1. Introduction
Research on flexible distributions capable of capturing skewness, multimodality, and heavier tails has gained increasing attention in the statistical literature, primarily because traditional normal-based models do not always provide an adequate fit for real-life data. Such endeavors seek to account for diverse distributional shapes, particularly in scenarios with marked skewness or the presence of more than one mode, while maintaining analytical tractability and theoretical coherence. In line with these motivations, the current research proposes the asymmetric double normal (ADN) distribution as a unifying construction to handle asymmetry and potential bimodality in both theoretical investigations and applied statistical modeling.
Before the advent of more comprehensive distributions, the skew-normal model represented one of the main solutions to capture asymmetric data while retaining a normal-like core structure. However, the skew-normal distribution often proved insufficient when the data exhibited more complex patterns, such as heavy tails or multiple modes. Consequently, multiple families of extended normal distributions have been formulated with varying degrees of flexibility. For instance, the two-piece extension of the normal distribution was studied to relax the symmetry constraint by splitting the normal density at a certain threshold and allowing each side to have distinct parameters. These two-piece constructions can be particularly effective for moderate asymmetry but might struggle to capture marked bimodality.
Another prominent line of work involves the introduction of folded- or half-normal transformations. Early foundational work on the folded-normal distribution, such as that by Leone et al. [
1], explored its basic properties and estimation techniques. More recently, Tsagris et al. [
2] derived characteristic functions, moments, asymptotic inference, and bootstrap confidence intervals for this distribution. These developments underscore the continuing need for adjustments to the classical normal framework in scenarios involving non-negative quantities or pronounced deviations from symmetric behavior. However, folded transformations focus predominantly on data restricted to particular domains (e.g., positive real line), limiting their utility for more general datasets prone to both skewness and potential bimodality.
Bimodality, a critical feature in many real-life datasets (e.g. biomedical markers or athletic performance metrics), has spurred further extensions of the normal paradigm. Salinas et al. [
3] proposed the symmetric bimodal two-piece normal (TN) distribution. On a related front, Elal-Olivero et al. [
4] developed a family of bimodal skew-normal models, where a skewness parameter allows the model to transition smoothly between unimodal and bimodal shapes. This construction behaves conceptually as a skewed mixture of symmetric distributions. In Bayesian and frequentist contexts, these formulations have demonstrated robust performance in settings where data exhibit significant tail asymmetry or splitting across two separate regions of concentration. Despite these innovations, model complexity and identifiability can impose practical limitations when implementing mixture-like distributions for certain finite-sample applications.
Additional contributions emerge from slash-type distributions, exemplified by the folded-normal slash distribution of Gui et al. [
5]. Their model builds upon the absolute value of a normal random variable combined with a power of the uniform distribution to capture heavier-tail behavior in non-negative observations. Although suitable for right-skewed data, slash families do not inherently address bimodality, highlighting the importance of a unifying approach that can simultaneously account for skewness and the possibility of two modes.
Recent explorations into two-piece distributions illuminate an alternative to mixture-based or exponentiated transformations. These approaches focus on a strategic splitting mechanism that allows distinct distributional properties on either side of a cutoff point. Such families, often characterized by a shape parameter that governs transitions between unimodality and bimodality, can even revert to the normal distribution in special cases. Notably, these constructions demonstrate how a parameter controlling curvature or skewness can introduce multimodal phenomena without invoking discrete mixing. Because two-piece structures often remain analytically tractable, especially with regard to cumulative distribution functions, likelihood-based parameter estimation, and regression, these methods suggest a template for more general double-asymmetric formulations.
The ADN framework adapts the foundational insights from two-piece modeling and skew-elliptical approaches, but expands the flexibility to accommodate pronounced asymmetry on both tails, along with the potential for bimodality. The need for such flexible models is evident in various fields; for instance, in economics, income distributions often exhibit significant skewness and can occasionally present bimodality reflecting different population subgroups [
6], while in biostatistics, the distribution of certain biomarkers or physiological measurements can be asymmetrically distributed and present multiple modes indicative of different health statuses or responses to treatment [
7]. The development of the ADN distribution responds to limitations identified in previous skew-normal or mixture-based families when faced with such complex data structures, while ensuring that methods such as maximum likelihood maintain validity in finite and large-sample conditions. Moreover, because earlier work emphasizes that different distributions can be nested or specialized cases of broader families (Elal-Olivero et al. [
4]; Bolfarine et al. [
8]), the ADN distribution is conceived to encompass normal and skew-normal forms as boundary or limiting instances.
The central objective of this research is to formalize the ADN distribution, defining its probability density function (PDF), the cumulative distribution function (CDF), and its principal theoretical properties. This work addresses the need for univariate models capable of flexibly and parsimoniously capturing both asymmetry and potential bimodality, characteristics frequently observed in real-world datasets where standard normal or skew-normal distributions may prove insufficient, and simpler alternatives to complex mixture models are desired. By incorporating dual-shape parameters, the ADN distribution aims to capture left- and right-sided asymmetry and, depending on their interplay, produce unimodal or bimodal contours. Such a dual-purpose construction provides a natural and analytically tractable alternative to existing skewed models or mixtures of distributions to handle data with these complex features.
In previous studies involving real-life datasets, it was emphasized that skew families and two-piece distributions can perform exceptionally well out of sample, especially when data deviate from normality (Bolfarine et al. [
8]; Arnold et al. [
9]). The study aims to further evaluate the ADN distribution within medical and sports datasets, particularly focusing on those with bimodal or highly skewed distributions. Through these assessments, we demonstrate not just the practical adaptability of the ADN distribution but also its ability to maintain a streamlined parameterization compared to traditional mixture models.
Moreover, this research seeks to extend the application of the ADN distribution to regression scenarios, where the assumption of normal error terms often falls short. By integrating ADN errors into linear or generalized linear models, we aim to provide a more accurate depiction of real-life phenomena characterized by elongated tails, asymmetric behavior, or bimodal patterns within residual distributions. By utilizing inference methods similar to those developed for classical normal theory, but modified to include shape parameters, ADN has the potential to broaden the horizons of parametric regression modeling.
Before introducing the stochastic representation of the new ADN variable, we first define some well-known distributions in the existing literature.
Definition 1. The skew-normal distribution (Azzalini [10]) is a natural extension of the normal distribution, introducing a skewness parameter that allows for modeling asymmetric data. The PDF of a random variable X, denoted as , is given bywhere ϕ and Φ
are the PDF and CDF of (the standard normal distribution), respectively. The folded-normal distribution (FN), originally proposed by Leone et al. [
1], extends the normal distribution by taking the absolute value of the standard normal random variable. It is defined by its location and scale parameters and has been widely studied for its references in asymmetric data modeling. This distribution is widely recognized for its utility in modeling asymmetric data, particularly in applications where only the magnitude of the data is of interest, such as reliability studies, survival analysis, and signal processing. Its moments, skewness, and kurtosis have been extensively studied, providing a foundation for both theoretical and applied work.
Definition 2. The folded-normal distribution with parameters defines the distribution of the random variable , where U is normally distributed with mean μ and variance . The PDF of Y is Using a convenient reparameterization by , where , the PDF can be expressed as another version, denoted ; then,where ϕ is the PDF of the standard normal distribution. Remark 1. Let ; the PDF can be expressed as 2. The Family of Uni/Bimodal Densities
In this section, we introduce a new class of distributions, termed the asymmetric double normal distribution, designed to model data with varying degrees of asymmetry, and this takes us to bimodality as another feature. This flexible distributional family provides a valuable alternative to existing asymmetric bimodal distributions in the literature. We also explore the unimodality and bimodality properties of this distribution, presenting key results and insights to analyze the variability of different data types in unimodal and bimodal scenarios, thus capturing diverse patterns commonly observed in real-life datasets.
Definition 3. It is said that the random variable has an asymmetric double normal distribution with parameters α and λ, denoted by , if its PDF is given bywhere is given in Equation (
1).
The ADN distribution generalizes the skew-normal and two-piece normal distributions, combining parameters ( for shape, for skewness) to capture both unimodal and bimodal behaviors. Hence, the ADN provides a uniform framework for switching between symmetric, skewed, and bimodal scenarios by including the normal, skew-normal, and folded normal distributions as special cases. Its versatility enables it to simulate real-life data with bimodality, thinner tails, or asymmetry, all of which are prevalent in domains such as biology, environmental science, and finance. In contrast to finite mixture models (such as two-component normals), the ADN achieves bimodality and captures complex shapes through a single unified distributional structure rather than by mixing separate components. This approach can simplify the modeling process and mitigate some of the computational complexities often associated with fitting mixture models. The ADN restores the mathematical properties of the normal distribution (such as closed-form formulas for moments, CDF, and MGF) while incorporating asymmetry. Simple simulation and parameter estimation with maximum likelihood techniques are made possible by its stochastic representation (via folded-normal and Bernoulli variables).
Figure 1 illustrates density plots of the ADN distribution for different values of parameters
and
. The densities can exhibit either unimodal or bimodal behavior depending on the parameter values. In particular, the densities are plotted for
; When
takes negative values, the resulting density is a reflection with respect to the origin of the density corresponding to positive values. The plots in this figure illustrate how skewness and kurtosis change depending on these parameter values.
The ADN distribution can be viewed as a weighted version of the skew-normal distribution
with the weight function
, that is,
, where the normalization constant
(see
Appendix A).
Remark 2. The PDF (
4)
can be represented as a sum of two functions, i.e., We refer to this distribution as the asymmetric double normal distribution. This name highlights the combination of two normal densities () and the asymmetry introduced by the skew mechanism . This distribution belongs to a general class of asymmetric distributions. It is a way of modulating a symmetric density by a cumulative distribution function. Here, the base density is , which is the PDF of an equal mixture of two normal distributions and . This density has about zero symmetry. The function that introduces the asymmetry is .
Furthermore, various properties can be derived from the definition of the asymmetric double normal distribution. The fundamental characteristics of the class
can be obtained directly from Equation (
4).
Proposition 1. If , then the CDF is given bywhere Proof. From the definition of the CDF and using Equation (
5), we get
Now, when we evaluate the limits of integration, we observe the following: For the first integral, when
(the upper limit),
. Thus,
. For the second integral, when
(the upper limit),
. Thus,
.
Therefore, using the definition of
, we have
which gives the desired outcome. □
This result provides an explicit and interpretable representation of the CDF for the asymmetric double normal distribution, expressed in terms of the integrals of standard normal densities. This formulation not only highlights the role of the shape parameters () and skewness () but also facilitates practical applications, including numerical evaluation and simulation.
Remark 3. The distribution lacks a closed-form expression for its quantile function due to the complexity of the CDF, which involves bivariate integrals of the standard normal density. Finding the p-th quantile requires solvingThis equation is not analytically solvable due to the non-linear dependence of within the function G. For practical applications, we recommend numerical approaches: root-finding methods (Newton–Raphson, bisection), interpolation using precomputed CDF values, or Monte Carlo simulations for less precision-critical applications. For implementation, we suggest combining bisection with Newton–Raphson iterations. The absence of closed-form quantiles is common in complex distributions and does not diminish the practical utility of the distribution. 3. Some Properties of the ADN Distribution
In this section, we explore the statistical properties of the ADN distribution, focusing on its fundamental characteristics, stochastic representation, and moment-generating function.
3.1. Basic Properties
The following properties can be obtained directly from Definition 3.
Properties 1. Let ; the following properties hold:
- (a)
.
- (b)
.
- (c)
.
- (d)
, where .
- (e)
.
- (f)
. In contrast, as , tends to degenerate at 0.
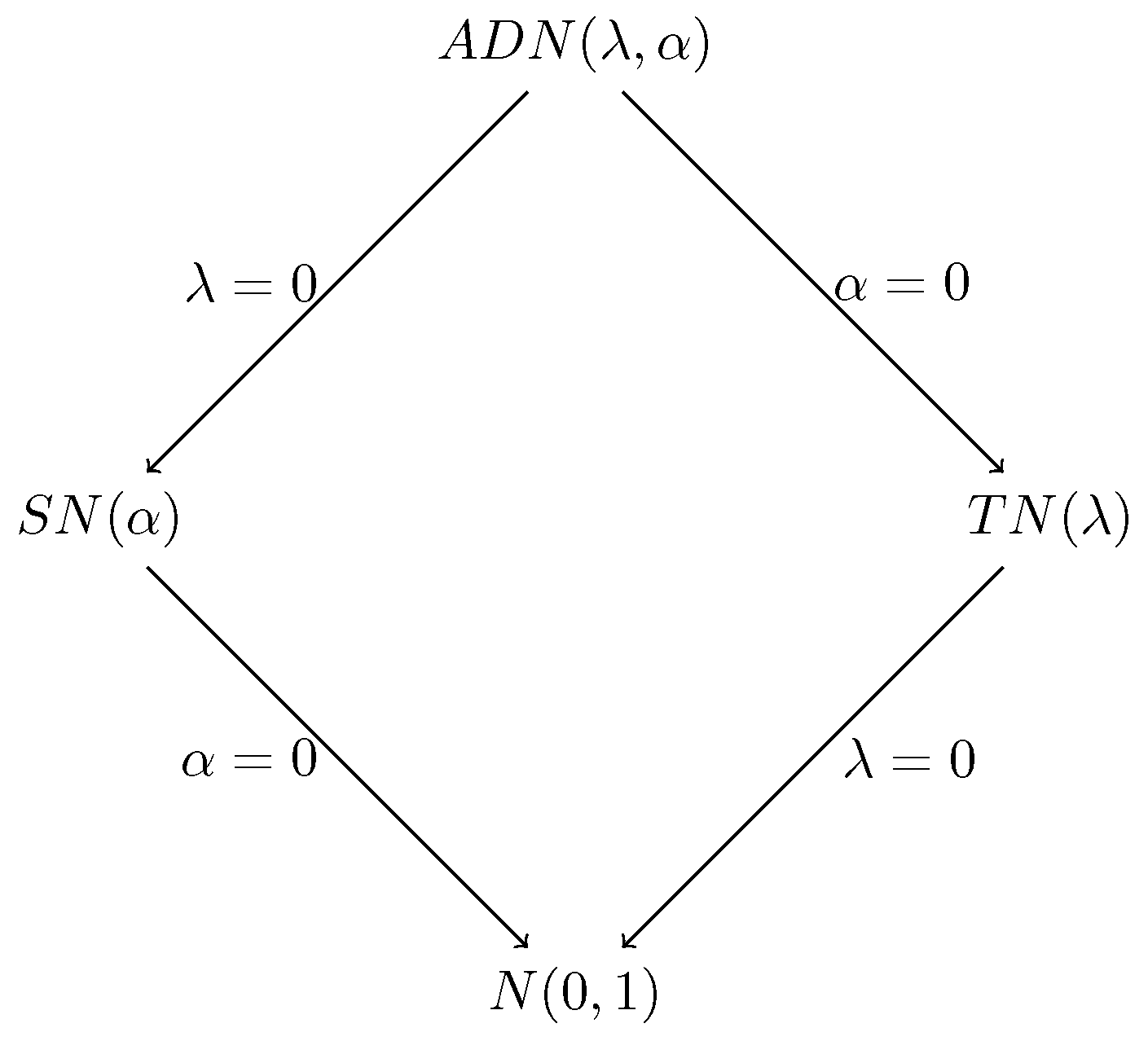
Property (a) shows that the ADN distribution includes the normal distribution as a special case when and , and it has similar properties to the normal distribution that make it a useful and applicable distribution in real-life applications. Property (b) establishes that for and any , the ADN density becomes an even function, , making it asymmetric around the y-axis. Property (c) shows that when the skewness parameter is , the ADN density is reduced to . This specific form is recognized in the literature as the two-piece normal distribution, denoted . Property (d) shows that the distribution of the absolute value of Z follows the folded-normal distribution, , which is the distribution of when . Property (e) illustrates the asymmetry of the ADN density around zero. Property (f) indicates that as , approaches , the ADN density simplifies to a symmetric form.
On the other hand, as , becomes concentrated at zero, this leads to a degenerate distribution. These properties provide insights into the behavior and flexibility of the ADN distribution, highlighting its ability to exhibit symmetry, asymmetry, and degeneracy for different parameter configurations. This flexibility will be used in subsequent sections for statistical inference and applications.
Remark 4. The PDF given in Equation (
4)
exhibits interesting properties due to its composition of normal density , normal CDF , and hyperbolic cosine term . The derivativereveals that the critical points and thus the maxima depend on a balance between the linear term , the ratio involving , and the non-linear term . This structure suggests that the density is asymmetric and multimodal, with the number and location of the modes being heavily influenced by the parameters α and λ. Numerical methods are essential for locating these modes, as the derivative equation lacks a closed-form solution. This density is particularly suited for modeling skewed and heavy-tailed distributions in various applications. Figure 2 illustrates the submodels of the ADN distribution depending on the values of the parameters
and
. Specifically, when
and
, the ADN distribution simplifies to the standard normal distribution
, while for
and
, it becomes the skew-normal distribution
, showing asymmetry. When
and
, the ADN distribution becomes
. Moreover, the absolute value of
Z, denoted
, follows a folded-normal distribution
, reflecting the behavior of
when
. These special cases highlight the flexibility of the ADN distribution, allowing it to model symmetric and skewed behaviors.
3.2. Stochastic Representation of the ADN Random Variable
The following proposition presents the mechanism for generating random numbers that follow the ADN distribution.
Proposition 2. if and only if there exist dependent random variables S and with , such that .
Proof. Let
S and
Y be defined as in the statement of the proposition. Using the joint distribution of
and the Jacobian method, the marginal distribution of
Z is obtained as follows: If
, then
and
. Therefore, we have
On the other hand, if
, then
and
, as follows:
□
This stochastic representation of the random variable highlights its structure as a combination of two components: a random sign, represented by S, and a non-negative magnitude modeled by the folded-normal distribution . This construction not only provides an intuitive understanding of Z but also underscores the flexibility of the ADN distribution to represent patterns of asymmetry and bimodality observed in real-life data. By combining the inherent asymmetry of the folded-normal distribution with the additional control introduced by the parameter , this distribution becomes a valuable tool to model phenomena that exhibit opposing directions or contrasting behaviors, such as those encountered in financial studies, biostatistics, and directional data analysis. Moreover, the stochastic representation facilitates simulations and numerical computations, enhancing its applicability in both practical and methodological analyses.
3.3. Derivation of Moments for the ADN Distribution
The random variable Z can be represented as a combination of two dependent random variables S and Y, as shown in Proposition 2. In this section, we derive a formula for computing the r-th moment of a random variable X that follows the distribution, where and , with .
Proposition 3. Let ; the r-th moment of Y is given bywhere is the incomplete normal moments. Proof. Using Equation (
3) and the definition of moments, we have
□
Proposition 4. Using Lin’s [11] results, we havewhere . Proof. For
, we have
. For
, we will derive the expression
, as follows:
□
Proposition 5. Let ; then, Proof. Using Proposition 4 and Corollary 1, it follows that
Then, applying Proposition 3, we have the results. □
Proposition 6. Let ; the r-th moment of X is given bywhere is given byand is the random variable in the stochastic representation of Z, as given in Proposition 2.
Proof. Applying the stochastic representation provided in Proposition 2 and applying the properties of conditional expectation, we can derive the required expression as follows.
The above leads to the conclusion that if
k is even, then
. On the other hand, if
k is odd, then
. To obtain
, it is possible to apply the binomial theorem along with the basic properties of the expectation. □
The mean and variance of a random variable X with the ADN distribution can be easily calculated using the following corollary.
Corollary 2. Let and . Then, the mean and variance of X are given bywhere , and . This result provides a straightforward way to compute the expected value and variance of the distributed random ADN variable X, where , , , and are the distribution parameters. The integral , along with the terms and that themselves depend on and the standard normal, can be numerically evaluated, making the calculation of and feasible in practice. Analyzing these moments offers valuable insights into how the ADN distribution’s parameters sculpt its overall shape and behavior. The mean is primarily centered on the location parameter and is scaled by . Crucially, the term incorporates the influence of both the shape parameter and the skewness parameter . A non-zero will contribute to shifting the mean away from what would be expected in a symmetric (non-skewed) scenario for a given , directly reflecting the asymmetry introduced by in the construction of ADN. Similarly, the variance is scaled by and is a complex function of and through , , and . This complexity reflects how the interaction between potential bimodality (mainly influenced by ) and skewness (governed by ) jointly determines the overall dispersion of the data. For example, increasing asymmetry (larger ) or more pronounced bimodal tendencies (related to ) can lead to variance changes that simpler symmetric or unimodal distributions might not adequately capture, underscoring the model’s enhanced capacity to represent complex data patterns.
Remark 5. The appropriate range for skewness has been a topic of discussion in statistical research. Typically, data are considered highly skewed when the absolute skewness exceeds 1, moderately skewed when it falls between 0.5 and 1, and approximately symmetric when it is within the range 0 to 0.5. Moreover, some studies suggest broader thresholds ( or ), which are encountered in some fields (e.g. psychology, education) where data features justify more lenient criteria; see Alyami et al. [12,13], where the latter notes as a stricter threshold for severe skewness. In the context of the ADN model, for values of and , the skewness coefficient was numerically found to lie within , while the kurtosis coefficient ranged between and . These results indicate that the ADN model can accommodate moderate to high skewness levels while maintaining a bounded range for kurtosis. The following result shows the moment-generating function (MGF) of .
Proposition 7. The MGF of is defined aswhere . Proof. By the definition of the MGF and using Equation (
5), we have
Expanding
, we note that it involves an exponential product. Simplifying the exponents, we get
. Adding and subtracting
, we complete the square
, resulting in
. Similarly, for
, completing the square for
, we obtain
.
Substituting these expressions into the MGF, we have
Next, we perform the substitutions
and
in the respective integrals.
This yields
where
.
This completes the proof. □
4. Estimation with Inference and a Simulation Study
This section explores the maximum likelihood estimation (MLE) parameters
,
,
and
for the ADN distributions. A simulation study was conducted to assess the performance of the derived estimators. To compute the MLE for each parameter, we used the R programming language (R Core Team [
14]), incorporating a machine learning tool as recommended by Byrd and Zhu [
15]. Furthermore, we provided the observed information matrix that corresponds to the MLE, for the purposes of constructing confidence intervals or conducting significance testing.
4.1. The Maximum Likelihood Estimation
For the estimation of the ADN model’s parameters, the MLE method is employed. This method is widely adopted in statistical inference due to its well-established and desirable asymptotic properties. Under standard regularity conditions, MLEs are known to be consistent, asymptotically efficient, and asymptotically normally distributed, which facilitates the subsequent construction of confidence intervals and hypothesis tests for model parameters. The log-likelihood function for the ADN distribution forms the basis for this estimation procedure.
Let
be a realization of the random sample
, where
are i.i.d. random variables following the
. The log-likelihood function based on a random sample
is given by
where
, which is a continuous function in each parameter. Thus, we have elements of the score vector.
is given by
where
.
The log-likelihood function of the ADN model can be decomposed into two main components: one related to the log-likelihood of the skew-normal distribution and another involving the logarithm of the hyperbolic cosine function. The skew-normal component benefits from well-established maximization algorithms documented in the statistical literature. The hyperbolic cosine component, derived from exponential functions, is smooth, continuously differentiable, and behaves well, ensuring stable convergence during optimization procedures.
The MLE
is obtained by solving the score equations
. However, closed-form expressions for the MLE are not available, necessitating numerical maximization of the log-likelihood function using non-linear optimization algorithms. In this study, we used the
optim function in the R programming language to maximize the
function, although other numerical methods, such as Nelder–Mead [
16], can also be applied.
To obtain the standard errors of the MLE, one should compute the information matrix
. It is well known that the elements in the matrix are given by
,
. If necessary,
can be approximated by the observed information matrix
, which is defined as the negative of the Hessian matrix evaluated at
, that is,
, where the second derivatives are given below:
It can be shown that for
and
, the information matrix of the model is non-singular. Thus, we can use the information matrix to compute the standard errors throughout the remainder of this paper.
4.2. Simulation Study
To evaluate the performance of MLEs
, we conducted a numerical experiment using the R programming language. The study involved 5000 Monte Carlo replications for sample sizes
. For simplicity, the location and scale parameters were kept constant at
throughout all experiments.
Table 1 and
Table 2 summarize the empirical mean, the absolute value of the bias, the root mean squared error (RMSE) and the coverage probability (CP) of the parameter estimates for the asymmetric double normal distribution, as follows:
where
is an indicator function that takes the value 1 if
is inside its
prediction interval
, and it takes a value of 0 otherwise.
Random numbers
can be generated using the following Algorithm 1:
| Algorithm 1 Simulating values from the distribution. |
- 1:
Choose the values , and the sample size n. - 2:
Generate . - 3:
Compute . - 4:
Generate . - 5:
If , compute , else .
|
Here, is the Bernoulli distribution with probability of success .
The results of
Table 1 and
Table 2 demonstrate the performance of the MLE for the ADN distribution in various sample sizes and different parameter settings (
and
). Generally, the bias (difference between the estimated mean and the true value) decreases as the sample size increases, indicating that the MLEs are asymptotically unbiased. The RMSE also decreases with larger sample sizes, suggesting improved precision.
The CP of the confidence intervals tends to be close to the desired 95%, especially for larger sample sizes, confirming the adequacy of the confidence intervals constructed from the MLEs. The standard errors of the estimators decrease with increasing sample sizes, consistent with the statistical theory.
Across different values of and , the MLEs demonstrate robustness and consistent performance, with significant improvements observed as the sample size increases. For smaller sample sizes, some variability and bias are evident, particularly for specific parameter combinations. However, as the sample size increases, both bias and RMSE decrease and CP approaches the desired levels. Overall, the results confirm the consistency and efficiency of the MLEs for the ADN distribution, with parameter estimates becoming increasingly precise and accurate as the amount of data increases. These findings highlight the effectiveness of the ADN distribution in modeling data with bimodality and asymmetry, offering reliable parameter estimation.
Further examination of the results, particularly by comparing scenarios with different values of the skewness parameter , provides insights into the model’s performance across varying degrees of asymmetry. For example, when is close to zero (representing near-symmetric cases, e.g., or ), the ADN model continues to produce stable and consistent estimates for all parameters, including itself; however, as expected, the precision for estimating a very small benefits from larger sample sizes. In contrast, for cases with more pronounced asymmetry (e.g., or ), the model effectively captures this skewness, with the estimators for and maintaining good accuracy and their RMSEs, which decrease appropriately with increasing sample size. This demonstrates the ADN distribution’s particular advantage in flexibly modeling datasets that deviate from symmetry, while also performing reliably in near-symmetric situations, underscoring its versatility.
5. Practical Data Illustrations
This study presents two examples of the asymmetric double normal distribution applied to real-life datasets. The first dataset, sourced from the Applied Statistics Center at the University of Sao Paulo, contains information on women diagnosed with breast cancer. The second dataset consists of records from Australian athletes, illustrating the applicability of the model in fitting a regression model. The fitting of the model and the estimation of the parameters were performed using the libraries optim in R version 4.3.2 [
14].
5.1. Illustration 1: Data Fitting
We considered a dataset from the Applied Statistics Center at the Institute of Mathematics and Statistics, University of Sao Paulo, Brazil, consisting of 250 samples of breast cancer cells from women, where the amount of DNA within the cell nucleus (ploidy) was measured. These data were previously analyzed by Siroky et al. [
17] using a bimodal power-normal model. The ploidy variable exhibits bimodal asymmetric behavior, with the Hartigan and Hartigan [
18,
19] bimodality test yielding statistics
and a
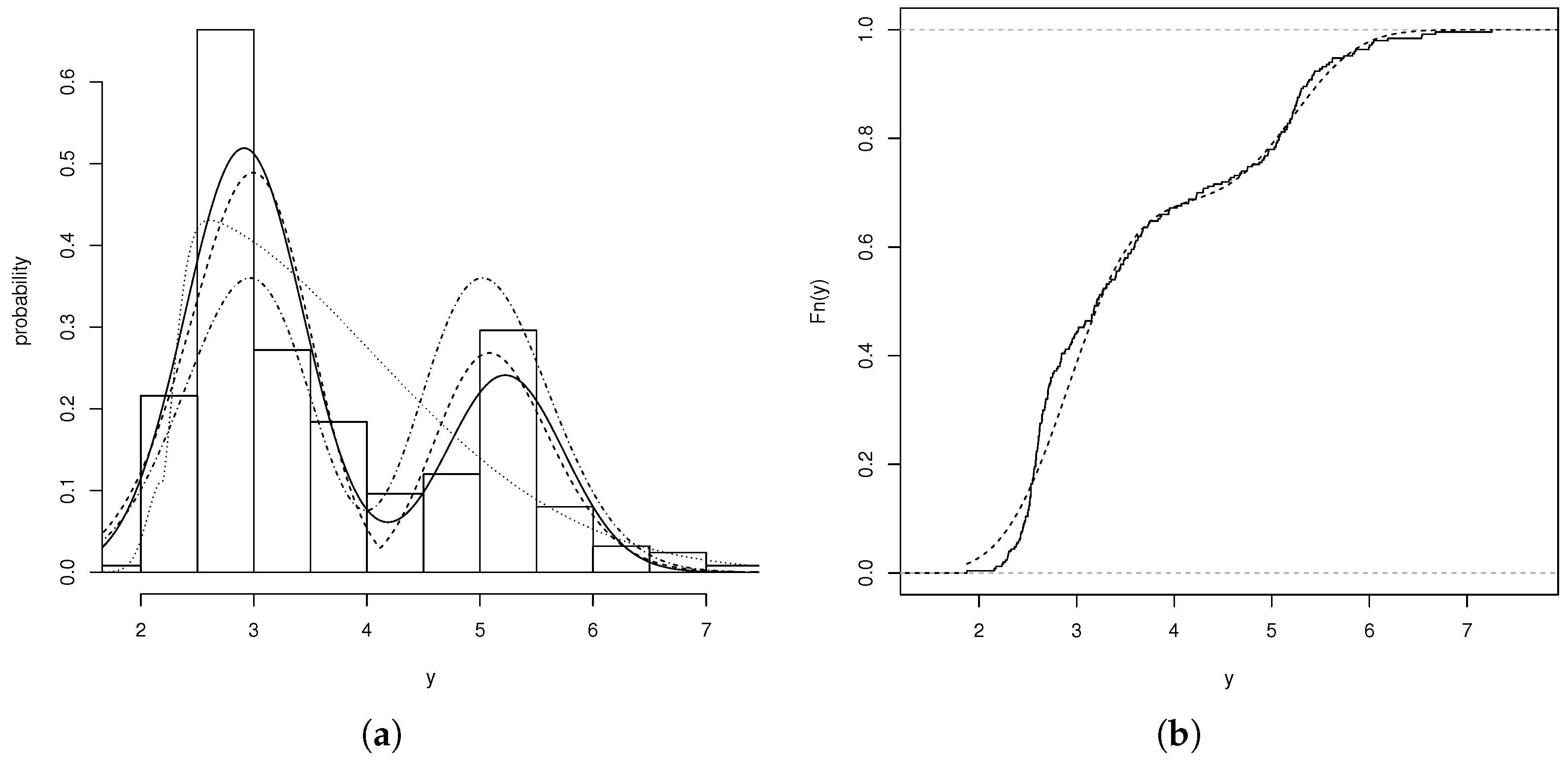
p-value = 0.0059. The ploidy data have a mean of 3.636 and variance 1.432. The data show a positive skewness of 0.452, indicating that the distribution is tilted to the right, with a longer tail in that direction. The kurtosis value of 0.865 suggests that the distribution is slightly flatter than a normal distribution, implying that the data do not exhibit extreme tails or very sharp peaks.
The following bimodal models were fitted: the bimodal skew-normal model (BSN) of Elal-Olivero et al. [
4], the asymmetric power-normal bimodal model (ABPN) of Bolfarine et al. [
8], the extended asymmetric double normal (ETN) of Arnold et al. [
9] and the ADN model.
This study employs various information criteria to determine the best fit model for the data, including the Akaike Information Criterion (AIC), defined as
, and the Bayesian Information Criterion (BIC), given by
. Here,
represents the estimated log-likelihood,
n is the sample size, and
k denotes the number of model parameters. The MLEs, along with the AIC and BIC values for the comparison of the model, are presented in
Table 3.
The results in
Table 3 highlight the performance of the ADN distribution compared to other fitted models, namely BSN, ABPN, and ETN. A key observation is that the ADN model achieves the lowest AIC and BIC values, with AIC = 685.07 and BIC = 699.15. These values are approximately 15 units lower than those of the competing models, highlighting the superior ability of the ADN distribution to capture the underlying data structure.
In terms of parameter estimation, the ADN model provides reasonable estimates with smaller standard errors, particularly for and , which means a stable and precise parameter fitting. The skewness parameter and the shape parameter further demonstrate the flexibility of the ADN model to account for asymmetry and other complex data characteristics.
These results suggest that the ADN distribution is better suited for modeling these datasets compared to the other models tested, providing a more accurate and efficient fit, as indicated by the goodness-of-fit metrics.
Figure 3a,b show the behavior of the fitted models and the empirical cumulative distribution functions for the adjusted models. These graphs reveal that the ADN model provides the best fit compared to the BSN, ABPN, and ETN models.
5.2. Illustration 2: Regression Analysis
The ADN distribution was extended to the case of having covariates that explain the response variable
Y, for example, a linear regression model:
where
is a set of covariates,
is a set of unknown parameters, and
are random variables representing model errors. The most common assumption is that
are random i.i.d. variables having a normal distribution with zero mean and constant variance
.
However, this assumption does not meet standard practices. Therefore, it is assumed that
are i.i.d. following a
distribution. For this example, a set of observations on various body features, such as height, weight, and body mass index, among others, is provided for all 202 athletes. These data are available at
http://azzalini.stat.unipd.it/SN/ (accessed on 16 April 2022). In this context, the model
will be fitted for male athletes
in this dataset, where
represents the percentage of body fat of the
i-th athlete, and the covariates
and
denote body mass index and lean body mass, respectively, for the
i-th athlete.
To obtain the estimates
for the model, we maximize the log-likelihood function (
11), where
.
Regression models will be fitted assuming normal errors, skew-normal errors, and ADN errors. The MLEs along with the corresponding AIC and BIC comparison criteria are provided in
Table 4.
According to these comparison criteria, the best regression model is the one with ADN errors, followed by the model with skew-normal errors and, finally, the one with normal errors.
To further validate the model fit quality beyond information criteria (AIC and BIC), we conducted a formal goodness-of-fit test on the residuals of the fitted models. Specifically, we apply the Anderson–Darling test, which is particularly sensitive to deviations in the tails of the distribution, making it suitable for assessing asymmetric distributions.
The Anderson–Darling test was implemented using goftest package in R version 4.3.2. [
20]. This test examines whether residuals follow the assumed distribution, with higher
p values indicating a better agreement with the theoretical distribution.
Table 5 presents the Anderson–Darling test statistics and the corresponding
p values for the residuals of each fitted model.
The results provide strong evidence supporting the ADN model as the most appropriate choice. The normal error model is decisively rejected (p-value ), while the skew-normal model shows marginal acceptability (p-value ). In contrast, the ADN model produces a high p (), indicating that the null hypothesis of ADN-distributed errors cannot be rejected. This finding strongly supports the previous conclusion based on information criteria that the ADN distribution provides the best fit to the data. These results further validate the superiority of the ADN distribution in modeling the data structure, particularly in capturing the asymmetric and potentially bimodal characteristics present in the dataset.
To identify atypical observations and/or model misalignment, we analyzed the transformation of the martingale residual, rMTi, proposed by Barros et al. [
21]. These residuals are defined by
where
is the martingale residual proposed by Ortega et al. [
22], where
indicates whether the observation
i-th is censored or not, respectively,
denotes the sign of
, and
represents the survival function evaluated at
(standardized classical residuals), where
represents the MLE for
.
To verify the assumptions of the model, error distribution, fit issues, and presence of potential outliers, we generated confidence bands through simulations for the martingale residuals, which are known in the diagnostic analysis literature as envelopes.
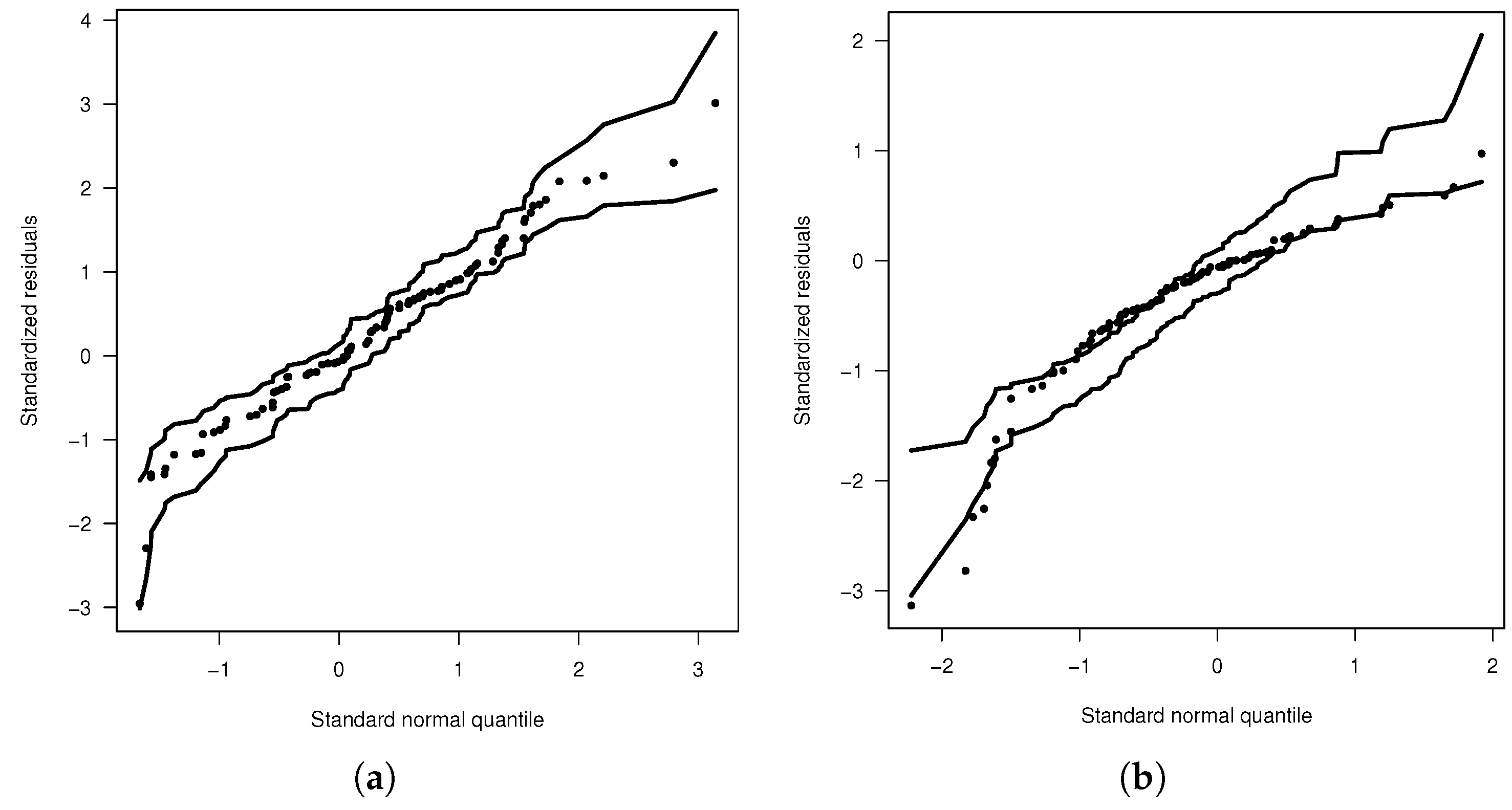
Figure 4a,b display the envelope plots for the fitted models. These plots reveal that the ADN regression model provides the best fit compared to the SN regression model. Recall that envelope plots also help confirm the validity of the model’s distributional assumptions and identify influential observations. From the envelope plot for the ADN model, it is clear that the model with ADN errors does not exhibit influential observations or distributional assumption issues.
6. Discussions and Conclusions
The asymmetric double normal distribution represents a significant advancement in statistical modeling, addressing the inherent limitations of the normal distribution in representing asymmetry and multimodality in real-life data. By incorporating shape and skewness parameters, it provides remarkable flexibility to accommodate both unimodal and bimodal forms, while elegantly maintaining the normal distribution as a special case. The comprehensive simulation study validates the robustness of the maximum likelihood estimators for the proposed model, confirming their desirable asymptotic behavior and the reliability of the associated statistical inference procedures. These findings strongly support the applicability of the method in practical scenarios where precise parameter estimation is essential for appropriate modeling of complex phenomena. The empirical applications presented in this work convincingly demonstrate the practical advantages of the proposed distribution over alternative models in both the distribution fitting and regression analysis contexts. For example, as illustrated in
Figure 3 and further detailed in
Table 3, the visual fit of the ADN model to bimodal ploidy data, along with its superior AIC and BIC values compared to competing models, such as BSN, ABPN, and ETN, provides compelling empirical evidence of its improved ability to capture complex data structures.
The model’s ability to simultaneously capture asymmetry and bimodality in data, while maintaining parsimonious parameterization, offers a powerful tool for data analysis. In the context of linear regression, the incorporation of asymmetric double normal errors substantially expands the scope of application of linear models in scenarios where the classical normality assumptions are inadequate. Thorough residual diagnostics confirm that the proposed model satisfies distributional assumptions appropriately, thus providing a more flexible and realistic framework for analyzing data with complex patterns that are prevalent in various scientific disciplines.
Despite its flexibility, the ADN model, like any statistical model, has certain limitations and specific domains of optimal applicability. The analytical determination of precise conditions for bimodality solely in terms of and can be complex, often necessitating numerical exploration, as discussed in Remark 4. Although the ADN distribution can model a wide array of skewed and bimodal shapes, for datasets exhibiting extremely heavy tails or more than two distinct modes, further extensions of the model or alternative specialized distributions might be more appropriate. Furthermore, parameter estimation relies on numerical optimization techniques; While found to be generally robust in our studies, these methods can, in some instances, be sensitive to starting values or encounter convergence issues with particularly challenging datasets or very small sample sizes. A formal investigation tail behavior of the model and a comparative study against specific heavy-tailed distributions are also warranted for future work. Furthermore, while this paper focuses on the frequentist MLE approach, the development and comparison of alternative estimation methods, such as a comprehensive Bayesian estimation framework for the ADN model, represent a valuable avenue for future research that could provide additional insight into parameter uncertainty and model robustness.
These considerations represent natural directions for future research, along with the promising possibility of being extended to trimodal models and the application of the model to non-Gaussian time-series analysis. The solid statistical foundation of this proposal, which includes a rigorous derivation of moments, characteristic functions, and stochastic representations, together with its empirical validation across different datasets, ensures its robustness and broad applicability in diverse fields, such as biomedicine, economics, and engineering. For practitioners facing univariate data that exhibit skewness and potential bimodality, the ADN model offers a clear workflow: initial data visualization to assess these features, followed by model fitting via MLE to estimate its parameters. Interpretation of these parameters, particularly for overall shape and for skewness, coupled with a model comparison using criteria such as AIC/BIC, allows for a nuanced understanding and robust modeling of the data.
Consequently, this flexible distribution is well positioned to gain significant traction in modeling complex phenomena, providing statisticians and data analysts with a powerful tool to explore intricate data structures. Future work will extend this distribution to a wider variety of scenarios and explore additional theoretical refinements to further enhance its flexibility and utility in statistical practice.




 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}