3.1. Task Description
Given a sentence in the field of cybersecurity containing n words, it can be expressed as details in Equation (2).
where k represents any word token in the sentence X and n is the length of the sentence X, 1 < k < n.
In this paper, the named entity recognition (NER) task is formulated as a sequence labeling problem, where each token in the input sentence is assigned a specific label indicating its role in forming a named entity. We adopt the widely used BIO (Begin, Inside, Outside) tagging scheme to encode entity boundaries and types. Specifically, the tag B-X denotes the beginning token of an entity of type X, I-X indicates a token that is inside the same entity, and O marks a token that does not belong to any named entity. Each word token in the sentence X is represented and elements in Y correspond to the labels for each word. A set of contiguous meaningful tokens constitutes an entity, also referred to as a continuous multi-token entity, which is an entity. It is also known as a continuous multi-token entity. Therefore, the goal of this paper is to learn parameterized mapping from input words to output labels.
3.3. Segment Masking Enhancement Mechanism (SME)
The SME mechanism is designed to improve the ability of the SSNER to extract multi-token entities, as described in
Section 2.3.1. This method involves three main steps: generating random contiguous segments, applying MASK intervention, and SecureBERT_SME model training. The specific details are as follows.
- (1)
Generate random continuous segments
Before intervening with the MASK mechanism, the SSNER first generates random continuous segments to be used as input for the pre-training BERT. The description is as follows.
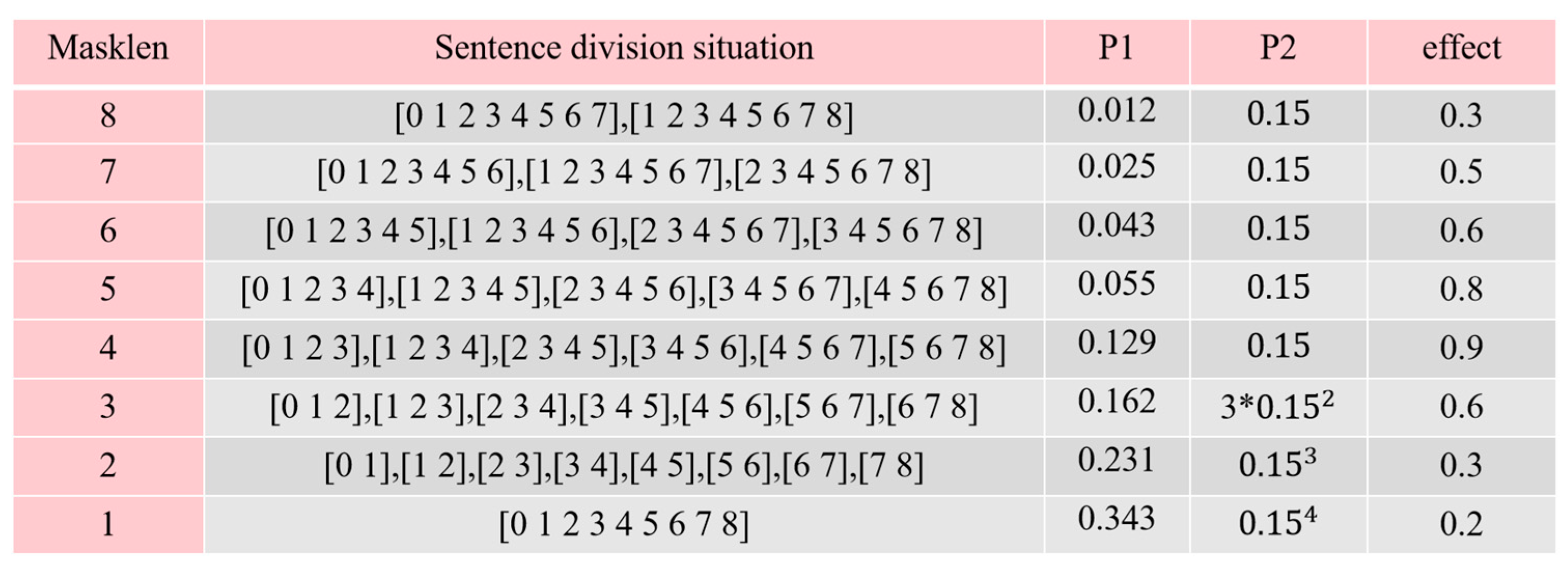
Step 1: For any dataset D, the occurrence probabilities for entities of varying lengths in the texts are calculated using the statistical function S(D), as detailed in Equation (3).
where S(·) represents the operation of calculating the distribution probability of all entity lengths and n is the length of the longest entity in dataset D. e
k is the probability of an entity of length k appearing, 1 ≤ k ≤ n.
Step 2: Following the generation of an activation threshold u in the range [0, 1), the SSNER employs the Inverse Transform Sampling (ITS) method to calculate the cumulative distribution function F(k) as defined in Equation (4). When u satisfies the condition given in Equation (5), the value of masklen can be determined accordingly.
where F(k) represents the cumulative probability of each data point,
, and u represents a random number in the range [0, 1), which is used in Equation (5) to generate the random number masklen that satisfies the probability distribution of the entity. The masklen is the length of the segmentation and F(0) = 0.
Step 3: The input set X is recursively partitioned into segments of masklen to get the target set Z as defined in Equation (6). Then put the set Z into the set Mask List using Equation (7).
where
is each token of the input text (1 ≤ i ≤ n),
represents the segment after the input text is partitioned (1 ≤ i ≤ n − masklen + 1), and n is the number of the input text token.
- (2)
MASK intervention
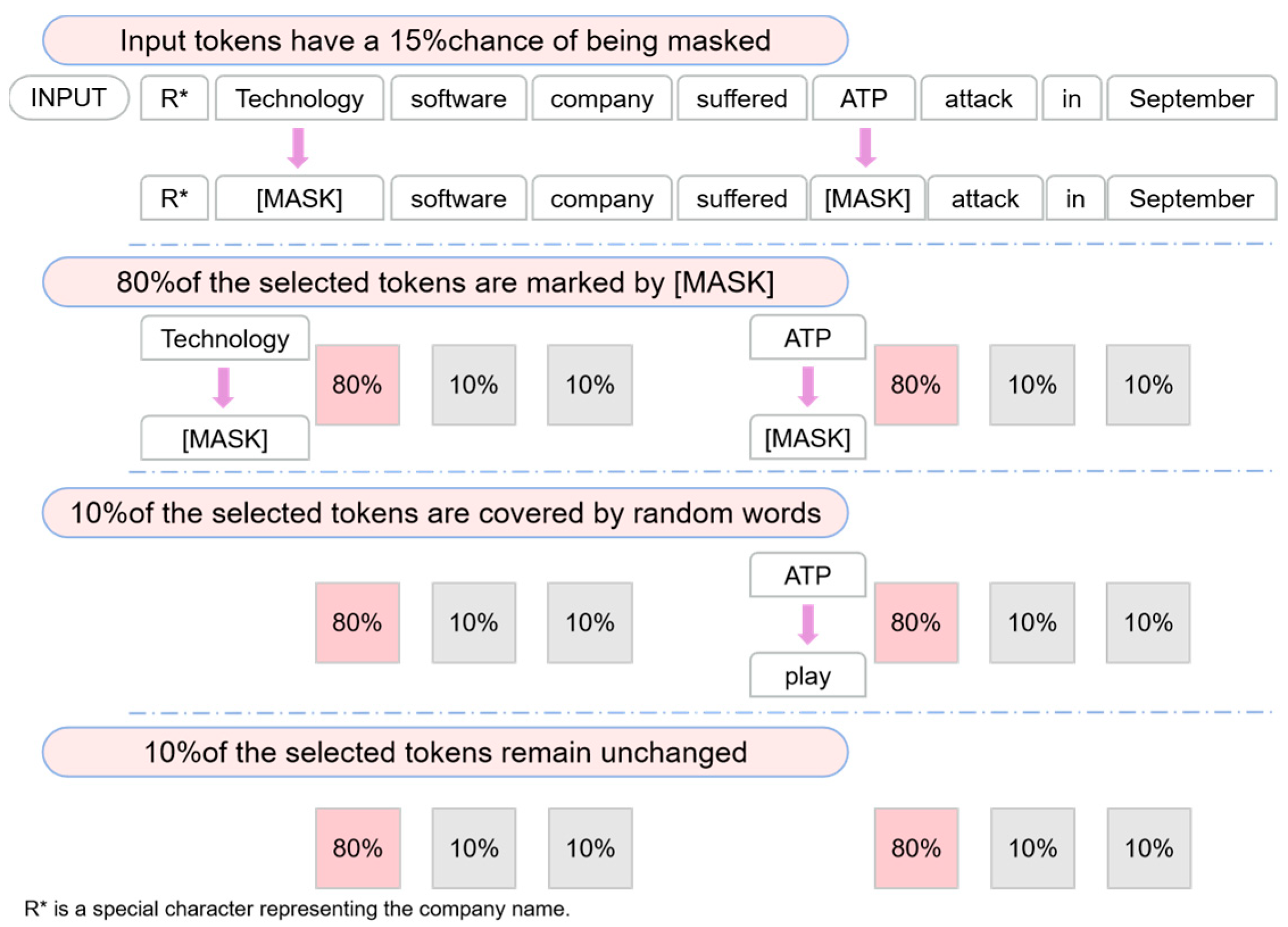
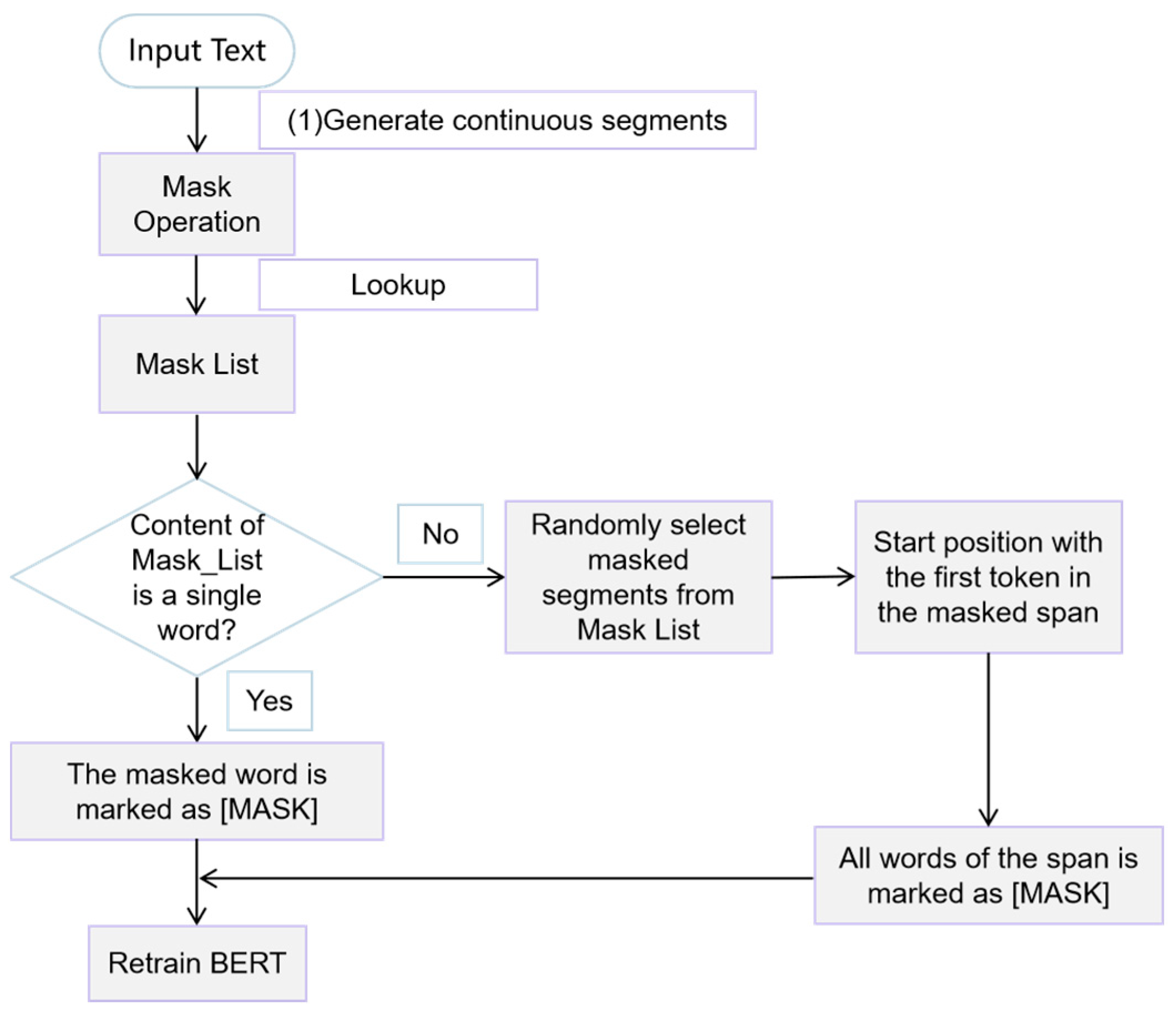
On the basis of the generated random segments, this paper masks the random segments with the intervention algorithm. The intervention algorithm flow is shown in
Figure 5.
In
Figure 5. If the Mask List contains a single character, the
masked in the Mask List is signed directly with the [MASK] symbol. If the Mask List contains a sequence of contiguous segments, the position of the first token in the segment is used as the starting position of this segment. Then, the masked segment in the Mask List is signed directly with the sequential [MASK] … [MASK] symbol. Finally, the algorithm retains the same strategy as the ratio of words masked in BERT.
- (3)
SecureBERT_SME model training
After the operation of the MASK intervention, this paper pre-trains BERT based on the CTI corpus and modifies BERT’s mask mechanism to become the SecureBERT_SME model. The description is as follows.
Step 1: Data collection
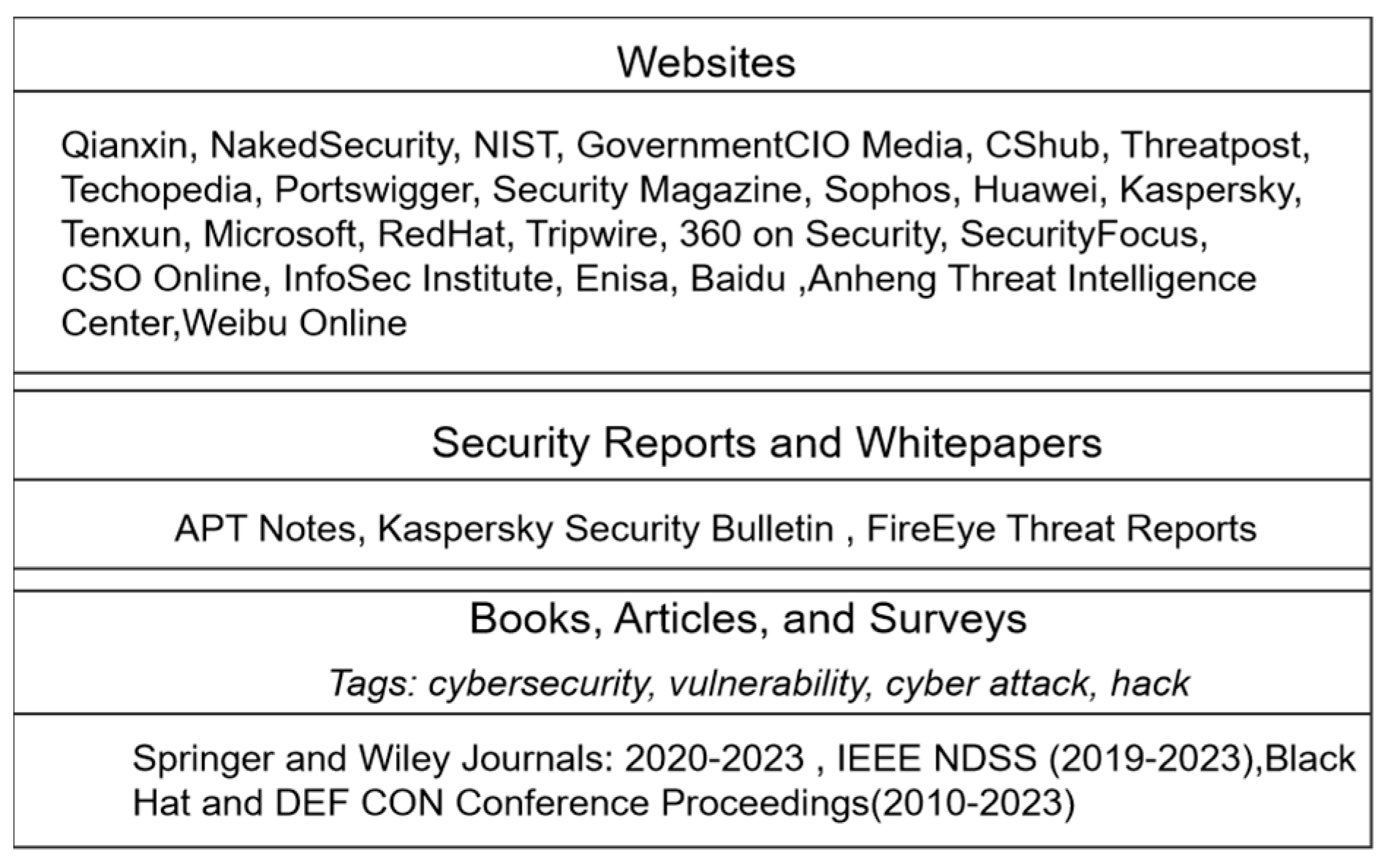
A large amount of online text data related to cybersecurity is collected, including books, blogs, news articles, security reports, journals, and survey reports. A web-crawling tool is employed to create a corpus containing 10 million words. The corpus encompasses various forms of cybersecurity texts, ranging from basic information, news articles, Wikipedia entries, and tutorials to more advanced materials such as malware analysis, intrusion detection, and vulnerability assessment, as shown in
Figure 6.
Step 2: Data preprocessing
By utilizing Equation (8) and Equation (9), an amount of irrelevant information is removed, such as unrelated HTML tags and specific formatted text. The text data is tokenized using the WordPiece Equation (10), and different forms of words are normalized to ensure that the model comprehends various expressions of the same meaning.
where sub(·) stands for removing irrelevant elements in the text and wordpiece_tokenizer(·) represents the operation of splitting text into words or subwords.
Step 3: Fine-tuning
The traditional BERT model is used as the foundation for transfer learning. Specifically, the NER is chosen as the target task, and BERT is fine-tuned based on the SME mechanism. During the training process, we adopt the Adam (Adaptive Moment Estimation) optimizer to update model parameters [
26]. Adam adaptively adjusts the learning rate for each parameter using estimates of the first and second moments of the gradients, which facilitates efficient convergence and stable optimization. Furthermore, to tackle cybersecurity dataset class imbalance, focal loss modulates cross-entropy loss to focus on hard, misclassified examples, improving minority class learning and generalization [
27]. By jointly leveraging the Adam optimizer and focal loss and continuously monitoring the loss function and classification accuracy, the training process is guided toward the effective development of the SecureBERT_SME model.
Based on the three steps described above, we have developed a comprehensive algorithmic framework that elucidates the logical relationships among these steps, as shown in the following Algorithm 1.
| Algorithm 1: Segment Masking Enhancement Mechanism
|
| | Input: Pre-trained BERT model, annotated datasets |
| | Output: model for cybersecurity NER |
| 1 | Initialization: Split annotated dataset into train, validation, and test sets; |
| 2 | Initialize optimizer (Adam) and loss function (focal loss); |
| 3 | Set hyperparameters (learning rate, batch size, epochs, etc.); |
| 4 | For each
epoch in epochs do |
| 5 |
For each
batch in train set do |
| 6 | Tokenize batch text into subwords; |
| 7 | Generate input IDs, attention masks, and token-type IDs; |
| 8 | Feed input data into BERT; |
| 9 | By utilizing Equations (3)–(5); |
| 10 | Generate random continuous segments ; |
| 11 | Utilizing intervention algorithm to MASK intervention based on ; |
| 12 | Compute predictions and calculate focal loss; |
| 13 | Backpropagate loss and update model weights; |
| 14 |
end |
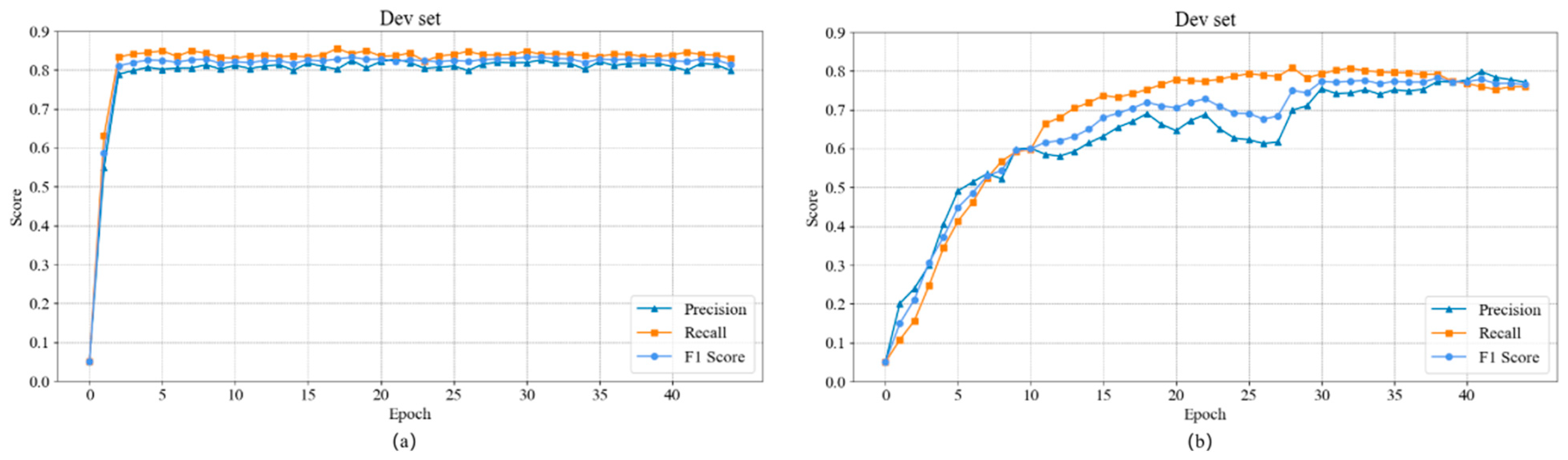
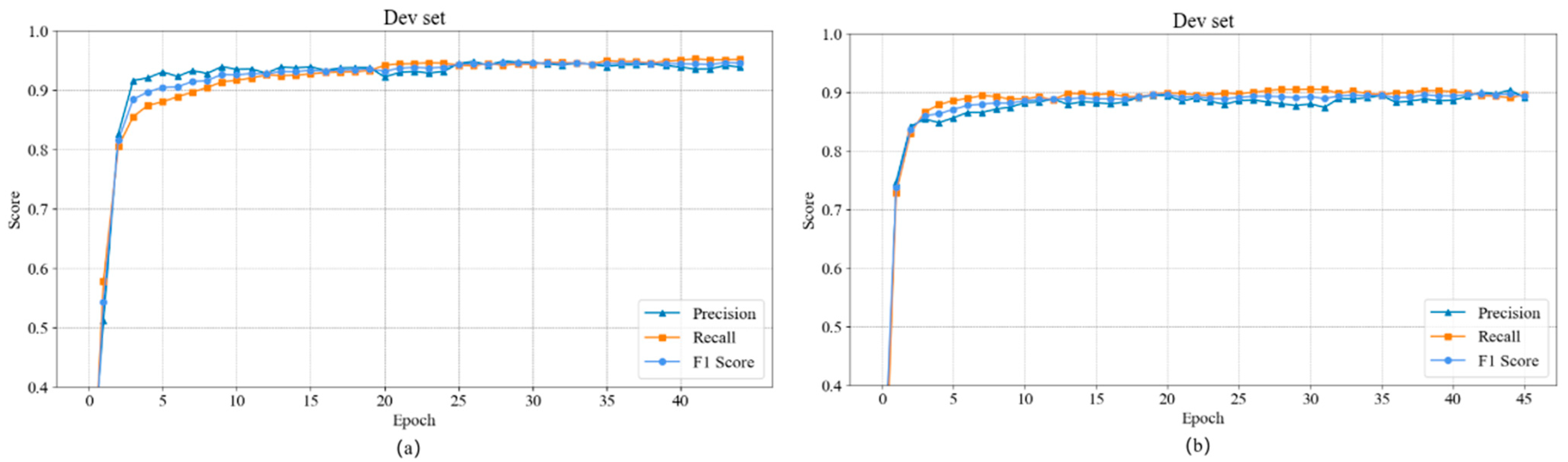
| 15 | Evaluate model on validation set using precision, recall, and F1-score; |
| 16 | Save best-performing model checkpoint; |
| 17 | end |
| 18 | Return retrained model |
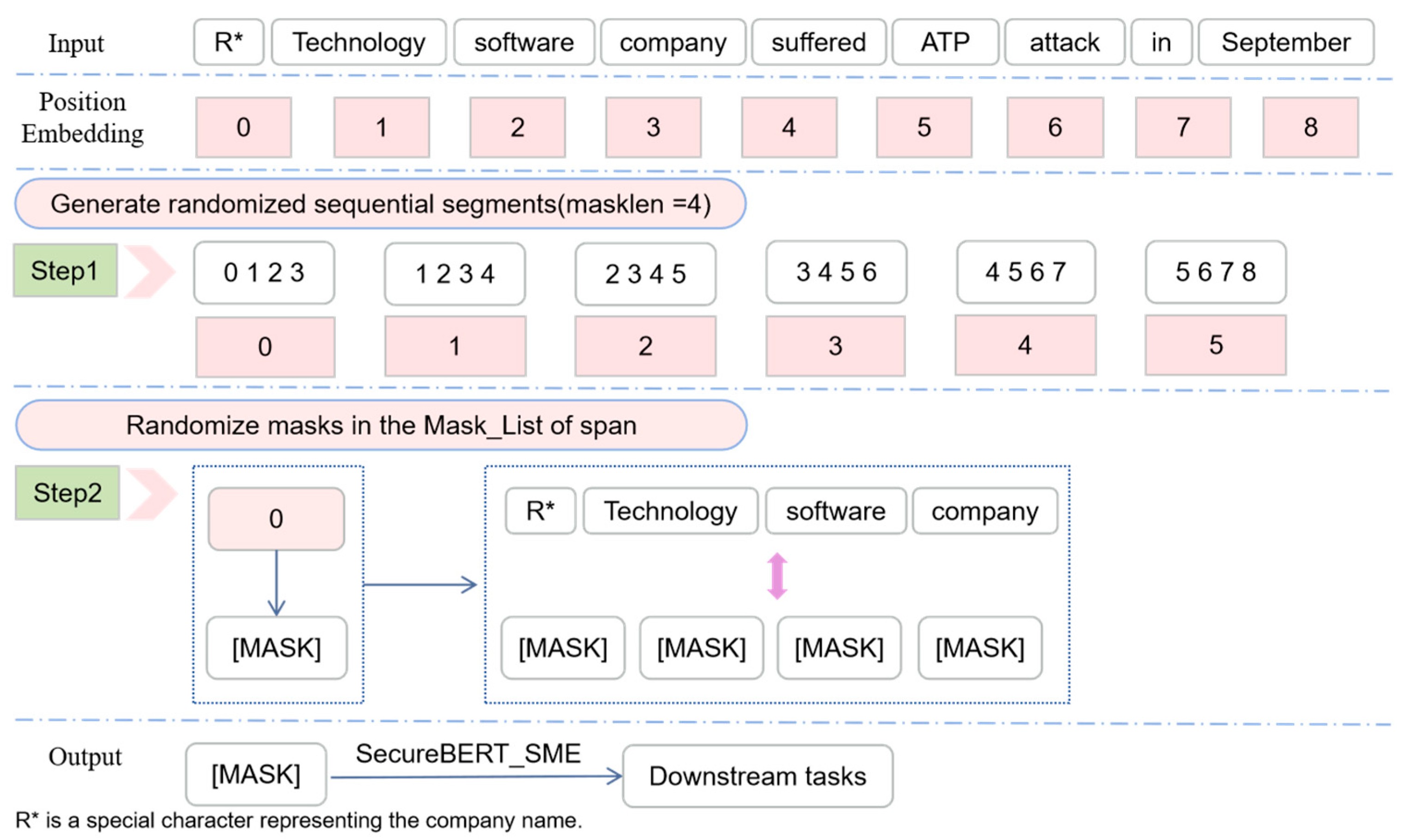
After BERT is retrained on the CTI corpus, the SecureBERT_SME model can generate segment-level information word embeddings with CTI knowledge to solve the issue of the incomplete extraction of multi-token entities. In
Figure 7, this paper gives an example to illustrate the effectiveness of the SME mechanism for the extraction of multi-token entities. X = “R* Technology software company suffered ATP attack in September” is the input text and the positional embeddings of the sentence are [0, 1, 2, 3, 4, 5, 6, 7, 8]. The goal is to completely extract the entity “R* Technology software company”. By utilizing the SME mechanism, the SSNER generated contiguous segments with a mask length of masklen to extract the segment-level word embedding, so that the ability of the SSNER to recognize multi-token entity is enhanced. Furthermore, we systematically analyze the impact of different “masklen” values on the performance of the SSNER model (see
Appendix A). As a result, by using the SME mechanism, the SSNER model can capture more segment information in the sentence, enhancing the ability to extract multi-token entities in intelligence texts.
3.4. Semantic Collaborative Embedding Mechanism (SCE)
The SCE mechanism is designed to address the issue of the low classification accuracy of polysemy entities, as described in
Section 2.3.2. SCE involves two main steps: Filtering similar word embedding and similar semantic space construction. The specific details are as follows.
- (1)
Filtering similar word embedding
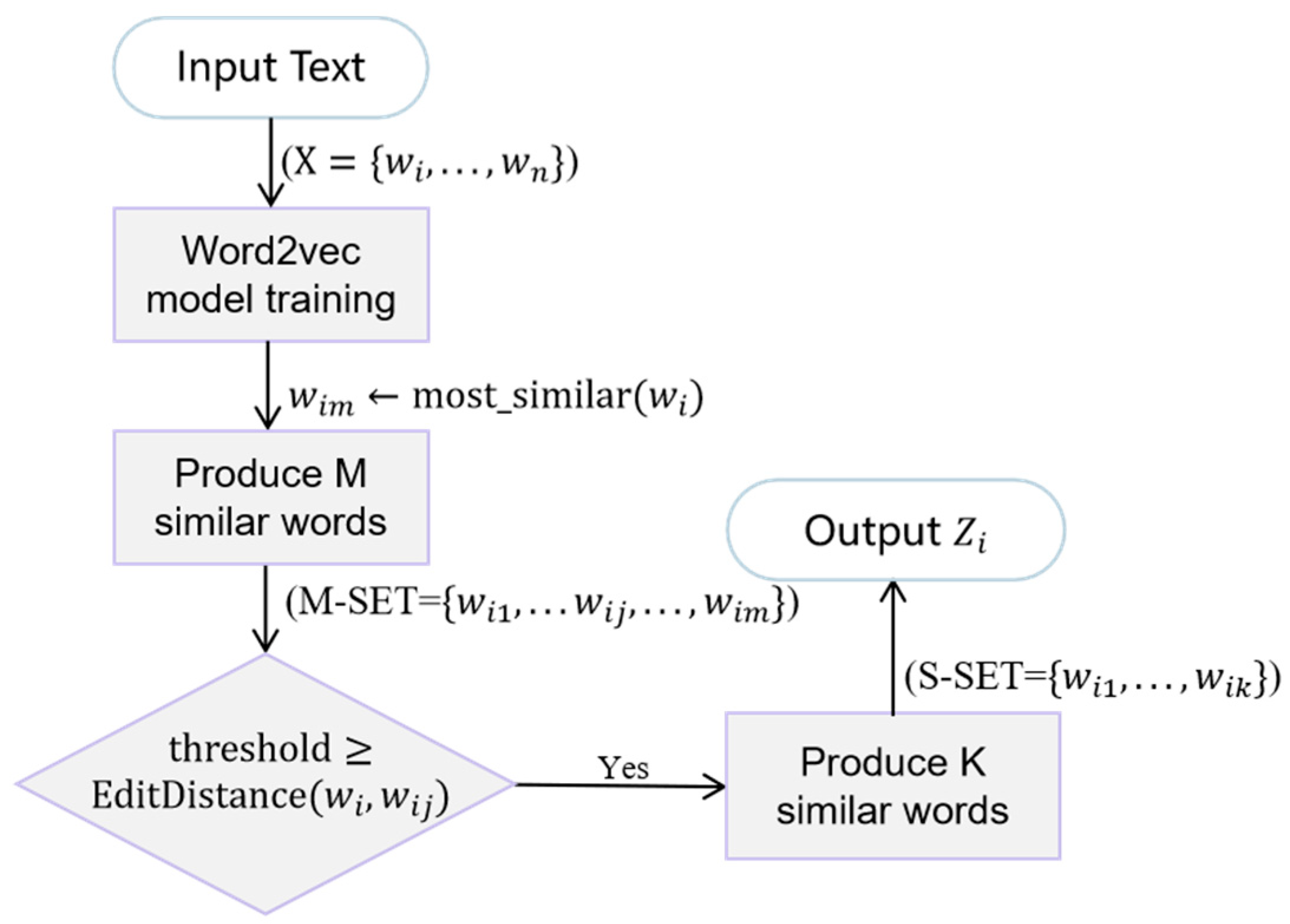
Before constructing the similar semantic space, SSNER first filters out the similar word embeddings for the keywords in threat intelligence text using the SSF algorithm.
Step 1: Use word2vec to train a word-embedding model on the threat intelligence datasets, generating word-embedding vectors as defined in Equation (11).
Step 2: By using the contextual semantic information in the Word2Vec model, SSNER filters out the first batch of similar word set M-SET of size m (m < n)
Step 3: While maintaining the accuracy of contextual semantics, a fuzzy string-matching algorithm is used to compare the internal structure of the text and filter out the final similar words set S-SET of size k (k < m) and the word vectors set
, as shown in Equations (13) and (14).
Through the above steps, SSNER obtains similar words that retain both contextual similarity and structural similarity. The SSF algorithm flow is presented in
Figure 8.
- (2)
Similar semantic space construction
Based on filtering similar word embeddings, SSNER uses the self-attention mechanism to construct a similar semantic space for input . The description is as follows.
Firstly, by utilizing Equation (15), the semantic relevance weight
between the target word and similar words in the S-SET set is calculated. Then, the semantic relevance weight is normalized by Equation (16). Finally, the normalized results are accumulated by Equation (17), resulting in the similar semantic space embedding
.
where
represents the mapping embedding of
,
represents the mapping embedding of the jth similar word, and
represents the number of final similar words.
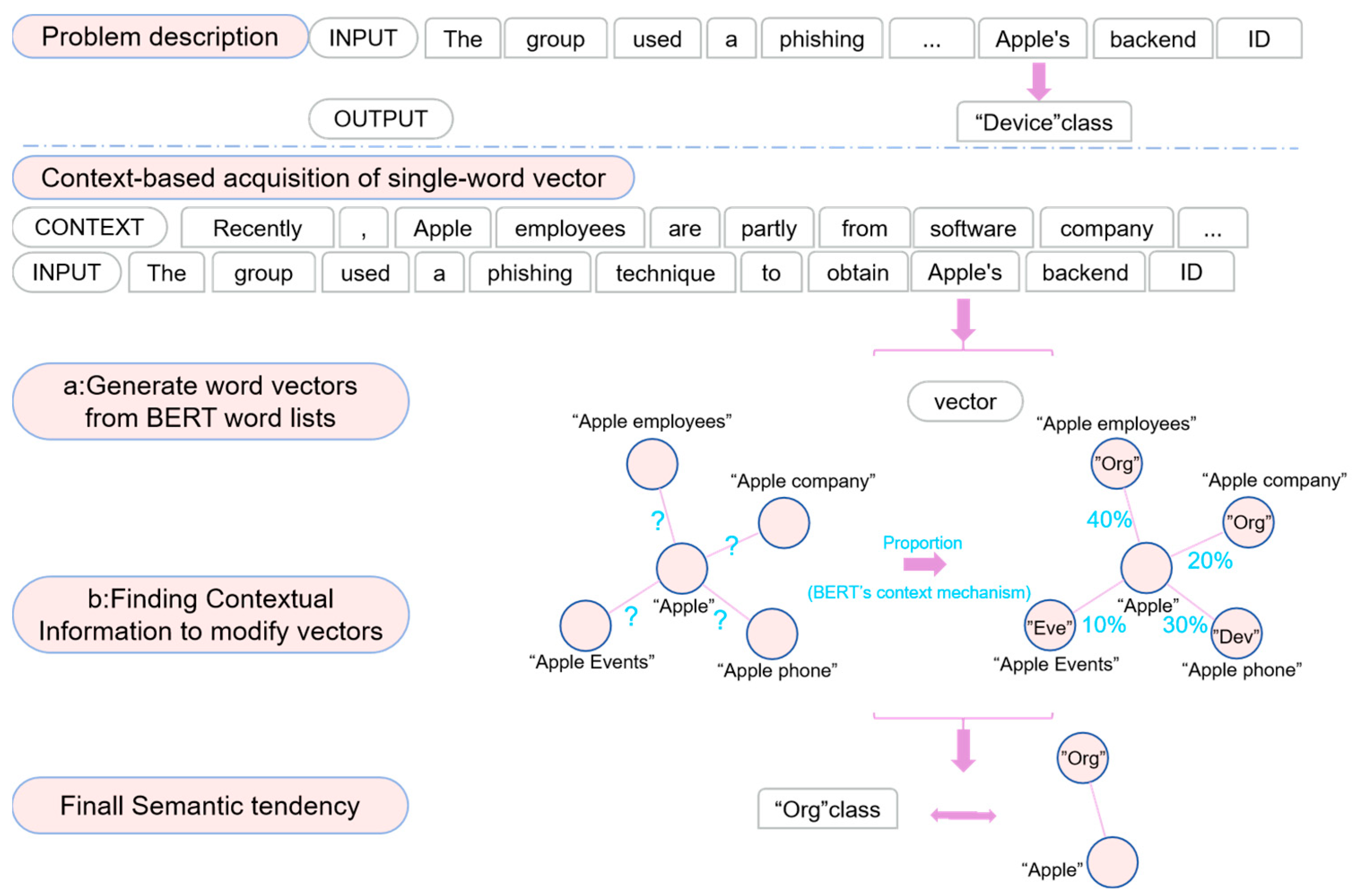
After the similar semantic space construction is complete, the SSNER will construct similar semantic spaces for the words in the intelligence texts to solve the issue of the low classification accuracy for polysemy entities. In
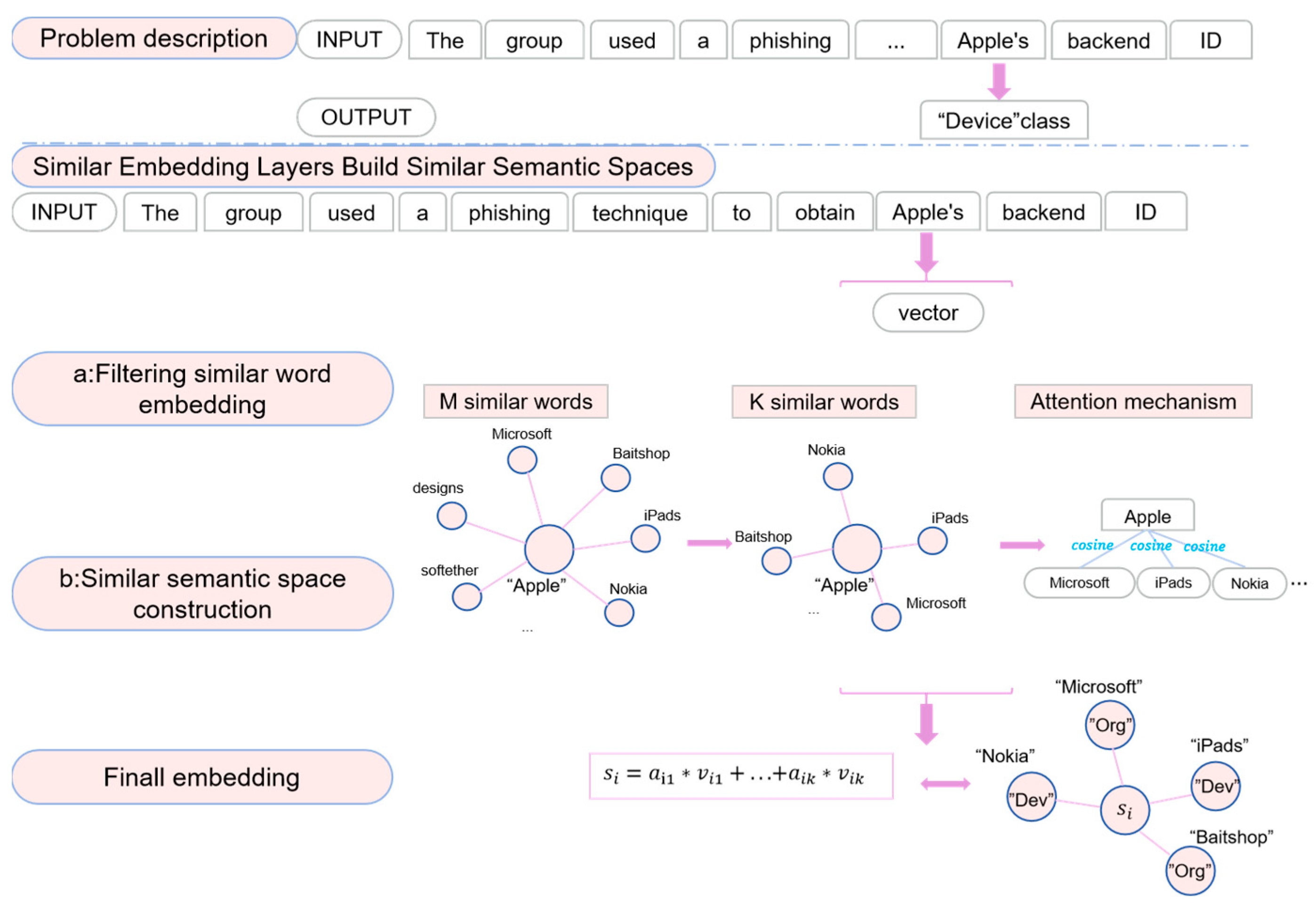
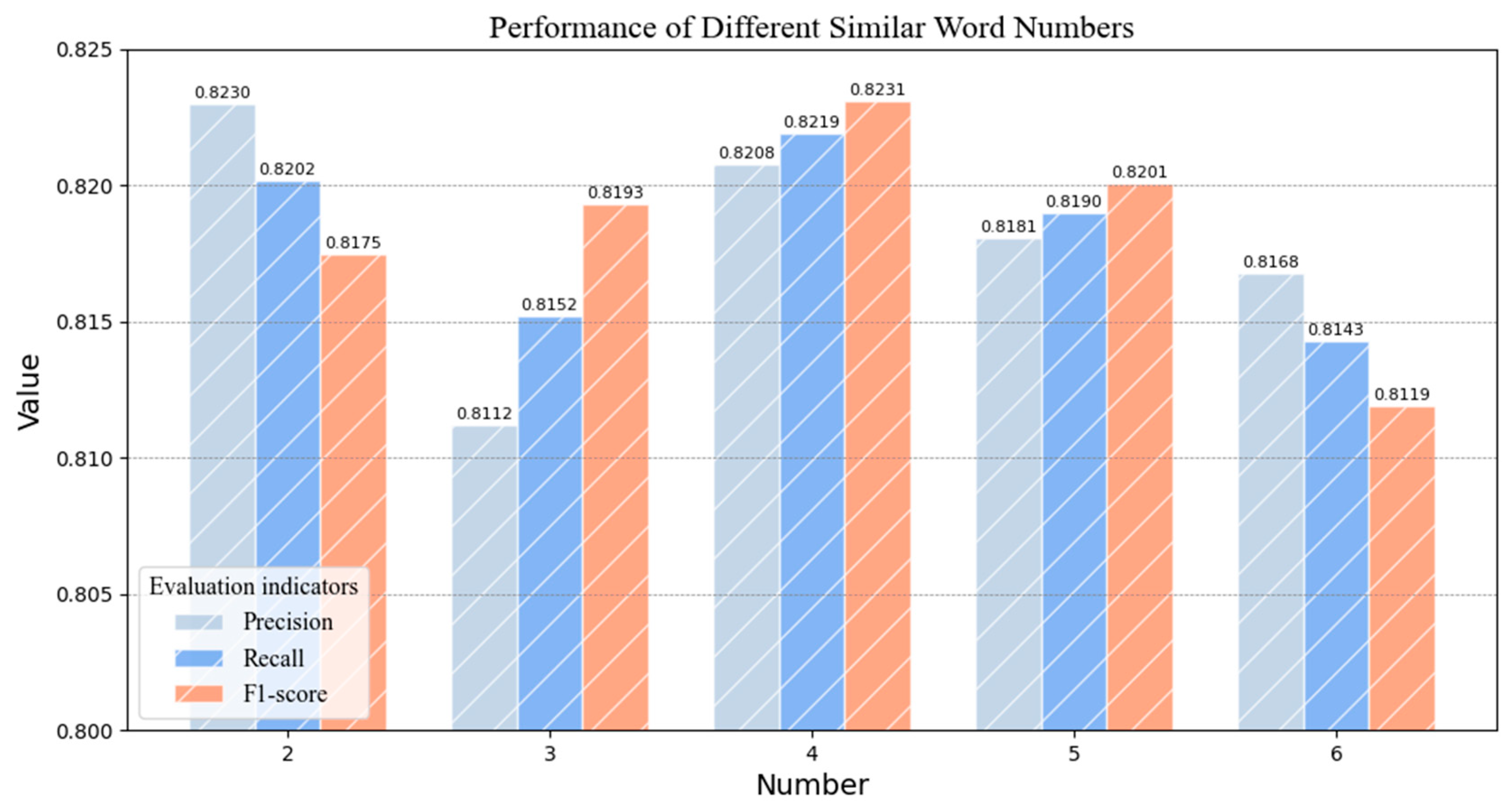
Figure 9, this paper gives an example to illustrate the effectiveness of the SCE mechanism for the classification of polysemy entities. X = “The group used a phishing technique to obtain Apple’s backend ID” is the input text and “Apple” is a polysemy entity that can refer to a device, event, and company. The goal is to accurately categorize the “Apple” entity in the “device (Dev)” category. The SSNER model first needs to train the word2vec model and filter out M similar words with similar meanings, which include “Microsoft, iPads, Nokia, designs, softether …”. Next, a fuzzy string-matching algorithm is used to filter out the final K similar words, which are “Nokia, iPads, Microsoft, Baitshop …”. Additionally, this paper conducts experimental evaluations on the value of K, as discussed in
Section 5.1. Finally, the self-attention mechanism is employed to calculate the semantic relevance weights of each similar word using Equation (15). Then, normalizing and accumulating is performed to obtain the final similar semantic space embedding
by Equations (16) and (17). The spatial structure of
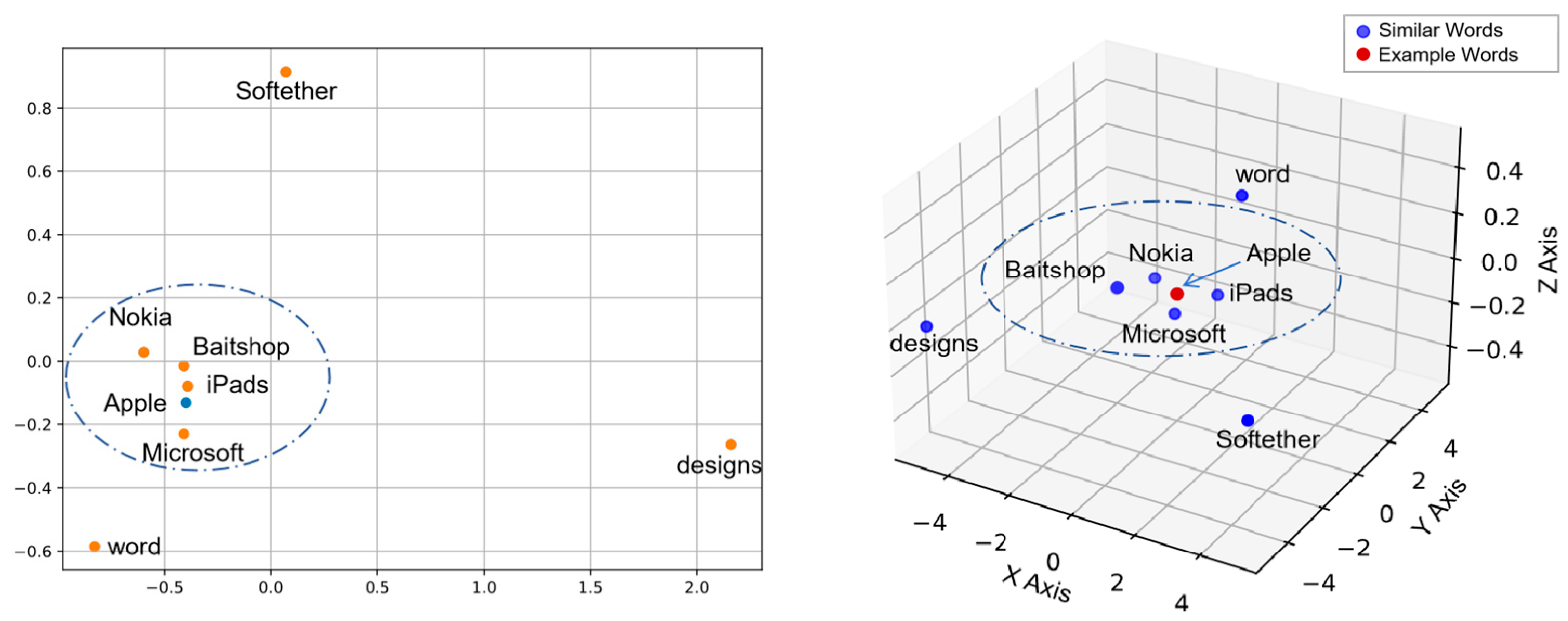
has the symmetry of semantics and structure rather than a single semantic expression. In
Figure 9, the similar space embedding
contains semantic information of the “Dev” category and “Org” category. Therefore, compared to the traditional single semantics, similar semantic space greatly improves the probability of a polysemy entity being predicted correctly.
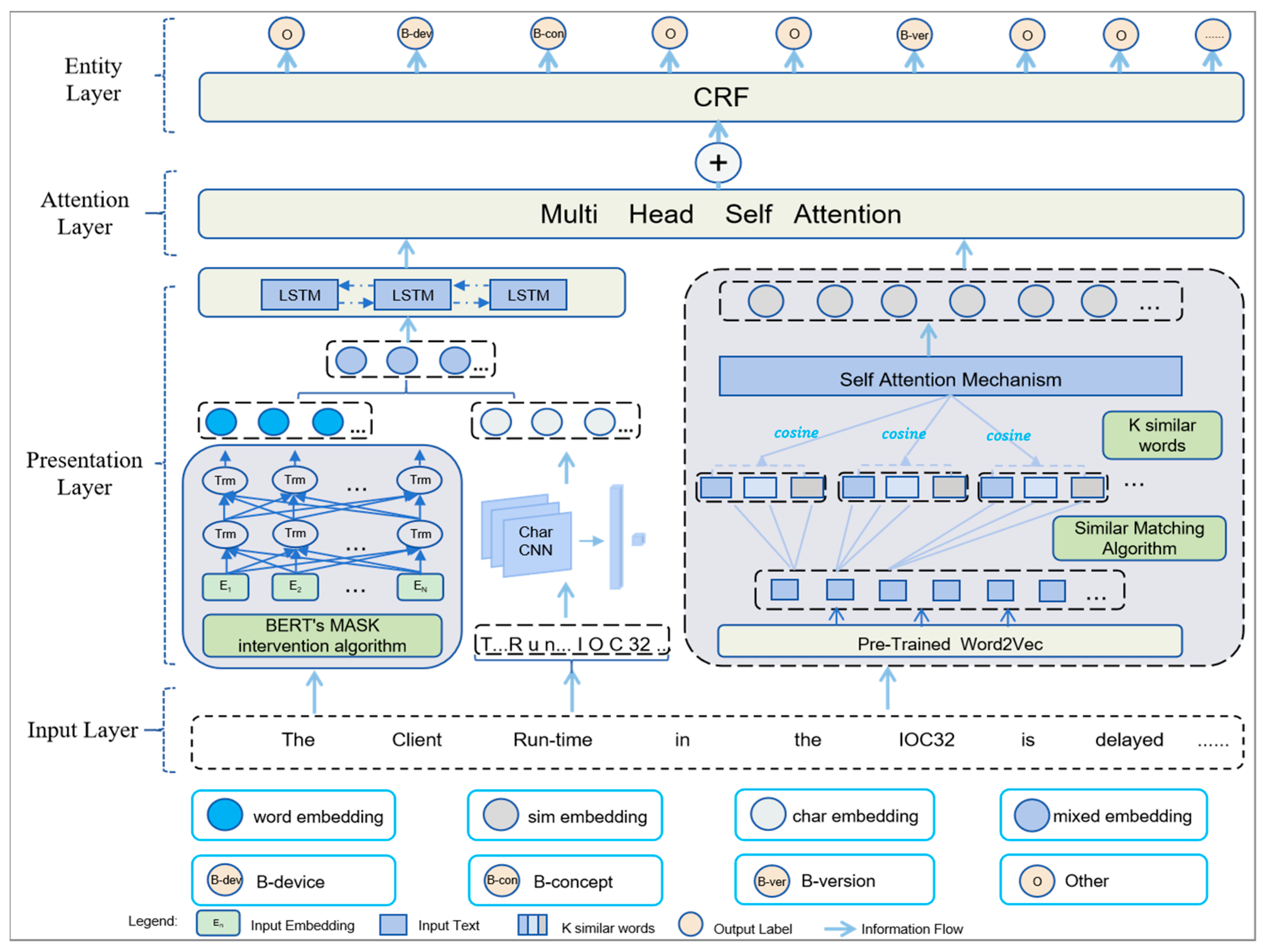
3.5. Integrated Semantic Construction
Based on the 3.3 SME mechanism and 3.4 SCE mechanism, this section will introduce how the SSNER combines segment-level embedding and similar semantic embedding to generate integrated semantics embedding. The specific details are as follows.
- (1)
Mixed feature embedding construction
Before integration, segment-level word embedding and character-level word embedding are combined to generate mixed feature embedding and obtain time sequence information through BiLSTM. The description is as follows.
Step 1: SSNER obtains segment-level word embedding by using Equation (18)
where
represents the operation of calculating the segment-level word embedding from the input,
, and
represents the dimension of the segment-level embedding vector.
Step 2: Due to the lack of index records for unknown words in the vocabulary of the BERT model, SSNER becomes challenging to generate relevant word vectors. Therefore, by using a Character-Based CNN (CharCNN) in Equation (19), SSNER obtains character-level word embedding.
where CharCNN(·) represents the operation of calculating the character-level word embedding for the input
.
Step 3: By using Equation (20), the word-level embedding
and the character-level embedding
are concatenated, resulting in the word embedding
. Then, by using Equation (21),
enters the BiLSTM to generate the mixed word embedding
with time sequence information.
where concat(∙) is the vector concatenation operation,
represents the state at the next moment, and
represents the state at the previous moment.
- (2)
Integrated semantic construction
After mixed feature embedding construction is achieved, the multi-head attention mechanism is used to construct the integrated semantic.
By using a multi-head attention mechanism, the similarity is computed between the mixed feature word embedding
and the similar semantic word embedding
. Then, the SSNER model learns multidimensional features from different representation subspaces and concatenates the results obtained from different attention heads to yield an integrated semantic representation
, as shown in Equation (23), finally entering the CRF layer to predict entity categories.
where
,
, and
are in vector form and
is the scaling factor for adjusting the inner product of
and
to prevent the inner product of
and
from becoming too large.
is defined by Equation (17).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}