
Research on Person Pose Estimation Based on Parameter Inverted Pyramid and High-Dimensional Feature Enhancement

Abstract
1. Introduction
2. Related Works
3. Methodology
3.1. Parameter Inverted Pyramid Structure (PIIP)
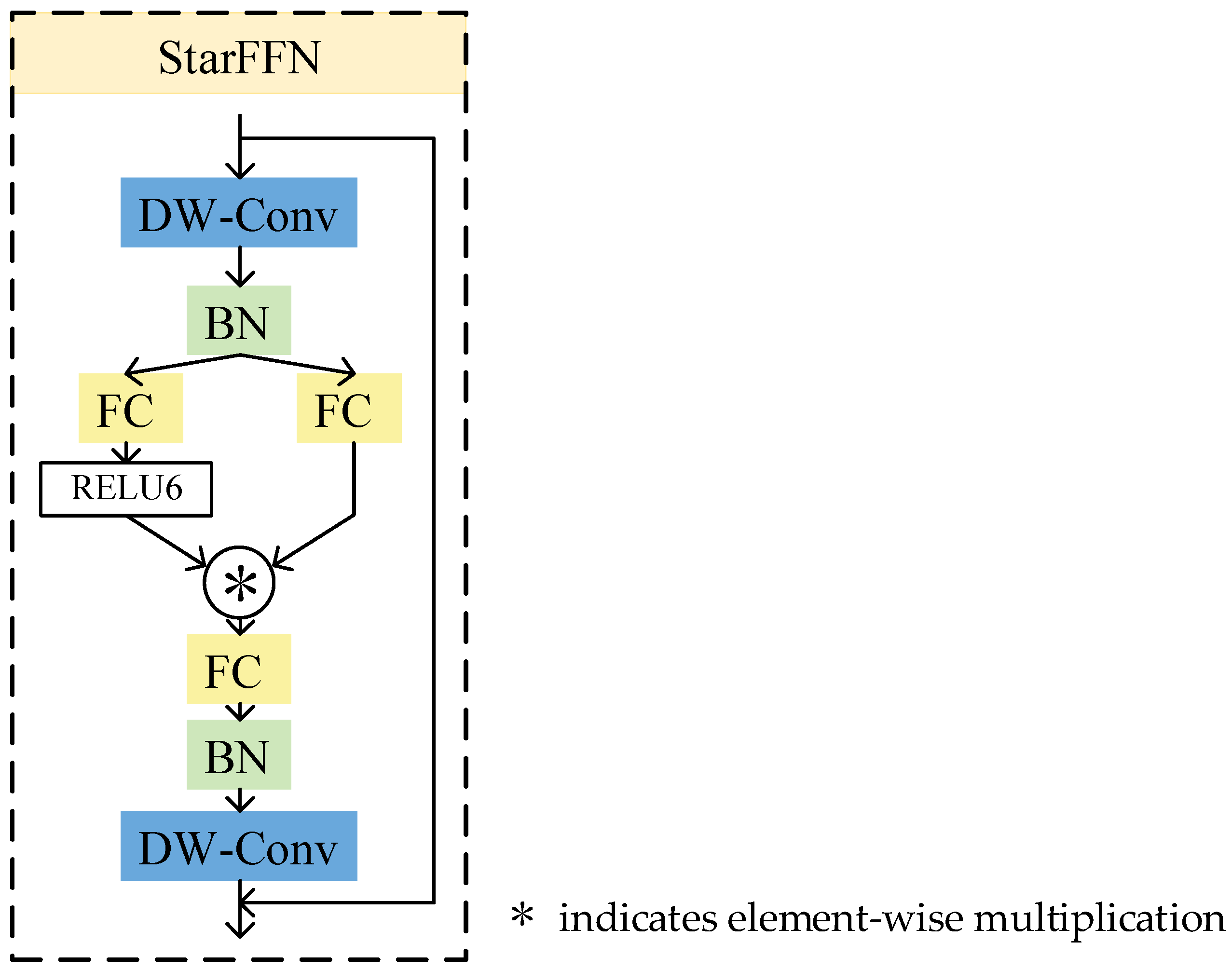
3.2. StarFFN
4. Experiment
4.1. Training and Reasoning
4.2. Data Sets and Experimental Details
4.3. Benchmark Results
4.4. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pérez-Lombard, L.; Ortiz, J.; Pout, C. A Review on Buildings Energy Consumption Information. Energy Build. 2008, 40, 394–398. [Google Scholar] [CrossRef]
- Standard 55—Thermal Environmental Conditions for Human Occupancy. Available online: https://www.ashrae.org/technical-resources/bookstore/standard-55-thermal-environmental-conditions-for-human-occupancy (accessed on 13 April 2025).
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6971–6980. [Google Scholar]
- Wang, Y.; Sun, F.; Li, D.; Yao, A. Resolution Switchable Networks for Runtime Efficient Image Recognition. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XV. Springer: Berlin, Germany, 2020; pp. 533–549. [Google Scholar]
- Luo, X.; Liu, D.; Kong, H.; Huai, S.; Chen, H.; Xiong, G.; Liu, W. Efficient Deep Learning Infrastructures for Embedded Computing Systems: A Comprehensive Survey and Future Envision. ACM Trans. Embed. Comput. Syst. 2024, 24, 21. [Google Scholar] [CrossRef]
- Fang, H.-S.; Xie, S.; Tai, Y.-W.; Lu, C. RMPE: Regional Multi-Person Pose Estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2353–2362. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.-E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [PubMed]
- Lu, P.; Jiang, T.; Li, Y.; Li, X.; Chen, K.; Yang, W. RTMO: Towards High-Performance One-Stage Real-Time Multi-Person Pose Estimation. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1491–1500. [Google Scholar]
- Pang, B.; Li, Y.; Li, J.; Li, M.; Cao, H.; Lu, C. TDAF: Top-Down Attention Framework for Vision Tasks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 14 December 2020; AAAI Press: Palo Alto, CA, USA, 2021; pp. 2384–2392. [Google Scholar]
- Cai, Y.; Wang, Z.; Luo, Z.; Yin, B.; Du, A.; Wang, H.; Zhang, X.; Zhou, X.; Zhou, E.; Sun, J. Learning Delicate Local Representations for Multi-Person Pose Estimation. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 455–472. [Google Scholar]
- Su, Z.; Ye, M.; Zhang, G.; Dai, L.; Sheng, J. Cascade Feature Aggregation for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1653–1660. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 5686–5696. [Google Scholar]
- Jin, S.; Liu, W.; Xie, E.; Wang, W.; Qian, C.; Ouyang, W.; Luo, P. Differentiable Hierarchical Graph Grouping for Multi-Person Pose Estimation. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 718–734. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 21–26 July 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, Netherlands, 8–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Jung, T.-W.; Jeong, C.-S.; Kim, I.-S.; Yu, M.-S.; Kwon, S.-C.; Jung, K.-D. Graph Convolutional Network for 3D Object Pose Estimation in a Point Cloud. Sensors 2022, 22, 8166. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Tan, D.; Chen, H.; Tian, W.; Xiong, L. DiffusionRegPose: Enhancing Multi-Person Pose Estimation Using a Diffusion-Based End-to-End Regression Approach. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 2230–2239. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3D Human Pose Estimation with Spatial and Temporal Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 11636–11645. [Google Scholar]
- Yu, N.; Ma, T.; Zhang, J.; Zhang, Y.; Bao, Q.; Wei, X.; Yang, X. Adaptive Vision Transformer for Event-Based Human Pose Estimation. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 18 October–1 November 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 2833–2841. [Google Scholar]
- Shi, D.; Wei, X.; Li, L.; Ren, Y.; Tan, W. End-to-End Multi-Person Pose Estimation with Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 11059–11068. [Google Scholar]
- Liu, H.; Zheng, Q. Vitcc: A Vision Transformer Coordinate Classification Perspective for Human Pose Estimation. In Proceedings of the 2024 International Conference on Intelligent Perception and Pattern Recognition, Qingdao, China, 19–21 July 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 63–69. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the Stars. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 5694–5703. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 936–944. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10778–10787. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 6230–6239. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. SNIPER: Efficient Multi-Scale Training. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Si, Y.; Xu, H.; Zhu, X.; Zhang, W.; Dong, Y.; Chen, Y.; Li, H. SCSA: Exploring the Synergistic Effects between Spatial and Channel Attention. Neurocomputing 2025, 634, 129866. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sünderhauf, N. VarifocalNet: An IoU-aware Dense Object Detector. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8510–8519. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- OpenMMLab Pose Estimation Toolbox and Benchmark. Available online: https://github.com/open-mmlab/mmpose (accessed on 13 April 2025).
- McNally, W.; Vats, K.; Wong, A.; McPhee, J. Rethinking Keypoint Representations: Modeling Keypoints and Poses as Objects for Multi-Person Human Pose Estimation. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 37–54. [Google Scholar]
- Ultralytics YOLO11. Available online: https://github.com/ultralytics/ultralytics (accessed on 13 April 2025).
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2636–2645. [Google Scholar]
- Li, J.; Bian, S.; Zeng, A.; Wang, C.; Pang, B.; Liu, W.; Lu, C. Human Pose Regression with Residual Log-likelihood Estimation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 11005–11014. [Google Scholar]
- Li, Y.; Yang, S.; Liu, P.; Zhang, S.; Wang, Y.; Wang, Z.; Yang, W.; Xia, S.-T. SimCC: A Simple Coordinate Classification Perspective for Human Pose Estimation. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 89–106. [Google Scholar]
- Jiang, T.; Lu, P.; Zhang, L.; Ma, N.; Han, R.; Lyu, C.; Li, Y.; Chen, K. RTMPose: Real-Time Multi-Person Pose Estimation Based on MMPose. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: Piscataway, NJ, USA. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. RTMDet: An Empirical Study of Designing Real-Time Object Detectors. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; IEEE: Piscataway, NJ, USA. [Google Scholar]
- Tian, Z.; Chen, H.; Shen, C. DirectPose: Direct End-to-End Multi-Person Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Mao, W.; Tian, Z.; Wang, X.; Shen, C. FCPose: Fully Convolutional Multi-Person Pose Estimation with Dynamic Instance-Aware Convolutions. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 9030–9039. [Google Scholar]
- Shi, D.; Wei, X.; Yu, X.; Tan, W.; Ren, Y.; Pu, S. InsPose: Instance-Aware Networks for Single-Stage Multi-Person Pose Estimation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6568–6577. [Google Scholar]
- Wang, D.; Zhang, S. Contextual Instance Decoupling for Robust Multi-Person Pose Estimation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 11050–11058. [Google Scholar]
- Yang, J.; Zeng, A.; Liu, S.; Li, F.; Zhang, R.; Zhang, L. Explicit Box Detection Unifies End-to-End Multi-Person Pose Estimation 2023. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: Piscataway, NJ, USA, 2023. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | #Params | Time (ms) | AP | AP 50 | AP 75 | APM | APL | AR |
|---|---|---|---|---|---|---|---|---|---|
| DirectPose [45] | ResNet-50 | - | 74 | 62.2 | 86.4 | 68.2 | 56.7 | 69.8 | - |
| DirectPose [45] | ResNet-110 | - | - | 63.3 | 86.7 | 69.4 | 57.8 | 71.2 | - |
| FCPose [46] | ResNet-50 | 41.7 M | 68 | 64.3 | 87.3 | 71.0 | 61.6 | 70.5 | - |
| FCPose [46] | ResNet-110 | 60.5 M | 93 | 65.6 | 87.9 | 72.6 | 62.1 | 72.3 | - |
| InsPose [47] | ResNet-50 | 50.2 M | 80 | 65.4 | 88.9 | 71.7 | 60.2 | 72.7 | - |
| InsPose [47] | ResNet-110 | - | 100 | 66.3 | 89.2 | 73.0 | 61.2 | 73.9 | - |
| CenterNet [48] | Hourglass | 194.9 M | 160 | 63.0 | 86.8 | 69.6 | 58.9 | 70.4 | - |
| PETR [23] | ResNet-50 | 43.7 M | 89 | 67.6 | 89.8 | 75.3 | 61.6 | 76.0 | - |
| PETR [23] | Swin-L | 213.8 M | 133 | 70.5 | 91.5 | 78.7 | 65.2 | 78.0 | - |
| CID [49] | HRNet-w32 | 29.4 M | 84.0 | 68.9 | 89.9 | 76.9 | 63.2 | 77.7 | 74.6 |
| CID [49] | HRNet-w48 | 65.4 M | 94.8 | 70.7 | 90.4 | 77.9 | 66.3 | 77.8 | 76.4 |
| ED-Pose [50] | ResNet-50 | 50.6 M | 135.2 | 69.8 | 90.2 | 77.2 | 64.3 | 77.4 | - |
| ED-Pose [50] | Swin-L | 218.0 M | 265.6 | 72.7 | 92.3 | 80.9 | 67.6 | 80.0 | - |
| KAPAO-s [38] | CSPNet | 12.6 M | 26.9 | 63.8 | 88.4 | 70.4 | 58.6 | 71.7 | 71.2 |
| KAPAO-m [38] | CSPNet | 35.8 M | 37.0 | 68.8 | 90.5 | 76.5 | 64.3 | 76.0 | 76.3 |
| KAPAO-l [38] | CSPNet | 77.0 M | 50.2 | 70.3 | 91.2 | 77.8 | 66.3 | 76.8 | 77.7 |
| YOLO-Pose-s [40] | CSPDarknet | 10.8 M | 7.9 | 63.2 | 87.8 | 69.5 | 57.6 | 72.6 | 67.6 |
| YOLO-Pose-m [40] | CSPDarknet | 29.3 M | 12.5 | 68.6 | 90.7 | 75.8 | 63.4 | 77.1 | 72.8 |
| YOLO-Pose-l [40] | CSPDarknet | 61.3 M | 20.5 | 70.2 | 91.1 | 77.8 | 65.3 | 78.2 | 74.3 |
| RTMO-s [8] | CSPDarknet | 9.9 M | 8.9 | 66.9 | 88.8 | 73.6 | 61.1 | 75.7 | 70.9 |
| RTMO-m [8] | CSPDarknet | 22.6 M | 12.4 | 70.1 | 90.6 | 77.1 | 65.1 | 78.1 | 74.2 |
| RTMO-l [8] | CSPDarknet | 44.8 M | 19.1 | 71.6 | 91.1 | 79.0 | 66.8 | 79.1 | 75.6 |
| Efficient-RTMO | CSPDarknet | 12.4 M | 6.2 | 66.4 | 86.9 | 71.3 | 59.9 | 73.6 | 68.2 |
| Model | Features | Latency (ms) | Accuracy | ||
|---|---|---|---|---|---|
| CPU | GPUs | AP | AR | ||
| Efficient-RTMO | {P3, P4, P5} | 44.8 | 6.24 | 66.4 | 68.2 |
| {P4, P5} | 31.7 | 4.83 | 65.9 | 65.1 | |
| RTMO-s [8] | {P3, P4, P5} | 65.3 | 8.96 | 67.6 | 71.8 |
| {P4, P5} | 48.7 | 8.91 | 67.6 | 71.4 | |
| FFN Block | Latency (ms) | Accuracy | ||
|---|---|---|---|---|
| CPU | GPUs | AP | AR | |
| Regular FFN | 2.8 | 0.15 | 63.8 | 65.1 |
| StarFFN | 3.1 | 0.22 | 67.6 | 71.4 |
| Model | #Param | i9-13900KF | Jeston Xavier NX | ||
|---|---|---|---|---|---|
| FPS | Time (ms) | FPS | Time (ms) | ||
| FCPose [46] | 60.5 M | 8.1 | 124.7 | 7.0 | 141.7 |
| PETR [23] | 43.7 M | 8.9 | 113.6 | 7.7 | 128.9 |
| CID [49] | 65.4 M | 7.8 | 128.5 | 6.2 | 133.1 |
| ED-Pose [50] | 50.6 M | 5.1 | 198.1 | 3.5 | 212.4 |
| KAPAO-m [38] | 35.8 M | 12.0 | 83.3 | 10.8 | 96.8 |
| YOLO-Pose-m [40] | 29.3 M | 22.8 | 43.8 | 17.6 | 53.5 |
| RTMO-m [8] | 22.6 M | 28.2 | 35.4 | 19.9 | 46.8 |
| Efficient-RTMO (Ours) | 12.4 M | 34.5 | 28.9 | 27.5 | 35.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, G.; Zhang, Q. Research on Person Pose Estimation Based on Parameter Inverted Pyramid and High-Dimensional Feature Enhancement. Symmetry 2025, 17, 941. https://doi.org/10.3390/sym17060941
Ma G, Zhang Q. Research on Person Pose Estimation Based on Parameter Inverted Pyramid and High-Dimensional Feature Enhancement. Symmetry. 2025; 17(6):941. https://doi.org/10.3390/sym17060941
Chicago/Turabian StyleMa, Guofeng, and Qianyi Zhang. 2025. "Research on Person Pose Estimation Based on Parameter Inverted Pyramid and High-Dimensional Feature Enhancement" Symmetry 17, no. 6: 941. https://doi.org/10.3390/sym17060941
APA StyleMa, G., & Zhang, Q. (2025). Research on Person Pose Estimation Based on Parameter Inverted Pyramid and High-Dimensional Feature Enhancement. Symmetry, 17(6), 941. https://doi.org/10.3390/sym17060941