1. Introduction
The field of artificial intelligence (AI) has witnessed significant transformations in recent years, largely driven by the advancement of deep learning techniques [
1]. Despite their remarkable performance, traditional deep learning models often require massive numbers of data and computational resources and significant memory bandwidth to achieve high accuracy [
2,
3]. This computational overhead makes them less practical for deployment in resource-constrained environments, such as mobile devices, edge computing systems, and embedded platforms [
4,
5,
6,
7]. Furthermore, these models typically operate as black boxes, offering little interpretability and limiting their usability in critical applications like medical diagnosis and autonomous control [
8,
9].
To address these challenges, researchers have turned toward biologically inspired computing paradigms that draw insights from the structure and function of the human brain [
10,
11]. Among these, dendritic learning has emerged as a promising direction [
12,
13]. It is rooted in the biological understanding that dendrites—the branched extensions of neurons—perform sophisticated, localized processing of synaptic inputs [
14]. This capability allows biological neurons to exhibit high computational power without significantly increasing their energy consumption or structural complexity [
15].
Dendritic neuron models (DNMs) emulate this biological principle by organizing input processing into distinct dendritic branches [
16,
17]. Each branch aggregates a subset of inputs through nonlinear operations and contributes to the final output through a competitive or cooperative mechanism. This design introduces interpretability and modularity into the learning process while also enabling sparsity and local computation [
18]. Moreover, the inherent structure of DNMs allows for the integration of neural plasticity, dendrite pruning, and dynamic expansion—traits that mirror the adaptability of real neural systems [
19].
The lightweight nature of DNMs makes them especially suitable for real-time applications [
20]. Experimental studies have validated their efficacy across a wide spectrum of tasks, including image classification, time-series prediction, medical image segmentation, and environmental monitoring [
21,
22,
23]. In medical imaging, for example, dendritic models have outperformed standard convolutional networks in segmenting fine-grained features within ultrasound and CT scans [
24]. In time-series forecasting, their ability to model nonlinear dependencies with fewer parameters has enabled efficient and accurate predictions in energy systems and financial domains [
25]. Furthermore, recent work by Wu et al. [
26] has formally proven that DNMs possess universal approximation power. In their study, the authors demonstrated that DNM architectures can approximate any continuous function to arbitrary precision, similar to multi-layer perceptrons (MLPs) but with more efficient structural representations.
Despite their advantages, training dendritic models remains a complex challenge [
18,
27]. Their nonlinear and modular structure poses difficulties for the gradient-based optimization techniques commonly used in deep learning. Furthermore, fixed architectures often limit the model’s flexibility to adapt to varying data distributions and tasks. To overcome these limitations, recent research has explored the use of evolutionary algorithms for model training and architecture optimization [
28,
29,
30].
Evolutionary algorithms (EAs) [
31], such as Genetic Algorithms, Particle Swarm Optimization, and differential evolution (DE), offer population-based search strategies that are particularly effective for high-dimensional, non-convex optimization problems [
32]. Among them, differential evolution is especially notable for its simplicity, convergence behavior, and ease of implementation [
33]. However, standard DE suffers from issues like premature convergence, a lack of diversity, and fixed parameter settings, which hinder its performance on complex tasks like DNM optimization [
34].
To address these issues, we propose a novel algorithm: Resource-Adaptive Differential Evolution (RADE). RADE is designed to complement dendritic learning by introducing several key innovations:
Dynamic population partitioning: RADE divides individuals into good and bad groups based on fitness ranking and adjusts this division adaptively throughout the search.
A reinforced mutation mechanism: By leveraging poor-performing individuals in the variation formula, RADE maintains exploration while guiding convergence.
Parameter adaptation: A memory-based scheme adjusts control parameters like mutation factor F and crossover rate based on historical success.
Lightweight archiving: A compact external archive preserves useful diversity and prevents population stagnation.
Time-varying control: The algorithm adapts its exploration–exploitation balance according to the search phase.
These innovations are not only biologically inspired but also computationally efficient, making RADE an ideal evolutionary framework for optimizing dendritic learning systems. In addition, the notion of symmetry plays a fundamental role in both natural and artificial systems. In biological neurons, dendritic processing often follows symmetric patterns where structurally similar branches perform localized computations in parallel. This structural symmetry contributes to energy-efficient processing and robustness. Similarly, RADE maintains and exploits symmetry within the population-based evolutionary search by partitioning individuals and balancing exploration and exploitation symmetrically across search phases. Moreover, the output architectures of DNMs optimized by RADE exhibit morphological symmetry, which enhances interpretability and facilitates logical rule extraction. Moreover, RADE aligns with the broader trend in AI toward sustainability and interpretability. As concerns about the carbon footprint of large models grow [
5], lightweight yet powerful alternatives are increasingly valued. RADE and dendritic learning together represent a paradigm that prioritizes biological plausibility, energy efficiency, and task-specific adaptability over brute-force computation.
This paper is organized as follows:
Section 2 introduces the theory and motivation behind lightweight dendritic learning.
Section 3 details the proposed RADE algorithm and its components.
Section 4 presents empirical evaluations across benchmark classification tasks, and discusses the results, interpretability, and potential applications. Finally,
Section 5 concludes with future research directions.
3. Proposed Resource-Adaptive Differential Evolution Algorithm
To improve the learning efficiency, robustness, and interpretability of the DNM in classification tasks, we propose a novel lightweight evolutionary optimization method termed Resource-Adaptive Differential Evolution (RADE). RADE introduces several biologically inspired and resource-aware mechanisms to address the limitations of conventional DE and its variants when applied to high-dimensional and dynamically evolving neural systems. This section elaborates on the architectural innovations, algorithmic framework, and theoretical motivations behind RADE, particularly its compatibility with interpretable and low-resource neural learning.
3.1. Overview and Motivation
Evolutionary algorithms (EAs) have been widely employed for neural optimization due to their ability to explore high-dimensional, non-convex landscapes effectively [
47,
48]. Among them, DE and its variants have proven successful in optimizing complex neural structures [
49,
50]. However, these methods often suffer from issues like premature convergence and inefficient exploration, which limit their application in dendritic neuron optimization. RADE addresses these limitations through dynamic population partitioning, lightweight archiving, and adaptive parameter control. It is conceived from a synthesis of ideas drawn from natural evolution, biological neural computation, and recent advances in adaptive differential evolution algorithms. Traditional differential evolution algorithms [
51,
52], while successful in many real-valued optimization problems, often fall short in tasks that demand both exploration and exploitation in a dynamically changing fitness landscape—such as those encountered in training DNMs [
53]. In such settings, overly aggressive exploitation leads to premature convergence, whereas excessive exploration sacrifices convergence speed and solution quality [
54,
55]. Furthermore, when applied to real-world classification problems under resource-constrained environments, classical DE methods often require extensive population sizes and computational time to converge to satisfactory solutions. This renders them impractical for lightweight, interpretable AI applications.
To mitigate these challenges, RADE introduces four primary innovations: (1) dynamic population partitioning, (2) reinforced mutation with poor-individual interference, (3) parameter self-adaptation via lightweight memory mechanisms, and (4) an efficient external archive that guides exploration without increasing model complexity. These innovations reflect a biologically grounded learning approach: rather than treating all individuals equally during evolution, RADE simulates a more nuanced model of survival and competition, akin to the way organisms in nature adapt based on their fitness relative to the environment.
The central idea behind RADE is to maintain evolutionary diversity while prioritizing computational efficiency. By continuously adjusting how the population is divided into exploratory and exploitative subgroups, and by tuning the mutation and crossover strategies based on recent historical successes, RADE is able to maintain robust performance over time. Moreover, its lightweight design makes it suitable for embedding within a broader DNM learning framework, particularly for single-neuron models aimed at classification tasks.
3.2. Dynamic Population Partitioning and Control
Unlike traditional DE approaches where variation is applied indiscriminately across the entire population, RADE introduces a biologically inspired mechanism to partition the population into “good” and “bad” individuals based on their fitness rankings. This dual-group strategy mirrors natural ecological competition, where fitter individuals are more likely to reproduce, while less fit individuals may still introduce useful genetic variation into the population.
In RADE, the concept of symmetry is incorporated at multiple levels of its evolutionary strategy, particularly in its population partitioning and mutation strategies. The population is divided into symmetric subgroups in search space exploration. This partitioning reduces redundancy and maximizes diversity by ensuring that different partitions explore distinct regions. Mathematically, if
P is the population, we express partitioning as follows:
In RADE, the size and composition of these subgroups are not static. Instead, they are adaptively controlled throughout the evolutionary process based on the number of function evaluations. This adaptive mechanism allows the algorithm to shift its focus from exploration to exploitation as the search progresses.
The proportion parameter
p used to dynamically adjust the split between subgroups is given by
where nFES is the number of function evaluations so far and FES is the total evaluation budget. Based on this
p, the boundary index for sorting is calculated by
Using the sorted population, we form two groups:
Each group is further divided into subgroups for mutation and crossover purposes:
Then, the variation group
and crossover group
U are constructed as follows:
3.3. Reinforced Mutation with Poor-Individual Interference
To enhance the global search and avoid local optima, RADE introduces a variation formula that combines the influence of top-performing individuals with noise from poorly performing ones:
where the variable
V represents the mutant vector generated for exploration, and
denotes the population of selected individuals for mutation. The parameter
F is the scaling factor that controls the amplification of the difference vectors during mutation. The term
indicates the best-performing individual from the current population, serving as a reference for the guided search.
The components and are randomly selected individuals from the variation group and crossover group, respectively, where and are random indices. This introduces stochastic diversity into the mutation operation, ensuring that the search process explores different regions of the solution space. The subtraction generates a perturbation vector that is scaled by F, pushing the mutant vector V towards less-explored areas while still being influenced by the best solution . This combination enhances the algorithm’s capability to escape local optima and improve global search efficiency. This hybrid variation mechanism incorporates both a directed search toward elite individuals and stochastic disturbance from low-fitness candidates, effectively boosting robustness and exploratory power.
3.4. Parameter Adaptation via Memory Mechanisms
RADE leverages success-history-based adaptive parameter control, similar to LSHADE [
56], with some simplifications for efficiency. The primary motivation for adopting this strategy is its proven effectiveness in maintaining population diversity and avoiding premature convergence. In LSHADE, for example, the historical success of parameter settings is used to guide future generations, effectively balancing exploration and exploitation. RADE extends this idea by introducing lightweight memory mechanisms that minimize memory overhead while still capturing successful parameter settings over the iterations. This design allows RADE to dynamically adapt its mutation and crossover rates with minimal computational cost, maintaining efficiency even with larger populations. While it is true that memory-based adaptation requires additional steps for updating historical records, we have optimized this process in RADE by using a simplified archiving strategy that only maintains the most relevant parameter values. This reduces memory allocation and accelerates the retrieval process, ensuring that the added computational time remains minimal compared to the optimization gains achieved.
First, the improvement degree of a successful individual is calculated by
The corresponding weight is then computed as follows:
These weights contribute to the weighted Lehmer mean:
Finally, the historical memory arrays for the crossover rate and scaling factor are updated:
For the next generation, new
F and
values are sampled as follows:
It is important to highlight that the Cauchy distribution is chosen for F due to its heavy-tailed nature, which promotes broader exploration in the search space and reduces the risk of premature convergence. In contrast, the normal distribution is applied to to maintain stability in crossover operations, ensuring consistent offspring generation. The weighted Lehmer mean is used to enhance adaptive memory by prioritizing historically successful mutations, thus improving convergence reliability. These choices are inspired by the parameter adaptation strategies used in LSHADE, but are further optimized to align with RADE’s lightweight structure for dendritic neuron model optimization.
3.5. Lightweight External Archiving
RADE integrates an external archive
A to store useful but rejected individuals, maintaining diversity. Its update mechanism is defined by
This mechanism helps to recycle good information and prevent population collapse.
3.6. Compatibility with Dendritic Neuron Learning
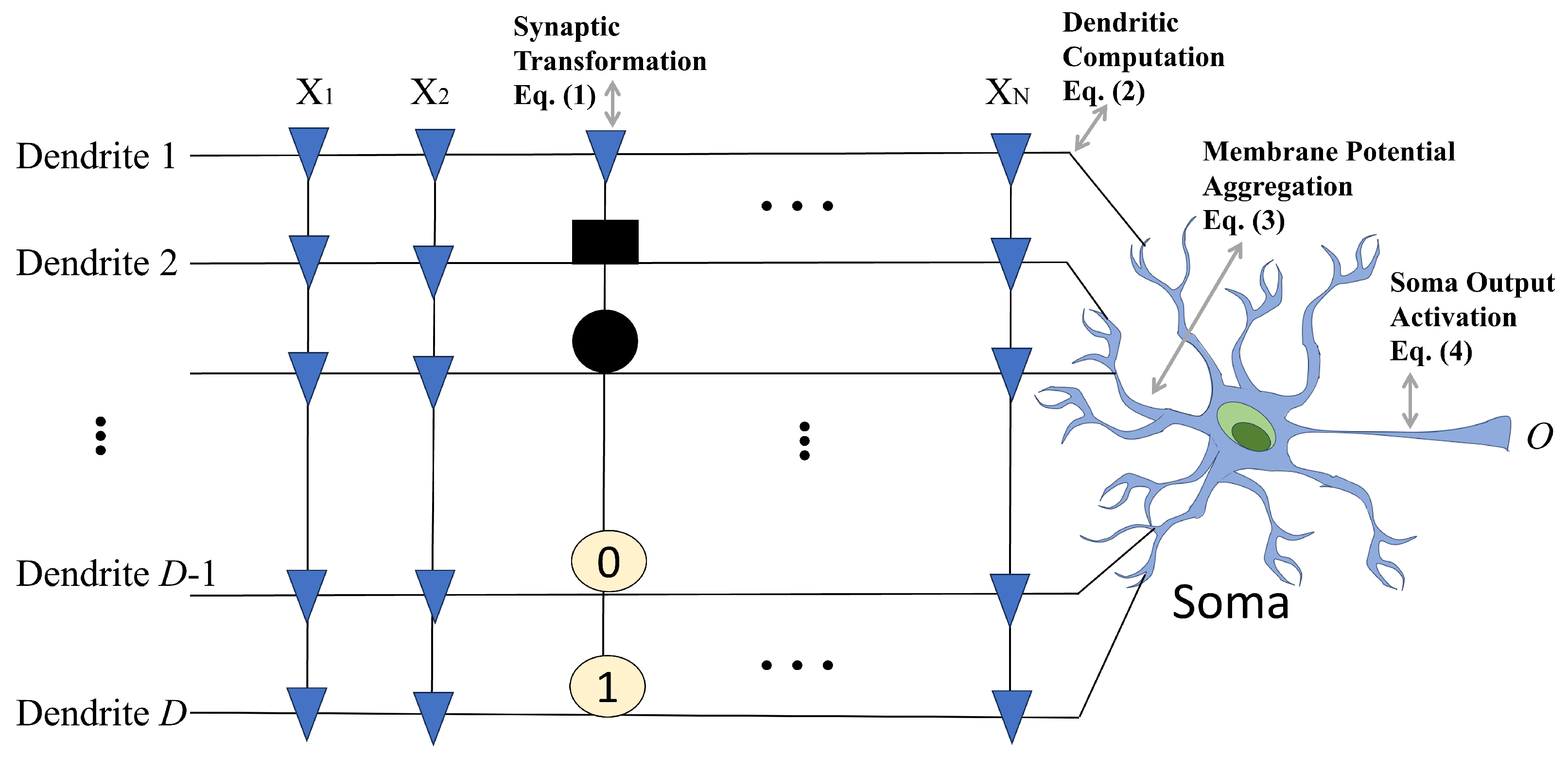
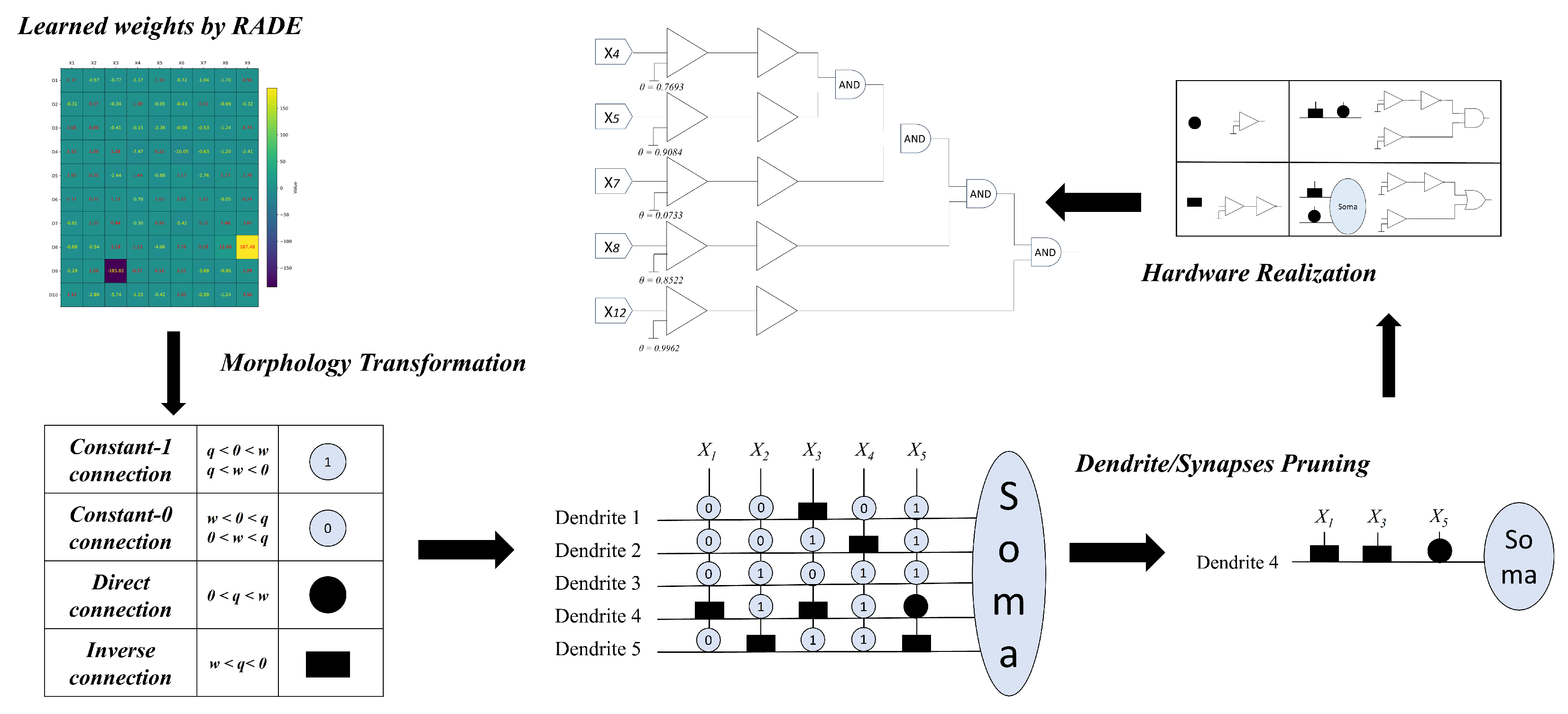
The RADE algorithm is specifically designed to address the unique learning characteristics of the DNM, which is inherently more complex than traditional artificial neurons due to its spatially compartmentalized and nonlinear processing. The diagram in
Figure 2 illustrates the entire flow of RADE-driven dendritic learning, from numerical optimization to structural interpretation and hardware realization.
(1) Learning and Weight Formation. RADE first learns the connection parameters for each synapse in the DNM structure by optimizing gain coefficients and bias shifts based on classification accuracy. As shown in the upper-left heatmap, each cell corresponds to the learned strength of a connection from input to dendrite .
(2) Morphology Transformation. Once numerical values are learned, each synaptic connection is interpreted according to its sign and magnitude. Based on the relationship between w and q, connections are categorized into four types:
Constant-1: or → Always active (output = 1);
Constant-0: or → Always inactive (output = 0);
Direct: → Monotonically increasing (positive logic);
Inverse: → Monotonically decreasing (inverted logic).
This transformation makes the model interpretable by transforming real-valued weights into logic-compatible symbols (e.g., open/closed circles, squares), facilitating the next stage of simplification.
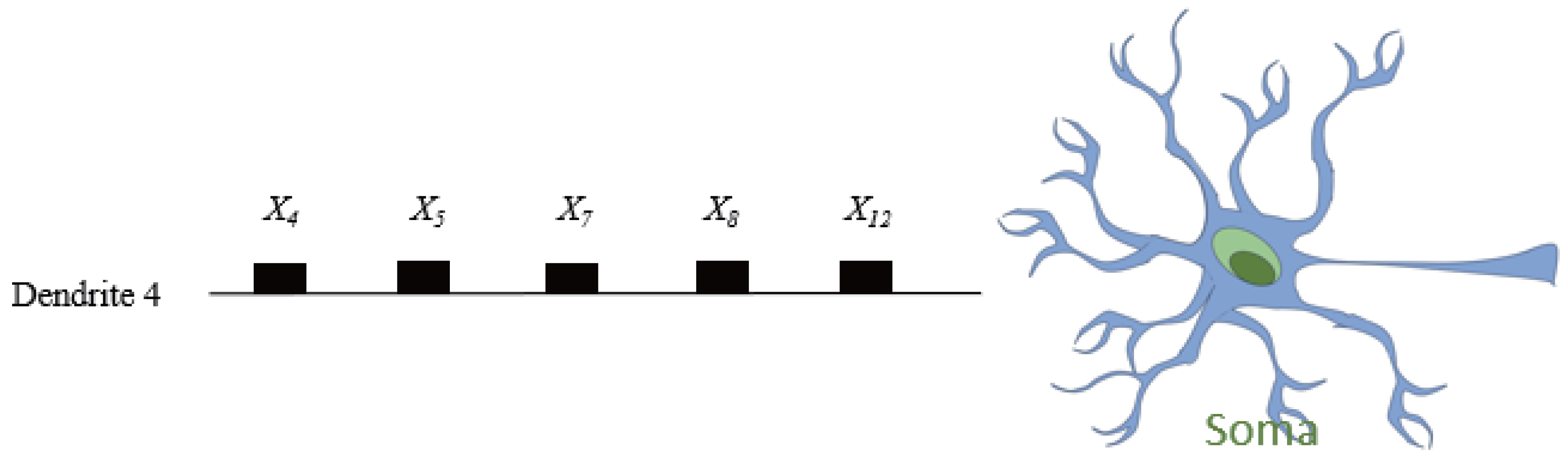
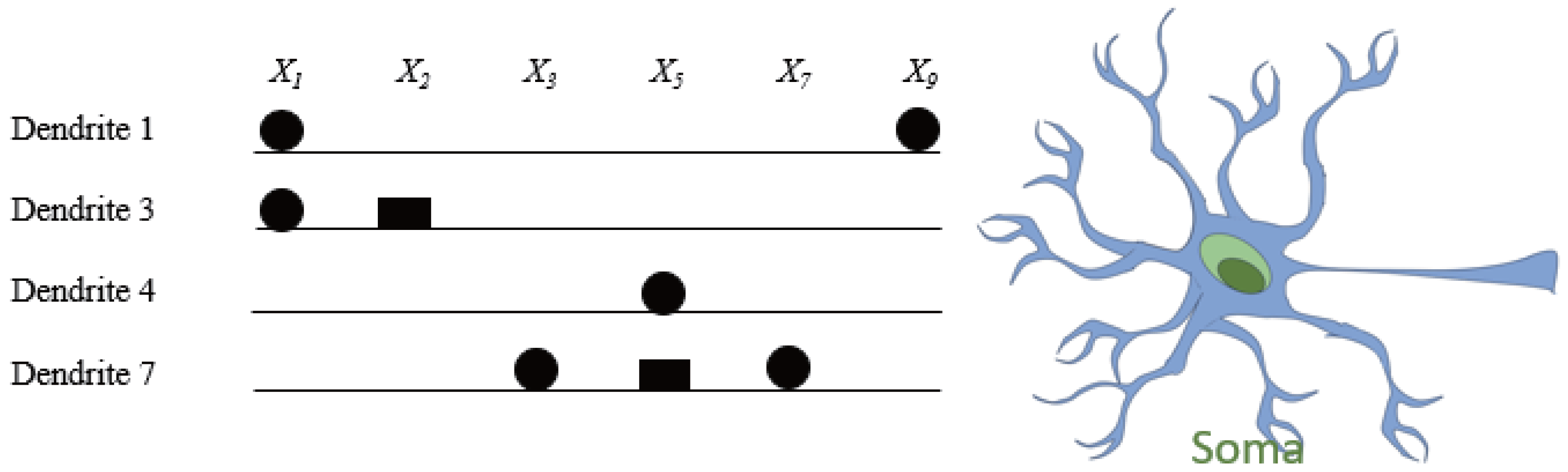
(3) Dendritic Pruning. Not all dendritic branches contribute equally to the final prediction. RADE identifies redundant or inactive dendrites—e.g., those composed entirely of constant signals or contributing negligible activation—and removes them. This structural pruning significantly reduces model complexity while preserving classification performance. An example shown in the bottom right of the figure highlights a single optimized dendrite with three meaningful inputs: two inverse connections and one direct.
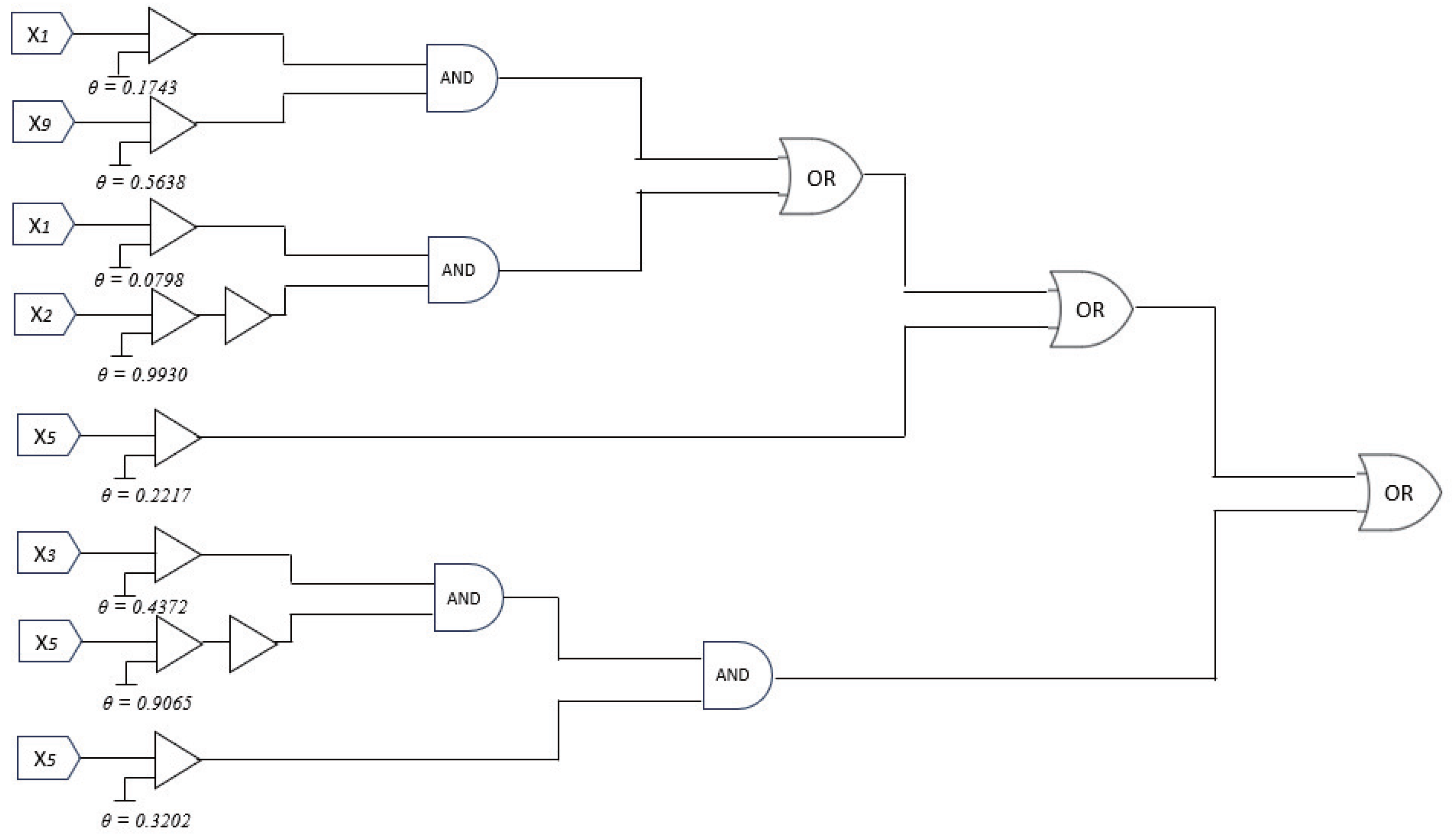
(4) Logic Mapping and Hardware Realization. The final set of active dendritic branches, each containing only interpretable logical conditions, is then translated into hardware-friendly logical operations. Each synapse becomes a comparator, inverter, or passthrough, and each dendrite functions as a logic gate (e.g., AND, OR). The soma output is implemented as a threshold decision gate.
As demonstrated in the top right of
Figure 2, the optimized DNM can be mapped to a layered logic circuit composed of NOT and AND gates, corresponding to inverse and direct synaptic roles. This not only enables deployment on energy-efficient digital or analog hardware but also guarantees transparency in model decision-making.
The integration of RADE with DNMs yields several significant advantages that enhance both biological realism and computational efficiency. First, RADE preserves the core principle of biological plausibility by maintaining localized processing and nonlinear synaptic interactions throughout the optimization process. This ensures that the learned model retains functional characteristics akin to real neural systems. Second, RADE supports structural adaptability by enabling dynamic exploration, pruning, and reconfiguration of the dendritic architecture in response to task-specific requirements. This allows the model to automatically discard redundant branches and reinforce informative pathways, resulting in an efficient and specialized neuronal morphology. Third, the output of RADE-guided training is highly interpretable. Through morphology transformation, each synaptic connection is translated into a logical rule that can be clearly understood and visualized. This bridges the gap between model transparency and performance, offering insight into the decision-making process of the network. Finally, a key practical advantage of RADE-trained DNMs is its compatibility with hardware implementation. The optimized neuron structure, consisting of simplified logical components such as comparators and logical gates, can be directly mapped onto digital or analog hardware circuits. This makes RADE-trained DNMs highly suitable for deployment in low-power, resource-constrained environments, such as neuromorphic chips and edge AI platforms. In summary, RADE not only enhances the learning capability and performance of dendritic neuron models but also systematically drives them toward interpretable, compact, and hardware-friendly representations. This comprehensive compatibility positions the RADE-DNM as a promising framework for the development of next-generation, biologically inspired intelligent systems.
3.7. Summary and Contributions
RADE stands as a biologically inspired, evolutionarily principled, and computationally efficient solution for training dendritic neuron models in classification tasks. RADE is implemented as computationally effectively as DE. In comparison with traditional DE, the additional requirement of computational resources in RADE comes from the update of the external archive and success memory. In the worst case, these additional operators require a computational complexity of . Therefore, the total complexity of RADE is , where is the maximal size of the external archive, N is the population size, and is the maximum number of generations. Its main contributions include the following:
A dynamic population grouping strategy that shifts from exploration to exploitation based on search progress.
A reinforced mutation mechanism that introduces diversity via poor-individual interference.
A lightweight, memory-based parameter adaptation framework that enhances convergence reliability.
An external archiving mechanism that maintains population diversity without increasing complexity.
Direct compatibility with interpretable and hardware-efficient dendritic learning systems.
Overall, the RADE-DNM represents a robust and scalable approach to evolving biologically inspired neural systems under real-world constraints. The demand for lightweight and interpretable models has surged with the rise of edge computing and neuromorphic architectures. Recent advancements have shown that biologically inspired models, including DNMs, can operate efficiently in resource-constrained environments [
57]. RADE is designed to leverage this lightweight nature, optimizing dendritic neuron learning with minimal computational overhead, making it well suited for edge AI applications. Interpretability is another critical aspect of modern AI models, especially for deployment in sensitive applications like medical diagnostics and autonomous systems [
58]. RADE enhances interpretability through dendritic pruning and logical rule extraction, transforming synaptic weights into understandable logic gates. This logical mapping not only improves transparency but also facilitates hardware implementation in neuromorphic chips. It opens the door to further research on embedding such evolution-based models into edge AI systems and neuromorphic architectures.
4. Experiments and Discussions
To rigorously evaluate the performance of the proposed RADE algorithm in optimizing DNMs for classification tasks, we conduct a series of controlled experiments across a diverse set of benchmark datasets. This section outlines the experimental design, datasets, evaluation protocol, baseline algorithms, and parameter configurations.
4.1. Datasets and Compared Algorithms
To comprehensively evaluate the effectiveness of the proposed RADE algorithm in optimizing dendritic neuron models (DNMs), we conduct experiments on a diverse collection of benchmark datasets, as summarized in
Table 1. These include eleven real-world datasets—
Australia,
BUPA,
BreastEW,
CongressEW,
Exactly,
German,
Heart,
Ionosphere,
KrVsKpEW,
SpectEW, and
Tic-tac-toe—which have been commonly used in the literature for evaluating classification algorithms due to their varying dimensionalities, class imbalances, and domain complexities. In addition, three synthetic datasets—
Moons,
XOR, and
Gaussians—are incorporated to assess the model’s capacity to handle nonlinear separability and logical dependencies. All datasets are normalized to the range
, and each is randomly split into 70% training and 30% testing sets. To ensure statistical reliability, each algorithm is independently run 30 times per dataset using different random seeds.
In order to validate the performance of RADE, we compare it with eight representative optimization algorithms, covering both classical and advanced differential evolution (DE) variants, as well as a gradient-based learning baseline. These include Biogeography-Based Optimization (BBO), Chaotic JADE (CJADE), Dynamic Permutation Differential Evolution (DPDE), Self-Adaptive Chaotic JADE (SCJADE), Selective Ensemble DE (SEDE), Success-History Adaptive DE (SHADE), States of Matter Search (SMS), and the classical Backpropagation (BP) algorithm.
BBO [
18] is a population-based metaheuristic that simulates the natural distribution and migration of species among habitats. Its exploitation of immigration and emigration rates enables a flexible balance between global and local searches, which is particularly valuable for navigating the complex fitness landscapes encountered in DNM optimization. CJADE [
59] enhances the JADE framework by incorporating chaotic maps, introducing stochastic perturbations that help the algorithm escape local optima and maintain diversity during convergence. This makes it well suited for tackling multimodal and irregular objective functions.
DPDE [
60] extends traditional DE by introducing an adaptive feedback mechanism that modifies search parameters dynamically based on evolutionary feedback. This ability to self-regulate improves convergence speed and helps avoid stagnation, making it ideal for training dendritic models that require precise weight and bias tuning. Similarly, SCJADE [
61] combines the adaptability of JADE with chaos-induced variability, which further enhances exploration in complex solution spaces while preserving convergence reliability.
SEDE [
62] integrates multiple mutation strategies and selects among them based on performance history. This selective ensemble design ensures robustness across different stages of the evolutionary process and has demonstrated success in real-world applications such as photovoltaic system modeling. SHADE [
63], another strong DE variant, maintains a history of successful parameter configurations and uses this to guide future sampling. Its self-adaptive mechanism is especially effective in maintaining search momentum and avoiding premature convergence, which are critical challenges in training compact DNM structures.
In addition to these DE-based approaches, we include SMS [
64], a physics-inspired algorithm that mimics the behavior of matter transitioning through gaseous, liquid, and solid states. This staged strategy enables a controlled shift from exploration to exploitation, aligning well with the progressive refinement required in DNM training. Finally, the Backpropagation (BP) method [
65] is selected as a non-evolutionary baseline. Although standard BP is typically not suitable for DNMs due to its non-differentiable architecture, prior adaptations have enabled gradient-based training by approximating error functions. This provides a meaningful reference for evaluating the performance and interpretability advantages of RADE and other evolutionary methods.
The choice of these algorithms is guided by their proven efficacy in related optimization tasks, their structural diversity, and their complementary search strategies. Together, they form a comprehensive benchmark suite to validate RADE’s ability to optimize dendritic models under a variety of learning challenges.
4.2. Dendritic Neuron Model Settings
The DNM used in the experiments consists of dendritic branches, each receiving a randomized subset of the input features. It is worth pointing out that one of the unique aspects of RADE is its automatic pruning mechanism, which dynamically reduces the number of dendrites during training based on relevance and contribution. This adaptive pruning allows the model to optimize its structure, ensuring that only the most effective dendritic connections are retained. Therefore, while the initial number of dendrites is set to 10, RADE’s optimization process significantly reduces this count, maintaining only the essential branches necessary for optimal classification. The automatic pruning mechanism consistently reduces redundancy and achieves optimal accuracy without requiring larger dendritic configurations. This design choice simplifies hyperparameter selection while preserving model efficiency and interpretability. Each synapse is initialized with random parameters drawn from a uniform distribution over . The sigmoid steepness parameter is set to 5, and the soma threshold is initialized to 0.5.
After training, a morphology transformation and pruning step is applied based on the conditions introduced in
Section 3, where constant-value and inactive synapses are removed to reduce model size and improve interpretability.
4.3. RADE Parameter Configuration
For RADE, the following parameter values are used throughout all experiments unless otherwise specified:
Population size ;
Maximum number of generations ;
Crossover rate (updated adaptively);
Scaling factor (updated adaptively);
Proportion parameter p dynamically adjusted via Equation (5);
Archive size .
The RADE-specific mechanisms—such as external archive updating, population partitioning, and reinforced mutation—are implemented following the procedures outlined in
Section 3.
4.4. Evaluation Metrics
To evaluate the performance of each algorithm on the classification tasks, two primary metrics are employed: classification accuracy (ACC) and the Area Under the Curve (AUC). ACC measures the proportion of correctly predicted instances in the test set, reflecting the overall predictive capability of the model. A higher ACC value indicates a stronger classification performance across the dataset. In addition to accuracy, we use the Area Under the Curve (AUC), a widely recognized evaluation metric that assesses the quality of both binary and multi-class classifiers. The AUC represents the degree of separability between classes and provides an aggregate measure of performance across all classification thresholds. Its value ranges from 0 to 1, where 1 indicates perfect classification and 0.5 represents random guessing. Higher AUC values signify the model’s enhanced ability to distinguish between positive and negative instances, even in cases of class imbalance. For RADE, this metric is particularly important since its logical representation relies on effectively capturing decision boundaries, ensuring precise class separability. Furthermore, both the ACC and AUC are evaluated with their respective standard deviation (STD) over 30 independent runs with different random seeds. The STD measures the robustness and stability of the algorithm under stochastic initialization, with lower deviations indicating more consistent performance across multiple trials. This evaluation framework allows us to comprehensively understand not only the accuracy of RADE but also its reliability and robustness in diverse experimental settings. All experiments are conducted using Python 3.10 on a machine equipped with an Intel i7 CPU, 32 GB RAM, and no GPU acceleration. Each algorithm is allowed the same maximum number of function evaluations for fairness. In the following subsection, we present and analyze the experimental results across all benchmark datasets, with a focus on RADE’s accuracy, efficiency, and compatibility with the DNM’s lightweight architecture.
4.5. Results and Analysis
Table 2 reports the classification performance of the proposed RADE algorithm against eight baseline methods on 14 benchmark datasets. Bold values indicate the best result among all algorithms for each dataset, while underlined values denote the second best.
The results show that RADE demonstrates excellent overall performance across various datasets. Specifically, RADE achieves the best classification accuracy on six datasets: BUPA (0.6333), BreastEW (0.9298), Exactly (0.7367), Heart (0.9395), KrVsKpEW (0.8140), and Tic-tac-toe (0.8294). Additionally, RADE obtains the second-best results on four other datasets, Australia, CongressEW, German, and Gaussians, indicating robust competitiveness. Notably, RADE achieves perfect classification accuracy on the Moons dataset (0.9800) with zero variance, demonstrating reliable convergence on clean, well-structured data.
Comparing RADE to individual baselines reveals several important insights. On the Australia dataset, DPDE slightly outperforms RADE by a margin of 0.52% (0.8585 vs. 0.8533), although both exhibit low variance. However, on more complex datasets such as Heart, RADE delivers the highest accuracy, surpassing DPDE (0.9395 vs. 0.9120) and clearly outperforming other methods, including gradient-based BP (0.5387). On BreastEW, which contains both linear and nonlinear features, RADE surpasses all competitors, including ensemble-based SEDE (0.9298 vs. 0.9196).
In contrast, some methods, while excelling on specific datasets, display inconsistent performance elsewhere. For instance, DPDE achieves the highest accuracy on Australia and CongressEW (0.9703) but performs poorly on BUPA, KrVsKpEW, and Tic-tac-toe. Similarly, BP shows high accuracy on SpectEW (0.9198) but fails on most other datasets, particularly on Australia, German, and XOR, where its performance falls close to random guessing.
An interesting observation is made for the XOR dataset, known for its strong logical structure. Here, the SMS algorithm yields the highest accuracy (0.9826), slightly outperforming SHADE (0.8829), RADE (0.8776), and DPDE (0.8814). This suggests that SMS, though weaker overall, may exploit discrete decision boundaries under ideal conditions. However, its performance on most real-world datasets remains unstable with large variances, such as on Ionosphere (STD = 0.0801) and Heart (STD = 0.0143).
In terms of robustness, RADE consistently achieves a low standard deviation across all datasets, with values mostly below 0.03, showing reliable performance regardless of data variability. Notably, on datasets such as BreastEW, KrVsKpEW, and SpectEW, RADE offers both high accuracy and low variance, validating the strength of its adaptive mechanisms and structure-aware mutation strategy.
The inclusion of the AUC allows us to observe how well RADE distinguishes between classes in both balanced and unbalanced settings. Notably, RADE achieves the highest AUC values on key datasets such as BreastEW, Exactly, German, Heart, KrVsKpEW, and Tic-tac-toe, indicating a strong discrimination capability. On datasets like Australia, CongressEW, and Gaussians, RADE consistently maintains competitive AUC scores, reflecting its robustness against false positives and false negatives.
Additionally, the advantage of RADE in maintaining high AUC values across various datasets confirms its ability to handle class imbalance effectively, preventing the model from ‘buying’ overall accuracy at the cost of misclassifying minority classes. This finding strengthens the empirical evidence that RADE optimizes decision boundaries while maintaining interpretability and efficiency.
Furthermore,
Table 3 reports the
average training time (in seconds) required by each competing algorithm under identical hardware and evaluation budgets. Several key observations can be made: (1) RADE strikes a favourable trade-off between speed and accuracy. Although RADE is 8.68 slower than the quickest competitor (SHADE, 18.30 s vs. 26.98 s), it delivers the highest
ACC and
AUC scores (see
Table 2). Considering training is performed offline, this modest additional cost is acceptable when weighed against the substantial gains in predictive performance and robustness. (2) Training time does
not translate directly to deployment latency. After optimization, RADE prunes redundant dendrites and converts the remaining ones into compact logical expressions. Consequently, the inference path relies on a minimal set of logic gates, making the deployed model at least as fast—and often faster—than those produced by the baseline algorithms. (3) Memory-based adaptation incurs negligible overhead. The slight increase in RADE’s runtime stems mainly from its memory-guided parameter adaptation. Our study confirms that this mechanism improves convergence speed and solution quality while adding less than 2 s of training overhead on average. (4) SEDE’s long runtime illustrates the diminishing returns of larger ensembles. SEDE records the slowest training time (42.83 s), yet its accuracy remains inferior to RADE and several other DE variants. This highlights that enlarging the ensemble of mutation strategies does not necessarily yield proportional performance benefits and may hinder the practicality of the algorithm. In summary, the results in
Table 3 demonstrate that RADE achieves a compelling balance between computational cost and model quality, reinforcing its suitability for scenarios where training resources are limited and inference efficiency and interpretability are paramount.
In conclusion, RADE demonstrates an effective balance between accuracy and stability, outperforming or closely matching top-performing methods across a wide variety of datasets. The results confirm that RADE’s resource-adaptive strategies and compatibility with dendritic architectures contribute to both performance and robustness, making it a strong candidate for lightweight and interpretable neural learning tasks.
4.6. Convergence and Robustness Analysis
To further examine the efficiency and reliability of the proposed RADE algorithm, we conduct convergence and robustness analyses on two representative datasets:
Tic-tac-toe and
KrVsKpEW.
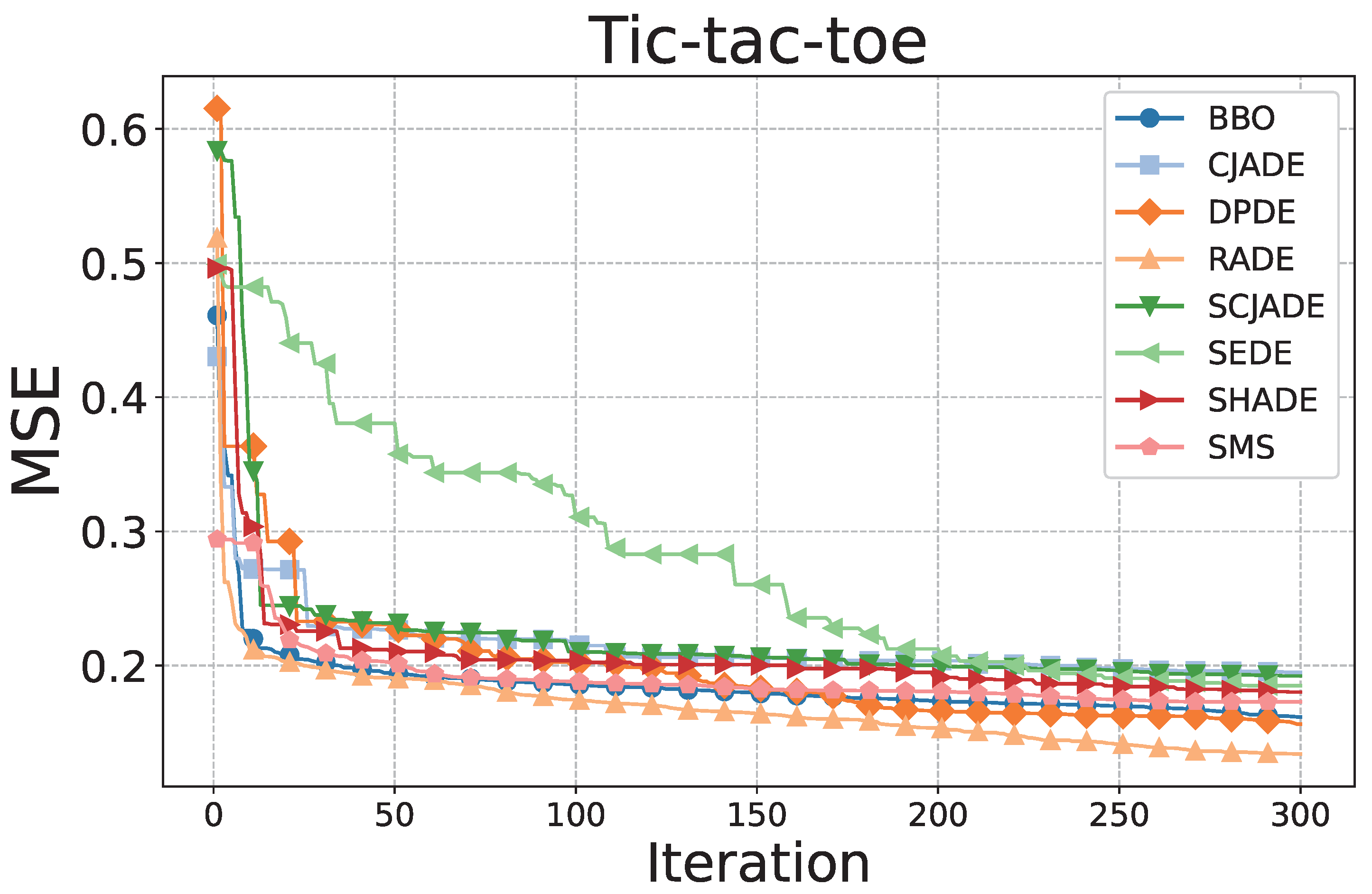
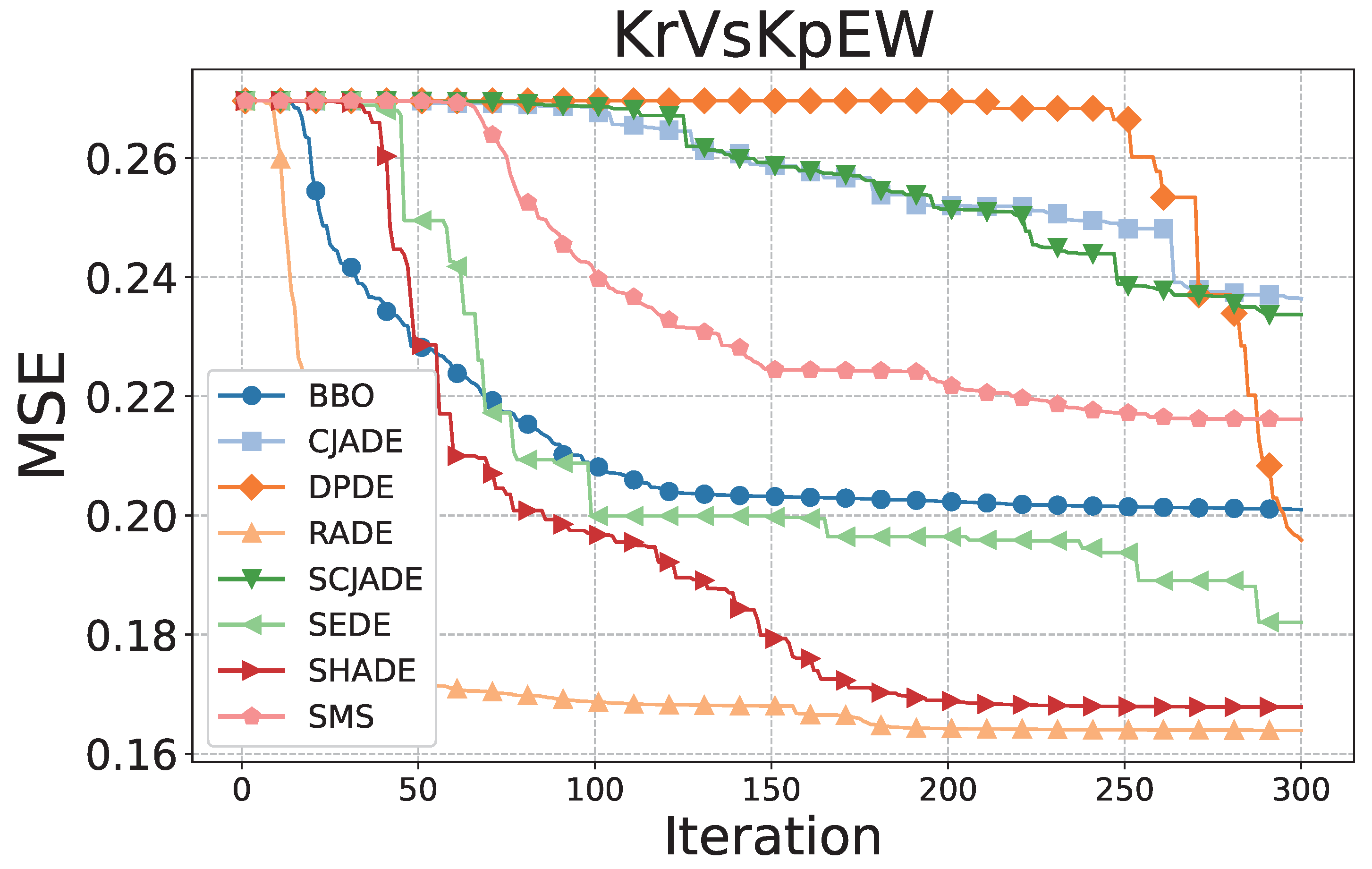
Figure 3 and
Figure 4 depict the convergence curves in terms of mean squared error (MSE) over 300 iterations. Meanwhile,
Figure 5 and
Figure 6 present the corresponding box–whisker plots of the classification accuracy obtained by all algorithms across 30 independent runs.
As shown in
Figure 3, on the
Tic-tac-toe dataset, RADE demonstrates the fastest convergence and reaches the lowest final MSE value among all compared methods. Its curve rapidly declines within the first 30 iterations and gradually stabilizes near 0.17, suggesting both fast learning and strong local refinement. This rapid convergence indicates RADE’s superior ability to quickly adjust dendritic neuron structures and optimize synaptic weights, enhancing learning efficiency. The stability near 0.17 reflects effective avoidance of overfitting and solid convergence behavior. In contrast, algorithms such as SCJADE and SMS show significantly slower convergence rates and higher final errors, highlighting their inefficiency in training DNMs on this logical classification task. These methods tend to oscillate or stagnate during training, suggesting an inadequate exploration–exploitation balance and suboptimal parameter adaptation.
On the more challenging
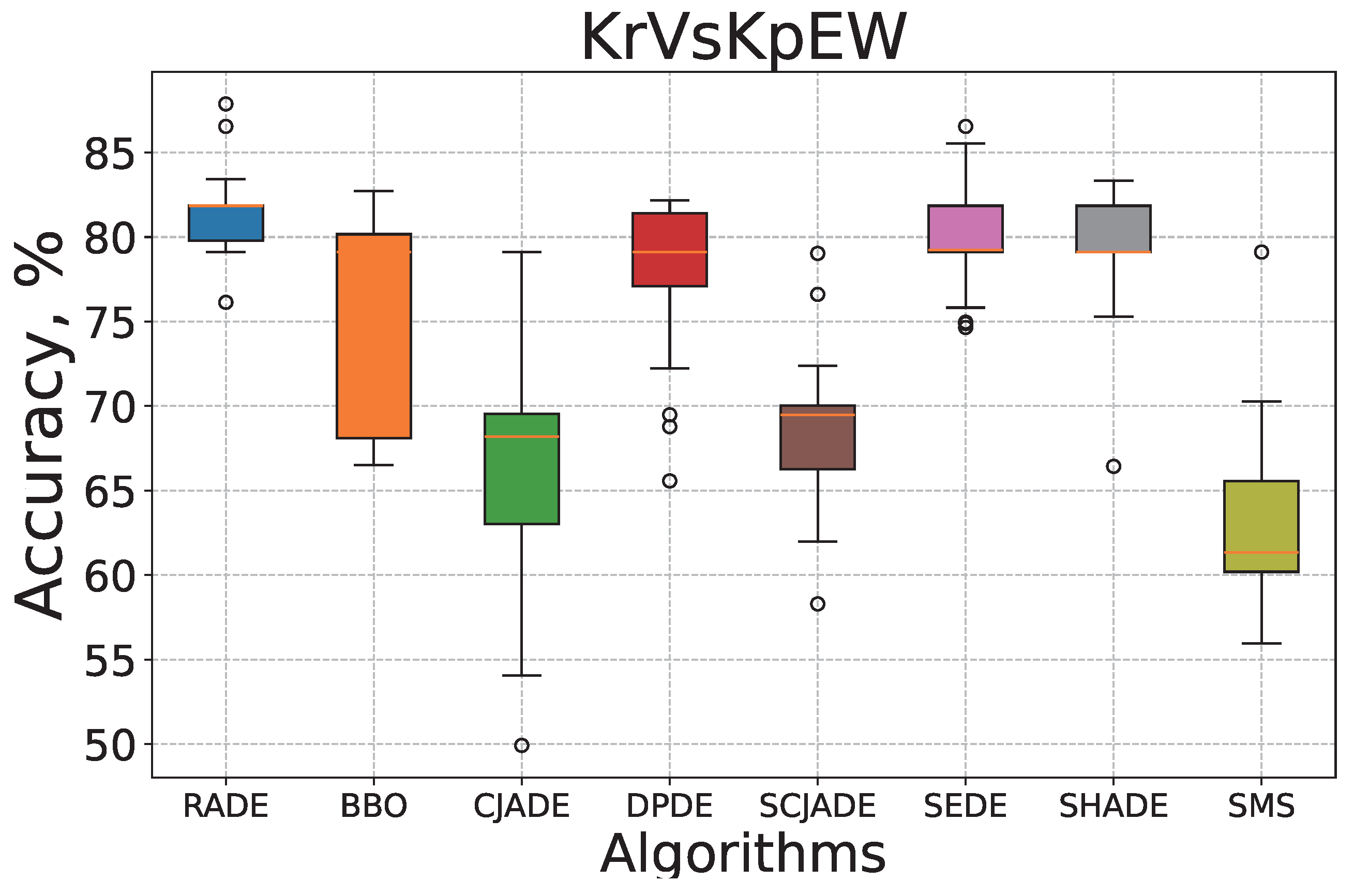
KrVsKpEW dataset (
Figure 4), RADE again outperforms others with a stable and monotonic descent throughout the training process. This dataset contains more complex, nonlinear decision boundaries, making it a challenging benchmark for evolutionary optimization. RADE’s smooth and continuous convergence path showcases its adaptive scaling mechanism, which dynamically balances global exploration with local exploitation. While some algorithms (e.g., DPDE and CJADE) stagnate early or experience late drops in performance, RADE consistently reduces error without sharp oscillations, signifying robust parameter control and effective synaptic pruning. Notably, methods such as SHADE and SEDE also demonstrate strong performance in this scenario but still converge to slightly higher MSE values compared to RADE, suggesting less efficient dendritic adjustments.
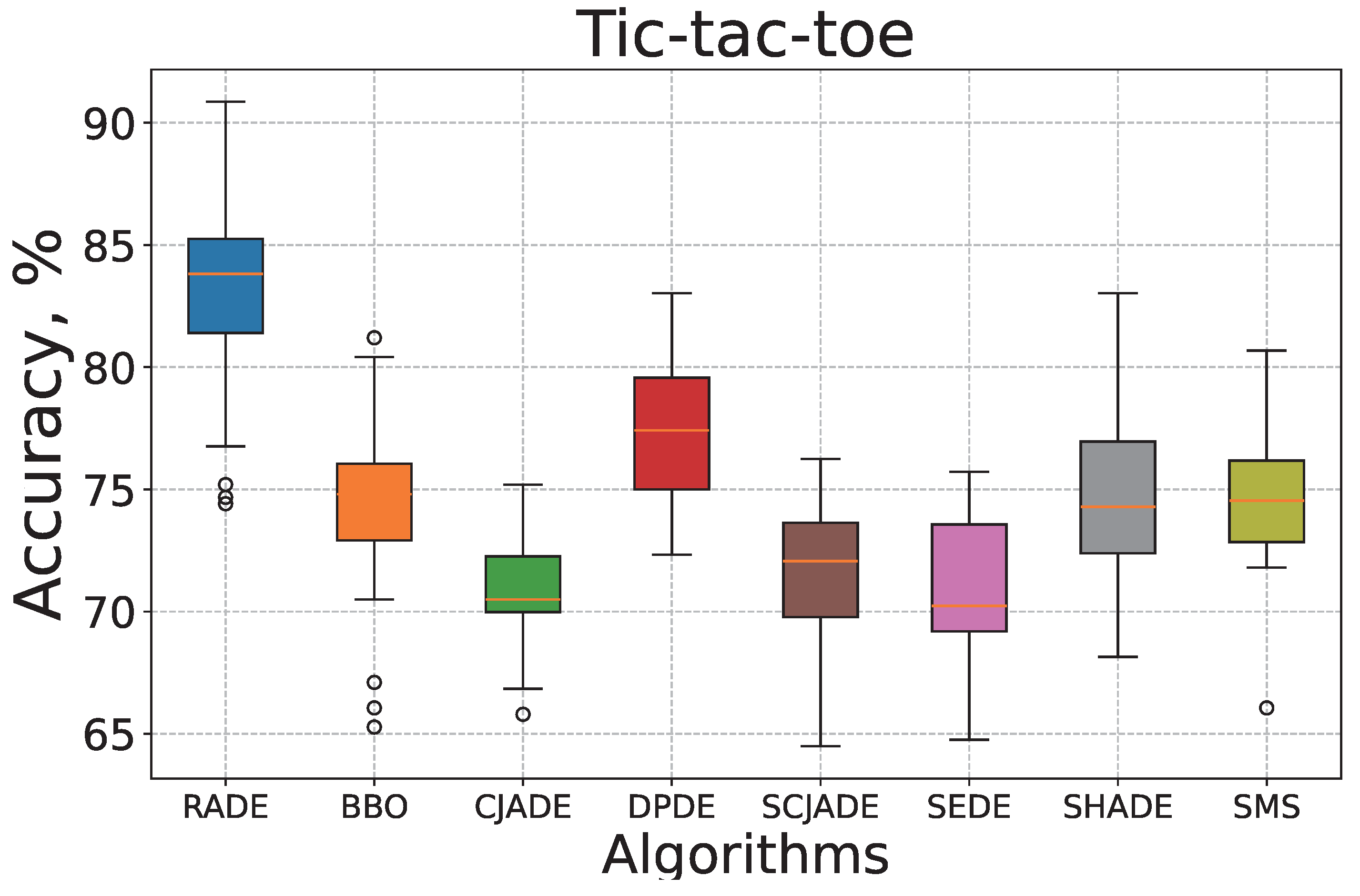
Figure 5 and
Figure 6 provide a statistical view of accuracy distributions. For
Tic-tac-toe, RADE achieves the highest median accuracy and the narrowest interquartile range, indicating both high prediction precision and low variance across runs. The interquartile range (IQR) is tightly clustered, which reflects the algorithm’s stability under varying initializations and random seeds. This robustness is attributed to RADE’s adaptive mutation and pruning strategies, which consistently enhance local dendritic adjustments. In contrast, BBO, SMS, and CJADE exhibit wider boxes and more outliers, implying unstable behavior under different random seeds. This instability suggests that these methods struggle to maintain consistent synaptic configurations during iterative updates, leading to greater performance variability.
On KrVsKpEW, RADE again secures a high median with a tightly bounded distribution, further confirming its robustness. Although DPDE and SEDE show comparable central tendencies, their distributions include more extreme values and wider spreads, suggesting less consistency in optimization. The variability in these methods is indicative of weaker dendritic pruning mechanisms and less effective synaptic control. CJADE and SMS, in particular, suffer from substantial instability, with performance occasionally dropping below 60%, making them unsuitable for high-reliability applications. RADE’s narrower spread and higher median accuracy highlight its capacity for stable and consistent learning across different seeds, driven by its memory-based adaptive scaling and efficient dendritic learning.
Overall, these visualizations confirm that RADE not only converges faster but also maintains stability across iterations, leading to superior classification accuracy and robustness compared to its evolutionary counterparts. These characteristics are critical for deploying dendritic neuron models in real-world classification tasks where stability and reliability are paramount.
4.7. Additional Discussion Regarding the Scaling Factor
In RADE, the scaling factor
F is generated based on a Cauchy distribution, introducing stochastic perturbations during the evolution process. To evaluate the effect of different strategies for updating
F, we conduct two additional experiments using a time-dependent adjustment mechanism. This approach allows for progressive refinement of the search behavior, as defined in the following two equations:
In Equations (
21) and (
22),
represents the current number of function evaluations, and
denotes the maximum number of function evaluations allowed. The scaling factor
F is designed to decrease linearly as the optimization progresses, encouraging broad exploration during the early stages and more focused convergence near the end of the search. This time-dependent adjustment mechanism is inspired by strategies employed in traditional DE variants, where the dynamic adjustment of
F promotes a better exploration–exploitation balance.
To compare the effectiveness of these two strategies against the original Cauchy-based generation of
F in RADE, we evaluate all three methods on a series of classification problems. The results are presented in
Table 4.
The experimental results demonstrate that RADE’s Cauchy-based random selection generally outperforms both time-dependent strategies in terms of classification accuracy across most datasets. In particular, the dynamic variability introduced by the Cauchy distribution enables more effective exploration during the early search phases, which translates to higher overall accuracy. Furthermore, the time-dependent strategy with performs slightly better than in most cases, indicating that a broader range of scaling factors contributes to stronger exploration capabilities. These findings validate the effectiveness of RADE’s stochastic perturbation mechanism and justify the choice of a Cauchy-based strategy for scaling factor generation.
4.8. Interpretable Morphology and Logical Representation
In addition to quantitative accuracy metrics, one of the most distinguishing features of the proposed RADE algorithm is its ability to yield interpretable and compact dendritic neuron structures.
Figure 7,
Figure 8,
Figure 9 and
Figure 10 present a detailed visual analysis of the model learned by RADE on the
Australia dataset. Similarly,
Figure 11,
Figure 12,
Figure 13 and
Figure 14 showcase the structural outcome on the
Tic-tac-toe dataset.
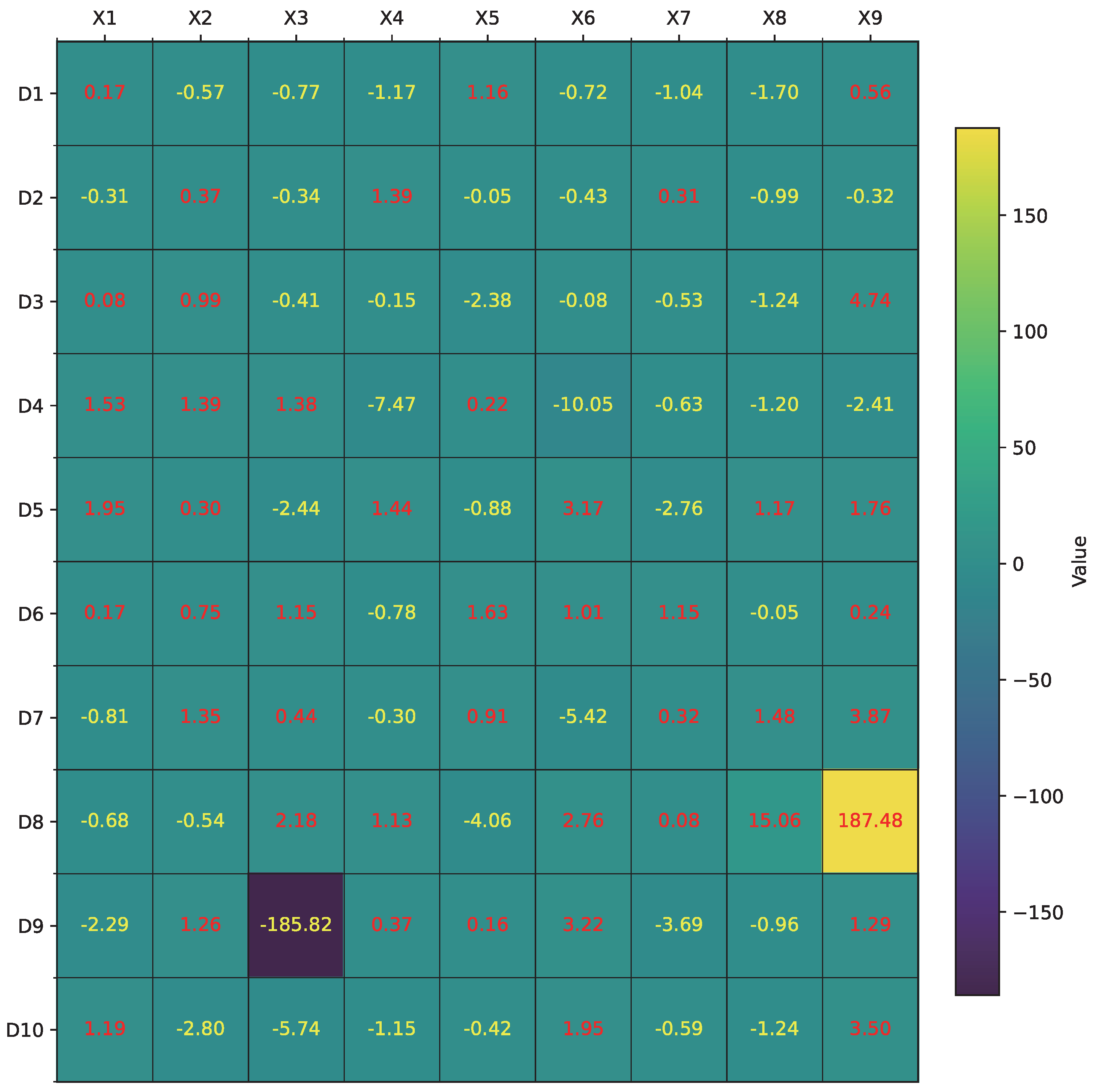
Figure 7 illustrates the learned
values across dendrites and synapses for all input features. This heatmap highlights the diverse distribution of synaptic contributions and effectively distinguishes strong activations (e.g.,
on
,
on
) from near-zero or highly negative values (e.g.,
on
), indicating potential candidates for pruning.
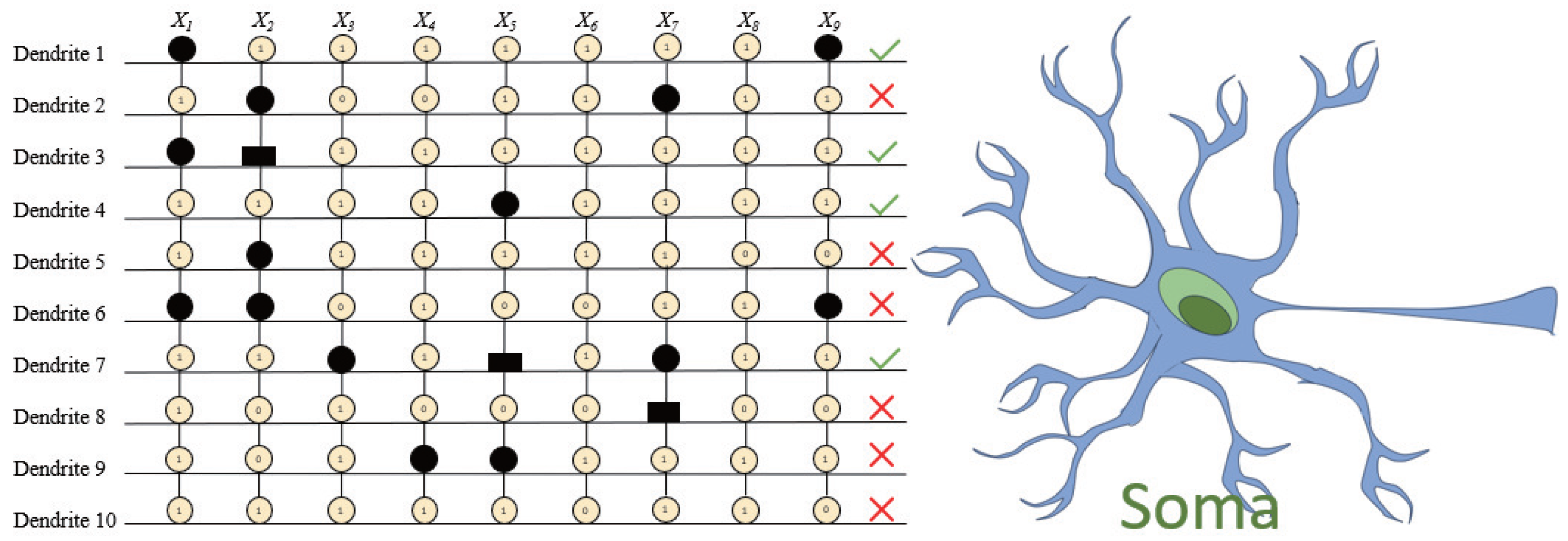
Based on these weight distributions, RADE proceeds to convert the learned parameters into a symbolic dendritic structure (
Figure 8), where different symbols (circles, squares, etc.) denote different synaptic connection types—constant-1, constant-0, direct, and inverse—defined by the threshold criteria in
Section 3. Synapses with constant outputs or minimal impact are systematically removed, yielding the simplified architecture in
Figure 9, where only dendrite
remains active with five retained synapses (
,
,
,
,
).
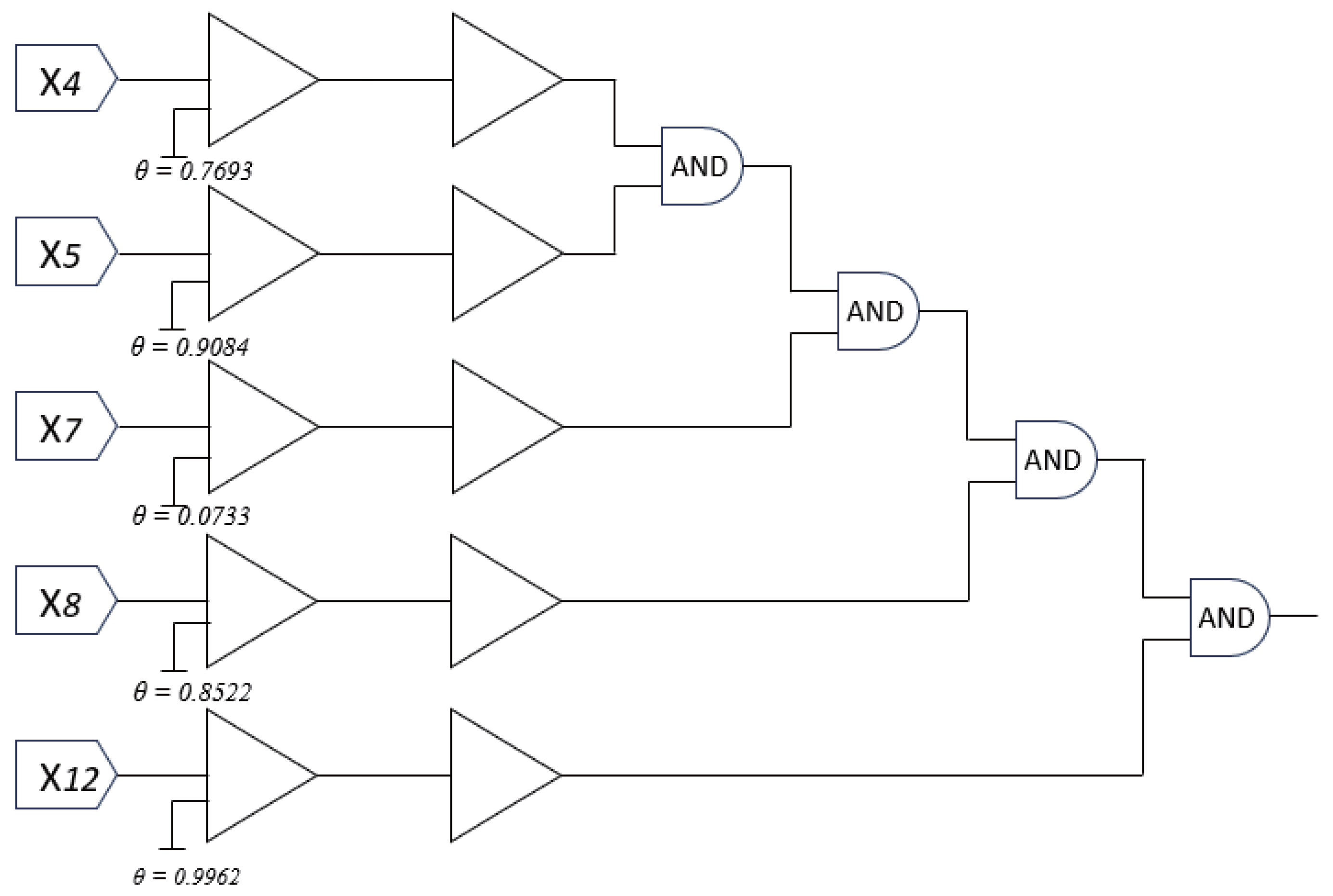
This pruned dendrite can be seamlessly translated into a digital logic circuit, as illustrated in
Figure 10. Each input undergoes a threshold-based comparator, and the resulting binary decisions are aggregated via logical
AND gates, emulating the nonlinear integration performed by the soma. This conversion highlights a unique advantage of DNMs trained by RADE: their compatibility with neuromorphic hardware and explainable AI paradigms.
A similar process is observed for the
Tic-tac-toe dataset.
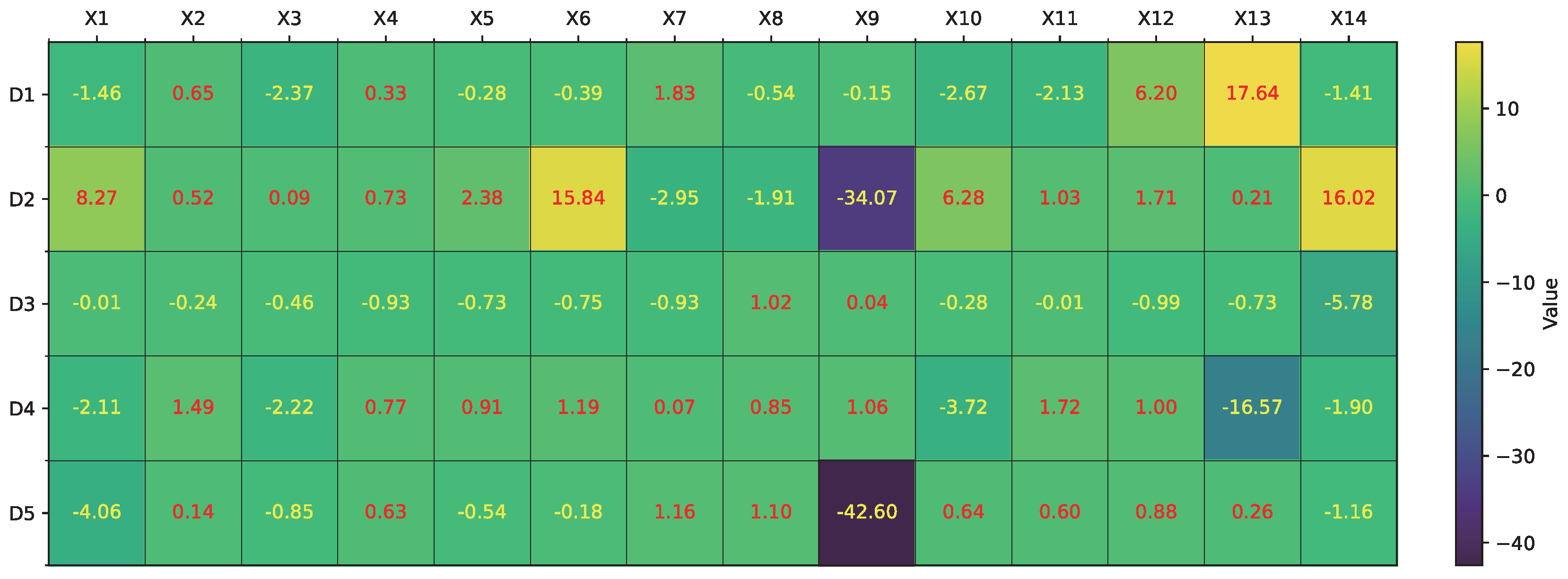
Figure 11 shows the learned
values across ten dendrites, indicating more complex and distributed contributions than in the previous case. The resulting morphology in
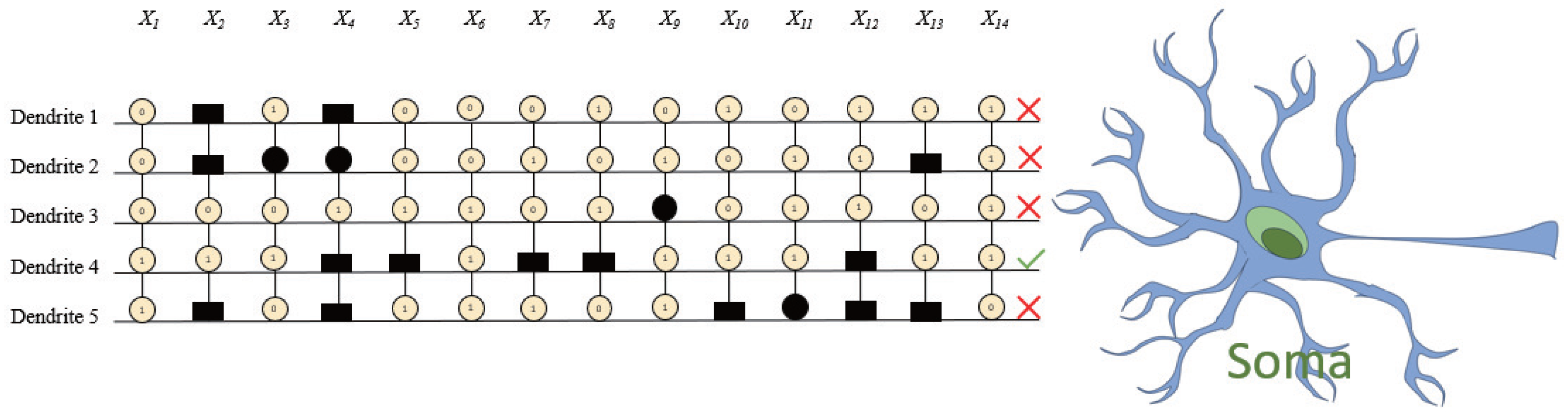
Figure 12 reveals redundant or inactive dendrites, which are removed during pruning (
Figure 13), leaving only four functional branches. The final logical realization of the pruned model is depicted in
Figure 14. Notably, the decision rule involves a combination of
AND and
OR gates, demonstrating the expressiveness of dendritic logic compared to linear perceptrons. This interpretable rule-based format opens up possibilities for verification, simplification, and rule extraction, which are often elusive in deep neural networks.
To further evaluate the interpretability and implementation efficiency of the RADE-trained DNM, we conduct a detailed analysis of the morphological complexity and hardware cost for the
Australia and
Tic-tac-toe datasets.
Table 5 summarizes the pruning statistics, including the initial synapses, final active synapses, pruning rate, final dendrites, input features, logic gates, and comparators. These metrics provide a comprehensive view of how RADE optimizes DNM structures for both interpretability and efficient hardware implementation.
The structural optimization achieved by RADE is evident in the significant pruning rates observed. For the Australia dataset, the model retains only 5 out of 70 original synapses, resulting in a pruning rate of 93%. The final logical representation is simplified to a four-AND tree structure with five comparators. This indicates not only morphological sparsity but also logical simplicity, which facilitates direct hardware implementation. Similarly, the Tic-tac-toe dataset is pruned to 8 active synapses from an initial 90, achieving a pruning rate of 91%. The optimized logic circuit comprises four AND gates and three OR gates, along with eight comparators, providing a well-structured decision logic with minimal hardware cost.
These results demonstrate that RADE not only improves model interpretability but also significantly reduces hardware costs by minimizing synaptic connections and logical complexity. This makes RADE-trained DNMs highly suitable for edge AI applications where memory and energy constraints are critical. In conclusion, the pruning strategy enforced by RADE balances both morphological complexity and hardware efficiency, achieving a compact and interpretable neuron model representation.
These qualitative findings, combined with the robust performance observed in quantitative evaluations (
Table 2), establish RADE not only as a powerful optimizer for DNMs but also as a facilitator of interpretable, efficient, and hardware-friendly neural models.
4.9. Limitations and Practical Benefits of RADE
RADE offers several practical benefits that make it particularly effective for DNM optimization. First, its resource-adaptive mechanism allows it to optimize DNMs with minimal computational overhead, which is crucial for real-time applications and deployment on edge devices. Inspired by dendritic processing in biological neurons, RADE effectively handles nonlinear decision boundaries, enhancing both interpretability and structural learning during optimization. Furthermore, the Cauchy-based scaling strategy enables robust global search capabilities, promoting diverse exploration of the solution space and reducing the risk of becoming trapped in local minima. This is complemented by RADE’s memory-based parameter adaptation, which dynamically adjusts evolutionary parameters to maintain stability even in complex optimization landscapes. Its lightweight architecture also ensures scalability, allowing it to tackle larger problems without substantial increases in memory or processing costs.
Another strength of the proposed DNM optimized by RADE is its reliance on logical gate representations for decision-making. This design inherently provides a certain level of resilience against small input perturbations. Unlike traditional neural networks that rely on continuous-valued weights and activation functions, the DNM’s logical operations (e.g., AND, OR, NAND) require discrete condition satisfaction to activate specific pathways. As a result, minor fluctuations in input values are less likely to trigger erroneous activations, enhancing robustness. Moreover, the multi-branch structure of DNMs allows for a localized decision logic, where individual dendrites independently process specific signal patterns. This compartmentalized processing further isolates the impact of adversarial perturbations, preventing local disturbances from propagating through the entire network. In addition, the optimization strategy employed by RADE, with its lightweight archiving and adaptive parameter control, promotes diverse solutions during training, reducing the chances of overfitting to adversarially biased samples. This distributed learning mechanism equips the model with a broader understanding of decision boundaries, improving its resistance to gradient-based attacks.
Despite these strengths, RADE also has some limitations. One notable challenge is its sensitivity to initialization, where suboptimal parameter settings may impact convergence speed, especially in highly non-convex search spaces. Additionally, while the external archive mechanism improves search diversity and memory, it introduces a slight memory overhead compared to standard DE variants. In very high-dimensional optimization tasks, the adaptive memory and pruning strategies may also elevate computational loads, requiring further optimization for efficiency. Finally, while RADE demonstrates strong empirical performance, its theoretical analysis is currently focused mainly on convergence guarantees. Future work is required to extend theoretical explorations, particularly regarding its complexity bounds and generalization capabilities.
5. Conclusions
In this study, we have proposed RADE (Resource-Adaptive Differential Evolution), a novel evolutionary optimization algorithm specifically designed to enhance the training of dendritic neuron models (DNMs) in lightweight and interpretable classification tasks. Inspired by biological evolution and dendritic computation, RADE incorporates a series of resource-aware and biologically motivated mechanisms, including dynamic population partitioning, reinforced mutation guided by poor individuals, adaptive parameter control based on historical memory, and a lightweight external archive for diversity maintenance. These innovations collectively enable RADE to balance exploration and exploitation effectively, adapt to dynamic search landscapes, and maintain structural compactness throughout the learning process.
Extensive experiments conducted on 14 benchmark datasets—covering both real-world and synthetic classification scenarios—demonstrate that RADE consistently outperforms or matches the performance of state-of-the-art evolutionary algorithms such as BBO, CJADE, SHADE, and SCJADE in terms of classification accuracy, robustness, and convergence behavior. Moreover, RADE exhibits strong compatibility with the architectural principles of DNMs, facilitating structural pruning, morphological simplification, and hardware-friendly logical transformation. The resulting models not only exhibit high predictive performance but also offer clear interpretability through logic-based rules derived from the pruned dendritic structure.
From a practical perspective, RADE enables the development of resource-efficient and transparent AI systems, making it well suited for deployment in neuromorphic hardware, embedded platforms, and edge computing scenarios where energy and interpretability are crucial. Unlike traditional deep learning approaches that rely heavily on overparameterized networks and large-scale datasets, the proposed framework demonstrates that small-scale, biologically plausible architectures, when coupled with intelligent evolutionary optimization, can yield competitive results with significantly reduced computational costs.
While RADE primarily focuses on evolutionary optimization for DNM, we acknowledge that modern lightweight strategies, including Neural Architecture Search (NAS) for micro-Net architectures [
66,
67], post-training compression [
68], quantization methods [
69], and distillation approaches [
70], have also achieved substantial progress in creating compact and explainable models. Nevertheless, RADE’s unique contribution lies in its biologically inspired dendritic structure combined with evolutionary pruning, which is distinct from the layer-wise compression and architecture search of NAS or distillation. Unlike traditional NAS methods, which often rely on gradient-based optimization, RADE performs symbolic optimization through logical gate representation, leading to more interpretable decision boundaries.
For future research, several promising directions can be explored. First, the integration of RADE with multi-objective optimization frameworks [
71] could further enhance its ability to trade off accuracy, interpretability, and complexity simultaneously. Second, the application of RADE-optimized DNMs to tasks beyond classification—such as sequence modeling, control systems, or continual learning—offers a pathway toward more general-purpose and adaptive intelligent agents [
72]. Third, hardware-level implementations of RADE-DNM logic circuits could be investigated for real-time and low-power AI applications [
73].
In summary, RADE represents a biologically inspired and resource-conscious approach to optimizing dendritic learning systems. It offers a practical and theoretically grounded alternative to conventional deep learning methods, advancing the field of interpretable and energy-efficient artificial intelligence.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}