
Integrated Scheduling Algorithm Based on the Improved Floyd Algorithm

Abstract
1. Introduction
- (1)
- The Floyd algorithm was improved to establish the scheduling sequence by taking the processing time of the immediate successor process as the path value of its adjacent processes;
- (2)
- In the aspect of vertical optimization, the path-weighted strategy is designed based on the improved Floyd algorithm, and the effect of horizontal and vertical optimization is improved by combining the position advantage of the leaf node process;
- (3)
- The scheduling advantage strategy is proposed. All devices are scheduled from the starting point, dynamically adjusting idle time for symmetric stability and asymmetric flexibility, and the utilization rate of the equipment is further improved.
2. Related Work
3. Problem Analysis and Mathematical Modeling
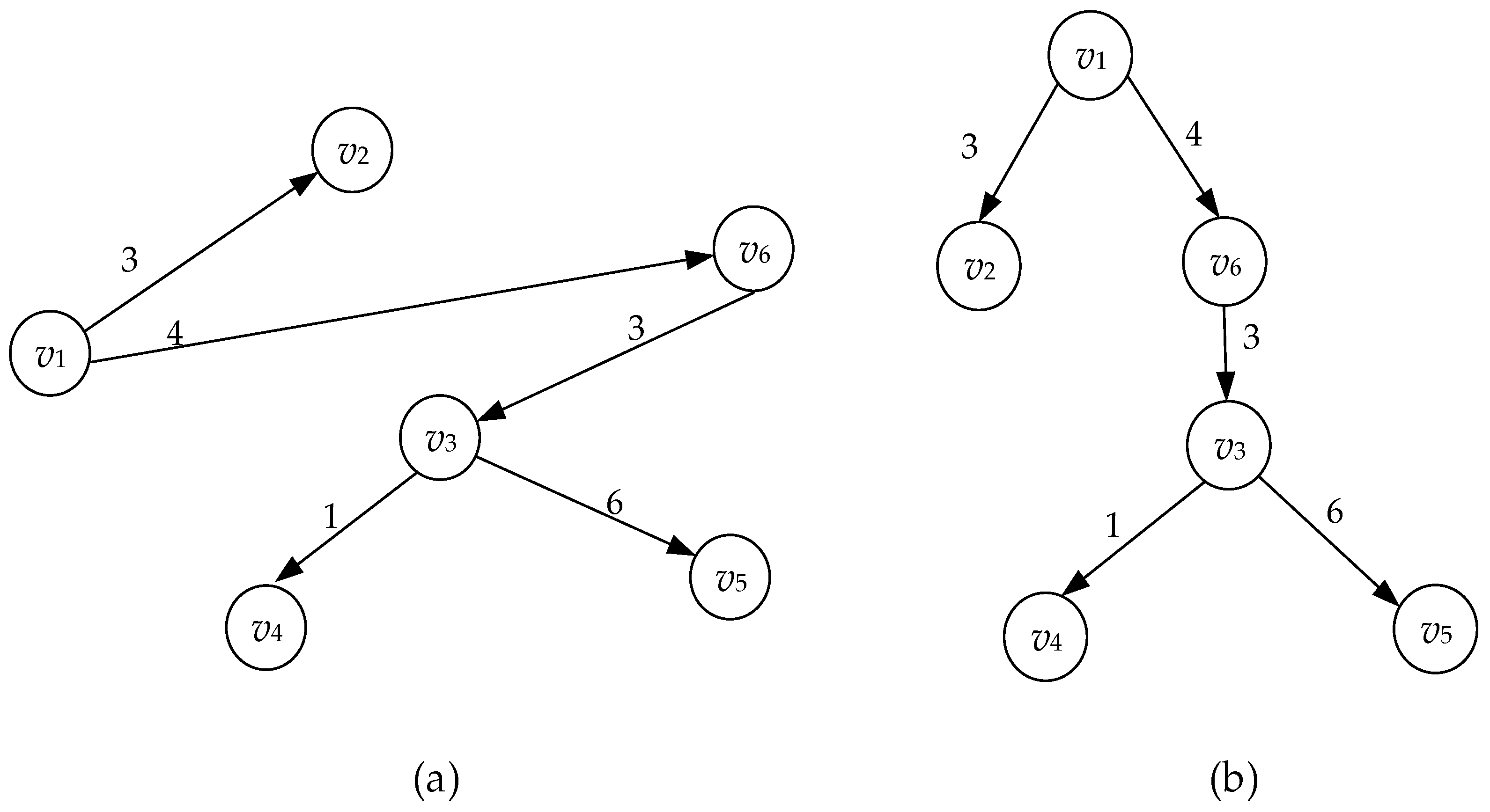
3.1. Floyd Algorithm Weight Matrix
3.2. Unidirectional Weighted Digraph
3.3. Integrated Scheduling Analysis
- (1)
- Each process contains a series of attributes: process numbers, machine numbers, and processing time. Additionally, the corresponding machine of each process is known, and the compulsory relationships between processes are known;
- (2)
- When the equipment executes the process processing, its operation time is clear, and once the processing begins, the continuous processing process will be maintained until the process is completed;
- (3)
- In addition to the process in the position of the leaf node, the sufficient and necessary condition for any other process to enter the processing stage is that in the processing sequence, all of its predecessor processes are completed;
- (4)
- When the final process on all the equipment has been completed, the time point at this time marks the end of the entire product processing cycle, that is, the total processing time of the product, the makespan.
- (1)
- Indices
- (2)
- Sets
- (3)
- Parameters
- (4)
- Decision Variables
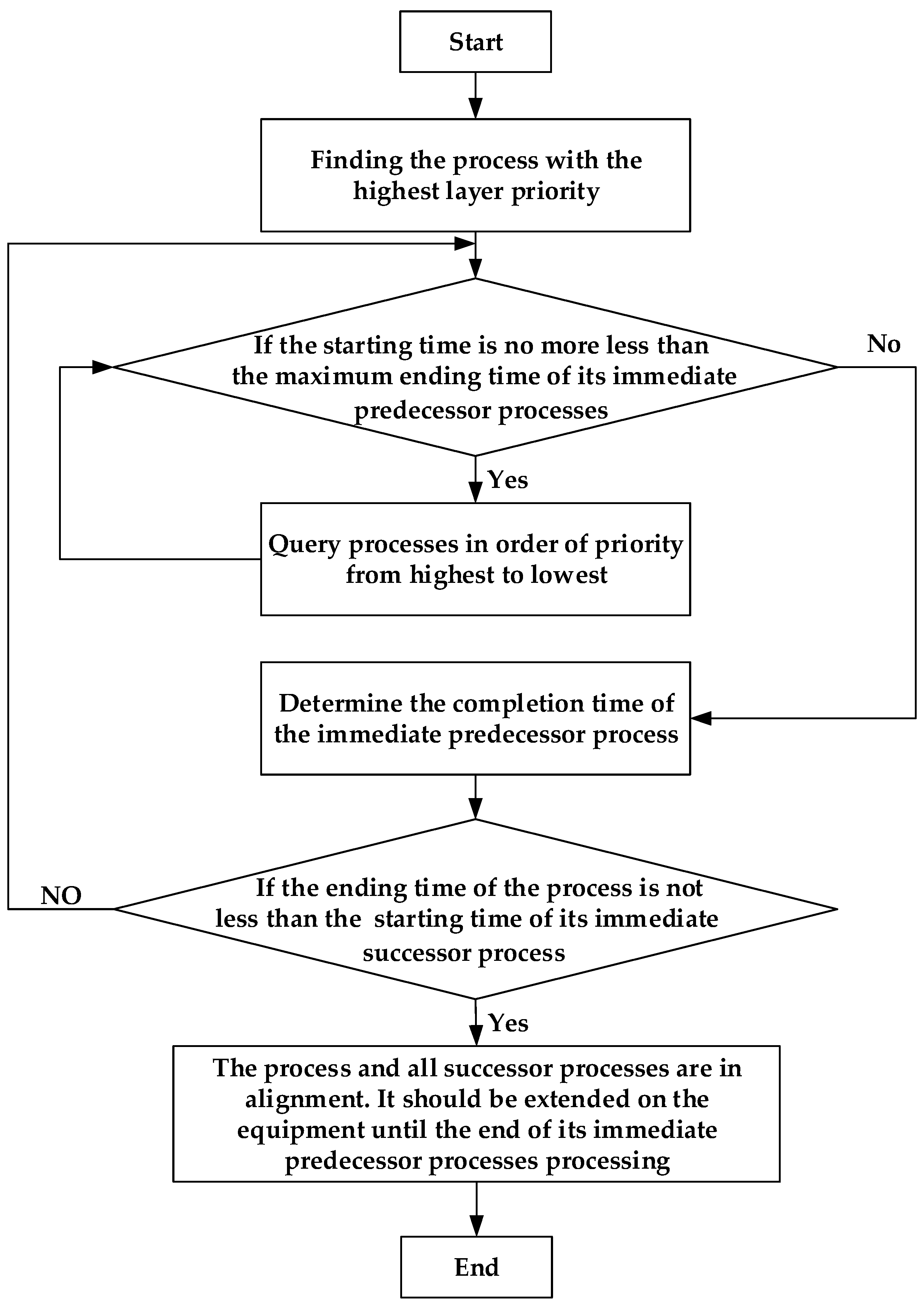
4. Algorithm Design and Analysis
4.1. Definitions and Policies
4.2. Analysis of Algorithm Design
4.3. Algorithm Code
| Algorithm 1 Hierarchical pruning optimization algorithm |
| BEGIN Initialize ComplexProductProcessTree() Apply FloyedAlgorithmStrategy() WHILE NOT AllProcessNodesComputed() IF IsLeafNodeProcessUnique(low_priority_layer) THEN Calculate RootNodeFloyedWeight() ELSE Select ShorterProcessingTimeProcess() Calculate RootNodeFloyedWeight() END IF PruneAndCreateSubProcessTrees() FOR EACH sub_tree IN sub_process_trees Calculate SubTreeRootFloyedWeight(sub_tree) END FOR END WHILE END |
4.4. Algorithm Complexity
5. Comparative Analysis Experiment
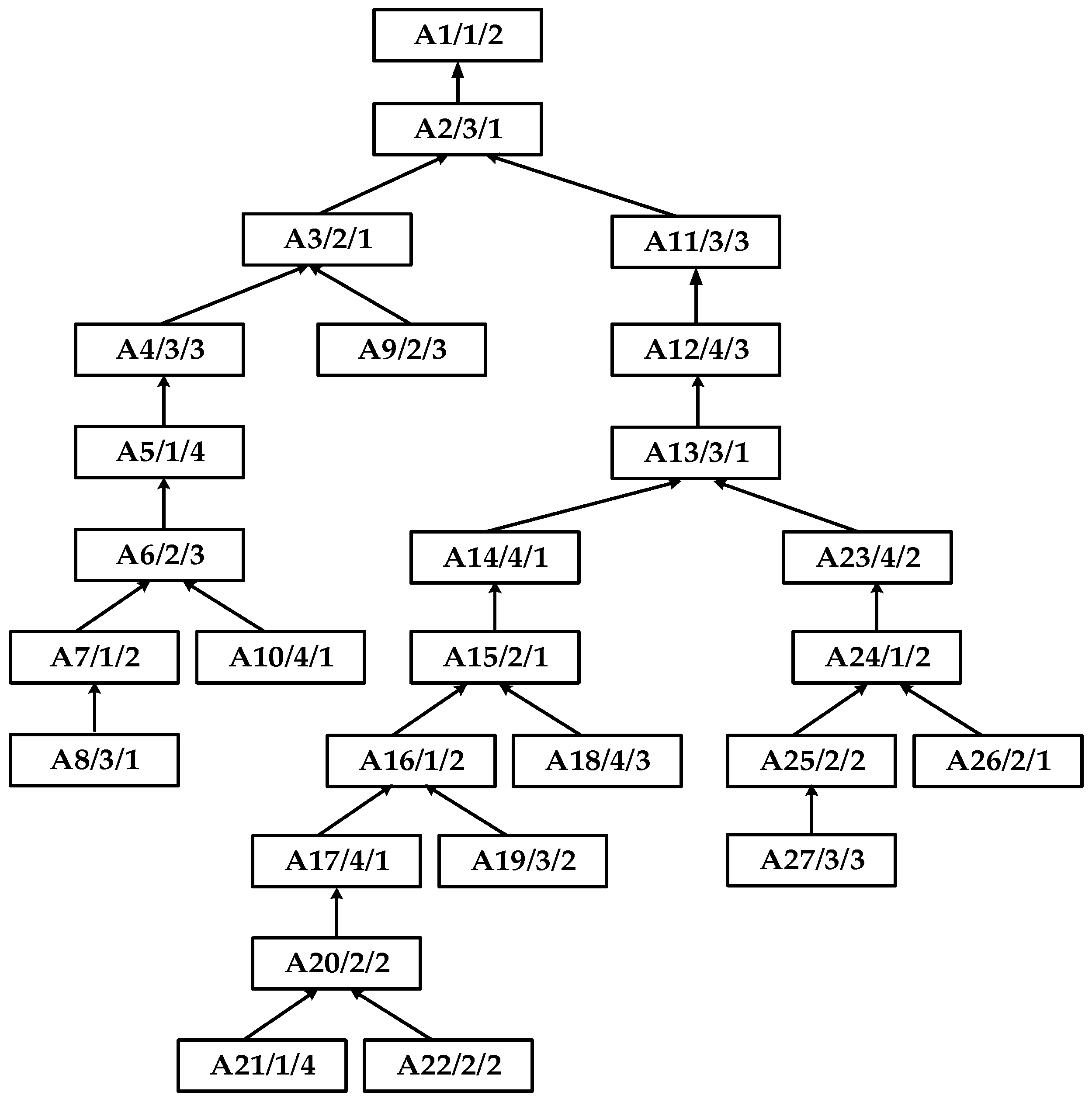
5.1. Random Scheduling Case Analysis
- (1)
- {A11, A12, A13, A23, A24, A26},
- (2)
- {A4, A5, A6, A10},
- (3)
- {A1, A2, A3, A9},
- (4)
- {A14, A15, A18}, {A17, A20, A22}, {A25, A27},
- (5)
- {A16, A19}, {A21},
- (6)
- {A7, A8}.
5.2. Comparison and Analysis of Asymmetric Complex Product Scheduling
5.3. Data Set Scheduling Instance Analysis
6. Discussion
- (1)
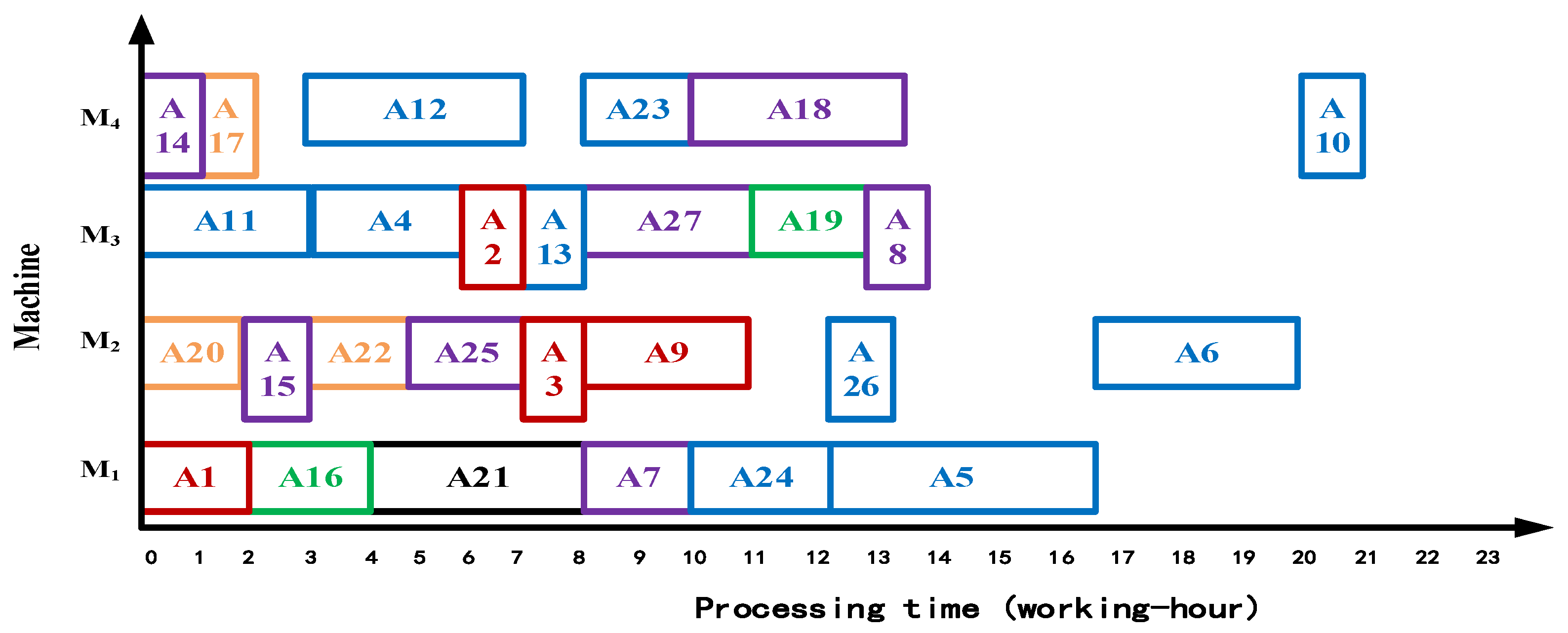
- In terms of vertical and horizontal bidirectional optimization, compared with ISA-NWCOG, ISA-IFA addresses vertical articulation weakening in multi-preprocessor scenarios via dynamic pruning, reducing the machining time by 1 working hour. In contrast, TISA-CCSP overlooks leaf-node scheduling advantages, whereas ISA-IFA innovatively introduces leaf node optimization with two-dimensional priorities, reducing the 4 working hours. For example, with the ISA-IFA, the starting time of all the equipment is set to be t = 0, and in terms of the working state of M4, the other three algorithms have idle time of 7 working hours, 13 working hours, and 7 working hours, respectively.
- (2)
- In terms of equipment utilization, the ISA-IFA adopts the scheduling advantage strategy, which addresses the key shortcoming of ignoring the scheduling potential of unconstrained leaf nodes in References [11,12,13], and reduces the idle time of the equipment. Compared with the other three algorithms, it improves the overall utilization rate of the equipment system by 2.3%, 9.5%, and 0.6%, respectively. For example, judging from the working state of M2, the total idle time of the ISA-IFA is 6 working hours, while the total idle time of the other three algorithms on the same equipment is 10 working hours, 12 working hours, and 8 working hours, respectively.
- (3)
- In terms of algorithmic time complexity, the algorithm can give the scheduling scheme within the quadratic complexity, which indicates that the algorithm is simple, feasible, and breaks through the computational bottleneck of traditional scheduling algorithms in large-scale complex product scenarios.
7. Summary and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shi, G.D.; Wu, G.; Huang, J.J. Digitalization Transformation and ESG Performance of Manufacturing Enterprises—From the ESG Segmentation Perspective. Statist. Decis. 2025, 05, 166–171. [Google Scholar] [CrossRef]
- Zhang, B.Y.; Liu, Y.; Meng, L.J. Construction of Quality Infrastructure and Upgrading of Manufacturing Foreign Trade: Theoretical Mechanism and Experimental Evidence. Int. Bus. Res. 2025, 46, 48–62. [Google Scholar] [CrossRef]
- Wang, X.; Mao, X.M.; Liu, M. The Coupling and Coordination Relationship between Digital Economy and Manufacturing Industry in China: A High-quality Development Perspective. Stat. Inf. Forum 2024, 39, 41–55. [Google Scholar] [CrossRef]
- Zhu, G.P.; Wang, K. Artificial Intelligence Applications and Green Innovation in Manufacturing Firms. J. Ind. Technol. Econ. 2024, 43, 73–81. [Google Scholar] [CrossRef]
- Gao, Y.; Song, Y. Research on the interactive relationship between information communication technology and manufacturing industry. Clust. Comput. 2019, 22, 5719–5729. [Google Scholar] [CrossRef]
- Ji, K.; Liu, X.; Xu, J. Digital Economy and the Sustainable Development of China’s Manufacturing Industry: From the Perspective of Industry Performance and Green Development. Sustainability 2023, 15, 5121. [Google Scholar] [CrossRef]
- Kovič, K.; Ojsteršek, R.; Palčič, I. Simultaneous Use of Digital Technologies and Industrial Robots in Manufacturing Firms. Appl. Sci. 2023, 13, 5890. [Google Scholar] [CrossRef]
- Xie, W.H.; Zheng, D.W.; Li, Z.S.; Wang, Y.J.; Wang, L.G. Digital technology and manufacturing industrial change: Evidence from the Chinese manufacturing industry. Comput. Ind. Eng. 2024, 187, 109825. [Google Scholar] [CrossRef]
- Zhang, X.H.; Wang, Z.; Zhang, D.; Xu, T.; Jiang, H. An Improved Intelligent Optimization Algorithm for Small-Batch Order Production Scheduling. Sci. Rep. 2024, 14, 21394. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.X.; Deng, Q.W.; Luo, Q.; Wang, Z.; Zhuang, H.N.; Huang, Y.T. A Double-Layer Q-Learning Driven Memetic Algorithm for Integrated Scheduling of Procurement, Production and Maintenance with Distributed Resources. Appl. Soft Comput. 2024, 165, 112110. [Google Scholar] [CrossRef]
- Xie, Z.Q.; Teng, Y.Z.; Yang, J. Integrated Scheduling Algorithm with No-wait Constraint Operation Group. Acta Autom. Sin. 2011, 37, 371–379. [Google Scholar] [CrossRef]
- Xie, Z.Q.; Zhang, X.H.; Gao, Y.L.; Xin, Y. Time-selective Integrated Scheduling Algorithm Considering The Compactness of Serial Processes. J. Mech. Eng. 2018, 54, 191–202. [Google Scholar] [CrossRef]
- Xie, Z.Q.; Zhou, W.; Yang, J. Resource cooperative integrated scheduling algorithm considering hierarchical scheduling order. Comput. Integr. Manuf. Syst. 2022, 28, 3391–3402. [Google Scholar] [CrossRef]
- Xie, Z.Q.; Xin, Y.; Yang, J. Integrated Scheduling Algorithm Based on Event-driven by Machines’ Idle. J. Mech. Eng. 2018, 54, 191–202. [Google Scholar] [CrossRef]
- Xie, Z.Q. Study on Operation Scheduling of Complex Product with Constraint among Jobs. Ph.D. Thesis, Harbin University of Science and Technology, Harbin, China, 2009. [Google Scholar]
- Wang, J.R.; Li, Y.; Zhang, Z.W.; Wu, Z.Y.; Wu, L.H.; Jia, S.; Peng, T. Dynamic Integrated Scheduling of Production Equipment and Automated Guided Vehicles in a Flexible Job Shop Based on Deep Reinforcement Learning. Processes 2024, 12, 2423. [Google Scholar] [CrossRef]
- Yang, D.; Xie, Z.Q.; Zhang, C. Multi-flexible integrated scheduling algorithm for multi-flexible integrated scheduling problem with setup times. Math. Biosci. Eng. 2023, 20, 9781–9817. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.; Xie, Z.Q.; Liu, Q.; Yu, X. Asignal-driven based flexible integrated scheduling algorithm with bidirectional coordination mechanism. Multimed. Tools Appl. 2023, 82, 34029–34051. [Google Scholar] [CrossRef]
- Wang, X.; Song, Y.; Zou, Y.; Guo, W.; Wang, Y. Integrated scheduling algorithm for multiple complex products with due date constraints. J. Phys. Conf. Ser. 2021, 1748, 032030. [Google Scholar] [CrossRef]
- Ding, X.Y.; Xie, Z.Q.; Zhou, W.; Tan, Z.J.; Sun, M. Flexible Integrated Scheduling Considering Periodic Maintenance. Electronics 2024, 13, 3730. [Google Scholar] [CrossRef]
- Ding, X.Y.; Zhou, W.; Xie, Z.Q.; Sun, M.; Tan, Z.J.; Cao, W.C. Integrated Scheduling Algorithm Based on Improved Semi-Numerical Algorithm. Symmetry 2025, 17, 434. [Google Scholar] [CrossRef]
- Xia, B.L.; Ma, Y.Z. Optimization of Distributed Flow Shop Scheduling Problem Based on Deep Q-network. Mach. Des. Res. 2025, 41, 311–319. [Google Scholar] [CrossRef]
- Han, J.H.; Lee, J.Y. Genetic algorithm-based approach for makespan minimization in a flow shop with queue time limits and skipping jobs. Adv. Prod. Eng. Manag. 2023, 18, 152–162. [Google Scholar] [CrossRef]
- Su, J.T.; Dong, S.H.; Zhu, S.M. Research on Machine Fault Rescheduling Problem of Multi Objective Hybrid Flow Shop Based on Intelligent Manufacturing. J. Mech. Eng. 2024, 60, 438–448. [Google Scholar]
- Badri, H.; Bahreini, T.; Grosu, D. Parallel shifting bottleneck algorithms for non-permutation flow shop scheduling. Ann. Oper. Res. 2024, 343, 39–65. [Google Scholar] [CrossRef]
- Hidri, L.; Elsherbeeny, A.M. Optimal Solution to the two-stage hybrid flow shop scheduling problem with removal and transportation times. Symmetry 2022, 14, 1424. [Google Scholar] [CrossRef]
- Ge, Z.P.; Wang, H.F. Integrated Optimization of Blocking Flowshop Scheduling and Preventive Maintenance Using a Q-Learning-Based Aquila Optimizer. Symmetry 2023, 15, 1600. [Google Scholar] [CrossRef]
- Li, Z.H.; Tang, H.T.; Zhang, W. Solving the Scheduling of Flexible Assembly Workshops with Outsourcing Cooperation Based on Improving Whale Dynamic Scheduling Algorithm. Mach. Tool Hydraul. 2024, 52, 1–9. [Google Scholar] [CrossRef]
- Momenikorbekandi, A.; Abbod, M. Intelligent Scheduling Based on Reinforcement Learning Approaches: Applying Advanced Q-Learning and State–Action–Reward–State–Action Reinforcement Learning Models for the Optimisation of Job Shop Scheduling Problems. Electronics 2023, 12, 4752. [Google Scholar] [CrossRef]
- Xu, G.D.; Chen, Y.F. Petri-net-based scheduling of flexible manufacturing systems using an estimate function. Symmetry 2022, 14, 1052. [Google Scholar] [CrossRef]
- Ding, L.S.; Guan, Z.L.; Luo, D.; Rauf, M.; Fang, W.K. An Adaptive Search Algorithm for Multiplicity Dynamic Flexible Job Shop Scheduling with New Order Arrivals. Symmetry 2024, 16, 641. [Google Scholar] [CrossRef]
- Yang, Z.; Bi, L.; Jiao, X. Combining Reinforcement Learning Algorithms with Graph Neural Networks to Solve Dynamic Job Shop Scheduling Problems. Processes 2023, 11, 1571. [Google Scholar] [CrossRef]
- He, Y.R.; Pang, J.M.; Xu, J.L.; Zhu, Y.; Tao, X.H. Implementation and Optimization of Floyd Parallel Algorithm Based on Sunway Platform. Comput. Sci. 2021, 48, 34–40. [Google Scholar] [CrossRef]
- Emara, S.F.; Abdelhady, S.; Zaki, M. A novel traceback model for DDoS attacks using modified Floyd-Warshall algorithm. Int. J. Inf. Comput. Secur. 2023, 20, 84–103. [Google Scholar]
- Xu, E. Strategic Evaluation and Optimization of Clan Sides Based on Floyd Algorithm. Adv. Comput. Signals Syst. 2023, 7, 105–112. [Google Scholar] [CrossRef]
- Lyu, D.S.; Chen, Z.W.; Cai, Z.S.; Piao, S.H. Robot path planning by leveraging the graph-encoded Floyd algorithm. Comput. Syst. 2021, 122, 204–208. [Google Scholar] [CrossRef]
- Li, N.; Xin, C.Y. Urban Logistics Distribution Routing Optimization of “Vehicle-Drone” Based on Clustering-Floyd-Genetic Algorithm. Sci. Technol. Engng. 2024, 24, 9186–9193. [Google Scholar]
- Habib, S.; Majeed, A.; Akram, M.; Ali Al-Shamiri, M.M. Floyd-Warshall Algorithm Based on Picture Fuzzy Information. CMES-Comput. Model. Eng. Sci. 2023, 136, 2873–2894. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Key Innovations | Limitations |
|---|---|---|
| [9] | Constructed a dynamic recombination neighborhood operation set using the adjacent exchange strategy of the Critical Path Method | Limited to local adjustments, non-adjacent synergies and vertical priorities were neglected |
| [10] | Integration of raw material procurement, production scheduling, and equipment maintenance | Weak dynamic multi-objective adaptation and insufficient supply chain disruption response |
| [11] | ISA-NWCOG | Vertical linkage weakens with non-unique preceding processes |
| [12] | TISA-CCSP | Neglected leaf-node scheduling and high-priority layer processes induce device idling |
| [13] | RCISA-CHSO | Excessive horizontal prioritization and loose vertical subtree scheduling |
| Makespan (Working Hours) | The Overall Utilization of the Equipment | The Relative Improvement Rate of the Overall Utilization Rate | |
|---|---|---|---|
| ISA-IFA | 27 | 55.9% | ----- |
| ISA-NWCOG | 28 | 53.6% | 2.3% |
| TISA-CCSP | 31 | 46.4% | 9.5% |
| RCISA-CHSO | 28 | 55.3% | 0.6% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, Y.; Zhou, W.; Xie, Z.; Sun, M.; Tan, Z.; Cao, W. Integrated Scheduling Algorithm Based on the Improved Floyd Algorithm. Symmetry 2025, 17, 682. https://doi.org/10.3390/sym17050682
Wei Y, Zhou W, Xie Z, Sun M, Tan Z, Cao W. Integrated Scheduling Algorithm Based on the Improved Floyd Algorithm. Symmetry. 2025; 17(5):682. https://doi.org/10.3390/sym17050682
Chicago/Turabian StyleWei, Yingxin, Wei Zhou, Zhiqiang Xie, Ming Sun, Zhenjiang Tan, and Wangcheng Cao. 2025. "Integrated Scheduling Algorithm Based on the Improved Floyd Algorithm" Symmetry 17, no. 5: 682. https://doi.org/10.3390/sym17050682
APA StyleWei, Y., Zhou, W., Xie, Z., Sun, M., Tan, Z., & Cao, W. (2025). Integrated Scheduling Algorithm Based on the Improved Floyd Algorithm. Symmetry, 17(5), 682. https://doi.org/10.3390/sym17050682