Abstract
Detecting aluminum defects in industrial environments presents significant challenges related to low-resolution images, subtle damage features, and an imbalance between easy and difficult samples. The You Only Look Once–Aluminum (YOLO-AL) algorithm proposed in this paper addresses these challenges. Firstly, to enhance the model’s performance on low-resolution images and small object detection, as well as to improve its flexibility and adaptability, C2f-US replaces the first two CSP bottleneck with 2 Convolutions (C2f) layers in the original Backbone network. Secondly, to boost multi-scale context capture and strip defect detection, a CPMSCA mechanism with a class-symmetric structure is proposed and integrated at the end of the Backbone network. Thirdly, to efficiently capture both high-level semantics and low-level spatial details, and improve detection of complex aluminum surface defects, ODE-RepGFPN is introduced to replace the entire Neck network. Finally, to address the imbalance between hard and easy samples, Focaler-WIoU is proposed. Extensive experiments conducted on the publicly available AliCloud dataset (APDDD) demonstrate that YOLO-AL achieves 86.5%, 77.8%, and 81.5% for Precision, Recall, and mAP@0.5, respectively, surpassing both the baseline model and other state-of-the-art methods. The model can be integrated with an industrial camera system for the automated inspection of aluminum profiles in a production environment.
1. Introduction
Aluminum parts are extensively employed in industry because of their advantages of light weight, high strength and low cost [1], but they are prone to various defects during casting, machining and usage, which not only reduce the performance and lifespan of the parts, but can also lead to safety accidents [2]. Defect detection of aluminum parts refers to the detection of defects in the interior and surface of aluminum parts by technical means to eliminate inferior products. The surface of aluminum can show a variety of defects, mainly including rubbing, bottom leakage, pitting, surface discoloration, and dirty spots By detecting these surface defects, it is possible to prevent defective products from entering the market and ensure product quality [3].
Traditional surface detection of aluminum still relies on manual visual inspection, which has the disadvantages of high labor intensity and low efficiency [3]. In recent years, a plethora of additional methods have been developed for the detection of flaws in industrial production. For instance, in the field of aluminum manufacturing, factories frequently utilize magnetic particle, ultrasonic and radiographic flaw detection techniques [4,5,6]. Furthermore, hybrid optical sensors and high-resolution three-dimensional surface imaging microscopes are surface inspection methods that have emerged in recent years with the advancement of technology [7]. Although these methods can detect the presence of damage to some extent, they fall short in classifying the type of damage and remain prone to false negatives. To overcome these limitations, it is imperative to develop more advanced methods capable of accurately identifying materials or components with critical damage, rendering them unsuitable for use.
As deep learning technology continues to mature, its optimization algorithms for industrial defect detection are becoming more common. Defect detection methods are broadly categorized into two types: two-stage algorithms like R-CNN [8] and Faster R-CNN [9], and single-stage algorithms such as SSD [10] and YOLO [11]. Compared to two-stage methods, YOLO offers a superior trade-off between accuracy and speed, outperforming other real-time detection systems [12] in terms of speed. Additionally, damage to aluminum surfaces is often subtle, with the affected areas being relatively small [13]. Correspondingly, the YOLO algorithm has achieved notable success in object detection, particularly in accurately recognizing small targets [14]. Therefore, for the detection of surface defects on aluminum parts, the YOLO algorithm has advantages in terms of accuracy, speed and real-time performance, and it is also more suitable as a basis for improved algorithms. However, challenges such as variations in spatial orientation, scale, noise, complex backgrounds, and limited computational resources persist in real-world industrial applications. Consequently, the YOLO algorithm requires further enhancement to address these issues and satisfy the real-time processing demands of industrial environments [15].
Although several YOLO iterations have been developed using the COCO dataset, significant performance discrepancies emerge when these models are applied to cross-domain datasets. YOLOv5, along with versions v8 to v12, each exhibit distinct advantages and limitations. A detailed comparison of these versions is provided in Table 1. Given YOLOv8’s more mature ecosystem for edge AI applications, it has been selected as the foundation for our improvements.

Table 1.
Comparison of key parameters, advantages, and limitations of mainstream YOLO architectures.
In order to address the challenges in industrial settings, we propose an enhanced YOLOv8n-based algorithm, termed YOLO-AL, which incorporates advancements such as re-parameterized Feature Pyramid Network (FPN), hybrid multidimensional attention mechanisms, and improved loss function. The key contributions of this study are summarized as follows:
- We design a C2f module incorporating Universal Inverted Bottleneck and Space-to-depth Conv (C2f-US) effectively, which enhances the model’s capability to extract features from low-resolution images and small objects, while simplifying its architecture and reducing computational overhead in terms of floating-point operations.
- We introduce the Channel Prior and Multi-scale Convolutional Attention (CPMSCA) mechanism, which improves the module’s ability to capture contextual information through a symmetry-like strip convolutional structure, enabling more efficient extraction of complex defective features.
- We propose an Omni-Dimensional Efficient-reparameterized Generalized Feature Pyramid Network (ODE-RepGFPN) to more effectively capture both high-level semantics and low-level spatial information. We also refactor the Rep module to make it more efficient when training.
- Integrating Wise-IoU (WIoU) and Focaler-IoU and Focaler-WIoU (FW-IoU) is proposed to make the model focus more on hard-to-classify samples that are on the edge of positive and negative samples and to solve the problem of data imbalance.
2. Related Works
Recent years have witnessed an increasing body of research focused on the deployment of deep learning algorithms in real-world engineering applications. To improve the performance of conventional models and address industrial demands, research focused on optimizing current object detection models has become increasingly prominent [16]. Researchers commonly enhance algorithm performance by refining model architectures, integrating attention mechanisms, selecting suitable loss functions, or modifying specific components.
Specifically, the enhanced YOLO algorithm has found widespread application in various engineering domains. Roy et al. [17] introduced DenseSPH-YOLOv5, a high-performance damage detection model leveraging real-time DL, where DenseNet blocks are integrated into the backbone to enhance the retention and reuse of critical feature information. Gao et al. [18] proposed the CFE-YOLO network model, enhancing its performance with the FReLU activation function, while incorporating the CBAM convolutional attention module and the RFB module in the head layer and backbone, respectively, thereby improving both the speed and accuracy of cattle face detection. Xu et al. [19] introduced a rebar junction location method based on the YOLOv5 model, incorporating object depth classification and a thinning algorithm to address the instability and susceptibility to environmental noise in rebar junction detection. Furthermore, Zhang et al. [20] introduced the YOLO11 Pear, an enhanced pear detection model based on YOLO 11, which improves the detection speed and accuracy of pears in complex orchard settings by integrating a small-object detection layer. Li et al. [21] proposed the YOLOv5-SFE model, which employs a convolution-based spatio-temporal feature fusion module and integrates spatial features post-extraction to capture temporal information across multiple frames, thereby enhancing the accuracy of real-time worker behavior detection. These enhancements to the YOLO algorithm have shown substantial promise and benefits in tackling real-world engineering problems.
The YOLO algorithm family also finds extensive use in the domain of surface defect detection. Wang et al. [22] proposed the BL-YOLOv8 model, which reconstructs the neck structure by incorporating the BiFPN concept and integrates the SimSPPF module to optimize the original YOLOv8s model and its feature pyramid layer, thereby enhancing the model’s operational capacity and improving road defect detection accuracy. Zhao et al. [23] introduced the lightweight LSD-YOLOv5 model for steel strip surface damage detection, incorporating the Coordinate Attention mechanism within MobileNetV2’s bottleneck structure and designing a smaller bi-directional feature pyramid network integrated with Concat, thereby enhancing the model’s efficiency and addressing the issues of large model parameters and low detection rates in metal material defect detection. Wu et al. [24] proposed an enhanced NBD-YOLOv5 algorithm by substituting the feature extraction network and refining the loss function, thereby achieving improved accuracy in industrial defect detection. Several researchers also refine the existing modules within the network architecture. Wang et al. [25] incorporated the C2f-DSConv convolutional module into the YOLOv8 network, enhancing both feature extraction accuracy and small target detection performance. These examples effectively demonstrate the broad applicability of the YOLO algorithm family in surface defect detection. These improved YOLO algorithms in surface flaw detection, while enhancing detection accuracy to some extent, typically face limitations such as a restricted defect variety, high memory and computational costs, and suboptimal detection efficiency. These challenges offer valuable insights for advancing surface flaw detection algorithms tailored to aluminum.
Although these approaches have advanced the use of deep learning-based visual models in engineering and surface defect detection, no high-performance, specialized method for aluminum surface inspection has been introduced. Aluminum surfaces exhibit a diverse range of defects and are affected by minute damage, as well as low-resolution images caused by vibration and noise in industrial environments. Current algorithms are insufficient for effectively detecting aluminum damage, particularly under challenging industrial conditions. In this paper, we propose YOLO-AL, a novel model specifically designed for aluminum surface flaw detection. The model seeks to enhance both the accuracy and efficiency of aluminum damage detection while ensuring that computational costs remain within feasible limits.
3. Methods
3.1. YOLOv8n Model Architecture
YOLOv8 is a high-performing model in the YOLO series, offering high performance in target detection tasks and demonstrating versatility across a broad range of applications [26]. The network architecture is composed of four primary modules: Input, Backbone, Neck, and Head, which collaboratively establish an efficient and robust detection system. This architecture is particularly optimized for industrial aluminum material inspection, owing to its enhanced detection accuracy and real-time processing capabilities, making it well suited to meet the demands of such specialized applications.
On the input side, YOLOv8n preprocesses input images with adaptive image scaling and diverse data enhancements (e.g., MixUp, CutMix). The Backbone component consists of a Convolution layer, a CSP bottleneck with 2 Convolutions (C2f) structure, and a Spatial Pyramid Pooling Fusion (SPPF). The Neck integrates a refined architecture that merges the Feature Pyramid Network (FPN) with the Path Aggregation Network (PAN). The detection head employs a decoupled head structure coupled with dynamic label assignment via the Task-Aligned Assigner, directly regressing the target center point and bounding box using an Anchor-Free approach. This design substantially enhances both detection accuracy and inference speed. These designs significantly improve the detection efficiency and accuracy of YOLOv8, solidifying its status as a leading target detection model that is widely employed in contemporary applications.
3.2. YOLO-AL Model Architecture
YOLOv8 is renowned for its outstanding performance in target detection, representing a significant improvement over YOLOv5. However, its relatively simplistic architecture reveals limitations in feature extraction, distribution, and fusion when applied to complex assembly line environments and the detection of hard-to-identify samples. These challenges arise primarily as a result of the difficulties in detecting aluminum defects under industrial imaging conditions, including polymorphic defect patterns, ambiguous data distributions in low-resolution datasets, and the presence of difficult samples. To address these issues, we present YOLO-AL, an improved version of YOLOv8 that is designed to optimize the extraction of diverse aluminum damage features, improve detection accuracy, and boost generalization capabilities.
As shown in Figure 1, in the backbone network, YOLO-AL integrates two new and improved modules, C2f-US and CPMSCA. C2f-US is employed to replace the initial two C2f layers of the backbone network, with the objective of optimizing feature extraction while ensuring model lightweighting. CPMSCA is incorporated at the end of the backbone network as an attention mechanism to enhance the model’s capacity for capturing complex and strip-like features. In the neck network, ODE-RepGFPN is introduced to replace the entire original neck network, optimizing the model’s ability to capture high-level semantic and low-level spatial information. Finally, FW-IoU is introduced to replace the original loss function, addressing the challenges of dataset imbalance and hard sample mining. Table 2 provides a clearer visualization of the modular and architectural enhancements implemented in this study.
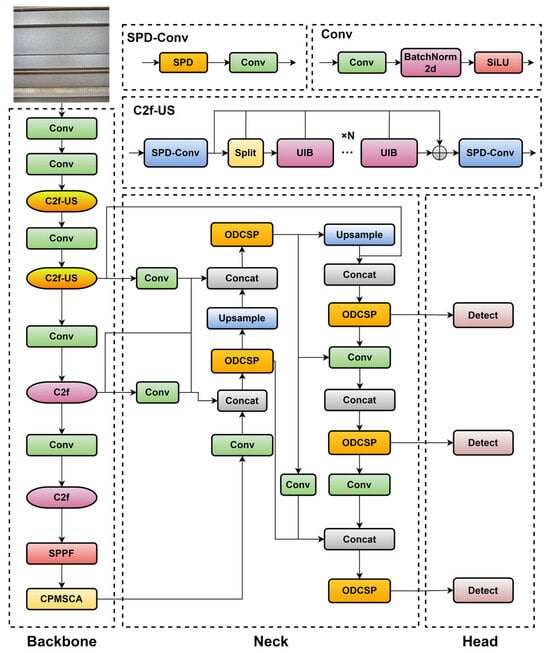
Figure 1.
YOLO-AL overall network architecture.
Table 2.
Module and structure comparison between YOLOv8n and YOLO-AL.
3.3. C2f-UIB with SPD-Conv
The C2f module employs a cascaded bottleneck architecture containing ordinary 3 × 3 convolution for multi-scale feature extraction. However, the inherent limitation of the convolution’s fixed receptive field restricts its capacity to effectively capture fine-grained details, hindering detailed feature representation at smaller scales. As a result, the performance of the model in detecting subtle defects on aluminum surfaces in complex industrial settings is hindered, reducing its accuracy in distinguishing between intricate textures and minute defects. In order to address this limitation, a new and improved C2f module, C2f module incorporating Universal Inverted bottleneck and Space-to-depth Conv (C2f-US), is proposed, which greatly improves the feature extraction capability of the model. The C2f-US improvement module comprises two distinct improvements. Firstly, the original bottleneck module in C2f is substituted with a more flexible Universal Inverted bottleneck (UIB) [27], thereby augmenting the model’s feature sensitivity. The UIB has a degree of sensitivity and lightness that exceeds that of other similar modules. Secondly, the Conv layer in C2f is replaced with SPD-Conv, a modification that enhances the robustness of the model when confronted with diverse features by incorporating SPD-Conv layers before and after the UIB module. The feature processing method of SPD is simpler and more effective than that of other modules. Figure 2 shows the internal structure of C2f-US, where a lighter and more efficient UIB module replaces the original bottleneck module.
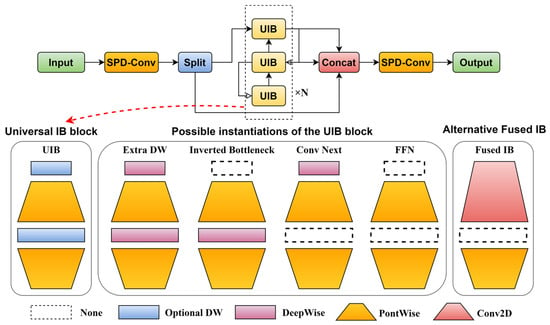
Figure 2.
Schematic representation of the C2f-US and UIB structures. The upper portion illustrates the C2f-US architecture, while the lower portion depicts potential instantiations of the UIB block.
UIB retains a relatively simple structure, incorporating two optional deep convolutional layers: one before the extension layer and another between the extension and projection layers. This seemingly minor modification unifies key elements such as Extra DW, Inverted bottleneck, Conv Next, FFN and Fused IB, enabling the model to flexibly adapt to various optimization objectives without adding significant complexity to the search process. During operation, the UIB adopts a reverse bottleneck structure, expanding channels prior to compression, which alleviates the computational burden of the intermediate layer and enhances feature extraction. By leveraging depth-separable convolution (DSConv) [28] and strategically matching its internal components, namely DeepWise Conv (DWConv) and PointWise Conv (PWConv), the UIB achieves significant reductions in both computational overhead and parameter count.
SPD-Conv is suitable for low-resolution image scenarios [29]. In this paper, it is applied at both ends of the C2f module, incorporating a Universal Inverted bottleneck (C2f-UIB) structure to enhance feature representation and extraction. SPD-Conv generates a refined feature representation by spatially partitioning the input image into multiple sub-maps, which are subsequently fused through feature aggregation and processed by a convolutional layer with a stride of one. As a result, SPD-Conv surpasses traditional methods in handling low-resolution images and small objects. The mathematical procedure is specified as Equation (1).
where f denotes the feature designator, X represents the subfeature map, and the expression within the following brackets describes the method by which the subfeature map is obtained. Specifically, the contents within the brackets are separated by commas, indicating the feature extraction methods along the x- and y-axes, respectively. Each part consists of three parameters: the starting point, the ending point S, and a step size of scale for the intercept. In this study, scale = 2 is selected to prevent overfitting of the features. The SPD-Conv principle is shown in Figure 3.
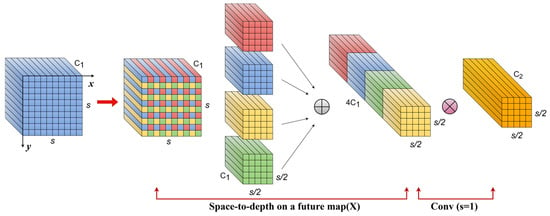
Figure 3.
SPD-Conv operation principle diagram.
As illustrated in Figure 3, for any given input feature map X, the SPDConv first passes through the SPD feature extraction and fusion module to generate a new feature map X′. Subsequently, a non-strided convolution layer is applied to reduce the channel dimensions, yielding the new feature map X″. This process is like the one described in Equation (2).
The integration of the UIB module improves the efficiency and adaptability of C2f-UIB in selecting feature extraction strategies, concurrently reducing the model’s computational complexity. By incorporating the SPD-Conv structure, feature extraction at the front end for the central UIB module is enhanced, while feature integration at the back end is optimized. These enhancements effectively mitigate the loss of fine-grained information, significantly increasing the accuracy of aluminum defect detection while maintaining an optimal balance between efficiency and model complexity.
3.4. Channel Prior and Multi-Scale Convolutional Attention
Obtaining high-resolution images of aluminum in typical industrial environments is considered difficult, which results in the features of aluminum damage not being evident in the photographs. This necessitates advanced feature extraction capabilities and effective information aggregation within the model to accurately detect and classify defects. Traditional channel and spatial attention mechanisms have been proven effective in enhancing the discriminative capacity of feature representations. However, when modeling cross-channel dependencies, dimensionality reduction often hampers deep visual representation learning, leading to a failure to detect certain features or defects. To address these issues, Channel Prior and Multi-Scale Convolutional Attention (CPMSCA) was proposed, which was inspired by Channel Prior Convolutional Attention (CPCA) [30] and Multi-Scale Convolutional Attention (MSCA) [31].
As depicted in Figure 4, the CPCA module combines both channel and spatial attention mechanisms. The channel attention module first aggregates spatial information via average and max pooling, which is then processed by a shared Multi-Layer Perceptron (MLP) and combined with channel data to generate the attention map. The input features are subsequently scaled by this map to obtain the channel prior. In the subsequent step, the deep convolution module generates the spatial attention map, followed by channel mixing. Finally, the element-wise multiplication of the channel mixing result with the channel prior significantly refines the feature representation. The structure of two attention mechanisms in tandem like this provides good modifiability.
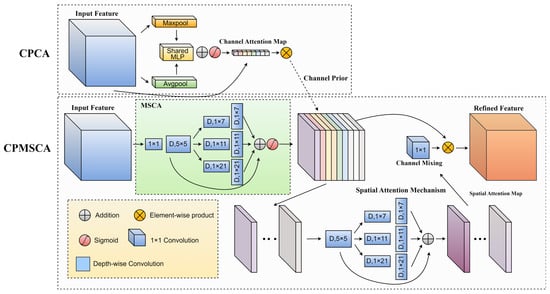
Figure 4.
Schematic of the Channel Prior and Multi-Scale Convolutional Attention (CPMSCA) structure, along with a comparative diagram of the Channel Prior Convolutional Attention (CPCA) structure.
Although CPCA integrates channel and spatial attention, its asymmetric attention structure and the channel attention module’s compression ratio often cause the loss of high-frequency information, leading to insufficient extraction of critical features, particularly strip-like features [31]. To address this issue, this paper replaces the channel attention in CPCA with MSCA, an attention mechanism that combines the lower-level convolution with the convolutional branches of each asymmetric strip. Consequently, the operation of the CPMSCA mechanism is formally described by the following equations.
Here, X denotes the input feature, and σ represents the Sigmoid activation. Att, Mid, and Out correspond to the attention map, intermediate feature map, and output feature map, respectively. ⊗ indicates element-wise matrix multiplication. DWConv refers to depth-wise convolution, and Scalei represents the ith branch, with Scale0 as the identity connection. The kernel sizes for each branch are 7, 11, and 21, respectively. N is the number of channels, and Fj refers to the feature map of each channel. CPCA was designed with MSCA as a reference, making the two components of CPMSCA appear similar. However, as shown in Figure 4 and Equations (3) and (5), their feature assignment strategies and computational methods differ. CPCA employs a channel-wise processing strategy for spatial attention, which is distinct from the MSCA approach, effectively preserving and extracting both channel and spatial features simultaneously. Therefore, CPMSCA can be regarded as a class-symmetric structure constrained by an intermediate feature map, optimizing feature extraction for strip-like convolution.
The input feature map passes through MSCA to produce the intermediate feature map. Unlike Channel Prior, this intermediate feature map does not undergo channel attention, allowing it to retain more spatial features. Consequently, CPMSCA functions as an attention mechanism employing two layers of spatial attention, forming a class-symmetric structure. This class-symmetric architecture facilitates more comprehensive spatial feature extraction and enhances the coherence of feature propagation. While this slightly increases computational complexity, it significantly enhances the model’s capability to handle low-resolution images and strip-like, hard-to-classify defects.
3.5. ODE-RepGFPN
In order to enhance the detection of challenging samples in the aluminum defect dataset and overcome the limited feature extraction and representation capabilities of existing neck networks, Omni-Dimensional Efficient-RepGFPN (ODE-RepGFPN) was proposed. By integrating Omni-Dimensional Dynamic Convolution (ODConv) [32] into both the Channel Spatial Pyramid Stage (CSPStage), a component of the Efficient-RepGFPN [33], and the Rep module within the CSPStage, multidimensional attention is effectively introduced, thereby improving the feature extraction capability of the neck network. Efficient-RepGFPN extends the FPN to enable more efficient multi-scale feature fusion through a novel Fusion Module (CSPStage) and ELAN, effectively capturing both high-level semantic and low-level spatial details. However, due to the complexity and interdependencies of the network, further optimization is needed to address training stability, challenging target detection, and computational efficiency in real-world applications.
ODConv is a four-dimensional convolution that dynamically tunes the convolution kernel parameters in four orthogonal dimensions through a multidimensional dynamic attention mechanism. The four dimensions are the spatial dimension, input channel dimension, output channel dimension, and kernel dimension. The enforcement principle of the ODConv module is illustrated in Figure 5.
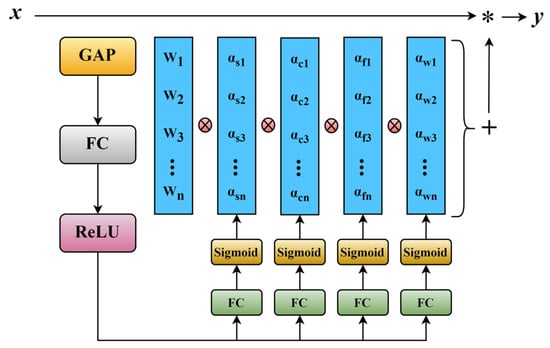
Figure 5.
The Structure of the OD-Conv Module.
Following the notations in Figure 5, ODConv can be defined as follows:
where x ∈ RH×W×Cin and y ∈ RH×W×Cout represent the input and output features, respectively. αwi ∈ R denotes the attention scalar for the convolutional kernel Wi. αsi ∈ Rk×k, αci ∈ RCin and αfi ∈ RCout denote three newly introduced attentions, which are computed along the spatial dimension, the input channel dimension and the output channel dimension of the kernel space for the convolutional kernel Wi, respectively.
CSPStage serves as the fusion block central to the Efficient-RepGFPN, yet its feature extraction and fusion capabilities prove inadequate for complex aluminum damage datasets. To address this, we propose ODCSP, a novel CSP-based architecture. Omni-Dimensional CSP (ODCSP) introduces two key improvements over the original design. First, in the Rep module, we replace the internal branching convolutional structure with ODConv to ensure more efficient model training. Second, ODConv is utilized to replace the Conv layers in both the Rep and Conv loops within the CSPStage, leading to the introduction of the ODRep (Omni-Dimensional Rep) module. This modification enhances the model’s ability to focus on critical features and improves its processing efficiency. Figure 6 is used to illustrate the improvement process mentioned above.
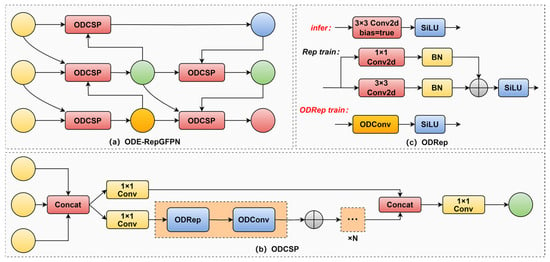
Figure 6.
ODE-RepGFPN structure schematic: (a) ODE-RepGFPN network structure; (b) ODCSP structure; (c) ODRep structure.
ODE-RepGFPN effectively facilitates multi-scale spatial information fusion while maintaining computational efficiency. It strikes an optimal balance between high-level semantic extraction and low-level spatial detail preservation, enhancing the processing of rich contextual cues. This architecture improves the model’s ability to interpret complex scenes and detect subtle features, enabling more accurate capture of intricate object details. Consequently, it enhances the defects identification capability of the model, particularly in challenging applications like aluminum defect detection.
3.6. Focaler-WIoU
In metal damage detection algorithms, selecting an appropriate loss function is critical for optimizing model performance. The damage characteristics of certain aluminum materials are subtle, limiting the effectiveness of conventional models. Enhancing the loss function is a promising solution to this issue. However, certain loss functions employed in the YOLO series exhibit notable limitations. To address this, a novel loss function, FW-IoU (Focaler-WIoU), is proposed, which integrates Focaler-IoU [34] with Wise IoU (WIoU) [35], leveraging the strengths of both components.
YOLOv8 employs an IoU-based loss function, where Intersection over Union (IoU) is a fundamental metric in object detection, quantifying the overlap between two bounding boxes. This metric is also known as the intersection-to-union ratio. The mathematical formulation is presented in Equation (7).
where Apred is the area of the prediction frame, Agt is the area of the real frame, and AInter is the area where the prediction frame and the real frame overlap.
In the absence of overlap between the predicted and ground truth bounding boxes, no gradient backpropagation occurs, preventing effective training in deep learning. The schematic diagram of the IoU is illustrated in Figure 7.
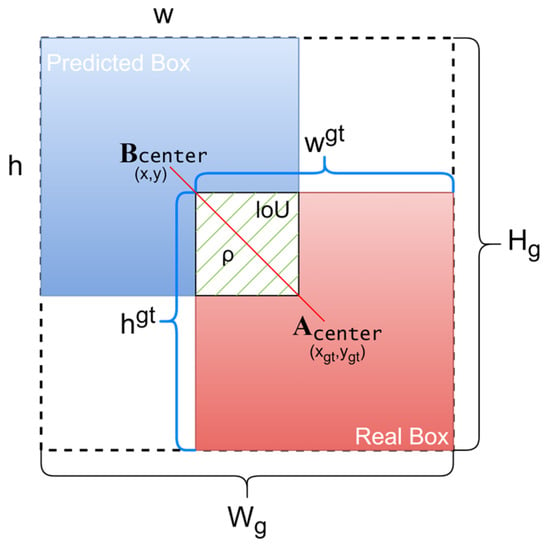
Figure 7.
IoU Schematic, where A denotes the ground truth bounding box and B represents the predicted bounding box.
To mitigate the inherent limitations of IoU metrics and overcome the dataset-specific challenges in aluminum defect detection, this work implements WIoU v3 with a dynamic monotonic aggregation mechanism integrated into the loss function formulation. Distinctively, WIoU v3 enhances the performance of WIoU v1 through parameterized adaptation, constructing non-monotonic focusing coefficients via a learnable parameter β that dynamically modulates gradient allocation. The fundamental formulation of WIoU v3 can be expressed as follows:
where x and y represent the coordinates of the prediction frame, whilst xgt and ygt represent the coordinates of the real frame and Wg and Hg represent the smallest enclosing frame. represents the gradient gain, with the parameter inside it. The dynamic normalization factor LIoU ensures the gradient gain k remains high, facilitating the model’s rapid convergence during training on challenging aluminum defect datasets.
To address the issue of an imbalanced aluminum defect dataset, this paper proposes the Focaler-IoU, which is applied subsequent to the WIoU. The Focaler-IoU processes the calculated cross-merge ratio loss, and the underlying mathematical principle is outlined in Equation (10).
Equation (4) defines u and d as preset parameters that influence the frequency of IoU values being judged as 0 or 1. Specifically, increasing d and decreasing u leads to a greater distortion effect rather than a balancing effect. Consequently, we selected parameter values of d = 0 and u = 0.95 to mitigate this distortion. This configuration enables FW-IoU to prioritize hard samples characterized by elevated loss values during backpropagation, effectively mitigating the class imbalance challenge that is particularly prevalent in aluminum defect detection scenarios where limited training samples exist for certain target categories.
4. Experiments and Results
4.1. Experiment Introduction
4.1.1. Experimental Settings
The training setup for YOLO-AL is meticulously configured. All experiments are conducted on a platform featuring an NVIDIA RTX 4090 GPU with 80 GB of RAM, running Ubuntu OS and CUDA 11.2. The deep learning framework utilized is PyTorch 2.0.0, within a Python 3.8.10 environment. The input image resolution is 640 × 640. Hyperparameter tuning significantly influences the model’s performance. In this study, the initial learning rate is set to 0.01 with a momentum of 0.937. The batch size is 16, utilizing 8 threads for parallel processing. The weight decay is set to 0.0005, and the model undergoes training for 200 epochs. The Mosaic data augmentation technique is employed to diversify the training dataset, improving the model’s robustness to variations in object scale and orientation, which is particularly advantageous for addressing the diverse and irregular shapes of aluminum defects.
4.1.2. Dataset
This paper utilizes the aluminum defect dataset from the Aliyun Tianchi competition, known as APDDD (Aluminum Profile Surface Detection Database), which encompasses a diverse set of aluminum damage types collected during manual defect inspection procedures. APDDD contains 10 aluminum damage types: non-conductive, scratch, corner-leaky-bottom, orange-peel, leaky-bottom, jet-stream, paint-bubble, pitting, variegated-color, and dirty-spots. Each defect type is represented by images with a resolution of 640 × 640, as illustrated in Figure 8A–J. In the assessment of aluminum surface damage, the most significant types of damage are loss of electrical conductivity, abrasion, scuffing, surface bottom leakage, paint blistering and pitting. These issues directly affect the performance, safety and service life of the material, and therefore warrant particular attention. As demonstrated in Figure 9, the visualization image shows the distribution of the dataset.

Figure 8.
Schematic diagram of aluminum defects.
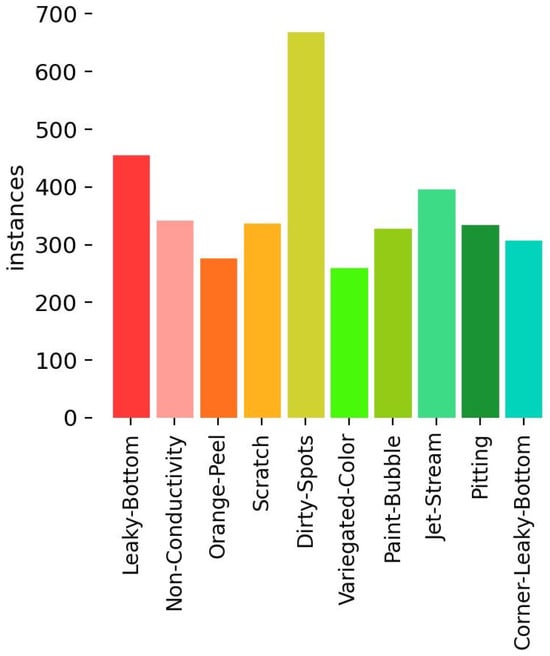
Figure 9.
Distribution of datasets.
The dataset employed in this study comprises 3719 images and 5279 labeled frames. To ensure optimal model training, the dataset is partitioned into training, validation, and testing sets in a 7:1.5:1.5 ratio.
4.1.3. Evaluation Indicators
This study uses precision, mean average precision (mAP), recall, giga floating-point operations per second (GFLOPs), parameters, and frames per second (FPSs) to evaluate performance. Precision measures the ratio of true positives to predicted positives, while recall assesses the proportion of correctly identified positives to actual positives. The formulas for precision and recall are given in Equations (11) and (12), respectively.
True positives (TPs) represent ground-truth positives correctly identified by the model, while false positives (FPs) are ground-truth negatives misclassified as positive. False negatives (FNs) are positive samples incorrectly classified as negative. The mean average precision (mAP) offers an aggregate evaluation of the model’s performance across various target classes, as defined in Equations (13) and (14).
This paper adopts mAP@0.5 and mAP@0.5:0.95 as key evaluation metrics. mAP@0.5 computes mean average precision at an IoU threshold of 0.5, while mAP@0.5:0.95 averages precision across IoU thresholds from 0.5 to 0.95.
Finally, FPSs represents the number of frames the model processes per second. In this paper, we calculate the FPSs by testing the average time taken by the model to process 200 images. The principle is demonstrated in Equation (15).
where ti denotes the time taken by the model to process the ith image.
The measurement of these metrics facilitates a more comprehensive evaluation of the performance of underwater target detection models.
4.2. Visualization of the Results
As depicted in Figure 10, the loss metrics of the YOLO-AL model show a continuous decline with increasing iterations, stabilizing before 200 epochs. This indicates ongoing optimization throughout training, leading to improved model fitting capabilities. Train Box Loss denotes the bounding box loss curve for the training set, Train Class Loss represents the target loss curve, and Train DFL (Distribution Focal Loss) indicates the classification loss curve. Similarly, Val Box Loss, Val Class Loss, and Val DFL Loss represent the corresponding loss curves for the validation set. The x-axis represents the number of iterations, and the y-axis corresponds to the loss values.
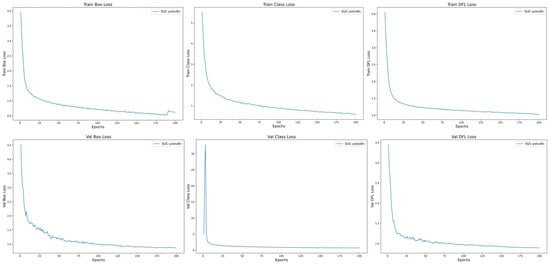
Figure 10.
Training loss results.
Figure 11 illustrates the variation curves of the YOLO-AL model for precision and recall and mAP over 200 training cycles. Specifically, the precision curve, the recall curve, and the mAP@0.5 curve and the mAP@0.5:0.95 curve, whose horizontal coordinates are the number of iterations and whose vertical coordinates are the values of precision, recall, mAP@0.5, and mAP@0.5:0.95, respectively. As is evident from Figure 11, the evaluation indexes of the model tend to increase and have stabilized by cycle 200 without overfitting. In summary, the convergence of the model in this paper is satisfactory, and the selection of 200 training cycles is appropriate.
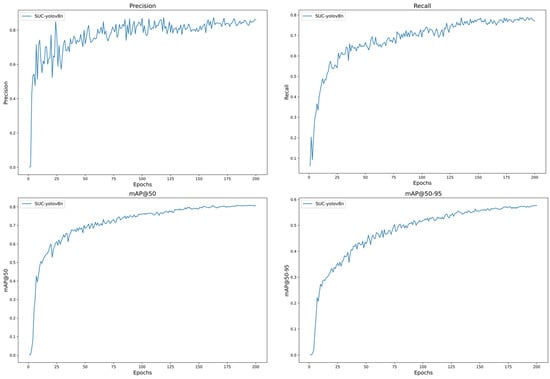
Figure 11.
Training results.
The confusion matrix serves as a graphical representation of the misclassification distribution across different categories. The intensity of the diagonal color gradation corresponds to the prediction accuracy, with darker hues indicating higher accuracy in classification. Figure 12 presents the confusion matrix of YOLO-AL, demonstrating that the optimized model achieves detection accuracy exceeding 85% for most aluminum damage and defects. Notably, for two distinct categories of damage, namely variegated-color and pitting, the model demonstrates an exceptional capacity, attaining an accuracy of 100%. However, the detection accuracy for damage types such as paint-bubble is comparatively lower, at approximately 40%.
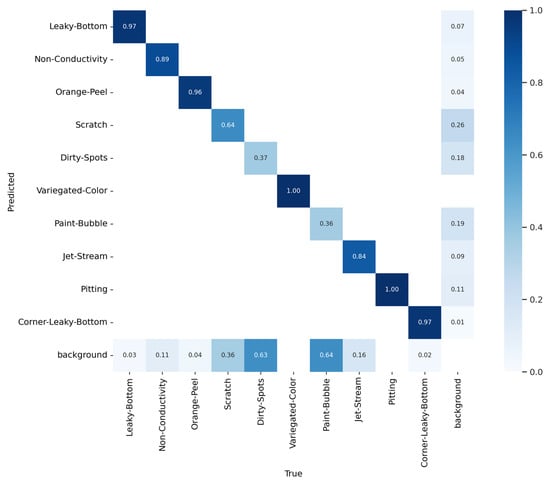
Figure 12.
Confusion matrix.
In this paper, Gradient-weighted Class Activation Mapping (Grad-CAM) [36] is utilized to visually compare the heatmaps generated by the model prior to and following the enhancement. As demonstrated in Figure 13, the red region in each plot indicates the region to which the model directs greater attention when performing the classification task. YOLO-AL focuses more attention on the detection box, as evidenced by the concentrated red regions, compared to the YOLOv8 model. In contrast, the heatmap of YOLOv8 exhibits more scattered red regions, failing to adequately highlight the critical features associated with aluminum damage. This suggests that the improvements made by YOLO-AL help to focus the model’s attention on the damage, which helps to improve model accuracy and the ability to detect the location of defects. Consequently, this suggests that YOLO-AL may possess a greater capability to surpass YOLOv8 in more challenging damage classification scenarios.

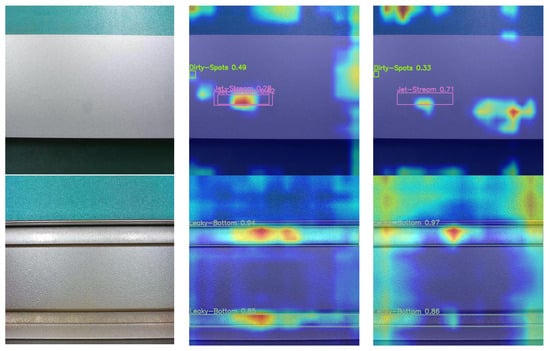
Figure 13.
Heatmaps of different models.
4.3. Ablation Experiment
A series of ablation tests were performed to assess the proposed algorithm’s effectiveness for aluminum defect detection. Using YOLOv8n as the baseline, experiments were conducted on the APDDD with a 640 × 640 input image size. The module replacements in the experiments align with the improvements in the YOLO-AL model. The results are presented in Table 3.
Table 3.
Ablation experiment.
The experimental results indicate that each module proposed in this study enhances the effectiveness of aluminum damage detection. Notably, the model utilizes the YOLOv8 default loss function, Complete-IoU (CIoU), in the absence of FW-IoU. Comparing the results across the first five experimental sets, it is observed that adding C2f-US improves the model’s mAP@0.5 by 1.6%, while reducing floating-point operations by 0.5 GFLOP. This suggests that the integration of C2f-US enables the model to achieve finer-grained feature representation, enhancing its flexibility and adaptability. Replacing the neck network with the ODE-RepGFPN results in a 3.2% increase in precision, suggesting that ODE-RepGFPN effectively captures both high-level semantics and low-level spatial features, improving precision. Substituting FW-IoU for the loss function enhances recall by 2.4%, demonstrating that FW-IoU improves boundary sample learning for both positive and negative instances. Incorporating the CPMSCA mechanism raises precision by 4.2%, with a marginal increase in computational cost, which does not affect the real-time performance, showcasing the enhanced feature extraction and fusion capabilities of the model.
Subsequent experiments demonstrate that the model’s overall performance is optimized through the combination of enhanced modules. Incorporating both C2f-US and ODE-RepGFPN into the network yields precision and recall values of 86.4% and 78%, respectively, while reducing GFLOPs by 4.9%. Seamless integration of all four improvement modules with the baseline model maximizes overall performance, resulting in a 4.1% increase in precision and a 2.2% improvement in mAP@0.5, accompanied by a slight 0.2 reduction in GFLOPs.
These experimental results clearly highlight the efficacy of the improvements introduced in this study, maintaining stable computational cost and model complexity while significantly enhancing the model’s precision in defect detection.
4.4. Comparative Experiment
4.4.1. Comparison with Other Models
To validate the effectiveness of YOLO-AL, a comparison was made with existing target detection networks, including the YOLO series of models of YOLOv3-tiny, YOLOv5n, YOLOv6n, YOLOv8n, YOLO10n, YOLOv11n, and the latest YOLOv12s. In addition, we have included other target detection algorithm models of Faster R-CNN, SSD, CenterNet and RetainNet. The performance evaluation metrics of the detection network models comprise P, R, mAP@0.5, GFlops, parameters, and FPSs. The aluminum defect dataset, referred to as APDDD, is employed for training without the use of pre-trained weights, and the results are provided in Table 4.
Table 4.
Comparative experiments on evaluation indicators of different models.
The experimental results demonstrate that the YOLOv8n algorithm delivers outstanding overall performance, effectively balancing accuracy and model complexity. The positive correlation between the baseline model’s performance and the observed improvements further justifies the selection of YOLOv8 as the baseline. Additionally, the experimental results indicate that the proposed YOLO-AL achieves the highest precision, recall, and mAP@0.5. In comparison, the performance of YOLOv3-tiny and YOLOv5n is suboptimal relative to YOLOv8n, which can be attributed to the architectural limitations of these models. YOLOv11 refines the network structure by replacing C2f with C3K2 and adding a C2PSA layer, akin to an attention mechanism, behind the SPPF. YOLOv12s, the latest official model in the YOLO series, integrates attention optimization techniques. None of these algorithms outperform YOLO-AL, which achieves 2.0% higher precision and 2.9% higher mAP@0.5 compared to YOLOv12s. Moreover, the computational cost and parameter count are significantly lower compared to some other models, demonstrating that the YOLO-AL proposed in this study excels in both model efficiency and high precision.
The non-YOLO models exhibit poor performance across precision, recall, and mAP@0.5 metrics. Specifically, Faster R-CNN, SSD, and CenterNet show suboptimal precision. While both RetainNet and FCOS demonstrate high precision, they suffer from low recall, with RetainNet also exhibiting a notably low mAP@0.5 of 36.1%. This suggests significant leakage and inherent model deficiencies. In contrast, the YOLO-AL proposed in this paper outperforms these models across most evaluation metrics.
According to the detection results in Table 5, the optimized YOLO-AL model in this paper shows a significant improvement in the detection of leaky-bottom (LB), non-conductivity (NC), dirty-spots (DS), paint-bubble (PB) and jet-stream (JS), while for defects leaky-bottom, orange-peel (OP), variegated-color (VC), pitting (PI) and corner-leaky-bottom (CL) all have over 95% mAP values. This result fully demonstrates that the YOLO-AL model optimized in this paper is well adapted to most of the defects and shows the highest accuracy in the detection of leaky-bottom, non-conductivity, dirty-spots, paint-bubble and jet-stream. However, YOLO-AL, like all other models, exhibits limited detection accuracy for paint-bubble (PB) defects. Analysis reveals that PB defects are extremely small on the aluminum surface, covering only a few tens of pixels. This presents a significant challenge for the model’s small-object detection capability and highlights a key area for further enhancement.
Table 5.
Detection results for each defect on the dataset.
To further illustrate the effect of the YOLO-AL detection categories, the precision–recall (PR) curve is plotted in this paper. Figure 14 presents the PR curve for YOLO-AL. A larger area enclosed by the PR curve and the axes indicates superior model performance, reflecting an optimal balance between precision and recall. The observed results are consistent with the previous analysis.
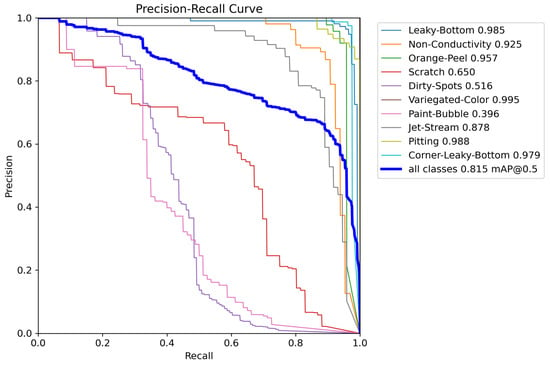
Figure 14.
Precision–recall curve of YOLO-AL.
In the following study, we undertake a visual comparison and analysis of the effectiveness of five YOLO series algorithms and the enhanced algorithm of this paper (YOLO-AL (f)). This enhanced algorithm is employed for the detection of six defect types through visual methods (see Figure 15). The location and extent of the actual damage are indicated by (g). The investigation revealed that the YOLOv3-tiny (a), YOLOv5n (b), YOLOv8n (c), YOLOv10n (d), and YOLOv11n (e) algorithms were not effective in detecting aluminum damage. The experimental results demonstrate that the enhanced YOLO-AL model presented in this paper exhibits the optimal detection efficacy. Notably, in scenarios involving defects such as leaky-bottom and variegated-color, the detection confidence attained a maximum of 100%. In summary, the newly developed algorithm YOLO-AL demonstrates remarkable performance.

Figure 15.
Detection effects of different methods: (a) YOLOv3-tiny; (b) YOLOv5n; (c) YOLOv8n; (d) YOLOv10n; (e) YOLOv11n; (f) YOLO-AL; (g) Ground truth.
4.4.2. Comparison of C2f-US Utilization Schemes
To evaluate the performance of the C2f-US module for aluminum surface damage detection and justify its replacement of the first two C2f modules in the YOLOv8 Backbone, three experimental scenarios were designed. These scenarios involve replacing C2f-US with the first and second C2f, the third and fourth C2f, and all C2f modules in the YOLOv8 backbone, respectively. As shown in Table 6, the Backbone-US-1,2 configuration achieves a recall of 78.1%, mAP@0.5 of 80.9%, and mAP@0.5:0.95 of 57.6%. These results demonstrate that the introduction of the C2f-US module enhances model precision and reduces computational overhead across all three scenarios compared to the baseline. Replacing C2f with C2f-US not only strengthens the model’s feature extraction capability but also marginally lowers the computational cost. However, replacing the first two C2f layers of the backbone with C2f-US proved to be the most advantageous. This highlights the significance of the model’s early feature extraction and contextual understanding, which are precisely the strengths of the C2f-US module. It is important to note that during the aforementioned experiments, no additional enhancement modules were incorporated into the model, and the default CIoU loss function was employed.
Table 6.
Comparison of C2f-US utilization schemes.
4.4.3. Comparison of FW-IoU Utilization Schemes
To evaluate the performance of Focaler-WIoU (FW-IoU) in aluminum surface damage detection and demonstrate the effectiveness of this optimization, three scenarios were designed. These scenarios involved replacing the loss function of the YOLOv8 model with Focaler-CIoU, Focaler-GIoU, and Focaler-WIoU, respectively. As shown in Table 7, incorporating Focaler-IoU into the original CIoU enhances model performance across all scenarios. This highlights the effectiveness of Focaler-IoU in addressing class imbalance and the presence of challenging samples. The recall, mAP@0.5, and mAP@0.5:0.95 reached their peak when the Focaler-WIoU scheme was applied, suggesting that combining WIoU with Focaler-IoU leverages the strengths of both, significantly improving model precision and mAP. It is important to note that during the aforementioned experiments, no additional enhancement modules were incorporated into the model.
Table 7.
Comparison of Focaler-WIoU utilization schemes.
5. Conclusions and Discussion
This paper presents the YOLO-AL inspection model, built upon YOLOv8n, for precise and real-time detection of aluminum surface defects in industrial environments. First, the backbone network of YOLOv8 is optimized, and the integration of C2f-US and CPMSCA mechanisms improves feature extraction capabilities without increasing computational cost. Second, the ODE-RepGFPN module is introduced into the Neck network to more efficiently fuse multi-scale features, enhancing focus on critical regions while effectively consolidating information from different feature layers. Finally, Focaler-WIoU is incorporated to improve the model’s ability to learn rare categories by reducing the loss weights for easy-to-classify samples, addressing the class imbalance issue in the aluminum defect dataset. Experimental comparisons with other models demonstrate superior performance across key metrics: precision, recall, and mAP@0.5. Notably, this enhancement does not significantly increase computational overhead, with GFLOPs decreasing by 0.2 compared to the original model, while computational and parametric costs remain low relative to state-of-the-art alternatives. This underscores the advantages of the enhanced model for real-time aluminum defect detection, particularly in terms of reduced deployment resource requirements. To further evaluate the proposed improvements, a series of ablation and comparative experiments were conducted to demonstrate the synergistic effect of the modules and validate their effectiveness. YOLO-AL is distinguished by its high inspection accuracy, minimal computational cost, and elevated frame rates. When integrated with an industrial camera, it is optimally configured for real-time non-destructive surface inspection of aluminum in production processes, such as conveyor lines.
Nonetheless, the limitations of the enhanced model must be recognized. For instance, although the model achieves the highest precision in detecting paint-bubble, the performance remains suboptimal and does not fully satisfy practical application requirements. This paper does not address the effects of domain shift or noise on model performance, which limits the comprehensive evaluation of its generalization capabilities. Industrial disturbances such as vibrations from aluminum on conveyor belts and optical interference within manufacturing environments can significantly impair the quality of images captured by industrial cameras. This degradation adversely impacts the defect detection accuracy of YOLO-AL, potentially leading to errors and omissions that compromise product quality and increase waste. Therefore, further investigation into the model’s robustness under real-world conditions is warranted. Additionally, the use of statistical significance testing and cross-validation is critical for enhancing the model’s reliability across diverse data partitions. Future research will concentrate on improving model efficiency and performance through techniques such as model pruning, the integration of small target detection heads, data augmentation, and semi-supervised learning, while advancing their deployment and practical application in industrial contexts.
Author Contributions
Conceptualization, J.H., H.C. (Huiye Chen), S.Z. and Y.D.; methodology, J.H., H.C. (Huiye Chen) and Y.D.; software, J.H. and H.C. (Huiye Chen); formal analysis, J.H. and H.C. (Huiye Chen); resources, J.H.; data curation, J.H.; writing—original draft preparation, J.H. and H.C. (Huiye Chen); writing—review and editing, C.Z. and J.H.; visualization, J.H. and H.C. (Hua Chen); project administration, J.H. and C.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data used to support this study are available from the corresponding author upon request.
Acknowledgments
The authors are thankful to the College Students’ Innovative Entrepreneurial Training Plan Program, China (No. 202410294189Y). And we thank the associate editors and reviewers for their helpful feedback that improved this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Stojanovic, B.; Bukvic, M.; Epler, I. Application of Aluminum and Aluminum Alloys in Engineering. Appl. Eng. Lett. 2018, 3, 52–62. [Google Scholar] [CrossRef]
- Fu, P.; Peng, L.; Ding, W. Automobile Lightweight Technology: Development Trends of Aluminum/Magnesium Alloys and Their Forming Technologies. Strateg. Study CAE 2018, 20, 84–90. [Google Scholar] [CrossRef]
- Yuferov, Y.; Zykov, F.; Malshakova, E. Defects of Porous Self-Structured Anodic Alumina Oxide on Industrial Aluminum Grades. Solid State Phenom. 2018, 284, 1134–1139. [Google Scholar] [CrossRef]
- Wu, Q.; Dong, K.; Qin, X.; Hu, Z.; Xiong, X. Magnetic Particle Inspection: Status, Advances, and Challenges—Demands for Automatic Non-Destructive Testing. NDT E Int. 2024, 143, 103030. [Google Scholar] [CrossRef]
- Alay, T.K.; Cagirici, M.; Yagmur, A.; Gur, C.H. Determination of the Anisotropy in Mechanical Properties of Laser Powder Bed Fusion Inconel 718 by Ultrasonic Testing. Nondestruct. Test. Eval. 2024, 40, 206–224. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, F.; Fang, L. The Summary on Important Damage Detection Technology of Composite Materials. Adv. Mat. Res. 2014, 1055, 32–37. [Google Scholar] [CrossRef]
- Gulhan, U.K. Development of hybrid optical sensor based on deep learning to detect and classify the micro-size defects in printed circuit board. Measurement 2023, 206, 112247. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Alkandary, K.; Yildiz, A.S.; Meng, H. A Comparative Study of YOLO Series (v3–v10) with DeepSORT and StrongSORT: A Real-Time Tracking Performance Study. Electronics 2025, 14, 876. [Google Scholar] [CrossRef]
- Zhang, G.; Cao, X.; Liu, S.; Jin, L.; Yang, Q. Electromagnetic Ultrasonic Nonlinear Detection of Plastic Damage in aluminum Based on Cumulative Effect. JET 2019, 34, 3961–3967. [Google Scholar] [CrossRef]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2024, arXiv:2305.09972. [Google Scholar] [CrossRef]
- Zhang, D.; Song, K.; Xu, J.; He, Y.; Yan, Y. Unified Detection Method of Aluminum Profile Surface Defects: Common and Rare Defect Categories. Opt. Lasers Eng. 2020, 126, 105936. [Google Scholar] [CrossRef]
- Wang, W.; Chen, J.; Han, G.; Shi, X.; Qian, G. Application of Object Detection Algorithms in Non-Destructive Testing of Pressure Equipment: A Review. Sensors 2024, 24, 5944. [Google Scholar] [CrossRef] [PubMed]
- Roy, A.M.; Bhaduri, J. DenseSPH-YOLOv5: An Automated Damage Detection Model Based on DenseNet and Swin-Transformer Prediction Head-Enabled YOLOv5 with Attention Mechanism. Adv. Eng. Inform. 2023, 56, 102007. [Google Scholar] [CrossRef]
- Gao, G.; Ma, Y.; Wang, J.; Li, Z.; Wang, Y.; Bai, H. CFR-YOLO: A Novel Cow Face Detection Network Based on YOLOv7 Improvement. Sensors 2025, 25, 1084. [Google Scholar] [CrossRef]
- Xu, K.; Lu, X.; Shen, T.; Zhu, X.; Wang, S.; Wang, X.; Wang, J. Rebar binding point location method based on improved YOLOv5 and thinning algorithm. Measurement 2025, 242, 116029. [Google Scholar] [CrossRef]
- Zhang, M.; Ye, S.; Zhao, S.; Wang, W.; Xie, C. Pear Object Detection in Complex Orchard Environment Based on Improved YOLO11. Symmetry 2025, 17, 255. [Google Scholar] [CrossRef]
- Li, L.; Zhang, P.; Yang, S.; Jiao, W. YOLOv5-SFE: An algorithm fusing spatio-temporal features for detecting and recognizing workers’ operating behaviors. Adv. Eng. Inform. 2023, 56, 101988. [Google Scholar] [CrossRef]
- Wang, X.; Gao, H.; Jia, Z.; Li, Z. BL-YOLOv8: An Improved Road Defect Detection Model Based on YOLOv8. Sensors 2023, 23, 8361. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, F.; Lei, G.B.; Xiong, Y.; Xu, L.; Xu, C.Z.; Zhu, W. LSD-YOLOv5: A Steel Strip Surface Defect Detection Algorithm Based on Lightweight Network and Enhanced Feature Fusion Mode. Sensors 2023, 23, 6558. [Google Scholar] [CrossRef]
- Wu, D.; Meng, F. NBD-YOLOv5: An Efficient and Accurate Aluminum Surface Defect Detection Method. In Proceedings of the 2024 7th International Conference on Advanced Algorithms and Control Engineering, Shanghai, China, 1–3 March 2024; pp. 1190–1196. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, G.; Wang, W.; Chen, J.; Jing, X.; Yuan, H.; Huang, Z. A defect detection method for industrial aluminum sheet surface based on improved YOLOv8 algorithm. Front. Phys. 2024, 12, 1419998. [Google Scholar] [CrossRef]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on ADICS, Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B.; et al. MobileNetV4: Universal Models for the Mobile Ecosystem. In Computer Vision—ECCV 2024. ECCV 2024. Lecture Notes in Computer Science; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Springer: Cham, Switzerland, 2025; Volume 15098. [Google Scholar] [CrossRef]
- Nascimento, M.G.D.; Prisacariu, V.; Fawcett, R. DSConv: Efficient Convolution Operator. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 5147–5156. [Google Scholar] [CrossRef]
- Sunkara, R.; Luo, T. No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD), Cham, Switzerland, 13–17 September 2022. [Google Scholar] [CrossRef]
- Huang, H.; Chen, Z.; Zou, Y.; Lu, M.; Chen, C.; Song, Y.; Zhang, H.; Yan, F. Channel prior convolutional attention for medical image segmentation. Comput. Biol. Med. 2024, 178, 108784. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.-H.; Lu, C.-Z.; Hou, Q.; Liu, Z.; Cheng, M.-M.; Hu, S.-M. SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation. arXiv 2022, arXiv:2209.08575. [Google Scholar] [CrossRef]
- Li, C.; Zhou, A.; Yao, A. Omni-Dimensional Dynamic Convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar] [CrossRef]
- Xu, X.; Jiang, Y.; Chen, W.; Huang, Y.; Zhang, Y.; Sun, X. DAMO-YOLO: A Report on Real-Time Object Detection Design. arXiv 2023, arXiv:2211.15444. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, S. Focaler-IoU: More Focused Intersection over Union Loss. arXiv 2024, arXiv:2401.10525. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vision 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. arXiv 2019, arXiv:1904.08189. [Google Scholar] [CrossRef]
- Sun, Y.; Dong, L.; Huang, S.; Ma, S.; Xia, Y.; Xue, J.; Wang, J.; Wei, F. Retentive Network: A Successor to Transformer for Large Language Models. arXiv 2023, arXiv:2307.08621. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar] [CrossRef]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems, Coimbatore, India, 6–7 March 2020; pp. 687–694. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. What is YOLOv5: A deep look into the internal features of the popular object detector. arXiv 2024, arXiv:2407.20892. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar] [CrossRef]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).