1. Introduction
The rise of Large Language Models (LLMs) has revolutionized Natural Language Processing (NLP), providing powerful tools for tasks such as information retrieval (Sentence-BERT for semantic similarity search and retrieval [
1] and document representation techniques such as Paragraph Vectors [
2]), text clustering (Doc2Vec and BERT-SCL methods for clustering tasks) [
3,
4], and STS assessment (Sentence-BERT’s performance on STS benchmarks, with applications to topic modeling) [
5,
6]. A core component of many LLM applications is sentence representation learning—encoding sentences into fixed-dimensional vectors. While pre-trained language models (PLMs) such as BERT [
7] and PPBERT [
8] provide a seemingly straightforward method for generating these embeddings (e.g., using the [CLS] token or averaging token embeddings [
2]), a critical limitation persists: the anisotropy problem—a phenomenon where learned sentence representations tend to collapse into a narrow cone in the embedding space, leading to poor semantic discriminability and suboptimal use of the representation capacity [
9,
10]. Embeddings derived from PLMs often cluster within a narrow cone in the vector space, limiting their representational power.
Unsupervised approaches, particularly those employing CL [
11,
12,
13], offer a promising path to high-quality embeddings without requiring labeled data. These methods typically rely on data augmentation (e.g., dropout [
14], random insertion) to create positive sample pairs and in-batch negative sampling. However, a fundamental flaw lies in the symmetric treatment of all negative samples. These methods fail to account for the inherent asymmetry in semantic relationships: negative samples possess varying degrees of similarity to the anchor sentence, a crucial nuance for effective representation learning. This indiscriminate treatment leads to suboptimal sentence embeddings.
To address this critical asymmetry, we introduce LS-RNS, a novel framework that integrates a negative ranking module and a label smoothing technique within the CL framework. LS-RNS moves beyond the symmetric assumption of standard contrastive learning in the following ways:
Asymmetric Similarity Assessment: We employ a semantic similarity language model based on a pre-trained LLM to generate contextualized embeddings, enabling more accurate cosine similarity assessments between each negative sample and the anchor sentence within a mini-batch. This quantifies the asymmetric relationship, providing a fine-grained measure of difficulty.
Ranking-Based Negative Sampling: A negative ranking module incorporates this detailed semantic ranking information, allowing the model to capture subtle distinctions between negative samples. This breaks the symmetry imposed by traditional methods, which lack this fine-grained ranking.
Adaptive Label Smoothing: An adaptive label smoothing technique approximates the true, asymmetric distribution of semantic similarity between each negative sample and the anchor. This promotes more effective model parameter optimization and mitigates overfitting, a common issue when treating all negatives as equally dissimilar.
Experimental evaluations on STS and transfer tasks demonstrate that LS-RNS significantly outperforms state-of-the-art methods, highlighting the importance of addressing asymmetry in unsupervised sentence representation learning. This work contributes to a more nuanced understanding of how to leverage LLMs for creating high-quality sentence embeddings.
2. Related Work
This section reviews work related to our LS-RNS method, which addresses unsupervised sentence representation by focusing on the asymmetric nature of negative sampling in CL. We discuss unsupervised sentence representation and advancements in negative sampling strategies within CL.
2.1. Unsupervised Sentence Representation
Advancements in unsupervised sentence representation have significantly impacted the field of NLP, with the goal of generating meaningful sentence embeddings without relying on labeled data [
15,
16]. Early research centered around embedding-based methods. Word2Vec [
17] and GloVe [
18] were instrumental in the development of word-level embeddings. Subsequently, methods such as Skip-Thought [
19], ArcCSE [
20], and WhiteningBERT [
21] were developed to learn sentence embeddings that capture syntactic and semantic relationships between words. However, these methods often lacked the contextual understanding provided by later approaches based on PLMs.
The advent of PLMs such as BERT [
7] marked a significant turning point in sentence representation. PLMs leverage deep contextual information and typically derive sentence embeddings from the [CLS] token or by averaging token embeddings across the final layer. The use of self-attention mechanisms allows PLMs to capture complex semantic relationships, leading to strong performance across a wide range of NLP tasks. Despite these advancements, Ethayarajh et al. [
9] identified the issue of anisotropy in contextualized word representations generated by PLMs such as BERT, ELMo, and GPT-2. This anisotropy means that sentence embeddings tend to cluster within a narrow cone in the vector space, restricting their representational capacity. To mitigate this, methods such as BERT-flow [
22] and BERT-whitening [
23] have been proposed, aiming to make the distribution of sentence embeddings more uniform and isotropic. While these methods improve uniformity, they do not directly address the asymmetric relationships between sentences that are crucial in CL settings.
2.2. Contrastive Sentence Representation Learning
CL [
24,
25] has emerged as a powerful paradigm for unsupervised sentence representation, with methods primarily built around the principle of pulling semantically similar sentences closer while pushing dissimilar ones apart. Methods such as SimCSE [
14] and DiffCSE [
26] achieve remarkable results by generating positive pairs through dropout noise or data augmentation and treating in-batch negatives uniformly. However, these approaches implicitly assume symmetric relationships among all negative samples, i.e., each negative is penalized equally regardless of its semantic proximity to the anchor. This assumption often leads to suboptimal training dynamics, especially in semantically rich or ambiguous contexts. To address this, several extensions have introduced structured priors or soft labels. For instance, PromptBERT [
27] enhances semantic discrimination through prompt-based sentence reformulation, and SNCSE [
28] constructs semantic neighborhoods to mitigate false negatives; while these approaches improve performance over SimCSE, they still predominantly rely on symmetric loss functions or introduce handcrafted or brittle pseudo-labeling strategies, which may limit generalization and scalability.
Another important research direction has been improving the quality of negative samples. Some approaches have adopted supervised sampling strategies, leveraging entailment pairs from natural language inference datasets as positive samples and contradiction pairs as hard negatives [
29,
30]; another study proposed the supervised contrastive loss (SupCon), using label information to pull together samples from the same class and push apart samples from different classes [
14]; yet another method introduced the label-aware contrastive loss (LCL), adapting weights for confusable negative samples to improve model performance in fine-grained classification tasks [
31]. However, since labeled data is not always available, unsupervised approaches have also been investigated. For instance, Huynh et al. [
32] used data augmentations to create “support views” for anchor and negative examples, identifying false negatives based on top-k similarity. These approaches, while valuable, still often operate under the assumption of a symmetric relationship between similarity and dissimilarity.
Our proposed method, LS-RNS, builds on this foundation but introduces two key innovations: (1) It leverages LLMs to estimate fine-grained semantic similarity, offering richer and more context-aware signals for distinguishing between easy and hard negatives; (2) It incorporates these signals into training via a novel combination of ranking-based negative sampling and adaptive label smoothing, effectively breaking the rigid symmetry of the contrastive loss. Compared to prior work, LS-RNS does not require explicit data augmentation, handcrafted templates, or external supervision. It outperforms SimCSE, DiffCSE, PromptBERT, and SNCSE consistently across STS benchmarks and transfer tasks, confirming that modeling asymmetry in semantic space—when guided by LLM-derived priors—is a powerful and generalizable principle.
3. Methodology
The core challenge in unsupervised sentence representation learning is to capture subtle semantic distinctions without explicit labels. CL offers a powerful framework, but standard approaches suffer from a critical limitation: they treat all negative samples symmetrically, assigning them equal weight regardless of their semantic distance from the anchor sentence. This ignores the inherent asymmetry of semantic relationships. Our proposed method, LS-RNS, directly addresses this asymmetry to learn more nuanced and effective sentence embeddings.
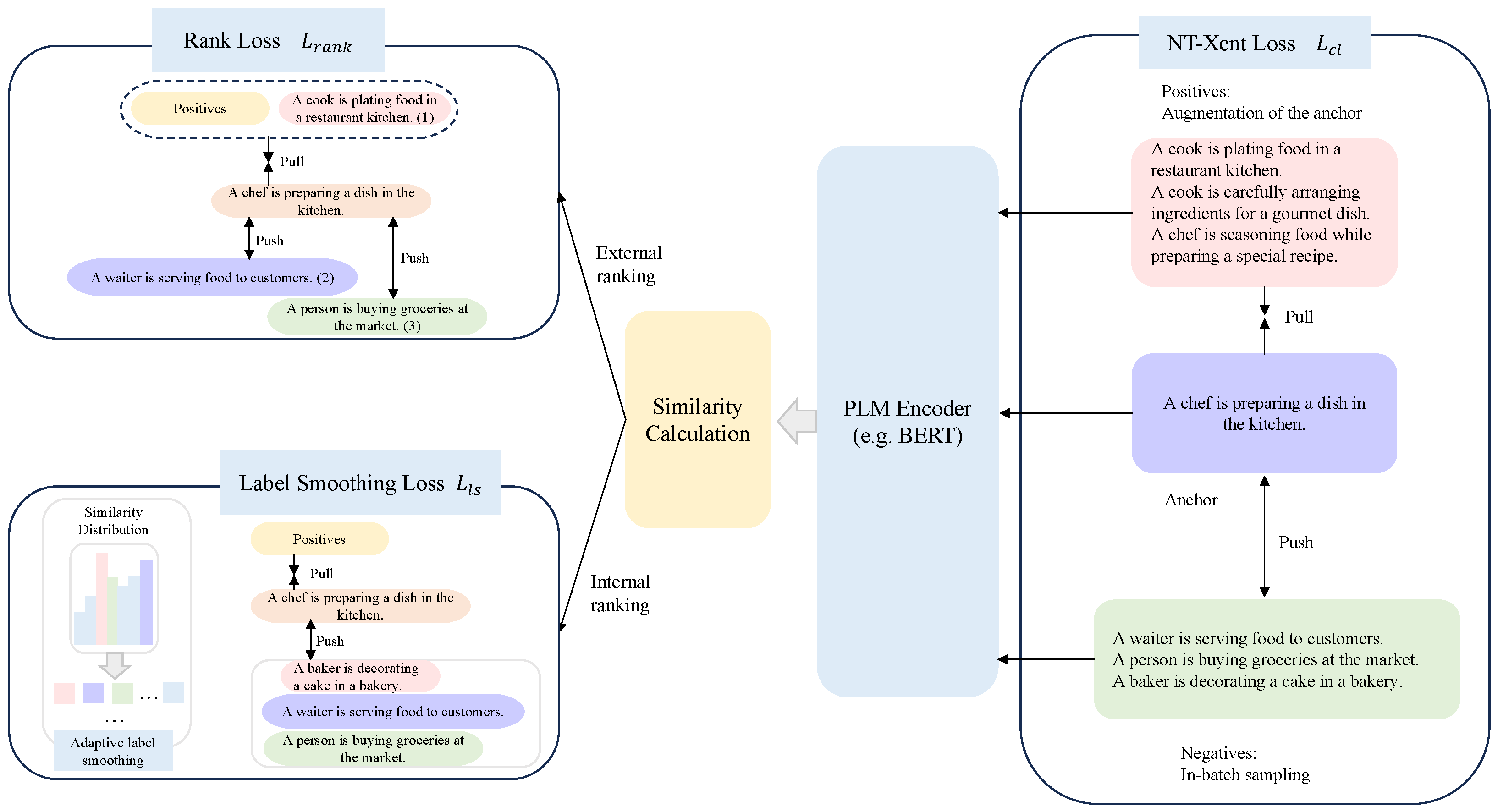
The framework is illustrated in
Figure 1. Using the sentence “A chef is plating food in a restaurant kitchen” as the anchor, it is compared with other sentences. In the Rank Loss module, sentences that are semantically close to the anchor (like “A chef is preparing a dish in the kitchen” (1)) are pulled closer, while semantically distant negative samples (like “A waiter is serving food to customers.” (2) and “A person is buying groceries at the market.” (3)) are pushed farther apart. Next, the Label Smoothing Loss adjusts the labels of the negative samples, allowing the model to handle semantic differences in a softer way, avoiding strict classification of negatives. Finally, the NT-Xent Loss module enhances the similarity between the anchor and positive samples while pushing negative samples away, further optimizing sentence embeddings. The entire process helps the model overcome the symmetry issue of traditional methods and learn the subtle semantic relationships between sentences more effectively.
3.1. Problem Formulation: The Asymmetric Contrastive Loss
Let
x be an input sentence, and let
be a stochastic data augmentation function. In a standard CL setup, we generate two augmented views of the sentence, namely,
and
, forming a positive pair. A mini-batch of
N sentences provides
in-batch negative samples, denoted
for
. The standard InfoNCE loss is then computed as follows:
Here, denotes an encoder (e.g., a pre-trained LLM such as RoBERTa) followed by a projection head such as a Multi-Layer Perceptron (MLP). The similarity function is typically cosine similarity, and is a temperature scaling parameter.
Equation (
1) reflects the symmetric treatment of all negative samples: each
is equally penalized without regard to its semantic proximity to the anchor
. However, this overlooks a key empirical reality: negative samples differ in their semantic closeness to the anchor. Some negatives may share topical or syntactic structure with
(hard negatives), while others are entirely unrelated (easy negatives). Treating these negatives symmetrically risks inefficient learning or even representational collapse.
3.2. LS-RNS: An Asymmetric Contrastive Framework
LS-RNS introduces two key components to address this asymmetry:
Semantic Similarity Ranking: We leverage a pre-trained LLM, denoted as , to estimate the semantic similarity scores between the anchor sentence and each negative sample . These scores are then used to rank the negative samples. A higher score indicates greater semantic similarity (a harder negative). We then define a ranking function, , which maps each similarity score to its ordinal rank within a mini-batch. To make the system robust to the choice of ranking granularity, we have evaluated multiple variants of —including discrete binning, percentile-based grouping, and continuous soft ranking. Empirically, we find that while all variants consistently improve over non-ranked baselines, soft ranking yields the most stable gains, suggesting that precise rank ordering plays a supportive but non-critical role when used jointly with adaptive label smoothing. This ranking mechanism effectively captures the asymmetric semantic relationships across samples. Lower ranks correspond to harder negatives.
Adaptive Label Smoothing: Instead of treating all negatives as equally dissimilar (probability 0 of being similar to the anchor), we introduce a soft target distribution. We leverage the similarity scores () and the ranking function () to create a target distribution, , for each negative sample. This distribution reflects the asymmetric semantic relationships.
We achieve this through a two-step process:
Initial Distribution: We first create an initial distribution,
, by applying a softmax function to the similarity scores:
where
is a temperature parameter for this initial distribution.
Adaptive Smoothing: We then smooth this distribution using an adaptive parameter,
, which depends on the rank of the negative sample. Harder negatives (lower rank) receive
less smoothing, while easier negatives (higher rank) receive
more smoothing. This is because we want the model to focus more on the harder negatives. We define
as a function of the rank:
where
is a monotonically decreasing function (e.g.,
, where
r is the rank and
N is the batch size). This function maps the rank of the negative sample to a value between 0 and 1. The final smoothed target distribution,
, is then as follows:
where
is a Dirac delta function (1 if
would be considered a perfect negative, 0 otherwise—in practice, we do not have access to perfect negatives). We use the softened target distribution to represent the difficulty of each negative sample.
3.3. Our Solution: Asymmetric Contrastive Loss via LS-RNS
We propose
LS-RNS, a novel loss that explicitly models semantic asymmetry. We first use an LLM to compute semantic similarity scores between the anchor and each negative, yielding a fine-grained ranking. These rankings are then translated into
soft weights through a calibrated label smoothing mechanism. The resulting
Asymmetric Contrastive Loss is defined as follows:
Here,
encodes the relative semantic hardness of negative sample
with respect to anchor
, with larger values for semantically similar negatives. These weights break the uniformity assumption of Equation (
1), allowing the model to focus more on challenging negatives while de-emphasizing trivially distant ones. This not only improves convergence but also yields embeddings that better reflect fine-grained semantic structures.
3.4. Overall Training Objective
The final training objective is a combination of the LS-RNS loss and, optionally, a standard contrastive loss (for stability):
where
is a hyperparameter controlling the weighting between the two losses. In practice, we found that using only
often yields good results, but the addition of
can sometimes improve stability, especially during the initial stages of training.
4. Experiments and Results
4.1. Experiment Settings
4.1.1. Datasets
We evaluate the effectiveness of our proposed LS-RNS framework across a comprehensive suite of benchmarks, encompassing seven STS tasks [
33,
34,
35,
36,
37,
38] and seven transfer learning tasks: MR [
39], CR [
40], SUBJ [
40], MPQA [
41], SST-2 [
42], TREC [
43], and MRPC [
39]. The STS tasks assess the semantic closeness of sentence pairs with fine-grained similarity scores, whereas the transfer tasks evaluate the transferability of sentence embeddings to downstream classification tasks involving sentiment analysis, subjectivity, question type classification, and paraphrase detection.
Table 1 summarizes key characteristics of all datasets, including the number of samples, task type, and number of classes (for classification tasks). This structured overview highlights the diversity and coverage of our evaluation protocol, ensuring that both semantic fidelity and cross-task generalizability are thoroughly assessed.
Consistent with prior work—specifically following SimCSE [
14]—we use one million randomly sampled sentences from English Wikipedia for training. For evaluation, we employ the SentEval toolkit [
44], using Spearman’s rank correlation for STS tasks and accuracy for classification. This setup ensures a fair and direct comparison with state-of-the-art unsupervised sentence embedding methods.
4.1.2. Training Details
Our experimental setup is based on the PyTorch framework (version 2.1.0) [
45] and leverages the Hugging Face Transformers library [
46] for efficient implementation and access to PLMs. All experiments are conducted on a single NVIDIA A100 GPU equipped with 80 GB of memory. Our LS-RNS framework is built upon the SimCSE [
14] architecture, a strong and widely-used baseline for unsupervised sentence representation learning. We integrate our novel ranking-based negative sampling and adaptive label smoothing techniques into the SimCSE framework. Sentence representations are derived from the output of an MLP projection head, which is applied to the [CLS] token embedding of the underlying pre-trained language model. We initialize our models with pre-trained BERT [
7] and PPBERT [
8] models, known for their strong performance across a broad spectrum of NLP tasks. During training, we explore a range of learning rates, specifically {1e-5, 2e-5, 3e-5}, and maintain a batch size of 64. The training process spans four epochs, and we set the temperature parameter,
, for the softmax computation to 0.05. To ensure rigorous evaluation and identify the best-performing model, we perform model evaluation every 125 training steps using the STS-B development dataset. The model checkpoint that achieves the highest Spearman’s correlation on the development set is then selected for final evaluation on the held-out test datasets.
4.2. Baselines
To provide a comprehensive and fair comparison, we evaluate LS-RNS against a carefully selected set of strong baseline models, categorized as follows: First, we include non-BERT-based methods, specifically GloVe average embeddings [
18] and USE [
47]. GloVe averaging provides a simple baseline based on averaging pre-trained word embeddings, while USE represents a more sophisticated non-contextualized approach to sentence encoding. Second, we consider post-processing techniques applied to pre-trained BERT embeddings, including BERT-flow [
22] and BERT-whitening [
23]. These methods aim to address the anisotropy problem in BERT embeddings without using CL. BERT-flow uses normalizing flows to transform the embedding distribution into an isotropic Gaussian, while BERT-whitening applies a whitening transformation to make the distribution more uniform. Finally and most importantly, we compare LS-RNS to state-of-the-art CL-based methods: SimCSE [
14], DiffCSE [
26], PromptBERT [
27], and SNCSE [
28]. SimCSE, a foundational method in this category, utilizes dropout as a minimal data augmentation strategy. DiffCSE learns robust representations by creating invariance to certain augmentations. PromptBERT incorporates template denoising within a contrastive framework, using prompts to guide the learning. SNCSE constructs soft negative samples using negated original sentences, representing a step towards addressing the asymmetry issue, although not as directly as our approach. This selection of baselines allows us to compare LS-RNS against older, non-contextualized methods; methods that address anisotropy without CL; and the current leading approaches in unsupervised sentence representation.
4.3. Main Results
4.3.1. Results on Semantic Textual Similarity (STS)
Table 2 presents the Spearman’s rank correlation results cross seven widely used STS benchmarks: STS12–STS16, STS-B, and SICK-R. The evaluation metric used is Spearman’s rank correlation, which captures the rank correlation between model-predicted similarity and human judgments.
A clear performance hierarchy is observed. Non-BERT methods such as GloVe averaging and USE consistently underperform, with average scores of 61.32 and 56.70, respectively. These models lack contextual understanding and fail to capture polysemy and compositional semantics. In contrast, BERT-based models, even without fine-tuning, substantially outperform these baselines, highlighting the value of contextualized pre-training. Post-processing techniques such as BERT-flow and whitening constitute improvements over raw BERT representations, with averages around 66.55–66.28, mainly by mitigating anisotropy in the embedding space. However, their gains are limited, as these techniques adjust spatial uniformity but not the underlying semantic structure. A further performance leap is observed with CL methods such as SimCSE, DiffCSE, and PromptBERT, which achieve averages between 76.25 and 78.54 on BERT and up to 79.12 on RoBERTa. These methods improve embeddings by explicitly learning semantic relationships through instance discrimination. However, most CL frameworks symmetrically treat all negatives as equally dissimilar to the anchor, neglecting the semantic asymmetry inherent in natural language.
Our proposed method, LS-RNS, addresses this critical shortcoming by introducing asymmetry-aware contrastive learning. Specifically, it leverages LLM-based similarity scoring to rank negatives, combined with adaptive label smoothing to softly modulate their influence during training. As shown in
Table 2, LS-RNS sets new state-of-the-art results across all datasets. For BERT, LS-RNS achieves an average score of 79.87, outperforming SimCSE (76.25), DiffCSE (78.49), and PromptBERT (78.54). This represents a +3.62 point gain over SimCSE and +1.38 over the strongest baseline. For RoBERTa, LS-RNS reaches an average of 80.41, the best overall, surpassing PromptBERT (79.12) and DiffCSE (79.18). Notably, it achieves 86.35 on STS13, 83.15 on STS-B, and 81.85 on SICK-R, consistently outperforming all baselines.
This empirical evidence supports our central claim: modeling the asymmetric difficulty of negative samples is critical to producing high-quality sentence embeddings. LS-RNS consistently improves both absolute performance and robustness across datasets, demonstrating its capacity to extract fine-grained semantic distinctions missed by symmetric CL. Even with a stronger backbone such as RoBERTa, which already encodes better representations due to enhanced pre-training, LS-RNS still yields notable gains, validating the general effectiveness and transferability of our approach.
The LLM-based similarity assessment provides a nuanced measure of the difficulty of each negative sample, enabling the ranking-based loss and adaptive label smoothing to prioritize learning from the most informative negatives; while this introduces additional computational cost, particularly during training, we find the overhead to be manageable when the similarity scoring is decoupled from backpropagation.
4.3.2. Results on Transfer Tasks
Table 3 reports classification accuracy on seven widely used transfer learning benchmarks from the SentEval suite: MR, CR, SUBJ, MPQA, SST-2, TREC, and MRPC. Following standard protocol, we freeze the sentence encoder and train a logistic regression classifier on top of the learned sentence embeddings. This setup isolates the quality of the embeddings themselves and evaluates their generalizability to downstream tasks beyond sentence similarity.
The results demonstrate a strong and consistent pattern: our proposed LS-RNS framework achieves state-of-the-art accuracy across all tasks, regardless of the underlying encoder (BERT or RoBERTa). Specifically, with BERT-base, LS-RNS achieves an average accuracy of 88.82, substantially outperforming SimCSE (86.22, +2.60), DiffCSE (85.87, +2.95), and PromptBERT (87.53, +1.29). It also surpasses SNCSE (86.28) by +2.54 points. With RoBERTa-base, LS-RNS reaches a new overall best score of 87.68, outperforming PromptBERT (87.53), DiffCSE (87.20), and SNCSE (86.92). The margin is smaller than with BERT, consistent with the hypothesis that RoBERTa benefits from a stronger pre-training objective and better data. Nevertheless, LS-RNS still provides a consistent improvement.
These results are critical in two ways. First, they rule out the possibility that LS-RNS simply overfits to semantic similarity tasks such as STS. The improvements on classification-based transfer tasks—spanning sentiment analysis, question classification, paraphrase detection, and subjective/objective classification—demonstrate that LS-RNS captures task-agnostic, semantically rich features that generalize well. Second, the consistent outperformance on both in-domain (e.g., SST) and cross-domain (e.g., TREC, MRPC) tasks highlights LS-RNS’s robustness. By explicitly modeling the semantic asymmetry of negative samples, the learned embedding space captures more fine-grained and discriminative features—beneficial across task boundaries.
In sum, LS-RNS not only advances state-of-the-art results across seven benchmark datasets but also provides strong empirical support for the general-purpose transferability of asymmetry-aware sentence representations, thereby strengthening the core thesis of this work.
4.3.3. Experiments on Image Representation
To examine whether the benefits of LS-RNS extend beyond the domain of natural language, we evaluate its effectiveness in the visual modality through image classification on the STL-10 dataset. STL-10 is a standard benchmark for evaluating representation learning methods under limited-label settings. We adopt a linear evaluation protocol, where a linear classifier is trained atop frozen visual embeddings learned by contrastive models. This setup ensures that the results reflect the intrinsic quality of the learned representations, not the capacity of downstream decoders.
We compare SimCLR and SimCLR+LS-RNS across five widely used backbone architectures of varying depth and inductive biases—VGG-16, ResNet-18, ResNet-34, ResNet-50, and Vision Transformer (ViT-b-16). The results, reported in
Table 4, reveal several important findings. First, LS-RNS consistently improves top-one classification accuracy across all tested backbones. Notably, with VGG-16, LS-RNS improves accuracy from 68.91% to 72.19% (+3.28%), showing that even weaker encoders benefit significantly. With ResNet-18, accuracy improves from 79.50% to 80.52% (+1.02%). The best result overall is obtained with ViT-b-16, where the accuracy of LS-RNS reaches 82.81%, outperforming the baseline (81.79%) by +1.02%. Second, these improvements demonstrate that LS-RNS enhances the learned embedding space quality regardless of encoder type, including both convolutional and transformer-based models. This suggests that LS-RNS addresses a core limitation in contrastive learning dynamics—namely, the asymmetric treatment of negatives—rather than exploiting domain- or model-specific artifacts. Third, perhaps most strikingly, LS-RNS enables SimCLR with ResNet-18 to outperform baseline SimCLR with a deeper ResNet-34 (80.52% vs. 79.96%). This finding indicates that LS-RNS partially compensates for the capacity limitations of shallower encoders, highlighting that representation quality is a function not only of network depth but also of how contrastive objectives structure the embedding space. Finally, the fact that a method originally developed for text embeddings provides consistent improvements on visual data supports the view that LS-RNS introduces general-purpose inductive biases into contrastive learning. Specifically, its hard-negative-aware sampling and adaptive label smoothing help learn semantically structured, domain-agnostic representation spaces.
In summary, LS-RNS achieves state-of-the-art performance in frozen linear evaluation on STL-10 under SimCLR settings and delivers consistent gains across CNNs and ViTs alike. These results not only validate the cross-domain robustness of the method but also open up exciting directions for unifying contrastive learning principles across modalities.
4.4. Ablation Study
We conduct a thorough ablation study to dissect the contributions of different components within the LS-RNS framework and to investigate the impact of various design choices. For all ablation experiments, we use SimCSE-BERTbase with LS-RNS as the baseline, allowing us to isolate the effect of each modification.
4.4.1. Impact of Removing Different Loss Components
Table 5 presents the results of systematically removing each of the three key loss components—
(the standard contrastive loss),
(the ranking-based loss), and
(the label smoothing loss)—from the overall objective function (
). The best overall performance is achieved when all three components are jointly used, with SimCSE-LS-RNS obtaining
71.55 on STS and
82.98 on TR tasks. This indicates a clear synergy among the three loss terms.
Notably, removing the ranking-based loss results in the most substantial drop in STS performance (to 69.28), emphasizing the critical role of ranking-based negative sampling. By explicitly modeling the relative difficulty of negative samples, encourages the model to learn finer-grained semantic distinctions, resulting in a more discriminative embedding space. Without this ranking information, the model treats all negatives as equally dissimilar, which weakens its ability to capture subtle semantic differences.
Excluding the standard contrastive loss also leads to a noticeable decline in performance, particularly in STS, though TR remains relatively robust. This suggests that while carries most of the discriminative power, provides a stabilizing influence by promoting similarity between positive pairs and offering a strong foundational training signal.
The removal of the label smoothing loss leads to a moderate performance degradation. Though less severe than the removal of or , this result still highlights the value of adaptive smoothing. By modulating the influence of each negative sample based on its rank, prevents the model from being overly influenced by easy negatives and shifts focus toward harder, more informative ones. Importantly, while determines the relative order of difficulty, assigns a graded magnitude of influence to each negative sample, yielding a more fine-grained and effective learning signal.
Interestingly, although the removal of results in a lower STS score, it achieves the highest TR score (83.85) when only and are used. This suggests that in specific transfer settings, ranking and smoothing alone can generalize well, though at the cost of semantic granularity. Nevertheless, the combination of all three losses yields the most balanced and robust performance across tasks.
In conclusion, these findings validate the complementary roles of contrastive learning, ranking-based sampling, and adaptive smoothing. Together, they address different facets of the negative sampling challenge and lead to the construction of a more semantically meaningful and transferable embedding space.
4.4.2. Pooling Strategy
Table 6 investigates the impact of different pooling strategies for extracting sentence representations from the pre-trained language model. Surprisingly, the attention-based pooling mechanism, despite its theoretical appeal and widespread use in other NLP tasks, does
not lead to improved performance in this unsupervised setting. In fact, it often performs worse than the simpler strategy of using the [CLS] token representation directly. This suggests that, in the absence of explicit supervision or task-specific guidance, the attention mechanism may struggle to learn meaningful attention weights. It might attend to irrelevant tokens, adding noise to the representation and hindering the learning process. The added complexity and parameters of the attention mechanism also make it more challenging to optimize effectively without labeled data.
By contrast, the simple [CLS] token representation performs competitively, especially on SICK (74.18, the best score on that dataset). This strong performance can be attributed to the fact that the [CLS] token is specifically trained during pre-training to encode sentence-level semantics, making it a robust choice for unsupervised sentence representation learning.
Among the various strategies, the best overall performance is achieved by applying mean pooling over the first and last hidden layers, which attains the highest average score (77.16) and the best STS-B result (78.82). This finding aligns with the understanding that different layers of a pre-trained language model capture different levels of linguistic information. Earlier layers tend to encode more syntactic and local information, while later layers capture more abstract semantic and global information. By combining the representations from the first and last layers, we obtain a richer and more balanced representation that incorporates both local and global aspects of sentence meaning. This simple, fixed combination of layers proves to be more effective than a learned attention mechanism in this unsupervised setting.
4.4.3. Integration Methods for Negative Ranking Information
Table 7 compares different approaches for integrating the negative ranking information into the CL framework. All methods that incorporate ranking information GPT-3.5-turbo, ListMLE, and our method) demonstrate superior performance compared to baselines that do not utilize ranking (as shown in previous tables). This further reinforces the core premise of our work: that acknowledging and modeling the relative difficulty of negative samples is crucial for learning high-quality sentence embeddings.
Using ChatGPT scoring, which involves querying GPT-3.5-turbo to directly obtain similarity scores for sentence pairs, provides a strong signal and achieves good results. This highlights the impressive semantic understanding capabilities of LLMs. As shown in
Table 7, this method attains the highest score on the SICK dataset (78.55) and a strong overall average (79.53), demonstrating the impressive semantic understanding capabilities of large language models (LLMs). However, this approach has practical limitations. Relying on an external, large-scale LLM for every batch during training can be computationally expensive and time-consuming. Furthermore, the performance becomes dependent on the availability and quality of the external LLM, which may not always be guaranteed or desirable.
ListMLE, a ranking-based loss function that directly optimizes for the correct ordering of negative samples, also performs well. It achieves the highest score on STS-B (81.45). This confirms the effectiveness of directly optimizing for ranking, rather than simply using a binary classification approach (positive vs. negative).
Our proposed method, which combines ranking information with adaptive label smoothing, achieving the highest average score (80.12) and the best result on SICK (78.95), while remaining competitive on STS-B (81.38). This demonstrates the synergistic benefits of these two components. Ranking provides the “relative order” of negative samples based on their semantic similarity to the anchor, while adaptive label smoothing provides a “magnitude” of influence for each negative sample in the loss function. The adaptive smoothing mechanism, controlled by the parameter, allows the model to focus more on harder negatives (those with higher similarity scores and lower ranks) and less on easier negatives. This creates a more nuanced and effective learning signal than either ranking alone or standard CL with uniform negative sampling. The smoothing helps to prevent the model from becoming overly confident about easy negatives, which can lead to overfitting and hinder its ability to learn subtle semantic distinctions. Our method, by combining the strengths of ranking and adaptive smoothing, provides a more principled and effective way to address the asymmetry inherent in negative sampling. It is also more computationally efficient than relying on external LLM calls for similarity scoring.
4.5. Analysis of Sentence Embedding Space
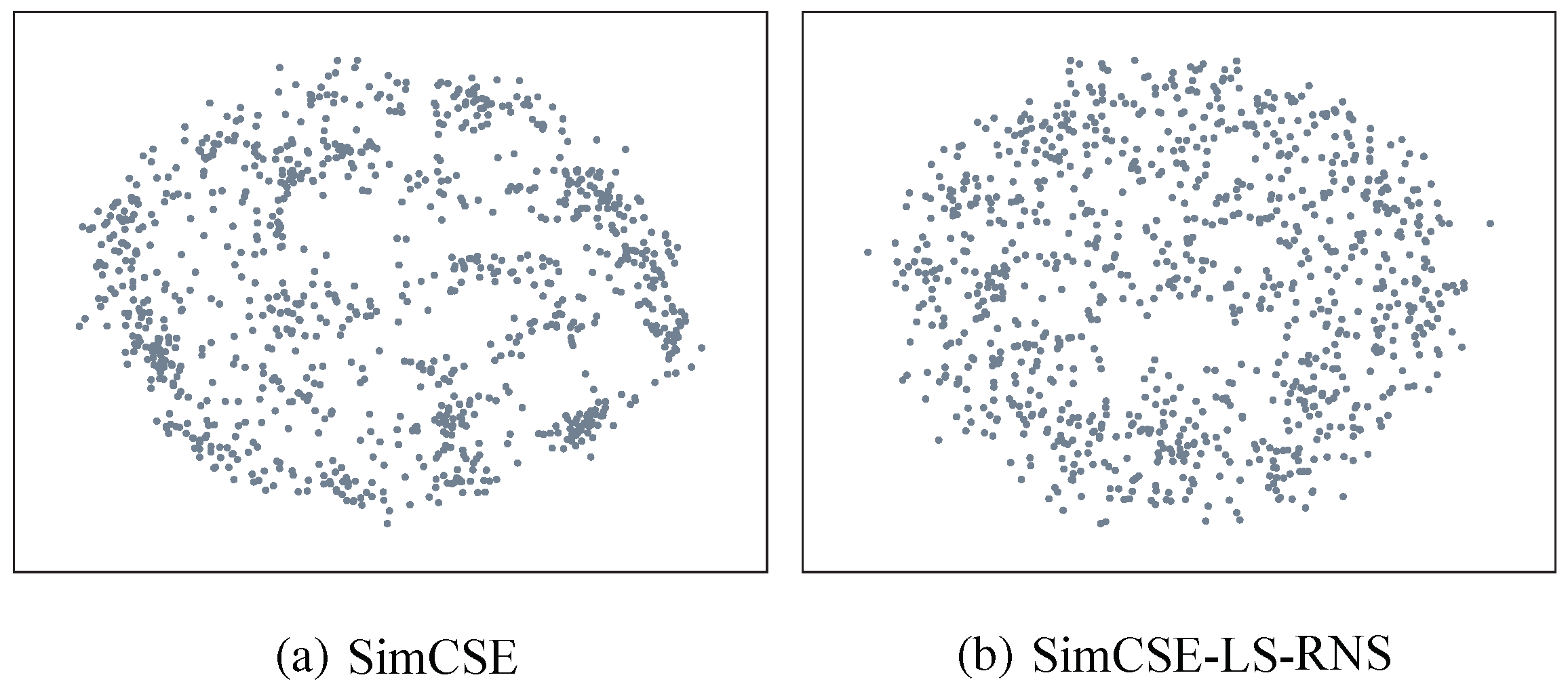
Figure 2 provides a visual analysis of the sentence embedding space, comparing the embeddings generated by SimCSE (the base encoder) with those generated by SimCSE-LS-RNS. We randomly sample 1000 sentences from the STS-B dataset and visualize their embeddings using t-SNE (not explicitly mentioned, but implied).
The visualization clearly reveals a significant difference between the two sets of embeddings. The SimCSE embeddings exhibit the characteristic anisotropy problem, with the majority of points tightly clustered together in a relatively small region of the vector space. This clustering indicates that the embeddings are not well distributed, and many sentence pairs, even if semantically dissimilar, end up having high cosine similarity due to their proximity in this dense region. This makes it difficult to distinguish between sentences with subtle meaning differences.
In stark contrast, the SimCSE-LS-RNS embeddings are much more dispersed and occupy a significantly larger portion of the vector space. This increased dispersion demonstrates that LS-RNS has effectively mitigated the anisotropy problem and created a more semantically meaningful embedding space. The improved distribution is a direct consequence of our core contribution: addressing the asymmetry in negative sampling during CL. By prioritizing harder negatives through ranking and adaptive label smoothing, LS-RNS forces the model to learn finer-grained distinctions between sentences. This, in turn, leads to a more structured embedding space where the distances between embeddings more accurately reflect the semantic relationships between the corresponding sentences. The increased dispersion means that small changes in sentence meaning are more likely to result in noticeable changes in the embedding, making the representation more sensitive and discriminative.
This improved embedding space has significant implications for downstream tasks. A more dispersed and semantically meaningful representation makes it easier for subsequent models, such as classifiers or similarity search algorithms, to differentiate between sentences and perform their respective tasks more accurately. The visual analysis provides compelling qualitative evidence that complements the quantitative results presented earlier, further demonstrating the effectiveness of LS-RNS in learning high-quality sentence embeddings.
5. Conclusions
In this study, we introduced LS-RNS, a novel framework that explicitly addresses the overlooked semantic asymmetry in contrastive learning for unsupervised sentence embedding. Unlike traditional methods that treat all negatives equally, LS-RNS uses a powerful LLM to assign asymmetric similarity scores, enabling ranking-based sampling and adaptive label smoothing to guide the learning process. Our extensive evaluations on seven STS datasets (STS12–16, STS-B, SICK-R) reveal consistent and significant improvements. On STS tasks, LS-RNS achieves 79.87 (BERT-base) and 80.41 (RoBERTa-base), significantly outperforming SimCSE, DiffCSE, and PromptBERT; on transfer learning, LS-RNS reaches 88.82 (BERT-base) and 87.68 (RoBERTa-base), showing consistent improvements across all seven tasks; on image classification (STL-10), LS-RNS improves SimCLR’s performance across all tested backbones and even allows a ResNet-18 to outperform a deeper ResNet-34, highlighting its robustness beyond the NLP domain. These results demonstrate that modeling asymmetric relationships is crucial for robust representation learning.
It is worth noting that the integration of LLM-based similarity scoring and dynamic sampling strategies in the LS-RNS framework inevitably incurs additional computational complexity; while our current experiments are conducted on datasets of moderate scale (e.g., Birdsong, 4K training instances), scalability to larger corpora (e.g., 100K to 100M samples) remains a crucial consideration for real-world deployment. Fortunately, key components—such as LLM-based similarity scoring and ranking—can be precomputed offline, while the adaptive label smoothing mechanism remains computationally lightweight during training. This design enables efficient scaling through parallelism and distributed precomputation. Furthermore, in high-resource scenarios, the LLM module can be approximated or distilled into compact, domain-adapted models, reducing latency without compromising semantic fidelity.
Future directions include the scalability of LS-RNS across orders of magnitude of data, incorporating dynamic temperature mechanisms, expanding to multilingual and multimodal embeddings, and conducting a theoretical analysis of asymmetric contrastive loss.
Author Contributions
Conceptualization, Y.H.; methodology, Y.H. and S.Z.; software, S.Z. and W.L.; validation, S.Z., W.L. and J.W.; formal analysis, S.Z. and J.W.; investigation, Y.H., S.Z., W.L. and J.W.; resources, Y.H.; data curation, J.W. and X.W.; writing—original draft preparation, S.Z.; writing—review and editing, Y.H. and W.L.; visualization, X.W.; supervision, Y.H.; project administration, J.W.; funding acquisition, Y.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Henan Science and Technology Research Project of China under grant 242102211060.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author. Restrictions apply to the availability of these data due to institutional policies and the protection of proprietary information.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-Bert: Sentence Embeddings Using Siamese Bert-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, 3–7 November 2019; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2019; pp. 3982–3992. [Google Scholar]
- Shi, H.; Sakai, T. Self-Supervised and Few-Shot Contrastive Learning Frameworks for Text Clustering. IEEE Access 2023, 11, 84134–84143. [Google Scholar] [CrossRef]
- Zhu, S.; Gu, S.; Li, S.; Xu, L.; Xiong, D. Mining parallel sentences from internet with multi-view knowledge distillation for low-resource language pairs. Knowl. Inf. Syst. 2024, 66, 187–209. [Google Scholar] [CrossRef]
- Kellert, O.; Mahmud Uz Zaman, M. Using Neural Topic Models to Track Context Shifts of Words: A Case Study of COVID-Related Terms Before and After the Lockdown in April 2020. In Proceedings of the 3rd Workshop on Computational Approaches to Historical Language Change, Dublin, Ireland, 26–27 May 2022; pp. 131–139. [Google Scholar]
- Zhu, R.; Zhao, B.; Liu, J.; Sun, Z.; Chen, C.W. Improving Contrastive Learning by Visualizing Feature Transformation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10306–10315. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar]
- Zhuang, L.; Wayne, L.; Ya, S.; Jun, Z. A Robustly Optimized BERT Pre-Training Approach with Post-Training. In Proceedings of the 20th Chinese National Conference on Computational Linguistics, Hohhot, China, 13–15 August 2021; pp. 1218–1227. [Google Scholar]
- Ethayarajh, K. How Contextual Are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP 2019), Hong Kong, 3–7 November 2019; pp. 55–65. [Google Scholar]
- Zhu, S.; Mi, C.; Zhang, L. Inducing Bilingual Word Representations for Non-Isomorphic Spaces by an Unsupervised Way. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Tokyo, Japan, 14–16 August 2021; Springer: Cham, Switzerland, 2021; pp. 458–466. [Google Scholar]
- Carlsson, F.; Gyllensten, A.C.; Gogoulou, E.; Hellqvist, E.Y.; Sahlgren, M. Semantic Re-Tuning with Contrastive Tension. In Proceedings of the 9th International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Zhang, Y.; He, R.; Liu, Z.; Lim, K.H.; Bing, L. An Unsupervised Sentence Embedding Method by Mutual Information Maximization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020), Online Conference, 16–20 November 2020; pp. 1601–1610. [Google Scholar]
- Giorgi, J.; Nitski, O.; Wang, B.; Bader, G. Declutr: Deep Contrastive learning for unsupervised textual representations. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online Conference, 1–6 August 2021; Curran Associates, Inc.: New York, NY, USA, 2021; Volume 1: Long Papers, pp. 879–895. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple Contrastive Learning of Sentence Embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online Conference, 7–11 November 2021; pp. 6894–6910. [Google Scholar]
- Zhu, S.; Mi, C.; Li, T.; Yang, Y.; Xu, C. Unsupervised parallel sentences of machine translation for Asian language pairs. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 1–14. [Google Scholar] [CrossRef]
- Sun, Y.; Zhu, S.; Yifan, F.; Mi, C. Parallel Sentences Mining with Transfer Learning in an Unsupervised Setting. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Workshop, Online Conference, 6–11 June 2021; pp. 136–142. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.R.; Zemel, R.; Urtasun, R.; Torralba, A.; Fidler, S. Skip-thought vectors. Adv. Neural Inf. Process. Syst. 2015, 28, 3294–3302. [Google Scholar]
- Hill, F.; Cho, K.; Korhonen, A. Learning Distributed Representations of Sentences from Unlabelled Data. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1367–1377. [Google Scholar]
- Zhang, Y.; Zhu, H.; Wang, Y.; Xu, N.; Li, X.; Zhao, B. A contrastive framework for learning sentence representations from pairwise and triple-wise perspective in angular space. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2022; Volume 1: Long Papers, pp. 4892–4903. [Google Scholar]
- Li, B.; Zhou, H.; He, J.; Wang, M.; Yang, Y.; Li, L. On the Sentence Embeddings from Pre-Trained Language Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020), Online Conference, 16–20 November 2020; pp. 9119–9130. [Google Scholar]
- Huang, J.; Tang, D.; Zhong, W.; Lu, S.; Shou, L.; Gong, M.; Jiang, D.; Duan, N. WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach. In Proceedings of the Findings of the Association for Computational Linguistics (EMNLP 2021), Punta Cana, Dominican Republic, 16–20 November 2021; pp. 238–244. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning, Online Conference, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chuang, Y.S.; Dangovski, R.; Luo, H.; Zhang, Y.; Chang, S.; Soljačić, M.; Li, S.W.; Yih, W.t.; Kim, Y.; Glass, J. DiffCSE: Difference-Based Contrastive Learning for Sentence Embeddings. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 4207–4218. [Google Scholar]
- Jiang, T.; Jiao, J.; Huang, S.; Zhang, Z.; Wang, D.; Zhuang, F.; Wei, F.; Huang, H.; Deng, D.; Zhang, Q. Promptbert: Improving Bert Sentence Embeddings with Prompts. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 8826–8837. [Google Scholar]
- Wang, H.; Dou, Y. SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples. In Proceedings of the International Conference on Intelligent Computing, Zhengzhou, China, 10–13 August 2023; Springer: Berlin, Germany, 2023; pp. 419–431. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Zhu, S.; Mi, C.; Shi, X. An Explainable Evaluation of Unsupervised Transfer Learning for Parallel Sentences Mining. In Web and Big Data, Proceedings of the 5th International Joint Conference (APWeb-WAIM 2021), Guangzhou, China, 23–25 August 2021; Proceedings, Part I 5; Springer: Cham, Switzerland, 2021; pp. 273–281. [Google Scholar]
- Suresh, V.; Ong, D.C. Not All Negatives Are Equal: Label-Aware Contrastive Loss for Fine-Grained Text Classification. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 4381–4394. [Google Scholar]
- Huynh, T.; Kornblith, S.; Walter, M.R.; Maire, M.; Khademi, M. Boosting Contrastive Self-Supervised Learning with False Negative Cancellation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2785–2795. [Google Scholar]
- Agirre, E.; Cer, D.; Diab, M.; Gonzalez-Agirre, A.; Guo, W. SEM 2013 shared task: Semantic textual similarity. In Second Joint Conference on Lexical and Computational Semantics, Volume 1: Proceedings of the Main Conference and the Shared Task: Semantic Textual Similarity, Atlanta, GA, USA, 13–14 June 2013; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2013; pp. 32–43. [Google Scholar]
- Agirre, E.; Banea, C.; Cardie, C.; Cer, D.M.; Diab, M.T.; Gonzalez-Agirre, A.; Guo, W.; Mihalcea, R.; Rigau, G.; Wiebe, J. SemEval-2014 Task 10: Multilingual Semantic Textual Similarity. In Proceedings of the SemEval@ COLING Confrerence, Dublin, Ireland, 23–24 August 2014; pp. 81–91. [Google Scholar]
- Agirre, E.; Banea, C.; Cardie, C.; Cer, D.; Diab, M.; Gonzalez-Agirre, A.; Guo, W.; Lopez-Gazpio, I.; Maritxalar, M.; Mihalcea, R.; et al. Semeval-2015 Task 2: Semantic Textual Similarity, English, Spanish and Pilot on Interpretability. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 252–263. [Google Scholar]
- Agirre, E.; Banea, C.; Cer, D.; Diab, M.; Gonzalez Agirre, A.; Mihalcea, R.; Rigau Claramunt, G.; Wiebe, J. Semeval-2016 Task 1: Semantic Textual Similarity, Monolingual and Cross-Lingual Evaluation. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2016; pp. 497–511. [Google Scholar]
- Cer, D.; Diab, M.; Agirre, E.; Lopez-Gazpio, I.; Specia, L. Semeval-2017 Task 1: Semantic Textual Similarity-Multilingual and Cross-Lingual Focused Evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 1–14. [Google Scholar]
- Marelli, M.; Menini, S.; Baroni, M.; Bentivogli, L.; Bernardi, R.; Zamparelli, R. A SICK Cure for the Evaluation of Compositional Distributional Semantic Models. In Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC’14), Reykjavik Iceland, 26–31 May 2014; pp. 216–223. [Google Scholar]
- Pang, B.; Lee, L. Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL′05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 115–124. [Google Scholar]
- Hu, M.; Liu, B. Mining and Summarizing Customer Reviews. In Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Wiebe, J.; Wilson, T.; Cardie, C. Annotating expressions of opinions and emotions in language. Lang. Resour. Eval. 2005, 39, 165–210. [Google Scholar] [CrossRef]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive Deep Models for Semantic Compositionality over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Voorhees, E.M.; Tice, D.M. Building a Question Answering Test Collection. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, 24–28 July 2000; pp. 200–207. [Google Scholar]
- Conneau, A.; Kiela, D. Senteval: An Evaluation Toolkit for Universal Sentence Representations. In Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems, Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; Volume 32, pp. 8024–8035.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems, Proceedings of the 2017 Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder for English. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; pp. 169–174. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



{kind=link}
{kind=link}