
Iterative Learning Control with Forgetting Factor for MIMO Nonlinear Systems with Randomly Varying Iteration Lengths and Disturbances


Abstract
1. Introduction
- (1)
- Randomly varying iteration lengths, initial state shifts and disturbances are dealt with simultaneously for MIMO nonlinear systems using the proposed method.
- (2)
- For randomly varying iteration lengths, a modified tracking error is designed. For the initial state shifts, state disturbances and measurement disturbances, a PD-type iterative learning control method with a forgetting factor, utilizing the modified tracking error, is proposed. The boundedness of errors is demonstrated using the contraction mapping method.
- (3)
- Two simulations, one with a subway train tracking control system and the other with a two-degree-of-freedom robot manipulator system are shown to verify the effectiveness of the theoretical studies.
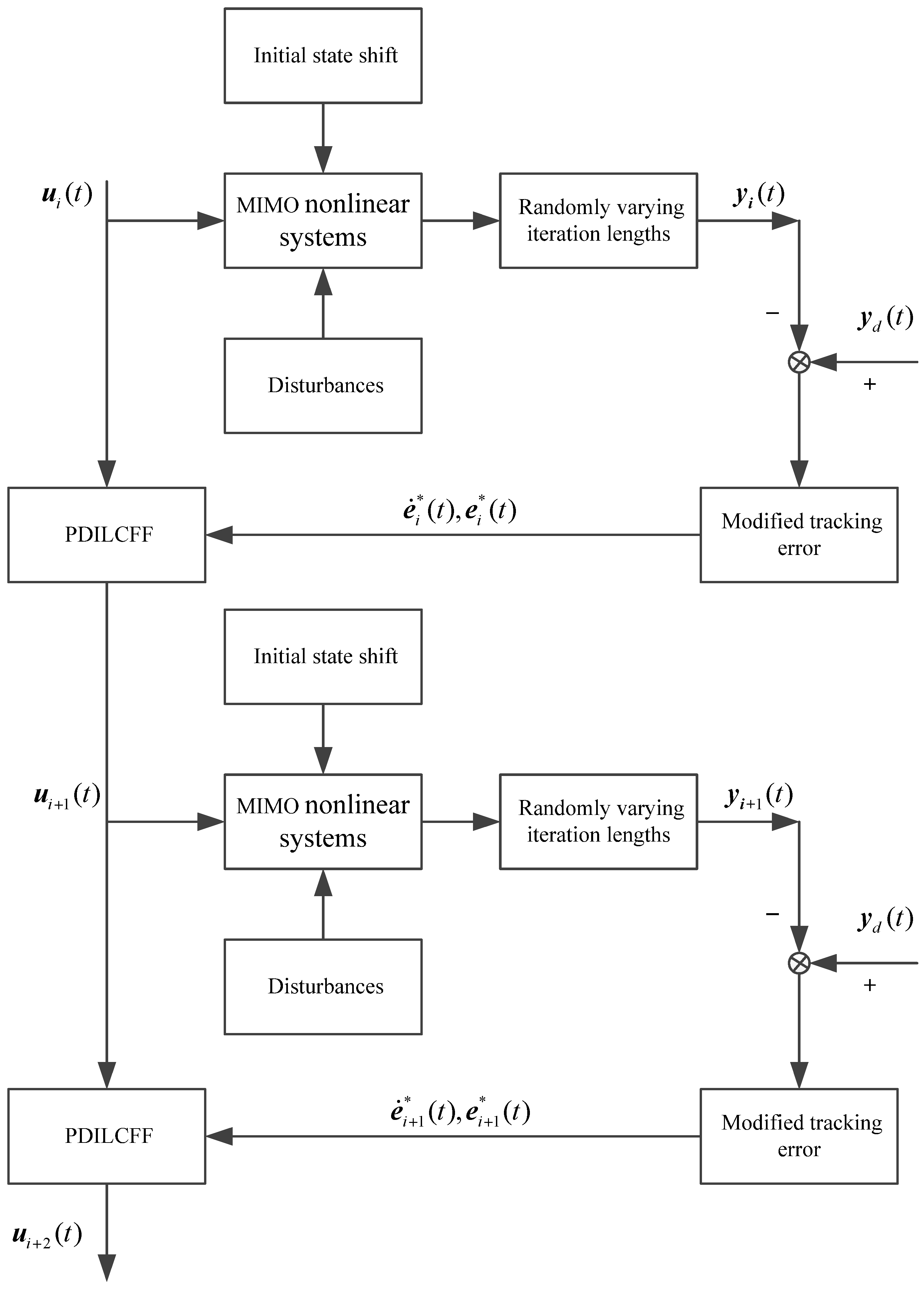
2. Problem Formulation
3. Controller Design and Convergence Analysis
3.1. Randomly Varying Iteration Lengths
3.2. Controller Design
3.3. Convergence Analysis
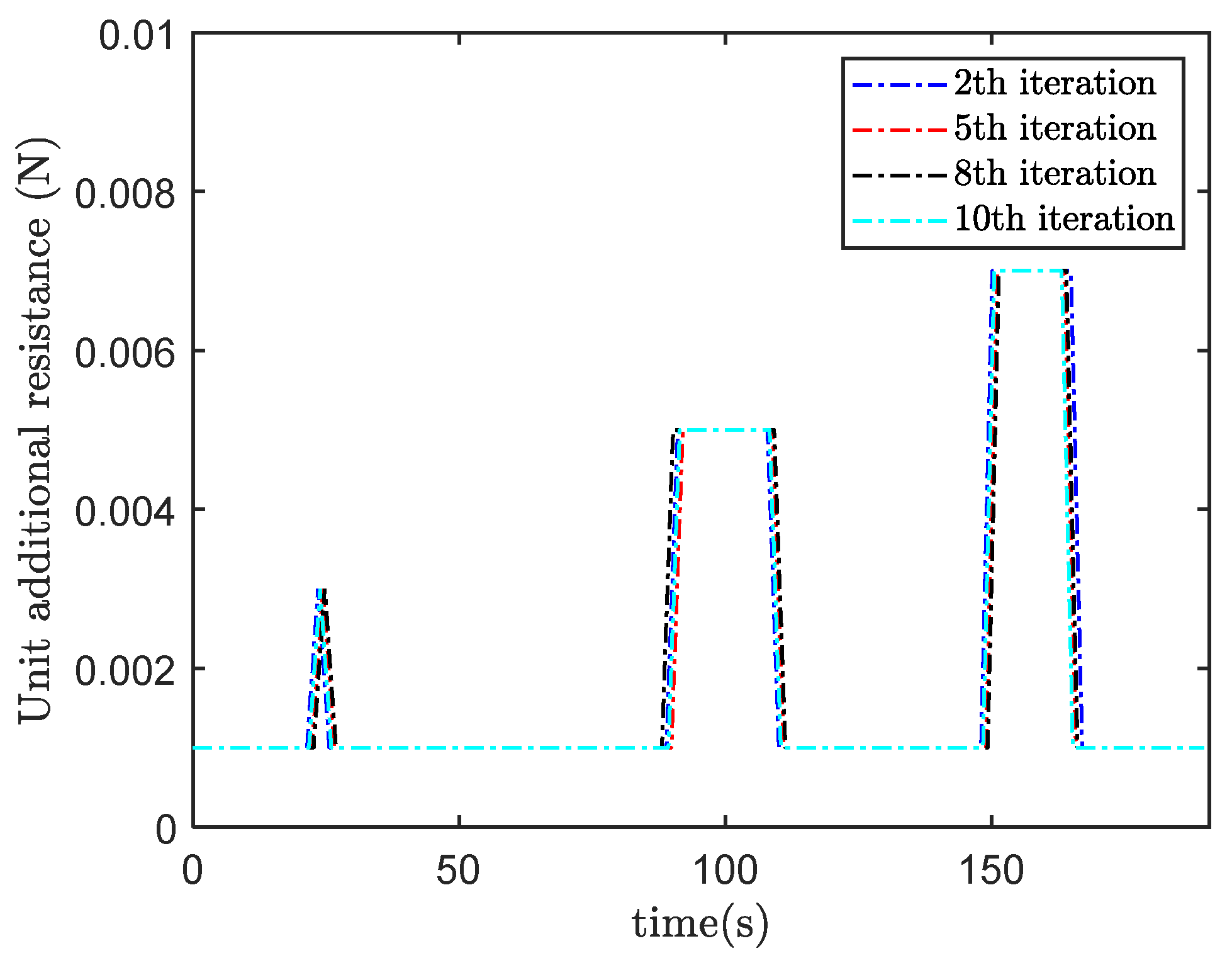
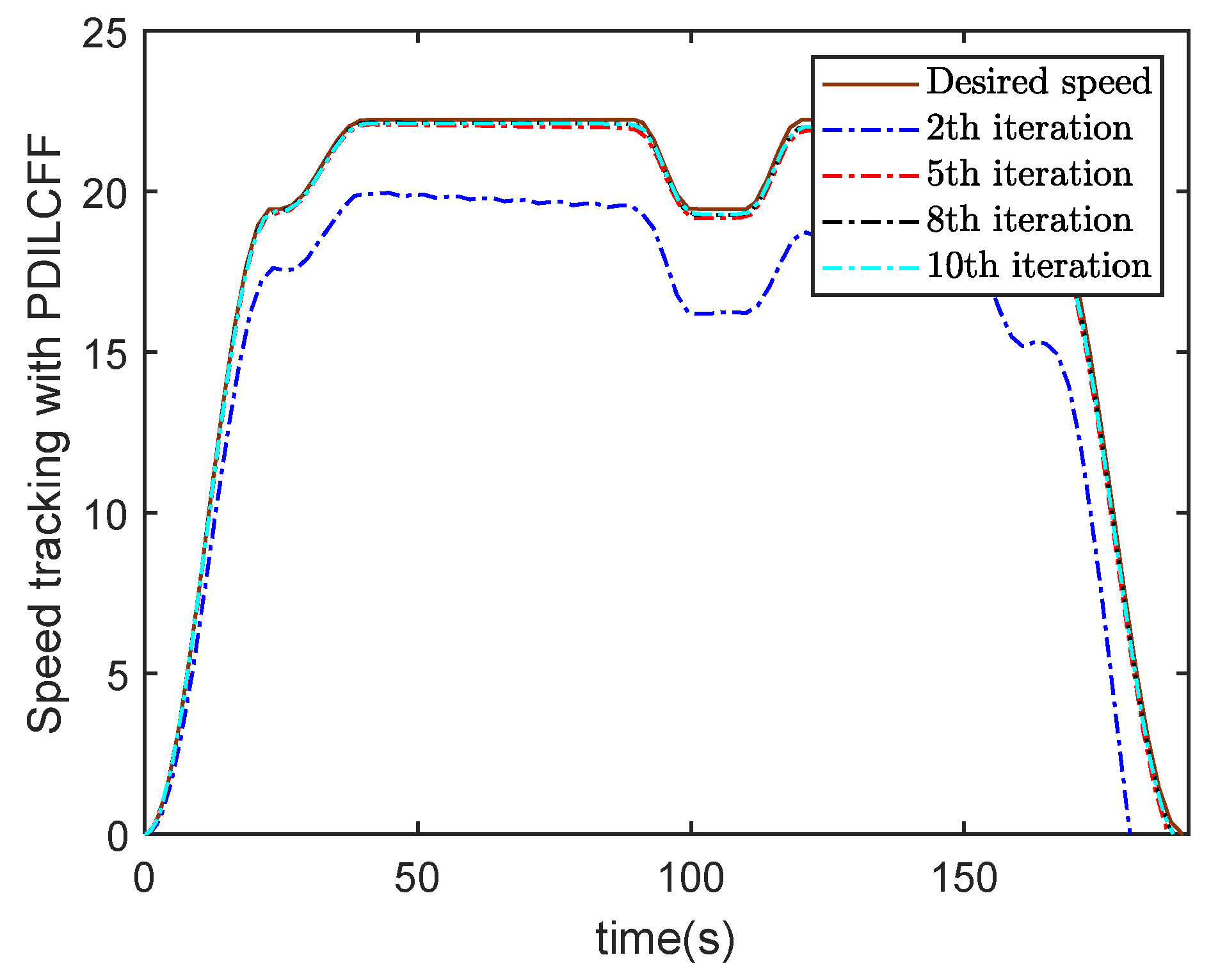
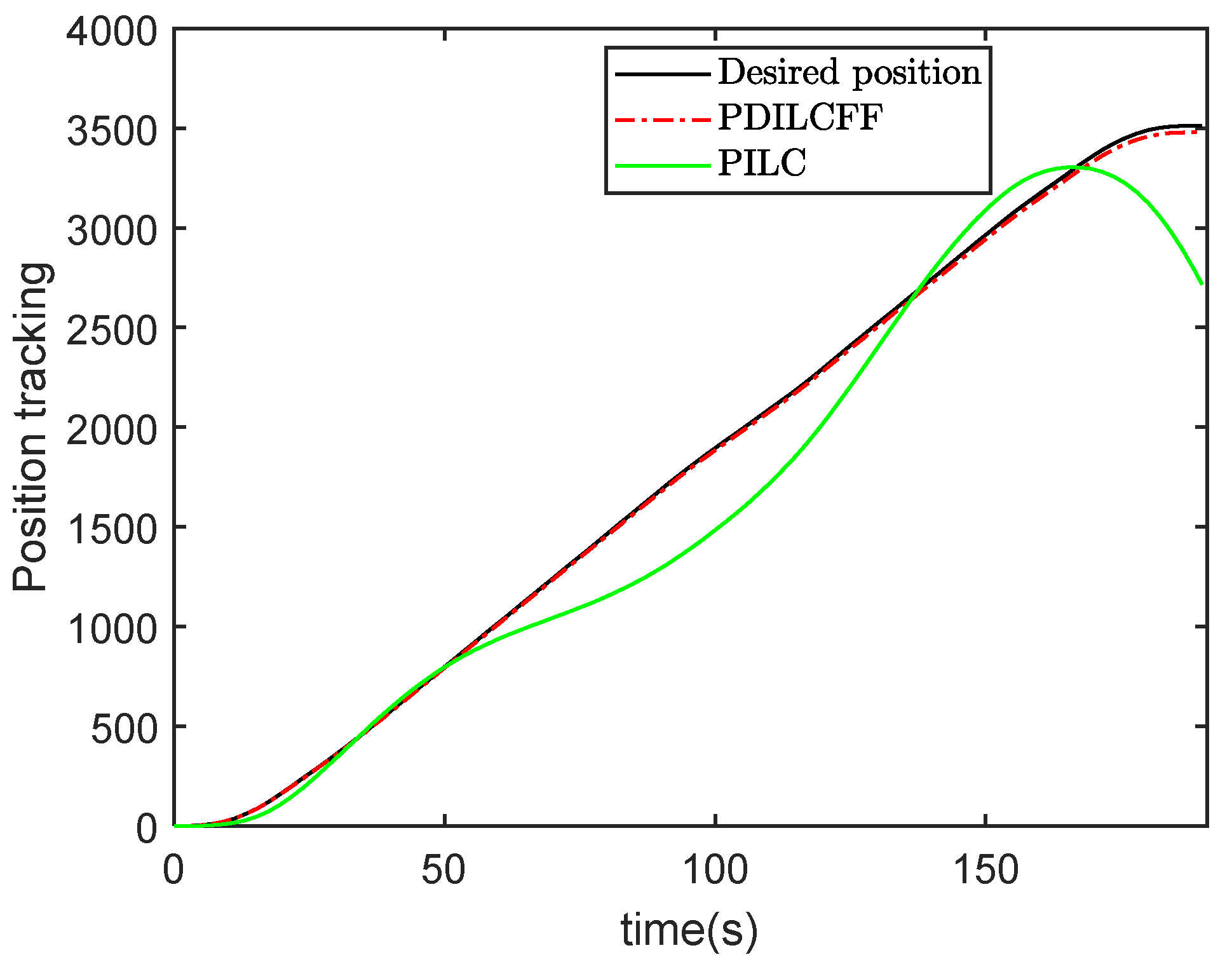
4. Simulation Study

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
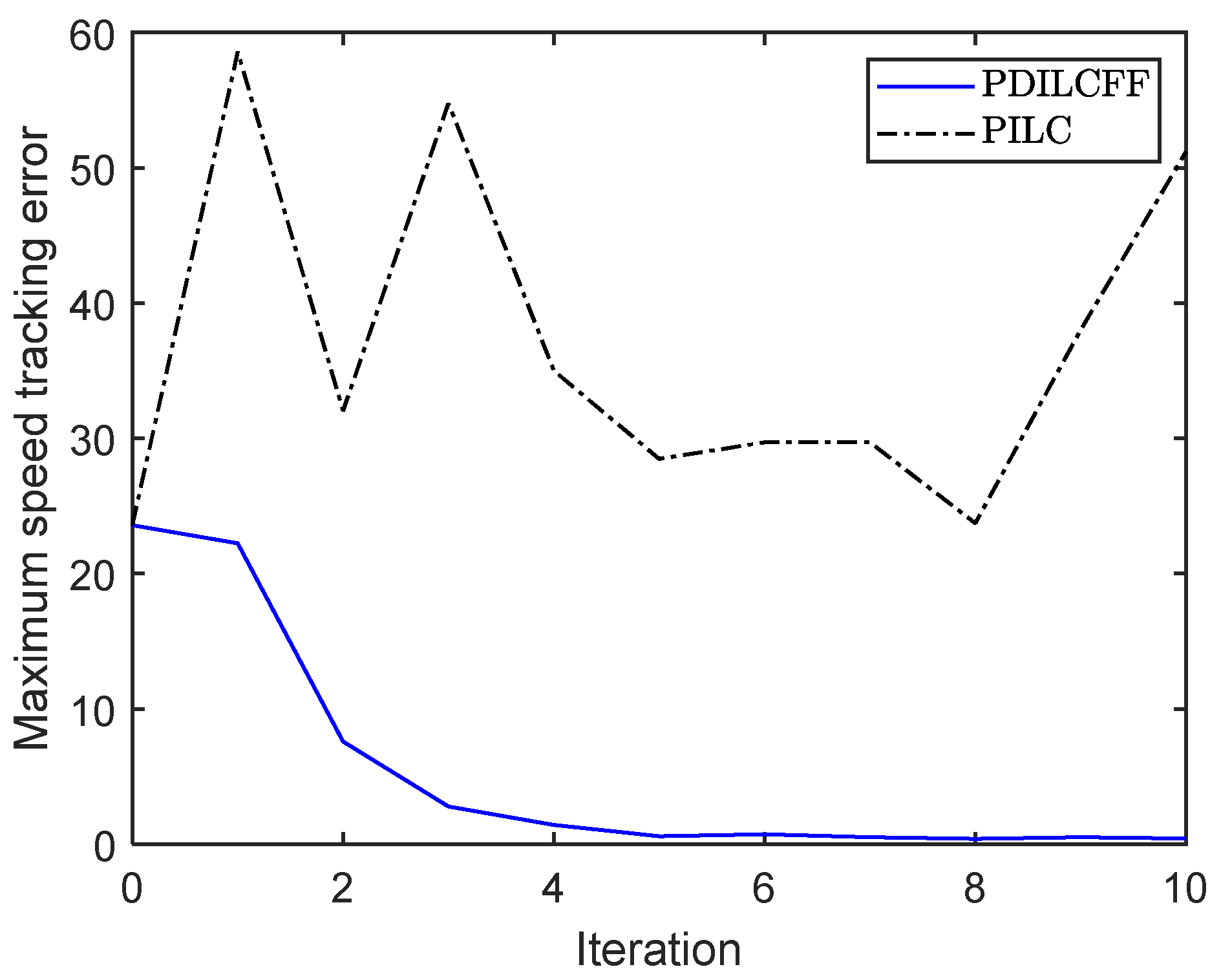
| Control Algorithm | The Maximum Speed Tracking Error of Different Iterations | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| PDILCFF | 22.23 | 7.58 | 2.78 | 1.43 | 0.60 | 0.73 | 0.51 | 0.38 | 0.50 | 0.42 |
| PILC | 58.58 | 32.04 | 57.46 | 35.00 | 28.49 | 29.70 | 29.71 | 23.73 | 38.02 | 51.19 |
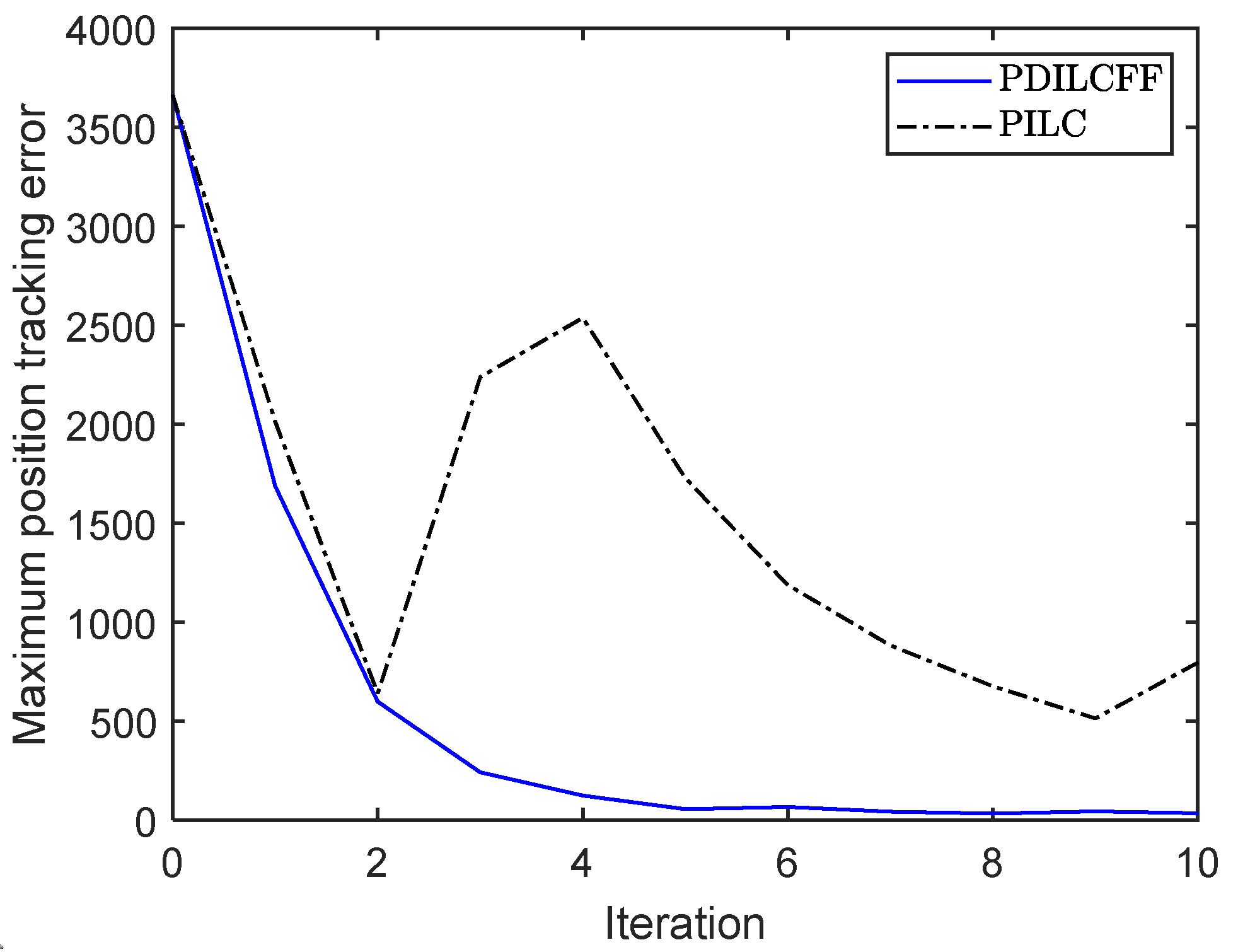
| Control Algorithm | The Maximum Position Tracking Error of Different Iterations | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| PDILCFF | 1687 | 641 | 242 | 125 | 56 | 67 | 43 | 33 | 45 | 34 |
| PILC | 2014 | 641 | 2239 | 2538 | 1727 | 1188 | 883 | 676 | 514 | 796 |
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arimoto, S.; Kawamura, S.; Miyazaki, F. Bettering operation of robots by learning. J. Field Robot. 1984, 1, 123–140. [Google Scholar] [CrossRef]
- Xu, J.-X. A survey on iterative learning control for nonlinear systems. Int. J. Control. 2011, 84, 1275–1294. [Google Scholar] [CrossRef]
- Tan, W.; Hou, Z.; Li, Y.X. Robust data-driven iterative learning control for high-speed train with aperiodic DoS attacks and communication delays. IEEE Trans. Intell. Vehicl. 2024, 1–10. [Google Scholar] [CrossRef]
- Li, S.; Li, X. Finite-time extended state observer-based iterative learning control for nonrepeatable nonlinear systems. Nonlinear Dyn. 2025, 113, 16531–16543. [Google Scholar] [CrossRef]
- Arimoto, S. Learning control theory for robotic motion. Int. J. Adapt. Control. Signal Process. 1990, 4, 543–564. [Google Scholar] [CrossRef]
- Saab, S.S. On the P-type learning control. IEEE Trans. Automat. Contr. 1994, 39, 2298–2302. [Google Scholar] [CrossRef]
- Xu, J.X.; Jin, X. State-Constrained Iterative Learning Control for a Class of MIMO Systems. IEEE Trans. Automat. Contr. 2013, 58, 1322–1327. [Google Scholar] [CrossRef]
- Bai, L.; Feng, Y.-W.; Li, N.; Xue, X.-F.; Cao, Y. Data-Driven Adaptive Iterative Learning Method for Active Vibration Control Based on Imprecise Probability. Symmetry 2019, 11, 746. [Google Scholar] [CrossRef]
- Hou, Z.S.; Chi, R.; Gao, H. An overview of dynamic-linearization-based data-driven control and applications. IEEE Trans. Ind. Electron. 2017, 64, 4076–4090. [Google Scholar] [CrossRef]
- Yu, X.; Chen, T. Distributed Iterative Learning Control of Nonlinear Multiagent Systems Using Controller-Based Dynamic Linearization Method. IEEE Trans. Cybern. 2023, 54, 4489–4501. [Google Scholar] [CrossRef]
- Zhang, H.; Chi, R.; Huang, B.; Hou, Z. Compensatory Data-Driven Networked Iterative Learning Control with Communication Constraints and DoS Attacks. IEEE Trans. Autom. Sci. Eng. 2025, 22, 10728–10740. [Google Scholar] [CrossRef]
- Chi, R.; Hou, Z.S.; Huang, B.; Jin, S. A unified data-driven design framework of optimality-based generalized iterative learning control. Comput. Chem. Eng. 2015, 77, 10–23. [Google Scholar] [CrossRef]
- Chi, R.; Liu, X.; Zhang, R.; Hou, Z.S.; Huang, B. Constrained data-driven optimal iterative learning control. J. Process Contr. 2017, 55, 10–29. [Google Scholar] [CrossRef]
- Huang, Y.; Tao, H.; Chen, Y.; Rogers, E.; Paszke, W. Point-to-point iterative learning control with quantised input signal and actuator faults. Int. J. Control. 2024, 97, 17. [Google Scholar] [CrossRef]
- Wang, L.; Dong, L.; Chen, Y.; Wang, K.; Gao, F. Iterative Learning Control for Actuator Fault Uncertain Systems. Symmetry 2022, 14, 1969. [Google Scholar] [CrossRef]
- Tayebi, A. Adaptive iterative learning control for robot manipulators. Automatica 2004, 40, 1195–1203. [Google Scholar] [CrossRef]
- Yin, C.; Xu, J.-X.; Hou, Z. A high-order internal model based iterative learning control scheme for nonlinear systems with time-iteration-varying parameters. IEEE Trans. Automat. Contr. 2010, 55, 2665–2670. [Google Scholar] [CrossRef]
- Chi, R.H.; Hou, Z.S.; Huang, B. Optimal iterative learning control of batch processes: From model-based to data-driven. Zidonghua Xuebao/Acta Autom. Sin. 2017, 43, 917–932. [Google Scholar]
- Liu, G.; Hou, Z.S. Cooperative adaptive iterative learning fault-tolerant control scheme for multiple subway trains. IEEE Trans. Cybern. 2022, 52, 1098–1111. [Google Scholar] [CrossRef]
- Liu, G.; Hou, Z.S. RBFNN-based adaptive iterative learning fault-tolerant control for subway trains with actuator faults and speed constraint. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 5785–5799. [Google Scholar] [CrossRef]
- Hou, Z.S.; Yan, J.; Xu, J.-X.; Li, Z. Modified iterative-learning-control-based ramp metering strategies for freeway traffic control with iteration-dependent factors. IEEE Trans. Intell. Transp. Syst. 2012, 13, 606–618. [Google Scholar] [CrossRef]
- Hou, Z.; Xu, X.; Yan, J.; Xu, J.X.; Xiong, G. A complementary modularized ramp metering approach based on iterative learning control and ALINEA. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1305–1318. [Google Scholar] [CrossRef]
- Longman, R.W.; Mombaur, K.D. Investigating the use of iterative learning control and repetitive control to implement periodic gaits. Lect. Notes Control Inform. Sci. 2006, 340, 189–218. [Google Scholar]
- Yu, Q.; Hou, Z.S. Adaptive fuzzy iterative learning control for high-speed trains with both randomly varying operation lengths and system constraints. IEEE Trans. Fuzzy Syst. 2021, 29, 2408–2418. [Google Scholar] [CrossRef]
- Seel, T.; Schauer, T.; Raisch, J. Iterative learning control for variable pass length systems. In Proceedings of the the 18th IFAC World Congress, Milano, Italy, 28 August–2 September 2011; pp. 4880–4885. [Google Scholar]
- Guth, M.; Seel, T.; Raisch, J. Iterative learning control with variable pass length applied to trajectory tracking on a crane with output constraints. In Proceedings of the 52nd IEEE Conference on Decision and Control, Florence, Italy, 10–13 December 2013; pp. 6676–6681. [Google Scholar]
- Li, X.; Xu, J.-X.; Huang, D. An iterative learning control approach for linear time-invariant systems with randomly varying trial lengths. IEEE Trans. Automat. Contr. 2014, 59, 1954–1960. [Google Scholar] [CrossRef]
- Li, X.; Xu, J.-X.; Huang, D. Iterative learning control for nonlinear dynamic systems with randomly varying trial lengths. Int. J. Adapt. Control Signal Process 2015, 29, 1341–1353. [Google Scholar] [CrossRef]
- Shen, D.; Zhang, W.; Wang, Y.; Chien, C.J. On almost sure and mean square convergence of P-type ILC under randomly varying iteration lengths. Automatica 2016, 63, 359–365. [Google Scholar] [CrossRef]
- Li, X.; Shen, D. Two novel iterative learning control schemes for systems with randomly varying trial lengths. Syst. Control. Lett. 2017, 107, 9–16. [Google Scholar] [CrossRef]
- Wang, L.; Li, X.; Shen, D. Sampled-data iterative learning control for continuous-time nonlinear systems with iteration-varying lengths. Int. J. Robust Nonlinear Control. 2018, 28, 3073–3091. [Google Scholar] [CrossRef]
- Shen, D.; Xu, J.-X. Robust learning control for nonlinear systems with nonparametric uncertainties and nonuniform trial lengths. Int. J. Robust Nonlinear Control. 2019, 29, 1302–1324. [Google Scholar] [CrossRef]
- Shen, D.; Xu, J.-X. Adaptive learning control for nonlinear systems with randomly varying iteration lengths. IEEE Trans. Neural. Networ. 2019, 30, 1119–1132. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Hou, Z. Adaptive iterative learning fault-tolerant control for state constrained nonlinear systems with randomly varying iteration lengths. IEEE Trans. Neural. Networ. 2024, 35, 1735–1749. [Google Scholar] [CrossRef]
- Bu, X.; Wang, S.; Hou, Z.S.; Liu, W. Model free adaptive iterative learning control for a class of nonlinear systems with randomly varying iteration lengths. J. Frankl. Inst. 2019, 356, 2491–2504. [Google Scholar] [CrossRef]
- Xu, R.; Chen, H.; Tang, Y.; Long, X. Model-free predictive iterative learning safety-critical consensus control for multi-agent systems with randomly varying trial lengths. Syst. Control. Lett. 2025, 196, 105987. [Google Scholar] [CrossRef]
- Shen, D.; Zhang, W.; Xu, J.-X. Iterative learning control for discrete nonlinear systems with randomly iteration varying lengths. Syst. Control. Lett. 2016, 96, 81–87. [Google Scholar] [CrossRef]
- Wei, Y.; Li, X. Robust higher-order ILC for non-linear discrete-time systems with varying trail lengths and random initial state shifts. IET Control. Theory Appl. 2017, 11, 2440–2447. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, Y.; Ao, Y.; Jia, Y. An iterative learning approach to formation control of discrete-time multi-agent systems with varying trial lengths. Int. J. Robust Nonlinear Control. 2022, 32, 9332–9346. [Google Scholar] [CrossRef]
- Hussain, M.; Muslim, F.B.; Khan, O.; Saqib, N.u. Robust anti-windup control atrategy for uncertain nonlinear system with time delays. Arab. J. Sci. Eng. 2022, 47, 3847–3860. [Google Scholar] [CrossRef]
- Liu, G.; Hou, Z. Adaptive iterative learning control for subway trains using multiple-point-mass dynamic model under speed constraint. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1388–1400. [Google Scholar] [CrossRef]
- Jin, X. Iterative learning control for MIMO nonlinear systems with iteration-varying trial lengths using modified composite energy function analysis. IEEE Trans. Cybern. 2021, 51, 6080–6090. [Google Scholar] [CrossRef]


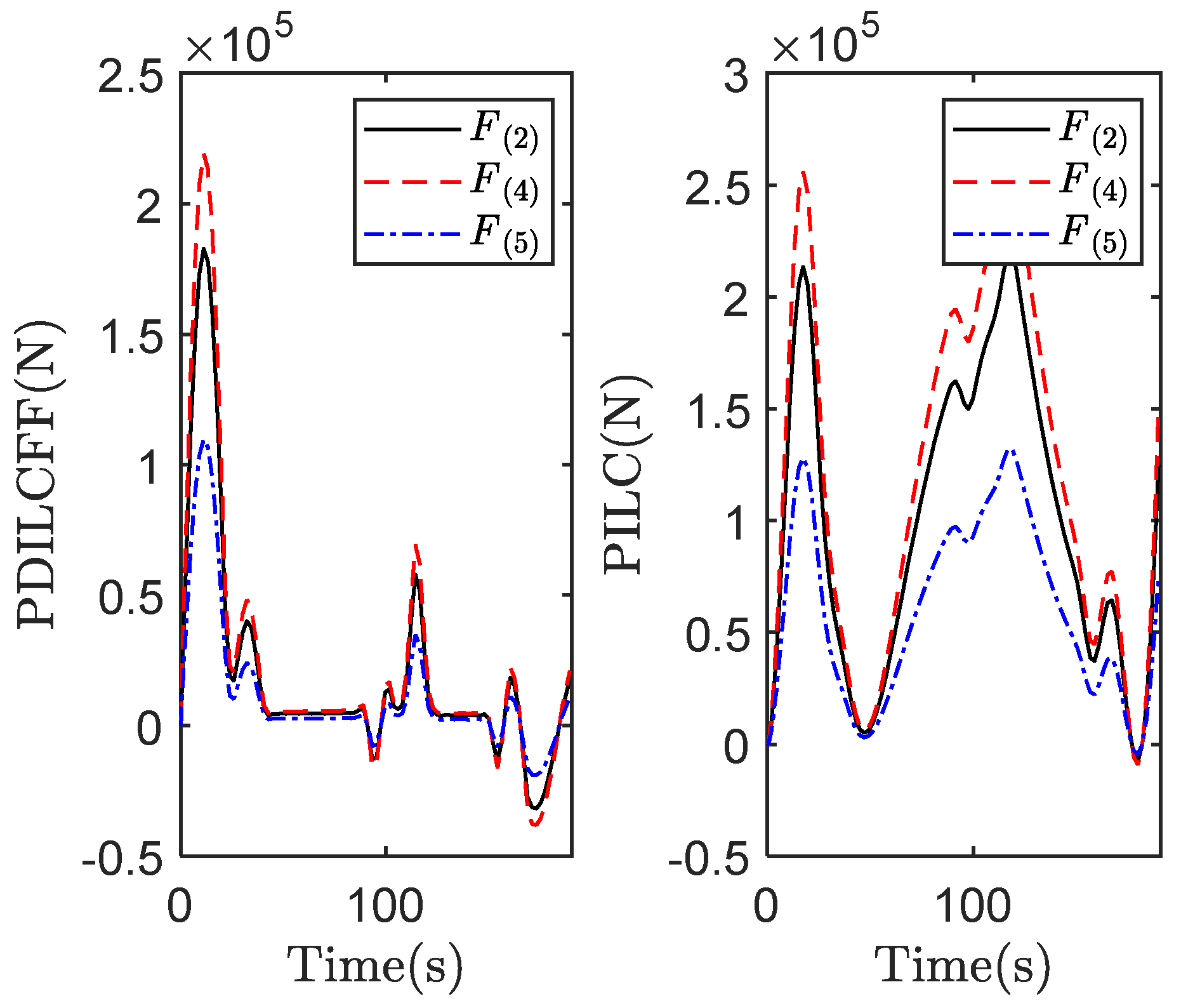

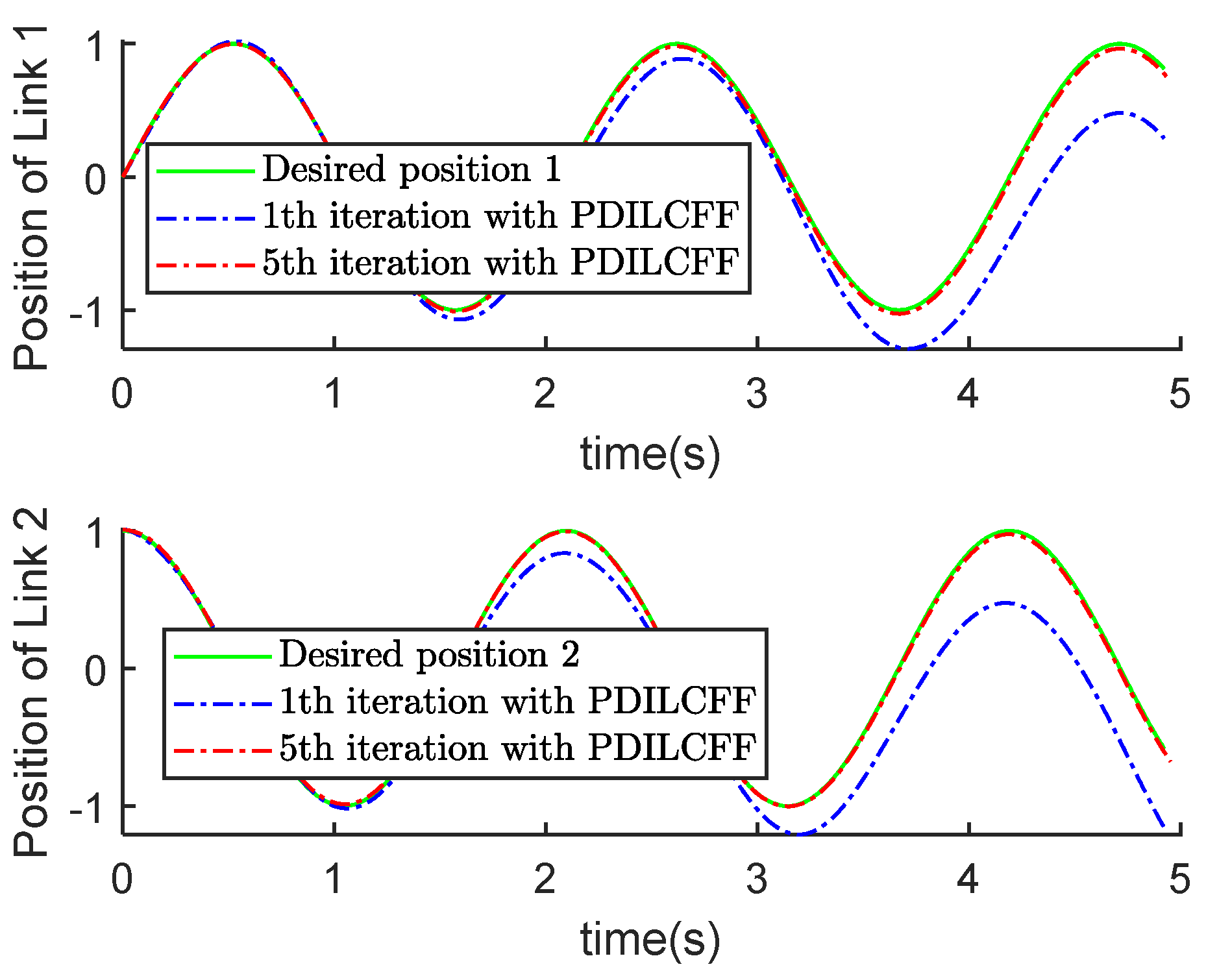
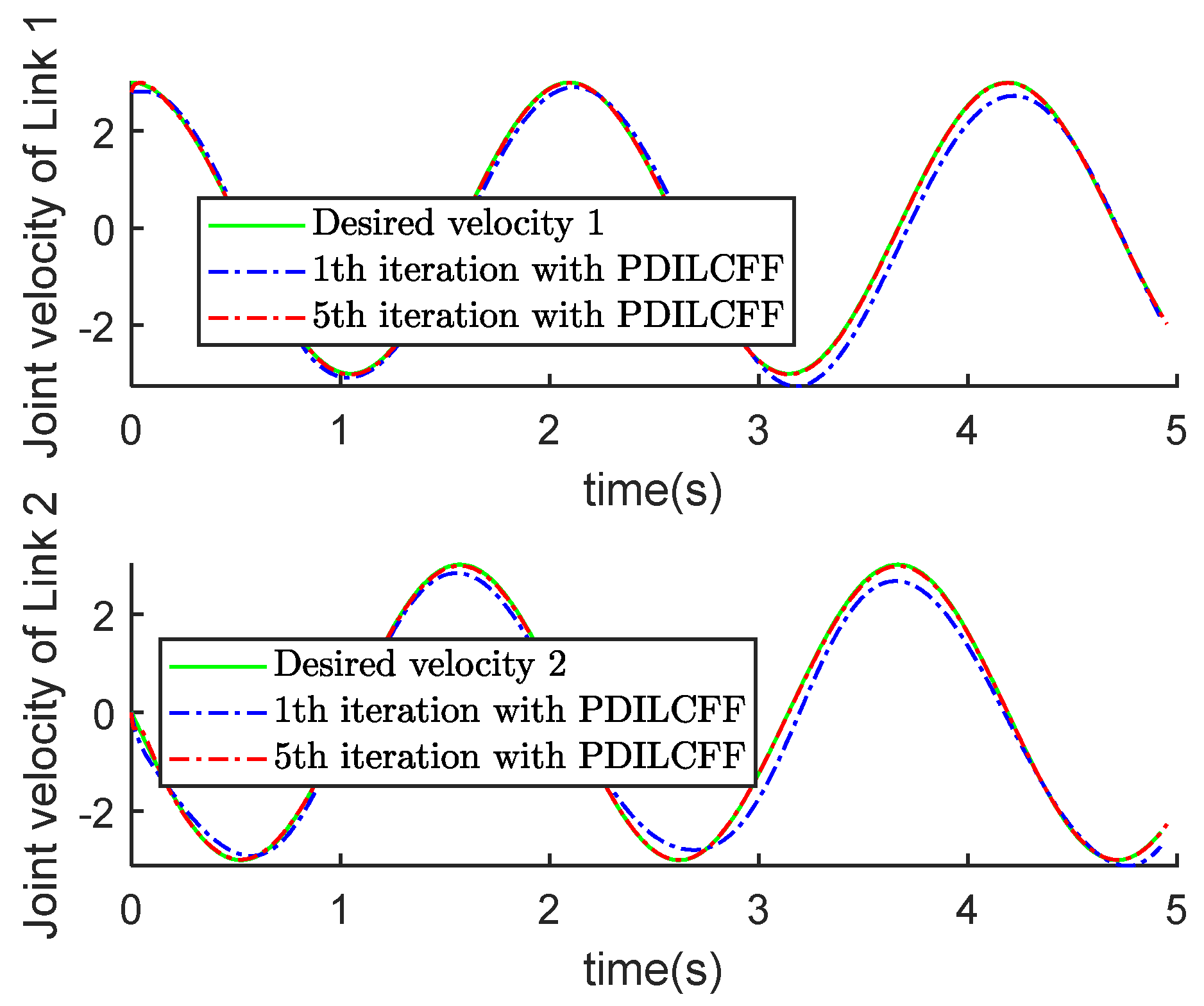
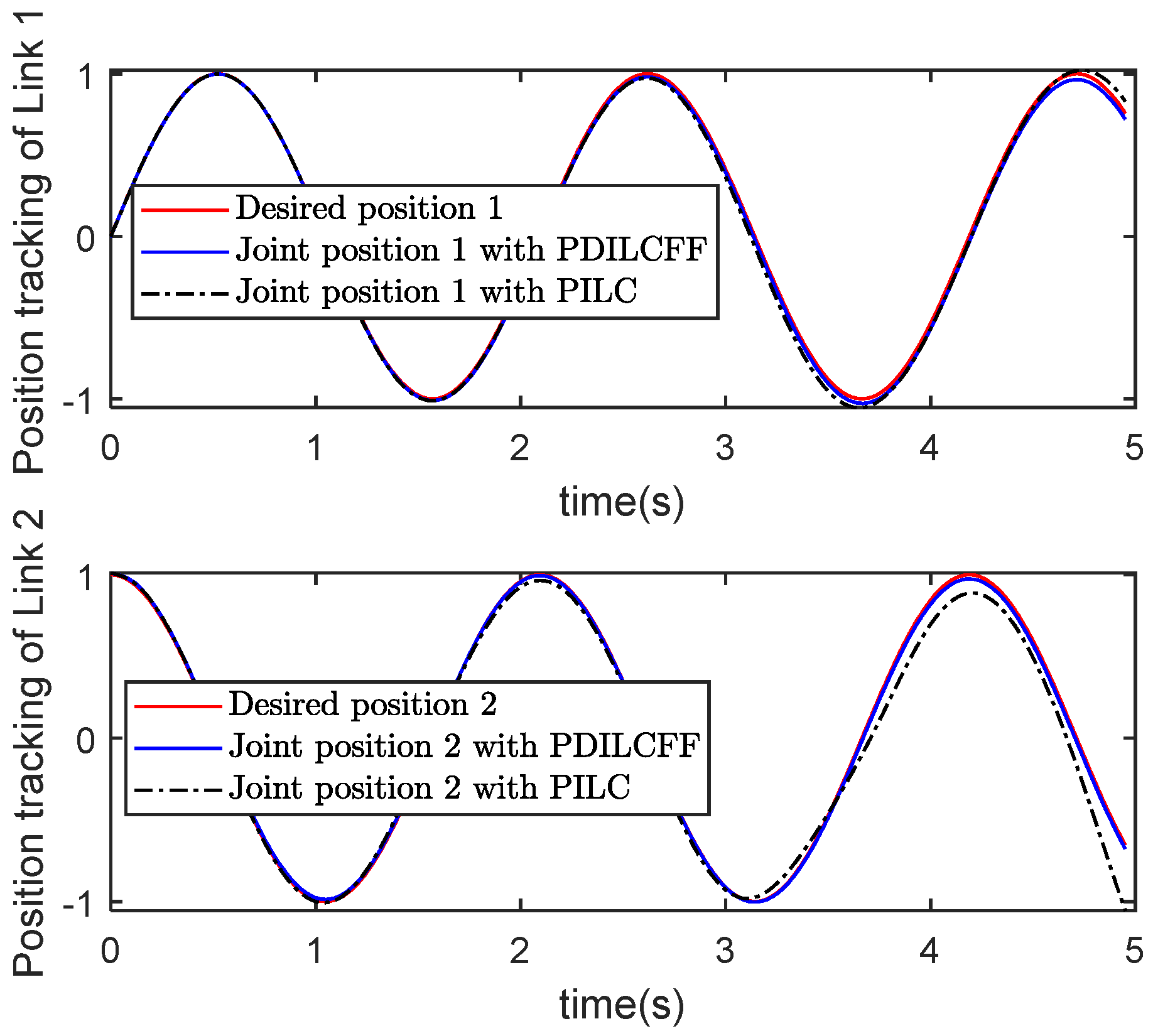
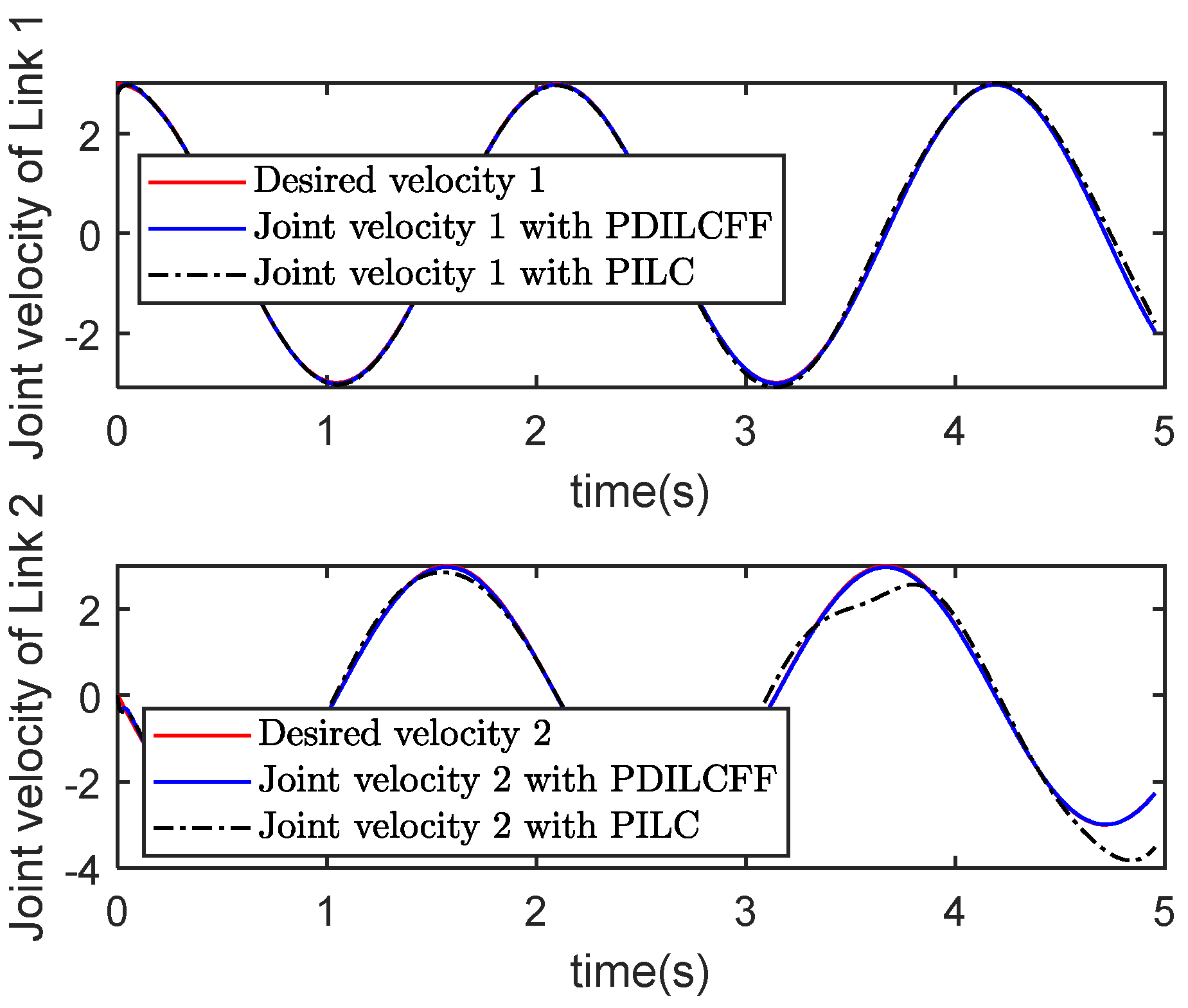
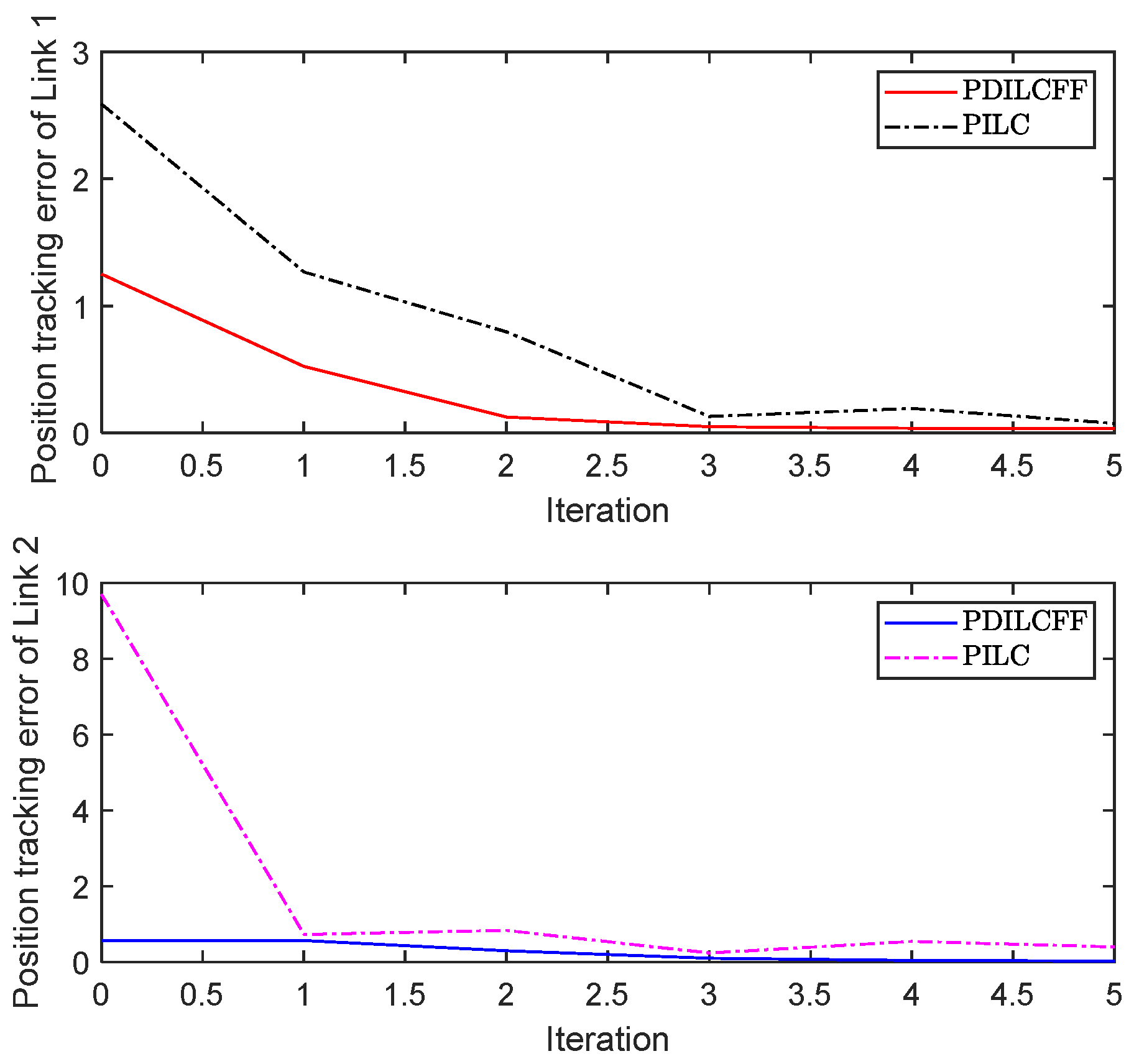
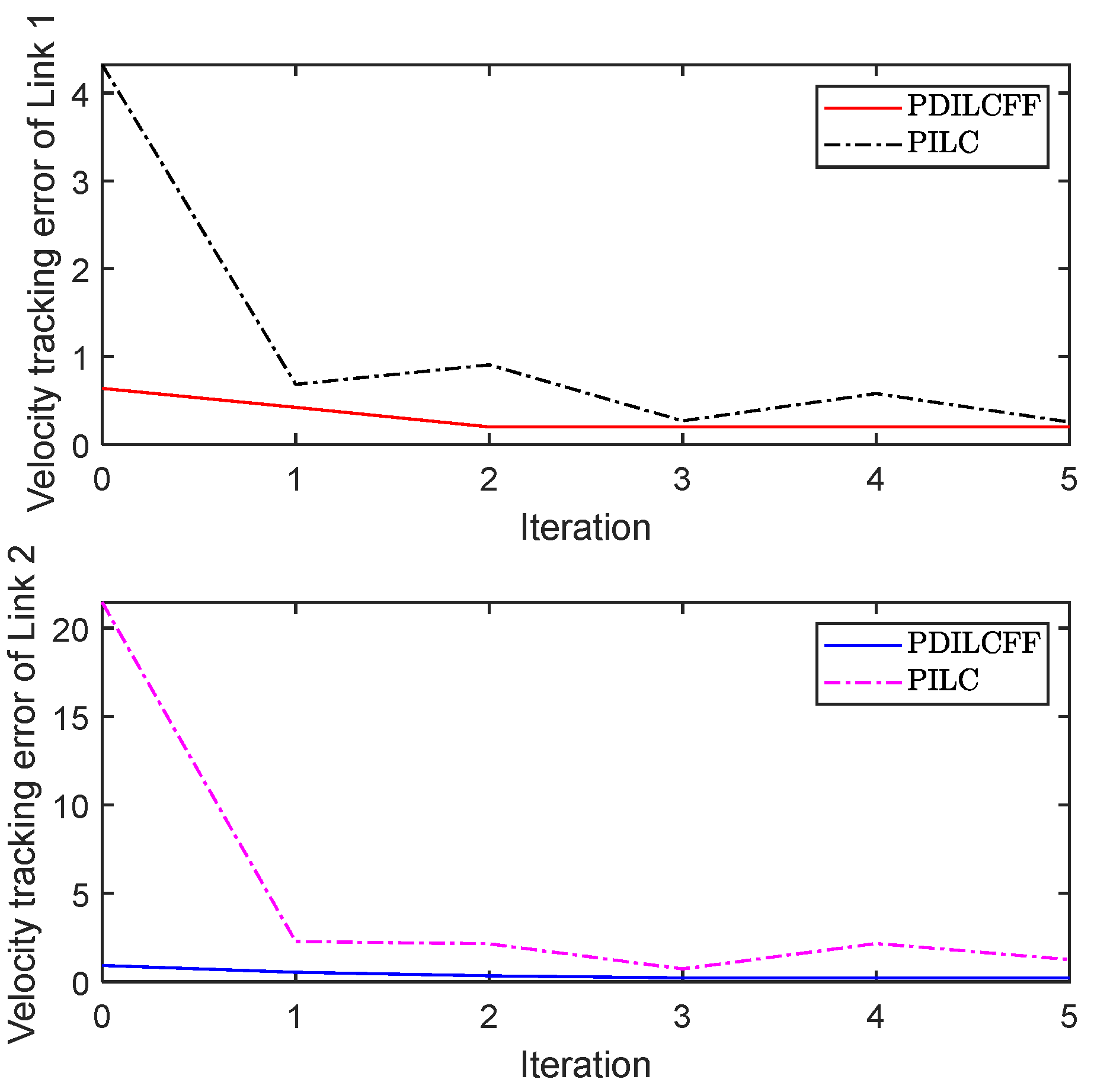
| Control Algorithm | Link 1 of Different Iterations | Link 2 of Different Iterations | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | |
| PDILCFF | 0.42 | 0.20 | 0.21 | 0.20 | 0.20 | 0.55 | 0.35 | 0.23 | 0.22 | 0.22 |
| PILC | 0.68 | 0.91 | 0.27 | 0.58 | 0.25 | 2.28 | 2.15 | 0.74 | 2.17 | 1.25 |
| Control Algorithm | Link 1 of Different Iterations | Link 2 of Different Iterations | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | |
| PDILCFF | 0.53 | 0.13 | 0.25 | 0.04 | 0.03 | 0.58 | 0.30 | 0.10 | 0.04 | 0.03 |
| PILC | 1.28 | 0.80 | 0.13 | 0.19 | 0.08 | 0.73 | 0.84 | 0.24 | 0.55 | 0.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, G.; Wang, Y.; Li, J.; Wang, Q. Iterative Learning Control with Forgetting Factor for MIMO Nonlinear Systems with Randomly Varying Iteration Lengths and Disturbances. Symmetry 2025, 17, 694. https://doi.org/10.3390/sym17050694
Liu G, Wang Y, Li J, Wang Q. Iterative Learning Control with Forgetting Factor for MIMO Nonlinear Systems with Randomly Varying Iteration Lengths and Disturbances. Symmetry. 2025; 17(5):694. https://doi.org/10.3390/sym17050694
Chicago/Turabian StyleLiu, Genfeng, Yangyang Wang, Jinhao Li, and Qinghe Wang. 2025. "Iterative Learning Control with Forgetting Factor for MIMO Nonlinear Systems with Randomly Varying Iteration Lengths and Disturbances" Symmetry 17, no. 5: 694. https://doi.org/10.3390/sym17050694
APA StyleLiu, G., Wang, Y., Li, J., & Wang, Q. (2025). Iterative Learning Control with Forgetting Factor for MIMO Nonlinear Systems with Randomly Varying Iteration Lengths and Disturbances. Symmetry, 17(5), 694. https://doi.org/10.3390/sym17050694