Abstract
High-dimensional data often contain noise and undancy, which can significantly undermine the performance of machine learning. To address this challenge, we propose an advanced robust principal component analysis (RPCA) model that integrates bidirectional graph Laplacian constraints along with the anchor point technique. This approach constructs two graphs from both the sample and feature perspectives for a more comprehensive capture of the underlying data structure. Moreover, the anchor point technique serves to substantially reduce computational complexity, making the model more efficient and scalable. Comprehensive evaluations on both GTdatabase and VGG Face2 dataset confirm that anchor-based methods maintain competitive accuracy with standard graph Laplacian approaches (within 0.5–2.0% difference) while achieving significant computational speedups of 5.7–27.1% and 12.9–14.6% respectively. The consistent performance across datasets, from controlled laboratory conditions to challenging real-world scenarios, demonstrates the robustness and scalability of the proposed anchor technique.
1. Introduction
With the rapid advancement of artificial intelligence technology, machine learning has found extensive applications in various domains, including information retrieval, person re-identification, and face recognition. In execution of these tasks, data are frequently represented as high-dimensional, inevitably exhibiting correlations and containing substantial redundancy and noisy features. The redundant and noisy features may undermine the performance of subsequent tasks, such as clustering, classification, retrieval, or reconstruction. Hence, high-dimensional data pose the “curse of dimensionality” challenge to machine learning algorithms. To enhance the efficacy of machine learning methods, it is imperative to employ feature selection techniques to eliminate irrelevant, redundant, and noisy features from high-dimensional data.
Face recognition has been a prominent area of focus in machine learning. Principal component analysis (PCA) and its various variants have been successfully used for face recognition [1,2,3,4,5,6,7]. Sirovich and Kirby firstly applied PCA to efficiently represent the face images in a lower-dimensional space. Based on the Karhunen-Loeve procedure for the characterization of human faces [1], Turk and Pentland presented the eigenface method for face recognition [2]. Subsequently, Yang et al. [3] proposed a novel technique known as 2DPCA to enhance the recognition rate of conventional PCA. Early PCA methods primarily addressed grayscale images by representing each image as a vector. Specifically, consider a data matrix with rows representing features and columns representing samples. PCA is typically utilized to identify the optimal principal directions that define the low-dimensional (k-dim) subspace. The projected data points with the low subspace U can be denoted as the matrix . Then the traditional PCA finds U and V with the following constrained problem
However, the performance of traditional PCA is typically poor. Outliers, which are prevalent in many scenarios due to factors such as sudden intense interference during transmission, sensor failures, and calibration errors, can significantly impact the results. To address this problem, robust PCA (RPCA) [8] has been proposed to decompose the observed matrix data into a sum of low-rank and sparse matrices, ensuring that no abnormal data disrupts the system. Intuitively, the RPCA can be formulated as the following minimization problem
To address (2) more effectively, researchers relaxed the rank function by the nuclear norm [9,10], thereby transforming the problem into a convex optimization problem, as follows
Although the convex model can accurately yield low-rank and sparse matrices under relatively mild conditions, it overlooks the presence of the noise with small magnitudes. This oversight is significant because, in real-world scenarios, data often suffer from contamination by the noise. To address this limitation, Zhou et al. [11] introduced a method that decomposed the data matrix into three components: a low-rank matrix, a sparse matrix, and a noise matrix
However, color information is not fully exploited, despite being a crucial characteristic for enhancing image discriminability. To address this, Torres et al. [4] extended traditional PCA to color face recognition by applying it separately to the color channels, with the final result obtained by fusing the outcomes from all three channels. Building upon this foundation, Yang et al. [5] proposed a general discriminant model for color face recognition, which employs a set of color component combination coefficients to merge the three color channels into a single channel, representing color face images. Furthermore, Xiang et al. [6] introduced a matrix-representation model for color images based on the PCA framework and applied 2DPCA to compute optimal projection vectors for feature extraction. A more generalized approach, as opposed to the aforementioned channel-wise processing techniques, involves representing color images through quaternion matrices, which inherently encode color channels in a holistic manner. This avoids artificial separation of Red-Green-Blue (RGB) components and preserves inter-channel correlations. Recent works have utilized quaternion PCA (QPCA) for dimensionality reduction [12,13,14,15,16,17,18]. Notably, Wang et al. [19] demonstrated that the matrix equation AXB = C is fundamental to optimizing quaternion-based models, where solutions over quaternions and their extensions enable efficient color image processing while preserving color integrity, particularly in feature extraction and multi-channel image encryption. In complementary technical advancement, Jia et al. [20] constructed general solutions for split-quaternion tensor equations, extending the processing scope to dynamic videos while significantly enhancing computational efficiency and security through the pseudo-Euclidean properties of split quaternions.
The purpose of these non-linear dimensionality reduction techniques is to find a representation of points in a low-dimensional space, in which all points still maintain the similarity in the lower-dimensional space. In recent years, optimization models that combine linear and non-linear dimensionality reduction methods, especially graph Laplacian embedding, have demonstrated their effectiveness. Cai et al. [21] proposed a graph regularized non-negative matrix factorization (GNMF) method, which combined graph structure and non-negative matrix factorization for an improved compact representation of the original data. Building upon this, Jiang et al. [22] developed graph Laplacian PCA (GLPCA), which sought a low-dimensional representation of image data with significant improvement in clustering and image reconstruction by incorporating graph structures and PCA. Further advancing this line of research, Feng et al. [23] employed PGLPCA based on graph Laplacian regularization and Lp-norm for feature selection and tumor clustering. Parallel developments include Liu et al.’s [24] graph Laplacian matrix formulation for semi-supervised feature extraction and Wang et al.’s [25] Laplacian regularized low-rank representation (LLRR), which successfully captures the intrinsic geometric structure of gene expression data for improved tumor sample clustering. Building on these methods, Yang et al. [26] developed an innovative online algorithm using Monte Carlo sampling for sparse graph-constrained matrix optimization, effectively solving feature selection problems while maintaining manifold structures.
To fully exploit the spatial and spectral features of images, we propose constructing two complementary graphs. One graph captures temporal or sample-based relationships among superpixels e.g., the columns of the data matrix X, while the other encodes spatial relationships among pixel locations e.g., the rows of the data matrix X. By integrating these two graphs, we effectively harness both spatial and spectral information, resulting in a more comprehensive representation of the image data. This dual-graph strategy enhances the model’s capacity to capture the inherent structure of the data, thereby improving performance in tasks like image segmentation, classification, and reconstruction.
Furthermore, to expedite the construction of the graph Laplacian matrix and streamline the computational process, we introduce the notion of anchor points. These anchor points serve as representative samples that encapsulate the data’s structure, significantly reducing the number of pairwise comparisons needed during graph construction. Instead of calculating relationships between all data points, we select a subset of anchor points (using methods such as random sampling, K-means, or other clustering techniques) and build the graph based on the relationships between data points and these anchors. This approach not only reduces computational complexity but also preserves the geometric and relational properties of the data, enabling the method to scale to large datasets without compromising the quality of the embeddings or the performance of downstream tasks.
The main contributions of our work are outlined as follows
- 1.
- Integration of Graph Laplacian Embedding with RPCA We incorporate graph Laplacian embedding into RPCA to account for the spatial information inherent in the data. By representing the data as a graph, where nodes correspond to data points and edges reflect pairwise relationships (such as similarity or distance), the graph Laplacian matrix effectively captures the dataset’s underlying geometric structure.
- 2.
- Exploitation of Two-Sided Data Structure We leverage a dual perspective by obtaining the graph Laplacian from both the sample and feature dimensions. This approach enables us to capture intrinsic relationships not only among data points (samples) but also among features, thereby providing a more holistic representation of the data.
- 3.
- Introduction of Anchors for Computational Efficiency We introduce the concept of anchors to enhance the model’s running speed and reduce computational complexity. Anchors serve as representative points that summarize the data’s structure, thereby minimizing the number of pairwise comparisons needed during graph construction. Instead of computing relationships between all data points, we select a subset of anchors (using methods like random sampling, K-means, or other clustering techniques) and construct the graph based on the relationships between data points and these anchors. This method significantly reduces the size of the adjacency matrix and, consequently, the computational burden associated with the graph Laplacian.
The rest of the paper is organized as follows. Section 2 provides an overview of the fundamental theoretical foundations including quaternion and quaternion matrix, graphs, graph Laplacian embedding and anchor point technique. In Section 3, we present the proposed algorithm and methodology. Subsequently, Section 4 demonstrates the experimental results using real-world facial image datasets. Finally, Section 5 concludes the paper with a summary of our findings and contributions.
2. Preliminaries
2.1. Quaternion and Quaternion Matrix
Introduced by mathematician Hamilton in 1843 [27], quaternion generalizes complex numbers by incorporating one real part and three imaginary parts. A quaternion can be expressed as
where , and are three imaginary units that follow the multiplication rules
The conjugate and modulus of quaternion a are defined as follows
A quaternion matrix takes the form
with , and its conjugate transposed matrix is given by . A pure quaternion matrix provides a representation for color images, with its three imaginary components corresponding to the red, green, and blue channels, respectively. Furthermore, the real representation method is a widely used technique for transforming quaternion matrices into the corresponding real matrices, the real representation of the matrix A is shown as
and the first block column of is denoted by
Property 1.
For , the following properties hold [28].
- 1.
- .
- 2.
- , where denotes transpose operation.
- 3.
- A is a column unitary matrix if and only if is a column orthogonal matrix.
2.2. Graph
Let be an undirected weighted graph. The weight value between and is denoted by . If there is no edge between and , i.e., , then . The matrix is called the adjacency matrix of G. We define the degree matrix D, which is a diagonal matrix whose diagonal entry equals to the sum of weights of all edges incident to i, i.e., . Subsequently, the graph Laplacian matrix is defined as follows
In some applications, the normalized graph Laplacian is used, defined as
Property 2.
Let L denote a graph Laplacian matrix. Then the following properties hold [29].
- 1.
- For each vector , we have
- 2.
- L is symmetric and positive semi-definite.
- 3.
- The smallest eigenvalue of L is 0, and corresponding eigenvector is 1 whose elements are all ones.
- 4.
- L has n non-negative real eigenvalues .
2.3. Graph Laplacian Embedding
Graph Laplacian embedding has emerged as a widely-used technique in nonlinear manifold learning, aiming to preserve the local geometric structure of data. The underlying assumption is that points which are close in the original data space should maintain their proximity in the embedded space. To achieve this, a nearest neighbor graph is constructed to capture and model the local relationships among data points.
Given the data matrix , where denotes a data sample or one vertex in the graph. For each data point , we connect each to its k nearest neighbors. Here, we adopt Euclidean distance to measure the similarity between the data samples.
Let represent embedding coordinates of data samples . The dissimilarity of the two data points in the lower-dimensional space can be measured by the Euclidean distance. Define the dissimilarity of the two data points in the lower-dimensional space as , combining with the weight matrix W, the smoothness of the low-dimensional representation can be measured by minimizing the following equation [30]
where is a diagonal matrix, and is the graph Laplacian matrix.
2.4. Anchors
Anchor point techniques play a critical role in data representation and learning, effectively reducing computational costs while capturing the underlying structure of the data. In practice, anchors serve as critical and highly representative entities within data samples, functioning similarly to a basis set in linear space. Given a dataset , anchor points with , act as reference points in the data space. These can be strategically selected based on prior knowledge, such as class centers, or learned through methods like K-means clustering. The primary advantage of using anchors, as discussed in this paper, is their ability to rapidly and efficiently construct similarity matrices. This characteristic endows anchors with significant benefits for handling large-scale datasets and uncovering latent relationships among data samples. Additionally, in the following context, various methodologies for anchor generation will be discussed.
- 1.
- K-means method for anchor pointsWe adopt the K-means clustering algorithm to derive a set of anchor points, which serve as representative prototypes for the underlying data distribution. Considering a dataset , the K-means algorithm aims to partition X into k disjoint clusters by minimizing the within-cluster sum of squares, formulated as [31]where denotes the i-th cluster and is its centroid, namely the anchor points.
- 2.
- BKHK method for anchor pointsThe Balanced and Hierarchical K-means (BKHK) algorithm is a hierarchical anchor point selection method that combines K-means and hierarchical clustering to recursively construct evenly distributed anchor points, thereby improving representation ability. In contrast to conventional K-means algorithms that execute a single-step partitioning of the dataset into a predetermined number of clusters, BKHK employs a hierarchical partitioning strategy. It recursively divides the dataset X into m sub-clusters, performing binary K-means at each step. This process continues until the desired number of clusters is achieved. The objective function of Balanced Binary K-means is defined as follows [32]where represents the two class centers, and is the class indicator matrix.
The construction of the similarity matrix based on representative anchors is a well-explored problem. In our approach, we choose to measure the distance using the Euclidean distance. To be specific, our objective is to learn a similarity matrix , in a way that a smaller distance corresponds to a larger affinity value. This allows us to formulate the optimization problem as follows
In many cases, we prefer Z to be a sparse matrix, such that has k nonzero values corresponding to the k-nearest anchors. Consequently, the maximal is determined by solving the following problem
Suppose , and are arranged from small to large. The solution to (19) is . Therefore, the solution to (18) can be obtained as follows
After obtaining the matrix Z, we construct the similarity matrix A using the formula
Here, is a diagonal matrix with the j-th diagonal element calculated as . In practical applications, we can obtain A without explicitly computing it by utilizing , where .
3. Methodology
Our methodology employs pure quaternion representation for color facial images to fundamentally preserve the holistic color structure, where the imaginary units’ multiplicative relationships inherently maintain photometric constraints between RGB channels. The sample dataset comprises l color facial images, where n labeled images form the training set X, denoted as , and unlabeled images constitute the test set Y, denoted as . Each color facial image is initially represented as a quaternion matrix , where denotes the quaternion space. To facilitate numerical computation, the quaternion matrix Q is transformed into its real representation matrix . The conversion from quaternion to real-valued matrix representations is theoretically justified by the isomorphic mapping that preserves the complete algebraic structure of quaternion operations through equivalent block matrix representations in real space, ensuring all inter-channel relationships critical for color processing are maintained. This transformation enables practical implementation within standard numerical computing frameworks where real-valued operations dominate, providing essential compatibility with hardware-accelerated matrix computation architectures and conventional machine learning pipelines while retaining the representational advantages of quaternion algebra. The approach effectively bridges theoretical purity with computational pragmatism, allowing quaternion-based color processing techniques to be deployed efficiently in real-world systems. Due to the information redundancy of the real representation matrix, the first column block of , is vectorized into , where . The data matrix X and the test matrix Y are constructed by column-wise concatenation of these vectors, resulting in and .
In robust principal component analysis (RPCA), it is well-established that data signals are typically decomposed into a sum of low-rank terms, sparse terms, and noise terms that are statistically modeled. This decomposition can be mathematically expressed as
The columns of matrix L span a low dimensional subspace, while matrix S contains only a sparse set of non-zero entries. Typically, it is assumed that the elements of matrix E are drawn from a Gaussian distribution with a mean of zero. The low-rank component L can be factorized as , allowing Equation (22) to be reformulated as
where and . It is important to note that, due to the inherent constraints imposed by this factorization, a low-rank structure is implicitly enforced on matrix L, even though k might still exceed the true rank of L. In Equation (23), the columns of matrix U define the low-dimensional subspace in which the columns of matrix L reside, while matrix V represents the corresponding coefficients within this subspace.
To capture the geometric structures of the sample and feature manifolds in facial data, we use two graphs, namely a sample graph for columns and a feature graph for rows, each tailored to its respective dimension.
Initially, a k-nearest-neighbors sample graph is constructed, with its vertices corresponding to the data points . We adopt a 0-1 weighting scheme to establish the k-nearest-neighbors data graph. Consequently, the sample weight matrix can be formally defined as
where is the k-nearest neighbor of and is the graph Laplacian matrix of the sample, where is a diagonal degree matrix.
Similarly to the methodology employed for constructing the sample weight matrix, we obtain the feature weight matrix as follows
The feature graph Laplacian matrix is defined as .
Via integrating graph regularization for both sample and feature manifolds with the RPCA model, we propose a novel dual graph regularized principal component analysis model. This model is designed to simultaneously capture the inherent geometric structures within the data across both manifolds. The corresponding objective function is formulated as follows
where the parameter is used to balance the contribution of the graph Laplacian regularization term and the parameter is used to balance the contribution of the sparse term. Furthermore, the overall workflow is depicted in Figure 1.
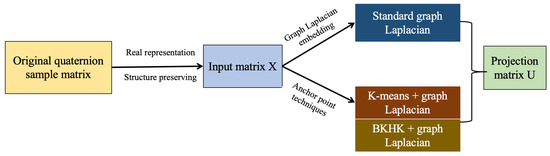
Figure 1.
The overall workflow for dual graph Laplacian RPCA model with the anchor techniques.
Our proposed method for deriving the projection matrix U, as detailed in the flowchart shown in Figure 1, comprises three fundamental components. The processing pipeline begins with the encoding of input color images as pure quaternion matrices, and these matrices undergo an isomorphic transformation to their real representation, preserving the complete quaternion algebraic structure through block matrix representation. Subsequent dimensionality reduction is achieved through strategic extraction and vectorization of the principal column block, yielding the final data matrix. For the second component, we implement a sophisticated dual-graph framework through two methods. Among them, the KNN graph serves as a standard method for constructing the graph Laplacian matrix. In contrast, the anchor techniques we employ here, namely K-means and the BKHK method, function as acceleration strategies. Finally, the complete model is solved through the ADMM to obtain the projection matrix U, which will be elaborated upon later.
We employ the Augmented Lagrangian Multiplier (ALM) method to optimize the objective function. This approach reformulates the constrained optimization problem into a sequence of unconstrained subproblems by incorporating Lagrange multipliers and penalty terms. Through this iterative process, the method progressively converges towards the optimal solution. In the context of utilizing the ALM method to derive the optimal solution, we substitute Z for , and (26) can be equivalently reformulated as follows
According to the ALM method, (27) can be equivalently minimized as
where and are Lagrange multipliers, and and are the step size in the update rule.
Given that there are four variables requiring solution, the Alternating Direction Method of Multipliers (ADMM) is employed to address this problem. It simplifies the solution process by allowing us to solve for a single variable while keeping the others fixed. By applying this method, the optimization problem represented by (28) can be naturally decomposed into four subproblems.
Problem 1.
Problem 2.
With variables fixed, the variable U is solved by rewriting (28)
By computing the partial derivative with respect to the variable U in (32), we obtain
By setting the Equation (33) equal to 0, the updated iteration formula for variable U can be addressed via the Sylvester equation, which takes the standard form where is the solution matrix, as showed below
Problem 3.
With variables fixed, the variable V is solved by rewriting (28)
Similar to the procedure outlined in (33), we derive the partial derivative of the variable U in Equation (37)
The updated iteration formula for variable V also involves solving the Sylvester equation, which also takes the standard form where is the solution matrix, as detailed below
Problem 4.
Therefore, building upon the Augmented Lagrangian Method (ALM) and Alternating Direction Method of Multipliers (ADMM), we present the detailed optimization procedure in Algorithm 1.
| Algorithm 1 The solution to optimize (26) |
Having established the optimization framework, we next present a rigorous convergence analysis of our algorithm.
Theorem 1.
Under the following conditions:
- 1.
- The graph Laplacian matrices are positive semi-definite,
- 2.
- The iterative matrices and maintain full column rank,
- 3.
- The parameters satisfy , , and ,
the proposed algorithm exhibits the following convergence properties:
- 1.
- Monotonic decrease of the objective function:where , with and .
- 2.
- Convergence of primal variables:
- 3.
- Convergence of Lagrangian multipliers:
Proof. Part 1:
Monotonicity of the Objective Function
The difference in the Lagrangian can be decomposed as:
For each subproblem, we establish the following bounds:
- Z-subproblem:
- S-subproblem:
- V-subproblem:
- U-subproblem:
Combining these bounds yields the monotonic decrease property in (43).
Part 2: Convergence of Primal Variables
Since the sequence is bounded below and monotonically decreasing, we have:
which implies (44).
Part 3: Convergence of Lagrangian Multipliers
From the update rules:
and similarly for , establishing (45). □
4. Experiments
4.1. Datasets
The proposed model is rigorously evaluated on the Georgia Tech face dataset [33] and the VGG Face2 dataset [34]. The Georgia Tech face dataset serves as a well-controlled benchmark, containing facial images from 50 distinct subjects with 15 samples per subject, exhibiting carefully captured variations in lighting conditions, diverse facial expressions including neutral, smiling and surprised states, and head poses (e.g., frontal, side views). While the VGG Face2 dataset serves as a comprehensive large-scale benchmark, containing over 3 million facial images from more than 9000 distinct subjects, with each subject represented by an average of 300 samples exhibiting natural variations in real-world conditions. The dataset captures significant challenges including extreme pose variations, diverse facial expressions in uncontrolled environments, substantial variations in illumination conditions (both indoor and outdoor settings), and various types of occlusions (e.g., glasses, hair, hands). This diversity facilitates robust assessment of model generalization under challenging real-world conditions. We use 50 subjects from GT database and select 40 subjects from VGG Face2 dataset, where representative samples of GT database are visualized in Figure 2. All images in both database are preprocessed by manual cropping and resizing to a uniform resolution of pixels.

Figure 2.
Sample images for one individual of the GTdatabase.
4.2. Parameter Selection
Our model involves six critical parameters: , , , , k and r, which must be carefully tuned in the formulation (28). The regularization parameters and were determined via comprehensive sensitivity analysis, as shown in Figure 3. For the regularization parameters and , we adopt and as suggested in [5,30]. Additionally, the parameter selection of k and r was carefully determined based on the dataset characteristics ( samples, features) and extensive empirical validation. For the graph construction, we set nearest neighbors, which represents approximately 2% of the total sample size. This proportion ensures adequate local structure representation while avoiding overfitting. Furthermore, considering the original dimensions, we respectively set and to compare the final results. These parameter choices are carefully calibrated to optimize the model’s performance across diverse scenarios.
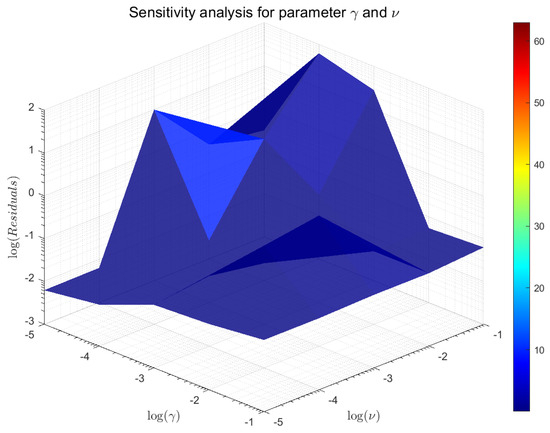
Figure 3.
Sensitivity analysis for parameter and , where the residual is .
4.3. Experiment Results
Using the learned projection matrix U, we project the test samples into the low-dimensional space and compute their similarity to the training samples in this reduced space using Euclidean distance. This enables nearest neighbor classification, where recognition results are determined by identifying the closest matches based on similarity. To evaluate the model’s performance, we employ two metrics: the standard accuracy (ACC) and the convergence time. ACC measures the face matching accuracy, defined as the ratio of correctly classified samples to the total number of test samples, providing a quantitative assessment of the model’s recognition capability. Specifically, ACC is calculated as
where is the predicted label of a test sample and is the real label of the test sample. equals 1 if and 0 otherwise.
We partitioned the dataset into training and test sets with ratios of 0.7 and 0.8 corresponding to the GTdatabase and VGG Face2 dataset, respectively. To ensure statistical reliability and robustness, the results reported are the average values obtained from 10 independent trials, providing a more precise and representative assessment of the model’s performance.
For the -nearest neighbors, we set the dimensionality reduction parameter to . The corresponding accuracy and runtime of the model, evaluated using the original graph Laplacian matrix, the graph Laplacian matrix constructed via K-means, and the graph Laplacian matrix generated by the BKHK method, are summarized in Table 1.

Table 1.
Results of RPCA with graph Laplacian constraint on GTdatabase (r = 200).
Similarly, for the -nearest neighbors, we conducted an additional experiment with the dimensionality reduction parameter set to . The accuracy and runtime of the model with original graph Laplacian matrix, graph Laplacian matrix constructed via K-means, and graph Laplacian matrix generated by the BKHK method are summarized in Table 2.
Table 2.
Results of RPCA with graph Laplacian constraint on GTdatabase (r = 100).
Additionally, we conducted the same experiments on VGG Face2 dataset and obtained the results at two dimensionality reduction settings ( and ) as shown in Table 3 and Table 4:
Table 3.
Results of RPCA with graph Laplacian constraint on VGG Face2 dataset ().
Table 4.
Results of RPCA with graph Laplacian constraint on VGG Face2 dataset ().
The experimental results demonstrate that while the standard graph Laplacian method achieves marginally superior accuracy (0.5–0.9% higher on GTdatabase and comparable performance within ±0.25% on VGG Face2), the BKHK-based anchor approach offers significantly enhanced computational efficiency, achieving speedups of 12.9–27.1% across both datasets. Crucially, these computational improvements are attained with minimal accuracy degradation (maintaining 94–97% of the standard method’s recognition performance). The BKHK method’s superior scalability characteristics, evidenced by its more favorable computational complexity growth with increasing dataset size, make it particularly well-suited for large-scale face recognition applications where processing efficiency is critical. These findings collectively demonstrate that the BKHK approach provides an optimal balance between recognition accuracy and computational efficiency, offering a practical solution for real-world deployment scenarios that demand both high performance and scalability.
5. Conclusions
In this study, we present an advanced RPCA framework incorporating bidirectional graph Laplacian constraints and an anchor point strategy, achieving enhanced computational efficiency while preserving recognition accuracy in facial analysis. The dual-graph architecture captures intrinsic geometric relationships from both sample and feature perspectives, maintaining structural and discriminative characteristics of high-dimensional data. The anchor point techniques serves as a core component of this paper, where anchor points are selected as referrence sample points to efficiently construct the similarity matrix. In this regard, this paper compares the accuracy of several different anchor technologies in face recognition. To verify the reliability of the algorithm, a convergence analysis is also provided in this paper. Finally, extensive experiments on the GTdatabase and VGG Face2 dataset demonstrate superior processing speed and sustained accuracy under challenging conditions including illumination variations, expressions, and pose changes. While the anchor point strategy effectively reduces computational complexity with minimal accuracy loss, several limitations warrant consideration regarding sensitivity to anchor selection in non-uniform data distributions, memory overhead from graph matrix storage, and performance degradation when handling extreme occlusions. These challenges motivate three key future directions: developing scalable network architectures through dynamic anchor selection and adaptive graph sparsification, optimizing real-time execution capabilities via hardware-aware parallel computing strategies, and extending the framework to broader computer vision objectives such as video-based action recognition and 3D object analysis. Beyond facial analysis, the framework’s core methodology shows potential for extension to other domains involving high-dimensional data with underlying geometric structure, such as medical image analysis and multimodal sensor fusion applications. Future work will focus on developing dynamic graph learning capabilities for video-based recognition systems and exploring quantum computing adaptations to address fundamental complexity challenges, potentially opening new possibilities for large-scale pattern recognition systems.
Author Contributions
Conceptualization, S.-T.Z. and J.-F.C.; methodology, S.-T.Z. and J.-F.C.; software, S.-T.Z. and J.-F.C.; validation, S.-T.Z. and J.-F.C.; formal analysis, S.-T.Z.; resources, Q.-W.W.; data curation, S.-T.Z.; writing—original draft preparation, Q.-W.W. and S.-T.Z.; writing—review and editing, Q.-W.W., S.-T.Z. and J.-F.C.; visualization, S.-T.Z. and J.-F.C.; supervision, Q.-W.W.; project administration, Q.-W.W.; funding acquisition, Q.-W.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by the National Natural Science Foundation of China (No. 12371023).
Data Availability Statement
Data are contained within the paper. Readers can contact the authors to obtain the code for this paper.
Conflicts of Interest
The authors declare no conflict of interest.
Notation
| Notation | Description |
| X | data matrix of size |
| n | number of samples |
| m | number of features |
| the i-th column of X | |
| the i-th row of X | |
| the trace norm of the matrix A | |
| the Frobenius norm of the matrix A |
References
- Kirby, M.; Sirovich, L. Application of the Karhunen-Loeve procedure for the characterization of human faces. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 103–108. [Google Scholar]
- Turk, M.; Pentland, A. Eigenfaces for recognition. J. Cognit. Neurosci. 1991, 3, 71–86. [Google Scholar]
- Yang, J.; Zhang, D.; Frangi, A.F.; Yang, J.Y. Two-dimensional PCA: A new approach to appearance-based face representation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 131–137. [Google Scholar] [PubMed]
- Torres, L.; Reutter, J.Y.; Lorente, L. The importance of the color information in face recognition. In Proceedings of the 1999 International Conference on Image Processing (Cat. 99CH36348), Kobe, Japan, 24–28 October 1999; Volume 3, pp. 627–631. [Google Scholar]
- Yang, J.; Liu, C. A general discriminant model for color face recognition. In Proceedings of the IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–6. [Google Scholar]
- Xiang, X.; Yang, J.; Chen, Q. Color face recognition by PCA-like approach. Neurocomputing 2015, 228, 231–235. [Google Scholar]
- Zhu, Y.; Zhu, C.; Li, X. Improved principal component analysis and linear regression classification for face recognition. Signal Process. 2018, 145, 175–182. [Google Scholar]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust Principal Component Analysis: Exact Recovery of Corrupted Low-rank Matrices via Convex Optimization. Adv. Neural Inf. Process. Syst.s 2009, 22, 2080–2088. [Google Scholar]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis. J. ACM 2009, 58, 1–37. [Google Scholar]
- Wright, J.; Ma, Y. Dense error correction via l1-minimization. lEEE Trans. Inf. Theory 2010, 56, 3540–3560. [Google Scholar]
- Zhou, T.; Tao, D. Greedy Bilateral Sketch, Completion & Smoothing. In Artificial Intelligence and Statistics; PMLR: Birmingham, UK, 2013; Volume 31, pp. 650–658. [Google Scholar]
- Le Bihan, N.; Sangwine, S.J. Quaternion principal component analysis of color images. In Proceedings of the 2003 International Conference on Image Processing (Cat. No.03CH37429), Barcelona, Spain, 14–17 September 2003; pp. 809–812. [Google Scholar]
- Jia, Z. The Eigenvalue Problem of Quaternion Matrix: Structure-Preserving Algorithms and Applications; Science Press: Beijing, China, 2019. [Google Scholar]
- Denis, P.; Carre, P.; Fernandez-Maloigne, C. Spatial and spectral quaternionic approaches for colour images. Comput. Vis. Image Understand. 2007, 107, 74–87. [Google Scholar]
- Shi, L.; Funt, B. Quaternion color texture segmentation. Comput. Vis. Image Understand. 2007, 107, 88–96. [Google Scholar]
- Zou, C.; Kou, K.I.; Wang, Y. Quaternion collaborative and sparse representation with application to color face recognition. IEEE Trans. Image Process. 2016, 25, 3287–3302. [Google Scholar]
- Xiao, X.; Chen, Y.; Gong, Y.J.; Zhou, Y. 2D quaternion sparse discriminant analysis. IEEE Trans. Image Process. 2020, 29, 2271–2286. [Google Scholar]
- Chen, Y.; Xiao, X.; Zhou, Y. Low-rank quaternion approximation for color image processing. IEEE Trans. Image Process. 2020, 29, 1426–1439. [Google Scholar]
- Wang, Q.W.; Xie, L.M.; Gao, Z.H. A Survey on Solving the Matrix Equation AXB = C with Applications. Mathematics 2025, 13, 450. [Google Scholar] [CrossRef]
- Jia, Z.R.; Wang, Q.W. The General Solution to a System of Tensor Equations over the Split Quaternion Algebra with Applications. Mathematics 2025, 13, 644. [Google Scholar] [CrossRef]
- Cai, D.; He, X.F.; Han, J.W.; Huang, T.S. Graph regularized nonnegative matrix factorization for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1548–1560. [Google Scholar]
- Jiang, B.; Ding, C.; Luo, B.; Tang, J. Graph-laplacian PCA: Closed-form solution and robustness. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013. [Google Scholar]
- Feng, C.; Gao, Y.L.; Liu, J.X.; Zheng, C.H.; Yu, J. PCA based on graph laplacian regularization and P-norm for gene selection and clustering. IEEE Trans. Nanobiosci. 2017, 16, 257–265. [Google Scholar]
- Liu, J.X.; Wang, D.; Gao, Y.L.; Zheng, C.H.; Shang, J.L.; Liu, F.; Xu, Y. A joint-L2,1-norm-constraint-based semi-supervised feature extraction for RNA Seq data analysis. Neurocomputing 2017, 228, 263–269. [Google Scholar]
- Wang, J.; Liu, J.X.; Kong, X.Z.; Yuan, S.S.; Dai, L.Y. Laplacian regularized low-rank representation for cancer samples clustering. Comput. Biol. Chem. 2019, 78, 504–509. [Google Scholar]
- Yang, N.Y.; Duan, X.F.; Li, C.M.; Wang, Q.W. A new algorithm for solving a class of matrix optimization problem arising in unsupervised feature selection. Numer. Algorithms 2024. [Google Scholar] [CrossRef]
- Hamilton, W.R. Lectures on Quaternions. In Landmark Writings in Western Mathematics 1640–1940; Hodges and Smith: Dublin, Ireland, 1853. [Google Scholar]
- Jiang, T. Algebraic methods for diagonalization of a quaternion matrix in quaternionic quantum theory. J. Math. Phys. 2005, 46, 052106. [Google Scholar]
- Ding, L.; Li, C.; Jin, D.; Ding, S.F. Survey of spectral clustering based on graph theory. Pattern Recognit. 2024, 151, 110366. [Google Scholar]
- Kong, X.Z.; Song, Y.; Liu, J.X.; Zheng, C.H.; Yuan, S.S.; Wang, J.; Dai, L.Y. Joint Lp-Norm and L2,1-Norm Constrained Graph Laplacian PCA for Robust Tumor Sample Clustering and Gene Network Module Discovery. Front. Genet. 2021, 12, 621317. [Google Scholar]
- Zhao, H. Design and Implementation of an Improved K-Means Clustering algorithm. Mob. Inf. Syst. 2022, 2022, 6041484. [Google Scholar] [CrossRef]
- Gao, C.H.; Chen, W.Z.; Nie, F.P.; Yu, W.Z.; Wang, Z.H. Spectral clustering with linear embedding: A discrete clustering method for large-scale data. Pattern Recognit. 2024, 151, 110396. [Google Scholar]
- The Georgia Tech Face Database. Available online: http://www.anefian.com/research/face_reco.htm (accessed on 15 February 2025).
- The VGG Face2 Dataset. Available online: https://www.robots.ox.ac.uk/~vgg/data/vgg_face2/ (accessed on 15 February 2025).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).