

GGD-YOLOv8n: A Lightweight Architecture for Edge-Computing-Optimized Allergenic Pollen Recognition with Cross-Scale Feature Fusion

Abstract
1. Introduction
- The integration of G-Ghost Bottleneck modules with C2f structures forms novel C2f-G-GhostBottleneck blocks, replacing standard backbone C2f modules. This structural modification optimizes conventional CNN architectures through enhanced GPU parallelization, reducing network complexity while preserving detection fidelity.
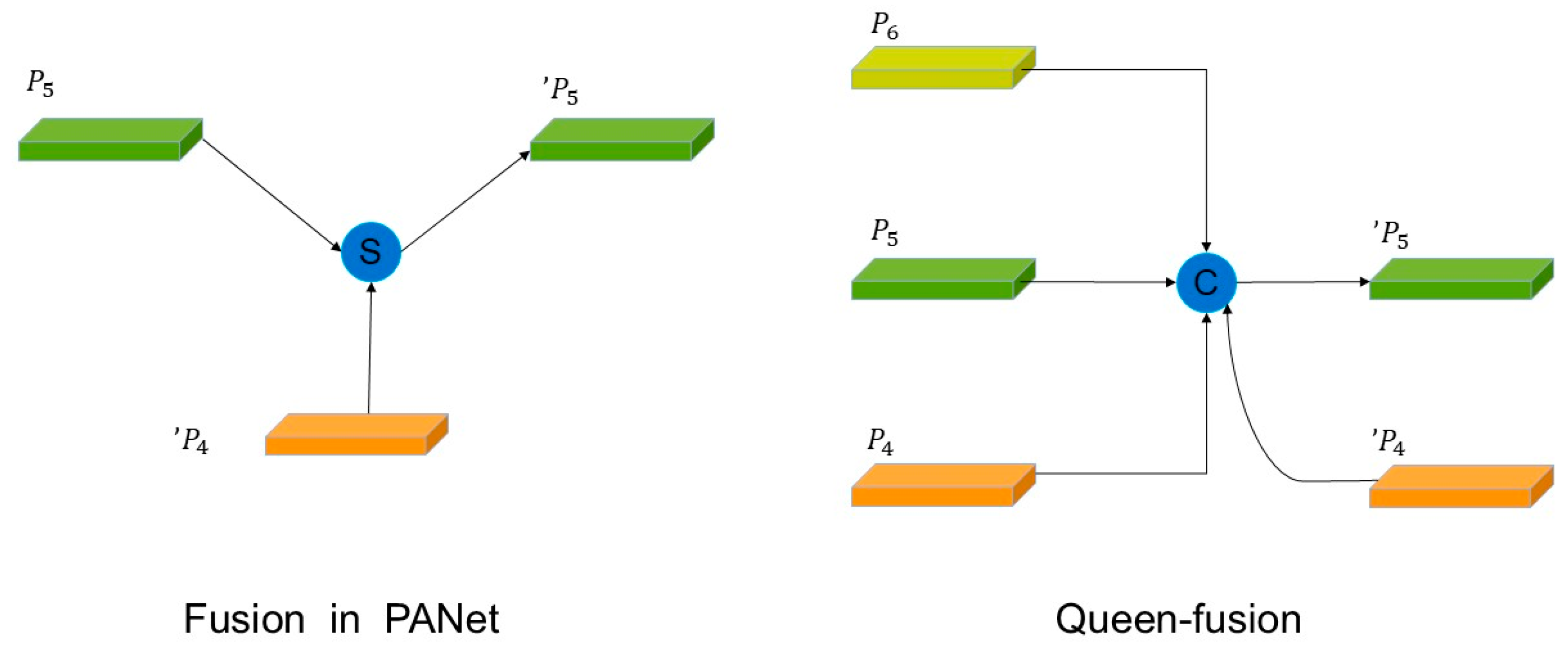
- The implementation of Generalized-FPN (GFPN) modules from GiraffeDet in detection heads supersedes traditional C2f modules. The GFPN architecture strengthens multi-dimensional pollen feature extraction through skip-connection intra-blocks and cross-scale linkages, improving hierarchical feature integration.
- Substituting standard Conv layers with DualConv operators, combining the GroupConv and HetConv paradigms, achieves parametric reduction without compromising detection performance, enabling efficient edge deployment.
2. Materials and Methods
2.1. Image Acquisition and Data and Production
2.2. Methods
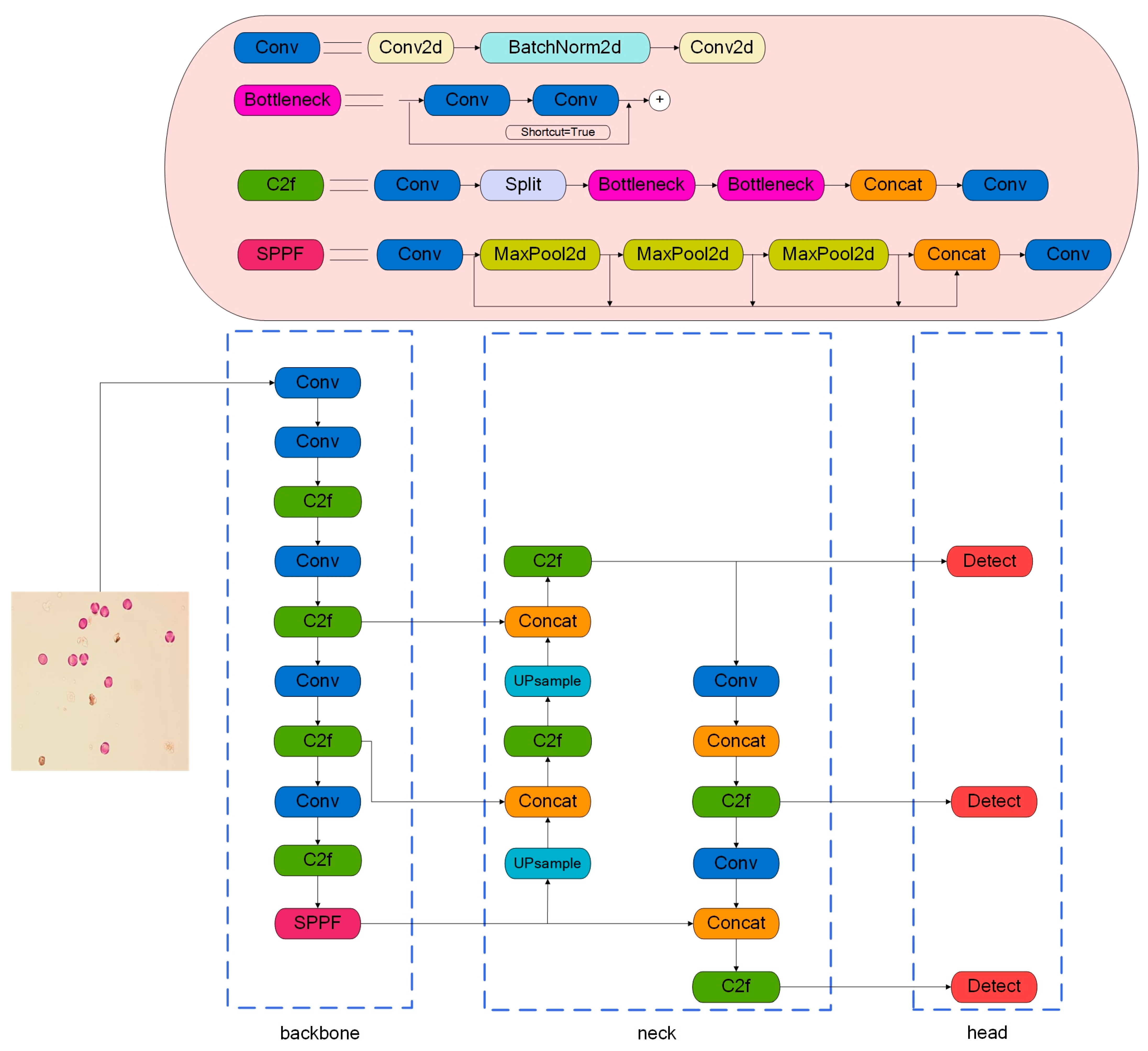
2.2.1. YOLOv8 Network
2.2.2. GGD-YOLOv8
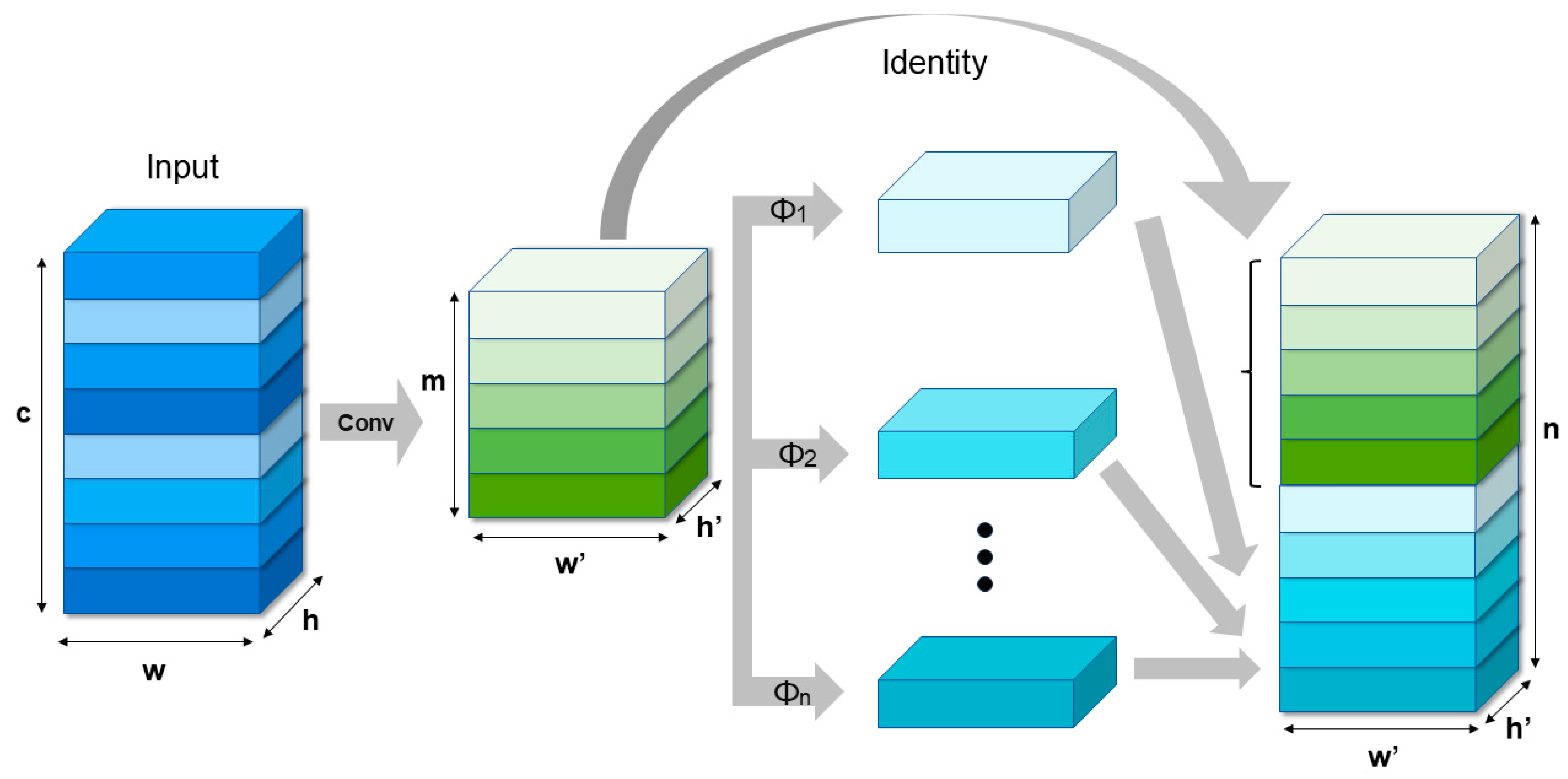
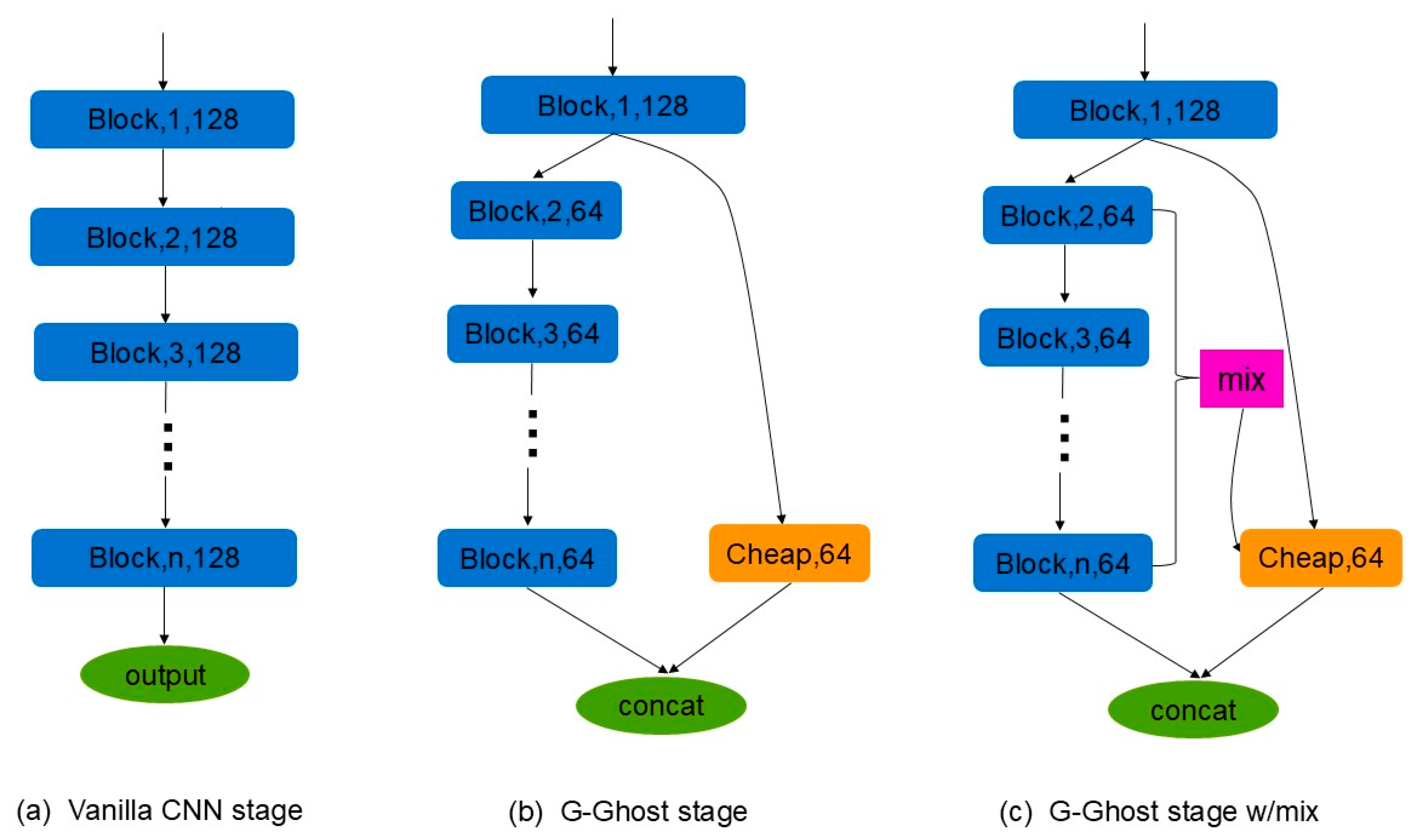
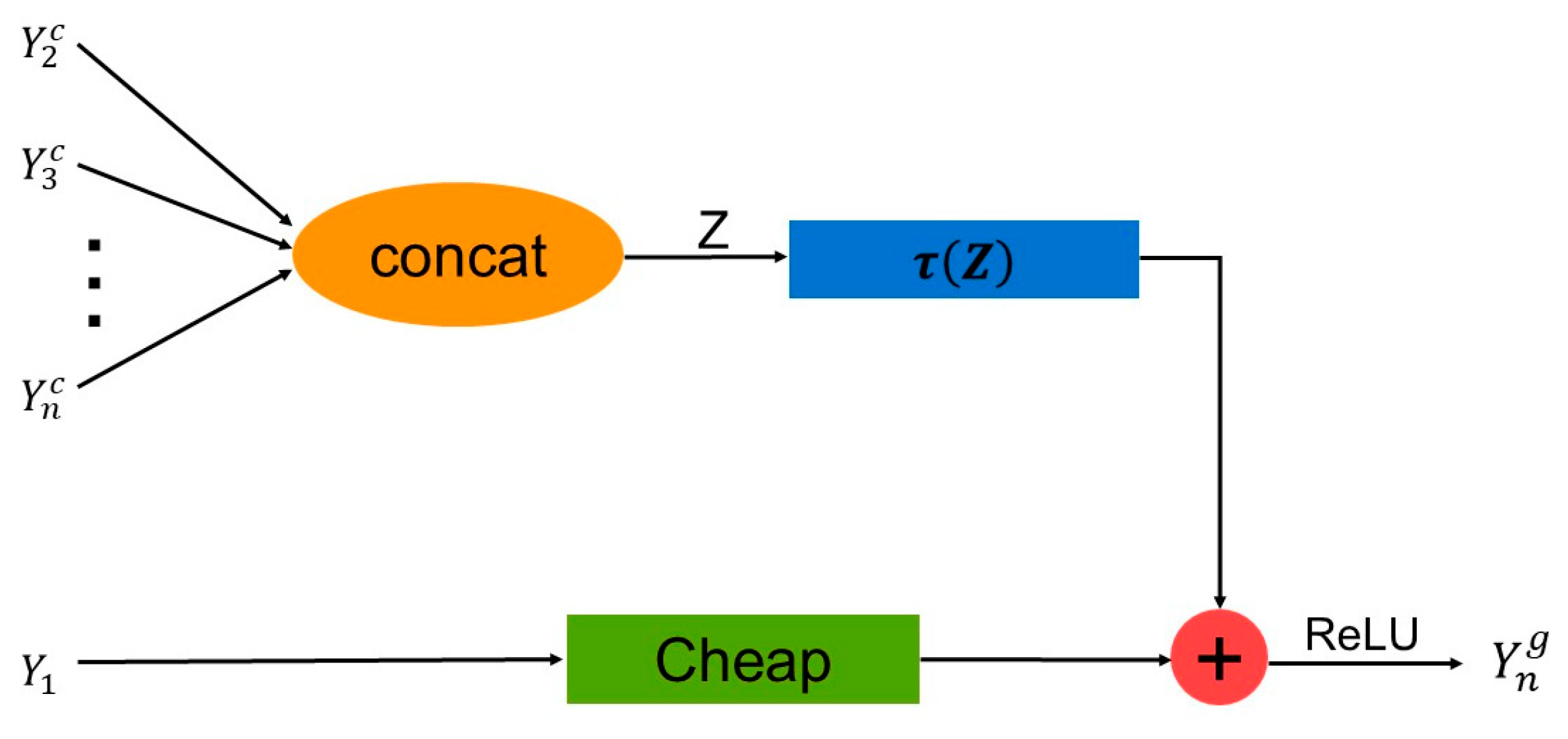
2.2.3. G-Ghost Bottleneck Module
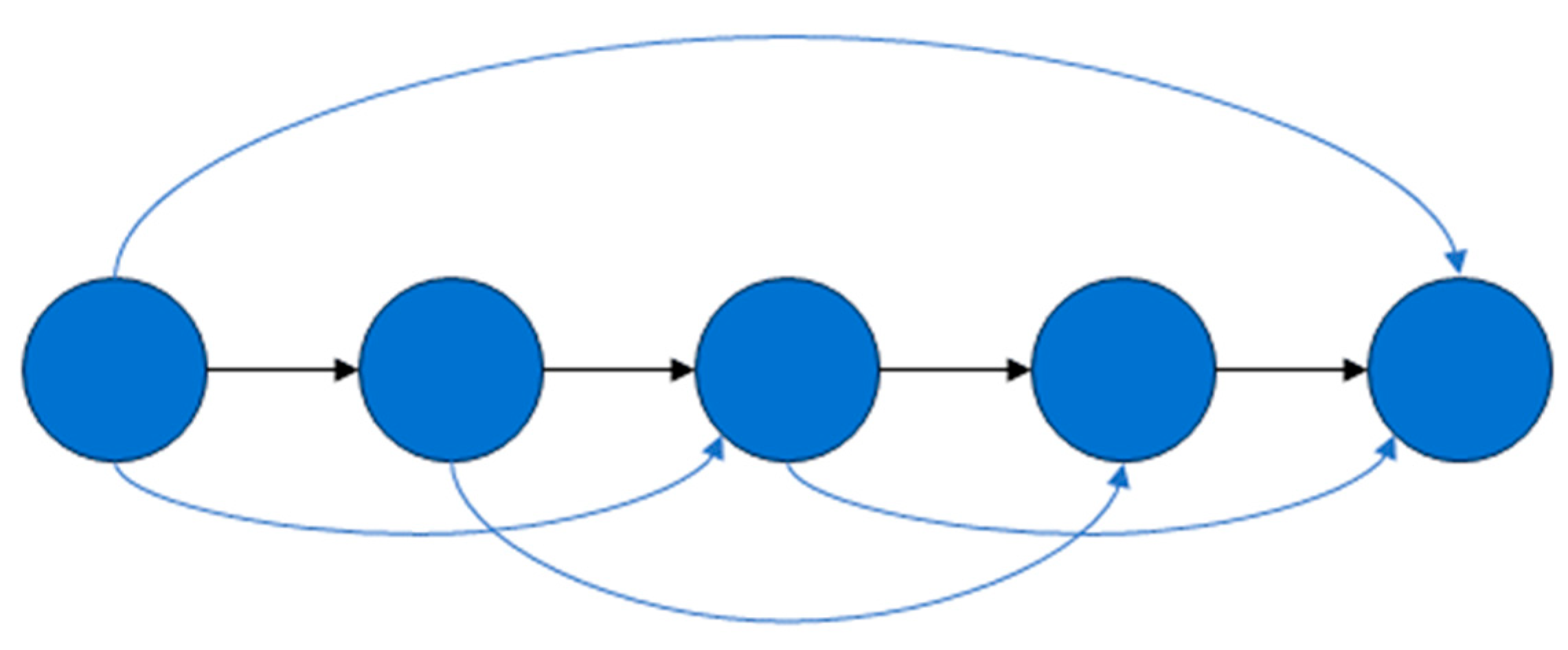
2.2.4. Generalized Feature Pyramid Network (GFPN)
2.2.5. Introduction of DualConv
3. Results: Analysis and Discussion
3.1. Experimental Environment Configuration
3.2. Model Parameter Settings
- The training parameter settings are shown in Table 1.
- 2.
- The training parameter settings are shown in Table 2.
3.3. Experimental Evaluation Indicators
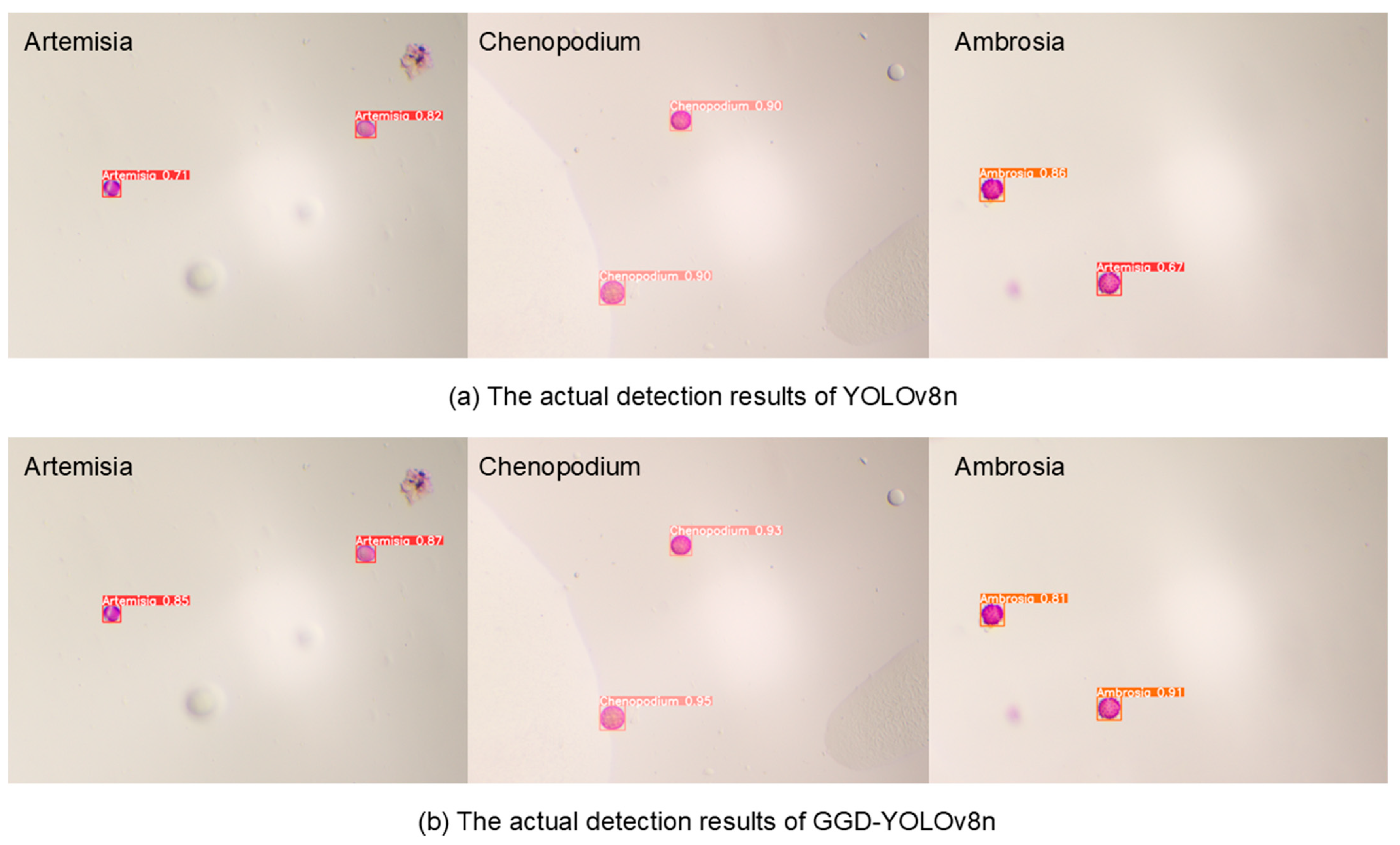
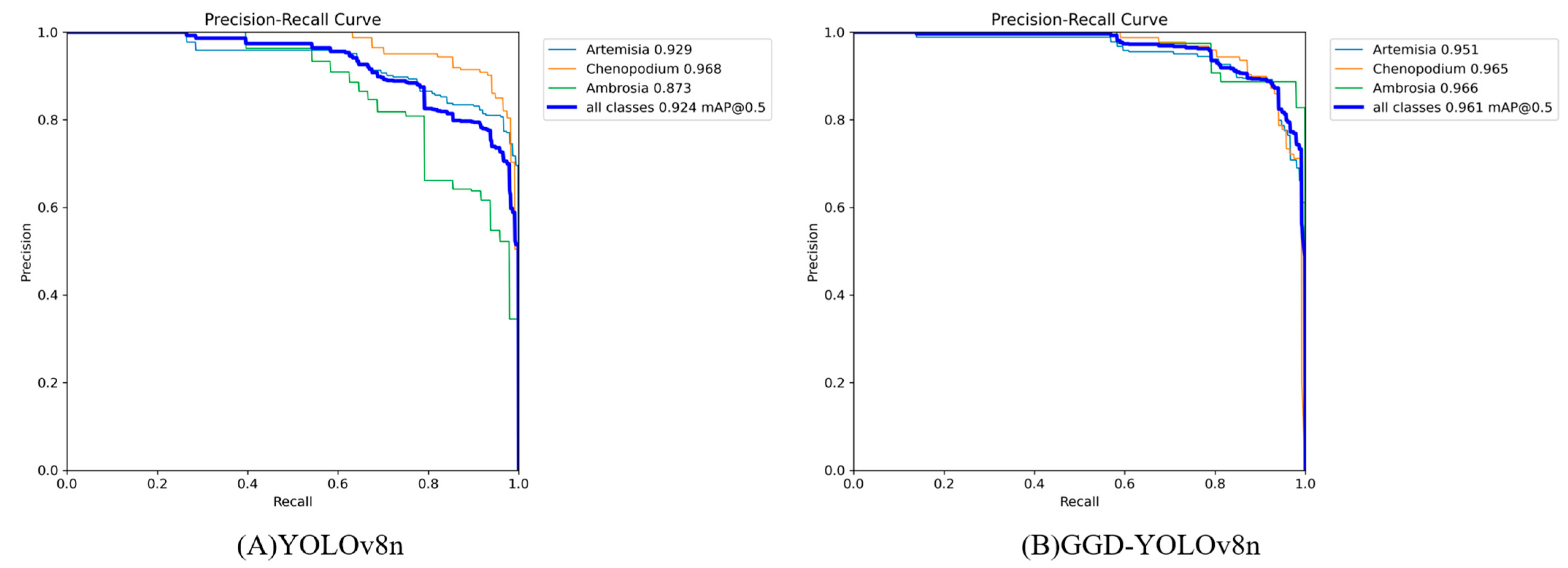
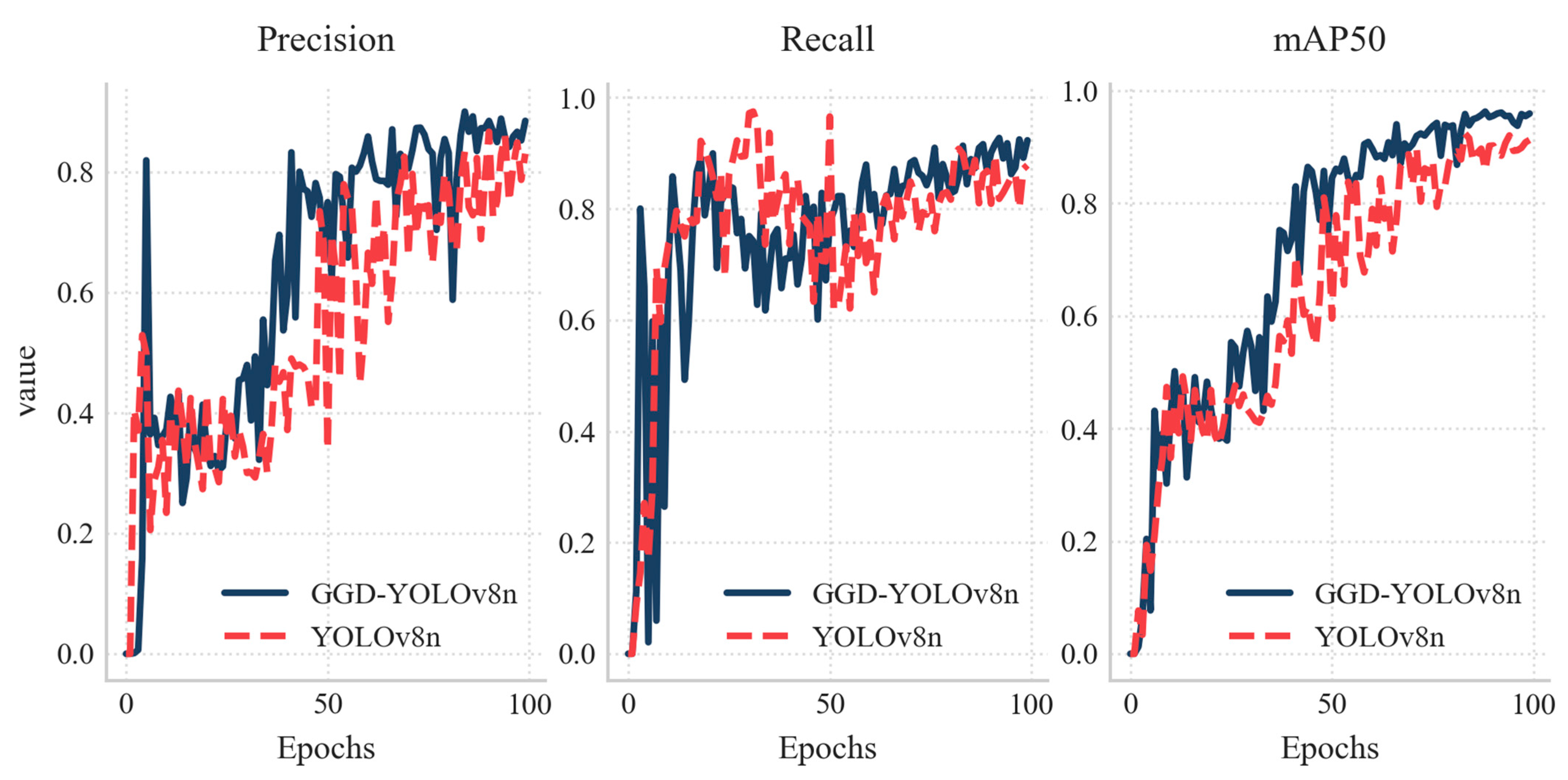
3.4. Comparison of Different Algorithms
3.5. Ablation Experiment
3.6. Embedded Deployment
3.7. Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Weinberg, E.G. THE WAO WHITE BOOK ON ALLERGY 2011–2012. Curr. Allergy Clin. Immunol. 2011, 24, 156–157. [Google Scholar]
- Platts-Mills, T.A.E. The Allergy Epidemics: 1870–2010. J. Allergy Clin. Immunol. 2015, 136, 3–13. [Google Scholar] [CrossRef] [PubMed]
- Tang, R.; Wang, L.; Yin, J.; Li, H.; Sun, J.; Zhi, Y.; Guan, K.; Wen, L.; Gu, J.; Wang, Z.; et al. History of hay fever in China. Sci. Sin.-Vitae 2021, 51, 901–907. [Google Scholar] [CrossRef]
- Stas, M.; Aerts, R.; Hendrickx, M.; Dendoncker, N.; Dujardin, S.; Linard, C.; Nawrot, T.S.; Van Nieuwenhuyse, A.; Aerts, J.-M.; Van Orshoven, J.; et al. Residential Green Space Types, Allergy Symptoms and Mental Health in a Cohort of Tree Pollen Allergy Patients. Landsc. Urban Plan. 2021, 210, 104070. [Google Scholar] [CrossRef]
- Kitinoja, M.A.; Hugg, T.T.; Siddika, N.; Yanez, D.R.; Jaakkola, M.S.; Jaakkola, J.J.K. Short-Term Exposure to Pollen and the Risk of Allergic and Asthmatic Manifestations: A Systematic Review and Meta-Analysis. BMJ Open 2020, 10, e029069. [Google Scholar] [CrossRef]
- Polling, M.; Li, C.; Cao, L.; Verbeek, F.; De Weger, L.A.; Belmonte, J.; De Linares, C.; Willemse, J.; De Boer, H.; Gravendeel, B. Neural Networks for Increased Accuracy of Allergenic Pollen Monitoring. Sci. Rep. 2021, 11, 11357. [Google Scholar] [CrossRef] [PubMed]
- Woosley, A.I. Pollen Extraction for Arid-Land Sediments. J. Field Archaeol. 1978, 5, 349–355. [Google Scholar] [CrossRef]
- Clot, B.; Gilge, S.; Hajkova, L.; Magyar, D.; Scheifinger, H.; Sofiev, M.; Bütler, F.; Tummon, F. The EUMETNET AutoPollen Programme: Establishing a Prototype Automatic Pollen Monitoring Network in Europe. Aerobiologia 2020, 40, 3–11. [Google Scholar] [CrossRef]
- Viertel, P.; König, M. Pattern Recognition Methodologies for Pollen Grain Image Classification: A Survey. Mach. Vis. Appl. 2022, 33, 18. [Google Scholar] [CrossRef]
- Battiato, S.; Ortis, A.; Trenta, F.; Ascari, L.; Politi, M.; Siniscalco, C. POLLEN13K: A Large Scale Microscope Pollen Grain Image Dataset. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2456–2460. [Google Scholar]
- Sun, X.-C.; Fu, D.-M.; Qin, L.-L.; Fu, J.-C.; Li, Z.-G. Pollen image recognition model based on dynamic and efficient network. Comput. Eng. Des. 2023, 44, 852–858. [Google Scholar] [CrossRef]
- Crouzy, B.; Stella, M.; Konzelmann, T.; Calpini, B.; Clot, B. All-Optical Automatic Pollen Identification: Towards an Operational System. Atmos. Environ. 2016, 140, 202–212. [Google Scholar] [CrossRef]
- Zhao, L.-N.; Li, J.-Q.; Cheng, W.-X.; Liu, S.-Q.; Gao, Z.-K.; Xu, X.; Ye, C.-H.; You, H.-L. Simulation Palynologists for Pollinosis Prevention: A Progressive Learning of Pollen Localization and Classification for Whole Slide Images. Biology 2022, 11, 1841. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhang, C.-J.; Liu, T.; Wang, J.; Zhai, D.; Chen, M.; Gao, Y.; Yu, J.; Wu, H.-Z. DeepPollenCount: A Swin-Transformer-YOLOv5-Based Deep Learning Method for Pollen Counting in Various Plant Species. Aerobiologia 2024, 40, 425–436. [Google Scholar] [CrossRef]
- Tan, Z.; Yang, J.; Li, Q.; Su, F.; Yang, T.; Wang, W.; Aierxi, A.; Zhang, X.; Yang, W.; Kong, J.; et al. PollenDetect: An Open-Source Pollen Viability Status Recognition System Based on Deep Learning Neural Networks. Int. J. Mol. Sci. 2022, 23, 13469. [Google Scholar] [CrossRef] [PubMed]
- Qingyuan, L.I.; Zhaohong, D.; Xiaoqing, L.U.O.; Xin, G.U.; Shitong, W. SSD Object Detection Algorithm with Attention and Cross-Scale Fusion. J. Front. Comput. Sci. Technol. 2022, 16, 2575. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497v3. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Han, K.; Wang, Y.; Xu, C.; Guo, J.; Xu, C.; Wu, E.; Tian, Q. GhostNets on Heterogeneous Devices via Cheap Operations. Int. J. Comput. Vis. 2022, 130, 1050–1069. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Jiang, Y.; Tan, Z.; Wang, J.; Sun, X.; Lin, M.; Li, H. GiraffeDet: A Heavy-Neck Paradigm for Object Detection. arXiv 2022, arXiv:2202.04256v2. [Google Scholar]
- Zhong, J.; Chen, J.; Mian, A. DualConv: Dual Convolutional Kernels for Lightweight Deep Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 9528–9535. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Parameter Settings |
|---|---|
| Weights | none |
| Img-size | 1280 × 1280 |
| Epochs | 100 |
| Batch-sizes | 8 |
| Parameter Name | Parameter Settings | Parameter Explanation |
|---|---|---|
| Lr0 | 0.01 | Initial learning rate |
| Lrf | 0.01 | Cyclic learning rate |
| Momentum | 0.937 | Learning rate momentum |
| Weight_decay | 0.0005 | Weight decay factor |
| Algorithm | Parameter/M | Precision/% | Recall/% | mAP/% |
|---|---|---|---|---|
| YOLOv5n | 2.5 | 86.1 | 91.5 | 94.2 |
| YOLOv7-tiny | 6.1 | 81.7 | 85.3 | 89.6 |
| YOLOv8n (baseline) | 3.0 | 83.1 | 87.8 | 91.2 |
| YOLOv10n | 2.7 | 84.4 | 86.7 | 92.2 |
| YOLOv11n | 2.6 | 88.1 | 91.8 | 95.6 |
| Swin-Transformer-YOLOv5l | 54.5 | 89.6 | 93.1 | 96.4 |
| GGD-YOLOv8n | 2.3 | 88.5 | 92.3 | 95.9 |
| Algorithm | Parameter/M | Precision/% | Recall/% | mAP/% |
|---|---|---|---|---|
| YOLOv8n | 3.01 | 83.1 | 87.8 | 91.2 |
| YOLOv8n + G-Ghost | 2.59 | 87.9 | 91.8 | 94.7 |
| YOLOv8n + GFPN | 2.98 | 83.3 | 86.7 | 92.0 |
| YOLOv8n + DualConv | 2.79 | 86.3 | 90.6 | 93.6 |
| YOLOv8n + G-Ghost + GFPN | 2.56 | 88.9 | 91.2 | 94.8 |
| YOLOv8n + G-Ghost + DualConv | 2.36 | 81.9 | 86.7 | 72.6 |
| YOLOv8n + GFPN + DualConv | 2.76 | 84.2 | 90.0 | 92.6 |
| YOLOv8n + G-Ghost+GFPN + DualConv | 2.33 | 88.5 | 92.3 | 95.9 |
| Models | Inference Time (Per Picture) |
|---|---|
| YOLOv5n | 392.4 ms |
| YOLOv7-tiny | 492.3 ms |
| YOLOv8n | 470.8 ms |
| YOLOv10n | 600.4 ms |
| YOLOv11n | 510.2 ms |
| GGD-YOLOv8n | 364.9 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Jia, X.; Cui, Y.; Zhang, H. GGD-YOLOv8n: A Lightweight Architecture for Edge-Computing-Optimized Allergenic Pollen Recognition with Cross-Scale Feature Fusion. Symmetry 2025, 17, 849. https://doi.org/10.3390/sym17060849
Zhang T, Jia X, Cui Y, Zhang H. GGD-YOLOv8n: A Lightweight Architecture for Edge-Computing-Optimized Allergenic Pollen Recognition with Cross-Scale Feature Fusion. Symmetry. 2025; 17(6):849. https://doi.org/10.3390/sym17060849
Chicago/Turabian StyleZhang, Tianrui, Xiaoqiang Jia, Ying Cui, and Hanyu Zhang. 2025. "GGD-YOLOv8n: A Lightweight Architecture for Edge-Computing-Optimized Allergenic Pollen Recognition with Cross-Scale Feature Fusion" Symmetry 17, no. 6: 849. https://doi.org/10.3390/sym17060849
APA StyleZhang, T., Jia, X., Cui, Y., & Zhang, H. (2025). GGD-YOLOv8n: A Lightweight Architecture for Edge-Computing-Optimized Allergenic Pollen Recognition with Cross-Scale Feature Fusion. Symmetry, 17(6), 849. https://doi.org/10.3390/sym17060849