
A Hypergraph-Based Approach to Attribute Reduction in an Incomplete Decision System

Abstract
1. Introduction
2. Preliminaries
2.1. Incomplete Information Systems
2.2. Hypergraphs
- (1)
- ;
- (2)
- .
3. Matrix-Based Method for Hypergraphs
- (1)
- For any vertex , the degree of vertex is , i.e., .
- (2)
- For any hyperedge , the degree of hyperedge is , i.e., .
- (1)
- is a symmetric matrix.
- (2)
- For any vertex , the neighborhood of is or , namely or .
- (1)
- there exists such that , where .
- (2)
- there exists such that , where .
4. Applying the Characteristic Matrix of a Hypergraph to Attribute Reduction in IISs
4.1. Hypergraph-Based Method for Attribute Reduction of IISs
- , where .
- , where .
- , where .
| Algorithm 1 A matrix-based algorithm to calculate the approximations of a subset of objects |
An IIS and a subset of object X. The lower and upper approximations of X. 1: Compute the characteristic matrix for any and the characteristic vector for X; 2: Compute for any and according to Proposition 4 and Theorem 4; 3: Compute and according to Propositions 7 and 8; 4: Return and |
- (1)
- A is a consistent set of if and only if .
- (2)
- A is a ruduct set of if and only if and for any .
- (1)
- A is a consistent set of if and only if for any , .
- (2)
- A is a reduct set of if and only if A is a minimal set satisfying for any .
- Case 1.
- and . According to Theorem 4, there exists at least one such that , which implies that , since , according to Definition 13, we have , which contradicts the fact .
- Case 2.
- and . This situation does not exist. In fact, if , according to Theorem 4, it is easy to see that , which contradicts .
| Algorithm 2 A hypergraph-based method for the attribute reduction in an IIS via matrix |
An IIS . The attribution reduction of an . 1: Compute the characteristic matrix for any according to Algorithm 1; 2: Compute the discernibility matrix of according to Definition 13 and Theorem 5; 3: Compute the consistent set and the reduct set of according to Theorem 6; 4: Return all the reductions of . |
- , where .
- , where .
- , where .
- , where .
4.2. Hypergraph-Based Method for Attribute Reduction of Consistent and Inconsistent IDSs
- (1)
- A is a relative consistent set of if and only if .
- (2)
- A is a relative consistent set of if and only if .
- (1)
- A is a relative reduct of if and only if A is a minimal set satisfying .
- (2)
- A is a relative consistent set of if and only if A is a minimal set satisfying .
- A is a relative reduct of ;
- ⇔A is a relative consistent set of and B is not a relative consistent set of for any ;
- ⇔ for any and for any and any ;
- ⇔ and for any and any ;
- ⇔A is a minimal set satisfying .
- , where .
- , where .
- , where .
- , where .
- , where .
- .
- .
- .
5. Conclusions and Further Study
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yao, Y.; Zhao, Y. Attribute reduction in decision-theoretic rough set models. Inf. Sci. 2008, 178, 3356–3373. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough sets. Int. J. Comput. Inf. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Wang, C.; He, Q.; Chen, D.; Hu, Q. A novel method for attribute reduction of covering decision systems. Inf. Sci. 2014, 254, 181–196. [Google Scholar] [CrossRef]
- Chen, J.; Li, J. An application of rough sets to graph theory. Inf. Sci. 2012, 201, 114–127. [Google Scholar] [CrossRef]
- Su, L.; Zhu, W. Dependence space of topology and its application to attribute reduction. Int. J. Mach. Learn. Cybern. 2018, 9, 691–698. [Google Scholar] [CrossRef]
- Kryszkiewicz, M. Rough set approach to incomplete information systems. Inf. Sci. 1998, 112, 39–49. [Google Scholar] [CrossRef]
- Stefanowski, J.; Tsoukiàs, A. Incomplete information tables and rough classification. Comput. Intell. 2001, 17, 545–566. [Google Scholar] [CrossRef]
- Qian, Y.; Liang, J.; Pedrycz, W.; Dang, C. Positive approximation: An accelerator for attribute reduction in rough set theory. Artif. Intell. 2010, 174, 597–618. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, X. Intuitionistic Fuzzy Granular Matrix: Novel Calculation Approaches for Intuitionistic Fuzzy Covering-Based Rough Sets. Axioms 2024, 13, 411. [Google Scholar] [CrossRef]
- Meng, Z.; Shi, Z. Extended rough set-based attribute reduction in inconsistent incomplete decision systems. Inf. Sci. 2012, 204, 44–69. [Google Scholar] [CrossRef]
- Wu, S.; Wang, L.; Ge, S.; Xiong, Z.; Liu, J. Feature selection algorithm using neighborhood equivalence tolerance relation for incomplete decision systems. Appl. Soft Comput. 2024, 157, 111463. [Google Scholar] [CrossRef]
- Kryszkiewicz, M. Rules in incomplete information systems. Inf. Sci. 1999, 113, 271–292. [Google Scholar] [CrossRef]
- Leung, Y.; Li, D. Maximal consistent block technique for rule acquisition in incomplete information systems. Inf. Sci. 2003, 153, 85–106. [Google Scholar] [CrossRef]
- Leung, Y.; Wu, W.; Zhang, W. Knowledge acquisition in incomplete information systems: A rough set approach. Eur. J. Oper. Res. 2006, 168, 164–180. [Google Scholar] [CrossRef]
- Qian, Y.; Liang, J.; Wang, F. A new method for measuring the uncertainty in incomplete information systems. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2009, 17, 855–880. [Google Scholar] [CrossRef]
- Wu, W. Attribute reduction based on evidence theory in incomplete decision systems. Inf. Sci. 2008, 178, 1355–1371. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, M.; Dou, H.; Yang, J. Neighborhood systems-based rough sets in incomplete information system. Knowl.-Based Syst. 2011, 6, 858–867. [Google Scholar] [CrossRef]
- Shu, W.; Qian, W. A fast approach to attribute reduction from perspective of attribute measures in incomplete decision systems. Knowl.-Based Syst. 2014, 72, 60–71. [Google Scholar] [CrossRef]
- Jiang, T.; Zhang, Y. Matrix-based local multigranulation reduction for covering decision information systems. Int. J. Approx. Reason. 2025, 181, 109415. [Google Scholar] [CrossRef]
- Wang, S.; Zhu, Q.; Zhu, W.; Min, F. Graph and matrix approaches to rough sets through matroids. Inf. Sci. 2014, 288, 1–11. [Google Scholar] [CrossRef]
- Chen, J.; Lin, Y.; Lin, G.; Li, J.; Ma, Z. The relationship between attribute reducts in rough sets and minimal vertex covers of graphs. Inf. Sci. 2015, 325, 87–97. [Google Scholar] [CrossRef]
- Chen, J.; Lin, Y.; Lin, G.; Li, J.; Zhang, Y. Attribute reduction of covering decision systems by hypergraph model. Knowl.-Based Syst. 2017, 118, 93–104. [Google Scholar] [CrossRef]
- Tan, A.; Li, J.J.; Lin, Y.J.; Lin, G.P. Matrix-based set approximations and reductions in covering decision information systems. Int. J. Approx. Reason. 2015, 59, 68–80. [Google Scholar] [CrossRef]
- Yang, T.; Liang, J.; Pang, Y.; Xie, P.; Qian, Y.; Wang, R. An efficient feature selection algorithm based on the description vector and hypergraph. Inf. Sci. 2023, 1629, 746–759. [Google Scholar] [CrossRef]
- Mao, H.; Wang, S.; Wang, L. Hypergraph-based attribute reduction of formal contexts in rough sets. Expert Syst. Appl. 2023, 234, 121062. [Google Scholar] [CrossRef]
- Li, X.; Pang, Y. Deterministic column-based matrix decomposition. IEEE Trans. Knowl. Data Eng. 2010, 22, 145–149. [Google Scholar] [CrossRef]
- Hu, C.; Zhang, L.; Huang, X.; Wang, H. Matrix-based approaches for updating three-way regions in incomplete information systems with the variation of attributes. Inf. Sci. 2023, 639, 119013. [Google Scholar] [CrossRef]
- Chen, D.; Wang, C.; Hu, Q. A new approach to attribute reduction of consistent and inconsistent covering decision systems with covering rough sets. Inf. Sci. 2007, 177, 3500–3518. [Google Scholar]
- Chen, X.; Gong, Z.; Wei, G. On incomplete matrix information completion methods and opinion evolution: Matrix factorization towards adjacency preferences. Eng. Appl. Artif. Intell. 2024, 133, 108140. [Google Scholar] [CrossRef]
- Luo, Y.; Chen, H.; Yin, T.; Horng, S.; Li, T. Dual hypergraphs with feature weighted and latent space learning for the diagnosis of Alzheimer s disease. Inf. Fusion 2024, 112, 102546. [Google Scholar] [CrossRef]
- Demri, S.; Orlowska, E. Incomplete Information: Structure, Inference, Complexity; Springer: Heidelberg/Berlin, Germany, 2002. [Google Scholar]
- Bondy, J.; Murty, U. Graph Theory with Applications; Macmillan: London, UK, 1976. [Google Scholar]
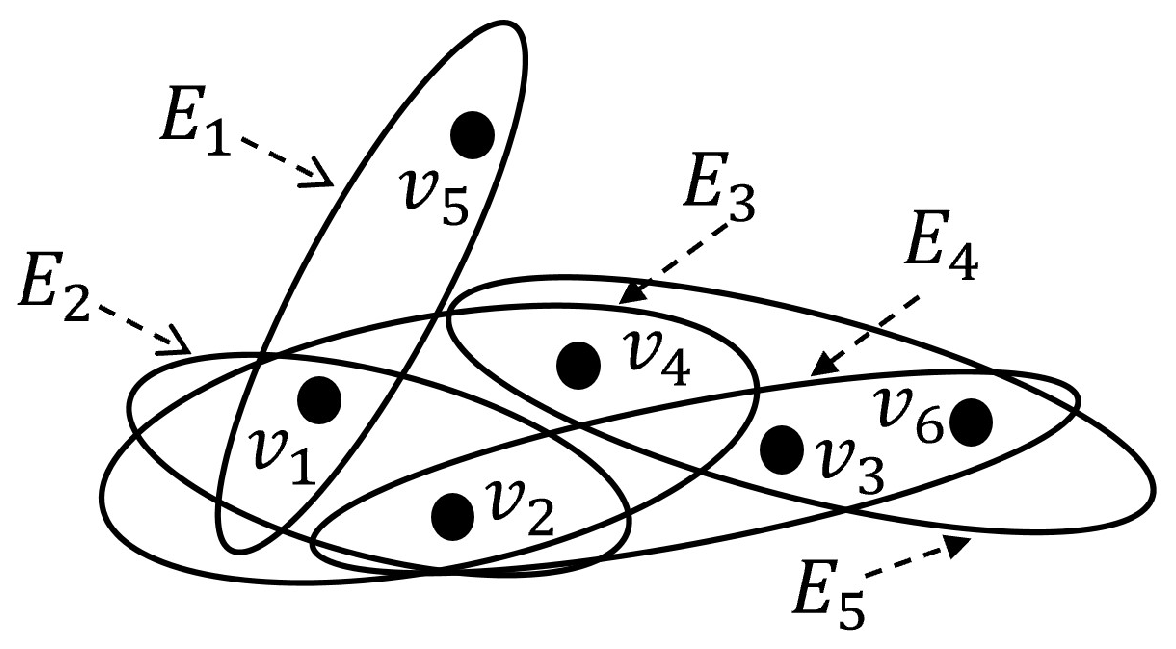
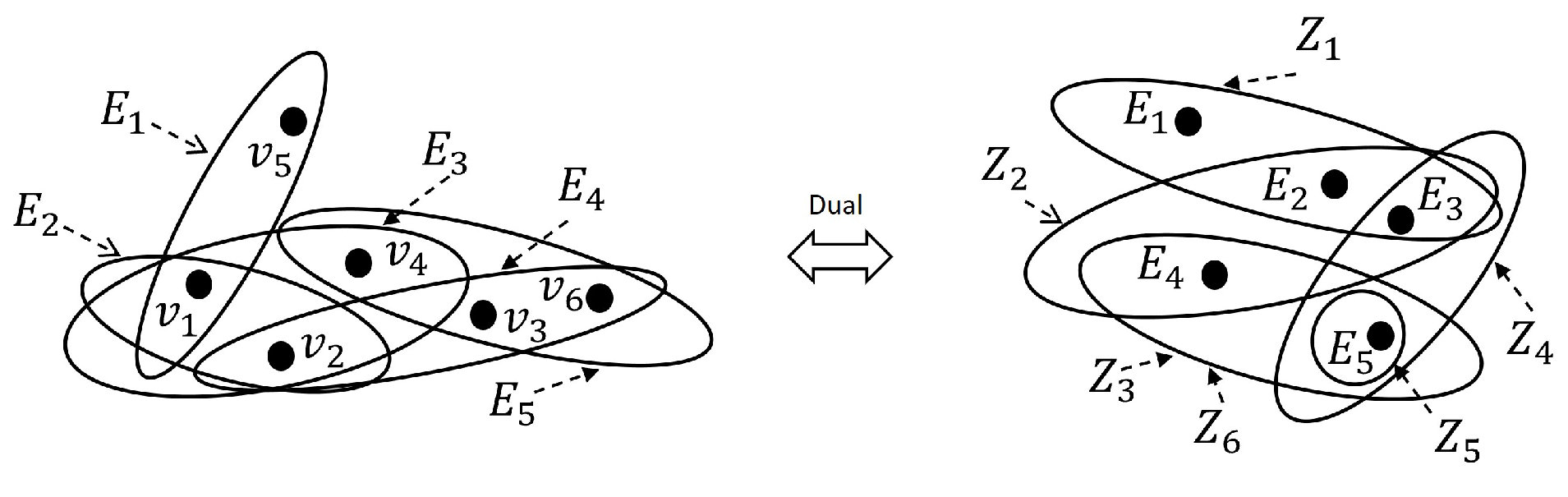

{kind=link}
{kind=link}
| Student | Chemistry (I) | Mathematics (S) | Geography (G) |
|---|---|---|---|
| Low | Medium | * | |
| Medium | * | Medium | |
| Medium | * | Medium | |
| * | Medium | Low | |
| Low | Medium | Low | |
| Low | High | High |
| X | |||
|---|---|---|---|
| ∅ | |||
| X | |||
|---|---|---|---|
| Car | Price (P) | Mileage (L) | Size (S) | Max-Speed (X) |
|---|---|---|---|---|
| High | Medium | Full | Low | |
| Low | * | Full | High | |
| High | * | Compact | * | |
| High | High | Compact | Low | |
| Low | High | Full | Low | |
| Low | High | Full | High |
| Car | Price (P) | Mileage (L) | Size (S) | Max-Speed (X) | Evaluation (I) | |
|---|---|---|---|---|---|---|
| High | High | Full | Low | Good | {Good, Excellent} | |
| Low | Medium | Compact | High | Poor | {Poor} | |
| High | Medium | Compact | Low | Poor | {Good, Poor} | |
| * | Medium | Compact | High | Poor | {Poor} | |
| high | Medium | Compact | Low | Good | {Good, Poor} | |
| high | High | Full | Low | Excellent | {Excellent} |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, L.; Jiang, C. A Hypergraph-Based Approach to Attribute Reduction in an Incomplete Decision System. Symmetry 2025, 17, 911. https://doi.org/10.3390/sym17060911
Su L, Jiang C. A Hypergraph-Based Approach to Attribute Reduction in an Incomplete Decision System. Symmetry. 2025; 17(6):911. https://doi.org/10.3390/sym17060911
Chicago/Turabian StyleSu, Lirun, and Chunmao Jiang. 2025. "A Hypergraph-Based Approach to Attribute Reduction in an Incomplete Decision System" Symmetry 17, no. 6: 911. https://doi.org/10.3390/sym17060911
APA StyleSu, L., & Jiang, C. (2025). A Hypergraph-Based Approach to Attribute Reduction in an Incomplete Decision System. Symmetry, 17(6), 911. https://doi.org/10.3390/sym17060911