1. Introduction
As global tensions rise, environmental crises deepen, and technological change accelerates, social attitudes play a crucial role in shaping our collective future, influencing everything from policy decisions to interpersonal relations [
1]. Social attitudes are commonly considered individual evaluations of various events and groups, influencing how people think and act in particular directions [
2]. Multiple factors contribute to shaping these attitudes, such as media exposure, educational experiences, and cultural background. Among these factors, reading has gained special attention from researchers. Studies have shown that people who read more tend to have less prejudice and more open worldviews [
3]. But not everyone has the same reading opportunities or motivations [
4]. This creates different (sometimes opposite) effects across population groups [
1].
While the relationship between reading exposure and social attitudes has gained considerable attention, the existing research has predominantly relied on traditional analytical approaches such as linear regression [
5] or logistic regression [
6]. These methods effectively identify direct associations but often fail to capture non-linear interaction effects and demographic-specific patterns. Machine learning offers promising alternatives for analyzing these complex relationships. Computational social scientists have increasingly employed ensemble techniques to analyze large-scale survey data, such as the China General Social Survey (CGSS) [
7]. These methods have shown a good performance in identifying feature importance and detecting implicit interactions [
8], but their “black-box” nature limits the interpretability of their results. SHAP (SHapley Additive exPlanations) values provide a solution by enhancing model transparency while maintaining analytical power. This study employs multiple machine learning models (Random Forest, XGBoost, LightGBM) with SHAP values to analyze CGSS data. The impact of reading on social attitudes across diverse social groups is explored, with a particular focus on assessing the potential symmetry or asymmetry in these effects. To guide this exploration, this study addresses the following research questions:
To what extent does reading volume serve as a predictor of social attitudes, after accounting for relevant sociodemographic and behavioral factors?
Do machine learning models (Random Forest, XGBoost, LightGBM) offer an improved predictive performance for social attitudes compared to that of traditional linear regression models?
Does the influence of reading volume on social attitudes exhibit symmetrical or asymmetrical patterns across key demographic subgroups?
Consequently, understanding the nuances of these relationships—specifically, whether reading’s influence is consistent or varies across diverse populations—carries direct practical implications. For instance, if reading volume consistently fosters more inclusive social attitudes, this would bolster arguments for universal reading promotion programs. Conversely, if the effects differ significantly based on demographic factors, this would underscore the need for targeted interventions. This study therefore aims to provide actionable insights into how media consumption, particularly reading, shapes social attitudes within a complex societal fabric, informing both educational policy and social intervention strategies.
This study makes several key contributions. First, it empirically demonstrates the robust predictive power of reading exposure in shaping social cognition. Second, it reveals detailed symmetrical and asymmetrical patterns of reading’s impact across diverse demographic subgroups. Third, it advances an interpretable machine learning pipeline tailored to analyzing large-scale survey data. The remainder of this paper is structured as follows:
Section 2 reviews the relevant literature;
Section 3 details the data and methodological approach;
Section 4 presents the empirical results;
Section 5 discusses the findings, their implications, and limitations; and
Section 6 provides the conclusion.
2. The Literature Review
2.1. The Link Between Reading and Social Attitudes
The influence of reading on social attitudes has been widely investigated in social sciences. Studies have shown that individuals who read more exhibit greater empathy and increased tolerance and understanding towards out-group members [
9,
10]. They also show more prosocial behaviors and higher social engagement [
11]. One possible reason is that reading offers knowledge and experiences beyond everyday life. These experiences can affect how people see the world, broaden their horizons, and shape the way they think [
12]. Fiction reading, in particular, has been shown to reduce prejudice, even in regions with longstanding socio-cultural inequalities [
13]. Similarly, Oľhová et al. [
14]. found that exposing students to fiction can cultivate more tolerant intergroup attitudes.
The evidence for this relationship mostly comes from studies relying on cross-sectional designs. Surveys and behavioral experiments have been employed to explore the direct impact of reading on social attitudes, including potential variations by reading material type [
15]. However, these methods have limitations. Cross-sectional designs and traditional linear statistical methods have a limited capacity to capture complex patterns. For example, they may not capture the non-linear effects of reading and the interactions with complex demographic variables. Thus, the external validity of these findings may be limited [
9]. A small number of longitudinal studies have explored the long-term effects of reading [
10]. However, these studies usually use small sample sizes, limiting the generalizability of their findings [
16]. Moreover, existing studies have insufficiently explored how reading effects might vary across diverse social groups. Although sociodemographic variables were included in some studies as control variables, few studies have examined systematic variations in the impact of reading across various populations [
17].
These limitations may lead to an insufficient understanding of the effects of reading on social attitudes, limiting the interpretability and application of the results.
2.2. Symmetry and Asymmetry in Reading’s Effects Across Social Groups
Understanding the consistency or divergence of reading’s effects across different social groups is crucial for obtaining a more comprehensive picture of how reading changes social attitudes. Sociodemographic variables such as age, gender, education level, and cultural background are considered fundamental indicators for characterizing group features and predicting the effects of media exposure [
18]. These factors can shape how people acquire information, why people read, and how they think. For example, studies have shown that individuals with higher education levels use more logical thinking when forming social attitudes through reading, exhibiting a 23% greater depth of cognitive processing than those with lower education levels [
19]. Additionally, it has been found to be easier for adolescents (aged 13–18) to change their attitudes in response to media messages [
20]. Cultural factors and ethnicity also matter. In a cross-cultural study, Suzuki et al. [
17] found that reading novels affected people’s stereotypes differently depending on their culture. In the UK group, reading novels was clearly linked to stereotype changes. But this link was not found in the Japanese group.
Besides these studies highlighting its differential impacts (asymmetry), the importance of influence symmetry has also been noted. Influence symmetry refers to a phenomenon where different groups exhibit similar patterns of attitudinal and behavioral changes after exposure to the same media content [
21]. Several studies have found that media exposure can affect different cultural or demographic groups in similar ways. For example, Liu [
22] found that during the COVID-19 pandemic, mass media exposure significantly increased people’s preventive behaviors in both Wuhan and other regions, demonstrating cross-regional consistency. Similarly, Armutcu et al. [
23] observed a cross-national symmetrical effect regarding the positive influence of social media marketing on brand awareness and purchase intentions. These findings suggest that the influence of certain media exposures can go beyond group differences.
Researchers generally recognize that influence symmetry offers valuable perspectives for understanding the cognitive processes in attitude formation. But few studies have explored this within the specific context of reading’s impact on social attitudes. Other media studies that have investigated influence symmetry have mostly relied on traditional statistical methods and have often focused on single or limited demographic variables [
24]. Thus, it is difficult to capture the complex interactions among multidimensional population characteristics. Although a few machine learning studies have attempted to explore symmetry using techniques such as stratified sampling [
25] and interaction terms [
26], research quantifying the degree of influence symmetry in the effects of media across different groups remains limited [
27].
These limitations suggest that future research should employ advanced methods, such as machine learning, to quantify and analyze the symmetry and asymmetry of media’s influence across different social groups, thereby offering a more comprehensive explanation of the mechanisms underlying attitude formation.
2.3. Machine Learning in Psychological Research
Machine learning (ML) is now widely used in psychology and other social sciences. For a long time, psychological research relied mainly on traditional statistical methods like multiple linear regression. These methods are simple and efficient but require strict linear relationships between variables, which limits their applicability when dealing with complex, non-linear data [
28]. Real-world psychological phenomena are often more complex. Therefore, standard software like SPSS or Mplus might struggle to analyze these complex data structures. Instead, ML techniques offer another option in dealing with large datasets. These methods show great capabilities in modeling and identifying complex non-linear relationships among variables [
29]. ML models also show a strong generalization performance. They can make accurate predictions on new, unseen data beyond the specific training set [
30]. Therefore, ML can effectively capture complex patterns and dynamic relationships in social science data. The utility of ML in social sciences is increasingly recognized, offering powerful tools for analyzing complex societal data and human behaviors [
31], with applications expanding rapidly across diverse fields such as entrepreneurship research [
32]. The superiority of ML models has been demonstrated in numerous psychological studies [
33,
34], offering new analytical insights for psychological research.
ML methods can be categorized based on how they use data labels. The main types are supervised learning, unsupervised learning, and semi-supervised learning [
35]. Supervised learning uses labeled data. An algorithm learns from examples where the inputs are matched with the correct outputs [
36]. The goal is to train a model that can predict labels for new, unlabeled data. Supervised learning includes classification and regression tasks. Common algorithms include k-Nearest Neighbors (KNN), logistic regression (LR), and Random Forest (RF). Unsupervised learning, conversely, works with unlabeled data. It aims to find hidden structures or patterns within the data itself. The algorithm explores the data without predefined labels [
37]. This includes methods for clustering (e.g., K-means), finding unusual data points (e.g., One-Class SVM), and reducing the data’s complexity (e.g., PCA). Semi-supervised learning combines both approaches. It uses a mix of labeled and unlabeled data to improve the learning outcomes. It typically leverages a larger amount of unlabeled data to improve the learning process, potentially leading to a better model performance than that when using the labeled data alone [
38]. Semi-supervised learning includes algorithms such as Semi-Supervised Support Vector Machines (S3VMs) and semi-supervised clustering.
Despite its strengths, ML faces a major challenge known as the “black-box” problem [
39]. This refers to the difficulty of understanding how complex models arrive at their predictions. High accuracy often comes with low interpretability. This lack of clarity is a critical issue in social science. Additionally, using many related features in training can cause multicollinearity problems. Furthermore, algorithms may inadvertently learn or perpetuate hidden biases present in the training data, which can be difficult to detect [
40]. These limitations restrict the adoption of ML models in social science domains requiring clear decision-making, such as educational assessment or clinical diagnosis [
41].
To address these challenges, Explainable Artificial Intelligence (XAI) has emerged. XAI provides methods to make ML models more transparent and understandable [
42]. One prominent XAI tool is SHAP (SHapley Additive exPlanations) analysis. SHAP values help quantify the contribution of each input feature to a specific prediction. This helps bridge the gap between prediction accuracy and interpretability.
2.4. Shapley Additive Explanations (SHAP) in Social Science Research
Shapley Additive exPlanations (SHAP) is an Explainable Artificial Intelligence (XAI) technique. It is based on cooperative game theory. Lundberg and Lee [
43] proposed SHAP to address the limitations of traditional machine learning model interpretation. The core principle of the SHAP method involves treating the prediction outcome as a “game”, where each feature acts as a “player” contributing its value to the final result. It calculates the relative importance of each feature by systematically considering all possible feature groups [
44]. Mathematically, SHAP values represent a fair way to share the prediction outcomes among the features. The calculation follows clear logical steps. It starts with an empty coalition, the features are randomly ordered and sequentially added, and their average marginal contributions are calculated [
45]. The SHAP scores for each prediction have three important properties: Missingness, Consistency, and Local Accuracy [
46]. These properties allow SHAP to provide feature explanations at both the local (instance-specific) and global (model-wide) levels [
47]. Compared to other interpretation tools, SHAP has advantages in revealing feature interactions, quantifying the contribution of each feature to the prediction outcome, and presenting complex feature relationships through diverse visualizations [
48]. These characteristics also make SHAP a potentially effective tool for addressing issues related to feature multicollinearity [
49].
The development of tools like SHAP marks a new stage in social science research methodologies. These techniques help address the dilemma of the balance between the predictive performance and explanatory power of machine learning methods [
50]. For example, in the field of health research, Sun et al. [
51] utilized a SHAP value analysis to quantify and reveal the different risk factor weights for disease predictions across age and gender subgroups. This application helped guide more precise medical treatments. In policy evaluation studies, Chatzimparmpas et al. [
52] developed an interactive visualization system based on SHAP, showing how the policy effects varied for different groups. This gave policymakers more detailed evidence for decision-making. In the mental health domain, researchers have used a SHAP analysis with ensemble learning models to build interpretable prediction models for suicide attempts. This approach improved prediction accuracy and provided clinicians with clear explanations of contributing risk factors [
47].
SHAP shows great promise for social science, but challenges remain. Pessach and Shmueli [
53] noted that the current research has paid little attention to the symmetry in feature effects. Future research should explore SHAP’s potential in handling data symmetry and asymmetry across diverse social contexts, assessing model fairness, and supporting the cross-disciplinary integration of knowledge. Using SHAP effectively in these ways will increase its value for studying complex social science problems [
45,
48].
2.5. The Present Study
In response to the existing limitations, this study employed machine learning models, specifically Random Forest, XGBoost, and LightGBM, alongside traditional linear regression, to analyze the CGSS2021 dataset. This analysis incorporated reading volume and relevant sociodemographic factors to investigate their influence on social attitudes, with particular emphasis on ecological validity.
The aim of this study is to examine the potential symmetry and asymmetry in reading volume’s impact on social attitudes across different population subgroups. To support this examination, we utilized SHAP for model interpretability. This approach allowed for a clear assessment of whether the influence of reading volume was consistent or varied significantly among different groups.
To address the objectives outlined above, this study will test the following hypotheses:
H1: Reading volume positively predicts social attitudes, with higher reading exposure associated with more open or progressive attitudes.
H2: Machine learning models (Random Forest, XGBoost, LightGBM) will demonstrate a superior predictive performance in modeling social attitudes compared to that of a traditional multiple linear regression model.
H3: The influence of reading volume on social attitudes will exhibit varying patterns of symmetry and asymmetry across demographic groups.
Expected symmetrical effects: It is proposed that reading volume will exert a consistent (symmetrical) influence on social attitudes across certain demographic groups. This expectation is based on the premise that the fundamental cognitive mechanisms engaged by reading may operate similarly irrespective of these specific group distinctions, reflecting potentially universal aspects of media’s influence [
22].
Expected asymmetrical effects: Conversely, it is proposed that the influence of reading volume on social attitudes will vary (exhibit asymmetry) across other demographic groups. This variability is expected due to moderating factors such as differences in educational attainment [
19], distinct life experiences and social roles [
4], and diverse cultural backgrounds [
17].
3. Methods
3.1. The Data Source
This study utilized data from the 2021 Chinese General Social Survey (CGSS2021). The Chinese General Social Survey (CGSS) is a nationally representative survey launched by Renmin University of China. The CGSS aims to collect quantitative data to measure the growing complexity of society and provide a national resource for policymakers, researchers, educators, and practitioners.
The survey employed a multistage stratified probability sampling method to accurately represent the country’s diverse population and geography. This method allowed the survey to include people from both urban and rural areas, capturing the varied population and geographical differences across the country. The CGSS covers a wide range of topics, such as education, employment, family structure, social attitudes, social trust, and quality of life. The 2021 survey wave, used in this study, encompassed 28 provincial-level administrative regions across China and initially yielded 8148 valid responses.
3.2. The Participants
The CGSS (2021) sampled adults aged 18 and older in mainland China. For the current analysis, specific exclusion criteria were applied based on theoretical and methodological considerations. First, participants aged 70 years or older were excluded. This decision was based on established research indicating an age-related decline in social cognitive processing [
54], which suggests potential declines in the abilities relevant to both reading behavior recall and attitude formation. Moreover, this age threshold addresses potential cohort effects, as older Chinese adults who experienced the Cultural Revolution may exhibit fundamentally different relationships with reading and social attitudes [
55]. Second, to ensure the robustness of the machine learning models, individuals with missing data on key study variables—namely, reading volume, the social attitude composite, and crucial sociodemographic predictors—were removed from the sample. Missing data included non-responses or responses coded as “refused,” “don’t know”, or “not applicable.
After applying these criteria, the final sample for the analysis comprised 2698 participants (1258 male). The mean age of the sample was 50.28 years (SD = 13.06).
3.3. Measures
This study selected variables based on their theoretical relevance and empirical evidence from prior research on social attitudes and media exposure [
1,
4]. The selection methodology involved identifying factors with established links to attitude formation in the literature on social psychology and computational social science, ensuring their alignment with the research goal of examining reading exposure’s influence. Below, the dependent and independent variables are described, along with their relevance to this study.
3.3.1. Dependent Variable: Social Attitudes
The primary dependent variable in this study is social attitudes. To measure this, a composite score was created based on a series of specific items primarily drawn directly from the ‘Social Attitudes’ section of the Chinese General Social Survey (CGSS) 2021 questionnaire. The selection of these items was guided by their relevance in reflecting individuals’ evaluations of social issues, encompassing everyday social understanding and perspective-taking, making them a suitable outcome variable for this research.
The Selected Items Covered Three Domains
Attitudes towards gender roles (e.g., “Men should prioritize career, women should prioritize family”; “Household chores should be shared equally”).
Attitudes towards marriage (e.g., “It is not necessary to have children after marriage”; “A bad marriage is better than being single”).
Attitudes towards family (e.g., “A wife helping her husband’s career is more important than pursuing her own”; “Children should do things that bring honor to parents”).
The participants responded to these items using a 5-point Likert scale (1 = strongly disagree, 5 = strongly agree). Several items reflecting traditional views were reverse-scored. This ensured that higher scores consistently indicated less traditional or more open social attitudes. The Cronbach’s alpha coefficient for the combined set of selected items was 0.79, indicating acceptable internal consistency. To validate the social attitudes measure further, a confirmatory factor analysis (CFA) was conducted. The CFA demonstrated the acceptable fit of the model (CFI = 0.92, TLI = 0.89, RMSEA = 0.067, SRMR = 0.055), indicating that the items effectively represented a unified construct. Therefore, the scores on these items were averaged to create a composite social attitude score. Higher scores in this composite measure were interpreted as reflecting a better social attitude performance.
3.3.2. Independent Variables: Reading Volume
The primary independent variable was reading volume. To measure this, we selected item A30a from the CGSS questionnaire: “In the past 12 months, including both print and electronic formats, how many books have you read in total?” This specific question was chosen because it directly and explicitly captures the quantity of books read by the participants, providing a clear indicator of their reading volume. The participants provided a specific numerical answer. Following the standard practice in related research, these numbers were log-transformed and then converted into standardized Z-scores for use in the analyses.
3.3.3. Sociodemographic and Behavioral Variables
The analyses also included several sociodemographic and behavioral variables given their potential influence on social attitudes and their role as important control variables or moderators. These variables were selected based on the established literature on social psychology and media effects [
4,
18,
56], which indicates their relevance in shaping both media exposure patterns and attitudinal outcomes. Including them allowed for a more robust assessment of reading volume’s unique contribution and an examination of the effect symmetry/asymmetry across these demographic lines. These included the following:
Sociodemographic factors: Gender, age, residence (urban or rural), educational level, ethnicity, marital status, and annual income.
3.3.4. Behavioral Factors
Social media browsing time (indicating the time spent searching for information on social media): This variable was selected because the amount of time individuals spend on social media platforms directly reflects their level of exposure to a distinct and increasingly influential information environment. Social media platforms serve as important channels for information acquisition and social interaction. Beyond this role, they also actively shape “information diets” and facilitate unique forms of engagement, which can significantly impact users’ attitudes, perceptions, and beliefs [
57]. The natural interactivity of these platforms [
58] and the commonness of electronic Word-of-Mouth (eWOM) [
59] mean that browsing time serves as an indicator of engagement with content. This engagement, in turn, can bring about emotional responses and influence perceptions of credibility, which are linked to changes in attitude. Furthermore, social media use has been associated with both the potential to build social capital and the risk of encouraging polarization and conflict [
57]. Therefore, understanding the duration of exposure through browsing time is crucial for assessing how these complex online dynamics contribute to the formation and evolution of social attitudes, distinguishing its influence from that of traditional media consumption like reading.
Leisure learning frequency (the frequency of self-directed learning during free time, measured on a 5-point scale): This factor was chosen because a higher frequency of self-directed learning in one’s leisure time may indicate greater intellectual curiosity and proactive engagement with diverse knowledge. Such engagement could foster cognitive flexibility and openness to new perspectives, which are considered conducive to developing less traditional or more progressive social attitudes [
12].
Self-rated Mandarin fluency (indicating an individual’s proficiency in Mandarin Chinese): This variable was included because proficiency in the national language is linked to an individual’s capacity for information access and comprehension from mainstream sources [
60]. Language fluency can also influence cognitive processing of social information and subsequent attitude formation [
61]. Therefore, proficiency in the common language is thus crucial for shaping social experiences and perspectives.
3.4. Data Preprocessing
Obtaining meaningful insights requires both an appropriate model selection and high-quality data. Therefore, we performed initial data preprocessing to improve the quality of dataset. First, duplicate entries were identified and removed. Second, consistent with the participant selection criteria described earlier, cases with missing values for the primary study variables were excluded. Finally, to ensure that features measured on different scales contributed comparably to the analysis, all continuous predictor variables were standardized using the Z-score method. This standardization prevents variables with naturally larger values from having an undue influence on the model outcomes.
3.5. Data Analysis Strategy
This study employed a four-step data analysis strategy to investigate the relationship between reading volume and social attitudes and to assess whether this relationship showed symmetry across different population groups.
3.5.1. Step 1: Model Building
We trained three machine learning models, including Random Forest, XGBoost, and LightGBM, as well as a standard multiple linear regression (MLR) model for comparison.
Random Forest: An ensemble method that constructs multiple decision trees using bootstrap samples and random feature selection. The final prediction is determined by averaging the outputs of all individual trees, which reduces overfitting and improves the generalization performance. Recent applications in social science research have demonstrated Random Forest’s effectiveness in handling complex behavioral data and providing robust feature importance measures [
31].
XGBoost (Extreme Gradient Boosting): A gradient boosting framework that builds trees sequentially, where each tree learns from the errors of previous trees, using regularization to prevent overfitting. Recent studies have shown its superior performance in psychological and social science applications, particularly for prediction tasks with complex feature interactions [
60].
LightGBM (Light Gradient Boosting Machine): This gradient boosting framework employs histogram-based algorithms for faster training and uses a leaf-wise tree growth strategy rather than the traditional level-wise approach [
62]. LightGBM has gained popularity in recent social science research due to its computational efficiency and ability to handle large-scale survey data effectively.
Multiple linear regression (MLR): A traditional parametric approach assuming linear relationships between the predictors and the outcome, serving as a baseline comparison.
These models used the preprocessed data (reading volume, sociodemographic factors, and behavioral factors) as the input features (predictors) to predict the composite social attitude score (outcome).
3.5.2. Step 2: Hyperparameter Optimization
To optimize the predictive accuracy of the machine learning models, their hyperparameters were tuned using a systematic grid search procedure, implemented with the GridSearchCV utility from the scikit-learn library. This process incorporated a 5-fold cross-validation strategy applied to the training dataset to ensure robust parameter selection and mitigate overfitting. For each model, a predefined grid of hyperparameter values was explored. Specifically, the following was implemented:
For Random Forest, the search space included n_estimators (number of trees, e.g., values such as 50, 100, 300, 500), max_depth (maximum depth of trees, e.g., values ranging from 2 to 10), and min_samples_split (the minimum samples required to split an internal node, e.g., 2, 5, 10).
For XGBoost and LightGBM, the grids encompassed n_estimators (e.g., 50, 100, 300, 500), max_depth (e.g., values from 2 to 10), and learning_rate (e.g., values such as 0.01, 0.05, 0.1, 0.2).
The performance of each hyperparameter combination was evaluated based on the mean R2 (coefficient of determination) score across the five cross-validation folds. The set of hyperparameters yielding the highest mean R2 score was selected as the optimal configuration for each model.
3.5.3. Step 3: Model Validation
We evaluated the final, optimized models’ ability to generalize to new data using K-fold cross-validation (with K = 5). In this process, the dataset was repeatedly split into a training set (4 folds) and a testing set (1 fold). Performance metrics (e.g., R-squared, Mean Absolute Error) were calculated on the testing set in each repetition, and the average metric across all folds was used as a reliable estimate of the model’s expected performance on unseen data.
3.5.4. Step 4: Feature Interpretation
We conducted a feature importance analysis to interpret the models and understand the specific influence of reading volume compared to that of the other predictors. We primarily used SHAP (SHapley Additive exPlanations) values for this purpose. This technique allowed us to quantify how much each predictor contributed to the model’s predictions of social attitudes. It also enabled us to examine whether the effect of reading volume was consistent (symmetric) or varied (asymmetric) when comparing different subgroups based on key sociodemographic characteristics (e.g., gender, age groups, education levels).
3.6. Software and Implementation Tools
All analyses were conducted using Python 3.7. Machine learning models were implemented using scikit-learn 1.0.2 (Random Forest, Linear Regression), XGBoost 1.6.2, and LightGBM 4.6.0. A SHAP analysis was performed using the SHAP library 0.42.1. The data preprocessing and statistical analyses utilized pandas 1.3.5 and numpy 1.21.6. Hyperparameter optimization employed GridSearchCV with 5-fold cross-validation. Visualizations were created using matplotlib 3.5.3 and seaborn 0.11.2.
A detailed flowchart of the implementation pipeline is provided in
Supplementary Materials (uploaded separately) for full transparency and reproducibility.
5. Discussion
5.1. The Key Findings
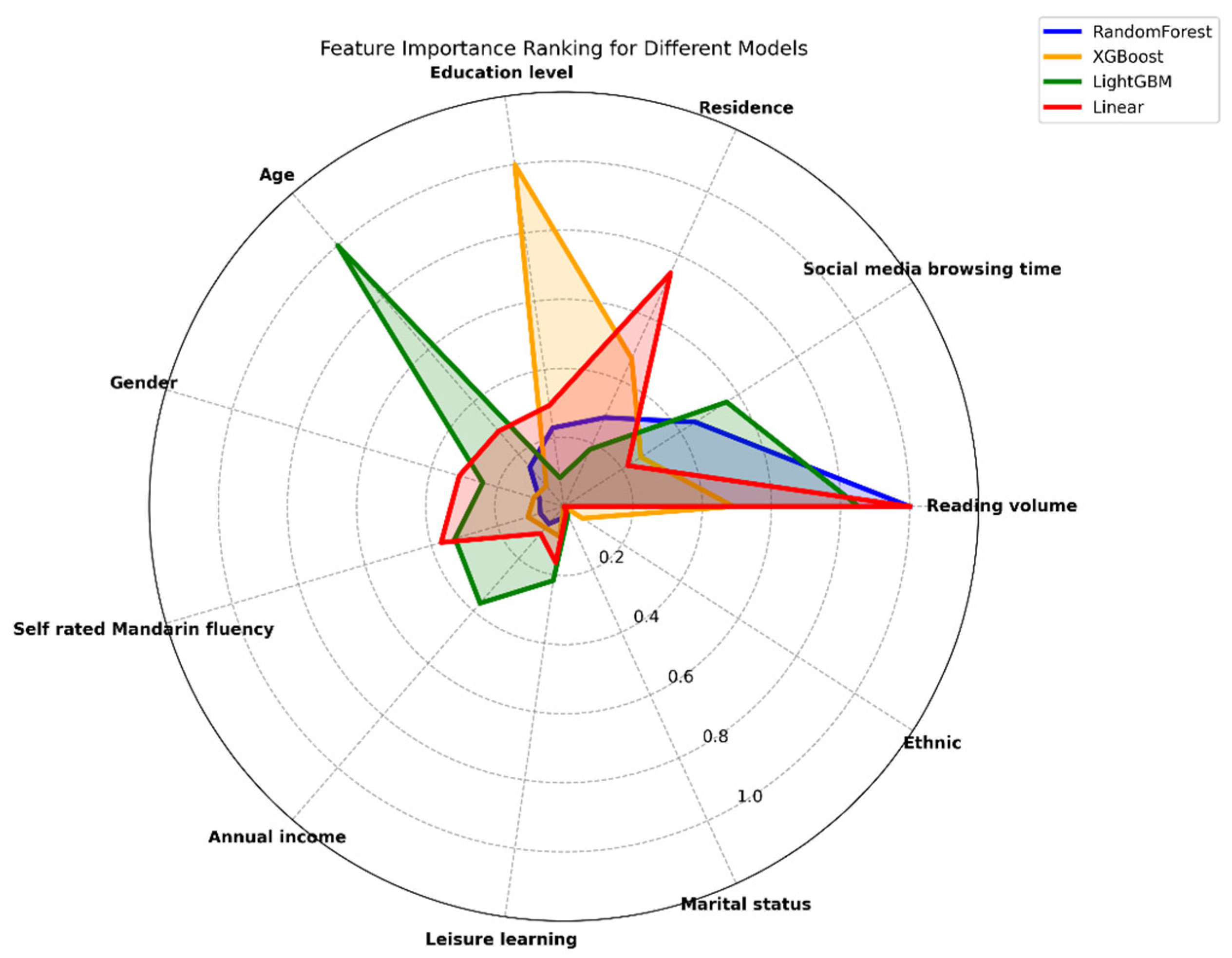
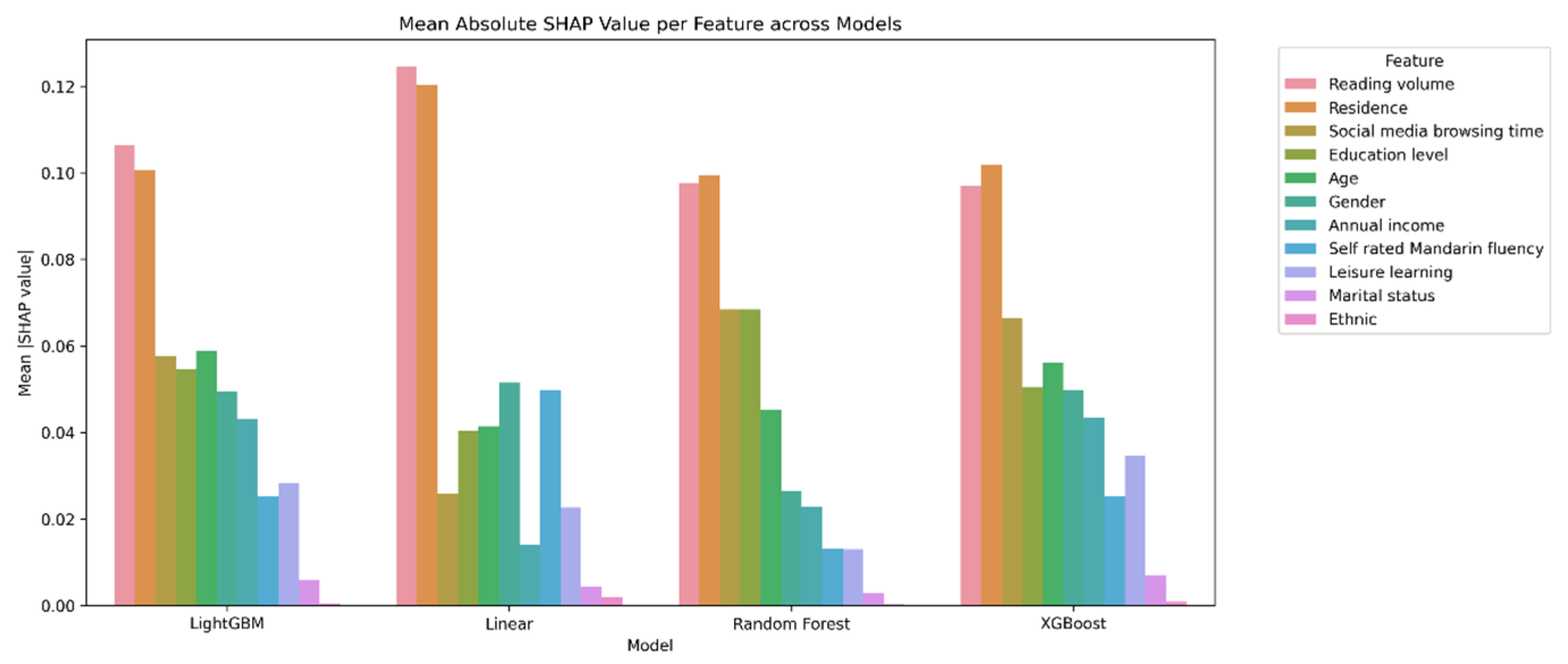
This study examines the influence of reading volume on social attitudes across different demographic groups, with a particular emphasis on effect symmetry. Analyzing the CGSS2021 data through machine learning methods (Random Forest, XGBoost, LightGBM) and linear regression revealed reading volume as a core predictor of social attitudes. This significance was consistently demonstrated across all four models. Specifically, the tree-based feature importance analyses (Random Forest: 0.43; XGBoost: 0.18; LightGBM: 0.11) highlight reading’s significance, further corroborated by its substantial positive coefficient in linear regression (β = 0.27, p < 0.001). The consistency across different modeling approaches highlights the robustness of the association between reading volume and social attitudes. This finding strongly supports Hypothesis 1, which posited that reading volume would positively predict social attitudes, with higher reading exposure associated with more open or progressive attitudes. The consistent positive coefficients and high feature importance scores across diverse models provide robust evidence for this hypothesis.
Additionally, this study’s results indicated that non-linear models demonstrated a slightly better fit, with LightGBM achieving the highest R2 value. This suggests that tree ensemble models possess advantages in capturing the complex interplay of factors influencing social attitudes. This result supports Hypothesis 2, which hypothesized that machine learning models (Random Forest, XGBoost, LightGBM) would demonstrate a superior predictive performance in modeling social attitudes compared to that of a traditional multiple linear regression model. Although this improvement was marginal, the higher R2 scores and lower error metrics of the machine learning models, particularly LightGBM, indicate their enhanced capability in capturing potential non-linearities in the data.
However, it should be noted that the R
2 values across all models fall within a moderate range. The observed R
2 values (ranging from 0.33 to 0.36) require further discussion within the context of social science research. Human attitudes and behaviors are naturally complex phenomena influenced by numerous unmeasured psychological, cultural, and experiential factors. This complexity limits the proportion of variance that can be explained by any measured variable. According to [
65], R
2 values of 0.02, 0.13, and 0.26 represent small, medium, and large effect sizes in behavioral sciences, respectively, suggesting that our results demonstrate practically meaningful relationships. These values are also comparable to or exceed those reported in similar studies examining the effects of media on attitudes, such as Wei et al. [
66], who reported an R
2 of 0.27 using similar large-scale survey data. The consistent performance levels observed across all models indicate that the identified patterns are robust and reliable. While some variance remains unexplained, the models successfully identify key predictor variables and reveal their relative importance in influencing social attitudes, which aligns with the primary objectives of this research.
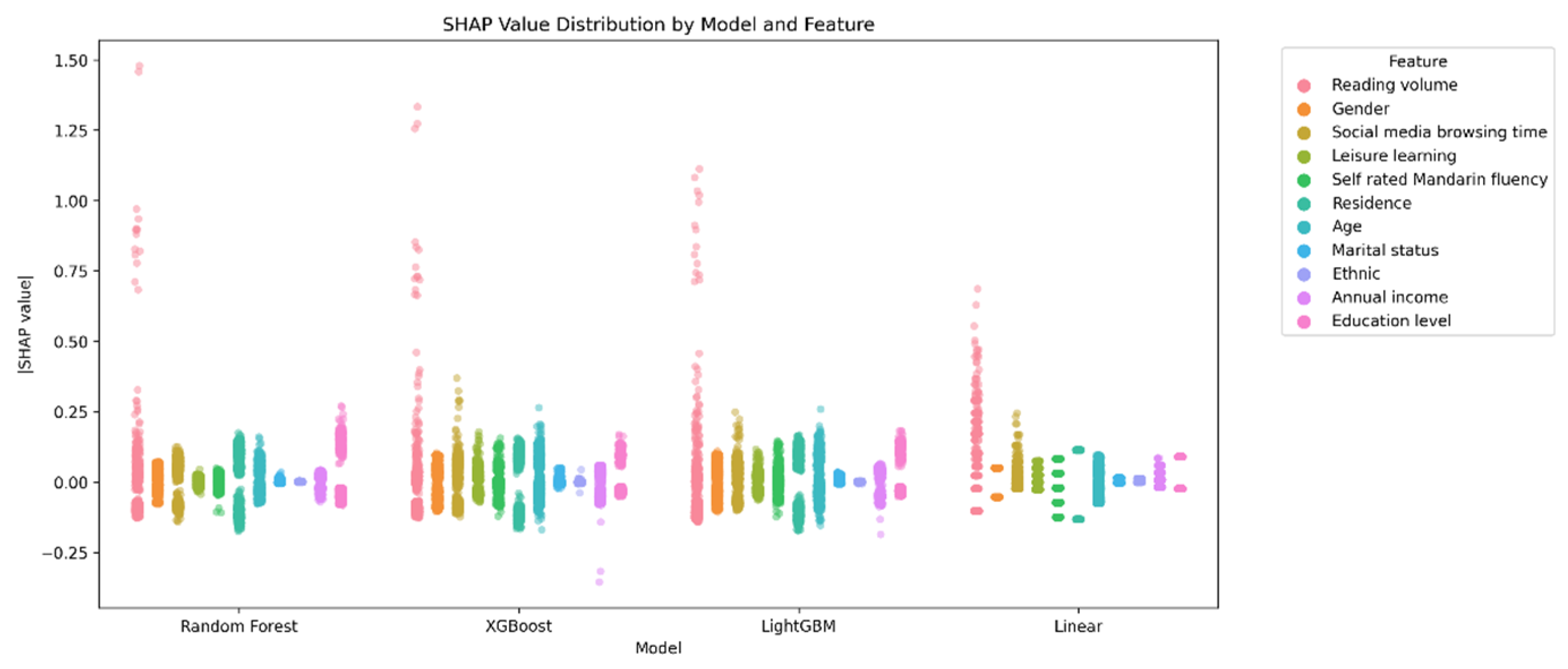
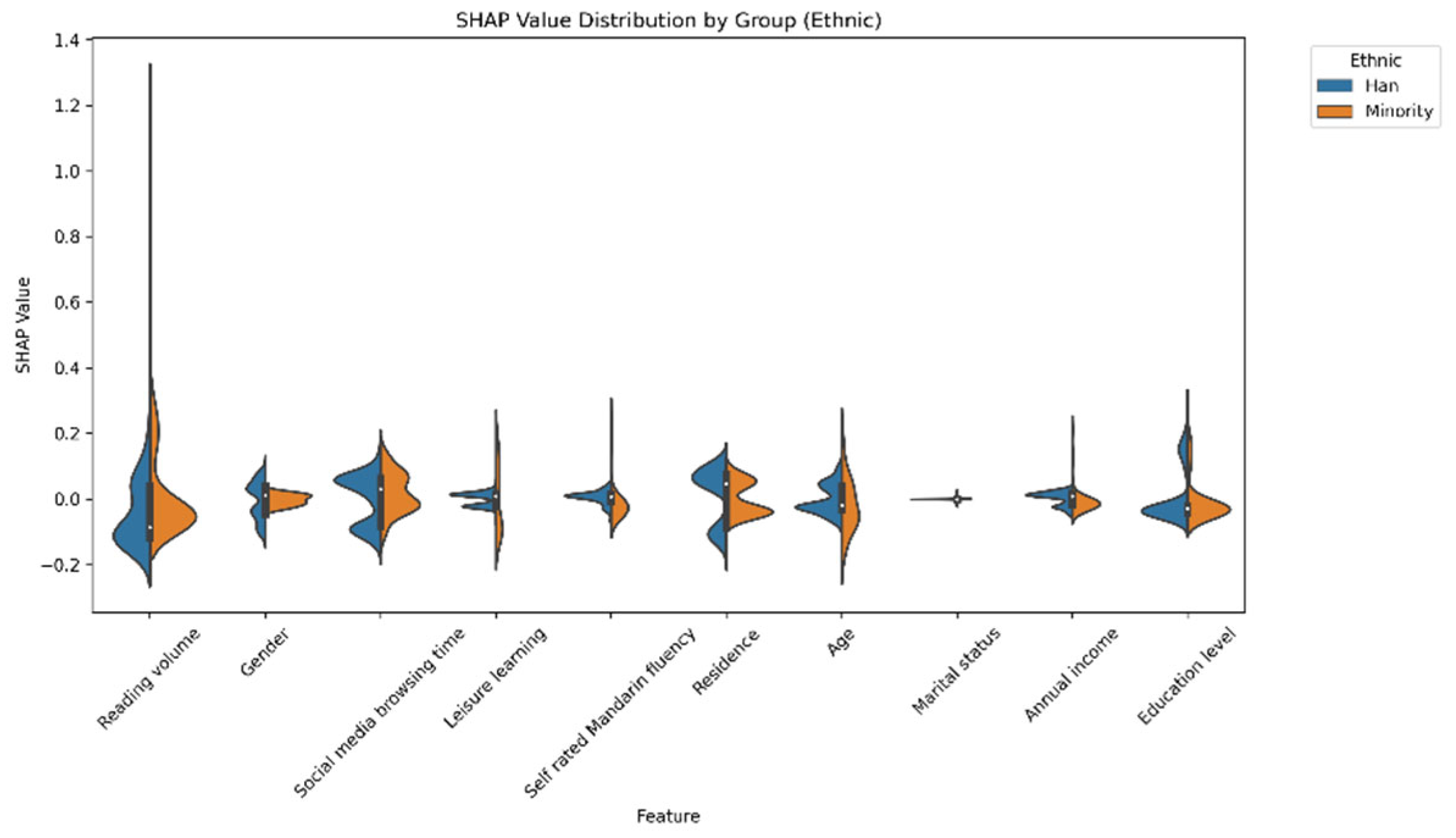
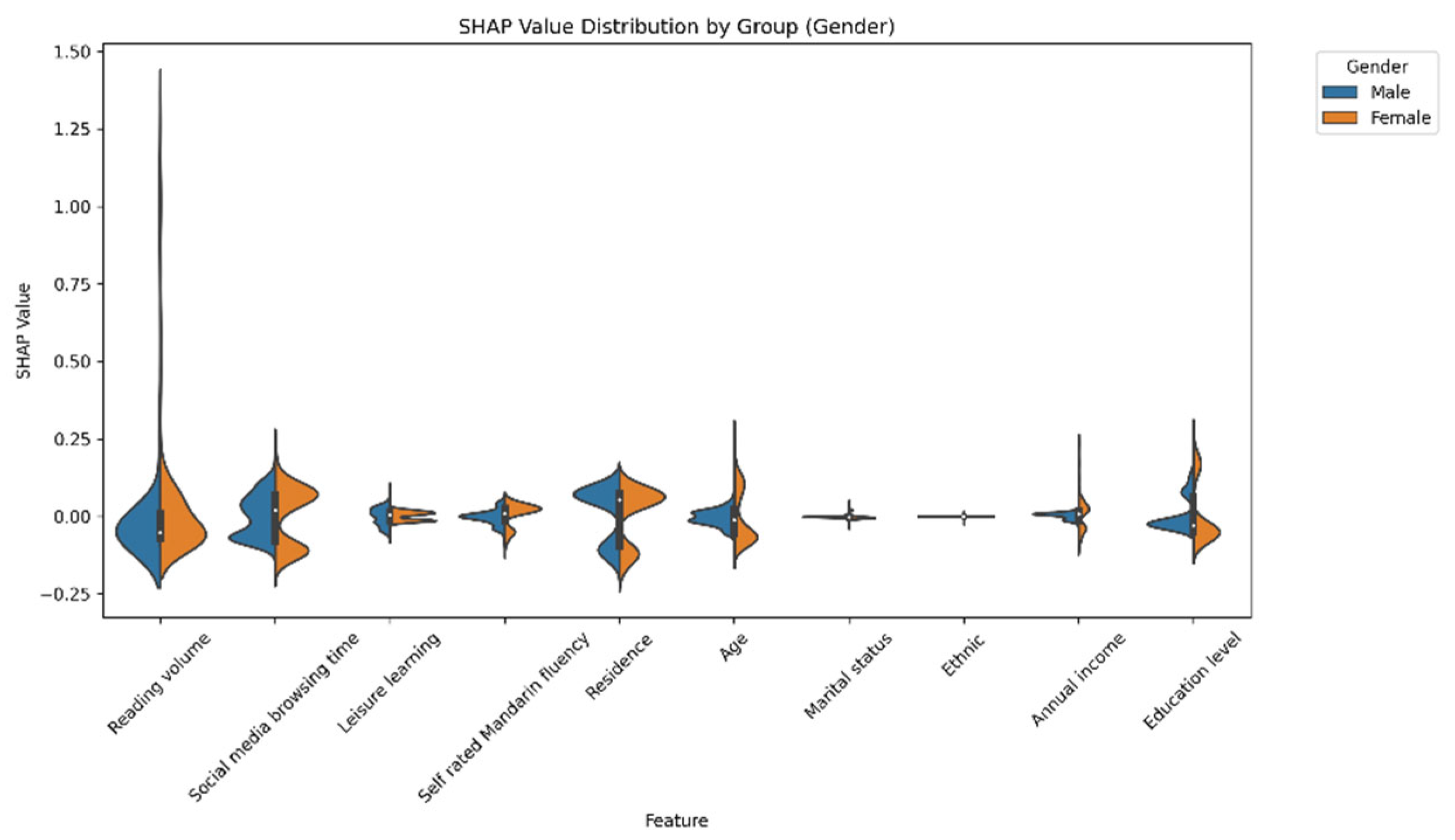
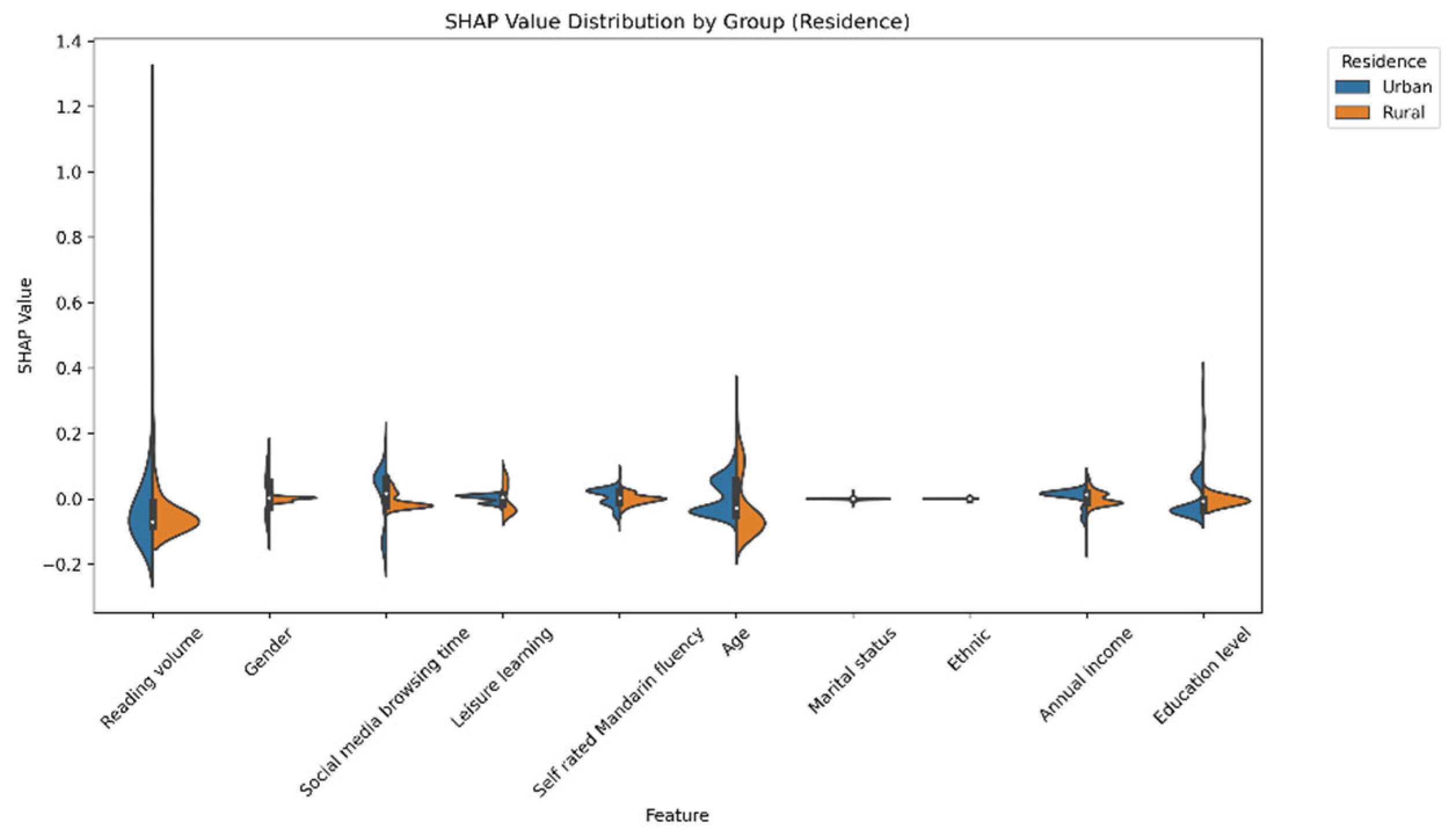
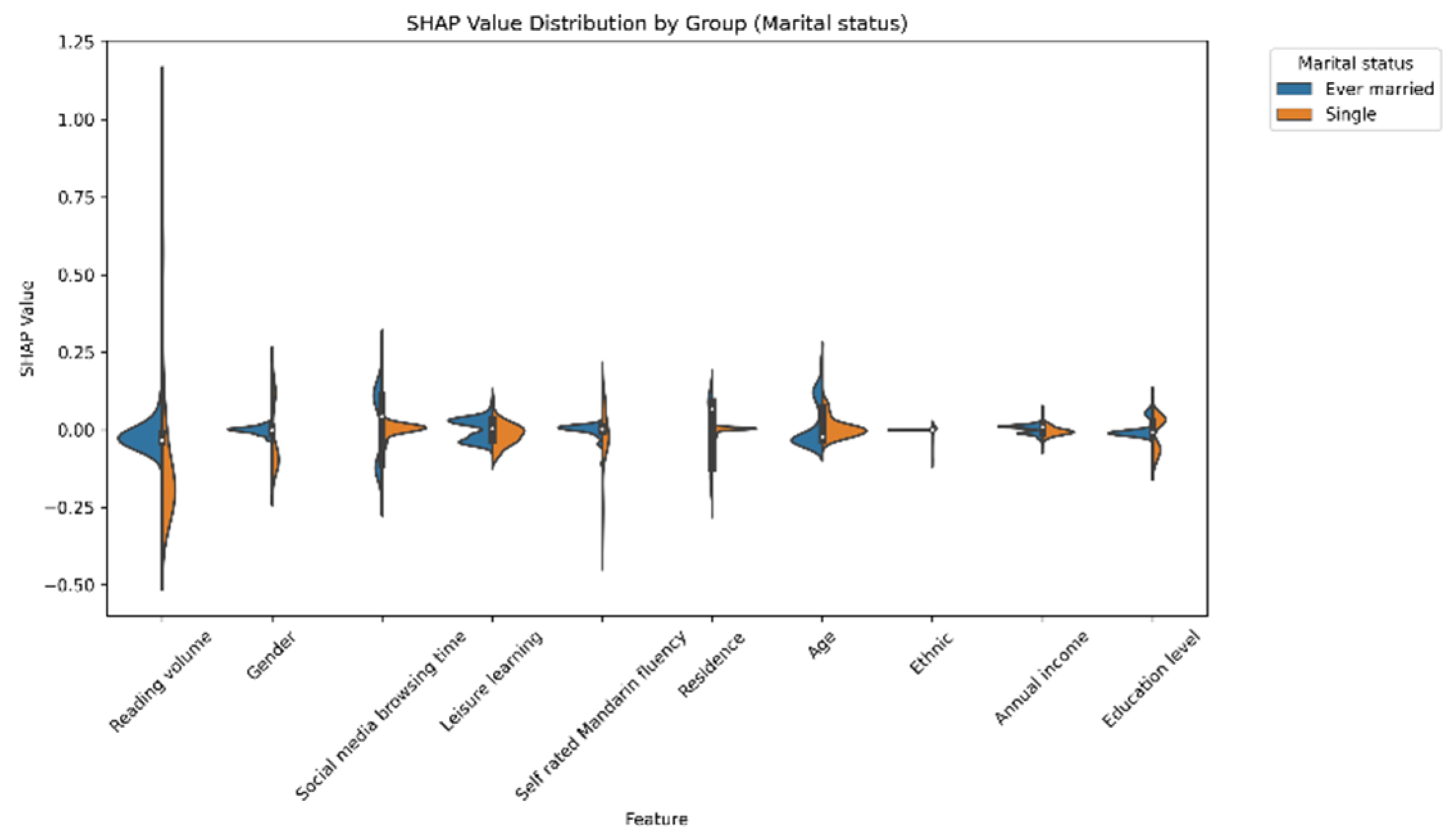
Beyond the overall model performance, the SHAP-value-based subgroup analyses provide nuanced insights into the symmetry of reading effects. The results reveal both symmetric and asymmetric patterns across demographic categories. For example, the effect of reading volume on different gender groups exhibited strong symmetry (SHAP values: male = 0.10, female = 0.09). Partially symmetric effects were also observed for ethnicity (Han Chinese = 0.11, ethnic minorities = 0.08) and place of residence (urban = 0.10, rural = 0.08). However, notable asymmetries emerge across education levels and marital status. Reading had a much greater effect on people with more education than those with less. Similarly, the relationship between reading volume and social attitudes was stronger for never-married individuals than those for ever-married individuals. These findings provide support for Hypothesis 3, which proposed that the influence of reading volume on social attitudes would exhibit varying patterns of symmetry and asymmetry across demographic groups. The observed strong symmetrical effect across genders aligns with the expected symmetrical effects part of H3. Concurrently, the significant differences in reading’s impact based on education level and marital status, along with the partial symmetries for ethnicity and residence, confirm the expected asymmetrical effects part of H3. This demonstrates that while reading’s core influence may be consistent in some demographic comparisons, its impact is indeed moderated by other sociodemographic factors, leading to varied effects in other contexts.
5.2. The Effects of Reading
A robust association between reading volume and social attitudes was consistently demonstrated across models. It is demonstrated that people who read more tend to show greater understanding and respect for individual differences. They are also more willing to challenge traditional values regarding family, marriage, and gender roles. These findings align with previous research suggesting that reading fosters empathy, reduces prejudice, and broadens worldviews through exposure to diverse perspectives and narratives [
11,
12]. This study builds on these findings by measuring the importance of reading within a wide range of social and demographic factors. Machine learning methods were used on large-scale, real-world data, which helped overcome the limitations of earlier lab-based studies, which have often used smaller groups of participants.
The strength of the connection found (effect size β = 0.27) was similar to or even greater than that found in earlier research. For example, Jiang’s [
9] study reported a correlation of 0.21 between reading and concern for others’ feelings (empathic concern). The stronger link identified in this research might have been because social attitudes were measured comprehensively, and the models used were capable of handling complex interactions between different factors.
The mechanisms through which reading volume influences social attitudes are considered to involve both cognitive and affective pathways. Buttrick et al. [
12] suggested that reading broadens perspectives by showing individuals viewpoints beyond their usual social circles. This proposition is consistent with the results of this study, as reading volume remained an important predictor even after accounting for other forms of media engagement, such as social media browsing time.
Furthermore, comparing the performance of different models suggests a potential non-linear relationship between reading volume and social attitudes. Specifically, the tree ensemble models (Random Forest, XGBoost, and LightGBM) exhibited a slightly superior predictive performance than that of standard linear regression. This indicates that reading might have a stronger effect at lower amounts, with its impact potentially leveling off or becoming more complex as reading volume increases. Machine learning models, through their inherent structures (e.g., decision tree splitting rules), are better suited to capturing these kinds of non-linear patterns [
29].
It is also noteworthy that the diagnostic checks for our standard linear regression model highlight the advantages of the machine learning approaches used in this study. While the variance inflation factors (VIFs) were all below 1.8, indicating that multicollinearity was not a significant concern despite the condition number, the Durbin–Watson statistic for the linear model was 0.74. This value suggests potential positive autocorrelation in the residuals, implying that their error terms may not be fully independent. Such autocorrelation can affect the efficiency of Ordinary Least Squares (OLS) estimates and the precision of their standard errors. Consequently, while the β coefficients from the linear regression offer insights into linear trends, they should be interpreted with this potential limitation in mind.
This finding demonstrates a benefit of our primary analytical approach, which centers on machine learning models (Random Forest, XGBoost, LightGBM) and their SHAP-based interpretations. These ensemble methods are generally more robust to the strict assumptions of OLS regression, such as the independence of errors, particularly when modeling complex, potentially non-linear relationships and assessing feature importance in a predictive context. The linear model served principally as a conventional benchmark in our broader analytical strategy, and its diagnostic characteristics in this instance further highlighted the value of the more flexible machine learning framework employed in this study.
5.3. The Symmetry and Asymmetry Between Demographic Groups
The results revealed strong symmetry in the effect of reading volume on social attitudes across genders and a partially symmetrical effect across regional and ethnic groups. This suggests that the mental processes through which reading shapes social attitudes may be relatively universal across the studied populations, transcending these specific social boundaries.
Specifically, symmetrical effects were observed across gender groups. This finding may extend and refine perspectives from studies suggesting gender-specific differences in the effects of media. While Valkenburg and Peter [
20] found that girls responded more strongly to emotional media content than boys, the symmetry effect observed in this study suggests that reading’s influence works through cognitive processes that are similar for both genders, at least within the context of contemporary Chinese culture.
Regarding the partial symmetry across regions and ethnicities, it was found that although starting attitude levels might differ, both urban and rural residents, as well as Han and ethnic minority groups, showed fairly consistent patterns in the direct effects of reading. While an individual’s residential environment and ethnicity can exert multifaceted influences on social attitudes, the fundamental cognitive impact of exposure to reading seems relatively stable. This highlights the potentially foundational role of reading in shaping social cognition beyond one’s direct environment. These findings are like Liu [
22] observation that the effects of mass media on health behaviors during COVID-19 were similar across regions, suggesting that some media effects go beyond regional and cultural boundaries. The findings of this study extend this concept to the domain of reading volume and social attitudes.
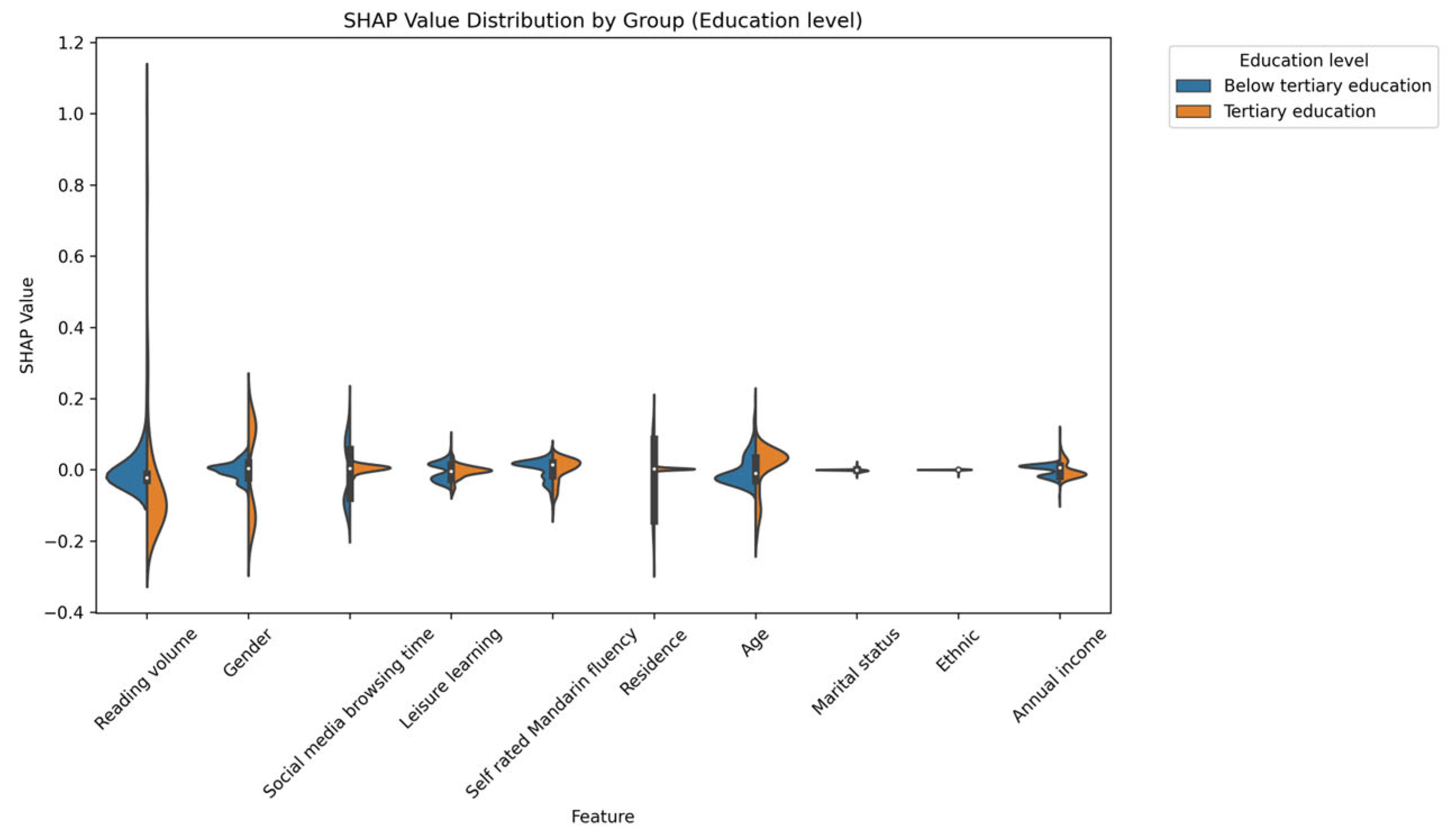
In contrast, significant asymmetries were found across education levels. Reading appears to have a greater influence on individuals with a higher education. This difference can be attributed to several factors. Higher education typically cultivates critical thinking abilities, enhances cognitive processing capacities, and exposes individuals to a wider range of more complex reading materials [
19]. Consequently, highly educated individuals may engage more deeply with the ideas encountered through reading and incorporate them more readily, leading to more pronounced changes in their attitudes. This finding highlights the potential interaction between reading volume exposure and pre-existing cognitive frameworks in shaping social attitudes.
Similarly, asymmetry was observed in the impact of reading volume across marital status groups. Individuals who had never been married were more susceptible to the effects of reading volume exposure. This may reflect differences in social roles, responsibilities, and life experiences [
4]. Never-married individuals may have more free time for reading and exhibit greater openness to novel ideas and perspectives during the processes of identity formation and social integration. In contrast, married individuals may be influenced by family life and established social networks, which could potentially lessen the direct impact of reading on their social attitudes.
These results demonstrate the advantages of interpretable machine learning methods in capturing intricate feature patterns. Such methods can reveal complex patterns in how factors affect outcomes across different groups. Traditional statistical tests comparing group averages might not capture these subtle variations. In contrast, the adoption of the SHAP-value-based analysis in this study enables the decomposition of each factor’s contribution for individuals, revealing more detailed patterns of influence at the group level.
5.4. Implications
This study combines interpretable machine learning with traditional statistical methods to analyze large-scale data. This approach allows the complex relationships in social science research to be captured, improving the understanding of the subtle ways various factors influence social cognition and behavior. The findings support the view of Kyriazos and Poga [
67] that machine learning techniques can effectively model non-linear relationships that the traditional methods might miss. Such a methodological advance offers policymakers with refined tools to evaluate how educational and media interventions affect different social groups in varied ways.
Furthermore, this research contributes to the concept of “influence symmetry” in media exposure studies. While previous work has noted the importance of examining such symmetrical effects [
21], empirical investigations in this area have been limited. This study provides a novel methodological framework by quantifying and analyzing the symmetry patterns across different demographic groups, enabling the application of this analytical approach to media influence contexts beyond reading.
Additionally, the findings provide ecologically valid tests of the effects of reading on social cognition, extending previous research and yielding important insights for policymakers and educators. The strong association between reading volume and progressive social attitudes supports the promotion of reading in schools and communities. Importantly, the asymmetries observed across education levels and marital status indicate that reading’s impact is varied. It depends on the amount of reading, as well as individual characteristics that influence how information is processed and integrated into existing views. This suggests that efforts to promote reading may need to be adapted to different demographic groups to be the most effective. Indeed, these nuanced findings carry significant practical implications. For educators and policymakers, an important insight is reading’s consistent impact across genders; this suggests that broad promotion initiatives are often suitable without needing gender-specific tailoring. Conversely, reading’s impact varies across education levels, presenting another key consideration. For individuals with lower educational attainment, the positive influence of reading programs on social attitudes can be significant. This effect may be amplified further by integrating these programs with cognitive skill-building activities. Furthermore, the more pronounced impact of reading among never-married individuals indicates a strategic opportunity for intervention. Targeting young adults during their formative years can be particularly effective. University and community-based programs offer potential avenues for such interventions. The goal is to foster more open social attitudes in this demographic. Collectively, these insights are crucial. They underscore the need for context-sensitive interventions. Such interventions must account for the varied effects of reading across different demographic groups.
5.5. Limitations and Future Directions
Several limitations should be noted. First, the cross-sectional nature of the CGSS 2021 data fundamentally limits causal inference. Our findings demonstrate robust associations but cannot definitively determine causality. It is plausible, for example, that individuals with more open social attitudes are more inclined to read, rather than reading directly causing such attitudes, or that a bidirectional relationship exists. Future longitudinal studies tracking changes in reading habits and social attitudes over time are necessary to disentangle these relationships. Alternatively, experimental intervention studies, where participants are assigned different types or volumes of reading materials, followed by an assessment of their attitudinal shifts, could also help disentangle the causal pathways. The use of self-reported reading volume, which may be susceptible to recall bias and social desirability effects, is another limitation. Future research could explore more objective measures of reading behavior, such as book purchase records or library loan data.
Second, while the social attitude measure demonstrated acceptable internal consistency (Cronbach’s α = 0.79), it mainly focused on views about gender roles, marriage, and family. Future research should investigate the generalizability of these findings to other domains of social attitudes, such as those concerning ethnicity, politics, or the environment.
Third, limitations in the survey questionnaire meant the reading measure included all book types together, without distinguishing by genre. This restricted the ability to interpret findings related to specific reading habits, like long-term reading of fiction. As demonstrated by Suzuki et al. [
17], the content of reading materials can significantly modulate their effects on stereotypes and social attitudes. Future research should incorporate more detailed measures of reading content to examine how different types of reading materials may differentially influence social attitudes.
Fourth, despite controlling for several sociodemographic and behavioral factors, unmeasured variables may have influenced the relationships observed to some extent. For example, personality traits like ‘openness to experience’ could potentially affect both reading habits and social attitudes, possibly confounding the observed connection.
Moreover, cross-cultural replications of this study would be valuable for determining whether the observed patterns of symmetry and asymmetry are specific to China or reflect more generalizable processes in attitude formation.
6. Conclusions
This study examined the relationship between reading volume and social attitudes across demographic groups in China using a machine learning framework with SHAP-based interpretability. Our key findings revealed that reading volume consistently predicts more open social attitudes, with tree-based ensemble models capturing non-linear relationships more effectively than traditional linear regression.
The analysis of the effect symmetry revealed important patterns in reading’s influence. While the effect was symmetric across gender and partially symmetric across ethnicity and residence, significant asymmetries emerged for education level and marital status. Specifically, reading showed stronger effects among individuals with a tertiary education and those who had never married.
Our methodological contribution lies in combining machine learning with a SHAP analysis to assess the symmetry in feature importance, advancing the computational approaches in social science research. These findings offer valuable insights for educators and policymakers, suggesting that targeted reading promotion strategies could effectively foster positive social attitudes across different demographic groups in contemporary society.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}