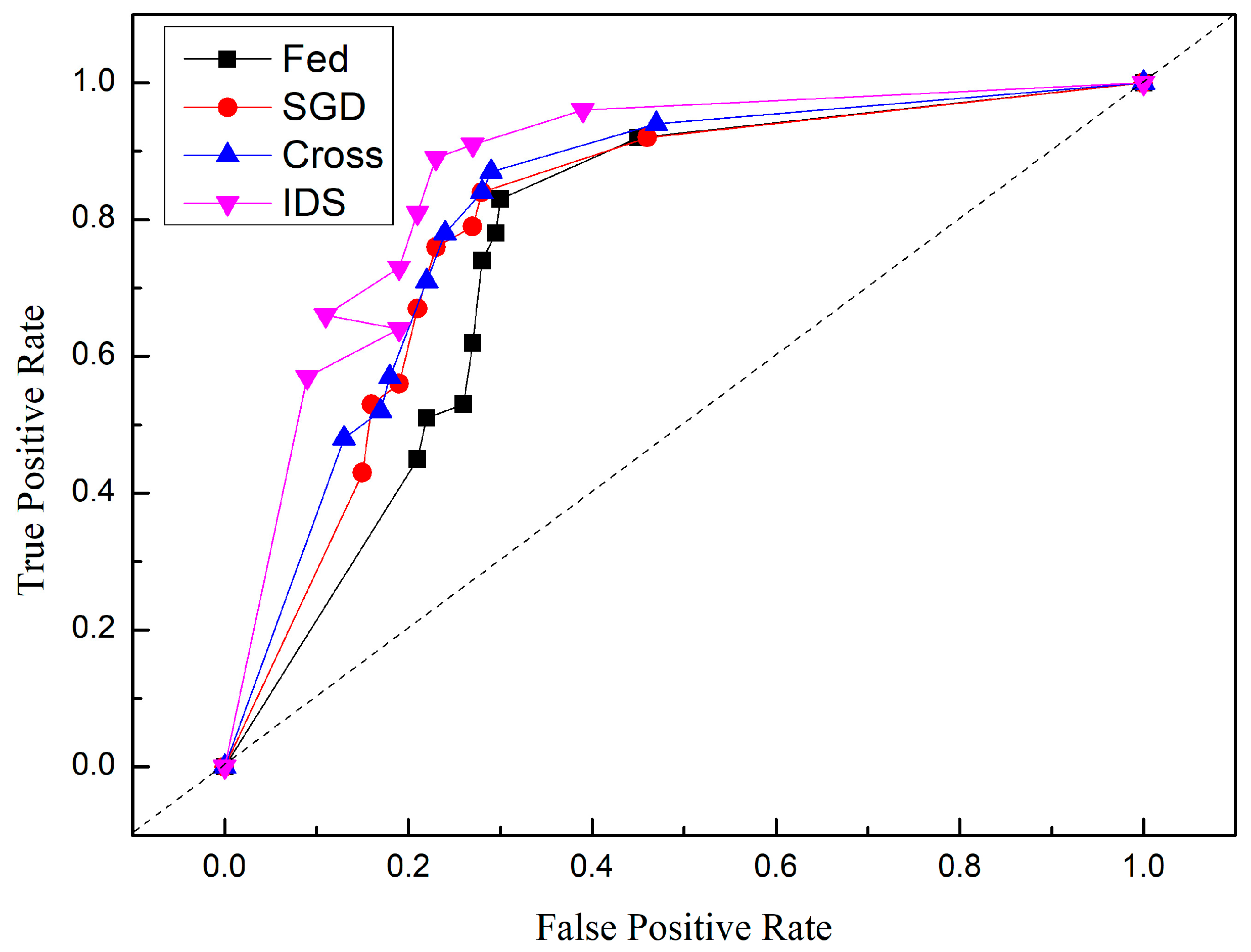
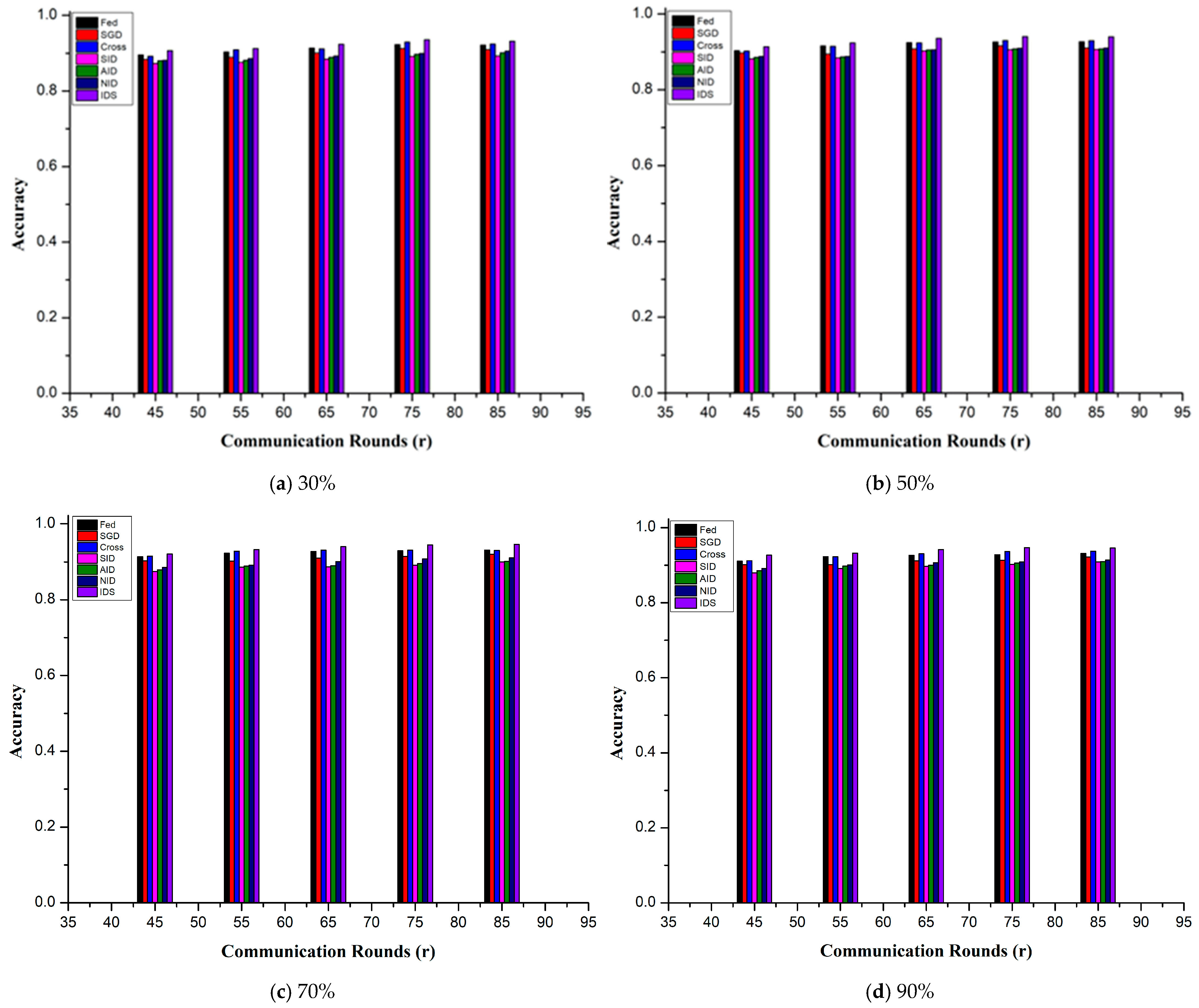
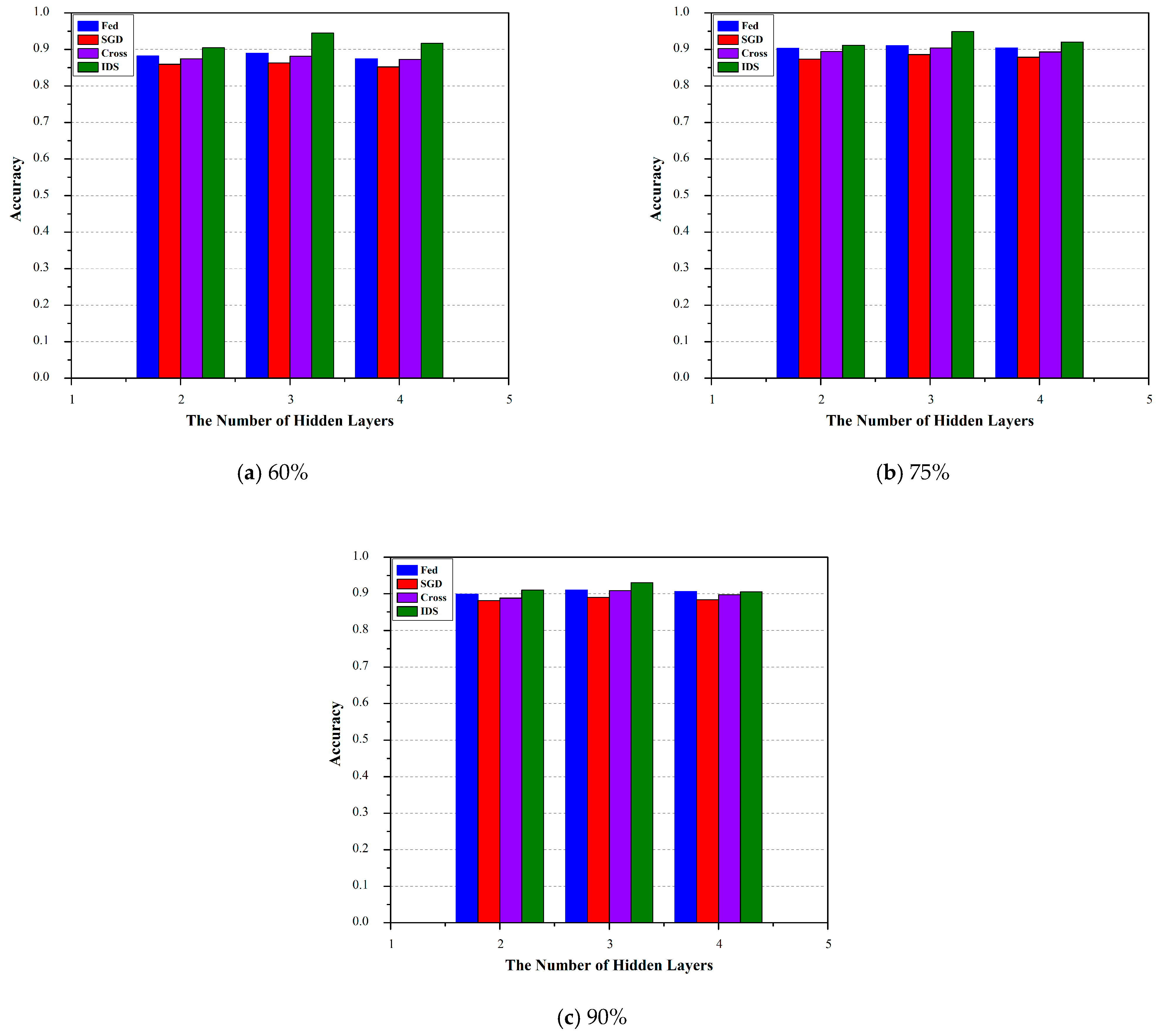
5. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Khan, M.; Ghafoor, L. Adversarial Machine Learning in the Context of Network Security: Challenges and Solutions. J. Comput. Intell. Robot. 2024, 4, 51–63. [Google Scholar]
- Nazir, R.; Laghari, A.A.; Kumar, K.; David, S.; Ali, M. Survey on wireless network security. Arch. Comput. Methods Eng. 2022, 29, 1591–1610. [Google Scholar] [CrossRef]
- Bakhsh, A.; Khan, M.A.; Ahmed, F.; Alshehri, M.S.; Ali, H.; Ahmad, J. Enhancing IoT network security through deep learning-powered Intrusion Detection System. Internet Things 2023, 24, 100936. [Google Scholar] [CrossRef]
- Fang, W.; Tan, X.; Wilbur, D. Application of intrusion detection technology in network safety based on machine learning. Saf. Sci. 2020, 124, 104604. [Google Scholar] [CrossRef]
- Liang, W.; Xiao, L.; Zhang, K.; Tang, M.; He, D.; Li, K.-C. Data fusion approach for collaborative anomaly intrusion detection in blockchain-based systems. IEEE Internet Things J. 2021, 9, 14741–14751. [Google Scholar] [CrossRef]
- Shayganmehr, M.; Kumar, A.; Luthra, S.; Garza-Reyes, J.A. A framework for assessing sustainability in multi-tier supply chains using empirical evidence and fuzzy expert system. J. Clean. Prod. 2021, 317, 128302. [Google Scholar] [CrossRef]
- Goel, A.; Goel, A.K.; Kumar, A. The role of artificial neural network and machine learning in utilizing spatial information. Spat. Inf. Res. 2023, 31, 275–285. [Google Scholar] [CrossRef]
- Liaqat, S.; Dashtipour, K.; Arshad, K.; Assaleh, K.; Ramzan, N. A hybrid posture detection framework: Integrating machine learning and deep neural networks. IEEE Sens. J. 2021, 21, 9515–9522. [Google Scholar] [CrossRef]
- Dong, S.; Wang, X.; Abbas, K. A survey on deep learning and its applications. Comput. Sci. Rev. 2021, 40, 100379. [Google Scholar] [CrossRef]
- Kan, X.; Fan, Y.; Fang, Z.; Cao, L.; Xiong, N.N.; Yang, D.; Li, X. A novel IoT network intrusion detection approach based on adaptive particle swarm optimization convolutional neural network. Inf. Sci. 2021, 568, 147–162. [Google Scholar] [CrossRef]
- Zhang, Z.; Tao, X.; Xiong, X. A Research of Investment Cooperation Mechanism of Network Intrusion Detection and Defense Subsystems in the Supply Chain. Ind. Eng. J. 2019, 22, 1. [Google Scholar]
- Oliveira, N.; Praça, I.; Maia, E.; Sousa, O. Intelligent cyber attack detection and classification for network-based intrusion detection systems. Appl. Sci. 2021, 11, 1674. [Google Scholar] [CrossRef]
- Kumar, R.; Kumar, P.; Tripathi, R.; Gupta, G.P.; Garg, S.; Hassan, M.M. A distributed intrusion detection system to detect DDoS attacks in blockchain-enabled IoT network. J. Parallel Distrib. Comput. 2022, 164, 55–68. [Google Scholar] [CrossRef]
- Kunang, Y.N.; Nurmaini, S.; Stiawan, D.; Suprapto, B.Y. Attack classification of an intrusion detection system using deep learning and hyperparameter optimization. J. Inf. Secur. Appl. 2021, 58, 102804. [Google Scholar] [CrossRef]
- Pinto, A.; Herrera, L.-C.; Donoso, Y.; Gutierrez, J.A. Survey on intrusion detection systems based on machine learning techniques for the protection of critical infrastructure. Sensors 2023, 23, 2415. [Google Scholar] [CrossRef] [PubMed]
- Thirimanne, S.P.; Jayawardana, L.; Yasakethu, L.; Liyanaarachchi, P.; Hewage, C. Deep neural network based real-time intrusion detection system. SN Comput. Sci. 2022, 3, 145. [Google Scholar] [CrossRef]
- Long, Y.-S.; Zhai, Z.-M.; Tang, M.; Liu, Y.; Lai, Y.-C. A rigorous and efficient approach to finding and quantifying symmetries in complex networks. arXiv 2021, arXiv:2108.02597. [Google Scholar]
- Kontoyiannis, I.; Lim, Y.H.; Papakonstantinopoulou, K.; Szpankowski, W. Symmetry and the entropy of small-world structures and graphs. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 12–20 July 2021; pp. 3026–3031. [Google Scholar]
- Smidt, T.E.; Geiger, M.; Miller, B.K. Finding symmetry breaking order parameters with euclidean neural networks. Phys. Rev. Res. 2021, 3, L012002. [Google Scholar] [CrossRef]
- Dervisevic, E.; Tankovic, A.; Fazel, E.; Kompella, R.; Fazio, P.; Voznak, M.; Mehic, M. Quantum Key Distribution Networks-Key Management: A Survey. ACM Comput. Surv. 2025, 57, 1–36. [Google Scholar] [CrossRef]
- Kapoor, J.; Thakur, D. Analysis of symmetric and asymmetric key algorithms. In ICT Analysis and Applications; Springer: Singapore, 2022; pp. 133–143. [Google Scholar]
- Liu, Z.; Luo, X.; Zhou, M. Symmetry and graph bi-regularized non-negative matrix factorization for precise community detection. IEEE Trans. Autom. Sci. Eng. 2023, 21, 1406–1420. [Google Scholar] [CrossRef]
- Yaqoob, M.M.; Alsulami, M.; Khan, M.A.; Alsadie, D.; Saudagar, A.K.J.; AlKhathami, M.; Khattak, U.F. Symmetry in privacy-based healthcare: A review of skin cancer detection and classification using federated learning. Symmetry 2023, 15, 1369. [Google Scholar] [CrossRef]
- Pan, Z.; Wu, Q.; Jiang, H.; Xia, M.; Luo, X.; Zhang, J.; Lin, Q.; Rühle, V.; Yang, Y.; Lin, C.Y.; et al. Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. arXiv 2024, arXiv:2403.12968. [Google Scholar]
- Shin, H.; Choi, D.-W. Teacher as a lenient expert: Teacher-agnostic data-free knowledge distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 14991–14999. [Google Scholar]
- Ni, J.; Liu, Z.; Wang, S.; Xi, M.; XI, W. TimeDistill: Efficient Long-Term Time Series Forecasting with MLP via Cross-Architecture Distillation. arXiv 2025, arXiv:2502.15016. [Google Scholar]
- Sallam, Y.F.; El-Nabi, S.A.; El-Shafai, W.; Ahmed, H.E.-D.H.; Saleeb, A.; El-Bahnasawy, N.A.; El-Samie, F.E.A. Efficient implementation of image representation, visual geometry group with 19 layers and residual network with 152 layers for intrusion detection from UNSW-NB15 dataset. Secur. Priv. 2023, 6, e300. [Google Scholar] [CrossRef]
- Al-Daweri, M.S.; Ariffin, K.A.Z.; Abdullah, S.; Senan, M.F.E.M. An analysis of the KDD99 and UNSW-NB15 datasets for the intrusion detection system. Symmetry 2020, 12, 1666. [Google Scholar] [CrossRef]
- Abrar, I.; Ayub, Z.; Masoodi, F.; Bamhdi, A.M. A machine learning approach for intrusion detection system on NSL-KDD dataset. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020; pp. 919–924. [Google Scholar]
- Ditcheva, B.; Fowler, L. Signature-based Intrusion Detection; University of North Carolina: Chapel Hill, NC, USA, 2005. [Google Scholar]
- Jyothsna, V.; Prasad, V.V.R. A review of anomaly based intrusion detection systems. Int. J. Comput. Appl. 2011, 28, 26–35. [Google Scholar] [CrossRef]
- Vigna, G.; Kemmerer, R.A. NetSTAT: A network-based intrusion detection system. J. Comput. Secur. 1999, 7, 37–71. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Amount of Data | Normal Sample (%) | Traffic Class | Number of Features |
|---|---|---|---|---|
| UNSW-NB15 | 700,001 | 96.83 | 10 | 43 |
| NSL-KDD | 48,517 | 51.88 | 5 | 41 |
| Indexes | Calculation Formulas |
|---|---|
| Precision | |
| Recall | |
| F-measure | |
| Accuracy |
| The Number of Rounds of Federated Learning | p | R | F | A |
|---|---|---|---|---|
| 25 | 0.5778 | 0.5652 | 0.5714 | 0.5142 |
| 30 | 0.6383 | 0.6250 | 0.6316 | 0.5749 |
| 35 | 0.7447 | 0.7292 | 0.7369 | 0.6964 |
| 40 | 0.7660 | 0.7500 | 0.7579 | 0.7206 |
| Metrics | Training Time | Testing Time | Response Time | |
|---|---|---|---|---|
| Data Size | ||||
| 30% | 30.2 min | 6.9 s | 9.7 s | |
| 50% | 42.7 min | 7.7 s | 11.3 s | |
| 70% | 51.6 min | 9.1 s | 12.9 s | |
| 90% | 58.5 min | 10.2 s | 14.4 s | |
| Prediction | Normal | DoS | Probe | R2L | U2R | |
|---|---|---|---|---|---|---|
| Actual Value | ||||||
| Normal | 9691 | 20 | 0 | 0 | 0 | |
| DoS | 0 | 5678 | 42 | 17 | 4 | |
| Probe | 0 | 32 | 1055 | 12 | 7 | |
| R2L | 13 | 11 | 207 | 1957 | 9 | |
| U2R | 0 | 0 | 5 | 13 | 19 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Ren, X.; Wu, C. An Intrusion Detection Method Based on Symmetric Federated Deep Learning in Complex Networks. Symmetry 2025, 17, 952. https://doi.org/10.3390/sym17060952
Wang L, Ren X, Wu C. An Intrusion Detection Method Based on Symmetric Federated Deep Learning in Complex Networks. Symmetry. 2025; 17(6):952. https://doi.org/10.3390/sym17060952
Chicago/Turabian StyleWang, Lei, Xuanrui Ren, and Chunyi Wu. 2025. "An Intrusion Detection Method Based on Symmetric Federated Deep Learning in Complex Networks" Symmetry 17, no. 6: 952. https://doi.org/10.3390/sym17060952
APA StyleWang, L., Ren, X., & Wu, C. (2025). An Intrusion Detection Method Based on Symmetric Federated Deep Learning in Complex Networks. Symmetry, 17(6), 952. https://doi.org/10.3390/sym17060952